Kapitel 4. Ökonomische Grundlagen der Pipeline
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In den vorangegangenen Kapiteln hast du gelernt, wie du Cloud Compute- und Speicherlösungen konzipierst, die den richtigen Kompromiss zwischen Kosten und Leistung für deine allgemeinen Produktziele darstellen. Damit hast du eine solide Grundlage für ein kosteneffizientes Design.
Der nächste Schritt besteht darin, Datenpipelines zu entwerfen und zu implementieren, die effektiv skalieren, die Verschwendung durch intelligente Nutzung von Technik- und Rechenressourcen einschränken und die Ausfallzeiten der Daten minimieren. Der erste Teil dieses Prozesses umfasst einige grundlegende Designstrategien für Datenpipelines: Idempotenz, Checkpointing, automatische Wiederholungen und Datenvalidierung.
In diesem Kapitel lernst du häufige Probleme in Datenpipelines kennen und erfährst, wie du sie mit diesen vier Strategien entschärfen kannst. Anstatt einfach nur Idempotenz, Checkpointing, Wiederholungen und Datenvalidierung zu definieren, zeige ich dir, wie du diese Strategien in Batch- und Streaming-Umgebungen implementieren kannst, und erkläre dir einige der Kompromisse, die dabei auftreten können. Außerdem erfährst du, wie diese Strategien (oder deren Fehlen) zu realen Misserfolgen und Erfolgen in der Pipeline beigetragen haben.
Entpotenzierung
Der erste Ansatzpunkt ist, deine Pipelines so zu gestalten, dass sie idempotent sind. Idempotenz bedeutet, dass du eine Pipeline wiederholt gegen dieselben Quelldaten laufen lassen kannst und die Ergebnisse genau dieselben sein werden. Das hat nicht nur Vorteile, sondern ist auch eine Voraussetzung für die Implementierung von Wiederholungen, wie du später in diesem Kapitel sehen wirst.
Verhindern von Datenduplizierung
Die Definition von Idempotenz kann variieren, je nachdem, wie die Pipeline-Ausgabe genutzt wird. Eine Möglichkeit, wie du dir Idempotenz vorstellen kannst, ist das Fehlen doppelter Daten, wenn die Pipeline mehrmals mit denselben Quelldaten ausgeführt wird.
Nehmen wir zum Beispiel eine Pipeline, die Daten in eine Datenbank einfügt, indem sie den Datensatz in einer Schleife durchläuft und jede Zeile in die Datenbank einfügt. Wenn ein Fehler auftritt, z. B. eine Netzwerkstörung, die die Verbindung zur Datenbank unterbricht, kannst du nicht feststellen, welcher Teil der Daten in die Datenbank geschrieben wurde und welcher nicht. Wenn du es in diesem Zustand erneut versuchst, könnte die Pipeline doppelte Daten erzeugen.
Um diesen Prozess idempotent zu machen, kannst du die Datenbankeinfügungen in eine Transaktion verpacken und so sicherstellen, dass, wenn eine der Einfügungen fehlschlägt, alle vorherigen Einfügungen zurückgenommen werden.1 Dadurch wird die Möglichkeit von partiellen Schreibvorgängen eliminiert.
Du kannst auch Datensenken erstellen, die doppelte Daten zurückweisen. Wenn du einen eindeutigen Schlüssel für die eingelesenen Daten erstellen kannst, kannst du doppelte Einträge erkennen und entscheiden, wie sie behandelt werden sollen. In diesem Fall musst du absolut sicher sein, dass der von dir erstellte Schlüssel wirklich eindeutig ist, wie z. B. ein natürlicher Schlüssel. Bedenke, dass eindeutige Beschränkungen das Einfügen von Daten verlangsamen können, da die Datenbank die Eindeutigkeit des Schlüssels überprüfen und den Index aktualisieren muss. In spaltenbasierten Datenbanken und Data Lakes kannst du die Eindeutigkeit durch einen Hash erzwingen, der Aktualisierungen und Einfügungen verhindert, wenn der Hash mit vorhandenen Daten übereinstimmt. Einige Data Lakes unterstützen Merge-Schlüssel, wie z. B. Delta Lake Merge, bei denen du einen eindeutigen Schlüssel und Anweisungen für den Umgang mit Übereinstimmungen angeben kannst.
Tipp
Die Reduzierung der Datenduplikation senkt die Kosten, indem sie den Platzbedarf für die Speicherung begrenzt. Je nachdem, wie die Daten genutzt werden, kann dies auch zu Einsparungen bei den Rechnerkosten führen.
Bei der Arbeit mit Cloud-Speicherung kannst du einen Überschreibungsansatz verwenden, der auch als Löschen-Schreiben bekannt ist. Stell dir eine Pipeline vor, die einmal am Tag läuft und Daten in einen Ordner mit dem Namen des aktuellen Datums schreibt. Bevor die Daten geschrieben werden, kann die Pipeline prüfen, ob im Ordner mit dem aktuellen Datum bereits Daten vorhanden sind. Wenn ja, werden die Daten gelöscht und dann die neuen Daten geschrieben. So wird verhindert, dass Daten nur teilweise aufgenommen werden und dass Daten doppelt vorhanden sind.
Bei Streaming-Prozessen kannst du Idempotenz durch eine eindeutige Identifizierung der Nachricht erreichen. Dies kannst du erreichen, indem du den Datenproduzenten so einrichtest, dass er dieselbe ID erstellt, wenn er auf dieselben Daten stößt. Auf der Konsumentenseite kannst du die IDs der Nachrichten, die bereits verarbeitet wurden, aufzeichnen, um zu verhindern, dass eine doppelte Nachricht eingelesen wird.
Vor allem bei Streaming- oder lang laufenden Prozessen solltest du eine dauerhafte Aufzeichnung der Informationen in Betracht ziehen, die du benötigst, um Idempotenz zu gewährleisten. Kafka zum Beispiel speichert Nachrichten auf der Festplatte und stellt so sicher, dass sie auch bei unerwarteten Ausfällen nicht verloren gehen.
Idempotenz kann schwer zu gewährleisten sein, vor allem bei Streaming-Prozessen, bei denen du viele Möglichkeiten hast, wie du Nachrichten behandeln kannst. Behalte deine Strategie für die Nachrichtenbestätigung (Ack) im Hinterkopf: Bestätigst du die Nachrichten, wenn sie aus einer Warteschlange gezogen werden, oder erst, wenn der Verbraucher fertig ist? Eine weitere Überlegung ist, von wo aus deine Konsumenten lesen; ist es immer das Ende des Streams oder gibt es Bedingungen, unter denen du bereits konsumierte Nachrichten erneut lesen kannst?
Wenn du zum Beispiel eine Nachricht zurückgibst, wenn der Konsument sie aus der Warteschlange liest, bedeutet ein Fehler im Konsumenten, dass die Nachricht nicht verarbeitet wird und Daten verloren gehen. Wenn du stattdessen die Nachrichten erst dann abrufst, wenn der Konsument die Verarbeitung abgeschlossen hat, hast du die Möglichkeit, die Nachricht bei einem Fehler erneut zu verarbeiten.
Diese Möglichkeit, es erneut zu versuchen, kann auch zu doppelten Daten führen. Ich habe das in einer Pipeline erlebt, in der die Datenquelle gelegentlich eine große Nachricht produzierte, die die Verarbeitungszeit erheblich verlängerte. Diese Prozesse schlugen manchmal auf halbem Weg fehl und erzeugten unvollständige Daten, ähnlich wie in dem Datenbankbeispiel, das du vorhin gesehen hast. Unser Team hat das Problem behoben, indem es eine Maximalmeldung festgelegt hat, um die langwierigen Prozesse zu verhindern.
Tolerieren von Datenduplikaten
Da es schwierig sein kann, Idempotenz im Sinne der Vermeidung von Datenduplikaten zu erreichen, solltest du überlegen, ob du eine Datendeduplizierung benötigst. Abhängig von deinem Pipeline-Design und den Datenkonsumenten kannst du eventuell doppelte Daten zulassen.
Ich habe zum Beispiel an einer Pipeline gearbeitet, die Kundendaten auf das Vorhandensein bestimmter Probleme untersucht hat. In diesem Fall spielte es keine Rolle, ob die Daten doppelt vorhanden waren; die Frage lautete: "Gibt es X?" Wäre die Frage stattdessen gewesen, wie oft X aufgetreten ist, wäre eine Datendeduplizierung notwendig gewesen.
