Capítulo 4. Almacenamiento de contenedores
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Aunque Kubernetes se inició en el mundo de las cargas de trabajo sin estado, la ejecución de servicios con estado es cada vez más común. Incluso las cargas de trabajo complejas con estado, como las bases de datos y las colas de mensajes, están llegando a los clústeres de Kubernetes. Para soportar estas cargas de trabajo, Kubernetes necesita proporcionar capacidades de almacenamiento más allá de las opciones efímeras. Es decir, sistemas que puedan proporcionar una mayor resistencia y disponibilidad ante diversos acontecimientos, como el fallo de una aplicación o la reprogramación de una carga de trabajo en un host diferente.
En este capítulo vamos a explorar cómo nuestra plataforma puede ofrecer servicios de almacenamiento a las aplicaciones. Empezaremos cubriendo las preocupaciones clave de la persistencia de las aplicaciones y las expectativas del sistema de almacenamiento, antes de pasar a abordar las primitivas de almacenamiento disponibles en Kubernetes. A medida que nos adentremos en necesidades de almacenamiento más avanzadas, recurriremos a la Interfaz de Almacenamiento de Contenedores (CSI), que permite nuestra integración con diversos proveedores de almacenamiento. Por último, exploraremos el uso de un plug-in CSI para proporcionar almacenamiento de autoservicio a nuestras aplicaciones.
Nota
El almacenamiento es un tema muy amplio en sí mismo. Nuestra intención es darte los detalles suficientes para que tomes decisiones informadas sobre el almacenamiento que puedes ofrecer a las cargas de trabajo. Si el almacenamiento no es tu especialidad, te recomendamos que repases estos conceptos con tu equipo de infraestructura/almacenamiento. Kubernetes no niega la necesidad de experiencia en almacenamiento en tu organización.
Consideraciones sobre el almacenamiento
Antes de entrar en los patrones y opciones de almacenamiento de Kubernetes , deberíamos dar un paso atrás y analizar algunas consideraciones clave en torno a las posibles necesidades de almacenamiento. A nivel de infraestructura y aplicación, es importante pensar en los siguientes requisitos.
-
Modos de acceso
-
Ampliación de volumen
-
Aprovisionamiento dinámico
-
Copia de seguridad y recuperación
-
Almacenamiento de bloques, archivos y objetos
-
Datos efímeros
-
Elegir un proveedor
Modos de acceso
Hay tres modos de acceso que pueden admitir las aplicaciones:
- LecturaEscrituraUna Vez (RWO)
-
Un único Pod puede leer y escribir en el volumen.
- SóloLecturaMuchos (ROX)
-
Varios Pods pueden leer el volumen.
- LecturaEscrituraMuchas (RWX)
-
Varios Pods pueden leer y escribir en el volumen.
Para las aplicaciones nativas de la nube, RWO es, con mucho, el patrón más común. Al aprovechar proveedores comunes como Amazon Elastic Block Storage (EBS) o Azure Disk Storage, estás limitado a RWO porque el disco sólo puede estar conectado a un nodo. Aunque esta limitación pueda parecer problemática, la mayoría de las aplicaciones nativas de la nube funcionan mejor con este tipo de almacenamiento, donde el volumen es exclusivamente suyo y ofrece lectura/escritura de alto rendimiento.
Muchas veces, nos encontramos con aplicaciones heredadas que necesitan RWX. A menudo, están construidas para asumir el acceso a un sistema de archivos de red (NFS). Cuando los servicios necesitan compartir estado, suele haber soluciones más elegantes que compartir datos a través de NFS; por ejemplo, el uso de colas de mensajes o bases de datos. Además, si una aplicación desea compartir datos, normalmente es mejor exponerlos a través de una API, en lugar de conceder acceso a su sistema de archivos. Esto hace que muchos casos de uso de RWX sean, a veces, cuestionables. A menos que NFS sea la opción de diseño correcta, los equipos de plataforma pueden enfrentarse a la difícil decisión de ofrecer almacenamiento compatible con RWX o pedir a sus desarrolladores que rediseñen las aplicaciones. Si se decide que es necesario ser compatible con ROX o RWX, hay varios proveedores con los que se puede integrar, como Amazon Elastic File System (EFS) y Azure File Share.
Ampliación de volumen
Con el tiempo, una aplicación puede empezar a llenar su volumen. Esto puede suponer un reto, ya que sustituir el volumen por otro mayor exigiría migrar los datos. Una solución a esto es soportar la expansión del volumen. Desde la perspectiva de un orquestador de contenedores como Kubernetes, esto implica unos cuantos pasos:
-
Solicita almacenamiento adicional al orquestador (por ejemplo, mediante una PersistentVolumeClaim).
-
Amplía el tamaño del volumen a través del proveedor de almacenamiento.
-
Amplía el sistema de archivos para aprovechar el volumen mayor.
Una vez completado, el Pod tendrá acceso al espacio adicional. Esta función depende de nuestra elección del backend de almacenamiento y de si la integración en Kubernetes puede facilitar los pasos anteriores. Exploraremos un ejemplo de expansión de volumen más adelante en este capítulo.
Aprovisionamiento de volumen
Dispones de dos modelos de aprovisionamiento: aprovisionamiento dinámico y estático. El aprovisionamiento estático supone que se crean volúmenes en los nodos para que Kubernetes los consuma. El aprovisionamiento dinámico es cuando un controlador se ejecuta dentro del clúster y puede satisfacer las peticiones de almacenamiento de las cargas de trabajo hablando con un proveedor de almacenamiento. De estos dos modelos, se prefiere el aprovisionamiento dinámico, siempre que sea posible. A menudo, la elección entre los dos es una cuestión de si tu sistema de almacenamiento subyacente tiene un controlador compatible con Kubernetes. Nos sumergiremos en estos controladores más adelante en el capítulo.
Copia de seguridad y recuperación
Las copias de seguridad son uno de los aspectos más complejos del almacenamiento, sobre todo cuando se requieren restauraciones automáticas. En términos generales, una copia de seguridad es una copia de datos que se almacena para utilizarla en caso de pérdida de datos. Normalmente, equilibramos las estrategias de copia de seguridad con las garantías de disponibilidad de nuestros sistemas de almacenamiento. Por ejemplo, aunque las copias de seguridad siempre son importantes, son menos críticas cuando nuestro sistema de almacenamiento tiene una garantía de replicación en la que la pérdida de hardware no supondrá la pérdida de datos. Otra consideración es que las aplicaciones pueden requerir distintos procedimientos para facilitar las copias de seguridad y las restauraciones. La idea de que podemos hacer una copia de seguridad de todo un clúster y restaurarlo en cualquier momento suele ser una perspectiva ingenua o, como mínimo, que requiere montañas de esfuerzo de ingeniería paraconseguirla.
Decidir quién debe responsabilizarse de las copias de seguridad y la recuperación de las aplicaciones puede ser uno de los debates más difíciles dentro de una organización. Podría decirse que ofrecer funciones de restauración como un servicio de plataforma puede ser algo "agradable de tener". Sin embargo, puede rasgarse por las costuras cuando nos adentramos en la complejidad específica de una aplicación; por ejemplo, cuando una aplicación no puede reiniciarse y necesita que se lleven a cabo acciones que sólo conocen los desarrolladores.
