Kapitel 1. Kubeflow: Was es ist und für wen es ist
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wenn du ein Datenwissenschaftler bist, der versucht, seine Modelle in die Produktion zu bringen, oder ein Dateningenieur, der versucht, seine Modelle skalierbar und zuverlässig zu machen, bietet Kubeflow Werkzeuge, die dir dabei helfen. Entgegen weit verbreiteter Missverständnisse ist Kubeflow mehr als nur Kubernetes und TensorFlow - du kannst es für alle möglichen Aufgaben im Bereich des maschinellen Lernens nutzen. Wir hoffen, dass Kubeflow das richtige Werkzeug für dich ist, solange deine Organisation Kubernetes nutzt."Alternativen zu Kubeflow" stellt dir einige Optionen vor, die du vielleicht erkunden möchtest.
Dieses Kapitel soll dir bei der Entscheidung helfen, ob Kubeflow das richtige Tool für deinen Anwendungsfall ist. Wir gehen auf die Vorteile ein, die du von Kubeflow erwarten kannst, auf die Kosten, die damit verbunden sind, und auf einige Alternativen. Nach diesem Kapitel werden wir uns mit der Einrichtung von Kubeflow und dem Aufbau einer End-to-End-Lösung beschäftigen, um dich mit den Grundlagen vertraut zu machen.
Lebenszyklus der Modellentwicklung
Maschinelles Lernen oder Modellentwicklung folgt im Wesentlichen dem Pfad: Daten → Informationen → Wissen → Erkenntnisse. Dieser Weg der Gewinnung von Erkenntnissen aus Daten kann mit Abbildung 1-1 grafisch beschrieben werden.
DerLebenszyklus der Modellentwicklung (Model Development Life Cycle, MDLC) ist ein Begriff, der häufig verwendet wird, um den Fluss zwischen Training und Inferenz zu beschreiben. Abbildung 1-1 ist eine visuelle Darstellung dieser kontinuierlichen Interaktion, bei der mit der Auslösung einer Modellaktualisierung der gesamte Zyklus von neuem beginnt.
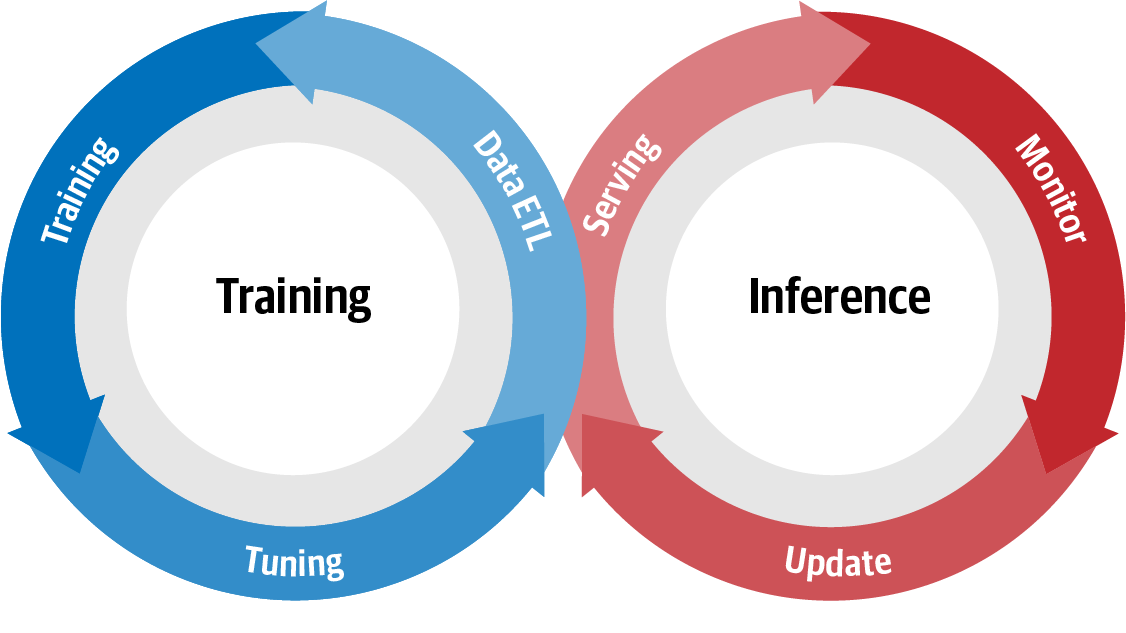
Abbildung 1-1. Lebenszyklus der Modellentwicklung
Wo passt Kubeflow ins Bild?
