Chapter 4. Pattern Matching with Regular Expressions
4.0 Introduction
Suppose you have been on the internet for a few years and have been faithful about saving all your correspondence, just in case you (or your lawyers, or the prosecution) need a copy. The result is that you have a 5 GB disk partition dedicated to saved mail. Let’s further suppose that you remember that somewhere in there is an email message from someone named Angie or Anjie. Or was it Angy? But you don’t remember what you called it or where you stored it. Obviously, you have to look for it.
But while some of you go and try to open up all 15,000,000 documents in a word processor, I’ll just find it with one simple command. Any system that provides regular expression support allows me to search for the pattern in several ways. The simplest to understand is:
Angie|Anjie|Angy
which you can probably guess means just to search for any of the variations. A more concise form (more thinking, less typing) is:
An[^ dn]
The syntax will become clear as we go through this chapter. Briefly, the “A” and the “n” match themselves, in effect finding words that begin with “An”, while the cryptic [^ dn] requires the “An” to be followed by a character other than (^ means not in this context) a space (to eliminate the very common English word “an” at the start of a sentence) or “d” (to eliminate the common word “and”) or “n” (to eliminate “Anne,” “Announcing,” etc.). Has your word processor gotten past its splash screen yet? Well, it doesn’t matter, because I’ve already found the missing file. To find the answer, I just typed this command:
grep 'An[^ dn]' *
Regular expressions, or regexes for short, provide a concise and precise specification of patterns to be matched in text. One good way to think of regular expressions is as a little language for matching patterns of characters in text contained in strings. A regular expression API is an interpreter for matching regular expressions.
As another example of the power of regular expressions, consider the problem of bulk-updating hundreds of files. When I started with Java, the syntax for declaring array references was baseType arrayVariableName[]. For example, a method with an array argument, such as every program’s main method, was commonly written like this:
public static void main(String args[]) {
But as time went by, it became clear to the stewards of the Java language that it would be better to write it as baseType[] arrayVariableName, like this:
public static void main(String[] args) {
This is better Java style because it associates the “array-ness” of the type with the type
itself, rather than with the local argument name, and the compiler still accepts both modes.
I wanted to change all occurrences of main written the old way to the new way. I used
the pattern main(String [a-z] with the grep utility described earlier to find the
names of all the files containing old-style main declarations (i.e., main(String
followed by a space and a name character rather than an open square bracket). I then used
another regex-based Unix tool, the stream editor sed, in a little shell script to change
all occurrences in those files from main(String *([a-z][a-z]*)[] to
main(String[] $1 (the regex syntax used here is discussed later in this chapter). Again,
the regex-based approach was orders of magnitude faster than doing it interactively, even
using a reasonably powerful editor such as vi or emacs, let alone trying to use a
graphical word processor.
Historically, the syntax of regexes has changed as they get incorporated into more tools and more languages, so the exact syntax in the previous examples is not exactly what you’d use in Java, but it does convey the conciseness and power of the regex mechanism.1
As a third example, consider parsing an Apache web server logfile, where some fields are delimited with quotes, others with square brackets, and others with spaces. Writing ad hoc code to parse this is messy in any language, but a well-crafted regex can break the line into all its constituent fields in one operation (this example is developed in Recipe 4.10).
These same time gains can be had by Java developers.
Regular expression support has been in the standard Java runtime for ages
and is well integrated (e.g., there are regex methods in
the standard class java.lang.String and in the new I/O package).
There are a few other regex packages for Java, and you may occasionally
encounter code using them, but pretty well all code from this century
can be expected to use the built-in package.
The syntax of Java regexes themselves is discussed in
Recipe 4.1, and the syntax of the Java API for using
regexes is described in Recipe 4.2. The remaining
recipes show some applications of regex technology in Java.
See Also
Mastering Regular Expressions by Jeffrey Friedl (O’Reilly) is the definitive guide to all the details of regular expressions. Most introductory books on Unix and Perl include some discussion of regexes; Unix Power Tools by Mike Loukides, Tim O’Reilly, Jerry Peek, and Shelley Powers (O’Reilly) devotes a chapter to them.
4.1 Regular Expression Syntax
Solution
Consult Table 4-1 for a list of the regular expression characters.
Discussion
These pattern characters let you specify regexes of considerable power. In building
patterns, you can use any combination of ordinary text and the metacharacters, or
special characters, in Table 4-1. These can all be used in any
combination that makes sense. For example, a+ means any number of occurrences of the
letter a, from one up to a million or a gazillion. The pattern Mrs?\. matches Mr. or
Mrs. And .* indicates any character, any number of times, and is similar in meaning to
most command-line interpreters’ meaning of the \* alone. The pattern \d+ means any
number of numeric digits. \d{2,3} means a two- or three-digit number.
