Chapter 7. More Collections
In Chapter 6 we were introduced to the Iterable root type and three of its immutable subtypes: the ordered collection List and the unordered collections Set and Map. These collections were labeled common because they are ubiquitous in modern programming languages, not to imply that they are basic and unadorned. In this chapter we will uncover Scala collections that may not be ubiquitous but are just as important.
We’ll start with mutable collections, which probably can be considered ubiquitous because more languages support them than they do immutable collections. Then we’ll move on to arrays, streams, and other collections.
Mutable Collections
The List, Set, and Map immutable collections we are familiar with cannot be changed after they have been created (see the definition of “immutable”). They can, however, be transformed into new collections. For example, we can create an immutable map, and then transform it by removing one mapping and adding another:
scala> val m = Map("AAPL" -> 597, "MSFT" -> 40)  m: scala.collection.immutable.Map[String,Int] =
Map(AAPL -> 597, MSFT -> 40)
scala> val n = m - "AAPL" + ("GOOG" -> 521)
m: scala.collection.immutable.Map[String,Int] =
Map(AAPL -> 597, MSFT -> 40)
scala> val n = m - "AAPL" + ("GOOG" -> 521)  n: scala.collection.immutable.Map[String,Int] =
Map(MSFT -> 40, GOOG -> 521)
scala> println(m)
n: scala.collection.immutable.Map[String,Int] =
Map(MSFT -> 40, GOOG -> 521)
scala> println(m)  Map(AAPL -> 597, MSFT -> 40)
Map(AAPL -> 597, MSFT -> 40)-
A new map with “AAPL” and “MSFT” keys.
-
Removing “APPL” and adding “GOOG” gives us a different collection…
-
… while the original collection in “m” remains the same.
What you end up with is a completely new collection stored in “n”. The original collection, stored in the “m” value, remains untouched. And this is exactly the point of immutable data, namely that data and data structures should not be mutable or change their state in order to improve code stability and prevent bugs. As an example, data structures that are rigid and never change state are safer to use with concurrent code than data structures that may change at any point and are prone to corruption (e.g., reading a data structure while it is undergoing a state change).
However, there are times when you do want mutable data, and when it is arguably safe to use it. For example, creating a mutable data structure that is only used within a function, or one that is converted to immutability before being returned, are considered to be safe use cases. You may want to add elements to a list in the course of a series of “if” condition blocks, or add them in the course of iterating over a separate data structure, without having to store each transformation in a series of local values.
In this section we will explore three methods for building mutable collections.
Creating New Mutable Collections
The most straightforward way to modify collections is with a mutable collection type. See Table 7-1 for the mutable counterparts to the standard immutable List, Map, and Set types.
| Immutable type | Mutable counterpart |
|
|
|
|
|
|
Whereas the collection.immutable package is automatically added to the current namespace in Scala, the collection.mutable package is not. When creating mutable collections, make sure to include the full package name for the type.
The collection.mutable.Buffer type is a general-purpose mutable sequence, and supports adding elements to its beginning, middle, and end.
Here is an example of using it to build a list of integers starting from a single element:
scala> val nums = collection.mutable.Buffer(1) nums: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1) scala> for (i <- 2 to 10) nums += i scala> println(nums) Buffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
Here is an example of using the same buffer but starting with an empty collection. Because there is no default value, we will have to specify the collection’s type with a type parameter (Int, in this case):
scala> val nums = collection.mutable.Buffer[Int]() nums: scala.collection.mutable.Buffer[Int] = ArrayBuffer() scala> for (i <- 1 to 10) nums += i scala> println(nums) Buffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
Building maps and sets is a similar process. Specifying the type parameter for a new set, or the key and value type parameters for a new map, is only required when creating an empty collection.
You can convert your mutable buffer back to an immutable list at any time with the toList method:
scala> println(nums) Buffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> val l = nums.toList l: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
Likewise for sets and maps, use the toSet and toMap methods to convert these mutable collections to their immutable counterparts.
Creating Mutable Collections from Immutable Ones
An alternative to creating mutable collections directly is to convert them from immutable collections. This is useful when you already have a starting immutable collection that you want to modify, or would just rather type “List()” instead of “collection.mutable.Buffer().”
The List, Map, and Set immutable collections can all be converted to the mutable collection.mutable.Buffer type with the toBuffer method. For lists this is obviously straightforward, because the buffer and list type are both sequences. Maps, as subtypes of Iterable, can be considered as sequences as well, and are converted to buffers as sequences of key-value tuples. Converting sets to buffers is trickier, however, because buffers do not honor the uniqueness constraint of sets. Fortunately, any duplicates in the buffer’s data will be removed when converted back to a Set.
Here is an example of converting an immutable map to a mutable one and then changing it back:
scala> val m = Map("AAPL" -> 597, "MSFT" -> 40)
m: scala.collection.immutable.Map[String,Int] =
Map(AAPL -> 597, MSFT -> 40)
scala> val b = m.toBuffer
b: scala.collection.mutable.Buffer[(String, Int)] =
ArrayBuffer((AAPL,597), (MSFT,40))
scala> b trimStart 1
scala> b += ("GOOG" -> 521)
res1: b.type = ArrayBuffer((MSFT,40), (GOOG,521))
scala> val n = b.toMap  n: scala.collection.immutable.Map[String,Int] =
Map(MSFT -> 40, GOOG -> 521)
n: scala.collection.immutable.Map[String,Int] =
Map(MSFT -> 40, GOOG -> 521)-
The map, containing key-value pairs, is now a sequence of tuples.
-
trimStartremoves one or more items from the start of the buffer.-
After removing the “AAPL” entry we’ll add a “GOOG” entry.
-
This buffer of tuples is now an immutable map again.
The buffer methods toList and toSet can be used in addition to toMap to convert a buffer to an immutable collection.
Let’s try converting this buffer of 2-sized tuples to a List and to a Set. After all, there’s no reason that a collection of 2-sized tuples created from a map must be converted back to its original form.
