Kapitel 1. Überblick über maschinelle Lernsysteme
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Im November 2016 gab Google bekannt, dass es sein mehrsprachiges neuronales maschinelles Übersetzungssystem in Google Translate ( ) integriert hat und damit eine der ersten Erfolgsgeschichten von tiefen künstlichen neuronalen Netzwerken in der Produktion in großem Maßstab schrieb.1 Nach Angaben von Google hat sich mit diesem Update die Qualität der Übersetzung in einem einzigen Schritt mehr verbessert als in den 10 Jahren zuvor zusammen.
Dieser Erfolg von Deep Learning hat das Interesse an maschinellem Lernen (ML) auf neu entfacht. Seitdem haben sich immer mehr Unternehmen ML zugewandt, um Lösungen für ihre schwierigsten Probleme zu finden. In nur fünf Jahren hat ML seinen Weg in fast jeden Aspekt unseres Lebens gefunden: wie wir auf Informationen zugreifen, wie wir kommunizieren, wie wir arbeiten, wie wir Liebe finden. Die Verbreitung von ML ist so rasant, dass es schon jetzt kaum noch wegzudenken ist. Doch es gibt noch viele weitere Anwendungsfälle für ML, die darauf warten, erforscht zu werden, z. B. im Gesundheitswesen, im Verkehrswesen, in der Landwirtschaft und sogar, um uns zu helfen, das Universum zu verstehen.2
Viele Menschen denken bei dem Begriff "maschinelles Lernsystem" nur an die verwendeten ML-Algorithmen wie die logistische Regression oder verschiedene Arten von neuronalen Netzen. Der Algorithmus ist jedoch nur ein kleiner Teil eines ML-Systems in der Produktion. Zum System gehören auch die geschäftlichen Anforderungen, die das ML-Projekt ins Leben gerufen haben, die Schnittstelle, über die Benutzer und Entwickler mit deinem System interagieren, der Datenstapel und die Logik für die Entwicklung, Überwachung und Aktualisierung deiner Modelle sowie die Infrastruktur, die die Bereitstellung dieser Logik ermöglicht. Abbildung 1-1 zeigt dir die verschiedenen Komponenten eines ML-Systems und in welchen Kapiteln dieses Buches sie behandelt werden.
Die Beziehung zwischen MLOps und ML Systems Design
Ops in MLOps kommt von DevOps, kurz für Developments and Operations. Etwas zu operationalisieren bedeutet, es in Produktion zu bringen, was die Bereitstellung, Überwachung und Wartung einschließt. MLOps ist eine Sammlung von Tools und bewährten Methoden, um ML in Produktion zu bringen.
Bei der Entwicklung von ML-Systemen wird ein Systemansatz verfolgt. Das bedeutet, dass ein ML-System ganzheitlich betrachtet wird, um sicherzustellen, dass alle Komponenten und ihre Beteiligten zusammenarbeiten können, um die festgelegten Ziele und Anforderungen zu erfüllen.
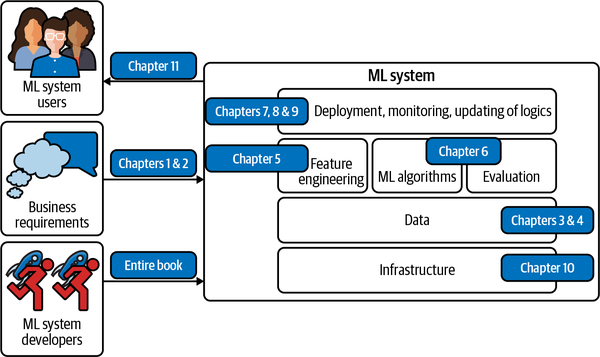
Abbildung 1-1. Verschiedene Komponenten eines ML-Systems. Wenn man von maschinellem Lernen spricht, denkt man meist an "ML-Algorithmen", aber das ist nur ein kleiner Teil des gesamten Systems.
Es gibt viele hervorragende Bücher über verschiedene ML-Algorithmen. Dieses Buch behandelt keine spezifischen Algorithmen im Detail, sondern hilft dem Leser, das ML-System als Ganzes zu verstehen. Mit anderen Worten: Das Ziel dieses Buches ist es, dir einen Rahmen zu geben, in dem du eine Lösung für dein Problem entwickeln kannst, unabhängig davon, welchen Algorithmus du letztendlich verwendest. Algorithmen können schnell veraltet sein, da ständig neue Algorithmen entwickelt werden, aber der in diesem Buch vorgeschlagene Rahmen sollte auch mit neuen Algorithmen funktionieren.
Das erste Kapitel des Buches soll dir einen Überblick darüber geben, was nötig ist, um ein ML-Modell in die Produktion zu bringen. Bevor wir uns mit der Entwicklung eines ML-Systems befassen, ist es wichtig, die grundlegende Frage zu stellen, wann ML eingesetzt werden sollte und wann nicht. Um das zu verdeutlichen, gehen wir auf einige der beliebtesten Anwendungsfälle von ML ein.
Nach den Anwendungsfällen gehen wir zu den Herausforderungen beim Einsatz von ML-Systemen über, indem wir ML in der Produktion mit ML in der Forschung und mit herkömmlicher Software vergleichen. Wenn du dich mit der Entwicklung angewandter ML-Systeme befasst hast, bist du mit dem Inhalt dieses Kapitels vielleicht schon vertraut. Wenn du jedoch nur in einem akademischen Umfeld Erfahrungen mit ML gemacht hast, wird dir dieses Kapitel einen ehrlichen Einblick in die reale Welt von ML geben und deine erste Anwendung erfolgreich machen.
Wann wird maschinelles Lernen eingesetzt?
Während die Akzeptanz in der Branche schnell wächst , hat sich ML als mächtiges Werkzeug für eine Vielzahl von Problemen erwiesen. Trotz der unglaublichen Aufregung und des Hypes, der von Menschen innerhalb und außerhalb der Branche ausgelöst wurde, ist ML kein magisches Werkzeug, das alle Probleme lösen kann. Selbst für Probleme, die mit ML gelöst werden können, sind ML-Lösungen möglicherweise nicht die optimalen Lösungen. Bevor du ein ML-Projekt beginnst, solltest du dich fragen, ob ML notwendig oder kosteneffizient ist.3
Um zu verstehen, was ML leisten kann, sollten wir uns ansehen, was ML-Lösungen im Allgemeinen tun:
Maschinelles Lernen ist ein Ansatz, um (1) komplexe Muster aus (3) vorhandenen Daten zu lernen und diese Muster zu nutzen, um (4) Vorhersagen für (5) ungesehene Daten zu treffen.
Wir werden uns jeden der kursiv gedruckten Schlüsselbegriffe im obigen Rahmen ansehen, um zu verstehen, was ML für Probleme lösen kann:
- 1. Lernen: Das System hat die Fähigkeit zu lernen
-
Eine relationale Datenbank ist kein ML-System , weil sie nicht in der Lage ist, zu lernen. Du kannst die Beziehung zwischen zwei Spalten in einer relationalen Datenbank explizit angeben, aber es ist unwahrscheinlich, dass sie in der Lage ist, die Beziehung zwischen diesen beiden Spalten selbst herauszufinden.
Damit ein ML-System lernen kann, muss es etwas geben, aus dem es lernen kann. In den meisten Fällen lernen ML-Systeme aus Daten. Beim überwachten Lernen lernen ML-Systeme anhand von beispielhaften Eingabe- und Ausgabepaaren, wie sie Ausgaben für beliebige Eingaben erzeugen können. Wenn du z. B. ein ML-System entwickeln willst, das den Mietpreis für Airbnb-Angebote vorhersagen kann, musst du einen Datensatz bereitstellen, bei dem jede Eingabe ein Angebot mit relevanten Merkmalen ist (Quadratmeterzahl, Anzahl der Zimmer, Nachbarschaft, Ausstattung, Bewertung des Angebots usw.) und die zugehörige Ausgabe der Mietpreis dieses Angebots ist. Sobald das ML-System gelernt hat, sollte es in der Lage sein, den Preis für ein neues Angebot anhand seiner Merkmale vorherzusagen.
- 2. Komplexe Muster: Es gibt Muster zu lernen, und sie sind komplex
-
ML-Lösungen sind nur sinnvoll, wenn es Muster gibt, die man lernen kann. Ein vernünftiger Mensch investiert kein Geld in die Entwicklung eines ML-Systems, das das nächste Ergebnis eines fairen Würfels vorhersagt, denn es gibt keine Muster, wie diese Ergebnisse zustande kommen.4 Es gibt jedoch Muster in der Preisbildung von Aktien, und deshalb haben Unternehmen Milliarden von Dollar in den Aufbau von ML-Systemen investiert, um diese Muster zu lernen.
Ob es ein Muster gibt, ist vielleicht nicht offensichtlich, oder wenn es Muster gibt, reichen dein Datensatz oder deine ML-Algorithmen vielleicht nicht aus, um sie zu erfassen. Es könnte zum Beispiel ein Muster darin bestehen, wie Elon Musks Tweets die Kryptowährungspreise beeinflussen. Das würdest du aber erst wissen, wenn du deine ML-Modelle gründlich auf seine Tweets trainiert und ausgewertet hättest. Selbst wenn alle deine Modelle bei der Vorhersage von Kryptowährungspreisen fehlschlagen, heißt das nicht, dass es kein Muster gibt.