Auch bei Zeitreihen, bei denen nur die aktuellsten Datensätze verwendet werden, kannst du die Duplizierung vielleicht tolerieren. Ich habe an einer Pipeline gearbeitet, die im Idealfall einmal am Tag Datensätze generierte, aber wenn Fehler auftraten, musste die Pipeline neu gestartet werden. Das machte es besonders schwierig, Duplikate zu erkennen, denn die Quelldaten änderten sich im Laufe des Tages, so dass die Ergebnisse eines früheren Pipelinelaufs andere Datensätze erzeugen konnten als die eines späteren Laufs. In diesem Fall fügte ich Metadaten hinzu, die den Zeitpunkt der Ausführung des Auftrags festhielten und die Datensätze nur nach der letzten Ausführung filterten. In diesem Fall kam es zu einer Verdoppelung der Daten, aber die Auswirkungen wurden durch diese Filterlogik abgeschwächt.
Wenn du eine eventuelle Deduplizierung tolerieren kannst, könntest du einen Prozess einrichten, der in regelmäßigen Abständen Duplikate bereinigt. So etwas könnte als Hintergrundprozess laufen, um die freien Rechenzyklen zu nutzen, wie du in Kapitel 1 gelernt hast.
Checkpointing
Beim Checkpointing wird der Status im Laufe des Pipeline-Betriebs regelmäßig gespeichert. So kannst du bei einem Fehler in der Pipeline die Datenverarbeitung vom letzten bekannten Zustand aus wiederholen.
Checkpointing ist besonders wichtig bei der Stream-Verarbeitung. Wenn bei der Verarbeitung des Streams ein Fehler auftritt, musst du wissen, wo du im Stream warst, als der Fehler auftrat. So weißt du, wo du die Verarbeitung wieder aufnehmen musst, wenn sich die Pipeline erholt hat.
Auch in Batch-Pipelines kannst du vom Checkpointing profitieren. Wenn du zum Beispiel Daten aus mehreren Quellen erfassen und dann eine lange, rechenintensive Transformation durchführen musst, kann es sinnvoll sein, die Quelldaten zu speichern. Wenn die Umwandlung unterbrochen wird, kannst du aus den gespeicherten Quelldaten lesen und die Umwandlung erneut versuchen, anstatt den Datenerfassungsschritt zu wiederholen.
Das spart nicht nur die Kosten für die Wiederholung der Pipeline-Phasen vor dem Ausfall, sondern du hast auch einen Cache der Quelldaten. Das kann besonders hilfreich sein, wenn sich die Quelldaten häufig ändern. In diesem Fall kann es passieren, dass du einen Teil der Quelldaten verpasst, wenn du die gesamte Pipeline neu starten musst.
Warnung
Bereinige Daten mit Checkpoints, sobald du sie nicht mehr brauchst. Wenn du das nicht tust, kann sich das negativ auf Kosten und Leistung auswirken. Ich habe zum Beispiel in einem Unternehmen gearbeitet, in dem eine große Airflow-DAG nach jeder Aufgabe einen Checkpoint gesetzt hat, aber nach Abschluss der Aufgabe nicht aufgeräumt wurde. Dadurch entstanden Terabytes zusätzlicher Daten, die zu hohen Latenzzeiten führten, die DAG-Ausführung unerträglich langsam machten und die Kosten für die Speicherung erhöhten. Ich bin zwar nicht mit den Details vertraut, aber ich vermute, dass das Checkpointing nach jeder Aufgabe zu viel des Guten war, was eine gute Erinnerung daran ist, mit Bedacht zu entscheiden, wo man Checkpointing einsetzt.
Entferne Checkpoint-Daten, nachdem ein Auftrag erfolgreich abgeschlossen wurde, oder verwende eine Lebenszyklus-Richtlinie, wie du in Kapitel 3 gesehen hast, wenn du sie für eine kurze Zeit zur Fehlersuche aufrechterhalten möchtest.
Zwischendaten können auch bei der Fehlersuche in der Pipeline hilfreich sein. Ziehe in Erwägung, eine Logik zum selektiven Checkpoint einzubauen, die Kriterien wie Datenquelle, Pipelinestufe oder Kunde berücksichtigt. Über eine Konfiguration kannst du den Checkpoint bei Bedarf ein- und ausschalten, ohne neuen Code zu implementieren. Diese feinere Granularität hilft dir, die Auswirkungen des Checkpoints auf die Leistung zu reduzieren und gleichzeitig die Vorteile der Statuserfassung für die Fehlersuche zu nutzen.
Um eine noch feinere Granularität zu erreichen, kannst du das Checkpointing für jeden Lauf aktivieren. Wenn ein Auftrag fehlschlägt, kannst du ihn mit aktiviertem Checkpointing erneut ausführen, um die Zwischendaten für die Fehlersuche zu erfassen.
Ich habe zum Beispiel Checkpointing in eine Pipeline-Stufe eingebaut, die Daten von einer API abruft. Das Checkpointing wurde nur aktiviert, wenn die Pipeline im Debug-Modus lief. So konnte ich die abgerufenen Daten überprüfen, falls es Probleme gab. Der Status war klein und wurde automatisch nach ein paar Tagen im Rahmen des Bereinigungszyklus der Pipeline-Metadaten geleert.
Automatische Wiederholungsversuche
Die Wiederholung eines fehlgeschlagenen Pipeline-Auftrags (oder mehrerer) ist im besten Fall ein Initiationsritus und im schlimmsten Fall ein alltägliches Phänomen. Manuelle Jobwiederholungen sind nicht nur nervtötend, sondern auch kostspielig.
Bei einem Projekt, an dem ich gearbeitet habe, gab es einen Ingenieur, der auf Abruf bereitstand und dessen Zeit hauptsächlich damit verbracht wurde, fehlgeschlagene Aufträge zu wiederholen. Stell dir das mal vor: die Kosten für einen Vollzeit-Ingenieur und die Kosten für die Ressourcen für die Wiederholung fehlgeschlagener Aufträge. Solange die SLAs eingehalten werden, bleiben die Kosten für die Wiederholung fehlgeschlagener Aufträge oft verborgen. Die Kosten für die verringerte Geschwindigkeit des Teams durch einen Ingenieur weniger sind schwieriger zu beziffern und können zu Burnout führen. Außerdem kann dieser manuelle Mehraufwand die Skalierbarkeit einschränken.
Meiner Erfahrung nach ist ein wichtiger Grund für fehlgeschlagene Pipeline-Aufträge die Verfügbarkeit von Ressourcen. Das kann alles sein, von einem CSP-Ausfall, der einen Teil deiner Infrastruktur lahmlegt, über eine vorübergehende Unterbrechung der Verfügbarkeit eines Anmeldedienstes oder zu wenig bereitgestellte Ressourcen bis hin zur Verfügbarkeit von Datenquellen, wie z. B. ein 500-Fehler bei einer REST-API-Anfrage. Es kann extrem frustrierend sein, wenn die Berechnungen eines ganzen Auftrags wegen eines solchen vorübergehenden Problems verloren gehen, ganz zu schweigen von den verschwendeten Cloud-Kosten.
Die gute Nachricht ist, dass viele dieser Pipeline-Killer mit automatisierten Prozessen behandelt werden können. Du musst nur wissen, wo diese Fehler auftreten und Wiederholungsstrategien implementieren. Bedenke, dass die Wiederholung von Aufträgen zu doppelten Daten führen kann, weshalb Idempotenz eine Voraussetzung für die Implementierung von Wiederholungen ist. Auch Checkpoints können für Wiederholungen erforderlich sein, wie du später in diesem Abschnitt sehen wirst.
Überlegungen zur Wiederholung
Im Großen und Ganzen umfasst ein Wiederholungsversuch vier Schritte:
Versuche es mit einem Prozess.
Empfange einen wiederholbaren Fehler.
Warte auf einen neuen Versuch.
Wiederhole das Ganze eine begrenzte Anzahl von Malen.
Im Allgemeinen ist ein wiederholbarer Fehler das Ergebnis eines fehlgeschlagenen Prozesses, von dem du erwartest, dass er innerhalb einer kurzen Zeitspanne nach deinem ersten Versuch erfolgreich sein wird, so dass es sinnvoll ist, die Pipeline-Ausführung zu verzögern.
Tipp
Konsistente, wiederholte Wiederholungsversuche können ein Zeichen für zu wenig Ressourcen sein, was zu einer schlechten Pipeline-Leistung führen und die Skalierung und Zuverlässigkeit einschränken kann. Die Protokollierung der Wiederholungsversuche gibt dir Aufschluss über diese Probleme und hilft dir festzustellen, ob zusätzliche Ressourcen benötigt werden, um die Leistung der Pipeline zu verbessern.
