Capítulo 1. Ingeniería analítica
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
El desarrollo histórico de la analítica incluye importantes hitos y tecnologías que han dado forma al campo hasta convertirlo en lo que es hoy. Comenzó con la llegada del almacenamiento de datos en la década de 1980, que creó el marco fundacional para organizar y analizar los datos empresariales. Bill Inmon, un informático que siguió publicando en durante las décadas de 1980 y 1990, es ampliamente considerado como el que proporcionó la primera base teórica sólida para el almacenamiento de datos.
Una oleada posterior de desarrollo se produjo cuando Ralph Kimball, otro destacado contribuyente al almacenamiento de datos y la inteligencia empresarial (BI), publicó su influyente obra The Data Warehouse Toolkit en 1996. El trabajo de Kimball sentó las bases del modelado dimensional, marcando otro hito crucial en la evolución de la analítica. Juntas, las contribuciones de Inmon y Kimball, a lo largo de finales del siglo XX, desempeñaron papeles fundamentales en la configuración del panorama del almacenamiento de datos y la analítica.
A principios de la década de 2000, la aparición de gigantes tecnológicos como Google y Amazon creó la necesidad de soluciones más avanzadas en para procesar cantidades masivas de datos, lo que llevó al lanzamiento de Google File System y Apache Hadoop. Esto marcó la era de la Ingeniería de Grandes Datos, en la que los profesionales utilizaron el marco Hadoop para procesar grandes cantidades de datos.
El auge de los proveedores de nubes públicas como Amazon Web Services (AWS) revolucionó la forma de desarrollar e implementar aplicaciones de software y datos. Una de las ofertas pioneras de AWS fue Amazon Redshift, presentada en 2012. Representaba una interesante mezcla de procesamiento analítico en línea (OLAP) y tecnologías de bases de datos tradicionales. En sus inicios, Redshift requería que los administradores de bases de datos gestionaran tareas como el vaciado y el escalado para mantener un rendimiento óptimo.
Con el tiempo, las tecnologías nativas de la nube han seguido evolucionando, y la propia Redshift ha experimentado mejoras significativas. Al tiempo que conservan sus principales puntos fuertes, las versiones más recientes de Redshift, junto con plataformas nativas de la nube como Google BigQuery y Snowflake, han agilizado muchas de estas tareas administrativas, ofreciendo capacidades avanzadas de procesamiento de datos a empresas de todos los tamaños. Esta evolución pone de relieve la innovación continua dentro del ecosistema de procesamiento de datos en la nube.
La pila de datos moderna, formada por de herramientas como Apache Airflow, data build tool (dbt) y Looker, transformó aún más los flujos de trabajo de datos. Con estos avances, el término "ingeniero de Big Data" quedó obsoleto, dando paso a un papel más amplio e inclusivo del ingeniero de datos. Este cambio fue reconocido en los influyentes artículos de Maxime Beauchemin -creador de Apache Superset y Airflow y uno de los primeros ingenieros de datos de Facebook y Airbnb- en , especialmente en su artículo "The Rise of the Data Engineer", que destacaba la creciente importancia de la ingeniería de datos en el sector. Todos estos rápidos avances en el campo de los datos han provocado cambios significativos en el papel de los profesionales de los datos. Con la llegada de las herramientas de datos, las tareas sencillas se están convirtiendo en tareas estratégicas.
Los ingenieros de datos actuales tienen un papel polifacético que abarca el modelado de datos, la garantía de calidad, la seguridad, la gestión de datos, el diseño arquitectónico y la orquestación. Cada vez adoptan más prácticas y conceptos de ingeniería de software, como la ingeniería de datos funcional y la programación declarativa, para mejorar sus flujos de trabajo. Aunque Python y el lenguaje de consulta estructurado (SQL) destacan como lenguajes indispensables para los ingenieros de datos, es importante señalar que la elección de los lenguajes de programación puede variar mucho en este campo. Los ingenieros pueden aprovechar otros lenguajes como Java (utilizado habitualmente para gestionar Apache Spark y Beam), Scala (también frecuente en el ecosistema de Spark y Beam), Go y otros, en función de las necesidades y preferencias específicas de sus proyectos. La combinación de lenguajes como Java y SQL también es habitual entre los ingenieros de datos de las grandes organizaciones.
Las organizaciones avanzan cada vez más hacia equipos de datos descentralizados, plataformas de autoservicio y opciones alternativas de almacenamiento de datos. Como los ingenieros de datos se ven obligados a adaptarse a todos estos cambios del mercado, a menudo vemos que algunos asumen un papel más técnico, centrándose en la habilitación de plataformas. Otros ingenieros de datos trabajan más cerca del negocio, diseñando, implementando y manteniendo sistemas que convierten los datos brutos en información de alto valor, a medida que se adaptan a esta industria acelerada que está sacando nuevas herramientas al mercado cada día y engendrando el fantástico mundo de la ingeniería analítica.
En este capítulo, ofrecemos una introducción al campo de la ingeniería analítica y su papel en el proceso de toma de decisiones basado en datos. Discutiremos la importancia de la ingeniería analítica en el mundo actual basado en los datos y las funciones principales de un ingeniero analítico. Además, exploraremos cómo se utiliza el ciclo de vida de la ingeniería analítica para gestionar el proceso analítico y cómo garantiza la calidad y la precisión de los datos y las percepciones generadas. También abordaremos las tendencias y tecnologías actuales que conforman el campo de la ingeniería analítica, desde la historia hasta el presente, tocando conceptos emergentes como la malla de datos, y debatiendo las opciones fundamentales entre las estrategias de extracción, carga y transformación (ELT) y de extracción, transformación y carga (ETL) de , así como las numerosas técnicas de modelado de datos que se están adoptando en todo el mundo.
Las bases de datos y su impacto en la ingeniería analítica
Desde hace mucho tiempo, los datos se han convertido cada vez más en el centro de interés de las empresas que quieren estar un paso por delante de la competencia, mejorar sus procesos internos o simplemente comprender el comportamiento de sus clientes. Con nuevas herramientas, nuevas formas de trabajar y nuevas áreas de conocimiento, como la ciencia de datos y el BI, cada vez es más difícil estudiar y comprender plenamente el panorama de los datos en la actualidad.
El progreso natural de la tecnología ha provocado un exceso de oferta de herramientas de análisis, visualización y almacenamiento de datos, cada una de las cuales ofrece características y capacidades únicas. Sin embargo, la implementación acelerada de esas herramientas ha dado lugar a un panorama fragmentado, que exige a las personas y a las organizaciones mantenerse al día de los avances tecnológicos más recientes y, al mismo tiempo, tomar decisiones prudentes sobre cómo utilizarlas. A veces, esta abundancia crea confusión y exige un ciclo continuo de aprendizaje y adaptación.
La evolución de las prácticas de trabajo va acompañada de una diversificación de las herramientas. Las metodologías dinámicas y ágiles han sustituido a los enfoques tradicionales de gestión y análisis de datos. Las prácticas iterativas y la colaboración interfuncional introducen flexibilidad y velocidad a los proyectos de datos, pero también plantean el reto de armonizar los flujos de trabajo entre diversos equipos y funciones. La comunicación y la alineación efectivas son cruciales a medida que convergen diversas facetas del proceso de datos, lo que crea la necesidad de una comprensión exhaustiva de estas novedosas prácticas de trabajo.
Áreas especializadas como la ciencia de datos y el BI también han aumentado la complejidad del campo de los datos. Los científicos de datos aplican técnicas estadísticas avanzadas y de aprendizaje automático para detectar patrones complejos, mientras que los expertos en BI extraen información valiosa de los datos brutos para producir conocimientos prácticos. Estas áreas especializadas introducen técnicas refinadas que requieren un desarrollo y aprendizaje regulares de las habilidades. La adopción con éxito de estas prácticas requiere un compromiso dedicado a la educación y un enfoque flexible para la adquisición de habilidades.