Stell dir eine Website wie Airbnb mit vielen Wohnungsangeboten vor; zu jedem Angebot gehört eine Postleitzahl. Wenn du die Angebote nach den Bundesstaaten sortieren willst, in denen sie sich befinden, brauchst du kein ML-System. Da das Muster einfach ist - jede Postleitzahl entspricht einem bekannten Bundesland - kannst du einfach eine Nachschlagetabelle verwenden.
Die Beziehung zwischen einem Mietpreis und all seinen Merkmalen folgt einem viel komplexeren Muster, das manuell nur sehr schwer zu bestimmen wäre. ML ist dafür eine gute Lösung. Anstatt deinem System mitzuteilen, wie es den Preis aus einer Liste von Merkmalen berechnen soll, kannst du Preise und Merkmale angeben und dein ML-System das Muster herausfinden lassen. Der Unterschied zwischen ML-Lösungen und der Lookup-Table-Lösung sowie allgemeinen traditionellen Softwarelösungen wird in Abbildung 1-2 dargestellt. Aus diesem Grund wird ML auch als Software 2.0 bezeichnet.5
ML hat sich bei Aufgaben mit komplexen Mustern wie der Objekterkennung und der Spracherkennung als sehr erfolgreich erwiesen. Was für Maschinen komplex ist, unterscheidet sich von dem, was für Menschen komplex ist. Viele Aufgaben, die für Menschen schwierig sind, sind für Maschinen einfach zu lösen - zum Beispiel das Erhöhen einer Zahl hoch 10. Andererseits können viele Aufgaben, die für Menschen leicht sind, für Maschinen schwer sein - zum Beispiel die Entscheidung, ob eine Katze auf einem Bild zu sehen ist.
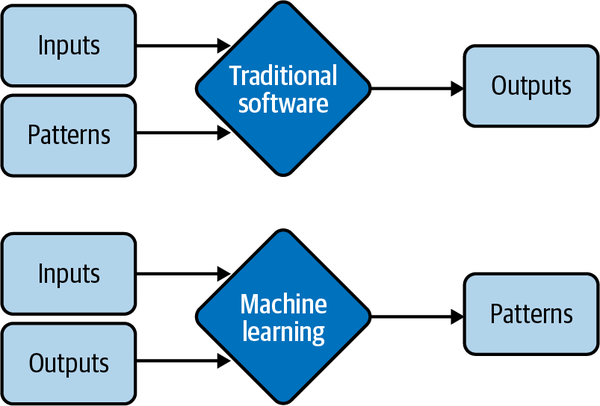
Abbildung 1-2. Anstatt von Hand spezifizierte Muster für die Berechnung der Ergebnisse zu benötigen, lernen ML-Lösungen Muster aus Eingaben und Ausgaben
- 3. Vorhandene Daten: Daten sind verfügbar oder es ist möglich, Daten zu sammeln
-
Da ML aus Daten lernt, muss es Daten geben, aus denen es lernen kann. Es ist amüsant, ein Modell zu entwickeln, das vorhersagt, wie viel Steuern eine Person pro Jahr zahlen sollte, aber das ist nicht möglich, wenn du keinen Zugang zu den Steuer- und Einkommensdaten einer großen Bevölkerung hast.
Beim Zero-Shot-Lernen (auch bekannt als Zero-Data-Lernen) ist es möglich, dass ein ML-System gute Vorhersagen für eine Aufgabe macht, ohne dass es auf Daten für diese Aufgabe trainiert wurde. Allerdings wurde dieses ML-System zuvor auf Daten für andere Aufgaben trainiert, die oft mit der betreffenden Aufgabe zusammenhängen. Obwohl das System also keine Daten für die betreffende Aufgabe benötigt, um daraus zu lernen, benötigt es dennoch Daten, um zu lernen.
Es ist auch möglich, ein ML-System ohne Daten zu starten. Im Rahmen des kontinuierlichen Lernens können ML-Modelle zum Beispiel eingesetzt werden, ohne dass sie auf Daten trainiert wurden.6 Allerdings birgt die Bereitstellung unzureichend trainierter Modelle für die Nutzer/innen gewisse Risiken, wie z. B. eine schlechte Kundenerfahrung.
Ohne Daten und ohne kontinuierliches Lernen verfolgen viele Unternehmen einen "Fake-it-til-you make it"-Ansatz: Sie bringen ein Produkt auf den Markt, das Vorhersagen von Menschen statt von ML-Modellen liefert, in der Hoffnung, die generierten Daten später zum Trainieren von ML-Modellen nutzen zu können.
- 4. Vorhersagen: Es ist ein Problem der Vorhersage
-
ML-Modelle machen Vorhersagen und können daher nur Probleme lösen, die vorausschauende Antworten erfordern. ML kann besonders attraktiv sein, wenn du von einer großen Menge günstiger, aber ungefährer Vorhersagen profitieren kannst. Im Englischen bedeutet "vorhersagen" "einen Wert in der Zukunft schätzen". Zum Beispiel: Wie wird das Wetter morgen sein? Wer wird dieses Jahr den Super Bowl gewinnen? Welchen Film wird sich ein Nutzer als nächstes ansehen wollen?
Da prädiktive Maschinen (z.B. ML-Modelle) immer effektiver werden, werden immer mehr Probleme als prädiktive Probleme umgedeutet. Egal, welche Frage du hast, du kannst sie immer so formulieren: "Wie würde die Antwort auf diese Frage lauten?", unabhängig davon, ob sich die Frage auf die Zukunft, die Gegenwart oder die Vergangenheit bezieht.
Rechenintensive Probleme sind eine Klasse von Problemen, die sehr erfolgreich als prädiktiv bezeichnet werden können. Anstatt das genaue Ergebnis eines Prozesses zu berechnen, was noch rechenintensiver und zeitaufwändiger sein kann als ML, kannst du das Problem wie folgt formulieren: "Wie würde das Ergebnis dieses Prozesses aussehen?" und es mithilfe eines ML-Modells annähern. Das Ergebnis ist zwar nur eine Annäherung an das genaue Ergebnis, aber oft ist es gut genug. Du siehst das häufig bei grafischen Renderings, z. B. bei der Bildentrauschung und der Schattierung des Bildschirmraums.7
- 5. Ungesehene Daten: Ungesehene Daten teilen Muster mit den Trainingsdaten
-
Die Muster, die dein Modell aus vorhandenen Daten lernt, sind nur dann nützlich, wenn auch die ungesehenen Daten diese Muster aufweisen. Ein Modell, das vorhersagen soll, ob eine App an Weihnachten 2020 heruntergeladen wird, wird nicht sehr gut funktionieren, wenn es mit Daten aus dem Jahr 2008 trainiert wurde, als die beliebteste App im App Store Koi Pond war. Was ist Koi Pond? Ganz genau.
Technisch ausgedrückt bedeutet das, dass deine ungesehenen Daten und die Trainingsdaten aus ähnlichen Verteilungen stammen sollten. Du fragst dich vielleicht: "Wenn die Daten ungesehen sind, woher wissen wir dann, aus welcher Verteilung sie stammen?" Das wissen wir nicht, aber wir können Annahmen treffen - zum Beispiel, dass sich das Verhalten der Nutzerinnen und Nutzer morgen nicht allzu sehr von dem von heute unterscheiden wird - und hoffen, dass unsere Annahmen zutreffen. Wenn das nicht der Fall ist, haben wir ein Modell, das schlecht abschneidet. Das können wir mit Monitoring (siehe Kapitel 8) und Tests in der Produktion (siehe Kapitel 9) herausfinden.
Aufgrund der Art und Weise, wie die meisten ML-Algorithmen heute lernen, werden ML-Lösungen besonders dann glänzen, wenn dein Problem die folgenden zusätzlichen Merkmale aufweist:
- 6. Es ist repetitiv
-
Menschen sind großartig im "few-shot learning": Du kannst Kindern ein paar Bilder von Katzen zeigen und die meisten von ihnen werden eine Katze erkennen, wenn sie das nächste Mal eine sehen. Trotz spannender Fortschritte in der Forschung zum "few-shot learning" benötigen die meisten ML-Algorithmen immer noch viele Beispiele, um ein Muster zu lernen. Wenn eine Aufgabe repetitiv ist, wird jedes Muster mehrfach wiederholt, was es für Maschinen einfacher macht, es zu lernen.
- 7. Die Kosten für falsche Vorhersagen sind gering
-
Wenn die Leistung deines ML-Modells nicht immer 100 % beträgt, was bei sinnvollen Aufgaben sehr unwahrscheinlich ist, wird dein Modell Fehler machen. ML ist besonders geeignet, wenn die Kosten einer falschen Vorhersage gering sind. Einer der häufigsten Anwendungsfälle von ML sind zum Beispiel Empfehlungssysteme, denn bei diesen Systemen wird eine schlechte Empfehlung in der Regel verziehen - der Nutzer klickt einfach nicht auf die Empfehlung.
Wenn ein Vorhersagefehler katastrophale Folgen haben kann, könnte ML trotzdem eine geeignete Lösung sein, wenn die Vorteile richtiger Vorhersagen im Durchschnitt die Kosten falscher Vorhersagen überwiegen. Die Entwicklung von selbstfahrenden Autos ist eine Herausforderung, weil ein algorithmischer Fehler zum Tod führen kann. Dennoch wollen viele Unternehmen selbstfahrende Autos entwickeln, weil sie das Potenzial haben, viele Leben zu retten, sobald selbstfahrende Autos statistisch gesehen sicherer sind als menschliche Fahrer.