To verify that Set imposes a uniqueness constraint, we’ll first add a duplicate entry to the buffer. Let’s see how this works out:
scala> b += ("GOOG" -> 521)
res2: b.type = ArrayBuffer((MSFT,40), (GOOG,521), (GOOG,521))
scala> val l = b.toList
l: List[(String, Int)] = List((MSFT,40), (GOOG,521), (GOOG,521))
scala> val s = b.toSet
s: scala.collection.immutable.Set[(String, Int)] = Set((MSFT,40), (GOOG,521))The list “l” and set “s” were created successfully, with the list containing the duplicated entries and the set restricted to contain only unique entries.
The Buffer type is a good, general-purpose mutable collection, similiar to a List but able to add, remove, and replace its contents. The conversion methods it supports, along with the toBuffer methods on its immutable counterparts, makes it a useful mechanism for working with mutable data.
About the only drawback of a buffer is that it may be too broadly applicable. If all you need is to put together a collection iteratively, e.g., inside a loop, a builder may be a good choice instead.
Using Collection Builders
A Builder is a simplified form of a Buffer, restricted to generating its assigned collection type and supporting only append operations.
To create a builder for a specific collection type, invoke the type’s newBuilder method and include the type of the collection’s element. Invoke the builder’s result method to convert it back into the final Set. Here is an example of creating a Set with a builder:
scala> val b = Set.newBuilder[Char] b: scala.collection.mutable.Builder[Char,scala.collection.immutable. Set[Char]] = scala.collection.mutable.SetBuilder@726dcf2c scala> b += 'h'
-
Adding a single item, one of two append operations.
-
Adding multiple items, the second of two append operations.
-
Unlike with buffers, a builder knows its immutable counterpart.
So, why use Builder versus Buffer or one of the mutable collection types? The Builder type is a good choice if you are only building a mutable collection iteratively in order to convert it to an immutable collection. If you need Iterable operations while building your mutable collection, or don’t plan on converting to an immutable collection, using one of the Buffer or other mutable collection types is a better match.
In this section we have investigated methods to convert between immutable and mutable collections, which are either unchangeable or fully modifiable. In the next section we’ll cover a “collection” that breaks these rules, being immutable in size but mutable in content.
Arrays
An Array is a fixed-size, mutable, indexed collection. It’s not officially a collection, because it isn’t in the “scala.collections” package and doesn’t extend from the root Iterable type (although it has all of the Iterable operations like map and filter). The Array type is actually just a wrapper around Java’s array type with an advanced feature called an implicit class allowing it to be used like a sequence. Scala provides the Array type for compatibility with JVM libraries and Java code and as a backing store for indexed collections, which really require an array to be useful.
Here are some examples of working with arrays, demonstrating their cell mutability and support for Iterable operations:
scala> val colors = Array("red", "green", "blue")
colors: Array[String] = Array(red, green, blue)
scala> colors(0) = "purple"
scala> colors
res0: Array[String] = Array(purple, green, blue)
scala> println("very purple: " + colors)
very purple: [Ljava.lang.String;@70cf32e3
scala> val files = new java.io.File(".").listFiles
files: Array[java.io.File] = Array(./Build.scala, ./Dependencies.scala,
./build.properties, ./JunitXmlSupport.scala, ./Repositories.scala,
./plugins.sbt, ./project, ./SBTInitialization.scala, ./target)
scala> val scala = files map (_.getName) filter(_ endsWith "scala")
scala: Array[String] = Array(Build.scala, Dependencies.scala,
JunitXmlSupport.scala, Repositories.scala, SBTInitialization.scala)-
Use a zero-based index to replace any item in an
Array.-
The Scala REPL knows how to print an
Array…-
… but not
println(), which can only call a type’stoString()method.-
The
listFilesmethod injava.io.File, a JDK class, returns an array that we can easily map and filter.
Java arrays do not override the toString() method inherent in all Java and Scala objects, and thus use the default implementation of printing out the type parameter and reference. Thus, calling toString() on an Array results in the unreadable output seen in the last example. Fortunately you won’t see this output with Scala collections, because they all override toString() to provide human-readable printouts of their contents and structure.
It’s important to hear about and understand the Array type, but I don’t recommend using it in regular practice unless you need it for JVM code. There are many other fine sequences that you can use instead, as you’ll see in the next section.
Seq and Sequences
Seq is the root type of all sequences, including linked lists like List and indexed (direct-access) lists like Vector. The Array type, if it were a collection, could be considered an indexed sequence because its elements are directly accessible without traversal. As a root type, Seq itself cannot be instantiated, but you can invoke it as a shortcut for creating a List:
scala> val inks = Seq('C','M','Y','K')
inks: Seq[Char] = List(C, M, Y, K)The Seq hierarchy of sequence collections appears in Figure 7-1, and Table 7-2 contains the descriptions for each of these types.
