Kapitel 4. Mustervergleiche mit regulären Ausdrücken
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
4.0 Einleitung
Angenommen, du bist seit ein paar Jahren im Internet unterwegs und speicherst deine gesamte Korrespondenz, nur für den Fall, dass du (oder deine Anwälte oder die Staatsanwaltschaft) eine Kopie brauchst. Das Ergebnis ist, dass du eine 5 GB große Festplattenpartition für deine gespeicherten E-Mails hast. Nehmen wir weiter an, du erinnerst dich daran, dass irgendwo darin eine E-Mail von jemandem namens Angie oder Anjie ist. Oder war es Angy? Aber du erinnerst dich nicht mehr daran, wie du sie genannt hast oder wo du sie gespeichert hast. Dann musst du natürlich danach suchen.
Aber während einige von euch versuchen, alle 15.000.000 Dokumente in einem Textverarbeitungsprogramm zu öffnen, finde ich es einfach mit einem einfachen Befehl. In jedem System, das reguläre Ausdrücke unterstützt, kann ich auf verschiedene Arten nach dem Muster suchen. Am einfachsten zu verstehen ist:
Angie|Anjie|Angy
was wahrscheinlich bedeutet, dass du einfach nach einer der Varianten suchen sollst. Eine prägnantere Form (mehr denken, weniger tippen) ist:
An[^ dn]
Die Syntax wird im Laufe dieses Kapitels klar werden. Kurz gesagt, das "A" und das "n" passen zueinander und finden Wörter, die mit "An" beginnen, während das kryptische [^ dn] verlangt, dass dem "An" ein anderes Zeichen folgt als(^ bedeutet in diesem Zusammenhang nicht ) ein Leerzeichen (um das sehr häufige englische Wort "an" am Anfang eines Satzes zu eliminieren) oder "d" (um das häufige Wort "und" zu eliminieren) oder "n" (um "Anne", "Ankündigung" usw. zu eliminieren). Ist dein Textverarbeitungsprogramm schon über seinen Startbildschirm hinausgekommen? Das macht nichts, denn ich habe die fehlende Datei bereits gefunden. Um die Antwort zu finden, habe ich einfach diesen Befehl eingegeben:
grep 'An[^ dn]' *
Reguläre Ausdrücke, oder kurz Regexe, ermöglichen eine präzise Spezifikation von Mustern, die in einem Text abgeglichen werden sollen. Man kann sich reguläre Ausdrücke als eine kleine Sprache zum Abgleichen von Zeichenmustern in Text, der in Zeichenketten enthalten ist, vorstellen. Eine API für reguläre Ausdrücke ist einInterpreterzum Abgleichen regulärer Ausdrücke.
Ein weiteres Beispiel für die Leistungsfähigkeit regulärer Ausdrücke ist das Problem der Massenaktualisierung hunderter Dateien. Als ich mit Java anfing, lautete die Syntax für die Deklaration von Array-Referenzen baseType arrayVariableName[]. Eine Methode mit einem Array-Argument, wie z. B. die Main-Methode eines jeden Programms, wurde üblicherweise so geschrieben:
public static void main(String args[]) {
Aber mit der Zeit wurde den Verwaltern der Java-Sprache klar, dass es besser wäre, sie als baseType[] arrayVariableName zu schreiben, etwa so:
public static void main(String[] args) {
Das ist der bessere Java-Stil, weil er die "Array-Eigenschaft" des Typs mit dem Typ selbst verbindet und nicht mit dem Namen des lokalen Arguments, und der Compiler akzeptiert immer noch beide Modi. Ich wollte alle Vorkommen von main, die auf die alte Art geschrieben wurden, in die neue Art ändern. Ich habe das Muster main(String [a-z] mit dem bereits beschriebenen grep-Dienstprogramm, um die Namen aller Dateien zu finden, die Main-Deklarationen im alten Stil enthalten (d.h. main(String, gefolgt von einem Leerzeichen und einem Namenszeichen anstelle einer offenen eckigen Klammer). Dann habe ich ein weiteres Regex-basiertes Unix-Werkzeug, den Stream-Editor sed, in einem kleinen Shell-Skript verwendet, um alle Vorkommen in diesen Dateien von main(String *([a-z][a-z]*)[] inmain(String[] $1 zu ändern (die hier verwendete Regex-Syntax wird später in diesem Kapitel erläutert). Auch hier war der Regex-basierte Ansatz um Größenordnungen schneller als die interaktive Bearbeitung, selbst mit einem einigermaßen leistungsfähigen Editor wie vi oder emacs, ganz zu schweigen von der Verwendung eines grafischen Textverarbeitungsprogramms.
In der Vergangenheit hat sich die Syntax von Regexen geändert, da sie in immer mehr Tools und Sprachen integriert werden. Die genaue Syntax in den vorherigen Beispielen entspricht also nicht genau der, die du in Java verwenden würdest, aber sie vermittelt die Prägnanz und Leistungsfähigkeit des Regex-Mechanismus.1
Ein drittes Beispiel ist das Parsen einer Apache-Webserver-Logdatei, bei der einige Felder durch Anführungszeichen, andere durch eckige Klammern und wieder andere durch Leerzeichen abgegrenzt sind. Ad-hoc-Code zu schreiben, um dies zu analysieren, ist in jeder Sprache unübersichtlich, aber eine gut formulierte Regex kann die Zeile in einem Arbeitsgang in alle Felder aufteilen, aus denen sie besteht (dieses Beispiel wird in Rezept 4.10 entwickelt).
Den gleichen Zeitgewinn können Java-Entwickler/innen erzielen. Die Unterstützung regulärer Ausdrücke ist seit langem in der Standard-Java-Laufzeitumgebung enthalten und gut integriert (z.B. gibt es Regex-Methoden in der Standardklasse und im neuen I/O-Paket), gibt es Regex-Methoden in der Standardklasse java.lang.String und im neuen I/O-Paket). Es gibt noch ein paar andere Regex-Pakete für Java, und du wirst gelegentlich auf Code stoßen, der sie verwendet, aber so gut wie jeder Code aus diesem Jahrhundert dürfte das eingebaute Paket verwenden. Die Syntax der Java-Regexe selbst wird inRezept 4.1 besprochen, und die Syntax der Java-API zur Verwendung von Regexen wird in Rezept 4.2 beschrieben. Die restlichen Rezepte zeigen einige Anwendungen der Regex-Technologie in Java.
Siehe auch
Mastering Regular Expressions von Jeffrey Friedl (O'Reilly) ist der maßgebliche Leitfaden für alle Details der regulären Ausdrücke. In den meisten Einführungsbüchern zu Unix und Perl werden Regexes erwähnt; Unix Power Tools von Mike Loukides, Tim O'Reilly, Jerry Peek und Shelley Powers (O'Reilly) widmet ihnen ein eigenes Kapitel.
4.1 Syntax der regulären Ausdrücke
Lösung
In Tabelle 4-1 findest du eine Liste der Zeichen für reguläre Ausdrücke.
Diskussion
Mit diesen Musterzeichen kannst du sehr mächtige Regexe erstellen. Beim Erstellen von Mustern kannst du jede beliebige Kombination aus normalem Text und den Metazeichen oder Sonderzeichen in Tabelle 4-1 verwenden. Diese können in jeder sinnvollen Kombination verwendet werden. Zum Beispiel steht a+ für eine beliebige Anzahl von Vorkommen des Buchstabens a, von eins bis zu einer Million oder einer Gazillion. Das Muster Mrs?\. passt zu Mr. oderMrs.. Und .* steht für ein beliebiges Zeichen, das beliebig oft vorkommt, und ist von der Bedeutung her ähnlich wie die meisten Befehlszeileninterpreter, die nur \* verwenden. Das Muster \d+ steht für eine beliebige Anzahl von numerischen Ziffern. \d{2,3} steht für eine zwei- oder dreistellige Zahl.
