Chapter 1. AI Is Magic
“Any sufficiently advanced technology is indistinguishable from magic.”
—Arthur C. Clarke
OK, AI is not actual magic. The truth is AI is a step above and beyond other technology to the point that it feels like magic. It’s easy enough to explain an effective sorting algorithm, but digging into intelligence itself touches the third rail and zaps us all into a whole new level of technological power. That exponential power-up is made possible through the wisdom and aptitude of TensorFlow.js.
For more than half a century scientists and engineers have re-created the metaphorical wheel in AI and fine-tuned the mechanics that control it. When we dig into AI in this book, we’ll grasp those concepts with the flexible yet durable framework of TensorFlow.js and, with it, bring our ideas to fruition in the expanding domain of JavaScript. Yes, JavaScript, the world’s most popular programming language.1
The concepts and definitions provided here will equip you with tech-ray vision. You’ll cut through acronyms and buzzwords to see and understand the AI infrastructure that’s been emerging in every field around us. AI and machine learning concepts will become clear, and the definitions from this chapter can serve as a reference for identifying core principles that will fuel our academic blastoff into TensorFlow.js illumination.
We will:
-
Clarify the domain of AI and intelligence
-
Discuss the types of machine learning
-
Review and define common terminology
-
Cross-examine concepts through the lens of TensorFlow.js
Let’s begin!
Tip
If you’re already familiar with TensorFlow.js and machine learning terminology, philosophy, and fundamental applications, you may want to skip directly to Chapter 2.
The Path of AI in JavaScript
TensorFlow.js, to put it in the most mundane definition possible, is a framework for handling specific AI concepts in JavaScript. That’s all. Luckily for you, you’re in the right book at the right time in history. The AI industrial revolution has only just begun.
When computers came into being, a person armed with a computer could do and nearly impossible tasks at significant scale. They could crack codes, instantly recall information from mountains of data, and even play games as if they were playing another human. What was impossible for one person to do became not only possible but customary. Since the dawn of that key digital invention, our goal has been to empower computers to simply “do more.” As singular human beings, we are capable of anything, but not everything. Computers expanded our limitations in ways that gave us all newfound power. Many of us spend our lives honing a few skills, and among those, even fewer become our specialties. We all build a lifetime’s worth of achievements, and some of us rise to the best in the world at one thing, a skill that could only be earned with luck, information, and thousands of days of effort…until now.
AI enables us to skip to the front of the line; to boldly build that which has never been built before. Daily we’re seeing companies and researchers take that computational leap over and over again. We’re standing at the entrance of a new industry that invites us to play a part in how the world will change.
You’re in the driver’s seat, headed to the next big thing, and this book is your steering wheel. Our journey in learning the magic of AI will be limited only by the extent of your imagination. Armed with JavaScript-enabled machine learning, you’re able to tap into with cameras, microphones, instant updates, locations, and other physical sensors, services, and devices!
I’m sure you’re asking, “But why hasn’t AI been doing this before? Why is this important now?” To appreciate that, you’ll need to take a trip into humanity’s search for reproduced intelligence.
What Is Intelligence?
Books upon books can be written on the concepts of thought and especially the path toward machine intelligence. And as with all philosophical endeavors, each concrete statement on intelligence can be argued along the way. You don’t need to know everything with certainty, but we need to understand the domain of AI so we can understand how we landed in a book on TensorFlow.js.
Poets and mathematicians throughout the centuries waxed that human thought was nothing more than the combination of preexisting concepts. The appearance of life was considered a machination of god-like design; we all are simply “made” from the elements. Stories from Greek mythology had the god of invention, Hephaestus, create automated bronze robots that walked and acted as soldiers. Basically, these were the first robots. The concept of robots and intelligence has rooted itself in our foundation as an ultimate and divine craft from this ancient lore. Talos, the gigantic animated warrior, was famously programmed to guard the island of Crete. While there was no actual bronze robot, the story served as fuel for mechanical aspiration. For hundreds of years, animatronic antiquity was always considered a path to what would seem like human “intelligence,” and centuries later, we’re starting to see life imitate art. As a child, I remember going to my local Chuck E. Cheese, a popular restaurant in the United States with animatronic musical performances for children. I remember believing, just for a moment, that the puppet-powered electric concert that ran every day was real. I was inspired by the same spark that’s driven scientists to chase intelligence. This spark has always been there, passed through stories, entertainment, and now science.
As the concepts of machines that can work autonomously and intelligently grew through history, we strived to define these conceptual entities. Scholars continued to research inference and learning with published works, all the while keeping their terminology in the realm of “machine” and “robot.” The imitation of intelligence from machinery was always held back by the lack of speed and electricity.
The concept of intelligence stayed fixed in human minds and far out of the reach of mechanical structures for hundreds of years, until the creation of the ultimate machine, computers. Computing was born like most machines—with a single purpose for the entire device. With the advent of computing, a new term emerged to illustrate a growing advancement in intelligence that significantly mirrors human intellect. The term AI stands for artificial intelligence and wasn’t coined until the 1950s.2 As computers grew to become general-purpose, the philosophies and disciplines began to combine. The concept of imitating intelligence leaped from mythology into a scientific field of study. Each electronic measuring device for humankind became a new sensory organ for computers and an exciting opportunity for electronic and intelligent science.