| Subexpression | Matches | Notes |
|---|---|---|
General |
||
|
Start of line/string |
|
|
End of line/string |
|
|
Word boundary |
|
|
Not a word boundary |
|
|
Beginning of entire string |
|
|
End of entire string |
|
|
End of entire string (except allowable final line terminator) |
See Recipe 4.9 |
. |
Any one character (except line terminator) |
|
|
“Character class”; any one character from those listed |
|
|
Any one character not from those listed |
See Recipe 4.2 |
Alternation and grouping |
||
|
Grouping (capture groups) |
See Recipe 4.3 |
|
Alternation |
|
|
Noncapturing parenthesis |
|
|
End of the previous match |
|
+\+ |
Back-reference to capture group number |
|
Normal (greedy) quantifiers |
||
|
Quantifier for from |
See Recipe 4.4 |
|
Quantifier for |
|
|
Quantifier for exactly |
See Recipe 4.10 |
|
Quantifier for 0 up to |
|
|
Quantifier for 0 or more repetitions |
Short for |
|
Quantifier for 1 or more repetitions |
Short for |
|
Quantifier for 0 or 1 repetitions (i.e., present exactly once, or not at all) |
Short for |
Reluctant (nongreedy) quantifiers |
||
|
Reluctant quantifier for from |
|
|
Reluctant quantifier for |
|
|
Reluctant quantifier for 0 up to |
|
|
Reluctant quantifier: 0 or more |
|
|
Reluctant quantifier: 1 or more |
See Recipe 4.10 |
|
Reluctant quantifier: 0 or 1 times |
|
Possessive (very greedy) quantifiers |
||
|
Possessive quantifier for from |
|
|
Possessive quantifier for |
|
|
Possessive quantifier for 0 up to |
|
|
Possessive quantifier: 0 or more |
|
|
Possessive quantifier: 1 or more |
|
|
Possessive quantifier: 0 or 1 times |
|
Escapes and shorthands |
||
|
Escape (quote) character: turns most metacharacters off; turns subsequent alphabetic into metacharacters |
|
|
Escape (quote) all characters up to |
|
|
Ends quoting begun with |
|
|
Tab character |
|
|
Return (carriage return) character |
|
|
Newline character |
See Recipe 4.9 |
|
Form feed |
|
|
Character in a word |
Use |
|
A nonword character |
|
|
Numeric digit |
Use |
|
A nondigit character |
|
|
Whitespace |
Space, tab, etc., as determined by |
|
A nonwhitespace character |
See Recipe 4.10 |
Unicode blocks (representative samples) |
||
|
A character in the Greek block |
(Simple block) |
|
Any character not in the Greek block |
|
|
An uppercase letter |
(Simple category) |
|
A currency symbol |
|
POSIX-style character classes (defined only for US-ASCII) |
||
|
Alphanumeric characters |
|
|
Alphabetic characters |
|
|
Any ASCII character |
|
|
Space and tab characters |
|
|
Space characters |
|
|
Control characters |
|
|
Numeric digit characters |
|
|
Printable and visible characters (not spaces or control characters) |
|
|
Printable characters |
Same as |
|
Punctuation characters |
One of |
|
Lowercase characters |
|
|
Uppercase characters |
|
|
Hexadecimal digit characters |
|
Regexes match any place possible in the string. Patterns followed by greedy quantifiers (the only type that existed in traditional Unix regexes) consume (match) as much as possible without compromising any subexpressions that follow. Patterns followed by possessive quantifiers match as much as possible without regard to following subexpressions. Patterns followed by reluctant quantifiers consume as few characters as possible to still get a match.
Also, unlike regex packages in some other languages, the Java regex package was designed to handle Unicode characters from the beginning. The standard Java escape sequence \u+nnnn is used to specify a Unicode character in the pattern. We use methods of java.lang.Character to determine Unicode character properties, such as whether a given character is a space.
Again, note that the backslash must be doubled if this is in a Java
string that is being compiled because the compiler would otherwise
parse this as “backslash-u” followed by some numbers.
To help you learn how regexes work, I provide a little program called REDemo.2 The code for REDemo is too long to include in the book; in the online directory regex of the darwinsys-api repo, you will find REDemo.java, which you can run to explore how regexes work.
In the uppermost text box (see Figure 4-1), type the regex pattern you want to test. Note that as you type each character, the regex is checked for syntax; if the syntax is OK, you see a checkmark beside it. You can then select Match, Find, or Find All. Match means that the entire string must match the regex, and Find means the regex must be found somewhere in the string (Find All counts the number of occurrences that are found). Below that, you type a string that the regex is to match against. Experiment to your heart’s content. When you have the regex the way you want it, you can paste it into your Java program. You’ll need to escape (backslash) any characters that are treated specially by both the Java compiler and the Java regex package, such as the backslash itself, double quotes, and others. Once you get a regex the way you want it, there is a Copy button (not shown in these screenshots) to export the regex to the clipboard, with or without backslash doubling, depending on how you want to use it.
Tip
Remember that because a regex is entered as a string that will be compiled by a Java compiler, you usually need two levels of escaping for any special characters, including backslash and double quotes. For example, the regex (which includes the double quotes):
"You said it\."
has to be typed like this to be a valid compile-time Java language String:
String pattern = "\"You said it\\.\""
In Java 14+ you could also use a text block to avoid escaping the quotes:
String pattern = """ "You said it\\.""""
I can’t tell you how many times I’ve made the mistake of forgetting the extra backslash in \d+, \w+, and their kin!
In Figure 4-1, I typed qu into the REDemo program’s Pattern box, which is a syntactically valid regex pattern: any ordinary characters stand as regexes for themselves, so this looks for the letter q followed by u. In the top version, I typed only a q into the string, which is not matched. In the second, I have typed quack and the q of a second quack. Because I have selected Find All, the count shows one match. As soon as I type the second u, the count is updated to two, as shown in the third version.
Regexes can do far more than just character matching. For example,
the two-character regex ^T would match beginning of line (^)
immediately followed by a capital T—that is, any line beginning with
a capital T. It doesn’t matter whether the line begins with “Tiny trumpets,” “Titanic tubas,” or “Triumphant twisted trombones,” as
long as the capital T is present in the first position.
But here we’re not very far ahead. Have we really invested all this effort in regex technology just to be able to do what we could already do with the java.lang.String method startsWith()? Hmmm, I can hear some of you getting a bit restless. Stay in your seats! What if you wanted to match not only a letter T in the first position, but also a vowel immediately after it, followed by any number of letters in a word, followed by an exclamation point? Surely you could do this in Java by checking startsWith("T") and charAt(1) == 'a' || charAt(1) == 'e', and so on? Yes, but by the time you did that, you’d have written a lot of very highly specialized code that you couldn’t use in any other application. With regular expressions, you can just give the pattern ^T[aeiou]\w*!. That is, ^ and T as before, followed by a character class listing the vowels, followed by any number of word characters (\w*), followed by the exclamation point.
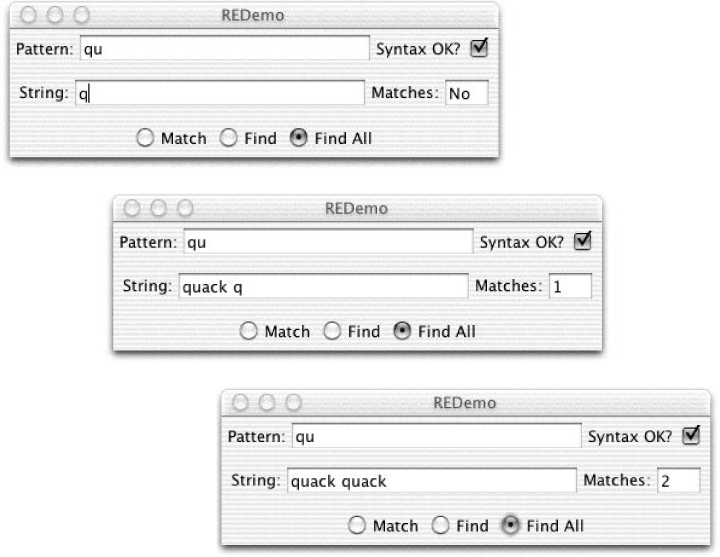
Figure 4-1. REDemo with simple examples
“But wait, there’s more!” as my late, great boss
Yuri Rubinsky used to say.
