Capítulo 1. Kubeflow: Qué es y a quién va dirigido
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Si eres un científico de datos que intenta poner sus modelos en producción, o un ingeniero de datos que intenta que sus modelos sean escalables y fiables, Kubeflow te proporciona herramientas para ayudarte. Kubeflow resuelve el problema de cómo llevar el aprendizaje automático de la investigación a la producción. A pesar de las ideas erróneas más comunes, Kubeflow es más que Kubernetes y TensorFlow: puedes utilizarlo para todo tipo de tareas de aprendizaje automático. Esperamos que Kubeflow sea la herramienta adecuada para ti, siempre que tu organización utilice Kubernetes."Alternativas a Kubeflow" presenta algunas opciones que tal vez desees explorar.
Este capítulo tiene como objetivo ayudarte a decidir si Kubeflow es la herramienta adecuada para tu caso de uso. Cubriremos los beneficios que puedes esperar de Kubeflow, algunos de los costes asociados a él y algunas de las alternativas. Después de este capítulo, nos sumergiremos en la configuración de Kubeflow y en la construcción de una solución de extremo a extremo para que te familiarices con los conceptos básicos.
Ciclo de vida del desarrollo de modelos
El aprendizaje automático o desarrollo de modelos sigue esencialmente el camino: datos → información → conocimiento → perspicacia. Este camino para generar conocimiento a partir de los datos puede describirse gráficamente en la Figura 1-1.
Elciclo de vida de desarrollo del modelo (MDLC) es un término que se utiliza habitualmente para describir el flujo entre el entrenamiento y la inferencia. La Figura 1-1 es una representación visual de esta interacción continua, en la que, al activar una actualización del modelo, todo el ciclo vuelve a ponerse en marcha.
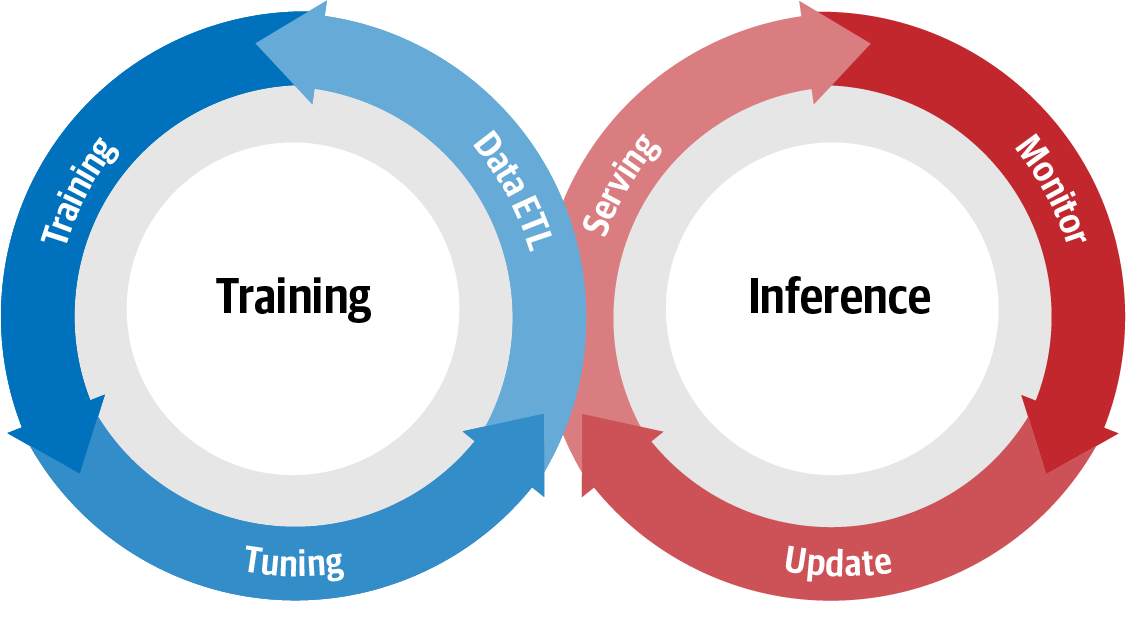
Figura 1-1. Ciclo de vida del desarrollo de modelos
¿Dónde encaja Kubeflow?
