Chapter 1. MySQL Architecture
MySQL’s architectural characteristics make it useful for a wide range of purposes. Although it is not perfect, it is flexible enough to work well in both small and large environments. These range from a personal website up to large-scale enterprise applications. To get the most from MySQL, you need to understand its design so that you can work with it, not against it.
This chapter provides a high-level overview of the MySQL server architecture, the major differences between the storage engines, and why those differences are important. We’ve tried to explain MySQL by simplifying the details and showing examples. This discussion will be useful for those new to database servers as well as readers who are experts with other database servers.
MySQL’s Logical Architecture
A good mental picture of how MySQL’s components work together will help you understand the server. Figure 1-1 shows a logical view of MySQL’s architecture.
The topmost layer, clients, contains the services that aren’t unique to MySQL. They’re services most network-based client/server tools or servers need: connection handling, authentication, security, and so forth.
The second layer is where things get interesting. Much of MySQL’s brains are here, including the code for query parsing, analysis, optimization, and all the built-in functions (e.g., dates, times, math, and encryption). Any functionality provided across storage engines lives at this level: stored procedures, triggers, and views, for example.
The third layer contains the storage engines. They are responsible for storing and retrieving all data stored “in” MySQL. Like the various filesystems available for GNU/Linux, each storage engine has its own benefits and drawbacks. The server communicates with them through the storage engine API. This API hides differences between storage engines and makes them largely transparent at the query layer. It also contains a couple of dozen low-level functions that perform operations such as “begin a transaction” or “fetch the row that has this primary key.” The storage engines don’t parse SQL1 or communicate with one another; they simply respond to requests from the server.
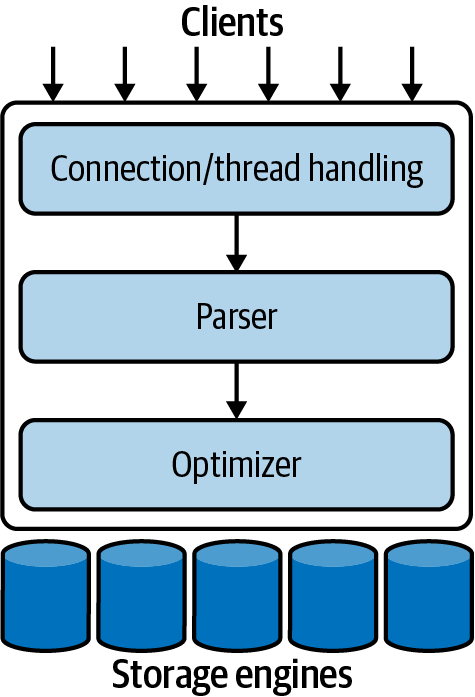
Figure 1-1. A logical view of the MySQL server architecture
Connection Management and Security
By default, each client connection gets its own thread within the server process. The connection’s queries execute within that single thread, which in turn resides on one core or CPU. The server maintains a cache of ready-to-use threads, so they don’t need to be created and destroyed for each new connection.2
When clients (applications) connect to the MySQL server, the server needs to authenticate them. Authentication is based on username, originating host, and password. X.509 certificates can also be used across a Transport Layer Security (TLS) connection. Once a client has connected, the server verifies whether the client has privileges for each query it issues (e.g., whether the client is allowed to issue a SELECT statement that accesses the Country table in the world database).
Optimization and Execution
MySQL parses queries to create an internal structure (the parse tree) and then applies a variety of optimizations. These can include rewriting the query, determining the order in which it will read tables, choosing which indexes to use, and so on. You can pass hints to the optimizer through special keywords in the query, affecting its decision-making process. You can also ask the server to explain various aspects of optimization. This lets you know what decisions the server is making and gives you a reference point for reworking queries, schemas, and settings to make everything run as efficiently as possible. There is more detail on this in Chapter 8.
The optimizer does not really care what storage engine a particular table uses, but the storage engine does affect how the server optimizes the query. The optimizer asks the storage engine about some of its capabilities and the cost of certain operations as well as for statistics on the table data. For instance, some storage engines support index types that can be helpful to certain queries. You can read more about schema optimization and indexing in Chapters 6 and 7.
In older versions, MySQL made use of an internal query cache to see if it could serve the results from there. However, as concurrency increased, the query cache became a notorious bottleneck. As of MySQL 5.7.20, the query cache was officially deprecated as a MySQL feature, and in the 8.0 release, the query cache is fully removed. Even though the query cache is no longer a core part of the MySQL server, caching frequently served result sets is a good practice. While outside the scope of this book, a popular design pattern is to cache data in memcached or Redis.
