Kapitel 4. Reinforcement Learning mit Ray RLlib
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In Kapitel 3 hast du eine RL-Umgebung, eine Simulation zum Spielen einiger Spiele, einen RL-Algorithmus und den Code zur Parallelisierung des Trainings des Algorithmus erstellt - alles von Grund auf.Es ist gut zu wissen, wie man das alles macht, aber in der Praxis ist das Einzige, was du beim Training von RL-Algorithmen wirklich tun willst, der erste Teil, nämlich die Festlegung deiner benutzerdefinierten Umgebung, des "Spiels", das du spielen willst.1 Die meiste Mühe wirst du darauf verwenden, den richtigen Algorithmus auszuwählen, ihn einzurichten, die besten Parameter für das Problem zu finden und dich generell darauf zu konzentrieren, eine gut funktionierende Strategie zu trainieren.
Ray RLlib ist eine industrietaugliche Bibliothek für die Entwicklung von RL-Algorithmen im großen Maßstab. Ein erstes Beispiel für RLlib hast du bereits in Kapitel 1 gesehen, aber in diesem Kapitel gehen wir noch viel weiter in die Tiefe. Das Tolle an RLlib ist, dass es eine ausgereifte Bibliothek für Entwickler ist, die gute Abstraktionen enthält, mit denen du arbeiten kannst. Wie du sehen wirst, kennst du viele dieser Abstraktionen bereits aus dem vorherigen Kapitel.
Zunächst geben wir dir einen Überblick über die Möglichkeiten von RLlib. Dann greifen wir das Labyrinthspiel aus Kapitel 3 auf und zeigen dir, wie du es sowohl mit der RLlib CLI als auch mit der RLlib Python API in ein paar Codezeilen lösen kannst. Du wirst sehen, wie einfach der Einstieg in RLlib ist, bevor du die wichtigsten Konzepte wie RLlib-Umgebungen und Algorithmen kennenlernst.
Wir werden uns auch einige fortgeschrittene RL-Themen genauer ansehen, die in der Praxis sehr nützlich sind, aber in anderen RL-Bibliotheken oft nicht richtig unterstützt werden.Du wirst zum Beispiel lernen, wie du einen Lehrplan für deine RL-Agenten erstellst, damit sie einfache Szenarien lernen können, bevor sie zu komplexeren übergehen. Du wirst auch sehen, wie RLlib mit mehreren Agenten in einer einzigen Umgebung umgeht und wie du Erfahrungsdaten, die du außerhalb deiner aktuellen Anwendung gesammelt hast, nutzen kannst, um die Leistung deines Agenten zu verbessern.
Ein Überblick über RLlib
Bevor wir uns mit den Beispielen beschäftigen, wollen wir kurz darauf eingehen, was RLlib ist und was sie kann.Als Teil des Ray-Ökosystems hat RLlib alle Leistungs- und Skalierungsvorteile von Ray geerbt. Insbesondere ist RLlib standardmäßig verteilt, sodass du dein RL-Training auf so viele Knoten skalieren kannst, wie du willst.
Ein weiterer Vorteil ist, dass RLlib eng mit anderen Ray-Bibliotheken zusammenarbeitet. So können zum Beispiel die Hyperparameter jedes RLlib-Algorithmus mit Ray Tune angepasst werden, wie wir in Kapitel 5 sehen werden. Außerdem kannst du deine RLlib-Modelle nahtlos mit Ray Serve einsetzen.2
Besonders nützlich ist, dass RLlib mit den beiden zum Zeitpunkt der Erstellung dieses Artikels vorherrschenden Deep-Learning-Frameworks funktioniert: PyTorch und TensorFlow. Du kannst beide als Backend verwenden und ganz einfach zwischen ihnen wechseln, indem du oft nur eine Codezeile änderst. Das ist ein großer Vorteil, denn Unternehmen sind oft an ihr zugrunde liegendes Deep-Learning-Framework gebunden und können es sich nicht leisten, zu einem anderen System zu wechseln und ihren Code neu zu schreiben.
RLlib hat sich bei der Lösung realer Probleme bewährt und ist eine ausgereifte Bibliothek, die von vielen Unternehmen genutzt wird, um ihre RL-Workloads in die Produktion zu bringen. Die RLlib-API spricht viele Ingenieure an, da sie für viele Anwendungen die richtige Abstraktionsebene bietet und dennoch flexibel genug ist, um erweitert zu werden.
Abgesehen von diesen allgemeinen Vorteilen verfügt RLlib über viele RL-spezifische Funktionen, die wir in diesem Kapitel behandeln werden. RLlib ist sogar so reich an Funktionen, dass es ein eigenes Buch verdienen würde, so dass wir hier nur einige Aspekte ansprechen können. RLlib verfügt zum Beispiel über eine umfangreiche Bibliothek mit fortgeschrittenen RL-Algorithmen, aus der du wählen kannst.In diesem Kapitel werden wir uns auf einige ausgewählte Algorithmen konzentrieren, aber du kannst die wachsende Liste der Optionen auf derSeite RLlib-Algorithmen verfolgen. RLlib verfügt auch über viele Optionen, um RL-Umgebungen festzulegen, und ist sehr flexibel im Umgang mit ihnen während des Trainings; einen Überblick über die RLlib-Umgebungen findest du in der Dokumentation.
Erste Schritte mit RLlib
Um RLlib zu verwenden, musst du sicherstellen, dass du es auf deinem Computer installiert hast:
pip install "ray[rllib]==2.2.0"
Hinweis
Sieh dir dasBegleitheft zu diesem Kapitel an, wenn du keine Lust hast, den Code selbst abzutippen.
Jedes RL-Problem beginnt mit einer interessanten Umgebung, die es zu untersuchen gilt. In Kapitel 1 haben wir uns das klassische Gleichgewichtsproblem der Karrenstangen angeschaut. Wir haben diese Karrenstangen-Umgebung nicht implementiert, sondern sie wurde direkt mit RLlib geliefert.
Im Gegensatz dazu haben wir in Kapitel 3 ein einfaches Labyrinthspiel selbst implementiert. Das Problem bei dieser Implementierung ist, dass wir sie nicht direkt mit RLlib oder einer anderen RL-Bibliothek verwenden können. Der Grund dafür ist, dass es im RL allgegenwärtige Standards gibt und unsere Umgebungen bestimmte Schnittstellen implementieren müssen.Die bekannteste und am weitesten verbreitete Bibliothek für RL-Umgebungen ist gym, ein Open-Source-Python-Projekt von OpenAI.
Schauen wir uns an, was Gym ist und wie wir unser Labyrinth Environmentaus dem vorherigen Kapitel in eine mit RLlib kompatible Gym-Umgebung umwandeln.
Aufbau einer Fitnessstudio-Umgebung
Wenn du dir die gut dokumentierte und übersichtliche Schnittstelle gym.Env auf GitHub ansiehst, wirst du feststellen, dass eine Implementierung dieser Schnittstelle zwei obligatorische Klassenvariablen und drei Methoden hat, die Unterklassen implementieren müssen. Du musst den Quellcode nicht überprüfen, aber wir empfehlen dir, einen Blick darauf zu werfen. Du wirst vielleicht überrascht sein, wie viel du bereits über diese Umgebungen weißt.
Kurz gesagt, sieht die Schnittstelle einer Gym-Umgebung wie der folgende Pseudocode aus:
importgymclassEnv:action_space:gym.spaces.Spaceobservation_space:gym.spaces.Spacedefstep(self,action):...defreset(self):...defrender(self,mode="human"):...
Die Schnittstelle
gym.Envhat einen Aktions- und einen Beobachtungsraum.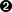
Die
Envkann einestepausführen und gibt ein Tupel mit Beobachtungen, Belohnung, erledigter Bedingung und weiteren Informationen zurück.
Eine
Envkann sich selbstreset, was die ersten Beobachtungen einer neuen Episode zurückgibt.
Wir können
rendereineEnvfür verschiedene Zwecke verwenden, z. B. für die menschliche Darstellung oder als String-Darstellung.
Du erinnerst dich aus Kapitel 3, dass dies der Schnittstelle des Labyrinths sehr ähnlich ist.Environment die wir dort gebaut haben.Tatsächlich hat Gym einen sogenannten Discrete Raum, der in gym.spaces implementiert ist. Das bedeutet, dass wir unser Labyrinth Environment wie folgt zu einem gym.Env machen können. Wir gehen davon aus, dass du diesen Code in einer Datei namens maze_gym_env.py speicherst und dass sich der Code für das Environment aus Kapitel 3 ganz oben in dieser Datei befindet (oder dorthin importiert wird):
# maze_gym_env.py | Original definition of Environment goes at the top.importgymfromgym.spacesimportDiscreteclassGymEnvironment(Environment,gym.Env):def__init__(self,*args,**kwargs):"""Make our original Environment a gym `Env`."""super().__init__(*args,**kwargs)gym_env=GymEnvironment()
Ersetze unsere eigene
DiscreteImplementierung durch die von Gym.Die
GymEnvironmentimplementiert einegym.Env. Die Schnittstelle ist im Wesentlichen dieselbe wie vorher.
Natürlich hätten wir unser ursprüngliches Environment auch dazu bringen können, gym.Env zu implementieren, indem wir einfach von ihm geerbt hätten. Aber der Punkt ist, dass die Schnittstelle gym.Env im Kontext von RL so selbstverständlich auftaucht, dass es eine gute Übung ist, sie zu implementieren, ohne auf externeBibliotheken zurückgreifen zu müssen.3
Die Schnittstelle gym.Env enthält außerdem hilfreiche Dienstprogramme und viele interessante Beispielimplementierungen. Die Umgebung CartPole-v1, die wir in Kapitel 1 verwendet haben, ist ein Beispiel aus Gym,4 und es gibt viele andere Umgebungen, in denen du deine RL-Algorithmen testen kannst.