Kubeflow es una colección de herramientas nativas de la nube para todas las etapas del MDLC (exploración de datos, preparación de características, entrenamiento/ajuste de modelos, servicio de modelos, pruebas de modelos y versionado de modelos). Kubeflow también tiene herramientas que permiten que estas herramientas, tradicionalmente separadas, trabajen juntas a la perfección. Una parte importante de estas herramientas es el sistema de canalización, que permite a los usuarios construir canalizaciones integradas de extremo a extremo que conectan todos los componentes de su MDLC.
Kubeflow es tanto para los científicos de datos como para los ingenieros de datos que buscan construir implementaciones de aprendizaje automático de nivel de producción. Kubeflow se puede ejecutar localmente en tu entorno de desarrollo o en un clúster de producción. A menudo, las canalizaciones se desarrollarán localmente y se migrarán una vez que estén listas. Kubeflow proporciona un sistema unificado que aprovecha Kubernetes para la contenerización y la escalabilidad, para la portabilidad y la repetibilidad de sus canalizaciones.
¿Por qué contenerizar?
El aislamiento que proporcionan los contenedores permite que las etapas del aprendizaje automático sean portátiles y reproducibles. Las aplicaciones en contenedores están aisladas del resto de tu máquina y tienen todos sus requisitos incluidos (desde el sistema operativo hacia arriba).1 La contenedorización significa que se acabaron las conversaciones que incluyen "Funcionó en mi máquina" o "Ah, sí, nos olvidamos sólo de uno, necesitas este paquete extra".
Los contenedores se construyen en capas componibles, lo que te permite utilizar otro contenedor como base.Por ejemplo, si tienes una nueva biblioteca de procesamiento del lenguaje natural (PLN) que quieres utilizar, puedes añadirla sobre el contenedor existente; no tienes que empezar de cero cada vez. La componibilidad te permite reutilizar una base común; por ejemplo, los contenedores R y Python que utilizamos comparten un contenedor base Debian.
Una preocupación común sobre el uso de contenedores es la sobrecarga. La sobrecarga de los contenedores depende de tu implementación, pero un documento de IBM2 encontró que la sobrecarga es bastante baja, y generalmente más rápida que la virtualización. Con Kubeflow, hay una sobrecarga adicional de por tener instalados operadores que puede que no utilices. Esta sobrecarga es insignificante en un clúster de producción, pero puede ser notable en un ordenador portátil.
Consejo
Los científicos de datos con experiencia en Python pueden pensar en los contenedores como en un entorno virtual pesado. Además de a lo que estás acostumbrado en un entorno virtual, los contenedores también incluyen el sistema operativo, los paquetes y todo lo demás.
¿Por qué Kubernetes?
Kubernetes es un sistema de código abierto para automatizar la implementación, escalado y gestión de aplicaciones en contenedores en . Permite que nuestras canalizaciones sean escalables sin sacrificar la portabilidad, lo que nos permite evitar encerrarnos en un proveedor de nube específico.3 Además de poder cambiar de una sola máquina a un clúster distribuido, las diferentes etapas de tu pipeline de aprendizaje automático pueden solicitar diferentes cantidades o tipos de recursos. Por ejemplo, tu paso de preparación de datos puede beneficiarse más de la ejecución en varias máquinas, mientras que el entrenamiento de tu modelo puede beneficiarse más de la computación sobre GPUs o unidades de procesamiento tensorial (TPUs). Esta flexibilidad es especialmente útil en entornos de nube, donde puedes reducir tus costes utilizando recursos caros sólo cuando sea necesario.
Por supuesto, puedes construir tus propios conductos de aprendizaje automático en contenedores sobre Kubernetes sin utilizar Kubeflow; sin embargo, el objetivo de Kubeflow es estandarizar este proceso y hacerlo sustancialmente más fácil y eficiente.4 Kubeflow proporciona una interfaz común sobre las herramientas que probablemente utilizarías para tus implementaciones de aprendizaje automático. También facilita la configuración de tus implementaciones para utilizar aceleradores de hardware como las TPU sin cambiar tu código.
