Capítulo 4. Consumidores de Kafka: Lectura de datos de Kafka
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Las aplicaciones que necesitan leer datos de Kafka utilizan un KafkaConsumer para suscribirse a temas de Kafka y recibir mensajes de estos temas. Leer datos de Kafka es un poco diferente a leer datos de otros sistemas de mensajería, y hay algunos conceptos e ideas únicos implicados. Puede ser difícil entender cómo utilizar la API del Consumidor sin entender primero estos conceptos. Empezaremos explicando algunos de los conceptos importantes, y luego veremos algunos ejemplos que muestran las diferentes formas en que se pueden utilizar las API de Consumidor para implementar aplicaciones con requisitos diversos.
Conceptos de consumo Kafka
Para entender cómo leer datos de Kafka, primero tienes que entender sus consumidores y grupos de consumidores. Las siguientes secciones cubren esos conceptos.
Consumidores y Grupos de Consumidores
Supón que tienes una aplicación que necesita leer mensajes de un tema Kafka, ejecutar algunas validaciones contra ellos, y escribir los resultados en otro almacén de datos. En este caso, tu aplicación creará un objeto consumidor, se suscribirá al tema apropiado y empezará a recibir mensajes, validarlos y escribir los resultados. Esto puede funcionar bien durante un tiempo, pero ¿qué ocurre si el ritmo al que los productores escriben mensajes en el tema supera el ritmo al que tu aplicación puede validarlos? Si te limitas a que un solo consumidor lea y procese los datos, tu aplicación puede quedarse cada vez más atrás, incapaz de seguir el ritmo de los mensajes entrantes. Obviamente, es necesario escalar el consumo a partir de temas. Al igual que varios productores pueden escribir en el mismo tema, necesitamos permitir que varios consumidores lean del mismo tema, repartiendo los datos entre ellos.
Los consumidores de Kafka suelen formar parte de un grupo de consumidores. Cuando varios consumidores están suscritos a un tema y pertenecen al mismo grupo de consumidores, cada consumidor del grupo recibirá mensajes de un subconjunto diferente de las particiones del tema.
Tomemos el tema T1 con cuatro particiones. Supongamos que creamos un nuevo consumidor, C1, que es el único consumidor del grupo G1, y lo utilizamos para suscribirnos al tema T1. El consumidor C1 recibirá todos los mensajes de las cuatro particiones T1. Véase la Figura 4-1.
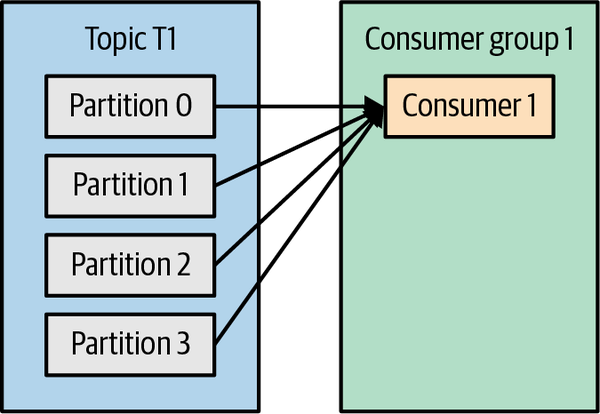
Figura 4-1. Un grupo de consumidores con cuatro particiones
Si añadimos otro consumidor, C2, al grupo G1, cada consumidor sólo recibirá mensajes de dos particiones. Quizá los mensajes de las particiones 0 y 2 vayan a C1, y los mensajes de las particiones 1 y 3 vayan al consumidor C2. Véase la Figura 4-2.
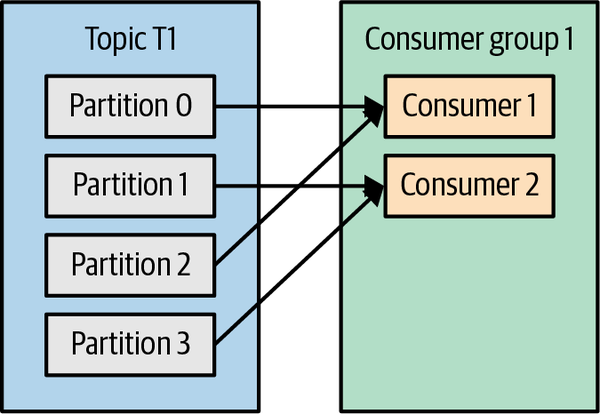
Figura 4-2. Cuatro particiones divididas a dos consumidores en un grupo
Si G1 tiene cuatro consumidores, cada uno leerá mensajes de una sola partición. Véase la Figura 4-3.
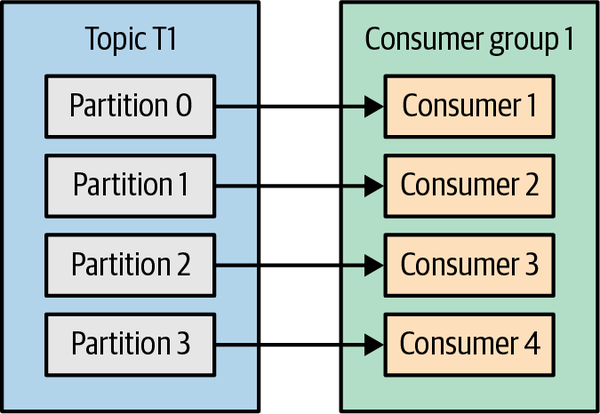
Figura 4-3. Cuatro consumidores en un grupo con una partición cada uno
Si añadimos más consumidores a un único grupo con un único tema que particiones tenemos, algunos de los consumidores estarán inactivos y no recibirán ningún mensaje. Véase la Figura 4-4.
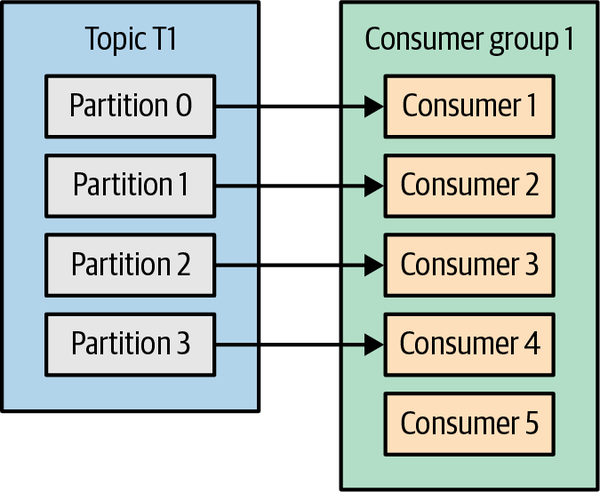
Figura 4-4. Más consumidores en un grupo que particiones significa consumidores ociosos
La principal forma de escalar el consumo de datos de un tema Kafka es añadiendo más consumidores a un grupo de consumidores. Es habitual que los consumidores de Kafka realicen operaciones de alta latencia, como escribir en una base de datos o realizar un cálculo que consuma mucho tiempo sobre los datos. En estos casos, un solo consumidor no puede seguir el ritmo de los flujos de datos en un tema, y añadir más consumidores que compartan la carga haciendo que cada consumidor posea sólo un subconjunto de las particiones y mensajes es nuestro principal método de escalado. Ésta es una buena razón para crear temas con un gran número de particiones: permite añadir más consumidores cuando aumenta la carga. Ten en cuenta que no tiene sentido añadir más consumidores de los que tienes particiones en un tema: algunos de los consumidores simplemente estarán inactivos. El Capítulo 2 incluye algunas sugerencias sobre cómo elegir el número de particiones de un tema.
Además de añadir consumidores para escalar una sola aplicación, es muy habitual tener varias aplicaciones que necesitan leer datos del mismo tema. De hecho, uno de los principales objetivos de diseño de Kafka era que los datos producidos en los temas de Kafka estuvieran disponibles para muchos casos de uso en toda la organización. En esos casos, queremos que cada aplicación obtenga todos los mensajes, en lugar de sólo un subconjunto. Para asegurarte de que una aplicación obtiene todos los mensajes de un tema, asegúrate de que la aplicación tiene su propio grupo de consumidores. A diferencia de muchos sistemas de mensajería tradicionales, Kafka se adapta a un gran número de consumidores y grupos de consumidores sin reducir el rendimiento.
En el ejemplo anterior, si añadimos un nuevo grupo de consumidores (G2) con un único consumidor, este consumidor obtendrá todos los mensajes del tema T1 independientemente de lo que haga G1. G2 puede tener más de un único consumidor, en cuyo caso cada uno de ellos obtendrá un subconjunto de particiones, igual que mostramos para G1, pero G2 en su conjunto seguirá obteniendo todos los mensajes independientemente de otros grupos de consumidores. Véase la Figura 4-5.
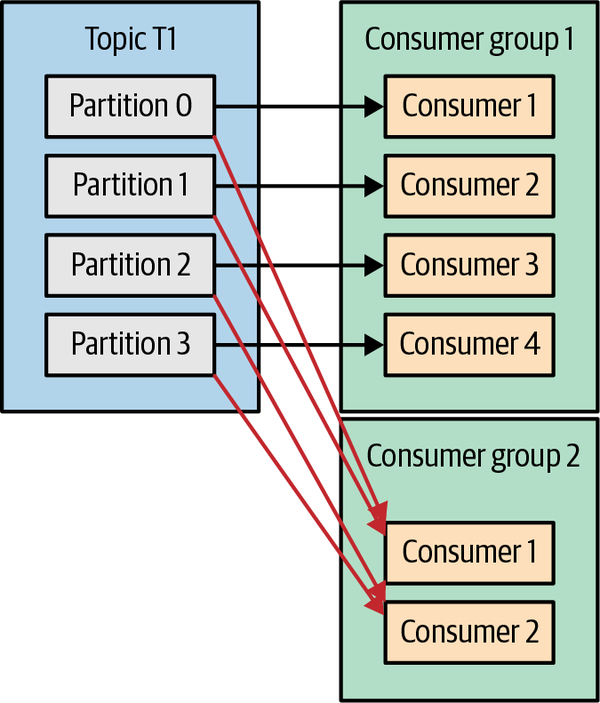
Figura 4-5. Añadir un nuevo grupo de consumidores, ambos grupos reciben todos los mensajes
En resumen, creas un nuevo grupo de consumidores para cada aplicación que necesite todos los mensajes de uno o varios temas. Añades consumidores a un grupo de consumidores existente para escalar la lectura y el procesamiento de los mensajes de los temas, de modo que cada consumidor adicional de un grupo sólo obtenga un subconjunto de los mensajes.
