Capítulo 4. Construir y ejecutar
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com

Nos deleitamos con la belleza de la mariposa, pero rara vez admitimos los cambios que ha sufrido para alcanzar esa belleza.
Maya Angelou
Construir y distribuir sistemas de software es complicado y caro: escribir código, compilarlo, probarlo, distribuirlo a un repositorio o a un entorno de preparación, y luego distribuirlo a producción para que lo consuman los usuarios finales. ¿Promover la resiliencia durante esas actividades no aumentará esa complejidad y esos gastos? En una palabra, no. Construir y entregar sistemas resistentes a los ataques no requiere conocimientos especiales de seguridad, y la mayor parte de lo que hace que un software sea "seguro" coincide también con lo que hace que un software sea de "alta calidad".
Como descubriremos en este capítulo, si podemos movernos con rapidez, sustituir con facilidad y apoyar la repetibilidad, podemos recorrer un largo camino para igualar la agilidad de los atacantes y reducir el impacto de los factores estresantes y las sorpresas -ya sean provocados por los atacantes o por otras influencias conspiradoras- en nuestros sistemas. Aunque este capítulo puede servir de guía para que los equipos de seguridad modernicen su estrategia en esta fase, nuestro objetivo en este capítulo es que los equipos de ingeniería de software o plataformas comprendan cómo pueden promover la resiliencia con sus propios esfuerzos. Necesitamos coherencia y repetibilidad. Tenemos que evitar tomar atajos sin perder velocidad. Necesitamos seguir innovando para crear más holgura en el sistema. Necesitamos cambiar para seguir siendo los mismos.
Cubriremos mucho terreno en este capítulo: ¡está repleto de sabiduría práctica! Después de hablar de los modelos mentales y las preocupaciones sobre la propiedad, inspeccionaremos el contenido mágico de nuestra poción de resiliencia para informarnos sobre cómo podemos construir y entregar sistemas de software resilientes. Consideraremos qué prácticas nos ayudan a cristalizar las funciones críticas del sistema y a invertir en su resistencia a los ataques. Exploraremos cómo podemos mantenernos dentro de los límites del funcionamiento seguro y ampliar esos umbrales para tener más margen de maniobra. Hablaremos de tácticas para observar las interacciones del sistema a través del espacio-tiempo y para hacerlas más lineales. Hablaremos de las prácticas de desarrollo que fomentan los circuitos de retroalimentación y una cultura de aprendizaje para que nuestros modelos mentales no se calcifiquen. Para terminar, descubriremos prácticas y pautas que nos mantengan flexibles, dispuestos y capaces de cambiar para apoyar el éxito de la organización a medida que el mundo evoluciona.
Modelos mentales en el desarrollo de software
En el último capítulo hablamos del buen diseño y la arquitectura desde la perspectiva de la resiliencia. Hay muchas formas de subvertir accidentalmente el diseño y la arquitectura resilientes una vez que empezamos a construir y entregar esos diseños. Ésta es la etapa en la que se reifican por primera vez las intenciones del diseño, porque los programadores deben tomar decisiones sobre cómo reifican el diseño, y estas decisiones también influyen en el grado de acoplamiento y complejidad interactiva del sistema. De hecho, los profesionales de todas las fases influyen en esto, pero trataremos cada una por separado en capítulos posteriores. Este capítulo explorará las numerosas compensaciones y oportunidades a las que nos enfrentamos cuando construimos y entregamos sistemas.
Esta fase -construir y entregar software- es uno de nuestros principales mecanismos de adaptación. En esta fase es donde podemos adaptarnos a medida que cambia nuestra organización, el modelo de negocio o el mercado. Es donde nos adaptamos a medida que nuestra organización escala. La forma de adaptarnos a estos factores de estrés crónicos suele ser construyendo un nuevo software, por lo que necesitamos la capacidad de traducir con precisión la intención de nuestra adaptación al nuevo sistema. La belleza de los experimentos de caos es que ponen al descubierto cuándo nuestros modelos mentales se alejan de la realidad. En esta fase, significa que tenemos una idea inexacta de lo que hace el sistema ahora, pero alguna idea -representada por nuestro diseño- de cómo queremos que se comporte en el futuro. Queremos viajar con seguridad desde el estado actual al estado futuro previsto.
En un mundo SCE, debemos pensar en términos de sistemas. Esto es parte de por qué esta fase se describe como "construir y entregar" y no sólo "desarrollar" o "codificar". Las interconexiones importan. El software sólo importa cuando está "vivo" en el entorno de producción y en el ecosistema de software más amplio. Que pueda sobrevivir en tu máquina local no significa que pueda sobrevivir en la naturaleza. Es cuando se entrega a los usuarios -de forma parecida a como describimos un nacimiento humano como un parto- cuando el software se vuelve útil, porque ahora forma parte de un sistema. Así que, aunque cubriremos las operaciones en el próximo capítulo, haremos hincapié en el valor de esta perspectiva de sistemas para los ingenieros de software que suelen centrarse más en la funcionalidad que en el entorno. Independientemente de que tus usuarios finales sean clientes externos u otros equipos internos (que siguen siendo en gran medida clientes), construir y ofrecer un sistema resistente requiere que pienses en su contexto final.
Los experimentos de caos de seguridad ayudan a los programadores a comprender el comportamiento de los sistemas que construyen en múltiples capas de abstracción. Por ejemplo, la herramienta de experimentación del caos kube-monkey borra aleatoriamente pods de Kubernetes ("k8s") en un clúster, exponiendo cómo los fallos pueden producirse en cascada entre aplicaciones en un sistema orquestado por k8s (donde k8s sirve como capa de abstracción). Esto es crucial porque los atacantes piensan a través de las capas de abstracción y explotan cómo se comporta realmente el sistema en lugar de cómo se pretende o está documentado que se comporte. Esto también es útil para depurar y probar hipótesis específicas sobre el sistema para refinar tu modelo mental del mismo y, por tanto, aprender lo suficiente para construir el sistema mejor con cada iteración.
¿A quién pertenece la seguridad de las aplicaciones (y la resiliencia)?
La SCE respalda que los equipos de ingeniería de software asuman la responsabilidad de construir y entregar software basado en patrones resistentes, como los que se describen en este libro. Esto puede adoptar varias formas en las organizaciones. Los equipos de ingeniería de software pueden autogestionarse por completo -un modelo totalmente descentralizado- en el que cada equipo proponga pautas basadas en la experiencia y acuerde cuáles deben convertirse en estándar (un modelo que probablemente sea el más adecuado para las organizaciones más pequeñas o nuevas). Otra opción es un modelo de asesoramiento: los equipos de ingeniería de software podrían aprovechar a los defensores como asesores que les ayuden a "desatascarse" o a superar mejor los retos de la resiliencia. Los defensores que lo hagan pueden ser el equipo de seguridad, pero también podrían ser fácilmente el equipo de SRE o de ingeniería de plataformas, que ya realiza actividades similares, aunque quizá no con la perspectiva de ataque actual. O, como trataremos en profundidad en el Capítulo 7, las organizaciones pueden elaborar un programa de resiliencia dirigido por un equipo de Ingeniería de Resiliencia de Plataforma que pueda definir directrices y patrones, así como crear herramientas que hagan que la forma resiliente sea la más conveniente para los usuarios internos.
Advertencia
Si tu organización tiene un modelo de defensa típico de -como un equipo de ciberseguridad independiente-, hay consideraciones importantes que debes tener en cuenta al pasar a un modelo de asesoramiento. Los defensores no pueden dejar que el resto de la organización se hunda o nade, declarando que la formación en concienciación sobre seguridad es suficiente; en el Capítulo 7 veremos por qué esto es cualquier cosa menos suficiente. Los defensores deben determinar, documentar y comunicar la capacidad de recuperación y las directrices de seguridad, permaneciendo accesibles como asesores para ayudar en la implementación cuando sea necesario. Esto se aleja del modelo tradicional de equipos de ciberseguridad que aplican políticas y procedimientos, y requiere un cambio de mentalidad de autócrata a diplomático.
El problema es que la seguridad tradicional de -incluido en su moderno maquillaje como "DevSecOps"- pretende microgestionar los equipos de ingeniería de software. En la práctica, los equipos de ciberseguridad suelen meterse en los procesos de ingeniería de software como pueden para controlar más y asegurarse de que se hace "bien", donde "bien" se ve exclusivamente a través de la lente de la optimización de la seguridad. Como sabemos por el mundo de la gestión organizativa, la microgestión suele ser señal de malos gestores, objetivos poco claros y una cultura de desconfianza. El resultado final es un acoplamiento cada vez más estrecho, una organización como un ouroboros.
El objetivo de un buen diseño y de las herramientas de la plataforma es hacer que la resiliencia y la seguridad pasen a un segundo plano y no a un primer plano. En un mundo ideal, la seguridad es invisible:el desarrollador ni siquiera es consciente de las cosas de seguridad que ocurren en segundo plano. Sus flujos de trabajo no parecen más engorrosos. Esto está relacionado con la mantenibilidad: no importa tu afán o tus nobles intenciones, las medidas de seguridad que impiden el trabajo en esta fase no son mantenibles. Como describimos en el último capítulo, nuestro propósito superior es resistir la gravedad de las presiones de producción que te arrastran a la Zona Peligrosa. Las organizaciones querrán que construyas más cosas de software más baratas y más rápidamente. Nuestro trabajo es encontrar un camino sostenible para ello. A diferencia de la infoseguridad tradicional, los programas de seguridad basados en la SCE buscan oportunidades para acelerar el trabajo de ingeniería de software, manteniendo al mismo tiempo la resiliencia, ya que la vía rápida será la que se utilice en la práctica, y hacer que la vía segura sea la vía rápida suele ser el mejor camino para ganar. Exploraremos esto a fondo en el Capítulo 7.
Es imposible que todos los equipos mantengan un contexto completo sobre todas las partes de los sistemas de tu organización. Pero el desarrollo resiliente depende de este contexto, porque la forma más óptima de construir un sistema para mantener la resiliencia -recuerda, resiliencia es un verbo- depende de su contexto. Si queremos sistemas resilientes, debemos fomentar la apropiación local. Los intentos de centralizar el control -como la ciberseguridad tradicional- sólo harán que nuestros sistemas sean frágiles porque ignoran el contexto local.
La determinación del contexto comienza con una misión lúcida: "El sistema funciona con la disponibilidad, velocidad y funcionalidad que pretendemos a pesar de la presencia de atacantes". Eso es realmente abierto, como debe ser. Para una empresa, la forma más eficaz de realizar esa misión es construir su aplicación para que sea inmutable y efímera. Para otra empresa, podría ser escribir el sistema en Rust1 (y evitar utilizar la palabra clave unsafe como escapatoria...2). Y para otra empresa, la mejor manera de cumplir esta misión es evitar la recopilación de datos sensibles, dejando que terceros se encarguen de ello y, por tanto, también de su seguridad.
Lecciones que podemos aprender de la administración de bases de datos al pasar a DevOps
La idea de que la seguridad pueda tener éxito mientras es "propiedad" de los equipos de ingeniería suele percibirse como un anatema para la infoseguridad. Pero ha ocurrido en otras áreas problemáticas complicadas, como la administración de bases de datos (DBA).
DBA se ha desplazado hacia el modelo "DevOps" (y, no, no se llama DevDBOps). Sin adoptar los principios DevOps, tanto la velocidad como la calidad se resienten debido a:
Desajuste entre responsabilidad y autoridad
Personal de operaciones de bases de datos sobrecargado
Ruptura de los circuitos de retroalimentación de la producción
Reducción de la productividad de los desarrolladores
¿Te suena? Al igual que el DBA, los programas de seguridad se sitúan tradicionalmente en un equipo central específico, separado de los equipos de ingeniería, y a menudo están reñidos con el trabajo de desarrollo. ¿Qué más podemos aprender sobre la aplicación de DevOps a DBA?
Los desarrolladores son dueños del esquema de la base de datos, la carga de trabajo y el rendimiento.
Los desarrolladores depuran, solucionan problemas y reparan sus propias averías.
Esquema y modelo de datos como código.
Existe un único canal de implementación totalmente automatizado.
La implementación de aplicaciones incluye migraciones automatizadas de esquemas.
Actualizaciones automatizadas de preproducción desde producción.
Existe automatización de las operaciones de la base de datos.
Estos atributos ejemplifican un paradigma descentralizado para el trabajo de base de datos. No hay un único equipo que "posea" el trabajo o la experiencia en bases de datos. Cuando algo va mal en una parte concreta del sistema, el equipo de ingeniería responsable de esa parte del sistema también es responsable de averiguar qué está fallando y solucionarlo. Los equipos aprovechan la automatización para el trabajo de base de datos, reduciendo la barrera de entrada y aligerando la carga cognitiva de los desarrolladores, lo que disminuye la necesidad desesperada de una profunda experiencia en bases de datos. Resulta que gran parte de la experiencia necesaria está envuelta en el trabajo duro; elimina las tareas manuales y tediosas y todo será más fácil para todos.
Merece la pena señalar que, en esta transformación, el trabajo y la complejidad no han desaparecido realmente (al menos, en su mayor parte); sólo se han automatizado en gran medida y se han ocultado tras las barreras de abstracción que ofrecen los proveedores de nube y SaaS. Y la mayor objeción a esta transformación -que arruinaría el rendimiento o dificultaría las operaciones- se ha demostrado (en su mayor parte) falsa. La mayoría de las organizaciones simplemente nunca se encuentran con problemas que pongan de manifiesto las limitaciones de este enfoque.
Como señala el ingeniero de datos y software Alex Rasmussen, ésta es la misma razón por la que SQL sobre almacenes en la nube ha sustituido en gran medida a los trabajos personalizados de Spark. Algunas organizaciones necesitan la potencia y flexibilidad que otorga Spark y están dispuestas a invertir el esfuerzo necesario para que tenga éxito. Pero la gran mayoría de las organizaciones sólo quieren agregar algunos datos estructurados y realizar algunas uniones. En este momento, hemos adquirido colectivamente una comprensión suficiente de este modo "común", por lo que nuestras soluciones dirigidas a este modo común son bastante sólidas. Siempre habrá casos atípicos, pero tu organización probablemente no sea uno de ellos.
También hay paralelismos con esta dinámica en la seguridad. ¿Cuánta gente hace su propio procesamiento de pagos en un mundo en el que abundan las plataformas de procesamiento de pagos? ¿Cuánta gente hace su propia autenticación cuando hay proveedores de plataformas de gestión de identidades? Esto también refleja el principio de "elegir lo aburrido" que tratamos en el último capítulo y que trataremos más adelante en este capítulo en el contexto de la construcción y la entrega. Debemos suponer que nuestro problema es aburrido a menos que se demuestre lo contrario.
Si adaptamos los atributos del DBA a la transformación DevOps para la seguridad, podrían ser algo así:
Los desarrolladores son dueños de los patrones de seguridad, la carga de trabajo y el rendimiento.
Los desarrolladores depuran, solucionan y reparan sus propias incidencias.
Políticas y normas de seguridad como código.
Existe un único canal de implementación totalmente automatizado.
La implementación de la aplicación incluye cambios automatizados en la configuración de seguridad.
Actualizaciones automatizadas de preproducción desde producción.
Automatización de las operaciones de seguridad.
No puedes lograr estos atributos a través de un equipo de seguridad que los gobierne a todos. La única forma de lograr esta alineación de responsabilidad y rendición de cuentas es descentralizando el trabajo de seguridad. Los programas de Campeones de la Seguridad representan una forma de empezar a descentralizar los programas de seguridad; las organizaciones que experimentaron con este modelo (como Twilio, cuyo estudio de caso sobre su programa se encuentra en el informe anterior de la SCE) están informando de resultados satisfactorios y de un ambiente de mayor colaboración entre la seguridad y la ingeniería de software. Pero los programas de Campeones de Seguridad son sólo un puente. Necesitamos un equipo dedicado a hacer posible la descentralización, por lo que dedicaremos todo el Capítulo 7 a la Ingeniería de Resiliencia de Plataformas.
¿Qué prácticas fomentan la resiliencia cuando se construye y entrega software? Ahora veremos qué prácticas fomentan cada ingrediente de nuestra poción de resiliencia.
Decisiones sobre la funcionalidad crítica antes de construir
¿Cómo cosechamos el primer ingrediente de la receta de nuestra poción de resiliencia -comprender la funcionalidad crítica del sistema- cuando construimos y entregamos sistemas? Bueno, probablemente deberíamos empezar un poco antes, cuando decidimos cómo implementar nuestros diseños de la fase anterior. Esta sección trata de las decisiones que debes tomar colectivamente antes de construir una parte del sistema y cuando lo reevalúes a medida que cambie el contexto. Cuando implementamos una funcionalidad crítica desarrollando código, nuestro objetivo es la simplicidad y la comprensibilidad de las funciones críticas; ¡el espíritu demoníaco de la complejidad puede asaltarnos para devorarnos en cualquier momento!
Una faceta de la funcionalidad crítica durante esta fase es que los ingenieros de software suelen estar construyendo y entregando parte del sistema, no el conjunto. Neville Holmes, autor de la columna "La profesión" en la revista Computer del IEEE, dijo: "En la vida real, los ingenieros deberían estar diseñando y validando el sistema, no el software. Si te olvidas del sistema que estás construyendo, el software a menudo será inútil". Perder de vista la funcionalidad crítica -a nivel de componente, pero sobre todo a nivel de sistema- nos llevará a asignar mal la inversión de esfuerzo y a echar a perder nuestra cartera.
¿Cuál es la mejor forma de asignar las inversiones de esfuerzo durante esta fase para garantizar que la funcionalidad crítica esté bien definida antes de que se ejecute en producción? Propondremos algunas oportunidades fructíferas -presentadas como cuatro prácticas- durante esta sección que nos permiten movernos con rapidez a la vez que sembramos semillas de resiliencia (y que apoyan nuestro objetivo de RAVE, del que hablamos en el Capítulo 2).
Consejo
Si formas parte de un equipo de seguridad o lo diriges, considera las oportunidades de este capítulo como prácticas que debes evangelizar en tu organización e invierte esfuerzos en facilitar su adopción. Es probable que quieras asociarte con quien establezca las normas dentro de la organización de ingeniería para hacerlo. Y cuando elijas proveedores que apoyen estas prácticas y patrones, incluye a los equipos de ingeniería en el proceso de evaluación.
Los equipos de ingeniería de software pueden adoptarlas por su cuenta. O bien, si existe un equipo de ingeniería de plataformas, pueden esforzarse para que estas prácticas se adopten lo más fácilmente posible en los flujos de trabajo de ingeniería. Hablaremos más del enfoque de ingeniería de plataformas en el Capítulo 7.
En primer lugar, podemos definir los objetivos y directrices del sistema utilizando el "enfoque de la esclusa". En segundo lugar, podemos llevar a cabo revisiones reflexivas del código para definir y verificar las funciones críticas del sistema mediante el poder de los modelos mentales en competencia; si alguien está haciendo algo raro en su código -lo que debería señalarse durante la revisión del código de un modo u otro-, probablemente se reflejará en las propiedades de resiliencia de su código. En tercer lugar, podemos fomentar el uso de patrones ya establecidos en el sistema, eligiendo tecnología "aburrida" (una iteración sobre el tema que exploramos en el último capítulo). Y, por último, podemos estandarizar las materias primas para liberar capital de esfuerzo que pueda invertirse en otras cosas para la resiliencia.
Veamos cada una de estas prácticas por separado.
Definición de objetivos del sistema y directrices sobre "qué tirar por la esclusa"
Una práctica para apoyar la funcionalidad crítica durante esta fase es lo que llamamos el "enfoque de la esclusa": siempre que estemos construyendo y entregando software, tenemos que definir lo que podemos "tirar por la esclusa". ¿Qué funcionalidades y componentes puedes descuidar temporalmente y que el sistema siga realizando sus funciones críticas? ¿Qué te gustaría poder desatender durante un incidente? Sea cual sea tu respuesta, asegúrate de que construyes el software de forma que puedas desatender esas cosas cuando sea necesario. Esto se aplica tanto a los incidentes de seguridad como a los de rendimiento; si un componente se ve comprometido, el enfoque de la esclusa te permite desconectarlo si no es crítico.
Por ejemplo, si el procesamiento de transacciones es la función crítica de tu sistema y la elaboración de informes no lo es, debes construir el sistema de modo que puedas tirar los informes "por la esclusa" para preservar recursos para el resto del sistema. Es posible que la presentación de informes sea extremadamente lucrativa -tu impresora de dinero más prolífica- y, sin embargo, como la puntualidad de la presentación de informes importa menos, aún puede sacrificarse. Es decir, para mantener la seguridad del sistema y la exactitud de los informes, sacrificas el servicio de informes durante un escenario adverso -aun siendo el servicio más valioso- porque su funcionalidad crítica aún puede mantenerse con un retraso.
Otra ventaja de definir las funciones críticas con la mayor precisión posible es que podemos limitar el tamaño de los lotes, una dimensión importante de nuestra capacidad para razonar sobre lo que estamos construyendo y entregando. Garantizar que los equipos puedan seguir el flujo de datos en un programa de su competencia ayuda a evitar que los modelos mentales se alejen demasiado de la realidad.
Este enfoque despiadado en la funcionalidad crítica puede aplicarse también a niveles más locales. Como comentamos en el último capítulo, tender hacia componentes de propósito único infunde más linealidad al sistema, y nos ayuda a comprender mejor la función de cada componente. Si la función crítica de nuestro código sigue siendo elusiva, ¿para qué lo escribimos?
Revisiones del código y modelos mentales
Las revisiones del código nos ayudan a verificar que la implementación de nuestra funcionalidad crítica (y no crítica también) se ajusta a nuestros modelos mentales. Las revisiones del código, en el mejor de los casos, implican que un modelo mental proporciona información sobre otro modelo mental. Cuando reificamos un diseño a través del código, estamos instanciando nuestro modelo mental. Cuando revisamos el código de otra persona, construimos un modelo mental del código y lo comparamos con nuestro modelo mental de la intención, proporcionando retroalimentación sobre cualquier cosa que se desvíe (u oportunidades para refinarlo).
En los flujos de trabajo modernos de desarrollo de software, las revisiones del código de suelen realizarse tras el envío de una solicitud pull (PR). Cuando un desarrollador cambia el código localmente y quiere fusionarlo con la base de código principal (conocida como "rama principal"), abre un PR que notifica a otro humano que esos cambios -denominados "commits"- están listos para ser revisados. En un modelo de integración continua y despliegue/entrega continuos (CI/CD), todos los pasos de las pull requests, incluida la fusión de los cambios en la rama principal, están automatizados, excepto la revisión del código.
En relación con el modelo de cambio iterativo que discutiremos más adelante en el capítulo, también queremos que nuestras revisiones de código sean pequeñas y rápidas. Cuando se envía el código, el desarrollador debe recibir comentarios pronto y con rapidez. Para garantizar que el revisor pueda ser rápido en su revisión, los cambios deben ser pequeños. Si a un revisor se le asigna un RP que incluye muchos cambios a la vez, puede haber un incentivo para hacer recortes. Pueden limitarse a hojear el código, comentar "lgtm" (a mí me parece bien), y pasar al trabajo que perciben como más valioso (como escribir su propio código). Al fin y al cabo, no obtendrán una bonificación ni ascenderán por hacer revisiones de código concienzudas; es mucho más probable que reciban recompensas por escribir código que aporte cambios valiosos a la producción.
A veces, las funciones críticas se pasan por alto durante la revisión del código porque nuestros modelos mentales, como comentamos en el último capítulo, son incompletos. Como descubrió un estudio, "la lógica de gestión de errores a menudo es simplemente errónea", y una simple comprobación de la misma evitaría muchos fallos críticos de producción en los sistemas distribuidos.3 También necesitamos revisiones de código para las pruebas, en las que otras personas validen las pruebas que escribimos.
Advertencia
Las revisiones formales del código suelen proponerse tras un incidente notable, con la esperanza de que un acoplamiento más estricto mejore la seguridad (no lo hará). Si el código de una revisión ya está escrito y tiene un volumen importante, tiene muchos cambios o es muy complejo, ya es demasiado tarde. El autor del código y el revisor sentados juntos para discutir los cambios (frente al modelo asíncrono e informal que es mucho más común) parece que podría ayudar, pero es sólo "teatro de revisión". Si tenemos características mayores, deberíamos utilizar el modelo de "rama de características" o, mejor aún, asegurarnos de realizar una revisión del diseño que informe sobre cómo se escribirá el código.
¿Cómo incentivamos las revisiones de código concienzudas? Hay algunas cosas que podemos hacer para disuadir de tomar atajos, empezando por asegurarnos de que las herramientas se encargan de todos los detalles. Los ingenieros nunca deberían tener que señalar problemas de formato o espacios finales; cualquier problema de estilo debería comprobarse automáticamente. Garantizar que las herramientas automatizadas se encarguen de este tipo de trabajo sucio y quisquilloso permite a los ingenieros centrarse en actividades de mayor valor que pueden fomentar la resistencia.
Advertencia
Hay muchos antipatrones de revisión de código que, por desgracia, son comunes en el statu quo de la ciberseguridad, a pesar de que los equipos de ingeniería de seguridad son posiblemente los que más lo sufren. Un antipatrón es el requisito estricto de que el equipo de seguridad apruebe cada RP para evaluar su "peligrosidad". Aparte de la nebulosidad del término " peligrosidad", también existe el problema de que el equipo de seguridad carece de contexto relevante para los cambios de código.
Como sabe muy bien cualquier ingeniero de software, un equipo de ingeniería no puede revisar eficazmente los RP de otro equipo. Tal vez el ingeniero de almacenamiento podría pasarse una semana leyendo los documentos de diseño del equipo de ingeniería de redes y luego revisar un RP, pero nadie lo hace. Desde luego, un equipo de seguridad no puede hacerlo. Puede que el equipo de seguridad ni siquiera entienda las funciones críticas del sistema y, en algunos casos, puede que ni siquiera sepa lo suficiente sobre el lenguaje de programación como para identificar posibles problemas de forma significativa.
Como resultado, el equipo de seguridad puede convertirse a menudo en un estrecho cuello de botella que ralentiza el ritmo de cambio del código, lo que, a su vez, perjudica la resiliencia al dificultar la adaptabilidad. Esto suele parecer miserable también para el equipo de seguridad, y sin embargo los líderes suelen sucumbir a la creencia de que existe un binario entre los extremos de revisiones manuales y "dejar que los problemas de seguridad se escapen de las manos". Sólo un Sith trata con absolutos.