Concurrency Control
Any time more than one query needs to change data at the same time, the problem of concurrency control arises. For our purposes in this chapter, MySQL has to do this at two levels: the server level and the storage-engine level. We will give you a simplified overview of how MySQL deals with concurrent readers and writers, so you have the context you need for the rest of this chapter.
To illustrate how MySQL handles concurrent work on the same set of data, we will use a traditional spreadsheet file as an example. A spreadsheet consists of rows and columns, much like a database table. Assume the file is on your laptop and only you have access to it. There are no potential conflicts; only you can make changes to the file. Now, imagine you need to collaborate with a coworker on that spreadsheet. It is now on a shared server that both of you have access to. What happens when both of you need to make changes to this file at the same time? What if we have an entire team of people actively trying to edit, add, and remove cells from this spreadsheet? We can say that they should take turns making changes, but that is not efficient. We need an approach for allowing concurrent access to a high-volume spreadsheet.
Read/Write Locks
Reading from the spreadsheet isn’t as troublesome. There’s nothing wrong with multiple clients reading the same file simultaneously; because they aren’t making changes, nothing is likely to go wrong. What happens if someone tries to delete cell number A25 while others are reading the spreadsheet? It depends, but a reader could come away with a corrupted or inconsistent view of the data. So, to be safe, even reading from a spreadsheet requires special care.
If you think of the spreadsheet as a database table, it’s easy to see that the problem is the same in this context. In many ways, a spreadsheet is really just a simple database table. Modifying rows in a database table is very similar to removing or changing the content of cells in a spreadsheet file.
The solution to this classic problem of concurrency control is rather simple. Systems that deal with concurrent read/write access typically implement a locking system that consists of two lock types. These locks are usually known as shared locks and exclusive locks, or read locks and write locks.
Without worrying about the actual locking mechanism, we can describe the concept as follows. Read locks on a resource are shared, or mutually nonblocking: many clients can read from a resource at the same time and not interfere with one another. Write locks, on the other hand, are exclusive—that is, they block both read locks and other write locks—because the only safe policy is to have a single client writing to the resource at a given time and to prevent all reads when a client is writing.
In the database world, locking happens all the time: MySQL has to prevent one client from reading a piece of data while another is changing it. If a database server is performing in an acceptable manner, this management of locks is fast enough to not be noticeable to the clients. We will discuss in Chapter 8 how to tune your queries to avoid performance issues caused by locking.
Lock Granularity
One way to improve the concurrency of a shared resource is to be more selective about what you lock. Rather than locking the entire resource, lock only the part that contains the data you need to change. Better yet, lock only the exact piece of data you plan to change. Minimizing the amount of data that you lock at any one time lets changes to a given resource occur simultaneously, as long as they don’t conflict with each other.
Unfortunately, locks are not free—they consume resources. Every lock operation—getting a lock, checking to see whether a lock is free, releasing a lock, and so on—has overhead. If the system spends too much time managing locks instead of storing and retrieving data, performance can suffer.
A locking strategy is a compromise between lock overhead and data safety, and that compromise affects performance. Most commercial database servers don’t give you much choice: you get what is known as row-level locking in your tables, with a variety of often complex ways to give good performance with many locks. Locks are how databases implement consistency guarantees. An expert operator of a database would have to go as far as reading the source code to determine the most appropriate set of tuning configurations to optimize this trade-off of speed versus data safety.
MySQL, on the other hand, does offer choices. Its storage engines can implement their own locking policies and lock granularities. Lock management is a very important decision in storage-engine design; fixing the granularity at a certain level can improve performance for certain uses yet make that engine less suited for other purposes. Because MySQL offers multiple storage engines, it doesn’t require a single general-purpose solution. Let’s have a look at the two most important lock strategies.
Table locks
The most basic locking strategy available in MySQL, and the one with the lowest overhead, is table locks. A table lock is analogous to the spreadsheet locks described earlier: it locks the entire table. When a client wishes to write to a table (insert, delete, update, etc.), it acquires a write lock. This keeps all other read and write operations at bay. When nobody is writing, readers can obtain read locks, which don’t conflict with other read locks.
