Chapter 19. Working with Structured Data
19.0. Introduction
Even though it’s primarily a client-side development tool, JavaScript has access to several very sophisticated techniques and mechanisms for working with structured data.
Originally, most complex data management, particularly in relation
to Ajax calls, was based either in HTML fragments or XML. HTML fragments
are still popular. When returned from an Ajax request, the HTML formatted
string can be used with innerHTML in
order to easily append the HTML into the page. Of course, you have to
trust the data you receive, and you can’t manipulate it until you actually
insert the data into the page. Either that, or use various String functions to parse pieces out of the HTML
string.
Data returned as XML is a richer option, because you can use the string to create a separate document object, from which you can access individual elements, just like you query the web page document now.
XML data is still widely supported, but another structure has gained a great deal of popularity: JavaScript Object Notation, or JSON. It’s so popular that JSON has been added to the most recent version of JavaScript, ECMAScript 5. JSON provides the richness of XML but without the performance hit client-side processing of XML can add.
JSON is basically the string serialization of JavaScript objects.
Before ECMAScript 5, you had to use the eval function to convert the string to an object
. Unfortunately, using the eval
function on an unknown string is an application-security vulnerability. To
ensure the string was safe, the originator of JSON, Douglas Crockford,
created a library to process the JSON safely. The same functionality is
now built into JavaScript.
Support for complex data extends beyond what is built into JavaScript. There are multiple approaches for annotating the web page elements with metadata that can be accessed within the page and without. Two metadata approaches, RDFa and Microformats, have widespread support, including specialized JavaScript libraries. I’ll be touching on these later in the chapter.
19.1. Process an XML Document Returned from an Ajax Call
Solution
Access the returned XML via the responseXML property on
the XMLHttpRequest object:
if (xmlHttpObj.readyState == 4 && xmlHttpObj.status == 200) {
var citynodes = xmlHttpObj.responseXML.getElementsByTagName("city");
...
}Discussion
When an Ajax request returns XML, it can be accessed as a document
object via the XMLHttpRequest
object’s responseXML property. You
can then use the query techniques covered in earlier chapters, such as
Chapter 11, to access any of the data in
the returned XML.
If the server-side application is returning XML, it’s important
that it return a MIME type of text/xml, or the responseXML property will be null. If you’re unsure whether the API returns
the proper MIME type, or if you have no control over the API, you can
override the MIME type when you access the XMLHttpRequest object:
if (window.XMLHttpRequest) {
xmlHttpObj = new XMLHttpRequest();
if (xmlHttpObj.overrideMimeType) {
xmlHttpObj.overrideMimeType('text/xml');
}
}The overrideMimeType is not supported with IE, nor is it supported in the
first draft for the W3C XMLHttpRequest specification. If you want to
use responseXML, either change the
server-side application so that it supports the text/xml MIME type, or convert the text into
XML using the following cross-browser technique:
if (window.DOMParser) {
parser=new DOMParser();
xmlResult = parser.parserFromString(xmlHttpObj.responseText,
"text/xml");
} else {
xmlResult = new ActiveXObject("Microsoft.XMLDOM");
xmlResult.async = "false"
xmlResult.loadXML(xmlHttpObj.responseText);
}
var stories = xmlResult.getElementsByTagName("story");Parsing XML in this way adds another level of processing. It’s better, if possible, to return the data formatted as XML from the service.
See Also
The W3C specification for XMLHttpRequest can be found at http://www.w3.org/TR/XMLHttpRequest/.
19.2. Extracting Pertinent Information from an XML Tree
Solution
Use the same DOM methods you use to query your web page elements
to query the XML document. As an example, the following will get all
elements that have a tag name of "story":
var stories = xmlHttpObj.responseXML.getElementsByTagName("story");Discussion
Once you have the XML document, you can use the DOM methods
covered in Chapter 11 to query any of
the data in the document via the Ajax responseXML property, or even one that you’ve
created yourself from scratch.
To demonstrate, Example 19-1 shows a PHP application that returns an XML result when passed a category value. The application returns a list of stories by category, and their associated URL. If the category string isn’t passed or the category isn’t found, the application returns an error message that’s formatted in the same formatting as the other values, except that the URL value is set to “none”. This ensures a consistent result from the application.