Kubeflow ist eine Sammlung von cloudbasierten Tools für alle Phasen des MDLC (Datenexploration, Feature-Vorbereitung, Modelltraining/-tuning, Modellbereitstellung, Modelltests und Modellversionierung). Kubeflow verfügt außerdem über Tools, mit denen diese traditionell getrennten Tools nahtlos zusammenarbeiten können. Ein wichtiger Teil dieser Tools ist das Pipeline-System, mit dem Nutzer integrierte End-to-End-Pipelines erstellen können, die alle Komponenten ihres MDLC miteinander verbinden.
Kubeflow richtet sich sowohl an Datenwissenschaftler als auch an Dateningenieure, die produktionsreife Machine-Learning-Implementierungen erstellen wollen. Kubeflow kann entweder lokal in deiner Entwicklungsumgebung oder auf einem Produktionscluster ausgeführt werden. Häufig werden Pipelines lokal entwickelt und migriert, sobald sie fertig sind. Kubeflow bietet ein einheitliches System, das Kubernetes für die Containerisierung und Skalierbarkeit nutzt, um die Portabilität und Wiederholbarkeit seiner Pipelines zu gewährleisten.
Warum containerisieren?
Durch die Isolierung, die Container bieten, können maschinelle Lernphasen portabel und reproduzierbar sein. Containerisierte Anwendungen sind vom Rest deines Rechners isoliert und haben alle ihre Anforderungen (vom Betriebssystem aufwärts) enthalten.1 Containerisierung bedeutet, dass es keine Gespräche mehr gibt, in denen es heißt: "Das hat auf meinem Rechner funktioniert" oder "Ach ja, eins haben wir vergessen, du brauchst dieses zusätzliche Paket."
Container sind in kompatiblen Schichten aufgebaut, so dass du einen anderen Container als Basis verwenden kannst.Wenn du zum Beispiel eine neue Bibliothek für natürliche Sprachverarbeitung (NLP) verwenden möchtest, kannst du sie auf den bestehenden Container aufsetzen - du musst nicht jedes Mal bei Null anfangen. Die Kompatibilität ermöglicht es dir, eine gemeinsame Basis wiederzuverwenden; die R- und Python-Container, die wir verwenden, nutzen beispielsweise beide einen Debian-Basiscontainer.
Eine häufige Sorge bei der Verwendung von Containern ist der Overhead. Der Overhead von Containern hängt von deiner Implementierung ab, aber ein Papier von IBM2 stellte jedoch fest, dass der Overhead recht gering und im Allgemeinen schneller als bei der Virtualisierung ist. Bei Kubeflow gibt es einen zusätzlichen Overhead durch die Installation von Operatoren, die du vielleicht nicht brauchst. Dieser Overhead ist auf einem Produktionscluster vernachlässigbar, kann sich aber auf einem Laptop bemerkbar machen.
Tipp
Datenwissenschaftler/innen mit Python-Erfahrung können sich Container wie eine virtuelle Umgebung für den harten Einsatz vorstellen. Zusätzlich zu dem, was du von einer virtuellen Umgebung gewohnt bist, enthalten Container auch das Betriebssystem, die Pakete und alles, was dazwischen liegt.
Warum Kubernetes?
Kubernetes ist ein Open-Source-System zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen. Es ermöglicht die Skalierbarkeit unserer Pipelines, ohne die Portabilität zu beeinträchtigen, so dass wir uns nicht an einen bestimmten Cloud-Provider binden müssen.3 Neben der Möglichkeit, von einer einzelnen Maschine zu einem verteilten Cluster zu wechseln, können verschiedene Phasen deiner Machine Learning Pipeline unterschiedliche Mengen oder Arten von Ressourcen anfordern. So kann es für die Datenaufbereitung sinnvoll sein, auf mehreren Rechnern zu arbeiten, während für das Modelltraining die Nutzung von GPUs oder Tensor Processing Units (TPUs) sinnvoller ist. Diese Flexibilität ist besonders in Cloud-Umgebungen nützlich, wo du deine Kosten senken kannst, indem du teure Ressourcen nur bei Bedarf nutzt.