Una de las soluciones de copia de seguridad más populares, tanto para el estado de Kubernetes como para el de las aplicaciones, es el Proyecto Velero. Velero puede hacer copias de seguridad de objetos de Kubernetes si deseas migrarlos o restaurarlos entre clústeres. Además, Velero admite la programación de instantáneas de volumen. A medida que profundicemos en las instantáneas de volumen en este capítulo, aprenderemos que la capacidad de programar y gestionar instantáneas no está pensada para nosotros. Es más, a menudo se nos dan las primitivas de las instantáneas, pero necesitamos definir un flujo de orquestación en torno a ellas. Por último, Velero admite ganchos de copia de seguridad y restauración. Estos nos permiten ejecutar comandos en el contenedor antes de realizar la copia de seguridad o la recuperación. Por ejemplo, algunas aplicaciones pueden requerir la detención del tráfico o la activación de una descarga antes de realizar una copia de seguridad. Esto es posible utilizando ganchos en Velero.
Dispositivos de bloques y almacenamiento de archivos y objetos
Los tipos de almacenamiento que esperan nuestras aplicaciones son clave para seleccionar el almacenamiento subyacente adecuado y la integración de Kubernetes. El tipo de almacenamiento más utilizado por las aplicaciones es el almacenamiento de archivos. El almacenamiento de archivos es un dispositivo de bloques con un sistema de archivos encima. Esto permite a las aplicaciones escribir en archivos de la forma que conocemos en cualquier sistema operativo.
Subyacente a un sistema de archivos hay un dispositivo de bloques. En lugar de establecer un sistema de archivos encima, podemos ofrecer el dispositivo de forma que las aplicaciones puedan comunicarse directamente con el bloque en bruto. Los sistemas de archivos añaden inherentemente sobrecarga a la escritura de datos. En el desarrollo de software moderno, es bastante raro preocuparse por la sobrecarga del sistema de archivos. Sin embargo, si tu caso de uso justifica la interacción directa con dispositivos de bloque en bruto, esto es algo que pueden soportar ciertos sistemas de almacenamiento.
El último tipo de almacenamiento es el almacenamiento de objetos. El almacenamiento de objetos se diferencia de los archivos en que no existe la jerarquía convencional. El almacenamiento de objetos permite a los desarrolladores tomar datos no estructurados, darles un identificador único, añadir algunos metadatos a su alrededor y almacenarlos. Los almacenes de objetos de proveedores en la nube, como Amazon S3, se han convertido en lugares populares para que las organizaciones alojen imágenes, binarios y mucho más. Esta popularidad se ha visto acelerada por su completa API web y su control de acceso. Lo más habitual es interactuar con los almacenes de objetos desde la propia aplicación, donde ésta utiliza una biblioteca para autenticarse e interactuar con el proveedor. Como hay menos estandarización en torno a las interfaces para interactuar con los almacenes de objetos, es menoshabitual verlos integrados como servicios de plataforma con los que las aplicaciones pueden interactuar de forma transparente.
Datos efímeros
Aunque el almacenamiento puede implicar un nivel de persistencia que está más allá del ciclo de vida de un Pod, existen casos de uso válidos para soportar el uso de datos efímeros. Por defecto, los contenedores que escriben en su propio sistema de archivos utilizarán almacenamiento efímero. Si el contenedor se reiniciara, este almacenamiento se perdería. El tipo de volumen emptyDir está disponible para el almacenamiento efímero resistente a los reinicios. No sólo es resistente a los reinicios del contenedor, sino que puede utilizarse para compartir archivos entre contenedores del mismo Pod.
El mayor riesgo con los datos efímeros es asegurarte de que tus Pods no consumen demasiada capacidad de almacenamiento del host. Aunque cifras como 4Gi por Pod pueden no parecer mucho, ten en cuenta que un nodo puede ejecutar cientos, y en algunos casos miles, de Pods. Kubernetes admite la capacidad de limitar la cantidad acumulada de almacenamiento efímero disponible para los Pods en un Espacio de Nombres. La configuración de estos aspectos se trata en el Capítulo 12.
Elegir un proveedor de almacenamiento
No faltan proveedores de almacenamiento a tu disposición. Las opciones van desde soluciones de almacenamiento que podrías gestionar tú mismo, como Ceph, hasta sistemas totalmente gestionados, como Google Persistent Disk o Amazon Elastic Block Store. La variedad de opciones va mucho más allá del alcance de este libro. Sin embargo, recomendamos comprender las capacidades de los sistemas de almacenamiento junto con cuáles de esas capacidades se integran fácilmente con Kubernetes. Esto te dará una perspectiva sobre lo bien que una solución puede satisfacer los requisitos de tu aplicación en relación con otra. Además, en el caso de que gestiones tu propio sistema de almacenamiento, considera la posibilidad de utilizar algo con lo que tengas experiencia operativa siempre que sea posible. Introducir Kubernetes junto a un nuevo sistema de almacenamiento añade mucha complejidad operativa nueva a tu organización.
Primitivas de almacenamiento de Kubernetes
Fuera de la caja, Kubernetes proporciona múltiples primitivas para soportar el almacenamiento de cargas de trabajo. Estas primitivas proporcionan los bloques de construcción que utilizaremos para ofrecer soluciones de almacenamiento sofisticadas. En esta sección, vamos a tratar PersistentVolumes, PersistentVolumeClaims y StorageClasses utilizando un ejemplo de asignación de almacenamiento rápido preaprovisionado a contenedores.
Volúmenes persistentes y reclamaciones
Los volúmenes y las reclamaciones son la base del almacenamiento en Kubernetes. Se exponen mediante las APIs PersistentVolume y PersistentVolumeClaim. El recurso PersistentVolume representa un volumen de almacenamiento conocido por Kubernetes. Supongamos que un administrador ha preparado un nodo para ofrecer 30Gi de almacenamiento rápido, en el host. Supongamos también que el administrador ha aprovisionado este almacenamiento en /mnt/fast-disk/pod-0. Pararepresentar este volumen en Kubernetes, el administrador puede crear un objeto PersistentVolume:
apiVersion:v1kind:PersistentVolumemetadata:name:pv0spec:capacity:storage:30GivolumeMode:FilesystemaccessModes:-ReadWriteOncestorageClassName:local-storagelocal:path:/mnt/fast-disk/pod-0nodeAffinity:required:nodeSelectorTerms:-matchExpressions:-key:kubernetes.io/hostnameoperator:Invalues:-test-w
La cantidad de almacenamiento disponible en este volumen. Se utiliza para determinar si una demanda puede vincularse a este volumen.
Especifica si el volumen es un dispositivo de bloque oun sistema de archivos.

Especifica el modo de acceso del volumen. Incluye
ReadWriteOnce,ReadMany, yReadWriteMany.
Asocia este volumen a una clase de almacenamiento. Se utiliza para asociar una demanda eventual a este volumen.

Identifica a qué nodo debe asociarse este volumen.
Como puedes ver, la PersistentVolume contiene detalles sobre la implementación del volumen. Para proporcionar una capa más de abstracción, se introduce una PersistentVolumeClaim, que se vincula a un volumen apropiado en función de su solicitud. Lo más habitual es que lo defina el equipo de la aplicación, se añada a su Espacio de nombres y se haga referencia a él desde su Pod:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc0spec:storageClassName:local-storageaccessModes:-ReadWriteOnceresources:requests:storage:30Gi---apiVersion:v1kind:Podmetadata:name:task-pv-podspec:volumes:-name:fast-diskpersistentVolumeClaim:claimName:pvc0containers:-name:ml-processerimage:ml-processer-imagevolumeMounts:-mountPath:"/var/lib/db"name:fast-disk
Busca un volumen de la clase
local-storagecon el modo de accesoReadWriteOnce.Se vincula a un volumen con >=
30Gide almacenamiento.Declara a este Pod consumidor de la reclamación PersistentVolumeClaim.