| Unterausdruck | Streichhölzer | Anmerkungen |
|---|---|---|
Allgemein |
||
|
Anfang der Zeile/des Strings |
|
|
Ende der Zeile/des Strings |
|
|
Wort-Grenze |
|
|
Nicht ein Wort Grenze |
|
|
Anfang des gesamten Strings |
|
|
Ende des gesamten Strings |
|
|
Ende der gesamten Zeichenkette (mit Ausnahme des zulässigen letzten Zeilenabschlusses) |
Siehe Rezept 4.9 |
. |
Ein beliebiges Zeichen (mit Ausnahme des Zeilenabschlusses) |
|
|
"Charakterklasse"; ein beliebiger Charakter aus der Liste |
|
|
Ein beliebiges Zeichen, das nicht auf der Liste steht |
Siehe Rezept 4.2 |
Abwechslung und Gruppierung |
||
|
Gruppierung (Erfassungsgruppen) |
Siehe Rezept 4.3 |
|
Abwechslung |
|
|
Nicht-einfangende Klammer |
|
|
Ende des vorherigen Spiels |
|
+\+ |
Rückverweis auf die Nummer der Erfassungsgruppe |
|
Normale (gierige) Quantoren |
||
|
Quantifizierer für von |
Siehe Rezept 4.4 |
|
Quantifizierer für |
|
|
Quantifizierer für genau |
Siehe Rezept 4.10 |
|
Quantifizierer für 0 bis zu |
|
|
Quantifizierer für 0 oder mehr Wiederholungen |
Kurz für |
|
Quantifizierer für 1 oder mehr Wiederholungen |
Kurz für |
|
Quantifizierer für 0 oder 1 Wiederholungen (d.h. genau einmal vorhanden oder gar nicht) |
Kurz für |
Zurückhaltende (nicht-freudige) Quantoren |
||
|
Zögernder Quantifizierer für von |
|
|
Zurückhaltender Quantifizierer für |
|
|
Zurückhaltender Quantifizierer für 0 bis zu |
|
|
Zögernder Quantifizierer: 0 oder mehr |
|
|
Zurückhaltender Quantifizierer: 1 oder mehr |
Siehe Rezept 4.10 |
|
Zögernder Quantifizierer: 0 oder 1 Mal |
|
Possessive (sehr gierige) Quantoren |
||
|
Possessivquantor für von |
|
|
Possessivquantor für |
|
|
Possessivquantor für 0 bis zu |
|
|
Possessivquantor: 0 oder mehr |
|
|
Possessivquantor: 1 oder mehr |
|
|
Possessivquantor: 0 oder 1 Mal |
|
Fluchten und Abkürzungen |
||
|
Escape-Zeichen (Anführungszeichen): schaltet die meisten Meta-Zeichen aus; macht nachfolgende Buchstaben zu Meta-Zeichen |
|
|
Escape (Anführungszeichen) alle Zeichen bis zu |
|
|
Beendet die Zitate, die mit |
|
|
Tabulatorzeichen |
|
|
Return (Wagenrücklauf) Zeichen |
|
|
Zeilenumbruchzeichen |
Siehe Rezept 4.9 |
|
Formularvorschub |
|
|
Charakter in einem Wort |
Verwende |
|
Ein Nicht-Wort-Zeichen |
|
|
Numerische Ziffer |
Verwende |
|
Ein nicht-ziffriges Zeichen |
|
|
Whitespace |
Leerzeichen, Tabulator usw., wie von |
|
Ein Zeichen, das kein Leerzeichen ist |
Siehe Rezept 4.10 |
Unicode-Blöcke (repräsentative Beispiele) |
||
|
Ein Zeichen im griechischen Block |
(Einfacher Block) |
|
Jedes Zeichen, das nicht im griechischen Block steht |
|
|
Ein Großbuchstabe |
(Einfache Kategorie) |
|
Ein Währungssymbol |
|
Zeichenklassen im POSIX-Stil (nur für US-ASCII definiert) |
||
|
Alphanumerische Zeichen |
|
|
Alphabetische Zeichen |
|
|
Jedes ASCII-Zeichen |
|
|
Leerzeichen und Tabulatorzeichen |
|
|
Leerzeichen |
|
|
Kontrollzeichen |
|
|
Numerische Zeichen |
|
|
Druckbare und sichtbare Zeichen (keine Leerzeichen oder Steuerzeichen) |
|
|
Druckbare Zeichen |
Dasselbe wie |
|
Interpunktionszeichen |
Einer der |
|
Kleinbuchstaben |
|
|
Großbuchstaben |
|
|
Hexadezimale Zahlenzeichen |
|
Regexe passen auf jede mögliche Stelle in der Zeichenkette. Muster, die von gierigen Quantifizierern gefolgt werden (der einzige Typ, den es in den traditionellen Unix-Regexen gab), verbrauchen (passen) so viel wie möglich, ohne nachfolgende Unterausdrücke zu beeinträchtigen. Muster, die von Possessivquantoren gefolgt werden, passen so weit wie möglich, ohne die folgenden Unterausdrücke zu berücksichtigen. Muster, die von zurückhaltenden Quantifizierern gefolgt werden, verbrauchen so wenige Zeichen wie möglich, um trotzdem eine Übereinstimmung zu erzielen.
Im Gegensatz zu Regex-Paketen in anderen Sprachen wurde das Java Regex-Paket von Anfang an für den Umgang mit Unicode-Zeichen entwickelt. Die Standard-Java-Escape-Sequenz \u+nnnn wird verwendet, um ein Unicode-Zeichen im Muster anzugeben. Wir verwenden die Methoden von java.lang.Character, um die Eigenschaften von Unicode-Zeichen zu bestimmen, z. B. ob es sich bei einem bestimmten Zeichen um ein Leerzeichen handelt. Auch hier ist zu beachten, dass der Backslash verdoppelt werden muss, wenn es sich um eine Java-Zeichenkette handelt, die kompiliert wird, da der Compiler dies sonst als "Backslash-u" gefolgt von einigen Zahlen parsen würde.
Damit du lernst, wie Regexe funktionieren, stelle ich ein kleines Programm namens REDemo zur Verfügung.2 Der Code für REDemo ist zu lang, um ihn in das Buch aufzunehmen; im Online-Verzeichnis regex des darwinsys-api repo findest du REDemo.java, das du ausführen kannst, um zu erkunden, wie Regexe funktionieren.
Gib im obersten Textfeld (siehe Abbildung 4-1) das Regex-Muster ein, das du testen möchtest. Während du die einzelnen Zeichen eingibst, wird die Regex auf ihre Syntax geprüft; wenn die Syntax in Ordnung ist, siehst du ein Häkchen daneben. Dann kannst du "Übereinstimmen", "Suchen" oder "Alles suchen" auswählen. Übereinstimmen bedeutet, dass die gesamte Zeichenfolge mit der Regex übereinstimmen muss, und Suchen bedeutet, dass die Regex irgendwo in der Zeichenfolge gefunden werden muss (Alles suchen zählt die Anzahl der gefundenen Vorkommen). Darunter gibst du eine Zeichenfolge ein, mit der die Regex übereinstimmen soll. Experimentiere nach Lust und Laune. Wenn du die Regex so hast, wie du sie haben willst, kannst du sie in dein Java-Programm einfügen. Du musst alle Zeichen, die sowohl vom Java-Compiler als auch vom Java-Regex-Paket besonders behandelt werden, wie den Backslash selbst, doppelte Anführungszeichen und andere, mit einem Escape (Backslash) versehen. Wenn du eine Regex nach deinen Vorstellungen erstellt hast, kannst du sie mit der Schaltfläche Kopieren (auf diesen Screenshots nicht zu sehen) in die Zwischenablage exportieren - je nachdem, wie du sie verwenden möchtest, mit oder ohne Backslash-Verdopplung.
Tipp
Erinnere dich daran, dass eine Regex als Zeichenkette eingegeben wird, die von einem Java-Compiler kompiliert wird. Deshalb brauchst du in der Regel zwei Escape-Ebenen für alle Sonderzeichen, einschließlich Backslash und Anführungszeichen. Zum Beispiel die Regex (die die doppelten Anführungszeichen enthält):
"You said it\."
muss so typisiert sein, um eine gültige Java-Sprache zur Kompilierzeit zu sein String:
String pattern = "\"You said it\\.\""
In Java 14+ kannst du auch einen Textblock verwenden, um die Anführungszeichen zu umgehen:
String pattern = """ "You said it\\.""""
Ich kann dir gar nicht sagen, wie oft ich schon den Fehler gemacht habe, den zusätzlichen Backslash in \d+, \w+ und Konsorten zu vergessen!
In Abbildung 4-1 habe ich qu in das Musterfeld des Programms REDemo eingegeben, was ein syntaktisch gültiges Regex-Muster ist: Alle gewöhnlichen Zeichen stehen als Regex für sich selbst, also wird nach dem Buchstaben q gefolgt von u gesucht. In der oberen Version habe ich nur ein q in die Zeichenfolge eingegeben, das nicht gefunden wird. In der zweiten Version habe ich quack und den q eines zweiten quack eingegeben. Da ich Alle suchen ausgewählt habe, zeigt die Zählung eine Übereinstimmung an. Sobald ich die zweite u eingebe, wird die Anzahl auf zwei aktualisiert, wie in der dritten Version zu sehen ist.
Regexe können weit mehr als nur Zeichen abgleichen. Die Zwei-Zeichen-Regex ^T würde zum Beispiel auf den Anfang einer Zeile (^) passen, die unmittelbar von einem großen T gefolgt wird - also auf jede Zeile, die mit einem großen T beginnt.
