Capítulo 1. Introducción Introducción
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
El aprendizaje automático consiste en extraer conocimientos de los datos. Es un campo de investigación en la intersección de la estadística, la inteligencia artificial y la informática, y también se conoce como análisis predictivo o aprendizaje estadístico. En los últimos años, la aplicación de métodos de aprendizaje automático se ha hecho omnipresente en la vida cotidiana. Desde recomendaciones automáticas sobre qué películas ver, hasta qué comida pedir o qué productos comprar, pasando por la radio online personalizada y el reconocimiento de tus amigos en tus fotos, muchos sitios web y dispositivos modernos tienen algoritmos de aprendizaje automático en su núcleo. Cuando miras un sitio web complejo como Facebook, Amazon o Netflix, es muy probable que cada parte del sitio contenga múltiples modelos de aprendizaje automático.
Al margen de las aplicaciones comerciales, el aprendizaje automático ha influido enormemente en la forma en que se realiza hoy en día la investigación basada en datos. Las herramientas presentadas en este libro se han aplicado a diversos problemas científicos, como comprender las estrellas, encontrar planetas lejanos, descubrir nuevas partículas, analizar secuencias de ADN y proporcionar tratamientos personalizados contra el cáncer.
Sin embargo, no es necesario que tu aplicación sea a gran escala o cambie el mundo como estos ejemplos para beneficiarte del aprendizaje automático. En este capítulo, explicaremos por qué el aprendizaje automático se ha hecho tan popular, y discutiremos qué tipo de problema puede resolverse utilizando el aprendizaje automático. A continuación, te mostraremos cómo construir tu primer modelo de aprendizaje automático, introduciendo conceptos importantes por el camino.
1.1 ¿Por qué aprendizaje automático?
En los primeros tiempos de las aplicaciones "inteligentes", muchos sistemas utilizaban reglas codificadas a mano de decisiones "si" y "no" para procesar datos o ajustarse a las entradas del usuario. Piensa en un filtro de correo basura cuyo trabajo consiste en mover los mensajes de correo electrónico entrantes apropiados a una carpeta de correo basura. Podrías confeccionar una lista negra de palabras que harían que un correo electrónico se marcara como spam. Éste sería un ejemplo de uso de un sistema de reglas diseñado por expertos para diseñar una aplicación "inteligente". La elaboración manual de reglas de decisión es factible para algunas aplicaciones, sobre todo para aquellas en las que los humanos conocen bien el proceso que hay que modelar. Sin embargo, utilizar reglas codificadas a mano para tomar decisiones tiene dos grandes desventajas:
-
La lógica necesaria para tomar una decisión es específica de un único dominio y tarea. Cambiar la tarea, aunque sea ligeramente, puede requerir reescribir todo el sistema.
-
Diseñar reglas requiere una comprensión profunda de cómo debe tomar una decisión un experto humano.
Un ejemplo de dónde fallará este enfoque codificado a mano es en la detección de caras en imágenes. Hoy en día, cualquier smartphone puede detectar un rostro en una imagen. Sin embargo, la detección de rostros era un problema sin resolver hasta una fecha tan reciente como 2001. El principal problema es que la forma en que los píxeles (que componen una imagen en un ordenador) son "percibidos" por el ordenador es muy diferente de cómo los humanos percibimos un rostro. Esta diferencia de representación hace que sea básicamente imposible que un humano pueda llegar a un buen conjunto de reglas para describir lo que constituye una cara en una imagen digital.
Sin embargo, mediante el aprendizaje automático, basta con presentar a un programa una gran colección de imágenes de caras para que un algoritmo determine qué características son necesarias para identificar una cara.
1.1.1 Problemas que puede resolver el aprendizaje automático
Los tipos de algoritmos de aprendizaje automático que tienen más éxito son los que automatizan los procesos de toma de decisiones generalizando a partir de ejemplos conocidos. En este escenario, que se conoce como aprendizaje supervisado, el usuario proporciona al algoritmo pares de entradas y salidas deseadas, y el algoritmo encuentra la forma de producir la salida deseada dada una entrada. En concreto, el algoritmo es capaz de crear una salida para una entrada que nunca ha visto antes sin ayuda humana. Volviendo a nuestro ejemplo de la clasificación del spam, utilizando el aprendizaje automático, el usuario proporciona al algoritmo un gran número de correos electrónicos (que son la entrada), junto con información sobre si alguno de esos correos es spam (que es la salida deseada). Dado un nuevo correo electrónico, el algoritmo realizará una predicción sobre si el nuevo correo es spam.
Los algoritmos de aprendizaje automático que aprenden a partir de pares de entrada/salida se denominan algoritmos de aprendizaje supervisado porque un "maestro" proporciona supervisión a los algoritmos en forma de las salidas deseadas para cada ejemplo del que aprenden. Aunque crear un conjunto de datos de entradas y salidas suele ser un laborioso proceso manual, los algoritmos de aprendizaje supervisado se comprenden bien y su rendimiento es fácil de medir. Si tu aplicación puede formularse como un problema de aprendizaje supervisado, y eres capaz de crear un conjunto de datos que incluya el resultado deseado, es probable que el aprendizaje automático pueda resolver tu problema.
Algunos ejemplos de tareas de aprendizaje automático supervisado son
- Identificar el código postal a partir de los dígitos escritos a mano en un sobre
-
Aquí la entrada es un escaneo de la escritura, y la salida deseada son los dígitos reales del código postal. Para crear un conjunto de datos para construir un modelo de aprendizaje automático, necesitas recoger muchos sobres. Entonces podrás leer tú mismo los códigos postales y almacenar los dígitos como tus resultados deseados.
- Determinar si un tumor es benigno a partir de una imagen médica
-
Aquí la entrada es la imagen, y la salida es si el tumor es benigno. Para crear un conjunto de datos para construir un modelo, necesitas una base de datos de imágenes médicas. También necesitas la opinión de un experto, por lo que un médico tiene que ver todas las imágenes y decidir qué tumores son benignos y cuáles no. Incluso podría ser necesario hacer un diagnóstico adicional más allá del contenido de la imagen para determinar si el tumor de la imagen es canceroso o no.
- Detectar actividades fraudulentas en las transacciones con tarjeta de crédito
-
Aquí la entrada es un registro de la transacción con tarjeta de crédito, y la salida es si es probable que sea fraudulenta o no. Suponiendo que seas la entidad que distribuye las tarjetas de crédito, recopilar un conjunto de datos significa almacenar todas las transacciones y registrar si un usuario denuncia alguna transacción como fraudulenta.