Ausführen der RLlib CLI
Jetzt, wo wir unser GymEnvironment als gym.Env implementiert haben, zeigen wir dir, wie du es mit RLlib verwenden kannst. Du hast das RLlib CLI in Kapitel 1 in Aktion gesehen, aber dieses Mal ist die Situation ein bisschen anders. Im ersten Kapitel haben wir einfach ein abgestimmtes Beispiel mit dem Befehl rllib example ausgeführt.
Diesmal wollen wir unsere eigene Umgebungsklasse gym mitbringen, nämlich die Klasse GymEnvironment, die wir in maze_gym_env.py definiert haben. Um diese Klasse in Ray RLlib anzugeben, verwendest du den vollständigen Qualifikationsnamen der Klasse, von der aus du sie referenzierst, also in unserem Fall maze_gym_env.GymEnvironment. Wenn du ein komplizierteres Python-Projekt hättest und deine Umgebung in einem anderen Modul gespeichert wäre, würdest du einfach den Modulnamen entsprechend hinzufügen.
Die folgende Python-Datei gibt die minimale Konfiguration an, die benötigt wird, um einen RLlib-Algorithmus auf die Klasse GymEnvironment zu trainieren. Um uns so weit wie möglich an unser Experiment aus Kapitel 3 anzupassen, in dem wir Q-Learning verwendet haben, verwenden wir eine DQNConfig, um einen DQN-Algorithmus zu definieren und ihn in einer Datei namens maze.py zu speichern:
fromray.rllib.algorithms.dqnimportDQNConfigconfig=DQNConfig().environment("maze_gym_env.GymEnvironment")\.rollouts(num_rollout_workers=2)
Das gibt einen kurzen Einblick in die Python-API von RLlib, die wir im nächsten Abschnitt behandeln. Um dies mit RLlib auszuführen, verwenden wir den Befehl rllib train. Dazu geben wir die file an, die wir ausführen wollen: maze.py. Um sicherzustellen, dass wir die Trainingszeit kontrollieren können, teilen wir unserem Algorithmus mit, dass er stopnach insgesamt 10.000 Zeitschritten ausführen soll (timesteps_total):
rllibtrainfilemaze.py--stop'{"timesteps_total": 10000}'
Diese eine Zeile erledigt alles, was wir in Kapitel 3 gemacht haben, aber auf eine bessere Art und Weise:
-
Es führt eine anspruchsvollere Version von Q-Learning für uns aus (DQN).5
-
Es kümmert sich um die Skalierung auf mehrere Arbeiter (in diesem Fall zwei).
-
Es erstellt sogar automatisch Checkpoints des Algorithmus für uns.
In der Ausgabe des Trainingsskripts solltest du sehen, dass Ray die Ergebnisse des Trainingsin das Verzeichnis ~/ray_results/maze_env schreibt. Und wenn der Trainingslauf erfolgreich abgeschlossen wurde,6 bekommst du einen Checkpoint und einen kopierbarenrllib evaluate Befehl in der Ausgabe, genau wie in dem Beispiel aus Kapitel 1. Anhand dieses Berichts <checkpoint> kannst du nun die trainierte Richtlinie in unserer benutzerdefinierten Umgebung auswerten, indem du den folgenden Befehl ausführst:
rllibevaluate~/ray_results/maze_env/<checkpoint>\--algoDQN\--envmaze_gym_env.Environment\--steps100
Der in --algo verwendete Algorithmus und die mit --env angegebene Umgebung müssen mit denen übereinstimmen, die im Trainingslauf verwendet wurden, und wir werten den trainierten Algorithmus für insgesamt 100 Schritte aus. Dies sollte zu einer Ausgabe der folgenden Form führen:
Episode #1: reward: 1.0 Episode #2: reward: 1.0 Episode #3: reward: 1.0 ... Episode #13: reward: 1.0
Es sollte keine große Überraschung sein, dass der DQN-Algorithmus von RLlib für das einfache Labyrinth, das wir ihm vorgaben, jedes Mal die maximale Belohnung von 1 erhält.
Bevor wir uns der Python-API zuwenden, sollten wir erwähnen, dass die RLlib CLI unter der Haube Ray Tune nutzt, um zum Beispiel die Checkpoints deiner Algorithmen zu erstellen. Mehr über diese Integration erfährst du in Kapitel 5.
Verwendung der RLlib Python API
Letztendlich ist die RLlib CLI nur ein Wrapper um die zugrundeliegende Python-Bibliothek. Da du wahrscheinlich die meiste Zeit damit verbringen wirst, deine RL-Experimente in Python zu programmieren, werden wir uns im Rest dieses Kapitels auf Aspekte dieser API konzentrieren.
Um RL-Workloads mit RLlib von Python aus auszuführen, ist die Klasse Algorithm dein Haupteinstiegspunkt. Beginne immer mit einer entsprechenden AlgorithmConfig Klasse, um einen Algorithmus zu definieren.Im vorherigen Abschnitt haben wir zum Beispiel eine DQNConfig als Ausgangspunkt verwendet, und der Befehl rllib train hat sich darum gekümmert, den DQN-Algorithmus für uns zu instanziieren. Alle anderen RLlib-Algorithmen folgen demselben Muster.
RLlib-Algorithmen trainieren
Jede RLlib Algorithm wird mit vernünftigen Standardparametern ausgeliefert, d.h. du kannstsie initialisieren, ohne irgendwelche Konfigurationsparameter für diese Algorithmen ändern zu müssen.7
Dennoch ist es erwähnenswert, dass RLlib-Algorithmen in hohem Maße konfigurierbar sind, wie du im folgenden Beispiel sehen wirst.Wir beginnen mit der Erstellung eines DQNConfig Objekts. Dann legen wir dessen environment fest und setzen die Anzahl der Rollout-Worker mit der Methode rollouts auf zwei.Das bedeutet, dass der DQN-Algorithmus zwei Ray-Akteure erzeugen wird, die standardmäßig jeweils eine CPU verwenden, um den Algorithmus parallel auszuführen. Außerdem setzen wir für spätere Auswertungszwecke create_env_on_local_worker auf True:
fromray.tune.loggerimportpretty_printfrommaze_gym_envimportGymEnvironmentfromray.rllib.algorithms.dqnimportDQNConfigconfig=(DQNConfig().environment(GymEnvironment).rollouts(num_rollout_workers=2,create_env_on_local_worker=True))pretty_print(config.to_dict())algo=config.build()foriinrange(10):result=algo.train()(pretty_print(result))
Setze die
environmentauf unsere benutzerdefinierteGymEnvironmentKlasse und konfiguriere die Anzahl der Rollout-Worker und stelle sicher, dass eine Umgebungsinstanz auf dem lokalen Worker erstellt wird.Verwende die
DQNConfigvon RLlib, umbuildeinen DQN-Algorithmus zu trainieren. Diesmal verwenden wir zwei Rollout-Arbeiter.Rufe die Methode
trainauf, um den Algorithmus für 10Iterationen zu trainieren.Mit dem Dienstprogramm
pretty_printkönnen wir eine für Menschen lesbare Ausgabe der Trainingsergebnisse erstellen.
Beachte, dass die Anzahl der Trainingsiterationen keine besondere Bedeutung hat, aber sie sollte ausreichen, damit der Algorithmus lernt, das Labyrinthproblem angemessen zu lösen. Das Beispiel soll nur zeigen, dass du die volle Kontrolle über den Trainingsprozess hast.
Wenn du das config Wörterbuch ausdruckst, kannst du feststellen, dass dernum_rollout_workers Parameter auf 2 gesetzt ist.8
result enthält detaillierte Informationen über den Zustand des DQN-Algorithmus und die Trainingsergebnisse, die zu ausführlich sind, um sie hier zu zeigen. Der Teil, der für uns jetzt am wichtigsten ist, ist die Information über die Belohnung des Algorithmus, die im Idealfall anzeigt, dass der Algorithmus gelernt hat, das Labyrinthproblem zu lösen. Du solltest eine Ausgabe der folgenden Form sehen (wir zeigen nur die wichtigsten Informationen, um die Übersichtlichkeit zu wahren):
... episode_reward_max: 1.0 episode_reward_mean: 1.0 episode_reward_min: 1.0 episodes_this_iter: 15 episodes_total: 19 ... training_iteration: 10 ...
Insbesondere zeigt diese Ausgabe, dass die minimale Belohnung, die im Durchschnitt pro Episode erreicht wurde, 1,0 beträgt, was wiederum bedeutet, dass der Agent das Ziel immer erreicht und die maximale Belohnung (1,0) erhalten hat.
Speichern, Laden und Auswerten von RLlib-Modellen
Das Ziel in diesem einfachen Beispiel zu erreichen, ist nicht allzu schwierig, aber wir wollen sehen, ob die Auswertung des trainierten Algorithmus bestätigt, dass der Agent dies auch auf optimale Weise tun kann, nämlich indem er nur die minimale Anzahl von acht Schritten macht, um das Ziel zu erreichen.
Dazu nutzen wir einen anderen Mechanismus, den du bereits aus der RLlib CLI kennst: Checkpointing.Das Erstellen von Algorithmus-Checkpoints ist nützlich, um sicherzustellen, dass du deine Arbeit im Falle eines Absturzes wiederherstellen kannst, oder einfach um den Trainingsfortschritt dauerhaft zu verfolgen.
