Chapter 4. Server Configuration Tools
Using scripts and automation to create, provision, and update servers is not especially new, but a new generation of tools has emerged over the past decade or so. CFEngine, Puppet, Chef, Ansible, and others define this category of tooling. Virtualization and cloud has driven the popularity of these tools by making it easy to create large numbers of new server instances which then need to be configured and updated.
Containerization tools such as Docker have emerged even more recently as a method for packaging, distributing, and running applications and processes. Containers bundle elements of the operating system with the application, which has implications for the way that servers are provisioned and updated.
As mentioned in the previous chapter, not all tools are designed to treat infrastructure as code. The guidelines from that chapter for selecting tools apply equally well to server configuration tools; they should be scriptable, run unattended, and use externalized configuration.
This chapter describes how server automation tools designed for infrastructure as code work. This includes different approaches that tools can take and different approaches that teams can use to implement these tools for their own infrastructure.
Patterns for Managing Servers
Several of the chapters in Part II build on the material covered in this chapter. Chapter 6 discusses general patterns and approaches for provisioning servers, Chapter 7 explores ways of managing server templates in more depth, and then Chapter 8 discusses patterns for managing changes to servers.
Goals for Automated Server Management
Using infrastructure as code to manage server configuration should result in the following:
-
A new server can be completely provisioned1 on demand, without waiting more than a few minutes.
-
A new server can be completely provisioned without human involvementâfor example, in response to events.
-
When a server configuration change is defined, it is applied to servers without human involvement.
-
Each change is applied to all the servers it is relevant to, and is reflected in all new servers provisioned after the change has been made.
-
The processes for provisioning and for applying changes to servers are repeatable, consistent, self-documented, and transparent.
-
It is easy and safe to make changes to the processes used to provision servers and change their configuration.
-
Automated tests are run every time a change is made to a server configuration definition, and to any process involved in provisioning and modifying servers.
-
Changes to configuration, and changes to the processes that carry out tasks on an infrastructure, are versioned and applied to different environments, in order to support controlled testing and staged release strategies.
Tools for Different Server Management Functions
In order to understand server management tooling, it can be helpful to think about the lifecycle of a server as having several phases (shown in Figure 4-1).

Figure 4-1. A serverâs lifecycle
This lifecycle will be the basis for discussing different server management patterns, starting in Chapter 6.
This section will explore the tools involved in this lifecycle. There are several functions, some of which apply to more than one lifecycle phase. The functions discussed in this section are creating servers, configuring servers, packaging templates, and running commands on servers.
Tools for Creating Servers
A new server is created by the dynamic infrastructure platform using an infrastructure definition tool, as described in the previous chapter. The server is created from a server template, which is a base image of some kind. This might be in a VM image format specific to the infrastructure platform (e.g., an AWS AMI image or VMware VM template), or it could be an OS installation disk image from a vendor (e.g., an ISO image of the Red Hat installation DVD). Most infrastructure platforms allow servers to be created interactively with a UI, as in Figure 4-2. But any important server should be created automatically.

Figure 4-2. AWS web console for creating a new server
There are many use cases where new servers are created:
-
A member of the infrastructure team needs to build a new server of a standard typeâfor example, adding a new file server to a cluster. They change an infrastructure definition file to specify the new server.
-
A user wants to set up a new instance of a standard applicationâfor example, a bug-tracking application. They use a self-service portal, which builds an application server with the bug-tracking software installed.
-
A web server VM crashes because of a hardware issue. The monitoring service detects the failure and triggers the creation of a new VM to replace it.
-
User traffic grows beyond the capacity of the existing application server pool, so the infrastructure platformâs autoscaling functionality creates new application servers and adds them to the pool to meet the demand.
-
A developer commits a change to the software they are working on. The CI software (e.g., Jenkins or GoCD) automatically provisions an application server in a test environment with the new build of the software so it can run an automated test suite against it.
Tools for Configuring Servers
Ansible, CFEngine, Chef, Puppet, and Saltstack are examples of tools specifically designed for configuring servers with an infrastructure-as-code approach. They use externalized configuration definition files, with a DSL designed for server configuration. The tool reads the definitions from these files and applies the relevant configuration to a server.
