Kapitel 1. Warum maschinelles Lernen und Sicherheit?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Sobald Akademiker und Wissenschaftler genug Computer über das Internet miteinander verbunden hatten, um ein Kommunikationsnetzwerk zu schaffen, das einen Mehrwert bot, erkannten andere Leute, dass dieses Medium der kostenlosen Übertragung und weiten Verbreitung ein perfekter Weg war, um zweifelhafte Produkte zu bewerben, Zugangsdaten zu stehlen und Computerviren zu verbreiten.
In den letzten 40 Jahren hat sich der Bereich der Computer- und Netzwerksicherheit zu einem riesigen Feld von Bedrohungen und Bereichen entwickelt: Intrusion Detection, Web Application Security, Malware-Analyse, Social Network Security, Advanced Persistent Threats und angewandte Kryptografie, um nur einige zu nennen. Aber auch heute noch ist Spam für die E-Mail- und Messaging-Branche ein wichtiges Thema, und für die breite Öffentlichkeit ist Spam wahrscheinlich der Aspekt der Computersicherheit, der ihr eigenes Leben am unmittelbarsten betrifft.
Das maschinelle Lernen wurde nicht von Spam-Bekämpfern erfunden, aber es wurde schnell von statistisch interessierten Technologen übernommen, die sein Potenzial im Umgang mit einer sich ständig weiterentwickelnden Missbrauchsquelle erkannten. E-Mail-Anbieter und Internet Service Provider (ISPs) haben Zugang zu einer Fülle von E-Mail-Inhalten, Metadaten und Nutzerverhalten. Mit Hilfe von E-Mail-Daten können inhaltsbasierte Modelle erstellt werden, um einen verallgemeinerbaren Ansatz zur Erkennung von Spam zu entwickeln. Metadaten und der Ruf von Entitäten können aus E-Mails extrahiert werden, um die Wahrscheinlichkeit vorherzusagen, dass es sich bei einer E-Mail um Spam handelt, ohne dass man sich den Inhalt ansehen muss. Durch die Einrichtung einer Feedbackschleife zum Nutzerverhalten kann das System eine kollektive Intelligenz aufbauen und sich mit Hilfe seiner Nutzerinnen und Nutzer mit der Zeit verbessern.
E-Mail-Filter haben sich daher nach und nach weiterentwickelt, um mit der wachsenden Vielfalt an Umgehungsmethoden der Spammer fertig zu werden. Obwohl heute 85% aller versendeten E-Mails Spam sind (laut einer Forschungsgruppe), blockieren die besten modernen Spamfilter mehr als 99,9% aller Spams, und es ist eine Seltenheit, dass Nutzer/innen großer E-Mail-Dienste ungefilterte und unentdeckte Spams in ihren Posteingängen vorfinden. Diese Ergebnisse sind ein enormer Fortschritt gegenüber den simplen Spam-Filtertechniken aus den Anfängen des Internets, die mit einfacher Wortfilterung und der Reputation von E-Mail-Metadaten bescheidene Ergebnisse erzielten.
Die grundlegende Lehre, die sowohl Forscher als auch Praktiker aus diesem Kampf gezogen haben, ist die Bedeutung der Nutzung von Daten, um böswillige Gegner zu besiegen und die Qualität unserer Interaktionen mit der Technologie zu verbessern. Die Geschichte der Spam-Bekämpfung ist ein repräsentatives Beispiel für den Einsatz von Daten und maschinellem Lernen in allen Bereichen der Computersicherheit. Heutzutage sind fast alle Unternehmen auf Technologie angewiesen, und fast jede Technologie weist Sicherheitslücken auf. Angetrieben von den gleichen Motiven wie die Spammer in den 1980er Jahren (unregulierter, kostenloser Zugang zu einem Publikum mit verfügbarem Einkommen und privaten Informationen), können bösartige Akteure Sicherheitsrisiken für fast alle Aspekte des modernen Lebens darstellen. Die grundlegende Natur des Kampfes zwischen Angreifer und Verteidiger ist in allen Bereichen der Computersicherheit die gleiche wie bei der Spam-Bekämpfung: Ein motivierter Gegner versucht ständig, ein Computersystem zu missbrauchen, und jede Seite versucht, die Schwachstellen im Design oder in der Technik zu beheben oder auszunutzen, bevor die andere Seite sie entdeckt. Die Problemstellung hat sich kein bisschen verändert.
Computersysteme und Webdienste werden immer zentraler und viele Anwendungen bedienen mittlerweile Millionen oder sogar Milliarden von Nutzern. Unternehmen, die zu Informationsvermittlern werden, sind ein größeres Ziel für Ausbeutung, aber sie sind auch in der perfekten Position, um die Daten und ihre Nutzerbasis zu nutzen, um mehr Sicherheit zu erreichen. In Verbindung mit dem Aufkommen leistungsfähiger Hardware zur Datenverarbeitung und der Entwicklung leistungsfähigerer Algorithmen zur Datenanalyse und zum maschinellen Lernen gab es noch nie einen besseren Zeitpunkt, um das Potenzial des maschinellen Lernens für die Sicherheit zu nutzen.
In diesem Buch zeigen wir Anwendungen von maschinellem Lernen und Datenanalysetechniken für verschiedene Problembereiche im Bereich Sicherheit und Missbrauch. Wir erforschen Methoden, um die Eignung verschiedener maschineller Lerntechniken in unterschiedlichen Szenarien zu bewerten, und konzentrieren uns auf Leitprinzipien, die dir helfen, Daten zu nutzen, um mehr Sicherheit zu erreichen. Unser Ziel ist es nicht, dir die Antwort auf jedes Sicherheitsproblem zu geben, sondern dir einen Rahmen zu geben, in dem du über Daten und Sicherheit nachdenken und aus dem du die richtige Methode für das jeweilige Problem auswählen kannst.
Der Rest dieses Kapitels stellt den Kontext für den Rest des Buches her: Wir erörtern, welchen Bedrohungen moderne Computer- und Netzwerksysteme ausgesetzt sind, was maschinelles Lernen ist und wie maschinelles Lernen auf die genannten Bedrohungen angewendet wird. Wir schließen mit einer detaillierten Untersuchung von Ansätzen zur Spam-Bekämpfung, die ein konkretes Beispiel für die Anwendung von maschinellem Lernen auf die Sicherheit liefert, das sich auf fast alle Bereiche übertragen lässt.
Landschaft der Cyber-Bedrohungen
Die Landschaft der Gegner und Übeltäter im Bereich der Computersicherheit hat sich im Laufe der Zeit weiterentwickelt, aber die allgemeinen Kategorien von Bedrohungen sind gleich geblieben. Die Sicherheitsforschung ist dazu da, die Ziele der Angreifer zu vereiteln, und es ist immer wichtig, die verschiedenen Arten von Angriffen zu kennen, die es in freier Wildbahn gibt. Wie du aus dem Baum der Cyber-Bedrohungs-Taxonomie in Abbildung 1-1 ersehen kannst,1 können die Beziehungen zwischen den Bedrohungen und Kategorien in manchen Fällen sehr komplex sein.
Wir beginnen mit der Definition der wichtigsten Bedrohungen, die wir in den folgenden Kapiteln untersuchen werden:
- Malware (oder Virus)
-
Die Abkürzung steht für "bösartige Software", d.h. jede Software, die darauf abzielt, Schaden anzurichten oder sich unbefugten Zugang zu Computersystemen zu verschaffen.
- Wurm
-
Eigenständige Malware, die sich selbst repliziert, um sich auf andere Computersysteme zu verbreiten.
- Trojaner
-
Malware, die als legitime Software getarnt ist, um nicht entdeckt zu werden.
- Spyware
-
Malware, die ohne Erlaubnis und/oder Wissen des Betreibers auf einem Computersystem installiert wird, um zu spionieren und Informationen zu sammeln. Keylogger fallen in diese Kategorie.
- Adware
-
Malware, die unerwünschtes Werbematerial (z. B. Pop-ups, Banner, Videos) in eine Benutzeroberfläche einfügt, oft wenn ein Benutzer im Internet surft.
- Ransomware
-
Malware, die die Verfügbarkeit von Computersystemen einschränkt, bis eine Geldsumme (Lösegeld) gezahlt wird.
- Rootkit
-
Eine Sammlung von (oft) Low-Level-Software, die den Zugriff auf ein Computersystem ermöglicht oder die Kontrolle darüber übernimmt. ("Root" bezeichnet die mächtigste Zugriffsebene auf ein System.)
- Hintertür
-
Ein absichtliches Loch in der Systemgrenze, um zukünftige Zugriffe zu ermöglichen, die den Schutz der Grenze umgehen können.
- Bot
-
Eine Variante von Malware, die es Angreifern ermöglicht, Computersysteme aus der Ferne zu übernehmen und zu kontrollieren und sie so zu Zombies zu machen.
- Botnet
- Ausnutzen
-
Ein Teil des Codes oder der Software, der bestimmte Schwachstellen in anderen Softwareanwendungen oder Frameworks ausnutzt.
- Scannen
-
Angriffe, bei denen eine Vielzahl von Anfragen an Computersysteme gesendet werden, oft in einer Brute-Force-Manier, mit dem Ziel, Schwachstellen und Verwundbarkeiten zu finden und Informationen zu sammeln.