Diseño y componentes principales de Kubeflow
En el panorama del aprendizaje automático, existe una variada selección de bibliotecas, conjuntos de herramientas y marcos de trabajo.Kubeflow no pretende reinventar la rueda ni proporcionar una solución única para todos, sino que permite a los profesionales del aprendizaje automático componer y personalizar sus propias pilas en función de sus necesidades específicas. Está diseñado para simplificar el proceso de creación e implementación de sistemas de aprendizaje automático a gran escala. Esto permite a los científicos de datos centrar sus energías en el desarrollo de modelos en lugar de en la infraestructura.
Kubeflow pretende abordar el problema de la simplificación del aprendizaje automático mediante tres características: componibilidad, portabilidad y escalabilidad.
- Composibilidad
-
Los componentes básicos de Kubeflow proceden de herramientas de ciencia de datos que ya son familiares para los profesionales del aprendizaje automático. Pueden utilizarse de forma independiente para facilitar etapas específicas del aprendizaje automático, o componerse juntos para formar pipelines de extremo a extremo.
- Portabilidad
-
Al tener un diseño basado en contenedores y aprovechar Kubernetes y su arquitectura nativa en la nube, Kubeflow no requiere que te ancles a ningún entorno de desarrollo concreto. Puedes experimentar y crear prototipos en tu portátil, e implementarlos en producción sin esfuerzo.
- Escalabilidad
-
Al utilizar Kubernetes, Kubeflow puede escalar dinámicamente según la demanda de tu clúster, cambiando el número y tamaño de los contenedores y máquinas subyacentes.5
La escalabilidad es importante a medida que crece tu conjunto de datos. La portabilidad es importante para evitar la dependencia del proveedor. La componibilidad te da la libertad de mezclar y combinar las mejores herramientas para el trabajo.
Echemos un vistazo rápido a algunos de los componentes de Kubeflow y cómo soportan estas características.
Exploración de datos con cuadernos
El MDLC siempre empieza con la exploración de datos: trazar, segmentar y manipular tus datos para comprender dónde puede existir una posible visión. Una potente herramienta que proporciona las herramientas y el entorno para dicha exploración de datos es Jupyter. Jupyter es una aplicación web de código abierto que permite a los usuarios crear y compartir datos, fragmentos de código y experimentos. Jupyter es popular entre los profesionales del aprendizaje automático debido a su simplicidad y portabilidad.
En Kubeflow, puedes crear instancias de Jupyter que interactúen directamente con tu clúster y sus demás componentes, como se muestra en la Figura 1-2. Por ejemplo, puedes escribir fragmentos de código de entrenamiento distribuido TensorFlow en tu portátil, y poner en marcha un clúster de entrenamiento con sólo unos clics.
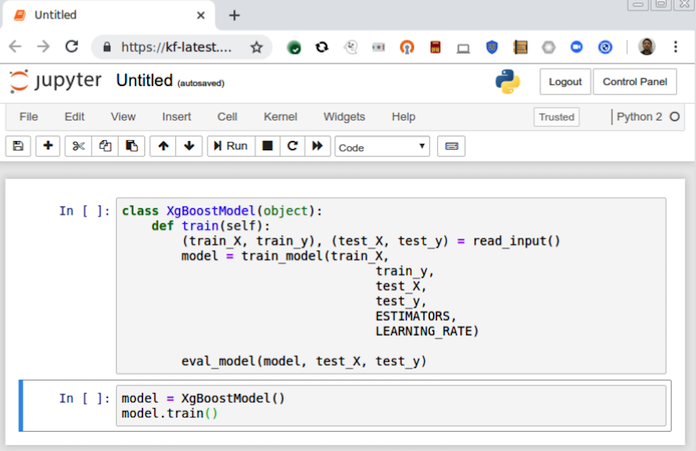
Figura 1-2. Cuaderno Jupyter ejecutándose en Kubeflow
Preparación de datos/características
Los algoritmos de aprendizaje automático requieren buenos datos para ser eficaces, y a menudo se necesitan herramientas especiales de para extraer, transformar y cargar datos con eficacia. Normalmente se filtran, normalizan y preparan los datos de entrada para extraer características útiles de datos que, de otro modo, serían desestructurados y ruidosos. Kubeflow admite algunas herramientas diferentes para ello:
-
Apache Spark (una de las herramientas de big data más populares)
-
Transformación TensorFlow (integrada con TensorFlow Serving para facilitar la inferencia)
Estos distintos componentes de preparación de datos pueden manejar una gran variedad de formatos y tamaños de datos, y están diseñados para adaptarse perfectamente a tu entorno de exploración de datos.6
Nota
La compatibilidad de Apache Beam con Apache Flink en Kubeflow Pipelines es un área de desarrollo activo.