Los Grupos de Consumidores y el Reequilibrio Partidario
Como vimos en la sección anterior, los consumidores de un grupo de consumo comparten la propiedad de las particiones de los temas a los que se suscriben. Cuando añadimos un nuevo consumidor al grupo, empieza a consumir mensajes de particiones previamente consumidas por otro consumidor. Lo mismo ocurre cuando un consumidor se apaga o se bloquea; abandona el grupo, y las particiones que consumía serán consumidas por uno de los consumidores restantes. La reasignación de particiones a consumidores también ocurre cuando se modifican los temas que consume el grupo de consumidores (por ejemplo, si un administrador añade nuevas particiones).
Trasladar la propiedad de una partición de un consumidor a otro se denomina reequilibrio. Los reequilibrios son importantes porque proporcionan al grupo de consumidores alta disponibilidad y escalabilidad (nos permiten añadir y eliminar consumidores de forma fácil y segura), pero en el curso normal de los acontecimientos pueden ser bastante indeseables.
Hay dos tipos de reequilibrios, según la estrategia de asignación de particiones que utilice el grupo de consumidores:1
- Reequilibrios ansiosos
-
Durante un reequilibrio ansioso, todos los consumidores dejan de consumir, renuncian a la propiedad de todas las particiones, se reincorporan al grupo de consumidores y obtienen una nueva asignación de particiones. Se trata esencialmente de una breve ventana de indisponibilidad de todo el grupo de consumidores. La duración de la ventana depende del tamaño del grupo de consumidores, así como de varios parámetros de configuración. La Figura 4-6 muestra cómo los reequilibrios ansiosos tienen dos fases distintas: en primer lugar, todos los consumidores renuncian a su asignación de particiones, y en segundo lugar, después de que todos hayan completado esto y se hayan reincorporado al grupo, obtienen nuevas asignaciones de particiones y pueden reanudar el consumo.
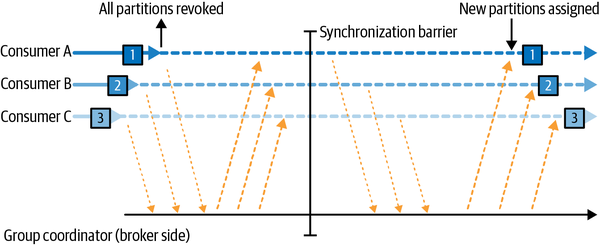
Figura 4-6. El reequilibrio ansioso revoca todas las particiones, detiene el consumo y las reasigna
- Reequilibrios cooperativos
-
Los reequilibrios cooperativos (también llamados reequilibrios incrementales) suelen implicar que reasigne sólo un pequeño subconjunto de las particiones de un consumidor a otro, y permita a los consumidores seguir procesando los registros de todas las particiones que no se reasignan. Esto se consigue reequilibrando en dos o más fases. Inicialmente, el líder del grupo de consumidores informa a todos los consumidores de que van a perder la propiedad de un subconjunto de sus particiones, entonces los consumidores dejan de consumir de estas particiones y renuncian a su propiedad en ellas. En la segunda fase, el líder del grupo de consumidores asigna estas particiones ahora huérfanas a sus nuevos propietarios. Este enfoque incremental puede llevar unas cuantas iteraciones hasta conseguir una asignación de particiones estable, pero evita la completa indisponibilidad de "parar el mundo" que se produce con el enfoque ansioso. Esto es especialmente importante en grandes grupos de consumidores, en los que los reequilibrios pueden llevar mucho tiempo. La Figura 4-7 muestra cómo los reequilibrios cooperativos son incrementales y que sólo interviene un subconjunto de consumidores y particiones.
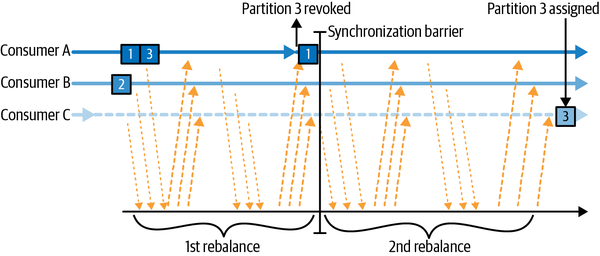
Figura 4-7. El reequilibrio cooperativo sólo detiene el consumo del subconjunto de particiones que serán reasignadas
Los consumidores mantienen su pertenencia a un grupo de consumidores y la propiedad de las particiones que se les asignan enviando heartbeats a un broker Kafka designado como coordinador del grupo (este broker puede ser diferente para distintos grupos de consumidores). Los latidos son enviados por un hilo de fondo del consumidor, y mientras el consumidor envíe latidos a intervalos regulares, se supone que está vivo.
Si el consumidor deja de enviar latidos durante el tiempo suficiente, su sesión expirará y el coordinador de grupo lo considerará muerto y activará un reequilibrio. Si un consumidor se bloquea y deja de procesar mensajes, el coordinador de grupo tardará unos segundos sin latidos en decidir que está muerto y activar el reequilibrio. Durante esos segundos, no se procesará ningún mensaje de las particiones propiedad del consumidor muerto. Al cerrar limpiamente un consumidor, éste notificará al coordinador de grupo que se marcha, y el coordinador de grupo activará un reequilibrio inmediatamente, reduciendo el desfase en el procesamiento. Más adelante en este capítulo, hablaremos de las opciones de configuración que controlan la frecuencia de los latidos del corazón, los tiempos de espera de las sesiones y otros parámetros de configuración que pueden utilizarse para afinar el comportamiento del consumidor.
¿Cómo funciona el proceso de asignación de particiones a los consumidores?
Cuando un consumidor quiere unirse a un grupo, envía una solicitud JoinGroup al coordinador del grupo. El primer consumidor que se una al grupo se convierte en el líder del grupo. El líder recibe del coordinador del grupo una lista de todos los consumidores del grupo (que incluirá a todos los consumidores que hayan enviado un heartbeat recientemente y que, por tanto, se consideran vivos) y se encarga de asignar un subconjunto de particiones a cada consumidor. Utiliza una implementación dePartitionAssignor para decidir qué particiones debe gestionar cada consumidor.
Kafka tiene incorporadas algunas políticas de asignación de particiones, que trataremos más a fondo en la sección de configuración. Tras decidir la asignación de particiones, el líder del grupo de consumidores envía la lista de asignaciones a GroupCoordinator, que envía esta información a todos los consumidores. Cada consumidor sólo ve su propia asignación: el líder es el único proceso cliente que tiene la lista completa de consumidores del grupo y sus asignaciones. Este proceso se repite cada vez que se produce un reequilibrio.
Pertenencia a un grupo estático
Por defecto, la identidad de un consumidor como miembro de su grupo de consumidores es transitoria. Cuando los consumidores abandonan un grupo de consumidores, se revocan las particiones que se le habían asignado, y cuando vuelve a unirse, se le asigna un nuevo ID de miembro y un nuevo conjunto de particiones mediante el protocolo de reequilibrio.
Todo esto es cierto a menos que configures un consumidor con un único group.instance.id, lo que convierte al consumidor en un miembro estático del grupo. Cuando un consumidor se une por primera vez a un grupo de consumidores como miembro estático del grupo, se le asigna un conjunto de particiones según la estrategia de asignación de particiones que esté utilizando el grupo, como es normal. Sin embargo, cuando este consumidor se apaga, no abandona automáticamente elgrupo, sino que sigue siendo miembro del grupo hasta que finaliza su sesión. Cuando el consumidor se reincorpora al grupo, se le reconoce con su identidad estática y se le reasignan las mismas particiones que tenía anteriormente sin provocar un reequilibrio. El coordinador del grupo que almacena en caché la asignación de cada miembro del grupo no necesita activar un reequilibrio, sino que puede limitarse a enviar la asignación en caché al miembro estático que se reincorpora.
Si dos consumidores se unen al mismo grupo con el mismo group.instance.id, el segundo consumidor obtendrá un error diciendo que ya existe un consumidor con ese ID.
La pertenencia estática a grupos es útil cuando tu aplicación mantiene un estado local o caché que se rellena con las particiones asignadas a cada consumidor. Cuando recrear esta caché lleva mucho tiempo, no quieres que este proceso ocurra cada vez que se reinicia un consumidor. Por otro lado, es importante recordar que lasparticiones propiedad de cada consumidor no se reasignarán cuando se reinicie un consumidor. Durante un cierto tiempo, ningún consumidor consumirá mensajes de estas particiones, y cuando el consumidor finalmente se reinicie, se retrasará con respecto a los últimos mensajes de estas particiones. Debes confiar en que el consumidor propietario de estas particiones será capaz de recuperar el retraso tras el reinicio.
Es importante tener en cuenta que los miembros estáticos de los grupos de consumidores no abandonan el grupo de forma proactiva cuando se apagan, y detectar cuándo se han "ido de verdad" depende de la configuración de session.timeout.ms. Querrás establecerlo lo suficientemente alto como para evitar que se activen reequilibrios en un simple reinicio de la aplicación, pero lo suficientemente bajo como para permitir la reasignación automática de sus particiones cuando se produzca un tiempo de inactividad más significativo, para evitar grandes lagunas en el procesamiento de estas particiones.
