Kapitel 4. Technisches Interview: Modellschulung und Bewertung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel befassen wir uns mit dem ML-Modelltrainingsprozess und den damit verbundenen Interviewfragen. Für viele Praktikerinnen und Praktiker ist das Modelltraining der aufregendste Teil, und ich stimme dem zu - es ist sehr befriedigend, zu sehen, wie das Modell im Laufe des Prozesses immer genauer wird. Um mit dem ML-Modelltraining, der Abstimmung der Hyperparameter und den Experimenten mit verschiedenen Algorithmen zu beginnen, brauchst du jedoch Daten. Beim maschinellen Lernen geht es im Kern darum, dass Algorithmen Muster in Daten finden und dann auf der Grundlage dieser Muster Vorhersagen und Entscheidungen treffen. Nützliche Daten sind die Grundlage des maschinellen Lernens, und wie das Sprichwort sagt: "Garbage in, garbage out". Das heißt, wenn die ML-Modelle auf unbrauchbaren Daten trainiert werden, dann sind auch das Modell und die daraus resultierenden Schlussfolgerungen unbrauchbar.
Ich beginne mit einem Überblick über die Datenverarbeitung und -bereinigung, bei der Rohdaten in ein Format umgewandelt werden, das für ML-Algorithmen nützlich (und mit ihnen kompatibel) ist. Danach gehe ich auf die Auswahl von Algorithmen ein, z. B. auf Kompromisse zwischen ML-Algorithmen in verschiedenen Szenarien und darauf, wie man generell den besten Algorithmus für ein bestimmtes Problem auswählt.
Danach gehe ich auf das Modelltraining und die Optimierung der Leistung des Modells ein. Das kann ein zweideutiger und schwieriger Prozess sein, und es gibt einige bewährte Methoden, die du lernen wirst, z. B. die Abstimmung der Hyperparameter und die Nachverfolgung von Experimenten, die verhindern können, dass die besten Ergebnisse verloren gehen und die sicherstellen, dass sie reproduzierbar sind. In diesem Zusammenhang gehe ich auch darauf ein, wie man erkennt, wann ein ML-Algorithmus im praktischen Sinne gut ist. Dazu gehören die Modellbewertung und der Vergleich mit einigen Basismodellen oder Basisheuristiken. Die Modellbewertung kann dir auch dabei helfen, die Wirksamkeit des Modells bei neuen, unbekannten Daten zu bestimmen und herauszufinden, ob das Modell in der realen Welt über- oder unterdurchschnittlich gut abschneidet.
Hinweis
Ich versuche, so viele gängige ML-Interviewtechniken zu erwähnen, wie es der Platz zulässt, aber es gibt noch viel mehr unter der Sonne. Sieh dir unbedingt die verlinkten Ressourcen an, um dein Wissen zu erweitern und dich auf das Vorstellungsgespräch vorzubereiten!
In diesem Kapitel gebe ich dir praktische Tipps und Beispiele, damit du deine ML-Interviews erfolgreich führen kannst. Am Ende dieses Kapitels solltest du ein solides Verständnis der Datenbereinigung, der Vorverarbeitung, des Modelltrainings und der Auswertung haben und in der Lage sein, sie in deinen eigenen Interviews gut zu diskutieren.
Definieren eines Machine Learning Problems
In diesem Abschnitt gebe ich einen Überblick über die Definition eines ML-Problems und zeige, warum und wie sich dies in den Interviewfragen niederschlägt.
Stell dir das folgende Szenario vor: Du, der Kandidat, gehst durch ein ML-Projekt, das du entwickelt hast. Das Ziel ist es, vorherzusagen, ob ein Nutzer auf eine Werbe-E-Mail für die Konzerte eines bestimmten Sängers klicken wird.1 Dein Gesprächspartner denkt nach deinem Überblick einige Sekunden nach und sagt dann: "Es klingt so, als könntest du die Zeit, die ein Nutzer dem Künstler A zuhört, nutzen, um zu bestimmen, wer Werbe-E-Mails für diesen Künstler erhält. Wenn er zum Beispiel mehr als fünf Stunden pro Woche Künstler A hört, schickst du ihm eine E-Mail, wenn er ein Konzert in seiner Nähe gibt. Warum hast du dich für maschinelles Lernen entschieden, wenn es auch einfachere Methoden gibt, die ohne maschinelles Lernen auskommen und das Gleiche erreichen wie dein Modell?"
Du erstarrst, weil du nicht an diese Frage gedacht hast. Damals schien es ein lustiges, selbstbestimmtes Projekt zu sein, und du wolltest einfach nur lernen. Du verstehst nicht ganz, worauf der Interviewer mit seiner Frage hinaus will. Was machen Sie beruflich?
Es ist wichtig, dass du dir im Voraus überlegst, wie du diese Fragen gut beantworten kannst. Hier sind einige mögliche Blickwinkel:
Hast du darüber nachgedacht, zunächst ein heuristisches (d.h. regelbasiertes) Basismodell zu verwenden? In bestimmten Situationen kannst du auch ein möglichst einfaches Modell, z. B. ein logistisches Regressionsmodell, als Grundlage verwenden. Das Ziel deines ML-Modells wäre es dann, besser abzuschneiden als das Basismodell.
In der Praxis werden neue ML-Initiativen oft nur dann gestartet oder genehmigt, wenn der Aufwand für die Entwicklung durch einen klaren geschäftlichen Nutzen gerechtfertigt ist. Wenn zum Beispiel die Kosten für die Implementierung eines ML-Systems zur Empfehlung von Konzerten den erwarteten Gewinn nicht aufwiegen, ist es einfacher, Heuristiken zu verwenden . Auch die erwarteten Einsparungen an Komplexität, manueller Arbeit oder Zeit sind ein Grund, ML der Heuristik vorzuziehen.
Aber keine Sorge - der Interviewer macht sich nicht über dein Projekt lustig, sondern fragt: "Warum ML?" Das ist in der professionellen ML-Welt sehr üblich. Die Frage "Warum ML?" bedeutet nicht: "Du hättest ML nicht einsetzen sollen." Es ist nur der Anfang einer Diskussion, die ML-Profis in ihrem Alltag oft führen. Die Art und Weise, wie du auf diese Frage antwortest, kann ein gutes Zeichen dafür sein, ob du dich gut in die ML-Arbeit in der Industrie einfinden kannst.
Du könntest Folgendes sagen, was in diesem Szenario funktionieren würde:
Sei ehrlich: "Um ehrlich zu sein, wollte ich nur ein paar neue Modellierungstechniken für ein Nebenprojekt lernen, und da ich Spotify sehr häufig benutze, wollte ich sehen, wie ich die E-Mail-Funktion mit ML nachahmen kann."
Wenn du über ein Arbeitsprojekt sprichst: "In der Realität habe ich festgestellt, dass Heuristiken funktionieren, aber nur für die meisten Durchschnittsnutzer. Heavy User brauchen zum Beispiel eine längere Hördauer, um ihre Lieblingskünstler zu bestimmen. Als wir dann auch noch andere Daten wie Likes und das Hinzufügen zu Wiedergabelisten in die Heuristik einfließen ließen, bemerkten wir eine höhere Reaktion auf die Werbe-E-Mails. Dadurch wurde die Heuristik zu kompliziert und schwer zu skalieren. Deshalb haben wir stattdessen ML eingesetzt, um Muster in einer größeren Anzahl von Merkmalen zu finden."
Tipp
Ehrlich sein ist gut. Als frischgebackener Absolvent habe ich einmal eines meiner Nebenprojekte mit den Worten eingeleitet: "Das ist ein Klassifikator für Bilder von Ariana Grande. Ich wollte dieses Projekt nur zum Spaß machen, und es gibt keinen wirklichen Grund, warum es Ariana Grande sein muss. Hier ist, wie ich es gemacht habe...". Aber ich schaffte es trotzdem, von den Interviewern ernst genommen zu werden, indem ich das Projekt als eine Möglichkeit rechtfertigte, Faltungsneuronale Netze einzusetzen.
Wenn du dein eigenes Nebenprojekt durchführst und vorhast, es für die Beantwortung von Interviewfragen zu nutzen, überlege, welche heuristischen Methoden das gewünschte Ziel erreichen könnten. Später kannst du sie als einfache Grundlage verwenden, um zu sehen, ob die ML-Methode besser ist. Das wird dir helfen, dich von anderen Bewerbern abzuheben. Auf die Modellauswahl und die Modellbewertung gehe ich später in diesem Kapitel ein.
Datenvorverarbeitung und Feature Engineering
In diesem Abschnitt fasse ich gängige Techniken und Szenarien für die Datenvorverarbeitung und das Feature-Engineering sowie gängige ML-Interviewfragen zusammen, die diesen Schritt im ML-Lebenszyklus abdecken. Der Einfachheit halber gehe ich davon aus, dass die Daten für die ML-Interviewfragen zur Verfügung stehen, auch wenn das in der Praxis oft eine Herausforderung darstellt. Ich beginne mit einer Einführung in die Datenerfassung,2 die explorative Datenanalyse (EDA) und das Feature Engineering.
Tipp
Alle Daten- und ML-Rollen werden Datenvorverarbeitung und EDA nutzen. Einige der Techniken in diesem Kapitel sind speziell für ML gedacht, sind aber auch für Datenanalysten oder Dateningenieure nützlich.
Einführung in die Datenerfassung
Die Datenerfassung, die im Zusammenhang mit ML gemeinhin als Datenerfassung bezeichnet wird, kann folgende Möglichkeiten beinhalten:
Zugang zur Arbeit, in der Regel zu geschützten Daten
Öffentliche Datensätze, z. B. von Kaggle, Volkszählungsbüros und dergleichen
Web Scraping (beachte die Allgemeinen Geschäftsbedingungen einiger Websites)
Akademischer Zugang, z. B. als Teil eines Forschungslabors an deiner Universität
Einkaufsdaten von Anbietern:
Einige Anbieter wie Figure Eight und Scale AI helfen auch beim Kommentieren und Beschriften von Daten.
Dein Arbeitsplatz oder deine akademische Einrichtung übernimmt in der Regel die Kosten, denn die Preise sind in der Regel zu hoch, um sich für einzelne Nebenprojekte zu lohnen.