Ich habe zum Beispiel an einer Pipeline gearbeitet, die die Arten von Datenbankfehlern unterscheidet, die sie bei Abfragen erhält. Ein Fehler kann entweder auf die Konnektivität oder auf ein Problem mit der Abfrage zurückzuführen sein, z. B. die Ausführung einer SELECT Anweisung gegen eine Tabelle, die nicht existiert. Ein Verbindungsfehler kann vorübergehend sein, während ein Abfragefehler so lange bestehen bleibt, bis eine Codeänderung vorgenommen wird. Bei separaten Fehlern könnte die Pipeline Datenbankabfragen nur dann erneut versuchen, wenn der Fehler mit der Konnektivität zusammenhängt.
Bei der Wiederholung wird eine gewisse Zeit gewartet, bevor der Prozess erneut versucht wird. Wenn möglich, solltest du dafür sorgen, dass dieser Vorgang nicht blockiert wird, damit andere Prozesse weiterlaufen können, während der wiederholte Prozess auf seinen nächsten Versuch wartet. Wenn du stattdessen zulässt, dass ein wartender Prozess einen Worker-Slot oder Thread in Anspruch nimmt, verschwendest du Zeit und Ressourcen.
Du kannst das Blockieren auf verschiedenen Ausführungsebenen verhindern, z. B. durch die Verwendung asynchroner Methoden oder Multithreading. Task-Runner und Zeitplanungsprogramme wie Airflow und Celery unterstützen nicht blockierende Wiederholungen mit Hilfe von Warteschlangen. Wenn eine wiederholbare Aufgabe fehlschlägt, stellen diese Systeme die fehlgeschlagene Aufgabe zurück in die Warteschlange, so dass andere Aufgaben weitermachen können, während die wiederholbare Aufgabe die Wiederholungsverzögerung abwartet.
Wiederholungsebenen in Datenpipelines
Die Prozesse in einer Datenpipeline lassen sich in drei Ebenen einteilen: niedrig, Aufgabe und Pipeline. Low-Level-Prozesse sind Prozesse, bei denen du mit einer Ressource interagierst, z. B. eine API-Anfrage stellst oder in eine Datenbank schreibst. Ein Fehler, der wiederholt werden kann, könnte eine 429 von einer API sein, die anzeigt, dass in einem bestimmten Zeitraum zu viele Anfragen gestellt wurden. Ein weiterer potenzieller Fehler, der wiederholt werden kann, ist ein Ressourcenkonflikt, z. B. wenn du auf einen Pool-Slot wartest, um in eine Datenbank zu schreiben, und die Timeout-Zeit überschritten wird.
Bei der Arbeit mit Cloud-Diensten können die Wiederholungen etwas komplizierter sein. Ich habe zum Beispiel an einer Pipeline gearbeitet, in der Daten in eine Cloud Speicherung geschrieben wurden. Die Datengröße war gering und die Anfragen lagen innerhalb der Bandbreiten- und Anfragebegrenzungen. Die meisten Uploads waren erfolgreich, aber gelegentlich schlug ein Upload fehl, und zwar nicht wegen Problemen mit der Speicherung, sondern weil es ein Problem mit dem Anmeldedienst gab, der den Zugriff auf den Speicher-Bucket gewährte.
Hinweis
Dies ist ein wichtiger Aspekt bei der Arbeit mit Cloud-Diensten: Auch wenn du denkst, dass du nur mit einem einzigen Dienst interagierst, wie z.B. der Speicherung in der Cloud, können mehrere Dienste an der Bearbeitung deiner Anfrage beteiligt sein.
Dieses Problem war besonders schwer zu lösen, weil der Wiederholungsmechanismus in der CSP-Client-Bibliothek gekapselt war. Ich habe den Google Cloud Storage (GCS) Client verwendet, der seine eigene Wiederholungsstrategie hat, die nur für die Speicherung gilt. Da der Anmeldedienst ein anderer Dienst war, konnte der GCS-Wiederholungsversuch keine Fälle behandeln, in denen der Anmeldedienst vorübergehend nicht verfügbar war. Letztendlich musste ich die Wiederholung des GCS-Clients in eine benutzerdefinierte Wiederholung verpacken, die die Tenacity-Bibliothek verwendet, um die Wiederholung bei Problemen mit dem Anmeldedienst durchzuführen.
Auf der nächsten Ebene über den Low-Level-Prozessen befinden sich die Prozesse auf Aufgabenebene. Du kannst dir diese als verschiedene Schritte in der Pipeline vorstellen, einschließlich Aufgaben wie die Ausführung einer Datenumwandlung oder die Durchführung einer Validierung. Zu den Prozessen auf Aufgabenebene gehören oft auch Low-Level-Prozesse, wie z. B. eine Aufgabe, die Daten in die Cloud Speicherung schreibt. In diesen Fällen gibt es zwei Stufen der Wiederholung: eine Wiederholung auf niedriger Ebene, die einige Sekunden bis einige Minuten dauern kann, und die Möglichkeit der Wiederholung auf Aufgabenebene über einen längeren Zeitraum.
Ein Beispiel: Eine Pipeline, an der ich gearbeitet habe, enthielt eine Aufgabe, die nach Abschluss der Datenverarbeitung E-Mails an die Kunden verschickte. Die Anfrage zum Senden der E-Mail ging an eine interne API, die auf der Grundlage der Kundendaten eine individuelle E-Mail vorbereitete. Die Pipeline hatte Wiederholungen auf Aufgabenebene für die Aufgabe "E-Mail senden" und Wiederholungen auf niedriger Ebene für die Anfrage an die interne E-Mail-API, wie in Abbildung 4-1 dargestellt.
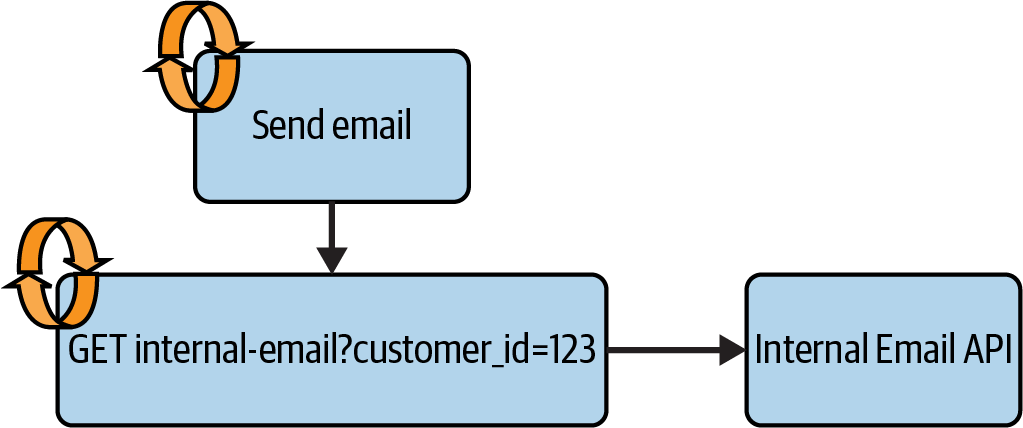
Abbildung 4-1. E-Mail-Versandprozess mit Wiederholungsversuchen
Der zeitliche Ablauf der Aufgabe und der Low-Level-Wiederholungen ist in Abbildung 4-2 dargestellt. Die Aufgabe "E-Mail senden" startete am Anfang des Zeitfensters und stellte eine Low-Level-Anfrage an die interne E-Mail-API. Wenn ein Fehler auftrat, der wiederholt werden konnte, wurde die Anfrage an GET mit einem exponentiellen Backoff wiederholt. Du kannst dies an der zunehmenden Zeitspanne zwischen dem ersten, zweiten und dritten Wiederholungsversuch auf der Zeitleiste "Low-level API retries" erkennen.