What if you want to be able to change the pattern you’re looking for at runtime? Remember all that Java code you just wrote to match T in column 1, plus a vowel, some word characters, and an exclamation point? Well, it’s time to throw it out. Because this morning we need to match Q, followed by a letter other than u, followed by a number of digits, followed by a period. While some of you start writing a new function to do that, the rest of us will just saunter over to the RegEx Bar & Grille, order a ^Q[^u]\d+\.. from the bartender, and be on our way.
OK, if you want an explanation: the [^u] means match
any one character that is not the character u. The \d+ means one or more numeric digits. The
+ is a quantifier meaning one or more occurrences of what it
follows, and \d is any one numeric digit. So \d+ means a number
with one, two, or more digits. Finally, the \.? Well, . by itself
is a metacharacter. Most single metacharacters are switched off by
preceding them with an escape character. Not the Esc key on your
keyboard, of course. The regex escape character is the backslash.
Preceding a metacharacter like . with this escape turns off its
special meaning, so we look for a literal period rather than any character.
Preceding a few selected alphabetic characters
(e.g., n, r, t, s, w) with escape turns them into
metacharacters. Figure 4-2 shows the ^Q[^u]\d+\..
regex in action. In the first frame, I have typed part of the regex
as ^Q[^u. Because there is an unclosed square bracket, the
Syntax OK flag is turned off; when I complete the regex, it will
be turned back on. In the second frame, I have finished typing the regex,
and I’ve typed the data string as QA577 (which you should expect to match
the $$^Q[^u]\d+$$ but not the period since I haven’t typed
it). In the third frame, I’ve typed the period so the Matches flag
is set to Yes.
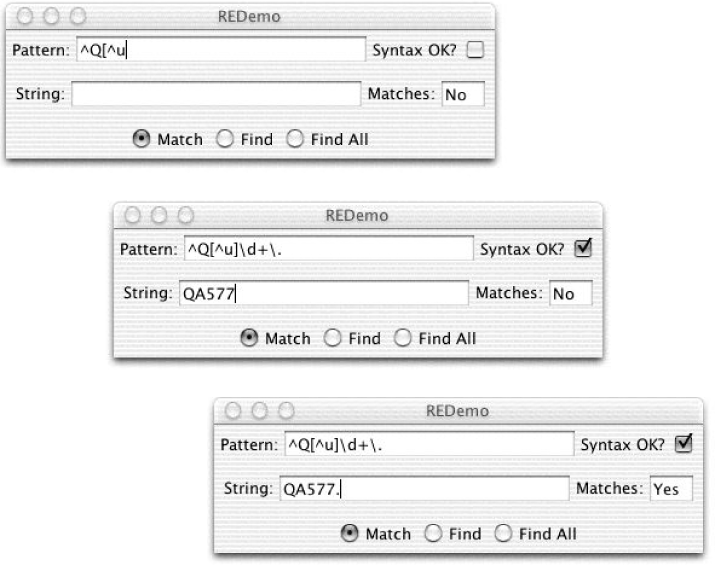
Figure 4-2. REDemo with “Q not followed by u” example
Because backslashes need to be escaped when pasting the regex into Java code, the current version of REDemo has both a Copy Pattern button, which copies the regex verbatim for use in documentation and in Unix commands, and a Copy Pattern Backslashed button, which copies the regex to the clipboard with backslashes doubled, for pasting into Java strings.
By now you should have at least a basic grasp of how regexes work in practice. The rest of this chapter gives more examples and explains some of the more powerful topics, such as capture groups. As for how regexes work in theory—and there are a lot of theoretical details and differences among regex flavors—the interested reader is referred to Mastering Regular Expressions. Meanwhile, let’s start learning how to write Java programs that use regular expressions.
4.2 Using Regexes in Java: Test for a Pattern
Solution
Use the Java Regular Expressions Package, java.util.regex.
Discussion
The good news is that the Java API for regexes is actually easy to use. If all you need is to find out whether a given regex matches a string, you can use the convenient boolean matches() method of the String class, which accepts a regex pattern in String form as its argument:
if(inputString.matches(stringRegexPattern)){// it matched... do something with it...}
This is, however, a convenience routine, and convenience always comes at a price. If the regex is going to be used more than once or twice in a program, it is more efficient to construct and use a Pattern and its Matcher(s). A complete program constructing a Pattern and using it to match is shown here:
publicclassRESimple{publicstaticvoidmain(String[]argv){Stringpattern="^Q[^u]\\d+\\.";String[]input={"QA777. is the next flight. It is on time.","Quack, Quack, Quack!"};Patternp=Pattern.compile(pattern);for(Stringin:input){booleanfound=p.matcher(in).lookingAt();System.out.println("'"+pattern+"'"+(found?" matches '":" doesn't match '")+in+"'");}}}
The java.util.regex package contains two classes, Pattern and Matcher, which provide the public API shown in Example 4-1.
Example 4-1. Regex public API
/*** The main public API of the java.util.regex package.*/packagejava.util.regex;publicfinalclassPattern{// Flags values ('or' together)publicstaticfinalintUNIX_LINES,CASE_INSENSITIVE,COMMENTS,MULTILINE,DOTALL,UNICODE_CASE,CANON_EQ;// No public constructors; use these Factory methodspublicstaticPatterncompile(Stringpatt);publicstaticPatterncompile(Stringpatt,intflags);// Method to get a Matcher for this PatternpublicMatchermatcher(CharSequenceinput);// Information methodspublicStringpattern();publicintflags();// Convenience methodspublicstaticbooleanmatches(Stringpattern,CharSequenceinput);publicString[]split(CharSequenceinput);publicString[]split(CharSequenceinput,intmax);}publicfinalclassMatcher{// Action: find or match methodspublicbooleanmatches();publicbooleanfind();publicbooleanfind(intstart);publicbooleanlookingAt();// "Information about the previous match" methodspublicintstart();publicintstart(intwhichGroup);publicintend();publicintend(intwhichGroup);publicintgroupCount();publicStringgroup();publicStringgroup(intwhichGroup);// Reset methodspublicMatcherreset();publicMatcherreset(CharSequencenewInput);// Replacement methodspublicMatcherappendReplacement(StringBufferwhere,StringnewText);publicStringBufferappendTail(StringBufferwhere);publicStringreplaceAll(StringnewText);publicStringreplaceFirst(StringnewText);// information methodspublicPatternpattern();}/* String, showing only the RE-related methods */publicfinalclassString{publicbooleanmatches(Stringregex);publicStringreplaceFirst(Stringregex,StringnewStr);publicStringreplaceAll(Stringregex,StringnewStr);publicString[]split(Stringregex);publicString[]split(Stringregex,intmax);}
This API is large enough to require some explanation. These are the normal steps for regex matching in a production program:
-
Create a
Patternby calling the static methodPattern.compile(). -
Request a
Matcherfrom the pattern by callingpattern.matcher(CharSequence)for eachString(or otherCharSequence) you wish to look through. -
Call (once or more) one of the finder methods (discussed later in this section) in the resulting
Matcher.