Aber hier sind wir nicht sehr weit voraus. Haben wir wirklich so viel Mühe in die Regex-Technologie investiert, nur um das tun zu können, was wir bereits mit der Methode java.lang.String startsWith() tun konnten? Hmmm, ich kann hören, wie einige von euch unruhig werden. Bleibt auf euren Plätzen! Was wäre, wenn du nicht nur einen Buchstaben T an der ersten Stelle finden wolltest, sondern auch einen Vokal direkt danach, gefolgt von einer beliebigen Anzahl von Buchstaben in einem Wort, gefolgt von einem Ausrufezeichen? Sicherlich könntest du das in Java tun, indem du startsWith("T") und charAt(1) == 'a' || charAt(1) == 'e' überprüfst, und so weiter? Ja, aber bis du das getan hast, hättest du eine Menge hochspezialisierten Code geschrieben, den du in keiner anderen Anwendung verwenden könntest. Mit regulären Ausdrücken kannst du einfach das Muster ^T[aeiou]\w*! angeben. Das heißt, ^ und T wie zuvor, gefolgt von einer Zeichenklasse, die die Vokale auflistet, gefolgt von einer beliebigen Anzahl von Wortzeichen (\w*), gefolgt von einem Ausrufezeichen.
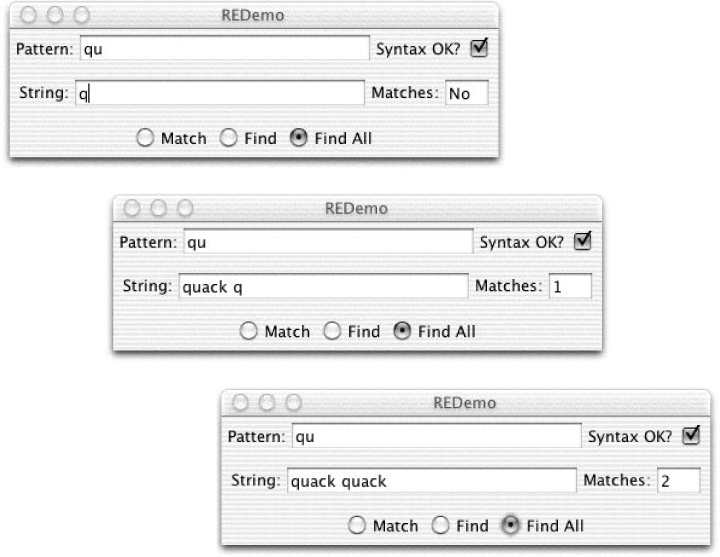
Abbildung 4-1. REDemo mit einfachen Beispielen
"Aber warte, da ist noch mehr!", wie mein verstorbener, großartiger ChefYuri Rubinsky zu sagen pflegte. Was ist, wenn du das Muster, nach dem du suchst, zur Laufzeit ändern möchtest? Erinnerst du dich an den Java-Code, den du gerade geschrieben hast, um T in Spalte 1 zu finden, plus einen Vokal, einige Wortzeichen und ein Ausrufezeichen? Nun, es ist an der Zeit, ihn wegzuwerfen. Denn heute Morgen müssen wir Q abgleichen, gefolgt von einem anderen Buchstaben als u, gefolgt von einer Reihe von Ziffern, gefolgt von einem Punkt. Während einige von euch anfangen, eine neue Funktion dafür zu schreiben, schlendern wir anderen einfach zur RegEx Bar & Grille, bestellen beim Barkeeper ein ^Q[^u]\d+\.. und machen uns auf den Weg.
OK, wenn du eine Erklärung willst: [^u] bedeutet, dass ein beliebiges Zeichen übereinstimmt, das nicht das Zeichen u ist. Das \d+ bedeutet eine oder mehrere numerische Ziffern. + ist ein Quantifizierer, der ein oder mehrere Vorkommen dessen bedeutet, was er folgt, und \d ist eine beliebige numerische Ziffer. \d+ bedeutet also eine Zahl mit einer, zwei oder mehr Ziffern. Und schließlich das \.? Nun, . ist an sich ein Meta-Zeichen. Die meisten einzelnen Metazeichen werden ausgeschaltet, indem ihnen ein Escape-Zeichen vorangestellt wird. Natürlich nicht mit der Esc-Taste auf deiner Tastatur. Das Escape-Zeichen der Regex ist der Backslash. Wenn du einem Metazeichen wie . dieses Escape-Zeichen voranstellst, wird seine besondere Bedeutung ausgeschaltet, so dass wir nach einem buchstäblichen Punkt und nicht nach einem beliebigen Zeichen suchen. Wenn du einigen ausgewählten alphabetischen Zeichen (z. B. n, r, t, s, w) ein Escape-Zeichen voranstellst, werden sie zu Metazeichen. Abbildung 4-2 zeigt die ^Q[^u]\d+\..Regex in Aktion. Im ersten Bild habe ich einen Teil der Regex als ^Q[^u eingegeben. Da die eckige Klammer nicht geschlossen ist, ist das Syntax-OK-Flag ausgeschaltet; wenn ich die Regex vervollständige, wird es wieder eingeschaltet. Im zweiten Bild habe ich die Regex fertig getippt und den Datenstring als QA577 eingegeben (du solltest erwarten, dass er mit $$^Q[^u]\d+$$ übereinstimmt, aber nicht mit dem Punkt, da ich ihn nicht getippt habe). Im dritten Frame habe ich den Punkt eingegeben, sodass das Flag Übereinstimmungen auf Ja gesetzt ist.
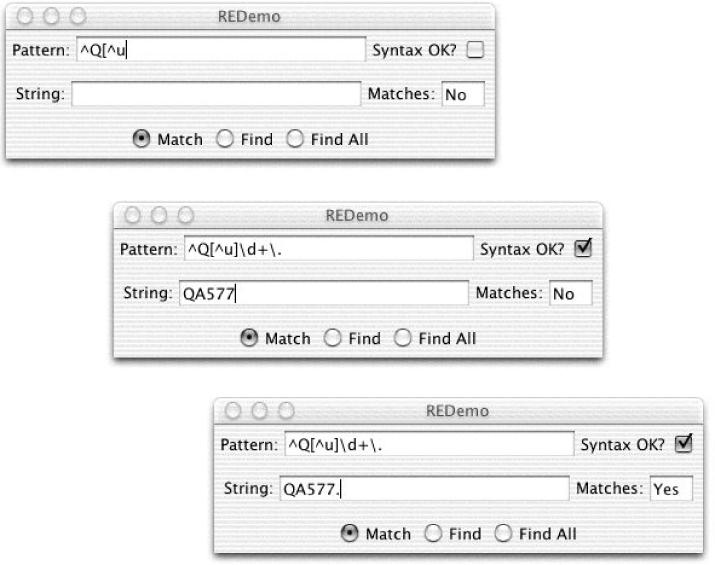
Abbildung 4-2. REDemo mit "Q nicht gefolgt von u" Beispiel
Da beim Einfügen der Regex in Java-Code Backslashes escaped werden müssen, gibt es in der aktuellen Version von REDemo sowohl einen Copy Pattern Button, der die Regex wortwörtlich für die Verwendung in der Dokumentation und in Unix-Befehlen kopiert, als auch einen Copy Pattern Backslashed Button, der die Regex mit verdoppelten Backslashes in die Zwischenablage kopiert, um sie in Java-Strings einzufügen.
Inzwischen solltest du zumindest ein Grundverständnis dafür haben, wie Regexe in der Praxis funktionieren. Der Rest dieses Kapitels enthält weitere Beispiele und erklärt einige der mächtigeren Themen, wie z. B. Capture-Gruppen. Wie Regexe in der Theorie funktionieren - und es gibt eine Menge theoretischer Details und Unterschiede zwischen den Regex-Varianten -, erfährst du in Mastering Regular Expressions. In der Zwischenzeit wollen wir lernen, wie man Java-Programme schreibt, die reguläre Ausdrücke verwenden.
4.2 Regexe in Java verwenden: Auf ein Muster testen
Lösung
Verwende das Java Regular Expressions Package, java.util.regex.
Diskussion
Die gute Nachricht ist, dass die Java-API für Regexe wirklich einfach zu benutzen ist. Wenn du nur herausfinden willst, ob eine bestimmte Regex mit einer Zeichenkette übereinstimmt, kannst du die praktische Methode boolean matches() der Klasse String verwenden, die ein Regex-Muster in String Form als Argument akzeptiert:
if(inputString.matches(stringRegexPattern)){// it matched... do something with it...}
Dies ist jedoch eine Komfortroutine, und Komfort hat immer seinen Preis. Wenn die Regex mehr als ein- oder zweimal in einem Programm verwendet werden soll, ist es effizienter, eine Pattern und ihre Matcher(s) zu erstellen und zu verwenden. Hier wird ein komplettes Programm gezeigt, das eine Pattern konstruiert und sie für match verwendet:
publicclassRESimple{publicstaticvoidmain(String[]argv){Stringpattern="^Q[^u]\\d+\\.";String[]input={"QA777. is the next flight. It is on time.","Quack, Quack, Quack!"};Patternp=Pattern.compile(pattern);for(Stringin:input){booleanfound=p.matcher(in).lookingAt();System.out.println("'"+pattern+"'"+(found?" matches '":" doesn't match '")+in+"'");}}}
Das Paket java.util.regex enthält zwei Klassen, Pattern und Matcher, die die in Beispiel 4-1 gezeigte öffentliche API bereitstellen.