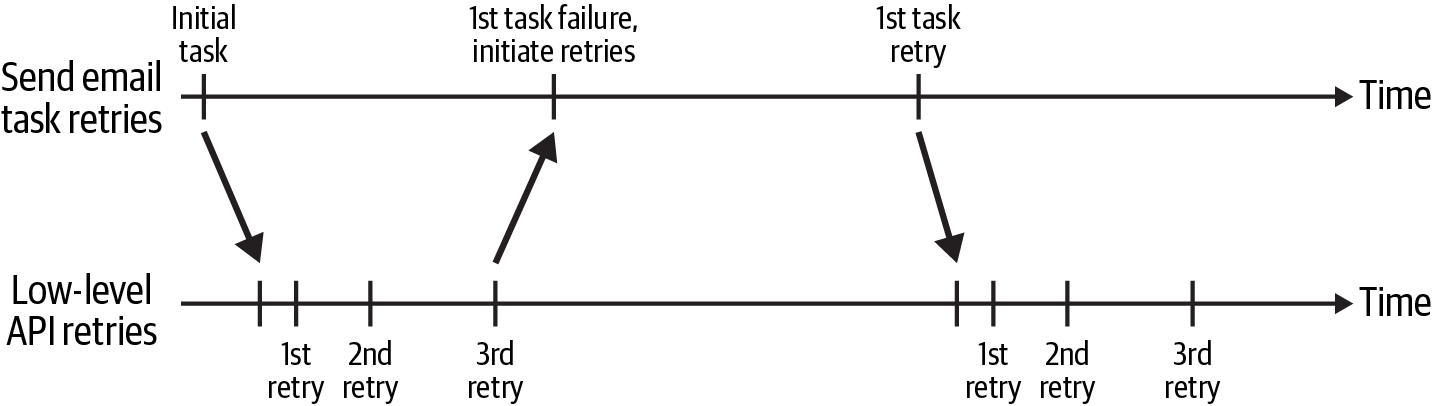
Abbildung 4-2. Zeitleiste für die Wiederholung der Aufgabe "E-Mail senden" und der API-Anfrage
Wenn die Anfrage GET nach drei Versuchen immer noch fehlschlug, schlug die Aufgabe "E-Mail senden" fehl. Dies löste den Wiederholungsversuch auf Aufgabenebene aus, der über einen längeren Zeitraum hinweg wiederholt wurde. Während der Low-Level-Prozess innerhalb weniger Minuten mehrmals wiederholt wurde, wurde der Task-Level-Prozess ab 10 Minuten einmal wiederholt und die Wartezeit bei jedem Versuch exponentiell erhöht. Solange die von der API zurückgegebenen Fehler wiederholt werden konnten, wurde die Wiederholung auf Aufgabenebene bis zu einer bestimmten Uhrzeit fortgesetzt, nach der die E-Mail nicht mehr relevant war.
Wiederholungen auf Aufgabenebene sind ein Bereich, in dem Checkpointing besonders hilfreich sein kann. Betrachte die HoD-Pipeline aus Kapitel 1, in der Daten aus der Vogelumfrage mit Daten aus der HoD-Datenbank für soziale Medien kombiniert werden. In Abbildung 4-3 ist dieser Prozess mit hinzugefügtem Checkpointing dargestellt, bei dem die Daten nach dem Extrahieren der Arteninformationen und vor dem Schritt "Enrich with social" in der Cloud im Temp Storage Bucket gespeichert werden. Wenn "Anreichern mit sozialen Daten" fehlschlägt, weil die HoD-Datenbank vorübergehend ausgelastet ist, kann die Pipeline "Anreichern mit sozialen Daten" mit den Daten im Temp-Storage-Bucket wiederholen, anstatt die Erhebungsdaten erneut zu erfassen und "Arten extrahieren" erneut zu starten.
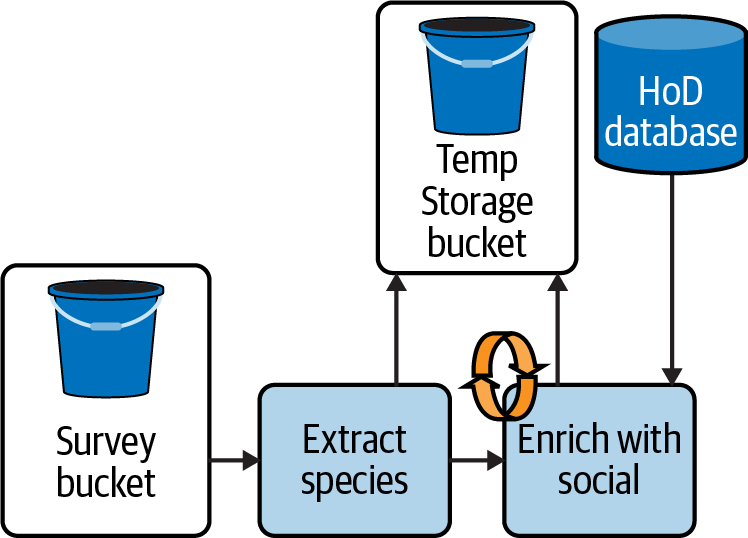
Abbildung 4-3. HoD-Batch-Pipeline mit Checkpointing und Wiederholung
Schließlich kann es auch auf der Pipeline-Ebene zu wiederherstellbaren Fehlern kommen. Wenn du über die Wahrscheinlichkeit verschiedener Stufen von wiederherstellbaren Fehlern nachdenkst, wobei die niedrige Stufe am häufigsten vorkommt, ist die Pipeline-Ebene die am wenigsten wahrscheinliche Stufe, auch weil du bereits Wiederholungsversuche auf der niedrigen und der Task-Ebene eingebaut hast, um die meisten temporären Fehler zu bewältigen.
Wiederholbare Fehler auf Pipeline-Ebene sind größtenteils auf temporäre Infrastrukturprobleme zurückzuführen. Eine mögliche Ursache ist die Beendigung von unterbrechbaren Instanzen. Wie du in Kapitel 1 gelernt hast, gehören diese zu den günstigsten Compute-Optionen, aber sie können beendet werden, bevor dein Auftrag abgeschlossen ist. In einer containerisierten Umgebung wie Kubernetes kann es zu vorübergehenden Ressourcenproblemen kommen, wenn deine Container ihre Ressourcenanforderungen überschreiten.
Die Entwicklung von Wiederholungsstrategien für diese Situationen kann es einfacher machen, billige unterbrechbare Instanzen zu nutzen, indem ein Selbstheilungsmechanismus eingebaut wird. Es kann schwierig sein festzustellen, ob eine Pipeline aufgrund von Ressourcenengpässen fehlgeschlagen ist und ob diese Engpässe auf ein vorübergehendes Serviceproblem oder ein nicht behebbares Problem zurückzuführen sind, wie z. B. ein Auftrag, der die bereitgestellten Ressourcen überschreitet und weiterhin fehlschlagen wird. In einigen Fällen kannst du Informationen von der Recheninfrastruktur erhalten, die dir helfen, dies herauszufinden.
Wenn du unterbrechbare Instanzen verwendest, kannst du Benachrichtigungen über Beendigungen abonnieren, um die daraus resultierende Instabilität der Pipeline zu erkennen. Als ich an der in Kapitel 1 beschriebenen Pipeline mit Kapazitätsproblemen gearbeitet habe, konnte ich den Grund für den Ausfall erfassen, wenn der AWS EMR-Cluster beendet wurde. Wenn der Auftrag aufgrund unzureichender Kapazität fehlschlug, wurde ein Wiederholungsmechanismus aktiviert, der das Team nur dann über den Fehler informierte, wenn der Auftrag auch nach einigen Stunden des Wartens auf eine Verbesserung der Kapazität noch fehlschlug.
Es gab ein paar Schlüsselelemente für diese Lösung. Erstens wusste ich aus Erfahrung, dass diese Ressourcenprobleme in der Regel innerhalb weniger Stunden behoben waren. Zweitens habe ich die Möglichkeit in Betracht gezogen, dass der Auftrag einfach zu groß für die zugewiesene Kapazität war. Ich habe die Anzahl der Wiederholungsversuche auf zwei begrenzt, um die Ressourcenverschwendung in diesem Szenario zu begrenzen. Eine andere Möglichkeit, einen großen Auftrag zu erkennen, ist der Vergleich der Datengröße mit historischen Werten, wie du im "Autoskalierungsbeispiel" gesehen hast .
Dieser Wiederholungsmechanismus reduzierte manuelle Eingriffe, menschliche Fehler und Ermüdungserscheinungen. Außerdem wurden die Kosten für die Wiederholung von Aufträgen gesenkt und der Durchsatz der Pipeline verbessert. Zuvor löste jeder fehlgeschlagene Auftrag einen Alarm aus, und ein Techniker musste den Prozess manuell neu starten. Wenn das Problem eine unzureichende Kapazität war, schlug auch die Wiederholung fehl, was zu einer Kaskade von Fehlern und verschwendeten Ressourcen führte. Da die Wiederholungsversuche ein manueller Prozess waren, verpasste unser Team unweigerlich einen der Wiederholungsläufe, während es die Kapazitätsprobleme abwartete, was zu fehlenden Daten führte.
Bislang wurden in diesem Kapitel Designstrategien behandelt, die sich auf die Mechanik von Datenpipelines konzentrieren und dir dabei helfen, Datenbeschädigungen zu vermeiden und häufige intermittierende Ausfälle zu beheben. Das letzte Thema in diesem Kapitel, die Datenvalidierung, ist eine Technik, die du in die Pipeline-Ausführung einbauen kannst, damit du Datenprobleme erkennst, bevor sie auftreten.