La tecnología "aburrida" es una tecnología resistente
Otra práctica que puede ayudarnos a refinar nuestras funciones críticas y priorizar el mantenimiento de su resistencia a los ataques es elegir tecnología "aburrida". Como se expone en el famoso post del ejecutivo de ingeniería Dan McKinley, "Elige tecnología aburrida", lo aburrido no es intrínsecamente malo. De hecho, lo aburrido probablemente indica capacidades bien comprendidas, lo que nos ayuda a manejar la complejidad y reducir la preponderancia de "interacciones desconcertantes" en nuestros sistemas (tanto el sistema como nuestros modelos mentales se vuelven más lineales).
En cambio, la tecnología nueva y "sexy" se comprende menos y es más probable que provoque sorpresas y desconciertos. El perímetro sangrante es un nombre apropiado dado el dolor que puede infligir cuando se implementa: al principio puede parecer sólo una herida superficial, pero a la larga puede drenar tu energía cognitiva y la de tus equipos. En efecto, estás añadiendo tanto un acoplamiento más estrecho como complejidad interactiva (linealidad decreciente). Si recuerdas el último capítulo, elegir "aburrido" nos proporciona una comprensión más amplia, que requiere menos conocimientos especializados -una característica de los sistemas lineales-, al tiempo que fomenta un acoplamiento más suelto de diversas maneras.
Por tanto, cuando recibas un diseño bien pensado (¡como uno basado en las enseñanzas del Capítulo 3!), considera si las elecciones de codificación, construcción y entrega que haces están añadiendo complejidad adicional y un mayor potencial de sorpresas, y si te estás vinculando estrechamente a ti mismo o a tu organización a esas elecciones. Los ingenieros de software deberían elegir el software -lenguajes, marcos, herramientas, etc.- que mejor resuelva los problemas empresariales específicos. Al usuario final realmente no le importa que hayas utilizado la última y mejor herramienta que se promociona en HackerNews. El usuario final quiere utilizar tu servicio cuando quiera, tan rápido como quiera y con la funcionalidad que quiera. A veces, resolver esos problemas empresariales requerirá una tecnología nueva y extravagante si te concede una ventaja sobre tus competidores (o si cumple de algún otro modo la misión de tu organización). Aun así, ten cuidado con la frecuencia con que buscas tecnología "no aburrida" para diferenciarte, pues el perímetro sangrante requiere muchos sacrificios de sangre para mantenerse.
Advertencia
Una bandera roja que indica que tu arquitectura de seguridad se ha desviado del principio de "elige lo aburrido" es si es probable que tus modelos de amenaza sean radicalmente distintos de los de tus competidores. Aunque la mayoría de los modelos de amenazas serán diferentes -porque pocos sistemas son exactamente iguales-, es raro que dos servicios que realizan la misma función por parte de organizaciones con objetivos similares parezcan extraños. Una excepción podría ser si tus competidores están atrapados en la edad oscura de la seguridad, pero tú persigues la seguridad por diseño.
Durante la fase de construcción y entrega, debemos tener cuidado con cómo priorizamos nuestros esfuerzos cognitivos, además de cómo gastamos los recursos de forma más general. Puedes gastar tus recursos finitos en una nueva herramienta muy ingeniosa que utilice IA para escribir pruebas unitarias por ti. O puedes gastarlos en crear una funcionalidad compleja que resuelva mejor un problema para los usuarios finales a los que te diriges. Lo primero no sirve directamente a tu negocio ni te diferencia; añade una importante sobrecarga cognitiva que no sirve a tus objetivos colectivos a cambio de un beneficio incierto (que sólo llegaría tras un doloroso proceso de ajuste y tirarse de los pelos a partir de unos documentos mínimos de resolución de problemas).
"Vale", dirás, "¿pero y si la cosa nueva y brillante es realmente genial?". ¿Sabes a quién más le gusta el software realmente guay, nuevo y brillante? A los atacantes. Les encanta que los desarrolladores adopten nuevas herramientas y tecnologías que aún no se conocen bien, porque eso crea muchas oportunidades para que los atacantes se aprovechen de los errores o incluso de la funcionalidad prevista que no se ha comprobado suficientemente contra el abuso. Los investigadores de vulnerabilidades también tienen currículos, y parecen impresionantes cuando pueden demostrar la explotación contra la cosa nueva y reluciente (lo que normalmente se conoce como "poseer" la cosa). Una vez que publican los detalles de cómo explotaron la nueva cosa brillante, los atacantes criminales pueden averiguar cómo convertirlo en un ataque repetible y escalable (completando el Fun-to-Profit Pipeline de la infoseguridad ofensiva).
Herramientas de seguridad y observabilidad tampoco están exentas de este principio de "elige lo aburrido". Independientemente de tu título "oficial" -y de si eres líder, gestor o colaborador individual-, debes elegir y fomentar herramientas de seguridad y observabilidad sencillas y bien comprendidas que se adopten en todos tus sistemas de forma coherente. A los atacantes les encanta encontrar implementaciones "especiales" de herramientas de seguridad u observabilidad y se enorgullecen de derrotar a las nuevas y relucientes mitigaciones que se jactan de derrotar a los atacantes de una forma u otra.
Muchas herramientas de seguridad y observabilidad requieren permisos especiales (como ejecutarse como root, administrador o administrador de dominio) y un amplio acceso a otros sistemas para realizar su supuesta función, lo que las convierte en herramientas fantásticas para que los atacantes obtengan un acceso profundo y potente a través de tus sistemas críticos (porque esos son los que especialmente quieres proteger y monitorizar). Una nueva y reluciente herramienta de seguridad puede decir que las matemáticas de fantasía resolverán todos tus problemas de ataque, pero esta fantasía es lo contrario de aburrida y puede engendrar una variedad de dolores de cabeza, incluyendo el tiempo necesario para ponerla a punto de forma continua, cuellos de botella en la red debido al acaparamiento de datos, pánicos en el kernel o, por supuesto, una vulnerabilidad en ella (o en su colección de fantasía y en sus canales impulsados por la IA, de empuje de reglas) que puede ofrecer a los atacantes un punto de apoyo encantador en todos los sistemas que te importan.
Por ejemplo, puedes tener la tentación de "hacer tu propia" autenticación o protección contra falsificación de petición en sitios cruzados (XSRF). Fuera de los casos de perímetro en los que la autenticación o la protección XSRF forman parte del valor que tu servicio ofrece a tus clientes, tiene mucho más sentido "elegir lo aburrido" implementando middleware para la autenticación o la protección XSRF. De ese modo, aprovechas la experiencia del proveedor en esta área "exótica".
Advertencia
No hagas bricolaje con el middleware.
La cuestión es que, si optimizas las herramientas "menos malas" para el mayor número posible de tus problemas no diferenciadores, entonces será más fácil mantener y hacer funcionar el sistema y, por tanto, mantenerlo seguro. Si optimizas para conseguir la mejor herramienta para cada problema individual, o Regla de Cool, entonces los atacantes explotarán gustosamente tu sobrecarga cognitiva resultante y la asignación insuficiente de monedas de complejidad en cosas que ayuden al sistema a ser más resistente a los ataques. Por supuesto, seguir con algo aburrido que es ineficaz tampoco tiene sentido y también erosionará la resiliencia con el tiempo. Queremos aspirar al punto óptimo de aburrido y eficaz.
Normalización de las materias primas
La última práctica que trataremos en el ámbito de la funcionalidad crítica es la normalización de las "materias primas" que utilizamos cuando construimos y entregamos software, o cuando recomendamos prácticas a los equipos de ingeniería de software. Como comentamos en el último capítulo, podemos pensar en las "materias primas" de los sistemas de software como lenguajes, bibliotecas y herramientas (esto también se aplica al firmware y a otras materias primas que se utilizan en el hardware de los ordenadores, como las CPU y las GPU). Estas materias primas son elementos entretejidos en el software que deben ser resistentes y seguros para el funcionamiento del sistema.
Cuando construimos servicios de software, debemos ser decididos con los lenguajes, bibliotecas, marcos, servicios y fuentes de datos que elegimos, ya que el servicio heredará algunas de las propiedades de estas materias primas. Muchos de estos materiales pueden tener propiedades peligrosas, inadecuadas para construir un sistema según tus requisitos. O puede que el peligro sea esperado y, como no hay una alternativa mejor para tu dominio del problema, tendrás que aprender a vivir con él o pensar en otras formas de reducir los peligros mediante el diseño (de lo que hablaremos más en el Capítulo 7). En general, elegir más de una materia prima en cualquier categoría significa que obtienes los inconvenientes de ambas.
La Agencia de Seguridad Nacional (NSA) recomienda oficialmente utilizar lenguajes seguros en memoria siempre que sea posible, como C#, Go, Java, Ruby, Rust y Swift. El CTO de Microsoft Azure, Mark Russovovich, tuiteó de forma más contundente: "Hablando de lenguajes, es hora de dejar de iniciar cualquier proyecto nuevo en C/C++ y utilizar Rust para aquellos escenarios en los que se requiera un lenguaje que no sea CGC. Por el bien de la seguridad y la fiabilidad, la industria debería declarar esos lenguajes como obsoletos". Los problemas de seguridad de la memoria perjudican tanto al usuario como al fabricante de un producto o servicio, porque los datos que no deberían cambiar pueden convertirse mágicamente en un valor diferente. Como Matt Miller, ingeniero de software de seguridad asociado de Microsoft, presentó en 2019, el ~70% de las vulnerabilidades corregidas con un CVE asignado son vulnerabilidades de seguridad de memoria debidas a que los ingenieros de software introducen por error errores de seguridad de memoria en su código C y C++.
Cuando construyas o refactorices software, deberías elegir uno de las docenas de lenguajes populares que son seguros para la memoria por defecto. La inseguridad de la memoria es muy impopular en el diseño de lenguajes, lo cual es estupendo para nosotros, ya que tenemos una cornucopia de opciones seguras para la memoria de las que podemos escoger. Incluso podemos pensar en el código C como si fuera plomo; era muy conveniente para muchos casos de uso, pero nos está envenenando con el tiempo, sobre todo a medida que se acumula más .
Idealmente, queremos adoptar materias primas menos peligrosas tan rápidamente como podamos, pero esta búsqueda a menudo no es trivial (como migrar de un lenguaje a otro). Las reescrituras completas pueden funcionar para sistemas más pequeños que tengan pruebas de integración, de extremo a extremo (E2E) y funcionales relativamente completas, pero esas condiciones no siempre serán ciertas. El patrón de la higa estranguladora, del que hablaremos al final del capítulo, es el enfoque más obvio para ayudarnos a cambiar iterativamente nuestra base de código.
Otra opción es elegir un lenguaje que se integre bien con C y hacer de tu aplicación una aplicación políglota, eligiendo cuidadosamente qué partes escribir en cada lenguaje. Este enfoque es más granular que el patrón de la higuera estranguladora y es similar al proyecto Oxidation, el enfoque de Mozilla para integrar código Rust en y alrededor de Firefox (que merece la pena explorar para obtener orientación sobre cómo migrar de C a Rust, en caso de que lo necesites). Algunos sistemas pueden incluso permanecer en este estado indefinidamente si hay ventajas en tener simultáneamente lenguajes de alto y bajo nivel en el mismo programa. Los juegos son un ejemplo común de esta dinámica: el código del motor necesita ser rápido para controlar la disposición de la memoria, pero el código del juego necesita ser rápido para iterar y el rendimiento importa mucho menos. Pero, en general, los servicios y programas políglotas son poco frecuentes, lo que hace que la normalización de algunos materiales sea algo más sencilla.
Los equipos de seguridad que deseen impulsar la adopción de la seguridad de la memoria deben asociarse con los humanos de tu organización que intentan impulsar las normas de ingeniería -ya sean prácticas, herramientas o marcos- y participar en ese proceso. En igualdad de condiciones, mantener la coherencia es significativamente mejor para la resiliencia. Los humanos que buscas están dentro de la organización de ingeniería, haciendo las conexiones y abogando por la adopción de estas normas.
Por otro lado, estos humanos tienen sus propios objetivos: construir de forma productiva más software y los sistemas que desea la empresa. Si tus peticiones son insensibles, te ignorarán. Así que no pidas cosas como desconectar los portátiles de los desarrolladores de Internet por motivos de seguridad. Sin embargo, hacer hincapié en las ventajas para la seguridad de refactorizar el código C en un lenguaje seguro para la memoria será más constructivo, ya que probablemente también encaje con sus objetivos, puesto que la productividad y los peligros operativos se cuelan notoriamente en C. La seguridad puede tener un terreno común sustancial con ese grupo de humanos sobre C, ya que ellos también quieren deshacerse de él (excepto por el humano ocasional que insiste en que todos deberíamos escribir en ensamblador y leer el manual de instrucciones de Intel).
Advertencia
Como subraya Mozilla, "cruzar la frontera C++/Rust puede ser difícil". Esto no debe subestimarse como inconveniente de este patrón. Dado que C define las API de la plataforma UNIX, la mayoría de los lenguajes tienen un sólido soporte de interfaz de funciones externas (FFI) para C. C++, sin embargo, carece de un soporte tan sustancial, ya que tiene muchas más rarezas de lenguaje con las que FFI tiene que lidiar y que potencialmente puede estropear.
El código que traspasa los límites de un lenguaje necesita atención adicional en todas las fases del desarrollo. Un enfoque emergente es atrapar todo el código C en una caja de arena WebAssembly con envoltorios FFI generados proporcionados automáticamente. Esto podría ser útil incluso para aplicaciones escritas totalmente en C, para poder atrapar las partes poco fiables y peligrosas en una caja de arena (como el análisis sintáctico de formatos ).
Las cachés son un ejemplo de materia prima peligrosa que a menudo se considera necesaria. Al almacenar datos en caché en nombre de un servicio, nuestro objetivo es reducir el volumen de tráfico hacia el servicio. Se considera un éxito tener un alto índice de aciertos de caché (CHR), y a menudo es más rentable escalar las cachés que escalar el servicio que hay detrás de ellas. Las cachés pueden ser la única forma de cumplir tus objetivos de rendimiento y coste, pero algunas de sus propiedades ponen en peligro la capacidad del sistema para mantener la resiliencia.
Existen dos peligros con respecto a la resiliencia. El primero es mundano: cada vez que cambian los datos, hay que invalidar las cachés o, de lo contrario, los datos parecerán obsoletos. La invalidación puede dar lugar a un comportamiento general del sistema peculiar o incorrecto -esas interacciones "desconcertantes" de la Zona de Peligro- si el sistema depende de datos coherentes. Si la coordinación no es correcta, los datos obsoletos pueden pudrirse en la caché indefinidamente.
El segundo peligro es un efecto sistémico en el que si las cachés fallan o se degradan alguna vez, ejercen presión sobre el servicio. Con CHRs altos, incluso un fallo parcial de la caché puede inundar un servicio backend. Si el servicio backend está caído, no puede llenar las entradas de la caché, y esto provoca que más tráfico bombardee el servicio backend. Los servicios sin caché se ralentizan, pero se recuperan con elegancia a medida que se añade más capacidad o disminuye el tráfico. Los servicios con caché se colapsan cuando se acercan a su capacidad y la recuperación suele requerir una capacidad adicional sustancial más allá del estado estacionario.
Sin embargo, incluso con estos peligros, las cachés tienen matices desde el punto de vista de la resiliencia. Benefician a la resiliencia porque pueden desacoplar las peticiones del origen (es decir, del servidor backend); el servicio soporta mejor las sorpresas, pero no necesariamente los fallos sostenidos. Mientras que los clientes están ahora menos estrechamente acoplados al comportamiento de nuestro origen, en su lugar pasan a estar estrechamente acoplados a la caché. Este acoplamiento estrecho garantiza una mayor eficacia y una reducción de costes, razón por la que se practica ampliamente el almacenamiento en caché. Pero, por las razones de resiliencia que acabamos de mencionar, pocas organizaciones "ruedan sus propias cachés". Por ejemplo, suelen subcontratar el almacenamiento en caché del tráfico web a un proveedor especializado, como una red de distribución de contenidos (CDN).
Consejo
Cada elección que hagas se resiste o capitula ante el acoplamiento estrecho. El colmo del acoplamiento débil es la plena intercambiabilidad de componentes y lenguajes en tus sistemas, pero los vendedores prefieren con mucho el bloqueo (es decir, el acoplamiento fuerte). Cuando tomes decisiones sobre tus materias primas, ten siempre en cuenta si te acercan o te alejan de la Zona de Peligro, introducida en el Capítulo 3.
Para recapitular, durante esta fase, podemos seguir cuatro prácticas para apoyar la funcionalidad crítica, el primer ingrediente de nuestra poción de resiliencia: el enfoque de la esclusa de aire, las revisiones meditadas del código, la elección de tecnología "aburrida" y la estandarización de las materias primas. Ahora, pasemos al segundo ingrediente: comprender los límites (umbrales) de seguridad del sistema .
Desarrollar y ofrecer para ampliar los límites de la seguridad
El segundo ingrediente de nuestra poción de resiliencia es comprender los límites de seguridad del sistema: los umbrales más allá de los cuales se desliza hacia el fracaso. Pero también podemos ayudar a ampliar esos límites durante esta fase, ampliando la ventana figurativa de tolerancia de nuestro sistema a las condiciones adversas. En esta sección se describe la gama de comportamientos que cabe esperar del sistema sociotécnico, en la que los humanos se encargan de curar el sistema a medida que se aleja del ideal diseñado (los modelos mentales construidos durante la fase de diseño y arquitectura). Hay cuatro prácticas clave que cubriremos y que apoyan los límites de seguridad: anticipar la escala, automatizar las comprobaciones de seguridad, estandarizar patrones y herramientas, y comprender las dependencias (incluida la priorización de las vulnerabilidades en ellas).
La buena noticia es que gran parte de conseguir una seguridad "correcta" es, en realidad, ingeniería sólida : cosas que quieres hacer para conseguir fiabilidad y resistencia a perturbaciones distintas de los ataques. En el mundo de la SCE, la seguridad de las aplicaciones se considera otra faceta de la calidad del software: dadas tus limitaciones, ¿cómo puedes escribir software de alta calidad que alcance tus objetivos? Las prácticas que exploraremos en esta sección generan un software de mayor calidad y resistencia.
En el último capítulo mencionamos que lo que queremos en nuestros sistemas es una adaptabilidad sostenida. Podemos cultivar la sostenibilidad durante esta fase como parte de la ampliación de nuestros límites de funcionamiento seguro también. La sostenibilidad y la resiliencia son conceptos interrelacionados en muchos ámbitos complejos. En la ciencia medioambiental, tanto la resiliencia como la sostenibilidad implican la preservación de la salud y el bienestar de la sociedad en presencia de cambios medioambientales.4 En ingeniería de software, solemos referirnos a la sostenibilidad como "mantenibilidad". No es menos cierto en nuestro trozo de vida que tanto la mantenibilidad como la resiliencia tienen que ver con la salud y el bienestar de los servicios de software en presencia de fuerzas desestabilizadoras, como los atacantes. Como exploraremos a lo largo de esta sección, apoyar las prácticas de ingeniería de software mantenibles -incluidos los flujos de trabajo repetibles- es vital para construir y entregar sistemas que puedan mantener la resiliencia frente a los ataques.
Los procesos por los que construyes y entregas deben ser claros, repetibles y mantenibles, tal y como describimos en el Capítulo 2 cuando presentamos RAVE. El objetivo es estandarizar la construcción y la entrega tanto como puedas para reducir las interacciones inesperadas. También significa que, en lugar de confiar en que todo esté perfecto antes de la implementación, puedes hacer frente a los errores porque solucionarlos es un proceso rápido, sencillo y repetible. Entretejer esta sostenibilidad en nuestras prácticas de construcción y entrega nos ayuda a ampliar nuestros límites de seguridad y a tener más gracia ante escenarios adversos.
Anticipar la escala y los SLO
La primera práctica de esta fase que puede ayudarnos a ampliar nuestros límites de seguridad es, sencillamente, anticipar la escala. Al construir sistemas de software resistentes, queremos considerar cómo pueden evolucionar las condiciones de funcionamiento y, por tanto, dónde están sus límites de funcionamiento seguro. A pesar de las mejores intenciones, los ingenieros de software a veces toman decisiones de arquitectura o implementación que inducen cuellos de botella de fiabilidad o escalabilidad.
Anticiparse a la escala es otra forma de desafiar esas suposiciones de "esto siempre será así" que describimos en el último capítulo, las que los atacantes explotan en sus operaciones. Piensa en un servicio de comercio electrónico. Podemos pensar: "En cada solicitud entrante, primero tenemos que correlacionar esa solicitud con la cesta de la compra anterior del usuario, lo que significa hacer una consulta a esta otra cosa". Hay una suposición de que "esto siempre será cierto" en este modelo mental: que la "otra cosa" siempre estará ahí. Si somos reflexivos, debemos cuestionarnos: "¿Y si esta otra cosa no está ahí? ¿Qué ocurriría entonces? Esto puede entonces refinar la forma en que construimos algo (y debemos documentar el por qué -lasuposición que hemos cuestionado-, como veremos más adelante en este capítulo). ¿Qué ocurre si la recuperación del carrito del usuario tarda en cargarse o no está disponible?
Cuestionar nuestras suposiciones de "esto siempre será así" también puede poner al descubierto posibles problemas de escalabilidad a niveles inferiores. Si decimos "siempre empezaremos con un gráfico de flujo de control, que es la salida de un análisis anterior", podemos cuestionarlo con una pregunta como "¿y si ese análisis es superlento o falla?". Invertir capital de esfuerzo en anticipar la escala puede garantizar que no constriñamos artificialmente los límites de seguridad de nuestro sistema, y que los umbrales potenciales se plieguen en nuestros modelos mentales del sistema.
Cuando construimos componentes que funcionarán como parte de sistemas grandes y distribuidos, parte de anticipar la escala consiste en prever lo que necesitarán los operadores durante los incidentes (es decir, qué inversiones de esfuerzo tienen que hacer). Si un ingeniero de guardia tarda horas en descubrir que el motivo de la repentina lentitud del servicio es una base de datos SQLite que nadie conocía, perjudicará a tus objetivos de rendimiento. También tenemos que prever cómo crecerá el negocio, como estimar el crecimiento del tráfico basándonos en hojas de ruta y planes de negocio, para prepararnos para ello. Cuando estimamos qué partes del sistema necesitaremos ampliar en el futuro y cuáles es improbable que necesiten ampliación, podemos ser ahorradores con nuestras inversiones de esfuerzo, al tiempo que garantizamos que el negocio pueda crecer sin impedimentos por las limitaciones del software.
Deberíamos ser cuidadosos a la hora de dar soporte a los patrones que discutimos en el último capítulo. Si diseñamos para la inmutabilidad y la efimeridad, esto significa que los ingenieros no pueden acceder por SSH al sistema para depurar o cambiar algo, y que la carga de trabajo se puede matar y reiniciar a voluntad. ¿Cómo cambia esto la forma en que construimos nuestro software? Una vez más, debemos captar estos porqués -que lo construimos así para apoyar la inmutabilidad y la efimeridad- para captar conocimientos (de los que hablaremos dentro de un rato). Hacerlo nos ayuda a ampliar nuestra ventana de tolerancia y solidifica nuestra comprensión de los umbrales del sistema más allá de los cuales estalla el fallo.
Automatizar las comprobaciones de seguridad mediante CI/CD
Una de las prácticas más valiosas para apoyar la ampliación de los límites de seguridad es automatizar las comprobaciones de seguridad aprovechando las tecnologías existentes para casos de uso de resiliencia. La práctica de la integración continua y la entrega continua5 (CI/CD) acelera el desarrollo y la entrega de funciones de software sin comprometer la fiabilidad ni la calidad.6 Una canalización CI/CD consiste en conjuntos de tareas (idealmente automatizadas) que entregan una nueva versión de software. Generalmente implica compilar la aplicación (lo que se conoce como "construcción"), probar el código, desplegar la aplicación en un repositorio o entorno de preparación, y entregar la aplicación a producción (lo que se conoce como "entrega"). Mediante la automatización, las canalizaciones de CI/CD garantizan que estas actividades se realicen a intervalos regulares con la mínima interferencia humana. Como resultado, CI/CD soporta las características de velocidad, fiabilidad y repetibilidad que necesitamos en nuestros sistemas para mantenerlos seguros y resistentes.
Consejo
- Integración continua (IC)
Los humanos integran y fusionan el trabajo de desarrollo (como el código) con frecuencia (como varias veces al día). Implica la construcción y comprobación automatizadas de software para conseguir ciclos de publicación más cortos y frecuentes, una mayor calidad del software y una productividad ampliada de los desarrolladores.
- Entrega continua (CD)
Los humanos introducen cambios en el software (como nuevas funciones, parches, ediciones de configuración, etc.) en la producción o para los usuarios finales. Implica la publicación e implementación automatizadas de software para conseguir actualizaciones de software más rápidas y seguras, que sean más repetibles y sostenibles.7
Deberíamos apreciar CI/CD no sólo como un mecanismo para evitar el trabajo de las implementaciones manuales, sino también como una herramienta para hacer que la entrega de software sea más repetible, predecible y coherente. Podemos aplicar invariantes, lo que nos permite conseguir las propiedades que queramos cada vez que creemos, implementemos y entreguemos software. Las empresas que pueden construir y entregar software más rápidamente también pueden mejorar las vulnerabilidades y los problemas de seguridad con mayor rapidez. Si puedes entregarlo cuando quieras, puedes estar seguro de que podrás enviar correcciones de seguridad cuando lo necesites. Para algunas empresas, eso puede ser cada hora y para otras, cada día. La cuestión es que tu organización puede entregar bajo demanda y, por tanto, responder a los eventos de seguridad bajo demanda.
Desde el punto de vista de la resiliencia, las Implementaciones manuales (y otras partes del flujo de trabajo de entrega) no sólo consumen un tiempo y un esfuerzo preciosos que sería mejor emplear en otra cosa, sino que también vinculan estrechamente al ser humano con el proceso, sin esperanza de linealidad. Los humanos son fabulosos adaptándose y respondiendo con variedad, y absolutamente inútiles haciendo lo mismo de la misma manera una y otra vez. El statu quo de seguridad y administración de sistemas de "ClickOps" es, desde este punto de vista, francamente peligroso. Aumenta el acoplamiento estrecho y la complejidad, sin las bendiciones de eficiencia que esperaríamos de este trato fáustico, equivalente a cambiar nuestra alma por una vida de tedio. La alternativa de las canalizaciones automatizadas CI/CD no sólo afloja el acoplamiento e introduce más linealidad, sino que también acelera la entrega del software, una de las situaciones en las que todos ganan que describimos en el último capítulo. Lo mismo ocurre con muchas formas de automatización del flujo de trabajo cuando el resultado son patrones estandarizados y repetibles.