Synthetische Daten durch Simulationen erstellen
Erstelle deine eigenen Rohdaten, z. B. durch eigene Fotos, Crowdsourcing von Daten oder durch selbst erstellte Kunst/Designs
Einführung in die explorative Datenanalyse
Jetzt, wo du die Daten erfasst hast, ist es an der Zeit, sie zu analysieren. Bei der EDA geht es in erster Linie darum, herauszufinden, ob die Daten als Ausgangspunkt ausreichen oder ob du mehr brauchst. Versuche also, dir einen Überblick über die Verteilung der Daten zu verschaffen und Fehler und Macken zu finden. Fehler und Macken können z. B. zu viele fehlende Werte, schiefe Datenverteilungen oder Duplikate sein. Die EDA befasst sich auch mit den allgemeinen Merkmalen jedes Merkmals: Mittelwerte, Verteilungen usw. Wenn du Fehler entdeckst, gibt es Möglichkeiten, diese später bei der Datenbereinigung und beim Feature-Engineering zu beheben; wichtig bei der EDA ist nur, dass du dir der möglichen Probleme bewusst bist.
Tipp
Für ML- und Datenexperten ist es wichtig, ein gewisses Fachwissen zu haben. In meinen Nebenprojekten zur Preisgestaltung von Videospielen kannte ich die Dynamik der Branche und das Kundenverhalten gut, da ich selbst ein begeisterter Gamer bin. Bei meiner Arbeit muss ich die einzelnen Bereiche kennenlernen, um nützliche ML-Modelle zu erstellen.
Mein üblicher Ansatz ist es, ydata-profiling, früher bekannt als pandas-profiling, auszuführen und den generierten Bericht zu analysieren (ein Beispielbericht ist in Abbildung 4-1 dargestellt). Beachte, dass dies nur ein Ausgangspunkt ist und dass es wichtig ist, mit Hilfe von Fachwissen Muster oder Anomalien herauszufinden. Was in manchen Branchen und Modellen ein Problem darstellt, kann in anderen erwartet werden. Bei einem RecSys-Problem zum Beispiel sind die Daten in der Regel spärlicher als bei einem Zeitreihen-Datensatz. Es reicht nicht aus, sich die generierten Statistiken anzusehen. Außerdem gibt es in einigen Bereichen Algorithmen, die sich um die üblichen Probleme kümmern, sodass diese Probleme weniger Anlass zur Sorge geben.
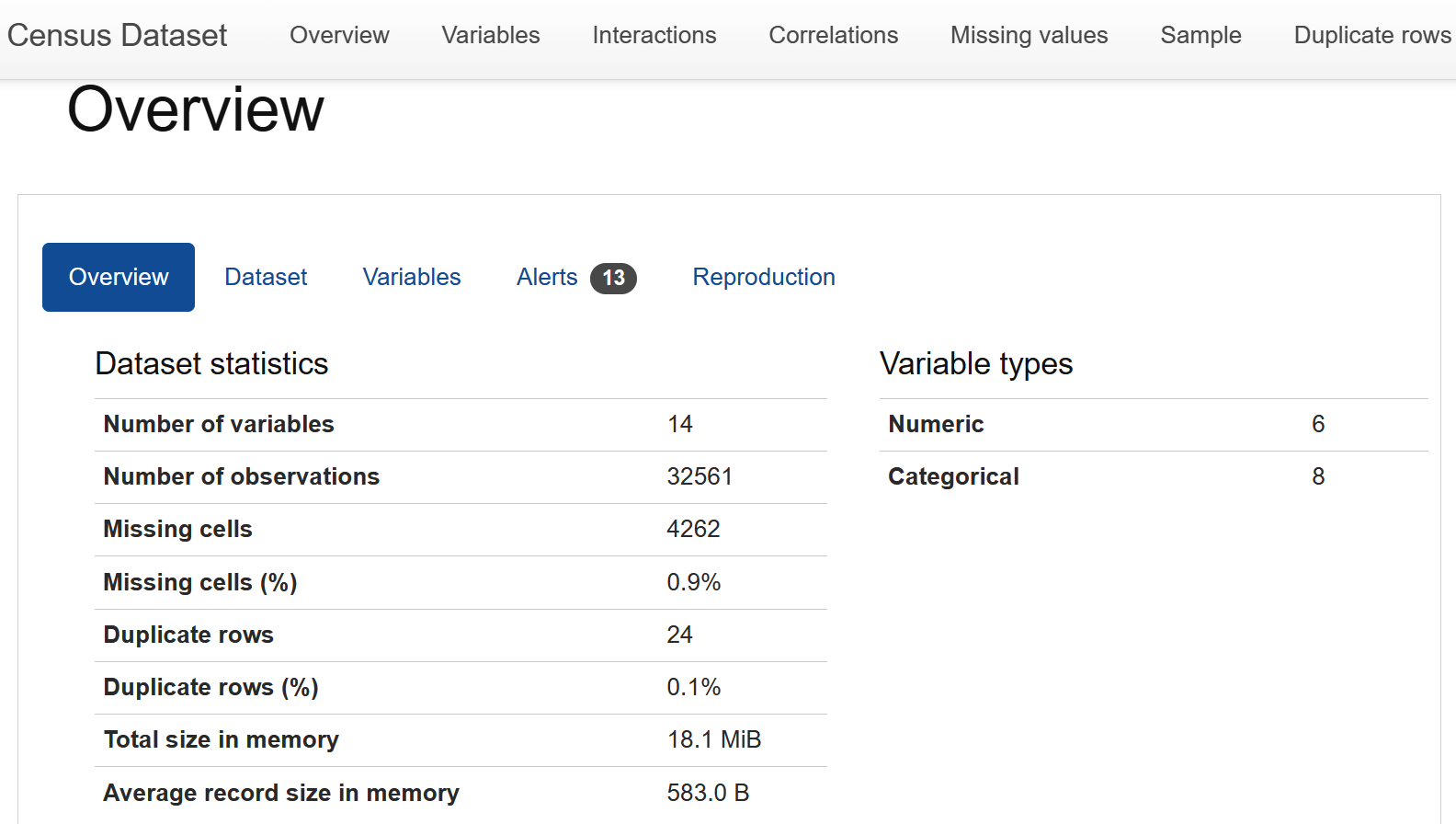
Abbildung 4-1. Screenshot von ydata-profiling; Quelle: ydata-profiling Dokumentation.
Mehr Details über EDA können in diesem Buch nicht behandelt werden, aber ich empfehle die Lektüre von Making Sense of Data von Glenn J. Myatt und Wayne P. Johnson (Wiley), um mehr zu erfahren.
Nach einigen Iterationen, sagen wir, du hast die EDA abgeschlossen, kommst du zu einem Entscheidungspunkt: Die Daten scheinen (vorerst) solide genug zu sein, um weiterzumachen, oder du musst vielleicht erst mehr Daten oder einen anderen Datensatz erfassen; spülen und wiederholen.
Tipp
Wenn Interviewer dich fragen, was du tun würdest, wenn du mit einem ML-Problem anfängst, erwarten sie, dass du EDA zu einem frühen Zeitpunkt im Prozess erwähnst, nachdem du eine oder mehrere Datenquellen erworben hast. Es ist wichtig, dass du zeigst, dass du in der Lage bist, die Daten kritisch zu betrachten und sogar Fehler zu finden, anstatt nur einen vorgereinigten Datensatz zu übernehmen.
Einführung in das Feature Engineering
Nach der Erkundung der Daten, der Iteration, bis ein guter Ausgangspunkt für das Modelltraining gefunden wurde, ist es Zeit für das Feature Engineering. Im ML sind Features die Eingaben für ML-Modelle. Das Ziel ist es, den Datensatz so zu verändern, dass er mit den ML-Modellen kompatibel ist, aber auch, um mit beobachteten Fehlern oder Unvollständigkeiten in den Daten umzugehen, z. B. mit fehlenden Werten. Zu den Themen, die ich hier bespreche, gehören der Umgang mit fehlenden Daten, der Umgang mit doppelten Daten, die Standardisierung von Daten und die Vorverarbeitung von Daten.
Hinweis
Einige der Techniken überschneiden sich mit dem, was gemeinhin als "Datenbereinigung" bezeichnet wird, die in mehr Phasen des ML-Lebenszyklus stattfinden kann als das Feature-Engineering, aber es ist sinnvoll, sie hier vorzustellen.
Umgang mit fehlenden Daten durch Imputation
Es gibt gängige Imputationstechniken für den Umgang mit fehlenden Daten, die du in einem Interview nennen können solltest, zusammen mit ihren Vor- und Nachteilen. Dazu gehören das Auffüllen mit dem Mittel- oder Medianwert und die Verwendung eines baumbasierten Modells.
In Tabelle 4-1 sind einige Dinge aufgeführt, die du beim Eintragen fehlender Werte beachten solltest.
| Technik | Profis | Nachteile |
|---|---|---|
| Mittelwert/Mittelwert/Modus | Einfach zu implementieren | Berücksichtigt im Vergleich zu baumbasierten Methoden möglicherweise keine Ausreißer Nicht so geeignet für kategoriale Variablen |
| Baumbasierte Modelle | Kann mehr zugrunde liegende Muster erfassen Sowohl für numerische als auch kategoriale Variablen geeignet |
Erhöht die Komplexität bei der Vorverarbeitung der Daten Das Modell muss neu trainiert werden, wenn sich die zugrunde liegende Verteilung der Daten ändert. |
Umgang mit doppelten Daten
Es gibt eine schier unendliche Anzahl von Möglichkeiten, wie Beobachtungen versehentlich dupliziert werden können:
Aufträge zur Datenübernahme können aufgrund eines Fehlers doppelt ausgeführt werden.
Bei einigen komplizierten Joins konnten einige Zeilen unbeabsichtigt dupliziert und dann nicht entdeckt werden.
Einige Kanten können dazu führen, dass die Datenquelle doppelte Daten liefert.
... und so weiter.
Wenn du auf doppelte Daten stößt, kannst du SQL oder Python verwenden, um die Daten zu deduplizieren und sicherzustellen, dass die Datensätze in einem Format dargestellt werden, auf das du später leichter zugreifen und es nutzen kannst.
Daten standardisieren
Nachdem du dich um fehlende und doppelte Daten gekümmert hast, sollten die Daten auf standardisiert werden. Dazu gehören die Behandlung von Ausreißern, die Skalierung von Merkmalen und die Sicherstellung, dass Datentypen und -formate einheitlich sind:
- Umgang mit Ausreißern
Zu den Techniken für den Umgang mit Ausreißern gehören das Entfernen extremer Ausreißer aus dem Datensatz, das Ersetzen durch weniger extreme Werte (bekannt als Winsorizing) und logarithmische Skalentransformationen. Ich würde davor warnen, Ausreißer zu entfernen, da dies sehr stark vom Fachwissen abhängt. In einigen Bereichen hat dies schwerwiegendere Folgen: Wenn du zum Beispiel Bilddaten von Pferdekutschen aus einem Trainingsdatensatz für selbstfahrende Autos entfernst, nur weil es sich dabei nicht um einen gängigen Fahrzeugtyp handelt, könnte das Modell Pferdekutschen in der realen Welt nicht erkennen. Deshalb solltest du die Auswirkungen sorgfältig abwägen, bevor du dich für eine bestimmte Technik entscheidest.