Según la configuración de nodeAffinity del PersistentVolume, el Pod se programará automáticamente en el host en el que esté disponible este volumen. No se requiere ninguna configuración adicional de afinidad por parte del desarrollador.
Este proceso ha demostrado un flujo muy manual de cómo los administradores podrían poner este almacenamiento a disposición de los desarrolladores. Nos referimos a esto como aprovisionamiento estático. Con la automatización adecuada, ésta podría ser una forma viable de exponer el disco rápido de los hosts a los Pods. Por ejemplo, el Aprovisionador estático de volúmenes de persistencia local puede desplegarse en elclúster para detectar el almacenamiento preasignado y exponerlo, automáticamente, como PersistentVolumes. También proporciona algunas capacidades de gestión del ciclo de vida, como la eliminación de datos tras la destrucción del PersistentVolumeClaim.
Advertencia
Existen múltiples formas de conseguir un almacenamiento local que pueden llevarte a una mala práctica. Por ejemplo, puede parecer convincente permitir a los desarrolladores utilizar hostPath en lugar de tener que preaprovisionar un almacenamiento local. hostPath te permite especificar una ruta en el host a la que vincularte en lugar de tener que utilizar un PersistentVolume y un PersistentVolumeClaim. Esto puede suponer un gran riesgo para la seguridad, ya que permite a los desarrolladores vincularse a directorios en el host, lo que puede tener un impacto negativo en el host y en otros Pods. Si deseas proporcionar a los desarrolladores un almacenamiento efímero que pueda soportar el reinicio de un Pod, pero no que el Pod sea eliminado o trasladado a un nodo diferente, puedes utilizar EmptyDir. Esto asignará almacenamiento en el sistema de archivos gestionado por Kube y será transparente para el Pod.
Clases de almacenamiento
En muchos entornos, esperar que los nodos estén preparados de antemano con discos y volúmenes no es realista. Estos casos suelen justificar un aprovisionamiento dinámico, en el que los volúmenes puedan estar disponibles en función de las necesidades de nuestras demandas. Para facilitar este modelo, podemos poner clases de almacenamiento a disposición de nuestros desarrolladores. Éstas se definen mediante la API StorageClass. Suponiendo que tu clúster se ejecuta en AWS y quieres ofrecer volúmenes EBS a los Pods de forma dinámica, se puede añadir la siguiente StorageClass:
apiVersion:storage.k8s.io/v1kind:StorageClassmetadata:name:ebs-standardannotations:storageclass.kubernetes.io/is-default-class:trueprovisioner:kubernetes.io/aws-ebsparameters:type:io2iopsPerGB:"17"fsType:ext4
El nombre de la StorageClass a la que se puede hacer referencia desde las reclamaciones.
Establece esta StorageClass como predeterminada. Si una reclamación no especifica una clase, se utilizará ésta.
Utiliza el aprovisionador
aws-ebspara crear los volúmenes en función de las reclamaciones.Configuración específica del proveedor para saber cómo aprovisionar volúmenes.
Puedes ofrecer diversas opciones de almacenamiento a los desarrolladores poniendo a su disposición varias StorageClasses. Esto incluye admitir más de un proveedor en un único clúster; por ejemplo, ejecutar Ceph junto con VMware vSAN. Alternativamente, puedes ofrecer diferentes niveles de almacenamiento a través del mismo proveedor. Un ejemplo sería ofrecer almacenamiento más barato junto a opciones más caras. Por desgracia, Kubernetes carece de controles granulares para limitar qué clases pueden solicitar los desarrolladores. El control puede implementarse como control de admisión de validación, que se trata en el Capítulo 8.
Kubernetes ofrece una amplia variedad de proveedores, como AWS EBS, Glusterfs, GCE PD, Ceph RBD y muchos más. Históricamente, estos proveedores se implementaban en el árbol. Esto significa que los proveedores de almacenamiento tenían que implementar su lógica en el núcleo del proyecto Kubernetes. A continuación, este código se incorporaba a los componentes del plano de control de Kubernetes correspondientes.
Este modelo tenía varios inconvenientes. Por un lado, el proveedor de almacenamiento no podía gestionarse fuera de banda. Todos los cambios en el proveedor debían estar vinculados a una versión de Kubernetes. Además, todas las implementaciones de Kubernetes incluían código innecesario. Por ejemplo, los clústeres que ejecutaban AWS seguían teniendo el código del proveedor para interactuar con los PD de la CME. Rápidamente se hizo evidente el gran valor de externalizar estas integraciones de proveedores y dejar obsoleta la funcionalidad dentro del árbol. Los controladores FlexVolume eran una especificación de implementación fuera del árbol que inicialmente pretendía resolver este problema. Sin embargo, FlexVolumes se ha puesto en modo de mantenimiento en favor de nuestro siguiente tema, la Interfaz de Almacenamiento de Contenedores (CSI).
La Interfaz de Almacenamiento de Contenedores (CSI)
La Interfaz de Almacenamiento de Contenedores es la respuesta a cómo proporcionamos almacenamiento de bloques y archivos a nuestras cargas de trabajo. Las implementaciones de la CSI se denominan controladores, que tienen los conocimientos operativos para hablar con los proveedores de almacenamiento. Estos proveedores abarcan desde sistemas en la nube, como Google Persistent Disks, hasta sistemas de almacenamiento (como Ceph) implementados y gestionados por ti. Los proveedores de almacenamiento implementan los controladores en proyectos que viven fuera del árbol. Pueden gestionarse completamente fuera de banda del clúster en el que están implementados.
A alto nivel, las implementaciones de CSI presentan un complemento de controlador y un complemento de nodo. Los desarrolladores de controladores CSI tienen mucha flexibilidad a la hora de implementar estos componentes. Normalmente, las implementaciones incluyen los plug-ins de controlador y de nodo en el mismo binario y activan cualquiera de los modos mediante una variable de entorno como X_CSI_MODE. Lo único que se espera es que el controlador se registre con el kubelet y que se implementen los puntos finales de la especificación CSI.
El servicio controlador se encarga de gestionar la creación y eliminación de volúmenes en el proveedor de almacenamiento. Esta funcionalidad se extiende a funciones (opcionales) como la toma de instantáneas de volúmenes y la expansión de volúmenes. El servicio de nodo se encarga de preparar los volúmenes que consumirán los Pods en el nodo. A menudo esto significa configurar los montajes y proporcionar información sobre los volúmenes en el nodo. Tanto el servicio de nodo como el de controlador también implementan servicios de identidad que informan sobre la información del plug-in, sus capacidades y si está en buen estado. Teniendo esto en cuenta, la Figura 4-1 representa una arquitectura de clúster con estos componentes implementados.