Un aspecto interesante de estos ejemplos es que, aunque las entradas y salidas parecen bastante sencillas, el proceso de recogida de datos para estas tres tareas es muy diferente. Aunque la lectura de sobres es laboriosa, es fácil y barata. La obtención de imágenes y diagnósticos médicos, por otra parte, requiere no sólo maquinaria cara, sino también conocimientos expertos raros y costosos, por no mencionar los problemas éticos y de privacidad. En el ejemplo de la detección del fraude con tarjetas de crédito, la recogida de datos es mucho más sencilla. Tus clientes te proporcionarán los resultados deseados, ya que denunciarán el fraude. Todo lo que tienes que hacer para obtener los pares de entrada/salida de actividad fraudulenta y no fraudulenta es esperar.
Algoritmos no supervisados son el otro tipo de algoritmo que trataremos en este libro. En el aprendizaje no supervisado, sólo se conocen los datos de entrada, y no se dan datos de salida conocidos al algoritmo. Aunque hay muchas aplicaciones con éxito de estos métodos, suelen ser más difíciles de entender y evaluar. Algunos ejemplos de aprendizaje no supervisado son:
- Identificar temas en un conjunto de entradas de blog
-
Si tienes una gran colección de datos de texto, quizá quieras resumirla y encontrar temas predominantes en ella. Puede que no sepas de antemano cuáles son esos temas, ni cuántos temas puede haber. Por lo tanto, no hay resultados conocidos.
- Segmentar a los clientes en grupos con preferencias similares
-
Dado un conjunto de registros de clientes, puede que quieras identificar qué clientes son similares y si hay grupos de clientes con preferencias parecidas. Para un sitio de compras, podrían ser "padres", "ratones de biblioteca" o "jugadores". Como no sabes de antemano cuáles pueden ser estos grupos, ni siquiera cuántos hay, no tienes salidas conocidas.
- Detectar patrones de acceso anómalos a un sitio web
-
Para identificar abusos o fallos, suele ser útil encontrar patrones de acceso diferentes de la norma. Cada patrón anormal puede ser muy diferente, y puede que no tengas ningún caso registrado de comportamiento anormal. Como en este ejemplo sólo observas el tráfico y no sabes qué constituye un comportamiento normal y anormal, se trata de un problema no supervisado.
Para las tareas de aprendizaje supervisado y no supervisado, es importante tener una representación de tus datos de entrada que un ordenador pueda entender. A menudo es útil pensar en tus datos como en una tabla. Cada punto de datos sobre el que quieres razonar (cada correo electrónico, cada cliente, cada transacción) es una fila, y cada propiedad que describe ese punto de datos (digamos, la edad de un cliente o el importe o la ubicación de una transacción) es una columna. Podrías describir a los usuarios por su edad, su sexo, cuándo crearon una cuenta y con qué frecuencia han comprado en tu tienda online. Podrías describir la imagen de un tumor por los valores en escala de grises de cada píxel, o tal vez utilizando el tamaño, la forma y el color del tumor.
Cada entidad o fila aquí se conoce como muestra (o punto de datos) en el aprendizaje automático, mientras que las columnas -las propiedades que describen estas entidades- se denominan características.
Más adelante en este libro profundizaremos en el tema de la construcción de una buena representación de tus datos, lo que se denomina extracción de característicaso ingeniería de características. Sin embargo, debes tener en cuenta que ningún algoritmo de aprendizaje automático podrá hacer una predicción sobre datos de los que no tenga información. Por ejemplo, si la única característica que tienes de un paciente es su apellido, ningún algoritmo podrá predecir su sexo. Simplemente, esta información no está contenida en tus datos. Si añades otra característica que contenga el nombre de pila del paciente, tendrás mucha más suerte, ya que a menudo es posible saber el sexo por el nombre de pila de una persona.
1.1.2 Conocer tu tarea y conocer tus datos
Posiblemente la parte más importante del proceso de aprendizaje automático sea comprender los datos con los que trabajas y cómo se relacionan con la tarea que quieres resolver. No será eficaz elegir al azar un algoritmo y arrojarle tus datos. Es necesario comprender lo que ocurre en tu conjunto de datos antes de empezar a construir un modelo. Cada algoritmo es diferente en cuanto al tipo de datos y al escenario del problema para el que funciona mejor. Mientras construyes una solución de aprendizaje automático, debes responder, o al menos tener presentes, las siguientes preguntas:
-
¿Qué pregunta(s) intento responder? ¿Creo que los datos recogidos pueden responder a esa pregunta?
-
¿Cuál es la mejor manera de plantear mi(s) pregunta(s) como un problema de aprendizaje automático?
-
¿He recogido suficientes datos para representar el problema que quiero resolver?
-
¿Qué características de los datos he extraído, y permitirán hacer las predicciones correctas?
-
¿Cómo mediré el éxito de mi candidatura?
-
¿Cómo interactuará la solución de aprendizaje automático con otras partes de mi producto de investigación o empresarial?
En un contexto más amplio, los algoritmos y métodos del aprendizaje automático son sólo una parte de un proceso mayor para resolver un problema concreto, y es bueno tener siempre presente el panorama general. Muchas personas dedican mucho tiempo a construir soluciones complejas de aprendizaje automático, sólo para descubrir que no resuelven el problema adecuado.
Cuando nos adentramos en los aspectos técnicos del aprendizaje automático (como haremos en este libro), es fácil perder de vista los objetivos finales. Aunque no trataremos en detalle las cuestiones enumeradas aquí, te animamos a que tengas en cuenta todas las suposiciones que puedas estar haciendo, explícita o implícitamente, cuando empieces a construir modelos de aprendizaje automático.
1.2 ¿Por qué Python?
Python se ha convertido en la lingua franca de muchas aplicaciones de la ciencia de datos. Combina la potencia de los lenguajes de programación de propósito general con la facilidad de uso de los lenguajes de scripting de dominio específico como MATLAB o R. Python dispone de bibliotecas para la carga de datos, visualización, estadística, procesamiento del lenguaje natural, procesamiento de imágenes y mucho más. Esta amplia caja de herramientas proporciona a los científicos de datos una gran variedad de funciones de uso general y especial. Una de las principales ventajas de utilizar Python es la posibilidad de interactuar directamente con el código, utilizando un terminal u otras herramientas como el Jupyter Notebook, que veremos en breve. El aprendizaje automático y el análisis de datos son fundamentalmente procesos iterativos, en los que los datos impulsan el análisis. Es esencial para estos procesos disponer de herramientas que permitan una iteración rápida y una interacción sencilla.
Como lenguaje de programación de uso general, Python también permite crear complejas interfaces gráficas de usuario (GUI) y servicios web, así como integrarse en los sistemas existentes.
1.3 scikit-learn
scikit-learn
es un proyecto de código abierto, lo que significa que es libre de usar y distribuir, y cualquiera puede obtener fácilmente el código fuente para ver lo que ocurre entre bastidores. El proyecto scikit-learn se desarrolla y mejora constantemente, y cuenta con una comunidad de usuarios muy activa. Contiene una serie de algoritmos de aprendizaje automático de última generación, así como documentación exhaustiva sobre cada algoritmo. scikit-learn es una herramienta muy popular, y la biblioteca de Python más destacada para el aprendizaje automático. Se utiliza mucho en la industria y en el mundo académico, y hay disponibles en Internet gran cantidad de tutoriales y fragmentos de código. scikit-learn funciona bien con otras herramientas científicas de Python, de las que hablaremos más adelante en este capítulo.