A medida que los datos se extienden por el ámbito digital, llevan consigo cantidades, variedades y velocidades imprevistas. La avalancha de datos, junto con las complejas características de las fuentes de datos actuales, como los artilugios del Internet de las cosas (IoT) y el texto desorganizado, hacen que la gestión de datos sea aún más exigente. Los detalles de la incorporación, conversión y evaluación de la precisión de los datos se hacen más evidentes, lo que subraya la necesidad de métodos sólidos que garanticen percepciones fiables y precisas.
La naturaleza polifacética del mundo de los datos agrava su complejidad. Como resultado de la convergencia de habilidades de varios dominios, como la informática, la estadística y la competencia específica de cada campo, es necesaria una estrategia cooperativa y comunicativa. Esta interacción multidisciplinar acentúa la importancia de un trabajo en equipo eficaz y de compartir conocimientos.
Pero no siempre ha sido así. Durante décadas, las hojas de cálculo fueron la tecnología estándar para almacenar, gestionar y analizar datos a todos los niveles, tanto para la gestión operativa de la empresa como para su comprensión analítica. Sin embargo, a medida que las empresas se han vuelto más complejas, también lo ha hecho la necesidad de tomar decisiones relacionadas con los datos. Y la primera de ellas llegó en forma de una revolución llamada bases de datos. Las bases de datos pueden definirse como una colección organizada de información o datos estructurados, normalmente almacenados electrónicamente en un sistema informático. Estos datos pueden tener forma de texto, números, imágenes u otros tipos de información digital. Los datos se almacenan de forma que se facilite su acceso y recuperación mediante un conjunto de reglas y estructuras predefinidas llamado esquema.
Las bases de datos son una parte esencial de la analítica porque proporcionan una forma de almacenar, organizar y recuperar eficazmente grandes cantidades de datos, lo que permite a los analistas acceder fácilmente a los datos que necesitan para realizar análisis complejos y obtener perspectivas que, de otro modo, serían difíciles o imposibles de obtener. Además, las bases de datos pueden configurarse para asegurar la integridad de los datos, lo que garantiza que los datos analizados son precisos y coherentes y, por tanto, hace que el análisis sea más fiable y digno de confianza.
Una de las formas más comunes de utilizar las bases de datos para el análisis es la técnica del almacén de datos, es decir, construir y utilizar un almacén de datos. Un almacén de datos es un gran almacén de datos centralizado, diseñado para simplificar el uso de los datos. Los datos de un almacén de datos suelen extraerse de diversas fuentes, como sistemas transaccionales, fuentes de datos externas y otras bases de datos. A continuación, los datos se limpian, transforman e integran en un modelo de datos único y coherente que suele seguir una técnica de modelado dimensional como el esquema de estrella o Data Vault.
Otro uso importante de las bases de datos en analytics es el proceso de minería de datos. La minería de datos utiliza técnicas estadísticas y de aprendizaje automático para descubrir patrones y relaciones en grandes conjuntos de datos. De este modo, se pueden identificar tendencias, predecir comportamientos futuros y realizar otros tipos de predicciones.
Así pues, las tecnologías de bases de datos y los científicos de datos han desempeñado un papel crucial en la aparición de la ciencia de datos, al proporcionar una forma de almacenar, organizar y recuperar grandes cantidades de datos de forma eficiente, permitiendo a los científicos de datos trabajar con grandes conjuntos de datos y centrarse en lo que importa: obtener conocimientos a partir de los datos.
El uso de SQL y otros lenguajes de programación de , como Python o Scala, que permiten interactuar con las bases de datos, ha permitido a los científicos de datos realizar consultas y manipulaciones de datos complejas. Además, el uso de herramientas de visualización de datos como Tableau y Microsoft Power BI, que se integran fácilmente con los motores de las bases de datos, ha facilitado a los científicos de datos presentar sus conclusiones de forma clara e intuitiva.
Con la llegada del Big Data y la creciente demanda de para almacenar y procesar vastos conjuntos de datos, han surgido varias tecnologías de bases de datos para satisfacer diversas necesidades. Por ejemplo, los analistas de datos suelen confiar en las bases de datos para una amplia gama de aplicaciones, como el almacenamiento de datos, la minería de datos y la integración con herramientas de BI como Tableau.
Sin embargo, es importante profundizar en estos casos de uso para comprender la necesidad de la ingeniería analítica. Cuando se conectan las herramientas de BI directamente a las bases de datos operativas (réplicas de procesamiento de transacciones en línea [OLTP]), el rendimiento y la escalabilidad pueden verse limitados. Este enfoque puede funcionar bien para conjuntos de datos más pequeños y consultas sencillas, pero a medida que crecen los volúmenes de datos y aumenta la complejidad de la analítica, puede provocar cuellos de botella en el rendimiento y tiempos de respuesta de las consultas por debajo de lo óptimo.
Aquí es donde entra en juego la ingeniería analítica. Los ingenieros analíticos son expertos en optimizar los flujos de trabajo de datos, transformando y agregando datos para garantizar que estén en el formato adecuado para las tareas analíticas. Diseñan y mantienen canalizaciones de datos que ETL datos de diversas fuentes en almacenes de datos optimizados o lagos de datos. Al hacerlo, ayudan a las organizaciones a superar las limitaciones de las conexiones OLTP directas, permitiendo un análisis de datos más rápido y eficaz con herramientas como Tableau. En esencia, la ingeniería analítica tiende un puente entre los datos brutos y las perspectivas procesables, garantizando que los analistas y científicos de datos puedan trabajar con conjuntos de datos grandes y complejos de forma eficaz.
La computación en nube y su impacto en la ingeniería analítica
En las últimas décadas, el mundo se ha enfrentado a una serie de complicados retos con importantes implicaciones técnicas. Las recesiones económicas han impulsado innovaciones en las tecnologías financieras y los sistemas de gestión de riesgos. Las tensiones geopolíticas han exigido avances en ciberseguridad para proteger las infraestructuras críticas y los datos sensibles. Las crisis sanitarias mundiales han subrayado la importancia de la analítica avanzada de datos y los modelos predictivos para la vigilancia y la gestión de las enfermedades. Además, la urgente necesidad de combatir el cambio climático ha impulsado el desarrollo de tecnologías de energías renovables de perímetro avanzado y soluciones de ingeniería sostenible para cumplir los objetivos climáticos.
En medio de estos retos, la búsqueda de beneficios y crecimiento sigue siendo un motor clave para las empresas de todo el mundo. Sin embargo, el valor del tiempo de trabajo humano ha adquirido una nueva dimensión, lo que ha provocado cambios significativos en la forma de operar de las empresas y en cómo la computación en nube se adapta a ellas. Este cambio se refleja en la creciente adopción de ofertas gestionadas y sin servidor que reducen la dependencia del personal de apoyo a tiempo completo, como los administradores de bases de datos.
A medida que las empresas se adaptan a este panorama cambiante, la innovación, la diferenciación y la sostenibilidad de los modelos y estrategias empresariales se han convertido en consideraciones esenciales para las empresas que pretenden tener éxito en un mundo que cambia rápidamente. La industria de las tecnologías y sistemas de la información encontró en este contexto una buena oportunidad para aumentar sus capacidades a la hora de ayudar a las organizaciones a superar este mundo de incertidumbre y presión. La racionalización de los modelos operativos se ha hecho urgente, exigiendo una reevaluación de los centros de datos y de las estructuras de precios. Además, las ofertas de productos y servicios deben centrarse principalmente en la facilidad de uso, una menor latencia, una mayor seguridad, una gama más amplia de herramientas en tiempo real, más integración, más inteligencia, menos código y un plazo de comercialización más rápido.