- 8. Es ist ein Maßstab
-
ML-Lösungen erfordern oft nicht unerhebliche Vorabinvestitionen in Daten, Rechner, Infrastruktur und Talente, daher wäre es sinnvoll, wenn wir diese Lösungen häufig nutzen können.
"In großem Maßstab" bedeutet für verschiedene Aufgaben unterschiedliche Dinge, aber im Allgemeinen bedeutet es, viele Vorhersagen zu treffen. Beispiele sind das Sortieren von Millionen von E-Mails pro Jahr oder die Vorhersage, an welche Abteilungen Tausende von Support-Tickets pro Tag weitergeleitet werden sollten.
Ein Problem kann wie eine einzelne Vorhersage aussehen, aber in Wirklichkeit ist es eine Reihe von Vorhersagen. Ein Modell, das vorhersagt, wer die Präsidentschaftswahlen in den USA gewinnt, scheint zum Beispiel nur alle vier Jahre eine Vorhersage zu machen, aber in Wirklichkeit macht es jede Stunde oder sogar noch häufiger eine Vorhersage, weil diese Vorhersage ständig aktualisiert werden muss, um neue Informationen zu berücksichtigen.
Ein Problem in großem Maßstab bedeutet auch, dass du viele Daten sammeln kannst, die für das Training von ML-Modellen nützlich sind.
- 9. Die Muster ändern sich ständig
-
Kulturen ändern sich. Geschmäcker ändern sich. Technologien ändern sich. Was heute in Mode ist, kann morgen schon Schnee von gestern sein. Betrachte die Aufgabe der Klassifizierung von E-Mail-Spam. Heute ist ein Hinweis auf eine Spam-E-Mail ein nigerianischer Prinz, aber morgen könnte es ein verzweifelter vietnamesischer Schriftsteller sein.
Wenn dein Problem ein oder mehrere sich ständig ändernde Muster umfasst, können fest kodierte Lösungen wie handschriftliche Regeln schnell veraltet sein. Herauszufinden, wie sich dein Problem verändert hat, damit du deine handschriftlichen Regeln entsprechend aktualisieren kannst, kann zu teuer oder unmöglich sein. Da ML aus Daten lernt, kannst du dein ML-Modell mit neuen Daten aktualisieren, ohne herausfinden zu müssen, wie sich die Daten verändert haben. Es ist auch möglich, dein System so einzurichten, dass es sich an die veränderte Datenverteilung anpasst - ein Ansatz, den wir im Abschnitt "Kontinuierliches Lernen" besprechen .
Die Liste der Anwendungsfälle lässt sich endlos fortsetzen und sie wird noch länger werden, wenn ML in der Branche weiter verbreitet ist. Auch wenn ML eine Reihe von Problemen sehr gut lösen kann, kann es viele Probleme nicht lösen bzw. sollte nicht für sie verwendet werden. Die meisten der heutigen ML-Algorithmen sollten unter den folgenden Bedingungen nicht verwendet werden:
-
Es ist unethisch. Im Abschnitt "Fallstudie I: Die Voreingenommenheit eines automatischen Beurteilers" gehen wir auf eine Fallstudie ein, in der der Einsatz von ML-Algorithmen als unethisch bezeichnet werden kann .
-
Einfachere Lösungen tun es auch. In Kapitel 6 werden wir die vier Phasen der ML-Modellentwicklung behandeln, wobei die erste Phase Nicht-ML-Lösungen sein sollten.
-
Das ist nicht kosteneffizient.
Aber selbst wenn ML dein Problem nicht lösen kann, ist es vielleicht möglich, dein Problem in kleinere Komponenten aufzuteilen und ML zur Lösung einiger dieser Komponenten einzusetzen. Wenn du zum Beispiel keinen Chatbot bauen kannst, der alle Fragen deiner Kunden beantwortet, ist es vielleicht möglich, ein ML-Modell zu erstellen, das vorhersagt, ob eine Anfrage einer der häufig gestellten Fragen entspricht. Wenn ja, verweise den Kunden auf die Antwort. Wenn nicht, verweist du ihn an den Kundenservice.
Ich möchte dich auch davor warnen, eine neue Technologie zu verwerfen, nur weil sie im Moment nicht so kosteneffizient ist wie die bestehenden Technologien. Die meisten technologischen Fortschritte sind schrittweise. Eine Technologie mag jetzt noch nicht effizient sein, aber mit der Zeit und weiteren Investitionen könnte sie es werden. Wenn du wartest, bis sich die Technologie in der Branche bewährt hat, bevor du einsteigst, könntest du am Ende Jahre oder Jahrzehnte hinter deinen Konkurrenten zurückbleiben.
Anwendungsfälle für maschinelles Lernen
ML wird zunehmend sowohl in Unternehmens- als auch in Verbraucheranwendungen eingesetzt. Seit Mitte der 2010er Jahre gibt es eine explosionsartige Zunahme von Anwendungen, die ML nutzen, um den Verbrauchern bessere oder zuvor unmögliche Dienste anzubieten.
Bei der explosionsartigen Zunahme von Informationen und Diensten wäre es für uns sehr schwierig gewesen, das Gewünschte ohne die Hilfe von ML zu finden, entweder in Form einer Suchmaschine oder eines Empfehlungssystems. Wenn du eine Website wie Amazon oder Netflix besuchst, werden dir Produkte empfohlen, die deinem Geschmack am ehesten entsprechen. Wenn dir eine der Empfehlungen nicht gefällt, möchtest du vielleicht nach bestimmten Artikeln suchen, und deine Suchergebnisse werden wahrscheinlich von ML unterstützt.
Wenn du ein Smartphone hast, unterstützt dich ML wahrscheinlich schon bei vielen deiner täglichen Aktivitäten. Das Tippen auf deinem Telefon wird durch Predictive Typing erleichtert, ein ML-System, das dir Vorschläge macht, was du als Nächstes sagen möchtest. Ein ML-System könnte in deiner Fotobearbeitungs-App laufen und dir vorschlagen, wie du deine Fotos am besten verbessern kannst. Du könntest dein Telefon mit deinem Fingerabdruck oder deinem Gesicht authentifizieren, wofür ein ML-System vorhersagen muss, ob ein Fingerabdruck oder ein Gesicht zu dir passt.
Der ML-Anwendungsfall, der mich in das Feld zog, war die maschinelle Übersetzung, die automatisch von einer Sprache in eine andere übersetzt. Sie hat das Potenzial, Menschen aus verschiedenen Kulturen die Kommunikation miteinander zu ermöglichen und die Sprachbarriere zu beseitigen. Meine Eltern sprechen kein Englisch, aber dank Google Translate können sie jetzt meine Texte lesen und sich mit meinen Freunden unterhalten, die kein Vietnamesisch sprechen.
ML ist mit intelligenten persönlichen Assistenten wie Alexa und Google Assistant zunehmend in unseren Häusern präsent. Intelligente Sicherheitskameras können dich benachrichtigen, wenn deine Haustiere das Haus verlassen oder du einen ungebetenen Gast hast. Ein Freund von mir machte sich Sorgen um seine alternde Mutter, die alleine lebt - wenn sie stürzt, ist niemand da, der ihr aufhilft - also verließ er sich auf ein Gesundheitsüberwachungssystem, das vorhersagt, ob jemand im Haus gestürzt ist.
Auch wenn der Markt für ML-Anwendungen für Verbraucher boomt, sind die meisten ML-Anwendungsfälle immer noch in der Unternehmenswelt zu finden. ML-Anwendungen in Unternehmen haben meist ganz andere Anforderungen und Überlegungen als Verbraucheranwendungen. Es gibt viele Ausnahmen, aber in den meisten Fällen haben Unternehmensanwendungen strengere Anforderungen an die Genauigkeit, sind aber nachsichtiger mit den Anforderungen an die Latenzzeit. Die Verbesserung der Genauigkeit eines Spracherkennungssystems von 95 % auf 95,5 % mag für die meisten Verbraucher/innen nicht spürbar sein, aber eine Verbesserung der Effizienz eines Ressourcenzuweisungssystems um nur 0,1 % kann einem Unternehmen wie Google oder General Motors helfen, Millionen von Dollar zu sparen. Gleichzeitig kann eine Latenzzeit von einer Sekunde dazu führen, dass ein Verbraucher abgelenkt wird und etwas anderes öffnet, aber Unternehmensnutzer/innen sind vielleicht toleranter gegenüber hohen Latenzzeiten. Wer daran interessiert ist, aus ML-Anwendungen Unternehmen zu machen, für den sind Verbraucheranwendungen zwar einfacher zu verbreiten, aber viel schwieriger zu monetarisieren. Die meisten Anwendungsfälle für Unternehmen sind jedoch nicht offensichtlich, es sei denn, du hast sie selbst schon erlebt.