Table locks have variations for improved performance in specific situations. For example, READ LOCAL table locks allow some types of concurrent write operations. Write and read lock queues are separate with the write queue being wholly of higher priority than the read queue.3
Row locks
The locking style that offers the greatest concurrency (and carries the greatest overhead) is the use of row locks. Going back to the spreadsheet analogy, row locks would be the same as locking just the row in the spreadsheet. This strategy allows multiple people to edit different rows concurrently without blocking one another. This enables the server to take more concurrent writes, but the cost is more overhead in having to keep track of who has each row lock, how long they have been open, and what kind of row locks they are as well as cleaning up locks when they are no longer needed.
Row locks are implemented in the storage engine, not the server. The server is mostly4 unaware of locks implemented in the storage engines, and as you’ll see later in this chapter and throughout the book, the storage engines all implement locking in their own ways.
Transactions
You can’t examine the more advanced features of a database system for very long before transactions enter the mix. A transaction is a group of SQL statements that are treated atomically, as a single unit of work. If the database engine can apply the entire group of statements to a database, it does so, but if any of them can’t be done because of a crash or other reason, none of them is applied. It’s all or nothing.
Little of this section is specific to MySQL. If you’re already familiar with ACID transactions, feel free to skip ahead to “Transactions in MySQL”.
A banking application is the classic example of why transactions are necessary.5 Imagine a bank’s database with two tables: checking and savings. To move $200 from Jane’s checking account to her savings account, you need to perform at least three steps:
-
Make sure her checking account balance is greater than $200.
-
Subtract $200 from her checking account balance.
-
Add $200 to her savings account balance.
The entire operation should be wrapped in a transaction so that if any one of the steps fails, any completed steps can be rolled back.
You start a transaction with the START TRANSACTION statement and then either make its changes permanent with COMMIT or discard the changes with ROLLBACK. So the SQL for our sample transaction might look like this:
1 START TRANSACTION; 2 SELECT balance FROM checking WHERE customer_id = 10233276; 3 UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276; 4 UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276; 5 COMMIT;
Transactions alone aren’t the whole story. What happens if the database server crashes while performing line 4? Who knows? The customer probably just lost $200. What if another process comes along between lines 3 and 4 and removes the entire checking account balance? The bank has given the customer a $200 credit without even knowing it.
And there are a lot more failure possibilities in this sequence of operations. You could see connection drops, timeouts, or even a crash of the database server running them midway through the operations. This is typically why highly complex and slow two-phase-commit systems exist: to mitigate against all sorts of failure scenarios.
Transactions aren’t enough unless the system passes the ACID test. ACID stands for atomicity, consistency, isolation, and durability. These are tightly related criteria that a data-safe transaction processing system must meet:
- Atomicity
- A transaction must function as a single indivisible unit of work so that the entire transaction is either applied or never committed. When transactions are atomic, there is no such thing as a partially completed transaction: it’s all or nothing.
- Consistency
- The database should always move from one consistent state to the next. In our example, consistency ensures that a crash between lines 3 and 4 doesn’t result in $200 disappearing from the checking account. If the transaction is never committed, none of the transaction’s changes are ever reflected in the database.
- Isolation
- The results of a transaction are usually invisible to other transactions until the transaction is complete. This ensures that if a bank account summary runs after line 3 but before line 4 in our example, it will still see the $200 in the checking account. When we discuss isolation levels later in this chapter, you’ll understand why we said “usually invisible.”
- Durability
- Once committed, a transaction’s changes are permanent. This means the changes must be recorded such that data won’t be lost in a system crash. Durability is a slightly fuzzy concept, however, because there are actually many levels. Some durability strategies provide a stronger safety guarantee than others, and nothing is ever 100% durable (if the database itself were truly durable, then how could backups increase durability?).
ACID transactions and the guarantees provided through them in the InnoDB engine specifically are one of the strongest and most mature features in MySQL. While they come with certain throughput trade-offs, when applied appropriately they can save you from implementing a lot of complex logic in the application layer.
Isolation Levels
Isolation is more complex than it looks. The ANSI SQL standard defines four isolation levels. If you are new to the world of databases, we highly recommend you get familiar with the general standard of ANSI SQL6 before coming back to reading about the specific MySQL implementation. The goal of this standard is to define the rules for which changes are and aren’t visible inside and outside a transaction. Lower isolation levels typically allow higher concurrency and have lower overhead.
Note
Each storage engine implements isolation levels slightly differently, and they don’t necessarily match what you might expect if you’re used to another database product (thus, we won’t go into exhaustive detail in this section). You should read the manuals for whichever storage engines you decide to use.