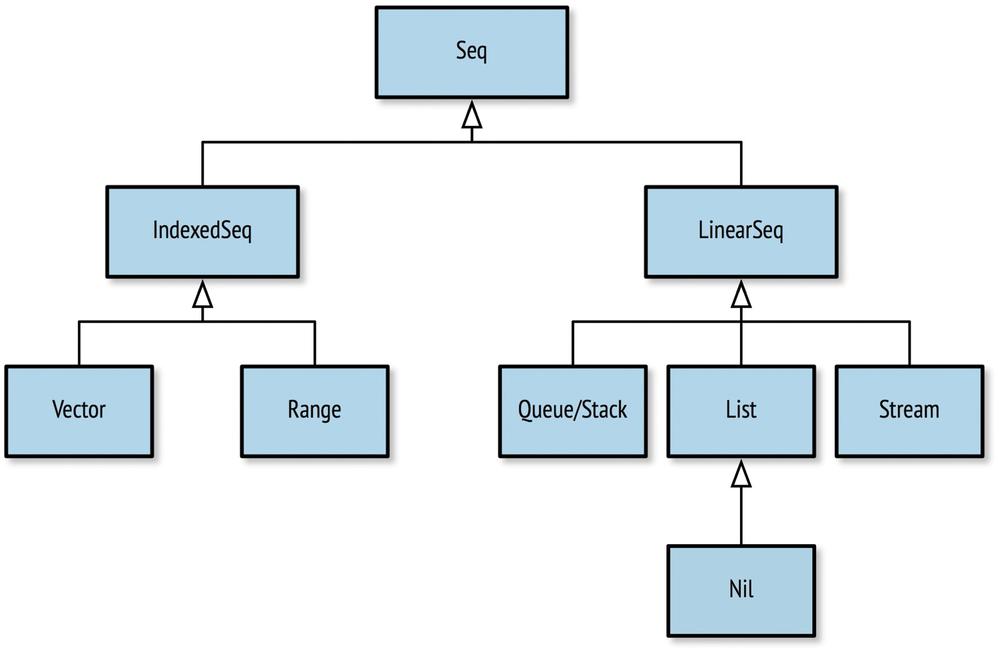
| Name | Description |
Seq | The root of all sequences. Shortcut for |
IndexedSeq | The root of indexed sequences. Shortcut for |
Vector | A list backed by an |
Range | A range of integers. Generates its data on-the-fly. |
LinearSeq | The root of linear (linked-list) sequences. |
List | A singly linked list of elements. |
Queue | A first-in-last-out (FIFO) list. |
Stack | A last-in-first-out (LIFO) list. |
Stream | A lazy list. Elements are added as they are accessed. |
String | A collection of characters. |
The Vector type is implemented with an Array for storage. As an indexed sequence (since arrays are indexed), you can access items in a Vector directly by their index. By contrast, accessing the nth item of a List (a linked list) requires n – 1 steps from the head of its list. Java developers will recognize Vector as analogous to Java’s “ArrayList,” whereas C++ developers will (more easily) recognize it as being similar to the “Vector” template.
The Seq shortcut for List linked lists and the IndexedSeq shortcut for Vector indexed lists are only marginally useful, because the savings for writing them is one character and negative four characters, respectively. Unless you have a fondness for high-level types (e.g., Seq) over concrete implementations (e.g., List), you may find little reason to use them yourself.
Seeing the String type listed with sequences may be a surprise, but in Scala it is a valid collection just like the others. A “string” derives its name, after all, from being a string of characters, in this case a sequence of Char elements. The String type is an immutable collection, extending Iterable and supporting its operations, while also serving as a wrapper for Java strings and supporting such java.lang.String operations as split and trim.
Here’s an example of using String as a subtype of Iterable and as a java.lang.String wrapper, using methods from both types:
scala> val hi = "Hello, " ++ "worldly" take 12 replaceAll ("w","W")
hi: String = Hello, WorldThe ++ and take operations derive from Iterable and act on the sequence of characters, while replaceAll is a java.lang.String operation invoked as a Scala operator.
The last sequence we’ll discuss in this chapter is the Stream type, which builds itself as its elements are accessed. It’s a popular collection in functional programming languages, but it takes some extra time to learn so it has its own section. Take the time to try out the examples and get familiar with Stream because it can be a very helpful collection to know about.
Streams
The Stream type is a lazy collection, generated from one or more starting elements and a recursive function. Elements are added to the collection only when they are accessed for the first time, in constrast to other immutable collections that receive 100% of their contents at instantiation time. The elements that a stream generates are cached for later retrieval, ensuring that each element is only generated once. Streams can be unbounded, theoretically infinite collections where elements are only realized upon access. They can also be terminated with Stream.Empty, a counterpart to List.Nil.
Streams, like lists, are recursive data structures consisting of a head (the current element) and a tail (the rest of the collection). They can be built with a function that returns a new stream containing the head element and a recursive invocation of that function to build the tail. You can use Stream.cons to construct a new stream with the head and tail.
Here is an example function that builds and recursively generates a new stream. By incrementing the starting integer value, it will end up creating a collection of consecutively increasing integers:
scala> def inc(i: Int): Stream[Int] = Stream.cons(i, inc(i+1)) inc: (i: Int)Stream[Int] scala> val s = inc(1) s: Stream[Int] = Stream(1, ?)
We have our stream but it only contains our starting value (1) and a promise of future values (?). Let’s force it to build out the next four elements by “taking” them and retrieving the contents as a list:
scala> val l = s.take(5).toList l: List[Int] = List(1, 2, 3, 4, 5) scala> s res1: Stream[Int] = Stream(1, 2, 3, 4, 5, ?)
We took the first five elements and retrieved them as a plain old list. Printing out the original stream instance shows that it now contains five elements and is ready to generate more. We could follow this up by taking 20, or 200, or 2,000 elements. The stream contains a recursive function call (specifically, a function value) that it can use to generate new elements without end.
An alternate syntax for the Stream.cons operator is the slightly cryptic #:: operator, which we’ll just call the cons operator for streams. This performs the same function as Stream.cons except with right-associative notation, complementing the cons operator for lists, :: (see The Cons Operator).
Here’s the “inc” function again, using the cons operator #::. I’ve also renamed the parameter to “head” to better demonstrate its use as the head element of the new Stream instance:
scala> def inc(head: Int): Stream[Int] = head #:: inc(head+1) inc: (head: Int)Stream[Int] scala> inc(10).take(10).toList res0: List[Int] = List(10, 11, 12, 13, 14, 15, 16, 17, 18, 19)
Where Is the Stream Being Constructed?
Many developers find the stream cons operator syntax, #::, confusing because it lacks an explicit creation of the underlying collection. The confusion is indeed warranted, because an advanced feature called implicit conversion is used to generate the new Stream instance from the recursive function’s type, => Stream[A]. If you can accept that the recursive function invocation (inc(i+1) in the preceding example) magically generates a Stream that acts as the tail, then prefixing this magic tail with your head element to create a new Stream should be acceptable.
