Capítulo 4. Optimizaciones de memoria y computación
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En el Capítulo 3, exploraste las buenas prácticas para experimentar y seleccionar un modelo base para tu caso de uso. El siguiente paso suele ser adaptar el modelo a tus necesidades y conjuntos de datos específicos. Esto podría incluir la adaptación del modelo a tus conjuntos de datos mediante una técnica denominada ajuste fino, que explorarás con más detalle en el Capítulo 5. Al entrenar o afinar grandes modelos de fundamentos, a menudo te enfrentas a retos informáticos, en particular, cómo hacer caber grandes modelos en la memoria de la GPU.
En este capítulo, explorarás técnicas que ayudan a superar las limitaciones de memoria. Aprenderás a aplicar la cuantización y el entrenamiento distribuido para minimizar la RAM necesaria en la GPU, y a escalar horizontalmente el entrenamiento del modelo en varias GPU para modelos más grandes.
Por ejemplo, el modelo Falcon original de 40.000 millones de parámetros de se entrenó en un clúster de 48 instancias de ml.p4d.24xlarge Amazon SageMaker compuesto por 384 GPUs NVIDIA A100, 15 TB de RAM de GPU y 55 TB de RAM de CPU. Una versión más reciente de Falcon se entrenó en un cluster de 392 instancias ml.p4d.24xlarge SageMaker compuesto por 3.136 GPUs NVIDIA A100, 125TB de RAM de GPU y 450TB de RAM de CPU. El tamaño y la complejidad del modelo Falcon requieren un cluster de GPUs, pero también se beneficia de la cuantización, como verás a continuación.
Retos de memoria
Uno de los problemas más comunes con los que te encontrarás cuando intentes entrenar o ajustar modelos de base es quedarte sin memoria. Si alguna vez has intentado entrenar o incluso simplemente cargar tu modelo en GPUs NVIDIA, el mensaje de error de la Figura 4-1 puede resultarte familiar.

Figura 4-1. Error CUDA fuera de memoria
CUDA, abreviatura de Compute Unified Device Architecture (Arquitectura de Dispositivos de Computación Unificada), es una colección de bibliotecas y herramientas desarrolladas para las GPU de NVIDIA con el fin de aumentar el rendimiento en operaciones comunes de aprendizaje profundo, como la multiplicación de matrices, entre muchas otras. Las bibliotecas de aprendizaje profundo como PyTorch y TensorFlow utilizan CUDA de forma extensiva para manejar los detalles específicos del hardware de bajo nivel, incluido el movimiento de datos entre la memoria de la CPU y la GPU. Como los modelos generativos modernos contienen varios miles de millones de parámetros, es probable que te hayas encontrado con este error de falta de memoria durante el desarrollo al cargar y probar un modelo en tu entorno de investigación.
Un parámetro de un solo modelo, con una precisión total de 32 bits, se representa con 4 bytes. Por tanto, un modelo de 1.000 millones de parámetros requiere 4 GB de RAM de la GPU sólo para cargar el modelo en la RAM de la GPU a máxima precisión. Si además quieres entrenar el modelo, necesitarás más memoria en la GPU para almacenar los estados del optimizador numérico, los gradientes y las activaciones, así como cualquier variable temporal utilizada por tus funciones, como se muestra en la Tabla 4-1.
| Estados | Bytes por parámetro |
|---|---|
| Parámetros del modelo (ponderaciones) | 4 bytes por parámetro |
| Optimizador Adam (2 estados) | 8 bytes por parámetro |
| Gradientes | 4 bytes por parámetro |
| Activaciones y memoria temporal (tamaño variable) | 8 bytes por parámetro (estimación de gama alta) |
| TOTAL | = 4 + 20 bytes por parámetro |
Consejo
Cuando experimentes entrenando un modelo, se recomienda que empieces con batch_size=1 para encontrar los límites de memoria del modelo con un solo ejemplo de entrenamiento. A continuación, puedes aumentar gradualmente el tamaño del lote hasta que llegues al error CUDA de falta de memoria. Esto determinará el tamaño máximo del lote para el modelo y el conjunto de datos. A menudo, un tamaño de lote mayor puede acelerar el entrenamiento de tu modelo.
Estos componentes adicionales suponen aproximadamente entre 12 y 20 bytes adicionales de memoria de la GPU por parámetro del modelo. Por ejemplo, para entrenar un modelo de 1.000 millones de parámetros, necesitarás aproximadamente 24 GB de RAM de la GPU a 32 bits de precisión total, seis veces más memoria en comparación con sólo 4 GB de RAM de la GPU para cargar el modelo, como se muestra en la Figura 4-2.
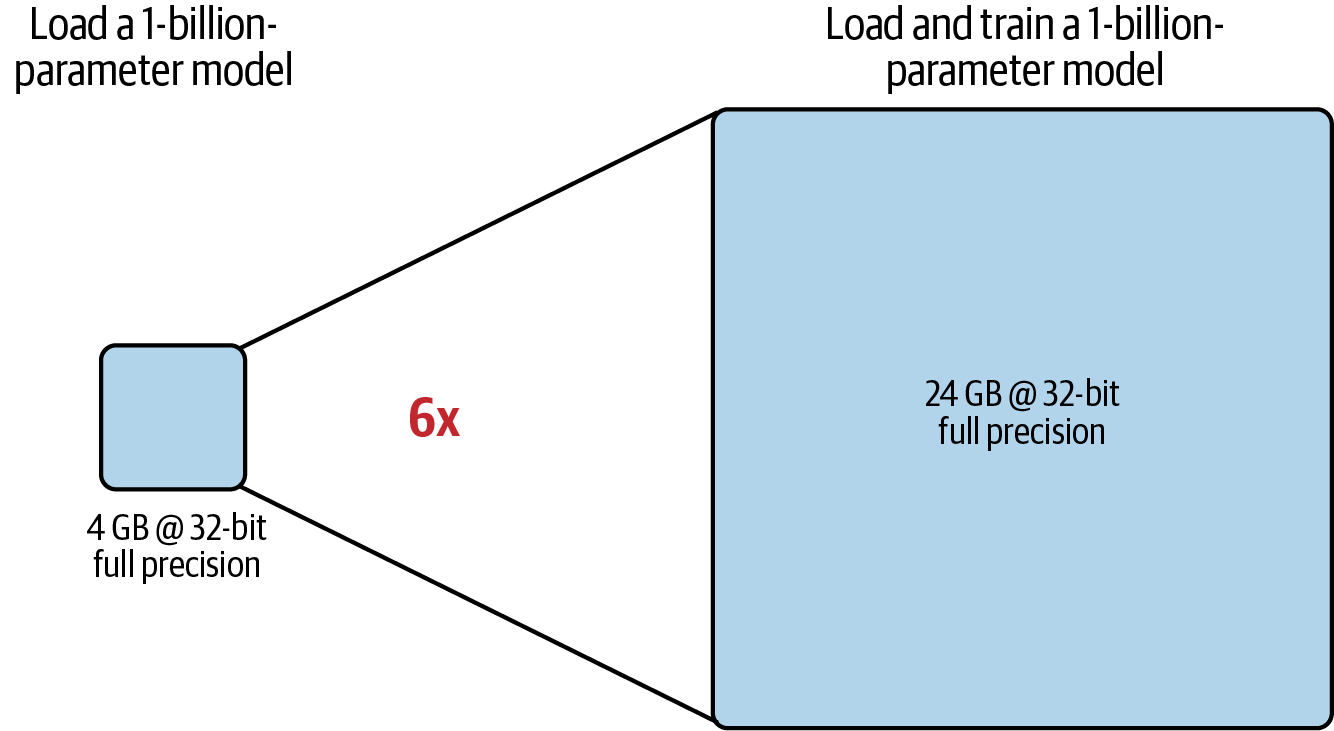
Figura 4-2. Comparación de la RAM aproximada de GPU necesaria para cargar frente a cargar y entrenar un modelo de 1.000 millones de parámetros a 32 bits de precisión total
Vale la pena señalar que las NVIDIA A100 y H100, utilizadas en el momento de escribir esto, sólo admiten hasta 80 GB de RAM de GPU. Y como es probable que quieras entrenar modelos de más de 1.000 millones de parámetros, tendrás que encontrar una solución, como cuantizar tu modelo.
AWS también ha desarrollado aceleradores de ML creados específicamente, AWS Trainium, para un entrenamiento de alto rendimiento y rentable de modelos de IA generativa de más de 100B de parámetros. Puedes aprovechar los chips de AWS Trainium a través de la familia de instancias Trn1. La instancia Trn1 más grande, en el momento de escribir este artículo, cuenta con 16 chips AWS Trainium y 512 GB de memoria compartida del acelerador. Además, las instancias Trn1 están optimizadas para la cuantificación y el entrenamiento distribuido de modelos, y admiten una amplia gama de tipos de datos.
La cuantización es una forma muy popular de convertir los parámetros de tu modelo de una precisión de 32 bits a una precisión de 16 bits, o incluso de 8 bits o 4 bits. Cuantificando los pesos de tu modelo de 32 bits de precisión total a 16 bits de precisión media, puedes reducir rápidamente los requisitos de memoria de tu modelo de 1.000 millones de parámetros en un 50%, a sólo 2 GB para la carga y 12 GB para el entrenamiento.
Pero antes de sumergirnos en la cuantización, exploremos los tipos de datos habituales para el entrenamiento de modelos y hablemos de la precisión numérica.
Tipos de datos y precisión numérica
A continuación se indican los distintos tipos de datos que utilizan PyTorch y TensorFlow: fp32 para precisión completa de 32 bits, fp16 para semiprecisión de 16 bits y int8 para precisión entera de 8 bits.
Más recientemente, bfloat16 se ha convertido en una alternativa popular a fp16 para la precisión de 16 bits en modelos de IA generativa más modernos. bfloat16 (o bf16) es la abreviatura de "punto flotante cerebral 16", ya que se desarrolló en Google Brain. En comparación con fp16, bfloat16 tiene un mayor rango dinámico con 8 bits para el exponente y, por tanto, puede representar una amplia gama de valores que encontramos en los modelos de IA generativa.
Analicemos cómo se comparan estos tipos de datos y por qué bfloat16 es una opción popular para la cuantización de 16 bits.