Crear un consumidor Kafka
El primer paso para empezar a consumir registros es crear una instancia KafkaConsumer. Crear un KafkaConsumer es muy similar a crear un KafkaProducer-creas una instancia Java Properties con las propiedades que quieras pasar al consumidor. Hablaremos de todas las propiedades en profundidad más adelante en el capítulo. Para empezar, sólo tenemos que utilizarlas tres propiedades obligatorias: bootstrap.servers, key.deserializer, y value.deserializer.
La primera propiedad, bootstrap.servers, es la cadena de conexión a un clúster Kafka.
Se utiliza exactamente igual que en KafkaProducer (consulta el Capítulo 3 para más detallessobre cómo se define). Las otras dos propiedades, key.deserializer y value.deserializer, son similares a la serializers definida para el productor, pero en lugar de especificar clases que conviertan objetos Java en matrices de bytes, debes especificar clases que puedan tomar una matriz de bytes y convertirla en un objeto Java.
Hay una cuarta propiedad, que no es estrictamente obligatoria, pero que se utiliza con mucha frecuencia. La propiedad es group.id, y especifica el grupo de consumidores al que pertenece la instancia. KafkaConsumer al que pertenece la instancia. Aunque es posible crear consumidores que no pertenezcan a ningún grupo de consumidores, esto es poco frecuente, por lo que en la mayor parte del capítulo supondremos que el consumidor forma parte de un grupo.
El siguiente fragmento de código muestra cómo crear una página KafkaConsumer:
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer =
new KafkaConsumer<String, String>(props);
La mayor parte de lo que veas aquí debería resultarte familiar si has leído el Capítulo 3 sobre la creación de productores. Suponemos que los registros que consumamos tendrán objetos String como clave y como valor del registro. La única propiedad nueva aquí es group.id, que es el nombre del grupo de consumidores al que pertenece este consumidor.
Suscribirse a Temas
Una vez creado un consumidor, el siguiente paso es suscribirse a uno o varios temas. El método subscribe() toma como parámetro una lista de temas, por lo que es bastante sencillo de utilizar:
consumer.subscribe(Collections.singletonList("customerCountries")); 
Aquí simplemente creamos una lista con un único elemento: el nombre del tema
customerCountries.
También es posible llamar a subscribe con una expresión regular. La expresión puede coincidir con varios nombres de temas, y si alguien crea un nuevo tema con un nombre que coincida, se producirá un reequilibrio casi inmediatamente y los consumidores empezarán a consumir desde el nuevo tema. Esto es útil para aplicaciones que necesitan consumir de varios temas y pueden manejar los diferentes tipos de datos que contendrán los temas. La suscripción a varios temas utilizando una expresión regular se utiliza más comúnmente en aplicaciones que replican datos entre Kafka y otro sistema o aplicaciones de procesamiento de flujos.
Por ejemplo, para suscribirnos a todos los temas de prueba, podemos llamar a
consumer.subscribe(Pattern.compile("test.*"));
Advertencia
Si tu clúster Kafka tiene un gran número de particiones, quizás 30.000 o más, debes tener en cuenta que el filtrado de temas para la suscripción se realiza en el lado del cliente. Esto significa que cuando te suscribes a un subconjunto de temas mediante una expresión regular en lugar de mediante una lista explícita, el consumidor solicitará al intermediario la lista de todos los temas y sus particiones a intervalos regulares. El cliente utilizará entonces esta lista para detectar nuevos temas que deba incluir en su suscripción y suscribirse a ellos. Cuando la lista de temas es grande y hay muchos consumidores, el tamaño de la lista de temas y particiones es significativo, y la suscripción por expresión regular tiene una sobrecarga importante en el corredor, el cliente y la red. Hay casos en los que el ancho de banda utilizado por los metadatos de los temas es mayor que el ancho de banda utilizado para enviar los datos. Esto también significa que, para suscribirse con una expresión regular, el cliente necesita permisos para describir todos los temas del clúster, es decir, una concesión completa de describe en todo el clúster.
El bucle de la encuesta
En el corazón de la API del Consumidor hay un sencillo bucle para sondear al servidor en busca de más datos. El cuerpo principal de un consumidor tendrá el siguiente aspecto:
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout); 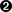 for (ConsumerRecord<String, String> record : records) {
for (ConsumerRecord<String, String> record : records) {  System.out.printf("topic = %s, partition = %d, offset = %d, " +
"customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString());
System.out.printf("topic = %s, partition = %d, offset = %d, " +
"customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
int updatedCount = 1;
if (custCountryMap.containsKey(record.value())) {
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(), updatedCount);
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString());  }
}
}
}
Se trata, efectivamente, de un bucle infinito. Los consumidores suelen ser aplicaciones de larga duración que continuamente sondean Kafka en busca de más datos. Más adelante mostraremos cómo salir limpiamente del bucle y cerrar el consumidor.
Esta es la línea más importante del capítulo. Del mismo modo que los tiburones deben seguir moviéndose o mueren, los consumidores deben seguir sondeando a Kafka o se considerarán muertos y las particiones que estén consumiendo se pasarán a otro consumidor del grupo para que siga consumiendo. El parámetro que pasamos a
poll()es un intervalo de tiempo de espera y controla cuánto tiempo se bloquearápoll()si no hay datos disponibles en el búfer del consumidor. Si se establece en 0 o si ya hay registros disponibles,poll()volverá inmediatamente; en caso contrario, esperará el número de milisegundos especificado.poll()devuelve una lista de registros. Cada registro contiene el tema y la partición de la que procede, el desplazamiento del registro dentro de la partición y, por supuesto, la clave y el valor del registro. Normalmente, queremos iterar sobre la lista y procesar los registros individualmente.El procesamiento suele terminar escribiendo un resultado en un almacén de datos o actualizando un registro almacenado. Aquí, el objetivo es mantener un recuento actualizado de los clientes de cada país, por lo que actualizamos una tabla hash e imprimimos el resultado como JSON. Un ejemplo más realista almacenaría el resultado de las actualizaciones en un almacén de datos.
El bucle poll hace mucho más que obtener datos. La primera vez que llamas a poll() con un nuevo consumidor, se encarga de encontrar a GroupCoordinator, unirse al grupo de consumidores y recibir una asignación de partición. Si se activa un reequilibrio, también se gestionará dentro del bucle de sondeo, incluidas las devoluciones de llamada relacionadas. Esto significa que casi todo lo que puede ir mal con un consumidor o en las retrollamadas utilizadas en sus oyentes es probable que aparezca como una excepción lanzada por poll().
Ten en cuenta que si poll() no se invoca durante más tiempo que max.poll.interval.ms, el consumidor se considerará muerto y será desalojado del grupo de consumidores, así que evita hacer cualquier cosa que pueda bloquearse durante intervalos impredecibles dentro del bucle de sondeo.
Seguridad de la rosca
No puedes tener varios consumidores que pertenezcan al mismo grupo en un hilo, y no puedes tener varios hilos que utilicen con seguridad el mismo consumidor. La regla es un consumidor por subproceso. Para ejecutar varios consumidores del mismo grupo en una aplicación, tendrás que ejecutar cada uno en su propio subproceso. Es útil envolver la lógica del consumidor en su propio objeto y luego utilizar ExecutorService de Java para iniciar varios hilos, cada uno con su propio consumidor. El blog de Confluent tiene un tutorial que muestra cómo hacerlo.
Advertencia
En versiones anteriores de Kafka, la firma completa del método era poll(long); esta firma está ahora obsoleta y la nueva API es poll(Duration). Además del cambio del tipo de argumento, la semántica de cómo se bloquea el método ha cambiado sutilmente. El método original, poll(long), se bloqueará todo el tiempo que tarde en obtener los metadatos necesarios de Kafka, incluso si éste es superior a la duración del tiempo de espera. El nuevo método, poll(Duration), respetará las restricciones de tiempo de espera y no esperará los metadatos. Si tienes código de consumidor existente que utiliza poll(0) como método para forzar a Kafka a obtener los metadatos sin consumir ningún registro (un hack bastante común), no puedes cambiarlo por poll(Duration.ofMillis(0)) y esperar el mismo comportamiento. Tendrás que encontrar una nueva forma de conseguir tus objetivos. A menudo la solución es colocar la lógica en el método rebalanceListener.onPartitionAssignment(), que está garantizado que se llama después de que tengas metadatos para las particiones asignadas, pero antes de que empiecen a llegar registros. Otra solución fue documentada por Jesse Anderson en su entrada del blog "Kafka's Got a Brand-New Poll".
Otro enfoque puede ser hacer que un consumidor rellene una cola de eventos y que varios subprocesos de trabajo realicen tareas a partir de esta cola. Puedes ver un ejemplo de este patrón en una entrada del blog de Igor Buzatović.