Let’s try creating a bounded stream. We’ll use two arguments to our recursive function, one specifying the new head element and another specifying the last element to add:
scala> def to(head: Char, end: Char): Stream[Char] = (head > end) match {
| case true => Stream.empty
| case false => head #:: to((head+1).toChar, end)
| }
to: (head: Char, end: Char)Stream[Char]
scala> val hexChars = to('A', 'F').take(20).toList
hexChars: List[Char] = List(A, B, C, D, E, F)Using the new “to” function, we were able to create a bounded stream consisting of the letters used in writing hexadecimal numbers. The stream’s take operation only returned the available elements, ending after we placed Stream.empty to terminate the collection.
The recursive function is used to generate a new Stream and (in our examples thus far) derive the new head element each time. We have used one or two parameter functions in the examples thus far, but you could easily have a function that had zero or a dozen parameters. The important part is defining the head value for your new stream.
All of the collections we have covered can hold zero, one, two, or more items, with the expectation that they can scale as far as your machine’s memory or the JVM environment will allow. Next, we’ll learn about a set of collections that can scale no longer than a single element, but are surprisingly applicable to situations where you never considered a collection would fit.
Monadic Collections
The last set of collections we’ll discuss in this chapter are the monadic ones, which support transformative operations like the ones in Iterable but can contain no more than one element. The term “monadic” applies in its Greek origins to mean a single unit, and in the category theory sense of a single link in a chain of operations.
We’ll start with the Option type, the one monadic collection that extends Iterable.
Option Collections
As a collection whose size will never be larger than one, the Option type represents the presence or absence of a single value. This potentially missing value (e.g., it was never initialized, or could not be calculated) can thus be wrapped in an Option collection and have its potential absence clearly advertised.
Some developers see Option as a safe replacement for null values, notifying users that the value may be missing and reducing the likelihood that its use will trigger a NullPointerException. Others see it as a safer way to build chains of operations, ensuring that only valid values will persist for the duration of the chain.
The Option type is itself unimplemented but relies on two subtypes for the implementation: Some, a type-parameterized collection of one element; and None, an empty collection. The None type has no type parameters because it never contains contents. You can work with these types directly, or invoke Option() to detect null values and let it choose the appropriate subtype.
Let’s try creating an Option with nonnull and null values:
scala> var x: String = "Indeed" x: String = Indeed scala> var a = Option(x) a: Option[String] = Some(Indeed) scala> x = null x: String = null scala> var b = Option(x) b: Option[String] = None
You can use isDefined and isEmpty to check if a given Option is Some or None, respectively:
scala> println(s"a is defined? ${a.isDefined}")
a is defined? true
scala> println(s"b is not defined? ${b.isEmpty}")
b is not defined? trueLet’s use a more realistic example by defining a function that returns an Option value. In this case we will wrap the divide operator (/) with a check to prevent division by zero. Valid inputs will return a Some wrapper and invalid inputs will return None:
scala> def divide(amt: Double, divisor: Double): Option[Double] = {
| if (divisor == 0) None
| else Option(amt / divisor)
| }
divide: (amt: Double, divisor: Double)Option[Double]
scala> val legit = divide(5, 2)
legit: Option[Double] = Some(2.5)
scala> val illegit = divide(3, 0)
illegit: Option[Double] = None -
The return type is the
Optionwith aDoubletype parameter, ensuring that valid results will retain the correct type.-
This will return a
Somewrapper because the dividend will be a nonnull value.-
With a valid divisor, our dividend comes wrapped in a
Some.-
With an invalid divisor we get
None, the absence of a value.
A function that returns a value wrapped in the Option collection is signifying that it may not have been applicable to the input data, and as such may not have been able to return a valid result. It offers a clear warning to callers that its value is only potential, and ensures that its results will need to be carefully handled. In this way, Option provides a type-safe option for handling function results, far safer than the Java standard of returning null values to indicate missing data.
Scala’s collections use the Option type in this way to provide safe operations for handling the event of empty collections. For example, although the head operation works for non-empty lists, it will throw an error for empty lists. A safer alternative is headOption, which (as you may have guessed) returns the head element wrapped in an Option, ensuring that it will work even on empty lists.
Here is an example of calling headOption to safely handle empty collections:
scala> val odds = List(1, 3, 5) odds: List[Int] = List(1, 3, 5) scala> val firstOdd = odds.headOption firstOdd: Option[Int] = Some(1) scala> val evens = odds filter (_ % 2 == 0) evens: List[Int] = List() scala> val firstEven = evens.headOption firstEven: Option[Int] = None
Another use of options in collections is in the find operation, a combination of filter and headOption that returns the first element that matches a predicate function. Here is an example of successful and unsuccessful collection searches with find:
scala> val words = List("risible", "scavenger", "gist")
words: List[String] = List(risible, scavenger, gist)
scala> val uppercase = words find (w => w == w.toUpperCase)
uppercase: Option[String] = None
scala> val lowercase = words find (w => w == w.toLowerCase)
lowercase: Option[String] = Some(risible)In a way, we have used list reduction operations to reduce a collection down to a single Option. Because Option is itself a collection, however, we can continue to transform it.
For example, we could use filter and map to transform the “lowercase” result in a way that retains the value, or in a way that loses the value. Each of these operations is type-safe and will not cause null pointer exceptions:
scala> val filtered = lowercase filter (_ endsWith "ible") map (_.toUpperCase) filtered: Option[String] = Some(RISIBLE) scala> val exactSize = filtered filter (_.size > 15) map (_.size) exactSize: Option[Int] = None
In the second example, the filter is inapplicable to the “RISIBLE” value and so it returns None. The ensuing map operation against None has no effect and simply returns None again.
This is a great example of the Option as a monadic collection, providing a single unit that can be executed safely (and type-safely) in a chain of operations. The operations will apply to present values (Some) and not apply to missing values (None), but the resulting type will still match the type of the final operation (an Option[Int] in the preceding example).
We have covered creating and transforming the Option collection. You may be wondering, however, what you do with an Option after you transform it into the desired value, type, or existence.