Beispiel 4-1. Regex öffentliche API
/*** The main public API of the java.util.regex package.*/packagejava.util.regex;publicfinalclassPattern{// Flags values ('or' together)publicstaticfinalintUNIX_LINES,CASE_INSENSITIVE,COMMENTS,MULTILINE,DOTALL,UNICODE_CASE,CANON_EQ;// No public constructors; use these Factory methodspublicstaticPatterncompile(Stringpatt);publicstaticPatterncompile(Stringpatt,intflags);// Method to get a Matcher for this PatternpublicMatchermatcher(CharSequenceinput);// Information methodspublicStringpattern();publicintflags();// Convenience methodspublicstaticbooleanmatches(Stringpattern,CharSequenceinput);publicString[]split(CharSequenceinput);publicString[]split(CharSequenceinput,intmax);}publicfinalclassMatcher{// Action: find or match methodspublicbooleanmatches();publicbooleanfind();publicbooleanfind(intstart);publicbooleanlookingAt();// "Information about the previous match" methodspublicintstart();publicintstart(intwhichGroup);publicintend();publicintend(intwhichGroup);publicintgroupCount();publicStringgroup();publicStringgroup(intwhichGroup);// Reset methodspublicMatcherreset();publicMatcherreset(CharSequencenewInput);// Replacement methodspublicMatcherappendReplacement(StringBufferwhere,StringnewText);publicStringBufferappendTail(StringBufferwhere);publicStringreplaceAll(StringnewText);publicStringreplaceFirst(StringnewText);// information methodspublicPatternpattern();}/* String, showing only the RE-related methods */publicfinalclassString{publicbooleanmatches(Stringregex);publicStringreplaceFirst(Stringregex,StringnewStr);publicStringreplaceAll(Stringregex,StringnewStr);publicString[]split(Stringregex);publicString[]split(Stringregex,intmax);}
Diese API ist so umfangreich, dass sie einige Erklärungen erfordert. Dies sind die normalen Schritte für den Regex-Abgleich in einem Produktionsprogramm:
-
Erstelle eine
Pattern, indem du die statische MethodePattern.compile()aufrufst. -
Fordere ein
Matcheraus dem Muster an, indem dupattern.matcher(CharSequence)für jedesString(oder andereCharSequence) aufrufst, das du durchsehen möchtest. -
Rufe (einmal oder mehrmals) eine der Finder-Methoden (die später in diesem Abschnitt besprochen werden) in der resultierenden
Matcherauf.
Die Schnittstelle java.lang.CharSequence ermöglicht einen einfachen Nur-Lese-Zugriff auf Objekte, die eine Sammlung von Zeichen enthalten. Die Standardimplementierungen sind String und StringBuffer/StringBuilder (beschrieben in Kapitel 3) sowie die neue I/O-Klasse java.nio.CharBuffer.
Natürlich kannst du den Regex-Abgleich auch auf andere Art und Weise durchführen, z. B. mit den Komfortmethoden in Pattern oder sogar in java.lang.String, wie hier:
publicclassStringConvenience{publicstaticvoidmain(String[]argv){Stringpattern=".*Q[^u]\\d+\\..*";Stringline="Order QT300. Now!";if(line.matches(pattern)){System.out.println(line+" matches \""+pattern+"\"");}else{System.out.println("NO MATCH");}}}
Aber die dreistufige Liste ist das Standardmuster für den Abgleich. Du würdest die String Routine wahrscheinlich in einem Programm verwenden, das die Regex nur einmal verwendet; wenn die Regex mehr als einmal verwendet wird, lohnt es sich, die Zeit für die Kompilierung zu nehmen, weil die kompilierte Version schneller läuft.
Außerdem hat Matcher mehrere Finder-Methoden, die mehr Flexibilität bieten als dieString Komfortroutine match(). Dies sind die Matcher Methoden:
match()-
Wird verwendet, um die gesamte Zeichenkette mit dem Muster zu vergleichen; dies ist die gleiche Routine wie in
java.lang.String. Da sie die gesamteStringabgleicht, musste ich.*vor und nach dem Muster einfügen. lookingAt()-
Wird verwendet, um das Muster nur am Anfang der Zeichenkette zu finden.
find()-
Wird verwendet, um das Muster in der Zeichenkette abzugleichen (nicht notwendigerweise am ersten Zeichen der Zeichenkette), beginnend am Anfang der Zeichenkette oder, wenn die Methode zuvor aufgerufen wurde und erfolgreich war, am ersten Zeichen, das bei der vorherigen Übereinstimmung nicht gefunden wurde.
Jede dieser Methoden gibt boolean zurück, wobei true für eine Übereinstimmung und false für keine Übereinstimmung steht. Um zu prüfen, ob eine bestimmte Zeichenkette mit einem bestimmten Muster übereinstimmt, musst du nur etwas wie das Folgende eingeben:
Matcherm=Pattern.compile(patt).matcher(line);if(m.find()){System.out.println(line+" matches "+patt)}
Aber vielleicht möchtest du auch den Text extrahieren, der übereinstimmt, was das Thema des nächsten Rezepts ist.
Die folgenden Rezepte behandeln die Verwendung der Matcher-API. Zunächst verwenden die Beispiele nur Argumente des Typs String als Eingabequelle. Die Verwendung von anderen CharSequence Typen wird in Rezept 4.5 behandelt.
4.3 Den übereinstimmenden Text finden
Lösung
Manchmal musst du mehr wissen als nur, ob eine Regex auf eine Zeichenfolge passt. In Editoren und vielen anderen Tools willst du genau wissen, welche Zeichen gefunden wurden. Erinnere dich daran, dass bei Quantifizierern wie * die Länge des übereinstimmenden Textes nicht unbedingt mit der Länge des übereinstimmenden Musters übereinstimmt. Unterschätze nicht das mächtige.*, das gerne Tausende oder Millionen von Zeichen abgleicht, wenn man es zulässt. Wie du im vorigen Rezept gesehen hast, kannst du herausfinden, ob ein bestimmter Treffer erfolgreich war, indem dufind() oder matches() verwendest. Aber in anderen Anwendungen möchtest du die Zeichen erhalten, auf die das Muster passt.
Nach einem erfolgreichen Aufruf einer der vorangegangenen Methoden kannst du diese Informationsmethoden auf Matcher verwenden, um Informationen über das Spiel zu erhalten:
start(), end()-
Gibt die Zeichenposition in der Zeichenkette der übereinstimmenden Anfangs- und Endzeichen zurück.
groupCount()-
Gibt die Anzahl der eingeklammerten Fanggruppen zurück, falls vorhanden; gibt 0 zurück, wenn keine Gruppen verwendet wurden.
group(int i)-
Gibt die übereinstimmenden Zeichen der Gruppe
ides aktuellen Treffers übereinstimmen, wennigrößer oder gleich Null und kleiner oder gleich dem Rückgabewert vongroupCount()ist. Gruppe 0 ist der gesamte Treffer, also gibtgroup(0)(oder nurgroup()) den gesamten Teil der Eingabe zurück, der übereinstimmt.
Das Konzept der Klammern oder Fanggruppen ist ein zentraler Bestandteil der Regex-Verarbeitung. Regexe können beliebig komplex verschachtelt werden. Mit der Methode group(int) kannst du die Zeichen abrufen, die mit einer bestimmten Klammergruppe übereinstimmen. Wenn du keine expliziten Klammern verwendet hast, kannst du einfach alle übereinstimmenden Zeichen als Stufe Null behandeln. Beispiel 4-2 zeigt einen Teil von REMatch.java.
Beispiel 4-2. Teil von main/src/main/java/regex/REMatch.java
publicclassREmatch{publicstaticvoidmain(String[]argv){Stringpatt="Q[^u]\\d+\\.";Patternr=Pattern.compile(patt);Stringline="Order QT300. Now!";Matcherm=r.matcher(line);if(m.find()){System.out.println(patt+" matches \""+m.group(0)+"\" in \""+line+"\"");}else{System.out.println("NO MATCH");}}}
Wenn sie ausgeführt wird, wird sie gedruckt:
Q[\^u]\d+\. matches "QT300." in "Order QT300. Now!"
Wenn die Schaltfläche Match aktiviert ist, zeigt REDemo alle Capture-Gruppen in einer bestimmten Regex an; ein Beispiel ist inAbbildung 4-3 zu sehen.