Configurar consumidores
Hasta ahora nos hemos centrado en aprender la API de consumidor, pero sólo hemos visto unas pocas de las propiedades de configuración: sólo las obligatorias bootstrap.servers, group.id, key.deserializer y value.deserializer. Toda la configuración del consumidor está documentada en la documentación de Apache Kafka. La mayoría de los parámetros tienen valores predeterminados razonables y no requieren modificación, pero algunos tienen implicaciones en el rendimiento y la disponibilidad de los consumidores. Veamos algunas de las propiedades más importantes.
buscar.min.bytes
Esta propiedad permite a un consumidor especificar la cantidad mínima de datos que desea recibir del corredor al obtener registros, por defecto un byte. Si un intermediario recibe una solicitud de registros de un consumidor, pero los nuevos registros suman menos bytes que fetch.min.bytes, el intermediario esperará hasta que haya más mensajes disponibles antes de devolver los registros al consumidor. Esto reduce la carga tanto del consumidor como del intermediario, ya que tienen que gestionar menos mensajes de ida y vuelta en los casos en que los temas no tienen mucha actividad nueva (o en las horas del día de menor actividad). Te conviene ajustar este parámetro más alto que el predeterminado si el consumidor está utilizando demasiada CPU cuando no hay muchos datos disponibles, o reducir la carga de los intermediarios cuando tienes un gran número de consumidores -aunque ten en cuenta que aumentar este valor puede aumentar la latencia en los casos de bajo rendimiento-.
fetch.max.espera.ms
Al establecer fetch.min.bytes, le dices a Kafka que espere hasta que tenga suficientes datos para enviar antes de responder al consumidor. fetch.max.wait.ms te permite controlar cuánto tiempo hay que esperar. Por defecto, Kafka esperará hasta 500 ms. Esto supone hasta 500 ms de latencia adicional en caso de que no haya suficientes datos fluyendo al tema Kafka para satisfacer la cantidad mínima de datos a devolver. Si quieres limitar la latencia potencial (normalmente debido a acuerdos de nivel de servicio que controlan la latencia máxima de la aplicación), puedes establecer fetch.max.wait.ms en un valor inferior. Si estableces fetch.max.wait.ms en 100 ms y fetch.min.bytes en 1 MB, Kafka recibirá una solicitud de obtención del consumidor y responderá con datos cuando tenga 1 MB de datos para devolver o después de 100 ms, lo que ocurra primero.
fetch.max.bytes
Esta propiedad te permite especificar el máximo de bytes que Kafka devolverá cada vez que el consumidor sondee a un intermediario (50 MB por defecto). Se utiliza para limitar el tamaño de la memoria que el consumidor utilizará para almacenar los datos devueltos por el servidor, independientemente del número de particiones o mensajes devueltos. Ten en cuenta que los registros se envían al cliente por lotes, y si el primer lote de registros que tiene que enviar el intermediario supera este tamaño, se enviará el lote y se ignorará el límite. Esto garantiza que el consumidor pueda seguir avanzando. Vale la pena señalar que existe una configuración del broker correspondiente que permite al administrador de Kafka limitar también el tamaño máximo de obtención. La configuración del corredor puede ser útil porque las solicitudes de grandes cantidades de datos pueden dar lugar a grandes lecturas desde el disco y largos envíos a través de la red, lo que puede causar contención y aumentar la carga en el corredor.
max.particion.buscar.bytes
Esta propiedad controla el número máximo de bytes que el servidor devolverá por partición (1 MB por defecto). Si KafkaConsumer.poll() devuelve ConsumerRecords, el objeto de registro utilizará como máximo max.partition.fetch.bytes por partición asignada al consumidor. Ten en cuenta que controlar el uso de memoria utilizando esta configuración puede ser bastante complejo, ya que no tienes control sobre cuántas particiones se incluirán en la respuesta del intermediario. Por lo tanto, te recomendamos encarecidamente que utilices fetch.max.bytes en su lugar, a menos que tengas razones especiales para intentar procesar cantidades similares de datos de cada partición.
session.timeout.ms y heartbeat.interval.ms
El tiempo que un consumidor puede estar fuera de contacto con los corredores sin dejar de considerarse vivo es, por defecto, de 10 segundos. Si pasa más de session.timeout.ms sin que el consumidor envíe un latido al coordinador del grupo, se considera muerto y el coordinador del grupo activará un reequilibrio del grupo de consumidores para asignar particiones del consumidor muerto a los demás consumidores del grupo. Esta propiedad está estrechamente relacionada con heartbeat.interval.ms, que controla la frecuencia con la que el consumidor Kafka enviará un heartbeat al coordinador del grupo, mientras que session.timeout.ms controla cuánto tiempo puede pasar un consumidor sin enviar un heartbeat. Por lo tanto, estas dos propiedades suelen modificarse juntas:heartbeat.interval.ms debe ser inferior a session.timeout.ms y suele fijarse en un tercio del valor del tiempo de espera. Así, si session.timeout.ms es de 3 segundos, heartbeat.interval.ms debe ser de 1 segundo. Establecer session.timeout.ms por debajo del valor predeterminado permitirá a los grupos de consumidores detectar y recuperarse antes de un fallo, pero también puede provocar reequilibrios no deseados. Establecer session.timeout.ms más alto reducirá la posibilidad de reequilibrios accidentales, pero también significa que se tardará más en detectar unfallo real.
max.intervalo.sondeo.ms
Esta propiedad te permite establecer el tiempo durante el cual el consumidor puede estar sin sondear antes de que se considere muerto. Como ya hemos mencionado, los heartbeats y los tiempos de espera de sesión son el principal mecanismo por el que Kafka detecta a los consumidores muertos y les retira sus particiones. Sin embargo, también hemos mencionado que los heartbeats son enviados por un hilo en segundo plano. Existe la posibilidad de que el hilo principal que consume de Kafka esté bloqueado, pero el hilo de fondo siga enviando heartbeats. Esto significa que no se están procesando los registros de las particiones que pertenecen a este consumidor. La forma más sencilla de saber si el consumidor sigue procesando registros es comprobar si está solicitando más registros. Sin embargo, los intervalos entre solicitudes de más registros son difíciles de predecir y dependen de la cantidad de datos disponibles, del tipo de procesamiento realizado por el consumidor y, a veces, de la latencia de los servicios adicionales. En las aplicaciones que necesitan realizar un procesamiento que requiere mucho tiempo en cada registro que se devuelve, max.poll.records se utiliza para limitar la cantidad de datos devueltos y, por tanto, limitar la duración antes de que la aplicación vuelva a estar disponible para poll(). Incluso con max.poll.records definido, el intervalo entre las llamadas a poll() es difícil de predecir, y max.poll.interval.ms se utiliza como mecanismo de seguridad o respaldo. Tiene que ser un intervalo lo suficientemente grande como para que muy raramente sea alcanzado por un consumidor sano, pero lo suficientemente bajo como para evitar un impacto significativo de un consumidor colgado. El valor por defecto es de 5 minutos. Cuando se alcance el tiempo de espera, el subproceso en segundo plano enviará una solicitud de "abandonar grupo" para informar al intermediario de que el consumidor está muerto y el grupo debe reequilibrarse, y luego dejará de enviar latidos.
tiempo.ms.de.espera.api.por.defecto
Es el tiempo de espera que se aplicará a (casi) todas las llamadas a la API realizadas por el consumidor cuando no especifiques un tiempo de espera explícito al llamar a la API. El valor por defecto es 1 minuto, y como es superior al valor por defecto del tiempo de espera de la solicitud, incluirá un reintento cuando sea necesario. La excepción notable a las API que utilizan este valor por defecto es el método poll(), que siempre requiere un tiempo de espera explícito.
tiempo espera.ms
Es el tiempo máximo que el consumidor esperará una respuesta del intermediario. Si el intermediario no responde en este tiempo, el cliente asumirá que el intermediario no responderá en absoluto, cerrará la conexión e intentará volver a conectarse. Esta configuración es por defecto de 30 segundos, y se recomienda no bajarla. Es importante dejar al intermediario tiempo suficiente para procesar la solicitud antes de darse por vencido: poco se gana reenviando solicitudes a un intermediario ya sobrecargado, y el acto de desconectarse y volver a conectarse añade aún más sobrecarga.
auto.offset.reset
Esta propiedad controla el comportamiento del consumidor cuando empieza a leer una partición para la que no tiene un desplazamiento comprometido, o si el desplazamiento comprometido que tiene no es válido (normalmente porque el consumidor estuvo inactivo durante tanto tiempo que el registro con ese desplazamiento ya había envejecido fuera del corredor). El valor predeterminado es "más reciente", lo que significa que, a falta de un desplazamiento válido, el consumidor empezará a leer los registros más recientes (los que se escribieron después de que el consumidor empezara a funcionar). La alternativa es "más antiguo", lo que significa que, a falta de un desplazamiento válido, el consumidor leerá todos los datos de la partición, empezando por el principio. Establecer auto.offset.reset a none hará que se lance una excepción cuando se intente consumir desde un desplazamiento no válido.
habilitar.auto.commit
Este parámetro controla si el consumidor consignará los desplazamientos automáticamente, y por defecto es true. Ajústalo a false si prefieres controlar cuándo se consignan los desplazamientos, lo cual es necesario para minimizar los duplicados y evitar que falten datos. Si estableces enable.auto.commit en true, es posible que también quieras controlar la frecuencia con la que se confirmarán las compensaciones utilizando auto.commit.interval.ms. Más adelante, en este mismo capítulo, hablaremos con más detalle de las distintas opciones para confirmar los desplazamientos.
estrategia.de.asignación.de.particiones
Hemos aprendido que las particiones se asignan a los consumidores de un grupo de consumidores. A PartitionAssignor es una clase que, dados los consumidores y los temas a los que se han suscrito, decide qué particiones se asignarán a cada consumidor. Por defecto, Kafka tiene las siguientes estrategias de asignación:
- Gama
-
Asigna a cada consumidor un subconjunto consecutivo de particiones de cada tema al que esté suscrito. Así, si los consumidores C1 y C2 están suscritos a dos temas, T1 y T2, y cada uno de los temas tiene tres particiones, a C1 se le asignarán las particiones 0 y 1 de los temas T1 y T2, mientras que a C2 se le asignará la partición 2 de esos temas. Como cada tema tiene un número impar de particiones y la asignación se hace para cada tema independientemente, el primer consumidor acaba teniendo más particiones que el segundo. Esto ocurre siempre que se utiliza la asignación por Rango y el número de consumidores no divide limpiamente el número de particiones de cada tema.