Mientras lees esto, te recomendamos que consultes también laguía del usuario scikit-learn y la documentación de la API para obtener detalles adicionales y muchas más opciones para cada algoritmo. La documentación en línea es muy completa, y este libro te proporcionará todos los requisitos previos en aprendizaje automático para comprenderlo en detalle.
1.3.1 Instalación de scikit-learn
scikit-learn
depende de otros dos paquetes de Python, NumPy ySciPy. Para el trazado y el desarrollo interactivo, también debes instalar matplotlib, IPython y el Jupyter Notebook. Te recomendamos que utilices una de las siguientes distribuciones preempaquetadas de Python, que te proporcionarán los paquetes necesarios:
- Anaconda
-
Una distribución de Python hecha para el procesamiento de datos a gran escala, el análisis predictivo y la computación científica. Anaconda incluye NumPy, SciPy,
matplotlib,pandasIPython, Jupyter Notebook yscikit-learn. Disponible en Mac OS, Windows y Linux, es una solución muy cómoda y es la que sugerimos para las personas que no tienen instalados los paquetes científicos de Python. - Toldo Pensado
-
Otra distribución de Python para la informática científica. Viene con NumPy, SciPy,
matplotlib,pandas, e IPython, pero la versión gratuita no viene conscikit-learn. Si formas parte de una institución académica que otorga títulos, puedes solicitar una licencia académica y obtener acceso gratuito a la versión de pago de Enthought Canopy. Enthought Canopy está disponible para Python 2.7.x, y funciona en Mac OS, Windows y Linux. - Python(x,y)
-
Una distribución gratuita de Python para computación científica, específicamente para Windows. Python(x,y) viene con NumPy, SciPy,
matplotlib,pandas, IPython yscikit-learn.
Si ya tienes configurada una instalación de Python, puedes utilizar pip para instalar todos estos paquetes:
$ pip install numpy scipy matplotlib ipython scikit-learn pandas pillow
Para las visualizaciones de árboles del Capítulo 2, también necesitarás los paquetesgraphviz; consulta las instrucciones en el código adjunto. Para elCapítulo 7, también necesitarás las bibliotecas nltk y spacy; consulta las instrucciones de ese capítulo.
1.4 Bibliotecas y herramientas esenciales
Entender qué es scikit-learn y cómo se utiliza es importante, pero hay algunas otras bibliotecas que mejorarán tu experiencia.scikit-learn está construida sobre las bibliotecas científicas de Python NumPy y SciPy. Además de NumPy y SciPy, utilizaremos pandas ymatplotlib. También presentaremos el Jupyter Notebook, que es un entorno de programación interactivo basado en navegador. Brevemente, esto es lo que debes saber sobre estas herramientas para sacar el máximo partido ascikit-learn.1
1.4.1 Cuaderno Jupyter
Jupyter Notebook es un entorno interactivo para ejecutar código en el navegador. Es una gran herramienta para el análisis exploratorio de datos y es muy utilizada por los científicos de datos. Aunque el Jupyter Notebook admite muchos lenguajes de programación, nosotros sólo necesitamos el soporte para Python. El Cuaderno Jupyter facilita la incorporación de código, texto e imágenes, y todo este libro se escribió, de hecho, como un Cuaderno Jupyter. Todos los ejemplos de código que incluimos pueden descargarse dehttps://github.com/amueller/introduction_to_ml_with_python.
1.4.2 NumPy
NumPy es uno de los paquetes fundamentales para la informática científica en Python. Contiene funciones para matrices multidimensionales, funciones matemáticas de alto nivel, como operaciones de álgebra lineal y la transformada de Fourier, y generadores de números pseudoaleatorios.
En scikit-learn, la matriz NumPy es la estructura de datos fundamental.scikit-learn recibe datos en forma de matrices NumPy. Cualquier dato que utilices tendrá que convertirse en una matriz NumPy. La funcionalidad principal de NumPy es la clase ndarray, una matriz multidimensional(n-dimensional). Todos los elementos de la matriz deben ser del mismo tipo. Una matriz NumPy tiene este aspecto
In[1]:
importnumpyasnpx=np.array([[1,2,3],[4,5,6]])("x:\n{}".format(x))
Out[1]:
x: [[1 2 3] [4 5 6]]
En este libro utilizaremos mucho NumPy, y nos referiremos a los objetos de la clase NumPy ndarray como "matrices NumPy" o simplemente "matrices".
1.4.3 SciPy
SciPy es una colección de funciones para la computación científica en Python. Proporciona, entre otras funcionalidades, rutinas avanzadas de álgebra lineal, optimización de funciones matemáticas, procesamiento de señales, funciones matemáticas especiales y distribuciones estadísticas. scikit-learn
se basa en la colección de funciones de SciPy para implementar sus algoritmos. La parte más importante de SciPy para nosotros es scipy.sparse: proporciona matrices dispersas, que son otra representación que se utiliza para los datos en scikit-learn. Las matrices dispersas se utilizan siempre que queramos almacenar una matriz 2D que contenga mayoritariamente ceros:
In[2]:
fromscipyimportsparse# Create a 2D NumPy array with a diagonal of ones, and zeros everywhere elseeye=np.eye(4)("NumPy array:\n",eye)
Out[2]:
NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]]
In[3]:
# Convert the NumPy array to a SciPy sparse matrix in CSR format# Only the nonzero entries are storedsparse_matrix=sparse.csr_matrix(eye)("\nSciPy sparse CSR matrix:\n",sparse_matrix)
Out[3]:
SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0
Normalmente no es posible crear representaciones densas de datos dispersos (ya que no cabrían en la memoria), por lo que necesitamos crear representaciones dispersas directamente. Aquí tienes una forma de crear la misma matriz dispersa que antes, utilizando el formato COO:
In[4]:
data=np.ones(4)row_indices=np.arange(4)col_indices=np.arange(4)eye_coo=sparse.coo_matrix((data,(row_indices,col_indices)))("COO representation:\n",eye_coo)
Out[4]:
COO representation: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0
Puedes encontrar más detalles sobre las matrices dispersas de SciPy en las Notas de clase de SciPy.