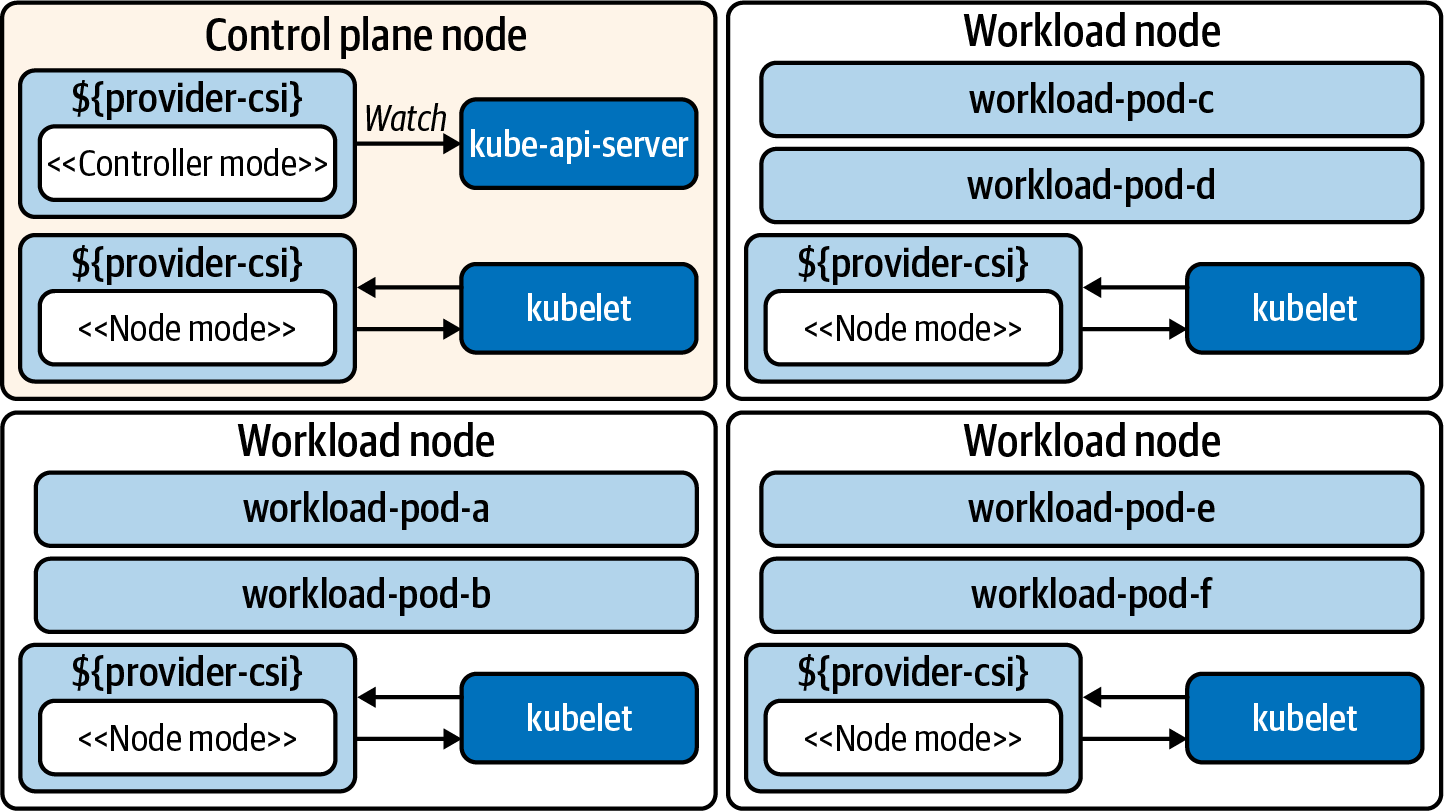
Figura 4-1. Cluster ejecutando un plug-in CSI. El controlador se ejecuta en modo nodo y controlador. El controlador suele ejecutarse como una Implementación. El servicio de nodo se implementa como un DaemonSet, que coloca un Pod en cada host.
Echemos un vistazo más profundo a estos dos componentes, el controlador y el nodo.
Controlador CSI
El servicio Controlador CSI proporciona APIs para gestionar volúmenes en un sistema de almacenamiento persistente. El plano de control de Kubernetes no interactúa directamente con el servicio Controlador CSI. En su lugar, los controladores mantenidos por la comunidad de almacenamiento de Kubernetes reaccionan a los eventos de Kubernetes y los traducen en instrucciones CSI, como CreateVolumeRequest cuando se crea un nuevo PersistentVolumeClaim. Dado que el servicio Controlador CSI expone sus API a través de sockets UNIX, los controladores suelen desplegarse como sidecars junto al servicio Controlador CSI. Hay varios controladores externos, cada uno con un comportamiento diferente:
- proveedor externo
-
Cuando se crea un PersistentVolumeClaims, éste solicita la creación de un volumen al controlador CSI. Una vez creado el volumen en el proveedor de almacenamiento, este proveedor crea un objeto PersistentVolume en Kubernetes.
- sujetador externo
-
Observa los objetos VolumeAttachment, que declaran que un volumen debe adjuntarse o separarse de un nodo. Envía la solicitud de conexión o desconexión al controlador CSI.
- resizer externo
-
Detecta cambios de tamaño de almacenamiento en PersistentVolumeClaims. Envía solicitudes de ampliación al controlador CSI.
- capturador externo
-
Cuando se crean objetos VolumeSnapshotContent, se envían solicitudes de instantáneas al controlador.
Nota
Al implementar plug-ins CSI, los desarrolladores no están obligados a utilizar los controladores mencionados. Sin embargo, se recomienda su uso para evitar la duplicación de lógica en cada complemento CSI.
Nodo CSI
El complemento Nodo suele ejecutar en el mismo código de controlador que el complemento controlador. Sin embargo, al ejecutarse en "modo nodo" se centra en tareas como montar volúmenes adjuntos, establecer su sistema de archivos y montar volúmenes en Pods. La solicitud de estos comportamientos se realiza a través del kubelet. Junto con el controlador, suelen incluirse en el Pod los siguientes sidecars:
- nodo-controlador-registrador
-
Envía una solicitud de registro al kubelet para que conozca el controlador CSI.
- liveness-probe
Implantar el almacenamiento como servicio
Ya hemos cubierto las consideraciones clave para el almacenamiento de aplicaciones, las primitivas de almacenamiento disponibles en Kubernetes, y la integración de controladores mediante el CSI. Ahora es el momento de reunir estas ideas y examinar una implementación que ofrezca a los desarrolladores el almacenamiento como servicio. Queremos proporcionar una forma declarativa de solicitar almacenamiento y ponerlo a disposición de las cargas de trabajo. También preferimos hacerlo dinámicamente, sin necesidad de que un administrador preaprovisione y adjunte volúmenes. Más bien, nos gustaría conseguirlo bajo demanda en función de las necesidades de las cargas de trabajo.
Para empezar con esta implementación, utilizaremos Amazon Web Services (AWS). Este ejemplo se integra con el sistema de almacenamiento de bloques elástico de AWS. Si tu elección de proveedor es diferente, ¡la mayor parte de este contenido seguirá siendo relevante! Simplemente estamos utilizando este proveedor como ejemplo concreto de cómo encajan todas las piezas.
A continuación vamos a sumergirnos en la instalación de la integración/driver, la exposición de las opciones de almacenamiento a los desarrolladores, el consumo del almacenamiento con cargas de trabajo, el cambio de tamaño de los volúmenes y la toma de instantáneas de volumen.
Instalación
La instalación es un proceso bastante sencillo que consta de dos pasos clave:
-
Configura el acceso al proveedor.
-
Implementa los componentes del controlador en el clúster.