Many server configuration tools use an agent installed on each server. The agent runs periodically, pulling the latest definitions from a central repository and applying them to the server. This is how both Chef and Puppet are designed to work in their default use case.2
Other tools use a push model, where a central server triggers updates to managed servers. Ansible uses this model by default, using SSH keys to connect to server and run commands.3 This has the advantage of not requiring managed servers to have configuration agents installed on them, but arguably sacrifices security. Chapter 8 discusses these models in more detail.
Security Trade-Offs with Automated Server Configuration Models
A centralized system that controls how all of your servers are configured creates a wonderful opportunity for evil-doers. Push-based configuration opens ports on your servers, which an attacker can potentially use to connect. An attacker might impersonate the configuration master and feed the target server configuration definitions that will open the server up for malicious use. It could even allow an attacker to execute arbitrary commands. Cryptographic keys are normally used to prevent this, but this requires robust key management.
A pull model simplifies security, but of course there are still opportunities for evil. The attack vector in this case is wherever the client pulls its configuration definitions from. If an attacker can compromise the repository of definitions, then they can gain complete control of the managed servers.
In any case, the VCS used to store scripts and definitions is a critical part of your infrastructureâs attack surface, and so must be part of your security strategy. The same is true if you use a CI or CD server to implement a change management pipeline, as described in Chapter 12.
Security concerns with infrastructure as code are discussed in more detail in âSecurityâ.
Server configuration products have wider toolchains beyond basic server configuration. Most have repository servers to manage configuration definitionsâfor example, Chef Server, Puppetmaster, and Ansible Tower. These may have additional functionality, providing configuration registries, CMDBs, and dashboards. Chapter 5 discusses broader infrastructure orchestration services of this type.
Arguably, choosing a vendor that provides an all-in-one ecosystem of tools simplifies things for an infrastructure team. However, itâs useful if elements of the ecosystem can be swapped out for different tools so the team can choose the best pieces that fit their needs.
Tools for Packaging Server Templates
In many cases, new servers can be built using off-the-shelf server template images. Infrastructure platforms, such as IaaS clouds, often provide template images for common operating systems. Many also offer libraries of templates built by vendors and third parties, who may provide images that have been preinstalled and configured for particular purposes, such as application servers.
But many infrastructure teams find it useful to build their own server templates. They can pre-configure them with their teamâs preferred tools, software, and configuration.
Packaging common elements onto a template makes it faster to provision new servers. Some teams take this further by creating server templates for particular roles such as web servers and application servers. Chapter 7 discusses trade-offs and patterns around baking server elements into templates versus adding them when creating servers (âProvisioning Servers Using Templatesâ).
One of the key trade-offs is that, as more elements are managed by packaging them into server templates, the templates need to be updated more often. This then requires more sophisticated processes and tooling to build and manage templates.
Netflix pioneered approaches for building server templates with everything pre-packaged. They open sourced the tool they created for building AMI templates an AWS, Aminator.4
Aminator is fairly specific to Netflixâs needs, limited to building CentOS/Red Hat servers for the AWS cloud. But HashiCorp has released the open source Packer tool, which supports a variety of operating systems as well as different cloud and virtualization platforms. Packer defines server templates using a file format that is designed following the principles of infrastructure as code.
Different patterns and practices for building server templates using these kinds of tools are covered in detail in Chapter 7.
Tools for Running Commands on Servers
Tools for running commands remotely across multiple machines can be helpful for teams managing many servers. Remote command execution tools like MCollective, Fabric, and Capistrano can be used for ad hoc tasks such as investigating and fixing problems, or they can be scripted to automate routine activities. Example 4-1 shows an example of an MCollective command.
Some people refer to this kind of tool as âSSH-in-a-loop.â Many of them do use SSH to connect to target machines, so this isnât completely inaccurate. But they typically have more advanced features as well, to make it easier to script them, to define groupings of servers to run commands on, or to integrate with other tools.