The java.lang.CharSequence interface provides simple read-only access to objects containing a collection of characters. The standard implementations are String and StringBuffer/StringBuilder (described in Chapter 3), and the new I/O class java.nio.CharBuffer.
Of course, you can perform regex matching in other ways, such as using the convenience methods in Pattern or even in java.lang.String, like this:
publicclassStringConvenience{publicstaticvoidmain(String[]argv){Stringpattern=".*Q[^u]\\d+\\..*";Stringline="Order QT300. Now!";if(line.matches(pattern)){System.out.println(line+" matches \""+pattern+"\"");}else{System.out.println("NO MATCH");}}}
But the three-step list is the standard pattern for matching. You’d
likely use the String convenience routine in a program that only used the regex once; if
the regex were being used more than once, it is worth taking the time to compile it because the compiled version runs faster.
In addition, the Matcher has several finder methods, which provide more flexibility than the
String convenience routine match(). These are the Matcher methods:
match()-
Used to compare the entire string against the pattern; this is the same as the routine in
java.lang.String. Because it matches the entireString, I had to put.*before and after the pattern. lookingAt()-
Used to match the pattern only at the beginning of the string.
find()-
Used to match the pattern in the string (not necessarily at the first character of the string), starting at the beginning of the string or, if the method was previously called and succeeded, at the first character not matched by the previous match.
Each of these methods returns boolean, with true meaning a match and false meaning no match. To check whether a given string matches a given pattern, you need only type something like the following:
Matcherm=Pattern.compile(patt).matcher(line);if(m.find()){System.out.println(line+" matches "+patt)}
But you may also want to extract the text that matched, which is the subject of the next recipe.
The following recipes cover uses of the Matcher API. Initially, the examples just use arguments of type String as the input source. Use of other CharSequence types is covered in Recipe 4.5.
4.3 Finding the Matching Text
Solution
Sometimes you need to know more than just whether a regex matched a string. In editors and
many other tools, you want to know exactly what characters were matched. Remember that
with quantifiers such as *, the length of the text that was matched may have no
relationship to the length of the pattern that matched it. Do not underestimate the mighty
.*, which happily matches thousands or millions of characters if allowed to. As you saw
in the previous recipe, you can find out whether a given match succeeds just by using
find() or matches(). But in other applications, you will want to get the characters
that the pattern matched.
After a successful call to one of the preceding methods, you can use these information methods on the Matcher to get information on the match:
start(), end()-
Returns the character position in the string of the starting and ending characters that matched.
groupCount()-
Returns the number of parenthesized capture groups, if any; returns 0 if no groups were used.
group(int i)-
Returns the characters matched by group
iof the current match, ifiis greater than or equal to zero and less than or equal to the return value ofgroupCount(). Group 0 is the entire match, sogroup(0)(or justgroup()) returns the entire portion of the input that matched.
The notion of parentheses, or capture groups, is central to regex processing. Regexes may be nested to any level of complexity. The group(int) method lets you retrieve the characters that matched a given parenthesis group. If you haven’t used any explicit parens, you can just treat whatever matched as level zero. Example 4-2 shows part of REMatch.java.
Example 4-2. Part of main/src/main/java/regex/REMatch.java
publicclassREmatch{publicstaticvoidmain(String[]argv){Stringpatt="Q[^u]\\d+\\.";Patternr=Pattern.compile(patt);Stringline="Order QT300. Now!";Matcherm=r.matcher(line);if(m.find()){System.out.println(patt+" matches \""+m.group(0)+"\" in \""+line+"\"");}else{System.out.println("NO MATCH");}}}
When run, this prints:
Q[\^u]\d+\. matches "QT300." in "Order QT300. Now!"
With the Match button checked, REDemo provides a display of
all the capture groups in a given regex; one example is shown in
Figure 4-3.
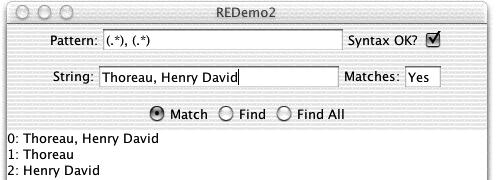
Figure 4-3. REDemo in action
It is also possible to get the starting and ending indices and the
length of the text that the pattern matched (remember that terms
with quantifiers, such as the \d+ in this example, can match
an arbitrary number of characters in the string). You can use these
in conjunction with the String.substring() methods as follows:
Stringpatt="Q[^u]\\d+\\.";Patternr=Pattern.compile(patt);Stringline="Order QT300. Now!";Matcherm=r.matcher(line);if(m.find()){System.out.println(patt+" matches \""+line.substring(m.start(0),m.end(0))+"\" in \""+line+"\"");}else{System.out.println("NO MATCH");}
Suppose you need to extract several items from a string. If the input is
Smith, John Adams, John Quincy
and you want to get out
John Smith John Quincy Adams
publicclassREmatchTwoFields{publicstaticvoidmain(String[]args){StringinputLine="Adams, John Quincy";// Construct an RE with parens to "grab" both field1 and field2Patternr=Pattern.compile("(.*), (.*)");Matcherm=r.matcher(inputLine);if(!m.matches())thrownewIllegalArgumentException("Bad input");System.out.println(m.group(2)+' '+m.group(1));}}
4.4 Replacing the Matched Text
Problem
Having found some text using a Pattern, you want to replace the text with different text, without disturbing the rest of the string.