Formación
Una vez preparadas tus características, estás listo para construir y entrenar tu modelo.Kubeflow admite una variedad de marcos de entrenamiento distribuido. En el momento de escribir esto, Kubeflow es compatible con:
En el Capítulo 7 examinaremos con más detalle cómo Kubeflow entrena un modelo TensorFlow, y en el Capítulo 9 exploraremos otras opciones.
Ajuste de hiperparámetros
¿Cómo optimizar la arquitectura y el entrenamiento de tu modelo? En el aprendizaje automático, los hiperparámetros son variables que rigen el proceso de entrenamiento. Por ejemplo, ¿cuál debe ser la tasa de aprendizaje del modelo? ¿Cuántas capas ocultas y neuronas debe tener la red neuronal? Estos parámetros no forman parte de los datos de entrenamiento, pero pueden tener un efecto significativo en el rendimiento de los modelos de entrenamiento.
Con Kubeflow, los usuarios pueden empezar con un modelo de entrenamiento del que no están seguros, definir el espacio de búsqueda de hiperparámetros, y Kubeflow se encargará del resto: realizará trabajos de entrenamiento utilizando diferentes hiperparámetros, recopilará las métricas y guardará los resultados en una base de datos de modelos para poder comparar su rendimiento.
Validación del modelo
Antes de poner tu modelo en producción, es importante saber cómo es probable que funcione.La misma herramienta que se utiliza para el ajuste de hiperparámetros puede realizar una validación cruzada para la validación del modelo. Cuando estés actualizando modelos existentes, se pueden utilizar técnicas como las pruebas A/B y el bandido de brazos múltiples en la inferencia del modelo para validarlo en línea.
Inferencia/Predicción
Después de entrenar tu modelo, el siguiente paso es servir el modelo en tu clúster para que pueda gestionar las solicitudes de predicción.Kubeflow facilita a los científicos de datos la implementación de modelos de aprendizaje automático en entornos de producción a escala. Actualmente, Kubeflow proporciona un componente multiframework para servir modelos (KFServing), además de soluciones existentes como TensorFlow Serving y Seldon Core.
Servir muchos tipos de modelos en Kubeflow es bastante sencillo. En la mayoría de las situaciones, no hay necesidad de construir o personalizar un contenedor: basta con apuntar Kubeflow al lugar donde se almacena tu modelo, y un servidor estará listo para atender las solicitudes.
Una vez servido el modelo, es necesario monitorear su rendimiento y, posiblemente, actualizarlo. Este monitoreo y actualización es posible gracias al diseño nativo en la nube de Kubeflow y se ampliará en Capítulo 8.