Datenvalidierung
In der Sitcom Laverne und Shirley aus den 1970er Jahren macht sich das Duo auf den Weg zu seiner Arbeit in der Shotz-Brauerei, wo sie die Bierflaschen kontrollieren, die auf dem Fließband laufen. Während die Flaschen vorbeiströmen, sehen Laverne und Shirley zu, wie sie die fehlerhaften Flaschen aussortieren, um ein qualitativ hochwertiges Produkt zu erhalten.
Die Datenvalidierung ist ein bisschen wie die Qualitätskontrolle, die Laverne und Shirley bei ihren Aufträgen durchführen: Sie prüfen die Daten im Vorbeigehen und beseitigen Fehler, bevor sie in die Hände der Datenkonsumenten gelangen.
Ein Mangel an Datenvalidierung führte zu dem millionenschweren Fehler, über den ich im Vorwort dieses Buches berichtet habe. Die Datenquelle, die unser Team importierte, enthielt neue Datenspalten. Wir verließen uns darauf, die Schemata manuell zu aktualisieren, um die Änderungen in den Quelldaten zu erfassen - eine Praxis, die ich dir in diesem Abschnitt zeige. Das Schema war nicht gepflegt worden und enthielt die neuen Spalten nicht, so dass sie von der Aufnahme ausgeschlossen wurden.
Bevor ich auf spezifische Datenvalidierungstechniken eingehe, möchte ich dich dazu bringen, über die Datenvalidierung auf einer hohen Ebene nachzudenken. Das wird dir helfen, einen Plan zur Datenvalidierung zu erstellen, in dem du die Techniken aus diesem Kapitel anwendest.
Meiner Erfahrung nach verfolgt die Datenvalidierung drei Hauptziele:
Verhindere Datenausfallzeiten.
Verhindere die Verschwendung von Zyklen bei der Verarbeitung schlechter Daten.
Informiere das Team über schlechte Daten und Pipeline-Fehler.
Um diese Ziele zu erreichen, solltest du dir Gedanken über die Quelldaten, die Art ihrer Verarbeitung und die Erwartungen an die Ergebnisdaten machen. Du kannst mit diesen Fragen beginnen:
Was macht gültige Quelldaten aus? Gibt es zum Beispiel Merkmale, die vorhanden sein müssen, damit du sicher sein kannst, dass die Quelle gute Daten geliefert hat?
Sollst du alle Daten aus einer Quelle aufnehmen, einschließlich neuer Attribute, oder nimmst du nur eine Teilmenge auf?
Benötigen die Daten bestimmte Formate, Datentypen oder Attribute, um erfolgreich aufgenommen zu werden?
Gibt es deterministische Beziehungen zwischen den einzelnen Phasen der Pipeline, z. B. die Form der Daten, die du nutzen kannst, um mögliche Probleme zu erkennen?
Wenn du über diese Fragen nachdenkst, kannst du feststellen, in welchen Bereichen eine Datenvalidierung sinnvoll ist. Außerdem solltest du den Aufwand bedenken, der entsteht, wenn du die Validierung in die Pipeline aufnimmst. Dies ist ein weiterer Prozess, der auf die Daten einwirkt, während sie die Ingestion durchlaufen, und kann sich je nach Ansatz auf die Leistung auswirken.
Überlege dir schließlich, was du tun willst, wenn die Datenüberprüfung fehlschlägt. Sollen die fehlerhaften Daten verworfen werden? Sollen sie zur Überprüfung beiseite gelegt werden? Soll der Auftrag fehlschlagen?
Validierung der Datenmerkmale
Anstatt zu versuchen, jedes einzelne Datenproblem zu erfassen, was eine unmögliche Aufgabe ist, solltest du die Validierung als Erkennung von Mustern in den Daten betrachten. "Kenne deine Daten" ist der erste Schritt zur erfolgreichen Verarbeitung und Analyse von Daten. Bei der Validierung geht es darum, zu kodifizieren, was du weißt und erwartest, um Datenfehler zu vermeiden.
In diesem Abschnitt lernst du einige grundlegende Prüfungen kennen, die relativ billig zu berechnen und einfach zu implementieren sind, sich aber bei der Suche nach häufigen Datenproblemen als sehr nützlich erweisen. Zu diesen Prüfungen gehören:
Form und Art der Daten prüfen
Identifizierung beschädigter Daten
Prüfen auf Nullen
Unabhängig davon, ob du Daten bereinigst oder analysierst, ist es eine gute Möglichkeit, die Form der Daten zu überprüfen, während sie die verschiedenen Phasen der Pipeline durchlaufen, um Probleme festzustellen. Das Problem der fehlenden Spalten im Vorwort des Buches hätte durch eine einfache Prüfung verhindert werden können, bei der die Anzahl der Spalten in den Eingabedaten mit der Anzahl der Spalten im Datenrahmen verglichen worden wäre, der die Daten verarbeitet hat. Tatsächlich war dies eine der ersten Validierungsprüfungen, die unser Team hinzugefügt hat, um das Problem zu entschärfen.
Während ein Vergleich der Anzahl der Spalten fehlende Attribute identifizieren kann, sind zusätzliche Überprüfungen der Spaltennamen und Datentypen notwendig, wenn Attribute hinzugefügt werden. Der Schritt "Arten extrahieren" in Abbildung 4-3 fügt zum Beispiel eine neue Spalte species zu den Rohdaten hinzu. Um zu überprüfen, ob der Schritt "Arten extrahieren" wie erwartet funktioniert hat, könntest du zunächst sicherstellen, dass es N + 1 Spalten in den "Arten extrahieren"-Daten gibt. Wenn dies der Fall ist, musst du im nächsten Schritt sicherstellen, dass die von "Arten extrahieren" erzeugten Daten dieselben Spaltennamen und -typen haben wie die Eingabedaten aus dem Survey Bucket, zusätzlich zum neuen Feld species. Damit wird sichergestellt, dass du die neue Spalte hinzugefügt und keine Eingabespalten ausgelassen hast.
Wenn du die Form des Datenrahmens abrufst, erhältst du eine zweite Information: die Länge der Daten. Dies ist ein weiteres hilfreiches Merkmal, das du überprüfen kannst, wenn die Daten die Pipeline durchlaufen. Du würdest zum Beispiel erwarten, dass "Arten extrahieren" die gleiche Anzahl von Zeilen wie die Eingabedaten erzeugt.
In manchen Fällen arbeitest du vielleicht mit Datenquellen, die fehlerhafte Daten liefern könnten. Das gilt vor allem dann, wenn du mit Datenquellen außerhalb deines Unternehmens arbeitest, bei denen du nur begrenzten oder gar keinen Einblick in mögliche Änderungen hast. Eine Datenpipeline, an der ich gearbeitet habe, nahm Daten aus Dutzenden von Drittanbieter-APIs auf, die das Rückgrat des Produkts des Unternehmens bildeten. Wenn die Pipeline auf fehlerhafte Daten stieß, wurde eine Ausnahme ausgelöst, die das Team darauf aufmerksam machte, dass etwas nicht in Ordnung war.
Werfen wir einen Blick auf einige Methoden für den Umgang mit fehlerhaften Daten, die du im Validierungsnotizbuch dieses Buches unter der Überschrift "Erkennen und Handeln bei fehlerhaften Daten" finden kannst.
Hier ist ein Beispiel für ein missgebildetes JSON, bei dem der letzte Datensatz teilweise geschrieben wurde:
bad_data=["{'user': 'pc@cats.xyz', 'location': [26.91756, 82.07842]}","{'user': 'lucy@cats.xyz', 'location': [26.91756, 82.07842]}","{'user': 'scout@cats.xyz', 'location': [26.91756,}"]
Wenn du versuchst, dies mit einfachem Python zu verarbeiten, bekommst du eine Ausnahme für den gesamten Datensatz, obwohl nur ein Datensatz beschädigt ist. Wenn du jede Zeile verarbeitest, kannst du die guten Datensätze einlesen und die fehlerhaften isolieren und bearbeiten.
PySpark DataFrames bieten dir einige Möglichkeiten, wie du mit fehlerhaften Daten umgehen kannst. Das Attribut mode für das Lesen von JSON-Daten kann auf PERMISSIVE, DROPMALFORMED oder FAILFAST gesetzt werden und bietet verschiedene Optionen für den Umgang mit fehlerhaften Daten.
Im folgenden Beispiel ist das Attribut mode auf PERMISSIVE gesetzt:
corrupt_df=spark.read.json(sc.parallelize(bad_data),mode="PERMISSIVE",columnNameOfCorruptRecord="_corrupt_record")corrupt_df.show()
PERMISSIVE Modus liest die Daten erfolgreich, isoliert aber fehlerhafte Datensätze in einer separaten Spalte zur Fehlersuche, wie du in Abbildung 4-4 sehen kannst.

