Capítulo 1. La evolución de las arquitecturas de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Como ingeniero de datos, quieres construir soluciones de datos a gran escala, aprendizaje automático, ciencia de datos e IA que ofrezcan un rendimiento de vanguardia. Construyes estas soluciones ingiriendo grandes cantidades de datos de origen, limpiando, normalizando y combinando los datos y, en última instancia, presentando estos datos a las aplicaciones posteriores a través de un modelo de datos fácil de consumir.
Como la cantidad de datos que necesitas ingerir y procesar es cada vez mayor, necesitas la capacidad de escalar tu almacenamiento horizontalmente. Además, necesitas la capacidad de escalar dinámicamente tus recursos informáticos para hacer frente a los picos de procesamiento y consumo. Puesto que estás combinando tus fuentes de datos en un modelo de datos, no sólo necesitas añadir datos a las tablas, sino que a menudo necesitas insertar, actualizar o eliminar (es decir, MERGE o UPSERT) registros basados en una lógica empresarial compleja. Quieres poder realizar estas operaciones con garantías transaccionales, y sin tener que reescribir constantemente grandes archivos de datos.
En el pasado, el conjunto de requisitos anterior se abordaba con dos conjuntos de herramientas distintos. Los lagos de datos basados en la nube ofrecían escalabilidad horizontal y desacoplamiento de almacenamiento y cálculo, mientras que los almacenes de datos relacionales ofrecían garantías transaccionales. Sin embargo, los almacenes de datos tradicionales acoplaban estrechamente el almacenamiento y el cálculo en un dispositivo local y no tenían el grado de escalabilidad horizontal asociado a los lagos de datos.
Delta Lake aporta a los lagos de datos capacidades como la fiabilidad transaccional y la compatibilidad con UPSERTs y MERGEs, al tiempo que mantiene la escalabilidad horizontal dinámica y la separación de almacenamiento y computación de los lagos de datos. Delta Lake es una solución para construir lagos de datos, una arquitectura de datos abierta que combina lo mejor de los almacenes de datos y los lagos de datos.
En esta introducción, echaremos un breve vistazo a las bases de datos relacionales y cómo evolucionaron hasta convertirse en almacenes de datos. A continuación, veremos los principales impulsores de la aparición de los lagos de datos. Abordaremos las ventajas e inconvenientes de cada arquitectura, y finalmente mostraremos cómo la capa de almacenamiento Delta Lake combina las ventajas de cada arquitectura, permitiendo a la creación de soluciones de lago de datos.
Breve historia de las bases de datos relacionales
En su histórico artículo de 19701 E.F. Codd introdujo el concepto de considerar los datos como relaciones lógicas, independientes del almacenamiento físico de los datos. Esta relación lógica entre entidades de datos se conoció como modelo o esquema de base de datos. Los escritos de Codd condujeron al nacimiento de la base de datos relacional. Los primeros sistemas de bases de datos relacionales fueron introducidos a mediados de los años 70 por IBM y la UBC.
Las bases de datos relacionales y su lenguaje SQL subyacente se convirtieron en la tecnología de almacenamiento estándar para las aplicaciones empresariales durante las décadas de 1980 y 1990. Una de las principales razones de esta popularidad fue que las bases de datos relacionales ofrecían un concepto llamado transacciones. Una transacción de base de datos es una secuencia de operaciones sobre una base de datos que satisface cuatro propiedades: atomicidad, consistencia, aislamiento y durabilidad, comúnmente conocidas por sus siglas ACID.
La atomicidad garantiza que todos los cambios de realizados en la base de datos se ejecuten como una única operación. Esto significa que la operación sólo tiene éxito cuando todos los cambios se han realizado correctamente. Por ejemplo, cuando se utiliza el sistema de banca online para transferir dinero de la cuenta de ahorros a la cuenta corriente, la propiedad de atomicidad garantizará que la operación sólo tendrá éxito cuando el dinero se deduzca de mi cuenta de ahorros y se añada a mi cuenta corriente. La operación completa tendrá éxito o fracasará como una unidad completa.
La propiedad de consistencia garantiza que la base de datos pasa de un estado consistente al principio de la transacción a otro estado consistente al final de la transacción. En nuestro ejemplo anterior, la transferencia del dinero sólo se produciría si la cuenta de ahorros tuviera fondos suficientes. Si no fuera así, la transacción fallaría, y los saldos permanecerían en su estado consistente original.
El aislamiento garantiza que las operaciones concurrentes de que se produzcan en la base de datos no se afecten entre sí. Esta propiedad garantiza que, cuando se ejecutan varias transacciones simultáneamente, sus operaciones no interfieran entre sí.
La durabilidad se refiere a la persistencia de las transacciones comprometidas. Garantiza que, una vez completada con éxito una transacción, ésta resultará en un estado permanente, incluso en caso de fallo del sistema. En nuestro ejemplo de transferencia de dinero, la durabilidad garantizará que las actualizaciones realizadas tanto en mi cuenta de ahorros como en mi cuenta corriente sean persistentes y puedan sobrevivir a un posible fallo del sistema.
Los sistemas de bases de datos siguieron madurando a lo largo de la década de 1990, y la llegada de Internet a mediados de esa década provocó un crecimiento explosivo de los datos y de la necesidad de almacenarlos. Las aplicaciones empresariales utilizaban con gran eficacia la tecnología de los sistemas de gestión de bases de datos relacionales (RDBMS). Productos emblemáticos como SAP y Salesforce recopilaban y mantenían cantidades ingentes de datos.
Sin embargo, este desarrollo no estuvo exento de inconvenientes. Las aplicaciones empresariales almacenaban los datos en sus propios formatos propietarios, lo que dio lugar al surgimiento de silos de datos. Estos silos de datos pertenecían y estaban controlados por un departamento o unidad empresarial. Con el tiempo, las organizaciones reconocieron la necesidad de desarrollar una visión empresarial a través de estos diferentes silos de datos, dando lugar al surgimiento de los almacenes de datos.
Almacenes de datos
Aunque todas las aplicaciones empresariales incorporan algún tipo de informe, se perdían oportunidades de negocio por falta de una visión global de toda la organización. Al mismo tiempo, las organizaciones reconocieron el valor de analizar los datos durante periodos de tiempo más largos. Además, querían poder trocear los datos sobre varios temas transversales, como clientes, productos y otras entidades empresariales.
Esto condujo a la introducción del almacén de datos, un repositorio relacional central de datos históricos integrados procedentes de múltiples fuentes de datos que presenta una única visión histórica e integrada del negocio con un esquema unificado, que abarca todas las perspectivas de la empresa.
Arquitectura del almacén de datos
En la Figura 1-1 se muestra una representación sencilla de una arquitectura típica de almacén de datos .
