Capítulo 4. Transformación de datos con dbt
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
El objetivo principal de dbt es ayudarte a transformar los datos de tus plataformas de datos de forma fácil e integrada, simplemente escribiendo sentencias SQL. Cuando colocamos dbt en un flujo de trabajo ELT, se ajusta a las actividades durante la etapa de transformación, proporcionándote componentes adicionales -como control de versiones, documentación, pruebas o implementación automatizada- que simplifican el trabajo general de un especialista en datos. ¿Te recuerda esto a las actividades reales de un ingeniero analítico? Bueno, eso es porque dbt es una de las herramientas modernas que define lo que hacen los ingenieros analíticos, proporcionándoles los instrumentos integrados con la plataforma, lo que reduce la necesidad de configurar servicios adicionales para responder a problemas específicos y disminuye la complejidad general del sistema.
dbt da soporte a las tareas descritas para un ingeniero de analítica, capacitándole para ejecutar el código de su plataforma de datos de forma colaborativa para obtener una única fuente de verdad para las métricas y las definiciones empresariales. Promueve el código analítico central y modular, aprovechando el código DRY con el lenguaje de plantillas Jinja, macros o paquetes. Paralelamente, dbt también proporciona la seguridad que solemos encontrar en las buenas prácticas de ingeniería de software, como colaborar en los modelos de datos, versionarlos, y probar y documentar tus consultas antes de implementarlas con seguridad en producción, con monitoreo y visibilidad.
Hemos proporcionado una introducción exhaustiva a la dbt. Sin embargo, en este capítulo profundizaremos aún más en los aspectos específicos de dbt y aclararemos su importancia en el mundo de la analítica de datos. Discutiremos la filosofía de diseño de dbt, los principios que sustentan esta herramienta de transformación y el ciclo de vida de los datos con dbt como núcleo, presentando cómo dbt transforma los datos brutos en modelos estructurados para facilitar su consumo. Exploraremos la estructura del proyecto dbt esbozando sus diversas características, como la construcción de modelos, la documentación y las pruebas, además de detallar otros artefactos de dbt, como los archivos YAML. Al final de este capítulo, tendrás una comprensión completa de dbt y sus capacidades, lo que te permitirá implementarlo eficazmente en tu flujo de trabajo de análisis de datos.
dbt Filosofía de diseño
A medida que la ingeniería de datos y los flujos de trabajo analíticos se hacen cada vez más complejos, son esenciales las herramientas que agilicen el proceso, manteniendo al mismo tiempo la calidad y fiabilidad de los datos. dbt ha surgido como una solución concentrada con una filosofía de diseño bien definida que sustenta su enfoque del modelado de datos y la ingeniería analítica.
En resumen, la filosofía de diseño dbt se basa en los siguientes puntos:
- Enfoque centrado en el código
-
En el núcleo de la filosofía de diseño de dbt hay un enfoque centrado en el código para el modelado y la transformación de datos. En lugar de confiar en interfaces basadas en GUI o scripts SQL manuales, dbt anima a los usuarios a definir las transformaciones de datos mediante código. Este cambio hacia un desarrollo basado en el código fomenta la colaboración, el control de versiones y la automatización.
- Modularidad para la reutilización
-
dbt promueve la modularidad, permitiendo a los profesionales de los datos crear componentes de código reutilizables . Los modelos, las macros y las pruebas pueden organizarse en paquetes, lo que facilita el mantenimiento y la escalabilidad del código. Este enfoque modular se ajusta a las buenas prácticas y mejora la reutilización del código.
- Transformaciones como sentencias SQL
SELECT -
Los modelos dbt se definen como sentencias SQL
SELECT, lo que los hace accesibles a analistas e ingenieros con conocimientos de SQL. Esta elección de diseño simplifica el desarrollo y garantiza que el modelado de datos siga de cerca las buenas prácticas de SQL. - Lenguaje declarativo
-
dbt utiliza un lenguaje declarativo para definir transformaciones de datos. Los analistas especifican el resultado deseado, y dbt se encarga de la implementación subyacente. Esta abstracción reduce la complejidad de escribir código SQL complejo y mejora la legibilidad.
- Construcciones incrementales
-
La eficiencia es un aspecto clave del diseño de dbt en . Admite construcciones incrementales, lo que permite a los ingenieros de datos actualizar sólo las piezas afectadas del conducto de datos en lugar de reprocesar todo el conjunto de datos. Esto acelera el desarrollo y reduce el tiempo de procesamiento.
- Documentación como código
-
dbt aboga por que documente los modelos de datos y las transformaciones como código. Las descripciones, explicaciones y metadatos se almacenan junto al código del proyecto, lo que facilita a los miembros del equipo la comprensión y la colaboración eficaz.
- Calidad de los datos, pruebas y validación
-
dbt pone un énfasis significativo en la comprobación de datos. Proporciona un marco de pruebas que permite a los analistas definir comprobaciones de la calidad de los datos y reglas de validación. Esto incluye la fiabilidad y calidad de los datos en todo el proceso, garantizando así que los datos cumplen los criterios predefinidos y se ajustan a las normas empresariales.
- Integración del control de versiones
-
Integración perfecta con sistemas de control de versiones como Git es un aspecto fundamental de dbt. Esta característica permite el desarrollo colaborativo, el seguimiento de los cambios y la posibilidad de revertirlos, garantizando que los conductos de datos permanezcan bajo control de versiones.
- Integración nativa con plataformas de datos
-
dbt está diseñado para trabajar sin problemas con plataformas de datos populares como Snowflake, BigQuery y Redshift. Aprovecha las capacidades nativas de estas plataformas para la escalabilidad y el rendimiento.
- Código abierto y extensible
-
dbt es una herramienta de código abierto con una próspera comunidad. Los usuarios pueden ampliar su funcionalidad creando macros y paquetes personalizados. Esta extensibilidad permite a las organizaciones adaptar dbt a sus necesidades específicas de datos.
- Separación de transformación y carga
-
dbt separa los pasos de transformación y carga de en la canalización de datos. Los datos se transforman dentro de dbt y luego se cargan en la plataforma de datos.
En esencia, la filosofía de diseño de dbt se basa en la creación de un entorno colaborativo, centrado en el código y modular para que los ingenieros de datos, analistas y científicos de datos transformen los datos de forma eficaz, garanticen su calidad y generen perspectivas valiosas. dbt permite a las organizaciones aprovechar todo el potencial de sus datos simplificando las complejidades del modelado de datos y la ingeniería analítica.
dbt Flujo de datos
La Figura 4-1 muestra el panorama general de un flujo de datos. Identifica dónde encajan el dbt y sus funciones en el panorama general de datos de .
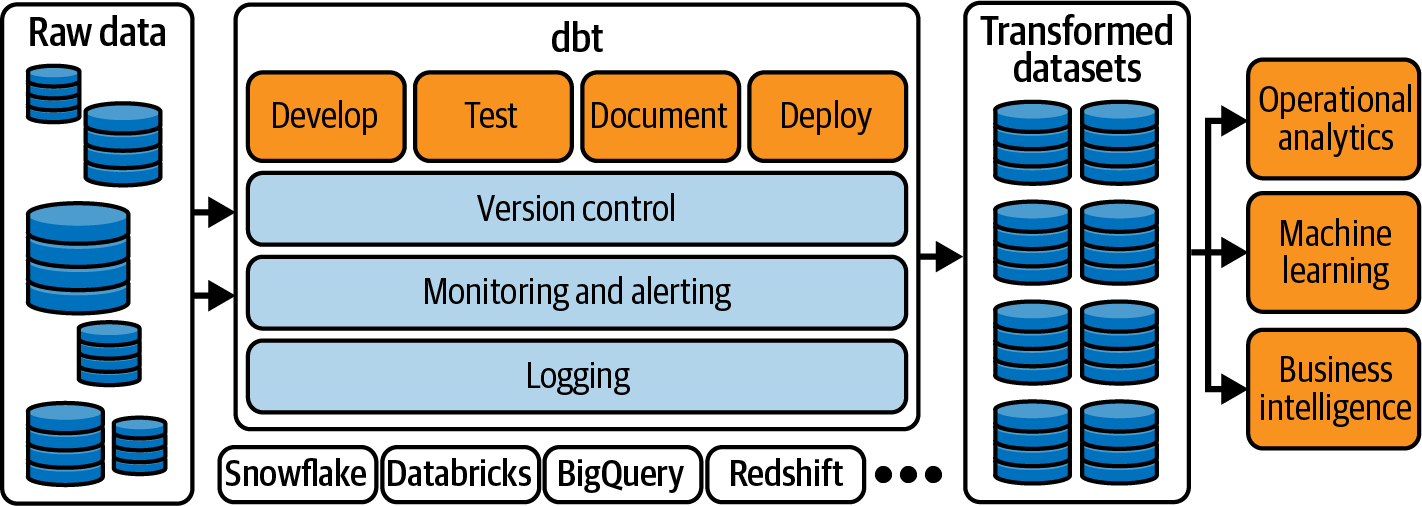
Figura 4-1. Flujo de datos típico con dbt que te ayuda a transformar tus datos desde BigQuery, Snowflake, Databricks y Redshift, entre otros (consulta la documentación de dbt para conocer las plataformas de datos compatibles).
Como ya se ha dicho, el objetivo principal de dbt es ayudarte a transformar los datos de tus plataformas de datos, y para ello, dbt ofrece dos herramientas para lograr ese objetivo:
-
dbt Nube
-
dbt Core, una herramienta CLI de código abierto, mantenida por dbt Labs, que puedes configurar en tus entornos gestionados o ejecutar localmente
Veamos un ejemplo para ver cómo funciona dbt en la vida real y lo que puede hacer. Imagina que estamos trabajando en una canalización que extrae periódicamente datos de una plataforma de datos como BigQuery. Después, transforma los datos combinando tablas(Figura 4-2).
Combinaremos las dos primeras tablas en una sola, aplicando varias técnicas de transformación, como la limpieza o la consolidación de datos. Esta fase tiene lugar en dbt, por lo que necesitaremos crear un proyecto dbt para realizar esta fusión. Lo conseguiremos, pero primero familiaricémonos con dbt Cloud y cómo configurar nuestro entorno de trabajo.
Nota
Para este libro, utilizaremos dbt Cloud para escribir nuestro código, ya que es la forma más rápida y fiable de empezar con dbt, desde el desarrollo hasta la escritura de pruebas, la programación, las implementaciones y la investigación de modelos de datos. Además, dbt Cloud se ejecuta sobre dbt Core, así que mientras trabajamos en dbt Cloud, nos familiarizaremos con los mismos comandos que se utilizan en la herramienta CLI de dbt Core.
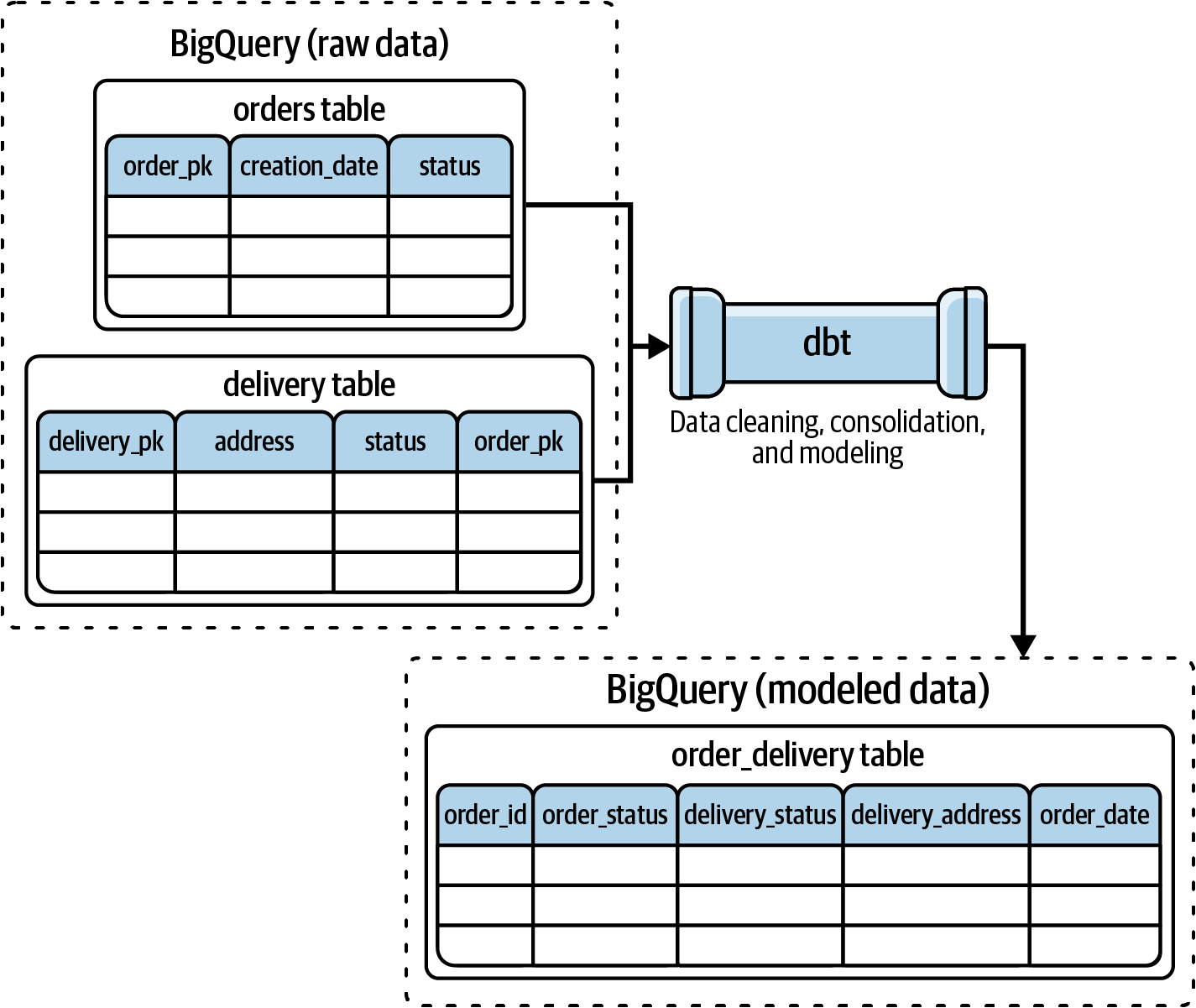
Figura 4-2. Caso práctico de canalización de datos con dbt
dbt Nube
dbt Cloud es una versión de dbt basada en la nube que ofrece una amplia gama de funciones y servicios para escribir y producir tu código analítico. dbt Cloud te permite programar tus trabajos de dbt, monitorizar su progreso y ver registros y métricas en tiempo real. dbt Cloud también proporciona funciones avanzadas de colaboración, como control de versiones, pruebas y documentación. Además, dbt Cloud se integra con varios almacenes de datos en la nube, como Snowflake, BigQuery y Redshift, lo que te permite transformar fácilmente tus datos.
Puedes utilizar dbt Core con la mayoría de las funciones indicadas, pero requerirá configuración e instalación en tu infraestructura, de forma similar a cuando ejecutas tu propio servidor o una instancia de Amazon Elastic Compute Cloud (EC2) para herramientas como Airflow. Esto significa que tendrás que mantenerlo y gestionarlo de forma autónoma, similar a la gestión de una máquina virtual (VM) en EC2.
En cambio, dbt Cloud funciona como un servicio gestionado, similar a Amazon Managed Workflows for Apache Airflow (MWAA). Ofrece comodidad y facilidad de uso, ya que muchos aspectos operativos se gestionan por ti, lo que te permite centrarte más en tus tareas analíticas y menos en la gestión de la infraestructura.
Configuración de dbt Cloud con BigQuery y GitHub
No hay nada mejor que aprender una tecnología específica de practicándola, así que vamos a configurar el entorno que utilizaremos para aplicar nuestros conocimientos. Para empezar, registrémonos primero en una cuenta dbt.
Tras registrarnos, aterrizaremos en la página Configuración completa del proyecto(Figura 4-3).

Figura 4-3. Página de inicio de dbt para completar la configuración del proyecto
Esta página tiene varias secciones para configurar adecuadamente nuestro proyecto dbt, incluyendo las conexiones a nuestra plataforma de datos deseada y a nuestro repositorio de código. Utilizaremos BigQuery como plataforma de datos y GitHub para almacenar nuestro código.
El primer paso en BigQuery es crear un nuevo proyecto. En GCP, busca Crear un proyecto en la barra de búsqueda y haz clic en él(Figura 4-4).
Figura 4-4. Configuración del proyecto BigQuery, paso 1
Aparece una pantalla similar a la de la Figura 4-5, en la que puedes configurar el proyecto. Lo hemos llamado dbt-analytics-engineer.
Figura 4-5. Configuración del proyecto BigQuery, paso 2
Tras la configuración, entra en tu IDE de BigQuery; puedes volver a utilizar la barra de búsqueda. Debería tener un aspecto similar al de la Figura 4-6.
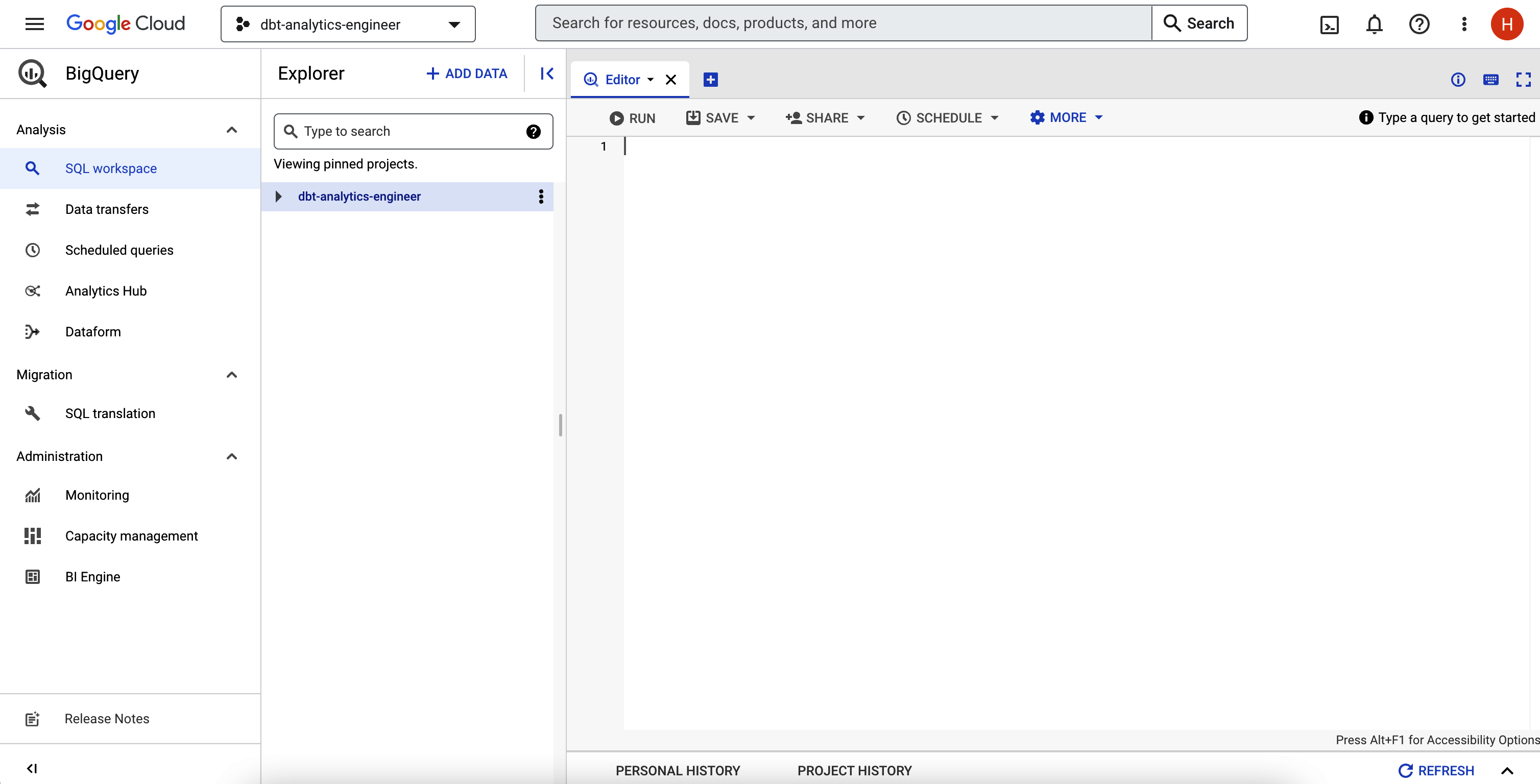
Figura 4-6. IDE de BigQuery
Por último, prueba el conjunto de datos público dbt para asegurarte de que BigQuery funciona correctamente. Para ello, copia el código del Ejemplo 4-1 en BigQuery y haz clic en Ejecutar.
Ejemplo 4-1. Conjuntos de datos públicos dbt en BigQuery
select*from`dbt-tutorial.jaffle_shop.customers`;select*from`dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
Si ves la página de la Figura 4-7, ¡lo has conseguido!
Nota
Como hemos ejecutado tres consultas simultáneamente, no veremos los resultados de salida. Para ello, haz clic en Ver resultados para inspeccionar la salida de la consulta individualmente.
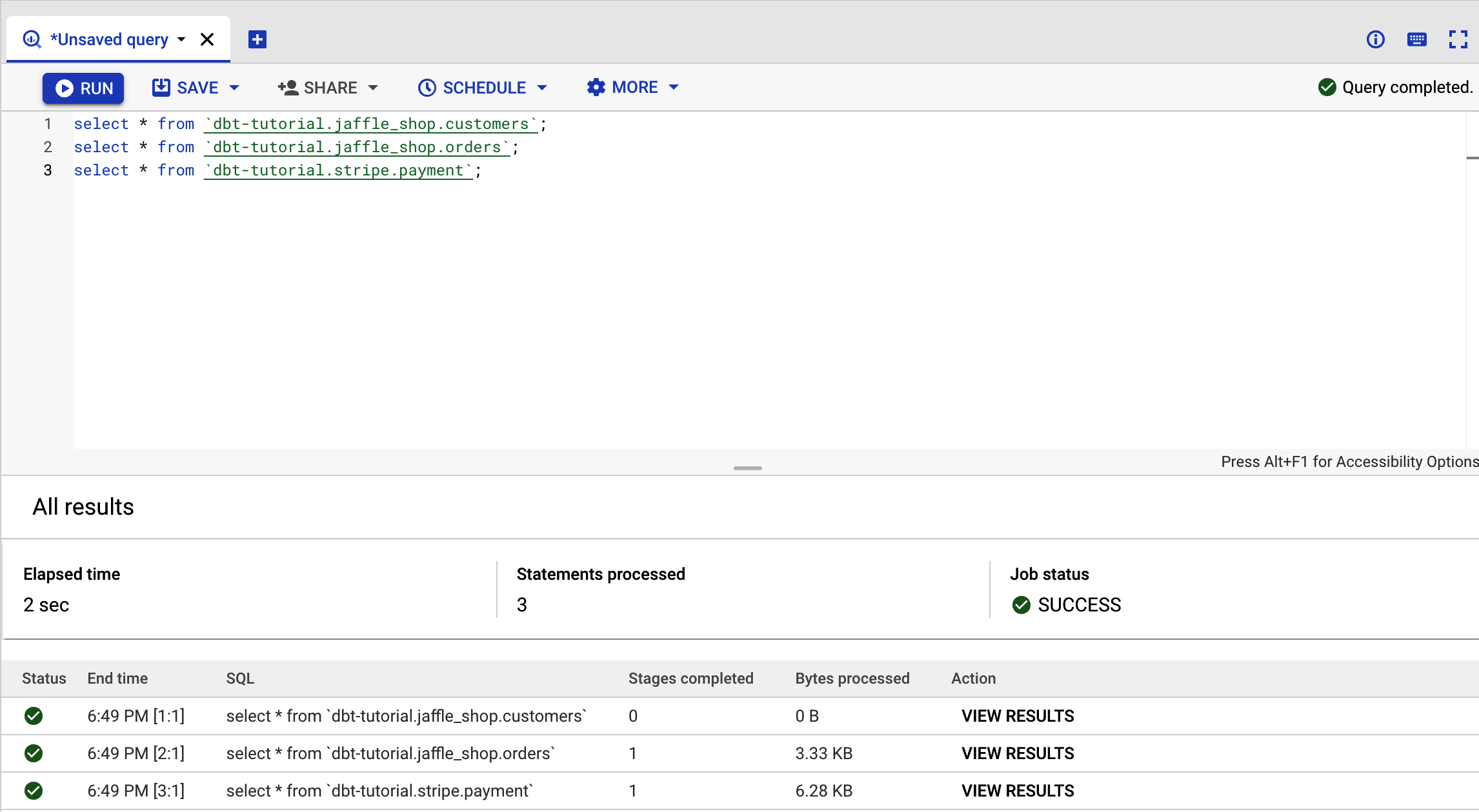
Figura 4-7. Salida del conjunto de datos BigQuery
Ahora vamos a conectar dbt con BigQuery y a ejecutar estas consultas dentro del IDE de dbt. Para que dbt se conecte a tu plataforma de datos, tendrás que generar un archivo de claves, similar al uso de un nombre de usuario y una contraseña de base de datos en la mayoría de las demás plataformas de datos.