- Schnüffeln
-
Unauffälliges Beobachten und Aufzeichnen des Netzwerk- und Serververkehrs und der Prozesse ohne das Wissen der Netzwerkbetreiber.
- Keylogger
-
Eine Hard- oder Software, die (oft im Verborgenen) die auf einer Tastatur oder einem ähnlichen Computer-Eingabegerät gedrückten Tasten aufzeichnet.
- Spam
-
Unerwünschte Massennachrichten, meist zu Werbezwecken. In der Regel per E-Mail, kann aber auch per SMS oder über einen Messaging-Anbieter (z. B. WhatsApp) erfolgen.
- Login-Angriff
-
Mehrere, in der Regel automatisierte Versuche, Anmeldedaten für Authentifizierungssysteme zu erraten, entweder durch Brute-Force-Verfahren oder mit gestohlenen/gekauften Anmeldedaten.
- Kontoübernahme (ATO)
-
Sich Zugang zu einem Konto verschaffen, das nicht dein eigenes ist, in der Regel zum Zweck des Weiterverkaufs, des Identitätsdiebstahls, des Gelddiebstahls und so weiter. Dies ist normalerweise das Ziel eines Login-Angriffs, kann aber auch in kleinem Maßstab und sehr gezielt erfolgen (z. B. Spyware, Social Engineering).
- Phishing (auch bekannt als Maskerade)
-
Kommunikation mit einem Menschen, der vorgibt, eine seriöse Einrichtung oder Person zu sein, um persönliche Informationen preiszugeben oder an private Vermögenswerte zu gelangen.
- Spear-Phishing
-
Phishing, das auf einen bestimmten Nutzer abzielt und Informationen über diesen Nutzer nutzt, die aus externen Quellen stammen.
- Social Engineering
-
Exfiltration (Extraktion) von Informationen von einem Menschen mit nicht-technischen Methoden wie Lügen, Betrug, Bestechung, Erpressung und so weiter.
- Aufrührerische Rede
-
Diskriminierende, diskreditierende oder anderweitig schädliche Äußerungen, die sich gegen eine Person oder Gruppe richten.
- Denial of Service (DoS) und Distributed Denial of Service (DDoS)
-
Angriffe auf die Verfügbarkeit von Systemen durch massenhaftes Bombardement und/oder missgestaltete Anfragen, die oft auch die Integrität und Zuverlässigkeit des Systems beeinträchtigen.
- Fortgeschrittene persistente Bedrohungen (APTs)
-
Gezielte Angriffe auf Netzwerke oder Hosts, bei denen ein heimlicher Eindringling absichtlich für lange Zeit unentdeckt bleibt, um Daten zu stehlen und zu exfiltrieren.
- Zero-Day-Schwachstelle
-
Eine Schwachstelle oder ein Fehler in Computersoftware oder -systemen, der dem Hersteller nicht bekannt ist und der ausgenutzt werden kann (Zero-Day-Angriff), bevor der Hersteller die Möglichkeit hat, das Problem zu beheben.
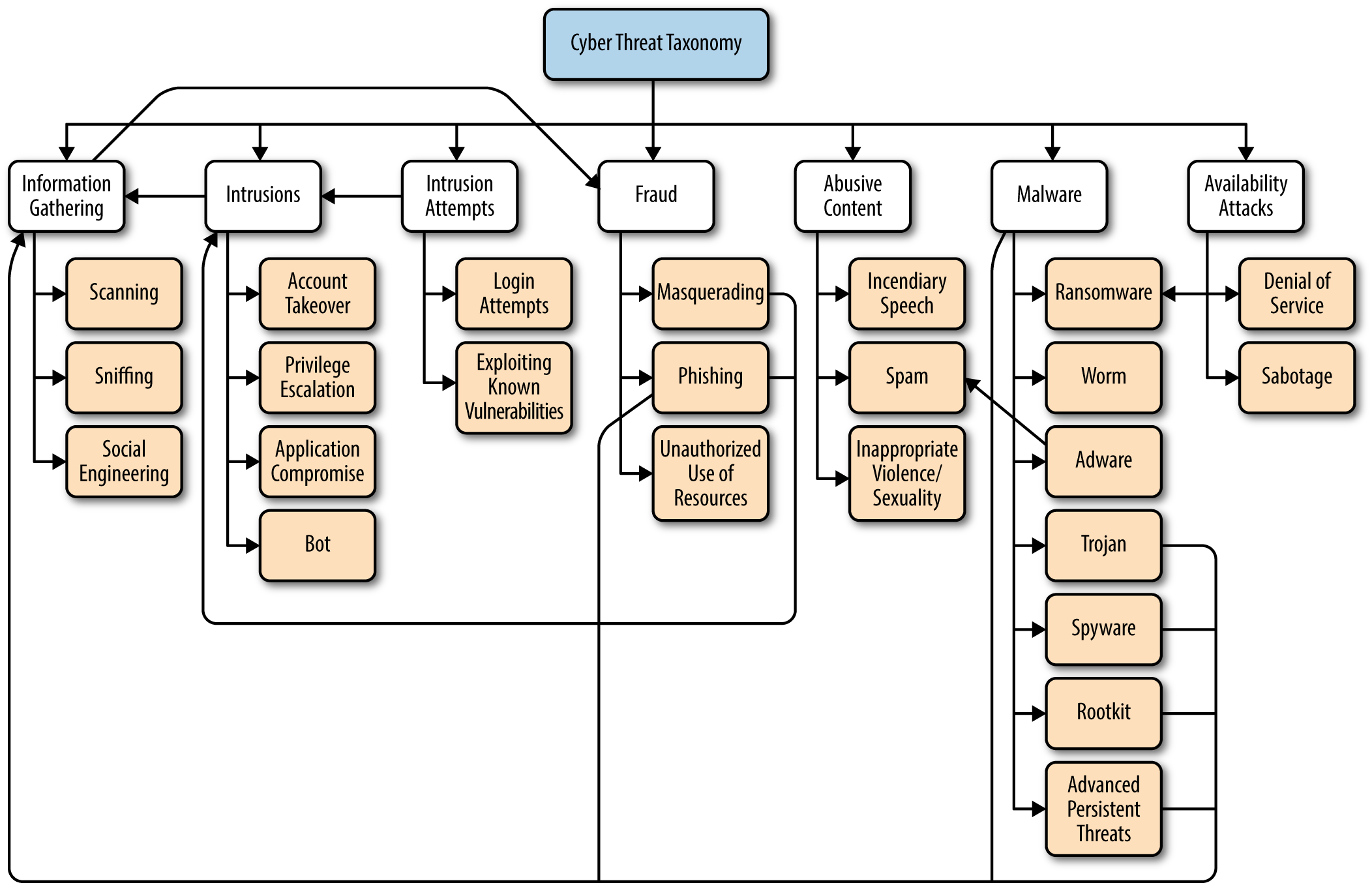
Abbildung 1-1. Baum der Cyber-Bedrohungs-Taxonomie
Die Wirtschaft der Cyberangreifer
Was treibt Angreifer zu ihren Taten? Die Internetkriminalität hat sich seit den Anfängen der Technologie zunehmend kommerzialisiert. Die Umwandlung von Cyberangriffen von einer Reputationsökonomie ("street cred", Ruhm, Unfug) zu einer Geldökonomie (direkte monetäre Gewinne, Werbung, Verkauf privater Informationen) ist ein faszinierender Prozess, vor allem aus der Sicht des Gegners. Die Motivation von Cyberangreifern ist heute weitgehend monetär. Angriffe auf Finanzinstitutionen oder Conduits (Online-Zahlungsplattformen, Wertkarten-/Geschenkkartenkonten, Bitcoin-Wallets usw.) können den Angreifern natürlich direkte finanzielle Vorteile bringen. Aber weil mehr auf dem Spiel steht, verfügen diese Institutionen oft über fortschrittlichere Verteidigungsmechanismen, die den Angreifern das Leben schwer machen. Aufgrund der Verlockung eines direkteren Weges zum finanziellen Gewinn ist der Markt für Schwachstellen, die auf solche Einrichtungen abzielen, auch vergleichsweise überfüllt und laut. Dies führt dazu, dass Angreifer Einrichtungen mit weniger strengen Sicherheitsvorkehrungen ins Visier nehmen. Sie missbrauchen Systeme, die von vornherein offen sind, und greifen auf indirektere Techniken zurück, die es ihnen schließlich doch ermöglichen, Geld zu verdienen.
Ein Marktplatz für Hacking-Fähigkeiten
Die Tatsache, dass Darknet-Marktplätze und illegale Hacking-Foren existieren, ist kein Geheimnis. Bevor es organisierte Untergrundgemeinschaften für illegale Tauschgeschäfte gab, konnten nur die fähigsten Computerhacker/innen Cyberangriffe starten und Konten und Computersysteme kompromittieren. Mit der Kommerzialisierung des Hackens und der Allgegenwärtigkeit der Computernutzung können jedoch auch weniger qualifizierte "Hacker" am Ökosystem der Cyberangriffe teilnehmen, indem sie Schwachstellen und benutzerfreundliche Hacking-Skripte, Software und Tools kaufen, um ihre eigenen Cyberangriffe zu starten.