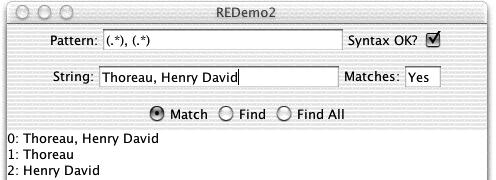
Abbildung 4-3. REDemo in Aktion
Es ist auch möglich, die Anfangs- und Endindizes und die Länge des Textes, auf den das Muster passt, zu erhalten (erinnere dich daran, dass Begriffe mit Quantifizierern, wie \d+ in diesem Beispiel, auf eine beliebige Anzahl von Zeichen in der Zeichenkette passen können). Du kannst diese in Verbindung mit den Methoden von String.substring() wie folgt verwenden:
Stringpatt="Q[^u]\\d+\\.";Patternr=Pattern.compile(patt);Stringline="Order QT300. Now!";Matcherm=r.matcher(line);if(m.find()){System.out.println(patt+" matches \""+line.substring(m.start(0),m.end(0))+"\" in \""+line+"\"");}else{System.out.println("NO MATCH");}
Angenommen, du musst mehrere Elemente aus einer Zeichenkette extrahieren. Wenn die Eingabe
Smith, John Adams, John Quincy
und du willst aussteigen
John Smith John Quincy Adams
publicclassREmatchTwoFields{publicstaticvoidmain(String[]args){StringinputLine="Adams, John Quincy";// Construct an RE with parens to "grab" both field1 and field2Patternr=Pattern.compile("(.*), (.*)");Matcherm=r.matcher(inputLine);if(!m.matches())thrownewIllegalArgumentException("Bad input");System.out.println(m.group(2)+' '+m.group(1));}}
4.4 Ersetzen des übereinstimmenden Textes
Problem
Nachdem du einen Text mit Hilfe eines Musters gefunden hast, möchtest du ihn durch einen anderen Text ersetzen, ohne den Rest der Zeichenfolge zu verändern.
Lösung
Wie wir im vorigen Rezept gesehen haben, können Regex-Muster mit Quantifizierern eine Menge Zeichen mit sehr wenigen Metazeichen übereinstimmen. Wir brauchen eine Möglichkeit, den Text, auf den die Regex zutrifft, zu ersetzen, ohne andere Texte davor oder danach zu verändern. Wir könnten das manuell mit der Methode String substring() machen. Da dies jedoch eine so häufige Anforderung ist, bietet die Java-API für reguläre Ausdrücke einige Ersetzungsmethoden.
Diskussion
Die Klasse Matcher bietet mehrere Methoden, um nur den Text zu ersetzen, der mit dem Muster übereinstimmt. Bei all diesen Methoden übergibst du den Ersetzungstext oder die "rechte Seite" der Ersetzung (dieser Begriff ist historisch bedingt: Bei dem Ersetzungsbefehl eines Texteditors ist die linke Seite das Muster und die rechte Seite der Ersetzungstext). Dies sind die Ersetzungsmethoden:
replaceAll(newString)-
Ersetzt alle Vorkommen, die übereinstimmen, durch die neue Zeichenfolge
replaceFirst(newString)-
Wie oben, aber nur das erste Vorkommen
appendReplacement(StringBuffer, newString)-
Kopien bis vor dem ersten Spiel, plus die angegebene
newString appendTail(StringBuffer)-
Fügt Text nach der letzten Übereinstimmung an (wird normalerweise nach
appendReplacementverwendet)
Trotz ihrer Namen verhalten sich die Methoden von replace* im Einklang mit der Unveränderlichkeit von Strings (siehe "Zeitlos, unveränderlich und unveränderbar"): Sie erstellen ein neues String Objekt mit der durchgeführten Ersetzung; sie ändern die Zeichenkette, auf die sich das Matcher Objekt bezieht, nicht (und können sie auch nicht ändern).
Beispiel 4-3 zeigt die Anwendung dieser drei Methoden.
Beispiel 4-3. main/src/main/java/regex/ReplaceDemo.java
/*** Quick demo of RE substitution: correct U.S. 'favor'* to Canadian/British 'favour', but not in "favorite"* @author Ian F. Darwin, http://www.darwinsys.com/*/publicclassReplaceDemo{publicstaticvoidmain(String[]argv){// Make an RE pattern to match as a word only (\b=word boundary)Stringpatt="\\bfavor\\b";// A test inputStringinput="Do me a favor? Fetch my favorite.";System.out.println("Input: "+input);// Run it from a RE instance and see that it worksPatternr=Pattern.compile(patt);Matcherm=r.matcher(input);System.out.println("ReplaceAll: "+m.replaceAll("favour"));// Show the appendReplacement methodm.reset();StringBuffersb=newStringBuffer();System.out.("Append methods: ");while(m.find()){// Copy to before first match,// plus the word "favor"m.appendReplacement(sb,"favour");}m.appendTail(sb);// copy remainderSystem.out.println(sb.toString());}}
Wenn du es ausführst, tut es genau das, was wir erwarten:
Input: Do me a favor? Fetch my favorite. ReplaceAll: Do me a favour? Fetch my favorite. Append methods: Do me a favour? Fetch my favorite.
Die Methode replaceAll() behandelt den Fall, dass die gleiche Änderung in der gesamten Zeichenkette vorgenommen werden soll. Wenn du jedes übereinstimmende Vorkommen in einen anderen Wert ändern willst, kannst du replaceFirst() in einer Schleife verwenden, wie in Beispiel 4-4.
In diesem Beispiel wird die gesamte Zeichenkette durchlaufen, wobei jedes Vorkommen von cat oder dog in feline oder canine umgewandelt wird. Dies ist eine Vereinfachung eines realen Beispiels, bei dem nach bit.ly-URLs gesucht und diese durch die tatsächliche URL ersetzt wurden; die Methode computeReplacement verwendete den Netzwerk-Client-Code aus Rezept 12.1.
Beispiel 4-4. main/src/main/java/regex/ReplaceMulti.java
/*** To perform multiple distinct substitutions in the same String,* you need a loop, and must call reset() on the matcher.*/publicclassReplaceMulti{publicstaticvoidmain(String[]args){Patternpatt=Pattern.compile("cat|dog");Stringline="The cat and the dog never got along well.";System.out.println("Input: "+line);Matchermatcher=patt.matcher(line);while(matcher.find()){Stringfound=matcher.group(0);Stringreplacement=computeReplacement(found);line=matcher.replaceFirst(replacement);matcher.reset(line);}System.out.println("Final: "+line);}staticStringcomputeReplacement(Stringin){switch(in){case"cat":return"feline";case"dog":return"canine";default:return"animal";}}}
Wenn du auf Teile des Vorkommens verweisen musst, die mit der Regex übereinstimmen, kannst du sie mit zusätzlichen Klammern im Muster markieren und auf den übereinstimmenden Teil mit $1, $2 usw. in der Ersetzungszeichenfolge verweisen.Beispiel 4-5 verwendet dies, um zwei Felder zu vertauschen, in diesem Fall, um Namen in der Form Firstname Lastname in Lastname, FirstName zu verwandeln.
Beispiel 4-5. main/src/main/java/regex/ReplaceDemo2.java
publicclassReplaceDemo2{publicstaticvoidmain(String[]argv){// Make an RE patternStringpatt="(\\w+)\\s+(\\w+)";// A test inputStringinput="Ian Darwin";System.out.println("Input: "+input);// Run it from a RE instance and see that it worksPatternr=Pattern.compile(patt);Matcherm=r.matcher(input);m.find();System.out.println("Replaced: "+m.replaceFirst("$2, $1"));// The short inline version:// System.out.println(input.replaceFirst("(\\w+)\\s+(\\w+)", "$2, $1"));}}
4.5 Alle Vorkommnisse eines Musters drucken
Lösung
Dieses Beispiel liest eine Datei Zeile für Zeile durch. Jedes Mal, wenn eine Übereinstimmung gefunden wird, extrahiere ich sie aus der line und gebe sie aus.
Dieser Code nimmt die Methoden group() aus Rezept 4.3, die Methode substring aus der Schnittstelle CharacterIterator und die Methode match() aus dem Regex und fügt sie einfach alle zusammen. Ich habe ihn so kodiert, dass er alle Namen aus einer bestimmten Datei extrahiert; wenn das Programm durchläuft, gibt es die Wörter import, java, until, regex usw. jeweils in einer eigenen Zeile aus:
C:\> java ReaderIter.java ReaderIter.java import java util regex import java io Print all the strings that match given pattern from file public ... C:\\>
Ich habe sie hier unterbrochen, um Papier zu sparen. Dies kann auf zwei Arten geschrieben werden: ein zeilenweises Muster, wie in Beispiel 4-6 gezeigt, und eine kompaktere Form, die neue E/A verwendet, wie in Beispiel 4-7 gezeigt (das neue E/A-Paket, das in beiden Beispielen verwendet wird, wird in Kapitel 10 beschrieben).