Abbildung 4-4. Lesen fehlerhafter Daten im Modus PERMISSIVE
PERMISSIVE Modus ist eine gute Option, wenn du die beschädigten Datensätze untersuchen willst. In einem medizinischen Datenmanagementsystem, an dem ich gearbeitet habe, isolierte die Pipeline solche Datensätze, damit ein Datenverwalter sie prüfen konnte. Das Datenmanagementsystem wurde für die Patientendiagnose verwendet, daher war es wichtig, dass alle Daten eingelesen wurden. Das Debugging der fehlerhaften Daten gab dem medizinischen Personal die Möglichkeit, die Quelldaten für die erneute Aufnahme zu reparieren.
DROPMALFORMED tut das, wonach es klingt: Die beschädigten Datensätze werden vollständig aus dem Datenrahmen entfernt. Das Ergebnis wären die Datensätze 0-1 in Abbildung 4-4. Schließlich würde FAILFAST bei fehlerhaften Datensätzen eine Ausnahme auslösen und den gesamten Stapel zurückweisen.
Wenn bestimmte Attribute für eine erfolgreiche Datenübernahme erforderlich sind, kann die Überprüfung auf Nullen während der Datenübernahme eine weitere Validierungsmaßnahme sein. Dazu kannst du in den Quelldaten nach dem erforderlichen Attribut suchen oder eine DataFrame-Spalte auf Null prüfen. Du kannst auch mit Schemata Nullprüfungen durchführen.
Schemata
Schemas können dir helfen, zusätzliche Validierungen durchzuführen, wie z.B. die Überprüfung auf Datentypänderungen oder Änderungen in Attributnamen. Du kannst auch erforderliche Attribute mit einem Schema definieren, die zur Überprüfung auf Nullwerte verwendet werden können. DoorDash nutzt die Schema-Validierung zur Verbesserung der Datenqualität, wie in "Aufbau einer skalierbaren Echtzeit-Ereignisverarbeitung mit Kafka und Flink" beschrieben .
Schemata können die Daten auch auf die Attribute beschränken, die du für die Aufnahme benötigst. Wenn du nur einige wenige Attribute aus einem großen Datensatz benötigst, kannst du mit einem Schema nur diese Attribute laden und so Rechen- und Speicherkosten einsparen, da keine ungenutzten Daten verarbeitet und gespeichert werden müssen.
Schemata können auch als Serviceverträge verwendet werden, in denen sowohl die Datenproduzenten als auch die Datenkonsumenten die erforderlichen Merkmale für die Aufnahme der Daten festlegen. Schemata können auch für die Generierung synthetischer Daten verwendet werden, ein Thema, das du in Kapitel 9 kennenlernen wirst.
In den folgenden Unterabschnitten beschreibe ich, wie man Schemata für die Validierung erstellt, pflegt und verwendet. Den entsprechenden Code findest du im Validierungsnotizbuch.
In einer idealen Welt würden die Datenquellen genaue, aktuelle Schemata für die von ihnen bereitgestellten Daten veröffentlichen. In der Realität kannst du froh sein, wenn du eine Dokumentation über den Zugriff auf die Daten findest, geschweige denn ein Schema.
Wenn du jedoch mit Datenquellen arbeitest, die von Teams in deinem Unternehmen entwickelt wurden, kannst du möglicherweise Schemainformationen erhalten. Ein Beispiel: Eine Pipeline, an der ich gearbeitet habe, interagierte mit einer API, die von einem anderen Team entwickelt wurde. Das API-Team verwendete Swagger-Annotationen und hatte einen automatisierten Prozess, der JSON-Schemata generierte, wenn sich die API änderte. Die Datenpipeline konnte diese Schemata abrufen und sie verwenden, um die API-Antwort zu validieren und die Testdaten der Pipeline auf dem neuesten Stand zu halten. Ein Thema, das du in Kapitel 9 kennenlernen wirst.
Schemata erstellen
Die meiste Zeit musst du deine eigenen Schemata erstellen. Möglicherweise noch wichtiger als die Erstellung der Schemata ist, dass du die Schemata auch auf dem neuesten Stand halten musst. Ein ungenaues Schema ist schlimmer als gar kein Schema. Sehen wir uns zunächst an, wie du Schemata erstellst, und im nächsten Abschnitt erfährst du, wie du sie mit minimalem manuellem Aufwand auf dem neuesten Stand halten kannst.
Betrachten wir als Beispiel die Erstellung von Schemata für die Umfragedaten-Pipeline in Abbildung 4-3. Tabelle 4-1 enthält ein Beispiel für die Rohdaten der Umfrage.
| Benutzer | Standort | Bilddateien | Beschreibung | Graf |
|---|---|---|---|---|
| pc@cats.xyz | ["26.91756", "82.07842"] | Heute waren mehrere Stieglitze im Garten. | 5 | |
| sylvia@srlp.org | ["27.9659", "82.800"] | s3://bird-2345/34541.jpeg | Ein windiger Morgen, bewölkt. Auf dem Intercoastal Waterway habe ich einen Schwarzscheitel-Nachtreiher gesehen. | 1 |
| birdlover124@email.com | ["26.91756", "82.07842"] | s3://bird-1243/09731.jpeg, s3://bird-1243/48195.jpeg | Heute Nachmittag bin ich zum Reiherhorst gegangen und habe einige Blaureiher gesehen. | 3 |
Die Umfragedaten enthalten eine Zeile für jede Sichtung, die von einem Nutzer einer Vogelumfrage-App aufgezeichnet wurde. Dazu gehören die E-Mail-Adresse des Nutzers, der Standort des Nutzers und eine frei formulierte Beschreibung. Die Nutzer können jeder Sichtung Bilder anhängen, die von der Erhebungs-App in einer Cloud-Speicherung gespeichert werden und deren Links in der Spalte "Bilddateien" in der Tabelle aufgeführt sind. Die Nutzer können auch die ungefähre Anzahl der gesichteten Vögel angeben.
In "Validierung von Datenmerkmalen" habe ich erwähnt, dass das Feld location von dem Schritt "Arten extrahieren" in Abbildung 4-3 verwendet wird. Hier ist der Code zum Extrahieren der Arten, den du in transform.py sehen kannst:
defapply_species_label(species_list,df):species_regex=f".*({'|'.join(species_list)}).*"return(df.withColumn("description_lower",f.lower('description')).withColumn("species",f.regexp_extract('description_lower',species_regex,1)).drop("description_lower"))
In diesem Code wird davon ausgegangen, dass description eine Zeichenkette ist, die kleingeschrieben und nach einer Artübereinstimmung durchsucht werden kann.
Ein weiterer Schritt in der Pipeline extrahiert den Breiten- und Längengrad aus dem Feld location und wird verwendet, um Nutzer in ähnliche geografische Regionen einzuteilen. Dies ist eine wichtige Funktion der HoD-Plattform, denn sie hilft Vogelliebhabern, sich für Vogelbeobachtungsreisen zusammenzuschließen. Der Standort wird als Array von Strings dargestellt, wobei der zugrunde liegende Code ein Format von [latitude, longitude] erwartet:
df.withColumn("latitude",f.element_at(df.location,1)).withColumn("longitude",f.element_at(df.location,2))
Ein Schema für die Umfragedaten sollte also mindestens die Einschränkung enthalten, dass das Feld location ein Array von Stringwerten und das Feld description ein String ist.
Was passiert, wenn eines dieser Attribute Null ist? Das ist eine interessante Frage. Eine bessere Frage ist, wie die Pipeline die Daten verarbeiten soll, wenn diese Attribute null sind. Wenn zum Beispiel das Feld location ungültig ist, löst der Code zum Extrahieren von Breiten- und Längengrad eine Ausnahme aus. Das könnte ein Fehler im Code sein, oder es könnte sein, dass location ein Pflichtfeld in den Erhebungsdaten ist, was bedeutet, dass ein ungültiger location Wert ein Zeichen für ein Problem mit den Quelldaten ist und die Datenvalidierung fehlschlagen sollte.
Für dieses Beispiel nehmen wir an, dass location ein Pflichtfeld ist und eine Null location auf ein Problem mit den Daten hinweist. Außerdem ist user ein Pflichtfeld, und count sollte, falls vorhanden, in eine ganze Zahl umgewandelt werden können. Wenn es darum geht, welche Attribute aufgenommen werden sollen, nehmen wir an, dass nur die aktuellen fünf Spalten in Tabelle 4-1 aufgenommen werden sollen und dass neue Attribute, die zu den Umfragedaten hinzugefügt werden, ignoriert werden sollen.