In a relatively short time, we have computers interfacing with humans and emulating human actions. The imitation of human-like activity provided a form of what we’re willing to call “intelligence.” Artificial intelligence is that blanket term for these strategic actions, regardless of the level of sophistication or technique. A computer that can play tic-tac-toe doesn’t have to win to be categorized as AI. AI is a low bar and shouldn’t be confused with the general intelligence of a person. The smallest bit of simplistic code can be legitimate AI, and the apocalyptic uprise of sentient machines from Hollywood is also AI.
When the term AI is used, it’s an umbrella term for intelligence that comes from an inert and generally nonbiological device. Regardless of the minimal threshold for the term, mankind, armed with a field of study and an ever-growing practical use, has a unifying term and straightforward goal. All that is measured is managed, and so humankind began measuring, improving, and racing to greater AI.
The History of AI
Frameworks for AI started by being terribly specific, but that’s not the case today. As you may or may not know, the concepts of TensorFlow.js as a framework can apply to music, video, images, statistics, and whatever data we can amass. But it wasn’t always that way. Implementations of AI started as domain-specific code that lacked any kind of dynamic capability.
There are a few jokes floating around on the internet that AI is just a collection of IF/THEN statements, and in my opinion, they’re not 100% wrong. As we’ve already mentioned, AI is a blanket term for all kinds of imitation of natural intelligence. Even beginning programmers are taught programming by solving simple AI in exercises like Ruby Warrior. These programming exercises teach fundamentals of algorithms, and require relatively little code. The cost for this simplicity is that while it’s still AI, it’s stuck mimicking the intelligence of a programmer.
For a long time, the prominent method of enacting AI was dependent on the skills and philosophies of a person who programs an AI are directly translated into code so that a computer can enact the instructions. The digital logic is carrying out the human logic of the people who communicated to make the program. This is, of course, the largest delay in creating AI. You need a person who knows how to make a machine that knows, and we’re limited by their understanding and ability to translate that understanding. AIs that are hardcoded are unable to infer beyond their instructions. This is likely the biggest blocker to translating any human intelligence into artificial intelligence. If you’re looking to teach a machine how to play chess, how do you teach it chess theory? If you want to tell a program the difference between cats and dogs, something that’s trivial for toddlers, would you even know where to start with an algorithm?
At the end of the ’50s and beginning of the ’60s, the idea of the teacher shifted from humans to algorithms that could read raw data. Arthur Samuel coined the term machine learning (ML) in an event that unhinged the AI from the practical limitations of the creators. A program could grow to fit the data and grasp concepts that the programmers of that program either couldn’t translate into code or themselves never understood.
The concept of using data to train the application or function of a program was an exciting ambition. Still, in an age where computers required entire rooms and data was anything but digital, it was also an insurmountable request. Decades passed before computers reached the critical tipping point to emulate human like capabilities of information and architecture.
In the 2000s, ML researchers began using the graphics processing unit (GPU) to get around the “lone channel between the CPU and memory,” known as the von Neumann bottleneck. In 2006, Geoffrey Hinton et al. leveraged data and neural networks (a concept that we will cover in our next section) to understand the patterns and have a computer read handwritten digits. This was a feat that was previously too volatile and imperfect for common computing. Deep learning was capable of reading and adapting to the randomness of handwriting to correctly identify characters at a state-of-the-art level of over 98%. In these published papers, the idea of data as a training agent jumps from the published works of academia into reality.
While Hinton was stuck crafting a ground-up academic proof that neural networks work, the “What number is this?” problem became a stalwart for machine learning practitioners. The problem has become one of the key trivial examples for machine learning frameworks. TensorFlow.js has a demo that solves this problem directly in your browser in less than two minutes. With the benefits of TensorFlow.js we can easily construct advanced learning algorithms that work seamlessly on websites, servers, and devices. But what are these frameworks actually doing?
The greatest goal of AI was always to approach or even outperform human-like capabilities in a single task, and 98% accuracy on handwriting did just that. Hinton’s research kindled a focus on these productive machine learning methods and coined industry terms like deep neural networks. We’ll elaborate on why in the next section, but this was the start of applied machine learning, which began to flourish and eventually find its way into machine learning frameworks like TensorFlow.js. While new machine-based learning algorithms are created left and right, one source of inspiration and terminology becomes quite clear. We can emulate our internal biological systems to create something advanced. Historically, we used ourselves and our cerebral cortex (a layer of our brains) as the muse for structured training and intelligence.