Laut der Algorithmia-Umfrage zum Stand des maschinellen Lernens in Unternehmen im Jahr 2020 sind ML-Anwendungen in Unternehmen vielfältig und dienen sowohl internen Anwendungsfällen (Kostenreduzierung, Gewinnung von Kundeneinblicken und -erkenntnissen, interne Prozessautomatisierung) als auch externen Anwendungsfällen (Verbesserung der Kundenerfahrung, Kundenbindung, Interaktion mit Kunden), wie in Abbildung 1-3 dargestellt.8
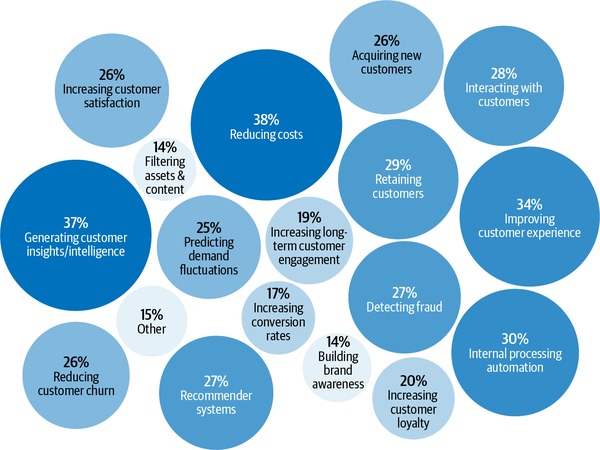
Abbildung 1-3. Stand 2020 beim maschinellen Lernen in Unternehmen. Quelle: Adaptiert von einem Bild von Algorithmia
Betrugserkennung ist eine der ältesten Anwendungen von ML in der Unternehmenswelt. Wenn dein Produkt oder deine Dienstleistung Transaktionen von beliebigem Wert beinhaltet, ist es anfällig für Betrug. Durch den Einsatz von ML-Lösungen zur Erkennung von Anomalien kannst du Systeme einsetzen, die aus historischen Betrugstransaktionen lernen und vorhersagen, ob eine zukünftige Transaktion betrügerisch ist.
Die Entscheidung, wie viel du für dein Produkt oder deine Dienstleistung verlangst, ist wahrscheinlich eine der schwierigsten Geschäftsentscheidungen; warum überlässt du das nicht ML? Bei der Preisoptimierung geht es darum, einen Preis für einen bestimmten Zeitraum zu schätzen, um eine bestimmte Zielfunktion zu maximieren, z. B. die Gewinnspanne, den Umsatz oder die Wachstumsrate des Unternehmens. Die ML-basierte Preisoptimierung eignet sich am besten für Fälle mit einer großen Anzahl von Transaktionen, bei denen die Nachfrage schwankt und die Verbraucher bereit sind, einen dynamischen Preis zu zahlen - z. B. bei Internetanzeigen, Flugtickets, Unterkunftsbuchungen, Mitfahrgelegenheiten und Veranstaltungen.
Um ein Unternehmen zu führen, ist es wichtig, dass du die Kundennachfrage vorhersagen kannst, damit du ein Budget aufstellen, Lagerbestände anlegen, Ressourcen zuweisen und die Preisstrategie anpassen kannst. Wenn du z. B. einen Lebensmittelladen betreibst, musst du genug vorrätig haben, damit die Kunden finden, was sie suchen, aber du darfst nicht zu viel vorrätig haben, denn sonst könnten deine Lebensmittel schlecht werden und du würdest Geld verlieren.
Einen neuen Nutzer zu gewinnen, ist teuer. Im Jahr 2019 kostet es eine App durchschnittlich 86,61 US-Dollar, einen Nutzer zu gewinnen, der einen In-App-Kauf tätigt.9 Die Akquisitionskosten für Lyft werden auf 158 Dollar pro Fahrer geschätzt.10 Diese Kosten sind für Unternehmenskunden noch viel höher. Die Kundenakquisitionskosten werden von Investoren als Startup-Killer bezeichnet.11 Eine Senkung der Kundenakquisitionskosten um einen kleinen Betrag kann zu einer großen Gewinnsteigerung führen. Dies kann durch eine bessere Identifizierung potenzieller Kunden, gezieltere Werbung, Rabatte zum richtigen Zeitpunkt usw. erreicht werden - alles geeignete Aufgaben für ML.
Nachdem du so viel Geld ausgegeben hast, um einen Kunden zu gewinnen, wäre es schade, wenn er dich verlässt. Die Kosten für die Gewinnung eines neuen Kunden sind schätzungsweise 5 bis 25 Mal so hoch wie die Kosten für die Bindung eines bestehenden Kunden.12 Bei der Abwanderungsvorhersage geht es darum, vorherzusagen, wann ein bestimmter Kunde aufhören wird, deine Produkte oder Dienstleistungen zu nutzen, damit du geeignete Maßnahmen ergreifen kannst, um ihn zurückzugewinnen. Die Abwanderungsprognose kann nicht nur für Kunden, sondern auch für Mitarbeiter/innen verwendet werden.
Um zu verhindern, dass Kunden abwandern, ist es wichtig, sie bei Laune zu halten, indem man sich um ihre Anliegen kümmert, sobald sie auftreten. Eine automatisierte Klassifizierung von Support-Tickets kann dabei helfen. Wenn ein Kunde ein Support-Ticket öffnete oder eine E-Mail schickte, musste das Ticket zunächst bearbeitet und dann an verschiedene Abteilungen weitergeleitet werden, bis es im Posteingang einer Person ankam, die es bearbeiten konnte. Ein ML-System kann den Inhalt des Tickets analysieren und vorhersagen, wohin es weitergeleitet werden soll, was die Antwortzeit verkürzen und die Kundenzufriedenheit verbessern kann. Es kann auch verwendet werden, um interne IT-Tickets zu klassifizieren.
Ein weiterer beliebter Anwendungsfall von ML in Unternehmen ist die Markenüberwachung. Die Marke ist ein wertvolles Gut für ein Unternehmen.13 Es ist wichtig, zu beobachten, wie die Öffentlichkeit und deine Kunden deine Marke wahrnehmen. Du möchtest vielleicht wissen, wann, wo und wie deine Marke erwähnt wird, sowohl explizit (z. B. wenn jemand "Google" erwähnt) als auch implizit (z. B. wenn jemand "der Suchgigant" sagt), und auch die damit verbundene Stimmung. Wenn du plötzlich einen Anstieg der negativen Stimmung bei den Erwähnungen deiner Marke feststellst, solltest du dich so schnell wie möglich darum kümmern. Die Stimmungsanalyse ist eine typische ML-Aufgabe.
Eine Reihe von ML-Anwendungsfällen, die in letzter Zeit für viel Aufregung gesorgt haben, betrifft das Gesundheitswesen. Es gibt ML-Systeme, die Hautkrebs erkennen und Diabetes diagnostizieren können. Auch wenn sich viele Anwendungen im Gesundheitswesen an Verbraucher/innen richten, werden sie aufgrund der strengen Anforderungen an Genauigkeit und Datenschutz in der Regel von einem Gesundheitsdienstleister wie einem Krankenhaus bereitgestellt oder zur Unterstützung von Ärzt/innen bei der Diagnose verwendet.
Maschinelle Lernsysteme verstehen
Ein Verständnis von ML-Systemen ist hilfreich, um sie zu entwerfen und zu entwickeln. In diesem Abschnitt gehen wir darauf ein, wie sich ML-Systeme sowohl von der ML in der Forschung (oder wie sie oft in der Schule gelehrt wird) als auch von herkömmlicher Software unterscheiden, was den Bedarf für dieses Buch begründet.
Maschinelles Lernen in der Forschung und in der Produktion
Da der Einsatz von ML in der Industrie noch relativ neu ist, haben die meisten Menschen mit ML-Kenntnissen diese in der Wissenschaft erworben: Sie haben Kurse besucht, geforscht und wissenschaftliche Arbeiten gelesen. Wenn das auf dich zutrifft, könnte es eine steile Lernkurve für dich sein, um die Herausforderungen beim Einsatz von ML-Systemen in der Praxis zu verstehen und sich in einer überwältigenden Anzahl von Lösungen für diese Herausforderungen zurechtzufinden. ML in der Produktion unterscheidet sich stark von ML in der Forschung. Tabelle 1-1 zeigt fünf der wichtigsten Unterschiede.
| Forschung | Produktion | |
|---|---|---|
| Anforderungen | State-of-the-Art Modellleistung auf Benchmark-Datensätzen | Unterschiedliche Stakeholder haben unterschiedliche Anforderungen |
| Rechnerische Priorität | Schnelle Ausbildung, hoher Durchsatz | Schnelle Schlussfolgerungen, geringe Latenzzeit |
| Daten | Statischa | Ständig in Bewegung |
| Fairness | Oft nicht im Fokus | Muss berücksichtigt werden |
| Interpretierbarkeit | Oft nicht im Fokus | Muss berücksichtigt werden |
a Ein Teilbereich der Forschung konzentriert sich auf kontinuierliches Lernen: die Entwicklung von Modellen, die mit sich ändernden Datenverteilungen arbeiten. Wir werden das kontinuierliche Lernen in Kapitel 9 behandeln. | ||
Unterschiedliche Interessengruppen und Anforderungen
Menschen, die an einem Forschungs- und Leaderboard Projekt beteiligt sind, haben oft nur ein einziges Ziel vor Augen. Das häufigste Ziel ist die Modellleistung - ein Modell zu entwickeln, das die besten Ergebnisse auf Benchmark-Datensätzen erzielt. Um eine kleine Leistungsverbesserung zu erreichen, greifen die Forscher oft auf Techniken zurück, die die Modelle zu komplex machen, um nützlich zu sein.