El proveedor, en este caso AWS, exigirá al conductor que se identifique, asegurándose de que tiene el acceso adecuado. En este caso, tenemos tres opciones disponibles. Una es actualizar el perfil de instancia de los nodos Kubernetes. Esto evitará que nos preocupemos de las credenciales a nivel de Kubernetes, pero proporcionará privilegios universales a las cargas de trabajo que puedan llegar a la API de AWS. La segunda opción, y probablemente la más segura, es introducir un servicio de identidad que pueda proporcionar permisos IAM a cargas de trabajo específicas. Un proyecto que es un ejemplo de esto es kiam. Este enfoque se trata en el Capítulo 10. Por último, puedes añadir credenciales en un secreto que se monta en el controlador CSI. En este modelo, el secreto tendría el siguiente aspecto:
apiVersion:v1kind:Secretmetadata:name:aws-secretnamespace:kube-systemstringData:key_id:"AKIAWJQHICPELCJVKYNU"access_key:"jqWi1ut4KyrAHADIOrhH2Pd/vXpgqA9OZ3bCZ"
Advertencia
Esta cuenta tendrá acceso a la manipulación de un sistema de almacenamiento subyacente. El acceso a este secreto debe gestionarse cuidadosamente. Consulta el Capítulo 7 para más información.
Con esta configuración, se pueden instalar los componentes CSI. En primer lugar, el controlador se instala como una Implementación. Cuando se ejecuten varias réplicas, utilizará la elección del líder para determinar qué instancia debe estar activa. A continuación, se instala el complemento de nodo, que viene en forma de un DaemonSet que ejecuta un Pod en cada nodo. Una vez inicializadas, las instancias del complemento de nodo se registrarán con sus kubelets. A continuación, el kubelet informará del nodo habilitado para CSI creando un objeto CSINode para cada nodo Kubernetes. La salida de un clúster de tres nodos es la siguiente:
$kubectl get csinode NAME DRIVERS AGE ip-10-0-0-205.us-west-2.compute.internal197m ip-10-0-0-224.us-west-2.compute.internal179m ip-10-0-0-236.us-west-2.compute.internal198m
Como podemos ver, hay tres nodos en la lista con un controlador registrado en cada nodo. Si examinamos el YAML de un CSINode, veremos lo siguiente:
apiVersion:storage.k8s.io/v1kind:CSINodemetadata:name:ip-10-0-0-205.us-west-2.compute.internalspec:drivers:-allocatable:count:25name:ebs.csi.aws.comnodeID:i-0284ac0df4da1d584topologyKeys:-topology.ebs.csi.aws.com/zone
El número máximo de volúmenes permitidos en este nodo.
Cuando se elija un nodo para una carga de trabajo, este valor se pasará en el CreateVolumeRequest para que el controlador sepa dónde crear el volumen. Esto es importante para los sistemas de almacenamiento en los que los nodos del clúster no tendrán acceso al mismo almacenamiento. Por ejemplo, en AWS, cuando un Pod se programa en una zona de disponibilidad, el Volumen debe crearse en la misma zona.
Además, el controlador está registrado oficialmente en el clúster. Puedes encontrar los detalles en en el objeto CSIDriver:
apiVersion:storage.k8s.io/v1kind:CSIDrivermetadata:name:aws-ebs-csi-driverlabels:app.kubernetes.io/name:aws-ebs-csi-driverspec:attachRequired:truepodInfoOnMount:falsevolumeLifecycleModes:-Persistent
El nombre del proveedor que representa a este controlador. Este nombre estará vinculado a la(s) clase(s) de almacenamiento que ofrezcamos a los usuarios de la plataforma.
Especifica que debe completarse una operación de adjuntar antes demontar los volúmenes.
No necesita pasar metadatos Pod como contexto al establecer un montaje.
El modelo por defecto para aprovisionar volúmenes persistentes. La compatibilidad en línea puede activarse estableciendo esta opción en
Ephemeral. En el modo efímero, se espera que el almacenamiento dure sólo lo que dure el Pod.
Las configuraciones y objetos que hemos explorado hasta ahora son artefactos de nuestro proceso de arranque. El objeto CSIDriver facilita el descubrimiento de los detalles del controlador y se incluyó en el paquete de implementación del controlador. Los objetos CSINode son gestionados por el kubelet. Se incluye un sidecar registrador genérico en el complemento Pod del nodo, que obtiene los detalles del controlador CSI y lo registra en el kubelet. A continuación, el kubelet informa de la cantidad de controladores CSI disponibles en cada host. La Figura 4-2 muestra este proceso de arranque.
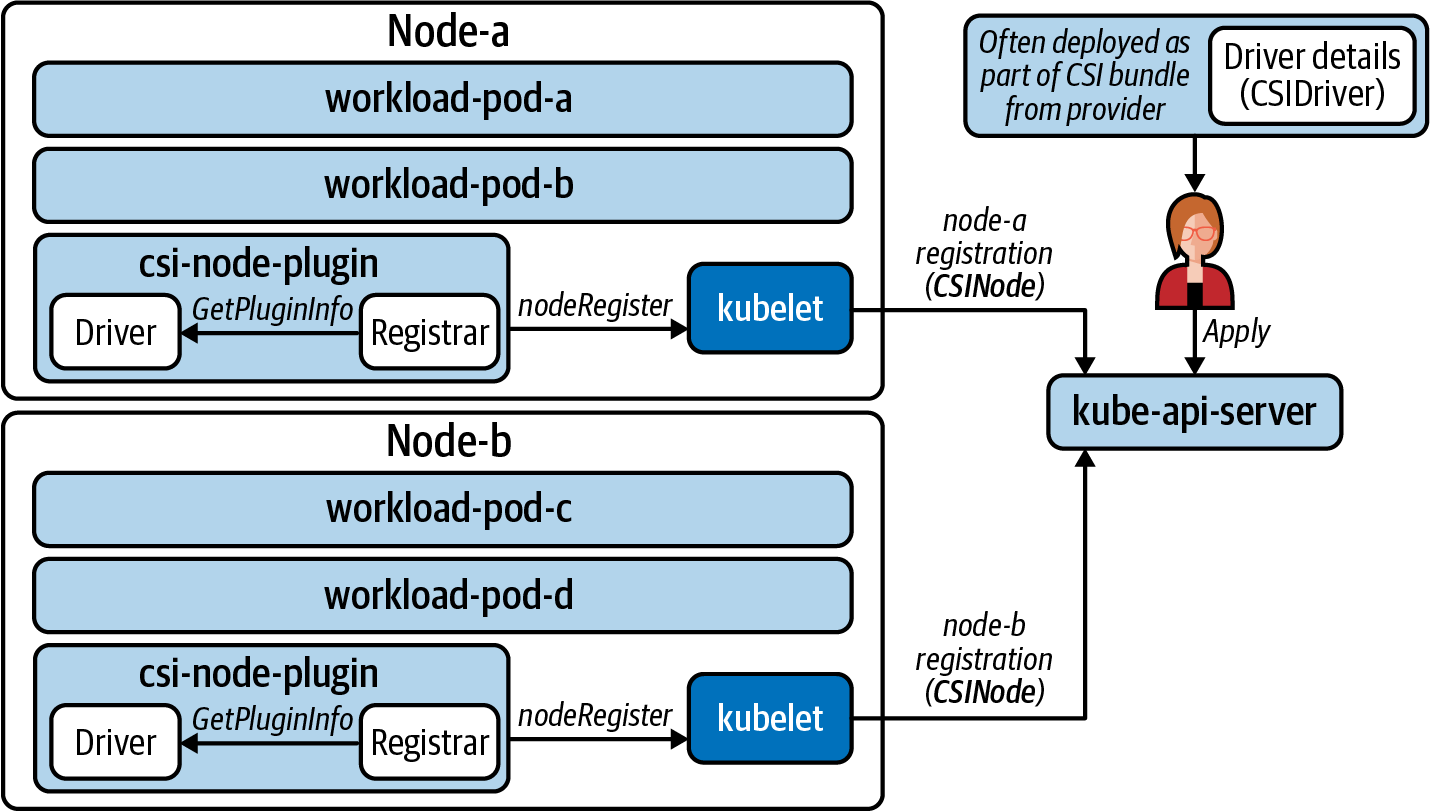
Figura 4-2. El objeto CSIDriver se implementa y forma parte del paquete, mientras que el complemento de nodo se registra en el kubelet. Éste, a su vez, crea/gestiona los objetos CSINode.