Although it is useful to be able to run ad hoc commands interactively across servers, this should only be done for exceptional situations. Manually running a remote command tool to make changes to servers isnât reproducible, so isnât a good practice for infrastructure as code.
Example 4-1. Sample MCollective command
$mco service httpd restart -S"environment=staging and /apache/"
If people find themselves routinely using interactive tools, they should consider how to automate the tasks theyâre using them for. The ideal is to put it into a configuration definition if appropriate. Tasks that donât make sense to run unattended can be scripted in the language offered by the teamâs preferred remote command tool.
The danger of using scripting languages with these tools is that over time they can grow into a complicated mess. Their scripting languages are designed for fairly small scripts and lack features to help manage larger codebases in a clean way, such as reusable, shareable modules. Server configuration tools are designed to support larger codebases, so they are more appropriate.
Using Configuration from a Central Registry
Chapter 3 described using a configuration registry to manage information about different elements of an infrastructure. Server configuration definitions can read values from a configuration registry in order to set parameters (as described in âReusability with Configuration Definitionsâ).
For example, a team running VMs in several data centers may want to configure monitoring agent software on each VM to connect to a monitoring server running in the same data center. The team is running Chef, so they add these attributes to the Chef server as shown in Example 4-2.
Example 4-2. Using Chef server attributes as configuration registration entries
default['monitoring']['servers']['sydney']='monitoring.au.myco'default['monitoring']['servers']['dublin']='monitoring.eu.myco'
When a new VM is created, it is given a registry field called data_center, which is set to dublin or sydney.
When the chef-client runs on a VM, it runs the recipe in Example 4-3 to configure the monitoring agent.
Example 4-3. Using configuration registry entries in a Chef recipe
my_datacenter=node['data_center']template'/etc/monitoring/agent.conf'doowner'root'group'root'mode0644variables(:monitoring_server=>node['monitoring']['servers'][my_datacenter])end
The Chef recipe retrieves values from the Chef server configuration registry with the node['attribute_name'] syntax. In this case, after putting the name of the data center into the variable my_datacenter, that variable is then used to retrieve the monitoring serverâs IP address for that data center. This address is then passed to the template (not shown here) used to create the monitoring agent configuration file.
Server Change Management Models
Dynamic infrastructure and containerization are leading people to experiment with different approaches for server change management. There are several different models for managing changes to servers, some traditional, some new and controversial. These models are the basis for Part II of this book, particularly Chapter 8, which digs into specific patterns and practices.
Ad Hoc Change Management
Ad hoc change management makes changes to servers only when a specific change is needed. This was the traditional approach before the automated server configuration tools became mainstream, and is still the most commonly used approach. It is vulnerable to configuration drift, snowflakes, and all of the evils described in Chapter 1.
Configuration Synchronization
Configuration synchronization repeatedly applies configuration definitions to servers, for example, by running a Puppet or Chef agent on an hourly schedule. This ensures that any changes to parts of the system managed by these definitions are kept in line. Configuration synchronization is the mainstream approach for infrastructure as code, and most server configuration tools are designed with this approach in mind.
The main limitation of this approach is that many areas of a server are left unmanaged, leaving them vulnerable to configuration drift.
Immutable Infrastructure
Immutable infrastructure makes configuration changes by completely replacing servers. Changes are made by building new server templates, and then rebuilding relevant servers using those templates. This increases predictability, as there is little variance between servers as tested, and servers in production. It requires sophistication in server template management.
Containerized Services
Containerized services works by packaging applications and services in lightweight containers (as popularized by Docker). This reduces coupling between server configuration and the things that run on the servers. So host servers tend to be very simple, with a lower rate of change. One of the other change management models still needs to be applied to these hosts, but their implementation becomes much simpler and easier to maintain. Most effort and attention goes into packaging, testing, distributing, and orchestrating the services and applications, but this follows something similar to the immutable infrastructure model, which again is simpler than managing the configuration of full-blown virtual machines and servers.
Containers
Containerization systems such as Docker, Rocket, Warden, and Windows Containers have emerged as an alternative way to install and run applications on servers. A container system is used to define and package a runtime environment for a process into a container image. It can then distribute, create, and run instances of that image. A container uses operating system features to isolate the processes, networking, and filesystem of the container, so it appears to be its own, self-contained server environment.