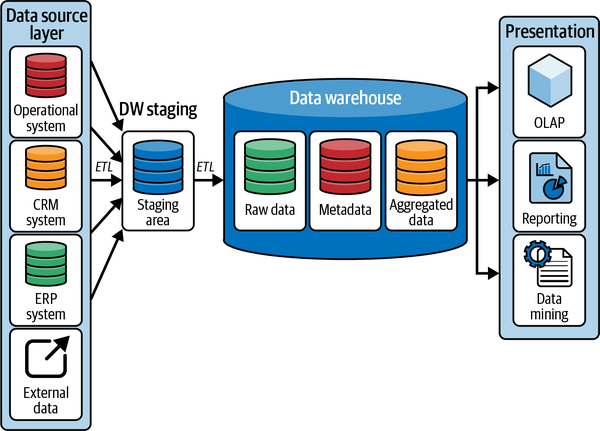
Figura 1-1. Arquitectura del almacén de datos
Cuando observamos el diagrama de la Figura 1-1, empezamos por la capa de la fuente de datos, a la izquierda. Las organizaciones necesitan ingerir datos de un conjunto de fuentes de datos heterogéneas. Aunque los datos del sistema o sistemas de planificación de recursos empresariales (ERP) de la organización forman la columna vertebral del modelo organizativo, necesitamos aumentar estos datos con los de los sistemas operativos que gestionan las operaciones cotidianas, como los sistemas de recursos humanos (RRHH) y el software de gestión de flujos de trabajo . Además, es posible que las organizaciones quieran aprovechar los datos de interacción con los clientes que abarcan sus sistemas de gestión de relaciones con los clientes (CRM) y de puntos de venta (POS). Además de las fuentes de datos principales enumeradas aquí, existe la necesidad de ingerir datos de una amplia gama de fuentes de datos externas, en diversos formatos, como hojas de cálculo, archivos CSV , etc.
Estos diferentes sistemas fuente pueden tener cada uno su propio formato de datos. Por lo tanto, el almacén de datos contiene un área de preparación donde los datos de las distintas fuentes pueden combinarse en un formato común. Para ello, el sistema debe ingerir los datos de las fuentes de datos originales. El proceso real de ingesta varía según el tipo de fuente de datos. Algunos sistemas permiten el acceso directo a la base de datos, y otros permiten la ingesta de datos a través de una API, mientras que muchas fuentes de datos siguen dependiendo de extractos de archivos.
A continuación, el almacén de datos debe transformar los datos en un formato normalizado, que permita a los procesos posteriores acceder a los datos con facilidad. Por último, los datos transformados se cargan en el área de preparación. En los almacenes de datos relacionales, esta zona de preparación suele ser un conjunto de tablas de preparación relacionales planas, sin claves primarias ni foráneas, ni tipos de datos simples.
Este proceso de extraer los datos, transformarlos a un formato estándar y cargarlos en el almacén de datos se conoce comúnmente como extraer, transformary cargar(ETL). Las herramientas ETL pueden realizar varias tareas más en los datos ingeridos antes de cargarlos finalmente en el almacén de datos. Estas tareas incluyen la eliminación de registros duplicados. Dado que un almacén de datos será la única fuente de verdad, no queremos que contenga varias copias de los mismos datos. Además, los registros duplicados impiden la generación de una clave única para cada registro.
Las herramientas ETL también nos permiten combinar datos de múltiples fuentes de datos. Por ejemplo, una visión de nuestros clientes puede captarse en los sistemas CRM, mientras que otros atributos se encuentran en un sistema ERP. La organización necesita combinar estos diferentes aspectos en una visión global de un cliente. Aquí es donde empezamos a introducir un esquema en el almacén de datos. En nuestro ejemplo de un cliente, el esquema definirá las distintas columnas de la tabla de clientes, qué columnas son necesarias, el tipo de datos y las restricciones de cada columna, etc.
Tener representaciones canónicas y estandarizadas de las columnas, como la fecha y la hora, es importante. Las herramientas ETL pueden garantizar que todas las columnas temporales tengan el mismo formato estándar en todo el almacén de datos.
Por último, las organizaciones quieren realizar comprobaciones de calidad de los datos de acuerdo con sus normas de gobernanza de datos. Esto podría incluir la eliminación de las filas de datos de baja calidad que no cumplan esta norma mínima.
Los almacenes de datos se implementan físicamente en una arquitectura física monolítica, formada por un único gran nodo, que combina memoria, cálculo y almacenamiento. Esta arquitectura monolítica obliga a las organizaciones a escalar su infraestructura verticalmente, lo que da lugar a una infraestructura cara, a menudo sobredimensionada, que se aprovisionó para los picos de carga de los usuarios, mientras que en otros momentos está casi inactiva.
Un almacén de datos suele contener datos que pueden clasificarse del siguiente modo:
- Metadatos
Información contextual sobre los datos. Estos datos suelen almacenarse en un catálogo de datos. Permite a los analistas de datos describir, clasificar y localizar fácilmente los datos almacenados en el almacén de datos.
- Datos brutos
Se mantienen en su formato original sin ningún procesamiento. Tener acceso a los datos en bruto permite al sistema de almacén de datos reprocesarlos en caso de fallos de carga.
- Datos resumidos
Creados automáticamente por el sistema de gestión de datos subyacente . Los datos resumidos se actualizarán automáticamente a medida que se carguen nuevos datos en el almacén. Contienen agregaciones a través de varias dimensiones conformadas. El objetivo principal de los datos de resumen es acelerar el rendimiento de las consultas.
Los datos del almacén se consumen en la capa de presentación. Aquí es donde los consumidores pueden interactuar con los datos almacenados en el almacén. A grandes rasgos, podemos identificar dos grandes grupos de consumidores:
- Consumidores humanos
Son las personas de que necesitan consumir los datos del almacén. Estos consumidores pueden variar desde trabajadores del conocimiento, que necesitan acceder a los datos como parte esencial de su trabajo, hasta ejecutivos que suelen consumir datos muy resumidos, a menudo en forma de cuadros de mando e indicadores clave de rendimiento (KPI).
- Sistemas internos o externos
Los datos de un almacén de datos pueden ser consumidos por diversos sistemas internos o externos. Esto puede incluir conjuntos de herramientas de aprendizaje automático e IA, o aplicaciones internas que necesiten consumir datos del almacén. Algunos sistemas pueden acceder directamente a los datos, otros pueden trabajar con extractos de datos, mientras que otros pueden consumir directamente los datos en un modelo pub-sub.
Los consumidores humanos aprovecharán diversas herramientas y tecnologías analíticas para crear perspectivas procesables de los datos, entre ellas:
- Herramientas de información
Estas herramientas permiten al usuario desarrollar perspectivas de los datos mediante visualizaciones como informes tabulares y una amplia gama de representaciones gráficas.
- Herramientas de procesamiento analítico en línea (OLAP)
Los consumidores necesitan cortar y trocear los datos de diversas formas. Las herramientas OLAP presentan los datos en un formato multidimensional, lo que permite consultarlos desde múltiples perspectivas. Aprovechan las agregaciones prealmacenadas, a menudo almacenadas en memoria, para servir los datos con un rendimiento rápido.
- Minería de datos
Estas herramientas permiten al analista de encontrar patrones en los datos mediante correlaciones y clasificaciones matemáticas. Ayudan a los analistas a reconocer relaciones previamente ocultas entre distintas fuentes de datos. En cierto modo, las herramientas de minería de datos pueden considerarse un precursor de las herramientas modernas de ciencia de datos.
Modelado dimensional
Los almacenes de datos introdujeron la necesidad de un modelo de datos global que abarcara las distintas áreas temáticas de una empresa corporativa. La técnica utilizada para crear estos modelos se conoció como modelado dimensional.