Auf dem Markt für Zero-Day-Schwachstellen gibt es Varianten, die sowohl legal als auch illegal existieren. Der Handel mit Schwachstellen und Exploits kann sowohl für Sicherheitsforscher als auch für Computerhacker zu einer lohnenden Einnahmequelle werden.2 Zunehmend sind es nicht mehr die elitärsten Computerhacker, die Zero-Days freisetzen und Angriffskampagnen starten. Die Risiken sind einfach zu hoch und der Prozess der Monetarisierung ist zu lang und unsicher. Die Entwicklung von Software, mit der gewöhnliche Skript-Kiddies das eigentliche Hacken durchführen können, der Verkauf von Schwachstellen auf Marktplätzen und in manchen Fällen sogar die Beratung von Boutique-Hackern versprechen einen direkteren und sichereren Weg zum finanziellen Gewinn. Wie beim kalifornischen Goldrausch in den späten 1840er Jahren sind die Händler , die die wachsende Zahl der Wohlstandssuchenden mit Annehmlichkeiten versorgen, häufiger die Empfänger des Geldes als die Suchenden selbst.
Indirekte Monetarisierung
Der Prozess der Monetarisierung für Übeltäter, die an verschiedenen Arten von Computerangriffen beteiligt sind, ist sehr vielfältig und verdient eine detaillierte Untersuchung. Wir werden nicht zu tief in diese Untersuchung eintauchen, aber wir werden uns ein paar Beispiele dafür ansehen, wie indirekte Monetarisierung funktionieren kann.
Die Verbreitung von Malware ist ähnlich wie die Entwicklung von Cloud-Computing und Infrastructure-as-a-Service (IaaS)-Anbietern zur Massenware geworden. Der Pay-per-Install (PPI)-Marktplatz für die Verbreitung von Malware ist ein komplexes und ausgereiftes Ökosystem, das Malware-Autoren und Käufern breite Vertriebskanäle zur Verfügung stellt.3 Die Vermietung von Botnetzen funktioniert nach demselben Prinzip wie die On-Demand-Cloud-Infrastruktur mit stundenweisen Ressourcenangeboten zu wettbewerbsfähigen Preisen. Auch die Verbreitung von Malware auf entfernten Servern kann auf unterschiedliche Weise finanziell lukrativ sein. Gezielte Angriffe auf Unternehmen sind manchmal mit einem Kopfgeld verbunden, und die Verbreitung von Ransomware kann ein effizienter Weg sein, um Geld von einer großen Zahl von Opfern zu erpressen.
Spyware kann dabei helfen, private Informationen zu stehlen, die dann in großen Mengen auf denselben Online-Marktplätzen verkauft werden können, auf denen auch die Spyware verkauft wird. Adware und Spam können als billiger Weg genutzt werden, um für fragwürdige Arzneimittel und Finanzinstrumente zu werben. Online-Konten werden häufig übernommen, um an gespeicherte Werte wie Geschenkkarten, Treuepunkte, Guthaben oder Bargeldprämien zu gelangen. Gestohlene Kreditkartennummern, Sozialversicherungsnummern, E-Mail-Konten, Telefonnummern, Adressen und andere private Informationen können online an Kriminelle verkauft werden, die es auf Identitätsdiebstahl, die Erstellung falscher Konten, Betrug und so weiter abgesehen haben. Aber der Weg zum Geld, insbesondere wenn du die Kreditkartennummer eines Opfers hast, kann lang und komplex sein. Weil diese Informationen so leicht gestohlen werden können, entwickeln Kreditkartenunternehmen und Unternehmen, die Konten mit gespeichertem Wert betreiben, oft clevere Methoden, um Angreifer an der Monetarisierung zu hindern. Zum Beispiel können Konten, bei denen der Verdacht besteht, dass sie kompromittiert wurden, für ungültig erklärt werden, oder die Einlösung von Geschenkkarten kann zusätzliche Authentifizierungsschritte erfordern.
Die Quintessenz
Die Beweggründe von Cyberangreifern sind komplex und die Wege zur Monetarisierung sind verschlungen. Die finanziellen Gewinne aus Internetangriffen können jedoch ein starker Motivator für technisch versierte Menschen sein, vor allem in weniger wohlhabenden Ländern und Gemeinden. Solange Computerangriffe für die Täter einen nicht zu vernachlässigenden Gewinn abwerfen, wird es sie weiterhin geben.
Was ist maschinelles Lernen?
Seit den Anfängen des technischen Zeitalters haben Forscher davon geträumt, Computern beizubringen, wie Menschen zu denken und "intelligente" Entscheidungen zu treffen, indem sie Verallgemeinerungen ziehen und Konzepte aus komplexen Informationsmengen ohne explizite Anweisungen destillieren.
Maschinelles Lernen bezieht sich auf einen Aspekt dieses Ziels, nämlich auf Algorithmen und Prozesse, die in dem Sinne "lernen", dass sie in der Lage sind, vergangene Daten und Erfahrungen zu verallgemeinern, um zukünftige Ergebnisse vorherzusagen. Im Kern handelt es sich beim maschinellen Lernen um eine Reihe von mathematischen Techniken, die auf Computersystemen implementiert werden und die es ermöglichen, Informationen zu sammeln, Muster zu entdecken und Schlussfolgerungen aus Daten zu ziehen.
Auf der allgemeinsten Ebene verfolgen überwachte maschinelle Lernmethoden einen Bayes'schen Ansatz zur Wissensentdeckung, bei dem Wahrscheinlichkeiten von zuvor beobachteten Ereignissen genutzt werden, um auf die Wahrscheinlichkeiten neuer Ereignisse zu schließen. Unüberwachte Methoden ziehen Abstraktionen aus unmarkierten Datensätzen und wenden diese auf neue Daten an. Beide Methodenfamilien können auf Probleme der Klassifizierung (Zuordnung von Beobachtungen zu Kategorien) oder Regression (Vorhersage numerischer Eigenschaften einer Beobachtung) angewendet werden.
Angenommen, wir wollen eine Gruppe von Tieren in Säugetiere und Reptilien einteilen. Bei einer überwachten Methode haben wir eine Reihe von Tieren, deren Kategorie wir definitiv kennen (z. B. Hund und Elefant sind Säugetiere und Alligator und Leguan sind Reptilien). Dann versuchen wir, aus jedem dieser beschrifteten Datenpunkte einige Merkmale zu extrahieren und Ähnlichkeiten in ihren Eigenschaften zu finden, die es uns ermöglichen, Tiere verschiedener Klassen zu unterscheiden. Wir sehen zum Beispiel, dass der Hund und der Elefant beide lebende Nachkommen gebären, im Gegensatz zum Alligator und zum Leguan. Die binäre Eigenschaft "bringt lebende Nachkommen zur Welt" nennen wir ein Merkmal, eine nützliche Abstraktion für beobachtete Eigenschaften, die es uns ermöglicht, Vergleiche zwischen verschiedenen Beobachtungen anzustellen. Nachdem wir eine Reihe von Merkmalen extrahiert haben, die uns dabei helfen, Säugetiere und Reptilien in den markierten Daten zu unterscheiden, können wir einen Lernalgorithmus auf die markierten Daten anwenden und das Gelernte auf neue, ungesehene Tiere übertragen. Wenn dem Algorithmus ein Erdmännchen vorgelegt wird, muss er es entweder als Säugetier oder als Reptil klassifizieren. Anhand der Merkmale dieses neuen Tieres weiß der Algorithmus, dass das Erdmännchen keine Eier legt, keine Schuppen hat und warmblütig ist. Aufgrund seiner Beobachtungen trifft er die Vorhersage, dass das Erdmännchen ein Säugetier ist, und liegt damit genau richtig.
Im unüberwachten Fall ist die Prämisse ähnlich, aber dem Algorithmus wird nicht die anfängliche Menge der markierten Tiere vorgelegt. Stattdessen muss der Algorithmus die verschiedenen Gruppen von Datenpunkten so gruppieren, dass eine binäre Klassifizierung entsteht. Da die meisten Tiere ohne Schuppen lebende Nachkommen zur Welt bringen und Warmblüter sind und die meisten Tiere mit Schuppen Eier legen und Kaltblüter sind, kann der Algorithmus die beiden Kategorien aus der vorgegebenen Menge ableiten und wie im überwachten Fall Vorhersagen für die Zukunft treffen.
Algorithmen für maschinelles Lernen basieren auf Mathematik und Statistik, und die Algorithmen, die Muster, Korrelationen und Anomalien in den Daten entdecken, sind sehr unterschiedlich komplex. In den folgenden Kapiteln gehen wir näher auf die Funktionsweise einiger der gängigsten Algorithmen für maschinelles Lernen ein, die in diesem Buch verwendet werden. Dieses Buch wird dir weder ein vollständiges Verständnis des maschinellen Lernens vermitteln, noch wird es einen Großteil der Mathematik und Theorie dieses Themas abdecken. Was es dir vermitteln wird, ist ein kritisches Gespür für maschinelles Lernen und praktische Fähigkeiten für die Entwicklung und Implementierung intelligenter, adaptiver Systeme im Bereich der Sicherheit.