Es gibt viele Beteiligte, die an der Einführung eines ML-Systems in die Produktion beteiligt sind. Jeder Stakeholder hat seine eigenen Anforderungen. Unterschiedliche, oft widersprüchliche Anforderungen können es schwierig machen, ein ML-Modell zu entwerfen, zu entwickeln und auszuwählen, das allen Anforderungen gerecht wird.
Stell dir eine mobile App vor, die den Nutzern Restaurants empfiehlt. Die App verdient Geld, indem sie von den Restaurants eine Servicegebühr von 10 % auf jede Bestellung erhebt. Das bedeutet, dass teure Bestellungen der App mehr Geld einbringen als billige Bestellungen. An dem Projekt sind ML-Ingenieure, Vertriebsmitarbeiter, Produktmanager, Infrastrukturingenieure und ein Manager beteiligt:
- ML-Ingenieure
-
Sie wollen ein Modell, das Restaurants empfiehlt, bei denen die Nutzerinnen und Nutzer mit hoher Wahrscheinlichkeit bestellen werden, und sie glauben, dass sie dies mit einem komplexeren Modell mit mehr Daten erreichen können.
- Verkaufsteam
-
Möchte ein Modell, das die teureren Restaurants empfiehlt, da diese Restaurants mehr Servicegebühren einbringen.
- Produktteam
-
Sie stellen fest, dass jede Erhöhung der Latenzzeit zu einem Rückgang der Bestellungen über den Dienst führt. Deshalb wollen sie ein Modell, das die empfohlenen Restaurants in weniger als 100 Millisekunden liefert.
- ML-Plattform-Team
-
Da der Datenverkehr zunimmt, wurde das Team mitten in der Nacht geweckt, weil es Probleme mit der Skalierung des bestehenden Systems hatte. Deshalb wollen sie die Modellaktualisierungen zurückstellen, um der Verbesserung der ML-Plattform Vorrang zu geben.
- Manager
-
Er will die Gewinnspanne maximieren, und eine Möglichkeit, dies zu erreichen, könnte darin bestehen, das ML-Team loszulassen.14
"Die Restaurants zu empfehlen, die die Nutzer am ehesten anklicken" und "die Restaurants zu empfehlen, die der App das meiste Geld einbringen" sind zwei unterschiedliche Ziele, und im Abschnitt "Entkopplung der Ziele" werden wir besprechen, wie man ein ML-System entwickelt, das verschiedene Ziele erfüllt. Spoiler: Wir entwickeln ein Modell für jedes Ziel und kombinieren ihre Vorhersagen.
Stellen wir uns vor, dass wir zwei verschiedene Modelle haben. Modell A ist das Modell, das die Restaurants empfiehlt, auf die die Nutzerinnen und Nutzer am ehesten klicken werden, und Modell B ist das Modell, das die Restaurants empfiehlt, die der App das meiste Geld einbringen werden. A und B können sehr unterschiedliche Modelle sein. Welches Modell soll den Nutzern zur Verfügung gestellt werden? Erschwerend kommt hinzu, dass weder A noch B die vom Produktteam gestellte Anforderung erfüllen: Sie können keine Restaurantempfehlungen in weniger als 100 Millisekunden liefern.
Bei der Entwicklung eines ML-Projekts ist es für ML-Ingenieure wichtig, die Anforderungen aller beteiligten Stakeholder zu verstehen und zu wissen, wie streng diese Anforderungen sind. Wenn es zum Beispiel ein Muss ist, Empfehlungen innerhalb von 100 Millisekunden auszusprechen - das Unternehmen hat herausgefunden, dass 10 % der Nutzer/innen die Geduld verlieren und die App schließen würden, wenn dein Modell mehr als 100 Millisekunden braucht, um Restaurants zu empfehlen - dann werden weder Modell A noch Modell B funktionieren. Wenn es sich jedoch nur um eine "Nice-to-have"-Anforderung handelt, solltest du Modell A oder Modell B in Betracht ziehen.
Dass die Produktion andere Anforderungen hat als die Forschung, ist einer der Gründe, warum erfolgreiche Forschungsprojekte nicht immer in der Produktion eingesetzt werden. Ein Beispiel: Ensembling ist eine Technik, die bei den Gewinnern vieler ML-Wettbewerbe beliebt ist, einschließlich des berühmten Netflix-Preises, der mit einer Million Dollar dotiert ist, und dennoch wird sie in der Produktion nicht häufig eingesetzt. Beim Ensembling werden "mehrere Lernalgorithmen kombiniert, um eine bessere Vorhersageleistung zu erzielen, als dies mit jedem der einzelnen Lernalgorithmen möglich wäre".15 Es kann zwar die Leistung deines ML-Systems ein wenig verbessern, aber Ensembling macht das System in der Regel zu komplex, um in der Produktion nützlich zu sein, z. B. weil es langsamer ist, Vorhersagen zu treffen oder die Ergebnisse schwerer zu interpretieren. Wir werden das Ensembling im Abschnitt "Ensembles" näher erläutern .
Bei vielen Aufgaben kann eine kleine Leistungsverbesserung zu einem enormen Anstieg der Einnahmen oder zu Kosteneinsparungen führen. So kann zum Beispiel eine Verbesserung der Klickrate eines Produktempfehlungssystems um 0,2 % den Umsatz einer E-Commerce-Website um Millionen von Dollar steigern. Bei vielen Aufgaben ist eine kleine Verbesserung für die Nutzer/innen jedoch möglicherweise nicht spürbar. Für die zweite Art von Aufgaben gilt: Wenn ein einfaches Modell eine vernünftige Arbeit leisten kann, müssen komplexe Modelle deutlich mehr leisten, um die Komplexität zu rechtfertigen.
Rechnerische Prioritäten
Bei der Entwicklung eines ML-Systems machen Leute, die noch kein ML-System eingesetzt haben, oft den Fehler, sich zu sehr auf die Modellentwicklung und zu wenig auf die Modellbereitstellung und -pflege zu konzentrieren.
Während des Modellentwicklungsprozesses trainierst du möglicherweise viele verschiedene Modelle, und jedes Modell durchläuft die Trainingsdaten mehrmals. Jedes trainierte Modell erstellt dann einmal Vorhersagen für die Validierungsdaten, um die Ergebnisse zu melden. Die Validierungsdaten sind normalerweise viel kleiner als die Trainingsdaten. Während der Modellentwicklung ist das Training der Engpass. Sobald das Modell jedoch eingesetzt wird, besteht seine Aufgabe darin, Vorhersagen zu erstellen, so dass die Inferenz der Engpass ist. In der Forschung wird in der Regel Wert auf schnelles Training gelegt, während in der Produktion schnelle Schlussfolgerungen im Vordergrund stehen.
Daraus folgt, dass in der Forschung Wert auf einen hohen Durchsatz legt, während in der Produktion eine niedrige Latenzzeit wichtig ist. Falls du eine Auffrischung brauchst: Latenz ist die Zeit, die vom Eingang einer Anfrage bis zur Rückgabe des Ergebnisses vergeht. Der Durchsatz gibt an, wie viele Abfragen innerhalb einer bestimmten Zeitspanne bearbeitet werden.
Terminologie-Kollision
In einigen Büchern wird unter zwischen Latenz und Antwortzeit unterschieden. Martin Kleppmann schreibt in seinem Buch Designing Data-Intensive Applications: "Die Antwortzeit ist das, was der Kunde sieht: Neben der tatsächlichen Zeit für die Bearbeitung der Anfrage (die Servicezeit) umfasst sie auch Netzwerkverzögerungen und Verzögerungen in der Warteschlange. Die Latenzzeit ist die Zeitspanne, in der eine Anfrage auf ihre Bearbeitung wartet - die Zeit, in der sie latent ist und auf ihre Bearbeitung wartet."19
Um die Diskussion zu vereinfachen und mit der in der ML-Community verwendeten Terminologie übereinzustimmen, verwenden wir in diesem Buch den Begriff Latenz für die Antwortzeit.
Die durchschnittliche Latenzzeit von Google Translate ist zum Beispiel die durchschnittliche Zeit, die vom Anklicken des Buttons "Übersetzen" bis zur Anzeige der Übersetzung vergeht, und der Durchsatz gibt an, wie viele Anfragen pro Sekunde verarbeitet und bedient werden.
Wenn dein System immer nur eine Abfrage auf einmal bearbeitet, bedeutet eine höhere Latenz einen geringeren Durchsatz. Wenn die durchschnittliche Latenzzeit 10 ms beträgt, was bedeutet, dass es 10 ms dauert, eine Abfrage zu bearbeiten, beträgt der Durchsatz 100 Abfragen/Sekunde. Wenn die durchschnittliche Latenzzeit 100 ms beträgt, liegt der Durchsatz bei 10 Abfragen/Sekunde.