Impulsado por los escritos y las ideas de visionarios como Bill Inmon y Ralph Kimball, el modelado dimensional se introdujo por primera vez en el libro seminal de Kimball The Data Warehouse Toolkit: La Guía Completa del Modelado Dimensional.2 Kimball define una metodología que se centra en un enfoque ascendente, garantizando que el equipo aporte valor real con el almacén de datos lo antes posible.
Un modelo dimensional se describe mediante un esquema en estrella. Un esquema en estrella organiza los datos de un determinado proceso empresarial (por ejemplo, ventas) en una estructura que facilita el análisis. Consta de dos tipos de tablas:
-
Una tabla de hechos, que es la tabla primaria o central del esquema. La tabla de hechos captura las medidas, métricas o "hechos" primarios del proceso empresarial. Siguiendo con nuestro ejemplo del proceso empresarial de ventas, una tabla de hechos de ventas incluiría las unidades vendidas y el importe de las ventas.
-
Las tablas de hechos tienen un grano bien definido. El grano viene determinado por la combinación de dimensiones (columnas) representadas en la tabla. Una tabla de hechos de ventas puede tener una granularidad baja, si es sólo un rollup anual de ventas, o alta, si incluye las ventas por fecha, tienda e identificador de cliente.
-
-
Múltiples tablas de dimensiones que están relacionadas con la tabla de hechos. Una dimensión proporciona el contexto que rodea al proceso empresarial seleccionado. En un ejemplo de escenario de ventas, la lista de dimensiones podría incluir producto, cliente, vendedor y tienda.
Las tablas de dimensiones "rodean" a la tabla de hechos, por eso este tipo de esquemas se denominan "esquemas estrella". Un esquema en estrella consta de tablas de hechos, vinculadas a sus tablas de dimensiones asociadas mediante relaciones de clave primaria y foránea. En la Figura 1-2 se muestra un esquema en estrella para nuestra área temática de ventas.

Figura 1-2. Modelo dimensional de ventas
Ventajas y retos del almacén de datos
Los almacenes de datos tienen ventajas inherentes que han servido bien a la comunidad empresarial. Ofrecen datos de alta calidad, depurados y normalizados, procedentes de distintas fuentes de datos, en un formato común. Como los datos de los distintos departamentos se presentan en un formato común, cada departamento revisará los resultados en consonancia con los demás. Disponer de datos puntuales y precisos es la base de unas decisiones empresariales sólidas.
-
Dado que almacenan grandes cantidades de datos históricos , permiten una visión histórica, que permite a los usuarios analizar distintos periodos y tendencias.
-
Los almacenes de datos suelen ser muy fiables, gracias a la tecnología de base de datos relacional subyacente, que ejecuta transacciones ACID.
-
Los almacenes se modelan con técnicas estándar de modelado de esquema en estrella, creando tablas de hechos y dimensiones. Cada vez hay más modelos de plantillas preconstruidas disponibles para diversas áreas temáticas, como ventas y CRM, lo que acelera aún más el desarrollo de dichos modelos.
-
Los almacenes de datos son idóneos para la inteligencia empresarial y la elaboración de informes, y básicamente responden a la pregunta "¿Qué ha pasado?" de la curva de madurez de los datos. Un almacén de datos combinado con herramientas de inteligencia empresarial (BI) puede generar información procesable para marketing, finanzas, operaciones y ventas.
El rápido auge de Internet y los medios sociales, así como la disponibilidad de dispositivos multimedia como los smartphones, trastocaron el panorama tradicional de los datos, dando lugar al término big data en . Los big data se definen como datos que llegan en volúmenes cada vez mayores, con más velocidad, en una mayor variedad de formatos y con mayor veracidad. Se conocen como las cuatro V de los datos:
- Volumen
El volumen de datos creados, capturados, copiados y consumidos en todo el mundo está aumentando rápidamente. Como se describe en Statista, en los próximos dos años se prevé que la creación mundial de datos crezca hasta más de 200 zettabytes (un zettabyte es un número de bytes de 2 a la potencia 70).
- Velocidad
En el clima empresarial moderno de hoy en día, es fundamental tomar decisiones a tiempo. Para tomar estas decisiones, las organizaciones necesitan que su información fluya rápidamente, idealmente lo más cerca posible del tiempo real. Por ejemplo, las aplicaciones de negociación bursátil necesitan tener acceso a datos casi en tiempo real para que los algoritmos avanzados de negociación puedan tomar decisiones en milisegundos, y necesitan comunicar estas decisiones a sus partes interesadas. El acceso a datos oportunos puede dar a las organizaciones una ventaja competitiva.
- Variedad
La variedad se refiere al número de "tipos" diferentes de datos que hay ahora disponibles. Los tipos de datos tradicionales eran todos estructurados y se ofrecían normalmente como bases de datos relacionales, o extractos de las mismas. Con el auge de los big data, los datos llegan ahora en nuevos tipos no estructurados. Los tipos de datos no estructurados y semiestructurados, como los mensajes de dispositivos del Internet de las Cosas (IoT), texto, audio y vídeo, requieren un preprocesamiento adicional para derivar el significado empresarial. La variedad también se expresa a través de los distintos tipos de ingesta. Algunas fuentes de datos se ingieren mejor por lotes, mientras que otras se prestan a la ingestión incremental, o a la ingestión en tiempo real basada en eventos, como los flujos de datos de IoT.
- Veracidad
La veracidad define la fiabilidad de los datos. Aquí, queremos asegurarnos de que los datos son precisos y de alta calidad. Los datos pueden ingerirse de varias fuentes; es importante comprender la cadena de custodia de los datos, asegurarnos de que tenemos metadatos ricos y comprender el contexto en el que se recogieron los datos. Además, queremos que garantice que nuestra visión de los datos sea completa, sin componentes que falten ni hechos que lleguen tarde.
Los almacenes de datos tienen dificultades para abordar estas cuatro V.
Las arquitecturas tradicionales de almacenes de datos tienen dificultades para facilitar volúmenes de datos que aumentan exponencialmente. En sufren problemas tanto de almacenamiento como de escalabilidad. Con volúmenes que alcanzan los petabytes, resulta difícil escalar las capacidades de almacenamiento sin gastar grandes cantidades de dinero. Las arquitecturas tradicionales de almacén de datos no utilizan técnicas de procesamiento en memoria y en paralelo, lo que les impide escalar verticalmente el almacén de datos.
Las arquitecturas de almacén de datos tampoco son adecuadas para hacer frente a la velocidad de los big data. Los almacenes de datos no soportan los tipos de arquitectura de flujo necesarios para soportar datos casi en tiempo real. Las ventanas de carga de datos ETL sólo pueden acortarse hasta que la infraestructura empieza a ceder.
Aunque los almacenes de datos son muy buenos para almacenar datos estructurados, no están bien adaptados para almacenar y consultar la variedad de datos semiestructurados o no estructurados.
Los almacenes de datos no llevan incorporado ningún soporte para rastrear la fiabilidad de los datos. Los metadatos de los almacenes de datos se centran principalmente en el esquema, y menos en el linaje, la calidad de los datos y otras variables de veracidad.