The Neural Network
The idea of deep neural networks was always inspired by our human bodies. The digital nodes (sometimes called a perceptron network) simulate neurons in our own brains and activate like our own synapses to create a balanced mechanism of thought. This is why a neural network is called neural, because it emulates our brain’s bio-chemical structure. Many data scientists abhor the analogy to the human brain, yet it often fits. By connecting millions of nodes, we can build deep neural networks that are elegant digital machines for making decisions.
By increasing the neural pathways with more and more layers, we arrive at the term deep learning. Deep learning is a vastly layered (or deep) connection of hidden layers of nodes. You’ll hear these nodes called neurons, artificial neurons, units, and even perceptrons. The diversity of terminology is a testament to the wide array of scientists who have contributed to machine learning.
This entire field of learning is just part of AI. If you’ve been following along, artificial intelligence has a subset or branch that is called machine learning, and inside that set, we have the idea of deep learning. Deep learning is primarily a class of algorithms that fuel machine learning, but it’s not the only one. See Figure 1-1 for a visual representation of these primary terms.
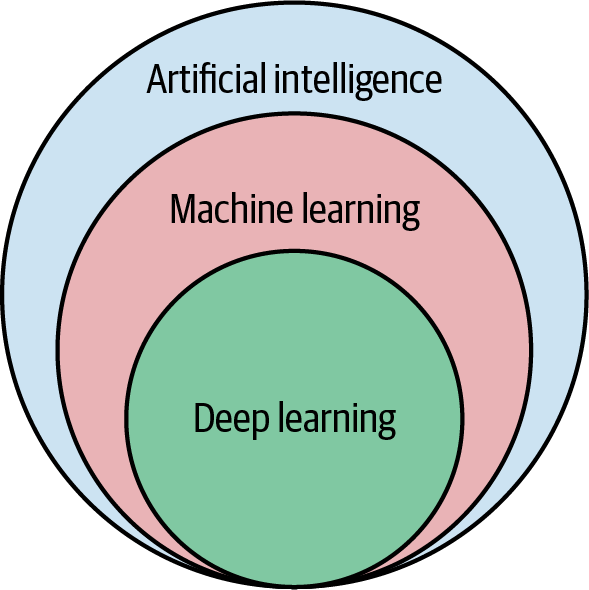
Figure 1-1. AI subdomains
Just like a human, an iteration of teaching or “training” is used to properly balance and build out the neurons based on examples and data. At first, these neural networks are often wrong and random, but as they see example after example of data, their predictive power “learns.”
But our brains don’t perceive the world directly. Much like a computer, we depend on electrical signals that have been organized into coherent data to be sent to our brain. For computers, these electrical signals are analogous to a tensor, but we’ll cover that a bit more in Chapter 3. TensorFlow.js embodies all these advancements that research and scientists have confirmed. All these techniques that help human bodies perform can be wrapped up in an optimized framework so that we can leverage decades of research that have been inspired by the human body.
For instance, our visual system, which starts in our retinas, uses ganglions to relay photoreceptive information to our brain to activate these neurons. As some of you remember from children’s biology, we have missing spots in our vision, and technically we see everything upside down. The signal isn’t sent to our brains “as is.” This visual system has technology built into it that we leverage in today’s software.
While we’re all excited to get our 8K resolution TV, you might believe our brains and vision are still beyond modern computing capabilities, but that’s not always the case. The wire connecting visual signals from our eyes to our brain has only about 10 Mb of bandwidth. That’s comparable to LAN connections in the early 1980s. Even a streaming broadband connection demands more bandwidth than that. But we perceive everything instantly and quickly, right? So what’s the trick? How are we getting superior signals over this surpassed hardware? The answer is that our retinas compress and “featurize” the data before sending it to our deeply connected neural network. So that’s what we started doing with computers.
Convolutional neural networks (CNNs) work on visual data the same way our eyes and brains work together to compress and activate our neural pathways. You’ll further understand and write your own CNN in Chapter 10. We’re learning more about how we work every day, and we’re applying those millions of years of evolution directly to our software. While it’s great for you to understand how these CNNs work, it’s far too academic to write them ourselves. TensorFlow.js comes with the convolutional layers you’ll need to process images. This is the fundamental benefit of leveraging a machine learning framework.
You can spend years reading and researching all the unique tricks and hacks that make computer vision, neural networks, and human beings function effectively. But we’re in an era where these roots have had time to grow, branch, and finally produce fruit: these advanced concepts are accessible and built into services and devices all around us.
Today’s AI
Today we use these best practices with AI to empower machine learning. Convolutions for edge detection, attention to some regions more than others, and even multi-camera inputs for a singular item have given us a prechewed gold mine of data over a fiber-optic server farm of cloud machines training AI.
In 2015 AI algorithms began outperforming humans in some visual tasks. As you might have heard in the news, AI has surpassed humans in cancer detection and even outperformed the US’s top lawyers in identifying legal flaws. As always with digital information, AI has done this in seconds, not hours. The “magic” of AI is awe-inspiring.
People have been finding new and interesting ways to apply AI to their projects and even create completely new industries.