1.4.4 matplotlib
matplotlib es la principal biblioteca de gráficos científicos de Python. Proporciona funciones para realizar visualizaciones con calidad de publicación, como gráficos de líneas, histogramas, diagramas de dispersión, etc. Visualizar tus datos y los distintos aspectos de tu análisis puede proporcionarte información importante, y utilizaremos matplotlib para todas nuestras visualizaciones. Cuando trabajes dentro de Jupyter Notebook, puedes mostrar figuras directamente en el navegador utilizando los comandos %matplotlib notebook y %matplotlib inline. Recomendamos utilizar %matplotlib notebook, que proporciona un entorno interactivo (aunque nosotros estamos utilizando %matplotlib inline para elaborar este libro). Por ejemplo, este código produce el gráfico de la Figura 1-1:
In[5]:
%matplotlibinlineimportmatplotlib.pyplotasplt# Generate a sequence of numbers from -10 to 10 with 100 steps in betweenx=np.linspace(-10,10,100)# Create a second array using siney=np.sin(x)# The plot function makes a line chart of one array against anotherplt.plot(x,y,marker="x")
Figura 1-1. Gráfico lineal simple de la función seno utilizando matplotlib
1.4.5 pandas
pandas
es una biblioteca de Python para la gestión y el análisis de datos. Está construida en torno a una estructura de datos llamada DataFrame que sigue el modelo de R DataFrame. En pocas palabras, una pandas DataFrame es una tabla, similar a una hoja de cálculo de Excel. pandas proporciona una gran variedad de métodos para modificar y operar sobre esta tabla; en particular, permite consultas y uniones de tablas similares a SQL. A diferencia de NumPy, que exige que todas las entradas de una matriz sean del mismo tipo, pandaspermite que cada columna tenga un tipo distinto (por ejemplo, enteros, fechas, números en coma flotante y cadenas). Otra valiosa herramienta que proporcionapandas es su capacidad de ingesta desde una gran variedad de formatos de archivo y bases de datos, como SQL, archivos Excel y archivos de valores separados por comas (CSV). Entrar en detalles sobre la funcionalidad de pandas está fuera del alcance de este libro. Sin embargo, Python for Data Analysis de Wes McKinney (O'Reilly, 2012) proporciona una guía estupenda. He aquí un pequeño ejemplo de creación de un DataFrame utilizando un diccionario:
In[6]:
importpandasaspd# create a simple dataset of peopledata={'Name':["John","Anna","Peter","Linda"],'Location':["New York","Paris","Berlin","London"],'Age':[24,13,53,33]}data_pandas=pd.DataFrame(data)# IPython.display allows "pretty printing" of dataframes# in the Jupyter notebookdisplay(data_pandas)
Esto produce el siguiente resultado:
| Edad | Ubicación | Nombre | |
|---|---|---|---|
0 |
24 |
Nueva York |
John |
1 |
13 |
París |
Anna |
2 |
53 |
Berlín |
Peter |
3 |
33 |
Londres |
Linda |
Hay varias formas posibles de consultar esta tabla. Por ejemplo
In[7]:
# Select all rows that have an age column greater than 30display(data_pandas[data_pandas.Age>30])
Esto produce el siguiente resultado:
| Edad | Ubicación | Nombre | |
|---|---|---|---|
2 |
53 |
Berlín |
Peter |
3 |
33 |
Londres |
Linda |
1.4.6 mglearn
Este libro viene con un código adjunto, que puedes encontrar enhttps://github.com/amueller/introduction_to_ml_with_python. El código adjunto incluye no sólo todos los ejemplos mostrados en este libro, sino también la biblioteca mglearn. Se trata de una biblioteca de funciones de utilidad que escribimos para este libro, para no saturar nuestros listados de código con detalles sobre el trazado y la carga de datos. Si te interesa, puedes consultar todas las funciones en el repositorio, pero los detalles del módulo mglearnno son realmente importantes para el material de este libro. Si ves una llamada a mglearn en el código, suele ser una forma de hacer una imagen bonita rápidamente, o de poner nuestras manos sobre algunos datos interesantes. Si ejecutas los cuadernos publicados en GitHub, el paquete mglearn ya estará en el lugar adecuado y no tendrás que preocuparte por él. Si quieres llamar a las funciones de mglearn desde cualquier otro lugar, la forma más sencilla de instalarlo es llamando a pip install mglearn .
Nota
A lo largo del libro hacemos un amplio uso de NumPy, matplotlib ypandas. Todo el código asumirá las siguientes importaciones:
import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn from IPython.display import display
También suponemos que ejecutarás el código en un cuaderno Jupyter con las magias%matplotlib notebook o %matplotlib inline activadas para mostrar gráficos. Si no utilizas el cuaderno o estos comandos mágicos, tendrás que llamar a plt.show para mostrar realmente cualquiera de las figuras.
1.5 Python 2 frente a Python 3
Hay dos versiones principales de Python que se utilizan ampliamente en la actualidad: Python 2 (más concretamente, 2.7) y Python 3 (siendo la última versión la 3.7 en el momento de escribir estas líneas). Esto a veces lleva a cierta confusión. Python 2 ya no se desarrolla activamente, pero como Python 3 contiene cambios importantes, el código de Python 2 normalmente no funciona en Python 3. Si eres nuevo en Python, o estás empezando un nuevo proyecto desde cero, te recomendamos encarecidamente que utilices la última versión de Python 3. Si tienes una gran base de código en la que confías y que está escrita para Python 2, por ahora estás exento de actualizarte. Sin embargo, deberías intentar migrar a Python 3 lo antes posible. Al escribir cualquier código nuevo, en su mayor parte es bastante fácil escribir código que funcione con Python 2 y Python 3.2 Si no tienes que interactuar con software heredado, definitivamente deberías utilizar Python 3. Todo el código de este libro está escrito de forma que funcione con ambas versiones. Sin embargo, la salida exacta puede diferir ligeramente bajo Python 2. También debes tener en cuenta que muchos paquetes como matplotlib, numpy, y scikit-learn ya no lanzan nuevas características bajo Python 2.7; necesitas actualizarte a Python 3.7 para beneficiarte de las mejoras que vienen con las versiones más nuevas.
1.6 Versiones utilizadas en este libro
En este libro utilizamos las siguientes versiones de las bibliotecas mencionadas anteriormente:
In[8]:
importsys("Python version:",sys.version)importpandasaspd("pandas version:",pd.__version__)importmatplotlib("matplotlib version:",matplotlib.__version__)importnumpyasnp("NumPy version:",np.__version__)importscipyassp("SciPy version:",sp.__version__)importIPython("IPython version:",IPython.__version__)importsklearn("scikit-learn version:",sklearn.__version__)
Out[8]:
Python version: 3.7.0 (default, Jun 28 2018, 13:15:42) [GCC 7.2.0] pandas version: 0.23.4 matplotlib version: 3.0.0 NumPy version: 1.15.2 SciPy version: 1.1.0 IPython version: 6.4.0 scikit-learn version: 0.20.0
Aunque no es importante que estas versiones coincidan exactamente, debes tener una versión de scikit-learn que sea al menos tan reciente como la que hemos utilizado nosotros.