Tuberías
Ahora que hemos completado todos los aspectos de MDLC, queremos permitir la reutilización y el gobierno de estos experimentos. Para ello, Kubeflow trata MDLC como un conducto de aprendizaje automático y lo implementa como un grafo, donde cada nodo es una etapa de un flujo de trabajo, como se ve en la Figura 1-3. Kubeflow Pipelines es un componente que permite a los usuarios componer fácilmente flujos de trabajo reutilizables. Entre sus características se incluyen:
-
Un motor de orquestación para flujos de trabajo multipaso
-
Un SDK para interactuar con los componentes del pipeline
-
Una interfaz de usuario que permite a los usuarios visualizar y seguir los experimentos, y compartir los resultados con los colaboradores
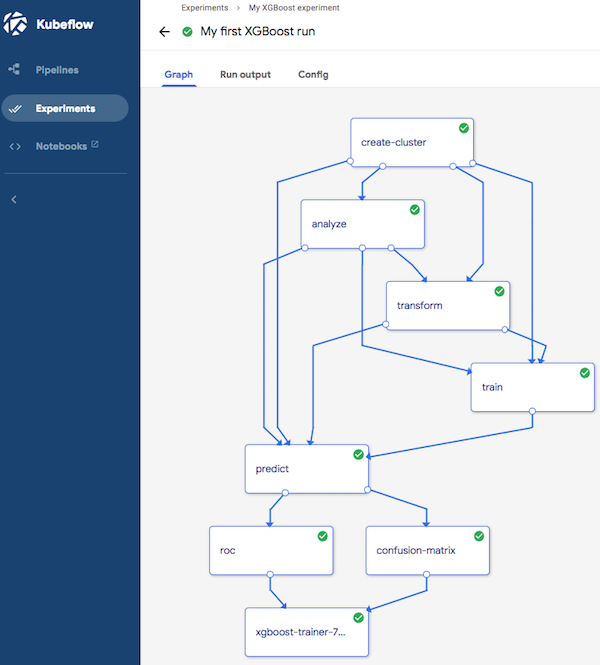
Figura 1-3. Una canalización Kubeflow
Visión general de los componentes
Como puedes ver, Kubeflow tiene componentes incorporados para todas las partes de MDLC: preparación de datos, preparación de características, entrenamiento de modelos, exploración de datos, ajuste de hiperparámetros e inferencia de modelos, así como pipelines para coordinarlo todo. Sin embargo, no estás limitado a los componentes incluidos en Kubeflow. Puedes construir sobre los componentes o incluso sustituirlos. Esto puede estar bien para componentes ocasionales, pero si te encuentras con que quieres sustituir muchas partes de Kubeflow, quizá quieras explorar algunas de las alternativas disponibles.
Alternativas a Kubeflow
Dentro de la comunidad investigadora, existen varias alternativas que proporcionan una funcionalidad singularmente distinta a la de Kubeflow.La mayor parte de la investigación reciente se ha centrado en el desarrollo y la formación de modelos, con grandes mejoras en infraestructura, teoría y sistemas.
En cambio, la predicción y el servicio de modelos han recibido relativamente menos atención. Por ello, los profesionales de la ciencia de datos a menudo acaban hackeando una amalgama de componentes críticos de los sistemas que se integran para soportar el servicio y la inferencia a través de diversas cargas de trabajo y marcos en continua evolución.
Dada la demanda de disponibilidad constante y escalabilidad horizontal, soluciones como Kubeflow y varias otras están ganando tracción en todo el sector, como potentes herramientas de abstracción arquitectónica y como convincentes ámbitos de investigación.
Clipper (RiseLabs)
Una alternativa interesante a Kubeflow es Clipper, un sistema de servicio de predicción de baja latencia y propósito general desarrollado por RiseLabs. En un intento de simplificar la implementación, optimización e inferencia, Clipper tiene un sistema de arquitectura en capas. Mediante varias optimizaciones y su diseño modular, Clipper, consigue predicciones de baja latencia y alto rendimiento a niveles comparables a TensorFlow Serving, en tres modelos TensorFlow de distintos costes de inferencia.
Clipper se divide en dos abstracciones, denominadas acertadamente capas de selección de modelos y de abstracción de modelos. La capa de selección de modelos es bastante sofisticada, ya que utiliza una política adaptativa de selección de modelos en línea y varias técnicas de ensamblaje. Dado que el modelo aprende continuamente de la retroalimentación durante toda la vida de la aplicación, la capa de selección de modelos autocalibra los modelos fallidos sin necesidad de interactuar directamente con la capa de política.
La arquitectura modular de Clipper y su enfoque en la contenedorización, similar al de Kubeflow, permite que los mecanismos de almacenamiento en caché y por lotes se compartan entre los distintos marcos, al tiempo que se aprovechan las ventajas de la escalabilidad, la concurrencia y la flexibilidad a la hora de añadir nuevos marcos de modelos.
Al pasar de la teoría a un sistema funcional de extremo a extremo, Clipper ha ganado adeptos en la comunidad científica y varias partes de sus diseños arquitectónicos se han incorporado a sistemas de aprendizaje automático introducidos recientemente. Sin embargo, aún tenemos que ver si se adoptará en la industria a gran escala.