- Merkmale skalieren
Bei Datensätzen mit mehreren Merkmalen mit numerischen Werten können größere Werte von ML-Algorithmen fälschlicherweise als aussagekräftiger interpretiert werden. Ein Beispiel: Eine Spalte ist der Preis, der zwischen 50 und 5.000 US-Dollar liegt, während ein anderes Merkmal die Häufigkeit der Anzeigenschaltung ist, die zwischen 0 und 10 Mal liegt. Die beiden Merkmale sind in unterschiedlichen Einheiten angegeben, aber beide sind numerisch, so dass es möglich ist, dass die Preisspalte eine größere Wirkung hat. Einige Modelle, wie z. B. gradient-descent-basierte Modelle, reagieren empfindlicher auf die Größe der Merkmale. Daher ist es besser, die Merkmale so zu skalieren, dass sie im Bereich [-1, 1] oder [0, 1] liegen.
Warnung
Sei vorsichtig bei der Skalierung von Merkmalen. Es ist sinnvoll, verschiedene Techniken zu kombinieren oder das zu verwenden, was du bei der EDA gefunden hast. Ein Merkmal könnte zum Beispiel extreme Ausreißer haben, z. B. dass die meisten Werte im Bereich [0, 100] liegen, mit Ausnahme einer Beobachtung von 1000. Ohne es zu überprüfen, könntest du die Merkmalswerte auf der Grundlage des Mindestwerts von 0 und des Höchstwerts von 1000 skalieren. Das kann dazu führen, dass die in den Merkmalen enthaltenen Informationen komprimiert werden.
- Konsistenz der Datentypen
Ich habe einmal an einem ML-Modell gearbeitet und erhielt Ergebnisse, die nicht den Erwartungen entsprachen, und ich brauchte eine Weile, um sie zu debuggen. Schließlich fand ich das Problem: Eine numerische Spalte war als String formatiert! Es ist sinnvoll, deine endgültigen Datentypen zu überprüfen, um sicherzustellen, dass sie in deinem ML-Modell Sinn ergeben, bevor du den Rest des Prozesses durchführst.
Tipp
Es kann sein, dass der Interviewer Folgefragen dazu stellt, wie genau du mit Ausreißern, der Merkmalsskala oder der Datentypenkonsistenz umgegangen bist, also solltest du dich über die Gründe und Kompromisse jedes Ansatzes informieren.
Vorverarbeitung der Daten
Die Vorverarbeitung der Daten ermöglicht es, dass die Merkmale für das ML-Modell im Kontext des von dir verwendeten Algorithmus Sinn ergeben. Die Vorverarbeitung strukturierter Daten kann One-Hot-Codierung, Label-Codierung, Binning, Merkmalsauswahl usw. umfassen.
Tipp
Unstrukturierte Daten sind "Informationen, die nicht nach einem vorgegebenen Datenmodell oder Schema angeordnet sind und daher nicht in einer herkömmlichen relationalen Datenbank oder einem RDBMS (relationales Datenbankmanagementsystem) gespeichert werden können. Text und Multimedia sind zwei gängige Arten von unstrukturierten Inhalten."3 Wenn du auf unstrukturierte Daten triffst, kann die Vorverarbeitung anders aussehen (möglicherweise werden die Daten sogar umgewandelt, um strukturiert zu werden). Zur Veranschaulichung konzentriere ich mich in diesem Kapitel auf Beispiele für die Vorverarbeitung von strukturierten Daten.
One-Hot-Codierung kategorialer Daten
Vielleicht möchtest du kategoriale Daten als numerische Daten darstellen. Jede Kategorie wird zu einem Merkmal, wobei 0 oder 1 für den Zustand des Merkmals in jeder Beobachtung steht. Stell dir zum Beispiel einen einfachen Wetterdatensatz vor, bei dem es nur sonniges oder bewölktes Wetter geben kann. Du hättest dann Folgendes:
- 1. März
-
Das Wetter: Sonnig
Temperatur (Celsius): 27
- 2. März
-
Das Wetter: Sonnig
Temperatur (Celsius): 25
- 3. März
-
Das Wetter: Bewölkt
Temperatur (Celsius): 20
Aber das Merkmal "Wetter" kann so kodiert werden, dass es alle möglichen Wetterzustände abdeckt:
- 1. März
-
Sonnig: 1
Bewölkt: 0
- 2. März
-
Sonnig: 1
Bewölkt: 0
- 3. März
-
Sonnig: 0
Bewölkt: 1
Die One-Hot-Kodierung wird oft verwendet, weil Zahlen für ML-Algorithmen leichter zu verstehen sind. Einige Algorithmen berücksichtigen keine kategorischen Werte, aber das hat sich im Laufe der Jahre verbessert, so dass einige Implementierungen kategorische Werte berücksichtigen und sie im Hintergrund umwandeln können.
Ein Nachteil der One-Hot-Codierung ist, dass bei Merkmalen mit hoher Kardinalität (d.h. es gibt viele eindeutige Werte in diesem Merkmal) die Anzahl der Merkmale drastisch ansteigen kann, was die Berechnungen verteuert.
Tipp
Manchmal kann mangelndes Fachwissen oder Verständnis der Geschäftslogik zu Problemen bei der Datenvorverarbeitung führen. Ein Beispiel ist die Definition von abgewanderten Nutzern als diejenigen, die ein Produkt innerhalb der letzten sieben Tage gekündigt haben, aber das Produkt oder die Geschäftslogik zählt die abgewanderten Nutzer als diejenigen, die innerhalb der letzten 60 Tage gegangen sind. (Wenn die Geschäftslogik aus irgendeinem Grund nicht gut für ML geeignet ist, können wir einen Mittelweg finden).
Kodierung der Etiketten
Bei der Label-Codierung werden die Kategorien auf Zahlen abgebildet, aber sie bleiben im selben Merkmal. Zum Beispiel können Wettertypen eindeutigen Nummern zugeordnet werden, wie in Abbildung 4-2 dargestellt.
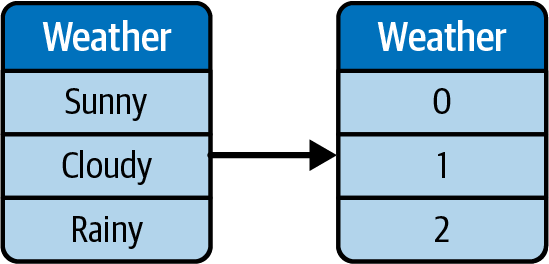
Abbildung 4-2. Illustration der Etikettenkodierung.
Einer der Nachteile der Label-Kodierung ist, dass einige ML-Algorithmen die Skala und die Werte so verwechseln können, dass sie ein höheres Ausmaß an Auswirkungen bedeuten. Um unser vorheriges Beispiel aufzugreifen: Das Wetter kann mit einem Label kodiert werden: Aus sonnig wird 0 und aus bewölkt wird 1. Für ML könnte dies jedoch bedeuten, dass "bewölkt" ein höheres Ausmaß hat, da 1 größer als 0 ist.
Glücklicherweise können in vielen ML-Algorithmen eingebaute Klassen verwendet werden (z. B. scikit-learn's LabelEncoder Klasse), so dass der Algorithmus im Hintergrund weiß, dass es sich nur um eine Kategorisierung handelt und nicht notwendigerweise eine Größenordnung angibt .
Tipp
Wenn du natürlich vergisst, dem Algorithmus mitzuteilen, dass beschriftete Merkmale tatsächlich beschriftet sind, dann wird der ML-Algorithmus dieses Merkmal wahrscheinlich wie ein normales numerisches Merkmal behandeln. Du kannst dir vorstellen, wie das zu Problemen führen kann, wenn du das bei den Interviewfragen nicht berücksichtigt hast.
Binning für numerische Werte
Binning kann die Menge der Kardinalität reduzieren und dazu beitragen, dass Modelle besser verallgemeinern. Wenn der Datensatz z. B. einen Preis von $100 hat, kann es sein, dass er beim ersten Mal, wenn er $95 sieht, nicht verallgemeinert, auch wenn in der jeweiligen Anwendung $95 ähnlich wie $100 ist. Zur Veranschaulichung kannst du die Bin-Kanten als [15, 25, 35, 45, 55, 65, 75, 85, 99] definieren, wodurch ähnliche Preisspannen wie "$15-$25", "$25-$35", "$35-$45" und so weiter entstehen.
Ein Nachteil des Binning ist, dass es harte Kanten in die Bedeutung der Bins einführt, so dass eine Beobachtung von $46 als völlig anders angesehen wird als die Bins "$35-$45", obwohl sie vielleicht noch ähnlich ist.
Auswahl der Merkmale
Manchmal enthält dein Datensatz Merkmale, die stark korreliert sind, d.h. es besteht eine Kollinearität zwischen den Merkmalen. Ein extremes Beispiel ist die Körpergröße in Zentimetern, aber auch die Körpergröße in Metern, die im Wesentlichen dieselbe Information erfassen. Es kann sein, dass es noch andere Merkmale gibt, die einen großen Teil der gleichen Informationen erfassen. Wenn du diese entfernst, kann das versehentliche Overfitting reduziert oder die Geschwindigkeit des Modells erhöht werden, weil das Modell nicht so viele Merkmale verarbeiten muss . Die Dimensionalitätsreduktion ist eine gängige Technik zur Auswahl von Merkmalen; sie reduziert die Dimensionalität der Daten, während die wichtigsten Informationen erhalten bleiben .
Du kannst auch Tabellen mit der Wichtigkeit von Merkmalen verwenden, wie sie in XGBoost oder CatBoost enthalten sind, und die Merkmale mit der geringsten Wichtigkeit, d.h. dem geringsten Beitrag zum Modell, entfernen.
Beispiel-Interviewfragen zu Datenvorverarbeitung und Feature Engineering
Nachdem ich nun die Grundlagen der Datenvorverarbeitung und des Feature-Engineerings erläutert habe, möchte ich einige Beispielfragen aus dem Interview durchgehen.