Supongamos que quieres almacenar pi con 20 decimales (3.14159265358979323846) utilizando una precisión total de 32 bits. Recuerda que los números en coma flotante se almacenan como una serie de bits formada sólo por 0s y 1s. Los números se almacenan en 32 bits utilizando 1 bit para el signo (negativo o positivo), 8 bits para el exponente (que representa el rango dinámico) y 23 bits para la fracción, también llamada mantisa o significando, que representa la precisión del número. La Tabla 4-2 muestra cómo fp32 representa el valor de pi.
| Firma | Exponente | Fracción (mantisa/significante) |
|---|---|---|
1 bit0
|
8 bits10000000
|
23 bits10010010000111111011011
|
fp32 puede representar números en un rango de -3e38 a +3e38. El siguiente código PyTorch muestra cómo imprimir la información del tipo de datos para fp32:
importtorchtorch.finfo(torch.float32)
La salida es:
finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32)
Almacenar un número real en 32 bits provocará en realidad una ligera pérdida de precisión. Puedes comprobarlo almacenando pi como un tipo de dato fp32 e imprimiendo después el valor del tensor con 20 decimales utilizando Tensor.item():
pi=3.14159265358979323846pi_fp32=torch.tensor(pi,dtype=torch.float32)('%.20f'%pi_fp32.item())
La salida es:
3.14159274101257324219
Puedes ver la ligera pérdida de precisión si comparas este valor con el valor real de pi, que empieza por 3.14159265358979323846. Esta ligera pérdida de precisión se debe a la conversión al rango de números fp32, como se muestra en la Figura 4-3.
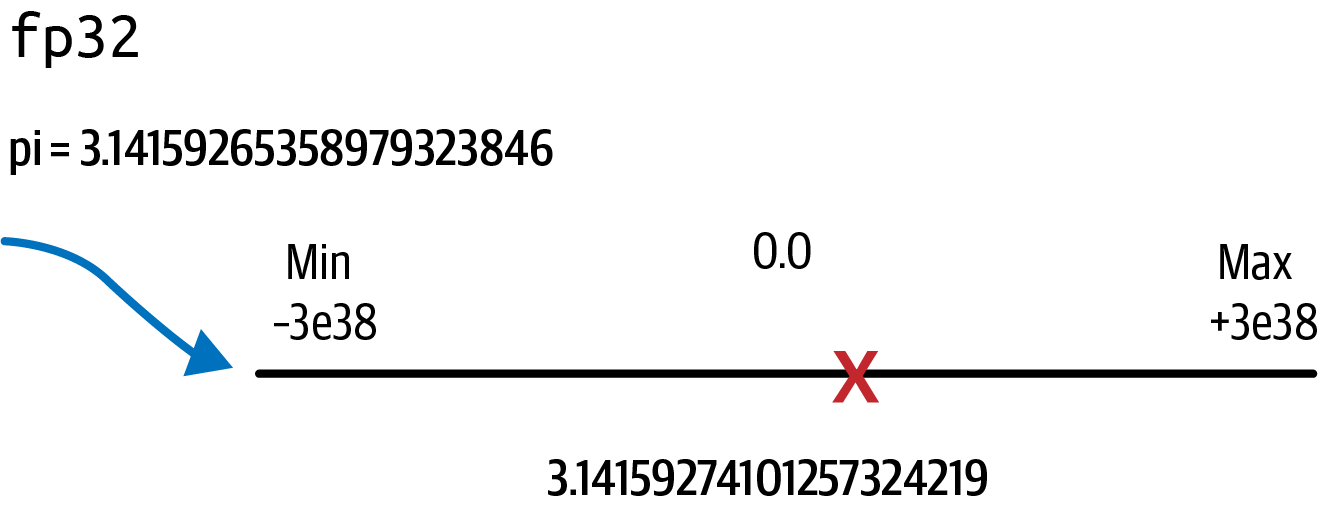
Figura 4-3. fp32 proyectando pi en el intervalo de -3e38 a +3e38
También puedes imprimir el consumo de memoria:
defshow_memory_comsumption(tensor):memory_bytes=tensor.element_size()*tensor.numel()("Tensor memory consumption:",memory_bytes,"bytes")show_memory_comsumption(pi_fp32)
La salida es:
Tensor memory consumption: 4 bytes
Ahora que has explorado los tipos de datos y las representaciones numéricas, pasemos a discutir cómo la cuantización puede ayudarte a reducir la huella de memoria necesaria para cargar y entrenar tu modelo de miles de millones de parámetros.
Cuantización
Cuando intentes entrenar un modelo de miles de millones de parámetros a 32 bits de precisión total, llegarás rápidamente al límite de una sola GPU NVIDIA A100 o H100 con sólo 80 GB de RAM de GPU. Por lo tanto, casi siempre tendrás que utilizar la cuantización cuando utilices una sola GPU.
La cuantización reduce la memoria necesaria para cargar y entrenar un modelo reduciendo la precisión de los pesos del modelo. La cuantización convierte los parámetros de tu modelo de una precisión de 32 bits a una precisión de 16 bits, o incluso de 8 bits o 4 bits.
Cuantizando los pesos de tu modelo de 32 bits de precisión total a 16 u 8 bits de precisión, puedes reducir rápidamente la memoria necesaria para tu modelo de 1.000 millones de parámetros en un 50% a sólo 2 GB, o incluso en un 75% a sólo 1 GB para la carga, como se muestra en la Figura 4-4.
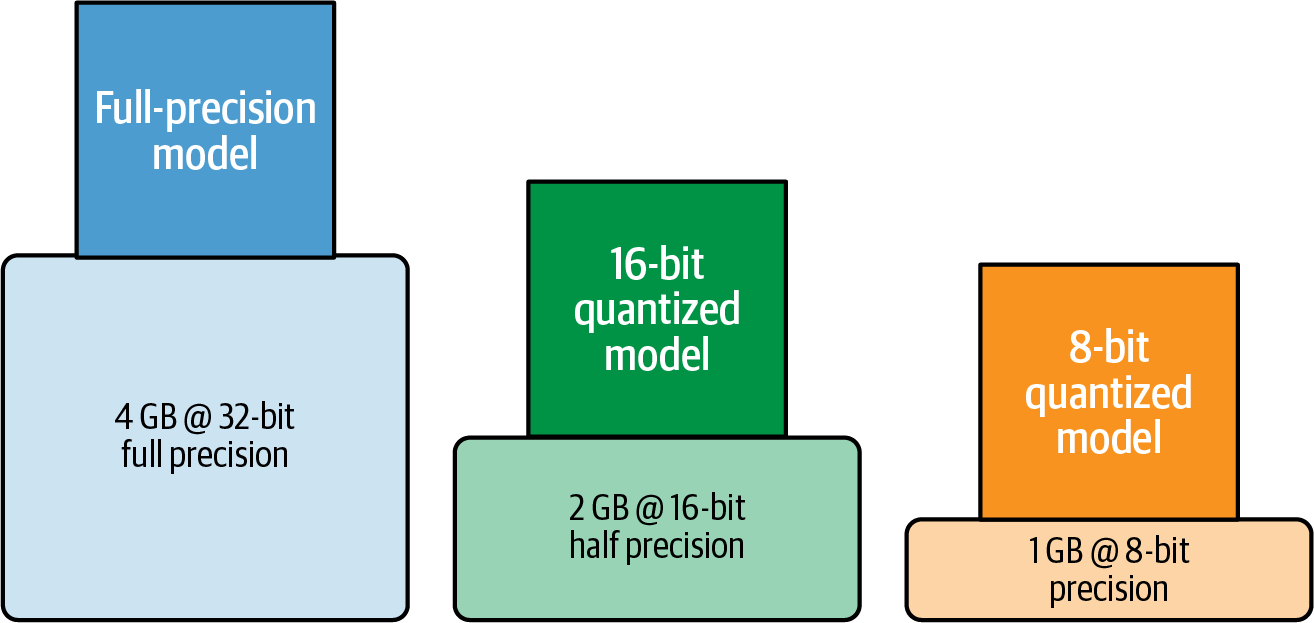
Figura 4-4. RAM aproximada de la GPU necesaria para cargar un modelo de 1.000 millones de parámetros con una precisión de 32 bits, 16 bits y 8 bits
La cuantización proyecta un conjunto fuente de números de coma flotante de mayor precisión en un conjunto destino de números de menor precisión. Utilizando los rangos de origen y destino, el mecanismo de cuantización calcula primero un factor de escala, realiza la proyección y, a continuación, almacena los resultados en precisión reducida, lo que requiere menos memoria y, en última instancia, mejora el rendimiento del entrenamiento y reduce el coste.
fp16
Con fp16, los 16 bits constan de 1 bit para el signo, pero sólo 5 bits para el exponente y 10 bits para la fracción, como se muestra en la Tabla 4-3.
| Firma | Exponente | Fracción (mantisa/significante) | |
|---|---|---|---|
fp32 (consume 4 bytes de memoria) |
1 bit0
|
8 bits10000000
|
23 bits10010010000111111011011
|
fp16 (consume 2 bytes de memoria) |
1 bit0
|
5 bits10000
|
10 bits1001001000
|
Con el número reducido de bits para el exponente y la fracción, el rango de números representables de fp16 es sólo de -65.504 a +65.504. También puedes ver esto cuando imprimas la información del tipo de datos para fp16:
torch.finfo(torch.float16)
La salida es:
finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16)
Almacenemos de nuevo pi con 20 decimales en fp16 y comparemos los valores:
pi=3.14159265358979323846pi_fp16=torch.tensor(pi,dtype=torch.float16)('%.20f'%pi_fp16.item())
La salida es:
3.14062500000000000000
Observa la pérdida de precisión después de esta proyección, ya que ahora sólo hay seis posiciones después del punto decimal. El valor fp16 de pi es ahora 3.140625. Recuerda que ya has perdido precisión sólo por almacenar el valor en fp32, como se muestra en la Figura 4-5.