Ve a la consola de BigQuery. Antes de continuar con los pasos siguientes, asegúrate de que seleccionas el nuevo proyecto en la cabecera. Si no ves tu cuenta o proyecto, haz clic en la imagen de tu perfil a la derecha y comprueba que estás utilizando la cuenta de correo electrónico correcta:
-
Ve a IAM & Admin y selecciona Cuentas de Servicio.
-
Haz clic en Crear cuenta de servicio.
-
En el campo Nombre, escribe
dbt-usery luego haz clic en Crear y Continuar. -
En "Conceder a esta cuenta de servicio acceso al proyecto", selecciona Administrador de BigQuery en el campo de rol. Haz clic en Continuar.
-
Deja los campos en blanco en la sección "Conceder a los usuarios acceso a esta cuenta de servicio" y haz clic en Listo.
La pantalla debe parecerse a la Figura 4-8.
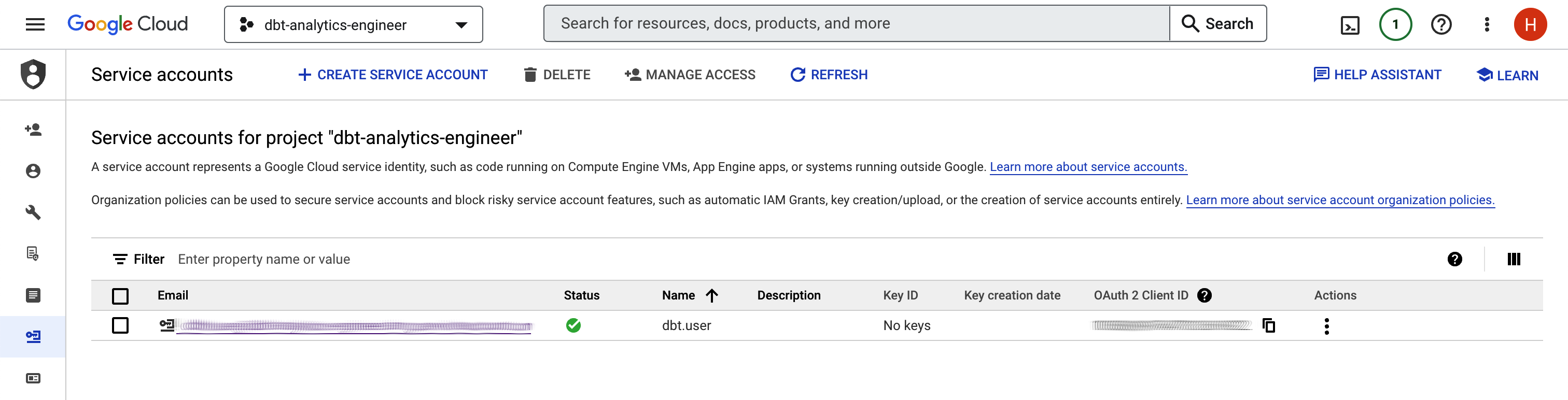
Figura 4-8. Pantalla Cuentas de servicio BigQuery
A continuación, sigue con los pasos restantes:
-
Haz clic en la cuenta de servicio que acabas de crear.
-
Selecciona las teclas.
-
Haz clic en Añadir clave; a continuación, selecciona "Crear nueva clave".
-
Selecciona JSON como tipo de clave y haz clic en Crear.
-
Se te pedirá que descargues el archivo JSON. Guárdalo localmente en un lugar fácil de recordar con un nombre de archivo claro; por ejemplo, dbt-analytics-engineer-keys.json.
Ahora volvamos a la Nube dbt para la configuración final:
-
En la pantalla de configuración del proyecto, dale un nombre más verboso a tu proyecto. En nuestro caso, elegimos dbt-analytics-engineer.
-
En la pantalla "Elegir un almacén", haz clic en el icono BigQuery y en Siguiente.
-
Sube el archivo JSON generado anteriormente. Para ello, haz clic en el botón "Subir un archivo JSON de Cuenta de Servicio", visible en la Figura 4-9.
Por último, después de subir el archivo, aplica el paso restante:
-
Ve a la parte inferior y haz clic en "Prueba". Si ves "Tu prueba se ha completado correctamente", como muestra la Figura 4-10, ¡ya puedes continuar! Ahora haz clic en "Siguiente". Por otro lado, si la prueba falla, es muy probable que te hayas encontrado con un problema con tus credenciales de BigQuery. Intenta regenerarlas de nuevo.
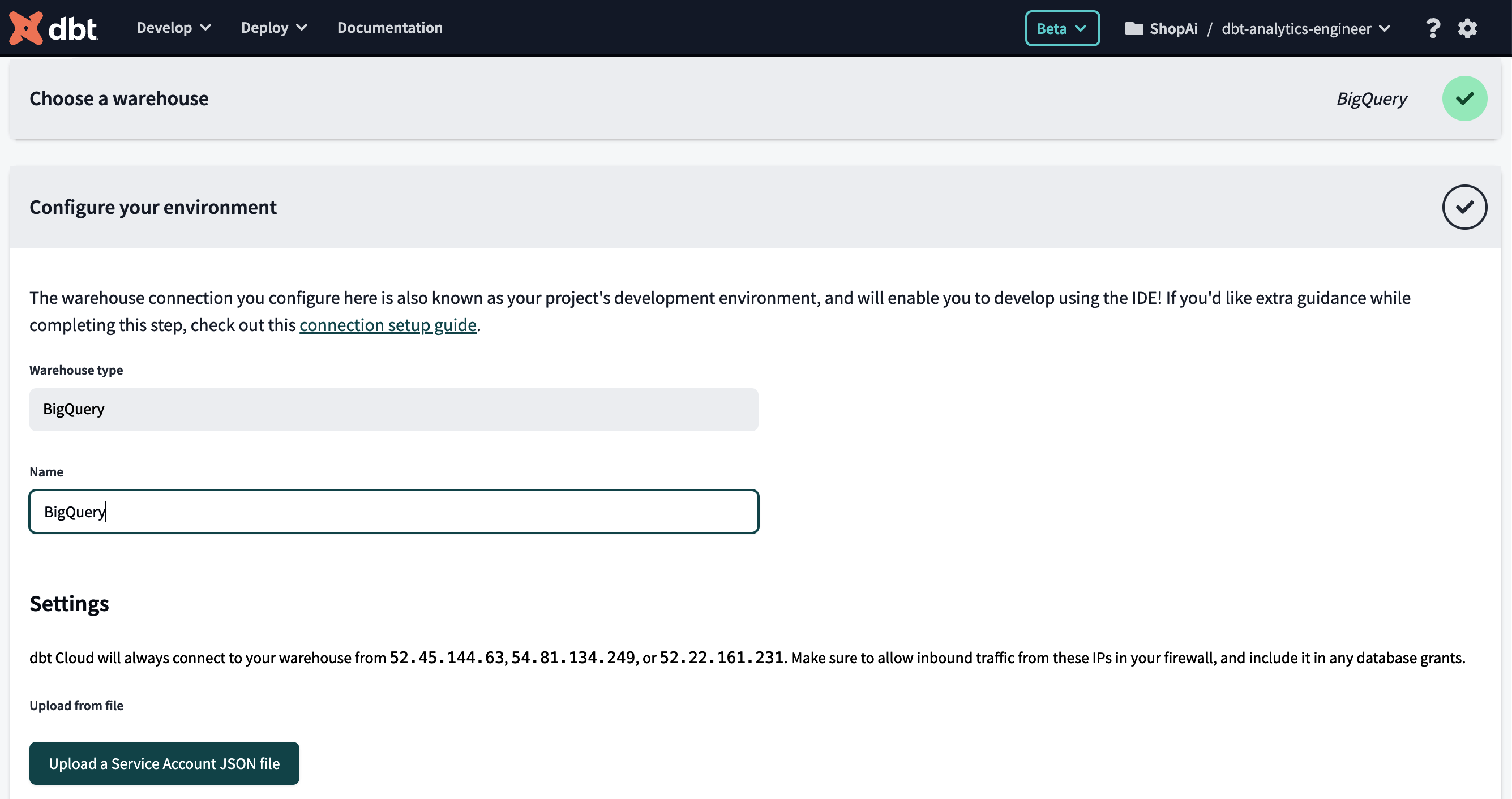
Figura 4-9. Pantalla dbt Cloud, enviar cuenta de servicio BigQuery
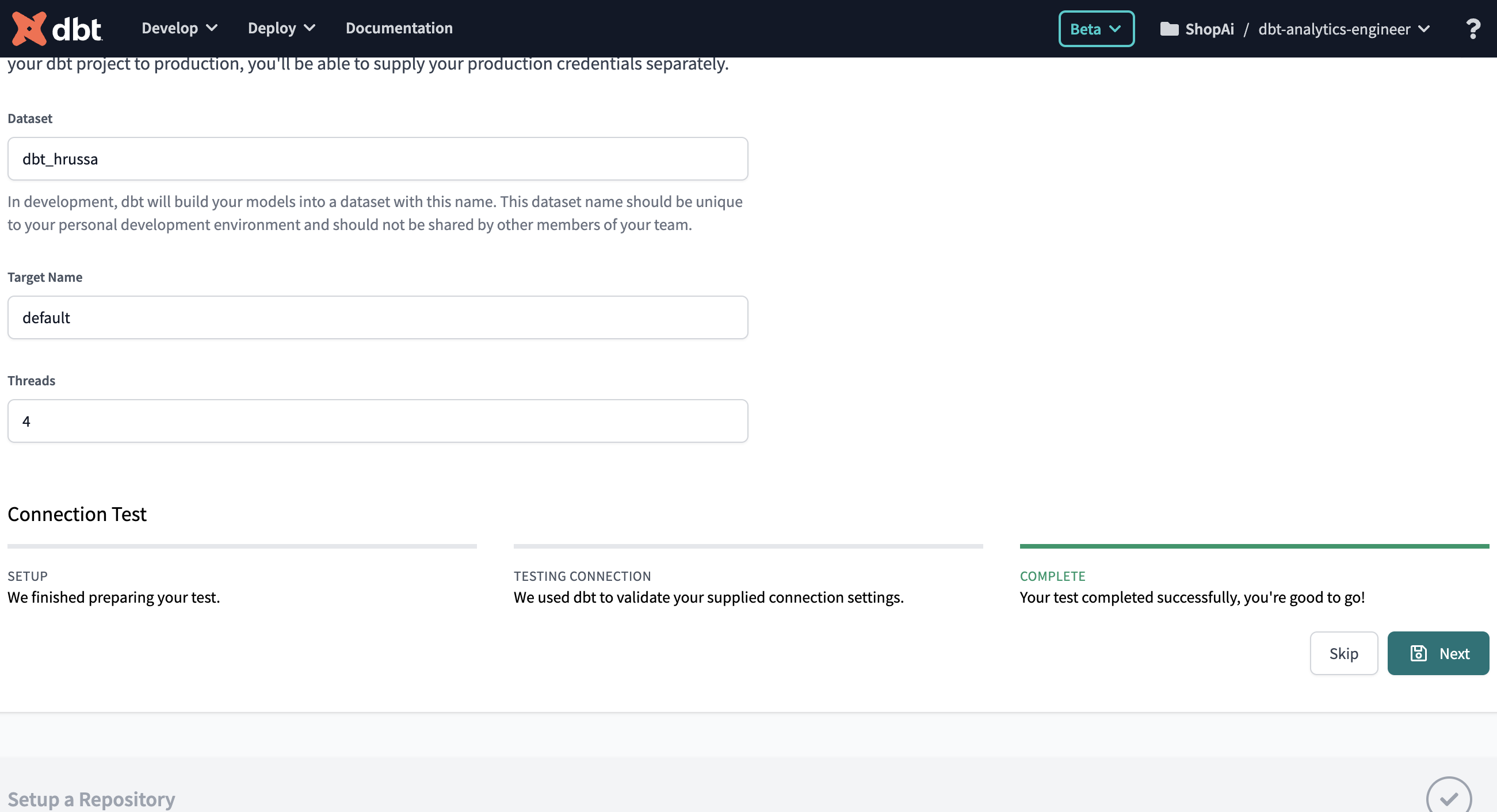
Figura 4-10. Prueba de conexión entre dbt y BigQuery
El último paso es configurar GitHub, pero antes, entendamos de qué estamos hablando. GitHub es una popular plataforma de control de versiones que aloja repositorios Git que te permiten hacer un seguimiento de los cambios en tu código y colaborar con otros de forma eficaz. Para utilizar correctamente Git, es esencial atenerse a estos principios y buenas prácticas:
- Comprométete a menudo, comprométete pronto
-
Haz confirmaciones frecuentes, incluso para pequeños cambios. Esto ayuda a seguir tu progreso y simplifica la depuración. Cada confirmación debe representar un cambio lógico o una característica.
- Utiliza mensajes de confirmación significativos
-
Escribe mensajes de confirmación concisos y descriptivos. Un buen mensaje de confirmación debe explicar qué se ha cambiado y por qué.
- Sigue una estrategia de ramificación
-
Utiliza ramas para distintas funciones, correcciones de errores o tareas de desarrollo.
- Tirar antes de empujar
-
Obtén siempre los últimos cambios del repositorio remoto (por ejemplo,
git pull) antes de enviar tus cambios. Esto reduce los conflictos y garantiza que tus cambios se basan en el código más reciente. - Revisa el código antes de comprometerte
-
Si tu equipo realiza revisiones del código, asegúrate de revisar y probar los cambios antes de confirmarlos. Ayuda a mantener la calidad del código.
- Utiliza .gitignore
-
Crea un archivo .gitignore para especificar los archivos y directorios que deben excluirse del control de versiones (por ejemplo, artefactos de construcción, archivos temporales).
- Utilizar confirmaciones atómicas
-
Mantén los commits centrados en un único cambio específico. Evita mezclar cambios no relacionados en la misma confirmación.
- Rebase en lugar de fusión
-
Utiliza
git rebasepara integrar los cambios de una rama de características en la rama principal, en lugar de la fusión tradicional. El resultado es un historial de confirmaciones más limpio. - Mantén limpio el historial de confirmaciones
-
Evita comprometer "trabajo en curso" o declaraciones de depuración. Utiliza herramientas como
git stashpara guardar temporalmente el trabajo inacabado. - Utiliza etiquetas
-
Crea etiquetas, como etiquetas de versión, para marcar puntos importantes en la historia de tu proyecto, como versiones o hitos importantes.
- Colabora y comunica
-
Comunica a tu equipo los flujos de trabajo y las convenciones de Git. Establece directrices para la gestión de problemas, pull requests y resolución de conflictos.
- Saber cómo deshacer cambios
-
Aprende a revertir commits (
git revert), restablecer ramas (git reset) y recuperar el trabajo perdido (git reflog) cuando sea necesario. - Documento
-
Documenta el flujo de trabajo y las convenciones Git de tu proyecto en un LÉEME o aportando directrices para incorporar eficazmente a los nuevos miembros del equipo.
- Utiliza copias de seguridad y repositorios remotos
-
Haz copias de seguridad periódicas de tus repositorios Git y utiliza repositorios remotos como GitHub para la colaboración y la redundancia.
- Seguir aprendiendo
-
Git es una gran herramienta con muchas funciones. Sigue aprendiendo y explorando conceptos avanzados de Git como el cherry-picking, el rebasing interactivo y los ganchos personalizados para mejorar tu flujo de trabajo.
Para entender mejor en la práctica algunos de los términos y comandos habituales de Git , echemos un vistazo a la Tabla 4-1.
| Término/comando | Definición | Comando Git (si procede) |
|---|---|---|
Repositorio (repo) |
Es similar a una carpeta de proyecto y contiene todos los archivos, historial y ramas de tu proyecto. |
- |
Rama |
Una rama es una línea de desarrollo independiente. Te permite trabajar en nuevas funciones o correcciones sin afectar al código base principal. |
|
Solicitud pull (PR) |
Una pull request es una propuesta de cambio que quieres fusionar en la rama principal. Es una forma de colaborar y revisar los cambios de código con tu equipo. |
- |
Alijo |
|
|
Comprométete |
Una confirmación es una instantánea de tu código en un momento determinado. Representa un conjunto de cambios que has realizado en tus archivos. |
|
Añade |
|
Para escenificar todos los cambios, el comando git es |
Horquilla |
Forjar un repositorio significa crear tu copia del proyecto de otra persona en GitHub. Puedes hacer cambios en tu repositorio bifurcado sin afectar al original. |
- |
Clon |
Clonar un repositorio significa hacer una copia local de un repositorio remoto. Puedes trabajar en tu código localmente y enviar los cambios al repositorio remoto. |
|
Empuja |
|
|
Tira de |
|
|
Estado |
|
|
Registro |
|
|
Dif |
El comando |
|
Fusiona |
El comando |
|
Rebase |
Rebase te permite mover o combinar una secuencia de confirmaciones a una nueva confirmación base. |
|
Pago |
El comando |
|
Estos comandos y términos de Git proporcionan la base para el control de versiones en tus proyectos. Sin embargo, los comandos de Git suelen tener muchos argumentos y opciones adicionales, que permiten un control más preciso de tus tareas de control de versiones. Aunque hemos cubierto aquí algunos comandos esenciales, es esencial tener en cuenta que la versatilidad de Git va mucho más allá de lo que hemos esbozado.
Para obtener una lista más completa de los comandos de Git y la diversa gama de argumentos que pueden aceptar, te recomendamos que consultes la documentación oficial de Git.
Ahora que ya sabes qué son Git y GitHub y cuál es su función dentro del proyecto, vamos a establecer una conexión con GitHub. Para ello, tienes que hacer lo siguiente:
-
Regístrate para obtener una cuenta de GitHub si aún no tienes una.
-
Haz clic en Nuevo para crear un nuevo repositorio, que es donde versionarás tu código analítico. En la pantalla "Crear un nuevo repositorio", dale un nombre a tu repositorio; luego haz clic en "Crear repositorio".
-
Con el repositorio creado, volvamos a dbt. En la sección Configurar un repositorio, selecciona GitHub y, a continuación, conecta la cuenta de GitHub.
-
Haz clic en Configurar integración con GitHub para abrir una nueva ventana en la que podrás seleccionar la ubicación para instalar la Nube dbt. A continuación, elige el repositorio que deseas instalar.
Ahora haz clic en "Empezar a desarrollar en el IDE". La Figura 4-11 es lo que deberías esperar ver.
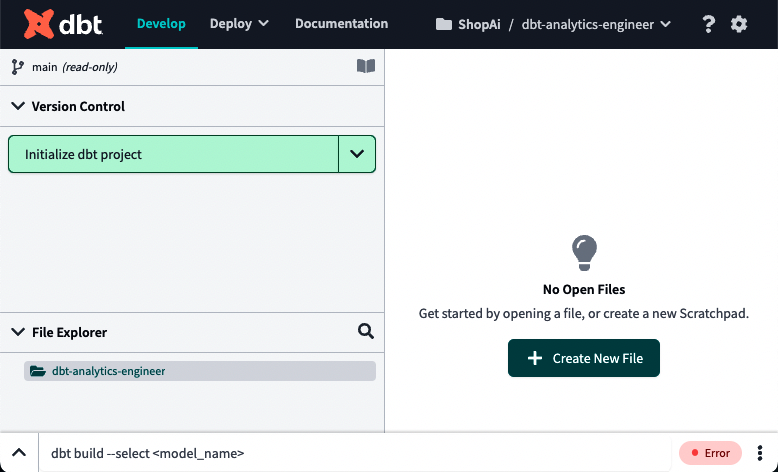
Figura 4-11. IDE dbt
Daremos una visión general del Entorno de Desarrollo Integrado (IDE) de dbt Cloud en "Uso del IDE de dbt Cloud" y lo trataremos con más detalle en "Estructura de un proyecto dbt".
Haz clic en "Inicializar proyecto dbt" en la parte superior izquierda. Ahora, deberías poder ver la pantalla tal y como aparece en la Figura 4-12.
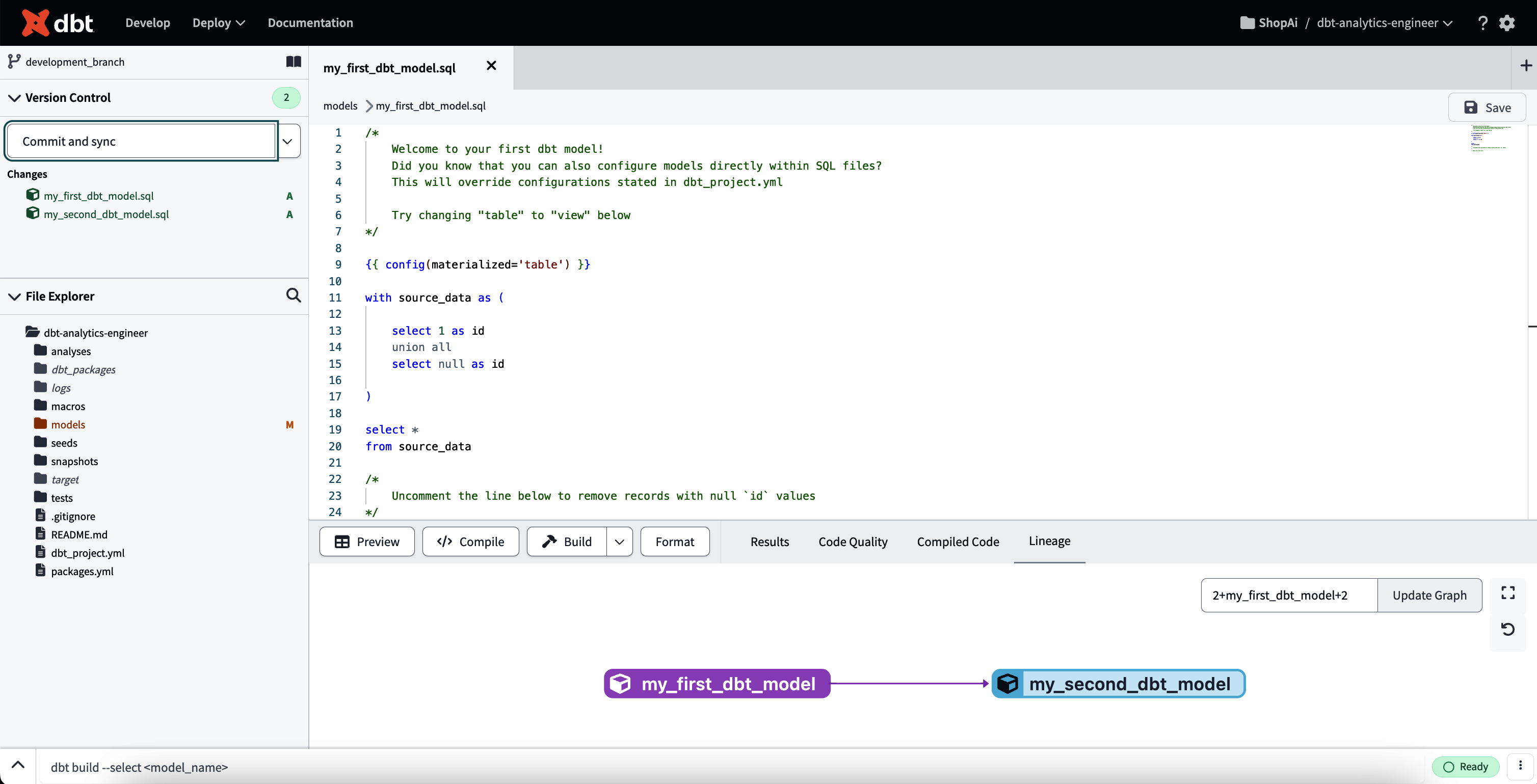
Figura 4-12. dbt tras la inicialización del proyecto
Detallaremos cada carpeta y archivo en "Estructura de un proyecto dbt". Por ahora, veamos si las consultas funcionan. Ejecútalas de nuevo copiando el código del Ejemplo 4-2 y haz clic en Vista Previa.