Solution
As we saw in the previous recipe, regex patterns involving quantifiers can match a lot of characters with very few metacharacters. We need a way to replace the text that the regex matched without changing other text before or after it. We could do this manually using the String method substring(). However, because it’s such a common requirement, the Java Regular Expression API provides some substitution methods.
Discussion
The Matcher class provides several methods for replacing just the text
that matched the pattern. In all these methods, you pass in the replacement text, or “righthand side,” of the substitution (this term is historical: in a command-line text editor’s substitute command, the lefthand side is the pattern and the righthand side is the replacement text). These are the replacement methods:
replaceAll(newString)-
Replaces all occurrences that matched with the new string
replaceFirst(newString)-
As above but only the first occurence
appendReplacement(StringBuffer, newString)-
Copies up to before the first match, plus the given
newString appendTail(StringBuffer)-
Appends text after the last match (normally used after
appendReplacement)
Despite their names, the replace* methods behave in accord with
the immutability of Strings (see “Timeless, Immutable, and Unchangeable”):
they create a new String object with the replacement performed; they do not
(indeed, could not) modify the string referred to in the Matcher object.
Example 4-3 shows use of these three methods.
Example 4-3. main/src/main/java/regex/ReplaceDemo.java
/*** Quick demo of RE substitution: correct U.S. 'favor'* to Canadian/British 'favour', but not in "favorite"* @author Ian F. Darwin, http://www.darwinsys.com/*/publicclassReplaceDemo{publicstaticvoidmain(String[]argv){// Make an RE pattern to match as a word only (\b=word boundary)Stringpatt="\\bfavor\\b";// A test inputStringinput="Do me a favor? Fetch my favorite.";System.out.println("Input: "+input);// Run it from a RE instance and see that it worksPatternr=Pattern.compile(patt);Matcherm=r.matcher(input);System.out.println("ReplaceAll: "+m.replaceAll("favour"));// Show the appendReplacement methodm.reset();StringBuffersb=newStringBuffer();System.out.("Append methods: ");while(m.find()){// Copy to before first match,// plus the word "favor"m.appendReplacement(sb,"favour");}m.appendTail(sb);// copy remainderSystem.out.println(sb.toString());}}
Sure enough, when you run it, it does what we expect:
Input: Do me a favor? Fetch my favorite. ReplaceAll: Do me a favour? Fetch my favorite. Append methods: Do me a favour? Fetch my favorite.
The replaceAll() method handles the case of making the same change
all through a string.
If you want to change each matching occurrence to a different value,
you can use replaceFirst() in a loop, as in Example 4-4.
Here we make a pass through an entire string, turning each occurrence
of either cat or dog into feline or canine.
This is simplified from a real example that looked for bit.ly URLs
and replaced them with the actual URL; the computeReplacement method
there used the network client code from Recipe 12.1.
Example 4-4. main/src/main/java/regex/ReplaceMulti.java
/*** To perform multiple distinct substitutions in the same String,* you need a loop, and must call reset() on the matcher.*/publicclassReplaceMulti{publicstaticvoidmain(String[]args){Patternpatt=Pattern.compile("cat|dog");Stringline="The cat and the dog never got along well.";System.out.println("Input: "+line);Matchermatcher=patt.matcher(line);while(matcher.find()){Stringfound=matcher.group(0);Stringreplacement=computeReplacement(found);line=matcher.replaceFirst(replacement);matcher.reset(line);}System.out.println("Final: "+line);}staticStringcomputeReplacement(Stringin){switch(in){case"cat":return"feline";case"dog":return"canine";default:return"animal";}}}
If you need to refer to portions of the occurrence that matched the regex,
you can mark them with extra parentheses in the pattern and
refer to the matching portion with $1, $2, and so on in the replacement
string.
Example 4-5 uses this to interchange two fields, in this case,
turn names in the form Firstname Lastname into Lastname, FirstName.
Example 4-5. main/src/main/java/regex/ReplaceDemo2.java
publicclassReplaceDemo2{publicstaticvoidmain(String[]argv){// Make an RE patternStringpatt="(\\w+)\\s+(\\w+)";// A test inputStringinput="Ian Darwin";System.out.println("Input: "+input);// Run it from a RE instance and see that it worksPatternr=Pattern.compile(patt);Matcherm=r.matcher(input);m.find();System.out.println("Replaced: "+m.replaceFirst("$2, $1"));// The short inline version:// System.out.println(input.replaceFirst("(\\w+)\\s+(\\w+)", "$2, $1"));}}
4.5 Printing All Occurrences of a Pattern
Solution
This example reads through a file one line at a time. Whenever a match is found, I extract it from the line and print it.
This code takes the group() methods from Recipe 4.3, the substring method from the CharacterIterator interface, and the match() method from the regex and simply puts them all together. I coded it to extract all the names from a given file; in running the program through itself, it prints the words import, java, until, regex, and so on, each on its own line:
C:\> java ReaderIter.java ReaderIter.java import java util regex import java io Print all the strings that match given pattern from file public ... C:\\>
I interrupted it here to save paper. This can be written two ways: a line-at-a-time pattern shown in Example 4-6 and a more compact form using new I/O shown in Example 4-7 (the new I/O package used in both examples is described in Chapter 10).