It’s not a complicated application or a complex XML result, but
it’s sufficient to demonstrate how XML querying works. Notice that the
header is instructed to return the content with a MIME type of text/xml.
<?php
//If no search string is passed, then we can't search
if(empty($_GET['category'])) {
$result =
"<story><url>none</url><title>No Category Sent</title></story>";
} else {
//Remove whitespace from beginning & end of passed search.
$search = trim($_GET['category']);
switch($search) {
case "CSS" :
$result = "<story><url>
http://realtech.burningbird.net/graphics/css/opacity-returns-ie8
</url>" .
"<title>Opacity returns to IE8</title></story>" .
"<story>
<url>
http://realtech.burningbird.net/graphics/css/embedded-fonts-font-face
</url>" .
"<title>Embedded Fonts with Font Face</title>
</story>";
break;
case "ebooks" :
$result = "<story><url>
http://realtech.burningbird.net/web/ebooks/kindle-clipping-limits
</url>" .
"<title>Kindle Clipping Limits</title></story>" .
"<story><url>
http://realtech.burningbird.net/web/ebooks/kindle-and-book-freebies
</url>" .
"<title>Kindle and Book Freebies</title></story>";
break;
case "video" :
$result = "<story><url>
http://secretofsignals.burningbird.net/science/how-things-work/
video-online-crap-shoot</url>" .
"<title>The Video Online Crap Shoot</title>
</story>" .
"<story>
<url>http://secretofsignals.burningbird.net/toys-and-technologies/
gadgets/review-flip-ultra-camcorder</url>" .
"<title>Review of the Flip Ultra Camcorder</title>
</story>" .
"<story><url>
http://secretofsignals.burningbird.net/reviews/movies-disc/gojira
</url>" .
"<title>Gojira</title></story>" .
"<story><url>
http://secretofsignals.burningbird.net/reviews/movies-disc/
its-raging-squid</url>" .
"<title>It's a Raging Squid</title></story>";
break;
case "missouri" :
$result =
"<story><url>http://missourigreen.burningbird.net/times-past/
missouri/tyson-valley-lone-elk-and-bomb</url>" .
"<title>Tyson Valley, a Lone Elk, and a Bomb</title>
</story>";
break;
default :
$result = "<story><url>none</url><title>No Stories Found</title></story>";
break;
}
}
$result ='<?xml version="1.0" encoding="UTF-8" ?>' .
"<stories>" . $result . "</stories>";
header("Content-Type: text/xml; charset=utf-8");
echo $result;
?>Example 19-2 shows a
web page with a JavaScript application that processes a radio button
selection for a story category. The
application forms an Ajax request based on the category, and then
processes the returned XML in order to output a list of stories, linked
with their URLs.
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Stories</title>
<meta charset="utf-8" />
<script type="text/javascript">
//<![CDATA[
var xmlHttpObj;
window.onload=function() {
var radios = document.forms[0].elements["category"];
for (var i = 0; i < radios.length; i++) {
radios[i].onclick=getStories;
}
}
function getStories() {
// category
var category = encodeURIComponent(this.value);
// ajax object
if (window.XMLHttpRequest) {
xmlHttpObj = new XMLHttpRequest();
}
// build request
var url = "stories.php?category=" + category;
xmlHttpObj.open('GET', url, true);
xmlHttpObj.onreadystatechange = getData;
xmlHttpObj.send(null);
}
function getData() {
if (xmlHttpObj.readyState == 4 && xmlHttpObj.status == 200) {
try {
var result = document.getElementById("result");
var str = "<p>";
var stories =
xmlHttpObj.responseXML.getElementsByTagName("story");
for (var i = 0; i < stories.length; i++) {
var story = stories[i];
var url = story.childNodes[0].firstChild.nodeValue;
var title = story.childNodes[1].firstChild.nodeValue;
if (url === "none")
str += title + "<br />";
else
str += "<a href='" + url + "'>" + title + "</a><br />";
}
// finish HTML and insert
str+="</p>";
result.innerHTML=str;
} catch (e) {
alert(e.message);
}
}
}
//]]>
</script>
</head>
<body>
<form id="categoryform">
CSS: <input type="radio" name="category" value="CSS" /><br />
eBooks: <input type="radio" name="category" value="ebooks" /><br />
Missouri: <input type="radio" name="category" value="missouri" />
<br />
Video: <input type="radio" name="category" value="video" /><br />
</form>
<div id="result">
</div>
</body>
</html>When processing the XML code, the application first queries for
all story elements, which returns a
nodeList. The application cycles
through the collection, accessing each story element in order to access the story URL
and the title, both of which are child nodes. Each is accessed via the
childNodes collection, and their data, contained in the nodeValue attribute, is extracted.