Exponer las opciones de almacenamiento
Para ofrecer opciones de almacenamiento a los desarrolladores, necesitamos crear StorageClasses. Para este escenario supondremos que hay dos tipos de almacenamiento que nos gustaría exponer.La primera opción es exponer un disco barato que pueda utilizarse para las necesidades de persistencia de la carga de trabajo. Muchas veces, las aplicaciones no necesitan un SSD, ya que sólo persisten algunos archivos que no requieren una lectura/escritura rápida. Como tal, el disco barato (HDD) será la opción por defecto. Luego nos gustaría ofrecer SSD más rápidos con una configuración personalizada de IOPS por gigabyte. La Tabla 4-1 muestra nuestras ofertas; los precios reflejan los costes de AWS en el momento de escribir esto.
| Nombre de la oferta | Tipo de almacenamiento | Rendimiento máximo por volumen | Coste AWS |
|---|---|---|---|
bloque por defecto |
Disco duro (optimizado) |
40-90 MB/s |
0,045 $ por GB al mes |
bloque de rendimiento |
SSD (io1) |
~1000 MB/s |
0,125 $ por GB al mes + 0,065 $ por IOPS provisionados al mes |
Para crear estas ofertas, crearemos una clase de almacenamiento para cada una. Dentro de cada clase de almacenamiento hay un campo parameters. Aquí es donde podemos configurar los ajustes que satisfagan las características de la Tabla 4-1.
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:default-blockannotations:storageclass.kubernetes.io/is-default-class:"true"provisioner:ebs.csi.aws.comallowVolumeExpansion:truevolumeBindingMode:WaitForFirstConsumerparameters:type:st1---kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:performance-blockprovisioner:ebs.csi.aws.comparameters:type:io1iopsPerGB:"20"
Es el nombre de la oferta de almacenamiento que proporcionamos a los usuarios de la plataforma. Se hará referencia a ella a partir de PeristentVolumeClaims.
Esto establece la oferta por defecto. Si se crea una PersistentVolumeClaim sin especificar una StorageClass, se utilizará
default-block.Mapeo al que debe ejecutarse el controlador CSI.
Permitir la ampliación del tamaño del volumen mediante cambios en una PersistentVolumeClaim.
No aprovisiones el volumen hasta que un Pod consuma el PersistentVolumeClaim. Esto garantizará que el volumen se cree en la zona de disponibilidad adecuada del Pod programado. También evita que los PVC huérfanos creen volúmenes en AWS, por los que se te facturará.

Especifica qué tipo de almacenamiento debe adquirir el controlador para satisfacer las reclamaciones.

Consumir almacenamiento
Con las piezas anteriores en su sitio, ya estamos preparados para que los usuarios consuman estas diferentes clases de almacenamiento. Empezaremos examinando la experiencia del desarrollador al solicitar almacenamiento. Luego recorreremos los aspectos internos de cómo se satisface. Para empezar, veamos lo que obtiene un desarrollador al listar las Clases de Almacenamiento disponibles:
$kubectl get storageclasses.storage.k8s.io NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE default-block(default)ebs.csi.aws.com Delete Immediate performance-block ebs.csi.aws.com Delete WaitForFirstConsumer ALLOWVOLUMEEXPANSIONtruetrue
Advertencia
Al permitir a los desarrolladores crear PVCs, les estaremos permitiendo hacer referencia a cualquier StorageClass. Si esto te resulta problemático, puedes plantearte implementar el control de Admisión por Validación para evaluar si las solicitudes son apropiadas. Este tema se trata enel Capítulo 8.
Supongamos que el desarrollador quiere poner a disposición de una aplicación un HDD más barato y un SSD de mayor rendimiento. En este caso, se crean dos PersistentVolumeClaims. Nos referiremos a ellas como pvc0 y pvc1, respectivamente:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc0spec:resources:requests:storage:11Gi---apiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc1spec:resources:requests:storage:14GistorageClassName:performance-block
Esto utilizará la clase de almacenamiento por defecto (
default-block) y asumirá otros valores por defecto como RWO y el tipo de almacenamiento del sistema de archivos.Asegúrate de que se solicita
performance-blockal conductor en lugar dedefault-block.
En función de la configuración de StorageClass, estos dos mostrarán comportamientos de aprovisionamiento diferentes. El almacenamiento de alto rendimiento (de pvc1) se crea como un volumen no conectado en AWS. Este volumen se puede conectar rápidamente y está listo para usar. El almacenamiento predeterminado (de pv0) estará en un estado Pending en el que el clúster esperará hasta que un Pod consuma el PVC para aprovisionar almacenamiento en AWS. Aunque esto requerirá más trabajo para aprovisionar cuando un Pod consuma finalmente la reclamación, ¡no se te facturará por el almacenamiento no utilizado! La relación entre la reclamación en Kubernetes y el volumen en AWS puede verse en la Figura 4-3.
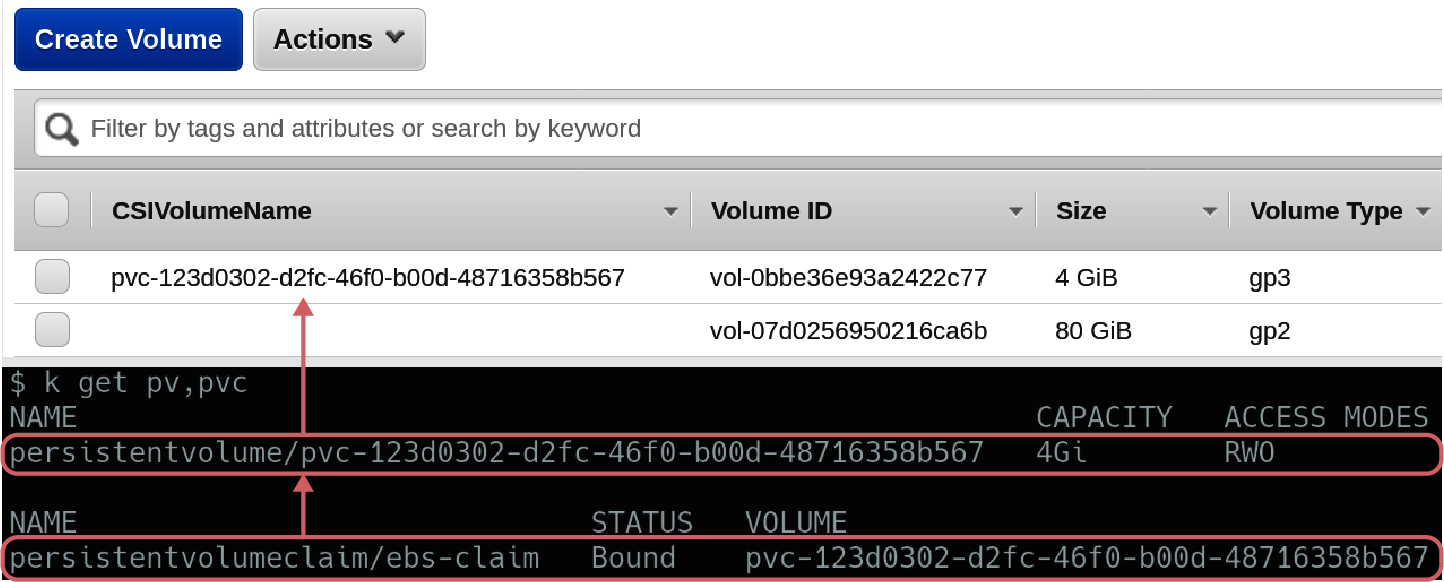
Figura 4-3. pv1 se aprovisiona como volumen en AWS, y el CSIVolumeName se propaga para facilitar la correlación. pv0 no tendrá un volumen respectivo creado hasta que un Pod haga referencia a él.