- RoundRobin
-
Toma todas las particiones de todos los temas suscritos y las asigna a los consumidores secuencialmente, una a una. Si C1 y C2 descritos anteriormente utilizaran la asignación RoundRobin, C1 tendría las particiones 0 y 2 del tema T1, y la partición 1 del tema T2. C2 tendría la partición 1 del tema T1, y las particiones 0 y 2 del tema T2. En general, si todos los consumidores están suscritos a los mismos temas (un escenario muy común), la asignación RoundRobin acabará con todos los consumidores teniendo el mismo número de particiones (o como mucho una partición de diferencia).
- Pegajoso
-
El Asignador Pegajoso tiene dos objetivos: el primero es tener una asignación lo más equilibrada posible, y el segundo es que, en caso de reequilibrio, dejará el mayor número posible de asignaciones en su sitio, minimizando la sobrecarga asociada al traslado de asignaciones de partición de un consumidor a otro. En el caso común de que todos los consumidores estén suscritos al mismo tema, la asignación inicial del Asignador Sticky estará tan equilibrada como la del Asignador RoundRobin. Las asignaciones posteriores serán igual de equilibradas, pero reducirán el número de movimientos de partición. En los casos en que los consumidores de un mismo grupo se suscriban a temas diferentes, la asignación conseguida por el Asignador Sticky estará más equilibrada que la del Asignador RoundRobin.
- Cooperativa Pegajosa
-
Esta estrategia de asignación es idéntica a la del Asignador Pegajoso, pero admite reequilibrios cooperativos en los que los consumidores pueden seguir consumiendo de las particiones que no se reasignan. Consulta "Grupos de consumidores y reequilibrio de particiones" para leer más sobre el reequilibrio cooperativo, y ten en cuenta que si estás actualizando desde una versión anterior a la 2.3, tendrás que seguir una ruta de actualización específica para activar la estrategia de asignación cooperativa pegajosa, así que presta especial atención a la guía de actualización.
La página partition.assignment.strategy te permite elegir una estrategia de asignación de particiones. Por defecto es org.apache.kafka.clients.consumer.RangeAssignor, que implementa la estrategia de Rango descrita anteriormente. Puedes sustituirla por org.apache.kafka.clients.consumer.RoundRobinAssignor, org.apache.kafka.clients.consumer.StickyAssignor, o org.apache.kafka.clients.consumer.CooperativeStickyAssignor. Una opción más avanzada es implementar tu propia estrategia de asignación, en cuyo caso partition.assignment.strategy debe apuntar al nombre de tu clase.
cliente.rack
Por defecto, los consumidores obtendrán los mensajes de la réplica líder de cada partición. Sin embargo, cuando el clúster abarca varios centros de datos o varias zonas de disponibilidad de la nube, la obtención de mensajes de una réplica situada en la misma zona que el consumidor tiene ventajas tanto en rendimiento como en coste. Para activar la obtención desde la réplica más cercana, tienes que establecer la configuración de client.rack e identificar la zona en la que se encuentra el cliente. A continuación, puedes configurar los intermediarios para que sustituyan el valor predeterminado replica.selector.class por org.apache.kafka.common.replica.RackAwareReplicaSelector.
También puedes implementar tu propio replica.selector.class con lógica personalizada para elegir la mejor réplica desde la que consumir, basándote en los metadatos del cliente y de la partición.
id.instancia.grupo
Puede ser cualquier cadena única y se utiliza para proporcionar a un consumidor la pertenencia a un grupo estático.
recibir.bytes.buffer y enviar.bytes.buffer
Son los tamaños de los búferes de envío y recepción TCP que utilizan los sockets al escribir y leer datos. Si se establecen en -1, se utilizarán los valores predeterminados del sistema operativo. Puede ser una buena idea aumentarlos cuando los productores o consumidores se comunican con intermediarios en un centro de datos diferente, porque esos enlaces de red suelen tener mayor latencia y menor ancho de banda.
compensaciones.retención.minutos
Se trata de una configuración del corredor, pero es importante tenerla en cuenta debido a su impacto en el comportamiento del consumidor. Mientras un grupo de consumidores tenga miembros activos (es decir, miembros que mantienen activamente su pertenencia al grupo enviando heartbeats), Kafka conservará el último offset comprometido por el grupo para cada partición, de modo que pueda recuperarse en caso de reasignación o reinicio. Sin embargo, una vez que un grupo se vacía, Kafka sólo conservará sus offsets comprometidos hasta la duración establecida por esta configuración-7 días por defecto. Una vez eliminados los desplazamientos, si el grupo vuelve a activarse, se comportará como un grupo consumidor completamente nuevo, sin memoria de nada de lo que haya consumido en el pasado. Ten en cuenta que este comportamiento ha cambiado algunas veces, así que si utilizasversiones anteriores a la 2.1.0, consulta la documentación de tu versión para conocer el comportamiento esperado.
Compromisos y compensaciones
Cada vez que llamamos a poll(), nos devuelve registros escritos en Kafka que los consumidores de nuestro grupo aún no han leído. Esto significa que tenemos una forma de rastrear qué registros ha leído un consumidor del grupo. Como ya hemos dicho, una de las características únicas de Kafka es que no hace un seguimiento de los acuses de recibo de los consumidores, como hacen muchas colas JMS. En su lugar, permite a los consumidores utilizar Kafka para realizar un seguimiento de su posición (desplazamiento) en cada partición.
Llamamos offseta la acción de actualizar la posición actual en la partición.commit. A diferencia de las colas de mensajes tradicionales, Kafka no consigna los registros individualmente. En su lugar, los consumidores consignan el último mensaje que han procesado con éxito de una partición y asumen implícitamente que todos los mensajes anteriores al último también se procesaron con éxito.
¿Cómo consigna un consumidor un desplazamiento? Envía un mensaje a Kafka, que actualiza un tema especial __consumer_offsets
Si el desplazamiento comprometido es menor que el desplazamiento del último mensaje que procesó el cliente, los mensajes entre el último desplazamiento procesado y el desplazamiento comprometido se procesarán dos veces. Ver la Figura 4-8.
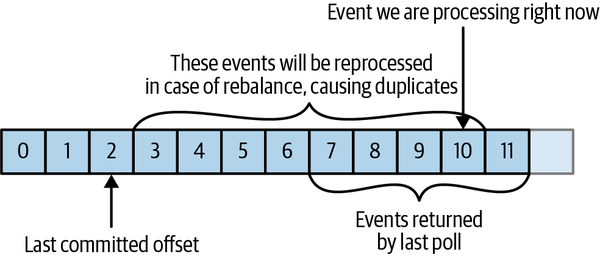
Figura 4-8. Mensajes reprocesados
Si el desplazamiento comprometido es mayor que el desplazamiento del último mensaje que el cliente procesó realmente, todos los mensajes entre el último desplazamiento procesado y el desplazamiento comprometido serán omitidos por el grupo de consumidores. Ver Figura 4-9.
Figura 4-9. Mensajes perdidos entre desplazamientos
Está claro que la gestión de las compensaciones tiene un gran impacto en la aplicación cliente. La API de KafkaConsumer API proporciona múltiples formas de comprometer los desplazamientos.
¿Qué compensación está comprometida?
Al consignar desplazamientos automáticamente o sin especificar los desplazamientos deseados, el comportamiento por defecto es consignar el desplazamiento posterior al último desplazamiento devuelto por poll(). Es importante tener esto en cuenta cuando intentes consignar manualmente desplazamientos específicos o busques consignar desplazamientos específicos. Sin embargo, también es tedioso leer repetidamente "Consigna el desplazamiento que sea uno mayor que el último desplazamiento que el cliente recibió de poll()," y el 99% de las veces no importa. Así que vamos a escribir "Confirmar el último desplazamiento" cuando nos refiramos al comportamiento por defecto, y si necesitas manipular manualmente los desplazamientos, ten en cuenta esta nota.
Compromiso automático
La forma más sencilla de confirmar los desplazamientos es permitir que el consumidor lo haga por ti. Si configuras enable.auto.commit=true, cada cinco segundos el consumidor confirmará el último desplazamiento que tu cliente haya recibido de poll(). El intervalo de cinco segundos es el predeterminado y se controla configurando auto.commit.interval.ms. Como todo lo demás en el consumidor, las confirmaciones automáticas están controladas por el bucle de sondeo. Cada vez que realiza un sondeo, el consumidor comprueba si ha llegado el momento de confirmar, y si es así, confirmará los desplazamientos que devolvió en el último sondeo.
Sin embargo, antes de utilizar esta cómoda opción, es importante comprender lasconsecuencias.
Considera que, por defecto, las confirmaciones automáticas se producen cada cinco segundos. Supongamos que, tres segundos después de la última confirmación, nuestro consumidor se ha bloqueado. Tras el reequilibrio, los consumidores supervivientes empezarán a consumir las particiones que antes pertenecían al corredor que se estrelló. Pero empezarán desde el último desplazamiento confirmado. En este caso, el desplazamiento es de hace tres segundos, por lo que todos los eventos que lleguen en esos tres segundos se procesarán dos veces. Es posible configurar el intervalo de confirmación para confirmar con más frecuencia y reducir la ventana en la que se duplicarán los registros, pero es imposible eliminarlos por completo.
Con la función de confirmación automática activada, cuando llegue el momento de confirmar los desplazamientos, el siguiente sondeo confirmará el último desplazamiento devuelto por el sondeo anterior. No sabe qué eventos se han procesado realmente, por lo que es fundamental procesar siempre todos los eventos devueltos por poll() antes de volver a llamar a poll(). (Al igual que poll(), close() también consigna los desplazamientos automáticamente.) Esto no suele ser un problema, pero presta atención cuando manejes excepciones o salgas del bucle de sondeo prematuramente.