Nota
Cuando utilices el código de este libro, es posible que a veces veasavisos DeprecationWarningso FutureWarningsde scikit-learn. Éstos te informan sobre comportamientos de scikit-learn que cambiarán en el futuro o serán eliminados. Mientras estés leyendo este libro, puedes ignorarlos sin problemas. Si estás ejecutando un algoritmo de aprendizaje automático en producción, debes considerar detenidamente cada advertencia, ya que podrían informarte de que se eliminará una funcionalidad en el futuro o de que cambiarán los resultados de las predicciones.
Ahora que lo tenemos todo preparado, vamos a sumergirnos en nuestra primera aplicación del aprendizaje automático.
1.7 Una primera aplicación: La clasificación de las especies de lirios
En esta sección, recorreremos una sencilla aplicación de aprendizaje automático y crearemos nuestro primer modelo. En el proceso, introduciremos algunos conceptos y términos básicos.
Supongamos que una botánica aficionada está interesada en distinguir la especie de unas flores de iris que ha encontrado. Ha recogido algunas medidas asociadas a cada iris: la longitud y la anchura de los pétalos y la longitud y la anchura de los sépalos, todas ellas medidas en centímetros (véase la Figura 1-2).
También tiene las medidas de algunos iris que un botánico experto ha identificado previamente como pertenecientes a las especies setosa,versicolor o virginica. Con estas medidas, puede estar segura de a qué especie pertenece cada iris. Supongamos que éstas son las únicas especies que nuestro botánico aficionado encontrará en la naturaleza.
Nuestro objetivo es construir un modelo de aprendizaje automático que pueda aprender de las mediciones de estos iris cuya especie se conoce, de modo que podamos predecir la especie de un nuevo iris.
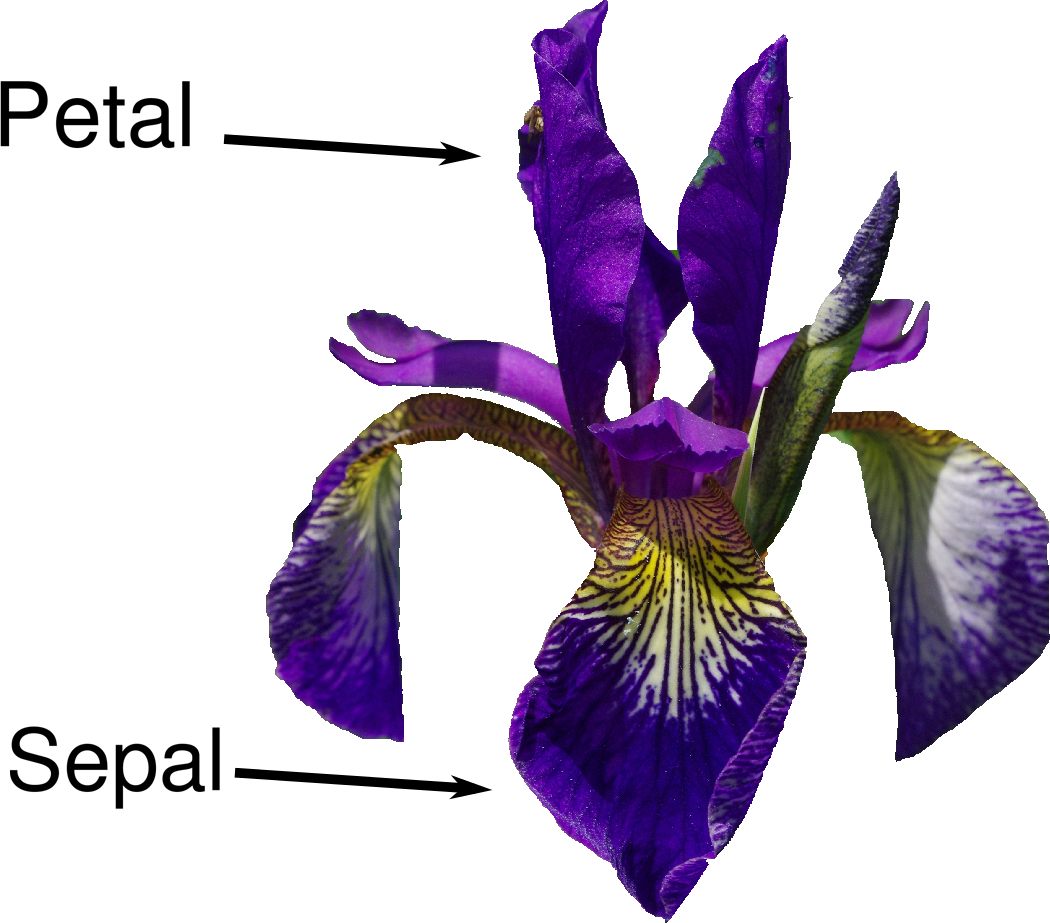
Figura 1-2. Partes de la flor del iris
Como tenemos mediciones para las que conocemos la especie correcta de iris, se trata de un problema de aprendizaje supervisado. En este problema, queremos predecir una de varias opciones (la especie de iris). Es un ejemplo de problema de clasificación. Las posibles salidas (distintas especies de iris) se denominan clases. Cada iris del conjunto de datos pertenece a una de las tres clases, por lo que este problema es un problema de clasificación de tres clases.
La salida deseada para un único punto de datos (un iris) es la especie de esta flor. Para un punto de datos concreto, la especie a la que pertenece se llama su etiqueta.
1.7.1 Conoce los Datos
Los datos que utilizaremos para este ejemplo son el conjunto de datos Iris, un conjunto de datos clásico en el aprendizaje automático y la estadística. Está incluido enscikit-learn en el módulo dataset. Podemos cargarlo llamando a la funciónload_iris:
In[9]:
fromsklearn.datasetsimportload_irisiris_dataset=load_iris()
El objeto iris que devuelve load_iris es un objeto Bunch, que es muy similar a un diccionario. Contiene claves y valores:
In[10]:
("Keys of iris_dataset:\n",iris_dataset.keys())
Out[10]:
Keys of iris_dataset: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
El valor de la clave DESCR es una breve descripción del conjunto de datos. Aquí mostramos el principio de la descripción (puedes buscar el resto tú mismo):
In[11]:
(iris_dataset['DESCR'][:193]+"\n...")
Out[11]:
Iris Plants Database
====================
Notes
----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive att
...