Supongamos ahora que el desarrollador crea dos Pods. Un Pod hace referencia a pv0 mientras que el otro hace referencia a pv1. Una vez que cada Pod esté programado en un Nodo, el volumen se adjuntará a ese Nodo para su consumo. En el caso de pv0, antes de que esto ocurra también se creará el volumen en AWS. Con los Pods programados y los volúmenes adjuntos, se establece un sistema de archivos y se monta el almacenamiento en el contenedor. Como se trata de volúmenes persistentes, ahora hemos introducido un modelo en el que incluso si el Pod se reprograma en otro nodo, el volumen puede venir con él. El flujo de extremo a extremo de cómo hemos satisfecho la solicitud de almacenamiento de autoservicio se muestra en la Figura 4-4.
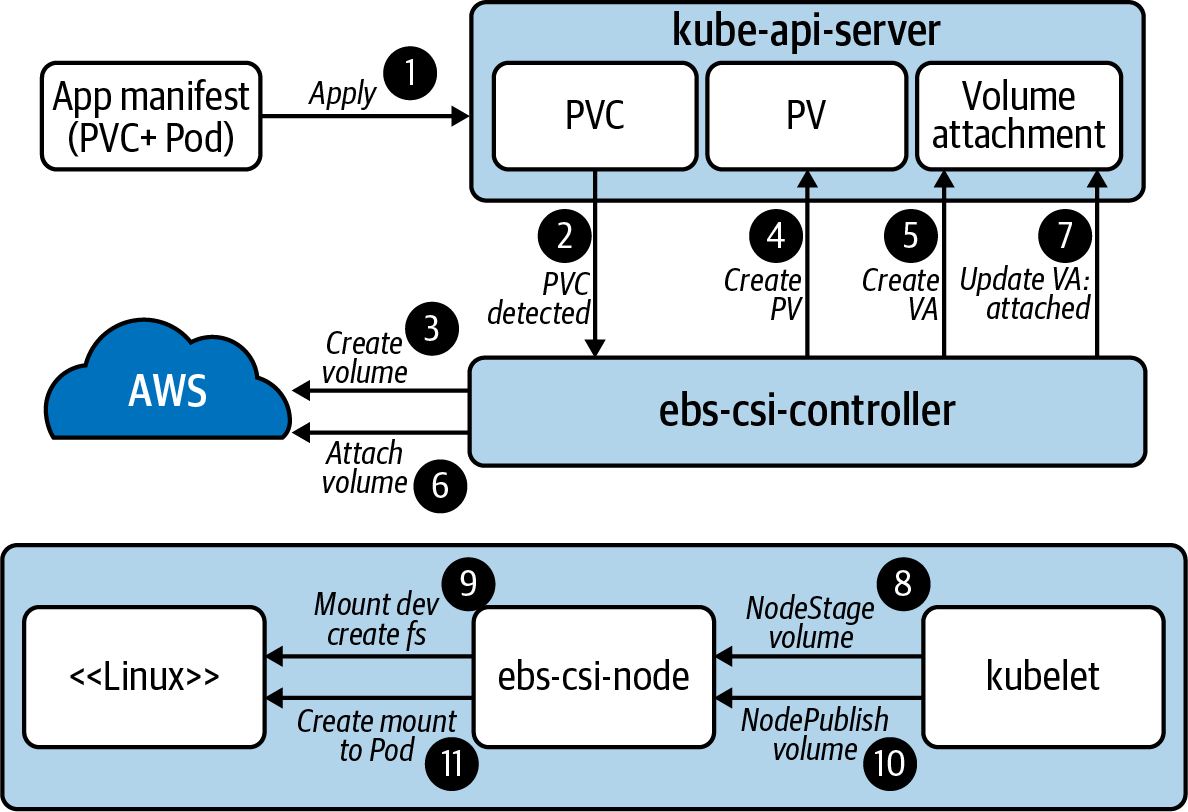
Figura 4-4. Flujo de extremo a extremo del controlador y Kubernetes trabajando juntos para satisfacer la petición de almacenamiento.
Nota
Los eventos son especialmente útiles para depurar la interacción del almacenamiento con el CSI. Dado que el aprovisionamiento, la conexión y el montaje se producen para satisfacer una PVC, debes ver los eventos de estos objetos a medida que los distintos componentes informan de lo que han hecho. kubectl describe -n $NAMESPACE pvc $PVC_NAME es una forma sencilla de ver estos eventos.
Redimensionar
El cambio de tamaño es una función admitida en el controlador aws-ebs-csi-driver. En la mayoría de las implementaciones de CSI, se utiliza el controlador external-resizer para detectar cambios en los objetos PersistentVolumeClaim. Cuando se detecta un cambio de tamaño, se reenvía al controlador, que expandirá el volumen. En este caso, el controlador que se ejecuta en el plug-in del controlador facilitará la expansión con la API de AWS EBS.
Una vez ampliado el volumen en EBS, el nuevo espacio no es inmediatamente utilizable para el contenedor. Esto se debe a que el sistema de archivos sigue ocupando sólo el espacio original. Para que el sistema de archivos se expanda, tendremos que esperar a que la instancia del controlador del complemento de nodo expanda el sistema de archivos. Todo esto puede hacerse sin terminar el Pod. La expansión del sistema de archivos puede verse en los siguientes registros del controlador CSI del plug-in del nodo:
mount_linux.go: Attempting to determine if disk "/dev/nvme1n1" is formatted using blkid with args: ([-p -s TYPE -s PTTYPE -o export /dev/nvme1n1]) mount_linux.go: Output: "DEVNAME=/dev/nvme1n1\nTYPE=ext4\n", err: <nil> resizefs_linux.go: ResizeFS.Resize - Expanding mounted volume /dev/nvme1n1 resizefs_linux.go: Device /dev/nvme1n1 resized successfully
Advertencia
Kubernetes no permite reducir el tamaño de un campo de tamaño de PVC. A menos que el controlador CSI proporcione una solución para esto, es posible que no puedas reducir el tamaño sin volver a crear un volumen. Tenlo en cuenta cuando hagas crecer volúmenes.
Instantáneas
Para facilitar las copias de seguridad periódicas de los datos de volumen utilizados por los contenedores, existe la funcionalidad de instantáneas. La funcionalidad suele estar dividida en dos controladores, responsables de dos CRD diferentes. Los CRDs son VolumeSnapshot y VolumeContentSnapshot. A alto nivel, el VolumeSnapshot es responsable del ciclo de vida de los volúmenes. A partir de estos objetos, las VolumeContentSnapshots son gestionadas por el controlador externo-snapshotter. Este controlador suele ejecutarse como un sidecar en el plug-in del controlador del CSI y reenvía las peticiones al controlador.