The story data is used to build a string of linked story titles,
which is output to the page, as shown in Figure 19-1. Note that rather
than use a succession of childNodes
element collections to walk the trees, I could have used the Selectors
API to access all URLs and titles, and then traversed both collections
at one time, pulling the paired values from each, in sequence:
var urls = xmlHttpObj.responseXML.querySelectorAll("story url");
var titles = xmlHttpObj.responseXML.querySelectorAll("story title");
for (var i = 0; i < urls.length; i++) {
var url = urls[i].firstChild.nodeValue;
var title = titles[i].firstChild.nodeValue;
if (url === "none")
str += title + "<br />";
else
str += "<a href='" + url + "'>" + title + "</a><br />";
}
}I could have also used getElementsByTagName against each returned
story element—anything that works
with the web page works with the returned XML.
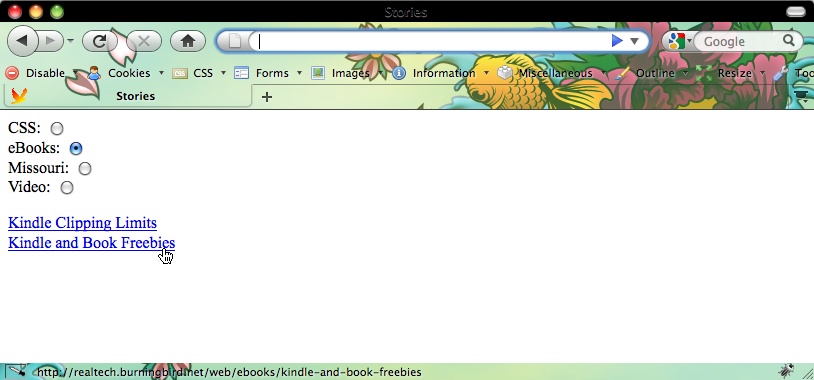
The try...catch error handling
should catch any query that fails because the XML is incomplete. In the
example, the error is printed out in an alert—but you’ll want to use
friendlier and more helpful error handling.
See Also
Chapter 11 covers most of the DOM
query techniques that work with the XML returned via responseXML, as well as accessing the web page
elements. Recipe 9.4
demonstrates how to process radio button events, and Recipe 12.1 demonstrates how
to use innerHTML to update the web
page contents.
Recipe 19.1
provides a way to process XML when it’s returned as text, via responseText.
19.3. Generate a JavaScript Object with JSON, Old-School Style
Solution
Use the eval function to evaluate the string formatted as JSON,
creating a JavaScript object using the following syntax:
var jsonobj = '{"test" : "value1", "test2" : 3.44, "test3" : true}';
var obj = eval("(" + jsonobj + ")");
alert(obj.test2); // prints out 3.44or the following:
var jsonobj = '{"test" : "value1", "test2" : 3.44, "test3" : true}';
eval("var obj="+jsonobj);
alert(obj.test);Discussion
The solution presents a simple, three-property object created in JSON. To figure out how to create JSON, think about how you create an object literal and just translate it into a string.