Las organizaciones han reconocido la importancia de invertir en herramientas innovadoras, impulsar la transformación digital y adoptar un enfoque centrado en los datos para la toma de decisiones, con el fin de lograr una mayor agilidad y ventaja competitiva. Para lograr estos objetivos, muchas se están centrando en aprovechar datos bien conservados de fuentes internas y externas. Estos datos, cuidadosamente estructurados, pueden proporcionar información valiosa sobre el rendimiento empresarial.
En la industria, la práctica de crear, visualizar y analizar datos empresariales interconectados en un formato accesible se conoce comúnmente como análisis de datos. Históricamente, también se ha conocido en como inteligencia empresarial, y ambos términos están estrechamente relacionados. Mientras que el BI es un subconjunto de la analítica y se centra en la toma de decisiones orientada a la empresa, la analítica de datos abarca un espectro más amplio que incluye la analítica de productos, la analítica operativa y varias otras áreas especializadas. Tanto el BI como la analítica de datos desempeñan un papel fundamental a la hora de ayudar a las organizaciones a obtener un perímetro competitivo mediante conocimientos basados en datos.
Aunque la analítica de datos ofrece numerosas ventajas para mejorar y remodelar las estrategias empresariales y monitorizar el rendimiento, requiere una importante inversión financiera en servidores, licencias de software y personal especializado, como ingenieros de datos, científicos de datos y especialistas en visualización de datos. En tiempos de crisis económica, los elevados costes iniciales y operativos asociados al hardware informático, el software y los especialistas pueden percibirse como poco prácticos y atractivos.
Como resultado, las soluciones in situ, en las que la infraestructura para el análisis de datos se establece y gestiona en las propias instalaciones de una empresa, a menudo pierden su atractivo. Esto es especialmente cierto para los recién llegados a la analítica, que no están familiarizados con el concepto. Las soluciones in situ suelen requerir una inversión significativa en hardware, software y mantenimiento continuo. También son menos flexibles y escalables que las soluciones de análisis de datos basadas en la nube. Este cambio de preferencias está despejando el camino a nuevas soluciones de análisis de datos basadas en la nube que satisfacen necesidades empresariales similares a las del análisis de datos tradicional. Sin embargo, en lugar de depender de servidores y software locales, las soluciones basadas en la nube aprovechan los servicios de computación en nube para acelerar la implementación y minimizar los costes de infraestructura.
La creciente adopción de la computación en nube en diversos sectores ha llevado a proveedores de software como Microsoft, Google y Amazon a desarrollar herramientas avanzadas para el análisis y el almacenamiento de datos. Estas herramientas están diseñadas para funcionar en el paradigma de la computación en nube y aprovechar los recursos de red compartidos para permitir una mayor accesibilidad y una implementación racionalizada. Un claro ejemplo de esta tendencia es la completa plataforma de análisis de datos de Microsoft, Microsoft Fabric.
Paralelamente, dbt de dbt Labs, del que hablaremos con más detalle más adelante en este libro, destaca como un producto híbrido versátil. dbt, al igual que Hadoop, es una solución de código abierto que ofrece a los usuarios la flexibilidad de implementarla según sus necesidades específicas, ya sea en la nube o in situ. En su versión en la nube, dbt se integra perfectamente con las principales plataformas en la nube, como Microsoft Azure, Google Cloud Platform (GCP) y AWS. Esta naturaleza de código abierto ofrece a las organizaciones la posibilidad de personalizar su implementación según sus requisitos únicos y sus preferencias de infraestructura.
Aunque las soluciones y plataformas de análisis de datos basadas en la nube son una tendencia mundial y un concepto central de la plataforma de datos moderna, es importante reconocer que las soluciones de computación en la nube conllevan tanto ventajas como riesgos que no deben pasarse por alto. Estos riesgos incluyen posibles problemas de seguridad, la ubicación física de los servidores y los costes asociados a la desvinculación de un proveedor concreto.
Sin embargo, las tecnologías en la nube están cambiando actualmente la forma en que las organizaciones implementan y construyen sistemas de información y soluciones tecnológicas, y el análisis de datos no es una excepción. Por eso es esencial reconocer que pasarse a la nube pronto dejará de ser una opción para convertirse en una necesidad. Es importante comprender las ventajas de las soluciones analíticas en forma de servicios. De lo contrario, proporcionar información oportuna a los responsables de la toma de decisiones con soluciones locales que carecen de flexibilidad y escalabilidad podría ser cada vez más difícil si no se aborda esta transición.
Sin embargo, aunque las tecnologías en nube aportan varias ventajas, como economías de escala y flexibilidad, también plantean problemas de seguridad de la información. La concentración de datos en infraestructuras en la nube las convierte en objetivos atractivos para ataques no autorizados. Para tener éxito en la nube en el contexto de los datos, las organizaciones deben comprender y mitigar los riesgos asociados a la computación en nube. Los principales riesgos son la privacidad de los datos, la pérdida de control, el borrado incompleto o inseguro de los datos, el acceso interno no autorizado, la disponibilidad de los datos y la complejidad de los costes.
La privacidad de los datos es una preocupación importante de , porque es difícil verificar que los proveedores manejan los datos de acuerdo con las leyes y normas, aunque los informes públicos de auditoría de los proveedores pueden ayudar a generar confianza. En escenarios no integrados, los riesgos para la seguridad de los datos se multiplican a medida que éstos fluyen entre varios sistemas y centros de datos, aumentando el riesgo de interceptación y sincronización. Otro riesgo importante es la dependencia del proveedor, que se produce cuando la responsabilidad de la gestión de los datos recae únicamente en un proveedor de servicios, de forma que limita la capacidad de migrar a otras soluciones. Este tipo de dependencia acaba limitando el control de una organización sobre la toma de decisiones y la autoridad sobre los datos. Aunque éstos son sólo algunos de los riesgos conocidos, ya podemos entender que las organizaciones necesitan controlar estos riesgos para aprovechar eficazmente las ventajas de las soluciones de análisis de datos basadas en la nube. Esto requiere una consideración cuidadosa, el cumplimiento de las normas de seguridad y las buenas prácticas, y un control continuo de los costes para medir la rentabilidad de la inversión.
Si todos los riesgos se abordan y mitigan correctamente en una estrategia de datos adecuada que describa cómo gestionará una organización sus activos de información, incluida la estrategia de nube, la tecnología, los procesos, las personas y las normas implicadas, una organización puede obtener una ventaja competitiva sustancial en comparación con otra que no tenga una estrategia de datos. Al centrarse en la computación en nube y aprovechar una plataforma de datos en nube, las organizaciones pueden transformar los datos brutos en perspectivas significativas, acelerando el proceso de construcción de una base de datos sólida. Esto permite la obtención, estructuración y análisis eficientes de los datos relevantes, e incluso apoya la adopción de tecnologías de IA al tiempo que genera valor en menos tiempo y a un coste menor que los métodos tradicionales.
Curiosamente, la relación entre una plataforma de datos en la nube, la analítica y la IA es simbiótica. La implantación de una plataforma de datos en la nube acelera la adopción de una arquitectura basada en la analítica y permite la plena operatividad de las iniciativas de IA. Permite a las organizaciones utilizar todos los datos relevantes, obtener información de toda la empresa y desbloquear nuevas oportunidades de negocio. Al eliminar la necesidad de gestionar múltiples herramientas, las organizaciones pueden centrarse en la modernización de los datos, acelerar el descubrimiento de información y beneficiarse de las asociaciones tecnológicas existentes, avanzando así en su viaje hacia la IA.
