Chapter 4. The AI Team’s Toolkit
So far, we’ve focused on the soft skills your adoption process will require, such as intuition, observation, and effective cross-functional communication. But your AI adoption cannot be successful without hard skills as well. Let’s say you’ve assembled the kind of cross-functional team described in the previous chapter that’s needed to get your product off the ground. Each role has its own unique set of skills. When we focus on AI teams, especially AI engineers, we’re considering a wide range of interests, talents, and tools. In this chapter, I want to explore the key components of this diverse skill set.
In addition to keeping up with the latest developments in language modeling, AI engineers are often very good prompters, thanks to their hands-on experience getting LLMs to do their bidding. Because effective prompting is so important to getting the results you want, avoiding hallucinations, and even saving money, I will look at it from a slightly different perspective in this chapter: prompting as programming in natural language. Then, we’ll move on to the most valuable resource of our time—data—and best practices for AI teams to take care of their organization’s data assets. We’ll see why well-governed and curated data is a necessity for the vast majority of generative AI applications in the enterprise. Finally, I’ll talk about how the composability principle of modern-day natural language processing (NLP) designs allows AI engineers to create ever more complex and powerful LLM applications.
Model Selection
For someone just starting their generative AI journey, the sheer number of language models—built for different purposes, sizes, languages, and modalities—can be overwhelming. But staying on top of what is possible with LLMs is one of the most important practices of an AI engineer. How do they do that? Often, those seeking information about the best, fastest, or otherwise high-performing models are directed to leaderboards and benchmarks. Leaderboards run a series of standardized tests on LLMs and then use the results to rank the models from best to worst. They are useful for understanding how well a new LLM performs against established models. They also give you a good sense of what metrics the broader AI engineering community uses to understand the quality of a model’s performance. Another popular and entirely community-driven format is the “Chatbot Arena Leaderboard” hosted by LMSYS, which uses an Elo rating system (like chess) to determine which chatbots users prefer.
But while these can be useful tools for getting an overview of what’s out there, they’re more oriented toward research rather than business. Unlike academic research, business use cases must cater to many different requirements from various stakeholders. When deciding which LLMs to use in your product, it’s therefore important to ask the right questions:
-
Do your business requirements dictate that you work with an open source model, or can you use one of the proprietary LLM APIs?
-
How important are issues like latency (that is, the time between sending the request and receiving an answer) to your users?
-
Does the model need to cater to specific languages or other skills, such as programming languages?
-
Would your application benefit from a larger context window?
To narrow down the range of models, it makes sense to talk to the AI engineers in your circle who know the most about these issues. They, in turn, often keep up with model developments through social media and by following thought leaders in the space. Note that, as we’ve highlighted in the previous chapter about the iterative process of AI product development, you do not need to set your model of choice in stone at any point in your product journey. In fact, it often makes sense to start with the most powerful, state-of-the-art LLM and experiment with it to understand what’s possible. Then, you can plug in smaller models associated with lower cost and latency and see if you can use prompting and other techniques to get them to perform at a level similar to the larger model.
Prompt Engineering
As we developed our hypothetical use case of a news digest app in the previous chapter, we’ve already got a glimpse of the role of the prompt in the context of LLMs. While AI practitioners have explored the capabilities of prompting, it’s become increasingly clear that with LLMs, the prompt acts as a programming interface for users. More than just the query input interface, prompts can be used to transmit data to the LLM, as well as guidance through examples in what is known as “few-shot prompting,” and measures to prevent unwanted behavior, like hallucinations. To use an LLM in an effective manner, AI teams need to understand that the right prompt can greatly affect the model’s performance. The emergence of structured prompting languages such as ChatML exemplifies the move toward more formalized and efficient interaction with LLMs, resulting in a safer and more controlled conversation flow.
Mastering the art of prompting takes practice. While there are many more or less evidence-based tips on how to prompt effectively, the most consistent advice is to be overly explicit and literal about what is being asked of the model (since LLMs are bad at reading subtext), and to double down on any points that are particularly important. Subject matter experts (SMEs) are often good writers of prompts because they have a deep understanding of their domain. For niche topics, it often makes sense for AI engineers to team up with SMEs, since their expertise can lead to more precise and effective prompts.
Because different user inputs can elicit a wide variety of responses, it’s important to use the prompt to control and direct the LLM’s output. This includes defining the tone, length, and whether the response should include citations. These requirements will generally depend on the specific needs dictated by your use case. Once a prompt is used with an actual LLM, its responses will in turn lead to adjustments to the prompt.