Interviewfrage 4-1: Was ist der Unterschied zwischen Feature Engineering und Feature Selection?
- Beispielantwort
Beim Feature-Engineering geht es um die Erstellung oder Umwandlung von Merkmalen aus Rohdaten. Dies geschieht, um die Daten besser darzustellen und sie im Vergleich zu ihrem Rohformat für ML besser geeignet zu machen. Zu den gängigen Techniken gehören der Umgang mit fehlenden Daten, die Standardisierung von Datenformaten und so weiter.
Bei der Merkmalsauswahl geht es darum, die relevanten ML-Merkmale einzugrenzen, um das Modell zu vereinfachen und eine Überanpassung zu verhindern. Gängige Techniken sind die PCA (Hauptkomponentenanalyse) oder die Verwendung der Merkmalsbedeutung von baumbasierten Modellen, um festzustellen, welche Merkmale mehr nützliche Signale liefern.
Interviewfrage 4-2: Wie verhinderst du Datenverluste bei der Datenvorverarbeitung?
- Beispielantwort
Eine der gängigsten Methoden, um Datenlecks zu vermeiden, ist die sorgfältige Aufteilung von Trainings-, Validierungs- und Testdaten. Doch die Dinge sind nicht immer so einfach. Wenn zum Beispiel der Mittelwert aller Beobachtungen des Merkmals imputiert wird, bedeutet das, dass der Mittelwert Informationen über alle Beobachtungen enthält, nicht nur über den Trainingssplit. Achte in diesem Fall darauf, dass du die Datenimprognose nur mit Informationen über den Trainingssplit durchführst, und zwar für den Trainingssplit. Andere Beispiele für Datenlecks sind Zeitreihensplits; wir sollten darauf achten, dass wir die Zeitreihen nicht versehentlich mischen und falsch aufteilen (z. B. indem wir den morgigen Tag für die Vorhersage des heutigen Tages verwenden und nicht umgekehrt).
Interviewfrage 4-3: Wie gehst du beim Feature Engineering mit einer schiefen Datenverteilung um, wenn du davon ausgehst, dass die Minderheitsklasse für das Problem des maschinellen Lernens erforderlich ist?
- Beispielantwort
Stichprobenverfahren,4 Ein Oversampling der Minderheitsklassen ( ) kann bei der Vorverarbeitung und beim Feature-Engineering helfen (z. B. mit Techniken wie SMOTE). Es ist wichtig zu beachten, dass beim Oversampling alle doppelten oder synthetischen Instanzen nur aus den Trainingsdaten generiert werden sollten, um Datenverluste in der Validierungs- oder Testmenge zu vermeiden.
Der Prozess der Modellschulung
Jetzt, wo die Daten für ML bereit sind, ist es an der Zeit, zum nächsten Schritt überzugehen: dem Modelltraining. Dieser Prozess umfasst die Schritte der Definition der ML-Aufgabe, der Auswahl der am besten geeigneten ML-Algorithmen für die Aufgabe und des eigentlichen Trainings des Modells. In diesem Abschnitt stelle ich dir außerdem allgemeine Fragen und Tipps für das Vorstellungsgespräch vor, die dir zum Erfolg verhelfen werden.
Der Iterationsprozess bei der Modellschulung
Zu Beginn eines ML-Projekts hast du dir wahrscheinlich Gedanken darüber gemacht, was das allgemeine Ergebnis sein soll, z. B. "die höchstmögliche Genauigkeit bei einem Kaggle-Wettbewerb erreichen" oder "diese Daten zur Vorhersage der Verkaufspreise von Videospielen verwenden". Vielleicht hast du auch damit begonnen, einige Algorithmen zu recherchieren, die für die Aufgabe geeignet sind, wie z. B. Zeitreihenvorhersagen. Die Festlegung der endgültigen ML-Aufgabe ist (oft) ein iterativer Prozess, bei dem du zwischen den einzelnen Schritten hin und her gehst, bevor du dich für etwas entscheidest, wie in Abbildung 4-3 dargestellt.
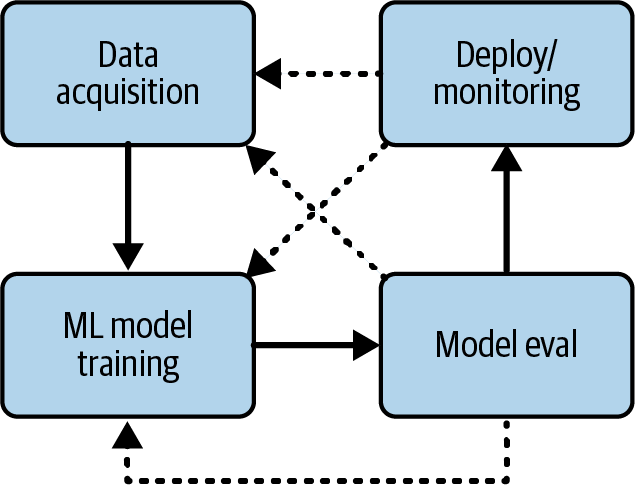
Abbildung 4-3. Beispielhafter Iterationsprozess beim ML-Training.
Schauen wir uns zum Beispiel alle Schritte in einem Projekt zur Vorhersage der Verkaufszahlen von Videospielen an:
Definiere die ML-Aufgabe, die Modellauswahl. Du könntest mit einer Idee beginnen: verwende Zeitreihendaten mit ARIMA (AutoRegressive Integrated Moving Average), denn das Problem scheint einfach zu sein - Preisvorhersagen verwenden oft Zeitreihendaten.
Datenerfassung. Es kann sein, dass du einen Datensatz mit Zeitreihendaten erwirbst, d.h. er enthält nur die Zeit, z.B. ein Datum oder einen Zeitstempel, und den Preis. Der zukünftige Preis ist die Ausgabe der Modellvorhersagen, und die historischen Preise sind die Eingaben.
Es kann aber auch vorkommen, dass die ARIMA-Methode nicht funktioniert und du das Problem durch eine genauere Analyse der Quelldaten löst. Es stellt sich heraus, dass du Daten von Spielen großer Unternehmen (auch "AAA"-Spiele genannt) mit kleineren Spielen von unabhängigen Studios (auch "Indie"-Spiele genannt) kombinierst. AAA-Spiele haben oft große Budgets für Marketing und Werbung, deshalb verkaufen sie sich im Durchschnitt besser als Indie-Spiele.
Definiere die ML-Aufgabe (erneut). Der nächste Schritt besteht darin, die ML-Aufgabe neu zu bewerten. Nach einigem Nachdenken entscheidest du dich dafür, die Zeitreihe weiterhin vorherzusagen, sodass die ML-Aufgabe unverändert bleibt.
Datenerfassung (wieder). Dieses Mal weißt du aber schon, was du anders machen musst, damit die Ergebnisse besser werden. So sammelst du mehr Daten: ob ein Spiel AAA oder Indie ist. Am Ende könntest du es sogar von Hand kennzeichnen.
Modellauswahl (wieder). Jetzt wird dir klar, dass das Modell geändert werden muss, da ARIMA keine kategorischen Variablen wie "Indie" und "AAA" verarbeiten kann. Also suchst du im Internet nach anderen Algorithmen, die kategoriale Variablen mit numerischen Variablen mischen können, und probierst einen davon aus.
Fahre damit fort, die vorherigen Schritte zu wiederholen, bis du gut genug bist. Wenn das immer noch nicht gut funktioniert, kannst du die Schritte wiederholen, indem du weitere Arten von Merkmalen hinzufügst, verschiedene Modelle ausprobierst oder eine Merkmalstechnik wie die One-Hot-Codierung anwendest. Auch die ML-Aufgabe kann sich im Laufe des Prozesses ändern: Statt die genauen Verkaufszahlen vorherzusagen, könntest du dich für die Vorhersage von Bins entscheiden, wie z. B. (hohe, mittlere, niedrige) Verkaufszahlen, wobei hohe Verkaufszahlen über 50.000 Einheiten liegen oder etwas, das du durch EDA definiert hast.
Wenn du ein Projekt von Anfang bis Ende durchgearbeitet hast, kennst du den iterativen Charakter der in diesem Abschnitt beschriebenen Schritte. Vielleicht fällt dir auf, dass du in diesem Beispiel deutlich erkennen kannst, warum du zur Datenerfassung und dann zur Definition der ML-Aufgabe zurückgekehrt bist. Es gibt immer einen Grund, auch wenn der Grund nur darin besteht, zu sehen, ob der neue Ansatz besser funktioniert als dein aktueller Ansatz. So erhältst du eine Menge interessanter Informationen, die du auf die Fragen deines Gesprächspartners antworten kannst.
Die Interviewer wollen sich von den folgenden Punkten überzeugen:
Du kennst dich mit den gängigen ML-Aufgaben in ihrem Bereich aus.
Du kennst die gängigen Algorithmen für die genannten Aufgaben.
Du weißt, wie du diese Modelle bewerten kannst.
Definieren der ML Aufgabe
Im vorherigen Abschnitt hast du gesehen, dass die Schritte von der Datenerfassung bis zum Modelltraining oft iterativ ablaufen und dass es für deine Antworten im Vorstellungsgespräch hilfreich ist, wenn du die Gründe für jede deiner Iterationen erläuterst.
Um das ML-Modell auszuwählen, musst du die ML-Aufgabe definieren. Um das herauszufinden, kannst du dich fragen, welcher Algorithmus verwendet werden soll und welche Aufgabe(n) mit dem Algorithmus verbunden sind. Geht es zum Beispiel um Klassifizierung oder Regression?
Es gibt keine vorgeschriebene Methode, die dir die richtigen Algorithmen verrät, aber im Allgemeinen solltest du das wissen wollen:
Hast du genug Daten?
Sagst du eine Menge/einen numerischen Wert oder eine Kategorie/einen kategorischen Wert voraus?
Hast du beschriftete Daten (d.h. du kennst die Grunddaten)? Dies könnte ausschlaggebend dafür sein, ob überwachtes oder unüberwachtes Lernen besser für die Aufgabe geeignet ist.
Zu den Aufgaben können Regression, Klassifizierung, Anomalieerkennung, Empfehlungssysteme, Reinforcement Learning, Verarbeitung natürlicher Sprache, generative KI und so weiter gehören, über die du in Kapitel 3 gelesen hast. Eine vereinfachte Übersicht über die Auswahl der ML-Aufgabe ist in Abbildung 4-4 dargestellt. Die Kenntnis des Ziels und der Daten, die dir zur Verfügung stehen (oder die du zu beschaffen gedenkst), kann dir bei der Auswahl der ersten Aufgaben helfen. Je nachdem, welche beschrifteten Daten zur Verfügung stehen oder ob die Zielvariable kontinuierlich oder kategorial ist, sind verschiedene ML-Aufgaben besser geeignet.