If the object is an array:
var arr = new Array("one","two","three");the JSON notation would be equivalent to the literal notation for the array:
"['one','two','three'];
If an object:
var obj3 = {
prop1 : "test",
result : true,
num : 5.44,
name : "Joe",
cts : [45,62,13]};the JSON notation would be:
{"prop1":"test","result":true,"num":5.44,"name":"Joe","cts":[45,62,13]}Notice in JSON how the property names are in quotes, but the values are only quoted when they’re strings. In addition, if the object contains other objects, such as an array, it’s also transformed into its JSON equivalent. However, the object cannot contain methods. If it does, an error is thrown. JSON works with data objects only.
The two “old-school” techniques to generate objects from the JSON
formatted string use the eval
method. The first assigns the object to a variable and
requires that you surround the JSON with parentheses:
var obj = eval ("(" + objJSON + ")");The reason for the parentheses is so the eval statement treats the text as an object
initializer, rather than some other type of code.
The second approach is to include the variable assignment as the
left side of the expression and the JSON as the right, within the
eval method:
eval("obj=" + objJSON);The result of the eval function
is a JavaScript object, in which you can access values directly:
alert(obj3.prop1); // prints out test
The use of JSON exploded with the growing popularity of Ajax. Rather than returning plain text, HTML, or XML, applications could return a text string formatted as JSON, and the text could be converted to a JavaScript object with one function call.
Of course, this meant that the JSON was inherently insecure. If
you couldn’t trust in the source of the string, you certainly couldn’t
trust it to the eval method, which
processes whatever string is passed to it. To work around the
insecurities of JSON, Douglas Crockford, the father of JSON, created
json2.js, a small library that provides a safe
version of eval. Once you include the
library, you process the JSON using the following syntax:
var obj = JSON.parse(objJSON);
Note
Discover more variations of JSON syntax at http://www.json.org. The site also includes a link to json2.js.
See Also
Until the built-in JSON capability is supported in all your site’s target browsers, you’ll still need the old-school JSON techniques. However, using the json2.js library can emulate a built-in JSON object, introduced in Recipe 19.5.
19.4. Parse a JSON Formatted String
Problem
You want to safely create a JavaScript object from JSON. You also want to replace the numeric representation of true and false (0 and 1, respectively) with their Boolean counterparts (false and true).
Solution
Parse the object with the new JSON built-in capability, added to
browsers in ECMAScript 5. To transform the numeric values to their
Boolean counterparts, create a replacer function:
var jsonobj = '{"test" : "value1", "test2" : 3.44, "test3" : 0}';
var obj = JSON.parse(jsonobj, function (key, value) {
if (typeof value == 'number') {
if (value == 0)
value = false;
else if (value == 1) {
value = true;
}
}
return value;
});
alert(obj.test3); // prints falseDiscussion
ECMAScript 5 added native support for JSON with the JSON object. It’s not a complex object, as it
only provides two methods: stringify
and parse. Like Math, it’s a static object that you use
directly.
The parse method takes two arguments: a JSON formatted string and
an optional replacer function. This
function takes a key/value pair as parameters, and returns either the
original value or a modified result.
In the solution, the JSON formatted string is an object with three properties: a string, a numeric, and a third property, which has a numeric value but is really a Boolean with a numeric representation: 0 is false, 1 is true.
To transform all 0, 1 values into false, true, a function is provided as the second
argument to JSON.parse. It checks
each property of the object to see if it is a numeric. If it is, the
function checks to see if the value is 0 or 1. If the value is 0, the
return value is set to false; if 1,
the return value is set to true;
otherwise, the original value is returned.
The ability to transform incoming JSON formatted data is essential, especially if you’re processing the result of an Ajax request or JSONP response. You can’t always control the structure of the data you get from a service.
See Also
See Recipe 19.5
for a demonstration of JSON.stringify.
19.5. Convert an Object to a Filtered/Transformed String with JSON
Problem
You need to convert a JavaScript object to a JSON formatted string for posting to a web application. However, the web application has data requirements that differ from your client application.