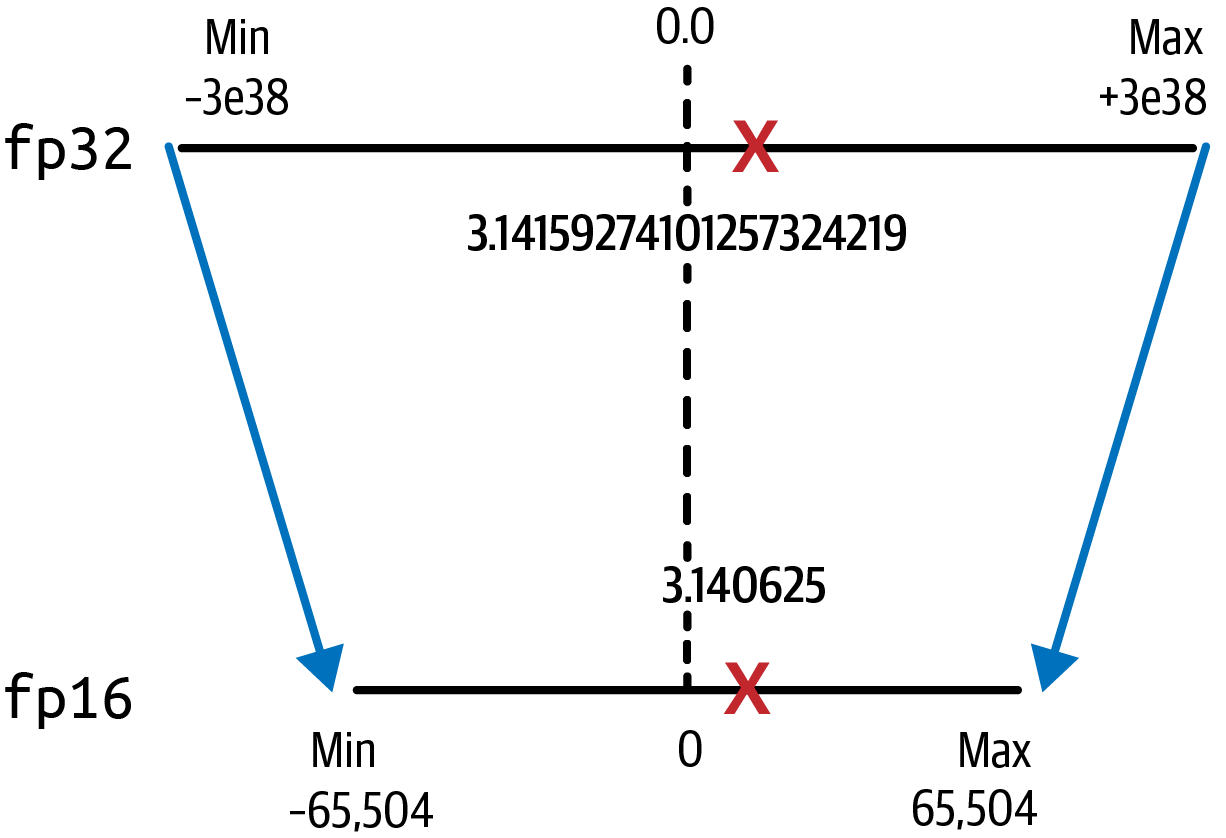
Figura 4-5. La cuantización de fp32 a fp16 ahorra un 50% de memoria
Sin embargo, la pérdida de precisión es aceptable en la mayoría de los casos. Las ventajas de una reducción del 50% en la memoria de la GPU para fp16 en comparación con fp32 suele merecer la pena, ya que fp16 sólo requiere 2 bytes de memoria frente a los 4 bytes de fp32.
Cargar un modelo de 1.000 millones de parámetros ahora sólo requiere 2 GB de RAM de la GPU, mientras que para entrenar el modelo se necesitan 12 GB de RAM de la GPU, como se muestra en la Figura 4-6.
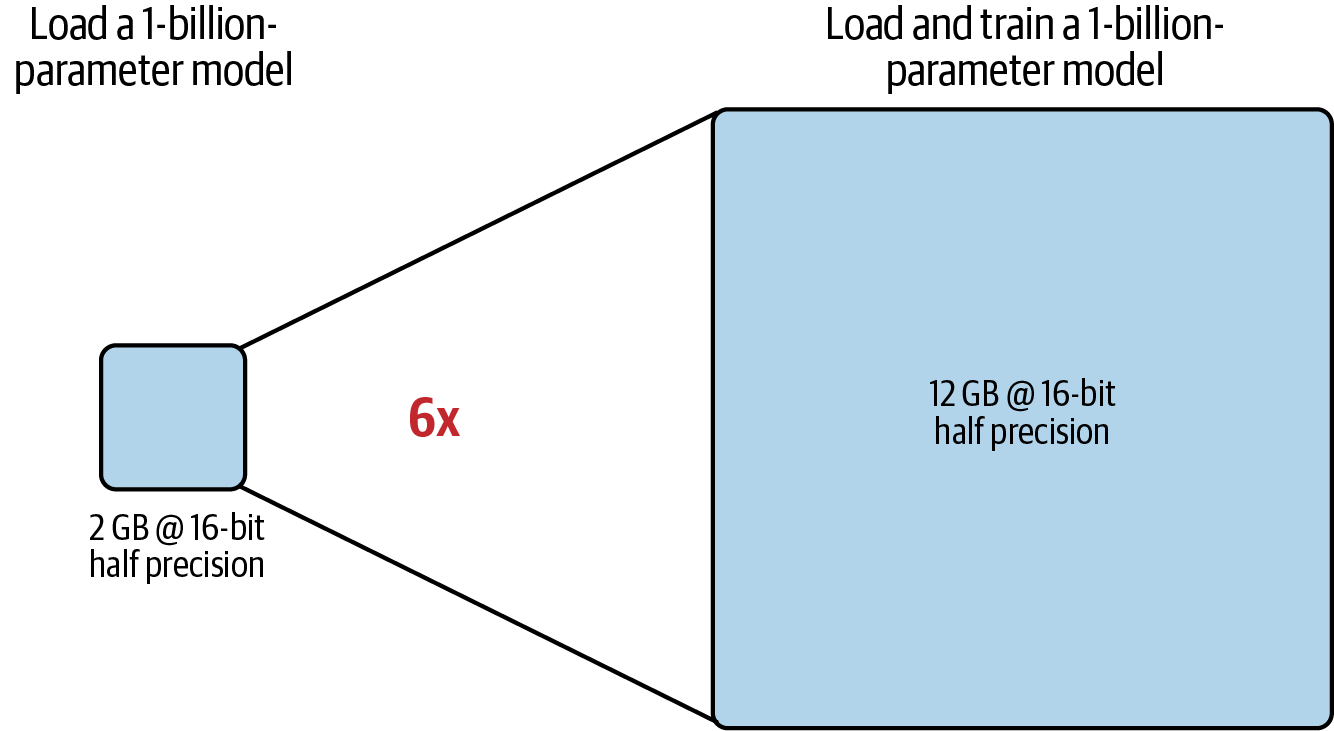
Figura 4-6. Sólo se necesitan 12 GB de RAM de la GPU para cargar y entrenar un modelo de 1.000 millones de parámetros a 16 bits de media precisión
bfloat16
bfloat16 se ha convertido en una alternativa popular a fp16, ya que captura todo el rango de fp32 con sólo 16 bits. Esto reduce las inestabilidades numéricas durante el entrenamiento del modelo causadas por el desbordamiento. El desbordamiento se produce cuando los números fluyen fuera del rango de representación al convertirlos de un espacio de alta precisión a otro de menor precisión, provocando errores NaN (no es un número).
Comparado con fp16, bfloat16 tiene un mayor rango dinámico pero menos precisión, lo que suele ser aceptable. bfloat16 utiliza un solo bit para el signo y los 8 bits completos para el exponente. Sin embargo, trunca la fracción a sólo 7 bits, por lo que a menudo se denomina "flotante truncado de 32 bits", como se muestra en la Tabla 4-4.
| Firma | Exponente | Fracción (mantisa/significante) | |
|---|---|---|---|
fp32 (consume 4 bytes de memoria) |
1 bit0
|
8 bits10000000
|
23 bits10010010000111111011011
|
bfloat16 (consume 2 bytes de memoria) |
1 bit0
|
8 bits10000000
|
7 bits1001001
|
El rango de números representables de bfloat16 es idéntico al de fp32. Imprimamos la información del tipo de datos de bfloat16:
torch.finfo(torch.bfloat16)
La salida es:
finfo(resolution=0.01, min=-3.38953e+38, max=3.38953e+38, eps=0.0078125, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=bfloat16)
Almacenemos de nuevo pi con 20 decimales en bfloat16 y comparemos los valores:
pi=3.14159265358979323846pi_bfloat16=torch.tensor(pi,dtype=torch.bfloat16)('%.20f'%pi_bfloat16.item())
La salida es:
3.14062500000000000000
Al igual que fp16, bfloat16 conlleva una pérdida mínima de precisión. El valor bfloat16 de pi es 3.140625. Sin embargo, las ventajas de mantener el rango dinámico de fp32 (mostrado en la Figura 4-7) y reducir así el desbordamiento, suelen compensar la pérdida de precisión.