Let’s take a quick look at the four isolation levels:
READ UNCOMMITTED- In the
READ UNCOMMITTEDisolation level, transactions can view the results of uncommitted transactions. At this level, many problems can occur unless you really, really know what you are doing and have a good reason for doing it. This level is rarely used in practice because its performance isn’t much better than the other levels, which have many advantages. Reading uncommitted data is also known as a dirty read. READ COMMITTED- The default isolation level for most database systems (but not MySQL!) is
READ COMMITTED. It satisfies the simple definition of isolation used earlier: a transaction will continue to see changes made by transactions that were committed after it began, and its changes won’t be visible to others until it has committed. This level still allows what’s known as a nonrepeatable read. This means you can run the same statement twice and see different data. REPEATABLE READ-
REPEATABLE READsolves the problems thatREAD UNCOMMITTEDallows. It guarantees that any rows a transaction reads will “look the same” in subsequent reads within the same transaction, but in theory it still allows another tricky problem: phantom reads. Simply put, a phantom read can happen when you select some range of rows, another transaction inserts a new row into the range, and then you select the same range again; you will then see the new “phantom” row. InnoDB and XtraDB solve the phantom read problem with multiversion concurrency control, which we explain later in this chapter.REPEATABLE READis MySQL’s default transaction isolation level. SERIALIZABLE- The highest level of isolation,
SERIALIZABLE, solves the phantom read problem by forcing transactions to be ordered so that they can’t possibly conflict. In a nutshell,SERIALIZABLEplaces a lock on every row it reads. At this level, a lot of timeouts and lock contention can occur. We’ve rarely seen people use this isolation level, but your application’s needs might force you to accept the decreased concurrency in favor of the data safety that results.
Table 1-1 summarizes the various isolation levels and the drawbacks associated with each one.
| Isolation level | Dirty reads possible | Nonrepeatable reads possible | Phantom reads possible | Locking reads |
|---|---|---|---|---|
READ UNCOMMITTED |
Yes | Yes | Yes | No |
READ COMMITTED |
No | Yes | Yes | No |
REPEATABLE READ |
No | No | Yes | No |
SERIALIZABLE |
No | No | No | Yes |
Deadlocks
A deadlock is when two or more transactions are mutually holding and requesting locks on the same resources, creating a cycle of dependencies. Deadlocks occur when transactions try to lock resources in a different order. They can happen whenever multiple transactions lock the same resources. For example, consider these two transactions running against a StockPrice table, which has a primary key of (stock_id, date):
Transaction 1
START TRANSACTION; UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = ‘2020-05-01’; UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = ‘2020-05-02’; COMMIT;
Transaction 2
START TRANSACTION; UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = ‘2020-05-02’; UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = ‘2020-05-01’; COMMIT;
Each transaction will execute its first query and update a row of data, locking that row in the primary key index and any additional unique index it is part of in the process. Each transaction will then attempt to update its second row, only to find that it is already locked. The two transactions will wait forever for each other to complete unless something intervenes to break the deadlock. We cover further in Chapter 7 how indexing can make or break the performance of your queries as your schema evolves.
To combat this problem, database systems implement various forms of deadlock detection and timeouts. The more sophisticated systems, such as the InnoDB storage engine, will notice circular dependencies and return an error instantly. This can be a good thing—otherwise, deadlocks would manifest themselves as very slow queries. Others will give up after the query exceeds a lock wait timeout, which is not always good. The way InnoDB currently handles deadlocks is to roll back the transaction that has the fewest exclusive row locks (an approximate metric for which will be the easiest to roll back).
Lock behavior and order are storage engine specific, so some storage engines might deadlock on a certain sequence of statements even though others won’t. Deadlocks have a dual nature: some are unavoidable because of true data conflicts, and some are caused by how a storage engine works.7
Once they occur, deadlocks cannot be broken without rolling back one of the transactions, either partially or wholly. They are a fact of life in transactional systems, and your applications should be designed to handle them. Many applications can simply retry their transactions from the beginning, and unless they encounter another deadlock, they should be successful.
Transaction Logging
Transaction logging helps make transactions more efficient. Instead of updating the tables on disk each time a change occurs, the storage engine can change its in-memory copy of the data. This is very fast. The storage engine can then write a record of the change to the transaction log, which is on disk and therefore durable. This is also a relatively fast operation, because appending log events involves sequential I/O in one small area of the disk instead of random I/O in many places. Then, at some later time, a process can update the table on disk. Thus, most storage engines that use this technique (known as write-ahead logging) end up writing the changes to disk twice.