The value of a containerization system is that it provides a standard format for container images and tools for building, distributing, and running those images. Before Docker, teams could isolate running processes using the same operating system features, but Docker and similar tools make the process much simpler.
The benefits of containerization include:
-
Decoupling the runtime requirements of specific applications from the host server that the container runs on
-
Repeatably create consistent runtime environments by having a container image that can be distributed and run on any host server that supports the runtime
-
Defining containers as code (e.g.,in a Dockerfile) that can be managed in a VCS, used to trigger automated testing, and generally having all of the characteristics for infrastructure as code
The benefits of decoupling runtime requirements from the host system are particularly powerful for infrastructure management. It creates a clean separation of concerns between infrastructure and applications. The host system only needs to have the container runtime software installed, and then it can run nearly any container image.7 Applications, services, and jobs are packaged into containers along with all of their dependencies, as shown in Figure 4-3. These dependencies can include operating system packages, language runtimes, libraries, and system files. Different containers may have different, even conflicting dependencies, but still run on the same host without issues. Changes to the dependencies can be made without any changes to the host system.
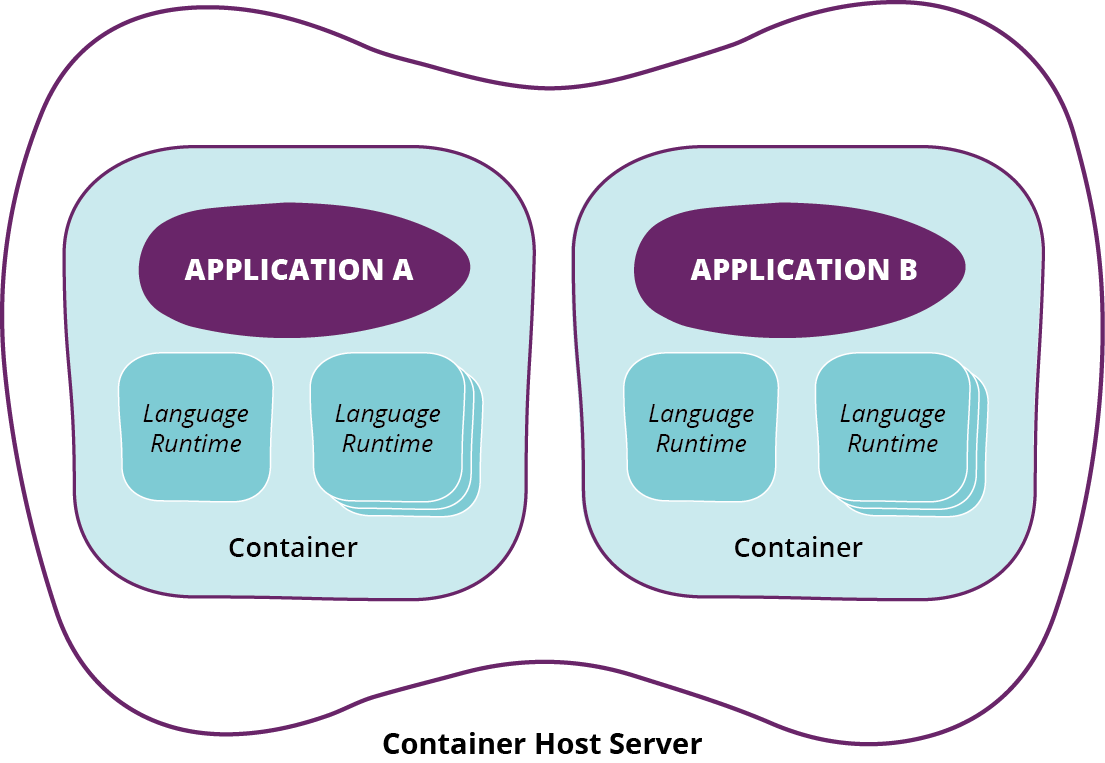
Figure 4-3. Isolating packages and libraries in containers
Managing Ruby Applications with and without Containers
For example, suppose a team runs many Ruby applications. Without containers, the server they run on might need to have multiple versions of the Ruby runtime installed. If one application requires an upgrade, the upgrade needs to be rolled out to any server where the application needs to run.