En un ejemplo mucho más preocupante que el de las implementaciones manuales, las poblaciones indígenas locales de Noepe (Martha's Vineyard) se enfrentaron a los peligros del acoplamiento estrecho cuando el único servicio de transbordador que entregaba alimentos se vio interrumpido por la pandemia COVID-19.8 Si pensamos en nuestro oleoducto como un oleoducto de alimentos (como parte de la cadena de suministro de alimentos más amplia), entonces percibimos la necesidad conmovedora de fiabilidad y resistencia. No es diferente para nuestros conductos de construcción (que, afortunadamente, no ponen vidas en peligro).
Consejo
Cuando realizas experimentos de caos en tus sistemas, disponer de flujos de trabajo repetibles de creación e implementación te garantiza una forma sencilla de incorporar las conclusiones de esos experimentos y perfeccionar continuamente tu sistema. Contar con registros de creación e implementación versionados y auditables significa que puedes comprender más fácilmente por qué el sistema se comporta de forma diferente después de un cambio. El objetivo es que los ingenieros de software reciban información lo más inmediata posible, cuando el contexto aún está fresco. Quieren llegar a la meta de que su código funcione con éxito y fiabilidad en producción, así que aprovecha ese impulso emocional y ayúdales a conseguirlo.
Parches y actualizaciones de dependencias más rápidas
Un subconjunto de la automatización de las comprobaciones de seguridad para ampliar los límites de seguridad es la práctica de parchear y actualizar las dependencias más rápidamente. CI/CD puede ayudarnos con la aplicación de parches y, más en general, a mantener actualizadas las dependencias, lo que ayuda a evitar chocar con esos límites de seguridad. El parcheado es un problema que asola la ciberseguridad. El ejemplo más famoso es la brecha de Equifax de 2017, en la que una vulnerabilidad de Apache Struts no se parcheó hasta cuatro meses después de su revelación. Esto violó su mandato interno de parchear las vulnerabilidades en 48 horas, poniendo de relieve una vez más por qué las políticas estrictas son insuficientes para promover la resiliencia de los sistemas en el mundo real. Más recientemente, la vulnerabilidad Log4Shell 2021 en Log4j, de la que hablamos en el Capítulo 3, precipitó una ventisca de actividad tanto para encontrar sistemas vulnerables en toda la organización como para parchearlos sin romper nada.
En teoría, los desarrolladores quieren estar en la última versión de sus dependencias. Las últimas versiones tienen más funciones, incluyen correcciones de errores y a menudo tienen mejoras de rendimiento, escalabilidad y operatividad.9 Pero cuando los ingenieros están apegados a una versión más antigua, suele haber una razón. En la práctica, hay muchas razones por las que podrían no estarlo; algunas son muy razonables, otras no tanto.
Las presiones de producción son probablemente la razón más importante, porque la actualización es una tarea que no aporta ningún valor empresarial inmediato. Otra razón es que el versionado semántico (SemVer) es un ideal al que aspirar, pero es resbaladizo en la práctica. No está claro si el sistema se comportará correctamente cuando actualices a una nueva versión de la dependencia, a menos que dispongas de pruebas asombrosas que cubran completamente sus comportamientos, cosa que nadie tiene.
En el extremo menos razonable del espectro está la refactorización forzada, como cuando se escribe una dependencia o experimenta cambios sustanciales en la API. Esto es un síntoma de la predilección de los ingenieros por elegir tecnologías brillantes y nuevas frente a estables y "aburridas", es decir, elegir cosas que no son apropiadas para el trabajo real. Una última razón son las dependencias abandonadas. El creador de la dependencia ya no la mantiene y no se hizo un reemplazo directo, o el reemplazo directo es significativamente diferente.
Esta es precisamente la razón por la que la automatización -incluidas las canalizaciones CI/CD- puede ayudar, al eliminar el esfuerzo humano de mantener las dependencias actualizadas, liberando ese esfuerzo para actividades más valiosas, como la adaptabilidad. No queremos quemar su concentración con el tedio. Las canalizaciones CI/CD automatizadas permiten probar y enviar a producción actualizaciones y parches en cuestión de horas (¡o antes!), en lugar de los días, semanas o incluso meses que se tardaba tradicionalmente. Puede hacer que los ciclos de actualizaciones y parches sean un asunto automático y diario, eliminando el trabajo pesado para que otras prioridades puedan recibir atención.
Las pruebas de integración automatizadas significan que las actualizaciones y los parches se evaluarán para detectar posibles problemas de rendimiento o corrección antes de su implementación en producción, al igual que el resto del código. La preocupación de que las actualizaciones o los parches interrumpan los servicios de producción -lo que puede dar lugar a postergaciones o evaluaciones prolongadas que duran días o semanas- puede automatizarse, al menos en parte, invirtiendo en pruebas. Debemos esforzarnos en escribir pruebas que podamos automatizar, pero ahorraremos un esfuerzo considerable con el tiempo si evitamos las pruebas manuales.
Automatizar la fase de lanzamiento de la entrega de software también ofrece ventajas de seguridad. Empaquetar y desplegar automáticamente un componente de software acelera el tiempo de entrega, los parches y los cambios de seguridad, como ya hemos dicho. El control de versiones también es una ventaja para la seguridad, porque acelera la reversión y la recuperación en caso de que algo vaya mal. Hablaremos de las ventajas del aprovisionamiento automatizado de la infraestructura en la siguiente sección.
Ventajas de la entrega continua para la resistencia
La entrega continua es una práctica que sólo debes adoptar después de haber puesto en marcha otras prácticas descritas en esta sección e incluso en todo el capítulo. Si no tienes CI y pruebas automatizadas que detecten la mayoría de los fallos inducidos por los cambios, la DC será peligrosa y roerá tu capacidad de mantener la resiliencia. La DC requiere más rigor que la IC; se siente significativamente diferente. La IC te permite añadir automatización a tus procesos existentes y conseguir ventajas en el flujo de trabajo, pero en realidad no impone cambios en tu forma de implementar y poner en funcionamiento el software. La CD, sin embargo, exige que pongas orden en tu casa. Cualquier posible error que puedan cometer los desarrolladores como parte del desarrollo, después de suficiente tiempo, lo cometerán los desarrolladores. (La mayoría de las veces, por supuesto, todo lo que pueda salir bien, saldrá bien.) Todos los aspectos de las pruebas y la validación del software deben automatizarse para detectar esos errores antes de que se conviertan en fallos, y requiere más planificación en torno a la compatibilidad hacia atrás y hacia delante, los protocolos y los formatos de datos.
Teniendo en cuenta estas advertencias, ¿cómo puede ayudarnos la DC a mantener la resiliencia? Es imposible que las Implementaciones manuales sean repetibles. Es injusto esperar que un ingeniero humano ejecute implementaciones manuales sin fallos en todo momento, especialmente en condiciones ambiguas. Muchas cosas pueden salir mal incluso cuando las Implementaciones están automatizadas, por no hablar de cuando un humano realiza cada paso. La capacidad de recuperación -mediante la repetibilidad, la seguridad y la flexibilidad- está integrada en el objetivo de la DC: ofrecer cambios -ya sean nuevas funciones, configuraciones actualizadas, actualizaciones de versiones, correcciones de errores o experimentos- a los usuarios finales con una velocidad y seguridad sostenidas.10
Liberar con más frecuencia en realidad aumenta la estabilidad y la fiabilidad. Las objeciones habituales a la DC incluyen la idea de que la DC no funciona en entornos muy regulados, que no puede aplicarse a sistemas heredados y que implica enormes proezas de ingeniería para conseguirla. Gran parte de esto se basa en el mito, ahora totalmente refutado , de que moverse con rapidez aumenta intrínsecamente el "riesgo" (donde "riesgo" sigue siendo un concepto turbio).11
Aunque somos reacios a sugerir que las empresas de hiperescala se utilicen como ejemplo, merece la pena considerar a Amazon como un caso de estudio para los DC que trabajan en entornos regulados. Amazon gestiona miles de transacciones por minuto (hasta cientos de miles durante el Prime Day), por lo que está sujeta a PCI DSS (una norma de cumplimiento que cubre los datos de las tarjetas de crédito). Y, al ser una empresa que cotiza en bolsa, también se le aplica la Ley Sarbanes-Oxley que regula las prácticas contables. Pero, incluso en 2011, Amazon lanzaba cambios a producción cada 11,6 segundos de media, lo que sumaba 1.079 implementaciones por hora en los picos.12 Jez Humble, SRE y autor, escribe: "Esto es posible porque las prácticas que constituyen el núcleo de la entrega continua -gestión exhaustiva de la configuración, pruebas continuas e integración continua- permiten descubrir rápidamente defectos en el código, problemas de configuración en el entorno y problemas con el proceso de implementación".13 Cuando combinas la entrega continua con la experimentación del caos, obtienes ciclos de retroalimentación rápidos y procesables.
Esto puede sonar desalentador. Puede que tu cultura de seguridad tenga un nivel de teatralidad shakesperiana. Tu pila tecnológica se parece más a una pila de LEGOs que pisas dolorosamente. Pero puedes empezar poco a poco. El primer paso perfecto para trabajar hacia la CD es "PasteOps". Documenta el trabajo manual que supone desplegar cambios de seguridad o realizar tareas relacionadas con la seguridad como parte de la construcción, prueba e implementación. Una lista con viñetas en un recurso compartido puede bastar como MVP para la automatización, permitiendo una mejora iterativa que con el tiempo puede convertirse en scripts o herramientas reales. La SCE se basa en este tipo de mejoras iterativas. Piensa en la evolución de los sistemas naturales: los peces no desarrollaron de repente piernas, pulgares oponibles y pelo para convertirse en humanos. Cada generación ofrece mejores adaptaciones al entorno, del mismo modo que cada iteración de un proceso es una oportunidad de perfeccionamiento. Resiste la tentación de realizar un gran cambio radical, una reorganización o una migración. Sólo necesitas lo suficiente para poner en marcha el volante.
Normalización de patrones y herramientas
De forma similar a la práctica de estandarizar las materias primas de para apoyar la funcionalidad crítica, la estandarización de herramientas y patrones es una práctica que apoya la ampliación de los límites de seguridad y el mantenimiento de las condiciones operativas dentro de esos límites. La normalización puede resumirse como la garantía de que el trabajo producido es coherente con las directrices preestablecidas. La normalización ayuda a reducir la posibilidad de que los humanos cometan errores, al garantizar que una tarea se realiza siempre de la misma manera (para lo que los humanos no están diseñados). En el contexto de los patrones y herramientas estandarizados, nos referimos a la coherencia en lo que utilizan los desarrolladores para una interacción eficaz con el desarrollo continuo del software.
Se trata de un área en la que los equipos de seguridad y los de ingeniería de plataformas pueden colaborar para lograr el objetivo compartido de la normalización. De hecho, los equipos de ingeniería de plataformas podrían incluso realizar este trabajo por su cuenta, si así conviene a su contexto organizativo. Como seguimos diciendo, el manto de "defensor" le viene bien a cualquiera, independientemente de su título habitual, si está apoyando la resiliencia de los sistemas (hablaremos de esto con mucha más profundidad en el Capítulo 7).
Si no tienes un equipo de ingeniería de plataformas y todo lo que tienes son unos cuantos defensores ansiosos y un presupuesto escaso, aún puedes ayudar a estandarizar los patrones para los equipos y reducir la tentación de poner en marcha su propia cosa de una forma que atente contra la seguridad. La táctica más sencilla es dar prioridad a los patrones para las partes del sistema con mayores implicaciones para la seguridad, como la autenticación o el cifrado. Si a tu equipo le resultara difícil crear patrones, herramientas o marcos estandarizados, también puedes buscar bibliotecas estándar para recomendarlas y asegurarte de que esa lista esté disponible como documentación accesible. De ese modo, los equipos sabrán que existe una lista de bibliotecas bien validadas que deben consultar y elegir cuando necesiten implementar una funcionalidad específica. Cualquier otra cosa que quieran utilizar fuera de esas bibliotecas puede merecer una discusión, pero por lo demás pueden avanzar en su trabajo sin interrumpir el trabajo del equipo de seguridad o de ingeniería de la plataforma.
Lo consigas como lo consigas, construir una "Carretera Pavimentada" para otros equipos es una de las actividades más valiosas de un programa de seguridad. Las carreteras asfaltadas son soluciones bien integradas y respaldadas a problemas comunes que permiten a los humanos centrarse en su creación de valor único (como crear una lógica empresarial diferenciada para una aplicación).14 Aunque la mayoría de las veces pensamos en las carreteras asfaltadas en el contexto de las actividades de ingeniería de productos, las carreteras asfaltadas son absolutamente aplicables en otras partes de la organización, como la seguridad. Imagina un programa de seguridad que encuentre formas de acelerar el trabajo. Facilitar a un vendedor la adopción de una nueva aplicación SaaS que le ayude a cerrar más tratos es una carretera asfaltada. Facilitar a los usuarios la auditoría de la seguridad de su cuenta, en lugar de enterrarla en menús anidados, también es un camino pavimentado. Hablaremos más sobre la habilitación de carreteras pavimentadas como parte de un programa de resiliencia en el Capítulo 7.
Carreteras asfaltadas en acción: Ejemplos de la naturaleza
Un buen ejemplo de un camino allanado -estandarizar unos cuantos patrones para los equipos en un marco de trabajo de valor incalculable-es el marco de trabajo Wall-E de Netflix. Como reconocerá cualquiera que haya tenido que hacer malabarismos para decidir sobre la autenticación, el registro, la observabilidad y otros patrones mientras intentaba crear una aplicación con un presupuesto reducido, que te leguen este tipo de marco suena como el paraíso. Dando un paso atrás, es un ejemplo perfecto de cómo podemos ser pioneros para que las soluciones de resiliencia (y seguridad) satisfagan las presiones de la producción: el "santo grial" en SCE. Como muchos de los que trabajan en tecnología, nos acobardamos ante la palabra sinergias, pero en este caso son reales -como en muchos caminos asfaltados- y puede que te congracie con tu director financiero para que te apoye en la transformación del SCE.
Partiendo de la base de un curioso programa de seguridad, Netflix empezó con la observación de que los equipos de ingeniería de software tenían que tener en cuenta demasiados aspectos de seguridad al crear y entregar software: autenticación, registro, certificados TLS y más. Tenían extensas listas de comprobación de seguridad para los desarrolladores que creaban esfuerzo manual y eran confusas de realizar (como Netflix declaró: "Había diagramas de flujo dentro de las listas de comprobación. Ouch"). El status quo también creaba más trabajo para su equipo de ingeniería de seguridad, que de todos modos tenía que guiar a los desarrolladores a través de la lista de comprobación y validar sus elecciones manualmente.
Por eso, el equipo de seguridad de aplicaciones (appsec) de Netflix se preguntó cómo construir un camino pavimentado para el proceso, produciéndolo. Su equipo piensa en el camino pavimentado como una forma de esculpir preguntas en proposiciones booleanas. En su ejemplo, en lugar de decir: "Dime cómo hace tu aplicación esto tan importante para la seguridad", comprueban que el equipo está utilizando el camino pavimentado pertinente para gestionar el tema de la seguridad.
El camino pavimentado que construyó Netflix, llamado Wall-E, estableció un patrón de adición de requisitos de seguridad como filtros que sustituyeron a las listas de comprobación existentes que requerían cortafuegos de aplicaciones web (WAF), prevención de DDoS, validación de encabezados de seguridad y registro duradero. En sus propias palabras: "Al final, pudimos añadir tantas ventajas de seguridad a Wall-E que la mayor parte de la lista de comprobación para las aplicaciones de Studio se redujo a un solo elemento: ¿Usarás Wall-E?"
También pensaron mucho en reduciendo la fricción de la adopción (en gran parte porque la adopción era una métrica de éxito clave para ellos; otros equipos de seguridad, tomen nota). Al comprender los patrones de flujo de trabajo existentes, pidieron a los equipos de ingeniería de productos que se integraran con Wall-E creando un archivo YAML controlado por versiones, lo que, aparte de facilitar el empaquetado de los datos de configuración, también "recogió la intención de los desarrolladores". Puesto que disponían de una "definición concisa y estandarizada de la aplicación que pretendían exponer", Wall-E podía automatizar proactivamente gran parte del arduo trabajo que los desarrolladores no querían hacer tras sólo unos minutos de configuración. Los resultados benefician tanto a la eficiencia como a la resiliencia, exactamente lo que buscamos para satisfacer la sed de nuestras organizaciones de hacer más rápidamente, y nuestra búsqueda de resiliencia: "Para una aplicación típica de carretera asfaltada sin complicaciones de seguridad inusuales, un equipo podría pasar de git init a una aplicación lista para producción, totalmente autenticada y accesible por Internet en algo menos de 10 minutos". A los desarrolladores del producto no les importaba necesariamente la seguridad, pero la adoptaron con entusiasmo cuando se dieron cuenta de que este patrón estandarizado les ayudaba a enviar el código a los usuarios con mayor rapidez y a iterar más rápidamente, y la iteración es una forma clave de fomentar la flexibilidad durante la construcción y la entrega, como veremos al final del capítulo.
Análisis de dependencia y priorización de vulnerabilidades
La última práctica que podemos adoptar para ampliar y preservar nuestros límites de seguridad es el análisis de dependencias y, en particular, la priorización prudente de las vulnerabilidades. El análisis de dependencias, especialmente en el contexto de la detección de errores (incluidas las vulnerabilidades de seguridad), nos ayuda a comprender los fallos de nuestras herramientas para que podamos corregirlos o mitigarlos , o incluso considerar la posibilidad de utilizar herramientas mejores. Podemos tratar esta práctica como una protección contra posibles factores de estrés y sorpresas, lo que nos permite invertir nuestro capital de esfuerzo en otra cosa. Sin embargo, el sector de la seguridad no ha facilitado la comprensión de cuándo una vulnerabilidad es importante, así que empezaremos revelando heurísticas para saber cuándo debemos invertir esfuerzo en solucionarlas.
Priorizar las vulnerabilidades
¿Cuándo debes preocuparte por una vulnerabilidad? Supongamos que una nueva vulnerabilidad se difunde en las redes sociales. ¿Significa esto que debes parar todo para implementar una solución o un parche? ¿O la fatiga de la alarma enervará tu motivación? Que debas preocuparte por una vulnerabilidad depende de dos factores principales:
¿Es fácil automatizar y escalar el ataque?
¿A cuántos pasos está el ataque del resultado del objetivo del atacante?
El primer factor -la facilidad para automatizar y escalar el ataque (es decir, el aprovechamiento de la vulnerabilidad)- se describe históricamente en con el término "wormable".15 ¿Puede un atacante aprovechar esta vulnerabilidad a escala? Un ataque que no requiera interacción alguna por parte del atacante sería fácil de automatizar y escalar. La minería de criptomonedas suele estar en esta categoría. El atacante puede crear un servicio automatizado que escanee una herramienta como Shodan en busca de instancias vulnerables de aplicaciones que requieran un amplio cómputo, como Kibana o una herramienta CI. A continuación, el atacante ejecuta un script de ataque automatizado contra la instancia, y luego descarga y ejecuta automáticamente la carga útil de minería criptográfica, si tiene éxito. El atacante puede ser notificado si algo va mal (igual que tu típico equipo de Operaciones), pero a menudo puede dejar que este tipo de herramienta funcione completamente sola mientras se centra en otra actividad delictiva. Su estrategia consiste en conseguir tantas pistas como puedan para maximizar el potencial de monedas minadas durante cualquier periodo de tiempo.
El segundo factor está, en esencia, relacionado con la facilidad de uso de la vulnerabilidad para los atacantes. Podría decirse que es un elemento de si el ataque es automatizable y escalable, pero merece la pena mencionarlo por sí solo dado que es aquí donde las vulnerabilidades descritas como "devastadoras" a menudo se quedan obviamente cortas en tales afirmaciones. Cuando los atacantes explotan una vulnerabilidad, ésta les da acceso a algo. La cuestión es lo cerca que está ese algo de sus objetivos. A veces los investigadores de vulnerabilidades -incluidos los cazadores de recompensas por fallos- insistirán en que un fallo es "trivial" de explotar, a pesar de que requiere que el usuario realice numerosos pasos. Como bromeó un atacante anónimo: "He tenido operaciones que casi fracasan porque una víctima voluntaria no conseguía seguir las instrucciones sobre cómo comprometerse".
Dilucidemos este factor mediante un ejemplo. En 2021, se publicó una prueba de concepto de Log4Shell, una vulnerabilidad de la biblioteca Apache Log4j -yahemos hablado de ella en capítulos anteriores-. La vulnerabilidad ofrecía una fantástica facilidad de uso a los atacantes, permitiéndoles obtener la ejecución de código en un host vulnerable pasando un texto especial "jni:"-en referencia a la Interfaz de Nombres y Directorios de Java (JNDI)- a un campo registrado por la aplicación. Si eso suena relativamente trivial, lo es. Podría decirse que sólo hay un paso real en el ataque: los atacantes proporcionan la cadena (una inserción "jndi:" en una cabecera HTTP registrable que contiene una URI maliciosa), lo que obliga a la instancia Log4j a realizar una consulta LDAP a la URI controlada por el atacante, que luego conduce a una cadena de eventos automatizados que dan lugar a que una clase Java proporcionada por el atacante se cargue en la memoria y sea ejecutada por la instancia Log4j vulnerable. ¿Sólo se requiere un paso (más algo de trabajo previo) para la ejecución remota de código? ¡Menudo valor añadido! Esta es precisamente la razón por la que Log4j era tan automatizable y escalable para los atacantes, lo que hicieron en las 24 horas siguientes a la publicación de la prueba de concepto.
Como otro ejemplo, Heartbleed está en el límite de la facilidad de uso aceptable para los atacantes. Heartbleed permite a los atacantes obtener memoria arbitraria, que podría incluir secretos, que los atacantes podrían tal vez utilizar para hacer algo más y entonces... puedes ver que la facilidad de uso es bastante condicional. Aquí es donde entra en juego el factor de la huella; si pocos sistemas de acceso público utilizaran OpenSSL, entonces realizar esos pasos podría no merecer la pena para los atacantes. Pero como la biblioteca es popular, algunos atacantes podrían esforzarse en elaborar un ataque que se amplíe. Decimos "algunos" porque, en el caso de Heartbleed, lo que el acceso a la memoria arbitraria proporciona a los atacantes es esencialmente la capacidad de leer cualquier basura que haya en la memoria reutilizada de OpenSSL, que podrían ser claves de cifrado u otros datos cifrados o descifrados. Y nos referimos a "basura". Es difícil y engorroso para los atacantes obtener los datos que podrían estar buscando, y aunque la misma vulnerabilidad exacta estuviera en todas partes y fuera accesible remotamente, se necesita mucha atención específica del objetivo para convertirla en algo útil. El único ataque genérico que se puede formar con esta vulnerabilidad es robar las claves privadas de los servidores vulnerables, y eso sólo es útil como parte de un elaborado y complicado ataque de intromisión en el medio.
En el extremo de requerir muchos pasos, considera una vulnerabilidad como Rowhammer -un fallo en muchos módulos DRAM en los que las activaciones repetidas de filas de memoria pueden lanzar volteos de bits en filas adyacentes-. En teoría, tiene una huella de ataque masiva porque afecta a "toda una generación de máquinas". En la práctica, hay bastantes requisitos para explotar el Martillo de Filas para la elevación de privilegios, y eso después de la limitación inicial de necesitar la ejecución de código local: eludir la caché y asignar un gran trozo de memoria; buscar filas defectuosas (ubicaciones propensas a voltear bits); comprobar si esas ubicaciones permitirán la explotación; devolver ese trozo de memoria al SO; obligar al SO a reutilizar la memoria; elegir dos o más "pares de direcciones en conflicto de fila" y martillear las direcciones (es decir, activando las direcciones elegidas) para forzar la inversión de bits, lo que da lugar a un acceso de lectura/escritura a, por ejemplo, una tabla de páginas, de la que el atacante puede abusar para luego ejecutar lo que realmente quiera hacer. Y eso antes de entrar en las complicaciones de provocar la inversión de los bits. Puedes ver por qué no hemos visto este ataque en la naturaleza y por qué es poco probable que lo veamos a escala como la explotación de Log4Shell.
Así que, a la hora de priorizar si solucionar una vulnerabilidad inmediatamente -especialmente si la solución provoca una degradación del rendimiento o una funcionalidad rota- o esperar hasta que esté disponible una solución más viable, puedes utilizar esta heurística: ¿puede el ataque escalar, y cuántos pasos requiere que realicen los atacantes? Como ya ha bromeado un autor: "Si hay una vulnerabilidad que requiere acceso local, ajustes de configuración especiales y delfines saltando por el anillo 0", entonces es una hipérbole total tratar el software afectado como "roto". Pero, si todo lo que hace falta es que el atacante envíe una cadena a un servidor vulnerable para obtener la ejecución remota de código sobre él, entonces es probable que sea una cuestión de con qué rapidez se verá afectada tu organización, no de si se verá afectada. En esencia, esta heurística te permite clasificar las vulnerabilidades en "deuda técnica" frente a "incidente inminente". Sólo una vez que hayas eliminado todas las posibilidades de ataques fortuitos -que son la mayoría- deberás preocuparte por los ataques selectivos súper hábiles que requieren que los atacantes se impliquen en tácticas del nivel de las películas de espías para tener éxito.
Consejo
Este es otro caso en el que aislamiento puede ayudarnos a mantener la resiliencia. Si el componente vulnerable está en una caja de arena, el atacante debe superar otro reto antes de poder alcanzar su objetivo.
Recuerda que los investigadores de vulnerabilidades no son atacantes. El hecho de que exageren su investigación no significa que el ataque pueda escalar o presentar suficiente eficacia para los atacantes. Tu administrador de sistemas o SRE local está más cerca del atacante típico que un investigador de vulnerabilidades.