Solution
Use the JSON.stringify method, passing in the object as first parameter and
providing a transforming function as the second parameter:
function convertBoolToNums(key, value) {
if (typeof value == 'boolean') {
if (value)
value = 1;
else
value = 0;
}
return value;
};
window.onload=function() {
var obj = {"test" : "value1", "test2" : 3.44, "test3" : false};
var jsonobj = JSON.stringify(obj, convertBoolToNums, 3);
alert(jsonobj); // test3 should be 0
}Discussion
The JSON.stringify method takes
three parameters: the object to be transformed into JSON, an optional
function or array used either to transform or filter one or more object
values, and an optional third parameter that defines how much and what
kind of whitespace is used in the generated result.
In the solution, a function is used to check property values, and
if the value is a Boolean, convert false to 0, and
true to 1. The function results are transformed into
a string if the return value is a number or Boolean. The function can
also act as a filter: if the returned value from the function is
null, the property/value pair are
removed from the JSON.
You can also use an array rather than a function. The array can contain strings or numbers, but is a whitelist of properties that are allowed in the result. The following code:
var whitelist = ["test","test2"];
var obj = {"test" : "value1", "test2" : 3.44, "test3" : false};
var jsonobj = JSON.stringify(obj, whitelist, 3);would result in a JSON string including the object’s test and test2 properties, but not the third property
(test3):
{
"test": "value1",
"test2": 3.44
}The last parameter controls how much whitespace is used in the result. It can be a number representing the number of spaces or a string. If it is a string, the first 10 characters are used as whitespace. If I use the following:
var jsonobj = JSON.stringify(obj, whitelist, "***");
the result is:
{
***"test": "value1",
***"test2": 3.44
}The use of stringify with a
replacer function worked with Safari 4, but did not successfully
transform the Boolean value with Firefox. At the time this was written,
there is an active bug for Firefox because the replacer function only
works with arrays.
See Also
See Recipe 19.4 for a
discussion on JSON.parse.
19.6. Convert hCalendar Microformat Annotations into a Canvas Timeline
Problem
You want to plot the events annotated with the hCalendar Microformat on a Canvas-based graph. The hCalendar event syntax can differ, as the following two legitimate variations demonstrate:
<p><span class="vevent"> <span class="summary">Monkey Play Time</span> on <span class="dtstart">2010-02-05</span> at <span class="location">St. Louis Zoo</span>. </span></p> <div class="vevent" id="hcalendar-Event"> <abbr class="dtstart" title="2010-02-25">February 25th</abbr>, <abbr class="dtend" title="2010-02-26"> 2010</abbr> <span class="summary">Event</span></div>
With one format, the dtstart class is on a
span element; with the other format,
the dtstart class is on an abbr element.
Solution
Find all elements with a class of vevent:
var events = document.querySelectorAll("[class='vevent']");
var v = events;Within each, find the element with a class of dtstart. There should only be one, and there
should always be one. By Microformat convention, if the dtstart element is an abbr, the start date is found in a title attribute on the element. If the
dtstart element is a span, the start date is found in the element’s
textContent, and is then split out of
the date string to find the actual day:
var days = new Array();
for (var i = 0; i < events.length; i++) {
var dstart = events[i].querySelectorAll("[class='dtstart']");
var dt;
if (dstart[0].tagName == "SPAN") {
dt = dstart[0].textContent; }
else if (dstart[0].tagName == "ABBR") {
dt = dstart[0].title;
}
var day = parseInt(dt.split("-")[2]);
days.push(day);
}The value is then used to graph the line in a canvas element.
Discussion
Microformats are both simple and complicated. They’re simple in that
it’s easy to find the data, but they’re complicated because the rules
surrounding the data are very loose. As the solution demonstrates, an
hCalendar event start date can be recorded in span elements or abbr elements; the dates are ISO 8601, but
could be just dates, or datetime.
The advantage to working with Microformats using client-side JavaScript is that we usually have some control over the format of the Microformats. For instance, if we have a social-networking site where people are entering events, we have no control over what events are created, but we do have control over the format and can ensure that it’s consistent.
Once we know the form of the Microdata used in the page, it isn’t
complicated to get the data. For the most part, we’re retrieving
elements based on class name, and making queries on these elements’
subtrees for elements with different class names. Though there are few
rules to Microformats, there are rules. For
instance, the hCalendar data used in the solution has at least three
rules: the outer element has a vevent
class, there must be a summary and a dtstart element, and if the dtstart element is a span, the data is the textContent; if it is an abbr, the data is the title.