Da die meisten modernen verteilten Systeme Abfragen in Stapeln verarbeiten, um sie gemeinsam und oft gleichzeitig zu bearbeiten, kann eine höhere Latenz auch einen höheren Durchsatz bedeuten. Wenn du 10 Abfragen gleichzeitig verarbeitest und es 10 ms dauert, einen Batch auszuführen, beträgt die durchschnittliche Latenz immer noch 10 ms, aber der Durchsatz ist jetzt 10 Mal höher - 1.000 Abfragen/Sekunde. Wenn du 50 Abfragen gleichzeitig verarbeitest und 20 ms für einen Batch brauchst, beträgt die durchschnittliche Latenzzeit jetzt 20 ms und der Durchsatz 2.500 Abfragen/Sekunde. Sowohl die Latenzzeit als auch der Durchsatz haben sich erhöht! Der Unterschied im Kompromiss zwischen Latenz und Durchsatz bei der Verarbeitung einzelner Abfragen und der Verarbeitung von Abfragen in Stapeln ist in Abbildung 1-4 dargestellt.
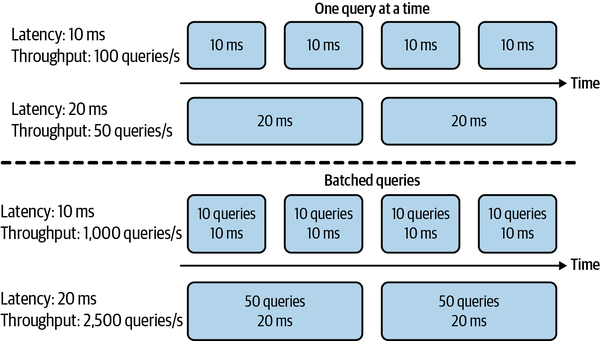
Abbildung 1-4. Wenn du eine Abfrage nach der anderen bearbeitest, bedeutet eine höhere Latenz einen geringeren Durchsatz. Bei der Verarbeitung von Abfragen in Stapeln kann eine höhere Latenz jedoch auch einen höheren Durchsatz bedeuten.
Noch komplizierter wird es, wenn du Online-Abfragen stapeln möchtest. Beim Batching muss dein System warten, bis genügend Abfragen in einem Stapel eingetroffen sind, bevor es sie verarbeiten kann, was die Latenz weiter erhöht.
In der Forschung ist es dir wichtiger, wie viele Proben du in einer Sekunde verarbeiten kannst (Durchsatz) und weniger, wie lange es dauert, bis die einzelnen Proben verarbeitet sind (Latenz). Du bist bereit, die Latenzzeit zu erhöhen, um den Durchsatz zu steigern, zum Beispiel durch aggressives Batching.
Sobald du dein Modell jedoch in der realen Welt einsetzt, spielt die Latenzzeit eine große Rolle. Eine Akamai-Studie aus dem Jahr 2017 ergab, dass eine Verzögerung von 100 ms die Konversionsraten um 7 % senken kann.20 Im Jahr 2019 stellte Booking.com fest, dass ein Anstieg der Latenz um 30 % die Konversionsraten um 0,5 % senkt - "ein relevanter Preis für unser Geschäft".21 Im Jahr 2016 stellte Google fest, dass mehr als die Hälfte der mobilen Nutzer/innen eine Seite verlassen, wenn sie länger als drei Sekunden zum Laden braucht.22 Heutzutage sind die Nutzer noch weniger geduldig.
Um die Latenzzeit in der Produktion zu verringern, musst du eventuell die Anzahl der Abfragen reduzieren, die du auf derselben Hardware gleichzeitig verarbeiten kannst. Wenn deine Hardware in der Lage ist, viel mehr Abfragen gleichzeitig zu verarbeiten, bedeutet die Verwendung für weniger Abfragen eine Unterauslastung deiner Hardware, was die Kosten für die Verarbeitung jeder Abfrage erhöht.
Wenn du über Latenz nachdenkst, ist es wichtig zu bedenken, dass die Latenz keine einzelne Zahl ist, sondern eine Verteilung. Es ist verlockend, diese Verteilung zu vereinfachen, indem man eine einzige Zahl verwendet, z. B. den Durchschnitt (das arithmetische Mittel) der Latenz aller Anfragen innerhalb eines Zeitfensters. Stell dir vor, du hast 10 Anfragen mit folgenden Latenzen: 100 ms, 102 ms, 100 ms, 100 ms, 99 ms, 104 ms, 110 ms, 90 ms, 3.000 ms, 95 ms. Die durchschnittliche Latenzzeit beträgt 390 ms, was dein System langsamer erscheinen lässt, als es tatsächlich ist. Möglicherweise ist ein Netzwerkfehler aufgetreten, der dazu geführt hat, dass eine Anfrage viel langsamer war als die anderen, und du solltest diese problematische Anfrage untersuchen.
In der Regel ist es besser, in Perzentilen zu denken, denn sie sagen etwas über einen bestimmten Prozentsatz deiner Anfragen aus. Das gängigste Perzentil ist das 50. Perzentil, abgekürzt als p50. Er ist auch als Median bekannt. Wenn der Median 100 ms beträgt, braucht die Hälfte der Anfragen länger als 100 ms und die Hälfte der Anfragen weniger als 100 ms.
Höhere Perzentile helfen dir auch dabei, Ausreißer zu entdecken, die ein Anzeichen für einen Fehler sein könnten. Die Perzentile, die du dir ansehen solltest, sind p90, p95 und p99. Das 90. Perzentil (p90) für die 10 obigen Anfragen liegt bei 3.000 ms, was ein Ausreißer ist.
Höhere Perzentile sind wichtig, denn auch wenn sie nur einen kleinen Prozentsatz deiner Nutzer ausmachen, können sie manchmal die wichtigsten Nutzer sein. Auf der Amazon-Website zum Beispiel sind die Kunden mit den langsamsten Anfragen oft diejenigen, die die meisten Daten auf ihren Konten haben, weil sie viele Einkäufe getätigt haben - sie sind also die wertvollsten Kunden.23
Es ist gängige Praxis, hohe Perzentile zu verwenden, um die Leistungsanforderungen für dein System zu spezifizieren. Ein Produktmanager könnte zum Beispiel festlegen, dass die Latenzzeit eines Systems im 90. oder 99,9.
Daten
In der Forschungsphase sind die Datensätze, mit denen du arbeitest, oft sauber und gut formatiert, so dass du dich auf die Entwicklung von Modellen konzentrieren kannst. Sie sind von Natur aus statisch, damit die Community sie zum Benchmarking neuer Architekturen und Techniken nutzen kann. Das bedeutet, dass viele Leute dieselben Datensätze verwendet und diskutiert haben und die Besonderheiten des Datensatzes bekannt sind. Vielleicht findest du sogar Open-Source-Skripte, mit denen du die Daten verarbeiten und direkt in deine Modelle einspeisen kannst.
In der Produktion sind die Daten, falls vorhanden, viel unordentlicher. Sie sind verrauscht, möglicherweise unstrukturiert und ändern sich ständig. Sie sind wahrscheinlich verzerrt, und du weißt wahrscheinlich nicht, wie sie verzerrt sind. Beschriftungen, wenn es welche gibt, könnten spärlich, unausgewogen oder falsch sein. Geänderte Projekt- oder Geschäftsanforderungen können es erforderlich machen, einige oder alle bestehenden Kennzeichnungen zu aktualisieren. Wenn du mit den Daten der Nutzer/innen arbeitest, musst du dich auch um den Datenschutz und die Einhaltung von Vorschriften kümmern. Im Abschnitt "Fallstudie II: Die Gefahr "anonymisierter" Daten" werden wir ein Fallbeispiel für einen unangemessenen Umgang mit Nutzerdaten diskutieren .
In der Forschung arbeitest du meist mit historischen Daten, d.h. mit Daten, die bereits existieren und irgendwo gespeichert sind. In der Produktion musst du höchstwahrscheinlich auch mit Daten arbeiten, die ständig von Nutzern, Systemen und Dritten erzeugt werden.
Abbildung 1-5 ist einer großartigen Grafik von Andrej Karpathy, dem Direktor für KI bei Tesla, entnommen, die die Datenprobleme, auf die er während seiner Promotion gestoßen ist, mit seiner Zeit bei Tesla vergleicht.
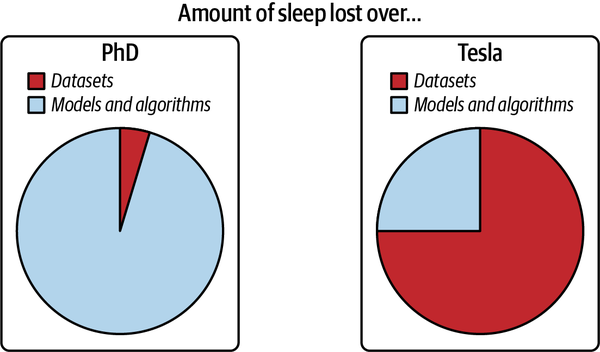
Abbildung 1-5. Daten in der Forschung versus Daten in der Produktion. Quelle: Adaptiert von einem Bild von Andrej Karpathy24
Fairness
In der Forschungsphase wird ein Modell noch nicht an Menschen angewandt, so dass die Forscher/innen Fairness leicht auf die lange Bank schieben können: "Lass uns zuerst versuchen, den Stand der Technik zu erreichen, und uns um Fairness kümmern, wenn wir in die Produktion gehen." Wenn es dann zur Produktion kommt, ist es zu spät. Wenn du deine Modelle für eine bessere Genauigkeit oder eine geringere Latenzzeit optimierst, kannst du zeigen, dass deine Modelle besser sind als der Stand der Technik. Aber als ich dieses Buch schrieb, gab es noch keinen entsprechenden Stand der Technik für Fairness-Kennzahlen.