Beispiel 4-6. main/src/main/java/regex/ReaderIter.java
publicclassReaderIter{publicstaticvoidmain(String[]args)throwsIOException{// The RE patternPatternpatt=Pattern.compile("[A-Za-z][a-z]+");// See the I/O chapter// For each line of input, try matching in it.Files.lines(Path.of(args[0])).forEach(line->{// For each match in the line, extract and print it.Matcherm=patt.matcher(line);while(m.find()){// Simplest method:// System.out.println(m.group(0));// Get the starting position of the textintstart=m.start(0);// Get ending positionintend=m.end(0);// Print whatever matched.// Use CharacterIterator.substring(offset, end);System.out.println(line.substring(start,end));}});}}
Beispiel 4-7. main/src/main/java/regex/GrepNIO.java
publicclassGrepNIO{publicstaticvoidmain(String[]args)throwsIOException{if(args.length<2){System.err.println("Usage: GrepNIO patt file [...]");System.exit(1);}Patternp=Pattern.compile(args[0]);for(inti=1;i<args.length;i++)process(p,args[i]);}staticvoidprocess(Patternpattern,StringfileName)throwsIOException{// Get a FileChannel from the given fileFileInputStreamfis=newFileInputStream(fileName);FileChannelfc=fis.getChannel();// Map the file's contentByteBufferbuf=fc.map(FileChannel.MapMode.READ_ONLY,0,fc.size());// Decode ByteBuffer into CharBufferCharBuffercbuf=Charset.forName("ISO-8859-1").newDecoder().decode(buf);Matcherm=pattern.matcher(cbuf);while(m.find()){System.out.println(m.group(0));}fis.close();}}
Die in Beispiel 4-7 gezeigte nicht-blockierende E/A (NIO)-Version beruht auf der Tatsache, dass ein NIO Buffer als CharSequence verwendet werden kann. Dieses Programm ist allgemeiner, da das Musterargument aus dem Befehlszeilenargument übernommen wird. Es gibt die gleiche Ausgabe wie das vorherige Beispiel aus, wenn es mit dem Musterargument aus dem vorherigen Programm auf der Befehlszeile aufgerufen wird:
java regex.GrepNIO "[A-Za-z][a-z]+" ReaderIter.java
Du könntest \w+ als Muster verwenden; der einzige Unterschied ist, dass mein Muster nach wohlgeformten, großgeschriebenen Wörtern sucht, während \w+ Java-zentrische Merkwürdigkeiten wie theVariableName einschließen würde, die Großbuchstaben an nicht standardmäßigen Positionen haben.
Beachte auch, dass die NIO-Version wahrscheinlich effizienter ist, weil sie Matcher nicht bei jeder Eingabezeile auf eine neue Eingabequelle zurücksetzt, wie es ReaderIter tut.
4.6 Zeilen mit einem Muster drucken
Lösung
Schreibe ein einfaches grep-ähnliches Programm.
Diskussion
Wie ich bereits erwähnt habe, kannst du, sobald du ein Regex-Paket hast, ein grep-ähnliches Programm schreiben. Ich habe bereits ein Beispiel für das Unix-Programm grep ( ) gegeben. grep wird mit einigen optionalen Argumenten aufgerufen, gefolgt von einem erforderlichen Muster für einen regulären Ausdruck, gefolgt von einer beliebigen Anzahl von Dateinamen. Es gibt jede Zeile aus, die das Muster enthält, im Gegensatz zu Rezept 4.5, das nur den übereinstimmenden Text selbst ausgibt. Hier ist ein Beispiel:
grep "[dD]arwin" *.txt
Der Code sucht nach Zeilen, die entweder darwin oder Darwin enthalten, in jeder Zeile jeder Datei, deren Name auf .txt endet.3 Beispiel 4-8 ist der Quellcode für die erste Version eines Programms, das dies tut, namens Grep0. Es liest Zeilen von der Standardeingabe und nimmt keine optionalen Argumente entgegen, aber es verarbeitet alle regulären Ausdrücke, die die Klasse Pattern implementiert (es ist also nicht identisch mit den gleichnamigen Unix-Programmen). Wir haben das Paket java.io für die Ein- und Ausgabe noch nicht behandelt (siehe Kapitel 10), aber unsere Verwendung hier ist so einfach, dass du sie wahrscheinlich intuitiv nachvollziehen kannst. Die Online-Quelle enthält Grep1, das dasselbe tut, aber besser strukturiert (und deshalb länger) ist. Später in diesem Kapitel wird in Rezept 4.11 ein JGrep-Programm vorgestellt, das eine Reihe von Kommandozeilenoptionen parst.
Beispiel 4-8. main/src/main/java/regex/Grep0.java
publicclassGrep0{publicstaticvoidmain(String[]args)throwsIOException{BufferedReaderis=newBufferedReader(newInputStreamReader(System.in));if(args.length!=1){System.err.println("Usage: MatchLines pattern");System.exit(1);}Patternpatt=Pattern.compile(args[0]);Matchermatcher=patt.matcher("");Stringline=null;while((line=is.readLine())!=null){matcher.reset(line);if(matcher.find()){System.out.println("MATCH: "+line);}}}}
4.7 Groß- und Kleinschreibung in regulären Ausdrücken kontrollieren
Lösung
Kompiliere Pattern und füge das Argument flags Pattern.CASE_INSENSITIVE hinzu , um anzugeben, dass der Abgleich unabhängig von der Groß- und Kleinschreibung erfolgen soll (d.h., dass die Groß- und Kleinschreibung ignoriert werden soll). Wenn dein Code in verschiedenen Sprachumgebungen laufen könnte (sieheRezept 3.12), solltest du Pattern.UNICODE_CASE hinzufügen. Ohne diese Flags ist der normale Abgleich unter Berücksichtigung der Groß- und Kleinschreibung die Standardeinstellung. Dieses Flag (und andere) werden an die Pattern.compile() Methode übergeben, etwa so:
// regex/CaseMatch.java
Pattern reCaseInsens = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE |
Pattern.UNICODE_CASE);
reCaseInsens.matches(input); // will match case-insensitively
Dieses Flag muss bei der Erstellung von Pattern übergeben werden. Da Pattern Objekte unveränderlich sind, können sie nach der Erstellung nicht mehr verändert werden.
Der vollständige Quellcode für dieses Beispiel ist online als CaseMatch.java verfügbar.
4.8 Übereinstimmende akzentuierte oder zusammengesetzte Zeichen
Lösung
Kompiliere die Pattern mit dem flags Argument Pattern.CANON_EQ für kanonische Gleichheit.
Diskussion
Zusammengesetzte Zeichen können in verschiedenen Formen eingegeben werden. Nehmen wir als einziges Beispiel den Buchstaben e mit einem akuten Akzent. Dieses Zeichen kann in verschiedenen Formen im Unicode-Text vorkommen, z. B. als einzelnes Zeichen é (Unicode-Zeichen \u00e9) oder als Zwei-Zeichen-Folge e´ (e gefolgt vom Unicode-Kombinationsakzent, \u0301). Damit du solche Zeichen unabhängig davon finden kannst, welche der möglicherweise mehreren vollständig zerlegten Formen zur Eingabe verwendet werden, verfügt das regex-Paket über eine Option für canonical matching, die jede der Formen als gleichwertig behandelt. Diese Option wird aktiviert, indem du CANON_EQ als (eines) der Flags im zweiten Argument von Pattern.compile() übergibst. Dieses Programm zeigt, wie CANON_EQ verwendet wird, um mehrere Formen abzugleichen:
publicclassCanonEqDemo{publicstaticvoidmain(String[]args){StringpattStr="\u00e9gal";// egalString[]input={"\u00e9gal",// egal - this one had better match :-)"e\u0301gal",// e + "Combining acute accent""e\u02cagal",// e + "modifier letter acute accent""e'gal",// e + single quote"e\u00b4gal",// e + Latin-1 "acute"};Patternpattern=Pattern.compile(pattStr,Pattern.CANON_EQ);for(inti=0;i<input.length;i++){if(pattern.matcher(input[i]).matches()){System.out.println(pattStr+" matches input "+input[i]);}else{System.out.println(pattStr+" does not match input "+input[i]);}}}}
Dieses Programm erkennt den kombinierenden Akzent richtig und lehnt die anderen Zeichen ab, von denen einige leider wie der Akzent auf einem Drucker aussehen, aber nicht als kombinierende Akzentzeichen gelten:
égal matches input égal égal matches input e?gal égal does not match input e?gal égal does not match input e'gal égal does not match input e´gal
Weitere Details findest du in den Zeichentabellen.
4.9 Zeilenumbrüche im Text abgleichen
Lösung
Verwende \n oder \r in deinem Regex-Muster. Siehe auch die Flaggenkonstante Pattern.MULTILINE, die dafür sorgt, dass Zeilenumbrüche als Zeilenanfang und Zeilenende erkannt werden (\^ und $).