Example 4-6. main/src/main/java/regex/ReaderIter.java
publicclassReaderIter{publicstaticvoidmain(String[]args)throwsIOException{// The RE patternPatternpatt=Pattern.compile("[A-Za-z][a-z]+");// See the I/O chapter// For each line of input, try matching in it.Files.lines(Path.of(args[0])).forEach(line->{// For each match in the line, extract and print it.Matcherm=patt.matcher(line);while(m.find()){// Simplest method:// System.out.println(m.group(0));// Get the starting position of the textintstart=m.start(0);// Get ending positionintend=m.end(0);// Print whatever matched.// Use CharacterIterator.substring(offset, end);System.out.println(line.substring(start,end));}});}}
Example 4-7. main/src/main/java/regex/GrepNIO.java
publicclassGrepNIO{publicstaticvoidmain(String[]args)throwsIOException{if(args.length<2){System.err.println("Usage: GrepNIO patt file [...]");System.exit(1);}Patternp=Pattern.compile(args[0]);for(inti=1;i<args.length;i++)process(p,args[i]);}staticvoidprocess(Patternpattern,StringfileName)throwsIOException{// Get a FileChannel from the given fileFileInputStreamfis=newFileInputStream(fileName);FileChannelfc=fis.getChannel();// Map the file's contentByteBufferbuf=fc.map(FileChannel.MapMode.READ_ONLY,0,fc.size());// Decode ByteBuffer into CharBufferCharBuffercbuf=Charset.forName("ISO-8859-1").newDecoder().decode(buf);Matcherm=pattern.matcher(cbuf);while(m.find()){System.out.println(m.group(0));}fis.close();}}
The non-blocking I/O (NIO) version shown in Example 4-7 relies on the fact that an NIO Buffer can be used as a CharSequence. This program is more general in that the pattern argument is taken from the command-line argument. It prints the same output as the previous example if invoked with the pattern argument from the previous program on the command line:
java regex.GrepNIO "[A-Za-z][a-z]+" ReaderIter.java
You might think of using \w+ as the pattern; the only difference is that my pattern looks for well-formed capitalized words, whereas \w+ would include Java-centric oddities like theVariableName, which have capitals in nonstandard positions.
Also note that the NIO version will probably be more efficient because it doesn’t reset the Matcher to a new input source on each line of input as ReaderIter does.
4.6 Printing Lines Containing a Pattern
Solution
Write a simple grep-like program.
Discussion
As I’ve mentioned, once you have a regex package, you can write a grep-like program. I gave an example of the Unix grep program earlier. grep is called with some optional arguments, followed by one required regular expression pattern, followed by an arbitrary number of filenames. It prints any line that contains the pattern, differing from Recipe 4.5, which prints only the matching text itself. Here’s an example:
grep "[dD]arwin" *.txt
The code searches for lines containing either darwin or Darwin in every line of every file whose name ends in .txt.3 Example 4-8 is the source for the first version of a program to do this, called Grep0. It reads lines from the standard input and doesn’t take any optional arguments, but it handles the full set of regular expressions that the Pattern class implements (it is, therefore, not identical to the Unix programs of the same name). We haven’t covered the java.io package for input and output yet (see Chapter 10), but our use of it here is simple enough that you can probably intuit it. The online source includes Grep1, which does the same thing but is better structured (and therefore longer). Later in this chapter, Recipe 4.11 presents a JGrep program that parses a set of command-line options.
Example 4-8. main/src/main/java/regex/Grep0.java
publicclassGrep0{publicstaticvoidmain(String[]args)throwsIOException{BufferedReaderis=newBufferedReader(newInputStreamReader(System.in));if(args.length!=1){System.err.println("Usage: MatchLines pattern");System.exit(1);}Patternpatt=Pattern.compile(args[0]);Matchermatcher=patt.matcher("");Stringline=null;while((line=is.readLine())!=null){matcher.reset(line);if(matcher.find()){System.out.println("MATCH: "+line);}}}}
4.7 Controlling Case in Regular Expressions
Solution
Compile the Pattern passing in the flags argument Pattern.CASE_INSENSITIVE to indicate that matching should be case-independent (i.e., that it should fold, ignore differences in case). If your code might run in different locales (see
Recipe 3.12), then you should add Pattern.UNICODE_CASE. Without these flags, the default is normal, case-sensitive matching behavior. This flag (and others) are passed to the Pattern.compile() method, like this:
// regex/CaseMatch.java
Pattern reCaseInsens = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE |
Pattern.UNICODE_CASE);
reCaseInsens.matches(input); // will match case-insensitively
This flag must be passed when you create the Pattern; because Pattern objects are immutable, they cannot be changed once constructed.
The full source code for this example is online as CaseMatch.java.
4.8 Matching Accented, or Composite, Characters
Solution
Compile the Pattern with the flags argument Pattern.CANON_EQ for canonical equality.
Discussion
Composite characters can be entered in various forms. Consider, as a single example, the letter e with an acute accent. This character may be found in various forms in Unicode text, such as the single character é (Unicode character \u00e9) or the two-character sequence e´ (e followed by the Unicode combining acute accent, \u0301). To allow you to match such characters regardless of which of possibly multiple fully decomposed forms are used to enter them, the regex package has an option for canonical matching, which treats any of the forms as equivalent. This option is enabled by passing CANON_EQ as (one of) the flags in the second argument to Pattern.compile(). This program shows CANON_EQ being used to match several forms:
publicclassCanonEqDemo{publicstaticvoidmain(String[]args){StringpattStr="\u00e9gal";// egalString[]input={"\u00e9gal",// egal - this one had better match :-)"e\u0301gal",// e + "Combining acute accent""e\u02cagal",// e + "modifier letter acute accent""e'gal",// e + single quote"e\u00b4gal",// e + Latin-1 "acute"};Patternpattern=Pattern.compile(pattStr,Pattern.CANON_EQ);for(inti=0;i<input.length;i++){if(pattern.matcher(input[i]).matches()){System.out.println(pattStr+" matches input "+input[i]);}else{System.out.println(pattStr+" does not match input "+input[i]);}}}}
This program correctly matches the combining accent and rejects the other characters, some of which, unfortunately, look like the accent on a printer, but are not considered combining accent characters:
égal matches input égal égal matches input e?gal égal does not match input e?gal égal does not match input e'gal égal does not match input e´gal
For more details, see the character charts.
4.9 Matching Newlines in Text
Solution
Use \n or \r in your regex pattern. See also the flags constant Pattern.MULTILINE, which makes newlines match as beginning-of-line and end-of-line (\^ and $).
Discussion
Though line-oriented tools from Unix such as sed and grep match regular expressions one line at a time, not all tools do. The sam text editor from Bell Laboratories was the first interactive tool I know of to allow multiline regular expressions; the Perl scripting language followed shortly after. In the Java API, the newline character by default has no special significance. The BufferedReader method readLine() normally strips out whichever newline characters it finds. If you read in gobs of characters using some method other than readLine(), you may have some number of \n, \r, or \r\n sequences in your text string.4 Normally all of these are treated as equivalent to \n. If you want only \n to match, use the UNIX_LINES flag to the Pattern.compile() method.