Los commits automáticos son cómodos, pero no dan a los desarrolladores suficiente control para evitar mensajes duplicados.
Compromete el desplazamiento actual
La mayoría de los desarrolladores ejercen un mayor control sobre el momento en que seconsignan los desplazamientos, tanto para eliminar la posibilidad de que falten mensajes como para reducir el número de mensajes duplicados durante el reequilibrio. La API del consumidor tiene la opción de consignar el desplazamiento actual en un punto que tenga sentido para el desarrollador de la aplicación, en lugar de basarse en un temporizador.
Si configuras enable.auto.commit=false, los desplazamientos sólo se confirmarán cuando la aplicación lo decida explícitamente. La API de confirmación más sencilla y fiable es commitSync(). Esta API confirmará el último desplazamiento devuelto por poll() y volverá una vez que el desplazamiento se haya confirmado, lanzando una excepción si la confirmación falla por alguna razón.
Es importante recordar que commitSync() consignará el último desplazamiento devuelto por poll(), por lo que si llamas a commitSync() antes de haber terminado de procesar todos los registros de la colección, corres el riesgo de perder los mensajes consignados pero no procesados, en caso de que la aplicación se bloquee. Si la aplicación se bloquea mientras aún está procesando registros de la colección, todos los mensajes desde el principio del lote más reciente hasta el momento del reequilibrio se procesarán dos veces, lo que puede ser preferible o no a perder mensajes.
Así es como utilizaríamos commitSync para confirmar los desplazamientos después de haber terminado de procesar el último lote de mensajes:
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %d, offset =
%d, customer = %s, country = %s\n",
record.topic(), record.partition(),
record.offset(), record.key(), record.value());
}
try {
consumer.commitSync();
} catch (CommitFailedException e) {
log.error("commit failed", e)
}
}
Supongamos que, al imprimir el contenido de un registro, hemos terminado de procesarlo. Es probable que tu aplicación haga muchas más cosas con los registros: modificarlos, enriquecerlos, agregarlos, mostrarlos en un panel de control o notificar a los usuarios eventos importantes. Debes determinar cuándo has "terminado" con un registro en función de tu caso de uso.
Una vez que hemos terminado de "procesar" todos los registros del lote actual, llamamos a
commitSyncpara consignar el último desplazamiento del lote, antes de sondear en busca demensajes adicionales.commitSyncreintentos cometidos siempre que no se produzca un error que no pueda recuperarse. Si esto ocurre, no hay mucho que podamos hacer, salvo registrar un error.
Confirmación asíncrona
Un inconveniente de la confirmación manual es que la aplicación se bloquea hasta que el intermediario responde a la solicitud de confirmación. Esto limitará el rendimiento de la aplicación. El rendimiento puede mejorarse realizando confirmaciones con menos frecuencia, pero entonces estaremos aumentando el número de duplicados potenciales que puede crear un reequilibrio.
Otra opción es la API de confirmación asíncrona. En lugar de esperar a que el intermediario responda a una confirmación, simplemente enviamos la solicitud y seguimos adelante:
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s,
offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
consumer.commitAsync();
}
Compromete el último desplazamiento y continúa.
El inconveniente es que, mientras que commitSync() reintentará la confirmación hasta que tenga éxito o se encuentre con un fallo no recuperable, commitAsync() no reintentará. La razón por la que no reintenta es que para cuando commitAsync() reciba una respuesta del servidor, puede haber habido una confirmación posterior que ya haya tenido éxito. Imagina que enviamos una petición para confirmar el offset 2000. Hay un problema temporal de comunicación, por lo que el broker nunca recibe la solicitud y, por tanto, nunca responde. Mientras tanto, procesamos otro lote y consignamos con éxito el desplazamiento 3000. Si commitAsync() reintenta ahora la consignación que falló anteriormente, puede que consiga consignar el desplazamiento 2000 después de que el desplazamiento 3000 ya se haya procesado y consignado. En el caso de un reequilibrio, esto provocará más duplicados.
Mencionamos esta complicación y la importancia del orden correcto de las confirmaciones porque commitAsync() también te da la opción de pasar una llamada de retorno que se activará cuando el intermediario responda. Es habitual utilizar la llamada de retorno para registrar errores de confirmación o para contabilizarlos en una métrica, pero si quieres utilizar la llamada de retorno para reintentos, tienes que ser consciente del problema con el orden de confirmación:
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s,
offset = %d, customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets, Exception e) {
if (e != null)
log.error("Commit failed for offsets {}", offsets, e);
}
});
}
Enviamos la confirmación y seguimos adelante, pero si la confirmación falla, se registrarán el fallo y las compensaciones.
Reintentar confirmaciones asíncronas
Un patrón sencillo para conseguir el orden de confirmación correcto para los reintentos asíncronos es utilizar un número de secuencia monotónicamente creciente. Aumenta el número de secuencia cada vez que realices una confirmación, y añade el número de secuencia en el momento de la confirmación a la llamada de retorno commitAsync. Cuando te dispongas a enviar un reintento, comprueba si el número de secuencia de confirmación que obtuvo la llamada de retorno es igual a la variable de instancia; si lo es, no hubo una confirmación más reciente y es seguro reintentar. Si el número de secuencia de la instancia es mayor, no reintentes porque ya se ha enviado una confirmación más reciente.
Combinar commits síncronos y asíncronos
Normalmente, los fallos ocasionales en la confirmación sin reintentar no son un gran problema, porque si el problema es temporal, la siguiente confirmación tendrá éxito. Pero si sabemos que ésta es la última confirmación antes de cerrar el consumidor, o antes de un reequilibrio, queremos asegurarnos aún más de que la confirmación tiene éxito.
Por lo tanto, un patrón común es combinar commitAsync() con commitSync() justo antes del cierre. Así es como funciona (hablaremos de cómo confirmar justo antes del reequilibrio cuando lleguemos a la sección sobre los oyentes de reequilibrio):
Duration timeout = Duration.ofMillis(100);
try {
while (!closing) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(),
record.offset(), record.key(), record.value());
}
consumer.commitAsync();
}
consumer.commitSync();
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
consumer.close();
}
Mientras todo esté bien, utilizamos
commitAsync. Es más rápido, y si una confirmación falla, la siguiente servirá como reintento.Pero si estamos cerrando, no hay "siguiente commit". Llamamos a
commitSync(), porque volverá a intentarlo hasta que tenga éxito o sufra un fallo irrecuperable.
Comprometiendo un Desplazamiento Especificado
Confirmar el último desplazamiento sólo te permite confirmar tan a menudo como termines de procesar los lotes. Pero, ¿y si quieres confirmar con más frecuencia? ¿Y si poll() devuelve un lote enorme y quieres consignar desplazamientos en mitad del lote para evitar tener que procesar de nuevo todas esas filas si se produce un reequilibrio? No puedes llamar simplemente a commitSync() o commitAsync()-esto consignará el último desplazamiento devuelto, que aún no has llegado a procesar.
Afortunadamente, la API del consumidor te permite llamar a commitSync() y commitAsync() y pasarles un mapa de particiones y desplazamientos que deseas consignar. Si estás en medio del procesamiento de un lote de registros, y el último mensaje que recibiste de la partición 3 en el tema "clientes" tiene el desplazamiento 5000, puedes llamar a commitSync() para consignar el desplazamiento 5001 para la partición 3 en el tema "clientes". Dado que tu consumidor puede estar consumiendo más de una partición, necesitarás hacer un seguimiento de los desplazamientos en todas ellas, lo que añade complejidad a tu código.
Este es el aspecto de un commit de compensaciones específicas:
private Map<TopicPartition, OffsetAndMetadata> currentOffsets =
new HashMap<>();
int count = 0;
....
Duration timeout = Duration.ofMillis(100);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()+1, "no metadata"));
if (count % 1000 == 0)
consumer.commitAsync(currentOffsets, null);  count++;
}
}
count++;
}
}
Éste es el mapa que utilizaremos para seguir manualmente los desplazamientos.
Recuerda,
printlnes un sustituto de cualquier procesamiento que hagas de los registros que consumes.Después de leer cada registro, actualizamos el mapa de desplazamientos con el desplazamiento del siguiente mensaje que esperamos procesar. El offset comprometido debe ser siempre el offset del siguiente mensaje que leerá tu aplicación. Aquí es donde empezaremos a leer la próxima vez que arranquemos.
Aquí, decidimos consignar los desplazamientos actuales cada 1.000 registros. En tu aplicación, puedes confirmar en función del tiempo o quizás del contenido de los registros.
He optado por llamar a
commitAsync()(sin devolución de llamada, por lo que el segundo parámetro esnull), perocommitSync()también es completamente válido en este caso. Por supuesto, al consignar desplazamientos específicos sigues necesitando realizar todo el tratamiento de errores que hemos visto en secciones anteriores.
Reequilibrar los oyentes
Como mencionamos en la sección anterior sobre la confirmación de compensaciones, un consumidor querrá hacer algún trabajo de limpieza antes de salir y también antes del reequilibrio de particiones.
Si sabes que tu consumidor está a punto de perder la propiedad de una partición, querrás confirmar los desplazamientos del último evento que hayas procesado. Quizá también necesites cerrar manejadores de archivos, conexiones a bases de datos y cosas así.