Since IE8 does not support textContent, the code performs a test for
textContent. If it isn’t found, then
IE8 gets the text from the (IE-originated) innerText or innerHTML property:
for (var i = 0; i < events.length; i++) {
var dstart = events[i].querySelectorAll("[class='dtstart']");
var dt;
if (dstart[0].tagName == "SPAN") {
if (dstart[0].textContent)
dt = dstart[0].textContent;
else
dt = dstart[0].innerText;
} else if (dstart[0].tagName == "ABBR") {
dt = dstart[0].title;
}
var day = parseInt(dt.split("-")[2]);
days.push(day);
}Make sure to include the ExplorerCanvas
excanvas.js library before your script, in order to ensure the canvas element
and commands work with IE:
<!--[if IE]><script src="excanvas.js"></script><![endif]-->
Example 19-3 pulls
all of the components together into a full-page application, including
the Canvas drawing. The tick marks in the Canvas element are expanded to 10 times their
size to make them easier to see on the line. The page is an event
calendar for a month at the zoo.
<!DOCTYPE html>
<head>
<title>Microformats</title>
<!--[if IE]><script src="excanvas.js"></script><![endif]-->
<script>
window.onload=function() {
var events = document.querySelectorAll("[class='vevent']");
var v = events;
var days = new Array();
for (var i = 0; i < events.length; i++) {
var dstart = events[i].querySelectorAll("[class='dtstart']");
var dt;
if (dstart[0].tagName == "SPAN") {
if (dstart[0].textContent)
dt = dstart[0].textContent;
else
dt = dstart[0].innerText;
} else if (dstart[0].tagName == "ABBR") {
dt = dstart[0].title;
}
var day = parseInt(dt.split("-")[2]);
days.push(day);
}
var ctx = document.getElementById("calendar").getContext('2d');
// draw out
days.sort(function(a,b) { return a - b});
ctx.fillStyle="red";
ctx.strokeStyle="black";
ctx.beginPath();
ctx.moveTo(0,100);
ctx.lineTo(280,100);
ctx.stroke();
for (var i = 0; i < days.length; i++) {
var x1 = days[i] * 10;
var t1 = 70;
var x2 = 5;
var t2 = 30;
ctx.fillRect(x1,t1,x2,t2);
}
}
</script>
</head>
<body>
<div>
<p><span class="vevent">
<span class="summary">Monkey Play Time</span>
on <span class="dtstart">2010-02-05</span>
at <span class="location">St. Louis Zoo</span>.
</span>
</p>
</div>
<div class="vevent">
<abbr class="dtstart" title="2010-02-25">February 25th</abbr>,
<abbr class="dtend" title="2010-02-26"> 2010</abbr>
<span class="summary">Event</span>
</div>
<p>
<span class="vevent">
<span class="summary">Tiger Feeding</span>
on <span class="dtstart">2010-02-10</span>
at <span class="location">St. Louis Zoo</span>.
</span>
</p>
<p><span class="vevent">
<span class="summary">Penguin Swimming</span>
on <span class="dtstart">2010-02-20</span>
at <span class="location">St. Louis Zoo</span>.
</span>
</p>
<div class="vevent">
<abbr class="dtstart" title="2010-02-19">February 19th</abbr>,
<abbr class="dtend" title="2010-02-26"> 2010</abbr>
<span class="summary">Sea Lion Show</span>
</div>
<canvas id="calendar" style="width: 600px; height: 100px; margin: 10px; ">
<p>Dates</p>
</canvas>
</body>The application works in all of our target browsers, including
IE8, as shown in Figure 19-2. IE7 does not
support the querySelectorAll
method.
See Also
For more on Microformats, see the Microformats website. See more on
the canvas element in Chapter 15, and more on
ExplorerCanvas in Recipe 15.2.