----
El valor de la clave target_names es una matriz de cadenas, que contiene la especie de flor que queremos predecir:
In[12]:
("Target names:",iris_dataset['target_names'])
Out[12]:
Target names: ['setosa' 'versicolor' 'virginica']
El valor de feature_names es una lista de cadenas con la descripción de cada característica:
In[13]:
("Feature names:\n",iris_dataset['feature_names'])
Out[13]:
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Los datos propiamente dichos están contenidos en los campos target y data. data
contiene las medidas numéricas de la longitud del sépalo, la anchura del sépalo, la longitud del pétalo y la anchura del pétalo en una matriz NumPy:
In[14]:
("Type of data:",type(iris_dataset['data']))
Out[14]:
Type of data: <class 'numpy.ndarray'>
Las filas de la matriz data corresponden a flores, mientras que las columnas representan las cuatro mediciones que se tomaron para cada flor:
In[15]:
("Shape of data:",iris_dataset['data'].shape)
Out[15]:
Shape of data: (150, 4)
Vemos que la matriz contiene mediciones de 150 flores diferentes. Recuerda que los elementos individuales se llaman muestras en el aprendizaje automático, y sus propiedades se llaman características. La forma de la matrizdata es el número de muestras multiplicado por el número de características. Esto es una convención en scikit-learn, y siempre se asumirá que tus datos tienen esta forma. Aquí tienes los valores de las características de las cinco primeras muestras:
In[16]:
("First five rows of data:\n",iris_dataset['data'][:5])
Out[16]:
First five rows of data: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]]
A partir de estos datos, podemos ver que las cinco primeras flores tienen una anchura de pétalo de 0,2 cm y que la primera flor tiene el sépalo más largo, de 5,1 cm.
La matriz target contiene la especie de cada una de las flores que se midieron, también como matriz NumPy:
In[17]:
("Type of target:",type(iris_dataset['target']))
Out[17]:
Type of target: <class 'numpy.ndarray'>
target es una matriz unidimensional, con una entrada por flor:
In[18]:
("Shape of target:",iris_dataset['target'].shape)
Out[18]:
Shape of target: (150,)
Las especies se codifican como números enteros de 0 a 2:
In[19]:
("Target:\n",iris_dataset['target'])
Out[19]:
Target: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
El significado de los números viene dado por la matriz iris['target_names']: 0 significa setosa, 1 significa versicolor y 2 significa virginica.
1.7.2 Medir el éxito: Datos de entrenamiento y prueba
Queremos construir un modelo de aprendizaje automático a partir de estos datos que pueda predecir la especie de iris para un nuevo conjunto de mediciones. Pero antes de poder aplicar nuestro modelo a nuevas mediciones, necesitamos saber si realmente funciona, es decir, si debemos confiar en sus predicciones.
Por desgracia, no podemos utilizar los datos que utilizamos para construir el modelo para evaluarlo. Esto se debe a que nuestro modelo siempre puede simplemente recordar todo el conjunto de entrenamiento, y por tanto siempre predecirá la etiqueta correcta para cualquier punto del conjunto de entrenamiento. Este "recordar" no nos indica si nuestro modelo generalizará bien (en otras palabras, si también funcionará bien con datos nuevos).
Para evaluar el rendimiento del modelo, le mostramos datos nuevos (datos que no ha visto antes) para los que tenemos etiquetas. Esto suele hacerse dividiendo los datos etiquetados que hemos recopilado (en este caso, nuestras 150 mediciones de flores) en dos partes. Una parte de los datos se utiliza para construir nuestro modelo de aprendizaje automático, y se denomina datos de entrenamiento o conjunto de entrenamiento. El resto de los datos se utilizará para evaluar lo bien que funciona el modelo; se denominan datos de prueba, conjunto de prueba o conjunto de espera.
scikit-learn
contiene una función que baraja el conjunto de datos y lo divide por ti: la función train_test_split. Esta función extrae el 75% de las filas de los datos como conjunto de entrenamiento, junto con las etiquetas correspondientes a estos datos. El 25% restante de los datos, junto con las etiquetas restantes, se declara como conjunto de prueba. Decidir cuántos datos quieres poner en el conjunto de entrenamiento y en el de prueba respectivamente es algo arbitrario, pero utilizar un conjunto de prueba que contenga el 25% de los datos es una buena regla general.
En scikit-learn, los datos se suelen denotar con una mayúscula X, mientras que las etiquetas se denotan con una minúscula y. Esto se inspira en la formulación estándar f(x)=y de las matemáticas, donde xes la entrada de una función e y es la salida. Siguiendo más convenciones de las matemáticas, utilizamos una X mayúscula porque los datos son una matriz bidimensional (una matriz) y una y minúscula porque el objetivo es una matriz unidimensional (un vector).
Llamemos a train_test_split sobre nuestros datos y asignemos las salidas utilizando esta nomenclatura:
In[20]:
fromsklearn.model_selectionimporttrain_test_splitX_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
Antes de realizar la división, la función train_test_split baraja el conjunto de datos utilizando un generador de números pseudoaleatorios. Si sólo tomáramos el último 25% de los datos como conjunto de prueba, todos los puntos de datos tendrían la etiqueta2, ya que los puntos de datos están ordenados por la etiqueta (véase la salida deiris['target'] mostrada anteriormente). Utilizar un conjunto de prueba que sólo contenga una de las tres clases no nos diría mucho sobre lo bien que generaliza nuestro modelo, así que barajamos nuestros datos para asegurarnos de que los datos de prueba contienen datos de todas las clases.
Para asegurarnos de que obtendremos el mismo resultado si ejecutamos la misma función varias veces, proporcionamos al generador de números pseudoaleatorios una semilla fija utilizando el parámetro random_state. Esto hará que el resultado sea determinista, por lo que esta línea tendrá siempre el mismo resultado. Esto hará que el resultado sea determinista, por lo que esta línea siempre tendrá el mismo resultado. Siempre fijaremos el random_state de esta forma cuando utilicemos procedimientos aleatorios en este libro.
La salida de la función train_test_split es X_train, X_test,y_train, y y_test, que son todas matrices NumPy. X_train contiene el 75% de las filas del conjunto de datos, y X_test contiene el 25% restante:
In[21]:
("X_train shape:",X_train.shape)("y_train shape:",y_train.shape)
Out[21]:
X_train shape: (112, 4) y_train shape: (112,)
In[22]:
("X_test shape:",X_test.shape)("y_test shape:",y_test.shape)
Out[22]:
X_test shape: (38, 4) y_test shape: (38,)
1.7.3 Lo primero es lo primero: Mira tus datos
Antes de construir un modelo de aprendizaje automático, suele ser buena idea inspeccionar los datos, para ver si la tarea se puede resolver fácilmente sin aprendizaje automático, o si la información deseada podría no estar contenida en los datos.
Además, inspeccionar tus datos es una buena forma de encontrar anomalías y peculiaridades. Quizá algunos de tus iris se midieron utilizando pulgadas y no centímetros, por ejemplo. En el mundo real, las incoherencias en los datos y las mediciones inesperadas son muy comunes.
Una de las mejores formas de inspeccionar los datos es visualizarlos. Una forma de hacerlo es utilizando un gráfico de dispersión. Un gráfico de dispersión de los datos coloca una característica a lo largo del eje x y otra a lo largo del eje y, y dibuja un punto para cada punto de datos. Por desgracia, las pantallas de ordenador sólo tienen dos dimensiones, lo que nos permite trazar sólo dos (o quizá tres) características a la vez. De este modo, es difícil representar conjuntos de datos con más de tres características. Una forma de evitar este problema es hacer un gráfico de pares, que examina todos los pares posibles de características. Si tienes un número pequeño de características, como las cuatro que tenemos aquí, esto es bastante razonable. Sin embargo, debes tener en cuenta que un gráfico de pares no muestra la interacción de todas las características a la vez, por lo que algunos aspectos interesantes de los datos pueden no revelarse al visualizarlos de esta forma.