Du kannst natürlich auch ohne Kubeflow deine eigenen Container-Pipelines für maschinelles Lernen in Kubernetes erstellen. Das Ziel von Kubeflow ist es jedoch, diesen Prozess zu standardisieren und ihn wesentlich einfacher und effizienter zu machen.4 Kubeflow bietet eine gemeinsame Schnittstelle zu den Tools, die du wahrscheinlich für deine Machine Learning-Implementierungen verwenden wirst. Es macht es auch einfacher, deine Implementierungen so zu konfigurieren, dass sie Hardwarebeschleuniger wie TPUs nutzen, ohne dass du deinen Code ändern musst.
Das Design und die Kernkomponenten von Kubeflow
In der Landschaft des maschinellen Lernens gibt es eine große Auswahl an Bibliotheken, Tools und Frameworks.Kubeflow versucht nicht, das Rad neu zu erfinden oder eine Einheitslösung zu bieten, sondern ermöglicht es Praktikern des maschinellen Lernens, ihre eigenen Stacks nach ihren spezifischen Bedürfnissen zusammenzustellen und anzupassen. Es wurde entwickelt, um die Entwicklung und den Einsatz von Machine-Learning-Systemen in großem Maßstab zu vereinfachen. So können Datenwissenschaftler/innen ihre Energie auf die Modellentwicklung statt auf die Infrastruktur konzentrieren.
Kubeflow versucht, das Problem der Vereinfachung des maschinellen Lernens durch drei Merkmale anzugehen: Zusammensetzbarkeit, Portabilität und Skalierbarkeit.
- Zusammensetzbarkeit
-
Die Kernkomponenten von Kubeflow stammen aus Data-Science-Tools, mit denen Machine-Learning-Experten bereits vertraut sind. Sie können unabhängig voneinander verwendet werden, um bestimmte Phasen des maschinellen Lernens zu erleichtern, oder sie können zusammengefügt werden, um End-to-End-Pipelines zu bilden.
- Tragbarkeit
-
Da Kubeflow auf Containern basiert und die Vorteile von Kubernetes und seiner Cloud-nativen Architektur nutzt, bist du nicht an eine bestimmte Entwicklungsumgebung gebunden. Du kannst auf deinem Laptop experimentieren und Prototypen erstellen, die du dann mühelos in der Produktion einsetzen kannst.
- Skalierbarkeit
-
Durch die Verwendung von Kubernetes kann Kubeflow dynamisch skalieren, indem es die Anzahl und Größe der zugrunde liegenden Container und Maschinen an die Anforderungen deines Clusters anpasst.5
Diese Funktionen sind für verschiedene Bereiche von MDLC entscheidend. Skalierbarkeit ist wichtig, wenn dein Datenbestand wächst. Portabilität ist wichtig, damit du nicht an einen bestimmten Anbieter gebunden bist. Die Kompatibilität gibt dir die Freiheit, die besten Tools für die jeweilige Aufgabe zu kombinieren.
Werfen wir einen kurzen Blick auf einige der Komponenten von Kubeflow und wie sie diese Funktionen unterstützen.
Datenexploration mit Notebooks
MDLC beginnt immer mit der Datenexploration - dem Plotten, Segmentieren und Manipulieren deiner Daten, um zu verstehen, wo mögliche Erkenntnisse liegen könnten. Ein leistungsfähiges Tool, das die Werkzeuge und die Umgebung für eine solche Datenexploration bereitstellt, ist Jupyter. Jupyter ist eine Open-Source-Webanwendung, mit der Nutzer Daten, Codeschnipsel und Experimente erstellen und teilen können. Jupyter ist wegen seiner Einfachheit und Übertragbarkeit bei den Praktikern des maschinellen Lernens sehr beliebt.
In Kubeflow kannst du Jupyter-Instanzen erstellen, die direkt mit deinem Cluster und seinen anderen Komponenten interagieren, wie in Abbildung 1-2 dargestellt. So kannst du zum Beispiel auf deinem Laptop Schnipsel von verteiltem TensorFlow-Trainingscode schreiben und mit ein paar Klicks einen Trainingscluster starten.