Nota
En el momento de escribir esto, estos objetos se implementan como CRD y no como objetos de la API de Kubernetes. Esto requiere que el controlador CSI o la distribución de Kubernetes desplieguen las definiciones CRD con antelación.
De forma similar a la oferta de almacenamiento mediante StorageClasses, la instantánea se ofrece introduciendo una clase Instantánea. El siguiente YAML representa esta clase:
apiVersion:snapshot.storage.k8s.io/v1beta1kind:VolumeSnapshotClassmetadata:name:default-snapshotsdriver:ebs.csi.aws.comdeletionPolicy:Delete
En qué controlador delegar la solicitud de instantánea.
Si el VolumeSnapshotContent debe borrarse cuando se borra el VolumeSnapshot. En efecto, podría borrarse el volumen real (dependiendo del soporte del proveedor).
En el Namespace de la aplicación y PersistentVolumeClaim, se puede crear un VolumeSnapshot. Un ejemplo es el siguiente:
apiVersion:snapshot.storage.k8s.io/v1beta1kind:VolumeSnapshotmetadata:name:snap1spec:volumeSnapshotClassName:default-snapshotssource:persistentVolumeClaimName:pvc0
Especifica la clase, que informa al controlador que debe utilizar.
Especifica la demanda de volumen, que informa del volumen que se va a instantanear.
La existencia de este objeto informará de la necesidad de crear un objeto VolumeSnapshotContent. Este objeto tiene un alcance de todo el clúster. La detección de un objeto VolumeSnapshotContent provocará una solicitud para crear una instantánea y el controlador la satisfará comunicándose con AWS EBS. Una vez satisfecha, la VolumeSnapshot informará de ReadyToUse. La Figura 4-5 muestra la relación entre los distintos objetos.
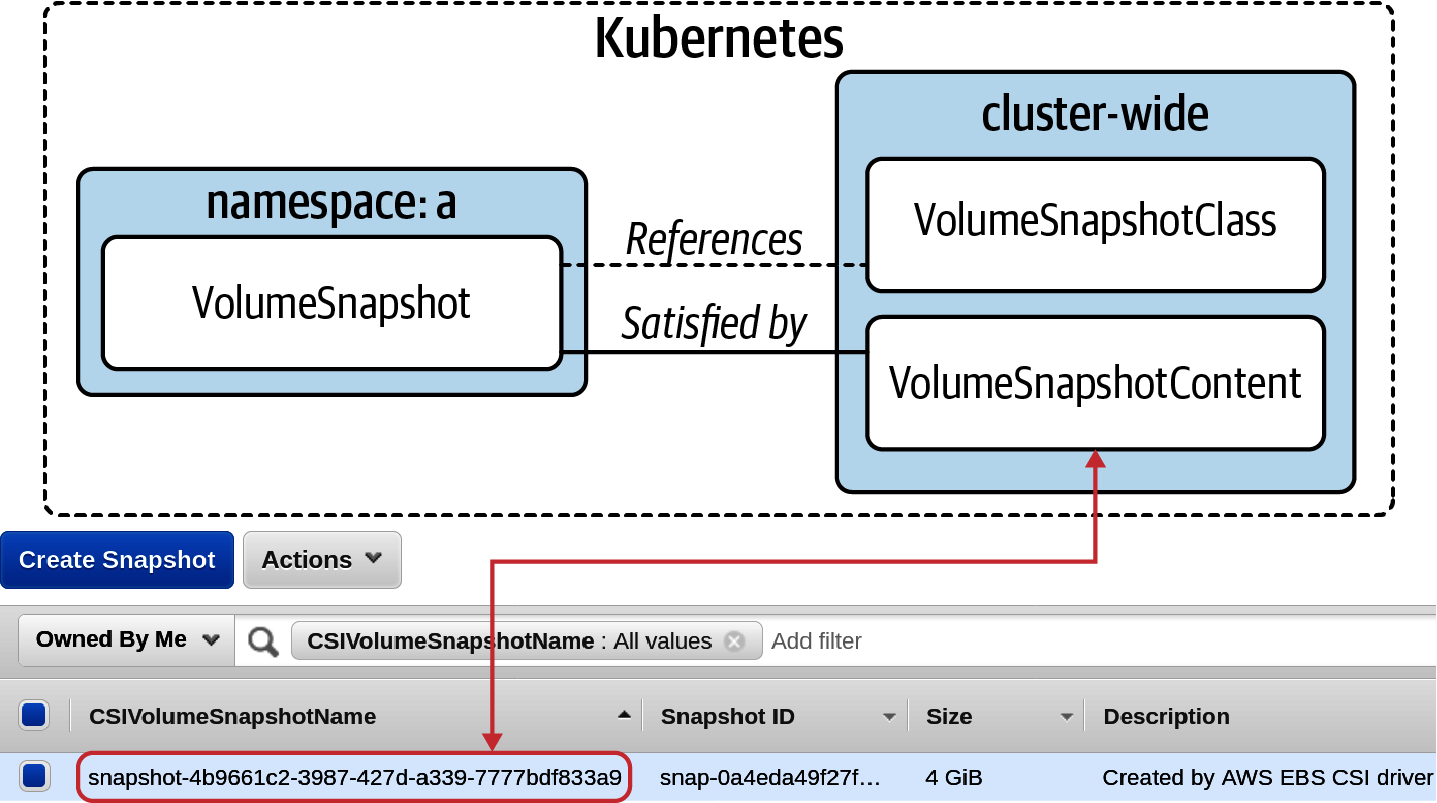
Figura 4-5. Los distintos objetos y sus relaciones que componen el flujo de instantáneas.
Con una instantánea en su lugar, podemos explorar un escenario de pérdida de datos. Tanto si el volumen original se borró accidentalmente, sufrió un fallo o se eliminó debido a un borrado accidental de un PersistentVolumeClaim, podemos restablecer los datos. Para ello, se crea una nueva PersistentVolumeClaim con el spec.dataSource especificado. dataSource admite la referencia a un VolumeSnapshot que puede rellenar los datos en la nueva reclamación. El siguiente manifiesto recupera la instantánea creada anteriormente:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:pvc-reclaimspec:accessModes:-ReadWriteOncestorageClassName:default-blockresources:requests:storage:600GidataSource:name:snap1kind:VolumeSnapshotapiGroup:snapshot.storage.k8s.io
La instancia de VolumeSnapshot que hace referencia a la instantánea de EBS para rellenar el nuevo PVC.
Una vez recreado el Pod para hacer referencia a esta nueva demanda, ¡el último estado instantáneo volverá al contenedor! Ahora tenemos acceso a todas las primitivas para crear una solución robusta de copia de seguridad y recuperación. Las soluciones pueden ir desde programar instantáneas mediante un CronJob, escribir un controlador personalizado o utilizar herramientas como Velero para realizar copias de seguridad de objetos Kubernetes junto con volúmenes de datos de forma programada.
Resumen
En este capítulo, hemos explorado diversos temas relacionados con el almacenamiento en contenedores. En primer lugar, queremos tener un conocimiento profundo de los requisitos de la aplicación para informar mejor nuestra decisión técnica. Después, queremos asegurarnos de que nuestro proveedor de almacenamiento subyacente puede satisfacer estas necesidades y de que tenemos la experiencia operativa (cuando sea necesario) para manejarlo. Por último, debemos establecer una integración entre el orquestador y el sistema de almacenamiento, que garantice que los desarrolladores puedan obtener el almacenamiento que necesitan sin ser expertos en un sistema de almacenamiento subyacente.
Get Kubernetes de producción now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