Además, los almacenes de datos se basan en un formato cerrado y propietario, y normalmente sólo admiten herramientas de consulta basadas en SQL. Debido a su formato propietario, los almacenes de datos no ofrecen un buen soporte para las herramientas de ciencia de datos y aprendizaje automático.
Debido a estas limitaciones, los almacenes de datos son caros de construir. Como resultado, los proyectos fracasan a menudo antes de ponerse en marcha, y los que se ponen en marcha tienen dificultades para mantenerse al día con los requisitos siempre cambiantes del clima empresarial moderno y las cuatro V.
Las limitaciones de la arquitectura tradicional de almacén de datos dieron lugar a una arquitectura más moderna, basada en el concepto de lago de datos.
Presentación de los lagos de datos
Un lago de datos es un repositorio central rentable para almacenar datos estructurados, semiestructurados o no estructurados a cualquier escala, en forma de archivos y blobs. El término "lago de datos" procede de la analogía de un río o lago real, que contiene el agua, o en este caso los datos, con varios afluentes que hacen fluir el agua (también conocida como "datos") hacia el lago en tiempo real. En la Figura 1-3 se muestra una representación canónica de un típico lago de datos.
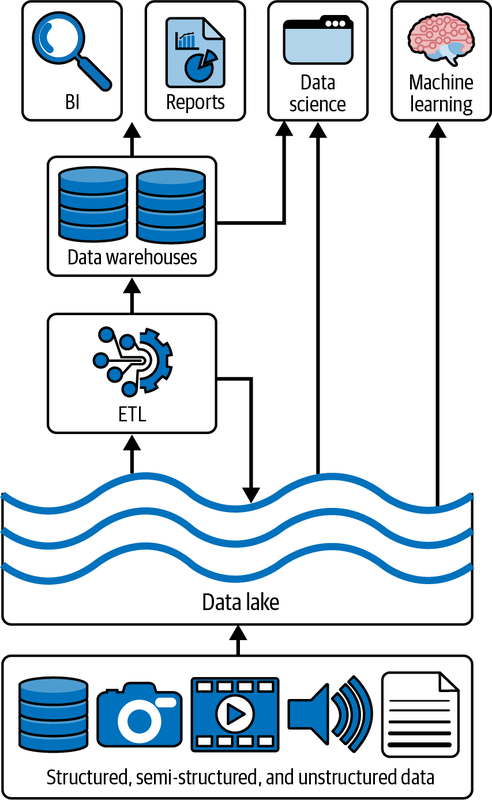
Figura 1-3. Lago de datos canónico
Los lagos de datos iniciales y las soluciones de big data se construyeron con clústeres locales, basados en el conjunto de marcos de código abierto Apache Hadoop. Hadoop se utilizó para almacenar y procesar eficientemente grandes conjuntos de datos cuyo tamaño oscilaba entre gigabytes y petabytes de datos. En lugar de utilizar un gran ordenador para almacenar y procesar los datos, Hadoop aprovechaba la agrupación de múltiples nodos de cálculo básicos para analizar grandes volúmenes de conjuntos de datos en paralelo con mayor rapidez.
Hadoop aprovecharía el marco MapReduce para paralelizar tareas de cálculo en varios nodos de cálculo. El Sistema de Archivos Distribuidos de Hadoop (HDFS) era un sistema de archivos diseñado para funcionar en hardware estándar o de gama baja. HDFS era muy tolerante a fallos y admitía grandes conjuntos de datos.
A partir de 2015, los lagos de datos en la nube, como Amazon Simple Storage Service (Amazon S3), Azure Data Lake Storage Gen 2 (ADLS) y Google Cloud Storage (GCS), empezaron a sustituir a HDFS. Estos sistemas de almacenamiento basados en la nube tienen acuerdos de nivel de servicio (SLA) superiores (a menudo superiores a 10 nueves), ofrecen georreplicación y, lo que es más importante, ofrecen un coste extremadamente bajo con la opción de utilizar un almacenamiento en frío incluso de menor coste para fines de archivo.
En el nivel más bajo, la unidad de almacenamiento en un lago de datos es un blob de datos. Los blobs son por naturaleza no estructurados, lo que permite almacenar datos semiestructurados y no estructurados, como grandes archivos de audio y vídeo. En un nivel superior, los sistemas de almacenamiento en la nube proporcionan semántica de archivos y seguridad a nivel de archivo sobre el almacenamiento de blobs, lo que permite almacenar datos altamente estructurados. Debido a sus canales de entrada y salida de gran ancho de banda, los lagos de datos también permiten casos de uso de streaming, como la ingestión continua de grandes volúmenes de datos IoT o streaming multimedia.
Los motores informáticos permiten procesar grandes volúmenes de datos de forma similar a ETL y entregarlos a los consumidores, como los almacenes de datos tradicionales y los conjuntos de herramientas de aprendizaje automático e IA. Los datos en flujo pueden almacenarse en bases de datos en tiempo real, y los informes pueden crearse con las herramientas tradicionales de BI y generación de informes.
Los lagos de datos se habilitan mediante diversos componentes:
- Almacenamiento
Los lagos de datos requieren sistemas de almacenamiento muy grandes y escalables, como los que suelen ofrecerse en los entornos de nube. El almacenamiento tiene que ser duradero y escalable, y debe ofrecer interoperabilidad con diversas herramientas, bibliotecas y controladores de terceros. Ten en cuenta que los lagos de datos separan los conceptos de almacenamiento y computación, permitiendo que ambos escalen independientemente. El escalado independiente del almacenamiento y la informática permite un ajuste fino y elástico de los recursos bajo demanda, permitiendo que las arquitecturas de nuestras soluciones sean más flexibles. Los canales de entrada y salida a los sistemas de almacenamiento deben soportar grandes anchos de banda, permitiendo la ingestión o consumo de grandes volúmenes de lotes, o el flujo continuo de grandes volúmenes de datos en streaming, como IoT y streaming multimedia.
- Calcula
Se necesitan grandes cantidades de potencia de cálculo para procesar las grandes cantidades de datos almacenados en la capa de almacenamiento. Hay varios motores de cálculo disponibles en las distintas plataformas en la nube. El motor informático de referencia para los lagos de datos es Apache Spark. Spark es un motor de análisis unificado de código abierto, que puede implementarse a través de diversas soluciones, como Databricks u otras desarrolladas por otros proveedores en la nube. Los motores informáticos de big data aprovecharán los clústeres informáticos. Los clústeres informáticos agrupan nodos informáticos para abordar tareas completas de recopilación y procesamiento de datos.
- Formatos
La forma de los datos en disco define los formatos. Existe una amplia gama de formatos de almacenamiento. Los lagos de datos utilizan sobre todo formatos estandarizados de código abierto, como Parquet, Avro JSON o CSV.
- Metadatos
Los sistemas modernos de almacenamiento en la nube mantienen metadatos (es decir, información contextual sobre los datos). Esto incluye varias marcas de tiempo que describen cuándo se escribieron o se accedió a los datos, esquemas de datos y una variedad de etiquetas que contienen información sobre el uso y el propietario de los datos.