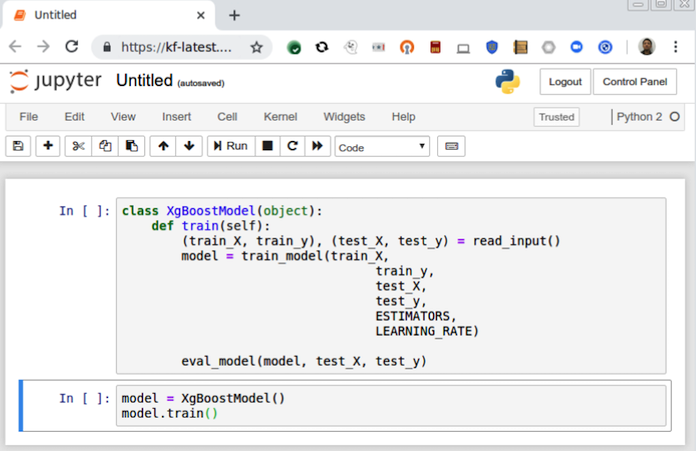
Abbildung 1-2. Jupyter-Notebook, das in Kubeflow läuft
Daten/Feature-Vorbereitung
Algorithmen für maschinelles Lernen benötigen gute Daten, um effektiv zu sein, und oft werden spezielle Tools benötigt, um Daten effektiv zu extrahieren, zu transformieren und zu laden. In der Regel werden die Eingabedaten gefiltert, normalisiert und aufbereitet, um aufschlussreiche Merkmale aus unstrukturierten, verrauschten Daten zu extrahieren. Kubeflow unterstützt dafür ein paar verschiedene Tools:
-
Apache Spark (eines der beliebtesten Big-Data-Tools)
-
TensorFlow Transform (integriert mit TensorFlow Serving für einfachere Inferenz)
Diese verschiedenen Datenaufbereitungskomponenten können mit einer Vielzahl von Formaten und Datengrößen umgehen und sind so konzipiert, dass sie sich gut in deine Datenexplorationsumgebung einfügen.6
Hinweis
Die Unterstützung von Apache Beam mit Apache Flink in Kubeflow Pipelines ist ein Bereich aktiver Entwicklung.
Ausbildung
Sobald deine Features vorbereitet sind, kannst du dein Modell erstellen und trainieren.Kubeflow unterstützt eine Vielzahl von verteilten Trainingsframeworks. Zum Zeitpunkt der Erstellung dieses Artikels bietet Kubeflow Unterstützung für:
In Kapitel 7 werden wir genauer untersuchen, wie Kubeflow ein TensorFlow-Modell trainiert, und in Kapitel 9 werden wir andere Optionen untersuchen.
Hyperparameter-Abstimmung
Wie optimierst du deine Modellarchitektur und das Training? Beim maschinellen Lernen sind Hyperparameter Variablen, die den Trainingsprozess bestimmen. Wie hoch sollte zum Beispiel die Lernrate des Modells sein? Wie viele versteckte Schichten und Neuronen sollte das neuronale Netz haben? Diese Parameter sind nicht Teil der Trainingsdaten, aber sie können einen erheblichen Einfluss auf die Leistung der Trainingsmodelle haben.
Mit Kubeflow können Nutzer/innen mit einem Trainingsmodell beginnen, bei dem sie sich nicht sicher sind, und den Hyperparameter-Suchraum definieren. Kubeflow kümmert sich dann um den Rest - es erstellt Trainingsaufträge mit verschiedenen Hyperparametern, sammelt die Metriken und speichert die Ergebnisse in einer Modelldatenbank, damit ihre Leistung verglichen werden kann.
Modellvalidierung
Bevor du dein Modell in Betrieb nimmst, ist es wichtig zu wissen, wie es voraussichtlich abschneiden wird.Mit demselben Tool, das für die Abstimmung der Hyperparameter verwendet wird, kannst du auch eine Kreuzvalidierung zur Modellvalidierung durchführen. Wenn du bestehende Modelle aktualisierst, können Techniken wie A/B-Tests und mehrarmige Banditen bei der Modellinferenz verwendet werden, um dein Modell online zu validieren.