Errores de configuración y mensajes de error
También debemos tener en cuenta los errores de configuración y los mensajes de error como parte del fomento de un análisis reflexivo de las dependencias. Los fallos de configuración -a menudo denominados "configuraciones erróneas"- surgen porque las personas que diseñaron y construyeron el sistema tienen modelos mentales distintos de los de las personas que utilizan el sistema. Cuando construimos sistemas, tenemos que estar abiertos a los comentarios de los usuarios; el modelo mental del usuario importa más que el nuestro, ya que sentirá el impacto de cualquier error de configuración. Como veremos más adelante en el Capítulo 6, no debemos confiar en el "error del usuario" o en el "error humano" como explicación superficial. Cuando construimos algo, tenemos que hacerlo basándonos en un uso realista, no en el ideal platónico de un usuario.
Debemos hacer un seguimiento de los errores y fallos de configuración y tratarlos igual que a los demás fallos.17 No debemos suponer que los usuarios u operadores leen los documentos o manuales lo suficiente como para asimilarlos por completo, ni debemos confiar en que los usuarios u operadores examinen detenidamente el código fuente. Desde luego, no deberíamos suponer que los humanos que configuran el software son infalibles o que poseerán el mismo contexto rico que nosotros como constructores. Lo que a nosotros nos parece básico, a los usuarios puede parecerles esotérico. Una respuesta icónica que ejemplifica este principio es de 2004, cuando un usuario envió un correo electrónico a la lista de correo de OpenLDAP en respuesta al comentario del desarrollador de que "el manual de referencia ya dice, cerca de la parte superior....". La respuesta decía "Das por sentado que los que leyeron eso, entendieron cuál era el contexto de 'usuario'. Yo, desde luego, no lo había hecho hasta ahora. Por desgracia, muchos de nosotros no procedemos de entornos UNIX y, aunque nos damos cuenta de muchas cosas, algunas que a vosotros os parecen básicas se nos escapan durante algún tiempo."
Como veremos en el Capítulo 6, no debemos culpar al comportamiento humano cuando las cosas van mal, sino esforzarnos por ayudar al ser humano a tener éxito incluso cuando las cosas van mal. Queremos que nuestro software facilite una adaptación grácil a los errores de configuración de los usuarios. Como aconseja un estudio "Si la configuración errónea de un usuario hace que el sistema se bloquee, se cuelgue o falle silenciosamente, el usuario no tiene más remedio que informar al soporte técnico. No sólo los usuarios sufren el tiempo de inactividad del sistema, sino también los desarrolladores, que tienen que dedicar tiempo y esfuerzo a solucionar los errores y quizá compensar las pérdidas de los usuarios."18
¿Cómo ayudamos al sistema sociotécnico a adaptarse ante los errores de configuración? Podemos fomentar mensajes de error explícitos que generen un bucle de retroalimentación (hablaremos más sobre los bucles de retroalimentación más adelante en este capítulo). Como descubrieron Yin et al. en un estudio empírico sobre errores de configuración en sistemas comerciales y de código abierto, sólo entre el 7,2% y el 15,5% de los errores de configuración ofrecían mensajes explícitos para ayudar a los usuarios a localizar el error.19 Cuando hay mensajes de error explícitos, el tiempo de diagnóstico se acorta entre 3 y 13 veces en relación con los mensajes ambiguos y entre 1,2 y 14,5 veces con la ausencia total de mensajes .
A pesar de esta evidencia empírica, la sabiduría popular infosec dice que los mensajes de error descriptivos son pestíferos porque los atacantes pueden aprender cosas del mensaje que les ayuden a operar. Claro, y el uso de Internet facilita los ataques, ¿deberíamos evitarlo también? Nuestra filosofía es que no debemos castigar a los usuarios legítimos sólo porque los atacantes puedan, en ocasiones, obtener una ventaja. Esto no significa que proporcionemos mensajes de error verbosos en todos los casos. La cantidad adecuada de elaboración depende del sistema o componente en cuestión y de la naturaleza del error. Si nuestra parte del sistema está cerca de un límite de seguridad, es probable que queramos ser más cautos en lo que revelamos. El ad absurdum de los mensajes de error expresivos en un límite de seguridad sería, por ejemplo, una página de inicio de sesión que devolviera el error "¡Te has acercado mucho a la contraseña correcta!".
Como heurística general, deberíamos tender a dar más información en los mensajes de error hasta que se demuestre cómo se podría hacer un mal uso de esa información (por ejemplo, cómo revelar que una contraseña adivinada se acercaba a la verdadera podría ayudar fácilmente a los atacantes). Si se trata de un error previsto sobre el que el usuario puede hacer algo razonablemente, deberíamos presentárselo en un texto legible por humanos. El sistema está ahí para que los usuarios y la organización puedan alcanzar algún objetivo, y los mensajes de error descriptivos ayudan a los usuarios a comprender qué han hecho mal y a remediarlo.
Si el usuario no puede hacer nada sobre el error, ni siquiera con los detalles, entonces no tiene sentido mostrárselos. Para esta última categoría de error, un patrón que podemos considerar es devolver algún tipo de identificador de rastreo que un operador de soporte pueda utilizar para consultar los registros y ver los detalles del error (o incluso qué más ocurrió en la sesión del usuario).20 Con este patrón, si un atacante quiere obtener algunos detalles jugosos del error de los registros, debe realizar ingeniería social con el operador de soporte (es decir, encontrar una manera de embaucarle para que revele sus credenciales). Si no se puede hablar con un operador de soporte, no tiene sentido mostrar el ID del rastreo de errores, ya que el usuario no puede hacer nada con él.
Consejo
Nunca debe un sistema arrojar una traza de pila a la cara de un usuario, a menos que quepa esperar que ese usuario construya una nueva versión del software (o realice alguna otra acción tangible). Es incivilizado hacerlo.
Recapitulando, durante la fase de construcción y entrega, podemos seguir cuatro prácticas para apoyar los límites de seguridad, el segundo ingrediente de nuestra poción de resiliencia: anticipar la escala, automatizar las comprobaciones de seguridad mediante CI/CD, estandarizar patrones y herramientas, y realizar un análisis reflexivo de las dependencias. Pasemos ahora al tercer ingrediente: observar las interacciones del sistema en el espacio-tiempo.
Observa las interacciones del sistema a través del espacio-tiempo (o hazlas más lineales)
El tercer ingrediente de nuestra poción de resiliencia es observar las interacciones del sistema a través del espacio-tiempo. Al construir y entregar sistemas, podemos apoyar esta observación y formar modelos mentales más precisos a medida que los comportamientos de nuestros sistemas se desarrollan en el tiempo y a través de su topología (porque observar un único componente en un único punto en el tiempo nos dice poco desde la perspectiva de la resiliencia). Pero también podemos ayudar a que las interacciones sean más lineales, aumentando nuestro debate sobre el diseño para la linealidad del último capítulo. Hay prácticas y pautas que podemos adoptar (o evitar) que pueden ayudarnos a introducir más linealidad cuando construimos y suministramos sistemas.
En esta sección, exploraremos cuatro prácticas durante esta fase que nos ayudan a observar las interacciones del sistema a través del espacio-tiempo o a alimentar la linealidad: La configuración como código, la inyección de fallos, las prácticas de prueba reflexivas y la navegación cuidadosa de las abstracciones. Cada práctica apoya nuestro objetivo general durante esta fase de aprovechar la velocidad para vitalizar las características y comportamientos que necesitamos para mantener la resistencia de nuestros sistemas a los ataques.
Configuración como código
La primera práctica que nos concede el don de hacer que las interacciones a través del espacio-tiempo sean más lineales (además de observarlas) es la Configuración como Código (CaC). La automatización de las actividades de implementación reduce la cantidad de esfuerzo humano necesario (que puede asignarse a otros fines) y favorece una entrega de software repetible y coherente. Parte de la entrega de software es también la entrega de la infraestructura subyacente a tus aplicaciones y servicios. ¿Cómo podemos asegurarnos de que la infraestructura también se entrega de forma repetible? En términos más generales, ¿cómo podemos verificar que nuestras configuraciones se ajustan a nuestros modelos mentales?
La respuesta está en las prácticas CaC: declarar configuraciones mediante marcado en lugar de procesos manuales. Aunque el movimiento SCE aspira a un futuro en el que todo tipo de configuraciones sean declarativas, la práctica actual consiste principalmente en la Infraestructura como Código (IaC). IaC es la capacidad de crear y gestionar infraestructuras mediante especificaciones declarativas en lugar de procesos de configuración manuales. La práctica utiliza el mismo tipo de proceso que el código fuente, pero en lugar de generar cada vez el mismo binario de aplicación, genera cada vez el mismo entorno. Crea servicios más fiables y predecibles. CaC es la idea de ampliar este enfoque a todas las configuraciones que importan, como la resiliencia, el cumplimiento y la seguridad. El CaC reside en la difusa superposición de la entrega y las operaciones, pero debe considerarse parte de lo que entregan los equipos de ingeniería.
Si ya conoces la IaC, quizá te sorprenda que se esté promocionando como herramienta de seguridad. Las organizaciones ya lo están adoptando por la pista de auditoría que genera, que apoya absolutamente la seguridad al hacer que las prácticas sean más repetibles. Veamos otras ventajas de la IaC para los programas de seguridad.
- Respuesta más rápida a los incidentes
IaC admite la redistribución automática de la infraestructura cuando se producen incidentes. Y lo que es mejor, también puede responder automáticamente a los indicadores de incidentes, utilizando señales como el umbral para anticiparse a los problemas (hablaremos más de esto en el próximo capítulo). Con el reaprovisionamiento automático de la infraestructura, podemos eliminar y volver a desplegar las cargas de trabajo comprometidas en cuanto se detecta un ataque, sin afectar a la experiencia del usuario final.
- Deriva ambiental minimizada
La deriva ambiental se refiere a configuraciones u otros atributos ambientales que "derivan" hacia un estado incoherente, como que la producción sea incoherente respecto a la puesta en escena. IaC admite el versionado automático de la infraestructura para minimizar la deriva ambiental y facilita la reversión de las implementaciones cuando sea necesario si algo va mal. Puedes realizar implementaciones en flotas de máquinas de forma impecable, de un modo que a los humanos les costaría llevar a cabo sin cometer errores. IaC te permite hacer cambios de forma casi atómica. Codifica tus procesos de implementación en una notación que puede pasarse de humano a humano, especialmente cuando los equipos cambian de miembros, lo que afloja nuestro acoplamiento en la capa 8 (es decir, la capa de las personas).
- Parches y correcciones de seguridad más rápidos
IaC permite parchear e implementar más rápidamente los cambios de seguridad. Como comentamos en la sección sobre CI/CD, la verdadera lección del infame incidente de Equifax es que los procesos de aplicación de parches deben ser utilizables, de lo contrario la dilación será un curso de acción lógico. IaC reduce las fricciones a la hora de lanzar parches, actualizaciones o correcciones, y también descentraliza el proceso, promoviendo un acoplamiento organizativo más laxo. Como punto más general, si cualquier proceso organizativo es engorroso o inutilizable, será eludido. Esto no se debe a que los humanos sean malos, sino todo lo contrario: los humanos son bastante buenos ideando formas eficientes de alcanzar sus objetivos.
- Configuraciones erróneas minimizadas
En el momento de escribir esto, las desconfiguraciones son la vulnerabilidad de seguridad en la nube más común según la Agencia Nacional de Seguridad (NSA); son fáciles de explotar por los atacantes y muy frecuentes. La IaC ayuda a corregir las desconfiguraciones tanto de los usuarios como de los sistemas automatizados. Tanto los humanos como los ordenadores son capaces de cometer errores, y esos errores son inevitables. Por ejemplo, IaC puede automatizar la implementación de configuraciones de control de acceso, que son notoriamente confusas y fáciles de estropear.
- Detección de configuraciones vulnerables
Para detectar configuraciones vulnerables, el statu quo suele ser el escaneado autenticado en entornos de producción, lo que introduce nuevas vías de ataque y peligros. IaC nos permite eliminar ese peligro, escaneando en su lugar los archivos de código para encontrar configuraciones vulnerables. IaC también facilita la redacción y aplicación de reglas en un conjunto de archivos de configuración, frente a la redacción y aplicación de reglas en todas las API de tu proveedor de servicios en la nube (CSP).
- Aplicación autónoma de políticas
IaC ayuda a automatizar la implementación y la aplicación de las políticas de IAM, como el Principio del Mínimo Privilegio (PoLP). Los patrones de IaC simplifican el cumplimiento de las normas del sector, como la conformidad, con un objetivo final de "conformidad continua"(Figura 4-1).
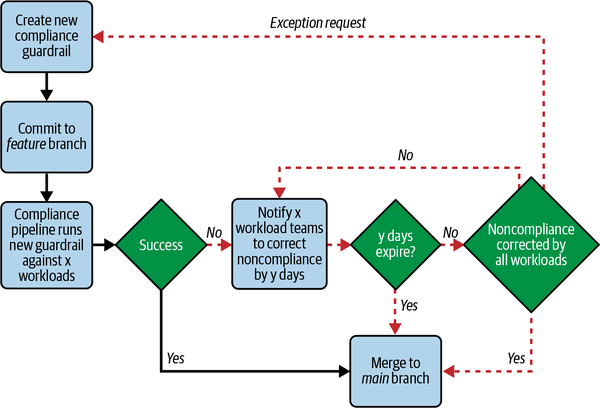
Figura 4-1. Un ejemplo de "flujo de trabajo de conformidad continua para IaC" de AWS
- Control de cambios más estricto
IaC introduce el control de cambios mediante la gestión del código fuente (SCM), lo que permite revisiones por pares de las configuraciones y un sólido registro de cambios. Esto también aporta importantes ventajas de cumplimiento.
Debido a todas estas ventajas, y al hecho de que todos los equipos de ingeniería pueden aprovecharlas para alcanzar objetivos compartidos, IaC favorece un programa de seguridad más flexible y libera capital de esfuerzo para otras actividades. La pista de auditoría que engendra y los entornos de experimentación que permite también favorecen la curiosidad, que es lo que queremos para nuestra poción de resiliencia. Refuerza nuestra poción de resiliencia haciendo que las interacciones en el espacio-tiempo sean más lineales, pero también engendra flexibilidad y voluntad de cambio, como una oferta de "compre un reactivo y llévese otro gratis" en la botica de la bruja.
Inyección de fallos durante el desarrollo
Otra práctica que podemos utilizar en esta fase para excavar y observar las interacciones del sistema a través del espacio-tiempo es la inyección de fallos.21 De hecho, esto presenta dos oportunidades para los equipos de seguridad: aprender sobre la inyección de fallos para defender su valor para la organización (e intentar allanar el camino para su adopción), y colaborar con los equipos de ingeniería para integrar la inyección de fallos en los flujos de trabajo existentes. Si sólo probamos el "camino feliz" en nuestro software, nuestro modelo mental del sistema será un engaño y nos quedaremos desconcertados cuando nuestro software se vuelva inestable en producción. Para construir sistemas de software resistentes, debemos concebir y explorar también los "caminos infelices".
Cuando añadas un nuevo componente al sistema, considera qué eventos de interrupción pueden ser posibles y escribe pruebas para capturarlos. Estas pruebas se denominan pruebas de inyección de fallos: estresan el sistema introduciendo a propósito un fallo, como introducir un pico de tensión o una entrada sobredimensionada. Dado que la mayoría de los sistemas de software que construimos se parecen más o menos a una aplicación web conectada a una base de datos, una primera prueba de inyección de fallos puede adoptar a menudo la forma de "desconecta y vuelve a conectar la base de datos para asegurarte de que tu capa de abstracción de la base de datos recupera la conexión". A diferencia de los experimentos de caos, que simulan escenarios adversos, con la inyección de fallos estamos introduciendo una entrada torcida a propósito para ver qué ocurre en un componente concreto.
Muchos equipos no dan prioridad a la inyección de fallos (o tolerancia a fallos) hasta que se produce un incidente o un cuasi accidente. En una realidad de recursos finitos, es razonable preguntarse si la inyección de fallos merece la pena, pero eso supone que tienes que realizarla en todas partes para adoptarla. Empezar con la inyección de fallos para tus funciones críticas (como las que definiste en la evaluación de nivel 1 del Capítulo 2) te ayuda a invertir tu esfuerzo en los lugares donde realmente importa. Supongamos que tu empresa ofrece una plataforma de subastas de equipos físicos, en la que el tráfico de servicio durante una subasta debe producirse continuamente sin tiempo de inactividad, pero no pasa nada si se retrasa el análisis de los usuarios. Tal vez inviertas más en la inyección de fallos y otras pruebas que informen de las mejoras de diseño en el sistema de subastas, pero confíes en el monitoreo y la observabilidad en el resto de tus sistemas para que la recuperación de fallos sea más sencilla.
Las pruebas de inyección de fallos deben escribirse mientras el problema esté presente, es decir, durante el desarrollo. Hacer de la inyección de fallos una práctica estándar para las funciones críticas ayudará a los desarrolladores a comprender mejor sus dependencias antes de entregarlas, y podría desalentar la introducción de componentes que dificulten la operatividad del sistema. De hecho, este principio es válido para la mayoría de las pruebas, a las que nos referiremos a continuación.
Pruebas de integración, pruebas de carga y teatro de pruebas
Pasemos ahora a una práctica vital, y controvertida, que puede apoyar la observación de las interacciones del sistema a través del espacio-tiempo: las pruebas. Como disciplina, la ingeniería de software necesita mantener una conversación incómoda en torno a las pruebas (por no hablar del pésimo statu quo de las pruebas de seguridad). ¿Estamos probando la resistencia o la corrección a lo largo del tiempo, o sólo para decir que hemos hecho pruebas? Algunas formas de pruebas pueden servir más como dispositivos de seguridad cuando se automatizan completamente, bloqueando fusiones o implementaciones sin necesidad de intervención humana. O bien, podemos escribir un montón de pruebas unitarias, utilizar la cobertura del código como una representación engañosa de un trabajo bien hecho, y afirmar que "lo hemos probado" si algo va mal. Como alternativa, podemos invertir nuestro capital de esfuerzo en formas más constructivas de observar las propiedades de resiliencia del sistema mediante pruebas de integración y de carga, o incluso realizar pruebas de estrés de resiliencia (experimentación del caos) como parte del nivel de experimentación del que hablamos en el Capítulo 2.
La jerarquía triangular tradicional de pruebas no sirve para la resiliencia; el triángulo (y sus hermanos geométricos) parecen bonitos e intuitivos, pero son más estéticos que reales. Diferentes tipos de pruebas son mejores para abordar determinadas cuestiones, y qué pruebas te pueden resultar útiles dependerá de lo que sea más relevante para tu contexto local: tus funciones críticas y tus objetivos y limitaciones que definen tus límites operativos.
Tenemos que pensar en las pruebas en términos de Cartera de Inversión de Esfuerzos. La combinación ideal de tipos de pruebas y cobertura en la que invertimos puede ser diferente según el proyecto y la parte del sistema. A un ingeniero de software puede no importarle si su código de análisis de configuración es lento o torpe, siempre que la aplicación se inicie de forma fiable con la configuración correcta, por lo que las pruebas de integración son suficientes. Sin embargo, si es fundamental validar los datos entrantes del usuario, entonces las pruebas fuzz podrían ser un candidato para esas rutas de código.
Las pruebas escritas por los ingenieros son un artefacto de sus modelos mentales en un determinado punto del espacio-tiempo. Dado que la realidad evoluciona -incluidos los sistemas y las cargas de trabajo que contiene-, las pruebas quedan desfasadas. Las ideas que aprendemos de los experimentos de caos, los incidentes reales e incluso la observación de sistemas en buen estado deben volver a introducirse en nuestros conjuntos de pruebas para garantizar que reflejan la realidad de la producción. Debemos dar prioridad a las pruebas que nos ayuden a refinar nuestros modelos mentales y puedan adaptarse a medida que evoluciona el contexto del sistema. Como dice el manual de SRE de Google: "Las pruebas son el mecanismo que utilizas para demostrar áreas específicas de equivalencia cuando se producen cambios. Cada prueba que se supera tanto antes como después de un cambio reduce la incertidumbre que el análisis debe tener en cuenta. Unas pruebas minuciosas nos ayudan a predecir la fiabilidad futura de un sitio determinado con suficiente detalle como para ser útiles en la práctica."
La historia ha jugado en contra de las pruebas sólidas en la ingeniería de software; las organizaciones solían mantener equipos de pruebas dedicados, pero hoy en día son raros de ver. Culturalmente, a menudo existe la sensación entre los ingenieros de software de que las pruebas son "problema de otros". El problema subyacente a esta excusa es que las pruebas se perciben como demasiado complicadas, especialmente las pruebas de integración. Por eso los caminos pavimentados para las pruebas de todo tipo, no sólo de seguridad, son una de las soluciones más valiosas que pueden construir los equipos de ingeniería de seguridad y plataformas. Para contrarrestar las objeciones sobre el rendimiento, podríamos incluso permitir que los desarrolladores especifiquen el nivel de sobrecarga con el que se sienten cómodos.22
En esta sección exploraremos por qué, en contra de la sabiduría popular, la categoría de pruebas más importante es posiblemente la prueba de integración (o "prueba de integración amplia"). Comprueba si el sistema hace realmente lo que se supone que debe hacer en el sentido más básico. Hablaremos de las pruebas de carga y de cómo podemos aprovechar la repetición del tráfico para observar cómo se comporta el sistema en el espacio-tiempo. A pesar de la sabiduría popular, discutiremos por qué las pruebas unitarias no deben considerarse la base necesaria antes de que una organización busque otras formas de pruebas. Algunas organizaciones pueden optar por renunciar por completo a las pruebas unitarias, por las razones que expondremos en esta sección. Terminaremos con las pruebas fuzz, una prueba que sólo merece la pena realizar una vez que hayamos establecido nuestros "fundamentos".
Pruebas de integración
Las pruebas de integración suelen considerarse parte de la "buena ingeniería", pero sus beneficios para la resiliencia son menos discutidos. Las pruebas de integración observan cómo funcionan juntos los distintos componentes del sistema, normalmente con el objetivo de verificar que interactúan como se espera, lo que las convierte en una valiosa primera pasada para descubrir "interacciones desconcertantes". Lo que observamos es el sistema idealizado, como cuando proponemos una nueva iteración del sistema y probamos para asegurarnos de que todo se integra según lo previsto. Los únicos cambios de los que informan las pruebas de integración son más o menos: "has cometido un error y quieres evitar que ese error se ponga en marcha". Para obtener información más exhaustiva sobre cómo podemos perfeccionar el diseño del sistema, necesitamos experimentos de caos: las pruebas de resistencia que tratamos en el Capítulo 2.
¿Cómo es una prueba de integración en la práctica? Volvamos a nuestro ejemplo anterior de una aplicación web conectada a una base de datos. Una prueba de integración podría y debería cubrir ese caso - "desconecta y vuelve a conectar la base de datos para asegurarte de que tu capa de abstracción de base de datos recupera la conexión"- en la mayoría de las bibliotecas cliente de base de datos.
La vulnerabilidad AttachMe -unavulnerabilidad de aislamiento de la nube en Oracle Cloud Infrastructure (OCI)- es un ejemplo de lo que esperamos descubrir con una prueba de integración, y otro ejemplo de lo peligroso que es centrarse sólo en los "caminos felices" cuando se realizan pruebas y desarrollos en general. El fallo permitía a los usuarios adjuntar volúmenes de disco para los que carecían de permisos -suponiendo que pudieran nombrar el volumen por su ID- a máquinas virtuales que controlaban para acceder a los datos de otro inquilino. Si un atacante lo intentaba, podía iniciar una instancia de cálculo, adjuntar el volumen de destino a la instancia de cálculo bajo su control y obtener privilegios de lectura/escritura sobre el volumen (lo que podría permitirle robar secretos, ampliar el acceso o, potencialmente, incluso hacerse con el control del entorno de destino). Aparte del escenario de ataque, sin embargo, este es el tipo de interacción que no queremos en entornos multiusuario también por razones de fiabilidad. Podríamos desarrollar múltiples pruebas de integración que describieran diversas actividades en un entorno multiinquilino, ya sea conectar un disco a una máquina virtual de otra cuenta, que varios inquilinos realicen la misma acción simultáneamente en una base de datos compartida, o picos de consumo de recursos en un inquilino.
Como principio general, queremos realizar pruebas de integración que nos permitan observar las interacciones del sistema a través del espacio-tiempo. Esto es mucho más útil para fomentar la resiliencia que probar propiedades individuales de componentes concretos (como las pruebas unitarias). Una entrada en un componente es insuficiente para reproducir fallos catastróficos en las pruebas. Se necesitan múltiples entradas, pero esto no tiene por qué desconcertarnos. Un estudio de 2014 descubrió que tres o menos nodos son suficientes para reproducir la mayoría de los fallos, pero se necesitan múltiples entradas y los fallos sólo se producen en sistemas de larga duración, lo que corrobora tanto la deficiencia de las pruebas unitarias como la necesidad de la experimentación del caos.25
El estudio también demostró que el código de gestión de errores de es un factor muy influyente en la mayoría de los fallos catastróficos, y que "casi todos" (92%) los fallos catastróficos del sistema se deben a una "gestión incorrecta de errores no fatales señalados explícitamente en el software". Ni que decir tiene que, como parte de nuestras inversiones en la asignación de esfuerzos, deberíamos dar prioridad a la comprobación del código de gestión de errores. Los autores del estudio de 2014 escribieron: "En otro 23% de los fallos catastróficos, la lógica de gestión de errores de un error no fatal era tan errónea que cualquier prueba de cobertura de enunciados o revisiones de código más cuidadosas por parte de los desarrolladores habrían detectado los fallos." Caitie McCaffrey, arquitecta asociada de Microsoft, aconseja al verificar sistemas distribuidos: "Lo mínimo debería ser emplear pruebas unitarias y de integración que se centren en la gestión de errores, nodos inalcanzables, cambios de configuración y cambios en la pertenencia a clusters". Estas pruebas no tienen por qué ser costosas; presentan un amplio retorno de la inversión tanto para la resiliencia como para la fiabilidad.
McCaffrey señaló que a menudo se omiten las pruebas de integración debido a "la creencia generalizada de que los fallos son difíciles de producir fuera de línea y de que crear un entorno similar al de producción para las pruebas es complicado y caro".26 La fabulosa noticia es que crear un entorno similar al de producción para las pruebas es cada vez más fácil y barato año tras año; hablaremos de algunas de las modernas innovaciones de infraestructura que permiten entornos de experimentación de bajo coste -una forma más rigurosa de entorno de pruebas, y con un alcance mayor- en el Capítulo 5. Ahora que la informática es más barata, los entornos tradicionales de "preproducción", en los que una colección de casos de uso se ven obligados a compartir la misma infraestructura por razones de coste, deberían considerarse un antipatrón. Queremos ejecutar pruebas de integración (y funcionales) antes del lanzamiento, o en cada fusión con la rama troncal si practicamos CD. Si incluimos metadatos de implementación en un formato declarativo al escribir el código, también podremos automatizar más fácilmente las pruebas de integración, en las que nuestra infraestructura de pruebas puede aprovechar un gráfico de dependencias de servicios.