Mit diesen Kriterien im Hinterkopf schauen wir uns ein paar verschiedene Möglichkeiten an, ein Schema mit Hilfe des Datenbeispiels in initial_source_data.json zu erstellen. Du findest diesen Code unter der Überschrift "Schema-Validierung" im Validierungsnotizbuch.
Wenn du mit Datenrahmen arbeitest, kannst du die Datenprobe lesen und das Schema speichern. Möglicherweise musst du die "nullable"-Informationen ändern, damit sie deinen Erwartungen entsprechen. Anhand des Datenbeispiels in initial_source_data.json nimmt das abgeleitete Schema an, dass der löschbare Wert für das Feld description True sein sollte:
df=(spark.read.option("inferSchema",True).json("initial_source_data.json"))source_schema=df.schemasource_schema>StructType([StructField("count",LongType(),True),StructField("description",StringType(),True),StructField("user",StringType(),False),StructField("img_files",ArrayType(StringType(),True),True),StructField("location",ArrayType(StringType(),True),False)])
Wenn deine Datenumwandlungslogik davon ausgeht, dass das Feld description immer ausgefüllt wird, musst du diesen Wert zur Validierung in False ändern.
Eine andere Möglichkeit, die Daten der Vogelumfrage zu validieren, ist ein JSON-Schema, das mehr Definitionen zulässt als das Spark-Schema. Du kannst ein JSON-Schema aus Beispieldaten mithilfe einiger Online-Tools oder von Hand erstellen, wenn die Datenattribute gering sind.
Validierung mit Schemata
Diese Methoden zur Schemaerstellung geben dir einen Ausgangspunkt. Von hier aus musst du das Schema verfeinern, um sicherzustellen, dass es Validierungsfehler auslöst, z. B. indem du die löschbaren Werte im generierten Spark-Schema änderst.
Wenn du zum Beispiel einen JSON-Schema-Generator für initial_source_data.json verwendest, erhältst du das Schema, das im Abschnitt "Arbeiten mit JSON-Schemata" des Validierungsnotizbuchs gezeigt wird. Beachte, dass der Schema-Generator location definiert hat:
#"location":["26.91756","82.07842"]"location":{"type":"array","items":[{"type":"string"},{"type":"string"}]}
Erinnere dich daran, dass der Code zum Extrahieren des Breiten- und Längengrads zwei Elemente in location erwartet.
Wenn du dieses Schema anhand einiger Testdaten validierst, kannst du sehen, dass diese Definition nicht ausreicht, um sicherzustellen, dass das Feld location zwei Elemente hat. Die JSON-Datei short_location hat zum Beispiel nur einen String, aber es gibt keine Ausgabe, wenn du diese Zeile ausführst, was bedeutet, dass die Validierung erfolgreich war:
validate(short_location,initial_json_schema)
Um dieses JSON-Schema für die Datenvalidierung zu verwenden, musst du die minItems im Array location angeben, wie in dieser aktualisierten Schemadefinition für location:
"location":{"type":"array","minItems":2,"items":[{"type":"string"}]},
Jetzt kommt der spannende Teil: Sieh dir all die schlechten Daten an, die mit dieser neuen Definition markiert werden.
Die folgenden Validierungsfehler aus der Python jsonschema-Bibliothek sagen dir genau, was mit den Daten nicht in Ordnung war. So kannst du die Ausführung anhalten, wenn fehlerhafte Daten gefunden werden, und hilfreiche Debug-Informationen erhalten :
- Nicht genug Elemente
validate(short_location,updated_schema)>ValidationError:['26.91756']istooshort- Wenn sich der
locationDatentyp von einem Array zu einem String ändert validate([{"user":"someone","location":"26.91756,82.07842"}],updated_schema)>ValidationError:'26.91756,82.07842'isnotoftype'array'- Wenn der Anbieter der Vermessungsdaten beschließt, den Datentyp der Breiten- und Längengradwerte von einer Zeichenkette in einen numerischen Wert zu ändern
validate([{"user":"pc@cats.xyz","location":[26.91756,82.07842]}],updated_schema)>ValidationError:26.91756isnotoftype'string'
Die letzten beiden Fehler, dass sich der Speicherort von einem Array zu einem String oder von einem Array mit Strings zu einem Array mit Floats ändert, können auch bei Verwendung eines Spark-Schemas erkannt werden. Wenn du mit Spark-Datensätzen in Scala oder Java arbeitest, kannst du das Schema verwenden, um eine Ausnahme auszulösen, wenn die Quelldaten nicht übereinstimmen.
In anderen Situationen kannst du das erwartete Schema mit dem Schema vergleichen, das beim Einlesen der Quelldaten abgeleitet wird, wie im Abschnitt "Vergleich zwischen abgeleiteten und expliziten Schemata" im Validierungsnotizbuch beschrieben.
Nehmen wir an, du hast ein erwartetes Schema für die Daten der Vogelumfrage, source_schema, wobei location ein Array von Strings ist. Um einen neuen Datenstapel mit source_schema abzugleichen, lies die Daten in einen Datenrahmen ein und vergleiche das abgeleitete Schema mit dem erwarteten Schema. In diesem Beispiel ist das Feld location in string_location.json ein String:
df=(spark.read.option("inferSchema",True).json('string_location.json'))inferred_schema=df.schema>StructType([...StructField("location",StringType(),True)...])inferred_schema==source_schemaFalse
Diese Prüfung ist nützlich, um einen Validierungsfehler zu erkennen, aber sie ist nicht gut geeignet, um die spezifischen Unterschiede zwischen den Schemas aufzuzeigen. Um einen besseren Einblick zu bekommen, prüft der folgende Code sowohl auf neue Felder als auch auf Unstimmigkeiten in bestehenden Feldern:
source_info={f.name:fforfinsource_schema.fields}forfininferred_schema.fields:iff.namenotinsource_info.keys():(f"New field in data source{f}")eliff!=source_info[f.name]:source_field=source_info[f.name](f"Field mismatch for{f.name}Source schema:{source_field},Inferredschema:{f}")>FieldmismatchforlocationSourceschema:StructField(location,ArrayType(StringType,true),true),Inferredschema:StructField(location,StringType,true)
Eine weitere nützliche Validierungsprüfung, die du in diesen Code einbauen kannst, ist die Kennzeichnung von Feldern in source_schema, die in inferred_schema fehlen.
Diese Art von Schemavergleichslogik war eine weitere Validierungstechnik, die zur Behebung des Fehlers mit den fehlenden Spalten eingesetzt wurde. Hätte die Pipeline von Anfang an eine Validierungsprüfung wie diese eingebaut, wäre unser Team schon beim ersten Batch, in dem die Änderung auftrat, auf neue Spalten in den Quelldaten aufmerksam gemacht worden.
Schemata auf dem neuesten Stand halten
Wie ich bereits zu Beginn dieses Abschnitts erwähnt habe, ist es absolut wichtig, dass Schemata auf dem neuesten Stand gehalten werden. Veraltete Schemata sind mehr als wertlos; sie können zu fehlerhaften Validierungsfehlern führen oder echte Validierungsfehler aufgrund veralteter Datendefinitionen übersehen. In diesem Abschnitt werden einige Methoden zur Automatisierung der Schema-Pflege beschrieben.
Für Schemata, die aus dem Quellcode generiert werden, wie das bereits erwähnte Swagger-Beispiel oder durch den Export einer Klasse in ein JSON-Schema, solltest du automatische Builds und zentrale Schema-Repositories in Betracht ziehen. So hat jeder, der auf die Schemas zugreift, eine einzige Quelle der Wahrheit. Als Teil des automatisierten Build-Prozesses kannst du die Schemas nutzen, um Testdaten für Unit-Tests zu erzeugen. Bei diesem Ansatz werden Änderungen am Schema als Fehler in den Unit-Tests angezeigt. Ich verspreche, dass dies das letzte Mal ist, dass ich "wie du in Kapitel 9 sehen wirst" sage. Schemas sind großartig, und es gibt noch weitere großartige Verwendungsmöglichkeiten für sie, abgesehen von ihrem noblen Einsatz bei der Datenvalidierung.
Validierungsprüfungen können auch genutzt werden, um Schemata auf dem neuesten Stand zu halten. Wenn eine Pipeline so konzipiert ist, dass sie alle Attribute der Datenquelle aufnimmt, könntest du einen Prozess starten, der das Schema aktualisiert, wenn sich die Quelldaten nicht grundlegend ändern. Wenn die Pipeline in Abbildung 4-3 beispielsweise so konzipiert ist, dass sie alle Felder der Vogelerhebungsdaten aufnimmt, können neue Spalten zum Quellschema hinzugefügt werden, solange die Felder "Benutzer" und "Standort" vorhanden und gültig sind.