AI has been applied to:
-
Generating new content in writing, music, and visuals
-
Recommending useful content
-
Replacing simple statistics models
-
Deducing laws from data
-
Visualizing classifiers and identifiers
All of these breakthroughs have been aspects of deep learning. Today we have the necessary hardware, software, and data to enable groundbreaking changes with deep machine learning networks. Each day, community and Fortune 500 companies alike release new datasets, services, and architectural breakthroughs in the field of AI.
With the tools at your disposal and the knowledge in this book, you can easily create things that have never been seen before and bring them to the web. Be it for pleasure, science, or fortune, you can create a scalable, intelligent solution for any real-world problem or business.
If anything, the current problem with machine learning is that it’s a new superpower, and the world is vast. We don’t have enough examples to understand the full benefits of having AI in JavaScript. When batteries made a significant improvement in life span, they enabled a whole new world of devices, from more powerful phones to cameras that could last for months on a single charge. This single breakthrough brought countless new products to the market in only a few years. Machine learning makes breakthroughs constantly, leaving a whirl of advancement in new technology that we can’t even clarify or recognize because the deluge has exponentially accelerated. This book will focus on concrete and abstract examples in proper measure, so you can apply pragmatic solutions with TensorFlow.js.
Why TensorFlow.js?
You have options. You could write your own machine learning model from scratch or choose from any existing framework in a variety of programming languages. Even in the realm of JavaScript, there are already competing frameworks, examples, and options. What makes TensorFlow.js capable of handling and carrying today’s AI?
Significant Support
TensorFlow.js is created and maintained by Google. We’ll cover more about this in Chapter 2, but it’s worth noting that some of the best developers in the world have come together to make TensorFlow.js happen. This also means, without any effort by the community, TensorFlow.js is capable of working with the latest and greatest groundbreaking developments.
Unlike other JavaScript-based implementations of machine learning libraries and frameworks, TensorFlow.js supports optimized and tested GPU-accelerated code. This optimization is passed on to you and your machine learning projects.
Online Ready
Most machine learning solutions are confined to a machine that is extremely customized. If you wanted to make a website to share your breakthrough technology, the AI is commonly locked behind an API. While this is completely doable with TensorFlow.js running in Node.js, it’s also doable with TensorFlow.js running directly in the browser. This no-install experience is rare in the world of machine learning, which gives you the ability to share your creations without barriers. You’re able to version and access a world of interactivity.
Offline Ready
Another benefit of JavaScript is that it runs everywhere. The code can be saved to the user’s device like a progressive web app (PWA), Electron, or React Native application, and then it can function consistently without any internet connection. It goes without saying that this also provides a significant speed and cost boost compared to hosted AI solutions. In this book, you’ll uncover countless examples that exist entirely on browsers that save you and your users from latency delays and hosting costs.
Privacy
AI can help users identify diseases, tax anomalies, and other personal information. Sending sensitive data across the internet can be dangerous. On-device results stay on-device. You can even train an AI and store the results on the user’s machine with zero information ever leaving the safety of the browser.
Diversity
Applied TensorFlow.js has a powerful and broad stroke across the machine learning domain and platforms. TensorFlow.js can take advantage of running Web Assembly for CPUs or GPUs for beefier machines. The spectrum of AI with machine learning today is a significant and vast world of new terminology and complexity for newcomers. Having a framework that works with a variety of data is useful as it keeps your options open.
Mastery of TensorFlow.js allows you to apply your skills to a wide variety of platforms that support JavaScript (see Figure 1-2).
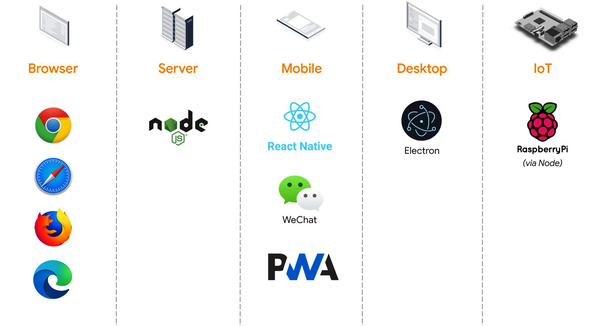
Figure 1-2. TensorFlow.js platforms
With TensorFlow.js you’re free to choose, prototype, and deploy your skills to a variety of fields. To take full advantage of your machine learning freedom, you’ll need to get your footing with some terms that can help you launch into machine learning.
Types of Machine Learning
Lots of people break machine learning into three categories, but I believe we need to look at all of ML as four significant elements:
-
Supervised
-
Unsupervised
-
Semisupervised
-
Reinforcement
Each of these elements deserves books upon books. The short definitions that follow are simple references to familiarize you with the terms you’ll hear in the field.
Quick Definition: Supervised Learning
In this book, we’ll focus on the most common category of machine learning, supervised machine learning (sometimes called supervised learning or just supervised for short). Supervised ML simply means that we have an answer key for every question we’re using to train our machine. That is to say, our data is labeled. So if we’re trying to teach a machine to distinguish if a photo contains a bird, we can immediately grade the AI on whether it was right or wrong. Like a Scantron, we have the answer key. But unlike a Scantron and because it’s probability math, we can also identify how wrong the answer was.