Extracting values from Options
The Option collection provides a safe mechanism and operations for storing and transforming values that may or may not be present. You shouldn’t be surprised that it also provides safe operations to extract its potential value.
For the curious, there is also an unsafe extraction operation, the get() method. If you call this for an Option that is actually a Some instance, you will successfully receive the value it contains. However, if you call get() on an instance of None, a “no such element” error will be triggered.
Avoid Option.get()
Option.get() is unsafe and should be avoided, because it disrupts the entire goal of type-safe operations and can lead to runtime errors. If possible, use an operation like fold or getOrElse that allows you to define a safe default value.
We will focus on the safe operations for extracting Option values. The core strategy of these operations is to provide a framework for handling missing values, such as a replacement (aka “default”) value to use instead of the missing one, or a function that can either generate a replacement or raise an error condition.
Table 7-3 has a selection of these operations. The examples in the table could have been written with literal Option values like Some(10) or None, but these would not have helped to illustrate the challenges of working with potential data. Instead, the following examples call the function nextOption, which randomly returns either a valid or missing Option value each time. Try out this function and the examples in the REPL to see how Some and None change the result of these operations:
scala> def nextOption = if (util.Random.nextInt > 0) Some(1) else None nextOption: Option[Int] scala> val a = nextOption a: Option[Int] = Some(1) scala> val b = nextOption b: Option[Int] = None
| Name | Example | Description |
|
| Returns the value from the given function for |
|
| Returns the value for |
|
| Doesn’t actually extract the value, but attempts to fill in a value for |
Match expressions |
| Use a match expression to handle the value if present. The |
The Option type is a great example of a monadic collection, being a singular and chainable unit. It is used throughout Scala’s collections library, for example in the find and headOption operations for sequences. It is also helpful in your own functions for input parameters and return values when you need to represent potential values. Many consider it a safer alternative than using null (i.e., the absence of an initialized value), as its potential nature is made clear, because its use cannot prevent all null pointer errors.
Option is a general-purpose monadic collection for potential values, able to contain any type of value as specified in its type parameters. We will now look at two monadic collections for specific purposes: Try for successful values and Future for eventual values.
Try Collections
The util.Try collection turns error handling into collection management. It provides a mechanism to catch errors that occur in a given function parameter, returning either the error or the result of the function if successful.
Scala provides the ability to raise errors by throwing exceptions, error types that may include a message or other information. Throwing an exception in your Scala code will disrupt your program’s flow and return control to the closest handler for that particular exception. Unhandled exceptions will terminate applications, although most Scala application frameworks and web containers take care to prevent this.
Exceptions may be thrown by your own code, by library methods that you invoke, or by the Java Virtual Machine (JVM). The JVM will throw a java.util.NoSuchElementException if you call None.get or Nil.head (the head of an empty list) or a java.lang.NullPointerException if you access a field or method of a null value.
To throw an exception, use the throw keyword with a new Exception instance. The text message provided to Exception is optional:
scala> throw new Exception("No DB connection, exiting...")
java.lang.Exception: No DB connection, exiting...
... 32 elidedTo really test out exceptions, let’s create a function that will throw an exception based on the input criteria. We can then use it to trigger exceptions for testing:
scala> def loopAndFail(end: Int, failAt: Int): Int = {
| for (i <- 1 to end) {
| println(s"$i) ")
| if (i == failAt) throw new Exception("Too many iterations")
| }
| end
| }
loopAndFail: (end: Int, failAt: Int)IntLet’s try loopAndFail with a larger iteration number than the check, ensuring we get an exception. This will demonstrate how the for-loop and the function overall get disrupted by an exception:
scala> loopAndFail(10, 3) 1) 2) 3) java.lang.Exception: Too many iterations at $anonfun$loopAndFail$1.apply$mcVI$sp(<console>:10) at $anonfun$loopAndFail$1.apply(<console>:8) at $anonfun$loopAndFail$1.apply(<console>:8) at scala.collection.immutable.Range.foreach(Range.scala:160) at .loopAndFail(<console>:8) ... 32 elided
The corollary to throwing exceptions is catching and handling them. To “catch” an exception, wrap the potentially offending code in the util.Try monadic collection.
No try/catch Blocks?
Scala does support try {} .. catch {} blocks, where the catch block contains a series of case statements that attempt to match the thrown error. I recommend using util.Try() exclusively because it offers a safer, more expressive, and fully monadic approach to handling errors.
The util.Try type, like Option, is unimplemented but has two implemented subtypes, Success and Failure. The Success type contains the return value of the attempted expression if no exception was thrown, and the Failure type contains the thrown Exception.
Let’s wrap some invocations of the loopAndFail function with util.Try and see what we get:
scala> val t1 = util.Try( loopAndFail(2, 3) )
-
util.Try()takes a function parameter, so our invocation ofloopAndFailis automatically converted to a function literal.-
The function literal (our safe invocation of
loopAndFail) exited safely, so we have aSuccesscontaining the return value.-
Invoking
util.Trywith expression blocks (see Function Invocation with Expression Blocks) is also acceptable.-
An exception was thrown in this function literal, so we have a
Failurecontaining said exception.
Now we’ll look at how to handle potential errors. Because util.Try and its subtypes are also monadic collections, you can expect to find a number of thrilling and yet familiar methods for handling these situations. You may find that selecting the right error-handling approach (including whether to handle them at all) for your application will depend on its requirements and context, however. Few error-handling methods are generally applicable, in my experience.