Wenn du Schemata automatisch aktualisierst, um je nach Quelldaten mehr oder weniger Attribute zu enthalten, solltest du sicherstellen, dass du Nullen berücksichtigst. Vor allem bei semistrukturierten Formaten wie JSON kann es vorkommen, dass ein Attributwert nicht aus der Quelle entfernt wurde, sondern einfach nur null ist.
Ein weiterer Punkt, den du beachten musst, ist die Auswirkung von Änderungen am Schema. Wenn neue Attribute hinzugefügt werden, musst du dann die Werte für ältere Daten ergänzen? Wenn ein Attribut entfernt wird, sollen alte Daten dieses Attribut beibehalten?
Schließlich kann auch ein pseudo-automatischer Ansatz für Schemaaktualisierungen effektiv sein, bei dem du bei schemaverändernden Änderungen in den Quelldaten benachrichtigt wirst. Das kann ein Fehler bei der Validierung sein, oder du kannst einen geplanten Auftrag einrichten, der das Schema regelmäßig mit einer Probe der Datenquelle vergleicht. Du könntest diese Prüfung sogar in die Pipeline einbauen, indem du eine Datenprobe abrufst, die Schemavalidierung durchführst und ohne weitere Schritte beendest.
Ich empfehle dir dringend, dich nicht auf manuelle Aktualisierungen zu verlassen, um die Schemata auf dem neuesten Stand zu halten. Wenn keine der oben genannten Optionen für dich in Frage kommt, solltest du dich bemühen, deine Schemata auf ein Minimum zu beschränken, um den Pflegeaufwand zu begrenzen. Außerdem solltest du die Schema-Pflege in den Release-Prozess integrieren, um sicherzustellen, dass sie regelmäßig gepflegt werden.
Zusammenfassung
Die Kombination aus Cloud-Infrastruktur, Diensten von Drittanbietern und den Eigenheiten der verteilten Softwareentwicklung ebnet den Weg für ein Füllhorn potenzieller Fehlermöglichkeiten in der Pipeline. Änderungen der Quelldaten oder des Pipeline-Codes, fehlerhafte Anmeldedaten, konkurrierende Ressourcen und Störungen bei der Verfügbarkeit von Cloud-Diensten sind nur einige der Möglichkeiten. Diese Probleme können vorübergehend sein, wie z. B. ein paar Sekunden in dem Moment, in dem du versuchst, in die Cloud Speicherung zu schreiben, oder sie können dauerhaft sein, wie z. B. wenn sich der Datentyp eines wichtigen Quelldatenfeldes ohne Vorankündigung ändert. Im schlimmsten Fall können sie zu Datenausfällen führen, wie bei dem Millionen-Dollar-Fehler.
Wenn sich diese Situation düster anhört, brauchst du nicht zu verzweifeln. Du bist jetzt gut gerüstet, um Pipelines zu entwickeln, die viele dieser Probleme mit einem Minimum an technischem Aufwand verhindern und beheben können, wodurch die Kosten für Cloud-Ressourcen, die Entwicklungszeit und der Verlust des Vertrauens der Datenkonsumenten in die Datenqualität reduziert werden.
Idempotenz ist ein wichtiger erster Schritt für den Aufbau atomarer Pipelines, die Wiederholungen unterstützen und die Datendopplung begrenzen.
Bei Batch-Prozessen unterstützen Delete-Write- und Datenbanktransaktionen die Idempotenz, indem sie dafür sorgen, dass der Batch vollständig oder gar nicht verarbeitet wird, so dass du einen Neuanfang machen kannst, ohne dass es zu Datenduplikaten kommt. Du kannst die Duplizierung auch an der Datensenke verhindern, indem du eindeutige Einschränkungen durchsetzt, z. B. mit Primärschlüsseln, die verhindern, dass doppelte Daten aufgezeichnet werden.
Bei der Verarbeitung von Datenströmen sorgt die Erstellung von Producern, die eindeutige IDs auf der Grundlage der Quelldaten garantieren, und von Consumern, die jeden eindeutigen Schlüssel nur einmal verarbeiten, für Idempotenz. Wenn du diese Systeme aufbaust, musst du berücksichtigen, wie die Nachrichten konsumiert, bestätigt und wiederholt werden. Eine dauerhafte Speicherung der idempotency-Daten hilft dir, die idempotency über Ausfälle und Einsätze hinweg sicherzustellen.
Denke daran, dass du je nach Verwendung der Pipelinedaten eine gewisse Datendopplung tolerieren kannst. Wenn die Daten verwendet werden, um das Vorhandensein oder Nichtvorhandensein bestimmter Merkmale zu überprüfen, sind doppelte Daten möglicherweise in Ordnung. Ziehe eine Deduplizierung der Daten nach dem Ingest in Betracht, wenn zwischen dem Abschluss des Ingests und dem Zugriff auf die Daten eine Zeitspanne liegt. Eine weitere Möglichkeit ist das Anhängen von Metadaten, um Duplikate bei der Datenabfrage herauszufiltern, wie du im Beispiel gesehen hast, in dem nur die Daten der letzten Laufzeit für die Analyse verwendet wurden.
Das nächste grundlegende Designelement ist das Checkpointing, das einen bekannten Zustand bereitstellt, von dem aus im Falle eines Fehlers ein neuer Versuch gestartet werden kann, sowie Debug-Informationen zur Untersuchung von Problemen. Du kannst von dieser Technik profitieren, ohne die Leistung und die Cloud-Ausgaben zu beeinträchtigen, indem du die Löschung der Checkpoint-Daten automatisierst.
Checkpointing und Idempotenz schaffen die Grundlage für automatische Wiederholungsversuche, mit denen sich Pipelines von vorübergehenden Problemen erholen können. Dadurch werden Ressourcenverschwendung und manuelle Eingriffe reduziert und du kannst die Vorteile von billiger, unterbrechbarer Rechenleistung nutzen.
Wenn du nach Möglichkeiten suchst, Wiederholungen zu nutzen, denke an Prozesse, die vorübergehend fehlschlagen und sich innerhalb eines angemessenen Zeitfensters wiederherstellen lassen, je nachdem, wie viel Durchsatz deine Pipeline benötigt. So könnte z. B. die Datenbankkonnektivität ein vorübergehendes Problem sein und wiederhergestellt werden, während eine ungültige Datenbankabfrage nicht gelingen würde, egal wie oft du sie versuchst.
Um vorübergehende Probleme zu überwinden, musst du zwischen den Wiederholungsversuchen warten. Nicht blockierende Wiederholungsversuche helfen dir, die Leistung zu erhalten und verschwendete Zyklen zu begrenzen. Vergiss nicht, die Wiederholungsversuche zu protokollieren, denn das kann dir helfen, Leistungs- und Skalierbarkeitsprobleme aufzuspüren.
Idempotenz, Checkpointing und automatische Wiederholungen sind wie die Hardware eines Fließbands - Komponenten, die zusammenarbeiten, damit alles effizient läuft. Das ist notwendig, aber nicht ausreichend, um ein Qualitätsprodukt herzustellen. Du brauchst auch ein scharfes Augenpaar, das die Produktqualität prüft, schlechte Produkte aussortiert, bevor sie die Kunden erreichen, und Alarm schlägt, wenn es ein Problem am Fließband gibt.
Bei der Datenvalidierung geht es zu wie bei Laverne und Shirley: Die Daten werden auf ihrem Weg durch die Pipeline sorgfältig geprüft und bei Bedarf zurückgewiesen. Wenn du schon einmal fehlerhafte Daten von Hand debuggen musstest, indem du Protokolle und Datensätze durchforstet hast, um herauszufinden, was wann falsch war, dann wirst du die in diesem Kapitel beschriebenen automatisierten Ansätze zu schätzen wissen - von der Überprüfung der Form und des Formats der Daten bis hin zur Verwendung von Schemata, um den Namen, den Typ und das Vorhandensein von Attributen anhand von Erwartungen zu überprüfen.
Schemas können ein mächtiges Werkzeug für die Datenvalidierung und andere Aktivitäten in der Datenpipeline sein, die ich in späteren Kapiteln beschreiben werde, aber sie müssen auf dem neuesten Stand gehalten werden, damit sie ein Vorteil und keine Belastung sind.
Genauso wie die in diesem Kapitel behandelten Strategien die Grundlage für das Design von Pipelines bilden, bildet eine effektive Entwicklungsumgebung die Basis für die Implementierung und das Testen von Pipelines. Im nächsten Kapitel gehe ich auf Techniken ein, mit denen sich die Kosten senken und die Entwicklungsumgebung für Datenpipelines optimieren lassen.
1 Dies setzt voraus, dass die Datenbank ACID-konform ist.
Get Kosteneffiziente Datenpipelines now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