Los lagos de datos tienen algunas ventajas muy importantes . Una arquitectura de lago de datos permite consolidar los activos de datos de una organización en una ubicación central. Los lagos de datos son agnósticos en cuanto a formato y se basan en formatos de código abierto, como Parquet y Avro. Estos formatos son bien comprendidos por diversas herramientas, controladores y bibliotecas, lo que permite una interoperabilidad sin problemas.
Los lagos de datos se despliegan en subsistemas maduros de almacenamiento en la nube, lo que les permite beneficiarse de la escalabilidad, el monitoreo, la facilidad de implementación y los bajos costes de almacenamiento asociados a estos sistemas. Las herramientas automatizadas de DevOps, como Terraform, tienen controladores bien establecidos, que permiten implementaciones y mantenimiento automatizados.
A diferencia de los almacenes de datos, los lagos de datos admiten todos los tipos de datos, incluidos los semiestructurados y los no estructurados, lo que permite cargas de trabajo como el procesamiento de medios. Debido a sus canales de entrada de alto rendimiento, son muy adecuados para casos de uso de streaming, como la ingesta de datos de sensores IoT, streaming multimedia o flujos de clics web.
Sin embargo, a medida que los lagos de datos se hacen más populares y se utilizan más ampliamente, las organizaciones empezaron a reconocer algunos retos con los lagos de datos tradicionales. Aunque el almacenamiento subyacente en la nube es relativamente barato, la construcción y el mantenimiento de un lago de datos eficaz requiere conocimientos especializados, lo que se traduce en una dotación de personal de alto nivel o en un aumento de los costes de los servicios de consultoría.
Aunque es fácil ingerir datos en su forma bruta, transformar los datos en una forma que pueda aportar valores empresariales puede ser muy costoso. Los lagos de datos tradicionales tienen un rendimiento de consulta de baja latencia, por lo que no pueden utilizarse para consultas interactivas. Como resultado, los equipos de datos de la organización deben seguir transformando y cargando los datos en algo parecido a un almacén de datos, lo que da lugar a un tiempo prolongado de obtención de valor. Esto dio lugar a una arquitectura de lago de datos + almacén. Esta arquitectura siguió dominando el sector durante bastante tiempo (hemos implantado personalmente docenas de estos tipos de sistemas), pero ahora está en declive debido al auge de los lakehouses.
Los lagos de datos suelen utilizar una estrategia de "esquema en lectura", en la que los datos se pueden ingerir en cualquier formato sin que se aplique ningún esquema. Sólo cuando se leen los datos puede aplicarse algún tipo de esquema. Esta falta de aplicación del esquema puede dar lugar a problemas de calidad de los datos, permitiendo que el prístino lago de datos se convierta en un "pantano de datos".
Los lagos de datos no ofrecen ningún tipo de garantía transaccional. Los archivos de datos sólo se pueden añadir, lo que conlleva costosas reescrituras de datos previamente escritos para realizar una simple actualización. Esto conduce a un problema denominado "problema de los archivos pequeños", en el que se crean varios archivos pequeños para una sola entidad. Si este problema no se gestiona bien, estos archivos pequeños ralentizan el rendimiento de lectura de todo el lago de datos, lo que provoca datos obsoletos y almacenamiento desperdiciado. Los administradores del lago de datos tienen que ejecutar operaciones repetidas para consolidar estos archivos pequeños en archivos más grandes optimizados para operaciones de lectura eficientes.
Ahora que hemos discutido en los puntos fuertes y débiles tanto de los almacenes de datos como de los lagos de datos, presentaremos el lago de datos, que combina los puntos fuertes y aborda los puntos débiles de ambas tecnologías.
Data Lakehouse
Armbrust, Ghodsi, Xin y Zaharia introdujeron por primera vez el concepto de lago de datos en 2021. Los autores definen un lakehouse como "un sistema de gestión de datos basado en un almacenamiento de bajo coste y directamente accesible, que también proporciona funciones analíticas de gestión y rendimiento del SGBD, como transacciones ACID, versionado de datos, auditoría, indexación, almacenamiento en caché y optimización de consultas".
Al desgranar esta afirmación, podemos definir un lakehouse como un sistema que fusiona la flexibilidad, el bajo coste y la escala de un lago de datos con la gestión de datos y las transacciones ACID de los almacenes de datos, abordando las limitaciones de ambos. Al igual que los lagos de datos, la arquitectura lakehouse aprovecha los sistemas de almacenamiento en la nube de bajo coste con la flexibilidad inherente y la escalabilidad horizontal de dichos sistemas. El objetivo de un lago de es utilizar los formatos de datos de alto rendimiento existentes, como Parquet, y al mismo tiempo permitir las transacciones ACID (y otras funciones). Para añadir estas capacidades, las casas de lago utilizan un formato de tabla abierta, que añade características como transacciones ACID, operaciones a nivel de registro, indexación y metadatos clave a esos formatos de datos existentes. Esto permite que los activos de datos almacenados en sistemas de almacenamiento de bajo coste tengan la misma fiabilidad que antes era exclusiva del dominio de un RDBMS. Delta Lake es un ejemplo de formato de tabla abierta que admite este tipo de capacidades.
Los Lakehouses son especialmente adecuados para la mayoría, si no todos, los entornos de nube con recursos informáticos y de almacenamiento separados. Diferentes aplicaciones informáticas pueden ejecutarse bajo demanda en nodos informáticos completamente separados, como un clúster Spark, mientras acceden directamente a los mismos datos de almacenamiento. Sin embargo, es concebible que se pueda implementar una casa lago sobre un sistema de almacenamiento local, como el ya mencionado HDFS.
Ventajas de Data Lakehouse
En la Figura 1-4 se muestra una visión general de la arquitectura de la casa del lago .
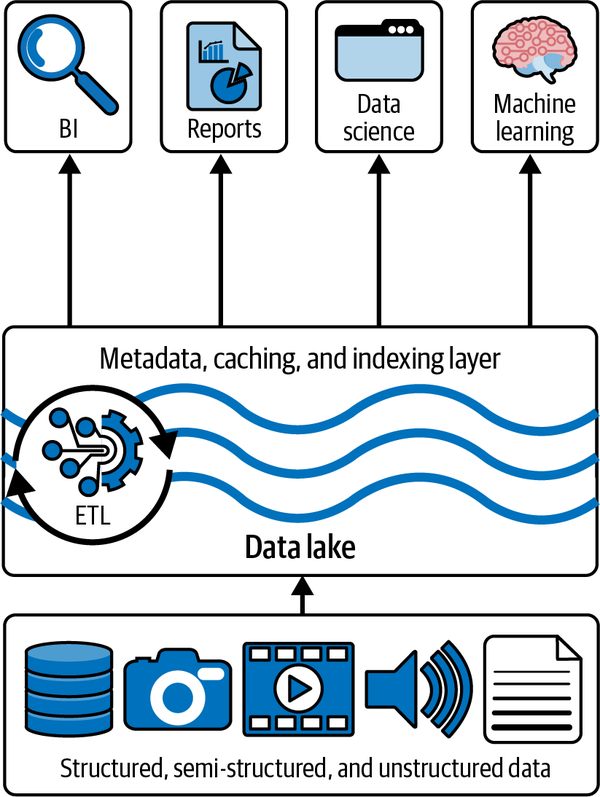
Figura 1-4. Visión general de la arquitectura de Lakehouse
Con la arquitectura Lakehouse, ya no necesitamos tener una copia de nuestros datos en el lago de datos, y otra copia en algún tipo de almacenamiento de almacén de datos. De hecho, podemos obtener nuestros datos del lago de datos a través del formato y protocolo de almacenamiento Delta Lake con un rendimiento comparable al de un almacén de datos tradicional.