This could impact other Ruby applications. Those other applications might start running with the newer Ruby version, but may have incompatibilities. Two applications that use the same version of Ruby might use different versions of a library that has been installed as a system gem (a Ruby shared library package). Although both versions of the gem can be installed, making sure each application uses the right version is tricky.
These issues are manageable, but it requires the people configuring the servers and applications to be aware of each requirement and potential conflict and do some work to make everything play nicely. And each new conflict tends to pop up and interrupt people from working on other tasks.
With Docker containers, each of these Ruby applications has its own Dockerfile, which specifies the Ruby version and which gems to bundle into the container image. These images can be deployed and run on a host system that doesnât need to have any version of Ruby installed. Each Ruby application has its own runtime environment and can be replaced and upgraded with different dependencies, regardless of the others applications running on the same host.
Example 4-4 is a Dockerfile that packages a Ruby Sinatra application.
Example 4-4. Dockerfile to create a Ruby Sinatra application
# Start with a CentOS docker imageFROMcentos:6.4# Directory of the Sinatra appADD. /app# Install SinatraRUNcd/app;gem install sinatra# Open the Sinatra portEXPOSE4567# Run the appCMD["ruby", "/app/hi.rb"]
Are Containers Virtual Machines?
Containers are sometimes described as being a type of virtual machine. There are similarities, in that they give multiple processes running on a single host server the illusion that they are each running in their own, separate servers. But there are significant technical differences. The use case of a container is quite different from that of a virtual machine.
The differences between virtual machines and containers
A host server runs virtual machines using a hypervisor, such as VMware ESX or Xen (which underlies Amazonâs EC2 service). A hypervisor is typically installed on the bare metal of the hardware host server, as the operating system. However, some virtualization packages can be installed on top of another operating system, especially those like VMware Workstation and VirtualBox, which are intended to run on desktops.
A hypervisor provides emulated hardware to a VM. Each VM can have different emulated hardware from the host server, and different hardware from one another. Consider a physical server running the Xen hypervisor, with two different VMs. One VM can have an emulated SCSI hard drive, 2 CPUs, and 8 GB of RAM. The other can be given an emulated IDE hard drive, 1 CPU, and 2 GB of RAM. Because the abstraction is at the hardware level, each VM can have a completely different OS installed; for example, you can install CentOS Linux on one, and Windows Server on the other, and run them side by side on the same physical server.
Figure 4-4 shows the relationship between virtual machines and containers. Containers are not virtual servers in this sense. They donât have emulated hardware, and they use the same operating system as their host server, actually running on the same kernel. The system uses operating system features to segregate processes, filesystems, and networking, giving a process running in a container the illusion that it is running on its own. But this is an illusion created by restricting what the process can see, not by emulating hardware resources.
Container instances share the operating system kernel of their host system, so they canât run a different OS. Containers can, however, run different distributions of the same OSâfor example, CentOS Linux on one and Ubuntu Linux on another. This is because a Linux distribution is just a different set of files and processes. But these instances would still share the same Linux kernel.

Figure 4-4. Containers and virtual machines
Sharing the OS kernel means a container has less overhead than a hardware virtual machine. A container image can be much smaller than a VM image, because it doesnât need to include the entire OS. It can start up in seconds, as it doesnât need to boot a kernel from scratch. And it consumes fewer system resources, because it doesnât need to run its own kernel. So a given host can run more container processes than full VMs.
Using Containers Rather than Virtual Machines
A naive approach to containers is to build them the same way that you would build a virtual machine image. Multiple processes, services, and agents could all be packaged into a single container and then run the same way you would run a VM. But this misses the sweet spot for containers.
The best way to think of a container is as a method to package a service, application, or job. Itâs an RPM on steroids, taking the application and adding in its dependencies, as well as providing a standard way for its host system to manage its runtime environment.