If an AI is 90% sure a photo of a bird is a bird, while it got the answer right, it could improve by 10%. This illuminates the “training” aspect of the AI with immediate data-driven gratification.
Tip
Don’t worry if you don’t have hundreds of ready-to-go labeled questions and answers. In this book, we’ll either provide you with labeled data or show you how to generate it yourself.
Quick Definition: Unsupervised Learning
Unsupervised learning doesn’t require us to have an answer key. We only need questions. Unsupervised machine learning would be ideal, as most information in the world does not come with labels. This category of machine learning focuses on what a machine could learn and report from unlabeled data. While this subject might seem a bit confusing, humans perform it every day! For instance, if I gave you a photo of my garden and asked you how many different types of plants I own, you could tell me the answer, and you don’t have to know the genus and species of each plant. It’s a bit of how we make sense of our own worlds. A lot of unsupervised learning is focused on categorizing large amounts of data for use.
Quick Definition: Semisupervised Learning
Most of the time, we don’t live with 100% unlabeled data. To bring back the garden example from earlier, you don’t know the genus and species of each plant, but you’re also not completely unable to classify the plants as As and Bs. You might tell me I have ten plants made up of three flowers and seven herbs. Having a small number of known labels goes a long way, and research today is on fire with semisupervised breakthroughs!
You might have heard the term generative networks or generative adversarial networks (GANs). These popular AI constructs are mentioned in numerous AI news articles and are derived from semisupervised learning tactics. Generative networks are trained on examples of what we would like the network to create, and through a semisupervised method, new examples are constructed. Generative networks are excellent at creating new content from a small subset of labeled data. Popular examples of GANs often get their own websites, like https://thispersondoesnotexist.com are growing in popularity, and creatives are having a field day with semisupervised output.
Note
GANs have been significant in generating new content. While popular GANs are semisupervised, the deeper concept of a GAN is not limited to semisupervised networks. People have adapted GANs to work on every type of learning we’ve defined.
Quick Definition: Reinforcement Learning
The simplest way to explain reinforcement learning is to show that it’s needed by handling a more real-world activity, versus the hypothetical constructs from earlier.
For instance, if we’re playing chess and I start my game by moving a pawn, was that a good move or a bad move? Or if I want a robot to kick a ball through a hoop, and it starts by taking a step, is that good or bad? Just like with a human, the answer depends on the results. It’s a collection of moves for maximum reward, and there’s not always a singular action that produces a singular result. Training a robot to step first or look first matters, but probably not as much as what it does during other critical moments. And those critical moments are all powered by rewards as reinforcement.
If I were teaching an AI to play Super Mario Bros., do I want a high score or a speedy victory? The rewards teach the AI what combination of moves is optimal to maximize the goal. Reinforcement learning (RL) is an expanding field and has often been combined with other forms of AI to cultivate the maximum result.
Information Overload
It’s OK to be surprised by how many applications of machine learning were just mentioned. In a way, that’s why we’re in need of a framework like TensorFlow.js. We can’t even comprehend all the uses of these fantastic systems and their effects for decades to come! While we wrap our heads around this, the age of AI and ML is here, and we’re going to be part of it. Supervised learning is a great first step into all the benefits of AI.
We’ll cover some of the most exciting yet practical uses of machine learning together. In some aspects, we’ll only scratch the surface, while in others, we’ll dive deep into the heart of how they work. Here are some of the broad categories we’ll cover. These are all supervised learning concepts:
-
Image categorization
-
Natural language processing (NLP)
-
Image segmentation
One of the main goals of this book is that while you can understand the concepts of the categories, you won’t be limited by them. We’ll lean into experimentation and practical science. Some problems can be solved by overengineering, and others can be solved by data engineering. Thinking in AI and machine learning is the key to seeing, identifying, and creating new tools with TensorFlow.js.
AI Is Everywhere
We’re entering a world where AI is creeping into everything. Our phones are now accelerated into deep learning hardware. Cameras are applying real-time AI detection, and at the time of this writing, some cars are driving around our streets without a human being.
In the past year, I’ve even noticed my emails have started writing themselves with a “tab to complete” option for finishing my sentences. This feature, more often than I’d like to admit, is clearer and more concise than anything I would have originally written. It’s a significant visible achievement that overshadows the forgotten machine learning AI that’s been protecting us from spam in that same inbox for years.
As each of these plans for machine learning unfurl, new platforms become in demand. We’re pushing models further and further on edge devices like phones, browsers, and hardware. It makes sense that we’re looking for new languages to carry the torch. It was only a matter of time before the search would end with the obvious option of JavaScript.
A Tour of What Frameworks Provide
What does machine learning look like? Here’s an accurate description that will make Ph.D. students cringe with its succinct simplicity.