Du kannst zu jedem Zeitpunkt des Trainingsprozesses einen Checkpoint eines RLlib-Algorithmus erstellen, indem du algo.save() aufrufst. Sobald du einen Checkpoint hast, kannst du damit ganz einfach dein Algorithm wiederherstellen. Die Auswertung eines Modells ist so einfach wie der Aufruf von algo.evaluate(checkpoint) mit dem erstellten Checkpoint.So sieht das aus, wenn du alles zusammenfasst:
fromray.rllib.algorithms.algorithmimportAlgorithmcheckpoint=algo.save()(checkpoint)evaluation=algo.evaluate()(pretty_print(evaluation))algo.stop()restored_algo=Algorithm.from_checkpoint(checkpoint)
Algorithmen speichern, um Checkpoints zu erstellen.
Evaluiere RLlib-Algorithmen zu einem beliebigen Zeitpunkt, indem du
evaluateaufrufst.Halte eine
algoan, um alle beanspruchten Ressourcen freizugeben.Stelle alle
Algorithmvon einem bestimmten Kontrollpunkt aus mitfrom_checkpointwieder her.
Wenn wir uns die Ausgabe dieses Beispiels ansehen, können wir bestätigen, dass der trainierte RLlib-Algorithmus tatsächlich zu einer guten Lösung für das Labyrinthproblem konvergiert hat, was durch Episoden der Länge 8 in der Auswertung angezeigt wird:
~/ray_results/DQN_GymEnvironment_2022-02-09_10-19-301o3m9r6d/checkpoint_000010/
checkpoint-10 evaluation:
...
episodes_this_iter: 5
hist_stats:
episode_lengths:
- 8
- 8
...
Aktionen berechnen
Die Algorithmen der RLlib haben viel mehr Funktionen als nur die Methoden train, evaluate, save und from_checkpoint, die wir bisher gesehen haben.Du kannst zum Beispiel direkt Aktionen für den aktuellen Zustand einer Umgebung berechnen. In Kapitel 3 haben wir Episoden-Rollouts implementiert, indem wir durch eine Umgebung schritten und Belohnungen sammelten. Wir können dasselbe mit RLlib für unsere GymEnvironment tun:
env=GymEnvironment()done=Falsetotal_reward=0observations=env.reset()whilenotdone:action=algo.compute_single_action(observations)observations,reward,done,info=env.step(action)total_reward+=reward
Um Aktionen für gegebene
observationszu berechnen, benutzecompute_single_action.
Falls du nicht nur eine, sondern viele Aktionen auf einmal berechnen musst, kannst du stattdessen die Methode compute_actions verwenden, die Wörterbücher mit Beobachtungen als Eingabe nimmt und Wörterbücher mit Aktionen mit denselbenSchlüsseln als Ausgabe produziert:
action=algo.compute_actions({"obs_1":observations,"obs_2":observations})(action)# {'obs_1': 0, 'obs_2': 1}
Verwende für mehrere Aktionen
compute_actions.
Zugriff auf Politik und Modellstatus
Erinnere dich daran, dass jeder Algorithmus des verstärkenden Lernens auf einer Strategie basiert, die die nächsten Handlungen auswählt (). Jede Strategie basiert wiederum auf einem zugrunde liegenden Modell.
Im Fall des Vanilla Q-Learnings, das wir in Kapitel 3 besprochen haben, war das Modell eine einfache Nachschlagetabelle mit Zustands-Aktionswerten, auch Q-Werte genannt.Und diese Politik nutzte dieses Modell für die Vorhersage der nächsten Aktionen, falls sie beschloss,das bisher Gelerntezu nutzen oder die Umgebung mit zufälligen Aktionen zu erkunden.
Beim Deep Q-Learning ist das zugrunde liegende Modell ein neuronales Netzwerk, das, grob gesagt, Beobachtungen auf Aktionen abbildet.Beachte, dass wir bei der Wahl der nächsten Aktionen in einer Umgebung nicht an den konkreten Werten der approximierten Q-Werte interessiert sind, sondern an denWahrscheinlichkeiten für jede Aktion.Die Wahrscheinlichkeitsverteilung über alle möglichen Aktionen wird Aktionsverteilung genannt. In dem Labyrinth, das wir als Beispiel verwenden, können wir uns nach oben, rechts, unten oder links bewegen. In unserem Fall ist eine Aktionsverteilung also ein Vektor mit vier Wahrscheinlichkeiten, eine für jede Aktion. Beim Q-Learning wählt der Algorithmus immer die Aktion mit der höchsten Wahrscheinlichkeit aus dieser Verteilung, während andere Algorithmen daraus eine Stichprobe ziehen.
Um das Ganze zu verdeutlichen, schauen wir uns an, wie du auf Richtlinien und Modelle in RLlib zugreifst:9
policy=algo.get_policy()(policy.get_weights())model=policy.model
Sowohl policy als auch model bieten viele nützliche Methoden. In diesem Beispiel verwenden wir get_weights, um die Parameter des Modells zu untersuchen, das der Politik zugrunde liegt (die nach der Standardkonvention Gewichte genannt werden).
Um dich davon zu überzeugen, dass hier nicht nur ein Modell im Spiel ist, sondern tatsächlich eine Sammlung von Modellen,10 können wir auf alle Arbeiterinnen und Arbeiter zugreifen, die wir beim Training verwendet haben, und mit foreach_worker die Gewichte der einzelnen Arbeiterinnen und Arbeiter abfragen:
workers=algo.workersworkers.foreach_worker(lambdaremote_trainer:remote_trainer.get_policy().get_weights())
Auf diese Weise kannst du in jedem deiner Worker auf jede Methode zugreifen, die auf einer Algorithm -Instanz verfügbar ist.Im Prinzip kannst du damit auch Modellparameter einstellen oder deine Worker anderweitig konfigurieren. RLlib-Worker sind letztlich Ray-Actors, du kannst sie also fast beliebig verändern und manipulieren.
Wir haben noch nicht über die spezifische Implementierung von Deep Q-Learning gesprochen, die im DQN verwendet wird, aber das verwendete Modell ist etwas komplexer als das, was wir bisher beschrieben haben.Jedes RLlib-Modell, das aus einer Richtlinie gewonnen wird, hat eine base_model, die eine ordentliche summaryMethode hat, sich selbst zu beschreiben:11
model.base_model.summary()
Wie du in der folgenden Ausgabe von sehen kannst, nimmt dieses Modell unsere observations auf. Die Form dieser observations ist etwas seltsam als [(None, 25)] annotiert, aber im Wesentlichen bedeutet dies, dass wir die erwarteten 5 × 5 Labyrinth-Gitterwerte korrekt kodiert haben.Das Modell folgt mit zwei sogenannten Dense Schichten und sagt am Ende einen einzigen Wert voraus:12
Model: "model" ________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================ observations (InputLayer) [(None, 25)] 0 ________________________________________________________________________________ fc_1 (Dense) (None, 256) 6656 observations[0][0] ________________________________________________________________________________ fc_out (Dense) (None, 256) 65792 fc_1[0][0] ________________________________________________________________________________ value_out (Dense) (None, 1) 257 fc_1[0][0] ================================================================================ Total params: 72,705 Trainable params: 72,705 Non-trainable params: 0 ________________________________________________________________________________
Beachte, dass es durchaus möglich ist, dieses Modell für deine RLlib-Experimente anzupassen. Wenn deine Umgebung zum Beispiel komplex ist und einen großen Beobachtungsraum hat, brauchst du vielleicht ein größeres Modell, um diese Komplexität zu erfassen. Das erfordert jedoch tiefgreifende Kenntnisse über das zugrunde liegende neuronale Netzwerk-Framework (in diesem Fall TensorFlow), die wir bei dir nicht voraussetzen.13
Als Nächstes wollen wir sehen, ob wir einige Beobachtungen aus unserer Umgebung an das Modell weitergeben können, das wir gerade aus unserer policy extrahiert haben. Dieser Teil ist technisch etwas kompliziert, weil Modelle in RLlib nicht so einfach direkt zugänglich sind. Normalerweise würdest du ein Modell nur über deine policy ansprechen, die sich unter anderem um die Vorverarbeitung der Beobachtungen kümmert. Glücklicherweise können wir auf den von der Richtlinie verwendeten Präprozessor zugreifen, transform die Beobachtungen aus unserer Umgebung und dann an das Modell übergeben:
fromray.rllib.models.preprocessorsimportget_preprocessorenv=GymEnvironment()obs_space=env.observation_spacepreprocessor=get_preprocessor(obs_space)(obs_space)observations=env.reset()transformed=preprocessor.transform(observations).reshape(1,-1)model_output,_=model({"obs":transformed})
Verwende
get_preprocessor, um auf den von der Richtlinie verwendeten Präprozessor zuzugreifen.Du kannst
transformfür alleobservationsverwenden, die du von deinemenvin das vom Modell erwartete Format gebracht hast. Beachte, dass wir auch die Beobachtungen umgestalten müssen.Erhalte die Modellausgabe, indem du das Modell mit einem vorverarbeitetenBeobachtungswörterbuch aufrufst.