Diskussion
Obwohl zeilenorientierte Unix-Tools wie sed und grep reguläre Ausdrücke zeilenweise abgleichen, tun das nicht alle Tools. Der sam Texteditor von Bell Laboratories war das erste mir bekannte interaktive Werkzeug, das mehrzeilige reguläre Ausdrücke zuließ; die Skriptsprache Perl folgte kurz darauf. In der Java-API hat das Zeilenumbruchszeichen standardmäßig keine besondere Bedeutung. Die Methode BufferedReader readLine() entfernt normalerweise alle Zeilenumbruchzeichen, die sie findet. Wenn du viele Zeichen mit einer anderen Methode als readLine() einliest, kann es sein, dass du eine Reihe von \n, \r oder \r\n Sequenzen in deinem Textstring hast.4 Normalerweise werden alle diese Sequenzen als gleichwertig mit \n behandelt. Wenn du möchtest, dass nur \n übereinstimmt, verwende das Flag UNIX_LINES für die Methode Pattern.compile().
Unter Unix werden ^ und $ üblicherweise verwendet, um den Anfang bzw. das Ende einer Zeile abzugleichen. In dieser API ignorieren die Regex-Metazeichen \^ und $ Zeilenabschlüsse und passen nur am Anfang bzw. am Ende der gesamten Zeichenfolge. Wenn du jedoch das Flag MULTILINE an Pattern.compile() übergibst, passen diese Ausdrücke genau nach bzw. genau vor einem Zeilenende; $ passt auch auf das Ende der Zeichenfolge. Da das Zeilenende nur ein gewöhnliches Zeichen ist, kannst du es mit . oder ähnlichen Ausdrücken abgleichen; und wenn du genau wissen willst, wo es sich befindet, passen auch \n oder \r im Muster dazu. Mit anderen Worten: Für diese API ist ein Zeilenumbruch nur ein weiteres Zeichen ohne besondere Bedeutung. Siehe die Seitenleiste "Pattern.compile() Flags". Ein Beispiel für den Abgleich von Zeilenumbrüchen ist in Beispiel 4-9 zu sehen.
Beispiel 4-9. main/src/main/java/regex/NLMatch.java
publicclassNLMatch{publicstaticvoidmain(String[]argv){Stringinput="I dream of engines\nmore engines, all day long";System.out.println("INPUT: "+input);System.out.println();String[]patt={"engines.more engines","ines\nmore","engines$"};for(inti=0;i<patt.length;i++){System.out.println("PATTERN "+patt[i]);booleanfound;Patternp1l=Pattern.compile(patt[i]);found=p1l.matcher(input).find();System.out.println("DEFAULT match "+found);Patternpml=Pattern.compile(patt[i],Pattern.DOTALL|Pattern.MULTILINE);found=pml.matcher(input).find();System.out.println("MultiLine match "+found);System.out.println();}}}
Wenn du diesen Code ausführst, passt das erste Muster (mit dem Platzhalterzeichen .) immer, während das zweite Muster (mit $) nur passt, wenn MATCH_MULTILINE gesetzt ist:
> java regex.NLMatch INPUT: I dream of engines more engines, all day long PATTERN engines more engines DEFAULT match true MULTILINE match: true PATTERN engines$ DEFAULT match false MULTILINE match: true
4.10 Programm: Apache Logfile Parsing
Der Apache Webserver ist der weltweit führende Webserver und war dies für den größten Teil der Geschichte des Internets. Er ist eines der bekanntesten Open-Source-Projekte der Welt und das erste von vielen, die von der Apache Foundation gefördert werden. Es wird oft behauptet, dass der Name Apache ein Wortspiel mit den Ursprüngen des Servers ist: Die Entwickler begannen mit dem freien NCSA-Server und hackten so lange an ihm herum, bis er tat, was sie wollten. Als er sich ausreichend vom Original unterschieden hatte, wurde ein neuer Name benötigt. Da es sich nun um einen patchbaren Server handelte, wurde der Name Apache gewählt. Von offizieller Seite wird diese Geschichte zwar bestritten, aber sie ist trotzdem niedlich. Ein Ort, an dem sich die tatsächliche Uneinheitlichkeit zeigt, ist das Logfile-Format. Siehe Beispiel 4-10.
Beispiel 4-10. Auszug aus der Apache-Logdatei
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html HTTP/1.0" 200 10450 "-" "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
Das Dateiformat wurde offensichtlich für die menschliche Inspektion, aber nicht für das einfache Parsen entwickelt. Das Problem ist, dass verschiedene Begrenzungszeichen verwendet werden: eckige Klammern für das Datum, Anführungszeichen für die Anfragezeile und Leerzeichen überall. Versuch doch mal, eine StringTokenizer zu verwenden; du könntest es vielleicht hinbekommen, aber du würdest eine Menge Zeit damit verbringen, daran herumzufummeln. Eigentlich nicht, du würdest es nicht hinbekommen. Aber dieser etwas verdrehte reguläre Ausdruck5 macht es jedoch einfach, ihn zu analysieren (es handelt sich um einen einzigen Regex in Moby-Größe; wir mussten ihn auf zwei Zeilen aufteilen, damit er in die Buchränder passt):
\^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) (\d+)
"([\^"]+)" "([\^"]+)"
Vielleicht findest du es informativ, wenn du dir die Tabelle 4-1 ansiehst und dir die vollständige Syntax ansiehst, die hier verwendet wird. Beachte vor allem die Verwendung des Quantifizierers +? in \"(.+?)\", um eine Zeichenkette in Anführungszeichen abzugleichen; du kannst nicht einfach .+ verwenden, weil das zu viel abgleichen würde (bis zum Anführungszeichen am Ende der Zeile). Der Code zum Extrahieren der verschiedenen Felder wie IP-Adresse, Anfrage, Referrer-URL und Browserversion wird in Beispiel 4-11 gezeigt.
Beispiel 4-11. main/src/main/java/regex/LogRegExp.java
publicclassLogRegExp{finalstaticStringlogEntryPattern="^([\\d.]+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+-]\\d{4})\\] "+"\"(.+?)\" (\\d{3}) (\\d+) \"([^\"]+)\" \"([^\"]+)\"";publicstaticvoidmain(Stringargv[]){System.out.println("RE Pattern:");System.out.println(logEntryPattern);System.out.println("Input line is:");StringlogEntryLine=LogParseInfo.LOG_ENTRY_LINE;System.out.println(logEntryLine);Patternp=Pattern.compile(logEntryPattern);Matchermatcher=p.matcher(logEntryLine);if(!matcher.matches()||LogParseInfo.MIN_FIELDS>matcher.groupCount()){System.err.println("Bad log entry (or problem with regex):");System.err.println(logEntryLine);return;}System.out.println("IP Address: "+matcher.group(1));System.out.println("UserName: "+matcher.group(3));System.out.println("Date/Time: "+matcher.group(4));System.out.println("Request: "+matcher.group(5));System.out.println("Response: "+matcher.group(6));System.out.println("Bytes Sent: "+matcher.group(7));if(!matcher.group(8).equals("-"))System.out.println("Referer: "+matcher.group(8));System.out.println("User-Agent: "+matcher.group(9));}}
Die implements Klausel ist für eine Schnittstelle, die nur den Eingabestring definiert; sie wurde in einer Demonstration verwendet, um den Modus für reguläre Ausdrücke mit der Verwendung eines StringTokenizer zu vergleichen. Der Quelltext für beide Versionen befindet sich in den Online-Quellen zu diesem Kapitel. Wenn du das Programm mit der Beispieleingabe aus Beispiel 4-10 ausführst, erhältst du diese Ausgabe:
Using regex Pattern:
\^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) (\d+) "([\^"]+)"
"([\^"]+)"
Input line is:
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html
HTTP/1.0" 200 10450 "-" "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
IP Address: 123.45.67.89
Date&Time: 27/Oct/2000:09:27:09 -0400
Request: GET /java/javaResources.html HTTP/1.0
Response: 200
Bytes Sent: 10450
Browser: Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)
Das Programm hat den gesamten Eintrag im Logfile-Format mit einem Aufruf von matcher.matches() erfolgreich geparst.