Among AI engineers, prompting is seen as a fun and creative process, where they can use the power of words to unlock AI capabilities. However, small adjustments to the prompt can lead to disproportionate variations in the LLM’s output: sometimes even a small change in punctuation can change the result significantly. A curious and experimental attitude is therefore crucial to prompt engineering.
It’s also useful to test prompts with real users. This can help determine not only how well a prompt works, but also whether it’s ready for real-world use. After all, a prompt can always be tweaked and improved, so user feedback is an essential part of determining when it’s really ready. As we’ll see later in this chapter, documenting your work is crucial in any AI project. The same holds true for prompts: since their shape and wording have such a high impact on the LLM’s output, it’s a good idea to track all changes to the prompt and how they affect the results.
The Role of Data
Without data, ML/AI as we know it today wouldn’t exist. You’ve probably heard some variation of this sentiment a million times. It’s clear that large and high-quality datasets are essential for training ML and AI, but what is their role in product development?
More than just a necessary resource to feed LLMs, enterprise-specific data can actually be what differentiates your product from the competition. Think about it: across your industry and beyond, all AI teams have equal access to the same LLMs—but for a particular company, it’s the proprietary data, collected over the organization’s lifetime, that makes it unique and sets it apart. With that in mind, let’s look at the three main ways that data can enrich, shape, and characterize LLM-based applications.
Training and Fine-Tuning
Ninety-nine percent of organizations will never train an LLM from scratch. Not only is LLM development prohibitively expensive, it’s also unnecessary, given the wealth of models already available. There is, however, a technique for further adapting an existing LLM to a specific use case. Fine-tuning is the process of improving the parameters of a pretrained model to fit a particular use case. This use case is represented by the domain-specific data the model sees during the fine-tuning process. For example, you might fine-tune an LLM used in customer service to match the voice of your brand better, using transcripts of previous real-world interactions with your clients. Or, if you’re building a RAG setup for business intelligence tables, you might want to fine-tune the retrieval model with the schemas in your database.
Fine-tuning requires much less data and computing power than training a model from scratch, and it has been used successfully to adapt a model to a particular tone or task. As a technique for feeding information into the model, however, fine-tuning is much less effective than RAG. That’s because it doesn’t reliably remove hallucinations. Moreover, if your goal is to update the LLM’s knowledge base, this means that you would have to fine-tune it for each new piece of data, which in turn will increase your costs significantly. However, for smaller language models, such as those used in retrieval, fine-tuning is often useful because it improves performance without consuming too many resources.
Evaluation
To understand how well your model or overall application is performing on your specific use case, it’s necessary to perform periodic quantitative evaluations. To do this, you need annotated data that represents your use case as accurately as possible. This data is then run through the model and various metrics are used to quantify how well the model’s predictions match your own annotations. Note that while quantitative evaluation of retrieval and classification tasks, for example, is well established, it’s much harder to quantitatively evaluate LLMs in an equally satisfactory way—though I’ll discuss some promising approaches in Chapter 5. It’s therefore often complemented with user feedback—a much more high-quality and costly method for LLM evaluation that is based on real users rather than evaluation datasets.
Retrieval Augmentation
Large language models are powerful but slow and expensive compared with other models. Retrieval augmentation, which we already discussed several times in this report, uses fast data-matching techniques to preselect the most appropriate data from your database to pass on to the more resource-intensive LLM. The type of data is completely dependent on your application, and could be anything from business intelligence tables to social media posts or comic books. What’s clear is that, in a retrieval-augmented setup, the quality of the data directly affects the quality of the LLM’s output. That’s why it’s important to have data curation practices in place that ensure the data is current and accurate.
Best Practices for Data Curation
In a survey sponsored by AWS among chief data officers, poor data quality was seen as an obstacle to AI adoption at the same scale as “finding a use case” (listed by almost 50% of respondents).1 Keeping data relevant and of high quality is an ongoing task. Just as real-world products must adapt to changing user needs, data must evolve with them to ensure it still reflects your use case. Regular quality checks and updates ensure that an LLM in production continues to perform optimally as conditions change. Stress testing LLM applications with complex data points can also provide valuable insight into the resilience of these systems.
The annotation process is a cornerstone of data quality. Annotation (also known as labeling) describes the process of attaching labels to your data, which the model then has to predict. At its simplest, these labels or categories can be binary, such as in retrieval or a basic type of sentiment analysis. However, when dealing with natural language, annotations are often much more complex. For example, annotating response sequences for extractive language models requires labelers to determine the start and end token of a response.
Much like teaching people to drive, annotation is a repetitive task that still requires a lot of attention. As we’ve seen, the quality of your annotated data directly affects downstream tasks such as fine-tuning, retrieval augmentation, and evaluation. To ensure efficient workflows, it’s important for organizations to establish clear and understandable guidelines that are tested on real data before they’re put into practice. Peer reviews and cross annotations ensure that annotators are applying the guidelines to the data in a consistent manner.