Table 7-4 has a selection of strategies for handling errors. To better portray the inherent dichotomy of the success and failure states, let’s define a randomized error function for use in the examples:
scala> def nextError = util.Try{ 1 / util.Random.nextInt(2) }
nextError: scala.util.Try[Int]
scala> val x = nextError
x: scala.util.Try[Int] = Failure(java.lang.ArithmeticException:
/ by zero)
scala> val y = nextError
y: scala.util.Try[Int] = Success(1)Now when you try out the following examples you’ll be able to test them with successes and failures.
| Name | Example | Description |
|
| In case of |
|
| Executes the given function once in case of |
|
| Returns the embedded value in the |
|
| The opposite of |
|
| Convert your |
|
| In case of |
Match expressions |
| Use a match expression to handle a |
Do nothing |
| This is the easiest error-handling method of all and a personal favorite of mine. To use this method, simply allow the exception to propagate up the call stack until it gets caught or causes the current application to exit. This method may be too disruptive for certain sensitive cases, but ensures that thrown exceptions will never be ignored. |
A common exception that many developers have to work with is validating numbers stored in strings. Here’s an example using the orElse operation to try to parse a number out of a string, and the foreach operation to print the result if successful:
scala> val input = " 123 "
input: String = " 123 "
scala> val result = util.Try(input.toInt) orElse util.Try(input.trim.toInt)
result: scala.util.Try[Int] = Success(123)
scala> result foreach { r => println(s"Parsed '$input' to $r!") }
Parsed ' 123 ' to 123!
scala> val x = result match {
| case util.Success(x) => Some(x)
| case util.Failure(ex) => {
| println(s"Couldn't parse input '$input'")
| None
| }
| }
x: Option[Int] = Some(123)I’ll repeat the assertion that the best error-handling strategy will depend on your current requirements and context. The one error-handling method to avoid is to encounter an exception and ignore it, e.g., by replacing it with a default value. If an exception was thrown, it at least deserves to be reported and handled.
Future Collections
The final monadic collection we’ll review is concurrent.Future, which initiates a background task. Like Option and Try, a future represents a potential value and provides safe operations to either chain additional operations or to extract the value. Unlike with Option and Try, a future’s value may not be immediately available, because the background task launched when creating the future could still be working.
By now you know that Scala code executes on the Java Virtual Machine, aka the JVM. What you may not know is that it also operates inside Java’s “threads,” lightweight concurrent processes in the JVM. By default Scala code runs in the JVM’s “main” thread, but can support running background tasks in concurrent threads. Invoking a future with a function will execute that function in a separate thread while the current thread continues to operate. A future is thus a monitor of a background Java thread in addition to being a monadic container of the thread’s eventual return value.
Fortunately, creating a future is a trivial task—just invoke it with a function you want to run in the background.
Let’s try creating a future with a function that prints a message. Before creating the future, it is necessary to specify the “context” in the current session or application for running functions concurrently. We’ll use the default “global” context, which makes use of Java’s thread library for this purpose:
scala> import concurrent.ExecutionContext.Implicits.global
import concurrent.ExecutionContext.Implicits.global
scala> val f = concurrent.Future { println("hi") }
hi
f: scala.concurrent.Future[Unit] =
scala.concurrent.impl.Promise$DefaultPromise@29852487Our background task printed “hi” before the future could even be returned to the value. Let’s try another example that “sleeps” the background thread with Java’s Thread.sleep to make sure we get the future back while the background task is still running!
scala> val f = concurrent.Future { Thread.sleep(5000); println("hi") }
f: scala.concurrent.Future[Unit] =
scala.concurrent.impl.Promise$DefaultPromise@4aa3d36
scala> println("waiting")
waiting
scala> hiThe background task, after sleeping for 5 seconds (i.e., 5,000 milliseconds), printed the “hi” message. In the meantime, our code in the “main” thread had time to print a “waiting” message before the background task completed.
You can set callback functions or additional futures to execute when a future’s task completes. As an example, an API call could start an important but prolonged operation in the background while it returns control to the caller. You can also choose to wait, blocking the “main” thread until the background task completes. An already-asynchronous event such as a network file transfer could be started in a future while the “main” thread sleeps until the task completes or a “timeout” duration is reached.
Futures can be managed asynchronously (while the “main” thread continues to operate) or synchronously (with the “main” thread waiting for the task to complete). Because asynchronous operations are more efficient, allowing both the background and current threads to continue executing, we will review them first.
Handling futures asynchronously
Futures, in addition to spawning background tasks, can be treated as monadic collections. You can chain a function or another future to be executed following the completion of a future, passing the first future’s successful result to the new function or feature.
A future handled this way will eventually return a util.Try containing either its function’s return value or an exception. In case of success (with a return value), the chained function or future will be passed to the return value and converted into a future to return its own success or failure. In case of a failure (i.e., an exception was thrown), no additional functions or futures will be executed. In this way, the future-as-monadic-collection is just a chain in a sequence of operations that carry an embedded value. This is similar to Try, which breaks the chain when a failure is reached, and Option, which breaks the chain when the value is no longer present.
To receive the eventual result of a future, or of a chain of futures, you can specify a callback function. Your callback function receives the eventual successful value or the exception, freeing the original code that created the future to move on to other tasks.
Table 7-5 has a selection of operations for chaining futures and setting callback functions. As with the previous tables of operations, we’ll start with a randomized function that can provide us with a realistic test case. This function, nextFtr, will sleep and then either return a value or throw an exception. Its inner function “rand” makes it easier to set a sleep time (up to 5 seconds / 5,000 milliseconds) and determine whether to succeed or fail:
scala> import concurrent.ExecutionContext.Implicits.global
import concurrent.ExecutionContext.Implicits.global
scala> import concurrent.Future
import concurrent.Future
scala> def nextFtr(i: Int = 0) = Future {
| def rand(x: Int) = util.Random.nextInt(x)
|
| Thread.sleep(rand(5000))
| if (rand(3) > 0) (i + 1) else throw new Exception
| }
nextFtr: (i: Int)scala.concurrent.Future[Int]Is Thread.sleep() Safe to Use?