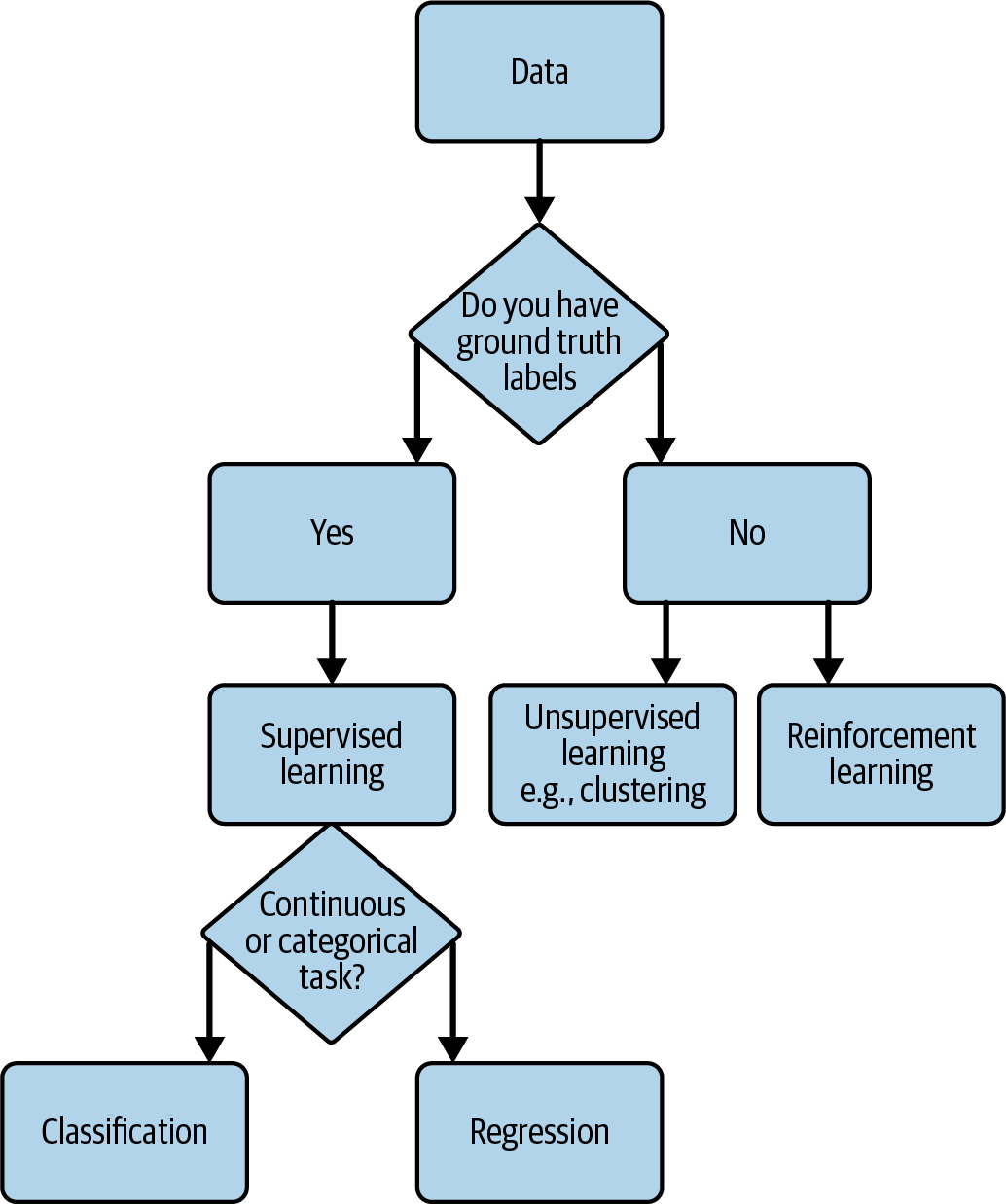
Abbildung 4-4. Vereinfachtes Flussdiagramm der ML-Aufgabenauswahl.
Überblick über die Modellauswahl
Jetzt, da du eine Vorstellung von der ML-Aufgabe hast,, lass uns zur Modellauswahl übergehen. Erinnere dich daran, dass es sich hierbei um einen iterativen Prozess handelt, den du also nicht in einem Rutsch entscheiden kannst. Dennoch musst du ein Modell (oder mehrere) als Ausgangspunkt auswählen. In Vorstellungsgesprächen wirst du gefragt werden, warum du dich für diesen oder jenen Algorithmus oder dieses oder jenes Modell entschieden hast, und eine Antwort aus dem Bauch heraus wird dir nicht genügen. Wie du in Abbildung 4-4 gesehen hast, hast du bereits einen Ausgangspunkt für die ML-Aufgabe(n), die du definiert hast. Lass uns nun einige gängige Algorithmen und Bibliotheken (meist in Python) genauer unter die Lupe nehmen, die du für die Umsetzung der Aufgabe verwenden kannst.
Ich möchte kurz die Terminologie klären: Wenn du zunächst einen Algorithmus auswählst, ist das technisch gesehen keine Modellauswahl, bis du ihn getestet und die Leistung des resultierenden Modells verglichen hast. Dieser Begriff wird oft synonym verwendet, da du die endgültige Entscheidung zwangsläufig auf der Grundlage der tatsächlichen Modellleistung treffen willst. Jason Brownlee schreibt in Machine Learning Mastery: "Die Modellauswahl ist ein Prozess, der sowohl auf verschiedene Modelltypen (z. B. logistische Regression, SVM, KNN usw.) als auch auf Modelle desselben Typs mit unterschiedlichen Modellhyperparametern (z. B. verschiedene Kernel in einem SVM) angewendet werden kann."5
Hier sind einige Algorithmen und Bibliotheken, die als einfache Ausgangspunkte für jede Aufgabe verwendet werden können. Beachte, dass viele Bibliotheken vielseitig sind und für mehrere Zwecke verwendet werden können (z. B. können Entscheidungsbäume sowohl für die Klassifizierung als auch für die Regression verwendet werden), aber ich führe einige vereinfachte Beispiele zum Verständnis auf:
- Klassifizierung
Zu den Algorithmen gehören Entscheidungsbäume, Random Forest und ähnliche. Zu den Python-Bibliotheken, mit denen du anfangen kannst, gehören scikit-learn, CatBoost und LightGBM.
- Regression
Zu den Algorithmen gehören logistische Regression, Entscheidungsbäume und Ähnliches. Beispiele für Python-Bibliotheken, mit denen du anfangen kannst, sind scikit-learn und statsmodels.
- Clustering (unüberwachtes Lernen)
Zu den Algorithmen gehören k-means clustering, DBSCAN und ähnliche. Eine Python-Bibliothek, mit der du anfangen kannst, ist scikit-learn.
- Zeitreihenvorhersage
Zu den Algorithmen gehören ARIMA, LSTM und ähnliche. Beispiele für Python-Bibliotheken, mit denen du beginnen kannst, sind Statsmodels, Prophet, Keras/TensorFlow und so weiter.
- Empfehlungssysteme
Zu den Algorithmen gehören Matrixfaktorisierungstechniken wie das kollaborative Filtern. Beispiele für Bibliotheken und Tools, mit denen du beginnen kannst, sind die MLlib von Spark oder Amazon Personalize auf AWS.
- Verstärkungslernen
Zu den Algorithmen gehören Multiarmed Bandit, Q-learning und Policy Gradient. Zu den Beispielbibliotheken, mit denen du beginnen kannst, gehören Vowpal Wabbit, TorchRL (PyTorch) und TensorFlow-RL.
- Computer Vision
Deep Learning-Techniken sind gängige Ausgangspunkte für Computer-Vision-Aufgaben. OpenCV ist eine wichtige Bildverarbeitungsbibliothek, die auch einige ML-Modelle unterstützt. Beliebte Deep-Learning-Frameworks sind TensorFlow, Keras, PyTorch und Caffe.
- Natürliche Sprachverarbeitung
Alle zuvor erwähnten Deep Learning-Frameworks können auch für NLP verwendet werden. Darüber hinaus ist es üblich, transformatorbasierte Methoden auszuprobieren oder etwas auf Hugging Face zu finden. Heutzutage ist es auch üblich, die OpenAI API und GPT-Modelle zu verwenden. LangChain ist eine schnell wachsende Bibliothek für NLP-Workflows. Außerdem gibt es das kürzlich von Google eingeführte Bard.
Tipp
Wenn die Aufgabe zu einer der bekannten ML-Familien gehört, gibt es auch bekannte Algorithmen, die speziell auf diese Aufgabe zugeschnitten sind. Wie immer sind die Heuristiken, die ich anbiete, nur ein allgemeiner Ausgangspunkt, und du könntest am Ende auch andere vielseitige Techniken ausprobieren, wie baumbasierte Modelle oder Ensembling.
Überblick über die Modellschulung
Nachdem du die Schritte der Definition der ML-Aufgabe und der Auswahl eines Algorithmus durchlaufen hast, beginnst du mit dem Modelltraining, das die Abstimmung der Hyperparameter und ggf. die Abstimmung des Optimierers oder der Verlustfunktion umfasst. Das Ziel dieses Schritts ist es, das Modell immer besser werden zu lassen, indem du die Parameter des Modells selbst veränderst. Manchmal klappt das nicht und du musst zu den früheren Schritten zurückkehren, um das Modell über die Eingabedaten zu verbessern. In diesem Abschnitt geht es um die Optimierung des Modells selbst, nicht um die Daten.
Im Vorstellungsgespräch ist es für den Arbeitgeber interessanter zu erfahren, wie du die Leistung deines Modells gesteigert hast, als nur, dass du ein leistungsstarkes Modell hast. In manchen Fällen kann auch ein Modell mit geringer Leistung deine Eignung für die Stelle beweisen, wenn du beim ML-Training sehr sorgfältig vorgegangen bist, auch wenn andere Faktoren, wie z. B. die Datenerfassung, außerhalb deines Einflussbereichs lagen. In anderen Fällen ist ein Modell mit hoher Genauigkeit für den Interviewer nicht so wichtig, wenn du es nicht eingesetzt hast. Es kommt häufig vor, dass Modelle in der Trainingsphase und bei der Offline-Evaluierung gut abschneiden, dann aber in der Produktion oder in Live-Szenarien schlecht abschneiden.