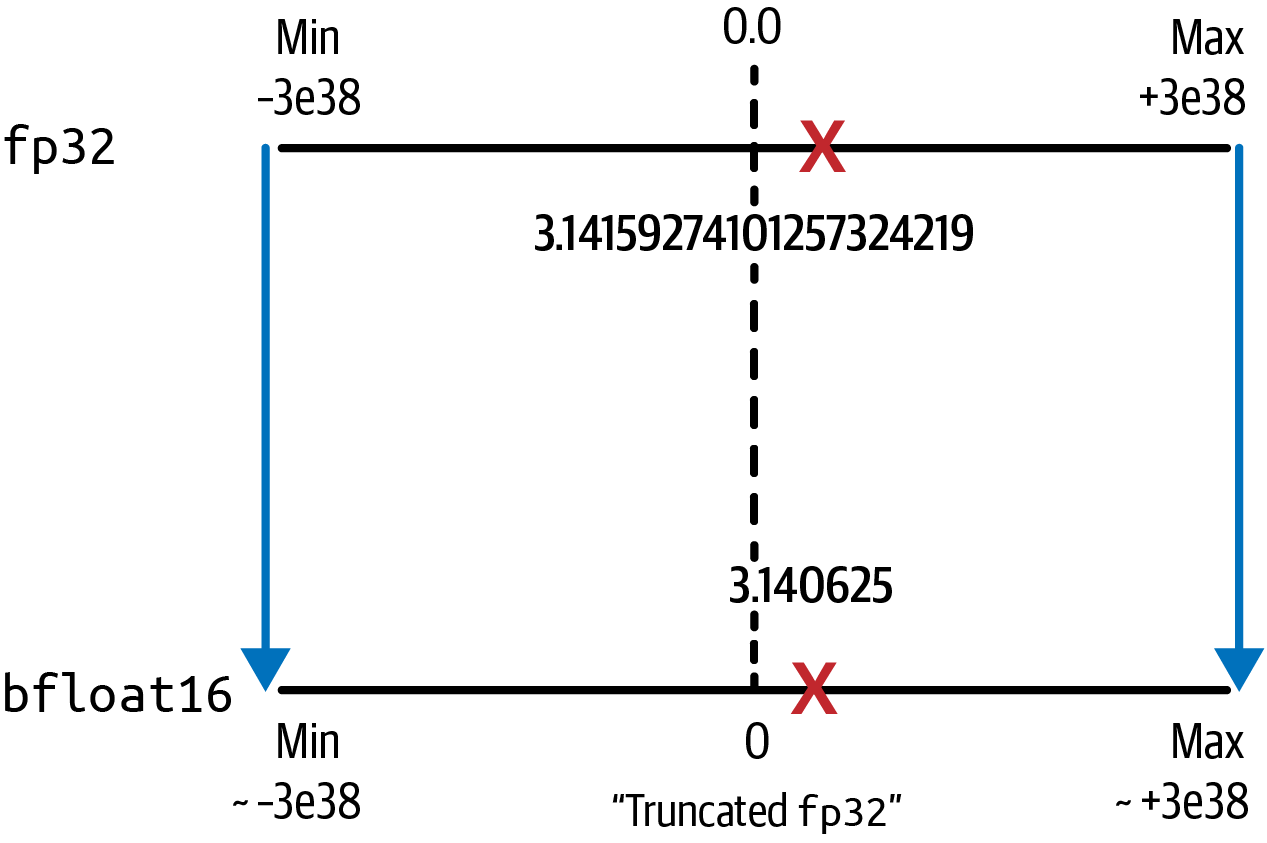
Figura 4-7. La cuantización de fp32 a bfloat16 mantiene el rango dinámico de fp32 ahorrando un 50% de memoria
bfloat16 es compatible de forma nativa con las GPU más recientes, como las A100 y H100 de NVIDIA. Muchos modelos de IA generativa modernos se preentrenaron con bfloat16, incluidos FLAN-T5, Falcon y Llama 2.
fp8
fp8 es un tipo de datos más reciente de y una progresión natural de fp16 y bfloat16 para reducir aún más la memoria y la huella computacional de los modelos de miles de millones de parámetros.
fp8 permite al usuario configurar el número de bits asignados al exponente y a la fracción en función de la tarea, como el entrenamiento, la inferencia o la cuantización post-entrenamiento. Las GPUs NVIDIA empezaron a soportar fp8 con el chip H100. AWS Trainium también admite fp8, llamado fp8 configurable , o simplemente cfp8. Con cfp8, se utiliza 1 bit para el signo, y los 7 bits restantes son configurables entre el exponente y la fracción, como se muestra en la Tabla 4-5.
| Firma | Exponente | Fracción (mantisa/significante) | |
|---|---|---|---|
fp32 (consume 4 bytes de memoria) |
1 bit0
|
8 bits10000000
|
23 bits10010010000111111011011
|
fp8 (consume 1 byte de memoria) |
1 bit0
|
7 bits0000011 (configurable) |
|
Los resultados empíricos muestran que fp8 puede igualar el rendimiento del entrenamiento de modelos de fp16 y bfloat16, al tiempo que reduce la huella de memoria en otro 50% y acelera el entrenamiento de modelos.
int8
Otra opción de cuantización es int8 cuantización de 8 bits. Utilizando 1 bit para el signo, los valores de int8 se representan con los 7 bits restantes, como se muestra en la Tabla 4-6.
| Firma | Exponente | Fracción (mantisa/significante) | |
|---|---|---|---|
fp32 (consume 4 bytes de memoria) |
1 bit0
|
8 bits10000000
|
23 bits10010010000111111011011
|
int8 (consume 1 byte de memoria) |
1 bit0
|
n/a |
7 bits0000011
|
El rango de números representables de int8 es de -128 a +127. Aquí tienes la información del tipo de datos para int8:
torch.iinfo(torch.int8)
La salida es:
iinfo(min=-128, max=127, dtype=int8)
Almacenemos de nuevo pi con 20 decimales en int8 y veamos qué ocurre:
pi=3.14159265358979323846pi_int8=torch.tensor(pi,dtype=torch.int8)(pi_int8.item())
La salida es:
3
Como era de esperar, pi se proyecta a sólo 3 en el espacio de 8 bits de menor precisión, como se muestra en la Figura 4-8.
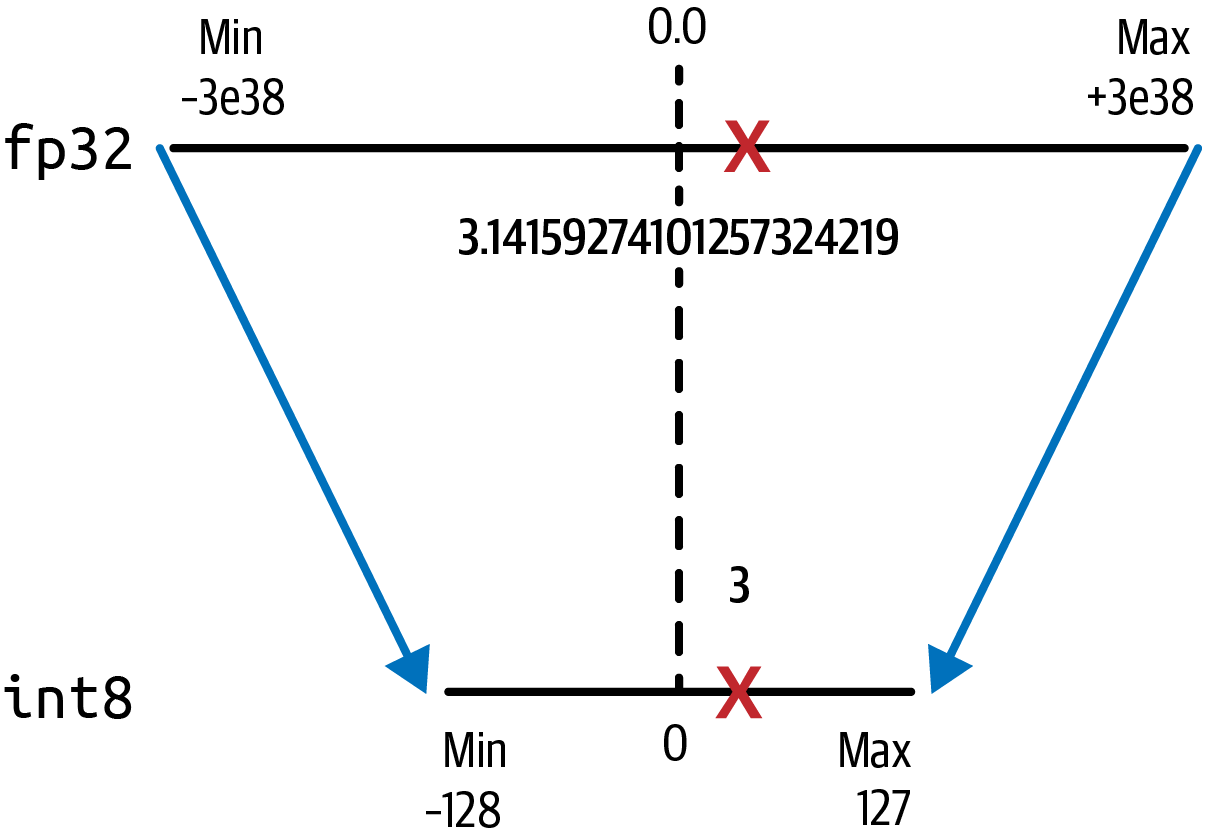
Figura 4-8. La cuantización de fp32 a int8 ahorra un 75% de memoria
Esto reduce los requisitos de memoria de los 4 bytes originales a sólo 1 byte, pero supone una mayor pérdida de precisión debido a la conversión de una representación en coma flotante a un valor entero.
Reducir la huella de memoria de los grandes modelos de fundamentos no sólo es útil para cargar y entrenar los modelos, sino también para la inferencia. A pesar de la pérdida de precisión, la cuantización de 8 bits se utiliza a menudo para mejorar el rendimiento y la latencia de la inferencia de los modelos implementados. Las implementaciones optimizadas para la cuantización int8, como la integración bitsandbytes de Hugging Face de LLM.int8(), han demostrado minimizar el impacto de la cuantización en el rendimiento del modelo. Aprenderás sobre la cuantización post-entrenamiento (PTQ) y la técnica de cuantización post-entrenamiento GPT (GPTQ)1 con más detalle cuando prepares el modelo para su implementación en el Capítulo 8.
La Tabla 4-7 compara los tipos de datos tratados hasta ahora.
| Bits totales | Bits de signo | Bits de exponente | Bits de fracción | Memoria necesaria para almacenar un valor | |
|---|---|---|---|---|---|
fp32 |
32 | 1 | 8 | 23 | 4 bytes |
fp16 |
16 | 1 | 5 | 10 | 2 bytes |
bf16 |
16 | 1 | 8 | 7 | 2 bytes |
fp8 |
8 | 1 | 7 | 1 byte | |
int8 |
8 | 1 | n/a | 7 | 1 byte |
En resumen, la elección del tipo de datos para la cuantización de modelos debe basarse en las necesidades específicas de tu aplicación. Aunque fp32 ofrece una elección segura si la precisión es primordial, es probable que te encuentres con límites de hardware, como la RAM disponible en la GPU, especialmente para modelos de miles de millones de parámetros.