Was maschinelles Lernen nicht ist
Künstliche Intelligenz (KI) ist ein populärer, aber weit gefasster Begriff, der algorithmische Lösungen für komplexe Probleme bezeichnet, die normalerweise von Menschen gelöst werden. Wie in Abbildung 1-2 dargestellt, ist maschinelles Lernen ein zentraler Baustein der KI. Selbstfahrende Autos müssen zum Beispiel Bilder als Menschen, Autos, Bäume usw. klassifizieren; sie müssen die Position und Geschwindigkeit anderer Autos vorhersagen; sie müssen bestimmen, wie weit sie die Räder drehen müssen, um abbiegen zu können. Diese Klassifizierungs- und Vorhersageprobleme werden mithilfe von maschinellem Lernen gelöst, und das selbstfahrende System ist eine Form der KI. Es gibt andere Teile der selbstfahrenden KI-Entscheidungsmaschine, die in Regelmaschinen fest einprogrammiert sind und die nicht als maschinelles Lernen gelten würden. Maschinelles Lernen hilft uns bei der Entwicklung von KI, ist aber nicht der einzige Weg, um sie zu erreichen.
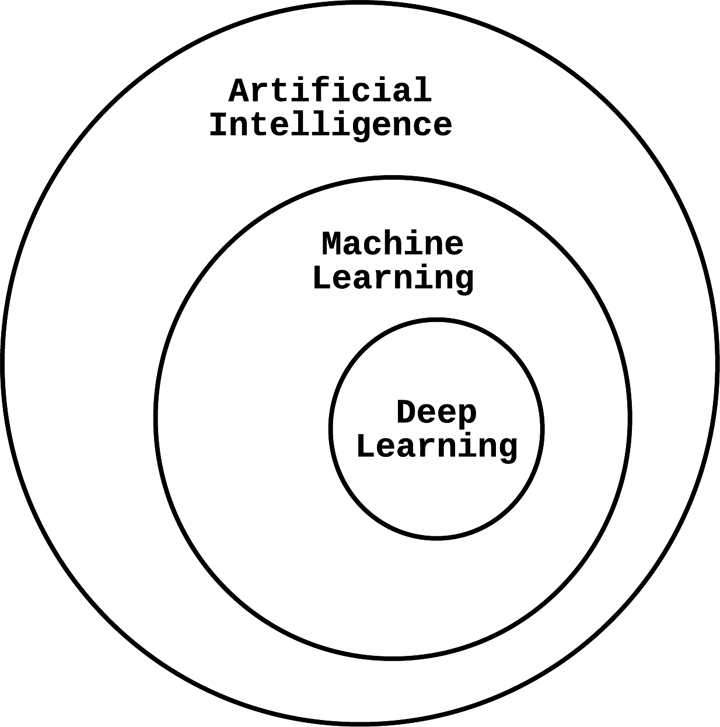
Abbildung 1-2. Künstliche Intelligenz im Zusammenhang mit maschinellem Lernen und Deep Learning
Deep Learning ist ein weiterer populärer Begriff, der häufig mit maschinellem Lernen verwechselt wird. Deep Learning ist eine strenge Untergruppe des maschinellen Lernens und bezieht sich auf eine bestimmte Klasse von mehrschichtigen Modellen, die Schichten von einfacheren statistischen Komponenten verwenden, um Darstellungen von Daten zu lernen. "Neuronales Netzwerk" ist ein allgemeinerer Begriff für diese Art von geschichteten statistischen Lernarchitekturen, die "tief" sein können (d. h. viele Schichten haben), aber nicht müssen. Eine ausgezeichnete Diskussion zu diesem Thema findest du in Deep Learning von Ian Goodfellow, Yoshua Bengio und Aaron Courville (MIT Press).
Die statistische Analyse ist ein zentraler Bestandteil des maschinellen Lernens: Die Ergebnisse von Algorithmen für maschinelles Lernen werden oft in Form von Wahrscheinlichkeiten und Konfidenzintervallen dargestellt. Wir werden in unserer Diskussion über die Erkennung von Anomalien einige statistische Techniken ansprechen, aber wir lassen Fragen zu Experimenten und statistischen Hypothesentests außen vor. Eine ausgezeichnete Diskussion zu diesem Thema findest du in Probability & Statistics for Engineers & Scientists von Ronald Walpole et al. (Prentice Hall).
Widersacher mit maschinellem Lernen
Beachte, dass nichts die Angreifer daran hindert, das maschinelle Lernen auszunutzen, um eine Entdeckung zu vermeiden und die Abwehrmaßnahmen zu umgehen. Genauso wie die Verteidiger aus den Angriffen lernen und ihre Gegenmaßnahmen entsprechend anpassen können, können auch die Angreifer die Art der Abwehrmaßnahmen zu ihrem eigenen Vorteil lernen. Es ist bekannt, dass Spammer ihre Nutzdaten polymorphisieren (d. h. das Aussehen des Inhalts verändern, ohne seine Bedeutung zu ändern), um die Erkennung zu umgehen, oder dass sie Spam-Filter testen, indem sie A/B-Tests mit E-Mail-Inhalten durchführen und lernen, was ihre Klickraten steigen und fallen lässt. Sowohl die Guten als auch die Bösen nutzen maschinelles Lernen in Fuzzing-Kampagnen, um die Suche nach Schwachstellen in Software zu beschleunigen. Die Angreifer können maschinelles Lernen sogar nutzen, um über soziale Medien etwas über deine Persönlichkeit und deine Interessen zu erfahren und so die perfekte Phishing-Nachricht für dich zu erstellen.
Schließlich birgt der Einsatz von dynamischen und adaptiven Methoden im Bereich der Sicherheit immer ein gewisses Risiko. Vor allem, wenn die Vorhersagen des maschinellen Lernens oft nicht erklärbar sind, haben Angreifer verschiedene Algorithmen dazu gebracht, falsche Vorhersagen zu treffen oder das Falsche zu lernen.4 In diesem wachsenden Forschungsbereich, der als " adversarial machine learning" bezeichnet wird, können Angreifer mit unterschiedlichem Zugriff auf ein maschinelles Lernsystem eine Reihe von Angriffen durchführen, um ihre Ziele zu erreichen. Kapitel 8 ist diesem Thema gewidmet und zeichnet ein umfassenderes Bild von den Problemen und Lösungen in diesem Bereich.
Algorithmen für maschinelles Lernen werden oft nicht mit Blick auf die Sicherheit entwickelt und sind oft anfällig für die Versuche eines motivierten Angreifers. Daher ist es wichtig, solche Bedrohungsmodelle zu kennen, wenn man maschinelle Lernsysteme für Sicherheitszwecke entwickelt und baut.
Reale Anwendungen von maschinellem Lernen in der Sicherheit
In diesem Buch erforschen wir eine Reihe von verschiedenen Computersicherheitsanwendungen, für die maschinelles Lernen vielversprechende Ergebnisse gezeigt hat. Die Anwendung von maschinellem Lernen und Data Science zur Lösung von Problemen ist keine einfache Aufgabe. Auch wenn praktische Programmierbibliotheken einen Teil der Komplexität aus der Gleichung nehmen, müssen Entwickler/innen immer noch viele Entscheidungen treffen.
Anhand verschiedener Beispiele in jedem Kapitel werden wir die häufigsten Probleme untersuchen, mit denen Praktiker bei der Entwicklung von Systemen für maschinelles Lernen konfrontiert werden, sei es im Bereich Sicherheit oder in anderen Bereichen. Die Anwendungen, die in diesem Buch beschrieben werden, sind nicht neu, und die von uns besprochenen Data-Science-Techniken finden sich auch im Kern vieler Computersysteme, mit denen du täglich zu tun hast.
Wir können die Anwendungsfälle des maschinellen Lernens im Sicherheitsbereich in zwei große Kategorien einteilen: Mustererkennung und Anomalieerkennung. Die Grenze zwischen Mustererkennung und Aufdeckung von Anomalien ist manchmal fließend, aber jede Aufgabe hat ein klar definiertes Ziel. Bei der Mustererkennung versuchen wir, explizite oder latente Merkmale zu entdecken, die in den Daten verborgen sind. Diese Merkmale können in Form von Merkmalen einem Algorithmus beigebracht werden, andere Formen von Daten zu erkennen, die dieselben Merkmale aufweisen. Die Erkennung von Anomalien nähert sich der Wissensentdeckung von der anderen Seite der Medaille. Anstatt spezifische Muster zu lernen, die in bestimmten Teilmengen der Daten vorkommen, besteht das Ziel darin, eine Vorstellung von der Normalität zu entwickeln, die den größten Teil (sagen wir mehr als 95 %) eines bestimmten Datensatzes beschreibt. Danach werden Abweichungen von dieser Normalität als Anomalien erkannt.
Häufig wird fälschlicherweise angenommen, dass die Erkennung von Anomalien darin besteht, eine Reihe normaler Muster zu erkennen und sie von einer Reihe abnormaler Muster zu unterscheiden. Muster, die durch Mustererkennung extrahiert werden, müssen strikt aus den beobachteten Daten abgeleitet werden, die zum Trainieren des Algorithmus verwendet werden. Bei der Erkennung von Anomalien hingegen kann es unendlich viele anormale Muster geben, die als Ausreißer gelten, selbst wenn sie aus hypothetischen Daten stammen, die weder in den Trainings- noch in den Testdatensätzen enthalten sind.