Hyperparameter-Abstimmung
Beim Hyperparameter-Tuning wählst du die optimalen Hyperparameter für das Modell durch manuelle Anpassungen, Rastersuche oder sogar AutoML aus. Zu den Hyperparametern gehören die Eigenschaften oder die Architektur des Modells selbst, z. B. die Lernrate, die Stapelgröße, die Anzahl der versteckten Schichten in einem neuronalen Netz und so weiter. Jedes spezifische Modell kann seine eigenen Parameter haben, wie z. B. den Veränderungspunkt und die saisonale Prioritätsskala in Prophet. Das Ziel der Abstimmung der Hyperparameter ist es zum Beispiel, herauszufinden, ob die Lernrate höher ist oder ob das Modell schneller konvergiert und bessere Ergebnisse erzielt.
Es ist wichtig, ein gutes System zu haben, um den Überblick über die Experimente zur Abstimmung der Hyperparameter zu behalten, damit die Experimente reproduzierbar sind. Stell dir vor, du hast einen Modelllauf gesehen, der großartige Ergebnisse geliefert hat, aber weil die Änderungen direkt im Skript vorgenommen wurden, hast du die genauen Änderungen verloren und konntest die guten Ergebnisse nicht reproduzieren! Auf die Nachverfolgung wird im Abschnitt "Nachverfolgung von Experimenten" näher eingegangen .
ML-Verlustfunktionen
Verlustfunktionen in der ML messen die Differenz zwischen den vorhergesagten Ergebnissen des Modells und der Grundwahrheit. Ein Ziel des Modells ist es, die Verlustfunktion zu minimieren, da das Modell auf diese Weise die genauesten Vorhersagen macht, je nachdem, wie du die Genauigkeit des Modells definierst. Beispiele für ML-Verlustfunktionen sind der mittlere quadratische Fehler (MSE) und der mittlere absolute Fehler (MAE).
ML-Optimierer
Optimierer sind die Art und Weise, wie die Parameter des ML-Modells angepasst werden, um die Verlustfunktion zu minimieren. Manchmal gibt es Optionen, um den Optimierer zu ändern; PyTorch hat zum Beispiel 13 gängige Optimierer zur Auswahl. Adam und Adagrad sind beliebte Optimierer, und es ist wahrscheinlich, dass die Hyperparameter des Modells selbst angepasst werden, um die Leistung zu verbessern. Je nach Struktur deines Modells und den vermuteten Gründen, warum dein aktueller Optimierer nicht funktioniert, könnte dies ein zusätzlicher Hebel sein, den du ziehen kannst.
Experiment verfolgen
Wenn du die Hyperparameter abstimmst, musst du die Leistung der einzelnen Iterationen des Modells verfolgen. Du wirst nicht herausfinden können, welcher Parametersatz besser ist, wenn du nicht die Aufzeichnungen der vergangenen Parameter zum Vergleich hast.
Ein Unternehmen, mit dem du ein Vorstellungsgespräch führst, verfügt vielleicht über Tools zur Verfolgung von ML-Experimenten. Im Allgemeinen spielt es keine Rolle, ob du Erfahrung mit dem speziellen Tool hast, das das Unternehmen verwendet, solange du weißt, wie man Experimente verfolgt. Ich habe schon früher Experimente mit Microsoft Excel nachverfolgt, und viele andere Praktiker auch. Es wird jedoch immer üblicher, eine zentrale Plattform für die Versuchsverfolgung zu nutzen. Beispiele dafür sind MLflow, TensorBoard, Weights & Biases und Keras Tuner. Es gibt noch viele weitere, wie Kubeflow, DVC, Comet ML und so weiter. Für das Vorstellungsgespräch ist es höchst unwahrscheinlich, dass es darauf ankommt, mit welchen Programmen du Erfahrung hast, solange du dir darüber im Klaren bist, dass du die Ergebnisse in irgendeiner Weise an einem zentralen Ort verfolgen solltest.
Zusätzliche Ressource für die Modellschulung
Google hat eine Google Machine Learning Education Seite (zum Zeitpunkt der Erstellung dieses Artikels kostenlos) für diejenigen, die an einem detaillierteren Überblick interessiert sind; beginne mit dem Machine Learning Crash Course (konzentriert auf ML und TensorFlow und lauffähig auf Google Colab).
Musterinterviewfragen zur Modellauswahl und -ausbildung
Nachdem wir nun die üblichen Überlegungen bei der Modellschulung besprochen haben, wollen wir uns einige Beispielfragen für ein Vorstellungsgespräch ansehen.
Interviewfrage 4-4: In welchem Szenario würdest du einen Reinforcement-Learning-Algorithmus anstelle einer baumbasierten Methode verwenden?
- Beispielantwort
RL-Algorithmen sind nützlich, wenn es wichtig ist, aus Versuch und Irrtum zu lernen und die Reihenfolge der Aktionen wichtig ist. RL ist auch nützlich, wenn das Ergebnis verzögert werden kann, der RL-Agent sich aber ständig verbessern soll. Beispiele hierfür sind Spiele, Robotik, Empfehlungssysteme und so weiter.
Im Gegensatz dazu sind baumbasierte Methoden wie Entscheidungsbäume oder Zufallswälder nützlich, wenn das Problem statisch und nicht sequenziell ist. Mit anderen Worten: Es ist nicht so sinnvoll, verzögerte Belohnungen oder sequenzielle Entscheidungen zu berücksichtigen, und ein statischer Datensatz (zum Zeitpunkt des Trainings) ist ausreichend.
Interviewfrage 4-5: Was sind häufige Fehler, die bei der Modellausbildung gemacht werden, und wie würdest du sie vermeiden?
- Beispielantwort
Überanpassung ist ein häufiges Problem, wenn das resultierende Modell zu komplexe Informationen in den Trainingsdaten erfasst und nicht gut auf neue Beobachtungen verallgemeinert werden kann. Regularisierungstechniken6 können eingesetzt werden, um eine Überanpassung zu verhindern.
Wenn du gängige Hyperparameter nicht abstimmst, kann das dazu führen, dass die Modelle nicht gut funktionieren, da die Standard-Hyperparameter (oft) nicht direkt die beste Lösung darstellen.
Manchmal ist es am besten, ein einfaches Basismodell auszuprobieren, bevor man sich an sehr komplexe Modelle oder Kombinationen von Modellen wagt.
Interviewfrage 4-6: In welchem Szenario könnten Ensemble-Modelle nützlich sein?
- Beispielantwort
Bei der Arbeit mit unausgewogenen Datensätzen, bei denen eine Klasse deutlich in der Überzahl ist, können Ensemble-Methoden helfen, die Genauigkeit der Ergebnisse für die Minderheitsklassen zu verbessern. Durch die Verwendung von Ensemble-Modellen und die Kombination mehrerer Modelle können wir eine Verzerrung des Modells in Richtung der Mehrheitsklasse vermeiden und reduzieren.
Modellbewertung
Jetzt, wo du dein Modell trainiert hast, ist es an der Zeit, es zu bewerten und zu entscheiden, ob du es weiter verbessern solltest oder ob es gut genug ist. Nebenbei bemerkt, wird und sollte die Geschäftsmetrik oft schon vor Beginn der ML-Modellierung festgelegt werden. Zu den Geschäftskennzahlen gehören z. B. die Erhöhung der Klickrate, die Verbesserung der Konversionsrate von Kunden oder eine höhere Zufriedenheit, die durch Kundenumfragen gemessen wird. Diese Metriken sind nicht mit den in diesem Abschnitt erwähnten Metriken für ML-Modelle identisch. Vielmehr werden sie verwendet, um zu sehen, ob das Modell auf dem Testdatensatz gut abschneidet, nachdem es auf dem Trainingsdatensatz trainiert und mit dem Evaluierungsdatensatz bewertet wurde.
Interviewer suchen nach Kenntnissen über gängige Methoden zur Bewertung von Modellen in der Praxis. Bei Vorstellungsgesprächen zu Zeitreihen wird zum Beispiel erwartet, dass du dich mit dem mittleren absoluten Fehler (MAE), dem mittleren quadratischen Fehler (RMSE) und ähnlichen Bewertungskennzahlen auskennst, die in einem meiner Vorstellungsgespräche für eine Stelle in der Finanzbranche eine Rolle spielten. Wahrscheinlich wirst du auch über Kompromisse zwischen falsch positiven und falsch negativen Ergebnissen sprechen, die mir bei meinem Vorstellungsgespräch für eine Stelle im Bereich maschinelles Lernen im Sicherheitsbereich begegnet sind. Andere häufige Erwartungen sind, den Kompromiss zwischen Varianz und Verzerrung zu kennen und zu wissen, wie man ihn misst, oder die Genauigkeit gegenüber der Präzision und dem Recall.
Zusammenfassung der gängigen ML-Bewertungsmetriken
Hier sind einige gängige Metriken, die zur Bewertung von ML-Modellen verwendet werden. Welche Metriken du wählst, hängt von der ML-Aufgabe ab.
Beachte, dass ich nicht alle Begriffe in diesem Buch definieren werde, auf die Gefahr hin, dass es sich in ein Statistik-Lehrbuch verwandelt, aber ich werde die gebräuchlichsten definieren und erläutern. Wenn du den Rest der Metriken in der Tiefe verstehen willst, findest du zusätzliche Ressourcen.