Ejemplo 4-2. Conjuntos de datos públicos dbt en BigQuery, prueba dbt
--select * from `dbt-tutorial.jaffle_shop.customers`;--select * from `dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
Si el resultado es similar al de la Figura 4-13, significa que tu conexión funciona. A continuación, puedes enviar consultas a tu plataforma de datos, que en nuestro caso es BigQuery.
Nota
Los pasos proporcionados aquí forman parte de la documentación del adaptador BigQuery en dbt. A medida que las tecnologías evolucionan y mejoran, estos pasos y configuraciones también pueden cambiar. Para asegurarte de que dispones de la información más actualizada, consulta la documentación más reciente de dbt para BigQuery. Este recurso te proporcionará la orientación y las instrucciones más actuales para trabajar con dbt y BigQuery.
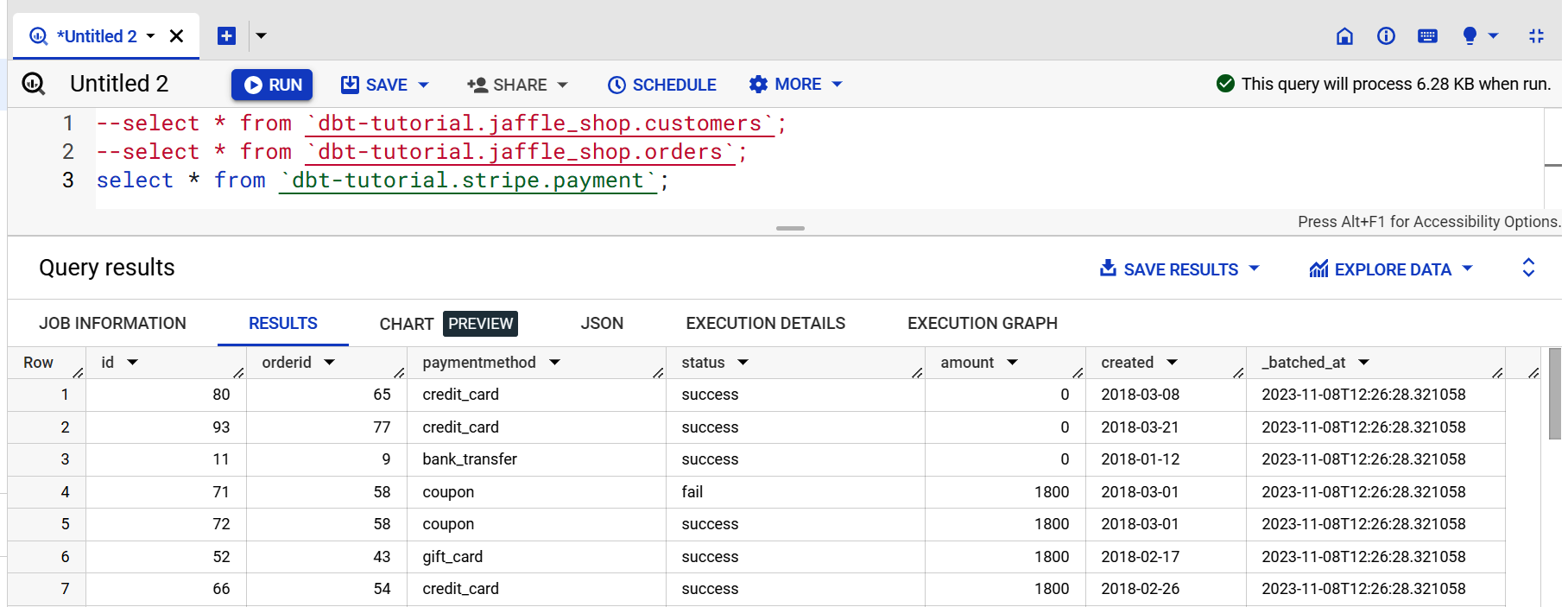
Figura 4-13. Salida dbt del conjunto de datos públicos de BigQuery
Por último, vamos a probar si tu integración con GitHub funciona como esperabas realizando tu primer "Commit and push". Haz clic en el botón con la misma descripción, visible en la Figura 4-14, a la izquierda. Aparecerá una pantalla emergente, la imagen de la derecha en la Figura 4-14, donde puedes escribir tu mensaje de confirmación. Haz clic en Confirmar cambios.
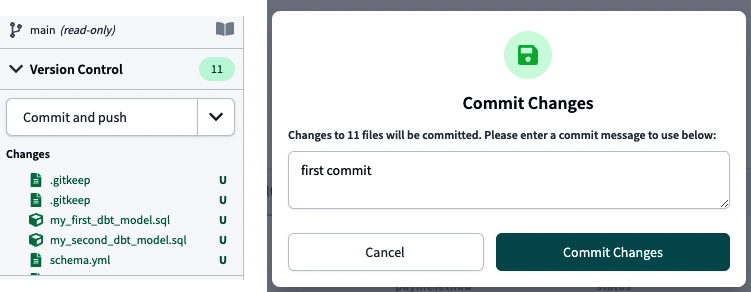
Figura 4-14. Confirmar y enviar a GitHub
Como no hemos creado una rama Git, versionará nuestro código dentro de la rama principal. Entra en el repositorio de GitHub que creaste durante esta configuración y comprueba si existe tu proyecto dbt. La Figura 4-15 debería ser similar a lo que ves en tu repositorio de GitHub.
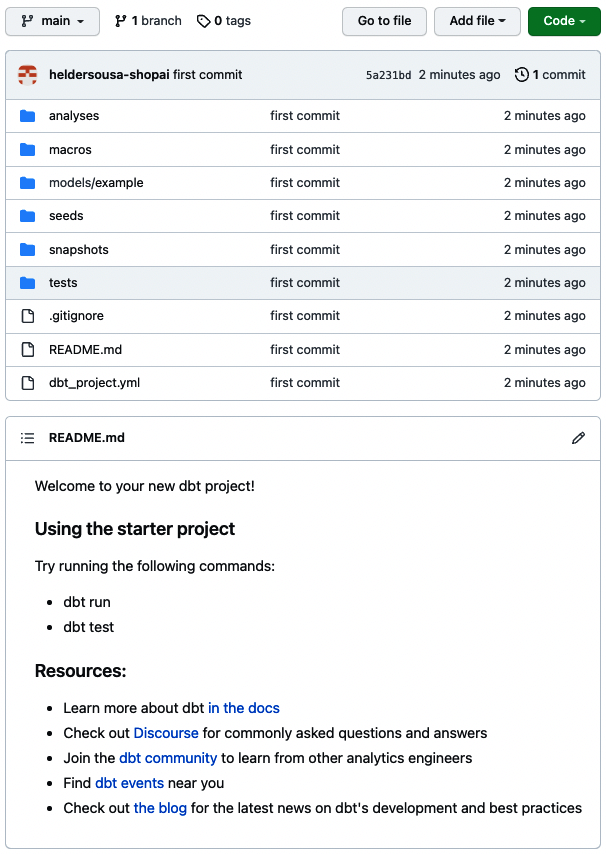
Figura 4-15. Repositorio dbt de GitHub, comprobación de la primera confirmación
Utilizar la interfaz de usuario de dbt Cloud
Cuando te registras en dbt Cloud, la página inicial muestra un mensaje de bienvenida y un resumen del historial de ejecución de tu trabajo. Como muestra la Figura 4-16, la página está vacía al principio, pero una vez que creemos y ejecutemos nuestros primeros trabajos, empezaremos a ver información. En "Trabajos e Implementación", detallamos más la ejecución de un trabajo.
Figura 4-16. Página de inicio de dbt
En la barra superior, verás varias opciones. Empezando por la izquierda, puedes acceder a la página Desarrollar, donde desarrollarás todo tu código analítico y crearás tus modelos, pruebas y documentación. Es el núcleo del desarrollo de dbt, y te daremos más información sobre esta sección en "Uso del IDE de dbt Cloud", y profundizaremos en cada componente en "Estructura de un proyecto dbt".
Justo al lado de la opción Desarrollar está el menú Implementación, como se muestra en la Figura 4-17. Desde este menú, puedes configurar los trabajos y monitorizar su ejecución mediante el Historial de Ejecución, configurar los entornos de desarrollo y verificar la frescura de las fuentes de tus instantáneas mediante las Fuentes de Datos.
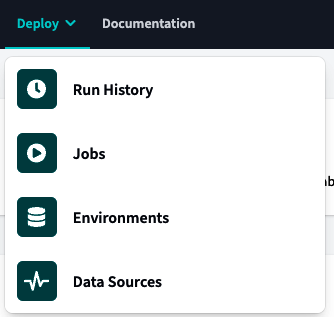
Figura 4-17. Menú dbt Implementación
La primera opción del menú Implementación es Historial de ejecuciones, que abre la página mostrada en la Figura 4-18. Aquí puedes ver el historial de ejecución de tu trabajo. En el contexto de dbt, los trabajos son tareas o procesos automatizados que configuras para realizar acciones específicas, como ejecutar modelos, pruebas o generar documentación. Estos trabajos son una parte integral de la orquestación de dbt, que implica gestionar y automatizar diversas tareas de transformación y análisis de datos.
Figura 4-18. Página Historial de Ejecuciones dbt
Supón que tienes trabajos configurados que ya tenían ejecuciones en esta sección. En ese caso, puedes inspeccionar la invocación y el estado de cada trabajo. En el historial de ejecución del trabajo hay disponible una gran cantidad de información, incluyendo su estado, duración, el entorno en el que se ejecutó el trabajo y otros detalles útiles. Puedes acceder a información sobre los pasos por los que pasó el trabajo, incluyendo los registros correspondientes a cada paso. Además, puedes encontrar artefactos generados por el trabajo, como modelos, pruebas o documentación.
La siguiente opción del menú Implementación es Trabajos. Esto abre una página para configurar toda tu automatización, incluidos los conductos CI/CD, ejecutar pruebas y otros comportamientos interesantes, sin ejecutar comandos dbt manualmente desde la línea de comandos.
La Figura 4-19 muestra la página de inicio de Trabajos vacía. Tenemos toda una sección dedicada a los Trabajos en "Trabajos e Implementaciones".
Figura 4-19. Página dbt Trabajos
La tercera opción del menú Implementación es Entornos. Dentro de dbt, tenemos dos tipos principales de entornos: desarrollo e implementación. Por defecto, dbt te configura el entorno de desarrollo, que es visible justo después de configurar tu proyecto dbt. La Figura 4-20 te muestra la página de inicio de Entornos, que debería ser similar a la tuya si has seguido los pasos de "Configurar dbt Cloud con BigQuery y GitHub".
Figura 4-20. Página Entornos dbt
Por último, tenemos la opción Fuentes de Datos. Esta página, que se muestra en la Figura 4-21, la rellena automáticamente dbt Cloud una vez que configuras un trabajo para hacer una instantánea de la frescura de los datos de origen. Aquí verás el estado de las instantáneas más recientes, lo que te permitirá analizar si la frescura de tus datos de origen cumple los acuerdos de nivel de servicio (ANS) que has definido con tu organización. Te daremos una mejor idea de la frescura de los datos en " Frescura de las fuentes " y de cómo comprobarla en "Comprobación de las fuentes".
Figura 4-21. Página Fuentes de Datos dbt
A continuación está la opción Documentación, y siempre que tú y tu equipo creéis rutinas para aseguraros de que vuestro proyecto dbt está correctamente documentado, este paso tendrá un nivel de importancia particular. Una documentación adecuada puede responder a preguntas como éstas:
-
¿Qué significan estos datos?
-
¿De dónde proceden estos datos?
-
¿Cómo se calculan estas métricas?
La Figura 4-22 muestra la página Documentación de tu proyecto. Explicaremos cómo aprovechar y escribir documentación dentro de tu proyecto dbt mientras escribes tu código en "Documentación".
Figura 4-22. Página de Documentación de dbt
El menú superior derecho te permite seleccionar tu proyecto dbt(Figura 4-23). Este breve menú facilita el desplazamiento entre proyectos dbt.
Figura 4-23. Menú dbt Seleccionar cuenta
Puedes acceder al menú Ayuda de dbt(Figura 4-24) haciendo clic en en el símbolo del signo de interrogación. Aquí puedes hablar directamente con el equipo de dbt a través del chat, dar tu opinión y acceder a la documentación de dbt. Por último, a través del menú Ayuda, puedes unirte a la comunidad dbt de Slack o a los debates dbt de GitHub.
Figura 4-24. Menú Ayuda de dbt
El menú Configuración, Figura 4-25, es donde puedes configurar todo lo relacionado con tu cuenta, perfil o incluso las notificaciones.
Figura 4-25. Menú Configuración dbt
Una vez que hagas clic en una de las tres opciones, aterrizarás en en la página Configuración, similar a la Figura 4-26. En la primera página, Configuración de la cuenta, puedes editar y crear nuevos proyectos dbt, gestionar los usuarios y su nivel de control de acceso (si eres propietario), y gestionar la facturación.
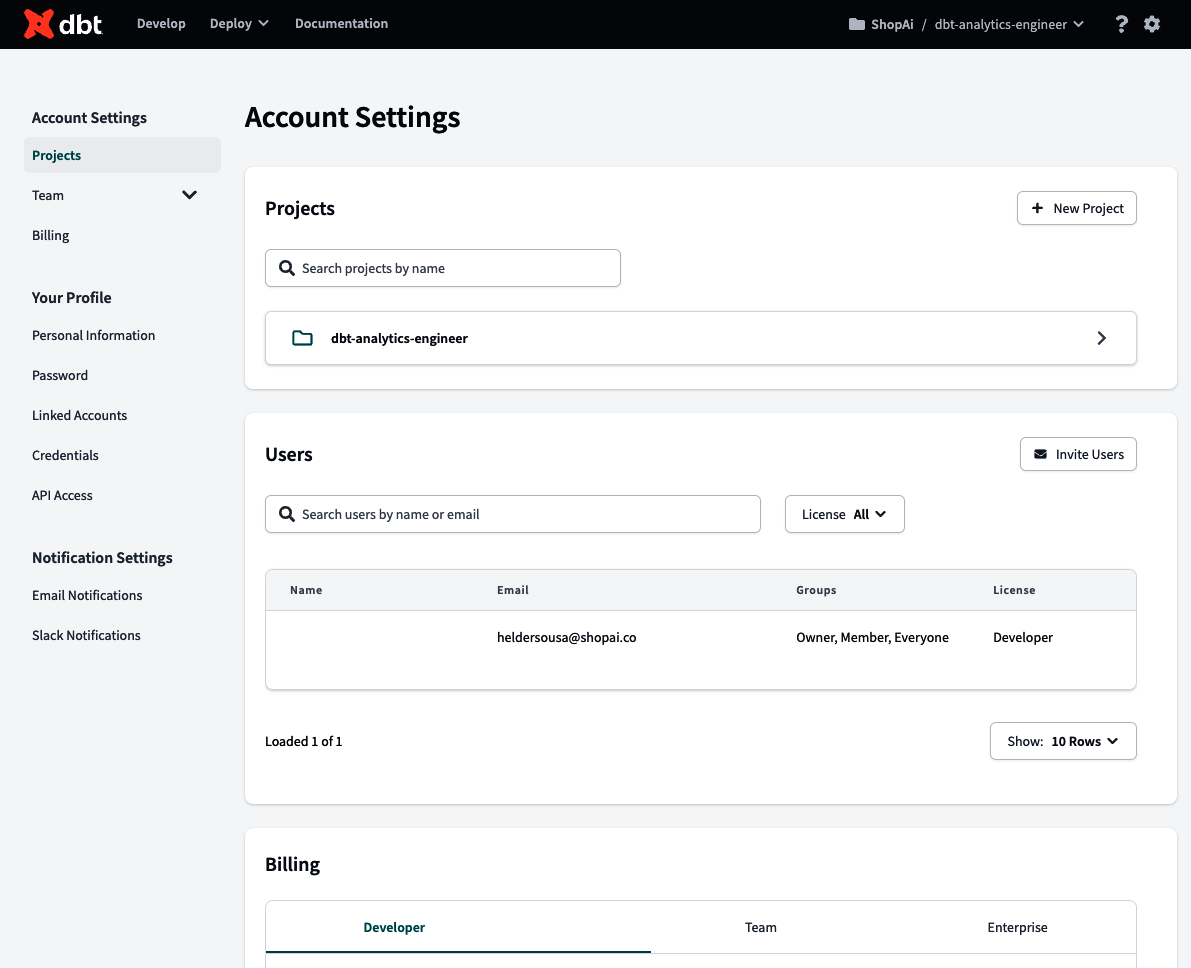
Figura 4-26. Página de Configuración de la Cuenta dbt
La segunda opción del menú, Configuración del perfil, accede a la página Tu perfil(Figura 4-27). En esta página, puedes revisar toda tu información personal y gestionar las cuentas vinculadas, como GitHub o GitLab, Slack y las herramientas de inicio de sesión único (SSO). También puedes revisar y editar las credenciales que definiste para tu plataforma de datos y la clave de acceso a la API.
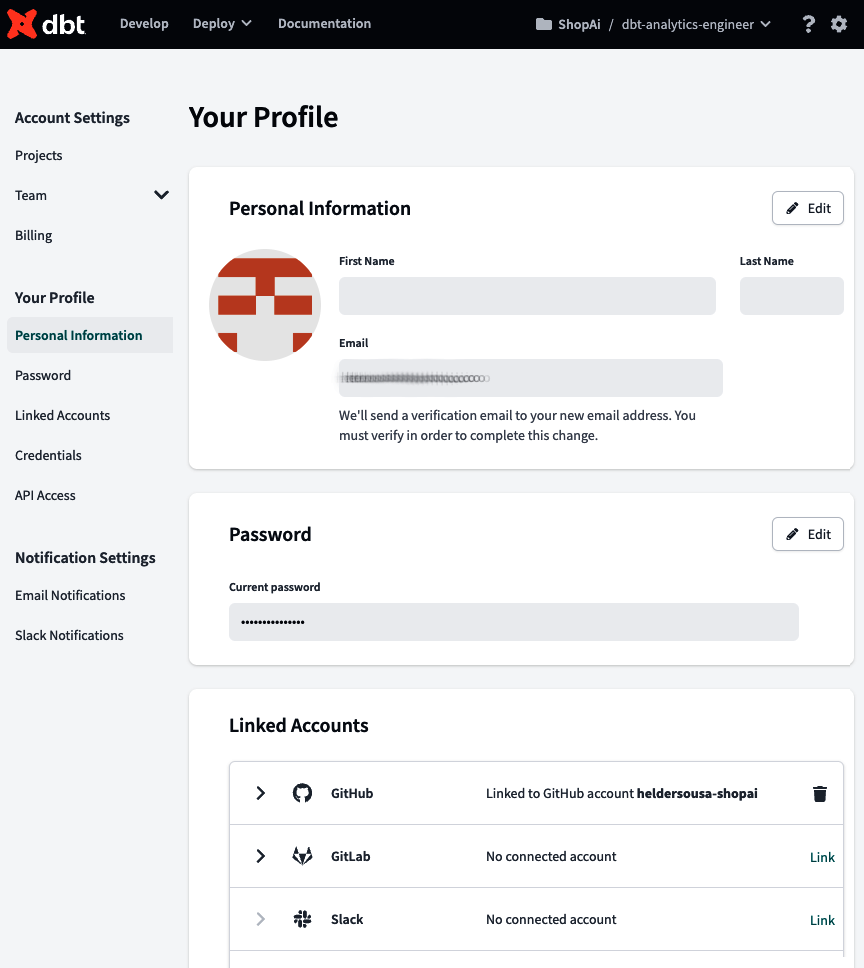
Figura 4-27. Página dbt Tu perfil
Por último, la opción Configuración de notificaciones accede al centro de Notificaciones (Figura 4-28), donde puedes configurar las alertas que se recibirán en un canal Slack elegido o por correo electrónico cuando la ejecución de un trabajo tenga éxito, falle o se cancele.
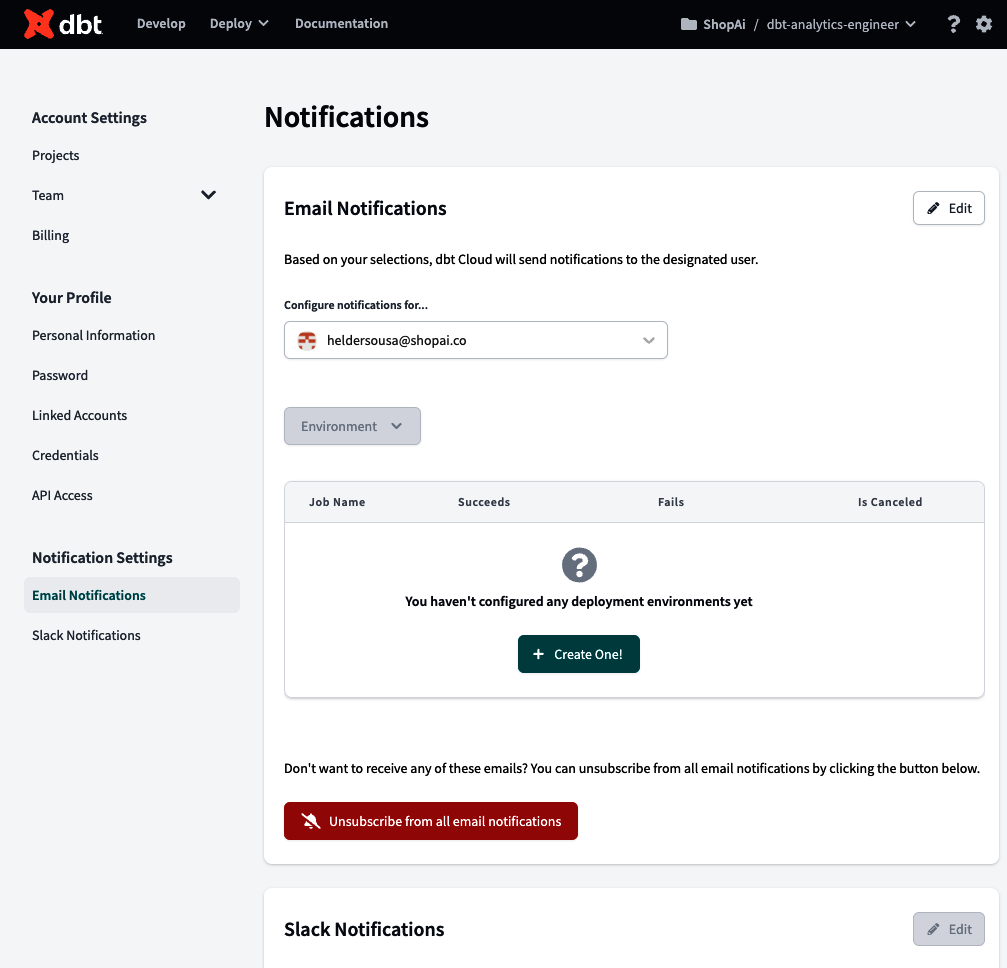
Figura 4-28. Centro de Notificaciones dbt
Utilizar el IDE de dbt Cloud
Una de las partes esenciales de la Nube de dbt es el IDE, donde se puede escribir todo tu código analítico, junto con las pruebas y la documentación. La Figura 4-29 muestra las secciones principales del IDE de dbt.