Die Spam-Erkennung ist vielleicht das klassische Beispiel für Mustererkennung, denn Spam hat in der Regel eine Reihe von vorhersehbaren Merkmalen, und ein Algorithmus kann darauf trainiert werden, diese Merkmale als Muster zu erkennen, nach denen E-Mails klassifiziert werden können. Man kann die Spam-Erkennung aber auch als ein Problem der Anomalieerkennung betrachten. Wenn es möglich ist, eine Reihe von Merkmalen abzuleiten, die den normalen Datenverkehr gut genug beschreiben, um erhebliche Abweichungen von dieser Normalität als Spam zu behandeln, haben wir es geschafft. In Wirklichkeit eignet sich die Spam-Erkennung jedoch nicht für das Paradigma der Anomalieerkennung, denn es ist nicht schwer, sich davon zu überzeugen, dass es in den meisten Kontexten einfacher ist, Ähnlichkeiten zwischen Spam-Nachrichten zu finden als innerhalb der breiten Menge des normalen Verkehrs.
Die Erkennung von Malware und Botnetzen sind weitere Anwendungen, die eindeutig in die Kategorie der Mustererkennung fallen. Hier ist maschinelles Lernen besonders nützlich, wenn die Angreifer Polymorphismus einsetzen, um eine Entdeckung zu vermeiden. Beim Fuzzing wird eine Software mit willkürlichen Eingaben versehen, um die Anwendung in einen unbeabsichtigten Zustand zu versetzen, meist um ein Programm zum Absturz zu bringen oder es in einen verwundbaren Modus zu versetzen, damit es weiter ausgenutzt werden kann. Naive Fuzzing-Kampagnen stoßen oft auf das Problem, dass sie über einen unüberschaubar großen Anwendungszustandsraum iterieren müssen. Die am weitesten verbreitete Fuzzing-Software verfügt über Optimierungen, die Fuzzing viel effizienter machen als blinde Iteration. Bei solchen Optimierungen wird auch maschinelles Lernen eingesetzt, indem Muster von zuvor gefundenen Schwachstellen in ähnlichen Programmen erlernt werden und der Fuzzer auf ähnlich verwundbare Codepfade oder Redewendungen gelenkt wird, um potenziell schnellere Ergebnisse zu erzielen.
Bei der Benutzerauthentifizierung und Verhaltensanalyse ist die Abgrenzung zwischen Mustererkennung und Anomalieerkennung weniger klar. In Fällen, in denen das Bedrohungsmodell eindeutig bekannt ist, kann es sinnvoller sein, das Problem durch die Brille der Mustererkennung zu betrachten. In anderen Fällen kann die Anomalieerkennung die Antwort sein. In vielen Fällen kann ein System beide Ansätze nutzen, um eine bessere Abdeckung zu erreichen. Die Erkennung von Netzwerkausreißern ist ein klassisches Beispiel für die Erkennung von Anomalien, denn der meiste Netzwerkverkehr folgt strengen Protokollen und das normale Verhalten entspricht in Form oder Reihenfolge einer Reihe von Mustern. Jede bösartige Netzwerkaktivität, die sich nicht gut tarnen kann, indem sie den normalen Datenverkehr nachahmt, wird von Algorithmen zur Ausreißererkennung erfasst. Andere netzwerkbezogene Erkennungsprobleme, wie die Erkennung bösartiger URLs, können ebenfalls aus dem Blickwinkel der Anomalieerkennung betrachtet werden.
Der BegriffZugriffskontrolle bezieht sich auf eine Reihe von Richtlinien, die den Zugriff von Systembenutzern auf bestimmte Informationen regeln. Die Zugriffskontrolle wird häufig eingesetzt, um sensible Daten vor unnötiger Offenlegung zu schützen, und ist oft die erste Verteidigungslinie gegen Datenschutzverletzungen und Informationsdiebstahl. Das maschinelle Lernen hat allmählich Einzug in Lösungen für die Zugriffskontrolle gehalten, da die Systembenutzer/innen den starren und unnachgiebigen Richtlinien für die Zugriffskontrolle ausgeliefert sind.5 Durch eine Kombination aus unüberwachtem Lernen und der Erkennung von Anomalien können solche Systeme auf Informationszugriffsmuster für bestimmte Nutzer oder Rollen in einer Organisation schließen und Gegenmaßnahmen ergreifen, wenn ein unkonventionelles Muster entdeckt wird.
Stell dir zum Beispiel die Speicherung von Patientenakten in einem Krankenhaus vor, wo Krankenschwestern und medizinisches Fachpersonal häufig auf einzelne Patientendaten zugreifen müssen, aber nicht unbedingt patientenübergreifende Zusammenhänge herstellen müssen. Ärzte hingegen fragen häufig die Krankenakten mehrerer Patienten ab und fassen sie zusammen, um nach Ähnlichkeiten zwischen den Fällen und Diagnosen zu suchen. Wir wollen nicht unbedingt verhindern, dass Krankenschwestern und medizinisches Fachpersonal mehrere Patientenakten abfragen, denn es kann seltene Fälle geben, die solche Aktionen rechtfertigen. Ein strenges, regelbasiertes System zur Zugriffskontrolle wäre nicht in der Lage, die Flexibilität und Anpassungsfähigkeit zu bieten, die maschinelle Lernsysteme bieten können.
Im weiteren Verlauf dieses Buches werden wir eine Auswahl dieser Anwendungen aus der Praxis näher beleuchten. Dann können wir die Feinheiten der Anwendung von maschinellem Lernen zur Mustererkennung und Erkennung von Anomalien im Sicherheitsbereich diskutieren. Im weiteren Verlauf dieses Kapitels konzentrieren wir uns auf das Beispiel der Spam-Bekämpfung, um die Grundprinzipien zu veranschaulichen, die bei der Anwendung von maschinellem Lernen im Sicherheitsbereich gelten.
Spam-Bekämpfung: Ein iterativer Ansatz
Wie bereits erwähnt, ist das Beispiel der Spambekämpfung eines der ältesten Probleme der Computersicherheit und eines, das mit maschinellem Lernen erfolgreich angegangen wurde. In diesem Abschnitt tauchen wir tief in dieses Thema ein und zeigen, wie man mithilfe von maschinellem Lernen schrittweise ein ausgeklügeltes System zur Spam-Klassifizierung aufbaut. Der Ansatz, den wir hier verfolgen, lässt sich auf viele andere Arten von Sicherheitsproblemen übertragen, unter anderem auch auf die, die in späteren Kapiteln dieses Buches behandelt werden.
Stell dir ein Szenario vor, in dem du gebeten wirst, das Problem des ausufernden E-Mail-Spams zu lösen, von dem die Mitarbeiter eines Unternehmens betroffen sind. Aus welchen Gründen auch immer wirst du angewiesen, eine individuelle Lösung zu entwickeln, anstatt kommerzielle Optionen zu nutzen. Mit Administratorenzugang zu den privaten E-Mail-Servern bist du in der Lage, eine Reihe von E-Mails zur Analyse zu extrahieren. Alle E-Mails sind von den Empfängern ordnungsgemäß als "Spam" oder "Ham" (Nicht-Spam) gekennzeichnet, so dass du nicht viel Zeit mit der Bereinigung der Daten verbringen musst.6
Menschen sind gut darin, Spam zu erkennen. Deshalb beginnst du mit der Implementierung einer einfachen Lösung, die dem Gedankengang eines Menschen bei der Ausführung dieser Aufgabe nahe kommt. Deine Theorie ist, dass das Vorhandensein oder Fehlen einiger prominenter Schlüsselwörter in einer E-Mail ein starker binärer Indikator dafür ist, ob die E-Mail Spam oder Schinken ist. Dir ist zum Beispiel aufgefallen, dass das Wort "Lotterie" in den Spam-Daten häufig vorkommt, aber nur selten in normalen E-Mails. Du könntest eine Liste mit ähnlichen Wörtern erstellen und die Klassifizierung vornehmen, indem du prüfst, ob eine E-Mail Wörter enthält, die auf dieser schwarzen Liste stehen.
Der Datensatz, den wir zur Untersuchung dieses Problems verwenden werden, ist der TREC Public Spam Corpus 2007. Dabei handelt es sich um einen leicht bereinigten, rohen E-Mail-Korpus mit 75.419 Nachrichten, die über einen Zeitraum von drei Monaten im Jahr 2007 von einem E-Mail-Server gesammelt wurden. Ein Drittel des Datensatzes besteht aus Spam-Beispielen, der Rest ist Schinken. Dieser Datensatz wurde von der Text REtrieval Conference (TREC) Spam Track im Jahr 2007 erstellt, um die Grenzen der modernen Spam-Erkennung zu erweitern.