19.7. Glean Page RDFa and Convert It into JSON Using rdfQuery and the jQuery RDF Plug-in
Problem
You’re using Drupal 7, a Content Management System (CMS) that annotates the page metadata with RDFa—Resource Description Framework (RDF) embedded into X/HTML. Here’s an example of the type of data in the page (from the RDFa specification):
<h1>Biblio description</h1>
<dl about="http://www.w3.org/TR/2004/REC-rdf-mt-20040210/"
id="biblio">
<dt>Title</dt>
<dd property="dc:title">
RDF Semantics - W3C Recommendation 10 February 2004</dd>
<dt>Author</dt>
<dd rel="dc:creator" href="#a1">
<span id="a1">
<link rel="rdf:type" href="[foaf:Person]" />
<span property="foaf:name">Patrick Hayes</span>
see <a rel="foaf:homepage"
href="http://www.ihmc.us/users/user.php?UserID=42">homepage</a>
</span>
</dd>
</dl>You want to convert that RDFa formatted data into a JavaScript object, and eventually into JSON for an Ajax call.

Solution
Use one of the RDFa JavaScript libraries, such as rdfQuery, which has the added advantage of being built on jQuery (the default JavaScript library used with Drupal). The rdfQuery library also implements an RDFa gleaner, which is functionality that can take a jQuery object and glean all of the RDFa from it and its subtree, automatically converting the data into RDF triples and storing them into an in-memory database:
var triplestore = $('#biblio').rdf()
.base('http://burningbird.net')
.prefix('rdf','http://www.w3.org/1999/02/22-rdf-synax-ns#')
.prefix('dc','http://purl.org/dc/elements/1.1/')
.prefix('foaf','http://xmlns.com/foaf/0.1/');Once you have the data, you can export a JavaScript object of the triples:
var data = triplestore.databank.dump(); And then you can convert that into JSON: var jsonStr = JSON.stringify(d);
Discussion
RDF is a way of recording metadata in such a way that data from one site can be safely combined with data from many others, and queried for specific information or used in rules-based derivations. The data is stored in a format known as a triple, which is nothing more than a simple subject-predicate-object set usually displayed as:
<http://www.example.org/jo/blog> foaf:primaryTopic <#bbq> . <http://www.example.org/jo/blog> dc:creator "Jo" .
These triples basically say that the subject in this, a blog identified by a specific URL, has a primary topic of “bbq,” or barbecue, and the creator is named Jo.
This is a book on JavaScript, so I don’t want to spend more time on RDFa or RDF. I’ll provide links later where you can get more information on both. For now, just be aware that we’re going to take that RDFa annotation in the page, convert it into a triple store using rdfQuery, and then export it as a JavaScript object, and eventually JSON.
The RDFa, embedded into X/HTML, has the opposite challenges from Microformats: the syntax is very regular and well-defined, but accessing the data can be quite challenging. That’s the primary reason to use a library such as rdfQuery.
In the solution, what the code does is use jQuery selector
notation to access an element identified by “biblio”, and then use the
.rdf() gleaner to extract all of the
RDFa out of the object and its subtree and store it in an in-memory data
store.
The solution then maps the prefixes for the RDFa: dc is mapped to http://purl.org/dc/elements/1.1/, and so on. Once these
two actions are finished, a dump of the store creates a JavaScript
object containing the triple objects extracted from the RDFa, which are
then converted into JSON using the JSON.stringify method. The resulting string with the five derived
triples looks like this:
{"http://www.w3.org/TR/2004/REC-rdf-mt-
20040210/":{"http://purl.org/dc/elements/1.1/title":[{"type":"literal",
"value":"RDF Semantics - W3C Recommendation 10 February
2004"}],"http://purl.org/dc/elements/1.1/creator":[{"type":"uri",
"value":
"http://burningbird.net/jscb/data/rdfa.xhtml#a1"}]},
"http://burningbird.net/jscb/data/rdfa.xhtml#a1":
{"http://www.w3.org/1999/02/22-rdf-syntax-
ns#type":[{"type":"uri","value":"http://xmlns.com/foaf/0.1/Person"}],
"http://xmlns.com/foaf/0.1/name":[{"type":"literal","value":"Patrick
Hayes"}],"http://xmlns.com/foaf/0.1/homepage":[{"type":"uri",
"value":"http://www.ihmc.us/users/user.php?UserID=42"}]}}Which converts into Turtle notation as:
<http://www.w3.org/TR/2004/REC-rdf-mt-20040210/> <http://purl.org/dc/elements/1.1/title> "RDF Semantics - W3C Recommendation 10 February 2004" . <http://www.w3.org/TR/2004/REC-rdf-mt-20040210/> <http://purl.org/dc/elements/1.1/creator> <http://burningbird.net/jscb/data/rdfa.xhtml#a1> . <http://burningbird.net/jscb/data/rdfa.xhtml#a1> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . <http://burningbird.net/jscb/data/rdfa.xhtml#a1> <http://xmlns.com/foaf/0.1/name> "Patrick Hayes" . <http://burningbird.net/jscb/data/rdfa.xhtml#a1> <http://xmlns.com/foaf/0.1/homepage> <http://www.ihmc.us/users/user.php?UserID=42> .