MLflow (Databricks)
MLflow fue desarrollado por Databricks como plataforma de desarrollo de aprendizaje automático de código abierto.La arquitectura de MLflow aprovecha muchos de los mismos paradigmas arquitectónicos que Clipper, incluida su naturaleza agnóstica respecto al marco de trabajo, al tiempo que se centra en tres componentes principales que denomina Seguimiento, Proyectos y Modelos.
MLflow Tracking funciona como una API con una interfaz de usuario complementaria para registrar parámetros, versiones de código, métricas y archivos de salida. Esto es muy potente en el aprendizaje automático, ya que el seguimiento de parámetros, métricas y artefactos es de suma importancia.
Los Proyectos MLflow proporcionan un formato estándar para empaquetar código reutilizable de ciencia de datos, definido por un archivo YAML que puede aprovechar el código de fuente controlada y la gestión de dependencias a través de Anaconda. El formato de proyecto facilita compartir código reproducible de ciencia de datos, ya que la reproducibilidad es fundamental para los profesionales del aprendizaje automático.
Los Modelos MLflow son una convención para empaquetar modelos de aprendizaje automático en múltiples formatos. Cada Modelo MLflow se guarda como un directorio que contiene archivos arbitrarios y un archivo descriptor MLmodel. MLflow también proporciona el registro del modelo, que muestra el linaje entre los modelos implementados y sus metadatos de creación.
Al igual que Kubeflow, MLflow sigue en desarrollo activo, y cuenta con una comunidad activa.
Otros
Debido a los retos que plantea el desarrollo del aprendizaje automático, muchas organizaciones han empezado a crear plataformas internas para gestionar su ciclo de vida de aprendizaje automático. Por ejemplo: Bloomberg, Facebook, Google, Uber e IBM han construido, respectivamente, la Plataforma de Ciencia de Datos, FBLearner Flow, TensorFlow Extended, Michelangelo y Watson Studio para gestionar la preparación de datos, el entrenamiento de modelos y la implementación.7
Con el panorama de la infraestructura del aprendizaje automático en constante evolución y maduración, nos entusiasma ver cómo los proyectos de código abierto, como Kubeflow, aportarán la simplicidad y abstracción tan necesarias al desarrollo del aprendizaje automático.
Presentación de nuestros casos prácticos
El aprendizaje automático puede utilizar muchos tipos diferentes de datos, y los enfoques y herramientas que utilices pueden variar. Para mostrar las capacidades de Kubeflow, hemos elegido casos prácticos con datos y buenas prácticas muy diferentes. Cuando sea posible, utilizaremos datos de estos casos prácticos para explorar Kubeflow y algunos de sus componentes.
Instituto Nacional de Normas y Tecnología modificado
En ML, el Instituto Nacional Modificado de Normas y Tecnología (MNIST) se refiere habitualmente al conjunto de datos de dígitos escritos a mano para su clasificación. El tamaño relativamente pequeño de los datos de dígitos, así como su uso habitual como ejemplo, nos permite explorar una gran variedad de herramientas. En cierto modo, MNIST se ha convertido en uno de los ejemplos estándar de "hola mundo" para el aprendizaje automático. En el Capítulo 2 utilizamos MNIST como primer ejemplo para ilustrar Kubeflow de principio a fin.
Datos de la lista de correo
Saber hacer buenas preguntas es una especie de arte. ¿Alguna vez has enviado un mensaje a una lista de correo, pidiendo ayuda, y nadie te ha respondido? ¿Cuáles son los distintos tipos de preguntas?Examinaremos algunos de los datos públicos de las listas de correo de la Fundación para el Software Apache e intentaremos crear un modelo que prediga si se responderá a un mensaje. Este ejemplo puede ampliarse y reducirse eligiendo qué proyectos y qué periodo de tiempo queremos analizar, de modo que podemos utilizar diversas herramientas para resolverlo.