La figura 1-3 es un gráfico de pares de las características del conjunto de entrenamiento. Los puntos de datos están coloreados según la especie a la que pertenece el iris. Para crear el gráfico, primero convertimos la matriz NumPy en una matriz pandas DataFrame .pandas tiene una función para crear gráficos de pares llamada scatter_matrix. La diagonal de esta matriz se rellena con histogramas de cada característica:
In[23]:
# create dataframe from data in X_train# label the columns using the strings in iris_dataset.feature_namesiris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)# create a scatter matrix from the dataframe, color by y_trainpd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=.8,cmap=mglearn.cm3)
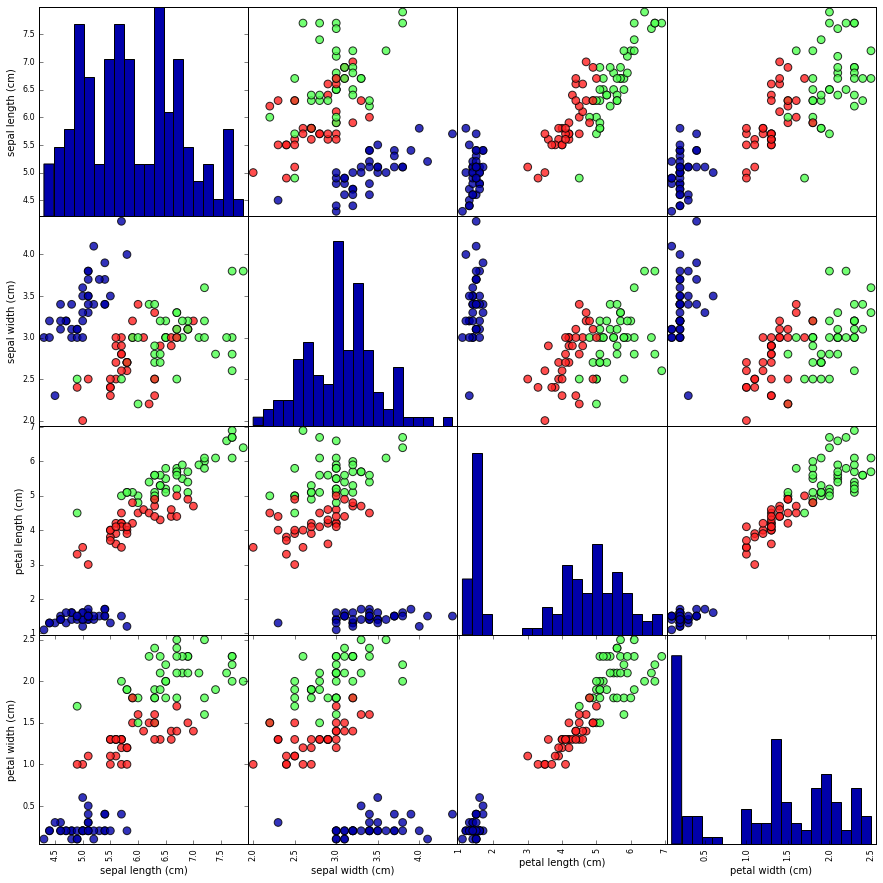
Figura 1-3. Diagrama de pares del conjunto de datos Iris, coloreado según la etiqueta de clase
A partir de los gráficos, podemos ver que las tres clases parecen estar relativamente bien separadas utilizando las medidas de los sépalos y los pétalos. Esto significa que es probable que un modelo de aprendizaje automático pueda aprender a separarlas.
1.7.4 Construir tu primer modelo: Vecinos más próximos k
Ahora podemos empezar a construir el modelo real de aprendizaje automático. Hay muchos algoritmos de clasificación en scikit-learn que podríamos utilizar. Aquí utilizaremos un clasificador k-vecinos más cercanos, que es fácil de entender. Construir este modelo sólo consiste en almacenar el conjunto de entrenamiento. Para hacer una predicción de un nuevo punto de datos, el algoritmo encuentra el punto del conjunto de entrenamiento más cercano al nuevo punto. A continuación, asigna la etiqueta de este punto de entrenamiento al nuevo punto de datos.
La k en k-vecinos más cercanos significa que, en lugar de utilizar sólo al vecino más cercano al nuevo punto de datos, podemos considerar cualquier número fijo k de vecinos en el entrenamiento (por ejemplo, los tres o cinco vecinos más cercanos). Entonces, podemos hacer una predicción utilizando la clase mayoritaria entre estos vecinos. Entraremos en más detalles sobre esto enel Capítulo 2; por ahora, sólo utilizaremos un único vecino.
Todos los modelos de aprendizaje automático de scikit-learn se implementan en sus propias clases, que se denominan clases Estimator. El algoritmo de clasificación k-próximos más cercanos se implementa en la claseKNeighborsClassifier del módulo neighbors. Antes de poder utilizar el modelo, debemos instanciar la clase en un objeto. Es entonces cuando estableceremos los parámetros del modelo. El parámetro más importante de KNeighborsClassifier es el número de vecinos, que fijaremos en 1:
In[24]:
fromsklearn.neighborsimportKNeighborsClassifierknn=KNeighborsClassifier(n_neighbors=1)
El objeto knn encapsula el algoritmo que se utilizará para construir el modelo a partir de los datos de entrenamiento, así como el algoritmo para hacer predicciones sobre nuevos puntos de datos. También contendrá la información que el algoritmo haya extraído de los datos de entrenamiento. En el caso deKNeighborsClassifier, sólo almacenará el conjunto de entrenamiento.
Para construir el modelo sobre el conjunto de entrenamiento, llamamos al método fit del objetoknn, que toma como argumentos la matriz NumPy X_trainque contiene los datos de entrenamiento y la matriz NumPy y_train de las etiquetas de entrenamiento correspondientes:
In[25]:
knn.fit(X_train,y_train)
Out[25]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')
El método fit devuelve el propio objeto knn (y lo modifica en su lugar), por lo que obtenemos una representación en forma de cadena de nuestro clasificador. La representación nos muestra qué parámetros se utilizaron al crear el modelo. Casi todos ellos son los valores por defecto, pero también puedes encontrarn_neighbors=1, que es el parámetro que pasamos. La mayoría de los modelos enscikit-learn tienen muchos parámetros, pero la mayoría de ellos son optimizaciones de velocidad o para casos de uso muy especiales. No tienes que preocuparte de los demás parámetros que se muestran en esta representación. Imprimir un modelo scikit-learn puede dar lugar a cadenas muy largas, pero no te dejes intimidar por ellas. Cubriremos todos los parámetros importantes enel Capítulo 2. En el resto de este libro, normalmente no mostraremos la salida de fit porque no contiene ninguna información nueva.