Consejo
Las objeciones habituales a las pruebas de integración incluyen la presencia de muchas dependencias externas, la necesidad de reproducibilidad y la mantenibilidad. Si combinas las pruebas de integración con experimentos del caos, habrá menos presión sobre las pruebas de integración para probar todo el espectro de interacciones potenciales. Puedes concentrarte en las pocas que supones más importantes y refinar esa suposición con experimentos del caos a lo largo del tiempo.
Sin embargo, la reticencia a utilizar pruebas de integración es aún más profunda. Las pruebas de integración disciernen proactivamente los fallos imprevistos, pero a veces los ingenieros siguen despreciándolas. ¿Por qué? En parte, porque cuando fallan las pruebas de integración, suele ser una odisea averiguar por qué y remediar el fallo. Una parte más subjetiva se refleja en el estribillo habitual de los ingenieros: "Mis pruebas de integración son lentas y defectuosas". Las pruebas "defectuosas" (a veces llamadas "flappy" o "flickering") son aquellas en las que ejecutas la prueba una vez y tiene éxito, y luego, cuando la vuelves a ejecutar, falla. Si las pruebas de integración son lentas y fallidas, el sistema es lento y fallido. Puede ser tu código o tus dependencias, pero, como pensadores de sistemas, tú eres el dueño de tus dependencias.
Los ingenieros suelen ser reticentes a actualizar su modelo mental a pesar de las pruebas de que la implementación no es fiable, normalmente porque sus pruebas unitarias les dicen que el código hace exactamente lo que quieren que haga (en breve hablaremos de los inconvenientes de las pruebas unitarias). Si implementaran un sistema más fiable y escribieran mejores pruebas de integración, no habría tanta necesidad de perseguir pruebas de integración "defectuosas". El verdadero problema -la fiabilidad del software- induce a los ingenieros a pensar que las pruebas de integración son una pérdida de tiempo porque no son fiables. Este es un estado de cosas indeseable si queremos apoyar la resiliencia cuando construimos software.
Advertencia
El compromiso de Codecov de 2021, en el que los atacantes obtuvieron acceso no autorizado al script Bash Uploader de Codecov y lo modificaron, es un buen ejemplo del principio "eres dueño de tus dependencias".
El diseño de Codecov no parecía reflejar un enfoque de resiliencia. Para utilizar Codecov, los usuarios tenían que añadir bash <(curl -s https://codecov.io/bash) en sus pipelines de compilación (el comando está ahora obsoleto). Codecov podría haber diseñado este script para comprobar las firmas del código o tener una cadena de confianza, pero no lo hizo. En el lado del servidor, podrían haber implementado medidas para limitar las implementaciones a ese servidor/ruta, pero no lo hicieron. Podrían haber insertado alertas y registros de las implementaciones en él, pero no lo hicieron. Había numerosos lugares en los que el diseño no reflejaba la confianza que los usuarios depositaban en ellos.
Dicho esto, los desarrolladores que escribieron el software e implementaron en él el agente de Codecov optaron por utilizar Codecov sin examinar a fondo el diseño ni pensar en sus efectos de n-orden. Recuerda, los atacantes estarán encantados de "examinar" estos diseños por ti y sorprenderte con sus hallazgos, pero es mejor adoptar la mentalidad de "tú eres el dueño de tus dependencias" y escudriñar primero lo que insertas en tus sistemas.
Para contrarrestar estos prejuicios es necesario cultivar una cultura curiosa y hacer hincapié incesantemente en la necesidad de refinar los modelos mentales en lugar de aferrarse a narrativas ilusorias pero convenientes. La revisión por pares de las pruebas, como ya se ha comentado en este capítulo, también puede ayudar a descubrir cuándo un ingeniero se siente ofendido por la prueba de integración y no por su código.
Pruebas de carga
Si queremos observar las interacciones a través del espacio-tiempo como parte de nuestra poción de resiliencia, tenemos que observar cómo se comporta el sistema bajo carga al probar una nueva versión del software. Probar con cargas de juguete es como probar una nueva receta en un horno Easy-Bake en lugar de en un horno real. Sólo cuando diseñamos cargas de trabajo realistas que simulan cómo interactúan los usuarios con el sistema, podemos descubrir los posibles problemas funcionales y no funcionales "desconcertantes" que surgirían al entregarlo en producción. Ni que decir tiene que no es ideal, desde el punto de vista de la resiliencia, que nos sorprendamos con un punto muerto después de que la nueva versión funcione en producción durante un tiempo.
Un enfoque automatizado garantiza que los ingenieros de software no se vean obligados a reescribir constantemente las pruebas, lo que va en contra del espíritu de mantener la flexibilidad y la disposición al cambio. Si podemos realizar pruebas de carga a demanda (o diariamente), podremos seguir el ritmo de la evolución del sistema. También debemos asegurarnos de que las conclusiones resultantes sean procesables. Si diseñar, ejecutar o analizar una prueba requiere demasiado esfuerzo, no se utilizará. ¿Podemos destacar si un resultado formaba parte de conclusiones de pruebas anteriores, reflejando un problema recurrente? ¿Podemos visualizar las interacciones para que sea más fácil comprender qué mejoras del diseño podrían mejorar la resistencia? Hablaremos más sobre la experiencia del usuario y el respeto a la atención en el Capítulo 7.
Sin embargo, diseñar cargas de trabajo realistas no es trivial. La forma en que los usuarios -ya sean humanos o máquinas- interactúan con el software (la carga) cambia constantemente, y recopilar todos los datos sobre esas interacciones requiere un esfuerzo considerable.27 Desde el punto de vista de la resiliencia, nos importa mucho menos captar el comportamiento agregado que captar la variedad de comportamientos. Si sólo hiciéramos pruebas con el comportamiento medio, probablemente confirmaríamos nuestros modelos mentales, pero no los cuestionaríamos.
Una táctica es realizar pruebas de carga basadas en personas, que modelan cómo interactúa un tipo específico de usuario con el sistema. Los investigadores que están detrás de esta táctica ponen el ejemplo de "los personajes de un sistema de comercio electrónico podrían incluir a los 'adictos a las compras' (usuarios que realizan muchas compras) y a los 'compradores de escaparate' (usuarios que ven muchos artículos sin realizar ninguna compra)". Podríamos crear personas para los usuarios de máquinas (API) y también para los usuarios humanos. Desde el punto de vista del perfeccionamiento de nuestros modelos mentales sobre las interacciones en el espacio-tiempo, descubrir personas desconocidas que influyen en el comportamiento del sistema (y en su resistencia) es fundamental.
Advertencia
Un peligro es escribir lo que crees que son pruebas de carga que en realidad son puntos de referencia. El objetivo de una prueba de carga es simular una carga realista que el sistema podría encontrar al funcionar en el mundo real. Por lo general, los puntos de referencia se toman en un punto fijo en el tiempo y se utilizan para todas las futuras versiones propuestas del software, y esos son los mejores puntos de referencia basados en un corpus del mundo real. En la práctica, la mayoría de lo que presenciamos son puntos de referencia sintéticos que miden una carga de trabajo concreta diseñada para la prueba.
Los investigadores de las pruebas de carga basadas en personas llegaron incluso a la conclusión de que, con su enfoque, "las pruebas de carga que utilizan cargas de trabajo diseñadas únicamente para cumplir objetivos de rendimiento son insuficientes para afirmar con seguridad que los sistemas funcionarán bien en producción". Los microcomprobadores se alejan aún más de la realidad del sistema, ejercitando sólo una pequeña parte del mismo para ayudar a los ingenieros a determinar si algún cambio hace que esa parte del sistema se ejecute más rápida o más lentamente.
Escribir un benchmark ad hoc para informar una decisión y luego tirarlo a la basura puede ser sensato en algunas circunstancias, pero como evaluación a largo plazo, son pésimos. Aun así, las pruebas de evaluación comparativa son súper complicadas. Es difícil saber si estás midiendo lo correcto, es difícil saber si tu prueba es representativa, es difícil interpretar los resultados y es difícil saber qué hacer a raíz de los resultados.28 Incluso cuando los resultados de algún cambio son supersignificativos, siempre hay que sopesarlos con la diversidad de factores en juego. Muchas bases de datos comerciales prohíben publicar los resultados de los puntos de referencia por ésta y otras razones (lo que se conoce como "cláusula DeWitt ").
La repetición del tráfico nos ayuda a obtener una mejor idea de cómo se comporta el sistema con entradas realistas. Si queremos observar las interacciones del sistema a través del espacio-tiempo e incorporarlas a nuestros modelos mentales, necesitamos simular cómo podría comportarse nuestro software en el futuro una vez ejecutado en producción. La escasez de flujos realistas al probar nuevos entornos provoca un desconcierto superfluo cuando implementamos y ejecutamos nuestro software en producción. Escribir peticiones con guión limita nuestras pruebas a nuestros modelos mentales, mientras que ingerir tráfico real de producción ofrece saludables sorpresas a nuestros modelos mentales .
La réplica de tráfico (o "shadowing" de tráfico) consiste en que captura tráfico real de producción que podemos reproducir para probar una nueva versión de una carga de trabajo. La versión existente del servicio no se ve afectada; sigue gestionando las peticiones como siempre. La única diferencia es que el tráfico se copia en la nueva versión, donde podemos observar cómo se comporta al gestionar peticiones realistas.
Utilizar la infraestructura de la nube puede hacer que la repetición de tráfico -y las pruebas de alta fidelidad en general- sean más rentables. Podemos aprovisionar un entorno completo en la nube para las pruebas, y luego desmontarlo cuando hayamos terminado (utilizando los mismos procesos que deberíamos tener en marcha para la recuperación ante desastres). La repetición del tráfico también funciona con servicios monolíticos heredados. En cualquier caso, al realizar las pruebas obtenemos una visión más empírica y panorámica del comportamiento futuro que si intentamos definir y adivinar nosotros mismos flujos realistas. Las herramientas pueden ser de código abierto, como GoReplay, mallas de servicios o herramientas nativas de los proveedores de servicios en la nube. De hecho, muchas soluciones de seguridad actuales -pensemos en los sistemas de detección de intrusos (IDS), la prevención de pérdida de datos (DLP) y la detección y respuesta ampliadas (XDR)- utilizan la duplicación de tráfico para analizar el tráfico de red.
Advertencia
Dependiendo de tu régimen de cumplimiento, reproducir el tráfico de usuarios legítimos en un entorno de prueba o experimentación puede añadir responsabilidad. Este problema puede mitigarse anonimizando o codificando el tráfico antes de reproducirlo en el entorno.
Las organizaciones de sectores muy regulados ya utilizan el método de generar conjuntos de datos sintéticos -que imitan los datos de producción pero no incluyen datos de usuarios reales- para rellenar los entornos de preproducción, ensayo y otros entornos de prueba, sin dejar de cumplir la normativa sobre privacidad (como la HIPAA). Las organizaciones de sectores menos concienciados con la privacidad pueden tener que adoptar un enfoque similar para evitar responsabilidades no deseadas.
Pruebas unitarias y teatro de pruebas
Puedes pensar en las pruebas unitarias como verificando la lógica de negocio local (dentro de un componente concreto) y en las pruebas de integración como comprobando las interacciones entre el componente y un grupo seleccionado de otros componentes. La ventaja de las pruebas unitarias es que son lo suficientemente granulares como para verificar resultados precisos que se producen como consecuencia de situaciones muy concretas. Hasta aquí todo bien. El problema es que también verifican cómo se consigue ese resultado comunicándose con la estructura interna de un programa. Si alguien cambiara alguna vez esa estructura interna, las pruebas dejarían de funcionar, bien porque fallarían, bien porque dejarían de compilarse o de comprobarse los tipos.
Las pruebas unitarias suelen ser una mala inversión de nuestro capital de esfuerzo; probablemente deberíamos asignar nuestros esfuerzos a otra cosa. Algunos podrían calificar de temeraria la implementación sin pruebas unitarias, pero puede ser sensata en función de tus objetivos y requisitos. Las pruebas unitarias preservan el statu quo añadiendo un nivel de fricción al desarrollo del software: un ejemplo de introducción del acoplamiento estrecho en las pruebas. De hecho, una prueba unitaria es el tipo de prueba más estrechamente acoplada que puedes escribir y se sitúa en el ámbito del pensamiento a nivel de componente. Podemos recurrir a una crítica similar de los métodos formales para entender por qué necesitamos una evaluación a nivel de sistema en lugar de a nivel de componente: "Los métodos formales pueden utilizarse para verificar que un único componente es demostrablemente correcto, pero la composición de componentes correctos no produce necesariamente un sistema correcto; se necesita una verificación adicional para demostrar que la composición es correcta."29
Esto no quiere decir que las pruebas unitarias sean inútiles. Añadir pruebas es útil cuando no esperas que cambie el estado del sistema. Cuando esperas que la implementación sea estable, probablemente sea una buena idea afirmar cuál es el comportamiento. Afirmar el comportamiento previsto en un componente puede exponerte a un acoplamiento estrecho, si los cambios en el resto del sistema rompen esta parte del mismo. La interacción inesperada y desconcertante queda expuesta en tu ciclo de desarrollo y no en tu ciclo de implementación y reversión.
Algunas pruebas unitarias llegan incluso a la estructura interna de un módulo para titiritearlo: casi un teatro de pruebas literal. Imagina que tienes un proceso de varios pasos que implementa un módulo. Otros módulos lo invocan a través de su interfaz expuesta, activando cada paso en el momento y con los datos adecuados. Las pruebas unitarias deberían llamar a esa interfaz expuesta y afirmar que los resultados son los esperados. Esto significa que para probar cualquiera de los pasos que tienen requisitos previos, tienes que ejecutar esos pasos previos, lo que puede ser lento y repetitivo. Una forma de evitar este tedio es rediseñar el módulo en un "estilo funcional" en el que cada paso reciba sus prerrequisitos explícitamente en lugar de implícitamente a través del estado interno del módulo. Los llamantes deben entonces pasar los prerrequisitos de la salida de un paso a la entrada de los pasos siguientes. En cambio, las pruebas pueden crear los prerrequisitos explícitamente con valores conocidos y pueden validar adecuadamente cada paso. Pero en lugar de refactorizar, muchos ingenieros intentarán "extraer" el estado interno y luego "inyectarlo" mediante código de inicio que se ejecuta como parte de la configuración de la prueba. La interfaz con el módulo no tiene que cambiar, sólo deben contornearse las pruebas, lo que nos aclara pocos conocimientos.
¿Qué ocurre cuando quieres añadir algunos comportamientos nuevos a tu sistema? Si puedes añadirlos sin cambiar la estructura del código, tus pruebas unitarias pueden ejecutarse tal cual y pueden informar de cambios involuntarios en el comportamiento del programa actualizado. Si no puedes añadir los nuevos comportamientos sin cambiar la estructura del código, ahora tienes que cambiar las pruebas unitarias junto con la estructura del código. ¿Puedes confiar en las pruebas que estás cambiando junto con el código que prueban? Tal vez, si el ingeniero que las actualiza es diligente. Con suerte, durante la revisión del código, el revisor examinará los cambios en las pruebas para asegurarse de que las nuevas afirmaciones coinciden con las antiguas... pero pregúntale a un ingeniero (o a ti mismo) cuándo fue la última vez que viste a alguien hacer eso. Necesitamos una prueba que verifique el comportamiento, pero que no dependa de la estructura del código. Por eso la Pirámide de Pruebas común ofrece más atractivo estético que orientación o valor real.
Así, para obtener el beneficio de las pruebas unitarias, nunca debes cambiar la estructura de tu código. Este inmovilismo es anatema para la resiliencia. Construir herramientas para mantener el statu quo y encerrar el sistema en su diseño actual no efectúa un software de alta calidad. Hace falta un alma valiente que reescriba tanto el código como las pruebas que conviven con él para hacer avanzar el diseño. Tal vez eso sea perfecto para los sistemas que están en modo de mantenimiento, donde es improbable que se hagan cambios sustanciales, o para los equipos que experimentan tal agitación que nadie entiende el diseño del sistema, lo que hace imposible rediseñarlo de todos modos. Esos sistemas ahogan la creatividad de los ingenieros y su sentido de la maravilla por el software -además de su fragilidad desecada-, así que deberíamos evitarlos de todos modos, no sea que perezca nuestra curiosidad.
Advertencia
La correlación entre la cobertura del código y encontrar más fallos puede ser débil.30 Los investigadores en ingeniería de software Laura Inozemtseva y Reid Holmes llegaron a la conclusión de que "la cobertura, aunque útil para identificar partes de un programa que no se han probado lo suficiente, no debe utilizarse como objetivo de calidad porque no es un buen indicador de la eficacia del conjunto de pruebas ."
No debemos confundir una alta cobertura del código con unas buenas pruebas. Como aconsejan estos investigadores "La cobertura del código sólo mide que se ha ejecutado una sentencia, bloque o rama. No da ninguna medida de si el código ejercitado se comportó correctamente".
Pruebas fuzz (fuzzing)
Un comprobador fuzz "genera entradas de forma iterativa y aleatoria con las que prueba un programa objetivo", normalmente buscando excepciones al comportamiento del programa (como fallos o fugas de memoria).31 Un comprobador fuzz (también conocido como "fuzzer") se ejecuta en un programa objetivo, como el que estamos desarrollando (los atacantes también utilizan los fuzzers para encontrar vulnerabilidades en programas potencialmente explotables). Cada vez que ejecutamos el fuzz tester -una "ejecución de fuzzing"- puede "producir resultados diferentes a los de la última vez debido al uso de la aleatoriedad".32 Lo mismo ocurre con los experimentos de caos (que exploraremos más a fondo en el Capítulo 8), que están sujetos a los caprichos de la realidad.
Para crear expectativas, los fuzzers pueden suponer un esfuerzo considerable de escritura e integración con cada parte del sistema que pueda aceptar datos (¿y qué partes del sistema no aceptan datos?). Realmente querrás asegurarte de que tus otras pruebas son fiables antes de intentarlo. Si los ingenieros siguen pasando por alto las pruebas de integración, averigua por qué y perfecciona el proceso antes de intentar algo más sofisticado, como el fuzzing. Sin embargo, una vez establecidos esos "fundamentos", las pruebas fuzz pueden ser una categoría de pruebas muy útil para la resiliencia.
Cuidado con las abstracciones prematuras e inadecuadas
La última práctica que podemos considerar en el contexto de las interacciones del sistema a través del espacio-tiempo es el arte de las abstracciones. Las abstracciones son un ejemplo feroz de la Cartera de Inversión en Esfuerzo, porque las abstracciones sólo son convenientes cuando no tienes que mantenerlas. Considera una abstracción no informática: la tienda de comestibles. La tienda de comestibles se asegura de que haya plátanos disponibles todo el año, a pesar de las fluctuaciones en el suministro basadas en la estacionalidad, los niveles de lluvia, etc. Las complejas interacciones entre la tienda y los proveedores, entre los proveedores y los agricultores, entre los agricultores y el platanero, entre el platanero y su entorno... todo eso se abstrae para el consumidor. Para el consumidor, es tan fácil como ir a la tienda, elegir plátanos con el grado de madurez deseado y comprarlos en la caja. Para la tienda, se trata de un laborioso proceso de interacción con varios proveedores de plátanos -porque una vinculación estrecha con un solo proveedor provocaría fragilidad (¿y si el proveedor tiene un año malo y ahora no hay plátanos para tus consumidores?)-, así como de almacenar y poner en cola los plátanos para suavizar los caprichos del suministro (manteniendo al mismo tiempo la eficiencia suficiente para obtener beneficios).
Consejo
Incluso podemos pensar en los equipos como abstracciones sobre un determinado problema o dominio que el resto de la organización puede utilizar. La mayoría de las organizaciones que ganan dinero tienen algún tipo de servicio de facturación. En esas organizaciones, no sólo los sistemas de software utilizan el servicio de facturación para facturar los productos a los clientes, sino que los humanos del sistema también utilizan el equipo de facturación para sus necesidades de facturación y esperan que el equipo de facturación conozca el dominio mucho mejor que nadie.
Cuando creamos abstracciones, debemos recordar que alguien debe mantenerlas. Deshacerse de todo ese esfuerzo para el consumidor tiene un alto coste, y alguien debe diseñar y mantener esas ilusiones. Para cualquier cosa que no aporte un valor organizativo diferenciado, merece la pena subcontratar toda esa creación de ilusiones a seres humanos cuyo valor se basa en abstraer esa complejidad. Una tienda de comestibles no moldea su propio plástico para hacer cestas de la compra. Del mismo modo, una empresa de transportes con un sitio de comercio electrónico no se dedica a crear y mantener abstracciones de infraestructura, como, por ejemplo, gestionar la exclusión mutua y los bloqueos.
Cada vez que creamos una abstracción, debemos recordar que estamos creando una ilusión. Éste es el peligro de crear abstracciones para nuestro propio trabajo; puede dar lugar a un autoengaño. Una abstracción es, en última instancia, un acoplamiento estrecho hacia una sobrecarga minimizada. Oculta la complejidad subyacente por diseño, pero no se deshace de ella a menos que sólo la consumamos, no la mantengamos. Así que, si somos los creadores y mantenedores de la abstracción, podemos erizarnos ante la idea del acoplamiento laxo, porque te obliga a dar cuenta de la verdad. No oculta esas complejas interacciones a través del espacio-tiempo, lo que puede asustarnos. Pensábamos que entendíamos el sistema y ahora ¡mira toda esta interactividad "desconcertante"! La abstracción nos dio la ilusión de comprender, pero no la verdad.
Necesariamente, una abstracción oculta algún detalle, y ese detalle puede ser importante para la resistencia de tu sistema. Cuando tus sistemas de software son un nido enmarañado de abstracciones y algo va mal, ¿cómo lo depuras? Sacrificas una memoria RAM en el altar de los dioses eldritch, buscas otra vocación o lloras en silencio delante de la pantalla del ordenador durante un rato antes de engullir cafeína y realizar el equivalente virtual de golpearte la cabeza contra un muro de ladrillos mientras desmenuzas las abstracciones. Las abstracciones intentan ocultar interacciones desconcertantes y efectos de n-orden de los acontecimientos, pero el acoplamiento estrecho no puede erradicar la complejidad interactiva. Los fallos más pequeños en los componentes se convierten en fallos a nivel de sistema, y la inmediatez de la respuesta a los incidentes que exige el acoplamiento estrecho es imposible porque la información necesaria es opaca bajo el grueso y brillante brillo de la abstracción.
Marcos de coste de oportunidad el compromiso de abstracción bien. ¿A qué ventajas renunciamos al elegir una abstracción? ¿Cómo se compara eso con la racionalización y legibilidad que recibimos desde el momento en que se implementa hasta que contribuye al fracaso? Lo que buscamos es que la parte socio del sistema se acerque lo más posible a la comprensión. Pronto hablaremos de la importancia vital de compartir el conocimiento cuando exploremos cómo podemos apoyar el cuarto ingrediente de la poción: los bucles de retroalimentación y la cultura del aprendizaje. Al igual que no queremos un único servicio del que dependa todo nuestro sistema, tampoco queremos un único ser humano del que dependa todo nuestro sistema. Nuestra fuerza proviene de la colaboración y la comunicación, de que las diferentes perspectivas no sólo ayudan, sino que son explícitamente necesarias para comprender el sistema tal y como se comporta en la realidad, no sólo en los modelos estáticos de nuestras mentes o en un diagrama de arquitectura o en líneas de código.
Fomentar los bucles de retroalimentación y el aprendizaje durante la construcción y la entrega
Nuestro cuarto ingrediente de la poción de resiliencia son los bucles de retroalimentación y la cultura del aprendizaje, la capacidad de recordar los fracasos y aprender de ellos. Cuando recordamos el comportamiento del sistema en respuesta a factores de estrés y sorpresas, podemos aprender de él y utilizarlo para informar cambios que mejoren la resiliencia del sistema ante esos acontecimientos en el futuro. ¿Qué podemos hacer para convocar, preservar y aprender de estos recuerdos para crear un bucle de retroalimentación al construir y suministrar?
Esta sección trata de cómo ser curioso y colaborativo sobre el sistema sociotécnico para construir de forma más eficaz, explorando cuatro oportunidades para fomentar los bucles de retroalimentación y el aprendizaje durante esta fase: automatización de pruebas, documentar por qué y cuándo, rastreo y registro distribuidos, y perfeccionar cómo interactúan los humanos con nuestras prácticas de desarrollo.
Automatización de pruebas
Nuestra primera oportunidad de alimentar los bucles de retroalimentación y el aprendizaje durante esta fase es la práctica de la automatización de pruebas. Necesitamos articular el porqué de las pruebas tanto como debemos hacerlo con otras cosas. Cuando escribimos una prueba, ¿podemos articular por qué estamos verificando cada cosa que verificamos? Sin saber por qué se verifica cada cosa, nos quedaremos perplejos cuando nuestras pruebas fallen después de cambiar o añadir código nuevo. ¿Hemos roto algo? ¿O simplemente las pruebas están obsoletas, incapaces de razonar sobre el estado actualizado del mundo?
Cuando el porqué de los tests -o de cualquier otra cosa- no está documentado ni es digerible, es más probable que los seres humanos supongan que son innecesarios, algo que se puede arrancar y sustituir con facilidad. Este razonamiento sesgado se conoce como la falacia de la valla de Chesterton, descrita por primera vez en el libro de G.K. Chesterton La Cosa:
En la cuestión de reformar las cosas, a diferencia de deformarlas, hay un principio simple y llano; un principio que probablemente se llamará paradoja. Existe en tal caso una determinada institución o ley; digamos, para simplificar, una valla o una puerta erigida a través de un camino. El reformador más moderno se acerca alegremente y dice: "No veo la utilidad de esto; eliminémoslo". A lo que el reformador más inteligente hará bien en responder: "Si no le ves la utilidad, desde luego no te dejaré que lo elimines. Vete y piensa. Entonces, cuando puedas volver y decirme que sí le ves utilidad, puede que te permita destruirlo".