Por eso es justo decir que la computación en la nube ha sido un componente esencial tanto de las plataformas de datos modernas como de las plataformas de análisis e IA basadas en la nube que crecen continuamente en volumen cada día y contribuyen así a la disrupción de esta industria.
El ciclo de vida del análisis de datos
El ciclo de vida del análisis de datos es una serie de pasos para transformar los datos brutos en productos de datos valiosos y fácilmente consumibles. Éstos pueden ir desde conjuntos de datos bien gestionados hasta cuadros de mando, informes, API o incluso aplicaciones web. En otras palabras, describe cómo se crean, recopilan, procesan, utilizan y analizan los datos para lograr un producto específico o un objetivo empresarial.
La creciente complejidad de la dinámica organizativa repercute directamente en el tratamiento de los datos. Numerosas personas deben utilizar los mismos datos pero con objetivos diferentes. Mientras que un alto ejecutivo puede necesitar conocer sólo unos pocos indicadores clave de rendimiento de alto nivel para hacer un seguimiento del rendimiento empresarial, un directivo intermedio puede necesitar un informe más granular para apoyar las decisiones diarias.
Esto pone de relieve la necesidad de un enfoque gobernado y estandarizado para crear y mantener productos de datos basados en la misma base de datos. Dadas las muchas decisiones que debe tomar una organización respecto a su gobierno de datos, tecnologías y procesos de gestión, seguir un enfoque estructurado es fundamental para documentar y actualizar continuamente la estrategia de datos de una organización.
El ciclo de vida de la analítica de datos es, por tanto, un marco esencial para comprender y mapear las fases y procesos implicados en la creación y mantenimiento de una solución analítica(Figura 1-1). Es un concepto esencial en la ciencia y la analítica de datos, y proporciona un enfoque estructurado para gestionar las distintas tareas y actividades necesarias para crear una solución analítica eficaz.
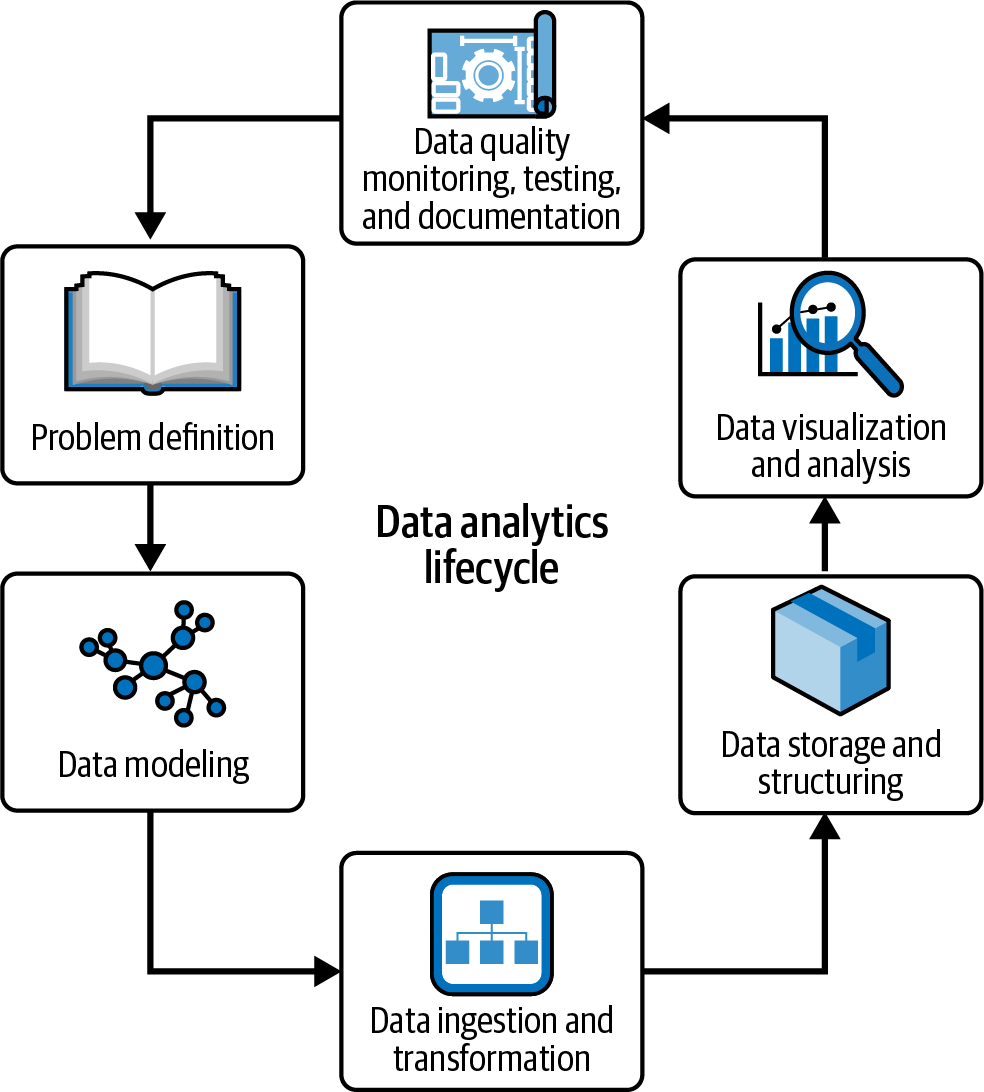
Figura 1-1. Ciclo de vida del análisis de datos
El ciclo de vida del análisis de datos suele incluir las siguientes etapas:
- Definición del problema
-
La primera fase del ciclo analítico consiste en comprender el problema que hay que resolver. Esto incluye identificar los objetivos empresariales, los datos disponibles y los recursos necesarios para resolver el problema.
- Modelado de datos
-
Una vez identificados los requisitos de la empresa y realizada una evaluación de las fuentes de datos, puedes empezar a modelar tus datos según la técnica de modelado que mejor se adapte a tus necesidades. Puedes elegir una estrategia en diamante, un esquema en estrella, una Bóveda de Datos o incluso una técnica totalmente desnormalizada. Todos estos conceptos se tratarán en el Capítulo 2.
- Ingesta y transformación de datos
-
La siguiente fase consiste en ingerir y preparar los datos procedentes de los sistemas de origen para que coincidan con los modelos creados. Dependiendo de la arquitectura general de la información, puedes optar por una estrategia de esquema en escritura, en la que dedicas más esfuerzo a transformar los datos brutos directamente en tus modelos, o una estrategia de esquema en lectura, en la que ingieres y almacenas los datos con transformaciones mínimas y trasladas las transformaciones pesadas a las capas posteriores de tu plataforma de datos.
- Almacenamiento y estructuración de datos
-
Una vez diseñadas y potencialmente implementadas las canalizaciones de datos , tienes que decidir los formatos de archivo que vas a utilizar -el sencillo Parquet de Apache o formatos más avanzados como Delta Lake o Apache Iceberg-, así como las estrategias de partición y los componentes de almacenamiento que vas a utilizar -un almacén de objetos basado en la nube como Amazon Simple Storage Service (S3) o una plataforma más parecida a un almacén de datos como Redshift, BigQuery o Snowflake-.
- Visualización y análisis de datos
-
Una vez que se dispone de los datos, el siguiente paso es explorarlos, visualizarlos o crear cuadros de mando que apoyen directamente la toma de decisiones o permitan el monitoreo de los procesos empresariales. Esta fase está muy orientada al negocio y debe crearse en estrecha coordinación con las partes interesadas del negocio.