Como podemos seguir aprovechando las tecnologías de almacenamiento de bajo coste basadas en la nube y ya no necesitamos copiar los datos del lago de datos a un almacén de datos, podemos conseguir un importante ahorro de costes, tanto en infraestructura como en gastos generales de personal y consultoría.
Como se produce menos movimiento de datos y se simplifica nuestro ETL, se reducen significativamente las oportunidades de que surjan problemas de calidad de los datos y, por último, como el lago combina la capacidad de almacenar grandes volúmenes de datos y modelos dimensionales refinados, se reducen los ciclos de desarrollo y el tiempo de obtención de valor.
En la Figura 1-5 se muestra la evolución de los almacenes de datos a los lagos de datos a una arquitectura de lago.
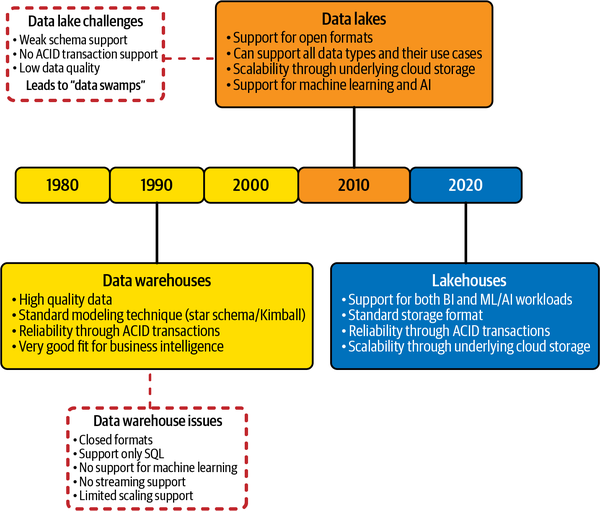
Figura 1-5. Evolución de las arquitecturas de datos
Implantar una casa en el lago
Como hemos mencionado antes, los lakehouses aprovechan almacenes de objetos de bajo coste, como Amazon S3, ADLS o GCS, almacenando los datos de en un formato de tabla de código abierto, como Apache Parquet. Sin embargo, como las implementaciones de lakehouse ejecutan transacciones ACID contra estos datos, necesitamos una capa de metadatos transaccionales sobre el almacenamiento en la nube, que defina qué objetos forman parte de la versión de la tabla.
Esto permitirá a lakehouse implementar en funciones como las transacciones ACID y el versionado dentro de esa capa de metadatos, mientras mantiene el grueso de los datos en el almacenamiento de objetos de bajo coste. El cliente de lakehouse puede seguir utilizando los datos en un formato de código abierto con el que ya está familiarizado.
A continuación, tenemos que abordar el rendimiento del sistema. Como hemos mencionado antes, las implementaciones de los almacenes de datos necesitan que consiga un gran rendimiento SQL para ser eficaces. Los almacenes de datos eran muy buenos para optimizar el rendimiento porque trabajaban con un formato de almacenamiento cerrado y un esquema bien conocido. Esto les permitía mantener estadísticas, crear índices agrupados, mover datos calientes en dispositivos SSD rápidos, etc.
En una lakehouse, que se basa en formatos estándar de código abierto, no podemos darnos ese lujo, ya que no podemos cambiar el formato de almacenamiento. Sin embargo, las lakehouses pueden aprovechar una plétora de otras optimizaciones que dejan inalterados los archivos de datos. Esto incluye el almacenamiento en caché, estructuras de datos auxiliares como índices y estadísticas, y optimizaciones de la disposición de los datos.
La última herramienta que puede acelerar las cargas de trabajo analíticas de es el desarrollo de una API DataFrame estándar. La mayoría de las herramientas de ML más populares, como TensorFlow y Spark MLlib, son compatibles con DataFrames. Los DataFrames fueron introducidos por primera vez por R y pandas, y proporcionan una simple abstracción en forma de tabla de los datos con multitud de operaciones de transformación, la mayoría de las cuales tienen su origen en el álgebra relacional.
En Spark, la API del DataFrame es declarativa, y se utiliza la evaluación perezosa para construir un DAG (grafo acíclico dirigido) de ejecución. Este grafo puede entonces optimizarse antes de que cualquier acción consuma los datos subyacentes en el DataFrame. Esto proporciona a la casa del lago varias características de optimización nuevas, como el almacenamiento en caché y los datos auxiliares. La Figura 1-6 muestra cómo encajan estos requisitos en el diseño general de un sistema Lakehouse.
Dado que el Lago Delta es el centro de atención de este libro, ilustraremos cómo el Lago Delta facilita los requisitos para implantar una casa lacustre.
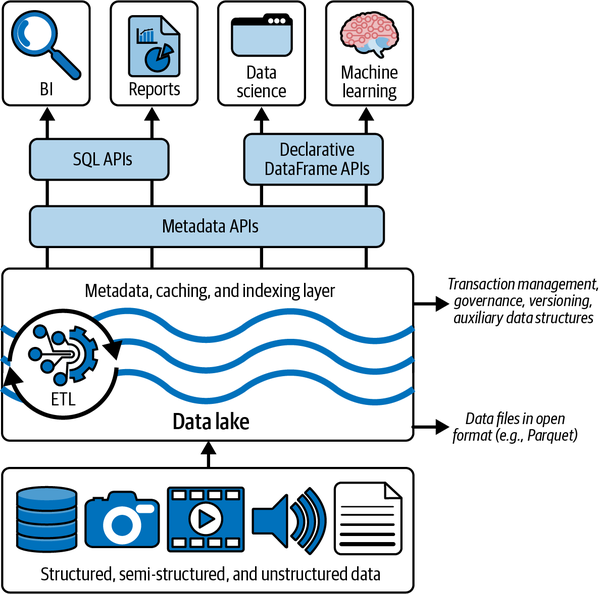
Figura 1-6. Implantación de la casa del lago
Lago Delta
Como se ha mencionado en la sección anterior, se puede construir una posible solución de lago de datos sobre Delta Lake. Delta Lake es un formato de tabla abierta que combina metadatos, almacenamiento en caché e indexación con un formato de almacenamiento de lago de datos. Juntos proporcionan un nivel de abstracción para servir a las transacciones ACID y otras características de gestión.
La capa de metadatos de código abierto y formato de tabla abierta de Delta Lake permite, en última instancia, las implementaciones lakehouse. Delta Lake proporciona transacciones ACID, manejo escalable de metadatos, un modelo de proceso unificado que abarca lotes y streaming, historial completo de auditorías y compatibilidad con sentencias SQL de lenguaje de manipulación de datos (DML). Puede ejecutarse en lagos de datos existentes y es totalmente compatible con varios motores de procesamiento, incluido Apache Spark.