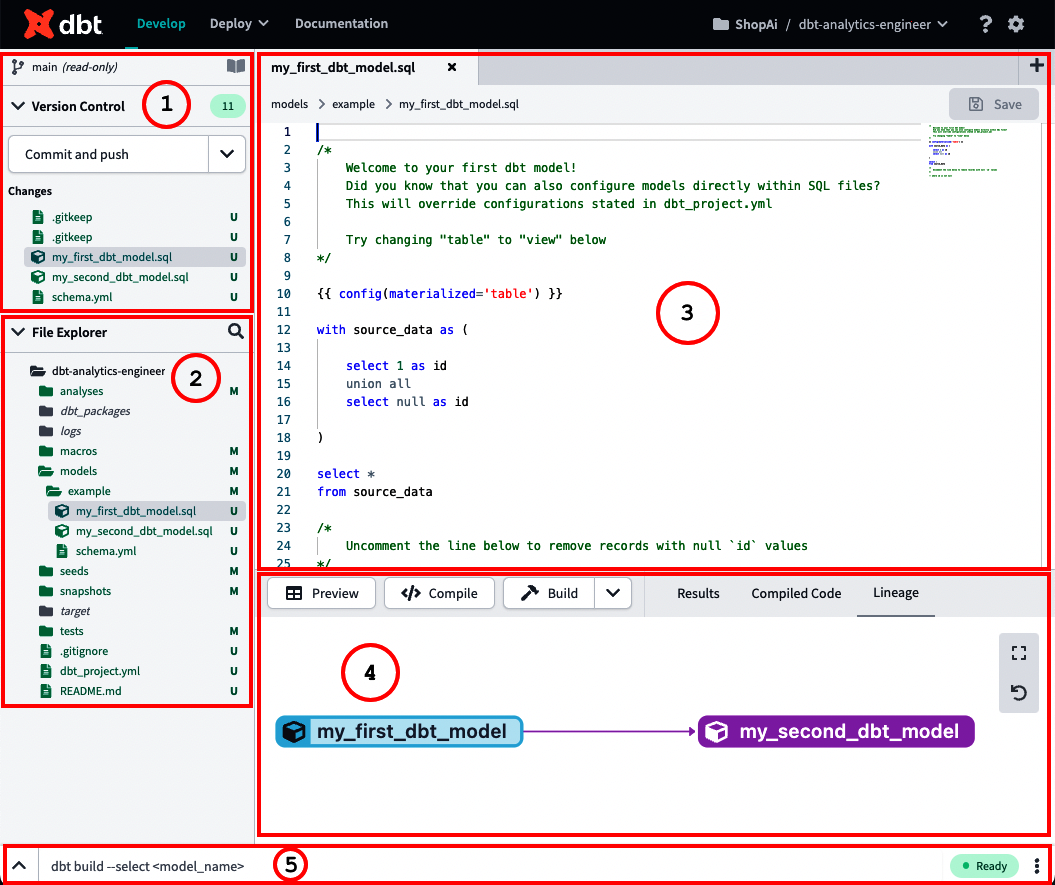
Figura 4-29. dbt IDE-anotado
A continuación, encontrarás una explicación detallada de lo que representa cada sección y su relevancia dentro del entorno de desarrollo integrado:
-
Controles y documentación Git
Este menú es donde interactúas con Git. Aquí puedes ver qué ha cambiado desde tu confirmación anterior y qué hay de nuevo. Todos los comandos Git del IDE están aquí, y puedes decidir si confirmar y enviar o revertir tu código. Además, en la parte superior derecha de esta ventana, puedes ver el icono de documentación. Una vez generada la documentación, puedes hacer clic en este acceso directo para acceder a la documentación de tu proyecto.
-
Explorador de archivos
El Explorador de archivos te ofrece la visión principal de tu proyecto dbt. Aquí puedes comprobar cómo está construido tu proyecto dbt, generalmente en forma de archivos .sql, .yml y otros tipos de archivos compatibles.
-
Editor de texto
Esta sección del IDE es donde se escribe y madura tu código analítico de . Aquí también puedes editar y crear otros archivos relevantes para tu proyecto, como los archivos YAML. Si seleccionas esos archivos desde el Explorador de archivos, aparecerán aquí. Se pueden abrir varios archivos simultáneamente.
-
Ventana de información y código Previsualizar, compilar y construir
Este menú mostrará tus resultados una vez que pulses los botones Previsualizar o Compilar. Previsualizar compilará y ejecutará tu consulta contra tu plataforma de datos y mostrará los resultados en la pestaña Resultados de la parte inferior de tu pantalla. Por otro lado, Compilar convertirá cualquier Jinja en SQL puro. Esto se mostrará en la ventana de información de la pestaña Código compilado, en la parte inferior de tu pantalla. Los botones Previsualizar o Compilar se aplican a sentencias y archivos SQL.
Construir es un botón especial que sólo aparece en determinados archivos. Dependiendo del tipo de construcción que elijas, los resultados de la ejecución incluirán información sobre todos los modelos, pruebas, semillas e instantáneas que se seleccionaron para construir, combinados en un único archivo.
La ventana de información también es útil para solucionar errores durante el desarrollo o utilizar la pestaña Linaje para comprobar el linaje de datos del modelo abierto actualmente en el editor de texto y sus antepasados y dependencias.
-
Línea de comandos
La línea de comandos es donde puedes ejecutar comandos dbt específicos como
dbt runodbt test. Durante o después de la ejecución del comando, también se muestra una pantalla emergente para mostrar los resultados a medida que se procesan; para ello, haz clic en la flecha situada al principio de la línea de comandos. Aquí también se pueden ver los registros. La Figura 4-30 muestra la línea de comandos expandida; el comando que se va a ejecutar está en la parte superior, y el registro de la ejecución le sigue.
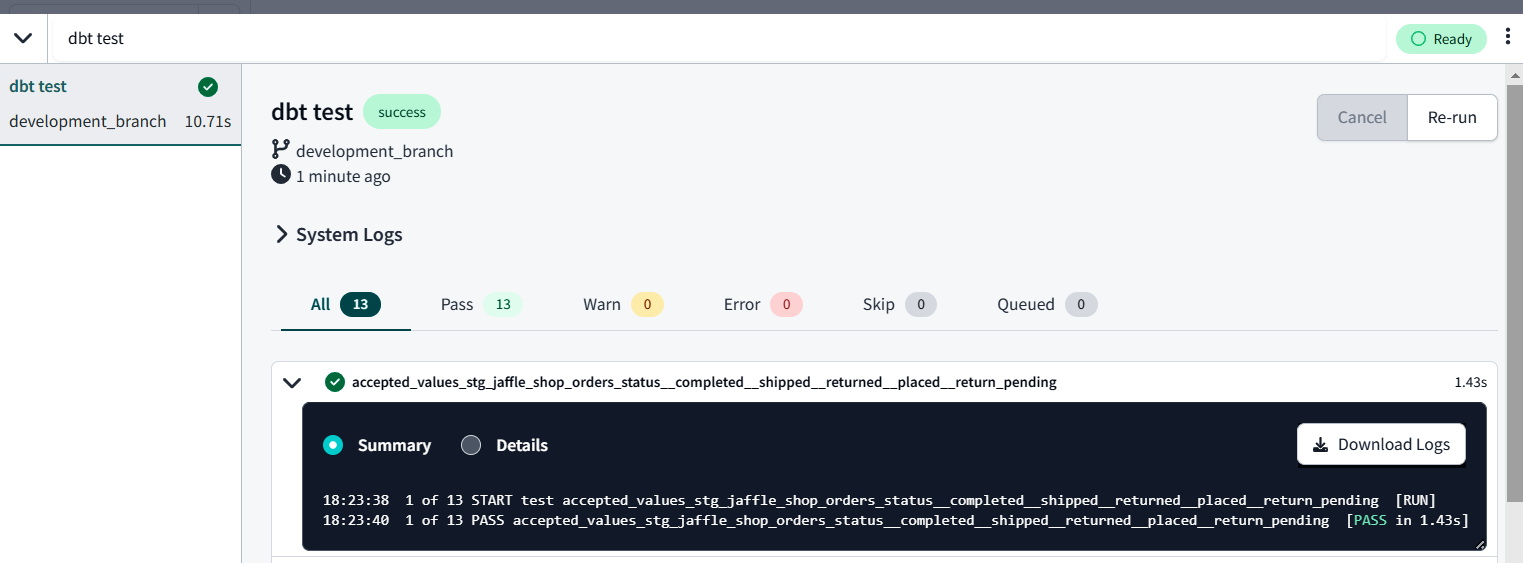
Figura 4-30. Línea de comandos dbt expandida
Estructura de un proyecto dbt
Un proyecto dbt es un directorio compuesto por carpetas y archivos, patrones de programación y convenciones de nomenclatura. Todo tu código analítico, pruebas, documentación y parametrizaciones que indicarán a dbt cómo funcionar estarán en esos archivos y carpetas. Utilizará esas convenciones de nomenclatura y patrones de programación. La forma en que organices tus carpetas y directorio de archivos es la estructura de tu proyecto dbt.
Construir un proyecto de dbt adecuado requiere esfuerzo. Para que esté bien implementado, debe reunir a los dominios y departamentos de la empresa, aprovechando su experiencia particular para trazar los objetivos y necesidades de toda la empresa. Por ello, es importante definir un conjunto de convenciones y pautas que sean claras, completas y coherentes. Lograrlo garantizará que el proyecto siga siendo accesible y mantenible a medida que tu empresa se amplíe, al tiempo que utilizas la dbt para capacitar y beneficiar al mayor número posible de personas.
La forma de organizar tu proyecto de dbt puede variar y puede estar sujeta a cambios definidos por ti o por las directrices de la empresa. Eso no es un problema. Lo importante es que declares explícitamente esos cambios de forma rigurosa y accesible para todos los colaboradores y, sobre todo, que te mantengas coherente con ello. Por el bien de este libro, mantendremos la estructura básica del proyecto dbt que te encuentras una vez inicializado(Ejemplo 4-3).
Ejemplo 4-3. Estructura inicial de un proyecto dbt
root/ ├─ analyses/ ├─ dbt_packages/ ├─ logs/ ├─ macros/ ├─ models/ │ ├─ example/ │ │ ├─ schema.yml │ │ ├─ my_second_dbt_model.sql │ │ ├─ my_first_dbt_model.sql ├─ seeds/ ├─ snapshots/ ├─ target/ ├─ tests/ ├─ .gitignore ├─ dbt_project.yml ├─ README.md
Cada carpeta y archivo se explicará en las secciones siguientes de este capítulo y del Capítulo 5. Algunas tendrán más énfasis y se utilizarán con más regularidad que otras. Sin embargo, es esencial tener una idea más amplia de su finalidad:
- carpeta de análisis
-
Detallada en "Análisis", esta carpeta se utiliza habitualmente para almacenar consultas de con fines de auditoría. Por ejemplo, puede que quieras encontrar discrepancias durante la migración de la lógica de otro sistema a dbt y seguir aprovechando las capacidades de dbt, como el uso de Jinja y el control de versiones, sin incluirlo en tus modelos construidos dentro de tu plataforma de datos.
- carpeta dbt_paquetes
-
Es donde instalarás tus paquetes dbt de . Trataremos el concepto de paquetes en "Paquetes dbt". Aún así, la idea es que los paquetes sean proyectos dbt independientes que aborden problemas específicos y puedan reutilizarse y compartirse entre organizaciones. Esto promueve un código más DRY, ya que no estás implementando la misma lógica una y otra vez.
- carpeta de registros
-
Es donde se escribirán por defecto todos los registros de tu proyecto , a menos que los configures de otro modo en tu dbt_project.yml.
- carpeta macros
-
Es donde se almacenará tu código de transformaciones DRY- up. Las macros, análogas a las funciones en otros lenguajes de programación, son piezas de código Jinja que pueden reutilizarse varias veces. Dedicaremos una sección entera en "Uso de macros SQL" a detallarlas.
- carpeta de modelos
-
Es una de las carpetas obligatorias de en dbt. En términos generales, un modelo es un archivo SQL que contiene una sentencia
SELECTcon una pieza modular de lógica que tomará tus datos brutos y los construirá en los datos transformados finales. En dbt, el nombre del modelo indica el nombre de una futura tabla o vista, o de ninguna de ellas si se configura como modelo efímero. Este tema se detallará en "Modelos". - carpeta de semillas
-
Es donde se almacenarán nuestras tablas de consulta . Hablaremos de ello en "Semillas". La idea general es que las semillas son archivos CSV que cambian con poca frecuencia, y se utilizan para modelar datos que no existen en ningún sistema fuente. Algunos casos de uso útiles podrían ser la asignación de códigos postales a estados o una lista de correos electrónicos de prueba que debamos excluir del análisis.
- carpeta de instantáneas
-
Contiene todos los modelos de instantáneas de tu proyecto, que deben estar separados de la carpeta de modelos. La función de instantáneas dbt registra los cambios en una tabla mutable a lo largo del tiempo. Aplica la dimensión de cambio lento (SCD) de tipo 2, que identifica cómo cambia una fila de una tabla a lo largo del tiempo. Esto se trata en detalle en "Instantáneas".
- carpeta de destino
-
Contiene los archivos SQL compilados que se escribirán cuando ejecutes los comandos
dbt run,dbt compileodbt test. Puedes configurar opcionalmente en dbt_project.yml que se escriban en otra carpeta. - carpeta pruebas
-
Sirve para probar varias tablas específicas simultáneamente. Ésta no será la única carpeta donde se escribirán tus pruebas. Un buen número seguirán estando bajo la carpeta de tu modelo dentro de los archivos YAML, o a través de macros. Sin embargo, la carpeta de pruebas es más adecuada para pruebas singulares, que informan de los resultados de cómo interactúan o se relacionan entre sí varios modelos concretos. Trataremos este tema en profundidad en "Pruebas".
- dbt_proyecto.yml
-
Es el núcleo de todo proyecto dbt. Así es como dbt sabe que un directorio es un proyecto dbt, y contiene información importante que indica a dbt cómo debe operar en tu proyecto. Cubriremos este archivo a lo largo de este libro. También se trata en "dbt_project.yml".
- .gitignore y README.md
-
Son archivos típicamente utilizados para tus proyectos Git. Mientras que gitignore especifica los archivos intencionados que Git debe ignorar durante tu commit y push, el archivo README es una guía esencial que proporciona a otros desarrolladores una descripción detallada de tu proyecto Git.
Trataremos estas carpetas con más detalle en este capítulo y en el capítulo 5, mientras profundizamos en el proyecto dbt y sus características.
Base de datos de la Tienda Jaffle
En este libro, daremos un conjunto de ejemplos prácticos de cómo trabajar con los componentes y funciones de dbt. En la mayoría de los casos, necesitaremos desarrollar consultas SQL para dar una idea de lo que queremos mostrar. Por eso, es esencial disponer de una base de datos con la que podamos trabajar. Esa base de datos es la Tienda Jaffle.
La base de datos de la Tienda Jaffle es una base de datos simple compuesta por dos tablas, para clientes y pedidos. Para dar más contexto, tendremos una base de datos lateral, de Stripe, con los pagos relacionados con los pedidos. Las tres tablas serán nuestros datos en bruto.
La razón por la que utilizamos esta base de datos es que ya está disponible públicamente, en BigQuery, por dbt Labs. Es una de las principales bases de datos utilizadas para su documentación y cursos, por lo que esperamos que simplifique la curva de aprendizaje general de la plataforma dbt en esta fase del libro.
La Figura 4-31 te muestra el ERD que representa nuestros datos brutos con clientes, pedidos y pagos.
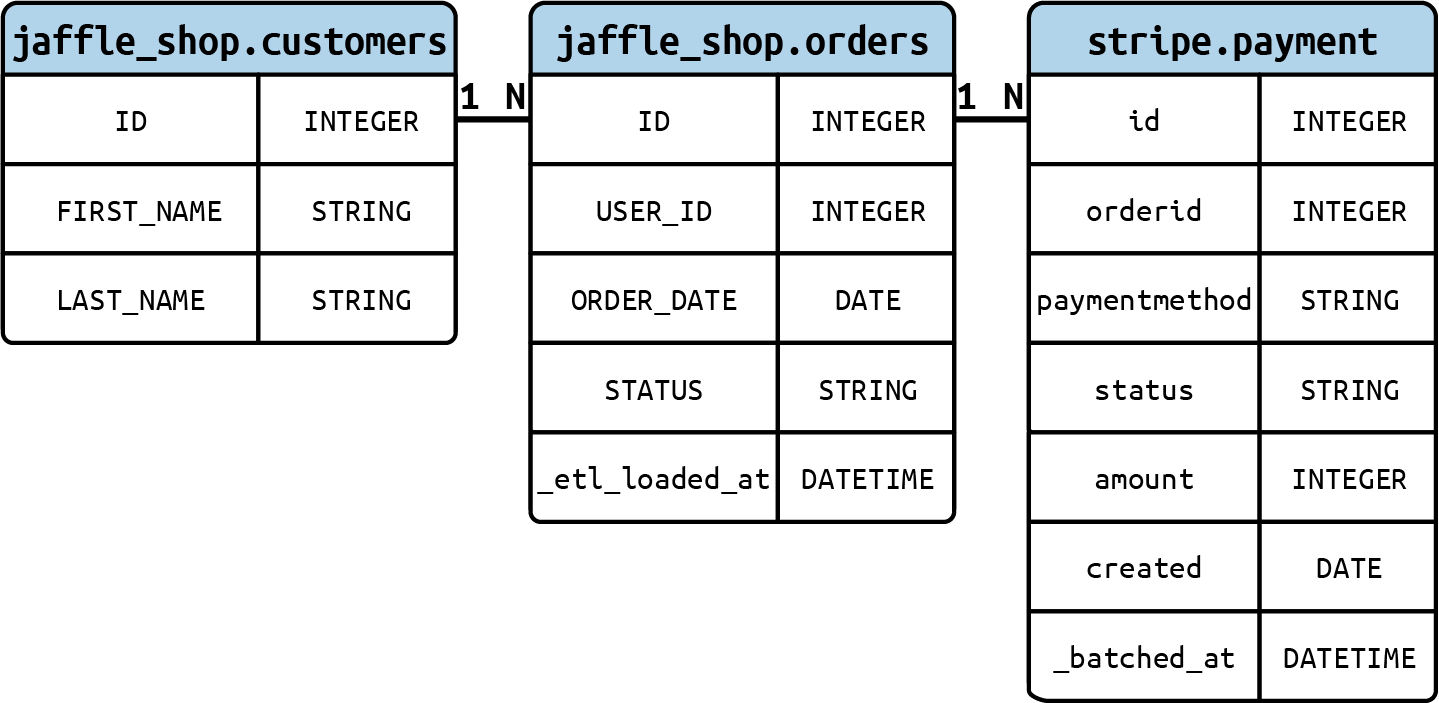
Figura 4-31. Un ERD de datos brutos de Jaffle Shop, que leemos como sigue: un único cliente (1) puede tener múltiples pedidos (N), y un único pedido (1) puede tener múltiples pagos de procesamiento (N)
Archivos YAML
YAML es un lenguaje de serialización de datos legible por humanos utilizado habitualmente para archivos de configuración y en aplicaciones en las que se almacenan o transmiten datos. En dbt, YAML se utiliza para definir propiedades y algunas configuraciones de los componentes de tu proyecto dbt: modelos, instantáneas, semillas, pruebas, fuentes, o incluso el propio proyecto dbt, dbt_project.yml.
Aparte de los archivos YAML de nivel superior, como dbt_project.yml y packages.yml, que deben ser nombrados específicamente y en ubicaciones concretas, la forma en que organices los demás archivos YAML dentro de tu proyecto dbt depende de ti. Recuerda que, al igual que con otros aspectos de la estructuración de tu proyecto dbt, las directrices más importantes son mantener la coherencia, tener claras tus intenciones y documentar cómo y por qué está organizado de esa manera. Es importante equilibrar la centralización y el tamaño del archivo para que las configuraciones específicas sean lo más fáciles de encontrar posible. A continuación encontrarás una serie de recomendaciones sobre cómo organizar, estructurar y nombrar tus archivos YAML:
-
Como se ha mencionado, equilibrar la centralización de la configuración y el tamaño del archivo es especialmente relevante. Tener todas las configuraciones en un único archivo puede dificultar encontrar una específica a medida que tu proyecto escala (aunque técnicamente puedes utilizar un único archivo). La gestión de cambios con Git también será complicada debido a la naturaleza repetitiva del archivo.
-
Como en el punto anterior, si seguimos un enfoque de configuración por carpeta, es mejor mantener todas tus configuraciones a largo plazo. En otras palabras, en el directorio de la carpeta de cada modelo, se recomienda tener un archivo YAML que facilite las configuraciones de todos los modelos de ese directorio. Amplía esta regla separando el archivo de configuración del modelo, teniendo un archivo específico para las configuraciones de tus fuentes dentro del mismo directorio(Ejemplo 4-4).
En esta estructura, hemos utilizado los modelos de montaje para representar lo que se está discutiendo, ya que cubre la mayoría de los casos, como fuentes, archivos YAML. Aquí puedes ver el sistema de configuración por carpetas, donde se dividen las configuraciones de fuentes y modelos de . También introduce los archivos Markdown para la documentación, de los que hablaremos con más detalle en "Documentación". Por último, el guión bajo al principio coloca todos estos archivos al principio de su respectivo directorio, para que sean más fáciles de encontrar.
Ejemplo 4-4. Archivos dbt YAML en el directorio del modelo
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ _jaffle_shop_docs.md │ │ │ ├─ _jaffle_shop_models.yml │ │ │ ├─ _jaffle_shop_sources.yml │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ _stripe_docs.md │ │ │ ├─ _stripe_models.yml │ │ │ ├─ _stripe_sources.yml │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
-
Cuando utilices bloques de documentación, sigue también el mismo enfoque creando un archivo Markdown (
.md) por directorio de modelos. En "Documentación" conoceremos mejor este tipo de archivo.
Se recomienda que establezcas configuraciones predeterminadas de tu proyecto dbt en tu archivo dbt_project.yml en el nivel de directorio y utilices la prioridad de ámbito en cascada para definir variaciones de estas configuraciones. Esto puede ayudarte a agilizar la gestión de tu proyecto dbt y garantizar que tus configuraciones sean coherentes y fáciles de mantener. Por ejemplo, aprovechando el Ejemplo 4-4, imagina que todos nuestros modelos de puesta en escena estuvieran configurados para materializarse como una vista por defecto. Eso estaría en tu dbt_project.yml. Pero si tienes un caso de uso específico en el que necesitas cambiar la configuración de materialización de tus modelos de montaje de jaffle_shop, puedes hacerlo modificando el archivo _jaffle_shop_models.yml. De este modo, puedes personalizar la configuración de materialización para este conjunto específico de modelos, manteniendo sin cambios el resto de configuraciones de tu proyecto.
La capacidad de anular las configuraciones predeterminadas para modelos específicos es posible gracias a la prioridad de ámbito en cascada utilizada en la compilación del proyecto dbt. Mientras que todos los modelos de montaje se materializarían como vistas porque ésta es la configuración por defecto, los modelos de montaje jaffle_shop se materializarían como tablas porque anulamos la configuración por defecto actualizando el archivo YAML específico _jaffle_shop_models.yml.
dbt_proyecto.yml
Uno de los archivos más críticos de dbt es dbt_project.yml. Este archivo debe estar en la raíz del proyecto y es el principal archivo de configuración de tu proyecto, que contiene la información pertinente para que dbt funcione correctamente.