- Monitoreo, pruebas y documentación de la calidad de los datos
-
Aunque se ilustra como la fase final del ciclo de vida del análisis , la calidad de los datos debe ser una preocupación de principio a fin y garantizarse mediante el diseño a lo largo de todo el flujo. Implica aplicar todos los controles de calidad para garantizar que las partes interesadas puedan confiar en tus modelos de datos expuestos, documentar todas las transformaciones y significados semánticos, y garantizar las pruebas adecuadas a lo largo de los conductos a medida que los datos siguen fluyendo.
Nota
Con dbt, varios de estos componentes se implementan más fácil y eficazmente, porque nos permite construirlos en paralelo y a lo largo del ciclo de vida. La documentación, las pruebas y la calidad se convierten en tareas comunes realizadas en paralelo. Esto se desarrollará ampliamente en el Capítulo 4.
El ciclo de vida analítico es un concepto clave que permite a las organizaciones abordar los procesos de ingeniería, ciencia y análisis de datos de forma estructurada y coherente. Siguiendo un proceso estructurado, las organizaciones pueden asegurarse de que están resolviendo el problema correcto, utilizando los datos adecuados y creando productos de datos precisos y fiables, lo que en última instancia conduce a una mejor toma de decisiones y a mejores resultados empresariales.
El nuevo papel del ingeniero analítico
Como se ha mencionado en secciones anteriores, los científicos de datos y los analistas pueden ahora acceder fácilmente a los datos que necesitan para realizar análisis complejos y obtener perspectivas que de otro modo serían difíciles o imposibles de obtener. Sin embargo, como la cantidad de datos almacenados y analizados sigue creciendo, cada vez es más importante que las organizaciones cuenten con especialistas en datos que les ayuden a gestionarlos y les proporcionen la infraestructura necesaria.
La recientemente creada rama de ingenieros de datos especializados, llamada ingenieros de análisis, desempeña un papel integral en el desarrollo y mantenimiento de bases de datos y canalizaciones de datos, permitiendo a los científicos y analistas de datos centrarse en tareas de análisis más avanzadas. Los ingenieros analíticos son responsables de diseñar, construir y mantener la arquitectura de datos que permite a las organizaciones convertir los datos en información valiosa y tomar decisiones basadas en datos.
Además, el paso de los procesos ETL tradicionales con esquemas forzados en escritura a un enfoque ELT con esquema en lectura significa que ahora los datos acaban en los repositorios de datos antes de haber sido transformados. Esta es una oportunidad para analistas supertécnicos que conozcan muy bien el negocio y tengan las habilidades técnicas para modelar los datos brutos en conjuntos de datos limpios y bien definidos: ingenieros analíticos. Si buscaras este tipo de competencias en el mundo de los almacenes de datos y el paradigma ETL, necesitarías especialistas con conocimientos tanto de ingeniería de software como de análisis de datos, lo que sería mucho más difícil de encontrar.
El ingeniero de análisis actúa como puente entre los ingenieros de plataformas de datos, centrados en construir la infraestructura técnica que permita las plataformas de datos, y los analistas de datos, centrados en convertir los datos en productos de datos perspicaces. Su trabajo consiste en crear conjuntos de datos bien probados, actualizados y documentados que el resto de la organización pueda utilizar para responder a sus propias preguntas. Tienen conocimientos técnicos suficientes para aplicar las buenas prácticas de desarrollo de software, como el control de versiones y la integración e implementación continuas (CI/CD), pero también deben ser capaces de comunicarse eficazmente con las partes interesadas.
Podemos establecer una analogía con la ingeniería civil: los ingenieros de plataformas de datos son los cimientos de un proyecto analítico, responsables de garantizar que la infraestructura sea sólida, incluyendo la fontanería, los sistemas eléctricos y los cimientos estructurales. Sientan las bases de todo lo que está por venir.
Los ingenieros analíticos pueden compararse a los arquitectos. Toman los sólidos cimientos creados por los ingenieros de datos y diseñan estructuras que se alinean con el modelo empresarial, construyendo desde cuadros de mando excepcionales hasta valiosos modelos de datos. Salvan la distancia entre la infraestructura técnica y los objetivos empresariales.
En esta analogía, los analistas de datos actúan como diseñadores de interiores. Se adentran en los edificios construidos, no sólo asegurándose de que el contenido está alineado con los usuarios, sino también haciéndolo fácil de usar y adaptado a las necesidades específicas de los consumidores de datos. Juntas, estas funciones colaboran para crear unentorno analítico holístico y funcional.
Si observamos el ciclo de vida de la analítica de datos, los ingenieros de plataformas de datos construyen plataformas e ingieren datos brutos en almacenes de datos de toda la empresa. Por otra parte, los ingenieros analíticos toman los datos brutos y los transforman para ajustarlos a los modelos de datos analíticos que la empresa necesita para apoyar la toma de decisiones.
Responsabilidades de un Ingeniero Analítico
El papel de un ingeniero analítico es cada vez más importante, ya que tanto el volumen como la complejidad de los datos, así como sus diversas aplicaciones, siguen creciendo. Esto incluye desde el diseño y la implementación de sistemas de almacenamiento y recuperación de datos, hasta la creación y el mantenimiento de canalizaciones de datos, y el desarrollo y la implementación de modelos de aprendizaje automático. En este panorama dinámico, los ingenieros analíticos desempeñan un papel vital en el aprovechamiento de los crecientes recursos de datos y la maximización de su valor en una amplia gama de aplicaciones.
Según las últimas tendencias del papel, una de las principales responsabilidades es diseñar e implantar sistemas eficaces de almacenamiento y recuperación de datos. Esto incluye trabajar con bases de datos y tecnologías de almacenamiento de datos para diseñar modelos y estructuras de datos que puedan manejar conjuntos de datos grandes y complejos. Otra responsabilidad inmediata es crear y mantener canalizaciones de datos que extraigan datos de diversas fuentes, los transformen y los carguen en un repositorio central para su análisis.
Para la mayoría de los ingenieros analíticos, el desarrollo y el uso de modelos de aprendizaje automático es algo menos observable, pero sigue ocurriendo. Esto incluye trabajar con los científicos de datos para comprender sus requisitos, seleccionar e implementar los algoritmos adecuados, y garantizar que los modelos se entrenan e implementan adecuadamente con el conjunto correcto de datos de entrenamiento y prueba. Cuando éste no es el caso, los ingenieros analíticos colaboran en la construcción de los conductos de datos adecuados para alimentar continuamente a los científicos de datos con datos de entrenamiento y prueba apropiados.
Además, los ingenieros analíticos son responsables de supervisar y mantener el rendimiento de los modelos de aprendizaje automático, tanto ayudando a estructurar la evaluación fuera de línea como combinando métricas específicas del modelo con métricas empresariales para el monitoreo en línea.
Un ingeniero analítico suele dominar lenguajes y herramientas de programación como Python, R, SQL y Spark para implementar canalizaciones de datos, modelos de datos y modelos de aprendizaje automático. También deben estar familiarizados con plataformas de computación en nube como AWS, GCP o Azure para implementar y escalar sus soluciones.
Al observar las responsabilidades que tienen los ingenieros analíticos en varias empresas, pueden incluirse las siguientes:
-
Diseñar e implantar sistemas de almacenamiento y recuperación de datos, como bases de datos y almacenes de datos, que puedan manejar conjuntos de datos grandes y complejos. Crear y mantener canalizaciones de datos para extraer, transformar y cargar datos de diversas fuentes en un repositorio central para su análisis.
-
Asegúrate de que los datos son precisos, completos, coherentes y accesibles, realizando comprobaciones de la calidad de los datos, haciendo un seguimiento de los flujos de datos y aplicando medidas de seguridad de los datos.
-
Aprovecha las plataformas de computación en la nube como AWS, GCP o Azure para implementar y escalar soluciones analíticas, así como la escalabilidad, seguridad y optimización de costes de la infraestructura de datos.