Um zu bewerten, wie gut die verschiedenen Ansätze funktionieren, führen wir einen einfachen Validierungsprozess durch.7 Wir teilen den Datensatz in einen Trainings- und einen Testdatensatz auf, die sich nicht überschneiden. Der Trainingsdatensatz besteht aus 70 % der Daten (ein willkürlich gewählter Anteil) und der Testdatensatz aus den restlichen 30 %. Diese Methode ist gängige Praxis, um zu beurteilen, wie gut ein Algorithmus oder ein Modell, das auf der Grundlage des Trainingssatzes entwickelt wurde, auf einen unabhängigen Datensatz verallgemeinert werden kann.
Der erste Schritt besteht darin, mit dem Natural Language Toolkit (NLTK) morphologische Affixe aus Wörtern zu entfernen, um einen flexibleren Abgleich zu ermöglichen (ein Prozess, der Stemming genannt wird). Auf diese Weise werden zum Beispiel die Wörter "Glückwunsch" und "Gratulation" auf das gleiche Stammwort, "Gratulation", reduziert. Außerdem entfernen wir Stoppwörter (z. B. "der", "ist" und "sind") vor der Tokenextraktion, da sie in der Regel nicht viel Bedeutung haben. Wir definieren eine Reihe von Funktionen8 die beim Laden und Vorverarbeiten der Daten und Labels helfen, wie im folgenden Code gezeigt wird:9
importstringimportimportnltkpunctuations=list(string.punctuation)stopwords=set(nltk.corpus.stopwords.words('english'))stemmer=nltk.PorterStemmer()# Combine the different parts of the email into a flat list of stringsdefflatten_to_string(parts):ret=[]iftype(parts)==str:ret.append(parts)eliftype(parts)==list:forpartinparts:ret+=flatten_to_string(part)elifparts.get_content_type=='text/plain':ret+=parts.get_payload()returnret# Extract subject and body text from a single email filedefextract_email_text(path):# Load a single email from an input filewithopen(path,errors='ignore')asf:msg=.message_from_file(f)ifnotmsg:return""# Read the email subjectsubject=msg['Subject']ifnotsubject:subject=""# Read the email bodybody=' '.join(mforminflatten_to_string(msg.get_payload())iftype(m)==str)ifnotbody:body=""returnsubject+' '+body# Process a single email file into stemmed tokensdefload(path):email_text=extract_email_text(path)ifnotemail_text:return[]# Tokenize the messagetokens=nltk.word_tokenize(email_text)# Remove punctuation from tokenstokens=[i.strip("".join(punctuations))foriintokensifinotinpunctuations]# Remove stopwords and stem tokensiflen(tokens)>2:return[stemmer.stem(w)forwintokensifwnotinstopwords]return[]
Als Nächstes fahren wir mit dem Laden der E-Mails und Labels fort. Dieser Datensatz enthält jede E-Mail in einer eigenen Datei(inmail.1, inmail.2, inmail.3, ...) sowie eine einzelne Beschriftungsdatei(full/index) im folgenden Format:
spam ../data/inmail.1 ham ../data/inmail.2 spam ../data/inmail.3 ...
Jede Zeile in der Etikettendatei enthält die Bezeichnung "Spam" oder "Ham" für jede E-Mail-Probe im Datensatz. Lesen wir den Datensatz und erstellen wir eine schwarze Liste mit Spam-Wörtern:10
importosDATA_DIR='datasets/trec07p/data/'LABELS_FILE='datasets/trec07p/full/index'TRAINING_SET_RATIO=0.7labels={}spam_words=set()ham_words=set()# Read the labelswithopen(LABELS_FILE)asf:forlineinf:line=line.strip()label,key=line.split()labels[key.split('/')[-1]]=1iflabel.lower()=='ham'else0# Split corpus into training and test setsfilelist=os.listdir(DATA_DIR)X_train=filelist[:int(len(filelist)*TRAINING_SET_RATIO)]X_test=filelist[int(len(filelist)*TRAINING_SET_RATIO):]forfilenameinX_train:path=os.path.join(DATA_DIR,filename)iffilenameinlabels:label=labels[filename]stems=load(path)ifnotstems:continueiflabel==1:ham_words.update(stems)eliflabel==0:spam_words.update(stems)else:continueblacklist=spam_words-ham_words
Wenn du dir die Token in blacklist ansiehst, wirst du vielleicht feststellen, dass viele der Wörter unsinnig sind (z. B. Unicode, URLs, Dateinamen, Symbole, Fremdwörter). Du kannst dieses Problem mit einem gründlicheren Datenbereinigungsprozess beheben, aber für die Zwecke dieses Experiments sollten diese einfachen Ergebnisse ausreichen:
greenback, gonorrhea, lecher, ...
Bei der Auswertung unserer Methode anhand der 22.626 E-Mails in der Testmenge stellen wir fest, dass dieser einfache Algorithmus nicht so gut abschneidet, wie wir gehofft hatten. Wir geben die Ergebnisse in einer Konfusionsmatrix an, einer 2 × 2-Matrix, die die Anzahl der Beispiele mit den vorhergesagten und tatsächlichen Bezeichnungen für jedes der vier möglichen Paare angibt:
| Vorausgesagte HAM | Vorausgesagter SPAM | |
|---|---|---|
Aktueller HAM |
6,772 |
714 |
Tatsächlicher SPAM |
5,835 |
7,543 |
Echt positiv: vorhergesagter Spam + tatsächlicher Schinken |
Wahres Negativ: vorhergesagter Schinken + tatsächlicher Schinken |
Falsch positiv: vorhergesagter Spam + tatsächlicher Schinken |
Falsch negativ: vorhergesagter Schinken + tatsächlicher Spam |
Wenn wir dies in Prozente umrechnen, erhalten wir folgendes Ergebnis:
| Vorausgesagte HAM | Vorausgesagter SPAM | |
|---|---|---|
Aktueller HAM |
32.5% |
3.4% |
Tatsächlicher SPAM |
28.0% |
36.2% |
Klassifizierungsgenauigkeit: 68,7% |
Lässt man die Tatsache außer Acht, dass 5,8 % der E-Mails aufgrund von Vorverarbeitungsfehlern nicht klassifiziert wurden, sehen wir, dass die Leistung dieses naiven Algorithmus eigentlich recht ordentlich ist. Die Klassifizierungsgenauigkeit (d. h. der Gesamtanteil der richtigen Kennzeichnungen) unserer Spam-Blacklist-Technik liegt bei 68,7 %. Allerdings enthält die schwarze Liste nicht viele Wörter, die in Spam-E-Mails verwendet werden, weil sie auch in legitimen E-Mails häufig vorkommen. Außerdem scheint es eine unmögliche Aufgabe zu sein, eine ständig aktualisierte Liste von Wörtern zu führen, die eine saubere Unterscheidung zwischen Spam und Schinken ermöglicht. Vielleicht ist es an der Zeit, wieder an das Reißbrett zu gehen.
Als Nächstes erinnerst du dich daran, dass eine der beliebtesten Methoden der E-Mail-Anbieter zur Spam-Bekämpfung in der Anfangszeit darin bestand, Spam-Nachrichten mit einem Fuzzy-Hash zu versehen und E-Mails zu filtern, die einen ähnlichen Hash ergaben. Dabei handelt es sich um eine Art kollaborative Filterung, die sich auf die Weisheit anderer Nutzer/innen auf der Plattform verlässt, um eine kollektive Intelligenz aufzubauen, die hoffentlich gut verallgemeinert und neu eingehende Spams erkennt. Die Hypothese ist, dass Spammerinnen und Spammer bei der Erstellung von Spam-Nachrichten einen gewissen Automatismus anwenden und daher Spam-Nachrichten produzieren, die sich nur geringfügig voneinander unterscheiden. Mit einem unscharfen Hash-Algorithmus, genauer gesagt mit einem ortsabhängigen Hash (LSH), kannst du ungefähre Übereinstimmungen von E-Mails finden, die als Spam markiert wurden.