Schlussfolgerung/Vorhersage
Nach dem Training deines Modells besteht der nächste Schritt darin, das Modell in deinem Cluster zu serven, damit es Vorhersageanfragen bearbeiten kann.Kubeflow macht es Datenwissenschaftlern leicht, Machine-Learning-Modelle in Produktionsumgebungen in großem Umfang einzusetzen. Derzeit bietet Kubeflow eine Multiframework-Komponente für das Model Serving (KFServing), zusätzlich zu bestehenden Lösungen wie TensorFlow Serving und Seldon Core.
Die Bedienung vieler Modelltypen mit Kubeflow ist ziemlich einfach. In den meisten Fällen ist es nicht nötig, selbst einen Container zu bauen oder anzupassen - zeige Kubeflow einfach an, wo dein Modell gespeichert ist, und ein Server steht bereit, um Anfragen zu bedienen.
Sobald das Modell ausgeliefert ist, muss es auf seine Leistung hin überwacht und gegebenenfalls aktualisiert werden. Diese Überwachung und Aktualisierung ist durch das Cloud-native Design von Kubeflow möglich und wird in Kapitel 8 weiter ausgeführt.
Pipelines
Nachdem wir nun alle Aspekte von MDLC abgeschlossen haben, möchten wir die Wiederverwendbarkeit und die Steuerung dieser Experimente ermöglichen. Zu diesem Zweck behandelt Kubeflow MDLC als eine Pipeline für maschinelles Lernen und implementiert sie als einen Graphen, in dem jeder Knoten eine Stufe in einem Workflow darstellt, wie in Abbildung 1-3 zu sehen. Kubeflow Pipelines ist eine Komponente, mit der sich wiederverwendbare Workflows ganz einfach zusammenstellen lassen. Zu ihren Funktionen gehören:
-
Eine Orchestrierungsmaschine für mehrstufige Arbeitsabläufe
-
Ein SDK zur Interaktion mit Pipeline-Komponenten
-
Eine Benutzeroberfläche, die es den Nutzern ermöglicht, Experimente zu visualisieren und zu verfolgen und die Ergebnisse mit Kollegen zu teilen
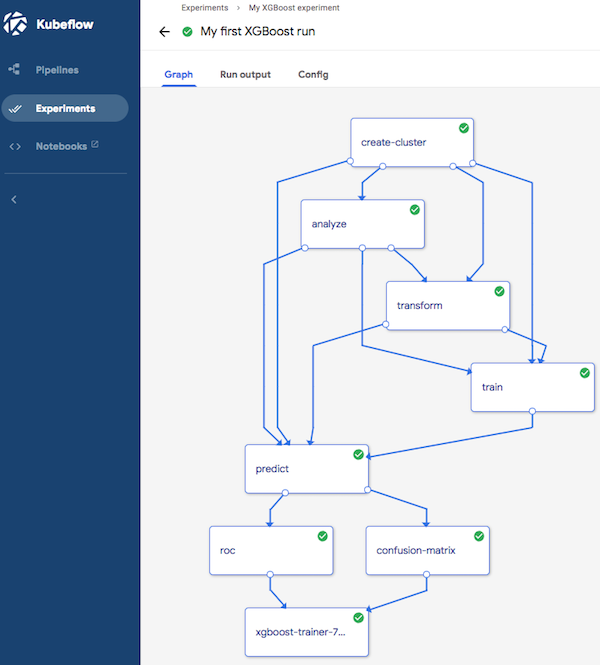
Abbildung 1-3. Eine Kubeflow-Pipeline
Komponentenübersicht
Wie du siehst, verfügt Kubeflow über integrierte Komponenten für alle Teile des MDLC: Datenvorbereitung, Feature-Vorbereitung, Modelltraining, Datenexploration, Hyperparameter-Tuning und Modellinferenz sowie Pipelines, um alles zu koordinieren. Du bist jedoch nicht nur auf die Komponenten beschränkt, die als Teil von Kubeflow geliefert werden. Du kannst auf den Komponenten aufbauen oder sie sogar ersetzen. Wenn du aber viele Teile von Kubeflow ersetzen möchtest, solltest du dich nach Alternativen umsehen.
Alternativen zu Kubeflow
In der Forschungsgemeinschaft gibt es verschiedene Alternativen, die sich in ihrer Funktionalität von Kubeflow unterscheiden.Die jüngste Forschung hat sich auf die Modellentwicklung und -schulung konzentriert, wobei große Verbesserungen in den Bereichen Infrastruktur, Theorie und Systeme erzielt wurden.