La API del consumidor te permite ejecutar tu propio código cuando se añaden o eliminan particiones del consumidor. Para ello, pasa un ConsumerRebalanceListener cuando llames al método subscribe() del que hemos hablado anteriormente. ConsumerRebalanceListener tiene tres métodos que puedes implementar:
public void onPartitionsAssigned(Collection<TopicPartition> partitions)-
Se llama después de que las particiones se hayan reasignado al consumidor, pero antes de que el consumidor empiece a consumir mensajes. Aquí es donde preparas o cargas cualquier estado que quieras utilizar con la partición, buscas los desplazamientos correctos si es necesario, o similares. Debe garantizarse que cualquier preparación que se haga aquí regrese dentro de
max.poll.timeout.mspara que el consumidor pueda unirse con éxito al grupo. public void onPartitionsRevoked(Collection<TopicPartition> partitions)-
Se invoca cuando el consumidor tiene que renunciar a particiones que antes poseía, ya sea como resultado de un reequilibrio o cuando se está cerrando el consumidor. En el caso común, cuando se utiliza un algoritmo de reequilibrio ansioso, este método se invoca antes de que comience el reequilibrio y después de que el consumidor haya dejado de consumir mensajes. Si se utiliza un algoritmo de reequilibrio cooperativo, este método se invoca al final del reequilibrio, sólo con el subconjunto de particiones que el consumidor tiene que abandonar. Aquí es donde quieres comprometer las compensaciones, para que quien obtenga esta partición a continuación sepa por dónde empezar.
public void onPartitionsLost(Collection<TopicPartition> partitions)-
Sólo se llama cuando se utiliza un algoritmo de reequilibrio cooperativo, y sólo en casos excepcionales en los que las particiones se asignaron a otros consumidores sin ser revocadas antes por el algoritmo de reequilibrio (en casos normales, se llamará a
onPartitionsRevoked()). Aquí es donde se limpia cualquier estado o recurso que se utilice con estas particiones. Ten en cuenta que esto debe hacerse con cuidado: es posible que el nuevo propietario de las particiones ya haya guardado su propio estado, y tendrás que evitar conflictos. Ten en cuenta que si no implementas este método, se llamará aonPartitionsRevoked()en su lugar.
Consejo
Si utilizas un algoritmo de reequilibrio cooperativo, ten en cuenta que:
-
onPartitionsAssigned()se invocará en cada reequilibrio, como forma de notificar al consumidor que se ha producido un reequilibrio. Sin embargo, si no hay nuevas particiones asignadas al consumidor, se invocará con una colección vacía. -
onPartitionsRevoked()se invocará en condiciones normales de reequilibrio, pero sólo si el consumidor renunció a la propiedad de las particiones. No se invocará con una colección vacía. -
onPartitionsLost()se invocará en condiciones excepcionales de reequilibrio, y las particiones de la colección ya tendrán nuevos propietarios en el momento en que se invoque el método.
Si implementaste los tres métodos, tienes garantizado que durante un reequilibrio normal, onPartitionsAssigned() será llamado por el nuevo propietario de las particiones que se reasignen sólo después de que el propietario anterior completara onPartitionsRevoked() y renunciara a su propiedad.
Este ejemplo mostrará cómo utilizar onPartitionsRevoked() para confirmar las compensaciones antes de perder la propiedad de una partición:
private Map<TopicPartition, OffsetAndMetadata> currentOffsets =
new HashMap<>();
Duration timeout = Duration.ofMillis(100);
private class HandleRebalance implements ConsumerRebalanceListener {
public void onPartitionsAssigned(Collection<TopicPartition>
partitions) {
}
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Lost partitions in rebalance. " +
"Committing current offsets:" + currentOffsets);
consumer.commitSync(currentOffsets);
}
}
try {
consumer.subscribe(topics, new HandleRebalance());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset()+1, null));
}
consumer.commitAsync(currentOffsets, null);
}
} catch (WakeupException e) {
// ignore, we're closing
} catch (Exception e) {
log.error("Unexpected error", e);
} finally {
try {
consumer.commitSync(currentOffsets);
} finally {
consumer.close();
System.out.println("Closed consumer and we are done");
}
}
Comenzamos poniendo en marcha un
ConsumerRebalanceListener.En este ejemplo no necesitamos hacer nada cuando obtengamos una nueva partición; simplemente empezaremos a consumir mensajes.
Sin embargo, cuando estamos a punto de perder una partición debido a un reequilibrio, tenemos que confirmar los desplazamientos. Confirmamos los offsets de todas las particiones, no sólo de las que estamos a punto de perder; como los offsets corresponden a eventos que ya se han procesado, no hay nada malo en ello. Y utilizamos
commitSync()para asegurarnos de que las compensaciones se comprometen antes de proceder al reequilibrio.Lo más importante: pasa el
ConsumerRebalanceListeneral métodosubscribe()para que sea invocado por el consumidor.
Consumir registros con desplazamientos específicos
Hasta ahora hemos visto cómo utilizar poll() para empezar a consumir mensajes desde el último desplazamiento comprometido en cada partición y proceder a procesar todos los mensajes en secuencia. Sin embargo, a veces quieres empezar a leer en un desplazamiento diferente. Kafka ofrece una variedad de métodos que hacen que el siguiente poll() comience a consumir en un desplazamiento diferente.
Si quieres empezar a leer todos los mensajes desde el principio de la partición, o quieres saltar hasta el final de la partición y empezar a consumir sólo los mensajes nuevos, existen APIs específicas para ello: seekToBeginning(Collection<TopicPartition> tp) y seekToEnd(Collection<TopicPartition> tp).
La API de Kafka también te permite buscar un desplazamiento específico. Esta capacidad se puede utilizar de diversas formas; por ejemplo, una aplicación sensible al tiempo podría saltarse unos cuantos registros cuando se quede rezagada, o un consumidor que escriba datos en un archivo podría retroceder a un punto específico en el tiempo para recuperar los datos si se perdiera el archivo.
Aquí tienes un ejemplo rápido de cómo establecer el desplazamiento actual en todas las particiones a los registros que se produjeron en un momento determinado:
Long oneHourEarlier = Instant.now().atZone(ZoneId.systemDefault())
.minusHours(1).toEpochSecond();
Map<TopicPartition, Long> partitionTimestampMap = consumer.assignment()
.stream()
.collect(Collectors.toMap(tp -> tp, tp -> oneHourEarlier));
Map<TopicPartition, OffsetAndTimestamp> offsetMap
= consumer.offsetsForTimes(partitionTimestampMap);
for(Map.Entry<TopicPartition,OffsetAndTimestamp> entry: offsetMap.entrySet()) {
consumer.seek(entry.getKey(), entry.getValue().offset());
}
Creamos un mapa desde todas las particiones asignadas a este consumidor (mediante
consumer.assignment()) a la marca de tiempo a la que queríamos revertir los consumidores.A continuación, obtenemos los desfases que estaban vigentes en esas marcas de tiempo. Este método envía una solicitud al corredor, donde se utiliza un índice de marca de tiempo para devolver los desfases relevantes.
Por último, reajustamos el desplazamiento de cada partición al desplazamiento devuelto en el paso anterior.
Pero, ¿cómo salimos?
Anteriormente en este capítulo, cuando hablamos del bucle de sondeo, te dijimos que no te preocuparas por el hecho de que el consumidor sondeara en un bucle infinito, y que hablaríamos de cómo salir del bucle limpiamente. Así que vamos a ver cómo salir limpiamente.
Cuando decidas cerrar el consumidor, y quieras salir inmediatamente aunque el consumidor pueda estar esperando en un largo poll(), necesitarás otro hilo para llamar a consumer.wakeup(). Si estás ejecutando el bucle consumidor en el hilo principal, esto puede hacerse desde ShutdownHook. Ten en cuenta que consumer.wakeup() es el único método consumidor que es seguro llamar desde un hilo diferente.Llamar a wakeup hará que poll() salga con WakeupException, o si se llamó a consumer.wakeup() mientras el hilo no estaba esperando en el sondeo, la excepción se lanzará en la siguiente iteración cuando se llame a poll(). El WakeupException no necesita ser manejado, pero antes de salir del hilo, debes llamar a consumer.close(). Al cerrar el consumidor se comprometerán las compensaciones si es necesario y se enviará al coordinador del grupo un mensaje indicando que el consumidor abandona el grupo. El coordinador de consumidores activará el reequilibrio inmediatamente, y no tendrás que esperar a que se agote el tiempo de espera de la sesión para que las particiones del consumidor que estás cerrando se asignen a otro consumidor del grupo.
Este es el aspecto que tendrá el código de salida si el consumidor se ejecuta en el hilo principal de la aplicación. Este ejemplo está un poco truncado, pero puedes ver el ejemplo completo en GitHub:
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
System.out.println("Starting exit...");
consumer.wakeup();
try {
mainThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
...
Duration timeout = Duration.ofMillis(10000);
try {
// looping until ctrl-c, the shutdown hook will cleanup on exit
while (true) {
ConsumerRecords<String, String> records =
movingAvg.consumer.poll(timeout);
System.out.println(System.currentTimeMillis() +
"-- waiting for data...");
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
for (TopicPartition tp: consumer.assignment())
System.out.println("Committing offset at position:" +
consumer.position(tp));
movingAvg.consumer.commitSync();
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
consumer.close();
System.out.println("Closed consumer and we are done");
}
ShutdownHookse ejecuta en un hilo independiente, por lo que la única acción segura que puedes realizar es llamar awakeuppara salir del buclepoll.Un tiempo de espera de sondeo especialmente largo. Si el bucle de sondeo es lo suficientemente corto y no te importa esperar un poco antes de salir, no necesitas llamar a
wakeup-basta con comprobar un booleano atómico en cada iteración. Los tiempos de espera de sondeo largos son útiles cuando se consumen temas de bajo rendimiento; de esta forma, el cliente utiliza menos CPU por estar constantemente en bucle mientras el intermediario no tiene nuevos datos que devolver.Otro hilo que llame a
wakeuphará que poll lance unaWakeupException. Querrás atrapar la excepción para asegurarte de que tu aplicación no sale inesperadamente, pero no es necesario hacer nada con ella.Antes de salir del consumidor, asegúrate de cerrarlo limpiamente.