With normal code, a human writes the code directly, and a computer reads and interprets that code, or some derivative of it. Now we’re in a world where a human doesn’t write the algorithm, so what actually happens? Where does the algorithm come from?
It’s simply one extra step. A human writes the algorithm’s trainer. Assisted by a framework, or even from scratch, a human outlines in code the parameters of the problem, the desired structure, and the location of the data to learn from. Now the machine runs this program-training program, which continuously writes an ever-improving algorithm as the solution to that problem. At some point, you stop this program and take the latest algorithm result out and use it.
That’s it!
The algorithm is much smaller than the data that was used to create it. Gigabytes of movies and images can be used to train a machine learning solution for weeks, all just to create a few megabytes of data to solve a very specific problem.
The resulting algorithm is essentially a collection of numbers that balance the outlined structure identified by the human programmer. The collection of numbers and their associated neural graph is often called a model.
You’ve probably seen these graphs surfacing in technical articles, drawn as a collection of nodes from left to right like Figure 1-3.
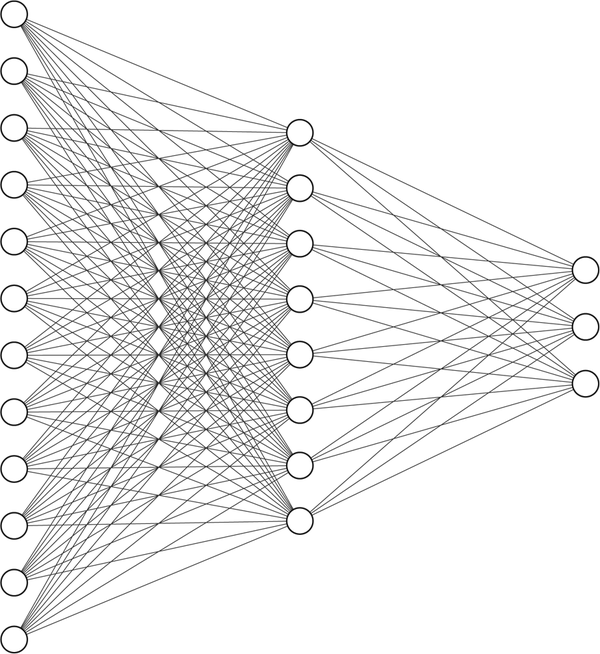
Figure 1-3. Example of a densely connected neural network
Our framework TensorFlow.js handles the API for specifying the structure or architecture of the model, loading data, passing data through our machine learning process, and ultimately tuning the machine to be better at predicting answers to the given input the next time. This is where the real benefits of TensorFlow.js come to bear. All we have to worry about is properly tuning the framework to solve the problem with sufficient data and then saving the resulting model.
What Is a Model?
When you create a neural network in TensorFlow.js, it’s a code representation of the desired neural network. The framework generates a graph with intelligently selected randomized values for each neuron. The model’s file size is generally fixed at this point, but the contents will evolve. When a prediction is made by shoving data through an untrained network of random values, we get an answer that is generally as far away from the right answer as pure random chance. Our model hasn’t trained on any data, so it’s terrible at its job. So as a developer, our code that we write is complete, but the untrained result is poor.
Once training iterations have occurred for some significant amount of time, the neural network weights are evaluated and then adjusted. The speed, often called the learning rate, affects the resulting solution. After taking thousands of these small steps at the learning rate, we start to see a machine that improves, and we are engineering a model with the probability of success far beyond the original machine. We have left randomness and converged on numbers that make the neural network work! Those numbers assigned to the neurons in a given structure are the trained model.
TensorFlow.js knows how to keep track of all these numbers and computational graphs so we don’t have to, and it also knows how to store this information in a proper and consumable format.
Once you have those numbers, our neural network model can stop training and just be used to make predictions. In programming terms, this has become a simple function. Data goes in, and data comes out.
Feeding data through a neural network looks a lot like chance, as shown in Figure 1-4, but in the world of computing it’s a delicate machine of balanced probability and sorting that has consistent and reproducible results. Data gets fed into the machine, and a probabilistic result comes out.
Figure 1-4. A balanced network metaphor
In the next chapter, we’ll experiment with importing and predicting with an entirely trained model. We’ll utilize the power of hours of training to get an intelligent analysis in microseconds.
In This Book
This book is constructed so that you could pack it away for a vacation and, once you’ve found your small slice of heaven, read along with the book, learn the concepts, and review the answers. The images and screenshots should suffice for explaining the deep underbelly of TensorFlow.js.
However, for you to really grasp the concepts, you’ll need to go beyond simply reading the book. As each concept unfolds, you should be coding, experimenting, and testing the boundaries of TensorFlow.js on an actual computer. For any of you who are new to machine learning as a field, it’s essential that you solidify the terminology and workflows you’re seeing for the first time. Take your time to work through the concepts and code from this book.