En este caso, la cuantización mediante fp16 y bfloat16 puede ayudar a reducir la huella de memoria necesaria en un 50%. bfloat16 suele preferirse a fp16, ya que mantiene el mismo rango dinámico que fp32 y reduce el desbordamiento. fp8 es un tipo de datos emergente para reducir aún más los requisitos de memoria y cálculo. Algunas implementaciones de hardware permiten configurar los bits para exponente y fracción; los resultados empíricos muestran que el rendimiento puede igualar el entrenamiento del modelo con fp16 y bfloat16. int8 se ha convertido en una opción popular para optimizar tu modelo para la inferencia. fp8 se está haciendo más popular a medida que surge la compatibilidad tanto del hardware como del marco de aprendizaje profundo.
Consejo
Se recomienda que evalúes siempre los resultados de la cuantización para asegurarte de que el tipo de datos seleccionado cumple tus requisitos de precisión y rendimiento.
Otra técnica de optimización de la memoria y el cálculo es FlashAttention. FlashAttention pretende reducir los requisitos cuadráticos de cálculo y memoria, O(n2), de las capas de autoatención en los modelos basados en Transformadores.
Optimizar las capas de autoatención
Como se menciona en el Capítulo 3, el rendimiento del Transformador suele verse atascado por la complejidad de cálculo y memoria de las capas de autoatención. Muchas mejoras de rendimiento se dirigen específicamente a estas capas. A continuación, aprenderás algunas técnicas potentes para reducir la memoria y aumentar el rendimiento de las capas de autoatención.
FlashAtención
La capa de atención del Transformador es un cuello de botella cuando se intenta escalar a secuencias de entrada más largas, porque los requisitos de cálculo y memoria escalan cuadráticamente O(n2) con el número de fichas de entrada. FlashAttention, propuesto inicialmente en un trabajo de investigación2 es una solución específica de la GPU a este problema de escalado cuadrático.
FlashAttention, en la versión 2 en el momento de escribir este artículo, reduce la cantidad de lecturas y escrituras entre la memoria principal de la GPU, llamada memoria de gran ancho de banda (HBM), y la RAM estática (SRAM) de la GPU en chip, mucho más rápida pero más pequeña. A pesar de su nombre, la memoria de gran ancho de banda de la GPU es un orden de magnitud más lenta que la SRAM de la GPU en chip.
En general, FlashAttention aumenta el rendimiento de la autoatención entre 2 y 4 veces y reduce el uso de memoria entre 10 y 20 veces, al reducir los requisitos computacionales y de memoria cuadráticos O(n2) a lineales O(n), donde n es el número de fichas de entrada en la secuencia. Con FlashAttention, el Transformador se escala para manejar secuencias de entrada mucho más largas, lo que permite un mejor rendimiento en ventanas de contexto de entrada más grandes.
Una implementación popular se puede instalar con un simple comando pip install flash-attn --no-build-isolation que instala la biblioteca flash-attn en sustitución de la atención original.
Las optimizaciones de la atención son un área activa de investigación, incluida la nueva generación FlashAttention-2,3 que sigue implementando optimizaciones específicas de la GPU para mejorar el rendimiento y reducir los requisitos de memoria.
Vamos a conocer otra técnica para mejorar el rendimiento de las capas de autoatención en el Transformer.
Atención a las consultas agrupadas
Otra optimización popular para las capas de atención es la atención a consultas agrupadas (GQA). La GQA mejora la atención multicabezal tradicional del Transformer, descrita en el Capítulo 3, compartiendo una única clave(k) y valor(v) para cada grupo de cabezas de consulta(q) (en lugar de cada cabeza de consulta), como se muestra en la Figura 4-9.
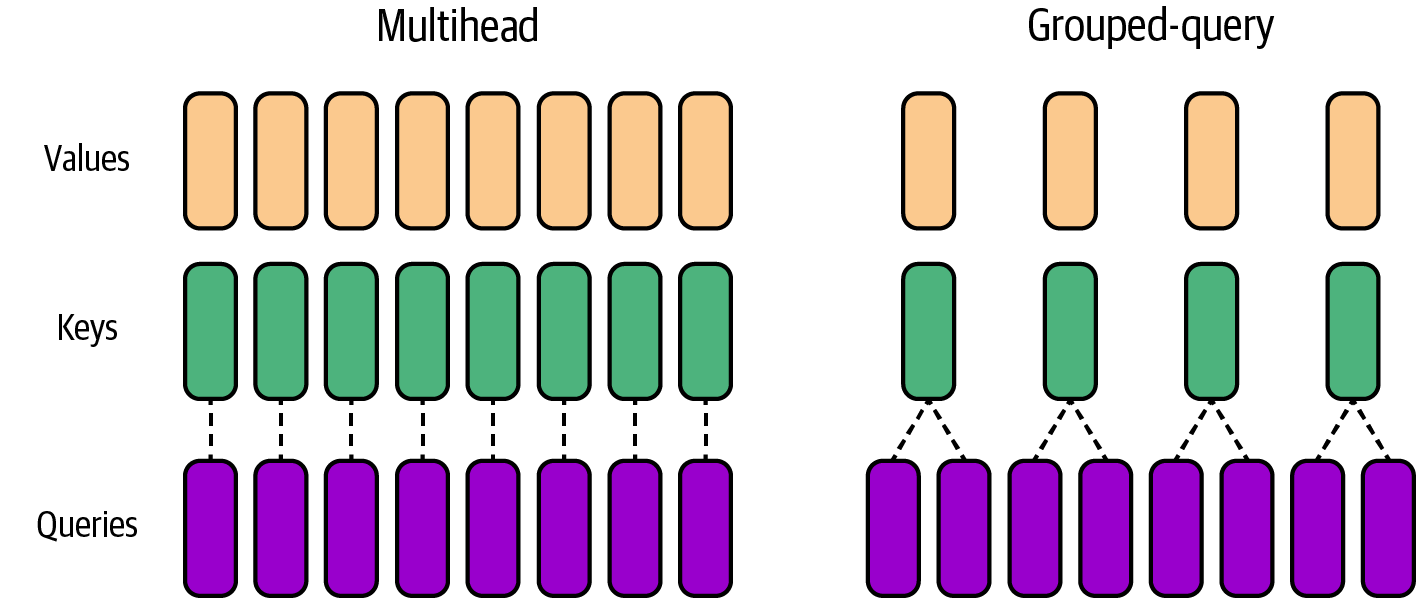
Figura 4-9. Atención a la consulta agrupada frente a la atención multicabezal tradicional
GQA permite agrupar las consultas en menos cabezas de clave y de valor y, por tanto, reduce el consumo de memoria de las cabezas de atención. Además, GQA mejora el rendimiento al reducir el número de lecturas y escrituras en memoria.
Como estas mejoras son proporcionales al número de tokens de entrada, el MQA es especialmente útil para secuencias de tokens de entrada más largas y permite una ventana de contexto mayor. Por ejemplo, el modelo Llama 2 de Meta utiliza MQA para mejorar el rendimiento y aumentar el tamaño de la ventana de contexto de los tokens de entrada a 4.096, el doble del tamaño de la ventana de contexto de 2.048 del modelo LLaMA original.
Informática distribuida
Para modelos más grandes, es probable que necesites utilizar un cluster distribuido de GPUs para entrenar estos modelos masivos en cientos o miles de GPUs. Hay muchos tipos diferentes de modelos de computación distribuida, como el paralelo de datos distribuidos (DDP) y el paralelo de datos totalmente fragmentados (FSDP). La principal diferencia radica en cómo se divide -o fragmenta- el modelo entre las GPU del sistema.
Si los parámetros del modelo caben en una sola GPU, entonces elegirías DDP para cargar una sola copia del modelo en cada GPU. Si el modelo es demasiado grande para una sola GPU -incluso después de la cuantización-, entonces tendrás que utilizar FSDP para repartir el modelo entre varias GPU. En ambos casos, los datos se dividen en lotes y se reparten entre todas las GPU disponibles para aumentar la utilización de la GPU y la eficiencia de costes, a expensas de cierta sobrecarga de comunicación, que verás dentro de un momento.
Datos Distribuidos Paralelos
PyTorch viene con una implementación optimizada de DDP que copia automáticamente tu modelo en cada GPU (suponiendo que quepa en una sola GPU utilizando una técnica como la cuantización), divide los datos en lotes y envía los lotes a cada GPU en paralelo. Con DDP, cada lote de datos se procesa en paralelo en cada GPU, seguido de un paso de sincronización en el que se combinan (por ejemplo, se promedian) los resultados de cada GPU (por ejemplo, los gradientes). Posteriormente, cada modelo -uno por GPU- se actualiza con los resultados combinados y el proceso continúa, como se muestra en la Figura 4-10.