Rather than a single container running multiple processes, aim for multiple containers, each running one process. These processes then become independent, loosely coupled entities. This makes containers a nice match for microservice application architectures.8
A container built with this philosophy can start up extremely quickly. This is useful for long-running service processes, because it makes it easy to deploy, redeploy, migrate, and upgrade them routinely. But quick startup also makes containers well suited for processes run as jobs. A script can be packaged as a container image with everything it needs to run, and then executed on one or many machines in parallel.
Containers are the next step in the evolution of managing resources across an infrastructure efficiently. Virtualization was one step, allowing you to add and remove VMs to scale your capacity to your load on a timescale of minutes. Containers take this to the next level, allowing you to scale your capacity up and down on a timescale of seconds.9
Running Containers
Packaging and running a single application in a container is fairly simple. Using containers as a routine way to run applications, services, and jobs across multiple host servers is more complicated. Container orchestration systems automate the distribution and execution of containers across host systems (Chapter 5 touches on container orchestration in a bit more detail, in âContainer Orchestration Toolsâ).
Containerization has the potential to create a clean separation between layers of infrastructure and the services and applications that run on it. Host servers that run containers can be kept very simple, without needing to be tailored to the requirements of specific applications, and without imposing constraints on the applications beyond those imposed by containerization and supporting services like logging and monitoring.
So the infrastructure that runs containers consists of generic container hosts. These can be stripped down to a bare minimum, including only the minimum toolsets to run containers, and potentially a few agents for monitoring and other administrative tasks. This simplifies management of these hosts, as they change less often and have fewer things that can break or need updating. It also reduces the surface area for security exploits.
Minimal OS Distributions
Container-savvy vendors are offering stripped down OS distributions for running container hosts, such as Red Hat Atomic, CoreOS, Microsoft Nano, RancherOS, Ubuntu Snappy, and VMware Photon.
Note that these stripped-down OSes are not the same as the earlier mentioned Unikernel. A stripped-down OS combines a full OS kernel with a stripped-down distribution of preinstalled packages and services. A Unikernel actually strips down the OS kernel itself, building one up from a set of libraries and including the application in the kernelâs memory space.
Some teams run container hosts as virtual machines on a hypervisor, which is in turn installed on hardware. Others take the next step and remove the hypervisor layer entirely, running the host OS directly on hardware. Which of these approaches to use depends on the context.
Teams that already have hypervisor-based virtualization and infrastructure clouds, but donât have much bare-metal automation, will tend to run containers on VMs. This is especially appropriate when the team is still exploring and expanding their use of containers, and particularly when there are many services and applications running outside of containers. This is likely to be the case for many organizations for some time.
When containerization becomes more routine for an organization, and when significant parts of their services are containerized, teams will probably want to test how well running containers directly on hardware-based hosts. This is likely to become easier as virtualization and cloud platform vendors build support for running containers directly into their hypervisors.
Security and Containers
One concern that is inevitably raised when discussing containers is security. The isolation that containers provide can lead people to assume they offer more inherent security than they actually do. And the model that Docker provides for conveniently building customer containers on top of images from community libraries can open serious vulnerabilities if it isnât managed with care.10
Container isolation and security
While containers isolate processes running on a host from one another, this isolation is not impossible to break. Different container implementations have different strengths and weaknesses. When using containers, a team should be sure to fully understand how the technology works, and where its vulnerabilities may lie.
Teams should be particularly cautious with untrusted code. Containers appear to offer a safe way to run arbitrary code from people outside the organization. For example, a company running hosted software might offer customers the ability to upload and run code on the hosted platform, as a plug-in or extension model. The assumption is that, because the customerâs code runs in a container, an attacker wonât be able to take advantage of this to gain access to other customersâ data, or to the software companyâs systems.
However, this is a dangerous assumption. Organizations running potentially untrusted code should thoroughly analyze their technology stack and its potential vulnerabilities. Many companies that offer hosted containers actually keep each customerâs containers isolated to their own physical servers (not just hypervisor-based virtual machines running the container host). As of late 2015, this is true of the hosted container services run by both Amazon and Google.