El archivo dbt_project.yml también tiene cierta relevancia a la hora de escribir tu código de análisis DRY-er. En términos generales, las configuraciones predeterminadas de tu proyecto se almacenarán aquí, y todos los objetos heredarán de él a menos que se anulen a nivel de modelo.
Estos son algunos de los campos más importantes que encontrarás en este archivo:
- nombre
-
(Obligatorio.) El nombre del proyecto dbt. Te recomendamos que cambies esta configuración por el nombre de tu proyecto. Acuérdate también de cambiarlo en la sección del modelo y en el archivo dbt_project.yml. En nuestro caso, lo llamamos dbt_analytics_engineer_book.
- versión
-
(Obligatorio.) Versión principal de tu proyecto. Diferente de la versión dbt.
- config-version
-
(Obligatorio.) La versión 2 es la versión disponible actualmente.
- perfil
-
(Obligatorio.) El perfil dentro de dbt se utiliza para conectar con tu plataforma de datos.
- [carpeta]-rutas
-
(Opcional.) Donde [carpeta] es la lista de carpetas del proyecto dbt. Puede ser un modelo, una semilla, una prueba, un análisis, una macro, una instantánea, un registro, etc. Por ejemplo, las rutas-modelo indicarán el directorio de tus modelos y fuentes. La macro-ruta es donde vive el código de tus macros, etc.
- ruta-objetivo
-
(Opcional.) Esta ruta almacenará el archivo SQL compilado.
- limpiar-objetivos
-
(Opcional.) Lista de directorios que contienen artefactos que el comando
dbt cleandebe eliminar. - modelos
-
(Opcional.) Configuración por defecto de los modelos. En el Ejemplo 4-5, queremos que todos los modelos de la carpeta de montaje se materialicen como vistas.
Ejemplo 4-5. dbt_project.yml, configuración del modelo
models:dbt_analytics_engineer_book:staging:materialized:view
paquetes.yml
Los paquetes son proyectos dbt independientes que abordan problemas específicos y pueden reutilizarse y compartirse entre organizaciones. Son proyectos con modelos y macros; al añadirlos a tu proyecto, esos modelos y macros pasarán a formar parte de él.
Para acceder a esos paquetes, primero tienes que definirlos en el archivo packages.yml. Los pasos detallados son los siguientes:
-
Debes asegurarte de que el archivo packages.yml está en tu proyecto dbt. Si no es así, créalo en el mismo nivel que tu archivo dbt_project.yml.
-
Dentro del archivo dbt packages.yml, define los paquetes que quieres tener disponibles para su uso dentro de tu proyecto dbt. Puedes instalar paquetes desde fuentes como el Hub dbt; repositorios Git, como GitHub o GitLab; o incluso paquetes que tengas almacenados localmente. El Ejemplo 4-6 te muestra la sintaxis necesaria para cada uno de estos escenarios.
-
Ejecuta
dbt depspara instalar los paquetes definidos. A menos que lo configures de otro modo, por defecto esos paquetes se instalan en el directorio dbt_paquetes.
Ejemplo 4-6. Sintaxis para instalar paquetes desde el hub dbt, Git o localmente
packages:-package:dbt-labs/dbt_utilsversion:1.1.1-git:"https://github.com/dbt-labs/dbt-utils.git"revision:1.1.1-local:/opt/dbt/bigquery
perfiles.yml
Si decides utilizar la CLI de dbt y ejecutar tu proyecto dbt localmente, tendrás que configurar un profiles.yml, que no es necesario si utilizas dbt Cloud. Este archivo contiene la conexión a la base de datos que dbt utilizará para conectarse a la plataforma de datos. Debido a su contenido sensible, este archivo vive fuera del proyecto para evitar que las credenciales se versionen en tu repositorio de código. Puedes utilizar con seguridad el versionado de código si tus credenciales se almacenan en variables de entorno.
Una vez que invocas a dbt desde tu entorno local, dbt analiza tu archivo dbt_project.yml y obtiene el nombre del perfil, que dbt necesita para conectarse a tu plataforma de datos. Puedes tener varios perfiles según necesites, aunque lo habitual es tener un perfil por proyecto dbt o por plataforma de datos. incluso utilizando dbt Cloud para este libro, y no siendo necesaria la configuración de perfiles. Te mostramos una muestra del profiles.yml por si tienes curiosidad o prefieres utilizar dbt CLI con BigQuery.
El típico archivo de esquema YAML para profiles.yml se muestra en el Ejemplo 4-7. En este libro estamos utilizando dbt Cloud, lo que significa que la configuración de perfiles no es necesaria. Sin embargo, mostramos una muestra de profiles.yml por si tienes curiosidad o prefieres utilizar la CLI de dbt con BigQuery.
Ejemplo 4-7. profiles.yml
dbt_analytics_engineer_book:target:devoutputs:dev:type:bigquerymethod:service-accountproject:[GCP project id]dataset:[the name of your dbt dataset]threads:[1 or more]keyfile:[/path/to/bigquery/keyfile.json]<optional_config>:<value>
La estructura más común de profiles.yaml tiene los siguientes componentes:
- nombre_perfil
-
El nombre del perfil debe ser igual al nombre que aparece en tu dbt_project.yml. En nuestro caso, lo hemos llamado
dbt_analytics_engineer_book. - objetivo
-
Así tendrás configuraciones diferentes para entornos diferentes. Por ejemplo, querrás conjuntos de datos/bases de datos separados para trabajar en ellos cuando desarrolles localmente. Pero al realizar la implementación en producción, es mejor tener todas las tablas en un único conjunto de datos o base de datos. Por defecto, el destino está configurado para ser
dev. - tipo
-
El tipo de plataforma de datos que quieres conectar: BigQuery, Snowflake, Redshift, entre otras.
- detalles de conexión específicos de la base de datos
-
El ejemplo 4-7 incluye atributos como
method,project,dataset, ykeyfileque son necesarios para establecer una conexión con BigQuery, utilizando este enfoque. - hilos
-
Número de hilos en los que se ejecutará el proyecto dbt. Crea un DAG de enlaces entre modelos. El número de hilos representa el número máximo de caminos a través del grafo que dbt puede trabajar en paralelo. Por ejemplo, si especificas
threads: 1, dbt empezará a construir sólo un recurso (modelos, pruebas, etc.) y lo terminará antes de pasar al siguiente. En cambio, si tienesthreads: 4, dbt trabajará hasta en cuatro modelos a la vez sin violar las dependencias.
Nota
Aquí se presenta la idea general del archivo profiles.yml. No iremos más allá ni daremos una guía detallada de configuración de tu proyecto local dbt con BigQuery. La mayoría de las tareas ya se describieron, como la generación del archivo de claves, en "Configuración de dbt Cloud con BigQuery y GitHub", pero puede haber algunos matices. Si quieres saber más, en dbt encontrarás una guía completa.
Modelos
Los modelos son donde tú, como especialista en datos , pasarás la mayor parte de tu tiempo dentro del ecosistema dbt. Normalmente se escriben como sentencias select, se guardan como .sql, y son una de las piezas más importantes de dbt que te ayudarán a transformar tus datos dentro de tu plataforma de datos.
Para construir adecuadamente tus modelos y crear una estructura de proyecto clara y coherente, necesitas sentirte cómodo con el concepto y las técnicas de modelado de datos. Se trata de un conocimiento básico si tu objetivo es convertirte en ingeniero analítico o, en términos genéricos, en alguien que quiera trabajar con datos.
Como vimos en el Capítulo 2, el modelado de datos es el proceso de que, analizando y definiendo los requisitos de los datos, crea modelos de datos que dan soporte a los procesos empresariales de tu organización. Da forma a tus datos fuente, los datos que tu empresa recopila y produce, en datos transformados, respondiendo a las necesidades de datos de los dominios y departamentos de tu empresa y generando valor añadido.
En línea con el modelado de datos, y también como se introdujo en el Capítulo 2, la modularidad es otro concepto vital para estructurar adecuadamente tu proyecto dbt y organizar tus modelos manteniendo tu código DRY-er. Conceptualmente hablando, la modularidad es el proceso de descomponer un problema en un conjunto de módulos que pueden separarse y recombinarse, lo que reduce la complejidad general del sistema, a menudo con el beneficio de la flexibilidad y la variedad de uso. En analítica, esto no es diferente. Al construir un producto de datos, no escribimos el código de una vez. En lugar de eso, lo hacemos pieza a pieza hasta llegar a los artefactos de datos finales.
Puesto que intentaremos que la modularidad esté presente desde el principio, nuestros modelos iniciales también se construirán teniendo en cuenta la modularidad y de acuerdo con lo que hemos tratado en el Capítulo 2. Siguiendo un flujo típico de transformación de datos dbt, habrá tres capas en el directorio de nuestro modelo:
- Capa de puesta en escena
-
Nuestro edificio modular inicial bloques se encuentra dentro de la capa de montaje de nuestro proyecto dbt. En esta capa, establecemos una interfaz con nuestros sistemas fuente, similar a la forma en que una API interactúa con fuentes de datos externas. Aquí, los datos se reordenan, se limpian y se preparan para el procesamiento posterior. Esto incluye tareas como la normalización de los datos y pequeñas transformaciones que preparan el terreno para un procesamiento de datos más avanzado más adelante.
- Capa intermedia
-
Esta capa consiste en modelos entre la capa de puesta en escena y la capa de marts. Estos modelos se construyen sobre nuestros modelos de puesta en escena y se utilizan para llevar a cabo amplias transformaciones de datos, así como la consolidación de datos de múltiples fuentes, lo que crea tablas intermedias variadas que servirán para fines distintos.
- Capa de mercado
-
Dependiendo de tu técnica de modelado de datos, los marts reúnen todas las piezas modulares para ofrecer una visión más amplia de las entidades que interesan a tu empresa. Si, por ejemplo, elegimos una técnica de modelado dimensional, la capa de marts contiene tus tablas de hechos y dimensiones. En este contexto, los hechos son sucesos que siguen ocurriendo a lo largo del tiempo, como pedidos, clics en páginas o cambios en el inventario, con sus respectivas medidas. Las dimensiones son atributos, como clientes, productos y geografía, que pueden describir esos hechos. Los mercados pueden describirse como subconjuntos de datos dentro de tu plataforma de datos que están orientados a dominios o departamentos específicos, como finanzas, marketing, logística, servicio al cliente, etc. También puede ser una buena práctica tener un mart llamado "núcleo", por ejemplo, que no esté orientado a un dominio específico, sino que sea el núcleo de los hechos y dimensiones empresariales.
Una vez hechas las presentaciones, vamos a construir ahora nuestros primeros modelos, inicialmente sólo en nuestra capa staging. Crea una nueva carpeta dentro de tu carpeta de modelos, llamada staging, y las respectivas carpetas por fuente, jaffle_shop y stripe, dentro de la carpeta staging. A continuación, crea los archivos SQL necesarios, uno para stg_stripe_order_payments.sql(Ejemplo 4-8), otro para stg_jaffle_shop_customers.sql(Ejemplo 4-9) y, por último, uno para stg_jaffle_shop_orders.sql(Ejemplo 4-10). Por último, elimina la carpeta de ejemplo dentro de tus modelos. Es innecesaria, por lo que crearía un ruido visual innecesario mientras codificas. La estructura de carpetas debería ser similar a la del Ejemplo 4-11.
Ejemplo 4-8. stg_tira_pedido_pagos.sql
selectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom`dbt-tutorial.stripe.payment`
Ejemplo 4-9. stg_jaffle_tienda_clientes.sql
selectidascustomer_id,first_name,last_namefrom`dbt-tutorial.jaffle_shop.customers`
Ejemplo 4-10. stg_jaffle_shop_orders.sql
selectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom`dbt-tutorial.jaffle_shop.orders`
Ejemplo 4-11. Estructura de carpetas de los modelos de puesta en escena
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
Ahora vamos a ejecutar y validar lo que hemos hecho. Normalmente, basta con escribir dbt run en tu línea de comandos, pero en BigQuery, puede que necesites escribir dbt run --full-refresh. Después, mira tus registros utilizando la flecha situada a la izquierda de tu línea de comandos. Los registros deberían tener un aspecto similar al de la Figura 4-32.
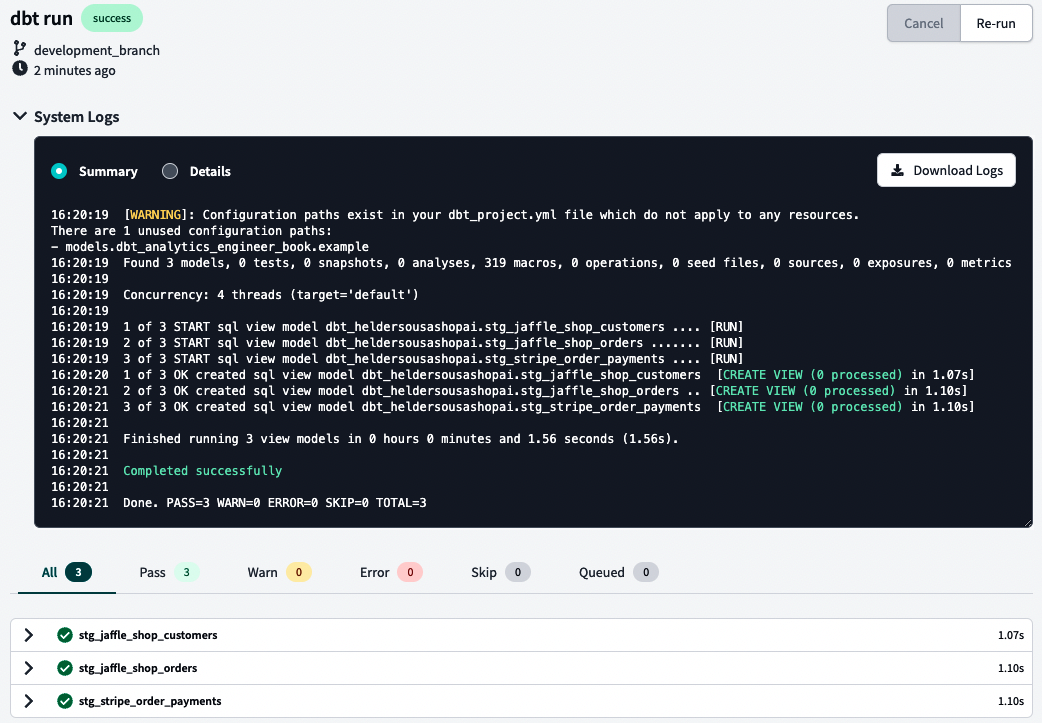
Figura 4-32. Registros del sistema dbt
Consejo
Tus registros también deberían darte una buena idea del problema si algo va mal. En la Figura 4-32, presentamos un resumen de los registros, pero también puedes consultar los registros detallados para obtener más verbosidad.
Esperando que hayas recibido el mensaje "Completado con éxito", echemos ahora un vistazo a BigQuery, donde deberías ver materializados los tres modelos, como muestra la Figura 4-33.
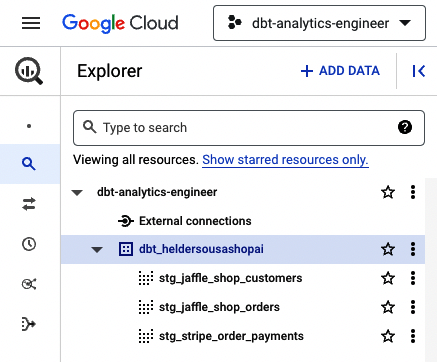
Figura 4-33. Modelos dbt BigQuery
Por defecto, dbt materializa tus modelos dentro de tu plataforma de datos como vistas. Aún así, puedes configurarlo fácilmente en el bloque de configuración situado en la parte superior del archivo del modelo(Ejemplo 4-12).
Ejemplo 4-12. Configuración de la materialización dentro del archivo del modelo
{{config(materialized='table')}}SELECTidascustomer_id,first_name,last_nameFROM`dbt-tutorial.jaffle_shop.customers`
Ahora que hemos creado nuestros primeros modelos, pasemos a los siguientes pasos. Reordena el código utilizando los archivos YAML, y sigue las buenas prácticas recomendadas en "Archivos YAML". Tomemos el bloque de código de allí y configuremos nuestras materializaciones dentro de nuestros archivos YAML(Ejemplo 4-12). El primer archivo que cambiaremos es dbt_project.yml. Éste debería ser el archivo YAML principal para las configuraciones por defecto. Como tal, cambiemos la configuración del modelo en su interior con el código que se presenta en el Ejemplo 4-13 y, a continuación, ejecutemos dbt run de nuevo.
Ejemplo 4-13. Materializar modelos como vistas y como tablas
models:dbt_analytics_engineer_book:staging:jaffle_shop:+materialized:viewstripe:+materialized:table
Nota
El prefijo + es una mejora de la sintaxis de dbt, introducida con dbt v0.17.0, diseñada para clarificar las rutas de los recursos y las configuraciones dentro de los archivos dbt_project.yml.
Como en el Ejemplo 4-13 se obligó a materializar todos los modelos de Stripe en una tabla, BigQuery debería tener el aspecto de la Figura 4-34.
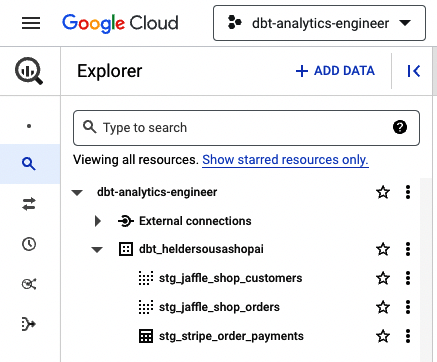
Figura 4-34. Modelos dbt BigQuery con tabla materializada
El Ejemplo 4-13 muestra cómo configurar, por carpeta, las materializaciones específicas deseadas dentro de dbt_project.yml. Tus modelos de montaje se mantendrán por defecto como vistas, por lo que anular esta configuración puede hacerse a nivel de carpeta del modelo, aprovechando la prioridad de alcance en cascada en la construcción del proyecto. En primer lugar, cambiemos nuestro dbt_project.yml para que todos los modelos de montaje se materialicen como vistas, como muestra el Ejemplo 4-14.
Ejemplo 4-14. Puesta en escena de modelos a materializar como vistas
models:dbt_analytics_engineer_book:staging:+materialized:view
Ahora vamos a crear el archivo YAML independiente para stg_jaffle_shop_customers, indicando que debe materializarse como una tabla. Para ello, crea el archivo YAML correspondiente, con el nombre _jaffle_shop_models.yml, dentro del directorio staging/jaffle_shop y copia el código del Ejemplo 4-15.
Ejemplo 4-15. Definir que el modelo se materializará como una tabla
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:table
Después de volver a ejecutar dbt, echa un vistazo a BigQuery. Debería ser similar a la Figura 4-35.
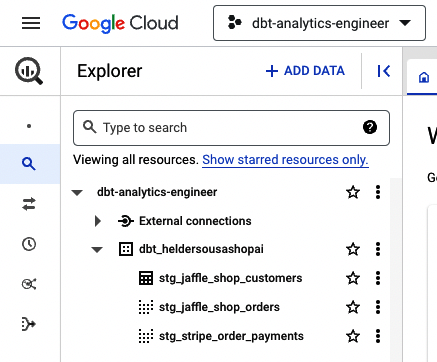
Figura 4-35. Modelo de clientes dbt BigQuery materializado en una tabla
Éste es un ejemplo sencillo de utilizar los archivos YAML, jugar con materializaciones de tablas y ver lo que significa en la práctica la prioridad de ámbito en cascada. Aún queda mucho por hacer y ver, y parte de lo que estamos discutiendo tendrá aún más aplicabilidad a medida que avancemos. Por ahora, sólo te pedimos que cambies tu modelo dentro de _jaffle_shop_models.yml para que se materialice como una vista. Esta será tuconfiguración por defecto.
Es de esperar que, llegados a este punto, hayas desarrollado tus primeros modelos y comprendas a grandes rasgos la finalidad general de los archivos YAML y la prioridad del ámbito en cascada. Los siguientes pasos consistirán en crear nuestros modelos intermedio y mart mientras aprendemos sobre las funciones de ref(). Este será nuestro primer uso de Jinja, que trataremos con más detalle en "SQL dinámico con Jinja".
Lo primero es lo primero: nuestro caso de uso. Con nuestros modelos dentro de nuestra área de preparación, necesitamos saber qué queremos hacer con ellos. Como mencionamos al principio de esta sección, necesitas definir los requisitos de los datos que dan soporte a los procesos empresariales de tu organización. Como usuario empresarial, podemos obtener múltiples flujos de nuestros datos. Uno de ellos, que será nuestro caso de uso, es analizar nuestros pedidos por cliente, presentando el importe total pagado por pedido realizado con éxito y el importe total por tipo de pedido realizado con éxito (al contado y a crédito).
Dado que aquí tenemos algunas transformaciones que requieren un cambio de granularidad desde el nivel de tipo de pago hasta el grano de pedido, se justifica aislar esta compleja operación antes de llegar a la capa de marts. Aquí es donde aterriza la capa intermedia. En tu carpeta de modelos, crea una nueva carpeta llamada intermedia. Dentro, crea un nuevo archivo SQL llamado int_payment_type_amount_per_order.sql y copia el código del Ejemplo 4-16.
Ejemplo 4-16. int_tipo_pago_importe_por_pedido.sql
withorder_paymentsas(select*from{{ref('stg_stripe_order_payments')}})selectorder_id,sum(casewhenpayment_type='cash'andstatus='success'thenamountelse0end)ascash_amount,sum(casewhenpayment_type='credit'andstatus='success'thenamountelse0end)ascredit_amount,sum(casewhenstatus='success'thenamountend)astotal_amountfromorder_paymentsgroupby1
Como puedes ver al crear la CTE order_payments, recogemos los datos de stg_stripe_order_payments utilizando la función ref(). Esta función hace referencia a las tablas y vistas ascendentes que estaban construyendo tu plataforma de datos. Utilizaremos esta función como estándar mientras implementamos nuestro código analítico debido a sus ventajas, como por ejemplo
-
Te permite construir dependencias entre modelos de forma flexible y que puedan compartirse en una base de código común, ya que compila el nombre del objeto de base de datos durante la
dbt run, recogiéndolo de la configuración del entorno cuando creas el proyecto. Esto significa que, en tu entorno, el código se compilará teniendo en cuenta tus configuraciones de entorno, disponibles en tu entorno de desarrollo particular, pero diferentes de las de tu compañero de equipo, que utiliza un entorno de desarrollo diferente pero comparte la misma base de código. -
Puedes construir gráficos de linaje en los que puede visualizar el flujo de datos y las dependencias de un modelo concreto. Hablaremos de ello más adelante en este capítulo, y también se trata en "Documentación".
Por último, aun reconociendo que el código anterior puede parecer un antipatrón, por la sensación de repetitividad de las condiciones de CASE WHEN, es esencial aclarar que el conjunto de datos incluye todos los pedidos, independientemente de su estado de pago. Sin embargo, para este ejemplo, elegimos realizar el análisis financiero sólo sobre los pagos asociados a los pedidos que han alcanzado el estado "éxito".
Con la tabla intermedia construida, pasemos a la capa final. Teniendo en cuenta el caso de uso descrito, necesitamos analizar los pedidos desde la perspectiva del cliente. Esto significa que debemos crear una dimensión cliente que conecte con nuestra tabla de hechos. Dado que el caso de uso actual puede satisfacer múltiples departamentos, no crearemos una carpeta específica de departamento, sino una denominada núcleo. Así que, para empezar, vamos a crear, en nuestra carpeta models, el directorio marts/core. A continuación, copia el Ejemplo 4-17 en un nuevo archivo llamado dim_clientes.sql y el Ejemplo 4-18 en un nuevo archivo llamado fct_pedidos.sql.