Nachdem wir unsere model_output berechnet haben, können wir nun auf die Q-Werte und die Aktionsverteilung des Modells für diese Ausgabe zugreifen:
q_values=model.get_q_value_distributions(model_output)(q_values)action_distribution=policy.dist_class(model_output,model)sample=action_distribution.sample()(sample)
RLlib-Experimente konfigurieren
Jetzt, wo du die grundlegende Python-Trainings-API von RLlib in einem Beispiel gesehen hast, lass uns einen Schritt zurückgehen und genauer besprechen, wie man RLlib-Experimente konfiguriert und ausführt. Inzwischen weißt du, dass du zur Definition eines Algorithm mit dem entsprechendenAlgorithmConfig beginnst und dann build deinen Algorithmus daraus ableitest. Bisher haben wir nur die rollout Methode eines AlgorithmConfig verwendet, um die Anzahl der Rollout-Worker auf zwei zu setzen, und unser environment entsprechend eingestellt.
Wenn du das Verhalten deines RLlib-Trainingslaufs ändern möchtest, hängst du weitere Utility-Methoden an die Instanz AlgorithmConfig und rufst am Ende build auf. Da RLlib-Algorithmen ziemlich komplex sind, verfügen sie über viele Konfigurationsoptionen. Um die Sache zu vereinfachen, sind die gemeinsamen Eigenschaften der Algorithmen in nützliche Kategorien eingeteilt.14
Für jede dieser Kategorien gibt es eine eigene Methode AlgorithmConfig:
training()-
Kümmert sich um alle trainingsbezogenen Konfigurationsoptionen deines Algorithmus. Die Methode
trainingist der einzige Ort, an dem sich die RLlib-Algorithmen in ihrer Konfiguration unterscheiden. Alle folgenden Methoden sind Algorithmus-unabhängig. environment()rollouts()-
Ändert die Einrichtung und das Verhalten deiner Rollout-Worker.
exploration()resources()-
Konfiguriert die Rechenressourcen, die von deinem Algorithmus verwendet werden.
offline_data()-
Definiert Optionen für das Training mit sogenannten Offline-Daten, ein Thema, das wir in "Arbeiten mit Offline-Daten" behandeln .
multi_agent()-
Legt Optionen für das Training von Algorithmen mit mehreren Agenten fest.Ein explizites Beispiel dafür besprechen wir im nächsten Abschnitt.
Die Algorithmus-spezifische Konfiguration in training() wird noch relevanter, wenn du dich für einen Algorithmus entschieden hast und ihn auf Leistung trimmen willst. In der Praxis bietet dir RLlib gute Standardeinstellungen für den Anfang.
Weitere Details zur Konfiguration von RLlib-Experimenten findest du unter Konfigurationsargumente in der API-Referenz für RLlib-Algorithmen. Bevor wir zu den Beispielen übergehen, solltest du jedoch diehäufigsten Konfigurationsoptionen in der Praxis kennenlernen.
Ressourcen-Konfiguration
Unabhängig davon, ob du Ray RLlib lokal oder in einem Cluster verwendest, kannst du die für den Trainingsprozess verwendeten Ressourcen festlegen.Hier sind die wichtigsten Optionen, die du beachten solltest. Wir verwenden weiterhin den DQN-Algorithmus als Beispiel, aber das gilt auch für jeden anderen RLlib-Algorithmus:
fromray.rllib.algorithms.dqnimportDQNConfigconfig=DQNConfig().resources(num_gpus=1,num_cpus_per_worker=2,num_gpus_per_worker=0,)
Lege die Anzahl der GPUs fest, die für das Training verwendet werden sollen. Es ist wichtig, dass du zuerst prüfst, ob der Algorithmus deiner Wahl GPUs unterstützt. Dieser Wert kann auch ein Bruchteil sein. Wenn du zum Beispiel vier Rollout-Worker in DQN (
num_rollout_workers=4) verwendest, kannst dunum_gpus=0.25so einstellen, dass alle vier Worker auf demselben Grafikprozessor arbeiten, damit alle Rollout-Worker von der potenziellen Beschleunigung profitieren. Dies betrifft nur den lokalen Lernprozess, nicht die Rollout-Worker.Lege die Anzahl der CPUs fest, die für jeden Rollout-Worker verwendet werden sollen.
Lege die Anzahl der GPUs fest, die pro Worker verwendet werden.
Rollout Worker Konfiguration
Mit RLlib kannst du konfigurieren, wie deine Rollouts berechnet werden und wie sie verteilt werden sollen:
fromray.rllib.algorithms.dqnimportDQNConfigconfig=DQNConfig().rollouts(num_rollout_workers=4,num_envs_per_worker=1,create_env_on_local_worker=True,)
Das hast du schon gesehen. Sie gibt die Anzahl der zu verwendenden Ray-Arbeiter an.
Lege die Anzahl der Umgebungen fest, die pro Arbeiter ausgewertet werden sollen. Mit dieser Einstellung kannst du die Auswertung von Umgebungen "stapeln". Insbesondere wenn die Auswertung deiner Modelle viel Zeit in Anspruch nimmt, kann die Gruppierung von Umgebungen das Training beschleunigen.
Wenn
num_rollout_workers> 0 ist, braucht der Treiber ("lokaler Arbeiter") keine Umgebung. Das liegt daran, dass das Sampling und die Auswertung von den Rollout-Workern übernommen werden. Wenn du trotzdem eine Umgebung auf dem Treiber haben willst, kannst du diese Option aufTruesetzen.
Umgebung Konfiguration
fromray.rllib.algorithms.dqnimportDQNConfigconfig=DQNConfig().environment(env="CartPole-v1",env_config={"my_config":"value"},observation_space=None,action_space=None,render_env=True,)
Gib die Umgebung an, die du für das Training verwenden willst. Das kann entweder eine Zeichenkette einer Umgebung sein, die Ray RLlib bekannt ist, wie eine beliebige Gym-Umgebung, oder der Klassenname einer benutzerdefinierten Umgebung, die du implementiert hast.15
Optional kannst du ein Wörterbuch mit Konfigurationsoptionen für deine Umgebung angeben, das an den Umgebungskonstruktor übergeben wird.
Du kannst auch die Beobachtungs- und Aktionsräume deiner Umgebung angeben. Wenn du sie nicht angibst, werden sie aus der Umgebung abgeleitet.
FalseStandardmäßig kannst du mit dieser Eigenschaft das Rendering der Umgebung einschalten, wofür du die Methoderenderdeiner Umgebung implementieren musst.
Beachte, dass wir viele verfügbare Konfigurationsoptionen für jeden der aufgelisteten Typen ausgelassen haben.Außerdem können wir in dieser Einführung nicht auf Aspekte eingehen, die das Verhalten des RL-Trainingsverfahrens verändern (wie z.B. die Änderung des zugrundeliegenden Modells).Aber die gute Nachricht ist, dass du alle Informationen, die du brauchst, in der RLlib Training API Dokumentation findest.
Arbeiten mit RLlib-Umgebungen
Bisher haben wir dir nur die Gym-Umgebungen vorgestellt, aber RLlib unterstützt eine Vielzahl von Umgebungen.Nachdem wir dir einen kurzen Überblick über alle verfügbaren Optionen gegeben haben (siehe Abbildung 4-1), zeigen wir dir zwei konkrete Beispiele für fortgeschrittene RLlib-Umgebungen in Aktion.
Ein Überblick über RLlib-Umgebungen
Alle verfügbaren RLlib-Umgebungen erweitern eine gemeinsame BaseEnv Klasse. Wenn du mit mehreren Kopien derselben gym.Env Umgebung arbeiten möchtest, kannst du den VectorEnv Wrapper von RLlib verwenden. Vektorisierte Umgebungen sind nützlich, aber sie sind einfache Verallgemeinerungen dessen, was du bereits kennst. Die beiden anderen Arten von Umgebungen, die in RLlib verfügbar sind, sind interessanter und verdienen mehr Aufmerksamkeit.
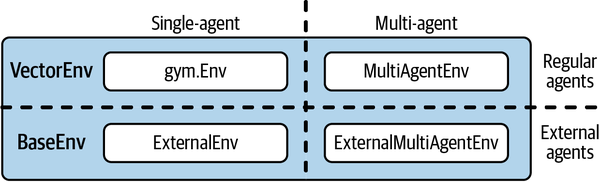
Abbildung 4-1. Ein Überblick über alle verfügbaren RLlib-Umgebungen
Die erste heißt MultiAgentEnv und ermöglicht es dir, ein Modell mit mehreren Agenten zu trainieren. Die Arbeit mit mehreren Agenten kann knifflig sein.Das liegt daran, dass du darauf achten musst, deine Agenten in deiner Umgebung mit einer geeigneten Schnittstelle zu definieren und die Tatsache zu berücksichtigen, dass jeder Agent eine völlig andere Art der Interaktion mit seiner Umgebung haben kann.
Außerdem können die Agenten miteinander interagieren und müssen die Aktionen der anderen respektieren. In fortgeschrittenen Situationen kann es sogar eine Hierarchie von Agenten geben, die explizit voneinander abhängig sind.Kurz gesagt, die Durchführung von RL-Experimenten mit mehreren Agenten ist schwierig, und wir werden im nächsten Beispiel sehen, wie RLlib damit umgeht.
Die andere Art von Umgebung, die wir uns ansehen werden, heißt ExternalEnv und kann verwendet werden, um externe Simulatoren mit RLlib zu verbinden.Stellen Sie sich zum Beispiel vor, dass unser einfaches Labyrinthproblem von vorhin die Simulation eines echten Roboters war, der durch ein Labyrinth navigiert. In solchen Szenarien ist es vielleicht nicht sinnvoll, den Roboter (oder seine Simulation, die in einem anderen Software-Stack implementiert ist) mit den Lernagenten von RLlib zu verbinden.