Once you have the string, you can use it in an Ajax call to a web service that makes use of RDF or JSON, or both.
Example 19-4
combines the pieces of the solution into a full-page application in
order to more fully demonstrate how each of the components works
together. The application prints out the JSON.stringify data dump of the data and then
prints out each trip individually, converting the angle brackets of the
triples first so that appending them to the page won’t trigger an XHTML
parsing error.
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:foaf="http://xmlns.com/foaf/0.1/" >
<head profile="http://ns.inria.fr/grddl/rdfa/">
<title>Biblio description</title>
<style type="text/css">
div { margin: 20px; }
</style>
<script type="text/javascript" src="json2.js"></script>
<script type="text/javascript" src="jquery.js"></script>
<script type="text/javascript"
src="jquery.rdfquery.rdfa.min-1.0.js"></script>
<script type="text/javascript">
//<![CDATA[
window.onload = function() {
var j = $('#biblio').rdf()
.base('http://burningbird.net')
.prefix('rdf','http://www.w3.org/1999/02/22-rdf-synax-ns#')
.prefix('dc','http://purl.org/dc/elements/1.1/')
.prefix('foaf','http://xmlns.com/foaf/0.1/');
var d = j.databank.dump();
var str = JSON.stringify(d);
document.getElementById("result1").innerHTML = str;
var t = j.databank.triples();
var str2 = "";
for (var i = 0; i < t.length; i++) {
str2 =
str2 + t[i].toString().replace(/</g,"<").replace(/>/g,">")
+ "<br />";
}
document.getElementById("result2").innerHTML = str2;
}
//]]>
</script>
</head>
<body>
<h1>Biblio description</h1>
<dl about="http://www.w3.org/TR/2004/REC-rdf-mt-20040210/"
id="biblio">
<dt>Title</dt>
<dd property="dc:title">
RDF Semantics - W3C Recommendation 10 February 2004</dd>
<dt>Author</dt>
<dd rel="dc:creator" href="#a1">
<span id="a1">
<link rel="rdf:type" href="[foaf:Person]" />
<span property="foaf:name">Patrick Hayes</span>
see <a rel="foaf:homepage"
href="http://www.ihmc.us/users/user.php?UserID=42">homepage</a>
</span>
</dd>
</dl>
<div id="result1"></div>
<div id="result2"></div>
</body>
</html>Figure 19-3 shows the page after the JavaScript has finished. The application uses the json2.js library for browsers that haven’t implemented the JSON object yet.
You can also do a host of other things with rdfQuery, such as add triples directly, query across the triples, make inferences, and anything else you would like to do with RDF.
See Also
rdfQuery was created by Jeni Tennison. You can download it and read more documentation on its use at http://code.google.com/p/rdfquery/. When I used the library for writing this section, I used it with jQuery 1.42. Another RDFa library is the RDFa Parsing Module for the Backplane library.
For more information on RDF, see the RDF Primer. The RDFa Primer can be found at http://www.w3.org/TR/xhtml-rdfa-primer/. There is a new effort to create an RDFa-in-HTML specification, specifically for HTML5.

Get JavaScript Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