In Unix, ^ and $ are commonly used to match the beginning or end of a line, respectively. In this API, the regex metacharacters \^ and $ ignore line terminators and only match at the beginning and the end, respectively, of the entire string. However, if you pass the MULTILINE flag into Pattern.compile(), these expressions match just after or just before, respectively, a line terminator; $ also matches the very end of the string. Because the line ending is just an ordinary character, you can match it with . or similar expressions; and, if you want to know exactly where it is, \n or \r in the pattern match it as well. In other words, to this API, a newline character is just another character with no special significance. See the sidebar “Pattern.compile() Flags”. An example of newline matching is shown in Example 4-9.
Example 4-9. main/src/main/java/regex/NLMatch.java
publicclassNLMatch{publicstaticvoidmain(String[]argv){Stringinput="I dream of engines\nmore engines, all day long";System.out.println("INPUT: "+input);System.out.println();String[]patt={"engines.more engines","ines\nmore","engines$"};for(inti=0;i<patt.length;i++){System.out.println("PATTERN "+patt[i]);booleanfound;Patternp1l=Pattern.compile(patt[i]);found=p1l.matcher(input).find();System.out.println("DEFAULT match "+found);Patternpml=Pattern.compile(patt[i],Pattern.DOTALL|Pattern.MULTILINE);found=pml.matcher(input).find();System.out.println("MultiLine match "+found);System.out.println();}}}
If you run this code, the first pattern (with the wildcard character .) always matches, whereas the second pattern (with $) matches only when MATCH_MULTILINE is set:
> java regex.NLMatch INPUT: I dream of engines more engines, all day long PATTERN engines more engines DEFAULT match true MULTILINE match: true PATTERN engines$ DEFAULT match false MULTILINE match: true
4.10 Program: Apache Logfile Parsing
The Apache web server is the world’s leading web server and has been for most of the web’s history. It is one of the world’s best-known open source projects, and it’s the first of many fostered by the Apache Foundation. The name Apache is often claimed to be a pun on the origins of the server; its developers began with the free NCSA server and kept hacking at it, or patching, it until it did what they wanted. When it was sufficiently different from the original, a new name was needed. Because it was now a patchy server, the name Apache was chosen. Officialdom denies the story, but it’s cute anyway. One place actual patchiness does show through is in the logfile format. Consider Example 4-10.
Example 4-10. Apache log file excerpt
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html HTTP/1.0" 200 10450 "-" "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
The file format was obviously designed for human inspection but not for easy parsing. The problem is that different delimiters are used: square brackets for the date, quotes for the request line, and spaces sprinkled all through. Consider trying to use a StringTokenizer; you might be able to get it working, but you’d spend a lot of time fiddling with it. Actually, no, you wouldn’t get it working. However, this somewhat contorted regular expression5 makes it easy to parse (this is one single Moby-sized regex; we had to break it over two lines to make it fit the book’s margins):
\^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) (\d+)
"([\^"]+)" "([\^"]+)"
You may find it informative to refer back to Table 4-1 and review the full syntax used here. Note in particular the use of the nongreedy quantifier +? in \"(.+?)\" to match a quoted string; you can’t just use .+ because that would match too much (up to the quote at the end of the line). Code to extract the various fields such as IP address, request, referrer URL, and browser version is shown in Example 4-11.
Example 4-11. main/src/main/java/regex/LogRegExp.java
publicclassLogRegExp{finalstaticStringlogEntryPattern="^([\\d.]+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+-]\\d{4})\\] "+"\"(.+?)\" (\\d{3}) (\\d+) \"([^\"]+)\" \"([^\"]+)\"";publicstaticvoidmain(Stringargv[]){System.out.println("RE Pattern:");System.out.println(logEntryPattern);System.out.println("Input line is:");StringlogEntryLine=LogParseInfo.LOG_ENTRY_LINE;System.out.println(logEntryLine);Patternp=Pattern.compile(logEntryPattern);Matchermatcher=p.matcher(logEntryLine);if(!matcher.matches()||LogParseInfo.MIN_FIELDS>matcher.groupCount()){System.err.println("Bad log entry (or problem with regex):");System.err.println(logEntryLine);return;}System.out.println("IP Address: "+matcher.group(1));System.out.println("UserName: "+matcher.group(3));System.out.println("Date/Time: "+matcher.group(4));System.out.println("Request: "+matcher.group(5));System.out.println("Response: "+matcher.group(6));System.out.println("Bytes Sent: "+matcher.group(7));if(!matcher.group(8).equals("-"))System.out.println("Referer: "+matcher.group(8));System.out.println("User-Agent: "+matcher.group(9));}}
The implements clause is for an interface that just defines the input string; it was used in a demonstration to compare the regular expression mode with the use of a StringTokenizer. The source for both versions is in the online source for this chapter. Running the program against the sample input from Example 4-10 gives this output:
Using regex Pattern:
\^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) (\d+) "([\^"]+)"
"([\^"]+)"
Input line is:
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html
HTTP/1.0" 200 10450 "-" "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
IP Address: 123.45.67.89
Date&Time: 27/Oct/2000:09:27:09 -0400
Request: GET /java/javaResources.html HTTP/1.0
Response: 200
Bytes Sent: 10450
Browser: Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)
The program successfully parsed the entire logfile format entry with one call to matcher.matches().
4.11 Program: Full Grep
Now that we’ve seen how the regular expressions package works, it’s time to write JGrep, a full-blown version of the line-matching program with option parsing. Table 4-2 lists some typical command-line options that a Unix implementation of grep might include. For those not familiar with grep, it is a command-line tool that searches for regular expressions in text files. There are three or four programs in the standard grep family, and several newer replacements such as ripgrep, or rg. This program is my addition to this family of programs.
| Option | Meaning |
|---|---|
-c |
Count only; don’t print lines, just count them |
-C |
Context; print some lines above and below each line that matches (not implemented in this version; left as an exercise for the reader) |
-f pattern |
Take pattern from file named after |
-h |
Suppress printing filename ahead of lines |
-i |
Ignore case |
-l |
List filenames only: don’t print lines, just the names they’re found in |
-n |
Print line numbers before matching lines |
-s |
Suppress printing certain error messages |
-v |
Invert: print only lines that do NOT match the pattern |
The Unix world features several getopt library routines for parsing
command-line arguments, so I have a reimplementation of this in Java.
As usual, because main() runs in a static context but our application main line does not, we could wind up passing a lot of information into the constructor.
To save space, this version just uses global variables to track the settings from the command line.
Unlike the Unix grep tool, this one does not yet handle combined options, so -l -r -i is OK,
but -lri will fail, due to a limitation in the GetOpt parser used.