Ejemplo 4-17. dim_clientes.sql
withcustomersas(select*from{{ref('stg_jaffle_shop_customers')}})selectcustomers.customer_id,customers.first_name,customers.last_namefromcustomers
Ejemplo 4-18. fct_pedidos.sql
withordersas(select*from{{ref('stg_jaffle_shop_orders')}}),payment_type_ordersas(select*from{{ref('int_payment_type_amount_per_order')}})selectord.order_id,ord.customer_id,ord.order_date,pto.cash_amount,pto.credit_amount,pto.total_amount,casewhenstatus='completed'then1else0endasis_order_completedfromordersasordleftjoinpayment_type_ordersasptoONord.order_id=pto.order_id
Con todos los archivos creados, vamos a establecer nuestras configuraciones por defecto dentro de dbt_project.yml, como se muestra en el Ejemplo 4-19, y luego ejecutar dbt run, o potencialmente dbt run --full-refresh en BigQuery.
Ejemplo 4-19. Configuración del modelo, por capa, dentro de dbt_project.yml
models:dbt_analytics_engineer_book:staging:+materialized:viewintermediate:+materialized:viewmarts:+materialized:table
Consejo
Si recibes un mensaje de error similar a "Compilation Error in rpc request...depends on a node named int_payment_type_amount_per_order which was not found", significa que tienes un modelo, dependiente del que intentas previsualizar, que aún no está dentro de tu plataforma de datos -en nuestro caso int_payment_type_amount_per_order. Para solucionarlo, ve a ese modelo concreto y ejecuta el comando dbt run --select MODEL_NAME sustituyendo MODEL_NAME por el nombre del modelo correspondiente.
Si todo se ha ejecutado correctamente, tu plataforma de datos debería estar totalmente actualizada con todos los modelos dbt. Fíjate en BigQuery, que debería ser similar a la Figura 4-36.
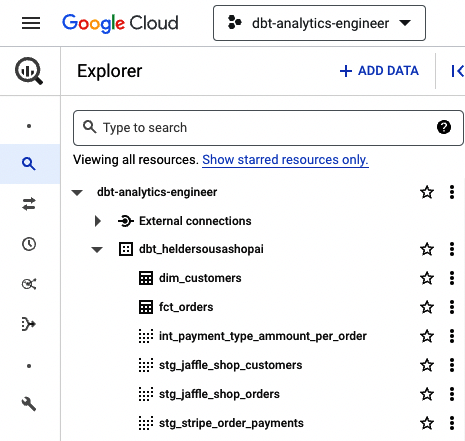
Figura 4-36. dbt BigQuery con todos los modelos
Por último, abre fct_orders.sql y observa la opción Linaje dentro de la ventana de información(Figura 4-37). Ésta es una de las grandes funciones que cubriremos en "Documentación", que nos da una buena idea del flujo de datos que alimenta un modelo concreto y de sus dependencias ascendentes y descendentes.

Figura 4-37. Línea de datos dbt fct_orders
Fuentes
En dbt, las fuentes son los datos en bruto disponibles en tu plataforma de datos, capturados mediante una herramienta genérica de extracción y carga (EL). Es esencial distinguir las fuentes dbt de las fuentes de datos tradicionales. Una fuente de datos tradicional puede ser interna o externa. Las fuentes de datos internas proporcionan los datos transaccionales que soportan las operaciones empresariales diarias dentro de tu organización. Los datos de clientes, ventas y productos son ejemplos del contenido potencial de una fuente de datos interna. Por otro lado, las fuentes de datos externas proporcionan datos que se originan fuera de tu organización, como los datos recopilados de tus socios comerciales, Internet y los estudios de mercado, entre otros. A menudo se trata de datos relacionados con la competencia, la economía, la demografía de los clientes, etc.
Las fuentes dbt se basan en datos internos y externos a demanda de la empresa, pero difieren en su definición. Como se ha mencionado, las fuentes dbt son los datos brutos dentro de tu plataforma de datos. Estos datos brutos suelen ser introducidos por los equipos de ingeniería de datos, mediante una herramienta EL, en tu plataforma de datos y serán la base que permita el funcionamiento de tu plataforma analítica.
En nuestros modelos, desde "Modelos", nos hemos referido a nuestras fuentes utilizando cadenas codificadas como dbt-tutorial.stripe.payment o dbt-tutorial.jaffle_shop.customers. Aunque esto funcione, ten en cuenta que si tus datos brutos cambian, como su ubicación o el nombre de la tabla para seguir unas convenciones de nomenclatura específicas, realizar los cambios en varios archivos puede ser difícil y llevar mucho tiempo. Aquí es donde entran en juego las fuentes dbt. Te permiten documentar esas tablas fuente dentro de un archivo YAML, donde puedes hacer referencia a tu base de datos fuente, al esquema y a las tablas.
Pongamos esto en práctica. Siguiendo las buenas prácticas recomendadas en "Archivos YAML", creemos ahora un nuevo archivo YAML en el directorio models/staging/jaffle_shop, llamado _jaffle_shop_sources.yml, y copiemos el código del Ejemplo 4-20. A continuación, crea otro archivo YAML, ahora en el directorio models/staging/stripe, llamado _stripe_sources.yml, copiando el código del Ejemplo 4-21.
Ejemplo 4-20. Archivo de parametrización _jaffle_shop_sources.yml-sources para todas las tablas del esquema Jaffle Shop
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:orders
Ejemplo 4-21. Archivo de parametrización _stripe_sources.yml-sources para todas las tablas del esquema stripe
version:2sources:-name:stripedatabase:dbt-tutorialschema:stripetables:-name:payment
Con nuestros archivos YAML configurados, tenemos que hacer un último cambio dentro de nuestros modelos. En lugar de tener nuestras fuentes codificadas, utilizaremos una nueva función llamada source(). Funciona como la función ref() que introdujimos en "Referenciar modelos de datos", pero en lugar de {{ ref("stg_stripe_order_payments") }}, para configurar una fuente ahora pasaremos algo como {{ source("stripe", "payment") }}, que, en este caso concreto, hará referencia al archivo YAML que hemos creado en el Ejemplo 4-21.
Ahora vamos a ensuciarnos las manos. Toma todo el código del modelo de puesta en escena SQL que creaste antes, y sustitúyelo por el código respectivo del Ejemplo 4-22.
Ejemplo 4-22. Modelos de escenificación de pagos, pedidos y clientes con la función source()
-- REPLACE IT IN stg_stripe_order_payments.sqlselectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom{{source('stripe','payment')}}-- REPLACE IT IN stg_jaffle_shop_customers.sql fileselectidascustomer_id,first_name,last_namefrom{{source('jaffle_shop','customers')}}-- REPLACE IT IN stg_jaffle_shop_orders.sqlselectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom{{source('jaffle_shop','orders')}}
Después de cambiar tus modelos con nuestra función source(), puedes comprobar cómo se ejecuta tu código en tu plataforma de datos ejecutando dbt compile o haciendo clic en el botón Compilar de tu IDE. En el backend, dbt buscará el archivo YAML referenciado y sustituirá la función source() por la referencia directa a la tabla, como se muestra en la Figura 4-38.
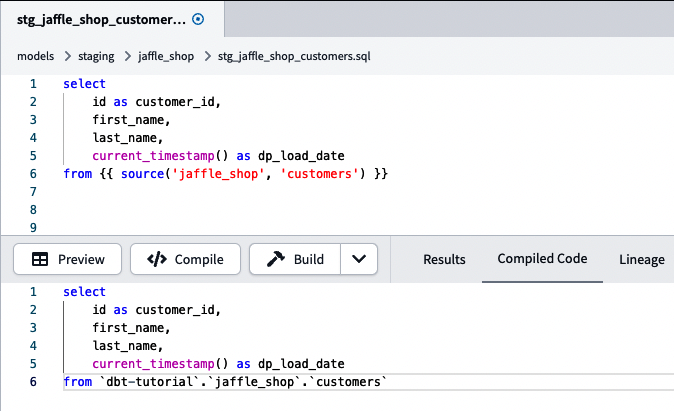
Figura 4-38. Modelo de montaje de clientes dbt con la función source() y el código respectivo compilados. El código compilado es el que se ejecutará dentro de tu plataforma de datos.
Otra ventaja de utilizar la función source() es que ahora puedes ver las fuentes en el gráfico de linaje. Echa un vistazo a , por ejemplo, al linaje fct_orders.sql. El mismo linaje mostrado en la Figura 4-37 debería parecerse ahora a la Figura 4-39.

Figura 4-39. dbt fct_orders linaje de datos con fuentes
Frescura de la fuente
La frescura de tus datos es un aspecto esencial de la calidad de los datos . Si los datos no están actualizados, están obsoletos, lo que podría causar problemas importantes en el proceso de toma de decisiones de tu empresa, ya que podría dar lugar a percepciones inexactas.
dbt te permite mitigar esta situación con la prueba de frescura del origen. Para ello, necesitamos disponer de un campo de auditoría que indique la marca de tiempo cargada de un artefacto de datos específico en tu plataforma de datos. Con él, dbt podrá comprobar la antigüedad de los datos y activar una advertencia o un error, en función de las condiciones especificadas.
Para conseguirlo, volvamos a nuestros archivos YAML fuente. Para este ejemplo concreto, utilizaremos los datos de pedidos de nuestra plataforma de datos, así que, por inferencia, sustituiremos el código de _jaffle_shop_sources.yml por el código del Ejemplo 4-23.
Ejemplo 4-23. Archivo de parametrización _jaffle_shop_sources.yml-sources para todas las tablas del esquema Jaffle Shop, con prueba de frescura de las fuentes
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:12,period:hour}error_after:{count:24,period:hour}
Como puedes ver, hemos utilizado el campo _etl_loaded_at en nuestra plataforma de datos. No tuvimos que introducirlo en nuestro proceso de transformación, ya que no tenía ningún valor añadido para los modelos ascendentes. Esto no es un problema porque estamos probando nuestros datos ascendentes, que en nuestro caso son nuestros datos brutos. En el archivo YAML, hemos creado dos propiedades adicionales: loaded_at_field freshness , que representa el campo que se va a monitorizar en la prueba de frescura de la fuente, y , con las reglas reales para monitorizar la frescura de la fuente. Dentro de la propiedad freshness, la hemos configurado para que emita una advertencia si los datos han caducado hace 12 horas con la propiedad warn_after y para que emita un error real si los datos no se han actualizado en las últimas 24 horas con la propiedad error_after.
Por último, veamos qué ocurre si ejecutamos el comando dbt source freshness. En nuestro caso, recibimos una advertencia, como puedes ver en la Figura 4-40.
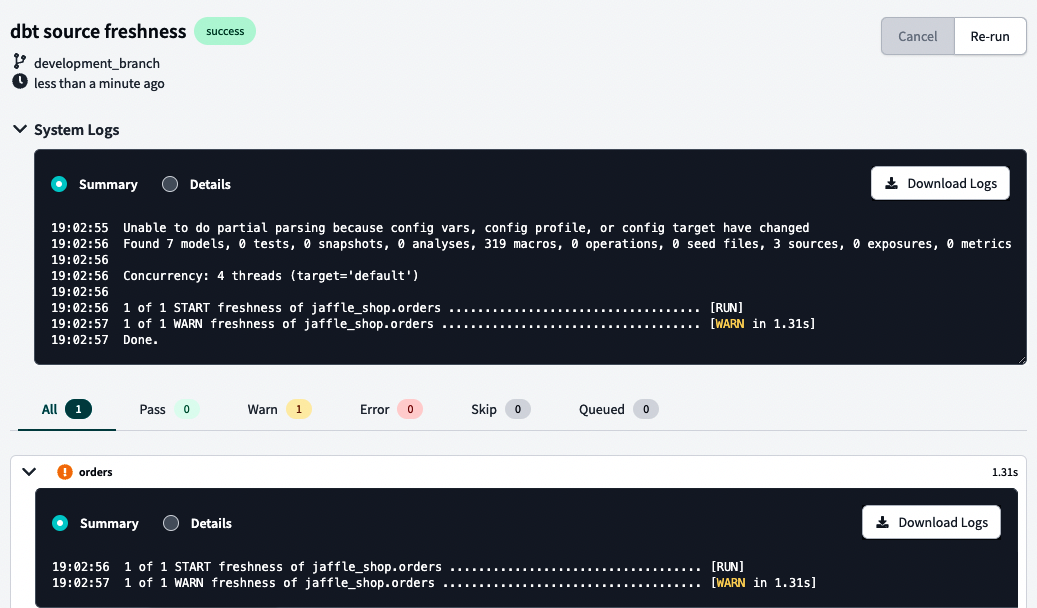
Figura 4-40. dbt ordena datos brutos y registros de pruebas de frescura de la fuente
Si compruebas los detalles del registro, podrás ver la consulta ejecutada en tu plataforma de datos y solucionar el problema. Esta advertencia en concreto era de esperar. El _etl_loaded_at se construyó para tardar 16 horas a partir de la hora actual, por lo que cualquier cosa inferior a eso generará una advertencia. Si quieres seguir jugando, cambia tu warn_after a algo superior, como 17 horas. Todas tus pruebas deberían pasar.
Esperamos que ahora esté claro el concepto de frescura del código fuente. Volveremos a él más adelante en el libro y te mostraremos cómo automatizar e instantanear las pruebas de frescura del origen. Mientras tanto, es esencial comprender su propósito en el panorama general de pruebas, cómo configurarlo y lo importante que puede ser esta prueba para mitigar los problemas de calidad de los datos.
Pruebas
Como ingeniero analítico, debes asegurarte en de que los datos son precisos y fiables para generar confianza en los análisis que ofreces y proporcionar perspectivas objetivas a tu organización. Todo el mundo está de acuerdo con esto, pero aunque sigas todas las buenas prácticas de ingeniería de vanguardia, siempre habrá excepciones, y más cuando tienes que lidiar con la volatilidad que supone trabajar con datos, sus variaciones, tipo, estructura, etc.
Hay muchas formas de capturar esas excepciones. Sin embargo, cuando trabajas con cantidades importantes de datos, necesitas pensar en un enfoque escalable para analizar grandes conjuntos de datos e identificar rápidamente esas excepciones. Aquí es donde entra dbt.
dbt te permite escalar rápida y fácilmente las pruebas a lo largo de tu flujo de trabajo de datos, de modo que puedas identificar cuándo se rompen las cosas antes que nadie. En unentorno de desarrollo, puedes utilizar pruebas para asegurarte de que tu código analítico produce el resultado deseado. En un entorno de implementación/producción, puedes automatizar las pruebas y configurar una alerta que te indique cuándo falla una prueba concreta, de modo que puedas reaccionar rápidamente y solucionarla antes de que genere una consecuencia más extrema.
Como profesional de los datos, es importante comprender que las pruebas en dbt pueden resumirse como afirmaciones sobre tus datos. Cuando ejecutas pruebas sobre tus modelos de datos, afirmas que esos modelos de datos producen la salida esperada, lo cual es un paso crucial para garantizar la calidad y fiabilidad de los datos. Estas pruebas son una forma de verificación similar a confirmar que tus datos siguen patrones específicos y cumplen criterios predefinidos.
Sin embargo, es esencial tener en cuenta que las pruebas dbt son sólo un tipo de prueba dentro del panorama más amplio de las pruebas de datos. En las pruebas de software, a menudo se diferencia entre verificación y validación. Las pruebas dbt se centran principalmente en la verificación, confirmando que los datos se ajustan a los patrones y estructuras establecidos. No están diseñadas para comprobar los detalles más sutiles de la lógica dentro de tus transformaciones de datos, comparable a lo que hacen las pruebas unitarias en el desarrollo de software.
Además, las pruebas dbt pueden ayudar en cierta medida a la integración de los componentes de datos, sobre todo cuando se ejecutan varios componentes juntos. Sin embargo, es crucial reconocer que las pruebas dbt tienen sus limitaciones y pueden no cubrir todos los casos de uso de las pruebas. Para realizar pruebas exhaustivas en proyectos de datos, puede que necesites emplear otros métodos y herramientas de prueba adaptados a necesidades específicas de validación y verificación.
Teniendo esto en cuenta, centrémonos en qué pruebas pueden emplearse con dbt. Hay dos clasificaciones principales de pruebas en dbt: singulares y genéricas. Conozcamos un poco mejor ambos tipos, su finalidad y cómo podemos aprovecharlos.
Pruebas genéricas
Las pruebas más sencillas pero altamente escalables en dbt son las pruebas genéricas. Con estas pruebas, normalmente no necesitas escribir ninguna lógica nueva, aunque las pruebas genéricas personalizadas también son una opción. No obstante, lo normal es que escribas un par de líneas de código YAML y luego pruebes un modelo o columna concretos, según la prueba. dbt viene con cuatro pruebas genéricas incorporadas:
uniqueprueba-
Comprueba que cada valor de una columna específica es único
not_nullprueba-
Comprueba que todos los valores de una columna concreta no son nulos
accepted_valuesprueba-
Asegura que cada valor de una columna específica existe en una lista predefinida dada
relationshipsprueba-
Garantiza que cada valor de una columna específica existe en una columna de otro modelo, y así garantizamos la integridad referencial
Ahora que tenemos algo de contexto sobre las pruebas genéricas, vamos a probarlas. Podemos elegir el modelo que queramos, pero para simplificar, vamos a elegir uno al que podamos aplicar todas las pruebas. Para ello, hemos elegido el modelo stg_jaffle_shop_orders.sql. Aquí podremos probar unique y not_null en campos como customer_id y order_id. Podemos utilizar accepted_values para comprobar si todos los pedidos status están en una lista predefinida. Por último, utilizaremos la prueba relationships para comprobar si todos los valores de customer_id están en el modelo stg_jaffle_shop_customers.sql. Empecemos sustituyendo nuestro _jaffle_shop_models.yml por el código del Ejemplo 4-24.
Ejemplo 4-24. Parametrizaciones de _jaffle_shop_models.yml con pruebas genéricas
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:viewcolumns:-name:customer_idtests:-unique-not_null-name:stg_jaffle_shop_ordersconfig:materialized:viewcolumns:-name:order_idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-name:customer_idtests:-relationships:to:ref('stg_jaffle_shop_customers')field:customer_id
Ahora, en tu línea de comandos, escribe dbt test y echa un vistazo a los registros. Si la prueba ha fallado en accepted_values, lo has hecho todo bien. Se suponía que tenía que fallar. Vamos a depurar para entender la posible causa raíz del fallo. Abre los registros y expande la prueba que falló. Luego haz clic en Detalles. Verás la consulta ejecutada para comprobar los datos, como muestra la Figura 4-41.
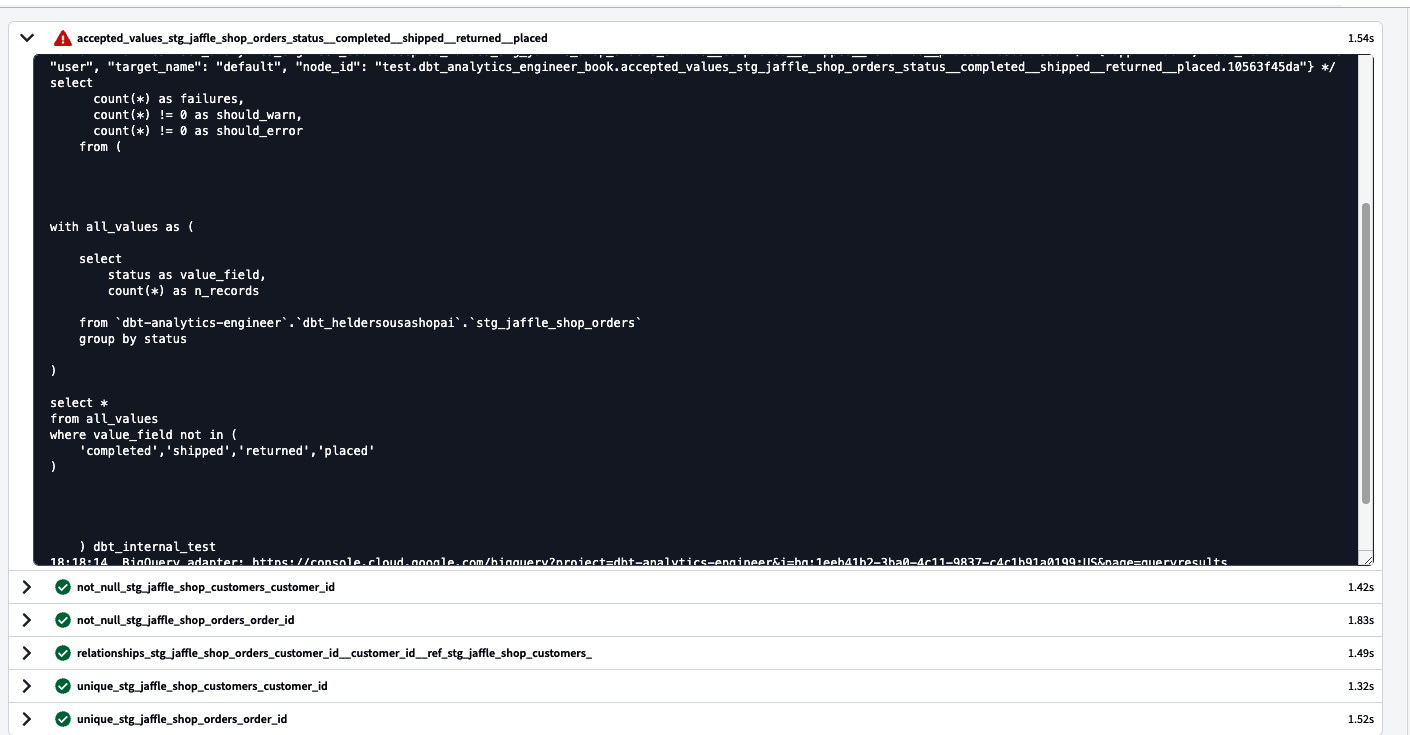
Figura 4-41. Prueba genérica, registros dbt con accepted_values prueba fallida
Copiemos esta consulta en tu editor de texto -conserva sólo la consulta interior- y ejecutémosla. Deberías obtener un resultado similar al de la Figura 4-42.
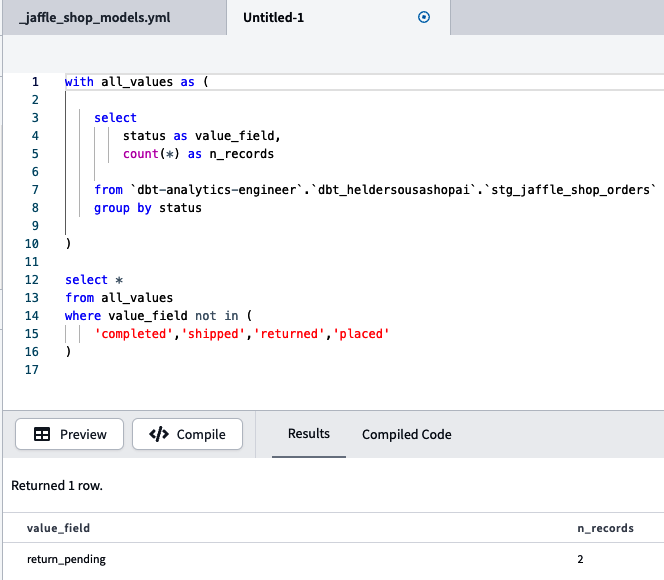
Figura 4-42. Prueba genérica de depuración
Y voilá. Hemos encontrado el problema. Falta el estado adicional return_pending en nuestra lista de pruebas. Añadámoslo y volvamos a ejecutar nuestro comando dbt test comando. Ahora todas las pruebas deberían pasar, como se muestra en la Figura 4-43.