Klassifizierungsmetriken
Klassifizierungsmetriken werden verwendet um die Leistung von Klassifizierungsmodellen zu messen. Als Kurzformel gilt: TP = wahr positiv, TN = wahr negativ, FP = falsch positiv und FN = falsch negativ, wie in Abbildung 4-5 dargestellt. Hier sind einige weitere Begriffe und Werte, die du kennen solltest:
Präzision = TP / (TP + FP) (wie in Abbildung 4-6 dargestellt)
Recall = TP / (TP + FN) (wie in Abbildung 4-6 dargestellt)
Genauigkeit = (TP + TN) / (TP + TN + FP + FN)
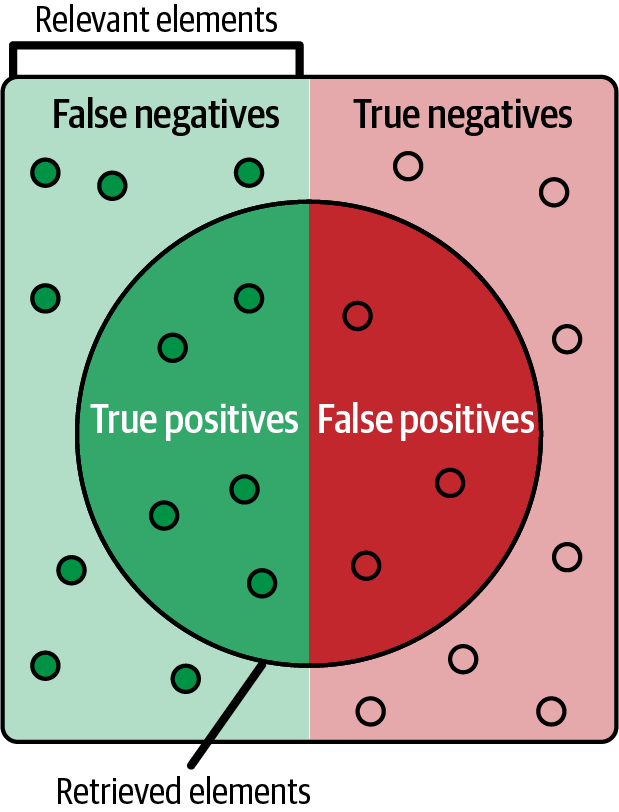
Abbildung 4-5. Darstellung von echten Positiven, falschen Positiven, falschen Negativen und echten Negativen; Quelle: Walber, CC BY-SA 4.0, Wikimedia Commons.
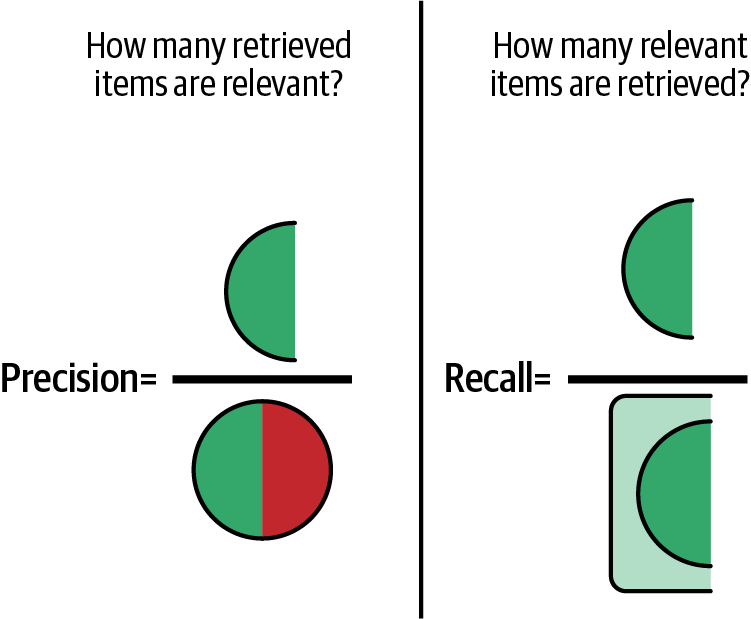
Abbildung 4-6. Veranschaulichung der Präzision im Vergleich zum Recall.
Mit diesen Begriffen können wir dann verschiedene Auswertungen konstruieren:
- Verwirrungsmatrix
Eine Zusammenfassung der TP/TN/FP/FN-Werte in Matrixform (wie in Abbildung 4-7 dargestellt).
- F1-Punktzahl
Harmonisches Mittel von Precision und Recall.
- AUC (Fläche unter der ROC-Kurve) und ROC (Receiver Operating Characteristic)
Die Kurve stellt die Rate der echten Positiven gegen die Rate der Falsch-Positiven bei verschiedenen Schwellenwerten dar.

Abbildung 4-7. Beispiel einer Konfusionsmatrix.
Regressionsmetriken
Regressionsmetriken werden verwendet, um die Leistung von Regressionsmodellen zu messen. Hier sind einige Begriffe und Werte, die du kennen solltest:
MAE: Mittlerer absoluter Fehler ()
MSE: Mittlerer quadratischer Fehler
RMSE: Wurzel des mittleren quadratischen Fehlers
R2: R-Quadrat
Clustering-Metriken
Clustering-Metriken werden verwendet, um die Leistung von Clustering-Modellen zu messen. Die Verwendung von Clustering-Metriken kann davon abhängen, ob du Ground-Truth-Labels hast oder nicht. Ich gehe davon aus, dass dies nicht der Fall ist, aber wenn doch, können auch Klassifizierungsmetriken verwendet werden. Hier ist eine Liste von Begriffen, die du kennen solltest:
- Silhouetten-Koeffizient
Misst den Zusammenhalt eines Gegenstands mit anderen Gegenständen in seinem Cluster und die Trennung mit Gegenständen in anderen Clustern; reicht von -1 bis 1
- Calinski-Harabasz-Index
Eine Punktzahl, die die Qualität von Clustern bestimmt; je höher die Punktzahl, desto dichter sind die Cluster und desto besser sind sie voneinander getrennt.
Ranking-Metriken
Ranking-Metriken werden für Empfehlungs- oder Ranking-Systeme verwendet. Hier sind einige Begriffe, die du kennen solltest:
- Mittlerer reziproker Rang (MRR)
Misst die Genauigkeit eines Rankingsystems daran, wie hoch oder niedrig das erste relevante Dokument erscheint
- Präzision bei K
Berechnet den Anteil der empfohlenen Artikel an der Spitze, die relevant sind
- Normalisierter diskontierter kumulativer Gewinn (NDCG)
Vergleicht die Bedeutung/Rangfolge, die das ML-Modell vorhergesagt hat, mit der tatsächlichen Relevanz
Jetzt, wo du dich für die Metriken entschieden hast (und manchmal wirst du ein paar verwenden wollen), musst du sie mit Code implementieren . In den gängigen ML-Bibliotheken in Python gibt es bereits Implementierungen für die meisten der genannten Metriken, sodass du sie nicht selbst von Grund auf neu implementieren musst. Die folgenden Metrik-Implementierungen sind gute Ausgangspunkte:
Diese Liste ist nicht vollständig. Sieh also in der Dokumentation der Bibliothek nach, die du verwendest. Wenn die eingebauten Implementierungen aus irgendeinem Grund nicht zu deinen speziellen Bedürfnissen passen, kannst du etwas Eigenes schreiben. Wenn das im Vorstellungsgespräch zur Sprache kommt, solltest du am besten erklären, warum. Wenn du zum Beispiel verschiedene Metriken aus unterschiedlichen Bibliotheken kombinieren möchtest, musst du vielleicht einen Code schreiben, um sie alle miteinander zu verbinden und zu aggregieren.
Kompromisse bei den Bewertungsmaßstäben
Für die Interviewer ist es wichtig, dass du zeigst, dass du kritisch über ML-Bewertungsmetriken und verschiedene Kompromisse nachdenken kannst. So kann zum Beispiel die alleinige Verwendung der Genauigkeit die Schwächen eines Modells bei der Vorhersage einer Minderheitenklasse (eine Kategorie, die im Vergleich zur Mehrheitsklasse nur sehr wenige Datenpunkte hat) verbergen, wenn das Modell bei der Vorhersage der Mehrheitsklasse einfach sehr gut ist. In diesem Fall wäre es gut, weitere Metriken wie den F1-Score hinzuzufügen. Manchmal muss man aber auch explizit einen Kompromiss eingehen.
Bei einem medizinischen Modell, das Lungenkrebs anhand von Röntgenbildern vorhersagt, haben falsch-negative Ergebnisse einen sehr großen Einfluss. Daher ist es wünschenswert, die Anzahl der falsch-negativen Ergebnisse zu reduzieren. Wenn falsche Negative reduziert werden, erhöht sich die Recall-Kennzahl (eine Definition findest du im vorherigen Abschnitt). Aber in manchen Situationen kann das Modell auf dem Weg zur Verringerung der falsch-negativen Ergebnisse versehentlich gelernt haben, mehr Patienten als positiv zu klassifizieren, auch wenn sie keinen Lungenkrebs haben. Mit anderen Worten: Die Zahl der falsch-positiven Ergebnisse hat indirekt zugenommen und die Genauigkeit des Modells verringert.
Daher ist es wichtig, Kompromisse zwischen falsch-positiven und falsch-negativen Ergebnissen zu finden; in manchen Fällen kann sich der Aufwand lohnen, in anderen nicht. Es ist hilfreich, wenn du solche Kompromisse bei der Beantwortung von Interviewfragen besprechen kannst.
Tipp
Der Interviewer kann an deinen durchdachten Antworten erkennen, dass du kritisch über Verzerrungen in den Modellen nachdenken und geeignete Modelle und Metriken auswählen kannst, was dich zu einem effektiveren ML-Praktiker macht.
Zusätzliche Methoden für die Offline-Bewertung
Mithilfe der Modellmetriken, die ich zuvor beschrieben habe, kannst du messen, wie effektiv das Modell bei der Vorhersage von zuvor unbekannten Bezeichnungen im Vergleich zu den vor dem Modell verborgenen Ground-Truth-Bezeichnungen geworden ist. Hoffentlich hast du mit ein paar Änderungen experimentiert, um zu diesem Ergebnis zu kommen. Selbst wenn dein erstes Modell am Ende das beste ist, was die Metriken zeigen, lohnt es sich, zu sehen, was nicht funktioniert. Dein Gesprächspartner könnte dich auch danach fragen!
Bevor das Modell jedoch eingesetzt wird, ist es schwierig zu bestätigen, dass es in der Produktion tatsächlich gut funktioniert. In diesem Fall bedeutet "live", dass es draußen in der Welt ist, ähnlich wie bei "live on air". Die Produktion bezieht sich auf Softwaresysteme, die mit echten Eingaben und Ausgaben arbeiten. Es gibt viele Gründe, warum ein Modell in der Produktion schlecht abschneidet, obwohl es in den Modellkennzahlen gut abschneidet: Die Datenverteilung in der realen Welt wird manchmal nicht von den Trainingsdaten erfasst, es gibt Kanten und Ausreißer und so weiter.