1.7.5 Hacer predicciones
Ahora podemos hacer predicciones utilizando este modelo sobre nuevos datos para los que quizá no conozcamos las etiquetas correctas. Imagina que encontramos un iris en estado salvaje con una longitud de sépalo de 5 cm, una anchura de sépalo de 2,9 cm, una longitud de pétalo de 1 cm y una anchura de pétalo de 0,2 cm. ¿Qué especie de iris sería? Podemos introducir estos datos en una matriz NumPy, calculando de nuevo la forma, es decir, el número de muestras (1) multiplicado por el número de características (4):
In[26]:
X_new=np.array([[5,2.9,1,0.2]])("X_new.shape:",X_new.shape)
Out[26]:
X_new.shape: (1, 4)
Observa que hemos convertido las medidas de esta única flor en una fila de una matriz NumPy bidimensional, ya que scikit-learn siempre espera matrices bidimensionales para los datos.
Para hacer una predicción, llamamos al método predict del objeto knn:
In[27]:
prediction=knn.predict(X_new)("Prediction:",prediction)("Predicted target name:",iris_dataset['target_names'][prediction])
Out[27]:
Prediction: [0] Predicted target name: ['setosa']
Nuestro modelo predice que este nuevo iris pertenece a la clase 0, lo que significa que su especie es setosa. Pero ¿cómo sabemos si podemos fiarnos de nuestro modelo? No sabemos cuál es la especie correcta de esta muestra, ¡que es el objetivo de construir el modelo!
1.7.6 Evaluar el modelo
Aquí es donde entra en juego el conjunto de prueba que creamos anteriormente. Estos datos no se utilizaron para construir el modelo, pero sabemos cuál es la especie correcta para cada iris del conjunto de prueba.
Por tanto, podemos hacer una predicción para cada iris de los datos de prueba y compararla con su etiqueta (la especie conocida). Podemos medir lo bien que funciona el modelo calculando la precisión, que es la fracción de flores para las que se predijo la especie correcta:
In[28]:
y_pred=knn.predict(X_test)("Test set predictions:\n",y_pred)
Out[28]:
Test set predictions: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]
In[29]:
("Test set score: {:.2f}".format(np.mean(y_pred==y_test)))
Out[29]:
Test set score: 0.97
También podemos utilizar el método score del objeto knn, que calculará por nosotros la precisión del conjunto de pruebas:
In[30]:
("Test set score: {:.2f}".format(knn.score(X_test,y_test)))
Out[30]:
Test set score: 0.97
Para este modelo, la precisión del conjunto de pruebas es de aproximadamente 0,97, lo que significa que hicimos la predicción correcta para el 97% de los iris del conjunto de pruebas. Con algunas suposiciones matemáticas, esto significa que podemos esperar que nuestro modelo acierte el 97% de las veces para los nuevos lirios. Para nuestra aplicación de botánico aficionado, este alto nivel de precisión significa que nuestro modelo puede ser lo suficientemente fiable como para utilizarlo. En capítulos posteriores hablaremos de cómo podemos mejorar el rendimiento y de las advertencias que hay que tener en cuenta al ajustar un modelo.
1.8 Resumen y perspectivas
Resumamos lo que hemos aprendido en este capítulo. Empezamos con una breve introducción al aprendizaje automático y sus aplicaciones, luego discutimos la distinción entre aprendizaje supervisado y no supervisado y dimos una visión general de las herramientas que utilizaremos en este libro. A continuación, formulamos la tarea de predecir a qué especie de iris pertenece una flor concreta utilizando medidas físicas de la flor. Para construir nuestro modelo, utilizamos un conjunto de datos de mediciones anotadas por un experto con la especie correcta, lo que lo convierte en una tarea de aprendizaje supervisado. Había tres especies posibles, setosa, versicolor o virginica, lo que convirtió la tarea en un problema de clasificación de tres clases. Las especies posibles se denominan clases en el problema de clasificación, y la especie de un único iris se denomina su etiqueta.
El conjunto de datos Iris consta de dos matrices NumPy: una que contiene los datos, que se denomina X en scikit-learn, y otra que contiene las salidas correctas o deseadas, que se denomina y. La matriz X es una matriz bidimensional de características, con una fila por punto de datos y una columna por característica. La matriz y es una matriz unidimensional, que aquí contiene una etiqueta de clase, un número entero comprendido entre 0 y 2, para cada una de las muestras.
Dividimos nuestro conjunto de datos en un conjuntode entrenamiento, para construir nuestro modelo, y unconjunto de prueba, para evaluar lo bien que nuestro modelo generalizará a datos nuevos, no vistos previamente.
Elegimos el algoritmo de clasificación k-vecinos más cercanos, que hace predicciones para un nuevo punto de datos teniendo en cuenta su(s) vecino(s) más cercano(s) en el conjunto de entrenamiento. Esto se implementa en la clase KNeighborsClassifier, que contiene el algoritmo que construye el modelo, así como el algoritmo que hace una predicción utilizando el modelo. Instanciamos la clase, estableciendo los parámetros. Luego construimos el modelo llamando al métodofit, pasando los datos de entrenamiento (X_train) y los resultados del entrenamiento (y_train) como parámetros. Evaluamos el modelo utilizando el método score, que calcula la precisión del modelo. Aplicamos el método scorea los datos del conjunto de pruebas y a las etiquetas del conjunto de pruebas, y descubrimos que nuestro modelo tiene una precisión aproximada del 97%, lo que significa que acierta el 97% de las veces en el conjunto de pruebas.
Esto nos dio confianza para aplicar el modelo a nuevos datos (en nuestro ejemplo, nuevas mediciones de flores) y confiar en que el modelo sería correcto aproximadamente el 97% de las veces.
Aquí tienes un resumen del código necesario para todo el procedimiento de entrenamiento y evaluación:
In[31]:
X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)knn=KNeighborsClassifier(n_neighbors=1)knn.fit(X_train,y_train)("Test set score: {:.2f}".format(knn.score(X_test,y_test)))
Out[31]:
Test set score: 0.97
Este fragmento contiene el código central para aplicar cualquier algoritmo de aprendizaje automático utilizando scikit-learn. Los métodos fit, predict y scoreson la interfaz común a los modelos supervisados en scikit-learn, y con los conceptos introducidos en este capítulo, puedes aplicar estos modelos a muchas tareas de aprendizaje automático. En el próximo capítulo, profundizaremos en los distintos tipos de modelos supervisados descikit-learn y en cómo aplicarlos con éxito.
1 Si no estás familiarizado con NumPy o matplotlib, te recomendamos que leas el primer capítulo de las SciPy Lecture Notes.
2 El paquetesix puede ser muy útil para ello.
Get Introducción al Aprendizaje Automático con Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