Um dem Rechnung zu tragen, bietet RLlib eine einfache Client-Server-Architektur für die Kommunikation mit externen Simulatoren, die eine Kommunikation über eine REST-API ermöglicht. Falls du sowohl in einer Multi-Agenten- als auch in einer externen Umgebung arbeiten möchtest, bietet RLlib eine MultiAgentExternalEnv Umgebung, die beides kombiniert.
Arbeiten mit mehreren Agenten
Die Grundidee der Definition von Multi-Agenten-Umgebungen in RLlib ist einfach. Du weist jedem Agenten zunächst eine Agenten-ID zu. Dann definierst du alles, was du vorher als einzelnen Wert in einer Gym-Umgebung definiert hast (Beobachtungen, Belohnungen usw.), als Wörterbuch mit Agenten-IDs als Schlüssel und Werten pro Agent. In der Praxis sind die Details natürlich etwas komplizierter. Aber sobald du eine Umgebung mit mehreren Agenten definiert hast, musst du festlegen, wie diese Agenten lernen sollen.
In einer Einzelagenten-Umgebung gibt es einen Agenten und eine Richtlinie, die gelernt werden muss. In einer Multi-Agenten-Umgebung gibt es mehrere Agenten, die einer oder mehreren Richtlinien entsprechen können.Wenn du zum Beispiel eine Gruppe homogener Agenten in deiner Umgebung hast, kannst du eine einzige Richtlinie für alle definieren. Wenn sie sich alle gleich verhalten, kann ihr Verhalten auch auf die gleiche Weise gelernt werden. Im Gegensatz dazu kann es Situationen mit heterogenen Agenten geben, in denen jeder von ihnen eine eigene Richtlinie lernen muss. Zwischen diesen beiden Extremen gibt es ein Spektrum von Möglichkeiten, wie in Abbildung 4-2 dargestellt.
Wir verwenden weiterhin unser Labyrinthspiel als laufendes Beispiel für dieses Kapitel.Auf diese Weise kannst du selbst überprüfen, wie sich die Schnittstellen in der Praxis unterscheiden. Um die soeben skizzierten Ideen in Code umzusetzen, definieren wir eine Multi-Agenten-Version der Klasse GymEnvironment.Unsere Klasse MultiAgentEnv wird genau zwei Agenten haben, die wir in einem Python-Wörterbuch namens agents kodieren, aber im Prinzip funktioniert das mit einer beliebigen Anzahl von Agenten.
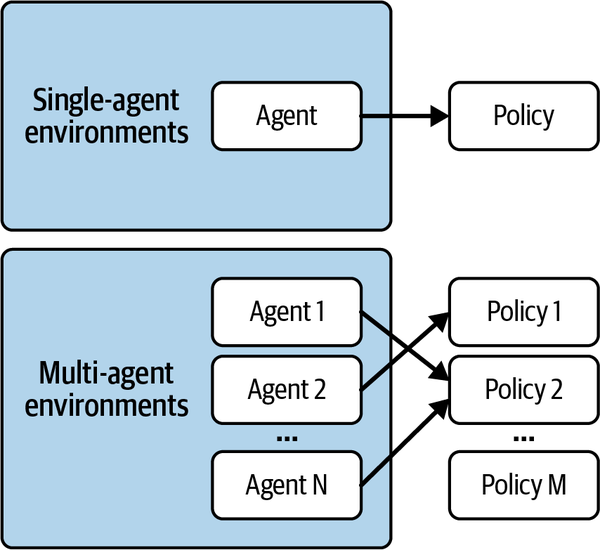
Abbildung 4-2. Zuordnung von Agenten zu Richtlinien in Multi-Agenten-Verstärkungslernproblemen
Wir beginnen damit, unsere neue Umgebung zu initialisieren und zurückzusetzen:
fromray.rllib.env.multi_agent_envimportMultiAgentEnvfromgym.spacesimportDiscreteimportosclassMultiAgentMaze(MultiAgentEnv):def__init__(self,*args,**kwargs):self.action_space=Discrete(4)self.observation_space=Discrete(5*5)self.agents={1:(4,0),2:(0,4)}self.goal=(4,4)self.info={1:{'obs':self.agents[1]},2:{'obs':self.agents[2]}}defreset(self):self.agents={1:(4,0),2:(0,4)}return{1:self.get_observation(1),2:self.get_observation(2)}
Die Aktions- und Beobachtungsräume bleiben genau so wie vorher.
Wir haben jetzt zwei Sucher mit den Startpositionen
(0, 4)und(4, 0)in einemagentsWörterbuch.Für das Objekt
infoverwenden wir die Agenten-IDs als Schlüssel.Beobachtungen sind jetzt Wörterbücher pro Agent.
Beachte, dass wir die Aktions- und Beobachtungsräume überhaupt nicht berührt haben.Das liegt daran, dass wir hier zwei im Wesentlichen identische Agenten verwenden, die dieselben Räume wiederverwenden können. In komplexeren Situationen müsstest du die Tatsache berücksichtigen, dass die Aktionen und Beobachtungen für einige Agenten anders aussehen könnten.16
Um fortzufahren, wollen wir unsere Hilfsmethoden get_observation, get_reward und is_done so verallgemeinern, dass sie mit mehreren Agenten arbeiten können.Wir tun dies, indem wir ein action_id an ihre Signaturen übergeben und jeden Agenten auf die gleiche Weise behandeln wie zuvor:
defget_observation(self,agent_id):seeker=self.agents[agent_id]return5*seeker[0]+seeker[1]defget_reward(self,agent_id):return1ifself.agents[agent_id]==self.goalelse0defis_done(self,agent_id):returnself.agents[agent_id]==self.goal
Um die Methode step auf unser Multi-Agenten-Setup zu portieren, musst du wissen, dassMultiAgentEnv nun erwartet, dass die action, die an step übergeben wird, ebenfalls ein Wörterbuch mit Schlüsseln ist, die den Agenten-IDs entsprechen.Wir definieren einen Schritt, indem wir eine Schleife durch alle verfügbaren Agenten ziehen und in ihrem Namen handeln:17
defstep(self,action):agent_ids=action.keys()foragent_idinagent_ids:seeker=self.agents[agent_id]ifaction[agent_id]==0:# move downseeker=(min(seeker[0]+1,4),seeker[1])elifaction[agent_id]==1:# move leftseeker=(seeker[0],max(seeker[1]-1,0))elifaction[agent_id]==2:# move upseeker=(max(seeker[0]-1,0),seeker[1])elifaction[agent_id]==3:# move rightseeker=(seeker[0],min(seeker[1]+1,4))else:raiseValueError("Invalid action")self.agents[agent_id]=seekerobservations={i:self.get_observation(i)foriinagent_ids}rewards={i:self.get_reward(i)foriinagent_ids}done={i:self.is_done(i)foriinagent_ids}done["__all__"]=all(done.values())returnobservations,rewards,done,self.info
Aktionen in einem
stepsind jetzt Wörterbücher pro Agent.Nachdem du die richtige Aktion für jeden Sucher durchgeführt hast, setze die richtigen Zustände für alle
agents.observations,rewardsunddonessind ebenfalls Wörterbücher mit Agenten-IDs als Schlüssel.Außerdem muss RLlib wissen, wann alle Agenten fertig sind.
Der letzte Schritt besteht darin, das Rendering der Umgebung zu ändern, indem wir jeden Agenten mit seiner ID bezeichnen, wenn wir das Labyrinth auf dem Bildschirm ausgeben:
defrender(self,*args,**kwargs):os.system('cls'ifos.name=='nt'else'clear')grid=[['| 'for_inrange(5)]+["|\n"]for_inrange(5)]grid[self.goal[0]][self.goal[1]]='|G'grid[self.agents[1][0]][self.agents[1][1]]='|1'grid[self.agents[2][0]][self.agents[2][1]]='|2'grid[self.agents[2][0]][self.agents[2][1]]='|2'(''.join([''.join(grid_row)forgrid_rowingrid]))
Das zufällige Ausrollen einer Episode, bis einer der Agenten das Ziel erreicht, kann zum Beispiel mit folgendem Code durchgeführt werden::18
importtimeenv=MultiAgentMaze()whileTrue:obs,rew,done,info=env.step({1:env.action_space.sample(),2:env.action_space.sample()})time.sleep(0.1)env.render()ifany(done.values()):break
Beachte, dass wir sicherstellen müssen, dass zwei Zufallsstichproben mit Hilfe eines Python-Wörterbuchs in die Methode step übergeben werden, und dass wir prüfen, ob einer der Agenten bereits done ist. Wir verwenden diese break Bedingung der Einfachheit halber, weil es höchst unwahrscheinlich ist, dass beide Suchenden zufällig zur gleichen Zeit den Weg zum Ziel finden. Aber natürlich möchten wir, dass beide Agenten das Labyrinth schließlich beenden.
Ausgestattet mit unserer MultiAgentMaze funktioniert das Training einer RLlib Algorithmauf jeden Fall genau so wie :
fromray.rllib.algorithms.dqnimportDQNConfigsimple_trainer=DQNConfig().environment(env=MultiAgentMaze).build()simple_trainer.train()
Dies deckt den einfachsten Fall des Trainings eines Multi-Agenten-Verstärkungslernproblems (MARL) ab.Aber wenn du dich daran erinnerst, was wir vorhin gesagt haben, gibt es bei der Verwendung mehrerer Agenten immer eine Zuordnung zwischen Agenten und Richtlinien.Da wir eine solche Zuordnung nicht angegeben haben, wurden unsere beiden Sucher implizit derselben Richtlinie zugewiesen.Dies kann geändert werden, indem wir die Methode .multi_agent auf unserem DQNConfig aufrufen und die Argumente policies und policy_mapping_fn entsprechend setzen:
algo=DQNConfig()\.environment(env=MultiAgentMaze)\.multi_agent(policies={"policy_1":(None,env.observation_space,env.action_space,{"gamma":0.80}),"policy_2":(None,env.observation_space,env.action_space,{"gamma":0.95}),},policy_mapping_fn=lambdaagent_id:f"policy_{agent_id}",).build()(algo.train())
Definiere mehrere
policiesfür unsere Agenten, jeder mit einem anderen"gamma"Wert.Jeder Agent kann dann einer Richtlinie mit einer benutzerdefinierten
policy_mapping_fnzugewiesen werden.