¿Cómo podemos promover bucles de retroalimentación más rápidos a partir de nuestras pruebas? Mediante la automatización de las pruebas. La automatización nos ayuda a conseguir repetibilidad y estandariza una secuencia de tareas (lo que nos proporciona tanto un acoplamiento más suelto como más linealidad). Queremos automatizar las tareas que no se benefician de la creatividad y la adaptación humanas, como las pruebas, lo que también puede facilitar el cambio del código. Si no automatizas tus pruebas, cualquier iteración del ciclo de aprendizaje se rezagará y será mucho más costosa. La automatización de las pruebas acelera nuestros bucles de retroalimentación y suaviza la fricción en torno al aprendizaje a partir de nuestras pruebas.
Por desgracia, la automatización de las pruebas a veces asusta a la gente de ciberseguridad, que le da mucha importancia a los pesados procesos de cambio en aras de la cobertura del "riesgo" (signifique eso lo que signifique realmente). El equipo de ciberseguridad tradicional no debería realizar pruebas de software, puesto que ya debería participar en el proceso de diseño (como se ha comentado en el último capítulo), y debería confiar en los ingenieros de software para implementar esos diseños (no queremos un panóptico). Cuando interferimos en la automatización de las pruebas y las vinculamos estrechamente a una entidad externa, como un equipo de ciberseguridad separado y aislado, ponemos en peligro la resiliencia al reducir la parte social de la capacidad de aprendizaje del sistema.
Pero, basta ya de hablar de todas las formas en que el sector de la ciberseguridad se equivoca actualmente. ¿Cómo podemos automatizar las pruebas correctamente? Las suites de pruebas de seguridad pueden activarse automáticamente una vez que se envía una RP, trabajando en tándem con las revisiones de código de otros desarrolladores para mejorar la eficacia (y satisfacer a los dioses eldritch de la presión de producción). Por supuesto, algunas herramientas tradicionales de pruebas de seguridad no son adecuadas para los flujos de trabajo automatizados; si una herramienta de análisis estático tarda 10 minutos -o, como lamentablemente sigue siendo habitual, unas horas- en realizar su análisis, entonces inevitablemente atascará la canalización. Según el informe Accelerate State of DevOps de 2019, sólo el 31% de los DevOps de élite utilizan pruebas de seguridad automatizadas, frente al escaso 15% de los de bajo rendimiento. Históricamente, las suites de pruebas de seguridad están controladas por el equipo de seguridad, pero como seguiremos insistiendo a lo largo del libro, esta centralización sólo perjudica nuestra capacidad de mantener la resiliencia, como ilustra la Figura 4-2.
Figura 4-2. Adopción de diferentes formas de automatización entre los ejecutores de DevOps(fuente: informe Accelerate State of DevOps 2019)
Podemos utilizar el análisis estático como ejemplo de cómo la automatización de pruebas puede mejorar la calidad. El análisis estático, aparte del coste de configuración de escribir la prueba, puede considerarse poco costoso cuando se amortiza en el tiempo, ya que descubre errores en tu código automáticamente. Dicho esto, a menudo existe una meta división sustancial entre los equipos de ingeniería de software. Cuando estás encima de tu backlog y refinando regularmente el diseño, puedes permitirte el lujo de preocuparte y hacer algo por los posibles fallos de seguridad. Cuando estás asfixiado bajo un montón de código C y desanimado para refinar el código, que te presenten más fallos de seguridad añade un insulto a la herida. La red de seguridad, por así decirlo, para ayudar a los equipos de ingeniería de software que luchan con un código heredado difícil de mantener se teje con herramientas que pueden ayudarles a modernizar y automatizar procesos de forma iterativa. La automatización de pruebas -entre otras automatizaciones de las que hemos hablado en este capítulo- puede ayudar a los equipos en apuros a salir poco a poco del fango, ya sea mediante autoservicio, mediante un equipo de ingeniería de plataformas o mediante un equipo de seguridad que siga un modelo de ingeniería de plataformas.
Por eso, los programas de seguridad deben incluir perspectivas de ingeniería de software a la hora de seleccionar herramientas; puede que ya existan herramientas de análisis estático -o herramientas más generales de "calidad del código"- que sean aptas para CI/CD, estén implementadas o en fase de estudio, y que podrían bastar para encontrar también errores con impacto en la seguridad. Por ejemplo, la integración de herramientas de análisis estático en los IDE puede reducir el tiempo que dedican los desarrolladores a corregir vulnerabilidades y aumentar la frecuencia con que los desarrolladores ejecutan el análisis de seguridad en su código. Los desarrolladores ya están familiarizados con este tipo de herramientas e incluso confían en ellas para mejorar sus flujos de trabajo. Puede que oigas a un desarrollador, por ejemplo, hablar maravillas de TypeScript, un lenguaje que existe puramente para añadir comprobación de tipos a un lenguaje existente menos seguro, porque les hace más productivos. Si podemos ayudar a los equipos de ingeniería de software a ser más productivos a la vez que aprenden más de los ciclos de retroalimentación más rápidos, nos merecemos chocar los cinco.
Documentar por qué y cuándo
Otra oportunidad para fomentar los bucles de retroalimentación y el aprendizaje al construir y suministrar sistemas es la práctica de la documentación; concretamente, documentar por qué y cuándo. Como expusimos en el Capítulo 1, la resiliencia se basa en la memoria. Nos debilitaremos al aprender si no podemos recordar los conocimientos pertinentes. Necesitamos que estos conocimientos sigan siendo accesibles para que el mayor número posible de seres humanos de la parte socio del sistema puedan emplearlos en sus bucles de retroalimentación. De ahí que debamos elevar la documentación a la categoría de práctica fundamental y más prioritaria que otras actividades más "sexys". Esta sección describirá cómo desarrollar docs para facilitar mejor el aprendizaje.
Cuando compartimos conocimientos, no podemos pensar en términos de componentes estáticos. Recuerda que la resiliencia es un verbo. Tenemos que compartir nuestra comprensión del sistema, no sólo cómo interactúan los componentes, sino por qué y cuándo interactúan, e incluso por qué existen. Tenemos que tratarlo como si describiéramos un ecosistema. Si estuvieras documentando una playa, podrías describir qué es cada cosa y cómo funciona. Hay arena. Hay olas que entran y salen. Hay conchas. Pero eso no nos dice mucho. Más significativo es cómo y cuándo interactúan estos componentes. La marea baja es a las 13:37 y, cuando ocurre, las gambas y las estrellas de mar se refugian en las pozas mareales; las pozas mareales quedan expuestas, al igual que las ostras; los cangrejos corretean por la playa en busca de comida, como esas sabrosas ostras y criaturas de las pozas mareales; las aves playeras también picotean en busca de bocados a lo largo de la costa. Cuando la marea sube seis horas más tarde (marea alta), las ostras y las vieiras abren sus conchas para alimentarse; las gambas y las estrellas de mar entran en el mar; los cangrejos hacen madrigueras; las aves playeras se posan; las tortugas marinas hembras se arrastran hasta la orilla para poner sus huevos, y las mareas altas acabarán arrastrando a las crías de tortuga hasta el océano.
Nuestros sistemas de software son complejos, hechos de componentes que interactúan. Son esas interacciones las que hacen que los sistemas sean "desconcertantes" y, por tanto, es imperativo captarlas como constructores. Tenemos que pensar en nuestros sistemas como un hábitat, no como una colección dispar de conceptos. Cuando nos encontramos con un sistema por primera vez, solemos preguntarnos: "¿Por qué se construyó así?" o, quizá más fundamentalmente, "¿Por qué existe esto?". Sin embargo, esto es lo que menos solemos documentar cuando construimos y entregamos software.
Hemos mencionado el proyecto Oxidation de Mozilla anteriormente en este capítulo en el contexto de la migración a un lenguaje seguro en memoria, pero también es un ejemplo loable de documentar el porqué. Para la mayoría de los componentes que han distribuido en Rust, responden a la pregunta "¿Por qué Rust?". Por ejemplo, con su integración del sistema de localización fluent-rs documentaron explícitamente que lo compilaron en Rust porque: "El rendimiento y las ganancias de memoria son sustanciales respecto a la implementación JS anterior. Aporta un análisis sintáctico de copia cero, y una resolución de cadenas de localización inteligente desde el punto de vista de la memoria. También allana el camino para migrar el resto de las API de Fluent lejos de JS, que es necesario para Fission".
Una respuesta tan detallada que indique el propósito e incluso el modelo mental que hay detrás de la decisión evita hábilmente el problema de la valla de Chesterton en el futuro. Pero incluso respuestas menos detalladas pueden apoyar una cultura de aprendizaje, bucles de retroalimentación y, lo que es crucial, la priorización. Por ejemplo, uno de los componentes propuestos para ser "oxidados" en Rust -sustituir los serializadores DOM (XML, HTML para Guardar como..., texto plano)- dice simplemente: "¿Por qué Rust? Necesita una reescritura de todos modos. Historial menor de vulnerabilidades de seguridad". Migrar a un lenguaje seguro en memoria puede ser una oportunidad para abordar problemas de larga data que dificultan la fiabilidad, la resistencia o incluso simplemente la mantenibilidad. Siempre que podamos, debemos buscar oportunidades para maximizar el rendimiento de nuestras inversiones en esfuerzo.
Documentar los requisitos de seguridad
Documentar por qué y cuándo es una parte crítica de la optimización de la asignación del esfuerzo en nuestra Cartera de Inversión del Esfuerzo. Los requisitos definen las expectativas en torno a cualidades y comportamientos, permitiendo a los equipos elegir cómo invertir su capital de esfuerzo para cumplir esos requisitos. Los requisitos de seguridad documentados favorecen la repetibilidad y la capacidad de mantenimiento -cualidades esenciales para los bucles de retroalimentación-, al tiempo que reducen el esfuerzo de todas las partes interesadas en la elaboración de requisitos específicos para cada proyecto.
Por ejemplo, los equipos de seguridad suelen invertir un esfuerzo considerable en responder a las preguntas ad hoc de los equipos de ingeniería de software sobre cómo crear un producto, una función o un sistema de forma que no sea vetado por el programa de seguridad. En la práctica, este esfuerzo manual provoca retrasos y cuellos de botella, dejando a los equipos de ingeniería "atascados" y a los equipos de seguridad con un capital de esfuerzo más limitado para invertirlo en otra cosa (como en actividades que podrían cumplir los objetivos del programa de seguridad de forma más fructífera).
Consejo
El informe 2021 Accelerate State of DevOps descubrió que los equipos con documentación de alta calidad tienen 3,8 veces más probabilidades de aplicar prácticas de seguridad (y 2,4 veces más probabilidades de cumplir o superar sus objetivos de fiabilidad).
Definir requisitos explícitos y conceder a los equipos de ingeniería la flexibilidad necesaria para construir sus proyectos respetando esos requisitos libera tiempo y esfuerzo para ambas partes: los equipos de ingeniería pueden autoservirse y autoiniciarse sin tener que interrumpir su trabajo para discutir y negociar con el equipo de seguridad, y el equipo de seguridad ya no se ve tan inundado de peticiones y preguntas, liberando tiempo y esfuerzo para un trabajo con un valor más duradero. Si escribimos documentación sobre, por ejemplo, "He aquí cómo implantar una política de contraseñas en un servicio", invertimos parte de nuestro capital de esfuerzo para que otros equipos tengan más libertad a la hora de asignar su propio capital de esfuerzo. Pueden acceder a la documentación, comprender los requisitos y evitar tener que hacer preguntas ad hoc sobre requisitos puntuales.
Como ejemplo reciente, el Arquitecto Principal de Software de , Greg Poirier, aplicó este enfoque a los conductos de CI/CD, eliminando la necesidad de un sistema centralizado de CI/CD y manteniendo al mismo tiempo la capacidad de atestiguar los cambios de software y determinar la procedencia del software. En lugar de instituir estrictos guardarraíles que se apliquen por igual a todos los equipos de ingeniería, podemos definir los requisitos deseados en los conductos de CI/CD (y hacer que estén disponibles en un único lugar accesible). Esto permite a los equipos de ingeniería construir y evolucionar sus canalizaciones CI/CD según sus necesidades locales, siempre que cumplan los requisitos.
También podemos mejorar la forma de gestionar las vulnerabilidades de compartiendo conocimientos. Cuando las vulnerabilidades se descubren en marcos y patrones estandarizados y compartidos, son más fáciles de solucionar. Si los equipos se desvían del camino trillado y construyen las cosas de forma extraña, debemos esperar más vulnerabilidades. Para utilizar la inyección SQL (SQLi) como ejemplo, no debería hacer falta que un equipo sufra un atacante que explote una vulnerabilidad SQLi en su servicio para que la organización descubra las consultas parametrizadas y los ORM(mapeadores relacionales de objetos), que dificultan la escritura de vulnerabilidades SQLi. En su lugar, la organización debería estandarizar sus patrones de acceso a la base de datos y tomar decisiones que hagan que la forma segura sea la predeterminada. Hablaremos más de los valores por defecto en el Capítulo 7. Si un equipo de ingenieros detecta una vulnerabilidad en su código, darla a conocer a otros equipos, en lugar de arreglar el caso concreto y seguir adelante, puede dar lugar a una lluvia de ideas sobre cómo comprobar la presencia de la vulnerabilidad en otros lugares y estrategias para mitigarla en todos los sistemas.
Escribir documentos orientados al aprendizaje
Nadie recibe una bonificación por escribir documentos excelentes. Por tanto, tenemos que facilitar a los humanos la creación y el mantenimiento de documentos, a pesar de que escribirlos no sea su principal habilidad ni su reto más brillante. El mejor recurso que podemos crear es una plantilla con un formato aprobado con el que todo el mundo esté de acuerdo y que requiera poco esfuerzo para rellenarlo. La plantilla debe reflejar el mínimo necesario para compartir conocimientos con otros humanos; esto dejará claro cuál es el mínimo al crear el documento, al tiempo que permite flexibilidad si el humano quiere añadir más al documento.
A veces los ingenieros piensan que una buena documentación para su función o servicio sólo es relevante si los usuarios son desarrolladores. Esa no es la mentalidad correcta si queremos apoyar la repetibilidad o preservar las posibilidades. ¿Y si nuestro servicio es consumido por otros equipos? ¿Y si es útil para nuestra organización que, en algún momento, nuestro servicio se venda como API? En un mundo cada vez más orientado a las API, la documentación nos proporciona esta flexibilidad y garantiza que nuestro software (incluido el firmware o incluso el hardware) sea consumible. Y desde este punto de vista, la documentación mejora directamente nuestras métricas.
Cuando construyes un sistema, estás interactuando con componentes que hacen cosas diferentes con distintas relaciones entre sí. Documenta tus suposiciones sobre estas interacciones. Cuando realizas un experimento de caos de seguridad, aprendes aún más sobre esos componentes y relaciones. Documenta esas observaciones. Como experimento mental, imagina que un amable desconocido te regala un billete de lotería cuando vas a por tu cafeína preferida durante una pausa en el trabajo; te toca la lotería, decides tomarte un año sabático para viajar por todas las islas preciosas del mundo, y luego vuelves a tu mesa el día 366 para sumergirte de nuevo en tu trabajo (suponiendo que relajarse en playas vírgenes y retozar con flora y fauna exóticas llegue a ser aburrido). Tu mente está totalmente renovada y, por tanto, lo has olvidado casi todo sobre lo que sea que estés haciendo. ¿La documentación que te dejaste sería suficiente para que volvieras a entender el sistema? ¿Estarías maldiciendo al Pasado por no haber escrito suposiciones sobre cómo este componente que hace una cosa se relaciona con otro componente que hace otra cosa?
Explícale a Tú del Futuro cómo construiste el sistema, cómo crees que funciona y por qué crees que funciona así. Puede que el Futuro Tú lleve a cabo un experimento de caos de seguridad que refute algunas de esas suposiciones, pero al menos es una base sobre la que el Futuro Tú puede incubar hipótesis para experimentos. Por supuesto, como probablemente ya habrás supuesto, no sólo escribimos estas cosas para Tu Futuro mientras desarrollas software; también es para los nuevos miembros del equipo y para los ya existentes que quizá no estén tan familiarizados con la parte del sistema que escribiste específicamente. La documentación también puede ser muy valiosa para la respuesta a incidentes, de la que hablaremos en el Capítulo 6.
Dicho esto, los documentos también benefician a Futuro Tú de otra manera, al capturar tus conocimientos en un formato digerible que elimina la necesidad de ponerse en contacto contigo directamente e interrumpir tu trabajo. Queremos incentivar a otros seres humanos para que utilicen la documentación como su fuente de consulta en lugar de realizar la acción de alto coste de ponerse en contacto con nosotros, lo que significa que no sólo tenemos que responder a lo básico en los documentos, sino también hacerlos accesibles y digeribles (y si nos siguen haciendo la misma pregunta, es una llamada a la acción para añadir la respuesta al documento). ¿Quién de nosotros no ha mirado alguna vez un documento novelesco con una estructura confusa y una redacción deficiente y ha querido abandonar? O el documento explicará las minucias sobre cómo se construye el componente como una entidad estática, pero omitirá por completo explicar por qué se construye así o cómo funciona en el espacio-tiempo.
Si no describimos cómo se comporta en tiempo de ejecución, incluidas sus interacciones habituales con máquinas y seres humanos por igual, sólo obtendremos una versión escrita de un retrato "naturaleza muerta" del componente. Una explicación visual de sus interacciones en el espacio-tiempo -una película, más que un retrato- puede hacer que el documento sea aún más digerible para los ojos humanos. ¿Por qué y cuándo interactúan los componentes? ¿Cuándo y dónde fluyen los datos? ¿Por qué hay un orden temporal determinado? Garantizar que esta explicación visual, ya sea un diagrama, un gif, un árbol de decisiones u otro formato, sea fácil de cambiar (y versionar) mantendrá los conocimientos actualizados a medida que evolucionen las condiciones y se recojan comentarios. Por ejemplo, un archivo README puede versionarse y desvincularse de un ingeniero individual, permitiéndote capturar un proceso CI/CD con una explicación visual y escrita de por qué se desarrolla cada paso y por qué existen interacciones en cada paso.
Como seguiremos insistiendo, es mucho más importante explicar por qué el sistema se comporta de una determinada manera y por qué decidimos construirlo así que cómo se comporta. Si nuestro objetivo es que un equipo totalmente nuevo pueda empezar a utilizar un sistema rápidamente y entender cómo mantenerlo y ampliarlo, entonces explicar por qué las cosas son como son colmará las lagunas de conocimiento mucho más rápidamente que el cómo. El por qué es lo que impulsa nuestro aprendizaje, y el estímulo continuo de esas suposiciones anima nuestros circuitos de retroalimentación.
Queremos componentes de software que se entiendan bien y estén bien documentados, porque cuando compartimos nuestros propios conocimientos sobre el sistema, nos resulta más fácil explicar por qué hemos construido algo utilizando esos componentes y por qué funciona como lo hace. Construir nuestro propio componente de software puede resultarnos más fácil de modelar mentalmente, pero más difícil de compartir ese modelo mental con los demás y de mantenerlo incorporando comentarios. También hace que los componentes sean más difíciles de cambiar; el efecto dotación33 (un subconjunto de la aversión a la pérdida)34 significa que nunca queremos deshacernos de nuestros "queridos". No queremos pegar las cosas en un lío enmarañado y estrechamente acoplado en el que tanto el por qué como el cómo sean difíciles de discernir. Si nos declaramos en bancarrota por tener un modelo mental en absoluto, actuando por fe ciega, entonces contaminaremos nuestra poción de resiliencia; no comprenderemos las funciones críticas de los sistemas, y no seremos conscientes de los límites de seguridad (y nos acercaremos a ellos), nos desconcertarán las interacciones a través del espacio-tiempo, y ni aprenderemos ni nos adaptaremos.
Rastreo y registro distribuidos
La tercera práctica que discutiremos que puede alimentar los bucles de retroalimentación y promover el aprendizaje durante esta fase es el rastreo y el registro distribuidos. Es difícil limitarse a mirar las pequeñas migas de pan esparcidas por el sistema que no se reúnen en la historia (y los humanos pensamos mucho en historias). Tanto si se trata de triar un incidente como de refinar tu modelo mental para informar sobre las mejoras, es esencial observar las interacciones a lo largo del tiempo. No puedes formar un bucle de retroalimentación sin poder ver lo que ocurre; la retroalimentación es una parte esencial del bucle.
Debemos planificar e incorporar esta información a nuestros servicios mediante el seguimiento y el registro. Ninguna de las dos cosas es algo que puedas atornillar después de la entrega o aplicar automáticamente a todos los servicios que operas. Inviertes esfuerzo durante la fase de construcción y entrega, y luego recibes un retorno de esa inversión en la fase de observación y funcionamiento. Alternativamente, puedes decidir no invertir capital de esfuerzo durante esta fase y arrancarte los pelos de frustración cuando intentes depurar tu complicado sistema de microservicios cuando falle adivinando qué mensajes de registro coinciden con cuáles (lo que es increíblemente engorroso en servicios con un volumen razonable). Podemos pensar en el rastreo y el registro como una protección contra una caída grave cuando nuestro software se ejecuta en producción: la retroalimentación que nos ayuda a mantener un bucle productivo en lugar de una espiral descendente. Esta sección explorará cómo podemos pensar en cada uno de ellos durante esta fase.
Rastreo distribuido para seguir los flujos de datos
El rastreo distribuido es un mecanismo para observar el flujo de datos a medida que se mueven por un sistema distribuido.35 El rastreo distribuido nos proporciona una línea temporal de los registros y del flujo de datos entre sistemas, una forma de dar sentido a las interacciones a través del espacio-tiempo. Te permite coser operaciones individuales de vuelta al evento original. A modo de analogía, considera una asociación con otra organización; cada vez que hacen una solicitud de producto o función, hay un ID de ticket. Cualquier actividad relacionada internamente con la solicitud recibe también ese ID de ticket, para que sepas cómo facturarla (y puedas hacer un seguimiento del trabajo dedicado a ella). El rastreo distribuido es la misma idea; una solicitud entrante se etiqueta con un ID de rastreo, que aparece en los registros de cada servicio a medida que fluye.
Consideremos un caso en el que un atacante está filtrando datos del portal de pacientes de un hospital. Podemos ver que se están filtrando datos, pero ¿cómo está ocurriendo? Hay un servicio frontend que se encarga de mostrar el panel de control que ve el paciente cuando se conecta (el servicio Portal del Paciente). El servicio Portal del Paciente necesita solicitar datos de otros servicios mantenidos por otros equipos, como informes de laboratorio recientes del servicio Laboratorios, verificar el token de inicio de sesión del servicio Token y consultar la lista de próximas citas del servicio Agenda. El frontend hará una única petición al servicio Portal del Paciente, que hace peticiones a todos esos otros servicios. Puede que los informes de laboratorio estén mezclados entre el trabajo de laboratorio interno y el externo. El servicio interno puede leer directamente de la base de datos interna y comprobar correctamente los ID de usuario. Sin embargo, para ingerir los informes de laboratorio de los socios, el servicio de Laboratorios debe consultar el servicio de integración de informes de laboratorio de un socio. Incluso en este escenario sencillo, tienes tres servicios de profundidad.
Supongamos que el equipo asociado al servicio de resultados de laboratorio asociado descubre que han cometido un error (como introducir accidentalmente una vulnerabilidad) y un atacante está exfiltrando datos. Podrían decir qué datos se están enviando, pero no podrían rastrear los flujos de datos sin conocer todas las solicitudes procedentes del servicio de Laboratorios, y tendrían que seguir hasta todas las solicitudes procedentes del servicio del Portal del Paciente. Esto es una pesadilla, porque no está claro qué operaciones (o eventos) podrían siquiera hacer una petición al servicio de resultados de laboratorio asociado, y mucho menos qué peticiones son del atacante frente a las de un usuario legítimo. Todo el tráfico que llega a este servicio procede de dentro de la empresa, de los equipos asociados, pero ese tráfico está asociado a algún tipo de operación del usuario que procede de fuera de la empresa (como un paciente que hace clic en su panel para ver los resultados de laboratorio recientes).
El rastreo distribuido disipa esta pesadilla asignando un ID de rastreo en el punto de entrada del tráfico, y ese ID de rastreo sigue al suceso a medida que fluye por el sistema. De este modo, el servicio de resultados de laboratorio asociado puede mirar dónde aparece el ID de rastreo en los registros de otros servicios para determinar la ruta del suceso a través del sistema.
El rastreo distribuido no sólo nos ayuda a observar las interacciones del sistema a través del espacio-tiempo, sino que también nos ayuda a refinar el diseño del sistema y a diseñar nuevas versiones, lo que nos proporciona un elegante bucle de retroalimentación. A escala empresarial, no tienes una visibilidad completa de lo que los equipos que consumen tus datos y acceden a tu servicio están haciendo con ellos. Sus incidentes pueden convertirse fácilmente en tus incidentes. Cuando estés perfeccionando el diseño de tu sistema, querrás comprender el impacto que tiene en tu árbol de consumidores. Cuantos más socios y consumidores estén trenzados en la cadena, más difícil será comprenderla. Tienes un modelo mental de cómo fluyen los acontecimientos a través del sistema y de cómo tu parte específica del sistema interactúa con otras partes... pero, ¿hasta qué punto es exacto tu modelo mental?
El rastreo distribuido te ayuda a refinar ese modelo mental aprendiendo sobre las interacciones reales en tu sistema y entre sus servicios. Podemos utilizar el rastreo distribuido para planificar la capacidad, corregir errores, informar a los consumidores del tiempo de inactividad y de los cambios en la API, y mucho más. Conviene repetir que el valor que obtenemos del rastreo distribuido es cuando el software se ejecuta en producción; sin embargo, debemos realizar nuestra inversión de esfuerzo durante la fase de desarrollo para darnos cuenta de este valor. El rastreo distribuido es, en esencia, hacer la declaración de que queremos ser capaces de correlacionar datos entre sistemas: que queremos ese ID de rastreo. Es durante el desarrollo cuando debes tomar la decisión de que quieres tener esa capacidad en el sistema, aunque gran parte del valor se obtenga durante la siguiente fase, la de funcionamiento y observación.
Si sigues el consejo de acoplar débilmente tus sistemas y dividirlos por límites lógicos, puedes acabar teniendo problemas de visibilidad y puede resultar más difícil ver el flujo, aunque ahora ese flujo sea más resistente. Eso es exactamente lo que el trazado distribuido está diseñado para divulgar. No es elegante, pero es indiscutiblemente útil para alimentar un bucle de retroalimentación.