Recomendador de productos
Los sistemas de recomendación son una de las aplicaciones más comunes y fáciles de entender del aprendizaje automático, con muchos ejemplos, desde el recomendador de productos de Amazon a las sugerencias de películas de Netflix. La mayoría de las implementaciones de recomendadores se basan en el filtrado colaborativo, es decir, en la suposición de que si la persona A tiene la misma opinión que la persona B sobre un conjunto de temas, es más probable que A comparta la opinión de B sobre otros temas que una tercera persona elegida al azar. Este enfoque se basa en un algoritmo bien desarrollado con bastantes implementaciones, incluida la implementación de TensorFlow/Keras.8
Uno de los problemas de los modelos basados en valoraciones es que no se pueden estandarizar fácilmente para datos con valores objetivo no escalados, como los datos de compra o frecuencia. Este excelente post de Medium muestra cómo convertir esos datos en una matriz de valoración que puede utilizarse para el filtrado colaborativo. Nuestro ejemplo aprovecha los datos y el código de Data Driven Investor y el código descrito en el GitHub de Piyushdharkar. Utilizaremos este ejemplo para explorar cómo construir un modelo inicial en Jupyter y pasar a construir unacanalización de producción.
TC
Mientras escribíamos este libro, el mundo atravesaba la pandemia de COVID-19. Se estaba pidiendo a los investigadores de IA que aplicaran métodos y técnicas para ayudar a los profesionales médicos a comprender la enfermedad. Algunas investigaciones demostraron que las tomografías computarizadas eran más eficaces para la detección precoz que las pruebas RT-PCR (la prueba tradicional del COVID). Sin embargo, los TAC de diagnóstico utilizan dosis bajas de radiación y, por tanto, son "ruidosos", es decir, los TAC son más claros cuando se utiliza más radiación.
Un nuevo artículo propone una solución de código abierto para eliminar el ruido de las tomografías con métodos disponibles en proyectos de código abierto (en lugar de soluciones patentadas aprobadas por la FDA). Ponemos en práctica este enfoque para ilustrar cómo se puede pasar de un artículo académico a una solución del mundo real, para mostrar el valor de Kubeflow para crear investigación reproducible y compartible, y para proporcionar un punto de partida a cualquier lector que quiera contribuir a la lucha contra el COVID-19.
Conclusión
Nos alegra mucho que hayas decidido utilizar este libro para iniciar tus aventuras en Kubeflow. Esta introducción debería haberte dado una idea de Kubeflow y sus capacidades. Sin embargo, como en todas las aventuras, puede llegar un momento en que tu guía no sea suficiente para llevarte a cabo. Afortunadamente, existe una colección de recursos comunitarios donde puedes interactuar con otras personas que siguen caminos similares. Te animamos a que te registres en el espacio de trabajo Slack de Kubeflow, una de las áreas de debate más activas. También existe una lista de correo de debate sobre Kubeflow, así como una página del proyecto Kubeflow.
Consejo
Si quieres explorar rápidamente Kubeflow de extremo a extremo, hay algunoscodelabs de Google que pueden ayudarte.
En el Capítulo 2, instalaremos Kubeflow y lo utilizaremos para entrenar y servir un modelo de aprendizaje automático relativamente sencillo para que te hagas una idea de lo básico.
1 Para más información sobre contenedores, consulta este recurso de Google sobre la nube. En situaciones con GPUs o TPUs, los detalles del aislamiento se vuelven más complicados.
2 W. Felter et al., "An Updated Performance Comparison of Virtual Machines and Linux Containers", 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 29-31 de marzo de 2015, doi: 10.1109/ISPASS.2015.7095802.
3 Kubernetes lo hace proporcionando una capa de orquestación de contenedores. Para más información sobre Kubernetes, consulta su documentación.
4 Spotify consiguió aumentar la tasa de experimentos ~7x; consulta esta entrada del blog Spotify Engineering.
5 Los clusters locales como Minikube están limitados a una máquina, pero la mayoría de los clusters en la nube pueden cambiar dinámicamente el tipo y número de máquinas según sea necesario.
6 Todavía queda algo de trabajo de configuración para que esto funcione, que trataremos en el Capítulo 5.
7 Si quieres explorar más a fondo estas herramientas, dos buenos resúmenes son la entrada del blog de Ian Hellstrom para 2020 y este artículo de Austin Kodra para 2019.
8 Por ejemplo, consulta el GitHub de Piyushdharkar.
Get Kubeflow para el aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