Bei deiner Recherche stößt du auf datasketch, ein umfassendes Python-Paket, das effiziente Implementierungen des MinHash + LSH-Algorithmus enthält11 zur Verfügung stellt, um String-Matching mit sublinearen Abfragekosten (in Bezug auf die Kardinalität der Spammenge) durchzuführen. MinHash konvertiert String-Token-Sets in kurze Signaturen, wobei die Eigenschaften der ursprünglichen Eingabe erhalten bleiben, die einen Ähnlichkeitsabgleich ermöglichen. LSH kann dann auf MinHash-Signaturen anstelle von rohen Token angewendet werden, was die Leistung erheblich verbessert. MinHash erkauft den Leistungsgewinn mit einem gewissen Verlust an Genauigkeit, so dass es in deinem Ergebnis einige falsch positive und falsch negative Ergebnisse geben wird. Die Durchführung eines naiven Fuzzy-String-Matchings für jede E-Mail-Nachricht gegen den gesamten Satz von n Spam-Nachrichten in deinem Trainingssatz verursacht jedoch entweder O(n) Abfragekomplexität (wenn du deinen Korpus jedes Mal scannst) oder O(n) Speicher (wenn du eine Hash-Tabelle deines Korpus aufbaust), und du beschließt, dass du mit diesem Kompromiss umgehen kannst:12,13
fromdatasketchimportMinHash,MinHashLSH# Extract only spam files for inserting into the LSH matcherspam_files=[xforxinX_trainiflabels[x]==0]# Initialize MinHashLSH matcher with a Jaccard# threshold of 0.5 and 128 MinHash permutation functionslsh=MinHashLSH(threshold=0.5,num_perm=128)# Populate the LSH matcher with training spam MinHashesforidx,finenumerate(spam_files):minhash=MinHash(num_perm=128)stems=load(os.path.join(DATA_DIR,f))iflen(stems)<2:continueforsinstems:minhash.update(s.encode('utf-8'))lsh.insert(f,minhash)
Jetzt ist es an der Zeit, dass der LSH-Matcher die Labels für die Testmenge vorhersagt:
deflsh_predict_label(stems):'''Queries the LSH matcher and returns:0 if predicted spam1 if predicted ham−1 if parsing error'''minhash=MinHash(num_perm=128)iflen(stems)<2:return−1forsinstems:minhash.update(s.encode('utf-8'))matches=lsh.query(minhash)ifmatches:return0else:return1
Wenn du dir die Ergebnisse ansiehst, siehst du Folgendes:
| Vorausgesagte HAM | Vorausgesagter SPAM | |
|---|---|---|
Aktueller HAM |
7,350 |
136 |
Tatsächlicher SPAM |
2,241 |
11,038 |
Wenn du das in Prozente umrechnest, erhältst du:
| Vorausgesagte HAM | Vorausgesagter SPAM | |
|---|---|---|
Aktueller HAM |
35.4% |
0.7% |
Tatsächlicher SPAM |
10.8% |
53.2% |
Klassifizierungsgenauigkeit: 88,6% |
Das ist etwa 20 % besser als der vorherige naive Blacklisting-Ansatz und deutlich besser in Bezug auf False Positives (d. h. vorhergesagter Spam + tatsächlicher Schinken). Dennoch spielen diese Ergebnisse noch immer nicht in der gleichen Liga wie moderne Spamfilter. Wenn du dich mit den Daten beschäftigst, wird dir klar, dass es vielleicht nicht am Algorithmus liegt, sondern an der Art der Daten, die du hast - der Spam in deinem Datensatz scheint sich einfach nicht zu wiederholen. E-Mail-Anbieter sind aufgrund des Umfangs und der Vielfalt der Nachrichten, die sie sehen, viel besser in der Lage, die kollaborative Spamfilterung zu nutzen. Wenn ein Spammer es nicht auf eine große Anzahl von Mitarbeitern in deinem Unternehmen abgesehen hat, gibt es keine nennenswerten Wiederholungen im Spam-Korpus. Wenn du einen Durchbruch erzielen willst, musst du mehr tun, als Stammwörter abzugleichen und Jaccard-Ähnlichkeiten zu berechnen.
An diesem Punkt bist du vom Experimentieren frustriert und beschließt, mehr zu recherchieren, bevor du weitermachst. Du siehst, dass viele andere vielversprechende Ergebnisse mit einer Technik namens Naive Bayes-Klassifizierung erzielt haben. Nachdem du ein gutes Verständnis für die Funktionsweise des Algorithmus bekommen hast, beginnst du mit der Erstellung eines Prototyps. Scikit-learn bietet eine erstaunlich einfache Klasse, sklearn.naive_bayes.MultinomialNBdie du verwenden kannst, um schnell Ergebnisse für dieses Experiment zu erzielen. Du kannst einen großen Teil des früheren Codes für das Parsen der E-Mail-Dateien und die Vorverarbeitung der Labels wiederverwenden. Du beschließt jedoch, den gesamten E-Mail-Betreff und den reinen Textkörper (durch eine neue Zeile getrennt) zu übergeben, ohne Stoppwörter zu entfernen oder mit NLTK Stemming durchzuführen. Du definierst eine kleine Funktion, die alle E-Mail-Dateien in diese Textform einliest:14,15
defread_email_files():X=[]y=[]foriinxrange(len(labels)):filename='inmail.'+str(i+1)email_str=extract_email_text(os.path.join(DATA_DIR,filename))X.append(email_str)y.append(labels[filename])returnX,y
Dann verwendest du die Hilfsfunktion sklearn.model_selection.train_test_split() um den Datensatz nach dem Zufallsprinzip in einen Trainings- und einen Testdatensatz aufzuteilen (das Argument random_state=123 wird aus Gründen der Reproduzierbarkeit der Ergebnisse mitgegeben):
fromsklearn.model_selectionimporttrain_test_splitX,y=read_email_files()X_train,X_test,y_train,y_test,idx_train,idx_test=\train_test_split(X,y,range(len(y)),train_size=TRAINING_SET_RATIO,random_state=2)
Nachdem du die Rohdaten aufbereitet hast, musst du die Token weiterverarbeiten, um jede E-Mail in eine Vektordarstellung zu konvertieren, die MultinomialNB als Eingabe akzeptiert.
Eine der einfachsten Möglichkeiten, einen Text in einen Merkmalsvektor umzuwandeln, ist die Bag-of-Words-Darstellung, die den gesamten Dokumentenkorpus durchläuft und ein Vokabular der im Korpus verwendeten Token erzeugt. Jedes Wort in diesem Vokabular enthält ein Merkmal, und jeder Merkmalswert gibt an, wie oft das Wort im Korpus vorkommt. Betrachten wir zum Beispiel ein hypothetisches Szenario, in dem du nur drei Nachrichten im gesamten Korpus hast:
tokenized_messages:{'A':['hello','mr','bear'],'B':['hello','hello','gunter'],'C':['goodbye','mr','gunter']}# Bag-of-words feature vector column labels:# ['hello', 'mr', 'doggy', 'bear', 'gunter', 'goodbye']vectorized_messages:{'A':[1,1,0,1,0,0],'B':[2,0,0,0,1,0],'C':[0,1,0,0,1,1]}
Obwohl dieser Prozess scheinbar wichtige Informationen wie die Reihenfolge der Wörter, die inhaltliche Struktur und Wortähnlichkeiten verwirft, ist er mit der Klassesklearn.feature_extraction.CountVectorizer sehr einfach zu implementieren:
fromsklearn.feature_extraction.textimportCountVectorizervectorizer=CountVectorizer()X_train_vector=vectorizer.fit_transform(X_train)X_test_vector=vectorizer.transform(X_test)
Du kannst auch versuchen, den Term Frequency/Inverse Document Frequency (TF/IDF)-Vektor anstelle der rohen Zählung zu verwenden. TF/IDF normalisiert die Anzahl der Rohwörter und ist im Allgemeinen ein besserer Indikator für die statistische Bedeutung eines Wortes im Text. Er wird bereitgestellt als sklearn.feature_extraction.text.TfidfVectorizer.
Jetzt kannst du deinen multinomialen Naive Bayes-Klassifikator trainieren und testen:
fromsklearn.naive_bayesimportMultinomialNBfromsklearn.metricsimportaccuracy_score# Initialize the classifier and make label predictionsmnb=MultinomialNB()mnb.fit(X_train_vector,y_train)y_pred=mnb.predict(X_test_vector)# Print results('Accuracy {:.3f}'.format(accuracy_score(y_test,y_pred)))>Accuracy:0.956
Eine Genauigkeit von 95,6 % - ganze 7 % besser als der LSH-Ansatz!16 Das ist kein schlechtes Ergebnis für ein paar Codezeilen und liegt in der Größenordnung dessen, was moderne Spamfilter leisten können. Einige moderne Spamfilter basieren auf einer Variante der Naive Bayes-Klassifizierung. Beim maschinellen Lernen ist die Kombination mehrerer unabhängiger Klassifizierer und Algorithmen zu einem Ensemble (auch bekannt als gestapelte Generalisierung oder Stacking) eine gängige Methode, um die Stärken der einzelnen Methoden zu nutzen. Du kannst dir also vorstellen, wie eine Kombination aus Wort-Blacklists, Fuzzy-Hash-Matching und einem Naive-Bayes-Modell helfen kann, dieses Ergebnis zu verbessern.
Leider ist die Spam-Erkennung in der realen Welt nicht so einfach, wie wir es in diesem Beispiel dargestellt haben. Es gibt viele verschiedene Arten von Spam, jede mit einem anderen Angriffsvektor und einer anderen Methode, um der Erkennung zu entgehen. Manche Spam-Nachrichten setzen zum Beispiel stark darauf, den Leser zum Klicken auf Links zu verleiten. Der Inhalt der E-Mail enthält daher vielleicht nicht so viel belastenden Text wie andere Arten von Spam. Diese Art von Spam kann dann versuchen, Link-Spam-Erkennungsprogramme mit komplexen Methoden wie Tarnungen und Umleitungsketten zu umgehen. Andere Arten von Spam setzen nur auf Bilder und verzichten ganz auf Text.
Für den Moment bist du mit deinen Fortschritten zufrieden und beschließt, diese Lösung einzusetzen. Wie es immer der Fall ist, wenn man es mit menschlichen Gegnern zu tun hat, werden die Spammer irgendwann merken, dass ihre E-Mails nicht mehr durchkommen, und versuchen, der Entdeckung zu entgehen. Diese Reaktion ist nichts Ungewöhnliches bei Sicherheitsproblemen. Du musst deine Erkennungsalgorithmen und Klassifikatoren ständig verbessern und deinen Gegnern immer einen Schritt voraus sein.