Deserializadores
Como se ha comentado en el capítulo anterior, los productores de Kafka necesitan serializadores para convertir los objetos en matrices de bytes que luego se envían a Kafka. Del mismo modo, los consumidores de Kafka necesitan deserializadores para convertir las matrices de bytes recibidas de Kafka en objetos Java. En los ejemplos anteriores, nos limitamos a suponer que tanto la clave como el valor de cada mensaje son cadenas, y utilizamos el StringDeserializer por defecto en laconfiguración del consumidor.
En el Capítulo 3 sobre el productor de Kafka, vimos cómo serializar tipos personalizados y cómo utilizar Avro y AvroSerializers para generar objetos Avro a partir de definiciones de esquema y luego serializarlos al producir mensajes para Kafka. Ahora veremos cómo crear deserializadores personalizados para tus propios objetos y cómo utilizar Avro y sus deserializadores.
Debería ser obvio que el serializador utilizado para producir eventos a Kafka debe coincidir con el deserializador que se utilizará al consumir eventos. Serializar con IntSerializer y luego deserializar con StringDeserializer no acabará bien. Esto significa que, como desarrollador, tienes que hacer un seguimiento de qué serializadores se utilizaron para escribir en cada tema y asegurarte de que cada tema sólo contiene datos que los deserializadores que utilizas pueden interpretar. Ésta es una de las ventajas de utilizar Avro y el Registro de Esquemas para serializar y deserializar: AvroSerializer puede asegurarse de que todos los datos escritos en un tema específico son compatibles con el esquema del tema, lo que significa que pueden deserializarse con el deserializador y el esquema adecuados. Cualquier error de compatibilidad -del lado del productor o del consumidor- se detectará fácilmente con un mensaje de error apropiado, lo que significa que no tendrás que intentar depurar matrices de bytes para detectar errores de serialización.
Empezaremos mostrando rápidamente cómo escribir un deserializador personalizado, aunque éste sea el método menos habitual, y luego pasaremos a un ejemplo de cómo utilizar Avro para deserializar claves y valores de mensajes.
Deserializadores personalizados
Tomemos el mismo objeto personalizado que serializamos en en el Capítulo 3 y escribamos un deserializador para él:
public class Customer {
private int customerID;
private String customerName;
public Customer(int ID, String name) {
this.customerID = ID;
this.customerName = name;
}
public int getID() {
return customerID;
}
public String getName() {
return customerName;
}
}
El deserializador personalizado tendrá el siguiente aspecto:
import org.apache.kafka.common.errors.SerializationException;
import java.nio.ByteBuffer;
import java.util.Map;
public class CustomerDeserializer implements Deserializer<Customer> {
@Override
public void configure(Map configs, boolean isKey) {
// nothing to configure
}
@Override
public Customer deserialize(String topic, byte[] data) {
int id;
int nameSize;
String name;
try {
if (data == null)
return null;
if (data.length < 8)
throw new SerializationException("Size of data received " +
"by deserializer is shorter than expected");
ByteBuffer buffer = ByteBuffer.wrap(data);
id = buffer.getInt();
nameSize = buffer.getInt();
byte[] nameBytes = new byte[nameSize];
buffer.get(nameBytes);
name = new String(nameBytes, "UTF-8");
return new Customer(id, name);
} catch (Exception e) {
throw new SerializationException("Error when deserializing " + "byte[] to Customer " + e);
}
}
@Override
public void close() {
// nothing to close
}
}
El consumidor también necesita la implementación de la clase
Customer, y tanto la clase como el serializador deben coincidir en las aplicaciones productoras y consumidoras. En una gran organización con muchos consumidores y productores que comparten el acceso a los datos, esto puede convertirse en un reto.Aquí estamos invirtiendo la lógica del serializador: sacamos el ID y el nombre del cliente de la matriz de bytes y los utilizamos para construir el objeto que necesitamos.
El código del consumidor que utilice este deserializador tendrá un aspecto similar al de este ejemplo:
Duration timeout = Duration.ofMillis(100);
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
CustomerDeserializer.class.getName());
KafkaConsumer<String, Customer> consumer =
new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("customerCountries"))
while (true) {
ConsumerRecords<String, Customer> records = consumer.poll(timeout);
for (ConsumerRecord<String, Customer> record : records) {
System.out.println("current customer Id: " +
record.value().getID() + " and
current customer name: " + record.value().getName());
}
consumer.commitSync();
}
De nuevo, es importante señalar que no se recomienda implementar un serializador y deserializador personalizados. Acopla estrechamente productores y consumidores y es frágil y propenso a errores. Una solución mejor sería utilizar un formato de mensaje estándar, como JSON, Thrift, Protobuf o Avro. Ahora veremos cómo utilizar los deserializadores Avro con el consumidor Kafka. Para más información sobre Apache Avro, sus esquemas y sus capacidades de compatibilidad de esquemas, consulta el Capítulo 3.
Uso de la deserialización Avro con el consumidor Kafka
Supongamos en que estamos utilizando la implementación de la clase Customer en Avro que se mostró en el Capítulo 3. Para consumir esos objetos de Kafka, quieres implementar una aplicación consumidora similar a ésta:
Duration timeout = Duration.ofMillis(100);
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("group.id", "CountryCounter");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"io.confluent.kafka.serializers.KafkaAvroDeserializer");
props.put("specific.avro.reader","true");
props.put("schema.registry.url", schemaUrl);
String topic = "customerContacts"
KafkaConsumer<String, Customer> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic));
System.out.println("Reading topic:" + topic);
while (true) {
ConsumerRecords<String, Customer> records = consumer.poll(timeout);
for (ConsumerRecord<String, Customer> record: records) {
System.out.println("Current customer name is: " +
record.value().getName());
}
consumer.commitSync();
}
Utilizamos
KafkaAvroDeserializerpara deserializar los mensajes Avro.schema.registry.urles un nuevo parámetro. Simplemente señala dónde almacenamos los esquemas. De este modo, el consumidor puede utilizar el esquema registrado por el productor para deserializar el mensaje.Especificamos la clase generada,
Customer, como tipo para el valor del registro.record.value()es una instancia deCustomer, y podemos utilizarla en consecuencia.
Consumidor Independiente: Por qué y cómo utilizar un consumidor sin grupo
Hasta ahora hemos hablado de los grupos de consumidores, en los que las particiones se asignan automáticamente a los consumidores y se reequilibran automáticamente cuando se añaden o eliminan consumidores del grupo. Normalmente, este comportamiento es justo lo que quieres, pero en algunos casos deseas algo mucho más sencillo. A veces sabes que tienes un único consumidor que siempre necesita leer datos de todas las particiones de un tema, o de una partición concreta de un tema. En este caso, no hay razón para grupos o reequilibrios: basta con asignar el tema y/o las particiones específicas del consumidor, consumir los mensajes y comprometer los desplazamientos de vez en cuando (aunque sigues necesitando configurar group.id para comprometer los desplazamientos, sin llamar a suscribir el consumidor no se unirá a ningún grupo).
Cuando sabes exactamente qué particiones debe leer el consumidor, no te suscribes a un tema, sino que te asignas unas particiones. Un consumidor puede suscribirse a temas (y formar parte de un grupo de consumidores) o asignarse particiones, pero no ambas cosas a la vez.
He aquí un ejemplo de cómo un consumidor puede asignarse a sí mismo todas las particiones de un tema concreto y consumir de ellas:
Duration timeout = Duration.ofMillis(100);
List<PartitionInfo> partitionInfos = null;
partitionInfos = consumer.partitionsFor("topic");
if (partitionInfos != null) {
for (PartitionInfo partition : partitionInfos)
partitions.add(new TopicPartition(partition.topic(),
partition.partition()));
consumer.assign(partitions);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record: records) {
System.out.printf("topic = %s, partition = %s, offset = %d,
customer = %s, country = %s\n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
consumer.commitSync();
}
}
Comenzamos preguntando al clúster por las particiones disponibles en el tema. Si sólo piensas consumir una partición concreta, puedes saltarte esta parte.
Una vez que sabemos qué particiones de queremos, llamamos a
assign()con la lista.
Aparte de la falta de reequilibrios y de la necesidad de encontrar manualmente las particiones, todo lo demás sigue como siempre. Ten en cuenta que si alguien añade nuevas particiones al tema, el consumidor no será notificado. Tendrás que manejar esto comprobando consumer.partitionsFor() periódicamente o simplemente rebotando la aplicación cada vez que se añadan particiones.
Resumen
Comenzamos este capítulo con una explicación en profundidad de los grupos de consumidores de Kafka y la forma en que permiten que varios consumidores compartan el trabajo de leer eventos de los temas. Hemos seguido la discusión teórica con un ejemplo práctico de un consumidor que se suscribe a un tema y lee eventos continuamente. A continuación, hemos estudiado los parámetros de configuración más importantes de los consumidores y cómo afectan a su comportamiento. Hemos dedicado gran parte del capítulo a discutir las compensaciones y cómo los consumidores hacen un seguimiento de ellas. Comprender cómo los consumidores consignan los offsets es fundamental a la hora de escribir consumidores fiables, por lo que dedicamos tiempo a explicar las distintas formas en que puede hacerse. A continuación, tratamos otras partes de las API de los consumidores, la gestión de los reequilibrios y el cierre del consumidor.
Concluimos hablando de los deserializadores que utilizan los consumidores para convertir los bytes almacenados en Kafka en objetos Java que las aplicaciones puedan procesar. Hablamos con cierto detalle de los deserializadores Avro, a pesar de que son sólo un tipo de deserializador que puedes utilizar, porque son los más utilizados con Kafka.
1 Diagramas de Sophie Blee-Goldman, de su entrada del blog de mayo de 2020, "De ansioso a más inteligente en los reequilibrios de consumo de Apache Kafka".
Get Kafka: La Guía Definitiva, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