Du oder jemand in deinem Leben könnte bereits ein Opfer von voreingenommenen mathematischen Algorithmen sein, ohne es zu wissen. Dein Kreditantrag könnte abgelehnt werden, weil der ML-Algorithmus deine Postleitzahl auswählt, die Vorurteile über den sozioökonomischen Hintergrund einer Person beinhaltet. Dein Lebenslauf könnte schlechter bewertet werden, weil das von den Arbeitgebern verwendete Bewertungssystem auf der Schreibweise deines Namens basiert. Dein Hypothekenzins könnte höher sein, weil er sich teilweise auf Kreditwürdigkeitswerte stützt, die die Reichen begünstigen und die Armen bestrafen. Andere Beispiele für ML-Verzerrungen in der realen Welt sind prädiktive Polizeialgorithmen, Persönlichkeitstests, die von potenziellen Arbeitgebern durchgeführt werden, und Hochschulrankings.
Im Jahr 2019 fanden Berkeley-Forscher heraus, dass sowohl persönliche als auch Online-Kreditgeber zwischen 2008 und 2015 insgesamt 1,3 Millionen kreditwürdige Schwarze und Latino-Antragsteller abgelehnt haben. Als die Forscher "das Einkommen und die Kreditwürdigkeit der abgelehnten Anträge verwendeten, aber die Angaben zur Ethnie löschten, wurde der Hypothekenantrag angenommen."25 Für noch mehr erschreckende Beispiele empfehle ich Cathy O'Neils Weapons of Math Destruction.26
ML-Algorithmen sagen nicht die Zukunft voraus, sondern kodieren die Vergangenheit, wodurch die Verzerrungen in den Daten und mehr fortbestehen. Wenn ML-Algorithmen in großem Umfang eingesetzt werden, können sie Menschen in großem Umfang diskriminieren. Während ein Mensch vielleicht nur pauschale Urteile über einige wenige Personen fällt, kann ein ML-Algorithmus in Sekundenbruchteilen pauschale Urteile über Millionen Menschen fällen. Dies kann vor allem für Angehörige von Minderheitengruppen von Nachteil sein, da sich eine falsche Klassifizierung bei ihnen nur geringfügig auf die Gesamtleistung der Modelle auswirken kann.
Wenn ein Algorithmus bereits für 98 % der Bevölkerung korrekte Vorhersagen treffen kann und die Verbesserung der Vorhersagen für die anderen 2 % ein Vielfaches an Kosten verursachen würde, könnten sich einige Unternehmen leider dafür entscheiden, dies nicht zu tun. In einer Studie von McKinsey & Company aus dem Jahr 2019 gaben nur 13 % der befragten Großunternehmen an, dass sie Maßnahmen ergreifen, um Risiken für Gerechtigkeit und Fairness, wie z. B. algorithmische Voreingenommenheit und Diskriminierung, zu mindern.27 Das ändert sich jedoch schnell. Wir werden Fairness und andere Aspekte verantwortungsvoller KI in Kapitel 11 behandeln.
Interpretierbarkeit
Anfang 2020 stellte der Turing-Preisträger Professor Geoffrey Hinton eine heftig diskutierte Frage über die Bedeutung der Interpretierbarkeit in ML-Systemen. "Angenommen, du hast Krebs und musst dich zwischen einem KI-Chirurgen, der nicht erklären kann, wie er funktioniert, aber eine Heilungsrate von 90% hat, und einem menschlichen Chirurgen mit einer Heilungsrate von 80% entscheiden. Willst du, dass der KI-Chirurg illegal ist?"28
Als ich diese Frage ein paar Wochen später einer Gruppe von 30 Führungskräften aus börsennotierten Nicht-Tech-Unternehmen stellte, wollte nur die Hälfte von ihnen, dass der hocheffektive, aber unfähige KI-Chirurg sie operiert. Die andere Hälfte wollte den menschlichen Chirurgen.
Während es den meisten von uns nichts ausmacht, eine Mikrowelle zu benutzen, ohne zu verstehen, wie sie funktioniert, haben viele noch nicht dasselbe Gefühl bei KI, vor allem wenn diese KI wichtige Entscheidungen über ihr Leben trifft.
Da die meisten ML-Forschungen immer noch anhand eines einzigen Ziels, der Modellleistung, bewertet werden, gibt es für die Forscher keinen Anreiz, an der Interpretierbarkeit der Modelle zu arbeiten. Für die meisten ML-Anwendungsfälle in der Industrie ist die Interpretierbarkeit jedoch nicht nur optional, sondern eine Voraussetzung.
Erstens ist die Interpretierbarkeit wichtig, damit die Nutzer - sowohl Führungskräfte als auch Endnutzer - verstehen, warum eine Entscheidung getroffen wird, damit sie einem Modell vertrauen und die bereits erwähnten potenziellen Verzerrungen erkennen können.29 Zweitens ist es für Entwickler wichtig, ein Modell debuggen und verbessern zu können.
Nur weil Interpretierbarkeit eine Anforderung ist, heißt das noch lange nicht, dass es auch alle tun. Im Jahr 2019 arbeiten nur 19 % der großen Unternehmen daran, die Erklärbarkeit ihrer Algorithmen zu verbessern.30
Diskussion
Manche mögen argumentieren, dass es in Ordnung ist, nur die akademische Seite von ML zu kennen, weil es viele Aufträge in der Forschung gibt. Der erste Teil - es ist in Ordnung, nur die akademische Seite von ML zu kennen - ist wahr. Der zweite Teil ist falsch.
Es ist zwar wichtig, reine Forschung zu betreiben, aber die meisten Unternehmen können sich das nicht leisten, wenn es nicht zu kurzfristigen Geschäftsanwendungen führt. Das gilt besonders jetzt, da die Forschungsgemeinschaft den Ansatz "größer, besser" gewählt hat. Für neue Modelle werden oft riesige Datenmengen und zweistellige Millionenbeträge allein an Rechenleistung benötigt.
Wenn ML-Forschung und Standardmodelle leichter zugänglich werden, werden mehr Menschen und Organisationen Anwendungen dafür finden wollen, was die Nachfrage nach ML in der Produktion erhöht.
Die überwiegende Mehrheit der ML-bezogenen Aufträge wird, und ist bereits in der Produktion von ML zu finden.
Maschinelle Lernsysteme im Vergleich zu traditioneller Software
Da ML ein Teil des Software engineering (SWE) ist und Software seit mehr als einem halben Jahrhundert erfolgreich in der Produktion eingesetzt wird, fragen sich manche vielleicht, warum wir nicht einfach bewährte Methoden aus der Softwareentwicklung auf ML anwenden.
Das ist eine ausgezeichnete Idee. In der Tat wäre die ML-Produktion ein viel besserer Ort, wenn ML-Experten bessere Softwareentwickler wären. Viele traditionelle SWE-Tools können für die Entwicklung und den Einsatz von ML-Anwendungen verwendet werden.
Viele Herausforderungen sind jedoch einzigartig für ML-Anwendungen und erfordern ihre eigenen Werkzeuge. In SWE wird davon ausgegangen, dass Code und Daten getrennt sind. In der SWE wollen wir die Dinge so modular und getrennt wie möglich halten (siehe die Wikipedia-Seite über die Trennung von Belangen).
Ganz im Gegenteil: ML-Systeme bestehen zum Teil aus Code, zum Teil aus Daten und zum Teil aus Artefakten, die aus diesen beiden Teilen entstehen. Der Trend des letzten Jahrzehnts zeigt, dass Anwendungen, die mit den meisten/besten Daten entwickelt werden, gewinnen. Anstatt sich auf die Verbesserung von ML-Algorithmen zu konzentrieren, werden sich die meisten Unternehmen auf die Verbesserung ihrer Daten konzentrieren. Da sich Daten schnell ändern können, müssen ML-Anwendungen an die sich ändernde Umgebung angepasst werden können, was schnellere Entwicklungs- und Bereitstellungszyklen erfordern kann.
Bei der traditionellen SWE musst du dich nur auf das Testen und Versionieren deines Codes konzentrieren. Mit ML müssen wir auch unsere Daten testen und versionieren, und das ist der schwierige Teil. Wie versioniert man große Datensätze? Woher weißt du, ob eine Datenprobe gut oder schlecht für dein System ist? Nicht alle Datenproben sind gleich - einige sind für dein Modell wertvoller als andere. Wenn dein Modell zum Beispiel bereits mit einer Million Scans normaler Lungen trainiert wurde und nur eintausend Scans krebskranker Lungen, ist ein Scan einer krebskranken Lunge viel wertvoller als ein Scan einer normalen Lunge. Wenn du wahllos alle verfügbaren Daten akzeptierst, kann das die Leistung deines Modells beeinträchtigen und es sogar anfällig für Data-Poisoning-Angriffe machen.31
Die Größe von ML-Modellen ist eine weitere Herausforderung. Ab 2022 ist es üblich, dass ML-Modelle Hunderte von Millionen, wenn nicht Milliarden von Parametern haben, was Gigabytes an Arbeitsspeicher (RAM) erfordert, um sie in den Speicher zu laden. In ein paar Jahren mag eine Milliarde Parameter wie ein "Kannst du dir vorstellen, dass der Computer, der die Menschen auf den Mond schickte, nur 32 MB RAM hatte?" wirken.