Der Vorhersage und dem Modellserving hingegen wurde relativ wenig Aufmerksamkeit geschenkt. Daher müssen Data-Science-Fachleute oft ein Sammelsurium kritischer Systemkomponenten zusammenstellen, die so integriert sind, dass sie das Serving und die Inferenz über verschiedene Workloads und sich ständig weiterentwickelnde Frameworks hinweg unterstützen.
Angesichts der Forderung nach ständiger Verfügbarkeit und horizontaler Skalierbarkeit gewinnen Lösungen wie Kubeflow und verschiedene andere in der gesamten Branche an Zugkraft, als leistungsstarke Architekturabstraktionswerkzeuge und als überzeugende Forschungsbereiche.
Clipper (RiseLabs)
Eine interessante Alternative zu Kubeflow ist Clipper ( ), ein von RiseLabs entwickeltes Allzweck-System für Vorhersagen mit niedriger Latenz. Um den Einsatz, die Optimierung und die Inferenz zu vereinfachen, verfügt Clipper über eine mehrschichtige Architektur. Durch verschiedene Optimierungen und seinen modularen Aufbau erreicht Clipper eine niedrige Latenz und einen hohen Durchsatz bei Vorhersagen, die mit TensorFlow Serving vergleichbar sind, und zwar auf drei TensorFlow-Modellen mit unterschiedlichen Inferenzkosten.
Clipper ist in zwei Abstraktionen unterteilt, die treffend als Modellauswahl- und Modellabstraktionsschicht bezeichnet werden. Die Modellauswahlschicht ist ziemlich ausgeklügelt, da sie eine adaptive Online-Modellauswahlpolitik und verschiedene Ensemble-Techniken verwendet. Da das Modell während der gesamten Lebensdauer der Anwendung kontinuierlich aus Rückmeldungen lernt, kalibriert die Modellauswahlschicht fehlgeschlagene Modelle selbst, ohne dass eine direkte Interaktion mit der Richtlinienschicht erforderlich ist.
Die modulare Architektur von Clipper und der Fokus auf Containerisierung, ähnlich wie bei Kubeflow, ermöglicht die gemeinsame Nutzung von Caching- und Batching-Mechanismen in verschiedenen Frameworks, während gleichzeitig die Vorteile der Skalierbarkeit, Gleichzeitigkeit und Flexibilität beim Hinzufügen neuer Modell-Frameworks genutzt werden können.
Clipper hat sich von der Theorie zu einem funktionsfähigen End-to-End-System entwickelt und hat in der wissenschaftlichen Gemeinschaft an Zugkraft gewonnen, sodass verschiedene Teile seiner Architektur in kürzlich eingeführte maschinelle Lernsysteme integriert wurden. Es bleibt jedoch abzuwarten, ob es in der Industrie in großem Umfang eingesetzt wird.
MLflow (Databricks)
MLflow wurde von Databricks als Open-Source-Entwicklungsplattform für maschinelles Lernen entwickelt.Die Architektur von MLflow nutzt viele der gleichen architektonischen Paradigmen wie Clipper, einschließlich seiner Framework-unabhängigen Natur, und konzentriert sich auf drei Hauptkomponenten, die es Tracking, Projects und Models nennt.
MLflow Tracking funktioniert wie eine API mit einer ergänzenden Benutzeroberfläche für die Protokollierung von Parametern, Codeversionen, Metriken und Ausgabedateien. Das ist beim maschinellen Lernen sehr hilfreich, da die Verfolgung von Parametern, Metriken und Artefakten von größter Bedeutung ist.
MLflow Projects bietet ein Standardformat für die Paketierung von wiederverwendbarem Data-Science-Code, das durch eine YAML-Datei definiert ist, die quellengesteuerten Code und das Abhängigkeitsmanagement über Anaconda nutzen kann. Das Projektformat erleichtert den Austausch von reproduzierbarem Data-Science-Code, denn Reproduzierbarkeit ist für Praktiker des maschinellen Lernens entscheidend.