Associated Code
Throughout the book, there is runnable source code to illustrate the lessons and functionality of TensorFlow.js. While in some cases the entire source is provided, in most cases the printed code will be limited to the salient portions. It’s advisable that you immediately download the source code that aligns with this book. Even if you plan on writing code from scratch alongside the examples, it’s likely that small configurations that you may struggle with will already be solved and referenceable in the associated code.
You can see the GitHub source page at https://github.com/GantMan/learn-tfjs.
If you are unfamiliar with GitHub and Git, you can simply download the latest project source code in a single ZIP file and reference that.
You can download the source ZIP file from https://github.com/GantMan/learn-tfjs/archive/master.zip.
The source code is structured to match each chapter. You should be able to find all chapter resources in the folder with the same name. In each chapter folder, you will find at most four folders that contain the lesson information. This will be reviewed in Chapter 2 when you run your first TensorFlow.js code. For now, familiarize yourself with the purpose of each folder so you can select the example code that works best for your learning needs.
The node folder
This folder contains a Node.js-specific implementation of the chapter’s code for a server-based solution. This folder will likely contain several specific projects within it. Node.js projects will come with some extra packages installed to simplify the experimentation process. The example projects for this book utilize the following:
nodemon-
Nodemon is a utility that will monitor for any changes in your source and automatically restart your server. This is used so you can save your files and immediately see their associated updates.
ts-node-
TypeScript has plenty of options, most notably strong typing. However, for approachability this book is focused on JavaScript and not TypeScript. The
ts-nodemodule is in place for ECMAScript support. You can write modern JavaScript syntax in these node samples, and via TypeScript, the code will work.
These dependencies are identified in the package.json file. The Node.js examples are to illustrate server solutions with TensorFlow.js and generally do not need to be opened in a browser.
To run these examples, install the dependencies with either Yarn or Node Package Manager (NPM), and then execute the start script:
# Install dependencies with NPM$npm i# Run the start script to start the server$npm run start# OR use yarn to install dependencies$yarn# Run the start script to start the server$yarn start
After starting the server, you will see the results of any console logs in your terminal. When you’re done reviewing the results, you can use Ctrl+C to exit the server.
The web folder
If you’re familiar with client-based NPM web applications, you will feel comfortable with the web folder. This folder will likely contain several specific projects within it. The web folder examples are bundled using Parcel.js. It is a fast multicore bundler for web projects. Parcel provides Hot Module Replacement (HMR) so you can save your files and immediately see the page reflect your code changes, while also providing friendly error logging and access to ECMAScript.
To run these examples, install the dependencies with either Yarn or NPM, and then execute the start script:
# Install dependencies with NPM$npm i# Run the start script to start the server$npm run start# OR use yarn to install dependencies$yarn# Run the start script to start the server$yarn start
After running the bundler, a web page with your default browser will open and access a local URL for that project.
Tip
If a project uses a resource like a photo, a credit.txt file will exist in that project’s root folder to properly credit the photographer and source.
Chapter Sections
Each chapter begins by identifying the goals of the chapter and then dives in immediately. At the end of each chapter, you’re presented with a Chapter Challenge, which is a resource for you to immediately apply what you’ve just learned. The answers for each challenge can be found in Appendix B.
Finally, each chapter ends with a grouping of thought-provoking questions to verify you’ve internalized the information from the chapter. It’s advised that you verify the answers for yourself by code when possible, but the answers are also provided for you in Appendix A.
Common AI/ML Terminology
You might be thinking to yourself, “Why isn’t a model just called a function? Models already have a meaning in programming, and they don’t need another!” The truth is this comes from the origin of problems that machine learning started with. Original data problems were rooted in statistics. Statistical models recognize patterns as statistical assumptions on sample data, and so our product from this mathematical operation on examples is a machine learning model. It’s quite common for machine learning terminology to heavily reflect the field and culture of the scientists who invented it.
Data science comes with a good bit of mathematical terminology. We’ll see this as a theme throughout the book, and we’ll identify the reasons for each. Some terms make sense instantly, some collide with existing JavaScript and framework terms, and some new terminology collides with other new terminology! Naming things is hard. We’ll do our best to explain some key terms in a memorable way and elaborate on etymology along the way. The TensorFlow and TensorFlow.js docs are replete with new vocabulary for developers. Read through the following machine learning terminology and see if you can grasp these fundamental terms. It’s OK if you can’t. You can come back to this chapter and reference these definitions at any time as we progress forward.
Training
Training is the process of attempting to improve a machine learning algorithm by having it review data and improve its mathematical structure to make better predictions in the future.
TensorFlow.js provides several methods to train and monitor training models, both on a machine and in a client browser.
e.g., “Please don’t touch my computer, it’s been training for three days on my latest air-bending algorithm.”
Training set
Sometimes called the training data, this is the data you’re going to show your algorithm for it to learn from. You might think, “Isn’t that all the data we have?” The answer is “no.”
Generally, most ML models can learn from examples they’ve seen before, but teaching the test doesn’t assure that our model can extrapolate to recognize data it has never seen before. It’s important that the data that we use to train the AI be kept separate for accountability and verification.
e.g., “My model keeps identifying hot dogs as sub sandwiches, so I’ll need to add more photos to my training set.”