Wie du siehst, ist die Durchführung von Multi-Agenten-RL-Experimenten eine erstklassige Eigenschaft von RLlib, und es gäbe noch viel mehr darüber zu sagen. Die Unterstützung von MARL-Problemen ist wahrscheinlich eine der stärksten Eigenschaften von RLlib.
Arbeiten mit Policy-Servern und Clients
Für das letzte Beispiel in diesem Abschnitt nehmen wir an, dass unsere ursprünglicheGymEnvironment nur auf einem Rechner simuliert werden kann, auf dem RLlib nicht ausgeführt werden kann, z.B. weil er nicht genügend Ressourcen zur Verfügung hat. Wir können die Umgebung auf einem PolicyClient ausführen, der einen entsprechenden Servernach geeigneten nächsten Aktionen für die Umgebung fragen kann.
Der Server wiederum weiß nichts von der Umgebung. Er weiß nur, wie man Eingabedaten von einem PolicyClient aufnimmt, und er ist für die Ausführung des gesamten RL-bezogenen Codes verantwortlich; insbesondere definiert er ein RLlib AlgorithmConfigObjekt und trainiert ein Algorithm.
In der Regel möchtest du den Server, der deinen Algorithmus trainiert, auf einem leistungsstarken Ray-Cluster laufen lassen, während der entsprechende Client außerhalb dieses Clusters läuft.Abbildung 4-3 veranschaulicht diesen Aufbau schematisch.
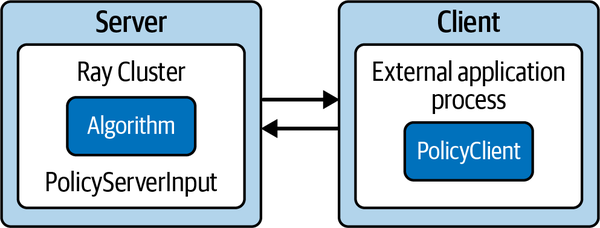
Abbildung 4-3. Arbeiten mit Policy Servern und Clients in RLlib
Definieren eines Servers
Beginnen wir damit, die Serverseite einer solchen Anwendung zu definieren. Wir definieren ein sogenanntes PolicyServerInput, das auf localhost auf Port 9900 läuft. Diese Richtlinieneingabe ist das, was der Client später bereitstellen wird.Mit diesem policy_input, das als input in unserer Algorithmuskonfiguration definiert ist, können wir einen weiteren DQN definieren, der auf dem Server läuft:
# policy_server.pyimportrayfromray.rllib.agents.dqnimportDQNConfigfromray.rllib.env.policy_server_inputimportPolicyServerInputimportgymray.init()defpolicy_input(context):returnPolicyServerInput(context,"localhost",9900)config=DQNConfig()\.environment(env=None,action_space=gym.spaces.Discrete(4),observation_space=gym.spaces.Discrete(5*5))\.debugging(log_level="INFO")\.rollouts(num_rollout_workers=0)\.offline_data(input=policy_input,input_evaluation=[])algo=config.build()
Die Funktion
policy_inputgibt einPolicyServerInputObjekt zurück, das auf localhost auf Port 9900 läuft.Wir stellen
envexplizit aufNoneein, weil dieser Server keinen braucht.Wir müssen daher sowohl eine
observation_spaceals auch eineaction_spacedefinieren, da der Server nicht in der Lage ist, sie aus der Umgebung abzuleiten.Damit das funktioniert, müssen wir unsere
policy_inputin dieinputdes Experiments einspeisen.
Mit dieser algo definiert,19 können wir jetzt eine Trainingssitzung auf dem Server wie folgt starten:
# policy_server.pyif__name__=="__main__":time_steps=0for_inrange(100):results=algo.train()checkpoint=algo.save()iftime_steps>=1000:breaktime_steps+=results["timesteps_total"]
Trainiere für maximal 100 Iterationen und speichere nach jeder Iteration Kontrollpunkte.
Wenn das Training mehr als 1.000 Zeitschritte umfasst, beenden wir das Training.
Im Folgenden gehen wir davon aus, dass du die letzten beiden Codeschnipsel in einer Datei namens policy_server.py speicherst. Wenn du möchtest, kannst du diesen Policy Server nun auf deinem lokalen Rechner starten, indem du python policy_server.py in einem Terminal ausführst.
Einen Kunden definieren
Als Nächstes definieren wir die entsprechende Client-Seite der Anwendung, indem wir eine PolicyClient definieren, die sich mit dem soeben gestarteten Server verbindet. Da wir nicht davon ausgehen können, dass du mehrere Computer zu Hause (oder in der Cloud) zur Verfügung hast, starten wir diesen Client entgegen unserer vorherigen Aussage auf demselben Rechner. Mit anderen Worten: Der Client verbindet sich mit http://localhost:9900, aber wenn du den Server auf einem anderen Rechner betreiben kannst, kannst du localhostdurch die IP-Adresse dieses Rechners ersetzen, sofern er im Netzwerk verfügbar ist.
Richtlinien-Clients haben eine recht schlanke Schnittstelle. Sie können den Server veranlassen, eine Episode zu starten oder zu beenden, die nächsten Aktionen von ihm zu erhalten und Belohnungsinformationen zu protokollieren (die er sonst nicht hätte). So definierst du einen solchen Client:
# policy_client.pyimportgymfromray.rllib.env.policy_clientimportPolicyClientfrommaze_gym_envimportGymEnvironmentif__name__=="__main__":env=GymEnvironment()client=PolicyClient("http://localhost:9900",inference_mode="remote")obs=env.reset()episode_id=client.start_episode(training_enabled=True)whileTrue:action=client.get_action(episode_id,obs)obs,reward,done,info=env.step(action)client.log_returns(episode_id,reward,info=info)ifdone:client.end_episode(episode_id,obs)exit(0)
Starte einen Richtlinienclient auf der Serveradresse mit dem Modus
remoteinference.Sag dem Server, er soll eine Episode starten.
Für bestimmte Umgebungsbeobachtungen können wir die nächste Aktion vom Server erhalten.
Die
clientmuss die Belohnungsdaten auf dem Server protokollieren.
Wenn eine bestimmte Bedingung erreicht ist, können wir den Client-Prozess stoppen.

Wenn die Umgebung
doneist, müssen wir den Server über denAbschluss der Episode informieren.
Angenommen, du speicherst diesen Code unter policy_client.py und startest ihn, indem dupython policy_client.py aufrufst, dann beginnt der Server, den wir zuvor gestartet haben, mit Umgebungsinformationen zu lernen, die er ausschließlich vom Client erhält.
Fortgeschrittene Konzepte
Bisher haben wir mit einfachen Umgebungen gearbeitet, die mit den grundlegenden Einstellungen des RL-Algorithmus in RLlib leicht zu bewältigen waren.In der Praxis hast du natürlich nicht immer so viel Glück und musst dir vielleicht andere Ideen einfallen lassen, um schwierigere Umgebungen zu bewältigen. In diesem Abschnitt stellen wir eine etwas schwierigere Version des Labyrinths vor und besprechen einige fortgeschrittene Konzepte, die dir bei der Lösung helfen.
Aufbau einer fortschrittlichen Umgebung
Machen wir unser Labyrinth GymEnvironment etwas anspruchsvoller. Zuerst vergrößern wir es von einem 5 × 5 auf ein 11 × 11-Gitter. Dann führen wir Hindernisse in das Labyrinth ein, die der Agent nur unter Inkaufnahme einer negativen Belohnung von -1 passieren kann. Auf diese Weise muss unser Suchagent lernen, Hindernissen auszuweichen und trotzdem das Ziel zu finden. Außerdem bestimmen wir die Startposition des Agenten nach dem Zufallsprinzip. All das macht das RL-Problem schwieriger zu lösen. Sehen wir uns zuerst die Initialisierung dieses neuen AdvancedEnv an:
fromgym.spacesimportDiscreteimportrandomimportosclassAdvancedEnv(GymEnvironment):def__init__(self,seeker=None,*args,**kwargs):super().__init__(*args,**kwargs)self.maze_len=11self.action_space=Discrete(4)self.observation_space=Discrete(self.maze_len*self.maze_len)ifseeker:assert0<=seeker[0]<self.maze_lenand\0<=seeker[1]<self.maze_lenself.seeker=seekerelse:self.reset()self.goal=(self.maze_len-1,self.maze_len-1)self.info={'seeker':self.seeker,'goal':self.goal}self.punish_states=[(i,j)foriinrange(self.maze_len)forjinrange(self.maze_len)ifi%2==1andj%2==0]
Lege die Position
seekerbei der Initialisierung fest.Führe
punish_statesals Hindernis für den Agenten ein.