Delta Lake es un marco de código abierto, cuya especificación puede encontrarse en https://delta.io. El trabajo de Armbrust et al. ofrece una descripción detallada de cómo Delta Lake proporciona transacciones ACID.
Delta Lake ofrece las siguientes características:
- Garantías ACID transaccionales
Delta Lake se asegurará de que todos los datos transacciones del lago utilizando Spark, o cualquier otro motor de procesamiento, se comprometan para su durabilidad y se expongan a otros lectores de forma atómica. Esto es posible gracias al registro de transacciones de Delta. En el Capítulo 2 trataremos en detalle el registro de transacciones.
- Soporte completo de DML
Los lagos de datos tradicionales no admiten actualizaciones transaccionales y atómicas de los datos. Delta Lake es totalmente compatible con todas las operaciones DML, incluidas las eliminaciones y actualizaciones, y los escenarios complejos de fusión o inserción de datos. Esta compatibilidad simplifica enormemente la creación de dimensiones y tablas de hechos al construir un almacén de datos moderno (MDW).
- Historial de auditoría
El registro de transacciones de Delta Lake registra todos los cambios realizados en los datos, en el orden en que se hicieron. Por tanto, el registro de transacciones se convierte en la pista de auditoría completa de cualquier cambio realizado en los datos. Esto permite a los administradores y desarrolladores volver a versiones anteriores de los datos tras eliminaciones y ediciones accidentales. Esta función se denomina viaje en el tiempo y se explica con detalle en el Capítulo 6.
- Unificación de batch y streaming en un único modelo de procesamiento
Delta Lake puede trabajar con fuentes o sumideros de flujo por lotes y . Puede realizar FUSIONES en un flujo de datos, que es un requisito común cuando se fusionan datos IoT con datos de referencia de dispositivos. También permite casos de uso en los que recibimos datos CDC de fuentes de datos externas. Trataremos el streaming en detalle en el Capítulo 8.
- Aplicación y evolución del esquema
Delta Lake aplica un esquema cuando escribe o lee datos del lago. Sin embargo, cuando se activa explícitamente para una entidad de datos, permite una evolución segura del esquema, posibilitando casos de uso en los que los datos necesitan evolucionar. La aplicación y la evolución del esquema se tratan en el Capítulo 7.
- Amplio soporte y escalado de metadatos
Tener la capacidad de soportar grandes volúmenes de datos es estupendo, pero si los metadatos no pueden escalar en consecuencia, la solución se quedará corta. Delta Lake escala todas las operaciones de procesamiento de metadatos aprovechando Spark u otros motores informáticos, lo que le permite procesar eficientemente los metadatos de petabytes de datos.
Una arquitectura lakehouse se compone de tres capas, como se muestra en la Figura 1-7. La capa de almacenamiento de Lakehouse se basa en tecnología estándar de almacenamiento en la nube, como ADLS, GCS o el almacenamiento Amazon S3. Esto proporciona a lakehouse una capa de almacenamiento altamente escalable y de bajo coste.
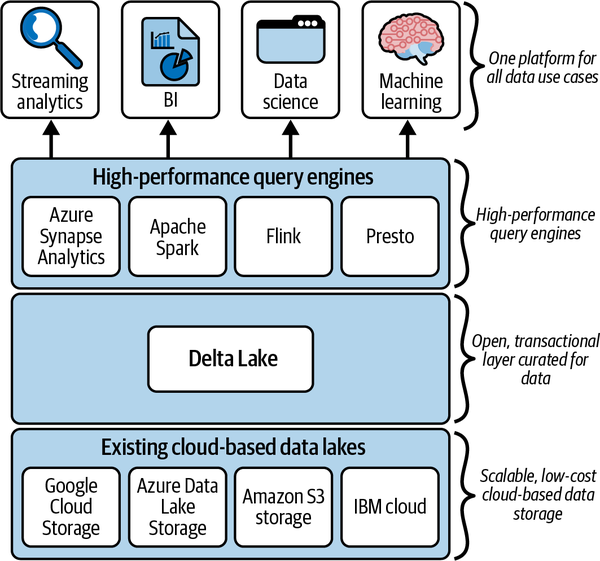
Figura 1-7. Arquitectura en capas de Lakehouse
La capa transaccional de la casa del lago la proporciona Delta Lake. Esto aporta garantías ACID a la casa del lago, permitiendo una transformación eficiente de los datos brutos en datos curados y procesables. Además del soporte ACID, Delta Lake ofrece un rico conjunto de características adicionales, como soporte DML, procesamiento escalable de metadatos, soporte de streaming y un rico registro de auditoría. La capa superior de la pila lakehouse está formada por motores de consulta y procesamiento de alto rendimiento, que aprovechan los recursos informáticos subyacentes de la nube. Los motores de consulta compatibles son:
-
Apache Spark
-
Colmena Apache
-
Presto
-
Trino
Consulta en el sitio web de Delta Lake la lista completa de motores de cálculo compatibles.
La Arquitectura del Medallón
En la Figura 1-8 se muestra un ejemplo de arquitectura de casa lacustre basada en el lago Delta. Este patrón arquitectónico con capas Bronce, Plata y Oro suele denominarse arquitectura medallón. Aunque es sólo uno de los muchos patrones de arquitectura lakehouse, se adapta perfectamente a los almacenes de datos modernos, a los data marts y a otras soluciones analíticas.
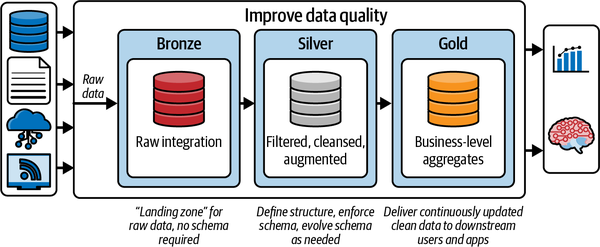
Figura 1-8. Arquitectura de la solución Data Lakehouse
En el nivel más alto, tenemos tres componentes en esta solución. A la izquierda tenemos las distintas fuentes de datos. Una fuente de datos puede adoptar muchas formas; aquí tienes algunos ejemplos:
-
Un conjunto de archivos CSV o TXT en un lago de datos externo
-
Una base de datos local, como Oracle o SQL Server
-
Fuentes de datos en streaming, como Kafka o Azure Event Hubs
-
API REST de un servicio SAS, como Salesforce o ADP
El componente central implementa la arquitectura medallón. Una arquitectura medallón es un patrón de diseño de datos que se utiliza para organizar lógicamente los datos en un lago, a través de las capas Bronce, Plata y Oro. La capa Bronce es donde aterrizamos los datos ingeridos desde nuestros sistemas fuente de la izquierda. Los datos de la zona Bronce suelen aterrizarse "tal cual", pero pueden aumentarse con metadatos adicionales, como la fecha y hora de carga, identificadores de procesamiento, etc.
En la capa Plata, los datos de la capa Bronce se limpian, normalizan, fusionan y conforman. Aquí es donde la visión empresarial de los datos de las distintas áreas temáticas se va uniendo gradualmente.
Los datos de la capa Oro son datos "listos para el consumo". Estos datos pueden tener el formato de un esquema en estrella clásico, que contenga dimensiones y tablas de hechos, o pueden estar en cualquier modelo de datos que se ajuste al caso de uso de consumo.