Test set
To test that our model can perform against data it has never seen before, we have to keep some data aside to test and never let our model train or learn from it. This is generally called the test set or test data. This set helps us test if we’ve made something that will generalize to new problems in the real world. The test set is generally significantly smaller than the training set.
e.g., “I made sure the test set was a good representation of the problem we’re trying to train a model to solve.”
Validation sets
This term is important to know even if you aren’t at the level where you need it. As you’ll hear often, training can sometimes take hours, days, or even weeks. It’s a bit alarming to kick off a long-running process just to come back and find out you’ve structured something wrong and you have to start all over again! While we probably won’t run into any of those mega-training needs in this book, those situations could use a group of data for quicker tests. When this is separate from your training data, it’s a “holdout method” for validation. Essentially, it’s a practice where a small set of training data is set aside to make validation tests before letting your model train on an expensive infrastructure or for an elongated time. This tuning and testing for validation is your validation set.
There’s a lot of ways to select, slice, stratify, and even fold your validation sets. This goes into a science that is beyond the scope of this book, but it’s good to know for when you discuss or read and advance your own mega-datasets.
TensorFlow.js has entire training parameters for identifying and graphing validation results during the training process.
e.g., “I’ve carved out a small validation set to use while we construct our model architecture.”
Tensors
We’ll cover tensors in great detail in Chapter 3, but it’s worth noting that tensors are the optimized data structure that allows for GPU and Web Assembly acceleration for immense AI/ML calculation sets. Tensors are the numerical holders of data.
e.g., “I’ve converted your photo into a grayscale tensor to see what kind of speed boost we can get.”
Normalization
Normalization is the action of scaling input values to a simpler domain. When everything becomes numbers, the difference in sparsity and magnitude of numbers can cause unforeseen issues.
For example, while the size of a house and the number of bathrooms in a house both affect the price, they are generally measured in different units with vastly different numbers. Not everything is measured in the same metric scale, and while AI can adapt to measure these fluctuations in patterns, one common trick is to simply scale data to the same small domain. This lets models train faster and find patterns more easily.
e.g., “I’ve applied some normalization to the house price and the number of bathrooms so our model can find patterns between the two more quickly.”
Data augmentation
In photo editing software, we can take images and manipulate them to look like the same thing in a completely different setting. This method effectively makes an entirely new photo. Perhaps you want your logo on the side of a building or embossed on a business card. If we were trying to detect your logo, the original photo and some edited versions would be helpful in our machine learning training data.
Oftentimes, we can create new data from our original data that fits the goal of our model. For example, if our model is going to be trained to detect faces, a photo of a person and a mirrored photo of a person are both valid and significantly different photos!
TensorFlow.js has libraries dedicated to data augmentation. We will see augmented data later in this book.
e.g., “We’ve performed some data augmentation by mirroring all the pumpkins to double our training set.”
Features and featurization
We mentioned featurizing earlier when we talked about the way eyes send what’s most important to the brain. We do the same thing with ML. If we were trying to make an AI that guesses how much a house is worth, we then have to identify what inputs are useful and what inputs are noise.
There’s no shortage of data on a house, from the number of bricks to the crown molding. If you watch a lot of home improvement TV, you know it’s smart to identify a house’s size, age, number of bathrooms, date the kitchen was last updated, and neighborhood. These are often key features in identifying a house’s price, and you’ll care more about feeding a model that information than something trivial. Featurization is the selection of these features from all the possible data that could be selected as inputs.
If we decided to throw in all the data we could, we give our model the chance to find new patterns at the cost of time and effort. There’s no reason to choose features like the number of blades of grass, house smell, or natural lighting at noon, even if we have that information or we feel it’s important to us.
Even once we’ve selected our features, there are often errors and outliers that will slow the training of a practical machine learning model. Some data just doesn’t move the needle toward a more successful predictive model, and selecting smart features makes a quick-trained, smarter AI.
e.g., “I’m pretty sure counting the number of exclamation marks is a key feature for detecting these marketing emails.”
Chapter Review
In this chapter, we’ve ensnared the terms and concepts of the umbrella term AI. We’ve also touched on the key principles of what we’ll cover in this book. Ideally, you are now more confident in the terms and structures that are essential in machine learning.
Review Questions
Let’s take a moment and make sure you’ve fully grasped the concepts we mentioned. Take a moment to answer the following questions:
-
Can you give an adequate definition of machine learning?
-
If a person identifies an idea for a machine learning project, but they have no labeled data, what would you recommend?
-
What kind of ML would be useful for beating your favorite video game?
-
Is machine learning the only form of AI?
-
Does a model hold all the training example data that was used to make it work?
-
How is machine learning data broken up?
Solutions to these exercises are available in Appendix A.
1 Programming language stats: https://octoverse.github.com
2 Artificial intelligence was coined by John McCarthy in 1956 at the first academic conference on the subject.
Get Learning TensorFlow.js now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