If there’s a crash after the update is written to the transaction log but before the changes are made to the data itself, the storage engine can still recover the changes upon restart. The recovery method varies between storage engines.
Transactions in MySQL
Storage engines are the software that drives how data will be stored and retrieved from disk. While MySQL has traditionally offered a number of storage engines that support transactions, InnoDB is now the gold standard and the recommended engine to use. Transaction primitives described here will be based on transactions in the InnoDB engine.
Understanding AUTOCOMMIT
By default, a single INSERT, UPDATE, or DELETE statement is implicitly wrapped in a transaction and committed immediately. This is known as AUTOCOMMIT mode. By disabling this mode, you can execute a series of statements within a transaction and, at conclusion, COMMIT or ROLLBACK.
You can enable or disable the AUTOCOMMIT variable for the current connection by using a SET command. The values 1 and ON are equivalent, as are 0 and OFF. When you run with AUTOCOMMIT=0, you are always in a transaction until you issue a COMMIT or ROLLBACK. MySQL then starts a new transaction immediately. Additionally, with AUTOCOMMIT enabled, you can begin a multistatement transaction by using the keyword BEGIN or START TRANSACTION. Changing the value of AUTOCOMMIT has no effect on nontransactional tables, which have no notion of committing or rolling back changes.
Certain commands, when issued during an open transaction, cause MySQL to commit the transaction before they execute. These are typically DDL commands that make significant changes, such as ALTER TABLE, but LOCK TABLES and some other statements also have this effect. Check your version’s documentation for the full list of commands that automatically commit a transaction.
MySQLlets you set the isolation level using the SET TRANSACTION ISOLATION LEVEL command, which takes effect when the next transaction starts. You can set the isolation level for the whole server in the configuration file or just for your session:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
It is preferable to set the isolation you use most at the server level and only change it in explicit cases. MySQL recognizes all four ANSI standard isolation levels, and InnoDB supports all of them.
Mixing storage engines in transactions
MySQL doesn’t manage transactions at the server level. Instead, the underlying storage engines implement transactions themselves. This means you can’t reliably mix different engines in a single transaction.
If you mix transactional and nontransactional tables (for instance, InnoDB and MyISAM tables) in a transaction, the transaction will work properly if all goes well. However, if a rollback is required, the changes to the nontransactional table can’t be undone. This leaves the database in an inconsistent state from which it might be difficult to recover and renders the entire point of transactions moot. This is why it is really important to pick the right storage engine for each table and to avoid mixing storage engines in your application logic at all costs.
MySQL will usually not warn you or raise errors if you do transactional operations on a nontransactional table. Sometimes rolling back a transaction will generate the warning, “Some nontransactional changed tables couldn’t be rolled back,” but most of the time, you’ll have no indication you’re working with nontransactional tables.
Warning
It is best practice to not mix storage engines in your application. Failed transactions can lead to inconsistent results as some parts can roll back and others cannot.
Implicit and explicit locking
InnoDB uses a two-phase locking protocol. It can acquire locks at any time during a transaction, but it does not release them until a COMMIT or ROLLBACK. It releases all the locks at the same time. The locking mechanisms described earlier are all implicit. InnoDB handles locks automatically, according to your isolation level.
However, InnoDB also supports explicit locking, which the SQL standard does not mention at all:8, 9
SELECT ... FOR SHARE SELECT ... FOR UPDATE
MySQL also supports the LOCK TABLES and UNLOCK TABLES commands, which are implemented in the server, not in the storage engines. If you need transactions, use a transactional storage engine. LOCK TABLES is unnecessary because InnoDB supports row-level locking.
Multiversion Concurrency Control
Most of MySQL’s transactional storage engines don’t use a simple row-locking mechanism. Instead, they use row-level locking in conjunction with a technique for increasing concurrency known as multiversion concurrency control (MVCC). MVCC is not unique to MySQL: Oracle, PostgreSQL, and some other database systems use it too, although there are significant differences because there is no standard for how MVCC should work.
You can think of MVCC as a twist on row-level locking; it avoids the need for locking at all in many cases and can have much lower overhead. Depending on how it is implemented, it can allow nonlocking reads while locking only the necessary rows during write operations.
MVCC works by using snapshots of the data as it existed at some point in time. This means transactions can see a consistent view of the data, no matter how long they run. It also means different transactions can see different data in the same tables at the same time! If you’ve never experienced this before, it might be confusing, but it will become easier to understand with familiarity.