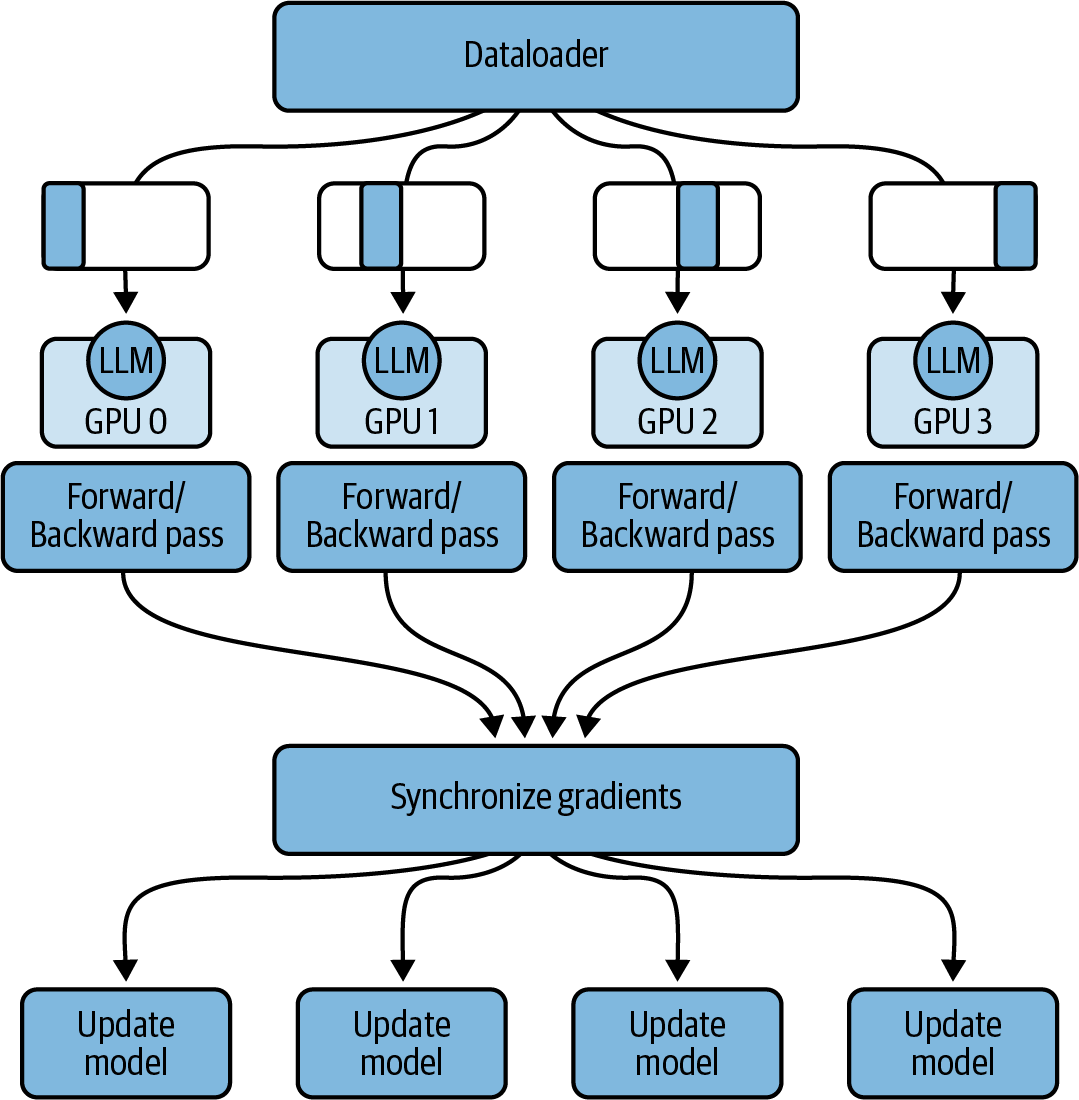
Figura 4-10. Datos distribuidos en paralelo (DDP)
Ten en cuenta que el DDP asume que en cada GPU caben no sólo los parámetros de tu modelo y los lotes de datos, sino también los datos adicionales que se necesitan para cumplir el bucle de entrenamiento, incluidos los estados del optimizador, las activaciones, las variables de función temporales, etc., como se muestra en la Figura 4-15. Si tu GPU no puede almacenar todos estos datos, tendrás que fragmentar tu modelo en varias GPUs. PyTorch tiene una implementación optimizada de la fragmentación de modelos que verás a continuación.
Datos totalmente fragmentados en paralelo
FSDP fue motivado por un artículo de ZeRO de 2019.4 El objetivo de ZeRO, u optimizador de redundancia cero, es reducir la redundancia de datos del DDP repartiendo el modelo -y sus gradientes, activaciones y estados de optimización adicionales- entre las GPU para conseguir una redundancia cero en el sistema. ZeRO describe tres etapas de optimización (1, 2, 3) en función de lo que se reparta entre las GPUs, como se muestra en la Figura 4-11.
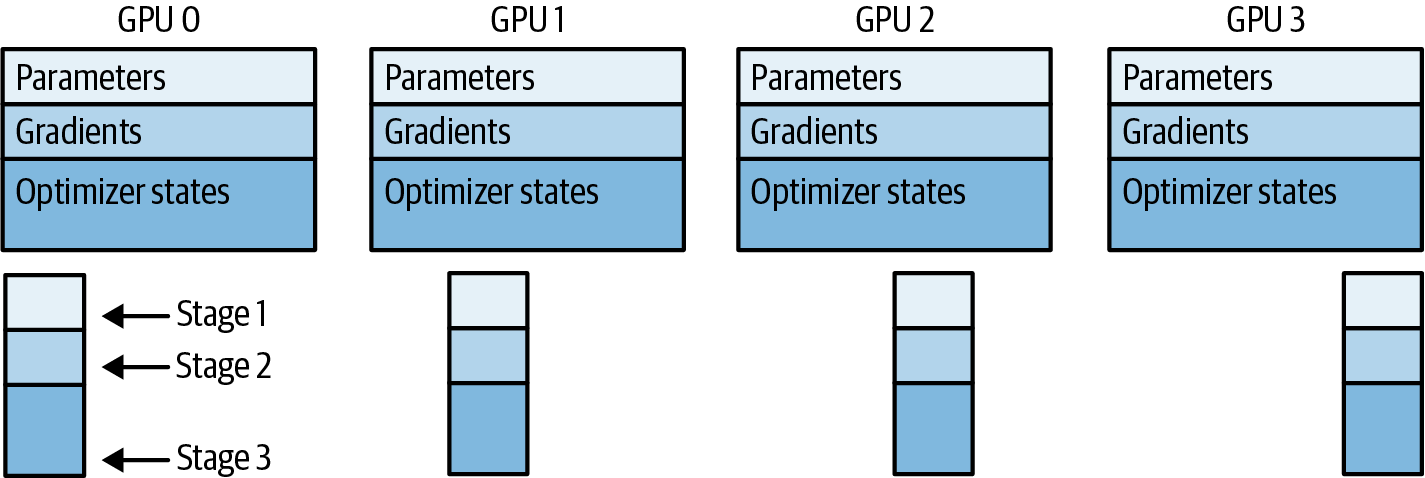
Figura 4-11. ZeRO consta de tres etapas en función de los fragmentos de GPU: parámetros, gradientes y estados del optimizador
La fase 1 de ZeRO sólo reparte los estados del optimizador entre las GPU, pero reduce la memoria de tu modelo hasta 4 veces. ZeRO Fase 2 distribuye tanto los estados del optimizador como los gradientes por las GPU para reducir la memoria de la GPU hasta 8 veces. ZeRO Fase 3 lo reparte todo -incluidos los parámetros del modelo- entre las GPU para ayudar a reducir la memoria de la GPU hasta n veces, donde n es el número de GPU. Por ejemplo, si utilizas ZeRO Stage 3 con 128 GPU, puedes reducir el consumo de memoria hasta 128 veces.
En comparación con el DDP, en el que cada GPU tiene una copia completa de todo lo necesario para realizar los pases hacia delante y hacia atrás, el FSDP necesita reconstruir dinámicamente una capa completa de los datos fragmentados en cada GPU antes de los pases hacia delante y hacia atrás, como se muestra en la Figura 4-12.
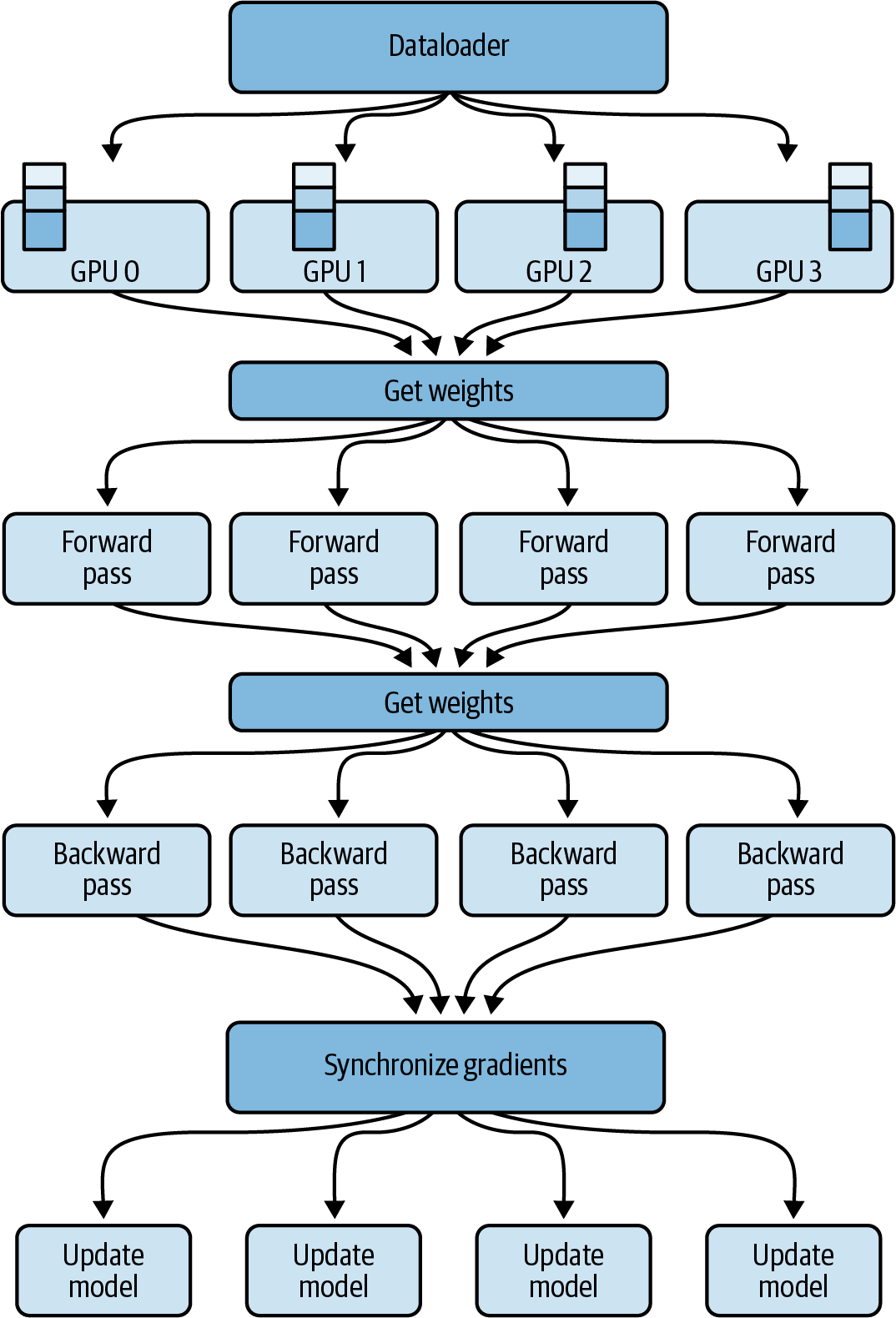
Figura 4-12. FSDP en varias GPUs
En la Figura 4-12, puedes ver que antes del paso hacia delante, cada GPU solicita datos a las otras GPU bajo demanda para materializar los datos fragmentados en datos locales no fragmentados durante la duración de la operación, normalmente por capas.