Bislang ist es jedoch eine große Herausforderung, diese großen Modelle in die Produktion zu bringen, vor allem auf Kantengeräten,32 ist eine große technische Herausforderung. Außerdem stellt sich die Frage, wie man diese Modelle so schnell macht, dass sie nützlich sind. Ein Autovervollständigungsmodell ist nutzlos, wenn die Zeit, die es braucht, um das nächste Zeichen vorzuschlagen, länger ist als die Zeit, die du zum Tippen brauchst.
Auch die Überwachung und Fehlerbehebung dieser Modelle in der Produktion ist nicht trivial. Da ML-Modelle immer komplexer werden, ist es schwierig, herauszufinden, was schief gelaufen ist, oder schnell genug gewarnt zu werden, wenn etwas schief läuft, da man keinen Einblick in die Arbeit der Modelle hat.
Die gute Nachricht ist, dass diese technischen Herausforderungen in rasantem Tempo angegangen werden. Im Jahr 2018, als das Papier über die bidirektionalen Encoder-Repräsentationen von Transformatoren (BERT) veröffentlicht wurde, hieß es, BERT sei zu groß, zu komplex und zu langsam, um praktikabel zu sein. Das vortrainierte große BERT-Modell hat 340 Millionen Parameter und ist 1,35 GB groß.33 Zwei Jahre später wurden BERT und seine Varianten bereits in fast jeder englischen Google-Suche verwendet.34
Zusammenfassung
Dieses Eröffnungskapitel soll den Lesern ein Verständnis dafür vermitteln, was nötig ist, um ML in die reale Welt zu bringen. Wir begannen mit einem Überblick über die vielfältigen Anwendungsfälle von ML in der heutigen Produktion. Während die meisten Menschen mit ML in verbraucherorientierten Anwendungen vertraut sind, wird ML in der Mehrzahl der Fälle in Unternehmen eingesetzt. Wir haben auch darüber gesprochen, wann ML-Lösungen sinnvoll sind. Auch wenn ML viele Probleme sehr gut lösen kann, kann es nicht alle Probleme lösen und ist sicherlich nicht für alle Probleme geeignet. Bei Problemen, die ML nicht lösen kann, ist es jedoch möglich, dass ML ein Teil der Lösung sein kann.
In diesem Kapitel wurden auch die Unterschiede zwischen ML in der Forschung und ML in der Produktion hervorgehoben. Zu den Unterschieden gehören die Beteiligung der Interessengruppen, die Priorität der Berechnungen, die Eigenschaften der verwendeten Daten, die Schwere der Fairness-Probleme und die Anforderungen an die Interpretierbarkeit. Dieser Abschnitt ist vor allem für diejenigen hilfreich, die von der Wissenschaft zur ML-Produktion kommen. Wir haben auch erörtert, wie sich ML-Systeme von herkömmlichen Softwaresystemen unterscheiden, was der Grund für dieses Buch war.
ML-Systeme sind komplex und bestehen aus vielen verschiedenen Komponenten. Datenwissenschaftler und ML-Ingenieure, die mit ML-Systemen in der Produktion arbeiten, werden wahrscheinlich feststellen, dass es bei weitem nicht ausreicht, sich nur auf die ML-Algorithmen zu konzentrieren. Es ist wichtig, auch über andere Aspekte des Systems Bescheid zu wissen, z. B. über den Datenstapel, die Bereitstellung, die Überwachung, die Wartung, die Infrastruktur usw. Dieses Buch verfolgt einen Systemansatz bei der Entwicklung von ML-Systemen. Das bedeutet, dass wir alle Komponenten eines Systems ganzheitlich betrachten, anstatt nur die ML-Algorithmen zu betrachten. Was dieser ganzheitliche Ansatz bedeutet, wird im nächsten Kapitel näher erläutert.
1 Mike Schuster, Melvin Johnson und Nikhil Thorat, "Zero-Shot Translation with Google's Multilingual Neural Machine Translation System," Google AI Blog, November 22, 2016, https://oreil.ly/2R1CB.
2 Larry Hardesty, "A Method to Image Black Holes", MIT News, June 6, 2016, https://oreil.ly/HpL2F.
3 Ich habe nicht gefragt, ob ML ausreicht, denn die Antwort ist immer nein.
4 Muster sind etwas anderes als Verteilungen. Wir kennen die Verteilung der Ergebnisse eines fairen Würfels, aber es gibt keine Muster in der Art und Weise, wie die Ergebnisse erzeugt werden.
5 Andrej Karpathy, "Software 2.0", Medium, November 11, 2017, https://oreil.ly/yHZrE.
6 Wir werden das Online-Lernen in Kapitel 9 besprechen.
7 Steke Bako, Thijs Vogels, Brian McWilliams, Mark Meyer, Jan Novák, Alex Harvill, Pradeep Sen, Tony Derose, and Fabrice Rousselle, "Kernel-Predicting Convolutional Networks for Denoising Monte Carlo Renderings," ACM Transactions on Graphics 36, no. 4 (2017): 97, https://oreil.ly/EeI3j; Oliver Nalbach, Elena Arabadzhiyska, Dushyant Mehta, Hans-Peter Seidel, and Tobias Ritschel, "Deep Shading: Convolutional Neural Networks for Screen-Space Shading", arXiv, 2016, https://oreil.ly/dSspz.
8 "2020 State of Enterprise Machine Learning", Algorithmia, 2020, https://oreil.ly/wKMZB.
9 "Average Mobile App User Acquisition Costs Worldwide from September 2018 to August 2019, by User Action and Operating System," Statista, 2019, https://oreil.ly/2pTCH.
10 Jeff Henriksen, "Valuing Lyft Requires a Deep Look into Unit Economics", Forbes, 17. Mai 2019, https://oreil.ly/VeSt4.
11 David Skok, "Startup Killer: Die Kosten der Kundenakquise", For Entrepreneurs, 2018, https://oreil.ly/L3tQ7.
12 Amy Gallo, "The Value of Keeping the Right Customers", Harvard Business Review, 29. Oktober 2014, https://oreil.ly/OlNkl.
13 Marty Swant, "The World's 20 Most Valuable Brands", Forbes, 2020, https://oreil.ly/4uS5i.
14 Es ist nicht ungewöhnlich, dass die ML- und Data-Science-Teams zu den ersten gehören, die bei einer Massenentlassung entlassen werden, wie bei IBM, Uber und Airbnb berichtet wurde. Siehe auch die Analyse von Sejuti Das "How Data Scientists Are Also Susceptible to the Layoffs Amid Crisis", Analytics India Magazine, Mai 21, 2020, https://oreil.ly/jobmz.
15 Wikipedia, s.v. "Ensemble learning ", https://oreil.ly/5qkgp.
16 Julia Evans, "Machine Learning Isn't Kaggle Competitions", 2014, https://oreil.ly/p8mZq.
17 Lauren Oakden-Rayner, "AI Competitions Don't Produce Useful Models," September 19, 2019, https://oreil.ly/X6RlT.
18 Kawin Ethayarajh und Dan Jurafsky, "Utility Is in the Eye of the User: A Critique of NLP Leaderboards", EMNLP, 2020, https://oreil.ly/4Ud8P.
19 Martin Kleppmann, Designing Data-Intensive Applications (Sebastopol, CA: O'Reilly, 2017).
20 Akamai Technologies, Akamai Online Retail Performance Report: Milliseconds Are Critical, 19. April 2017, https://oreil.ly/bEtRu.
21 Lucas Bernardi, Themis Mavridis, und Pablo Estevez, "150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com," KDD '19, August 4-8, 2019, Anchorage, AK, https://oreil.ly/G5QNA.
22 "Consumer Insights", Think with Google, https://oreil.ly/JCp6Z.
23 Kleppmann, Designing Data-Intensive Applications.
24 Andrej Karpathy, "Building the Software 2.0 Stack", Spark+AI Summit 2018, Video, 17:54, https://oreil.ly/Z21Oz.
25 Christopher J. Brooks, "Disparity in Home Lending Costs Minorities Millions, Researchers Find," CBS News, November 15, 2019, https://oreil.ly/UiHUB.
26 Cathy O'Neil, Weapons of Math Destruction (New York: Crown Books, 2016).
27 Stanford University Human-Centered Artificial Intelligence (HAI), The 2019 AI Index Report, 2019, https://oreil.ly/xs8mG.
28 Tweet by Geoffrey Hinton (@geoffreyhinton), February 20, 2020, https://oreil.ly/KdfD8.
29 Für bestimmte Anwendungsfälle in bestimmten Ländern haben Nutzerinnen und Nutzer ein "Recht auf Erklärung": ein Recht darauf, eine Erklärung für eine Ausgabe des Algorithmus zu erhalten.
30 Stanford HAI, The 2019 AI Index Report.
31 Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song, "Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning," arXiv, December 15, 2017, https://oreil.ly/OkAjb.
32 Wir werden uns in Kapitel 7 mit Kanten-Geräten beschäftigen.
33 Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding," arXiv, October 11, 2018, https://oreil.ly/TG3ZW.
34 Google-Suche On, 2020, https://oreil.ly/M7YjM.
Get Maschinelle Lernsysteme entwerfen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