With the frequent iterations of AI product development, it is easy to lose track of what data was used in a given cycle. Thorough documentation is therefore essential—not only for code, but also for datasets. It helps keep track of important metadata, such as when and where a particular data point was created, as well as the context in which it was created. Depending on your use case, you might want to augment your internal company data with external datasets. AI teams need to make sure they understand that data well before using it to build any products, by using established data exploration techniques from data science. It’s important to know the origin of the data, the annotators involved, and the conditions under which the annotations were made. This transparency is not only helpful for current use, but also for future reference and understanding.
Advanced Composable LLM Setups
LLMs are advanced pieces of software all on their own, but the composability principle in modern AI applications makes it so that we can, in theory, build increasingly complex and powerful architectures. For example, it allows us to use multiple language models in one product, or even embed different modalities like images, sound, and text. Here, I want to take a brief look at some advanced concepts that will likely gain traction in the following months.
What Is Composability?
Composability is a well-established concept in applied NLP. It allows AI engineers to build modular applications consisting of multiple parts that work independently but can be combined for a different experience. The classic RAG application uses this principle, for example, by stacking a generative LLM on top of a retrieval module, resulting in a product that is more powerful than the sum of its parts. In addition to this extended capability, composable systems have two major advantages:
-
Parts of the architecture can be replaced independently. This is critical in a field that evolves as rapidly as LLM development.
-
Models can be evaluated independently, making it easier to find sources of error in a complex composed system. This is especially important since some language models are easier to evaluate than others. For example, there are several useful metrics for evaluating retrieval quality, while LLM evaluation is only partially solved and only for specific setups.
Loops and Branches
Simple LLM system designs, such as a basic RAG setup, are based on a unidirectional graph with a starting point (the input query) and an end point (the LLM’s response). This linear graph has only one possible trajectory, as can be seen in the sketch in Figure 4-1: upon receiving the user query, it’s used by the retriever to identify relevant documents from the database. Those documents are then embedded in the prompt along with the query and sent to the LLM, which generates an answer.
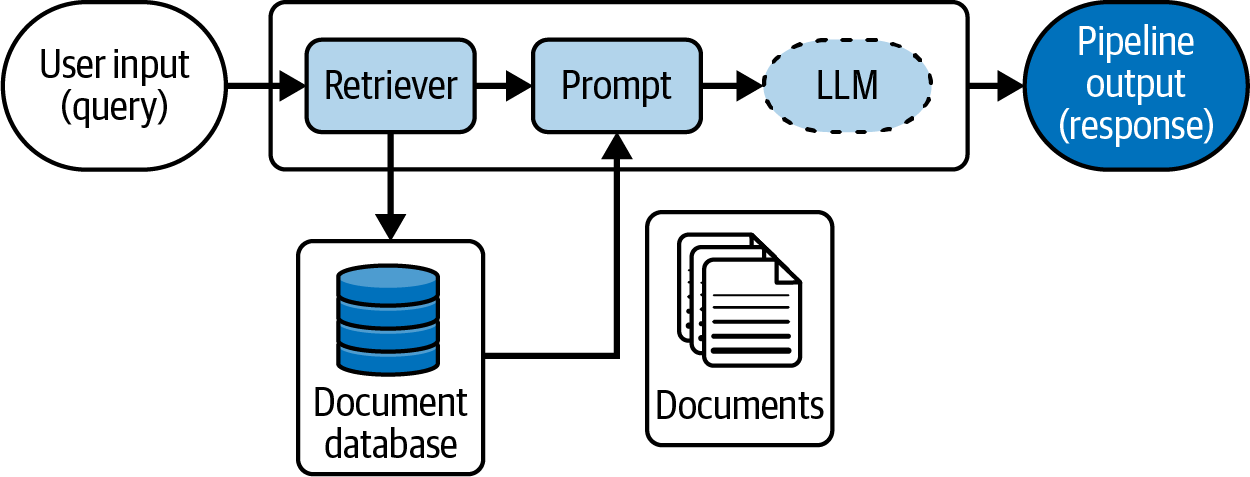
Figure 4-1. A sketch of a straightforward RAG pipeline
However, graphs can be much more complex, and LLMs have the potential to be used in more intricate setups. For example, graphs can contain branching structures where the same starting point can lead to several different paths. A common way to improve retrieval performance is to use a hybrid retrieval setup that combines two categorically different retrievers, whose results are combined before they’re passed on to the LLM. This setup often includes one based on lexical similarity and another based on semantic similarity, resulting in a higher overall recall. Other pipelines use classifiers that examine the query or some other part of the pipeline and route it to different workflows, each designed to solve a specific task.