Some of the examples in this section on futures use the Java library method Thread.sleep to help demonstrate the concurrent and potentially delayed nature of running background tasks. However, actually using Thread.sleep in your own futures is a practice best avoided due to its inefficiences. If you really need to put a future to sleep, you should consider using callback functions instead.
| Name | Example | Description |
|
| Chains the second future to the first and returns a new overall future. If the first is unsuccessful, the second is invoked. |
|
| Chains the second future to the first and returns a new overall future. If the first is successful, its return value will be used to invoke the second. |
|
| Chains the given function to the future and returns a new overall future. If the future is successful, its return value will be used to invoke the function. |
|
| After the future’s task completes, the given function will be invoked with a |
|
| If the future’s task throws an exception, the given function will be invoked with that exception. |
|
| If the future’s task completes successfully, the given function will be invoked with the return value. |
|
| Runs the futures in the given sequence concurrently, returning a new future. If all futures in the sequence are successful, a list of their return values will be returned. Otherwise the first exception that occurs across the futures will be returned. |
The code examples we have used with futures should help to illustrate how to create and manage them. However, futures require creation, management, and extraction to be useful. Let’s try a more realistic example of futures that shows how to work with them from start to finish.
In this example we will use the OpenWeatherMap API (remember this from Exercises ?) to check the current temperature (in Kelvin!) for two cities and report which one is warmer. Because calling a remote API can be time-intensive we will make the API calls in concurrent futures, running concurrently with our main thread:
scala> import concurrent.Future| Future(cityTemp("Fresno")), Future(cityTemp("Tempe")) | ) cityTemps: scala.concurrent.Future[Seq[Double]] = scala.concurrent.impl.Promise$DefaultPromise@51e0301d scala> cityTemps onSuccess { | case Seq(x,y) if x > y => println(s"Fresno is warmer: $x K")
| case Seq(x,y) if y > x => println(s"Tempe is warmer: $y K") | } Tempe is warmer: 306.1 K
-
Okay, sometimes typing “concurrent.Future” too many times is a pain. The
importcommand brings a package’s type into the current session’s namespace.-
io.Sourcehas many useful I/O operations for Scala applications.-
Capturing the “temp” field in a JSON response.
-
Using
Regexto produce a value from a capture group (see Regular expressions for a refresh on this topic).-
By invoking
Future.sequence, the sequence of futures are invoked concurrently and a list of their results are returned.-
Pattern matching on sequences using a pattern guard (see Pattern Matching with Collections for an overview of using pattern matching with collections).
In this example we were able to make multiple concurrent calls to a remote API without blocking the main thread, i.e. the Scala REPL session. Calling a remote API and parsing its JSON result using regular expressions only took a few lines to implement (“few” = “less then a dozen” here), and executing this concurrently took up about the same amount of code.
You should now have a good understanding of how to create futures and work with them asynchronously. In the next section we will cover what to do if you absolutely must wait for a future to complete.
Handling futures synchronously
Blocking a thread while waiting for a background thread to complete is a potentially resource-heavy operation. It should be avoided for high-traffic or high-performance applications in favor of using callback functions like onComplete or onSuccess. However, there are some times when you just need to block the current thread and wait for a background thread to complete, successfully or otherwise.
To block the current thread and wait for another thread to complete, use concurrent.Await.result(), which takes the background thread and a maximum amount of time to wait. If the future completes in less time than the given duration, its result is returned, but a future that doesn’t complete in time will result in a java.util.concurrent.TimeoutException. This thrown unwieldy exception may require using util.Try to manage timeout conditions safely, so be sure to choose acceptable durations that can minimize the chance of this occurring.
To demonstrate the use of concurrent.Await.result, let’s use the “nextFtr” demonstration function we created for testing asynchronous operations (see Handling futures asynchronously). We’ll start by importing the contents of the “duration” package to get access to the Duration type for specifying time spans as well as the types for their units:
scala> import concurrent.duration._
-
The underscore (
_) at the end imports every member of the given package into the current namespace.-
SECONDSis a member of theconcurrent.durationpackage and signifies that the given duration (10, in this case) is in seconds.-
When “nextFtr()” returns a successful value,
concurrent.Awaitwill return it…-
… but when “nextFtr()” throws an exception, the current thread will be disrupted.
While our first call to concurrent.Await.result gave us a successful call, the second one caused an exception that disrupted the Scala REPL. When working with synchronous operations, you may want to add your own util.Try wrapper to ensure that exceptions thrown in a future will not disrupt the current flow. Doing so is not a requirement, because allowing exceptions to propagate may be a valid design choice.
Summary
Mutable collections, well known and available in most programming languages, have the best of both worlds in Scala. They can be used as incremental buffers to expand collections one item at a time using buffers, builders, or other approaches, but also support the wide variety of operations available to immutable collections.
And collections are, especially as Scala broadly defines them, more than simple containers for application data. Monadic collections provide type-safe chainable operations and management for sensitive and complex situations such as missing data, error conditions, and concurrent processing.
In Scala, immutable, mutable, and monadic collections are indispensable building blocks and foundations for safe and expressive software development. They are ubiquitious in Scala code, and are generally applicable to a wide range of uses.
By learning and becoming familiar with the core operations of Iterable, and with the safe operation chaining of monadic collections, you can better leverage them as a core foundation for your applications in Scala.
This chapter concludes the Scala instructions for Part 1. In Part 2 we will cover object-oriented Scala, a core feature of this programming language, while continuing to use what we have learned thus far.
Exercises
The Fibonacci series starts with the numbers “1, 1” and then computes each successive element as the sum of the previous two elements. We’ll use this series to get familiarized with the collections in this chapter.
-
Write a function that returns a list of the first x elements in the Fibonacci series Can you write this with a
Buffer? Would aBuilderbe appropriate here? -
Write a new Fibonacci function that adds new Fibonacci numbers to an existing list of numbers. It should take a list of numbers (
List[Int]) and the count of new elements to add and return a new list (List[Int]). Although the input list and returned lists are immutable, you should be able to use a mutable list inside your function. Can you also write this function using only immutable lists? Which version, using mutable versus immutable collections, is more appropriate and readable? -
The
Streamcollection is a great solution for creating a Fibonacci series. Create a stream that will generate a Fibonacci series. Use it to print out the first 100 elements in the series, in a formatted report of 10 comma-delimited elements per line. -
Write a function that takes an element in the Fibonacci series and returns the following element in the series. For example,
fibNext(8)should return13. How will you handle invalid input such asfixNext(9)? What are your options for conveying the lack of a return value to callers?