El objetivo de la arquitectura medallón es mejorar la estructura y la calidad de los datos de forma incremental y progresiva a medida que fluyen por cada capa de la arquitectura, teniendo cada capa un propósito inherente. Este patrón de diseño de datos se tratará con mucha más profundidad en el Capítulo 10, pero es importante comprender cómo una casa lago, junto con Delta Lake, puede soportar patrones de diseño de datos fiables y de alto rendimiento, o arquitecturas multisalto. Los patrones de diseño, como la arquitectura medallón, proporcionan algunos de los fundamentos arquitectónicos para unificar tus canalizaciones de datos en una casa del lago con el fin de soportar múltiples casos de uso de (por ejemplo, datos por lotes, datos en streaming y aprendizaje automático).
El Ecosistema del Delta
Como hemos expuesto en este capítulo, Delta Lake nos permite construir arquitecturas de lago de datos, que permiten alojar directamente en un lago de datos las aplicaciones de almacenamiento de datos y aprendizaje automático/AI de . Hoy en día, Delta Lake es el formato de lago de datos más utilizado, y actualmente lo emplean más de 7.000 organizaciones, que procesan exabytes de datos al día.
Sin embargo, los almacenes de datos y las aplicaciones de aprendizaje automático no son el único objetivo de aplicación de Delta Lake. Más allá de su soporte ACID transaccional básico, que aporta fiabilidad a los lagos de datos, Delta Lake nos permite ingerir y consumir sin problemas tanto datos de flujo como de lote con una arquitectura de solución.
Otro componente importante de Delta Lake es Delta Sharing, que permite a las empresas compartir conjuntos de datos de forma segura. Delta Lake 3.0 admite ahora lectores y escritores autónomos, lo que permite a cualquier cliente (Python, Ruby o Rust) escribir datos directamente en Delta Lake sin necesidad de ningún motor de big data, como Spark o Flink. Delta Lake incluye un conjunto ampliado de conectores de código abierto, como Presto, Flink y Trino. La capa de almacenamiento de Delta Lake se utiliza ahora ampliamente en muchas plataformas, como ADLS, Amazon S3 y GCS. Todos los componentes de Delta Lake 2.0 son de código abierto de Databricks.
El éxito de Delta Lake y de las casas del lago ha generado un ecosistema completamente nuevo, construido en torno a la tecnología Delta. Este ecosistema está formado por diversos componentes individuales, como el formato de almacenamiento Delta Lake, Delta Sharing y los Conectores Delta.
Almacenamiento en el lago Delta
El formato de almacenamiento Delta Lake es una capa de almacenamiento de código abierto que se ejecuta sobre los lagos de datos basados en la nube. Añade capacidades transaccionales a los archivos y tablas de los lagos de datos, aportando características similares a las de un almacén de datos a un lago de datos estándar. El almacenamiento Delta Lake es el componente central del ecosistema, porque todos los demás componentes dependen de esta capa.
Compartir Delta
Compartir datos es un caso de uso común en los negocios de . Por ejemplo, una empresa minera podría querer compartir de forma segura la información del IoT de los motores de sus enormes camiones mineros con el fabricante, con fines de mantenimiento preventivo y diagnóstico. Un fabricante de termostatos podría querer compartir de forma segura datos de climatización con una empresa de servicios públicos para optimizar la carga de la red eléctrica en días de alto consumo. Sin embargo, en el pasado, implantar una solución segura y fiable para compartir datos era muy difícil y requería un costoso desarrollo a medida.
Delta Sharing es un protocolo de código abierto para compartir de forma segura grandes conjuntos de datos de Delta Lake. Permite a los usuarios compartir de forma segura datos almacenados en Amazon S3, ADLS o GCS. Con Delta Sharing, los usuarios pueden conectarse directamente a los datos compartidos, utilizando sus herramientas favoritas como Spark, Rust, Power BI, etc., sin tener que implementar ningún componente adicional. Observa que los datos pueden compartirse entre proveedores de nubes, sin ningún desarrollo personalizado.
Compartir Delta permite casos de uso como
-
Los datos almacenados en ADLS pueden ser procesados por un motor Spark en AWS.
-
Los datos almacenados en Amazon S3 pueden ser procesados por Rust en GCP.
Consulta el Capítulo 9 para un análisis detallado del reparto Delta.
Conectores Delta
El objetivo principal de los Conectores Delta3,4 es acercar Delta Lake a otros motores de big data de distintos de Apache Spark. Los Conectores Delta son conectores de código abierto que se conectan directamente a Delta Lake. El marco incluye Delta Standalone, una biblioteca nativa de Java que permite leer y escribir directamente en las tablas de Delta Lake sin necesidad de un clúster de Apache Spark. Las aplicaciones consumidoras pueden utilizar Delta Standalone para conectarse directamente a las tablas Delta escritas por su infraestructura de big data. Esto elimina la necesidad de duplicar los datos en otro formato antes de poder consumirlos.
Hay otras bibliotecas nativas disponibles para:
- Colmena
El Conector Hive lee las tablas Delta directamente de Apache Hive.
- Flink
El Conector Flink/Delta lee y escribe tablas Delta desde la aplicación Apache Flink. El conector incluye un sumidero para escribir en tablas Delta desde Apache Flink, y una fuente para leer tablas Delta utilizando Flink.
- sql-delta-import
Este conector permite importar datos de una fuente de datos JDBC directamente a una tabla Delta.
- Power BI
El conector Power BI es una función personalizada de Power Query que permite a Power BI leer una tabla Delta de cualquier fuente de datos basada en archivos que admita Microsoft Power BI.
Delta Connectors es un ecosistema en rápido crecimiento, con más conectores disponibles regularmente. De hecho, en la recién anunciada versión Delta Lake 3.0 se incluye Delta Kernel. Delta Kernel y sus bibliotecas simplificadas eliminan la necesidad de entender los detalles del protocolo Delta, por lo que hace mucho más fácil construir y mantener conectores.
Conclusión
Dado el volumen, la velocidad, la variedad y la veracidad de los datos, las limitaciones y los retos tanto de los almacenes de datos como de los lagos de datos han impulsado un nuevo paradigma de arquitecturas de datos. La arquitectura de lago, establecida por los avances en formatos de tabla abierta como Delta Lake, proporciona una arquitectura de datos moderna que aprovecha los mejores elementos de sus predecesoras para aportar un enfoque unificado a una plataforma de datos.
Como se menciona en el Prefacio, este libro hará algo más que arañar la superficie; se sumergirá en algunas de las características principales de Delta Lake que ya se han tocado en este capítulo. Aprenderás a configurar Delta Lake de la mejor manera posible, a identificar casos de uso para las distintas funciones, a conocer las buenas prácticas y los distintos aspectos a tener en cuenta, y mucho más. Proporcionará continuamente a los profesionales de los datos contexto y pruebas de cómo este formato de tabla abierta soporta una plataforma de datos moderna en forma de arquitectura de lago. Al final de este libro te sentirás seguro para ponerte en marcha con Delta Lake y construir una arquitectura moderna de lago de datos.
Get Lago Delta: En marcha now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