So teams should use stronger isolation between containers running untrusted code than the isolation provided by the containerization stack. They should also take measures to harden the host systems, all the way down to the metal. This is another good reason to strip down the host OS to only the minimum needed to run the containerization system. Platform services should ideally be partitioned onto different physical infrastructure from that used to run untrusted code.
Even organizations that donât run arbitrary code from outsiders should take appropriate care to ensure the segregation of code, rather than assuming containers provide fully protected runtime environments. This can make it more difficult for an attacker who compromises one part of the system from leveraging it to widen their access.
Container image provenance
Even when outsiders canât directly run code in containers on your infrastructure, they may be able to do so indirectly. Itâs common for insiders to download outside code and then package and run it. This is not unique to containers. As will be discussed in âProvenance of Packagesâ in Chapter 14, itâs common to automatically download and install system packages and language libraries from community repositories.
Docker and other containerization systems offer the ability to layer container images. Rather than having to take an OS installation image and build a complete container from scratch, you can use common images that have a basic OS install already. Other images offer prepackaged applications such as web servers, application servers, and monitoring agents. Many OS and application vendors are offering this as a distribution mechanism.
A container image for an OS distribution like CentOS, for example, may be maintained by people with deep knowledge of that OS. The maintainers can make sure the image is optimized, tuned, and hardened. They can also make sure updated images are always made available with the latest security patches. Ideally, these maintainers are able to invest more time and expertise in maintaining the CentOS image than the people on an infrastructure team that is supporting a variety of systems, servers, and software. Spreading this model out over the various pieces of software used by the infrastructure team means the team is able to leverage a great deal of industry expertise.
The risk is when there arenât sufficient guarantees of the provenance of container base images used in a teamâs infrastructure. An image published on a public repository may be maintained by responsible, honest experts, or it could have been put there by evil hackers or the NSA. Even if the maintainers are well intentioned, someone evil could have compromised their work, adding subtle back doors.
While community-provided container images arenât inherently less trustworthy than community-provided RPMs or RubyGems, their growing popularity emphasizes the need to manage all of these things carefully. Teams should ensure the provenance of each image used within the infrastructure is well known, trusted, and can be verified and traced. Containerization tool vendors are building mechanisms to automatically validate the provenance of images.11 Teams should ensure that they understand how these mechanisms work and that they are being properly used.
Conclusion
The intention of this chapter was to understand several different high-level models for managing individual servers and how these models relate to the types of tooling available. Hopefully it will help you consider how your team could go about provisioning and configuring servers.
However, before selecting specific tools, it would be a good idea to be familiar with the patterns in Part II of this book. Those chapters provide more detail on specific patterns and practices for provisioning servers, building server templates, and updating running servers.
The next chapter will look at the bigger picture of the infrastructure, exploring the types of tools that are needed to run the infrastructure as a whole.
1 See Definition of âProvisioningâ in Chapter 3 for clarity on how I use the term in this book.
2 It is perfectly possible to use Chef or Puppet in a pull model, for example, by having a central server run an ssh command to connect to servers and run the client command-line tool.
3 Although Ansibleâs main use case is the push model, it can also be run in a pull model, as described in a blog post by Jan-Piet Mens.
4 Netflix described their approach to using AMI templates in this blog post.
5 Neal Ford coined the term âpolyglot programming.â See this interview with Neal for more about it.
6 The pace of change in containerization is currently quite fast. In the course of writing this book, Iâve had to expand coverage from a couple of paragraphs, to a section, and made it one of the main models for managing server configuration. Many of the details Iâve described will have changed by the time you read this. But hopefully the general concepts, particularly how containers relate to infrastructure-as-code principles and practices, will still be relevant.
7 There is actually some dependency between the host and container. In particular, container instances use the Linux kernel of the host system, so a given image could potentially behave differently, or even fail, when run on different versions of the kernel.
8 See my colleague Sam Newmanâs book Building Microservices (OâReilly) for more on microservices.
9 The folks at force12 are doing interesting things with microscaling.
10 The folks at Docker have published an article on container security that offers a number of useful insights.
Get Infrastructure as Code now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