Decidir cómo y qué registrar
El registro nos ayuda a aprender sobre el comportamiento del sistema; cuando insertamos sentencias de registro en el código a medida que se escribe, sembramos semilleros para estimular nuestros bucles de retroalimentación. Las sentencias de registro generan un registro de los comportamientos de ejecución del sistema, a lo que nos referimos como logs. Cuando descubrimos que necesitamos alguna información sobre el sistema (o parte del sistema) para añadir una nueva función, solucionar un problema (como un error) o ampliar la capacidad, necesitamos que el registro proporcione esa información para el bucle de retroalimentación. Los ingenieros de software a veces incluso crean una nueva versión del sistema con nuevas declaraciones de registro sólo para obtener esa información. Por ejemplo, durante un incidente, un equipo de ingeniería de software puede acelerar la implementación de una versión que añada un nuevo logger.log para poder asomarse al sistema y deducir qué está pasando con la desconcertante sorpresa. La mayoría de los ingenieros de software conocen la mecánica de añadir declaraciones de registro, así que no cubriremos esos detalles en esta sección. Sin embargo, merece la pena recordar a todos los interesados qué debemos registrar y cómo debemos pensar en el registro.
Consejo
Los bloques son las construcciones que utilizan los desarrolladores de cuando añaden sentencias de registro. Los bloques son la estructura organizativa del código. Por ejemplo, en Python, los niveles de indentación -como el contenido de la función- reflejan un bloque. Si tienes indentaciones dentro de la función, habrá un subbloque para la condición true y un subbloque para la parte else (si la hay). Básicamente, cada uno de los mecanismos de flujo de control abre un bloque independiente. Si tienes un for loop o un while loop, obtendrás un bloque.
Un bloque es algo así como un párrafo. En el terreno de los compiladores y la ingeniería inversa, un bloque básico es la subestructura que siempre se ejecuta de arriba abajo. Una expresión es el equivalente a una frase: una línea dentro de un bloque. Una expresión se refiere a una parte de la sentencia que se evalúa por separado. Y una cláusula se refiere al predicado de una sentencia if o while.
Puede que no sepamos qué necesitamos registrar hasta que empecemos a interpretar los datos generados cuando nuestro código se ejecuta realmente. Debemos ser un tanto especulativos sobre lo que podría ser útil para recuperarnos de un futuro incidente, para informar sobre el crecimiento del tráfico, para saber lo eficaces que son nuestras cachés, o cualquiera de las otras mil cosas que son relevantes. Al añadir declaraciones de registro en nuestro código a medida que lo escribimos, queremos preservar las posibilidades una vez que nuestro código esté funcionando en producción y alimentar un bucle de retroalimentación. Los informáticos Li et al. describen el equilibrio entre escasez y verbosidad: "Por un lado, registrar demasiado poco puede aumentar la dificultad de mantenimiento debido a la omisión de información importante sobre la ejecución del sistema. Por otro lado, registrar demasiado puede introducir registros excesivos que enmascaren los problemas reales y causen una importante sobrecarga de rendimiento".36
Advertencia
No hace falta decirlo, pero no queremos incluir contraseñas, tokens, claves, secretos u otra información sensible en nuestros registros. Por ejemplo, si eres una empresa de servicios financieros o de tecnología financiera que maneja multitud de IIP sensibles, que esa información sensible -ya sean nombres, direcciones de correo electrónico, identificadores nacionales (como números de la Seguridad Social) o números de teléfono- acabe en tus registros constituye una fuga de datos que podría dar lugar a resultados problemáticos.
En general, rara vez hay una razón por la que se deba registrar la IPI en lugar de utilizar un identificador de base de datos. Un registro que describa "Hay un problema con Charles Kinbote, charles@zembia.gov, id de base de datos 999" puede sustituirse, sin pérdida de utilidad, por "Hay un problema con el usuario id de base de datos 999". El ingeniero investigador puede utilizar sistemas autenticados para buscar más información sobre el usuario o registro de base de datos afectado, pero sin el riesgo de revelar datos sensibles.
El objetivo de los registros es informar sobre los circuitos de retroalimentación, no hacer tanto ruido que no ayude a nadie, ni ser tan parco que tampoco ayude a nadie. Registramos para aprender. Si el éxito o el fracaso de algo es importante para tu empresa, considera la posibilidad de registrarlo. Debemos pensar en las operaciones -la funcionalidad del sistema- y asegurarnos de que se reflejan de forma útil en nuestras herramientas de registro y observabilidad. Lo que necesites registrar depende del contexto local. Lo más parecido a la sabiduría generalizada sobre el registro es que necesitas registrar los fallos que se producen en tu sistema si quieres preservar la posibilidad de descubrirlos. Si la transacción de tu base de datos se agota, eso puede indicar que los datos no se guardaron. Este tipo de evento no es algo que quieras ignorar en un bloque catch vacío, y probablemente debería categorizarse al menos en el nivel ERROR.
Fundamentalmente, queremos asegurarnos de que los errores -y su contexto- sean evaluados por un humano. A menudo, hay un torrente de declaraciones de registro que brotan en un cubo (o agujero negro, según a quién preguntes) para consultarlas más tarde en caso de que las necesites. Nuestro modelo mental podría ser que los errores llegan a la bandeja de entrada o al flujo de notificaciones de alguien en algún momento, pero puede que no sea así, por lo que los experimentos de caos pueden verificar este comportamiento esperado. De hecho, uno de los mejores puntos de partida de los experimentos de caos es verificar que tus conductos de registro (o conductos de alerta) se comportan como esperas. Hablaremos más sobre este caso concreto de uso de la experimentación en "Informe de experiencia: Monitoreo de la seguridad (OpenDoor)".
Consejo
Los niveles de registro indican la importancia del mensaje; FATAL ("Crítico" en Windows) es visceralmente funesto, mientras que INFO ("Informativo" en Windows) es menos catastrofista. Cuando los ingenieros de software establecen los niveles de registro, se basan en sus modelos mentales de lo importante que es este comportamiento para comprender el sistema (ya sea para solucionar problemas o para perfeccionarlo). Esto hace que la decisión de qué nivel aplicar sea subjetiva y, por tanto, delicada.
También debemos considerar dónde debemos entretejer el contexto local de en los mensajes de registro: como las solicitudes de ID de usuario asociadas, los ID de rastreo, si el usuario ha iniciado sesión o no, y más cosas dependiendo del contexto local. Si estás construyendo un sistema de procesamiento de transacciones, quizá asocies a cada transacción un ID, de modo que si falla una transacción concreta, puedas utilizar el ID para solucionar problemas e investigar.
Como nota final de precaución, los equipos de ingeniería ya mantienen una infraestructura de registro, por lo que realmente no hay necesidad de que el equipo de seguridad cree una infraestructura paralela. En su lugar, los equipos de seguridad deben insistir en que sus proveedores interoperen con esa infraestructura existente. No hay razón para inventar la rueda -recuerda, queremos "elegir lo aburrido"- y, cuando los equipos de seguridad crean este reino en la sombra de infraestructura duplicada, se interrumpe su capacidad de aprender, un ingrediente crucial de nuestra poción de resiliencia.
Perfeccionar la interacción humana con las prácticas de construcción y entrega
Por último, podemos perfeccionar el modo en que los humanos interactúan con nuestras prácticas de desarrollo, como otra oportunidad para reforzar los circuitos de retroalimentación y alimentar una cultura de aprendizaje. Para construir y entregar sistemas de software que mantengan la resiliencia, nuestras prácticas en esta fase tienen que ser sostenibles. Tenemos que estar en un modo de aprendizaje constante de cómo interactúan los seres humanos de nuestros sistemas sociotécnicos con las prácticas, patrones y herramientas que les permiten construir y entregar sistemas. Tenemos que estar abiertos a probar nuevos IDE, patrones de diseño de software, herramientas CLI, automatización, emparejamiento, prácticas de gestión de problemas y todas las demás cosas que se entretejen a lo largo de esta fase.
Parte de este modo de aprendizaje consiste también en estar abierto a la idea de que el statu quo no funciona: escuchar las opiniones de que las cosas podrían ir mejor. Tenemos que estar dispuestos a descartar nuestras viejas prácticas, pautas y herramientas cuando ya no nos sirvan o si dificultan la construcción de un sistema resistente o fiable. Recordar el contexto local también nos ayuda a refinar la forma de trabajar en esta fase; algunos proyectos pueden exigir prácticas diferentes y debemos decidir refinarlas en consecuencia.
Recapitulando, tenemos cuatro oportunidades para fomentar los bucles de retroalimentación y alimentar el aprendizaje -el cuarto ingrediente de la receta de nuestra poción de resiliencia- durante la construcción y la entrega: la automatización de las pruebas, la documentación de por qué y cuándo, el seguimiento y el registro distribuidos, y el perfeccionamiento de la forma en que los seres humanos interactúan con los procesos de desarrollo. Cómo cambiamos estas interacciones -y cómo cambiamos cualquier cosa durante esta fase- nos lleva al ingrediente final de nuestra poción de resistencia: flexibilidad y voluntad de cambio.
Flexibilidad y voluntad de cambio
Con estos cuatro ingredientes mezclados en en nuestro brebaje caliente y achocolatado, podemos hablar de cómo verter nuestro ingrediente final, el malvavisco -que simboliza la flexibilidad y la voluntad de cambio- en nuestra poción de resiliencia que podemos preparar mientras construimos y suministramos. Esta sección describe cómo construir y entregar sistemas para que podamos seguir siendo flexibles ante los fallos y las condiciones cambiantes que, de otro modo, anularían el éxito. El investigador de sistemas distribuidos Martin Kleppmann dijo: "La agilidad en el producto y el proceso significa que también necesitas la libertad de cambiar de opinión sobre la estructura de tu código y tus datos", y esto encaja perfectamente con el último ingrediente de nuestra poción de resiliencia.
Para algunas organizaciones con muchas aplicaciones "clásicas", la voluntad de cambiar significa estar dispuesto a seguir con la iteración y la migración durante muchos trimestres, si no años, para transformar sus aplicaciones y servicios en versiones más adaptables y cambiantes. Una startup tecnológica en fase inicial está construyendo desde cero y el cambio puede producirse de la noche a la mañana. Una empresa centenaria con mainframes y lenguajes antiguos posiblemente necesite aún más flexibilidad y voluntad de cambio, puesto que ya parte de una base frágil, pero ese cambio no puede producirse de la noche a la mañana. La naturaleza es un arquitecto paciente, que permite que la evolución se desarrolle a lo largo de ciclos generacionales. Migrar de un paradigma clásico, fuertemente acoplado, a uno moderno, débilmente acoplado, también requiere paciencia y una evolución cuidadosamente arquitectónica. Hay victorias rápidas en el camino, con beneficios de resiliencia que se acumulan con cada iteración. Nada de lo que describimos en este libro está fuera del alcance de las organizaciones más mainframes y COBOL; lo que hace falta es una evaluación cuidadosa de tu cartera de inversión de esfuerzos y priorizar qué ingredientes de resiliencia perseguirás primero.
En esta sección, presentaremos cinco prácticas y oportunidades para ayudar a que la flexibilidad y la disposición al cambio florezcan durante esta fase: la iteración, la modularidad, las banderas de características, la preservación de las posibilidades de refactorización y el patrón de la figura estranguladora. Muchas de estas estrategias fomentan la evolución y entrelazan la voluntad de cambio con el diseño, promoviendo la velocidad de la que depende nuestra adaptabilidad elegante.
Iteración para imitar la evolución
La primera práctica que podemos adoptar para fomentar la flexibilidad y mantener la disposición al cambio es la iteración. Como primera aproximación a lo que constituye un "buen código", se trata de código fácil de sustituir. Nos ayuda a fomentar la flexibilidad y la voluntad de cambio que son esenciales para la resiliencia de los sistemas, al permitirnos modificar y refactorizar el código a medida que recibimos comentarios y cambian las condiciones. El código que es fácil de sustituir es fácil de parchear. Los equipos de seguridad suelen decir a los ingenieros de software que arreglen los problemas de seguridad del código a un nivel más "fundamental", en lugar de ponerle una venda; el código que es fácil de sustituir también es fácil de refactorizar para remediar esos problemas.
Un enfoque iterativo de la construcción y entrega de sistemas permite la capacidad de evolución que necesitamos para apoyar la resiliencia de los sistemas. Los productos mínimos viables (PMV) y la experimentación de características son nuestros mejores amigos durante esta fase. No sólo aceleran el tiempo de comercialización del código -llegando más rápidamente a los usuarios finales-, sino que también nos permiten determinar más rápidamente lo que funciona, o no, para escapar de la trampa de la rigidez (que erosiona la resiliencia). Es un medio para conseguir no sólo un acoplamiento más suelto, sino las fáciles sustituciones que caracterizan a los sistemas más lineales. Tenemos que fomentar la experimentación, facilitando la innovación rápida, pero descartando lo que no funciona sin vergüenza ni culpa.
También tenemos que seguir adelante con nuestros MVP y experimentos. Por ejemplo, si desarrollas un nuevo patrón de autenticación que es mejor que el status quo, asegúrate de terminar el trabajo: pasa del MVP a un producto real. Es fácil perder fuelle después de conseguir que un prototipo funcione en parte del sistema, pero el seguimiento es necesario para la resiliencia. Si no hacemos un seguimiento ni invertimos en mantenerlo, reducimos la holgura del sistema y dejamos que la fragilidad se apodere de él. Este seguimiento es necesario incluso si nuestros experimentos no resultan como esperábamos. Si las pruebas sugieren que el experimento no es viable, necesitamos un seguimiento en forma de limpieza y eliminación del experimento del código base. Los restos de experimentos fallidos abarrotarán la base de código, causando confusión a cualquiera que tropiece con ellos. (Podría decirse que el asombroso fracaso de Knight Capital en 2014 es un ejemplo de ello).
Desgraciadamente, el enfoque incremental de la construcción y la entrega suele fracasar por razones sociales. A los humanos nos gusta la novedad. A menudo nos encanta conseguir una gran victoria de una sola vez, en lugar de un montón de pequeñas victorias a lo largo del tiempo. Por supuesto, esta inclinación por la novedad y los lanzamientos de características llamativas significa que sacrificaremos el progreso incremental y, por tanto, nuestra capacidad de mantener la resiliencia. Es mucho más difícil hacer evolucionar un software que sólo recibe lanzamientos "big bang" una vez al trimestre que un software que se despliega bajo demanda, como cada día o cada semana. Cuando una nueva vulnerabilidad de gran impacto golpea como un trueno, el enfoque incremental significa que puede lanzarse un parche rápidamente, mientras que el modelo de lanzamiento a lo grande y con bombo y platillo probablemente será más lento de parchear por razones tanto técnicas como sociales.
¿Cómo podemos mantener la sensación de frescura en el modelo iterativo? Los experimentos de caos, ya sean del tipo de seguridad o de rendimiento, pueden desatar la adrenalina y ofrecer una perspectiva novedosa que puede llevar a los ingenieros a ver su código y su software a través de una lente diferente. Por ejemplo, podríamos analizar la arquitectura y el código de un sistema para intentar comprender su rendimiento, pero un enfoque más eficaz es acoplar un perfilador mientras se simula la carga; las herramientas nos dirán exactamente en qué invierte el tiempo el sistema. También podemos incentivar a la gente para que siga adelante, sea curiosa y se apropie del código, como en "este módulo te pertenece personalmente".
Un enfoque iterativo también se alinea con la modularidad en el diseño, que trataremos a continuación.
Modularidad: la antigua herramienta de la humanidad para la resiliencia
La segunda oportunidad que tenemos a nuestro alcance para cultivar la flexibilidad y mantener la adaptabilidad es la modularidad. Según el Servicio de Parques Nacionales de EE.UU. (NPS), la modularidad en sistemas complejos "permite que partes estructural o funcionalmente distintas conserven su autonomía durante un periodo de estrés, y permite recuperarse más fácilmente de una pérdida". Es una propiedad del sistema que refleja el grado en que los componentes del sistema -normalmente densamente conectados en una red37-pueden desacoplarse en grupos separados (a veces denominados "comunidades").38
Puede que pensemos en los módulos en términos de software, pero los humanos han comprendido intuitivamente cómo la modularidad favorece la resiliencia en los sistemas sociotécnicos durante miles de años. En la antigua Palestina, las terrazas modulares de piedra cultivaban olivos, vides y otros productos.39 Los anglosajones implantaron sistemas de tres campos, rotando los cultivos de un campo a otro, una estrategia pionera en China durante el primer milenio a.C.40 Por esta razón, el NPS describe la modularidad como reflejo de "una respuesta humana a la escasez de recursos o a factores de estrés que amenazan las actividades económicas". La modularidad está inscrita en la historia de la humanidad, y con ella podemos tejer también un futuro resiliente.
En el contexto de los paisajes culturales -un paisaje natural modelado por un grupo cultural-, poseer unidades modulares (como zonas de uso del suelo) o características (como huertos o campos) mejora la resistencia al estrés. Durante una perturbación, una unidad o rasgo modular puede persistir o funcionar independientemente del resto del paisaje o de otros rasgos modulares. Ofrece un acoplamiento más suelto, sofocando el efecto contagio. La naturaleza monofuncional de los módulos también introduce la linealidad, una forma de hacer el paisaje más "legible" sin la homogeneidad de la Normalbaum estrechamente acoplada de la que hablamos en el Capítulo 3.
En el Sitio Histórico Nacional John Muir, por ejemplo, hay varios bloques de árboles multiespecie y multivariedad que fomentan la resistencia a las heladas, como se muestra en la Figura 4-3. Este inteligente diseño garantiza que, si las heladas tardías dañan algunos de los árboles en flor, aún pueda haber cierta producción de fruta. Esta resistencia tampoco floreció a expensas de la eficiencia, sino que en realidad la mejoró. El NPS escribe: "El sistema histórico de huertos del Sitio Histórico Nacional John Muir se plantó como unidades modulares de bloques de especies que contenían variedades mixtas, ganando eficiencia en las operaciones pero también incorporando resiliencia al sistema."
Figura 4-3. Un ejemplo de arquitectura modular en un paisaje cultural, del Sitio Histórico Nacional John Muir, gestionado por el NPS (fuente: Servicio de Parques Nacionales).
Ya se trate de paisajes culturales o de paisajes de software, cuando hay poca modularidad, se producen cascadas de fallos. La baja modularidad desencadena efectos de contagio, en los que un factor estresante o una sorpresa en un componente pueden provocar un fallo en la mayor parte o en todo el sistema. Un sistema con alta modularidad, sin embargo, puede contener o "amortiguar" esos estresores y sorpresas para que no se propaguen de un componente a los demás. Gracias a esta ventaja, la modularidad puede caracterizarse como una "medida de la fuerza de división de un sistema en grupos de comunidades y está relacionada con el grado de conectividad dentro de un sistema".41
Por ejemplo, una mayor modularidad puede ralentizar la propagación de enfermedades infecciosas, precisamente la teoría que subyace al distanciamiento social y, en particular, a las "burbujas COVID", en las que un grupo de menos de 10 personas permanece unido, pero minimiza la interacción con otros grupos. Otros ejemplos de modularidad en nuestra vida cotidiana son la cuarentena aeroportuaria para evitar la fauna invasora o las epidemias y los cortafuegos -espacios en el material combustible- que frenan la propagación de los incendios forestales.42
Aunque nuestras "especies" de software -servicios o aplicaciones independientes con una finalidad única- rara vez realizan la misma función43 (como los árboles frutales), podemos beneficiarnos de la modularidad. Para ampliar la analogía del huerto, la labor común de riego y mantenimiento aplicada a todos los árboles del huerto es similar a la infraestructura común de nuestros "huertos" de software, como el registro, el monitoreo y la orquestación. La modularidad puede incluso refinar nuestras funciones críticas. Una empresa de tecnología publicitaria podría crear servicios duplicados que compartieran el 95% del comportamiento, pero con pequeñas partes críticas para enfrentarse entre sí en estrategias de segmentación de usuarios.
Nota
En la dimensión sociotécnica de nuestros sistemas de software, se añade un frenesí de nuevas funciones a un sistema, y luego el sistema se estabiliza mientras contemplamos las ramificaciones de nuestros cambios. El hecho de que las funciones se etiqueten como alfa, beta, disponibilidad limitada o GA es un reflejo de esto. Podemos pensar en esto como un ciclo de "inhalar, exhalar" para los proyectos de software (o un ciclo de "tic-tac " en la ya desaparecida metáfora de la arquitectura Intel).
Los módulos suelen introducir más linealidad, permitiendo la encapsulación básica y la separación de intereses. También crean un límite local sobre el que más tarde podemos introducir el aislamiento. A un nivel más localizado tenemos la modularidad con fines organizativos, para facilitar la navegación y la actualización del sistema, y para proporcionar un nivel de linealidad lógica (donde los datos fluyen en una dirección, pero la contrapresión y los fallos interrumpen la linealidad completa), aunque los módulos no estén aislados.
La modularidad, cuando se hace bien, favorece directamente un acoplamiento más laxo: mantiene las cosas separadas y limita la coordinación en toda la base de código. También favorece la linealidad, al permitirnos dividir las cosas en componentes más pequeños que nos acercan a un único propósito. Si intentamos mantener la funcionalidad unida, podemos añadir complejidad. En el post de tef sobre la sabiduría contraintuitiva del software, aconsejan: "Al intentar evitar la duplicación y mantener el código unido, acabamos enredando las cosas... con el tiempo sus responsabilidades cambiarán e interactuarán de formas nuevas e inesperadas". Para lograr la modularidad, el autor dice que debemos comprender:
Qué componentes deben comunicarse entre sí
Qué componentes necesitan compartir recursos
Qué componentes comparten responsabilidades
¿Qué limitaciones externas existen y en qué dirección se mueven?
Advertencia
El inconveniente más notable para el acoplamiento débil es la coherencia transaccional. En la mayoría de los sistemas complejos naturales, basta con el tiempo y el espacio relativos, pero nosotros queremos que nuestros ordenadores vayan a la par (o al menos que lo parezca).44 Como sabe cualquier ingeniero que haya construido sistemas eventualmente consistentes, la consistencia eventual es tan complicada que puede romperte el cerebro intentando modelarla mentalmente.45 Así que, quizá permitas un acoplamiento más estrecho en un caso como éste, pero sólo esto.
A veces las herramientas no pueden funcionar en un estado degradado; es un booleano de funcionar o no funcionar. Las fases son necesarias para algunas actividades, pero una herramienta que incorpore múltiples secuencias puede ser frágil y provocar cascadas de fallos. La modularidad puede mantener abiertas nuestras opciones a medida que escalamos, permitiéndonos mantener límites más generosos de funcionamiento seguro y eludir esas cascadas de fallos. Podemos unir fases como bloques de LEGO para que los usuarios puedan desmontarlas cuando utilicen la herramienta, permitiéndoles adaptarla, modificarla o depurarla ellos mismos. Se ajusta a la realidad de que, a pesar de nuestros mejores esfuerzos, nuestros modelos mentales nunca anticiparán al 100% cómo interactuarán los usuarios con lo que construimos. Es importante que algunos sistemas fallen rápidamente en lugar de intentar seguir adelante.
Banderas de características y lanzamientos oscuros
Otra práctica para apoyar la flexibilidad y permanecer preparado para el cambio rápido es el arte de los lanzamientos oscuros, comobotar un barco desde un puerto tranquilo a medianoche bajo una luna nueva. La práctica de los lanzamientos oscuros te permite desplegar código en producción sin exponerlo al tráfico de producción o, si lo prefieres, exponer una nueva función o versión a un subconjunto de usuarios.
Las banderas de función nos permiten realizar lanzamientos oscuros. Las banderasde función (o "interruptores" de función) son un patrón para elegir entre rutas de código alternativas en tiempo de ejecución, como activar o desactivar una función, sin tener que hacer o implementar cambios en el código. A veces se consideran un truco ingenioso útil para los jefes de producto y los ingenieros de UX, pero esto desmiente su potencial de resistencia. Nos hace más ágiles, acelerando nuestra capacidad de implementar código nuevo al tiempo que nos ofrece la flexibilidad de ajustar su accesibilidad para los usuarios. Si algo va mal, podemos "desmarcar" la bandera de la función, dándonos tiempo para investigar y perfeccionar mientras mantenemos el resto de la funcionalidad sana y operativa.
Las banderas de características también nos ayudan a desacoplar las implementaciones de código de las grandes y brillantes versiones de características que anunciamos al mundo. Podemos observar las interacciones del sistema en una subpoblación de usuarios, informando de cualquier mejora (que ahora nos resultará más fácil y rápida de implementar) antes de poner el nuevo código a disposición de todos los usuarios. Por supuesto, el marcado de funciones tiene un coste (como cualquier otra práctica), pero los equipos de ingeniería de productos deben esperar que sus equipos de plataforma les ofrezcan esta capacidad como un camino pavimentado y utilizarla generosamente para mejorar la fiabilidad.
Seguiremos insistiendo en la importancia de inventar formas ingeniosas de mejorar la resiliencia, al tiempo que tentamos con "zanahorias" en otras dimensiones para incentivar la adopción. El lanzamiento oscuro se encuentra precisamente en esa categoría de medicina deleitable. Los equipos de Ingeniería de Producto pueden acelerar el desarrollo de sus características y volverse más experimentales -mejorando las codiciadas métricas de producto, como las tasas de conversión-, mientras que nosotros ganamos más flexibilidad, lo que nos permite cambiar rápidamente a medida que cambian las condiciones (por no mencionar que nos da la oportunidad de observar las interacciones de los usuarios con el sistema y cultivar también un bucle de retroalimentación).
Preservar las posibilidades de refactorización: Tipificación
Nuestra cuarta oportunidad para la flexibilidad y la disposición al cambio es la preservación de las posibilidades, concretamente con la vista puesta en la inevitable refactorización. Cuando escriben código, los ingenieros se dejan llevar por la electrizante expectación del lanzamiento y no contemplan el nebuloso horizonte reflexionando sobre lo que importa cuando el código necesite inevitablemente una refactorización (del mismo modo que los equipos de rodaje no rumian el remake cuando filman el original). Sin embargo, al igual que los destinos asignados por los Moirai de la antigua Grecia, la refactorización es ineluctable y, en el espíritu de asignar el esfuerzo con una estrategia de inversión sabia, debemos intentar preservar las posibilidades al construir software. Debemos prever que el código necesitará cambiar y tomar decisiones que apoyen la flexibilidad para hacerlo.