One particular AI system design that takes modularity to the next level is the agent. Agents are complex pipelines that can traverse multiple trajectories depending on the task. They make use of an LLM’s reasoning abilities by employing it to develop advanced response strategies for complex queries. Agents have multiple “tools” at their disposal, which they use iteratively to arrive at the optimal answer. They can perform autonomous planning and decision making, using the tools to accomplish a given task without explicit instructions. Agents use branching to navigate different paths and looping to potentially repeat actions. Another common component in agents is an implementation of memory—most notably, it is used by chatbots (also known as conversational agents) to keep track of a conversation. Figure 4-2 shows an agent setup with access to multiple tools. In the figure, at least one of the tools is connected to a database (thus, it can perform document retrieval on demand, if the agent’s plan deems it necessary).
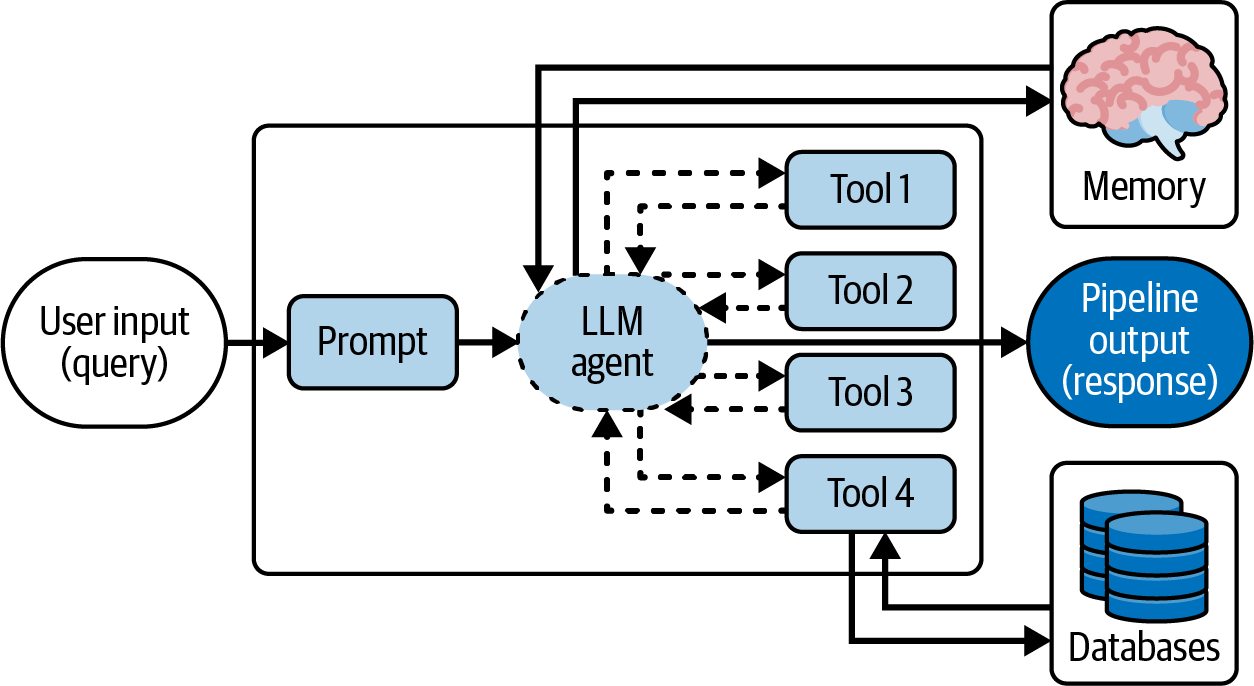
Figure 4-2. A sketch of an LLM agent that can use four tools and memory to solve a task
As part of their strategic planning capabilities, agents decide when they have completed the task and are ready to respond. Autonomous agents may be the closest we’ve come to artificial general intelligence (AGI). But for now, agents that go beyond the capabilities of regular chatbots are still too complex a product for most production use cases. And if it’s hard to reliably evaluate LLMs, imagine how much harder it is for such a complex system with many moving parts that may be integrated with multiple LLMs. But at the rate we’re seeing LLMs evolve, it’s likely that the big agent moment is near.
Putting the Pieces Together
Now that we’ve learned about some of the key tools, skills, and knowledge that AI teams need to curate, it’s time to regroup and see what we’ve learned about product development with AI. In the next chapter, I’ll talk about why the approach I’ve outlined is essential for successful AI adoption in the enterprise, and what other aspects you need to consider to arrive at a mature, LLM-powered product.
Get LLM Adoption in the Enterprise now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