Cuando finaliza el paso hacia delante, el FSDP devuelve los datos locales no fragmentados a las otras GPUs, devolviendo los datos a su estado fragmentado original para liberar memoria en la GPU para el paso hacia atrás. Tras el paso hacia atrás, el FSDP sincroniza los gradientes entre las GPUs, de forma similar al DDP, y actualiza los parámetros del modelo en todos los fragmentos del modelo, donde los diferentes fragmentos se almacenan en diferentes GPUs.
Al materializar los datos bajo demanda, FSDP equilibra la sobrecarga de comunicación con la huella total de memoria de la GPU. Puedes configurar manualmente el factor de fragmentación a través de la configuración de computación distribuida. Más adelante en este capítulo, verás un ejemplo utilizando el parámetro de configuración sharded_data_parallel_degree de Amazon SageMaker. Este parámetro de configuración ayuda a gestionar el equilibrio entre el rendimiento y la utilización de la memoria en función de tu entorno específico, como se muestra en la Figura 4-13.
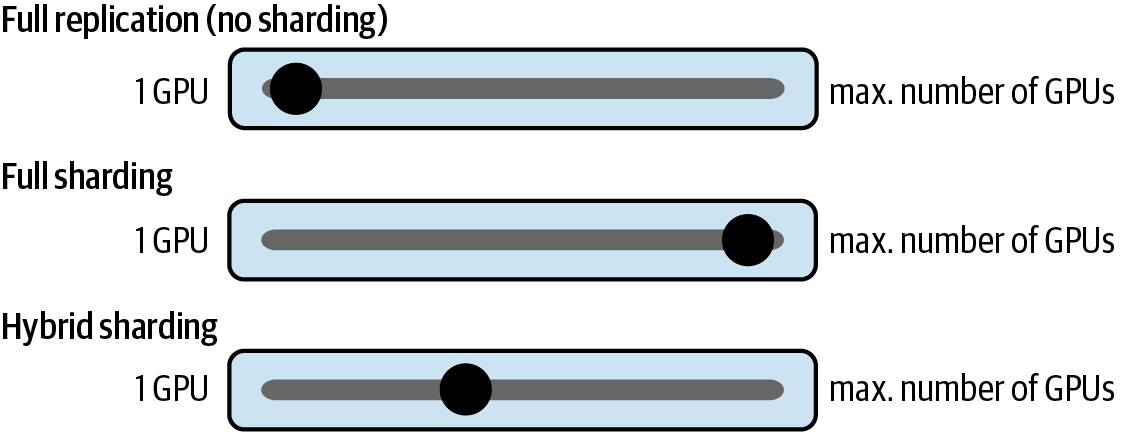
Figura 4-13. Elegir un factor de fragmentación en función de los recursos de tu entorno
Un factor de fragmentación de 1 evita la fragmentación del modelo y replica el modelo en todas las GPUs, volviendo el sistema a DDP. Puedes establecer el factor de fragmentación en un máximo de n número de GPUs para liberar el potencial de la fragmentación completa. La fragmentación completa ofrece el mayor ahorro de memoria, a costa de la sobrecarga de comunicación con la GPU. Si estableces el factor de compartición a un valor intermedio, activarás la compartición híbrida.
Comparación del rendimiento del FSDP sobre el DDP
La Figura 4-14 es una comparación de FSDP y DDP de un trabajo 2023 PyTorch FSDP.5 Estas pruebas se realizaron en modelos T5 de diferentes tamaños utilizando 512 GPUs NVIDIA A100, cada una con 80 GB de memoria. Comparan el número de FLOPs por GPU. Un teraFLOP es 1 billón de operaciones de coma flotante por segundo.
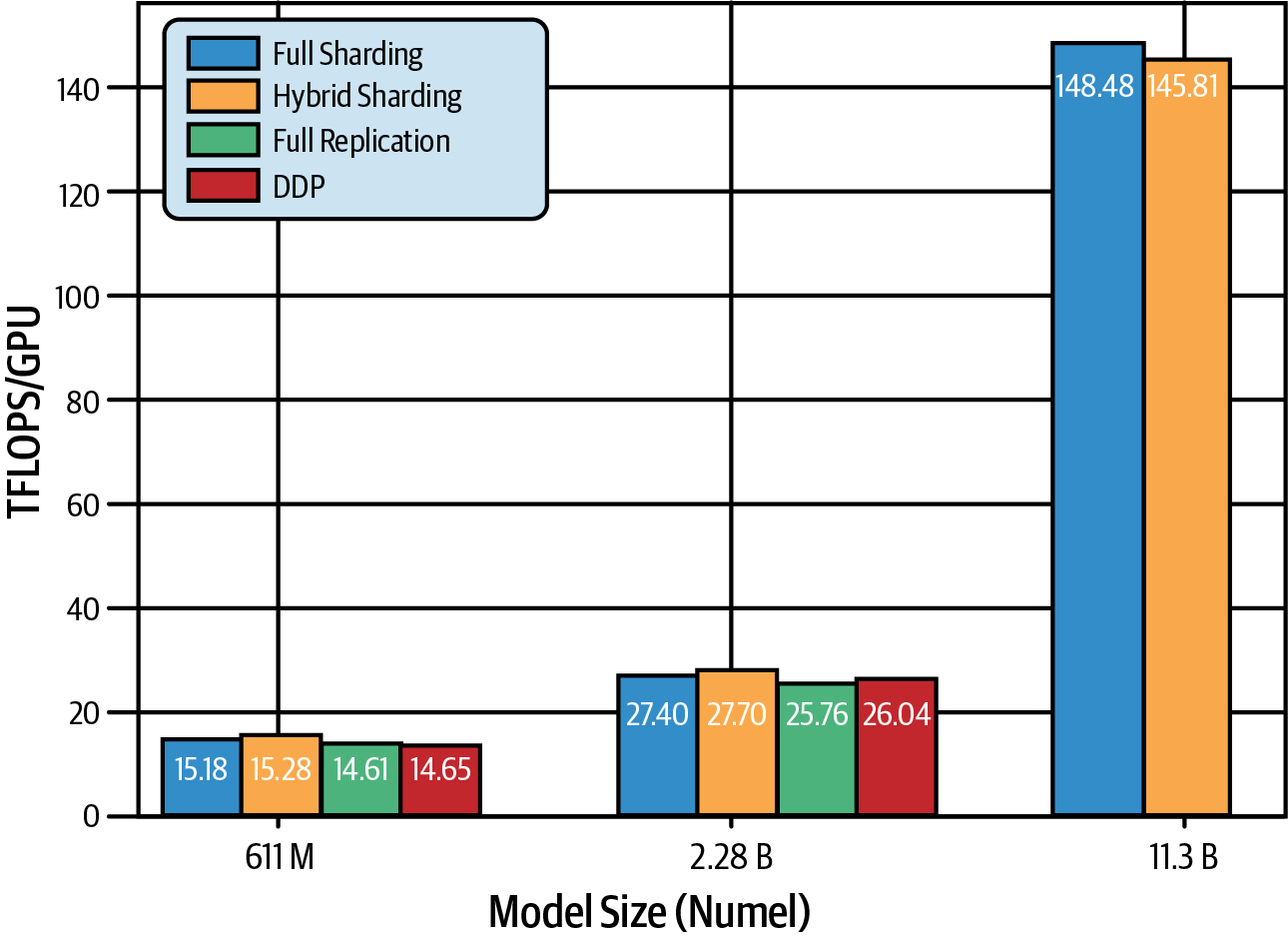
Figura 4-14. Mejora del rendimiento con FSDP sobre DDP (fuente: adaptado de una imagen de Zhao et al.)
Ten en cuenta que la replicación completa significa que no hay fragmentación. Y como la replicación completa es equivalente a la DDP, el rendimiento de las configuraciones de replicación completa y DDP es casi idéntico.
Para los modelos T5 más pequeños, 611 millones de parámetros y 2.280 millones de parámetros, el FSDP tiene el mismo rendimiento que el DDP. Sin embargo, con 11.300 millones de parámetros, el DDP se queda sin memoria en la GPU, por lo que no hay datos para el DDP en la dimensión de 11.300 millones. El FSDP, sin embargo, admite fácilmente el mayor tamaño de los parámetros cuando se utiliza la fragmentación híbrida y completa.
Además, el entrenamiento del modelo de 11.000 millones de parámetros con diferentes tamaños de clúster, desde 8 GPUs hasta 512 GPUs, sólo muestra una disminución del 7% en teraFLOPs por GPU debido a la sobrecarga de comunicación de la GPU. Estas pruebas se ejecutaron con tamaños de lote de 8 (azul) y 16 (naranja), como se muestra en la Figura 4-15, que también procede del documento 2023 PyTorch FSDP.