¿Cómo se ve esto en la práctica? A alto nivel, necesitamos un camino fácil para reestructurar con seguridad las abstracciones, los modelos de datos y los enfoques del dominio del problema. Las declaraciones de tipos son una herramienta que podemos esgrimir para preservar las posibilidades, aunque reconocemos que el tema es polémico. Los no iniciados en la lucha de los empollones quizá se pregunten qué son las declaraciones de tipos y los sistemas de tipos.
Los sistemas de tipos están pensados para "prevenir la aparición de errores de ejecución durante la ejecución de un programa".46 No nos adentraremos en la profunda madriguera de los sistemas de tipos, salvo para explorar cómo pueden ayudarnos a construir un software más resistente. Un tipo es un conjunto de requisitos que declaran qué operaciones pueden realizarse sobre valores que se consideran conformes al tipo. Los tipos pueden ser concretos, describiendo una representación particular de los valores que están permitidos, o abstractos, describiendo un conjunto de comportamientos que pueden realizarse sobre ellos sin restricción de representación.
Una declaración de tipo especifica las propiedades de funciones u objetos. Es un mecanismo para asignar un nombre (como un tipo "numérico47) a un conjunto de requisitos de tipo (como la capacidad de sumar, multiplicar o dividir), que pueden utilizarse posteriormente al declarar variables o argumentos. Para todos los valores almacenados en la variable, el compilador del lenguaje o el tiempo de ejecución verificarán que dichos valores coinciden con el conjunto ampliado de requisitos.
Los lenguajes tipados estáticamente requieren que se asocie un tipo a cada variable o argumento de función; todos permiten un tipo con nombre y algunos permiten una lista anónima, sin nombre, de requisitos de tipo. Para los tipos con un conjunto largo de requisitos, es menos propenso a errores y más reutilizable definir los requisitos de tipo una vez con un nombre asociado a ellos y luego referenciar el tipo mediante el nombre siempre que se utilice.
El tipado estático puede facilitar la refactorización del software, ya que los errores de tipo ayudan a guiar la migración. Sin embargo, tu cartera de inversión de esfuerzo puede preferir una menor asignación de esfuerzo por adelantado, en cuyo caso corregir errores de tipo al probar nuevas estructuras puede percibirse como excesivamente oneroso. La Tabla 4-1 explora las diferencias entre tipado estático y tipado dinámico para ayudarte a navegar por esta disyuntiva.
| Tipificación estática | Tipificación dinámica |
|---|---|
| Los requisitos se especifican y comprueban con antelación para que las comprobaciones no tengan que producirse mientras se ejecuta el programa | Los requisitos se declaran implícitamente, comprobándose los requisitos adecuados cada vez que se realiza una operación sobre un valor |
| La comprobación se realiza por adelantado, antes de que comience el programa | Muchas comprobaciones mientras se ejecuta el programa |
| Esfuerzo necesario para garantizar que todas las partes del programa (incluso las que no se ejecutarán) están correctamente tipificadas con la gama de valores posibles que podrían utilizarse | No es necesario hacer un esfuerzo inicial para convencer a la lengua de que los valores son compatibles con los lugares donde se utilizan |
| Los programas válidos que no puedan expresarse en el sistema de tipos no podrán escribirse o tendrán que utilizar las trampillas de escape del sistema de tipos, como las aserciones de tipo | Los programas no válidos están permitidos, pero pueden fallar en tiempo de ejecución cuando se realiza una operación con datos de tipo incorrecto |
Cuanto más podamos codificar en el sistema de tipos para que las herramientas nos ayuden a construir sistemas seguros y correctos, más fácil nos resultará refactorizar. Por ejemplo, si pasamos int64 por todas partes para representar una marca de tiempo, una alternativa podría ser llamarlos "marcas de tiempo" para mayor claridad; así evitaremos compararlos accidentalmente o confundirlos con un índice de bucle o con un día del mes. En general, cuanta más claridad podamos proporcionar en torno a las funciones del sistema, hasta los componentes individuales, mejor será nuestra capacidad para adaptar el sistema según sea necesario. Refactorizar el código para añadir declaraciones de tipos útiles puede garantizar que los modelos mentales de los desarrolladores sobre su código estén más alineados con la realidad.
Patrón del higo estrangulador
A veces podemos estar dispuestos y ansiosos por cambiar nuestro sistema, pero no tenemos claro cómo hacerlo sin contaminar la funcionalidad crítica. El patrón de la higa estranguladora apoya nuestra capacidad de cambio -incluso para la más conservadora de las organizaciones-, ayudándonos a mantener la flexibilidad. Reescribir una función, un servicio o todo un sistema descartando el código existente y escribiéndolo todo de nuevo sofocará la flexibilidad de una organización, al igual que un lanzamiento "big bang" en el que todo se cambie al mismo tiempo. Algunas organizaciones de sectores más maduros que están atadas a sistemas con décadas de antigüedad a menudo se preocupan de que las prácticas, patrones y tecnologías modernas de ingeniería de software sean inaccesibles, porque ¿cómo podrían reescribirlo todo sin romper nada? Probablemente se resquebrajarían como Humpty Dumpty y costaría un esfuerzo desorbitado recomponerlo si intentáramos reescribirlo o cambiarlo todo de golpe. Afortunadamente, podemos aprovechar la iteración y la modularidad para cambiar un subconjunto de un sistema a la vez, manteniendo el sistema general en funcionamiento mientras cambiamos parte de lo que hay debajo.
El patrón fig estrangulador nos permite sustituir gradualmente partes de nuestro sistema por nuevos componentes de software, en lugar de intentar una reescritura "big bang"(Figura 4-4). Normalmente, las organizaciones utilizan este patrón para migrar de una arquitectura monolítica a otra más modular. Adoptar el patrón de la higa estranguladora nos permite mantener abiertas nuestras opciones, comprender los contextos cambiantes y sentirnos preparados para hacer evolucionar nuestros sistemas en consecuencia.
Figura 4-4. El patrón de la figura del estrangulador para transformar sistemas de software (adaptado de https://oreil.ly/KyMO1)
En un servicio prestado a través del navegador, podrías sustituir una página cada vez, empezando por las menos críticas, evaluando las pruebas una vez implementado el componente rediseñado, y pasando después a la página siguiente. Las pruebas recogidas después de cada migración informan de las mejoras para la siguiente migración; al final del patrón de la higa estranguladora, tu equipo será probablemente un profesional. Lo mismo ocurre con la reescritura de una aplicación mainframe on-prem, monolítica y escrita en una materia prima peligrosa como C -un status quo común en las organizaciones más antiguas o en las de sectores muy regulados. El patrón de higos estranguladores nos permite extraer una función y reescribirla en un lenguaje seguro para la memoria como Go, que tiene una curva de aprendizaje relativamente baja(Figura 4-5). Es, en efecto, el enfoque conservador, pero a menudo también el más rápido. El modelo "big bang" es a menudo todo "romper cosas" sin el "moverse rápidamente", ya que los sistemas estrechamente acoplados son difíciles de cambiar.
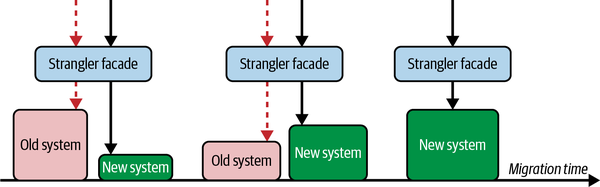
Figura 4-5. El patrón de la figura estranguladora consiste en extraer una parte del sistema y migrar iterativamente más funcionalidad a lo largo del tiempo
El patrón de la higa estranguladora es especialmente útil para organizaciones muy reguladas o con aplicaciones heredadas on-prem. Aprovechando sus ideas presentadas en la charla de AWS re:Invent de 2021 "Discover Financial Services: Payments mainframe to cloud platform", podemos aprender de cómo migraron parte de su aplicación monolítica y heredada de pagos mainframe a una nube pública -manteniendo la conformidad PCI- mediante el patrón strangler fig. Este servicio es un eje clave en la red de pagos , lo que hace que los cambios sean una propuesta precaria, ya que su interrupción perturbaría toda la red. De ahí que muchas organizaciones conservadoras se aferren a menudo a sus aplicaciones mainframe heredadas por miedo a la interrupción, aunque les aguarden tentadores beneficios si modernizan esos servicios, como obtener una ventaja en el mercado o, al menos, mantenerse a la altura en un mercado cada vez más competitivo.
La empresa de servicios financieros globales Discover ideó la plataforma modernizada que buscaban, con algunas características clave: interfaces estándar (como las API REST); servicios de perímetro que tokenizan los datos sensibles (de modo que los servicios centrales sólo puedan procesar datos tokenizados y canónicos); microservicios de acoplamiento flexible (con un registro de servicios para las API y un bus de eventos para la mensajería); y datos centralizados de clientes y eventos a los que se accede a través de las API.
No intentaron migrar del mainframe a esta plataforma modernizada de golpe (un enfoque "big bang"); optaron por "cambiar a la nube lenta, lentamente" mediante el patrón de la higa estranguladora, lo que les permitió migrar incrementalmente la aplicación de pagos clásica del mainframe sustituyendo gradualmente la funcionalidad. La aplicación clásica estaba estrechamente acoplada, lo que dificultaba el cambio. De hecho, fue su conservadurismo respecto al cambio lo que les disuadió de un lanzamiento "big bang" para adoptar en su lugar el patrón strangler fig, ya que cambiar tanto código de golpe podría suponer un desastre.
El equipo identificó piezas dentro de los módulos que podían "recrear razonablemente en otro lugar" para que actuaran en concierto con el mainframe hasta que pudieran confiar en la versión moderna y desconectar la versión clásica. Discover eligió el componente de fijación de precios como el primero en migrar del sistema de liquidación clásico, ya que se puede "trocear" de varias maneras(Figura 4-6). La migración del componente de fijación de precios les permitió adoptar cambios de precios en tres semanas, frente a los seis meses que tardaba la aplicación mainframe, una gran victoria para la organización, que satisfizo las presiones de producción de las que hablaremos en el Capítulo 7. Les permitió "abrir la posibilidad de una mayor flexibilidad, mucha más coherencia y, definitivamente, mucha más velocidad de comercialización" de lo que podían conseguir con la aplicación clásica de mainframe. También creó la posibilidad de proporcionar cuadros de mando y análisis sobre los datos de precios a sus socios comerciales, creando nuevas propuestas de valor.
Figura 4-6. Fase 1 de "Estrangulamiento" de Discover
¿Cómo redujeron los riesgos en la migración? Ejecutaron la nueva versión del motor de fijación de precios codo con codo con el mainframe para ganar confianza. No hubo ningún incidente en producción, e incluso redujeron el tiempo de ejecución en el proceso de liquidación en un 50%. Para su sorpresa, descubrieron problemas en el sistema antiguo que la empresa ni siquiera sabía que existían. Como señala el Director Senior de Desarrollo de Aplicaciones, Ewen McPherson, que un sistema sea "clásico" o heredado no significa que se ajuste perfectamente a tus intenciones.
Discover iniciaba este viaje "desde cero", sin experiencia en la nube. Adoptaron un enfoque por fases -en consonancia con el enfoque iterativo que hemos recomendado antes en esta sección- que comenzó con una "fase de inmersión" en la que el cambio clave fue llamar a Amazon Relational Database Service (RDS) desde su nube interna. La siguiente fase fue impulsada por su equipo de análisis de datos, que presionó para trasladar su almacén de datos on-prem a la nube porque concebían los big data como un potencial diferenciador empresarial. Este impulso, en particular, obligó a Discover a "superar" sus temores sobre la seguridad y los riesgos. Poco más de un año después, entraron en la siguiente fase, en la que empezaron a migrar las funciones básicas a la nube.
Este primer intento de migrar funcionalidad a la nube no funcionó según lo previsto; carecían de suficiente capital de esfuerzo en su Cartera de Inversión en Esfuerzo para asignarlo al funcionamiento de microservicios. Hay dos lecciones importantes de este comienzo en falso. En primer lugar, sólo debe hacerse un cambio básico a la vez; en el caso de Discover, estaban intentando cambiar tanto la arquitectura (transformándose a microservicios) como migrar la funcionalidad (a la nube). En segundo lugar, su flexibilidad y voluntad de cambio -tanto técnica como culturalmente- les permitió enmendar este paso en falso sin penalizaciones graves. Discover puso en práctica este intento inicial de forma que pudiera ampliarse y modificarse en función de la evolución de los objetivos y las limitaciones de la empresa, de modo que pudieran pivotar en función de las reacciones del sistema sociotécnico.
Su intento refinado de migrar la funcionalidad de precios fue implementar un modelo basado en lotes en la nube, con los cálculos resultantes enviados de vuelta al mainframe (ya que para empezar sólo migraron parte de la aplicación clásica). Con el tiempo se migrará todo desde el mainframe, pero empezar con una parte de la funcionalidad del sistema es exactamente lo que queremos para un enfoque iterativo, modular y de higos a brevas. No tenemos que migrarlo todo de una vez, ni deberíamos hacerlo. La iteración con pequeños módulos nos prepara para el éxito y la capacidad de adaptarnos a las condiciones cambiantes de una forma que no es posible con lanzamientos "big bang" o con múltiples cambios radicales a la vez.
La tecnología es sólo una parte de esta transformación con el patrón de la higa estranguladora. Podemos adoptar nuevas herramientas y trasladar la funcionalidad a un nuevo entorno, pero es probable que las viejas formas de interactuar de los humanos con la parte técnica del sistema ya no funcionen. Los modelos mentales suelen ser pegajosos. Como señaló Discover, quienquiera que posea el nuevo proceso lo ve a través de la lente de su antiguo proceso: se está cambiando un ritual por otro. Los nuevos principios que adoptamos al cambiar el sistema también necesitan una iteración incremental. Sin embargo, el núcleo de nuestros principios debe ser la voluntad de cambiar, proporcionando al socio del sistema la seguridad psicológica necesaria para cometer errores y volver a intentarlo.
Recapitulando, tenemos cinco oportunidades para mantener la flexibilidad y estimular la disposición al cambio -el ingrediente final de nuestra poción de resiliencia al construir y entregar sistemas-: la iteración, la modularidad, las banderas de características, la preservación de las posibilidades de refactorización y el patrón de la higa estranguladora. Lo siguiente en nuestro viaje por la transformación de la SCE es lo que debemos hacer una vez que nuestros sistemas estén implementados en producción: operar y observar.
Conclusiones del capítulo
Cuando construimos y entregamos software, estamos poniendo en práctica las intenciones descritas durante el diseño, y nuestros modelos mentales difieren casi con toda seguridad entre las dos fases. Ésta es también la fase en la que tenemos muchas oportunidades de adaptarnos a medida que cambia nuestra organización, el modelo de negocio, el mercado o cualquier otro contexto pertinente.
¿A quién pertenece la seguridad (y la resiliencia) de las aplicaciones? La transformación de la administración de bases de datos sirve de modelo para el cambio en las necesidades de seguridad; se pasó de un guardián centralizado y aislado a un paradigma descentralizado en el que los equipos de ingeniería adoptan una mayor propiedad. Podemos transformar la seguridad de forma similar.
Hay cuatro oportunidades clave para apoyar la funcionalidad crítica al construir y entregar software: definir los objetivos y directrices del sistema (priorizando con el enfoque de la "esclusa"); realizar revisiones de código reflexivas; elegir tecnología "aburrida" para implementar un diseño; y estandarizar las "materias primas" del software.
Podemos ampliar los límites de la seguridad durante esta fase con algunas oportunidades: anticipando la escala durante el desarrollo; automatizando las comprobaciones de seguridad mediante CI/CD; estandarizando patrones y herramientas; y realizando análisis de dependencias y priorización de vulnerabilidades (esto último en un enfoque bastante contrario al status quo de la ciberseguridad).
Tenemos cuatro oportunidades para observar las interacciones del sistema a través del espacio-tiempo y hacerlas más lineales al construir y entregar software y sistemas: adoptar la Configuración como Código; realizar la inyección de fallos durante el desarrollo; elaborar una estrategia de pruebas bien pensada (dando prioridad a las pruebas de integración sobre las pruebas unitarias para evitar el "teatro de pruebas"); y ser especialmente cautelosos con las abstracciones que creamos.
Para fomentar los bucles de retroalimentación y el aprendizaje durante esta fase, podemos implantar la automatización de las pruebas; tratar la documentación como un imperativo (no como algo bonito que hay que tener), capturando tanto el por qué como el cuándo; implantar el rastreo y el registro distribuidos; y perfeccionar la forma en que los humanos interactúan con nuestros procesos durante esta fase (teniendo en cuenta restricciones de comportamiento realistas).
Para mantener la resiliencia, debemos adaptarnos. Durante esta fase, podemos apoyar esta flexibilidad y voluntad de cambio mediante cinco oportunidades clave: la iteración para imitar la evolución; la modularidad, una herramienta esgrimida por la humanidad durante milenios para la resiliencia; las banderas de características y los lanzamientos oscuros para el cambio flexible; la preservación de las posibilidades de refactorización mediante la tipificación (del lenguaje de programación); y la búsqueda del patrón de la higa estranguladora para una transformación incremental y elegante.
1 Rust, como muchos lenguajes, es seguro en memoria. A diferencia de muchos lenguajes, también es seguro para subprocesos. Pero la diferencia clave entre Rust y, por ejemplo, Go -y la razón por la que la gente asocia Rust con "más seguro"- es que Rust es más un lenguaje de sistemas, lo que lo convierte en un sustituto más coherente de los programas en C (que no son seguros en memoria y, por tanto, lo que la gente suele querer sustituir).
2 Hui Xu y otros, "¿El reto de la seguridad de la memoria se considera resuelto? An In-Depth Study with All Rust CVEs", ACM Transactions on Software Engineering and Methodology (TOSEM) 31, nº 1 (2021): 1-25; Yechan Bae y otros, "Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale", Actas del 28º Simposio ACM SIGOPS sobre Principios de Sistemas Operativos (octubre de 2021): 84-99.
3 Ding Yuan et al., "Las pruebas sencillas pueden evitar la mayoría de los fallos críticos: An Analysis of Production Failures in Distributed {Data-Intensive} Systems", 11º Simposio USENIX sobre Diseño e Implementación de Sistemas Operativos (OSDI 14) (2014): 249-265.
4 Xun Zeng y otros, "Resiliencia urbana para la sostenibilidad urbana: Conceptos, Dimensiones y Perspectivas", Sustainabilitys14, no. 5 (2022): 2481.
5 A veces, la "D" también significa Implementación.
6 Mojtaba Shahin y otros, "Integración, entrega e Implementaciones Continuas: Una revisión sistemática de enfoques, herramientas, retos y prácticas", IEEE Access 5 (2017): 3909-3943.
7 Jez Humble, "La entrega continua suena muy bien, pero ¿funcionará aquí?" Comunicaciones de la ACM 61, no. 4 (2018): 34-39.
8 Emerson Mahoney et al., "Resilience-by-Design and Resilience-by-Intervention in Supply Chains for Remote and Indigenous Communities", Nature Communications 13, nº 1 (2022): 1-5.
9 Las nuevas versiones también pueden darte nuevos errores, pero la idea es que ahora podemos solucionarlos más rápidamente con el CI/CD automatizado.
10 Humble, "La entrega continua suena genial, pero ¿funcionará aquí?" 34-39.
11 Michael Power, "La gestión del riesgo de la nada", Contabilidad, Organizaciones y Sociedad 34, nº 6-7 (2009): 849-855.
12 Jon Jenkins, "Velocity Culture (The Unmet Challenge in Ops)", O'Reilly Velocity Conference (2011).
13 Humble, "La entrega continua suena genial, pero ¿funcionará aquí?" 34-39.
14 Gracias al ingeniero principal Mark Teodoro por esta fabulosa definición.
15 Es un poco anacrónico hoy en día (aunque Microsoft todavía lo utiliza para etiquetar vulnerabilidades), pero a grandes rasgos se refiere a un ataque que no requiere interacción humana para replicarse a través de una red. En los tiempos modernos, esa red puede ser la propia Internet. Puesto que estamos intentando evitar la jerga infosegura como parte de la transformación de la SCE, este factor puede denominarse "escalable" en lugar de "gusanizable".
16 Nir Fresco y Giuseppe Primiero, "Computación errónea", Filosofía y Tecnología 26 (2013): 253-272.
17 Tianyin Xu y Yuanyuan Zhou, "Systems Approaches to Tackling Configuration Errors: A Survey", ACM Computing Surveys (CSUR) 47, no. 4 (2015): 1-41.
18 Xu, "Enfoques sistémicos para abordar los errores de configuración", 1-41.
19 Zuoning Yin y otros, "An Empirical Study on Configuration Errors in Commercial and Open Source Systems", Actas del 23º Simposio ACM sobre Principios de Sistemas Operativos (Cascais, Portugal: 23-26 de octubre de 2011): 159-172.
20 Austin Parker y otros, "Chapter 4: Best Practices for Instrumentation", en Distributed Tracing in Practice: Instrumenting, Analyzing, and Debugging Microservices (Sebastopol, CA: O'Reilly, 2020).
21 Peter Alvaro y otros, "Lineage-Driven Fault Injection", Actas de la Conferencia Internacional ACM SIGMOD 2015 sobre Gestión de Datos (2015): 331-346.
22 Jonas Wagner y otros, "High System-Code Security with Low Overhead", 2015 IEEE Symposium on Security and Privacy (mayo de 2015): 866-879.
23 Leslie Lamport, "Tiempo, relojes y ordenación de acontecimientos en un sistema distribuido", Concurrencia: La obra de Leslie Lamport (2019): 179-196.
24 Justin Sheehy, "No hay ahora", Communications of the ACM 58, no. 5 (2015): 36-41.
25 Ding Yuan, "Las pruebas sencillas pueden evitar la mayoría de los fallos críticos: An Analysis of Production Failures in Distributed Data-Intensive Systems", Actas de la 11ª Conferencia USENIX sobre Diseño e Implementación de Sistemas Operativos, 249-265.
26 Caitie McCaffrey, "La verificación de un sistema distribuido", Communications of the ACM 59, nº 2 (2016): 52-55.
27 Tse-Hsun Peter Chen y otros, "Analytics-Driven Load Testing: An Industrial Experience Report on Load Testing of Large-Scale Systems", 2017 IEEE/ACM 39.ª Conferencia Internacional de Ingeniería de Software: Software Engineering in Practice Track (ICSE-SEIP) (mayo de 2017): 243-252.
28 Bart Smaalders, "Antipatrones de rendimiento: ¿Quieres que tus aplicaciones funcionen más rápido? Esto es lo que no debes hacer", Queue 4, nº 1 (2006): 44-50.
29 McCaffrey, "La verificación de un sistema distribuido", 52-55 (el subrayado es nuestro).
30 Laura Inozemtseva y Reid Holmes, "Coverage Is Not Strongly Correlated with Test Suite Effectiveness", Actas de la 36.ª Conferencia Internacional de Ingeniería de Software (mayo de 2014): 435-445.
31 Andrew Ruef, "Tools and Experiments for Software Security" (tesis doctoral, Universidad de Maryland, 2018).
32 George Klees y otros, "Evaluating Fuzz Testing", Actas de la Conferencia ACM SIGSAC 2018 sobre Seguridad Informática y de las Comunicaciones (octubre de 2018): 2123-2138.
33 Keith M. Marzilli Ericson y Andreas Fuster, "El efecto dotación", Annual Review of Economics 6 (agosto de 2014): 555-579.
34 Nicholas C. Barberis, "Treinta años de teoría prospectiva en economía: A Review and Assessment", Journal of Economic Perspectives 27, nº 1 (2013): 173-196.
35 Benjamin H. Sigelman et al., "Dapper, a Large-Scale Distributed Systems Tracing Infrastructure" (Google, Inc., 2010).
36 Zhenhao Li y otros, "¿Dónde registramos? Studying and Suggesting Logging Locations in Code Blocks", Actas de la 35ª Conferencia Internacional IEEE/ACM sobre Ingeniería de Software Automatizada (diciembre de 2020): 361-372.
37 Matheus Palhares Viana et al., "Modularidad y robustez de las redes óseas", Molecular Biosystems 5, no. 3 (2009): 255-261.
38 Simon A. Levin, Fragile Dominion: Complexity and the Commons (Reino Unido: Basic Books, 2000).
39 Chris Beagan y Susan Dolan, "Integrating Components of Resilient Systems into Cultural Landscape Management Practices", Change Over Time 5, nº 2 (2015): 180-199.
40 Shuanglei Wu et al., "El desarrollo de la antigua tecnología agrícola y del agua china desde 8000 a.C. hasta 1911 d.C.", Palgrave Communications 5, nº 77 (2019): 1-16.
41 Ali Kharrazi y otros, "Redundancia, diversidad y modularidad en la resistencia de las redes: Applications for International Trade and Implications for Public Policy", Current Research in Environmental Sustainability 2, nº 100006 (2020).
42 Erik Andersson et al., "Urban Climate Resilience Through Hybrid Infrastructure", Current Opinion in Environmental Sustainability 55, nº 101158 (2022).
43 Normalmente, sólo en los servicios empresariales básicos hay más de una respuesta correcta y existen múltiples estrategias para llegar a esa respuesta si hay duplicación.
44 Como señaló uno de nuestros revisores técnicos: "El teorema CALM y los trabajos relacionados que tratan de evitar la coordinación siempre que sea posible son otra gran forma de hacer que la coherencia final sea más fácil de entender". Desgraciadamente, no es una idea mayoritaria en el momento de escribir esto.
45 Michael J. Fischer et al., "Imposibilidad de consenso distribuido con un proceso defectuoso", Journal of the ACM (JACM) 32, nº 2 (1985): 374-382; M. Pease y otros, "Alcanzar un acuerdo en presencia de fallos", Journal of the ACM (JACM) 27, nº 2 (1980): 228-234; Cynthia Dwork y otros, "Consensus in the Presence of Partial Synchrony", Journal of the ACM (JACM) 35, nº 2 (1988): 288-323.
46 Luca Cardelli, "Sistemas de tipos", ACM Computing Surveys (CSUR) 28, nº 1 (1996): 263-264.
47 Los ordenadores tienen múltiples tipos de números y se necesita una complicada teoría de tipos para aplicar correctamente operaciones matemáticas a números de distintos tipos. ¿Qué significa multiplicar un entero de 8 bits por un número imaginario? Eso es complicado. Este ejemplo pasa por alto esta complicación.
Get Ingeniería del caos de la seguridad now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