-
Optimiza el rendimiento de los sistemas de almacenamiento y recuperación de datos, las canalizaciones de datos y los modelos de aprendizaje automático para garantizar que puedan manejar el volumen y la complejidad de los datos.
-
Utiliza lenguajes de programación y herramientas como Python, R, SQL y Spark para implementar canalizaciones de datos, modelos de datos y modelos de aprendizaje automático.
-
Colabora con los científicos de datos para comprender sus necesidades, seleccionar e implementar los algoritmos adecuados y garantizar que los modelos de aprendizaje automático se entrenan e implementan correctamente. Monitorea y mantiene el rendimiento de los modelos de aprendizaje automático y soluciona y optimiza los problemas según sea necesario.
-
Mantente al día de las últimas tecnologías y tendencias en ingeniería de datos, aprendizaje automático y análisis, y busca continuamente oportunidades para mejorar la infraestructura de datos y las capacidades de análisis de la organización.
El papel de un analista es amplio y requiere una combinación de habilidades técnicas, capacidad de resolución de problemas y comprensión de las necesidades empresariales. Los ingenieros analíticos deben sentirse cómodos con los aspectos técnicos y empresariales de la ciencia de datos, y deben ser capaces de tender puentes entre los científicos de datos de y los informáticos.
Habilitar la analítica en una malla de datos
Una malla de datos es un marco moderno que esboza la estrategia de datos de una organización . Permite a los equipos de dominio empresarial asumir la propiedad de sus datos y de los servicios que proporcionan acceso a ellos, en lugar de depender únicamente de un equipo de datos central. Descompone una arquitectura de datos monolítica en un conjunto de servicios de datos independientes y autónomos, lo que permite un escalado más fino, más autonomía y una mejor gestión de los datos. Proporciona más flexibilidad en el manejo de diferentes tipos de datos y permite una cultura de experimentación, innovación y colaboración. Con una malla de datos, las empresas deberían poder moverse más rápido y responder con mayor celeridad a las cambiantes necesidades empresariales.
La aparición de la metodología de malla de datos como patrón arquitectónico ha revolucionado la forma en que los analistas interactúan con la infraestructura de datos. Al descomponer una arquitectura de datos monolítica en una serie de servicios de datos independientes y autónomos que pueden desarrollarse, implementarse y funcionar de forma independiente, los equipos pueden abordar los retos de escalabilidad, manejabilidad y autonomía de la arquitectura de datos de una forma más granular y sin esfuerzo.
Con este novedoso enfoque, los equipos pueden escalar su infraestructura de datos de forma más granular, reduciendo el riesgo de silos de datos y duplicación. Cada equipo de dominio empresarial también tiene más autonomía, lo que les permite elegir las mejores herramientas y tecnologías para sus necesidades específicas, pero aprovechando los servicios ofrecidos centralmente para gestionar todo el ciclo de vida de los datos. Esto les permite moverse más rápido, ser más ágiles y responder con rapidez a las cambiantes necesidades empresariales. Además, un enfoque de malla de datos proporciona más flexibilidad en el manejo de distintos tipos de datos, como los estructurados, los semiestructurados y los no estructurados. También permite mejores prácticas de gobernanza de datos al romper la arquitectura monolítica de datos y permitir un mapeo claro de los servicios de datos.
Un ingeniero analítico puede aportar valor en una organización de malla de datos centrándose en construir y mantener servicios de datos independientes y autónomos que den soporte a las necesidades de múltiples equipos y aplicaciones, como modelos de datos compartidos, bien gobernados y documentados para garantizar la descubribilidad, accesibilidad y seguridad de los datos sin esfuerzo.
Otro aspecto significativo de trabajar en una malla de datos es garantizar la gobernanza y la seguridad de los datos, lo que puede incluir la aplicación de políticas y procedimientos de datos, como controles de acceso a los datos, secuenciación de datos y comprobaciones de calidad de los datos, para garantizar que los datos son seguros y de alta calidad. Además, los ingenieros analíticos deben trabajar con los propietarios de los datos y las partes interesadas para comprender y cumplir todos los requisitos normativos de almacenamiento y gestión de datos.
Trabajar en una malla de datos requiere una mentalidad diferente a la de las arquitecturas de datos monolíticas tradicionales. Los ingenieros analíticos deben alejarse de la noción de que los datos son un recurso centralizado y considerarlos como servicios autónomos distribuidos que varios equipos pueden utilizar.
Productos de datos
Otro concepto que hemos estado utilizando en y que es importante definir es el de producto de datos. Se trata de aplicaciones accesibles que proporcionan acceso a conocimientos basados en datos que apoyarán los procesos de toma de decisiones empresariales o incluso los automatizarán. Internamente pueden contener componentes para recuperar, transformar, analizar e interpretar datos. Otro aspecto importante es que los productos de datos deben exponer sus datos de forma que otras aplicaciones o servicios internos o externos puedan acceder a ellos y utilizarlos.
Algunos ejemplos de productos de datos son los siguientes:
-
Una API REST que permite a los usuarios consultar un modelo de datos empresarial específico
-
Una canalización de datos que ingiere y procesa los datos de procedentes de diversas fuentes
-
Un lago de datos que almacena y gestiona grandes cantidades de datos estructurados y no estructurados
-
Una herramienta de visualización de datos que ayuda a los usuarios a comprender y comunicar las perspectivas de los datos
Los productos de datos también pueden consistir en microservicios . Se trata de servicios pequeños, independientes y centrados que pueden desarrollarse, implementarse y escalarse de forma independiente. Se puede acceder a ellos a través de una API y reutilizarlos en toda la empresa.
dbt como Habilitador de la Malla de Datos
dbt es una herramienta de código abierto que ayuda a los ingenieros de datos, ingenieros analíticos y analistas de datos a construir una malla de datos, proporcionando una forma de crear, probar y gestionar servicios de datos. Permite a los equipos definir, probar y construir modelos de datos y crear una interfaz clara y bien definida para estos modelos, de modo que otros equipos y aplicaciones puedan utilizarlos fácilmente.
Las funciones dbt que permiten crear una malla de datos son las siguientes:
- Capacidades de modelado de datos
-
Las funciones de modelado de datos permiten a los equipos definir sus modelos de datos utilizando una sintaxis sencilla y familiar basada en SQL, que facilita a los ingenieros y analistas de datos la definición y prueba conjunta de modelos de datos.
- Capacidad de comprobación de datos
-
dbt proporciona un marco de pruebas que permite a los equipos probar sus modelos de datos y asegurarse de que son precisos y fiables. Esto ayuda a identificar errores en una fase temprana del proceso de desarrollo y garantiza que los servicios de datos sean de alta calidad.
- Documentación de datos
-
dbt permite documentar los modelos de datos y los servicios para que otros equipos y aplicaciones puedan entenderlos y utilizarlos fácilmente.
- Capacidad de seguimiento de datos
-
Rastreo de datos Las capacidades de permiten a los equipos rastrear el origen de los modelos de datos. Esto facilita la comprensión de cómo se utilizan los datos y de dónde proceden.
- Capacidades de gobernanza de datos
-
Capacidades de gobernanza de datos permiten aplicar políticas de gobernanza de datos, como controles de acceso a los datos, linaje de datos y comprobaciones de calidad de los datos, que ayudan a garantizar que los datos son seguros y de alta calidad.