Heutzutage suchen viele Arbeitgeber nach Erfahrungen damit, wie sich Modelle in der Produktion verhalten können. Das ist ein Unterschied zu einer schulischen oder akademischen Perspektive, denn bei realen Inputs können Modelle, die sich schlecht verhalten, einem Unternehmen reale Verluste zufügen. Ein schlechtes Betrugserkennungsmodell kann eine Bank zum Beispiel Millionen kosten. Ein Empfehlungssystem, das immer wieder irrelevante oder ungeeignete Inhalte anzeigt, könnte dazu führen, dass die Kunden das Vertrauen in ein Unternehmen verlieren. In manchen Fällen könnte das Unternehmen sogar verklagt werden. Deine Gesprächspartner/innen werden sich dafür interessieren, ob du dir dessen bewusst bist und ob du dir Gedanken darüber gemacht hast, wie du solche Szenarien verhindern kannst.
Andererseits ist es ziemlich erfüllend, im Bereich ML zu arbeiten und zu wissen, dass man, wenn das Modell erfolgreich ist, dazu beitragen kann, Verluste in Millionenhöhe durch Betrug zu verhindern oder hinter den Kulissen deiner Lieblings-Musik-Streaming-App zu arbeiten!
Du kannst die Modelle bewerten, bevor sie in die Produktion gehen, und feststellen, ob die Modelle tatsächlich robust sind und sich auf neue Daten verallgemeinern lassen. Zu den Methoden, die dies ermöglichen, gehören:
- Störungstests7
Füge etwas Rauschen hinzu oder verändere die Testdaten. Prüfe zum Beispiel bei Bildern, ob das zufällige Hinzufügen einiger Pixel dazu führt, dass das Modell das richtige Ergebnis nicht vorhersagen kann.
- Invarianz-Tests
Teste, ob ein ML-Modell unter verschiedenen Bedingungen konsistent funktioniert. Wenn du z. B. bestimmte Eingaben entfernst oder änderst, sollte das nicht zu drastischen Veränderungen der Ergebnisse führen. Wenn du ein Merkmal komplett entfernst und das Modell andere Vorhersagen macht, solltest du dieses Merkmal untersuchen. Das ist besonders wichtig , wenn es sich bei dem Merkmal um sensible Informationen wie Ethnie oder Demografie handelt oder damit zusammenhängt .
- Slice-basierte Auswertung
Teste die Leistung deines Modells an verschiedenen Slices oder Untergruppen der Testgruppe. Zum Beispiel könnte dein Modell bei Kennzahlen wie Genauigkeit und F1 insgesamt gut abschneiden, aber wenn du es untersuchst, schneidet es bei Personen über 35 Jahren und Personen unter 15 Jahren schlecht ab. Es ist wichtig, dies zu untersuchen und zu korrigieren, vor allem wenn du beim Training einige Gruppen übersehen hast.
Mehr zu diesen Evaluierungstechniken findest du unter in Designing Machine Learning Systems von Chip Huyen (O'Reilly).
Modellversionierung
Das Ziel der Modellevaluierung ist es, zu sehen, ob ein Modell gut genug ist, oder ob es besser ist als die Grundlinie oder ein anderes ML-Modell. Nach jedem Modelltraining hast du verschiedene Modellartefakte, wie die Modelldefinition, die Modellparameter, den Daten-Snapshot und so weiter. Wenn du das Modell herausfinden willst, das gut funktioniert hat, ist es praktisch, wenn die Modellartefakte leicht abgerufen werden können. Eine Modellversionierung ist bequemer, als die gesamte Modelltrainings-Pipeline zu durchlaufen, um die Modellartefakte neu zu generieren, selbst wenn du die spezifischen Hyperparameter kennst, die zu diesem Modell geführt haben.
Die Werkzeuge, die für die Versuchsverfolgung verwendet werden (siehe "Versuchsverfolgung" weiter oben in diesem Kapitel), unterstützen oft auch die Modellversionierung.
Musterinterviewfragen zur Modellbewertung
Nachdem wir nun gängige Techniken und Überlegungen zur Modellbewertung durchgesprochen haben, wollen wir uns einige Beispielfragen für ein Vorstellungsgespräch ansehen.
Interviewfrage 4-7: Was ist die ROC-Metrik und wann ist sie nützlich?
- Beispielantwort
Die ROC-Kurve (Receiver Operating Characteristic) kann verwendet werden, um ein binäres Klassifizierungsmodell zu bewerten. Die Kurve stellt die wahr-positive Rate gegen die falsch-positive Rate bei verschiedenen Schwellenwerten dar - der Schwellenwert ist die Wahrscheinlichkeit zwischen 0 und 1, ab der die Vorhersage als diese Klasse angesehen wird. Wenn der Schwellenwert z. B. auf 0,6 gesetzt wird, werden alle Vorhersagen des Modells, die mit einer Wahrscheinlichkeit von mehr als 0,6 der Klasse 1 entsprechen, als Klasse 1 eingestuft.
Mithilfe von ROC können wir den Kompromiss zwischen der Rate der echten Positiven und der Falsch-Positiven bei verschiedenen Schwellenwerten ermitteln und dann entscheiden, welcher Schwellenwert optimal ist.
Interviewfrage 4-8: Was ist der Unterschied zwischen Precision und Recall; wann würdest du bei einer Klassifizierungsaufgabe das eine dem anderen vorziehen?
- Beispielantwort
DiePräzision misst die Genauigkeit des Modells bei der Erstellung korrekter Vorhersagen (Qualität), und der Recall misst die Genauigkeit des Modells in Bezug darauf, wie viele relevante Elemente korrekt vorhergesagt wurden (Quantität). Mathematisch gesehen ist die Präzision gleich TP / (TP + FP) und der Recall gleich TP / (TP + FN).
Die Präzision kann wichtiger sein als die Rückrufquote, wenn es wichtiger ist, die Anzahl der Falschmeldungen zu reduzieren und sie niedrig zu halten. Ein Beispiel dafür ist die Erkennung von Malware oder E-Mail-Spam, wo zu viele falsch-positive Ergebnisse zu Misstrauen bei den Nutzern führen können. FPs in der E-Mail-Spam-Erkennung können legitime geschäftliche E-Mails in den Spam-Ordner verschieben, was zu Verzögerungen und Geschäftsverlusten führt.
Andererseits kann die Aufklärungsquote bei wichtigen Vorhersagen, z. B. in der medizinischen Diagnostik, wichtiger sein als die Genauigkeit. Eine höhere Aufklärungsquote bedeutet, dass es weniger falsch-negative Ergebnisse gibt, auch wenn dies möglicherweise zu einigen versehentlichen FPs führt. In dieser Situation ist es wichtiger, die Wahrscheinlichkeit zu minimieren, dass echte Fälle übersehen werden.
Interviewfrage 4-9: Was ist der NDCG (normalized discounted cumulative gain), der auf einer hohen Ebene erklärt wird? Für welche Art von ML-Aufgabe wird er verwendet?
- Beispielantwort
Die NDCG wird verwendet, um die Qualität von Ranking-Aufgaben zu messen, z. B. bei Empfehlungssystemen, Information Retrieval und Suchmaschinen/Anwendungen. Sie vergleicht die Wichtigkeit/Rangfolge, die das ML-Modell vorhergesagt hat, mit der tatsächlichen Relevanz. Weichen die Vorhersagen des Modells stark von der tatsächlichen (oder idealen) Relevanz ab, z. B. wenn auf einer Shopping-Website Produkte ganz oben angezeigt werden, an denen der Kunde nicht interessiert ist, wird die Punktzahl niedriger ausfallen. Der NDCG wird berechnet, indem die Summe der vorhergesagten Relevanzwerte (DCG, oder diskontierter kumulativer Gewinn) durch den IDCG (idealer diskontierter kumulativer Gewinn) geteilt wird. Dieser Wert wird dann normalisiert, so dass das Ergebnis zwischen 0 und 1 liegt.
Zusammenfassung
In diesem Kapitel habe ich dir einen Überblick über den ML-Modellierungs- und Trainingsprozess gegeben und erklärt, wie jeder Schritt mit dem ML-Interview zusammenhängt. Zuerst hast du die ML-Aufgabe definiert und geeignete Daten gesammelt. Als Nächstes wähltest du das Modell anhand der Algorithmen aus, die für die Aufgabe als Ausgangspunkt geeignet waren. Du hast auch ein Basismodell ausgewählt und mit etwas Einfachem begonnen, mit dem du alle weiteren ML-Modelle vergleichen konntest, z. B. mit einer heuristischen Methode oder einem möglichst einfachen Modell wie der logistischen Regression.
Bei all diesen Schritten ist es wichtig, im Vorstellungsgespräch zu erwähnen, wie du den Prozess iteriert hast, um das Modell zu verbessern, was sogar bedeuten kann, dass du zu einem früheren Schritt zurückgegangen bist, z. B. zur Datenerfassung. Bei der Beantwortung von Fragen zu deinen Erfahrungen mit ML-Modellen in deinen eigenen Projekten, egal ob es sich um ein Schul-, Privat- oder Arbeitsprojekt handelt, ist es wichtig, über die Kompromisse zu sprechen, mit denen du konfrontiert wurdest, und über die Gründe, warum du dachtest, dass eine bestimmte Technik helfen würde.
Es reicht nicht aus, einfach nur ein sehr genaues Modell zu haben (gemessen an der Testmenge), denn heutzutage ist es für Arbeitgeber sehr wichtig, dass der ML-Bewerber weiß, wie sich die Modelle in der Produktion verhalten könnten. Wenn du dich für eine ML-Stelle bewirbst, die die Produktionspipelines und die Infrastruktur aufbaut, ist das sogar noch wichtiger. Schließlich hast du gelernt, wie man ML-Modelle bewertet und das beste Modell auswählt.
Im nächsten Kapitel gehe ich auf die nächste wichtige Komponente der technischen ML-Interviews ein: das Codieren.
1 Gehen wir davon aus, dass es für dieses Projekt einen öffentlichen Datensatz gibt, der sich gut für dieses Problem eignet.
2 Beachte alle Lizenz-, Urheberrechts- und Datenschutzfragen.
3 "Unstructured Data", MongoDB, Zugriff am 24. Oktober 2023, https://oreil.ly/3DqzA.
4 Stichprobenverfahren werden in Kapitel 3 behandelt.
5 Jason Brownlee, "A Gentle Introduction to Model Selection for Machine Learning," Machine Learning Mastery (Blog), 26. September 2019, https://oreil.ly/2ylZa.
7 Diese Terminologie wird in Chip Huyens Buch Designing Machine Learning Systems (O'Reilly) verwendet, und ich verwende der Einfachheit halber dieselben Begriffe für diesen Abschnitt, da es keine einheitliche Terminologie zu geben scheint, sondern eher eine übergeordnete Gruppierung.
Get Machine Learning Interviews now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