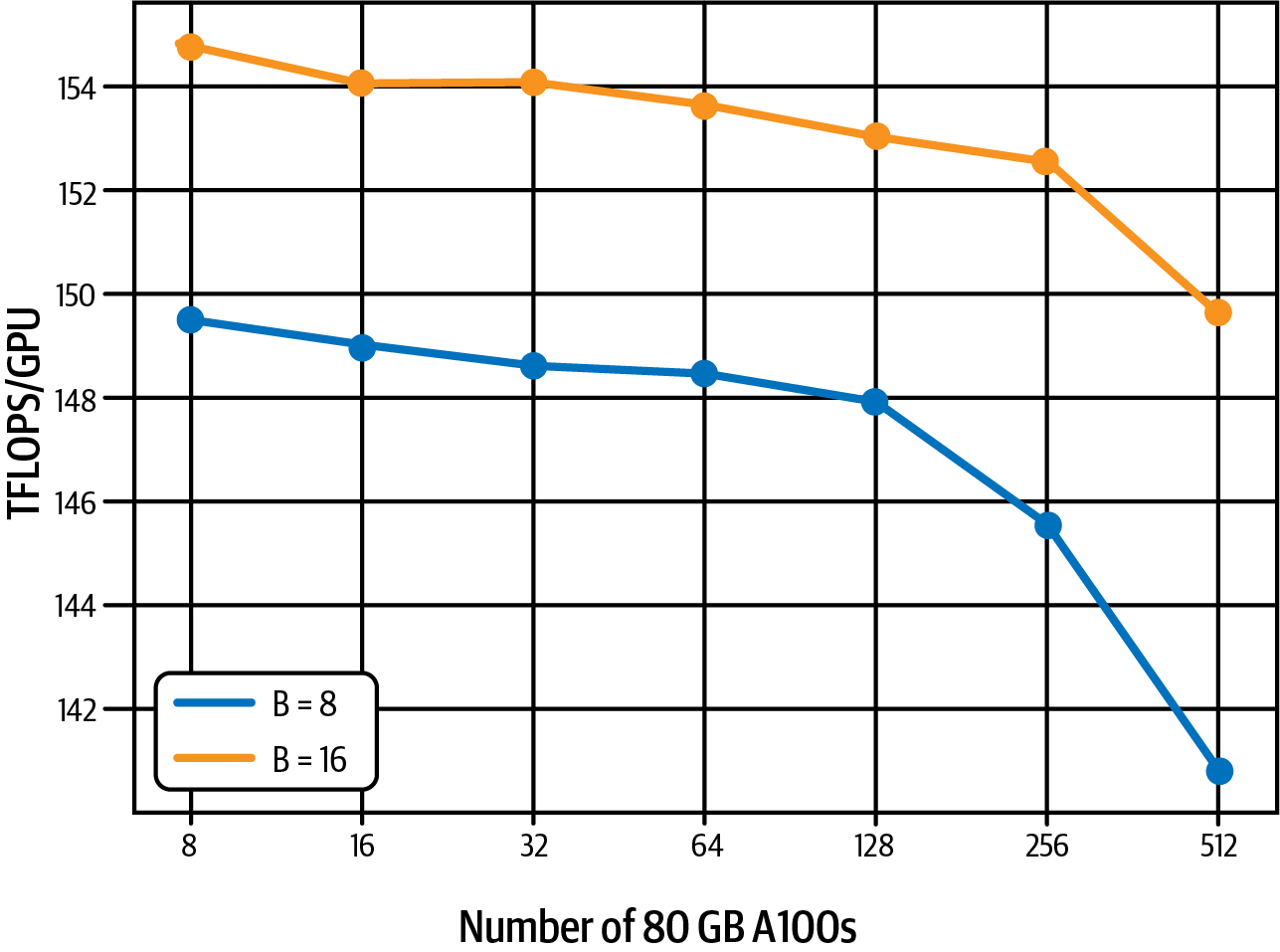
Figura 4-15. Sólo hay una pequeña disminución del rendimiento debida a la sobrecarga de comunicación de la GPU (fuente: adaptado de una imagen de Zhao et al.)
Esto demuestra que FSDP puede escalar el entrenamiento de modelos pequeños y grandes a través de diferentes tamaños de clúster de GPU. A continuación, aprenderás a realizar computación distribuida y FSDP en AWS utilizando Amazon SageMaker.
Computación distribuida en AWS
El entrenamiento distribuido de Amazon SageMaker se ha utilizado para entrenar algunos de los modelos de fundamentos más potentes del mundo, incluidos Falcon y BloombergGPT. Falcon-180B, por ejemplo, se entrenó utilizando un clúster de entrenamiento distribuido de Amazon SageMaker de 512 instancias ml.p4d.24xlarge, cada una con 8 GPU NVIDIA A100 (40 GB de RAM de GPU cada una) para un total de 4.096 GPU y aproximadamente 164 TB de RAM de GPU. BloombergGPT se entrenó en 64 instancias de ml.p4d.24xlarge para un total de 512 GPU y aproximadamente 20 TB de RAM de GPU.
Con la infraestructura informática distribuida de SageMaker, puedes ejecutar cargas de trabajo de IA generativa altamente escalables y rentables con sólo unas pocas líneas de código. A continuación, aprenderás a implementar FSDP con Amazon SageMaker.
Datos totalmente fragmentados en paralelo con Amazon SageMaker
FSDP es una estrategia común de computación distribuida soportada por Amazon SageMaker. El siguiente código muestra cómo lanzar un trabajo de entrenamiento distribuido FSDP utilizando el Estimador PyTorch con 2 instancias de ml.p4d.24xlarge SageMaker, cada una con 8 GPUs y 320 GB de RAM de GPU:
# Choose instance type and instance count# based on the GPU memory requirements# for the model variant we are using# e.g. Llama2 7, 13, 70 billioninstance_type="ml.p4d.24xlarge"# 8 GPUs eachinstance_count=2# Set to the number of GPUs on that instanceprocesses_per_host=8# Configure the sharding factor# In this case, 16 is the maximum, fully-sharded configuration# since we have 2 instances * 8 GPUs per instancesharding_degree=16# Set up the training jobsmp_estimator=PyTorch(entry_point="train.py",# training scriptinstance_type=instance_type,instance_count=instance_count,distribution={"smdistributed":{"modelparallel":{"enabled":True,"parameters":{"ddp":True,"sharded_data_parallel_degree":sharding_degree}}},...},...)
Aquí, configura el trabajo para usar smdistributed con modelparallel.enabled y ddp establecidos en True. Esto configura el cluster SageMaker para usar la estrategia de computación distribuida FSDP. Ten en cuenta que fijamos el parámetro sharded_data_parallel_degree en 16 porque tenemos dos instancias con ocho GPUs cada una. Este parámetro es nuestro factor de fragmentación, como se explica en la sección "Paralelo de datos totalmente fragmentado". En este caso, elegimos la fragmentación completa estableciendo el valor en el número total de GPU del clúster.
A continuación hay algunos fragmentos interesantes del train.py al que se hace referencia en el código anterior del Estimador PyTorch. El código completo está en el repositorio de GitHub asociado a este libro:
fromtransformersimportAutoConfig,AutoModelForCausalLMimportsmp# SageMaker distributed library# Create FSDP config for SageMakersmp_config={"ddp":True,"bf16":args.bf16,"sharded_data_parallel_degree":args.sharded_data_parallel_degree,}# Initialize FSDPsmp.init(smp_config)# Load HuggingFace modelmodel=AutoModelForCausalLM.from_pretrained(model_checkpoint)# Wrap HuggingFace model in SageMaker DistributedModel classmodel=smp.DistributedModel(model)# Define the distributed training step@smp.stepdeftrain_step(model,input_ids,attention_mask,args):ifargs.logits_output:output=model(input_ids=input_ids,attention_mask=attention_mask,labels=input_ids)loss=output["loss"]else:loss=model(input_ids=input_ids,attention_mask=attention_mask,labels=input_ids)["loss"]model.backward(loss)ifargs.logits_output:returnoutputreturnloss
A continuación, verás cómo entrenar un modelo en el hardware AWS Trainium, que está especialmente diseñado para cargas de trabajo de aprendizaje profundo. Para ello, aprenderás sobre el SDK de Neuron de AWS, así como sobre la biblioteca Neuron Óptima de Hugging Face, que integra el ecosistema de Transformadores de Hugging Face con el SDK de Neuron.
AWS Neuron SDK y AWS Trainium
El SDK Neuron de AWS es la interfaz para desarrolladores de AWS Trainium. La biblioteca Optimum Neuron de Hugging Face es la interfaz entre el SDK de AWS Neuron y la biblioteca Transformers. Aquí tienes un ejemplo que muestra la clase NeuronTrainer de la biblioteca Optimum Neuron, que sustituye directamente a la clase Transformers Trainer al entrenar con AWS Trainium:
fromtransformersimportTrainingArgumentsfromoptimum.neuronimportNeuronTrainerdeftrain():model=AutoModelForCausalLM.from_pretrained(model_checkpoint)training_args=TrainingArguments(...)trainer=NeuronTrainer(model=model,args=training_args,train_dataset=...,eval_dataset=...)trainer.train()
Resumen
En este capítulo, has explorado los retos computacionales del entrenamiento de grandes modelos de fundamentos debido a las limitaciones de memoria de la GPU y has aprendido a utilizar la cuantización para ahorrar memoria, reducir costes y mejorar el rendimiento.
También aprendiste a escalar el entrenamiento de modelos en múltiples GPUs y nodos de un clúster utilizando estrategias de entrenamiento distribuido como el paralelo de datos distribuidos (DDP) y el paralelo de datos totalmente fragmentados (FSDP).
Combinando la cuantización y la informática distribuida, puedes entrenar modelos muy grandes de forma eficaz y rentable, con un impacto mínimo en el rendimiento del entrenamiento y la precisión del modelo.
También aprendiste a entrenar modelos con el SDK de Neuronas de AWS y el hardware específico de AWS Trainium para cargas de trabajo de aprendizaje profundo generativo. Viste cómo utilizar la biblioteca Hugging Face Optimum Neuron, que se integra con el SDK de AWS Neuron para mejorar la experiencia de desarrollo al trabajar con AWS Trainium.
En el Capítulo 5, aprenderás a adaptar los modelos generativos de base existentes a tus propios conjuntos de datos mediante una técnica denominada ajuste fino. El ajuste fino de un modelo básico existente puede ser una alternativa menos costosa pero suficiente que el preentrenamiento del modelo desde cero.
1 Elias Frantar y otros, "GPTQ: Cuantización precisa post-entrenamiento para transformadores generativos pre-entrenados", arXiv, 2023.
2 Tri Dao y otros, "FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness", arXiv, 2022.
3 Tri Dao, "FlashAttention-2: Atención más rápida con mejor paralelismo y partición del trabajo", arXiv, 2023.
4 Samyam Rajbhandari et al., "ZeRO: Optimizaciones de memoria para entrenar modelos de billones de parámetros", arXiv, 2020.
5 Yanli Zhao y otros, "PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel", arXiv, 2023.
Get IA Generativa en AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