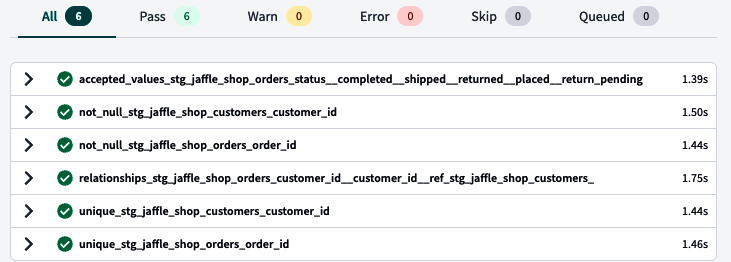
Figura 4-43. Prueba genérica con todas las pruebas ejecutadas correctamente
Nota
Además de las pruebas genéricas dentro de dbt Core, hay muchas más en el ecosistema dbt. Estas pruebas se encuentran en los paquetes dbt porque son una extensión de las pruebas genéricas creadas dentro de dbt. "Paquetes dbt" detallará el concepto de paquetes y cómo instalarlos, pero para ampliar las capacidades de prueba, paquetes como dbt_utils del equipo dbt, o dbt_expectations de la biblioteca Python Great Expectations, son claros ejemplos del excelente uso de los paquetes y un elemento imprescindible en cualquier proyecto dbt. Por último, las pruebas genéricas personalizadas son otra función de dbt que te permite definir tus propias reglas y comprobaciones de validación de datos, adaptadas a los requisitos específicos de tu proyecto.
Pruebas singulares
A diferencia de las pruebas genéricas, las pruebas singulares son definidas en archivos .sql bajo el directorio de pruebas. Normalmente, estas pruebas son útiles cuando quieres probar un atributo específico dentro de un modelo concreto, pero las pruebas tradicionales creadas dentro de dbt no se ajustan a tus necesidades.
Analizando nuestro modelo de datos, una buena prueba es comprobar que ningún pedido tenga un importe total negativo. Podríamos realizar esta prueba en una de las tres capas: estadiaje, intermedia o marts. Hemos elegido la capa intermedia porque hemos realizado algunas transformaciones que podrían influir en los datos. Para empezar, crea un archivo llamado assert_total_payment_amount_is_positive.sql en el directorio de pruebas y copia el código del Ejemplo 4-25.
Ejemplo 4-25. assert_total_payment_amount_is_positive.sql prueba singular para comprobar si el atributo total_amount dentro de int_payment_type_amount_per_order sólo tiene valores no negativos
selectorder_id,sum(total_amount)astotal_amountfrom{{ref('int_payment_type_amount_per_order')}}groupby1havingtotal_amount<0
Ahora puedes ejecutar uno de los siguientes comandos para ejecutar tu prueba, que debería pasar:
dbt test-
Ejecuta todas tus pruebas
dbt test --select test_type:singular-
Ejecuta sólo pruebas singulares
dbt test --select int_payment_type_amount_per_order-
Ejecuta todas las pruebas del modelo
int_payment_type_amount_per_order dbt test --select assert_total_payment_amount_is_positive-
Ejecuta sólo la prueba específica que hemos creado
Estos comandos ofrecen la posibilidad de ejecutar pruebas de forma selectiva según tus necesidades. Tanto si necesitas ejecutar todas las pruebas, pruebas de un tipo específico, pruebas para un modelo concreto, o incluso una sola prueba específica, dbt te permite aprovechar varias opciones de sintaxis de selección dentro de sus comandos. Esta variedad de opciones garantiza que puedas seleccionar con precisión las pruebas, junto con otros recursos de dbt, que desees ejecutar. En "Comandos dbt y sintaxis de selección", ofreceremos una visión general de los comandos dbt disponibles e investigaremos en cómo utilizar eficazmente la sintaxis de selección para especificar recursos.
Fuentes de pruebas
Para probar tus modelos en tu proyecto dbt, también puedes extender esas pruebas a tus fuentes. Ya lo hiciste con la prueba de frescura de las fuentes en " Frescura de las fuentes". Aún así, también puedes potenciar las pruebas genéricas y singulares para ese fin. Utilizar las capacidades de prueba en tus fuentes nos dará la confianza de que los datos brutos están construidos para ajustarse a nuestras expectativas.
Del mismo modo que configuras pruebas en tus modelos, también puedes hacerlo para tus fuentes. Ya sea en archivos YAML para pruebas genéricas, o en archivos .sql para pruebas singulares, la norma sigue siendo la misma. Veamos un ejemplo para cada tipo de prueba.
A partir de las pruebas genéricas, tendrás que editar el archivo YAML específico de las fuentes. Vamos a mantener las mismas pruebas de unique, not_null y accepted_values que tenemos para las tablas de preparación de clientes y pedidos, pero ahora probarás sus fuentes. Para ello, sustituye el código de _jaffle_shop_sources.yml por el código del Ejemplo 4-26.
Ejemplo 4-26. _jaffle_shop_sources.yml-parametrización con pruebas genéricas
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customerscolumns:-name:idtests:-unique-not_null-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:17,period:hour}error_after:{count:24,period:hour}columns:-name:idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-return_pending
Una vez que tengas tu nuevo código en el archivo YAML, puedes ejecutar dbt test o, para ser más exactos, ejecutar el comando que probará sólo el código fuente para el que hemos creado estas pruebas, dbt test --select source:jaffle_shop. Todas tus pruebas deberían pasar.
Por último, también puedes realizar pruebas singulares como hiciste antes. Reproduzcamos la prueba singular que realizamos anteriormente en el Ejemplo 4-25. Crea un nuevo archivo llamado assert_source_total_payment_amount_is_positive.sql en tu directorio de pruebas y copia el código del Ejemplo 4-27. Esta prueba comprueba si la suma del atributo amount, por pedido, dentro de la tabla fuente de pago sólo tiene valores no negativos.
Ejemplo 4-27. assert_source_total_payment_amount_is_positive.sql prueba singular
selectorderidasorder_id,sum(amount)astotal_amountfrom{{source('stripe','payment')}}groupby1havingtotal_amount<0
Ejecuta dbt test o dbt test --select source:stripe, ya que en este caso miramos en la fuente de Stripe. Todo debería pasar también.
Análisis
La carpeta de análisis puede almacenar tus consultas ad hoc, consultas de auditoría, consultas de entrenamiento o consultas de refactorización, utilizadas, por ejemplo, para comprobar cómo quedará tu código antes de afectar a tus modelos.
Los análisis son archivos SQL con plantillas que no puedes ejecutar durante dbt run, pero como puedes utilizar Jinja en tus análisis, puedes seguir utilizando dbt compile para ver cómo quedará tu código, a la vez que conservas tu código bajo el control de versiones. Teniendo en cuenta su finalidad, veamos un caso de uso en el que podemos aprovechar la carpeta de análisis.
Imagina que no quieres construir un modelo completamente nuevo, pero quieres conservar una parte de la información para futuras necesidades aprovechando el versionado del código. Con los análisis, puedes hacer precisamente eso. Para nuestro caso de uso, analicemos los 10 clientes más valiosos en términos del importe total pagado, considerando sólo los pedidos en estado "completado". Para ello, dentro del directorio de análisis, crea un nuevo archivo llamado clientes_más_valiosos.sql y copia el código del Ejemplo 4-28.
Ejemplo 4-28. Análisis most_valuable_customers.sql, que muestra los 10 clientes más valiosos en función de los pedidos completados
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}})selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_nameorderby3desclimit10
Ahora ejecuta el código y comprueba los resultados. Te dará los 10 clientes más valiosos si todo va bien, como muestra la Figura 4-44.
Figura 4-44. Los 10 clientes más valiosos, según el importe total global pagado con los pedidos completados
Semillas
Las semillas son archivos CSV dentro de tu plataforma dbt con una pequeña cantidad de datos no volátiles que se materializarán como una tabla dentro de tu plataforma de datos. Simplemente escribiendo dbt seed en tu línea de comandos, las semillas se pueden utilizar en tus modelos de forma estándar, como todos los demás modelos, utilizando la función ref().
Podemos encontrar múltiples aplicaciones para las semillas, desde mapear códigos de país (por ejemplo, PT a Portugal o US a Estados Unidos), códigos postales a estados, direcciones de correo electrónico ficticias para excluirlas de nuestros análisis, o incluso otros análisis complejos, como la clasificación por rangos de precios. Lo importante es recordar que las semillas no deben tener datos grandes o que cambien con frecuencia. Si ese es el caso, replantéate tu método de captura de datos, por ejemplo, utilizando un SFTP (protocolo de transferencia de archivos SSH) o una API.
Para entender mejor cómo utilizar las semillas, sigamos el siguiente caso de uso. Teniendo en cuenta lo que hicimos en "Análisis", queremos no sólo ver los 10 clientes más valiosos, en función de los pedidos pagados completados, sino también clasificar a todos los clientes con pedidos como regulares, bronce, plata u oro, teniendo en cuenta los total_amount pagados. Para empezar, vamos a crear nuestra semilla. Para ello, crea un nuevo archivo llamado rango_cliente_por_importe_pagado.csv en tu carpeta seeds y copia los datos del Ejemplo 4-29.
Ejemplo 4-29. semilla_cliente_rango_por_importe_pagado.csv con asignación de rangos
min_range,max_range,classification 0,9.999,Regular 10,29.999,Bronze 30,49.999,Silver 50,9999999,Gold
Después de completar esto, ejecuta dbt seed. Materializará tu archivo CSV en una tabla de tu plataforma de datos. Por último, en el directorio de análisis, creemos un nuevo archivo llamado rango_cliente_basado_en_el_importe_total_pagado.sql y copiemos el código del Ejemplo 4-30.
Ejemplo 4-30. rango_cliente_basado_en_importe_total_pagado.sql te muestra, en función de los pedidos completados y del importe total pagado, el rango de clasificación de clientes
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}}),total_amount_per_customer_on_orders_completeas(selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_name),customer_range_per_paid_amountas(select*from{{ref('seed_customer_range_per_paid_amount')}})selecttac.customer_id,tac.first_name,tac.global_paid_amount,crp.classificationfromtotal_amount_per_customer_on_orders_completeastacleftjoincustomer_range_per_paid_amountascrpontac.global_paid_amount>=crp.min_rangeandtac.global_paid_amount<=crp.max_range
Ejecutemos ahora nuestro código y veamos los resultados. Dará a cada cliente el importe total pagado y su rango correspondiente(Figura 4-45).
Figura 4-45. Rango de clientes, basado en el importe total global pagado con los pedidos completados
Documentación
La documentación es fundamental en el panorama global de la ingeniería de software , y sin embargo parece un tabú. Algunos equipos la hacen, otros no, o está incompleta. Puede volverse demasiado burocrática o compleja, o verse como una sobrecarga en la lista de tareas pendientes del desarrollador, y por tanto evitarse a toda costa. Es posible que oigas una lista gigantesca de razones para justificar que no se cree documentación o que se posponga para un momento menos exigente. Nadie dice que la documentación no sea esencial. Sólo que "no la haremos", "ahora no" o "no tenemos tiempo".
He aquí varias razones que justifican la creación y el uso de la documentación:
-
Facilita los procesos de incorporación, traspaso y contratación . Con la documentación adecuada, cualquier nuevo miembro del equipo tendrá la salvaguarda de que no está siendo "arrojado a los lobos". El nuevo compañero tendrá el proceso de incorporación y la documentación técnica por escrito, lo que reduce su curva de aprendizaje sobre los procesos, conceptos, normas y avances tecnológicos actuales del equipo. Lo mismo se aplica a la rotación de personal y a la transición del intercambio de conocimientos.
-
Potenciará una única fuente de la verdad. Desde definiciones de negocio, procesos y artículos sobre cómo hacerlo, hasta permitir que los usuarios respondan a preguntas de autoservicio, disponer de documentación ahorrará a tu equipo tiempo y energía tratando de llegar a esa información.
-
Compartir conocimientos a través de la documentación mitigará el trabajo duplicado o redundante. Si la documentación ya estaba hecha, podría reutilizarse sin necesidad de empezar de cero.
-
Fomenta un sentido de responsabilidad compartida, garantizando que los conocimientos críticos no se limiten a una sola persona. Esta propiedad compartida es crucial para evitar interrupciones cuando los miembros clave del equipo no están disponibles.
-
Es esencial cuando quieres establecer la calidad, controlar los procesos y cumplir las normas de conformidad. Disponer de documentación permitirá a tu equipo trabajar con cohesión y alineación en toda la empresa.
Una razón que justifica la falta de motivación para crear documentación es que se trata de una corriente paralela al flujo de desarrollo real, como utilizar una herramienta para el desarrollo y otra para la documentación. Con dbt, esto es diferente. Construyes la documentación de tu proyecto mientras desarrollas el código analítico, las pruebas y te conectas a las fuentes, entre otras tareas. Todo está dentro de dbt, no en una interfaz separada.
La forma en que dbt gestiona la documentación te permite crearla mientras construyes tu código. Normalmente, una buena parte de la documentación ya se genera dinámicamente, como los gráficos de linaje que hemos presentado antes, y sólo requiere que configures adecuadamente tus funciones ref() y source(). La otra parte está parcialmente automatizada, necesitando que introduzcas manualmente lo que representa un modelo o columna concretos. Pero, una vez más, todo se hace dentro de dbt, directamente en los archivos YAML o Markdown.
Empecemos con nuestra documentación. El caso de uso de que queremos conseguir es documentar nuestros modelos y las respectivas columnas de fct_orders y dim_customers. Utilizaremos los archivos YAML de los modelos, y para una documentación más rica, utilizaremos bloques doc dentro de los archivos Markdown. Como todavía tenemos que crear un archivo YAML para los modelos del núcleo dentro del directorio marts, vamos a hacerlo con el nombre _core_models.yml.
Copia el Ejemplo 4-31. A continuación, crea un archivo Markdown en la misma carpeta del directorio llamado _code_docs.md, copiando el Ejemplo 4-32.
Ejemplo 4-31. Archivo _core_models.yml-YAML con el parámetro description
version:2models:-name:fct_ordersdescription:Analytical orders data.columns:-name:order_iddescription:Primary key of the orders.-name:customer_iddescription:Foreign key of customers_id at dim_customers.-name:order_datedescription:Date that order was placed by the customer.-name:cash_amountdescription:Total amount paid in cash by the customer with "success" paymentstatus.-name:credit_amountdescription:Total amount paid in credit by the customer with "success"payment status.-name:total_amountdescription:Total amount paid by the customer with "success" payment status.-name:is_order_completeddescription:"{{doc('is_order_completed_docblock')}}"-name:dim_customersdescription:Customer data. It allows you to analyze customers perspective linkedfacts.columns:-name:customer_iddescription:Primary key of the customers.-name:first_namedescription:Customer first name.-name:last_namedescription:Customer last name.
Ejemplo 4-32. Archivo _core_doc.md-markdown con un bloque doc
{% docs is_order_completed_docblock %}Antes de generar la documentación, vamos a intentar comprender lo que hemos hecho. Analizando el archivo YAML _core_models.yml, puedes ver que hemos añadido una nueva propiedad: description. Esta propiedad básica te permite complementar la documentación con tus aportaciones manuales. Estas entradas manuales pueden ser texto, como utilizamos en la mayoría de los casos, pero también pueden hacer referencia a bloques doc dentro de archivos Markdown, como se hace en fct_orders, columna is_order_completed. Primero creamos el bloque doc dentro del archivo Markdown _code_docs.md y lo llamamos is_order_completed_docblock. Este nombre es el que hemos utilizado para referenciar el bloque doc dentro del campo de descripción: "{{ doc('is_order_completed_docblock') }}".
Vamos a generar nuestra documentación escribiendo dbt docs generate en tu línea de comandos. Cuando termine correctamente, podrás navegar por la página de documentación.
Llegar a la página de documentación es sencillo. Después de ejecutar correctamente dbt docs generate, dentro del IDE, en la parte superior izquierda de la pantalla, puedes hacer clic en el icono del libro del sitio de documentación, justo al lado de la información de la rama Git(Figura 4-46).
Figura 4-46. Ver documentación
Una vez que entres en la página de documentación, verás la página de resumen, similar a la Figura 4-47. Por ahora, tienes la información por defecto proporcionada por dbt, pero esta página también es totalmente personalizable.
Figura 4-47. Página de inicio de la documentación
En la página de vista general, puedes ver la estructura de tu proyecto a la izquierda(Figura 4-48), con pruebas, semillas y modelos, entre otros, por los que puedes navegar libremente.
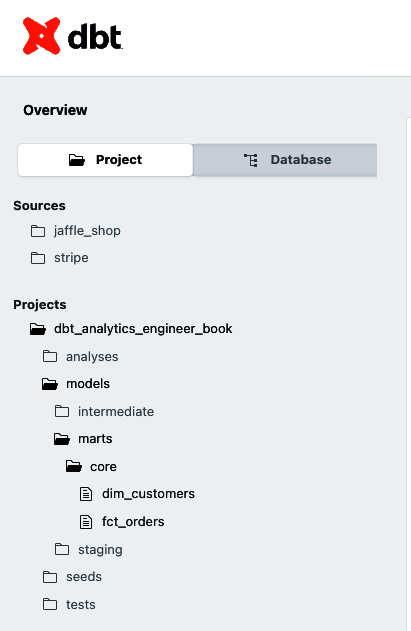
Figura 4-48. Estructura del proyecto dbt dentro de la documentación
Ahora elige uno de nuestros modelos desarrollados y consulta su documentación correspondiente. Hemos seleccionado el modelo fct_orders. Una vez que hagamos clic en su archivo, la pantalla te mostrará varias capas de información sobre el modelo, como se muestra en la Figura 4-49.
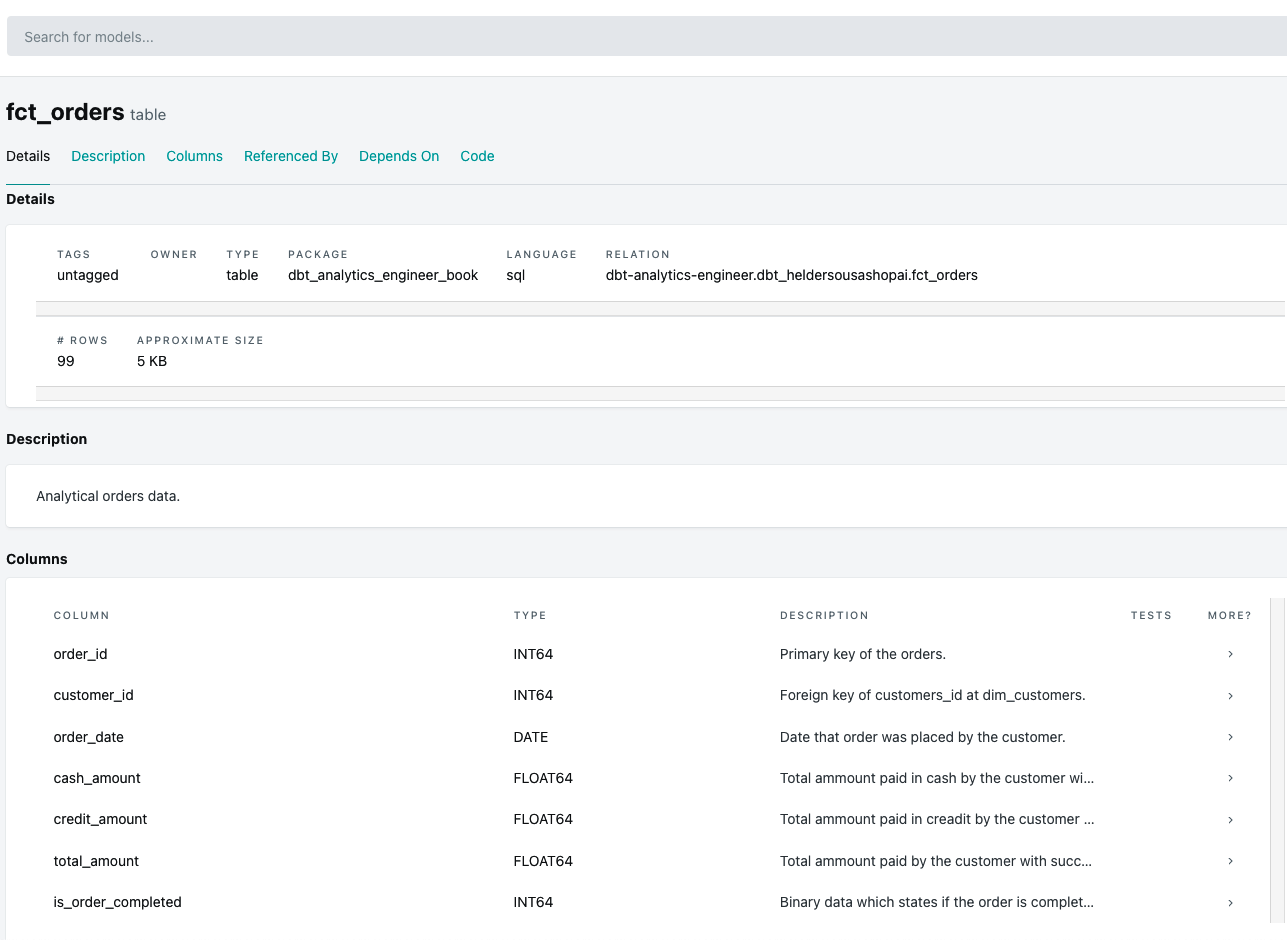
Figura 4-49. Página de documentaciónfct_orders
En la parte superior, la sección Detalles te ofrece información sobre los metadatos de la tabla, como el tipo de tabla (también conocido como materialización). El idioma utilizado, el número de filas y el tamaño aproximado de la tabla son otros detalles disponibles.
Justo después, tenemos la Descripción del modelo. Como recordarás, fue el que configuramos en el archivo _core_models.yml para la tabla fct_orders.
Por último, tenemos la información de Columnas relacionada con fct_orders. Esta documentación está parcialmente automatizada (por ejemplo, el tipo de columna), pero también recibe entradas manuales (como las descripciones de las columnas). Ya dimos esas entradas rellenando las propiedades de descripción y proporcionamos información completa utilizando bloques doc para el atributo is_order_completed. Para ver el bloque doc escrito en la página de documentación, haz clic en el campo is_order_completed, que debería expandirse y presentar la información deseada(Figura 4-50).
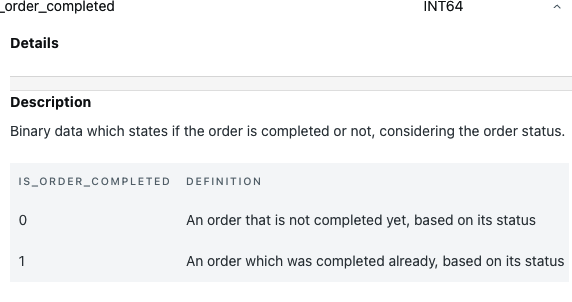
Figura 4-50. Columnais_order_completed que muestra el bloque doc configurado
Tras la información de las Columnas, tenemos las dependencias descendentes y ascendentes del modelo, con las secciones Referenciado por y Depende de, respectivamente. Estas dependencias también se muestran en la Figura 4-51.
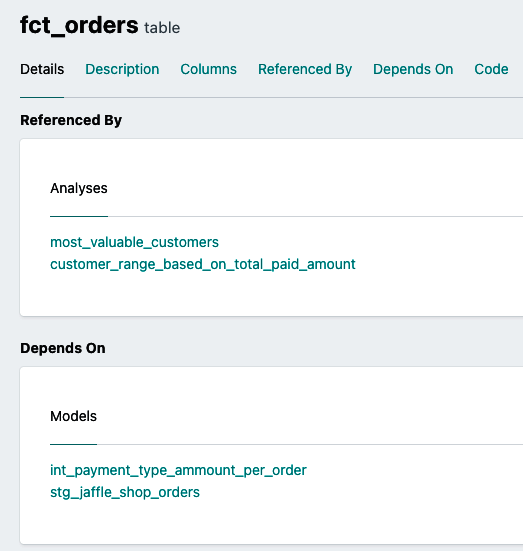
Figura 4-51. fct_orders dependencias en la documentación
En la parte inferior de la página de documentación fct_orders se encuentra el Código que generó el modelo específico. Puedes visualizar el código fuente en formato raw, con Jinja, o el código compilado. La Figura 4-52 muestra su forma bruta.