In den folgenden Kapiteln untersuchen wir, wie du mit Methoden des maschinellen Lernens vermeiden kannst, dass du dich ständig mit Angreifern messen musst, und wie du eine anpassungsfähigere Lösung entwickeln kannst, um die ständigen manuellen Anpassungen zu minimieren.
Grenzen des maschinellen Lernens in der Sicherheit
Die Vorstellung, dass Methoden des maschinellen Lernens in verschiedenen Anwendungsfällen immer gute Ergebnisse liefern, ist kategorisch falsch. In der Praxis gibt es in der Regel andere Faktoren als Präzision, Recall oder Genauigkeit, die optimiert werden müssen.
So kann beispielsweise die Erklärbarkeit von Klassifizierungsergebnissen in manchen Anwendungen wichtiger sein als in anderen. Es kann wesentlich schwieriger sein, die Gründe für eine von einem maschinellen Lernsystem getroffene Entscheidung herauszufinden, als bei einer einfachen Regel. Einige maschinelle Lernsysteme können auch wesentlich ressourcenintensiver sein als andere Alternativen, was für die Ausführung in eingeschränkten Umgebungen, wie z. B. eingebetteten Systemen, ein entscheidender Faktor sein kann.
Es gibt keinen Patentrezept-Algorithmus für maschinelles Lernen, der in allen Problembereichen gut funktioniert. Die verschiedenen Algorithmen unterscheiden sich stark in ihrer Eignung für verschiedene Anwendungen und unterschiedliche Datensätze. Obwohl maschinelle Lernverfahren zum Begriff der künstlichen Intelligenz beitragen, können ihre Fähigkeiten nur in bestimmten Bereichen mit der menschlichen Intelligenz verglichen werden.
Der menschliche Entscheidungsfindungsprozess basiert auf einer Vielzahl von Kontexten, die auf kulturellem und Erfahrungswissen beruhen. Dieser Prozess lässt sich von maschinellen Lernsystemen nur schwer nachahmen. Nehmen wir als Beispiel den ursprünglichen Ansatz der schwarzen Liste, den wir für die Spam-Filterung verwendet haben. Wenn eine Person den Inhalt einer E-Mail bewertet, um festzustellen, ob es sich um Schinken oder Spam handelt, ist der Entscheidungsprozess nie so einfach wie die Suche nach dem Vorhandensein bestimmter Wörter. Der Kontext, in dem ein auf der schwarzen Liste stehendes Wort verwendet wird, kann dazu führen, dass es auch in Nicht-Spam-E-Mails verwendet werden kann. Außerdem könnten Spammer in zukünftigen E-Mails Synonyme von Wörtern auf der schwarzen Liste verwenden, um die gleiche Bedeutung zu vermitteln. Das System hat einfach nicht den Kontext, den ein Mensch hat - es weiß nicht, welche Bedeutung ein bestimmtes Wort für den Leser hat. Das ständige Aktualisieren der schwarzen Liste mit neuen verdächtigen Wörtern ist ein mühsamer Prozess und garantiert keineswegs eine perfekte Abdeckung.
Auch wenn dein maschinengelerntes Modell in einem Trainingsdatensatz perfekt funktioniert, kann es sein, dass es in einem Testdatensatz schlecht abschneidet. Ein häufiger Grund für dieses Problem ist, dass das Modell seine Klassifizierungsgrenzen zu sehr an die Trainingsdaten angepasst hat und dadurch Merkmale des Datensatzes erlernt hat, die sich nicht gut auf andere, nicht gesehene Datensätze übertragen lassen. Dein Spamfilter könnte zum Beispiel aus dem Trainingsdatensatz lernen, dass alle E-Mails, die die Wörter "Erbschaft" und "Nigeria" enthalten, sofort als verdächtig eingestuft werden können, aber er weiß nichts über die legitime E-Mail-Kettendiskussion zwischen Angestellten über Erbschaften in nigerianischen Landwirtschaftsversicherungen.
In Anbetracht all dieser Einschränkungen sollten wir uns dem maschinellen Lernen zu gleichen Teilen mit Enthusiasmus und Vorsicht nähern und uns daran erinnern, dass nicht alles mit KI sofort besser gemacht werden kann.
1 Angelehnt an die Taxonomie für Sicherheitsvorfälle des europäischen CSIRT-Netzwerkprojekts.
2 Charlie Miller, "The Legitimate Vulnerability Market: Inside the Secretive World of 0-day Exploit Sales," Proceedings of the 6th Workshop on the Economics of Information Security (2007).
3 Juan Caballero et al., "Measuring Pay-per-Install: The Commoditization of Malware Distribution," Proceedings of the 20th USENIX Conference on Security (2011).
4 Ling Huang et al., "Adversarial Machine Learning", Proceedings of the 4th ACM Workshop on Artificial Intelligence and Security (2011): 43-58.
5 Evan Martin und Tao Xie, "Inferring Access-Control Policy Properties via Machine Learning", Proceedings of the 7th IEEE International Workshop on Policies for Distributed Systems and Networks (2006): 235-238.
6 In der Praxis wirst du einen großen Teil deiner Zeit damit verbringen, die Daten zu bereinigen, damit sie für deine Algorithmen verfügbar und nützlich sind.
7 Dieses Validierungsverfahren, das manchmal auch als konventionelle Validierung bezeichnet wird, ist nicht so streng wie die Kreuzvalidierung, die sich auf eine Klasse von Methoden bezieht, bei der wiederholt alle (oder viele) verschiedene mögliche Aufteilungen des Datensatzes (in Trainings- und Testmengen) erzeugt werden und der Vorhersagealgorithmus des maschinellen Lernens für jede dieser Aufteilungen separat validiert wird. Das Ergebnis der Kreuzvalidierung ist die durchschnittliche Vorhersagegenauigkeit über diese verschiedenen Teilmengen hinweg. Die Kreuzvalidierung schätzt die Modellgenauigkeit besser ein als die herkömmliche Validierung, weil sie den Informationsverlust vermeidet, der durch eine einzige Aufteilung in Trainings- und Testdaten entsteht, die die statistischen Eigenschaften der Daten möglicherweise nicht angemessen erfasst (dies ist in der Regel kein Problem, wenn die Trainingsmenge ausreichend groß ist). Hier haben wir uns der Einfachheit halber für die konventionelle Validierung entschieden.
8 Diese Hilfsfunktionen sind in der Datei chapter1/email_read_util.py in unserem Code-Repository definiert.
9 Um diesen Code auszuführen, musst du die Punkt Tokenizer-Modelle und den Stoppwörter-Korpus in NLTK mit dem Dienstprogramm nltk.download() installieren.
10 Dieses Beispiel findest du im Python-Jupyter-Notizbuch chapter1/spam-fighting-blacklist.ipynb in unserem Code-Repository.
11 Siehe Kapitel 3 in Mining of Massive Datasets, 2. Aufl., von Jure Leskovec, Anand Rajaraman, und Jeffrey David Ullman (Cambridge University Press).
12 Dieses Beispiel findest du im Python-Jupyter-Notizbuch chapter1/spam-fighting-lsh.ipynb in unserem Code-Repository.
13 Beachte, dass wir den threshold Parameter des MinHashLSH Objekts mit 0,5 angegeben haben. Diese spezielle LSH-Implementierung verwendet die Jaccard-Ähnlichkeiten zwischen den MinHashes in deiner Sammlung und dem abgefragten MinHash und gibt die Liste der Objekte zurück, die die Schwellenwertbedingung erfüllen (d.h. Jaccard-Ähnlichkeitswert > 0,5). Der MinHash-Algorithmus erzeugt kurze und eindeutige Signaturen für eine Zeichenfolge, indem er zufällige Permutationen der Zeichenfolge durch eine Hash-Funktion leitet. Wenn du den Parameter num_perm auf 128 einstellst, bedeutet das, dass 128 zufällige Permutationen der Zeichenkette berechnet und durch die Hash-Funktion geleitet wurden. Generell gilt: Je mehr zufällige Permutationen der Algorithmus verwendet, desto höher ist die Genauigkeit des Hashwerts.
14 Dieses Beispiel findest du im Python-Jupyter-Notizbuch chapter1/spam-fighting-naivebayes.ipynb in unserem Code-Repository.
15 Im Code für maschinelles Lernen ist es eine lockere Konvention, Variablennamen für einzelne Wertespalten in Kleinbuchstaben und für mehrere Wertespalten in Großbuchstaben zu schreiben.
16 Im Allgemeinen ist es grob und unvollständig, nur die Genauigkeit der Modellvorhersage zu messen. Die Bewertung von Modellen ist ein wichtiges Thema, auf das wir in Kapitel 2 näher eingehen. Hier entscheiden wir uns für die Einfachheit und verwenden die Genauigkeit als ungefähres Maß für die Leistung. Die Methode sklearn.metrics.classification_report() liefert Präzision, Recall, f1-Score und Support für jede Klasse, die in Kombination verwendet werden können, um ein genaueres Bild der Leistung des Modells zu erhalten.
Get Maschinelles Lernen und Sicherheit now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