MLflow-Modelle sind eine Konvention, um Machine-Learning-Modelle in verschiedenen Formaten zu verpacken. Jedes MLflow-Modell wird in einem Verzeichnis gespeichert, das beliebige Dateien und eine MLmodel-Deskriptor-Datei enthält. MLflow stellt auch die Registry des Modells zur Verfügung, in der die Abstammung der eingesetzten Modelle und ihre Erstellungsmetadaten verzeichnet sind.
Wie Kubeflow befindet sich auch MLflow noch in der Entwicklung und hat eine aktive Community.
Andere
Aufgrund der Herausforderungen bei der Entwicklung von maschinellem Lernen haben viele Unternehmen damit begonnen, interne Plattformen aufzubauen, um den Lebenszyklus ihres maschinellen Lernens zu verwalten. Zum Beispiel: Bloomberg, Facebook, Google, Uber und IBM haben die Data Science Platform, FBLearner Flow, TensorFlow Extended, Michelangelo und Watson Studio entwickelt, um die Datenaufbereitung, das Modelltraining und den Einsatz zu verwalten.7
Da sich die Infrastruktur für maschinelles Lernen ständig weiterentwickelt und reift, sind wir gespannt, wie Open-Source-Projekte wie Kubeflow die dringend benötigte Einfachheit und Abstraktion in die Entwicklung von maschinellem Lernen bringen werden.
Einführung in unsere Fallstudien
Beim maschinellen Lernen können viele verschiedene Arten von Daten verwendet werden, und die Ansätze und Werkzeuge, die du einsetzt, können variieren. Um die Fähigkeiten von Kubeflow zu zeigen, haben wir Fallstudien mit sehr unterschiedlichen Daten und bewährten Methoden ausgewählt. Wenn möglich, werden wir Daten aus diesen Fallstudien verwenden, um Kubeflow und einige seiner Komponenten zu erkunden.
Geändertes National Institute of Standards and Technology
Im maschinellen Lernen bezieht sich das Modified National Institute of Standards and Technology (MNIST) üblicherweise auf den Datensatz der handgeschriebenen Ziffern für die Klassifizierung. Die relativ kleine Datenmenge von Ziffern und ihre häufige Verwendung als Beispiel ermöglichen es uns, eine Vielzahl von Werkzeugen zu erforschen. In gewisser Weise ist MNIST zu einem der Standardbeispiele für maschinelles Lernen geworden: "Hallo Welt". Wir verwenden MNIST als erstes Beispiel in Kapitel 2, um Kubeflow von Anfang bis Ende zu veranschaulichen.
Mailinglisten-Daten
Es ist eine Kunst, gute Fragen zu stellen. Hast du schon einmal eine Nachricht an eine Mailingliste geschickt und um Hilfe gebeten, aber niemand hat geantwortet? Welche Arten von Fragen gibt es?Wir werden uns einige der öffentlichen Mailinglisten der Apache Software Foundation ansehen und versuchen, ein Modell zu erstellen, das vorhersagt, ob eine Nachricht beantwortet wird. Dieses Beispiel lässt sich nach oben und unten skalieren, indem wir auswählen, welche Projekte und welchen Zeitraum wir betrachten wollen.
Produktempfehlungsprogramm
Empfehlungssysteme sind eine der häufigsten und am leichtesten verständlichen Anwendungen des maschinellen Lernens, mit vielen Beispielen von Amazons Produktempfehlung bis zu Netflix' Filmvorschlägen. Die meisten Empfehlungssysteme basieren auf kollaborativem Filtern, d. h. auf der Annahme, dass, wenn Person A die gleiche Meinung wie Person B zu einer Reihe von Themen hat, A mit größerer Wahrscheinlichkeit die Meinung von B zu anderen Themen teilt als eine zufällig ausgewählte dritte Person. Dieser Ansatz basiert auf einem gut entwickelten Algorithmus, für den es eine Reihe von Implementierungen gibt, darunter auch eine TensorFlow/Keras-Implementierung.8
Eines der Probleme mit ratingbasierten Modellen ist, dass sie sich nicht einfach für Daten mit nicht skalierten Zielwerten, wie z. B. Kauf- oder Häufigkeitsdaten, standardisieren lassen. Dieser ausgezeichnete Medium-Beitrag zeigt, wie man solche Daten in eine Rating-Matrix umwandelt, die für kollaboratives Filtern verwendet werden kann. Unser Beispiel nutzt die Daten und den Code von Data Driven Investor und den Code, der auf Piyushdharkars GitHub beschrieben ist. Anhand dieses Beispiels werden wir erkunden, wie man ein erstes Modell in Jupyter erstellt und dann mit dem Aufbau einerProduktionspipeline fortfährt.