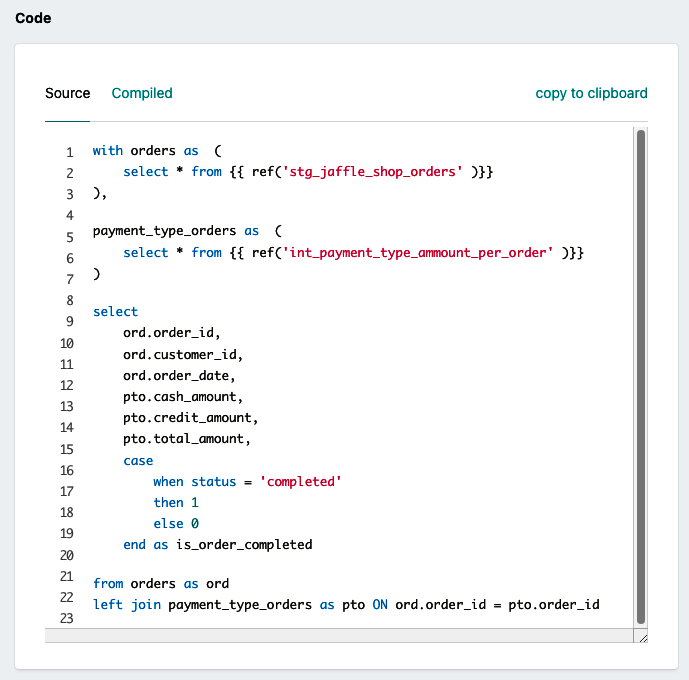
Figura 4-52. fct_orders código fuente
Por último, si miras en la parte inferior derecha de tu página de documentación, verás un botón azul. Al hacer clic en este botón, accederás al gráfico de linaje del modelo respectivo que estés visualizando. Hemos seleccionado el gráfico de linaje fct_orders, donde puedes ver las dependencias ascendentes, como las tablas de origen o las tablas intermedias, así como las dependencias descendentes, como los archivos de análisis que se muestran en la Figura 4-53. El gráfico de linaje es potente, ya que proporciona una visión holística de cómo se mueven los datos desde el momento en que los consumes hasta que los transformas y sirves.
Otro aspecto interesante de la documentación de dbt que merece la pena mencionar es la capacidad de persistir descripciones a nivel de columnas y tablas directamente en la base de datos utilizando la configuración persist_docs. Esta función es valiosa para todos los usuarios de tualmacén de datos, incluidos los que no tengan acceso a dbt Cloud. Garantiza que los metadatos y descripciones esenciales estén fácilmente disponibles para los consumidores de datos, facilitando una mejor comprensión y utilización de tus activos de datos.

Figura 4-53. Gráfico de linajefct_orders
Comandos dbt y sintaxis de selección
Ya hemos presentado varios comandos dbt, como dbt run y dbt test, y cómo interactuamos con la CLI para ejecutarlos. En esta sección, exploraremos los comandos dbt esenciales y la sintaxis de selección que te permiten ejecutar, gestionar y controlar diversos aspectos de tu proyecto dbt. Ya sea ejecutando transformaciones, ejecutando pruebas o generando documentación, estos comandos son tu kit de herramientas para una gestión eficaz del proyecto.
Empecemos por el principio. En esencia, dbt es una herramienta de línea de comandos diseñada para agilizar tus flujos de trabajo de transformación de datos. Proporciona un conjunto de comandos que te permiten interactuar con tu proyecto dbt de forma eficaz. Exploremos cada uno de estos comandos con más detalle.
dbt ejecutar
El comando dbt run es tu herramienta para ejecutar las transformaciones de datos definidas en tus modelos dbt. Funciona con los archivos de configuración de tu proyecto, como dbt_project.yml, para saber qué modelos ejecutar y en qué orden. Este comando identificará los modelos que deben ejecutarse en función de sus dependencias y los ejecutará en el orden adecuado.
dbt docs
Una documentación adecuada es esencial para los proyectos de datos colaborativos. dbt docs automatiza la generación de documentación para tu proyecto dbt, incluyendo descripciones de modelos, descripciones de columnas y relaciones entre modelos. Para generar la documentación, necesitas ejecutar dbt docs generate.
dbt construir
Antes de ejecutar tu proyecto dbt, a menudo es necesario compilarlo . El comando dbt build realiza esta tarea, creando los artefactos necesarios para la ejecución. Este paso es esencial para optimizar el proceso de ejecución y garantizar que todo está en su sitio. Una vez que tu proyecto se compile correctamente, podrás proceder con otros comandos como dbt run con más confianza.
Otros comandos
Aunque los comandos anteriores pueden ser los más utilizados, debes conocer otros comandos de dbt , como éstos:
dbt seed-
Carga datos brutos o de referencia en tu proyecto
dbt clean-
Elimina los artefactos generados por
dbt build dbt snapshot-
Toma una instantánea de tus datos para versionarlos
dbt archive-
Archiva tablas o modelos en cámaras frigoríficas
dbt deps-
Instala las dependencias del proyecto definidas en packages.yml
dbt run-operation-
Ejecuta una operación personalizada definida en tu proyecto
dbt source snapshot-freshness-
Comprueba la frescura de tus datos de origen
dbt ls-
Lista los recursos definidos en un proyecto dbt
dbt retry-
Vuelve a ejecutar el último comando dbt ejecutado desde el punto de fallo
dbt debug-
Ejecuta dbt en modo depuración, proporcionando información de depuración detallada
dbt parse-
Analiza los modelos dbt sin ejecutarlos, lo que resulta útil para comprobar la sintaxis
dbt clone-
Clona los modelos seleccionados del estado especificado
dbt init-
Crea un nuevo proyecto dbt en el directorio actual
Sintaxis de selección
A medida que tus proyectos dbt crezcan, necesitarás para seleccionar modelos, pruebas u otros recursos específicos para su ejecución, comprobación o generación de documentación, en lugar de ejecutarlos todos cada vez. Aquí es donde entra en juego la sintaxis de selección.
La sintaxis de selección te permite especificar con precisión qué recursos incluir o excluir al ejecutar comandos dbt. La sintaxis de selección incluye varios elementos y técnicas, como los siguientes.
Comodín *
El asterisco (*) representa cualquier carácter o secuencia de caracteres. Veamos el Ejemplo 4-33.
Ejemplo 4-33. Sintaxis de selección con el comodín *
dbtrun--selectmodels/marts/core/*
Aquí, estamos utilizando el comodín * junto con la bandera --select para dirigirnos a todos los recursos o modelos dentro del directorio del núcleo. Este comando ejecutará todos los modelos, pruebas u otros recursos que se encuentren en ese directorio.
Etiquetas
Los tags son etiquetas que puedes asignar a los modelos, macros u otros recursos de en tu proyecto dbt, en concreto, dentro de los archivos YAML. Puedes utilizar la sintaxis de selección para seleccionar recursos con etiquetas específicas. Por ejemplo, el Ejemplo 4-34 muestra cómo seleccionar recursos basándose en la etiqueta marketing.
Ejemplo 4-34. Sintaxis de selección con una etiqueta
dbtrun--selecttag:marketing
Nombre del modelo
Puedes seleccionar con precisión un único modelo en utilizando su nombre en la sintaxis de selección, como se muestra en el Ejemplo 4-35.
Ejemplo 4-35. Sintaxis de selección con un modelo
dbtrun--selectfct_orders
Dependencias
Utiliza los símbolos + y - para seleccionar modelos que dependen o de los que dependen otros. Por ejemplo, fct_orders+ selecciona los modelos de que dependen de fct_orders, mientras que +fct_orders selecciona los modelos de los que depende fct_orders (Ejemplo 4-36).
Ejemplo 4-36. Sintaxis de selección con dependencias
# run fct_orders upstream dependencies dbt run --select +fct_orders # run fct_orders downstream dependencies dbt run --select fct_orders+ # run fct_orders both up and downstream dependencies dbt run --select +fct_orders+
Paquetes
Si organizas tu proyecto dbt en paquetes, puedes utilizar la sintaxis de paquete para seleccionar todos los recursos de un paquete concreto, como se muestra en el Ejemplo 4-37.
Ejemplo 4-37. Sintaxis de selección con un paquete
dbtrun--selectmy_package.some_model
Múltiples selecciones
Puedes combinar elementos de la sintaxis de la selección para crear selecciones complejas, como se muestra en el Ejemplo 4-38.
Ejemplo 4-38. Sintaxis de selección con varios elementos
dbtrun--selecttag:marketingfct_orders
En este ejemplo, combinamos elementos como el etiquetado y la selección de modelos. Ejecutará el modelo dbt llamado fct_orders sólo si tiene la etiqueta marketing.
La sintaxis de selección te permite controlar qué recursos dbt se ejecutan en función de varios criterios, como nombres de modelos, etiquetas y dependencias. Puedes utilizar la sintaxis de selección con la bandera --select para adaptar tus operaciones dbt a subconjuntos específicos de tu proyecto.
Además, dbt ofrece otros indicadores y opciones relacionados con la selección, como --selector, --exclude, --defer, etc., que proporcionan un control aún más preciso sobre cómo interactúas con tu proyecto dbt. Estas opciones facilitan la gestión y ejecución de los modelos y recursos de dbt de forma que se ajusten a los requisitos y flujos de trabajo de tu proyecto.
Trabajos e Implementación
Hasta ahora, hemos estado cubriendo cómo desarrollar en utilizando dbt. Hemos aprendido sobre modelos y sobre cómo implementar pruebas y escribir documentación, entre otros componentes relevantes que proporciona dbt. Hemos realizado y probado todo esto utilizando nuestro entorno de desarrollo y ejecutando manualmente nuestros comandos dbt.
No hay que minimizar el uso de un entorno de desarrollo. Te permite seguir construyendo tu proyecto dbt sin afectar al entorno de implementación/producción hasta que estés preparado. Pero ahora hemos llegado a la fase en la que necesitamos producir y automatizar nuestro código. Para ello, necesitamos desplegar nuestro código analítico en una rama de producción, normalmente denominada rama principal, y en un esquema de producción dedicado, como dbt_analytics_engineering.core en BigQuery, o el objetivo de producción equivalente en tu plataforma de datos.
Por último, tenemos que configurar y programar un trabajo para automatizar lo que queremos poner en producción. Configurar un trabajo es una parte esencial del proceso CI/CD. Te permite automatizar la ejecución de tus comandos en una cadencia que se ajuste a tus necesidades empresariales.
Para empezar, vamos a confirmar y sincronizar todo lo que hemos hecho hasta ahora en nuestra rama de desarrollo y luego fusionarlo con la rama principal. Haz clic en el botón "Confirmar y sincronizar"(Figura 4-54). No olvides escribir un mensaje completo.
Figura 4-54. "Botón "Confirmar y sincronizar
Puede que necesites hacer un pull request. Como se explica brevemente en "Configuración de dbt Cloud con BigQuery y GitHub", los pull requests (PR) desempeñan un papel esencial en el desarrollo colaborativo. Sirven como mecanismo fundamental para comunicar a tu equipo los cambios que propones. Sin embargo, es crucial que entiendas que los PR no sólo sirven para notificar tu trabajo a tus compañeros, sino que son un paso fundamental en el proceso de revisión e integración.
Cuando creas un RP, esencialmente estás invitando a tu equipo a que revise tu código, aporte comentarios y decida colectivamente si esos cambios se ajustan a los objetivos y normas de calidad del proyecto.
Volviendo a nuestro código, después de tu PR, fúndelo con tu rama principal en GitHub. Tu pantalla final en GitHub debería ser similar a la de la Figura 4-55.
Figura 4-55. Pantalla de solicitud de extracción tras fusionarse con la rama principal
En esta fase, tu rama principal debería ser igual a tu rama de desarrollo. Ahora es el momento de desplegarla en tu plataforma de datos. Antes de crear un trabajo, tienes que configurar tu entorno de implementación:
-
En el menú Implementación, haz clic en la opción Entornos y, a continuación, en el botón Crear entorno. Aparecerá una pantalla en la que podrás configurar tu entorno de implementación.
-
Mantén la última versión de dbt, y no marques la opción de ejecutar en una rama personalizada, ya que hemos fusionado nuestro código en la rama principal.
-
Nombra el entorno "Implementación".
-
En la sección Credenciales de Implementación, escribe el conjunto de datos que vinculará tu entorno de implementación/producción. Nosotros lo hemos llamado
dbt_analytics_engineer_prod, pero puedes utilizar el nombre que mejor se adapte a tus necesidades.
Si todo va bien, deberías tener establecido un entorno de implementación con configuraciones similares a las de la Figura 4-56.
Figura 4-56. Configuración del entorno de Implementación
Ahora es el momento de configurar tu trabajo. Dentro de la interfaz de usuario de dbt Cloud, haz clic en la opción Trabajos del menú Implementación y, a continuación, haz clic en el botón Crear nuevo trabajo. La creación de un trabajo puede abarcar desde conceptos sencillos a otros más complejos. Vamos a configurar un trabajo que cubra las ideas principales que hemos tratado:
-
Ponle un nombre al trabajo(Figura 4-57).
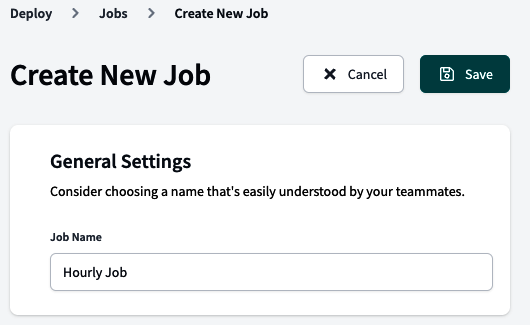
Figura 4-57. Definir el nombre del trabajo
-
En la sección Entorno, señalaremos el entorno de Implementación. Configura la versión dbt para que herede de la versión definida en el entorno de Implementación. A continuación, deja el Nombre del objetivo configurado como predeterminado. Esto es útil si quieres definir condiciones basadas en tu entorno de trabajo (por ejemplo: si estás en el entorno de Implementación, haz esto; si estás en Desarrollo, haz aquello). Por último, cubrimos los Hilos en "profiles.yml". Dejémoslo con la configuración por defecto. No hemos creado ninguna Variable de Entorno, por lo que esta sección se dejará vacía. La Figura 4-58 presenta la configuración general de la sección Entorno.
Figura 4-58. Definir el entorno de trabajo
-
La Figura 4-59 muestra las configuraciones globales de la Configuración de Ejecución. Hemos establecido el Tiempo de espera de ejecución en 0, para que dbt nunca mate el trabajo si se ejecuta durante más de un tiempo determinado. También hemos elegido "no aplazar a otra ejecución". Por último, hemos seleccionado las casillas "Generar docs en ejecución" y "Ejecutar frescura de fuentes". Esta configuración reducirá el número de comandos que tienes que escribir en la sección Comandos. Para este caso de uso, hemos mantenido sólo la opción por defecto
dbt build.
Figura 4-59. Definir la configuración del trabajo
-
El último ajuste de configuración es Disparadores, en el que configuras cómo lanzar el trabajo. Hay tres opciones para lanzar un trabajo:
-
Un horario configurado dentro de dbt
-
A través de Webhooks
-
A través de una llamada a la API
-
Para este caso de uso, hemos elegido la opción Programar y hemos configurado la programación para que se ejecute cada hora, como se muestra en la Figura 4-60.
Figura 4-60. Definir el activador del trabajo
Es hora de ejecutar y ver qué ocurre. Guarda tu trabajo; a continuación, selecciona Ejecutar ahora o espera a que el trabajo se active automáticamente cuando alcance la programación configurada.
Mientras se ejecuta el trabajo, o después de que termine, siempre puedes inspeccionar el estado y lo que se ha ejecutado. En el menú Implementación, selecciona la opción Historial de ejecuciones. Verás las ejecuciones de tus trabajos. Selecciona una y echa un vistazo al Resumen de Ejecuciones. La Figura 4-61 es lo que deberías esperar ver.
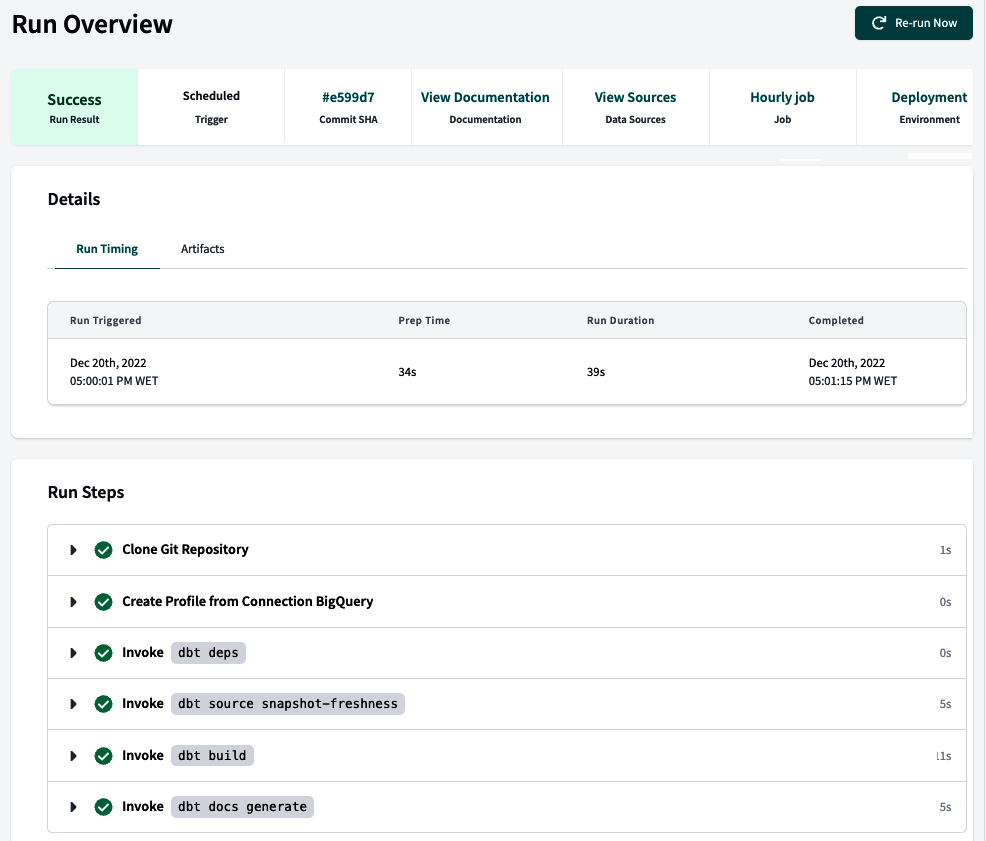
Figura 4-61. Pantalla de resumen de ejecución del trabajo
Una vez dentro de la Visión General de la Ejecución, dispones de información relevante sobre la ejecución del trabajo concreto, que podría ser útil para solucionar posibles problemas. En la parte superior hay un resumen del estado de ejecución del trabajo, la persona o el sistema que activó el trabajo, el commit de Git indexado a esta ejecución de trabajo, la documentación generada, las fuentes y el entorno en el que se ejecutó este trabajo.
Justo después del resumen del trabajo, puedes encontrar los detalles de la ejecución, como el tiempo que tardó en ejecutarse el trabajo y cuándo empezó y terminó. Por último, una de las piezas esenciales de información que te proporciona el Resumen de Ejecución son los Pasos de Ejecución, que detallan todos los comandos ejecutados durante la ejecución del trabajo y te permiten inspeccionar cada paso aislado y sus registros, como se muestra en la Figura 4-62. Explorar los registros de cada paso te permitirá comprender qué se ejecutó en cada uno y buscar problemas durante su ejecución.
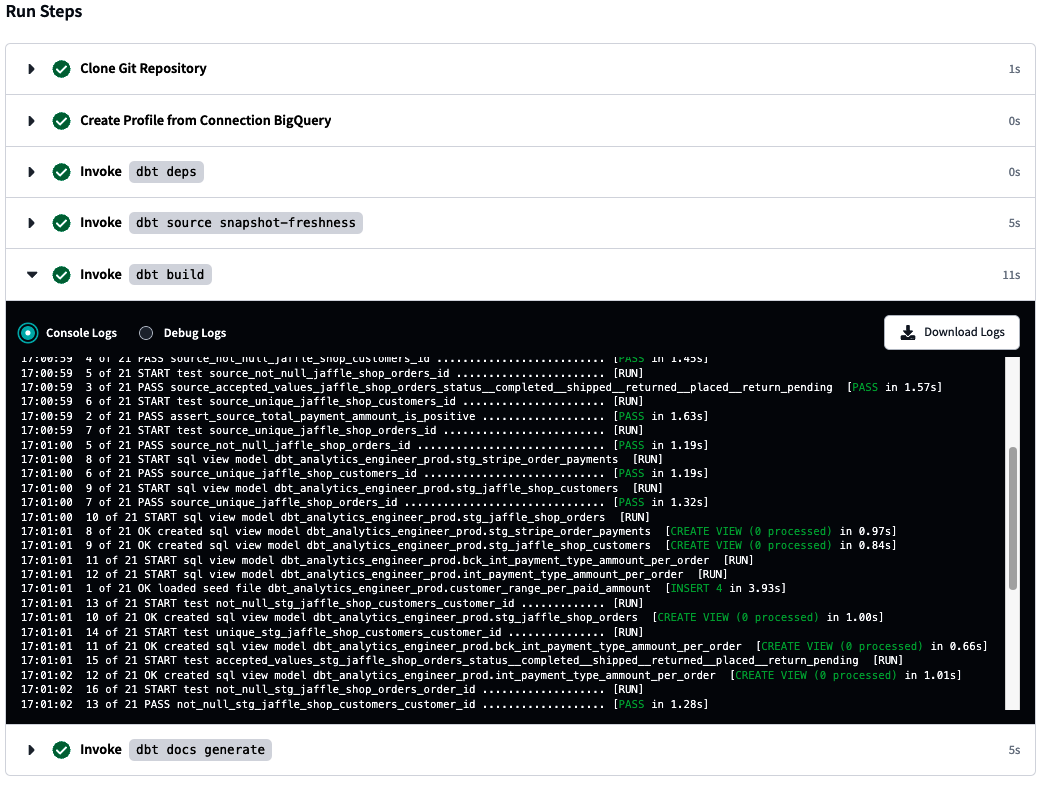
Figura 4-62. Detalles de los Pasos de ejecución del trabajo
Utilizando las tareas de dbt, puedes automatizar fácilmente tus transformaciones e implementar tus proyectos en producción de forma eficiente y escalable. Tanto si eres analista de datos, ingeniero de datos o ingeniero analítico, dbt puede ayudarte a abordar la complejidad de tus transformaciones de datos y garantizar que tus modelos de datos sean siempre precisos y estén actualizados.
Resumen
Este capítulo demuestra que la ingeniería analítica es un campo en constante evolución en el que siempre influyen las innovaciones. la dbt no es sólo un aspecto de esta historia; es una herramienta crucial en este campo.
El objetivo principal de la ingeniería analítica es convertir los datos brutos en ideas valiosas, y esta herramienta desempeña un papel crucial a la hora de simplificar las complejidades de la transformación de datos y promover la cooperación entre una amplia gama de partes interesadas. dbt garantiza que la transformación de datos no sea sólo un cambio técnico, sino que también hace gran hincapié en la apertura, la inclusión y el intercambio de conocimientos.
dbt es famoso por su capacidad para agilizar procesos complicados integrándose sin esfuerzo con grandes almacenes de datos. También promueve un enfoque colaborativo de la transformación de datos, garantizando una trazabilidad y precisión óptimas. Además, destaca la importancia de probar a fondo los procesos de datos para garantizar la fiabilidad. Su interfaz fácil de usar refuerza la noción de que la ingeniería analítica es un campo inclusivo, que acepta contribuciones de personas de todos los niveles de competencia.
Para concluir, animamos encarecidamente a los ingenieros analíticos que quieran mantenerse a la vanguardia del sector a que se sumerjan en esta herramienta transformadora. Dado que el dbt es cada vez más importante e inequívocamente beneficioso, dominar esta herramienta no sólo puede mejorar tu conjunto de habilidades, sino también facilitar transformaciones de datos más fluidas y cooperativas en el futuro.
Get Ingeniería analítica con SQL y dbt now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