4.11 Programm: Full Grep
Nachdem wir nun gesehen haben, wie das Paket für reguläre Ausdrücke funktioniert, ist es an der Zeit, JGrep zu schreiben, eine vollwertige Version des Zeilenvergleichsprogramms mit Optionsparsing. In Tabelle 4-2 sind einige typische Befehlszeilenoptionen aufgelistet, die eine Unix-Implementierung von grep enthalten könnte. Für diejenigen, die mit grep nicht vertraut sind: grep ist ein Befehlszeilenprogramm, das nach regulären Ausdrücken in Textdateien sucht. Es gibt drei oder vier Programme in der Standard grep-Familie und einige neuere Ersatzprogramme wie ripgrep oder rg. Dieses Programm ist meine Ergänzung zu dieser Programmfamilie.
| Option | Bedeutung |
|---|---|
-c |
Nur zählen; Zeilen nicht ausdrucken, nur zählen |
-C |
Kontext; einige Zeilen über und unter jeder übereinstimmenden Zeile ausgeben (in dieser Version nicht implementiert; als Übung für den Leser belassen) |
-f Muster |
Muster aus der Datei mit dem Namen |
-h |
Dateinamen vor den Zeilen nicht ausgeben |
-i |
Fall ignorieren |
-l |
Nur Dateinamen auflisten: keine Zeilen ausgeben, sondern nur die Namen, in denen sie vorkommen |
-n |
Zeilennummern vor passenden Zeilen drucken |
-s |
Drucken bestimmter Fehlermeldungen unterdrücken |
-v |
Invertieren: nur Zeilen drucken, die NICHT mit dem Muster übereinstimmen |
In der Unix-Welt gibt es mehrere getopt-Bibliotheksroutinen zum Parsen von Kommandozeilenargumenten, also habe ich diese in Java neu implementiert. Da main() in einem statischen Kontext läuft, unsere Anwendungshauptzeile aber nicht, könnten wir wie üblich eine Menge Informationen in den Konstruktor übergeben.
Um Platz zu sparen, verwendet diese Version nur globale Variablen, um die Einstellungen aus der Befehlszeile zu verfolgen. Im Gegensatz zum Unix-Tool grep kann dieses Tool noch nicht mit kombinierten Optionen umgehen, daher ist -l -r -i in Ordnung, aber -lri wird aufgrund einer Einschränkung im verwendeten GetOpt Parser fehlschlagen.
Das Programm liest im Grunde nur Zeilen, vergleicht das Muster darin und gibt, wenn eine Übereinstimmung gefunden wird (oder nicht gefunden wird, mit -v), die Zeile aus (und optional auch einige andere Dinge). Nach all dem wird der Code in Beispiel 4-12 gezeigt.
Beispiel 4-12. darwinsys-api/src/main/java/regex/JGrep.java
/** A command-line grep-like program. Accepts some command-line options,* and takes a pattern and a list of text files.* N.B. The current implementation of GetOpt does not allow combining short* arguments, so put spaces e.g., "JGrep -l -r -i pattern file..." is OK, but* "JGrep -lri pattern file..." will fail. Getopt will hopefully be fixed soon.*/publicclassJGrep{privatestaticfinalStringUSAGE="Usage: JGrep pattern [-chilrsnv][-f pattfile][filename...]";/** The pattern we're looking for */protectedPatternpattern;/** The matcher for this pattern */protectedMatchermatcher;privatebooleandebug;/** Are we to only count lines, instead of printing? */protectedstaticbooleancountOnly=false;/** Are we to ignore case? */protectedstaticbooleanignoreCase=false;/** Are we to suppress printing of filenames? */protectedstaticbooleandontPrintFileName=false;/** Are we to only list names of files that match? */protectedstaticbooleanlistOnly=false;/** Are we to print line numbers? */protectedstaticbooleannumbered=false;/** Are we to be silent about errors? */protectedstaticbooleansilent=false;/** Are we to print only lines that DONT match? */protectedstaticbooleaninVert=false;/** Are we to process arguments recursively if directories? */protectedstaticbooleanrecursive=false;/** Construct a Grep object for the pattern, and run it* on all input files listed in args.* Be aware that a few of the command-line options are not* acted upon in this version - left as an exercise for the reader!* @param args args*/publicstaticvoidmain(String[]args){if(args.length<1){System.err.println(USAGE);System.exit(1);}Stringpatt=null;GetOptgo=newGetOpt("cf:hilnrRsv");charc;while((c=go.getopt(args))!=0){switch(c){case'c':countOnly=true;break;case'f':/* External file contains the pattern */try(BufferedReaderb=newBufferedReader(newFileReader(go.optarg()))){patt=b.readLine();}catch(IOExceptione){System.err.println("Can't read pattern file "+go.optarg());System.exit(1);}break;case'h':dontPrintFileName=true;break;case'i':ignoreCase=true;break;case'l':listOnly=true;break;case'n':numbered=true;break;case'r':case'R':recursive=true;break;case's':silent=true;break;case'v':inVert=true;break;case'?':System.err.println("Getopts was not happy!");System.err.println(USAGE);break;}}intix=go.getOptInd();if(patt==null)patt=args[ix++];JGrepprog=null;try{prog=newJGrep(patt);}catch(PatternSyntaxExceptionex){System.err.println("RE Syntax error in "+patt);return;}if(args.length==ix){dontPrintFileName=true;// Don't print filenames if stdinif(recursive){System.err.println("Warning: recursive search of stdin!");}prog.process(newInputStreamReader(System.in),null);}else{if(!dontPrintFileName)dontPrintFileName=ix==args.length-1;// Nor if only one fileif(recursive)dontPrintFileName=false;// unless a directory!for(inti=ix;i<args.length;i++){// note starting indextry{prog.process(newFile(args[i]));}catch(Exceptione){System.err.println(e);}}}}/*** Construct a JGrep object.* @param patt The regex to look for* @throws PatternSyntaxException if pattern is not a valid regex*/publicJGrep(Stringpatt)throwsPatternSyntaxException{if(debug){System.err.printf("JGrep.JGrep(%s)%n",patt);}// compile the regular expressionintcaseMode=ignoreCase?Pattern.UNICODE_CASE|Pattern.CASE_INSENSITIVE:0;pattern=Pattern.compile(patt,caseMode);matcher=pattern.matcher("");}/** Process one command line argument (file or directory)* @param file The input File* @throws FileNotFoundException If the file doesn't exist*/publicvoidprocess(Filefile)throwsFileNotFoundException{if(!file.exists()||!file.canRead()){thrownewFileNotFoundException("Can't read file "+file.getAbsolutePath());}if(file.isFile()){process(newBufferedReader(newFileReader(file)),file.getAbsolutePath());return;}if(file.isDirectory()){if(!recursive){System.err.println("ERROR: -r not specified but directory given "+file.getAbsolutePath());return;}for(Filenf:file.listFiles()){process(nf);// "Recursion, n.: See Recursion."}return;}System.err.println("WEIRDNESS: neither file nor directory: "+file.getAbsolutePath());}/** Do the work of scanning one file* @param ifile Reader Reader object already open* @param fileName String Name of the input file*/publicvoidprocess(Readerifile,StringfileName){StringinputLine;intmatches=0;try(BufferedReaderreader=newBufferedReader(ifile)){while((inputLine=reader.readLine())!=null){matcher.reset(inputLine);if(matcher.find()){if(listOnly){// -l, print filename on first match, and we're doneSystem.out.println(fileName);return;}if(countOnly){matches++;}else{if(!dontPrintFileName){System.out.(fileName+": ");}System.out.println(inputLine);}}elseif(inVert){System.out.println(inputLine);}}if(countOnly)System.out.println(matches+" matches in "+fileName);}catch(IOExceptione){System.err.println(e);}}}
1 Nicht-Unix-Fans müssen keine Angst haben, denn du kannst Tools wie grep auf Windows-Systemen mit einem von mehreren Paketen verwenden. Eines davon ist ein Open-Source-Paket, das abwechselnd CygWin (nach Cygnus Software) oder GnuWin32 genannt wird. Ein anderes ist der Befehl findstr von Microsoft für Windows. Oder du kannst mein Grep-Programm in Rezept 4.6 verwenden, wenn du grep nicht auf deinem System hast. Der Name grep stammt übrigens von einem alten Unix-Zeileneditor-Befehl g/RE/p, der die Regex global in allen Zeilen im Editierpuffer sucht und die übereinstimmenden Zeilen ausgibt - genau das, was das Programm grep mit Zeilen in Dateien macht.
2 REDemo wurde durch ein ähnliches Programm inspiriert, das mit dem inzwischen eingestellten Apache Jakarta Regular Expressions-Paket geliefert wurde (aber keinen Code daraus verwendet).
3 Unter Unix expandiert die Shell oder der Kommandozeileninterpreter *.txt in alle passenden Dateinamen, bevor das Programm ausgeführt wird, aber der normale Java-Interpreter macht das für dich auf Systemen, auf denen die Shell nicht energisch oder intelligent genug ist, um das zu tun.
4 Oder ein paar verwandte Unicode-Zeichen, einschließlich der Zeichen für die nächste Zeile (\u0085), den Zeilentrenner (\u2028) und den Absatztrenner (\u2029).
5 Man könnte meinen, dass dies eine Art Weltrekord für Komplexität in Regex-Wettbewerben ist, aber ich bin mir sicher, dass es schon oft übertroffen wurde.
Get Java Kochbuch, 4. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