CT-Scans
Als wir dieses Buch schrieben, erlebte die Welt gerade die COVID-19-Pandemie. KI-Forscherinnen und -Forscher wurden aufgefordert, Methoden und Techniken anzuwenden, um medizinische Dienstleister beim Verständnis der Krankheit zu unterstützen. Einige Untersuchungen zeigten, dass CT-Scans bei der Früherkennung effektiver waren als RT-PCR-Tests (der traditionelle COVID-Test). Diagnostische CT-Scans verwenden jedoch eine geringe Strahlendosis und sind daher "verrauscht" - das heißt, CT-Scans sind deutlicher, wenn mehr Strahlung eingesetzt wird.
In einem neuen Artikel wird eine Open-Source-Lösung für die Entrauschung von CT-Scans mit Standardmethoden aus Open-Source-Projekten vorgeschlagen (im Gegensatz zu proprietären, von der FDA zugelassenen Lösungen). Wir setzen diesen Ansatz um, um zu veranschaulichen, wie man von einem akademischen Artikel zu einer realen Lösung kommt, um den Wert von Kubeflow für die Erstellung reproduzierbarer und gemeinsam nutzbarer Forschungsergebnisse zu zeigen und um einen Ausgangspunkt für alle Leser zu bieten, die einen Beitrag zum Kampf gegen COVID-19 leisten möchten.
Fazit
Wir freuen uns, dass du dich entschieden hast, dieses Buch zu nutzen, um deine Abenteuer mit Kubeflow zu beginnen. Diese Einführung sollte dir ein Gefühl für Kubeflow und seine Möglichkeiten vermittelt haben. Wie bei allen Abenteuern kann jedoch ein Punkt kommen, an dem dein Leitfaden nicht mehr ausreicht, um dich zu begleiten. Zum Glück gibt es eine Reihe von Community-Ressourcen, in denen du dich mit anderen austauschen kannst, die einen ähnlichen Weg eingeschlagen haben. Wir empfehlen dir, dich im Kubeflow-Slack-Arbeitsbereich anzumelden, einem der aktivsten Diskussionsbereiche. Es gibt auch eine Kubeflow-Diskussions-Mailingliste. Außerdem gibt es eine Kubeflow-Projektseite.
Tipp
Wenn du Kubeflow schnell von Anfang bis Ende erkunden willst, gibt es einigeGoogle Codelabs, die dir dabei helfen können.
In Kapitel 2 installieren wir Kubeflow und verwenden es, um ein relativ einfaches Machine-Learning-Modell zu trainieren und zu bedienen, damit du einen Eindruck von den Grundlagen bekommst.
1 Weitere Informationen zu Containern findest du in dieser Google-Cloud-Ressource. In Situationen mit GPUs oder TPUs werden die Details der Isolierung komplizierter.
2 W. Felter et al., "An Updated Performance Comparison of Virtual Machines and Linux Containers", 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), March 29-31, 2015, doi: 10.1109/ISPASS.2015.7095802.
3 Kubernetes stellt dafür eine Container-Orchestrierungsschicht zur Verfügung. Weitere Informationen über Kubernetes findest du in der Dokumentation.
4 Spotify konnte die Rate der Experimente um das 7-fache erhöhen; siehe diesen Blogbeitrag von Spotify Engineering.
5 Lokale Cluster wie Minikube sind auf eine Maschine beschränkt, aber die meisten Cloud-Cluster können die Art und Anzahl der Maschinen je nach Bedarf dynamisch ändern.
6 Damit das funktioniert, müssen noch einige Einstellungen vorgenommen werden, die wir in Kapitel 5 behandeln.
7 Wenn du mehr über diese Tools erfahren möchtest, sind zwei gute Übersichten der Blogbeitrag von Ian Hellstrom aus dem Jahr 2020 und dieser Artikel von Austin Kodra aus dem Jahr 2019.
8 Siehe zum Beispiel Piyushdharkar's GitHub.
Get Kubeflow für maschinelles Lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