Als Nächstes wollen wir beim Zurücksetzen der Umgebung sicherstellen, dass die Position des Agenten auf einen zufälligen Zustand zurückgesetzt wird.20 Außerdem erhöhen wir die positive Belohnung für das Erreichen des Ziels auf 5, um die negative Belohnung für das Durchqueren eines Hindernisses auszugleichen (was häufig vorkommen wird, bevor der RL-Algorithmus die Hindernisse erkennt). Das Ausbalancieren von Belohnungen wie dieser ist eine wichtige Aufgabe bei der Kalibrierung deiner RL-Experimente:
defreset(self):"""Reset seeker position randomly, return observations."""self.seeker=(random.randint(0,self.maze_len-1),random.randint(0,self.maze_len-1))returnself.get_observation()defget_observation(self):"""Encode the seeker position as integer"""returnself.maze_len*self.seeker[0]+self.seeker[1]defget_reward(self):"""Reward finding the goal and punish forbidden states"""reward=-1ifself.seekerinself.punish_stateselse0reward+=5ifself.seeker==self.goalelse0returnrewarddefrender(self,*args,**kwargs):"""Render the environment, e.g. by printing its representation."""os.system('cls'ifos.name=='nt'else'clear')grid=[['| 'for_inrange(self.maze_len)]+["|\n"]for_inrange(self.maze_len)]forpunishinself.punish_states:grid[punish[0]][punish[1]]='|X'grid[self.goal[0]][self.goal[1]]='|G'grid[self.seeker[0]][self.seeker[1]]='|S'(''.join([''.join(grid_row)forgrid_rowingrid]))
Es gibt noch viele andere Möglichkeiten, die Umgebung schwieriger zu gestalten, z. B. das Labyrinth viel größer zu machen, eine negative Belohnung für jeden Schritt in eine bestimmte Richtung einzuführen oder den Agenten zu bestrafen, wenn er versucht, das Gitter zu verlassen. Inzwischen solltest du die Problemstellung gut genug verstehen, um das Labyrinth weiter anzupassen.
Auch wenn du in dieser Umgebung erfolgreich trainieren kannst, ist dies eine gute Gelegenheit, einige fortgeschrittene Konzepte einzuführen, die du auf andere RL-Probleme anwenden kannst.
Den Lehrplan anwenden Lernen
Eine der interessantesten Funktionen von RLlib ist es, Algorithmeinen Lehrplan zur Verfügung zu stellen, aus dem es lernen kann. Anstatt den Algorithmus aus beliebigen Umgebungen lernen zu lassen, wählen wir Zustände aus, die viel einfacher zu lernen sind, und führen dann langsam aber sicher schwierigere Zustände ein. Die Erstellung eines Lernlehrplans ist eine großartige Möglichkeit, damit deine Experimente schneller zu Lösungen konvergieren.
Um den Lehrplan anzuwenden, brauchst du nur eine Vorstellung davon, welche Startzustände leichter sind als andere. Das kann für viele Umgebungen eine Herausforderung sein, aber für unser fortgeschrittenes Labyrinth ist es einfach, einen einfachen Lehrplan zu erstellen. Die Entfernung des Suchers vom Ziel kann nämlich als Maß für die Schwierigkeit verwendet werden.Das Entfernungsmaß, das wir der Einfachheit halber verwenden, ist die Summe der absoluten Entfernung der beiden Sucherkoordinaten vom Ziel, um ein difficulty zu definieren.
Um Curriculum Learning mit RLlib zu betreiben, definieren wir ein CurriculumEnv, das sowohl unser AdvancedEnv als auch ein sogenanntes TaskSettableEnv aus RLLib erweitert. Die Schnittstelle von TaskSettableEnv ist sehr einfach, da man nur definieren muss, wie man die aktuelle Schwierigkeit erhält (get_task) und wie man eine gewünschte Schwierigkeit setzt (set_task). Hier ist die vollständige Definition dieses CurriculumEnv:
fromray.rllib.env.apis.task_settable_envimportTaskSettableEnvclassCurriculumEnv(AdvancedEnv,TaskSettableEnv):def__init__(self,*args,**kwargs):AdvancedEnv.__init__(self)defdifficulty(self):returnabs(self.seeker[0]-self.goal[0])+\abs(self.seeker[1]-self.goal[1])defget_task(self):returnself.difficulty()defset_task(self,task_difficulty):whilenotself.difficulty()<=task_difficulty:self.reset()
Definiere die
difficultydes aktuellen Zustands als die Summe der absoluten Entfernung der beiden Sucherkoordinaten vom Ziel.Um
get_taskzu definieren, können wir dann einfach die aktuelledifficultyzurückgeben.Um eine Aufgabenschwierigkeit festzulegen,
resetwir die Umgebung, bis ihredifficultyhöchstens die angegebenetask_difficultyist.
Um diese Umgebung für das Lernen nach dem Lehrplan zu nutzen, müssen wir eine Lehrplanfunktion definieren, die dem Algorithmus sagt, wann und wie er die Schwierigkeit der Aufgabe einstellen soll. Wir haben hier viele Möglichkeiten, aber wir verwenden einen Zeitplan, der die Schwierigkeit einfach alle 1.000 trainierten Zeitschritte um eins erhöht:
defcurriculum_fn(train_results,task_settable_env,env_ctx):time_steps=train_results.get("timesteps_total")difficulty=time_steps//1000(f"Current difficulty:{difficulty}")returndifficulty
Um diese Lehrplanfunktion zu testen, müssen wir sie zu unserem RLlib-Algorithmus config hinzufügen, indem wir die Eigenschaft env_task_fn auf unseren curriculum_fn setzen. Beachte, dass wir vor dem Training eines DQN für 15 Iterationen auch einen Ausgabeordner in unserer Konfiguration festlegen. Dadurch werden die Erfahrungsdaten unseres Trainingslaufs in dem angegebenen temporären Ordner gespeichert:21
fromray.rllib.algorithms.dqnimportDQNConfigimporttempfiletemp=tempfile.mkdtemp()trainer=(DQNConfig().environment(env=CurriculumEnv,env_task_fn=curriculum_fn).offline_data(output=temp).build())foriinrange(15):trainer.train()
Erstelle eine temporäre Datei, um unsere Trainingsdaten für die spätere Verwendung zu speichern.
Lege die
CurriculumEnvals unsere Umgebung imenvironmentTeil unserer Konfiguration fest und weise unserecurriculum_fnderenv_task_fnEigenschaft zu.Verwende die Methode
offline_data, umoutputin unserem Temp-Ordner zu speichern.
Wenn du diesen Algorithmus ausführst, solltest du sehen, wie die Schwierigkeit der Aufgabe mit der Zeit zunimmt. So erhält der Algorithmus zunächst einfache Beispiele, aus denen er lernen und sich zu schwierigeren Aufgaben weiterentwickeln kann.
Das Lernen mit Lehrplänen ist eine großartige Technik, die du kennen solltest, und mit RLlib kannst du sie durch die eben besprochene Lehrplan-API leicht in deine Experimente einbauen.
Arbeiten mit Offline-Daten
In unserem vorangegangenen Beispiel für das Curriculum-Lernen haben wir die Trainingsdaten in einem temporären Ordner gespeichert.Interessant ist, dass du bereits aus Kapitel 3 weißt, dass du in Q-Learning zuerst Erfahrungsdaten sammeln und erst später entscheiden kannst, wann du sie in einem Trainingsschritt verwendest. Diese Trennung von Datensammlung und Training eröffnet viele Möglichkeiten. Vielleicht hast du zum Beispiel eine gute Heuristik, die dein Problem auf unvollkommene, aber dennoch vernünftige Weise lösen kann. Oder du hast Aufzeichnungen über die menschliche Interaktion mit deiner Umgebung, die zeigen, wie man das Problem beispielhaft löst.
Das Sammeln von Erfahrungsdaten für das spätere Training wird oft als Arbeit mit Offline-Daten bezeichnet. Sie werden "offline" genannt, weil sie nicht direkt von einer Richtlinie erzeugt werden, die online mit der Umgebung interagiert. Algorithmen, die nicht auf das Training mit ihren eigenen Richtlinienoutputs angewiesen sind, werden alsOff-Policy-Algorithmen bezeichnet, und Q-Learning, insbesondere DQN, ist nur ein Beispiel dafür. Algorithmen, die diese Eigenschaft nicht haben, werden als On-Policy-Algorithmen bezeichnet. Mit anderen Worten: Off-Policy-Algorithmen können zum Training mit Offline-Daten verwendet werden.22
Um die Daten zu nutzen, die wir im temp-Ordner gespeichert haben, können wir ein neues DQNConfigerstellen, das diesen Ordner als input annimmt. Wir werden auch explore auf False setzen, da wir einfach die zuvor für das Training gesammelten Daten nutzen wollen - der Algorithmus wird nicht nach seinen eigenen Richtlinien erkunden.
Der daraus resultierende RLlib-Algorithmus funktioniert genauso wie zuvor, was wir demonstrieren, indem wir ihn für 10 Iterationen trainieren und dann auswerten:
imitation_algo=(DQNConfig().environment(env=AdvancedEnv).evaluation(off_policy_estimation_methods={}).offline_data(input_=temp).exploration(explore=False).build())foriinrange(10):imitation_algo.train()imitation_algo.evaluate()
Beachte, dass wir den Algorithmus imitation_algo genannt haben. Das liegt daran, dass dieses Trainingsverfahren darauf abzielt, das Verhalten zu imitieren, das sich in den zuvor gesammelten Daten widerspiegelt.Diese Art des Lernens durch Demonstration im RL wird daher oft alsImitationslernen oder Verhaltensklonen bezeichnet.