The program basically just reads lines, matches the pattern in them, and, if a match is found (or not found, with -v), prints the line (and optionally some other stuff, too). Having said all that, the code is shown in Example 4-12.
Example 4-12. darwinsys-api/src/main/java/regex/JGrep.java
/** A command-line grep-like program. Accepts some command-line options,* and takes a pattern and a list of text files.* N.B. The current implementation of GetOpt does not allow combining short* arguments, so put spaces e.g., "JGrep -l -r -i pattern file..." is OK, but* "JGrep -lri pattern file..." will fail. Getopt will hopefully be fixed soon.*/publicclassJGrep{privatestaticfinalStringUSAGE="Usage: JGrep pattern [-chilrsnv][-f pattfile][filename...]";/** The pattern we're looking for */protectedPatternpattern;/** The matcher for this pattern */protectedMatchermatcher;privatebooleandebug;/** Are we to only count lines, instead of printing? */protectedstaticbooleancountOnly=false;/** Are we to ignore case? */protectedstaticbooleanignoreCase=false;/** Are we to suppress printing of filenames? */protectedstaticbooleandontPrintFileName=false;/** Are we to only list names of files that match? */protectedstaticbooleanlistOnly=false;/** Are we to print line numbers? */protectedstaticbooleannumbered=false;/** Are we to be silent about errors? */protectedstaticbooleansilent=false;/** Are we to print only lines that DONT match? */protectedstaticbooleaninVert=false;/** Are we to process arguments recursively if directories? */protectedstaticbooleanrecursive=false;/** Construct a Grep object for the pattern, and run it* on all input files listed in args.* Be aware that a few of the command-line options are not* acted upon in this version - left as an exercise for the reader!* @param args args*/publicstaticvoidmain(String[]args){if(args.length<1){System.err.println(USAGE);System.exit(1);}Stringpatt=null;GetOptgo=newGetOpt("cf:hilnrRsv");charc;while((c=go.getopt(args))!=0){switch(c){case'c':countOnly=true;break;case'f':/* External file contains the pattern */try(BufferedReaderb=newBufferedReader(newFileReader(go.optarg()))){patt=b.readLine();}catch(IOExceptione){System.err.println("Can't read pattern file "+go.optarg());System.exit(1);}break;case'h':dontPrintFileName=true;break;case'i':ignoreCase=true;break;case'l':listOnly=true;break;case'n':numbered=true;break;case'r':case'R':recursive=true;break;case's':silent=true;break;case'v':inVert=true;break;case'?':System.err.println("Getopts was not happy!");System.err.println(USAGE);break;}}intix=go.getOptInd();if(patt==null)patt=args[ix++];JGrepprog=null;try{prog=newJGrep(patt);}catch(PatternSyntaxExceptionex){System.err.println("RE Syntax error in "+patt);return;}if(args.length==ix){dontPrintFileName=true;// Don't print filenames if stdinif(recursive){System.err.println("Warning: recursive search of stdin!");}prog.process(newInputStreamReader(System.in),null);}else{if(!dontPrintFileName)dontPrintFileName=ix==args.length-1;// Nor if only one fileif(recursive)dontPrintFileName=false;// unless a directory!for(inti=ix;i<args.length;i++){// note starting indextry{prog.process(newFile(args[i]));}catch(Exceptione){System.err.println(e);}}}}/*** Construct a JGrep object.* @param patt The regex to look for* @throws PatternSyntaxException if pattern is not a valid regex*/publicJGrep(Stringpatt)throwsPatternSyntaxException{if(debug){System.err.printf("JGrep.JGrep(%s)%n",patt);}// compile the regular expressionintcaseMode=ignoreCase?Pattern.UNICODE_CASE|Pattern.CASE_INSENSITIVE:0;pattern=Pattern.compile(patt,caseMode);matcher=pattern.matcher("");}/** Process one command line argument (file or directory)* @param file The input File* @throws FileNotFoundException If the file doesn't exist*/publicvoidprocess(Filefile)throwsFileNotFoundException{if(!file.exists()||!file.canRead()){thrownewFileNotFoundException("Can't read file "+file.getAbsolutePath());}if(file.isFile()){process(newBufferedReader(newFileReader(file)),file.getAbsolutePath());return;}if(file.isDirectory()){if(!recursive){System.err.println("ERROR: -r not specified but directory given "+file.getAbsolutePath());return;}for(Filenf:file.listFiles()){process(nf);// "Recursion, n.: See Recursion."}return;}System.err.println("WEIRDNESS: neither file nor directory: "+file.getAbsolutePath());}/** Do the work of scanning one file* @param ifile Reader Reader object already open* @param fileName String Name of the input file*/publicvoidprocess(Readerifile,StringfileName){StringinputLine;intmatches=0;try(BufferedReaderreader=newBufferedReader(ifile)){while((inputLine=reader.readLine())!=null){matcher.reset(inputLine);if(matcher.find()){if(listOnly){// -l, print filename on first match, and we're doneSystem.out.println(fileName);return;}if(countOnly){matches++;}else{if(!dontPrintFileName){System.out.(fileName+": ");}System.out.println(inputLine);}}elseif(inVert){System.out.println(inputLine);}}if(countOnly)System.out.println(matches+" matches in "+fileName);}catch(IOExceptione){System.err.println(e);}}}
1 Non-Unix fans fear not, for you can use tools like grep on Windows systems using one of several packages. One is an open source package alternately called CygWin (after Cygnus Software) or GnuWin32. Another is Microsoft’s findstr command for Windows. Or you can use my Grep program in Recipe 4.6 if you don’t have grep on your system. Incidentally, the name grep comes from an ancient Unix line editor command g/RE/p, the command to find the regex globally in all lines in the edit buffer and print the lines that match—just what the grep program does to lines in files.
2 REDemo was inspired by (but does not use any code from) a similar program provided with the now-retired Apache Jakarta Regular Expressions package.
3 On Unix, the shell or command-line interpreter expands *.txt to all the matching filenames before running the program, but the normal Java interpreter does this for you on systems where the shell isn’t energetic or bright enough to do it.
4 Or a few related Unicode characters, including the next-line (\u0085), line-separator (\u2028), and paragraph-separator (\u2029) characters.
5 You might think this would hold some kind of world record for complexity in regex competitions, but I’m sure it’s been outdone many times.
Get Java Cookbook, 4th Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