-
Write a function that returns a list of the first x elements in the Fibonacci series Can you write this with a
-
In the example for
Arraycollections (see Arrays) we used thejava.io.File(<path>).listFilesoperation to return an array of files in the current directory. Write a function that does the same thing for a directory, and converts each entry into itsStringrepresentation using thetoStringmethod. Filter out any dot-files (files that begin with the . character) and print the rest of the files separated by a semicolon (;). Test this out in a directory on your computer that has a significant number of files. - Take the file listing from exercise 2 and print a report showing each letter in the alphabet followed by the number of files that start with that letter.
-
Write a function to return the product of two numbers that are each specified as a
String, not a numeric type. Will you support both integers and floating-point numbers? How will you convey if either or both of the inputs are invalid? Can you handle the converted numbers using a match expression? How about with a for-loop? Write a function to safely wrap calls to the JVM library method
System.getProperty(<String>), avoiding raised exceptions or null results.System.getProperty(<String>)returns a JVM environment property value given the property’s name. For example,System.getProperty("java.home")will return the path to the currently running Java instance, whileSystem.getProperty("user.timezone")returns the time zone property from the operating system. This method can be dangerous to use, however, because it may throw exceptions or returnnullfor invalid inputs. Try invokingSystem.getProperty("")orSystem.getProperty("blah")from the Scala REPL to see how it responds.Experienced Scala developers build their own libraries of functions that wrap unsafe code with Scala’s monadic collections. Your function should simply pass its input to the method and ensure that exceptions and null values are safely handled and filtered. Call your function with the example property names used here, including the valid and invalid ones, to verify that it never raises exceptions or returns null results.
Write a function that reports recent GitHub commits for a project. GitHub provides an RSS feed of recent commits for a given user, repository, and branch, containing XML that you can parse out with regular expressions. Your function should take the user, repository, and branch, read and parse the RSS feed, and then print out the commit information. This should include the date, title, and author of each commit.
You can use the following RSS URL to retrieve recent commits for a given repository and branch:
https://github.com/<user name>/<repo name>/commits/<branch name>.atom
Here is one way to grab the RSS feed as a single string:
scala> val u = "https://github.com/scala/scala/commits/2.11.x.atom" u: String = https://github.com/scala/scala/commits/2.11.x.atom scala> val s = io.Source.fromURL(u) s: scala.io.BufferedSource = non-empty iterator scala> val text = s.getLines.map(_.trim).mkString("") text: String = <?xml version="1.0" encoding="UTF-8"?><feed xmlns=...Working with the XML will be a bit tricky. You may want to use
text.split(<token>)to split the text into the separate<entry>components, and then use regular expression capture groups (see Regular expressions) to parse out the<title>and other elements. You could also just try iterating through all the lines of the XML file, adding elements to a buffer as you find them, and then converting that to a new list.Once you have completed this exercise (and there is a lot to do here), here are some additional features worth investigating:
- Move the user, repo, and branch parameters into a tuple parameter.
- Following exercise (a), have the function take a list of GitHub projects and print a report of each one’s commits, in order of specified project.
- Following exercise (b), retrieve all of the projects, commit data concurrently using futures, await the result (no more than 5 seconds), and then print a commit report for each project, in order of project specified.
Following exercise (c), mix the commits together and sort by commit date, then print your report with an additional “repo” column.
These additional features will take some time to implement, but are definitely worthwhile for learning and improving your Scala development skills.
Once you have finished these features, test out your commit report using entries from the following projects:
https://github.com/akka/akka/tree/master https://github.com/scala/scala/tree/2.11.x https://github.com/sbt/sbt/tree/0.13 https://github.com/scalaz/scalaz/tree/series/7.2.x
These features are all active (as of 2014), so you should see an interesting mix of commit activity data in your report. It’s worthwhile to browse the repositories for these core open source Scala projects, or at least their documentation, to understand some of the excellent work being done.
Write a command-line script to call your GitHub commit report function from exercise 6 and print out the results. This will require a Unix shell; if you are on a Windows system you will need a compatible Unix environment such as Cygwin or Virtualbox (running a Unix virtual machine). You’ll also need to install SBT (Simple Build Tool), a build tool that supports dependency management and plug-ins and is commonly used by Scala projects. You can download SBT from http://www.scala-sbt.org/ for any environment, including an MSI Windows Installer version. SBT is also available from popular package managers. If you are using Homebrew on OS X you can install it with
brew install sbt.Isn’t SBT Hard to Learn?
Maybe. In this exercise we’ll only use it as a shell script launcher, so you can get comfortable with writing and executing shell scripts in Scala. We’ll cover how to write SBT-built scripts to manage your own projects in later chapters.
Here is an example SBT-based Scala script that reads the command-line arguments as a
Listand prints a greeting. The comment block starting with triple asterisks is reserved for SBT settings. In this script we are specifying that we want version 2.11.1 of the Scala language to be used:#!/usr/bin/env sbt -Dsbt.main.class=sbt.ScriptMain /*** scalaVersion := "2.11.1" */ def greet(name: String): String = s"Hello, $name!" // Entry point for our script args.toList match { case List(name) => { val greeting = greet(name) println(greeting) } case _ => println("usage: HelloScript.scala <name>") }Copy this into a file titled HelloScript.scala, and change the permissions to be executable (
chmod a+x HelloScript.scalain a Unix environment). Then you can run the script directly:$ ./HelloScript.scala Jason [info] Set current project to root-4926629s8acd7bce0b (in build file:/Users/jason/.sbt/boot/4926629s8acd7bce0b/) Hello, Jason!
Your commit report script will need to take multiple GitHub projects as arguments. To keep the arguments concise, you may want to combine each project’s input into a single string to be parsed, such as
scala/scala/2.11.x.The printout should be clean, well-formatted, and easily readable. Using fixed column widths could help, using the
printf-style formatting codes in string interpolation (see String interpolation).
Get Learning Scala now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