Andere fortgeschrittene Themen
Bevor wir dieses Kapitel abschließen, werfen wir noch einen Blick auf ein paar andere fortgeschrittene Themen, die RLlib zu bieten hat.Du hast bereits gesehen, wie flexibel RLlib ist: Du kannst mit verschiedenen Umgebungen arbeiten, deine Experimente konfigurieren, nach einem Lehrplan trainieren oder Imitationslernen durchführen. Dieser Abschnitt gibt dir einen Vorgeschmack darauf, was noch alles möglich ist.
Mit RLlib kannst du die Modelle und Richtlinien, die unter der Haube verwendet werden, vollständig anpassen. Wenn du schon einmal mit Deep Learning gearbeitet hast, weißt du, wie wichtig es ist, eine gute Modellarchitektur zu haben. Beim RL ist dies oft nicht so wichtig wie beim überwachten Lernen, aber es ist dennoch ein wichtiger Bestandteil für die erfolgreiche Durchführung fortgeschrittener Experimente.
Du kannst auch die Art der Vorverarbeitung deiner Beobachtungen ändern, indem du benutzerdefinierte Vorverarbeitungsprogramme bereitstellst. Bei unseren einfachen Labyrinth-Beispielen gab es nichts zu verarbeiten, aber wenn du mit Bild- oder Videodaten arbeitest, ist die Vorverarbeitung oft ein wichtiger Schritt.
In unserem AdvancedEnv haben wir Zustände eingeführt, die es zu vermeiden gilt. Unsere Agenten mussten das erst lernen, aber RLlib hat eine Funktion, mit der sie diese Zustände durch sogenannte parametrische Aktionsräume automatisch vermeiden können. Grob gesagt, kannst du alle unerwünschten Aktionen für jeden Zeitpunkt aus dem Aktionsraum "ausblenden". In manchen Fällen kann es auch notwendig sein, variable Beobachtungsräume zu haben, was von RLlib ebenfalls vollständig unterstützt wird.
Wir haben das Thema Offline-Daten kurz angeschnitten. RLlib hat eine vollwertige Python-API zum Lesen und Schreiben von Erfahrungsdaten, die in verschiedenen Situationen genutzt werden kann.
Der Einfachheit halber haben wir hier nur mit DQN gearbeitet, aber RLlib hat eine beeindruckende Auswahl an Trainingsalgorithmen. Der MARWIL-Algorithmus, um nur einen zu nennen, ist ein komplexer Hybridalgorithmus, mit dem du Nachahmungslernen mit Offline-Daten durchführen und gleichzeitig reguläres Training mit "online" erzeugten Daten einbauen kannst.
Zusammenfassung
In diesem Kapitel hast du eine Auswahl interessanter RLlib-Funktionen kennengelernt.Wir haben uns mit dem Training von Multi-Agenten-Umgebungen, der Arbeit mit Offline-Daten, die von einem anderen Agenten generiert wurden, der Einrichtung einer Client-Server-Architektur, um Simulationen vom RL-Training zu trennen, und der Verwendung von Curriculum-Learning zur Spezifizierung immer schwierigerer Aufgaben beschäftigt.
Außerdem haben wir dir einen kurzen Überblick über die wichtigsten Konzepte der RLlib gegeben und dir gezeigt, wie du ihre CLI und Python-API nutzen kannst. Insbesondere haben wir dir gezeigt, wie du deine RLlib-Algorithmen und -Umgebungen nach deinen Bedürfnissen konfigurieren kannst. Da wir nur einen kleinen Teil der Möglichkeiten der RLlib abgedeckt haben, empfehlen wir dir, die Dokumentation zu lesen und ihre API zu erkunden.
Im nächsten Kapitel lernst du, wie du die Hyperparameter deiner RLlib-Modelle und -Richtlinien mit Ray Tune abstimmst.
1 Wir verwenden ein einfaches Spiel, um den Prozess des RL zu veranschaulichen. Es gibt eine Vielzahl interessanter industrieller Anwendungen von RL, die keine Spiele sind.
2 Wir behandeln diese Integration nicht in diesem Buch, aber du kannst mehr über den Einsatz von RLlib-Modellen im Tutorial "Serving RLlib Models" in der Ray-Dokumentation erfahren.
3 Ab Ray 2.3.0 wird RLlib die Gymnasium-Bibliothek als Drop-in-Ersatz für Gym verwenden. Dies wird wahrscheinlich einige Änderungen mit sich bringen, daher ist es am besten, wenn du bei Ray 2.2.0 bleibst, um dieses Kapitel zu lesen.
4 Gym bietet eine Vielzahl interessanter Umgebungen, die es wert sind, erkundet zu werden. So findest du zum Beispiel viele der Atari-Umgebungen, die in der berühmten Arbeit "Playing Atari with Deep Reinforcement Learning" von DeepMind verwendet wurden, oder fortschrittliche Physiksimulationen mit der MuJoCo-Engine.
5 Um genau zu sein, verwendet RLlib einen doppelten und einen duellierten DQN.
6 Im GitHub-Repository für dieses Buch haben wir auch eine entsprechende maze.yml-Datei bereitgestellt, die du über rllib train file maze.yml verwenden kannst (keine --type erforderlich).
7 Natürlich ist die Konfiguration deiner Modelle ein wichtiger Teil der RL-Experimente. Wir werden die Konfiguration der RLlib-Algorithmen im nächsten Abschnitt ausführlicher besprechen.
8 Wenn du num_rollout_workers auf 0 setzt, wird nur der lokale Worker auf dem Head Node erstellt, und alle Samples von env werden dort durchgeführt. Dies ist besonders nützlich für die Fehlersuche, da keine zusätzlichen Ray-Actor-Prozesse erzeugt werden.
9 Die Klasse Policy in der heutigen RLlib wird in einer zukünftigen Version ersetzt werden. Die neue Klasse Policy wird wahrscheinlich größtenteils ein Ersatz sein und einige kleinere Unterschiede aufweisen. Der Grundgedanke der Klasse bleibt jedoch derselbe: Eine Richtlinie ist eine Klasse, die die Logik der Auswahl von Aktionen aufgrund von Beobachtungen kapselt und dir Zugang zu den zugrunde liegenden Modellen verschafft.
10 Technisch gesehen wird nur das lokale Modell für das eigentliche Training verwendet. Die beiden Arbeitermodelle werden für die Aktionsberechnung und die Datenerfassung (Rollouts) verwendet. Nach jedem Trainingsschritt sendet das lokale Modell seine aktuellen Gewichte zur Synchronisation an die Worker. Vollständig verteiltes Training, im Gegensatz zum verteilten Sampling, wird in zukünftigen Ray-Versionen für alle RLlib-Algorithmen verfügbar sein.
11 Das ist standardmäßig der Fall, da wir TensorFlow und Keras unter der Haube verwenden. Solltest du dich dafür entscheiden, die framework Spezifikation deines Algorithmus zu ändern, um direkt mit PyTorch zu arbeiten, tippe auf print(model). In diesem Fall ist model ein torch.nn.Module. Der Zugriff auf das zugrunde liegende Modell wird in Zukunft über alle Frameworks hinweg vereinheitlicht.
12 Der "Wert"-Ausgang dieses Netzes stellt den Q-Wert der Zustands-Aktions-Paare dar.
13 Wenn du mehr darüber erfahren möchtest, wie du deine RLlib-Modelle anpassen kannst, schau dir den Leitfaden für benutzerdefinierte Modelle in der Ray-Dokumentation an.
14 Wir listen nur die Methoden auf, die wir in diesem Kapitel vorstellen. Neben den genannten Methoden findest du auch Optionen für evaluation deiner Algorithmen, reporting, debugging, checkpointing, das Hinzufügen von callbacks, das Ändern deines Deep Learning framework, das Anfordern von resources und den Zugriff auf experimental Funktionen.
15 Es gibt auch eine Möglichkeit, deine Umgebungen zu registrieren, damit du auf sie mit einem Namen verweisen kannst, aber dazu musst du Ray Tune verwenden. Du wirst diese Funktion in Kapitel 5 kennenlernen.
16 Ein gutes Beispiel, das verschiedene Beobachtungs- und Aktionsräume für mehrere Agenten definiert, findest du in der RLlib-Dokumentation.
17 Beachte, dass dies zu Problemen wie der Entscheidung führen kann, welcher Agent zuerst handeln darf. In unserem einfachen Labyrinthproblem ist die Reihenfolge der Aktionen irrelevant, aber in komplexeren Szenarien wird dies zu einem entscheidenden Teil der korrekten Modellierung des RL-Problems.
18 Die Entscheidung darüber, wann eine Episode abgeschlossen ist, ist ein entscheidender Teil des Multi-Agenten-RL und hängt ganz von dem Problem ab, um das es geht und was du erreichen willst.
19 Aus technischen Gründen müssen wir hier Beobachtungs- und Aktionsräume angeben, was in zukünftigen Versionen von RLlib vielleicht nicht mehr nötig ist, da dadurch Umgebungsinformationen verloren gehen. Beachte auch, dass wir input_evaluation auf eine leere Liste setzen müssen, damit dieser Server funktioniert.
20 In der Definition von reset erlauben wir dem Suchenden, sich auf das Ziel zurückzusetzen, um die Definition einfacher zu halten. Dieser triviale Kantenfall hat keine Auswirkungen auf das Lernen.
21 Beachte, dass es eine Weile dauern kann, bis der Trainingsprozess abgeschlossen ist, wenn du das Notebook für dieses Kapitel in der Cloud ausführst.
22 Beachte, dass RLlib auch eine breite Palette von Algorithmen wie PPO hat.
Get Lernstrahl now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