Aunque el objetivo principal de la ingeniería analítica es diseñar e implantar modelos de datos, es importante señalar que las capacidades de seguimiento y gobierno de datos pueden mejorar significativamente la eficacia de los procesos de ingeniería analítica. Estas capacidades pueden ser especialmente valiosas en escenarios en los que los modelos de datos necesitan rastrear el origen de los datos y adherirse a estrictas políticas de gobierno de datos. La adopción de tales prácticas y modelos de gobierno, incluida una malla de datos, puede variar en función de las necesidades específicas y la complejidad del entorno de datos. Muchas Implementaciones exitosas de dbt comienzan con modelos de datos de esquema de estrella única más sencillos y pueden explorar conceptos avanzados como la malla de datos a medida que sus necesidades de datos evolucionan con el tiempo.
El corazón de la ingeniería analítica
La transformación de datos convierte los datos de un formato o estructura a otro para hacerlos más útiles o adecuados para una aplicación o finalidad concreta. Este proceso es necesario porque permite a las organizaciones transformar datos brutos y no estructurados en información valiosa que puede servir de base para tomar decisiones empresariales, mejorar las operaciones e impulsar el crecimiento.
La transformación de datos es un paso crítico en el ciclo de vida de la analítica, y es importante que las organizaciones dispongan de las herramientas y la tecnología necesarias para realizar esta tarea con eficiencia y eficacia. Algunos ejemplos de transformación de datos son la limpieza y preparación de datos, la agregación y resumen de datos, y el enriquecimiento de datos con información adicional. El uso de dbt está muy extendido para la transformación de datos, porque permite a las organizaciones realizar tareas complejas de transformación de datos de forma rápida y sencilla, y puede integrarse con otras herramientas, como Airflow, para la gestión integral del canal de datos.
dbt es el gemba para los analistas y las partes interesadas de la empresa . El valor para las empresas y las partes interesadas llega cuando los datos se transforman y se entregan en un formato fácil de usar.
Consejo
Gemba es un término japonés que significa "el lugar real". En el mundo empresarial, gemba se refiere al lugar donde se crea valor.
En una estrategia ETL, la transformación de datos suele realizarse antes de cargar los datos en un sistema de destino, como un almacén de datos o un lago de datos. Los datos se extraen de varias fuentes, se transforman para que coincidan con la estructura y el formato del sistema de destino, y luego se cargan en el sistema de destino. Este proceso garantiza que los datos sean coherentes y utilizables en todos los sistemas y aplicaciones.
En cambio, una estrategia ELT representa un enfoque más novedoso y flexible del tratamiento de datos. En esta estrategia, los datos se extraen primero y se cargan en un sistema de destino antes de someterse a la transformación. La ELT ofrece varias ventajas, como una mayor flexibilidad y la capacidad de admitir una gama más amplia de aplicaciones de datos que el paradigma ETL tradicional. Una ventaja significativa es su versatilidad para dar cabida a diversas transformaciones de datos y perspectivas en tiempo real directamente dentro del sistema de destino. Esta flexibilidad permite a las organizaciones obtener información procesable de sus datos con mayor rapidez y adaptarse a las cambiantes necesidades analíticas.
Sin embargo, es importante reconocer que el ELT puede conllevar mayores costes de almacenamiento e ingestión, dado que se almacenan datos en bruto o mínimamente transformados. Muchas empresas consideran que estos costes son justificables por el valor sustancial que aportan, en particular, la flexibilidad que aportan a sus operaciones. Por lo tanto, la ELT ha ganado popularidad, especialmente con la aparición de soluciones de almacenamiento de datos basadas en la nube y las capacidades mejoradas de transformación y procesamiento de datos que ofrecen.
Independientemente de la estrategia utilizada, sin una adecuada limpieza, transformación y normalización de los datos, éstos pueden acabar siendo inexactos, incompletos o difíciles de utilizar, lo que da lugar a una mala toma de decisiones.
Los procesos heredados
Tradicionalmente, los procesos ETL heredados eran , a menudo complejos, consumían mucho tiempo y requerían conocimientos especializados para su desarrollo, implantación y mantenimiento. También solían requerir una importante codificación manual y manipulación de datos, lo que los hacía propensos a errores y difíciles de escalar.
Además, estos procesos eran a menudo inflexibles y no podían adaptarse a las necesidades cambiantes del negocio o a nuevas fuentes de datos. Con el creciente volumen, variedad y velocidad de los datos, los procesos ETL heredados resultan cada vez más inadecuados, por lo que están siendo sustituidos por enfoques más modernos y flexibles, como el ELT.
En el pasado, la ETL solía realizarse mediante scripts personalizados o herramientas ETL especializadas basadas en visuales. Estos scripts o herramientas extraían los datos de diversas fuentes, como archivos planos o bases de datos, realizaban las transformaciones necesarias en los datos y luego los cargaban en un sistema de destino, como un almacén de datos.
Un ejemplo de proceso ETL heredado sería utilizar una combinación de scripts SQL y lenguajes de programación como Java o C# para extraer datos de una base de datos relacional, transformar los datos utilizando el lenguaje de programación y, a continuación, cargar los datos transformados en un almacén de datos. Otro ejemplo es el uso de herramientas ETL especializadas, como Oracle Data Integrator o IBM InfoSphere DataStage, para extraer, transformar y cargar datos entre sistemas. Estos procesos ETL heredados pueden ser complejos, difíciles de mantener y escalar, y a menudo requieren un equipo dedicado de desarrolladores.
Uso de SQL y procedimientos almacenados para ETL/ELT
En el pasado, las plataformas de datos específicas utilizaban procedimientos almacenados en un sistema de gestión de bases de datos relacionales (RDBMS), como SQL Server u Oracle, para fines de ETL. Los procedimientos almacenados son código SQL preparado que puedes almacenar en tu motor de base de datos para que el código pueda utilizarse repetidamente. Dependiendo de si se trata de una entrada o salida de datos, los scripts se ejecutan en la base de datos de origen o en la de destino.
Supón que quieres crear un procedimiento almacenado sencillo para extraer de una tabla, transformar los datos y cargarlos en otra tabla, como se muestra en el Ejemplo 1-1.
Ejemplo 1-1. Procedimiento SQL para extraer datos
CREATEPROCEDUREetl_exampleASBEGIN-- Extract data from the source tableSELECT*INTO#temp_tableFROMsource_table;-- Transform dataUPDATE#temp_tableSETcolumn1=UPPER(column1),column2=column2*2;-- Load data into the target tableINSERTINTOtarget_tableSELECT*FROM#temp_table;END
Este procedimiento almacenado utiliza primero la sentencia SELECT INTO para extraer todos los datos de la tabla fuente y almacenarlos en una tabla temporal (#temp_table). A continuación, utiliza la sentencia UPDATE para cambiar los valores de column1 a mayúsculas y duplicar el valor de column2. Por último, el procedimiento almacenado utiliza la sentencia INSERT INTO para cargar los datos de #temp_table en target_table.
Nota
No te asustes si no estás familiarizado con la sintaxis SQL. El Capítulo 3 está totalmente dedicado a darte las bases para trabajar con ella.
Es importante tener en cuenta que éste es un ejemplo elemental y que los procesos ETL reales suelen ser mucho más complejos e implican muchos más pasos, como la validación de datos, el tratamiento de valores nulos y errores, y el registro de los resultados del proceso.
Aunque es posible utilizar procedimientos almacenados para los procesos ETL, es esencial tener en cuenta que su uso puede tener algunas implicaciones, como la necesidad de conocimientos y experiencia especializados para escribir y mantener esos procedimientos y la falta de flexibilidad y escalabilidad. Además, utilizar procedimientos almacenados para ETL puede dificultar la integración con otros sistemas y tecnologías y la resolución de problemas que surjan durante el proceso ETL.
Uso de herramientas ETL
Como ya se ha dicho, las herramientas ETL son aplicaciones de software que aceleran el proceso de construcción de conductos de ingestión y transformación, proporcionando una interfaz visual, un kit de desarrollo de software (SDK) o una biblioteca de programación con código y artefactos preempaquetados que pueden utilizarse para extraer, transformar y cargar datos de diversas fuentes en un destino, como un almacén de datos o un lago de datos. Suelen utilizarse en muchas organizaciones para automatizar el proceso de transferencia de datos desde diversos sistemas y bases de datos a un almacén o lago de datos central, donde pueden analizarse.
Airflow es una popular plataforma de código abierto para gestionar y programar canalizaciones de datos. Desarrollada por Airbnb, ha ganado popularidad en los últimos años por su flexibilidad y escalabilidad. Airflow permite a los usuarios definir, programar y monitorizar canalizaciones de datos utilizando código Python, lo que facilita su creación a los ingenieros y científicos de datos.
Enel Ejemplo 1-2 se presenta un DAG Airflow sencillo . Un grafo acíclico dirigido (DAG) es un grafo dirigido sin ciclos dirigidos.
Ejemplo 1-2. Un DAG de flujo de aire
fromairflowimportDAGfromairflow.operators.bash_operatorimportBashOperatorfromdatetimeimportdatetime,timedeltadefault_args={'owner':'me','start_date':datetime(2022,1,1),'depends_on_past':False,'retries':1,'retry_delay':timedelta(minutes=5),}dag=DAG('simple_dag',default_args=default_args,schedule_interval=timedelta(hours=1),)task1=BashOperator(task_id='print_date',bash_command='date',dag=dag,)task2=BashOperator(task_id='sleep',bash_command='sleep 5',retries=3,dag=dag,)task1>>task2
Este código define un DAG llamado simple_dag que se ejecuta cada hora. Tiene dos tareas, print_date y sleep. La primera tarea ejecuta el comando date, que imprime la fecha y hora actuales. La segunda tarea ejecuta el comando sleep 5, que hace que la tarea duerma durante cinco segundos. La segunda tarea tiene el número de reintentos fijado en 3. Así, si falla, reintentará tres veces antes de rendirse. Las dos tareas están conectadas por el operador >>. Esto también significa que task2 depende de task1 y sólo se ejecutará después de que task1 finalice con éxito.
Airflow es una herramienta productiva para programar y gestionar canalizaciones ETL, pero tiene algunas limitaciones. En primer lugar, Airflow puede ser muy complejo de configurar y gestionar, especialmente para canalizaciones grandes o complicadas. En segundo lugar, no está diseñado explícitamente para la transformación de datos y puede requerir herramientas adicionales o código personalizado para realizar determinados tipos de manipulación de datos.
Nota
dbt puede abordar estas limitaciones de Airflow proporcionando un conjunto de buenas prácticas y convenciones para la transformación de datos y una interfaz sencilla y directa para realizar y gestionar la transformación de datos. También puede integrarse con Airflow para proporcionar una solución ETL/ELT completa que sea fácil de configurar y gestionar, al tiempo que ofrece una gran flexibilidad y control sobre los conductos de datos.
La Revolución dbt
dbt es una herramienta de línea de comandos de código abierto cada vez más popular en el sector del análisis de datos, porque simplifica y agiliza el proceso de transformación y modelado de datos. Por otra parte, Airflow es una potente plataforma de código abierto para crear, programar y monitorizar flujos de trabajo mediante programación. Cuando dbt se integra con Airflow, la canalización de datos puede gestionarse y automatizarse con mayor eficacia. Airflow puede utilizarse para programar las ejecuciones de dbt, y dbt puede utilizarse para realizar las tareas de transformación de datos en el conducto.
Esta integración permite a los equipos gestionar toda la canalización de datos, desde su extracción hasta su carga en un almacén de datos, garantizando que los datos estén siempre actualizados y sean precisos. La integración facilita la automatización de las tareas de canalización de datos, la programación y el monitoreo de la canalización, y la resolución de problemas a medida que surgen.
Para ilustrar la sencillez de construir un modelo dbt simple, imagina que quieres construir un modelo que calcule los ingresos totales de una empresa sumando los ingresos de cada pedido. El modelo podría definirse mediante un archivo de modelo dbt que especificara el código SQL del cálculo y las dependencias o parámetros necesarios. El Ejemplo 1-3 presenta el aspecto que podría tener el archivo modelo.
Ejemplo 1-3. Un modelo dbt
{{config(materialized='table')}}selectsum(orders.revenue)astotal_revenuefrom{{ref('orders')}}asorders
Una de las principales ventajas de dbt es que los ingenieros analíticos pueden escribir código reutilizable, mantenible y comprobable para las transformaciones de datos en un lenguaje sencillo de alto nivel que elimina la complejidad de escribir SQL. Esto facilita la colaboración en equipo en los proyectos de datos y reduce el riesgo de errores en la canalización de datos.
Otra ventaja de dbt es que permite una gestión más eficaz de los conductos de datos. Al integrarse con herramientas de orquestación como Airflow y otras como Dagster o Prefect, así como con el propio producto dbt Cloud de dbt Labs, dbt permite a los equipos planificar, programar y monitorizar eficazmente los conductos de datos. Esto garantiza que los datos permanezcan siempre actualizados y precisos. La sinergia entre dbt y herramientas de orquestación como Airflow permite actualizar los datos y la implementación de nueva lógica sin interrupciones, de forma similar a las prácticas de CI/CD en ingeniería de software. Esta integración garantiza que, a medida que se disponga de nuevos datos o se actualicen las transformaciones, la canalización de datos pueda orquestarse y ejecutarse eficazmente para ofrecer información fiable y oportuna.
En general, el dbt se está generalizando para las organizaciones que buscan mejorar sus capacidades de análisis de datos y racionalizar sus conductos de datos. Aunque sigue siendo una tecnología relativamente nueva, muchas empresas la utilizan y se considera una herramienta valiosa para los profesionales de los datos. El Capítulo 4 proporcionará una visión más profunda de la dbt y sus capacidades y características .
Resumen
En las últimas décadas, el campo de la gestión de datos ha experimentado profundas transformaciones, pasando de métodos estructurados de almacenamiento y acceso a los datos, como los procedimientos almacenados basados en SQL, a flujos de trabajo más flexibles y escalables. Estos flujos de trabajo modernos se apoyan en potentes herramientas como Airflow y dbt. Airflow facilita la orquestación dinámica, mientras que dbt eleva el código analítico al nivel de software de producción, introduciendo enfoques innovadores para la comprobación y transformación de datos.
En medio de este entorno dinámico, han surgido nuevas funciones, y el ingeniero analítico se sitúa en la intersección de la ingeniería de datos y el análisis de datos, garantizando la obtención de conocimientos sólidos. A pesar de la evolución de las herramientas y las funciones, el valor intrínseco de los datos permanece inalterado. Sin embargo, la gestión de datos está evolucionando hacia una disciplina que se centra no sólo en los datos en sí, sino también en los profesionales que los manejan.
Incluso con estos avances, persisten los retos fundamentales: adquirir datos críticos, mantener los más altos estándares de calidad de los datos, almacenarlos con eficacia y satisfacer las expectativas de las partes interesadas en la entrega de datos. En el centro de la cadena de valor de los datos se encuentra la revitalización del modelado de datos. Un modelado de datos eficiente va más allá de la recopilación de datos; estructura y organiza los datos para reflejar las relaciones y jerarquías del mundo real. El Capítulo 2 profundizará en el modelado de datos y su papel fundamental en la ingeniería analítica.
A lo largo de este capítulo, hemos explorado la evolución de la gestión de datos, la aparición del papel del ingeniero analítico, y conceptos como la malla de datos y la distinción entre las estrategias ELT y ETL. Este variado conjunto de temas pretende ofrecer una visión global del panorama de los datos.
Get Ingeniería analítica con SQL y dbt now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