Each storage engine implements MVCC differently. Some of the variations include optimistic and pessimistic concurrency control. We illustrate one way MVCC works by explaining InnoDB’s behavior10 in the form of a sequence diagram in Figure 1-2.
InnoDB implements MVCC by assigning a transaction ID for each transaction that starts. That ID is assigned the first time the transaction reads any data. When a record is modified within that transaction, an undo record that explains how to revert that change is written to the undo log, and the rollback pointer of the transaction is pointed at that undo log record. This is how the transaction can find the way to roll back if needed.
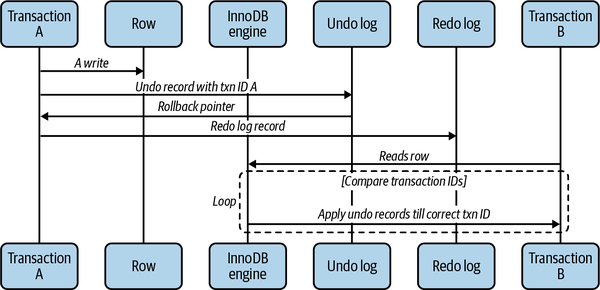
Figure 1-2. A sequence diagram of handling multiple versions of a row across different transactions
When a different session reads a cluster key index record, InnoDB compares the record’s transaction ID versus the read view of that session. If the record in its current state should not be visible (the transaction that altered it has not yet committed), the undo log record is followed and applied until the session reaches a transaction ID that is eligible to be visible. This process can loop all the way to an undo record that deletes this row entirely, signaling to the read view that this row does not exist.
Records in a transaction are deleted by setting a “deleted” bit in the “info flags” of the record. This is also tracked in the undo log as a “remove delete mark.”
It is also worth noting that all undo log writes are also redo logged because the undo log writes are part of the server crash recovery process and are transactional.11 The size of these redo and undo logs also plays a large part in how transactions at high concurrency perform. We cover their configuration in more detail in Chapter 5.
The result of all this extra record keeping is that most read queries never acquire locks. They simply read data as fast as they can, making sure to select only rows that meet the criteria. The drawbacks are that the storage engine has to store more data with each row, do more work when examining rows, and handle some additional housekeeping operations.
MVCC works only with the REPEATABLE READ and READ COMMITTED isolation levels. READ UNCOMMITTED isn’t MVCC compatible12 because queries don’t read the row version that’s appropriate for their transaction version; they read the newest version, no matter what. SERIALIZABLE isn’t MVCC compatible because reads lock every row they return.
Replication
MySQL is designed for accepting writes on one node at any given time. This has advantages in managing consistency but leads to trade-offs when you need the data written in multiple servers or multiple locations. MySQL offers a native way to distribute writes that one node takes to additional nodes. This is referred to as replication. In MySQL, the source node has a thread per replica that is logged in as a replication client that wakes up when a write occurs, sending new data. In Figure 1-3, we show a simple example of this setup, which is usually called a topology tree of multiple MySQL servers in a source and replica setup.
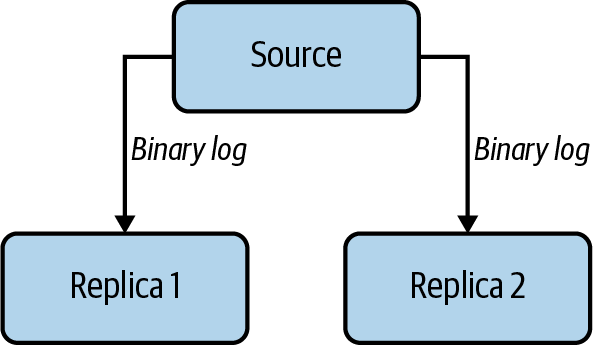
Figure 1-3. A simplified view of a MySQL server replication topology
For any data you run in production, you should use replication and have at least three more replicas, ideally distributed in different locations (in cloud-hosted environments, known as regions) for disaster-recovery planning.
Over the years, replication in MySQL gained more sophistication. Global transaction identifiers, multisource replication, parallel replication on replicas, and semisync replication are some of the major updates. We cover replication in great detail in Chapter 9.
Datafiles Structure
In version 8.0, MySQL redesigned table metadata into a data dictionary that is included with a table’s .ibd file. This makes information on the table structure support transactions and atomic data definition changes. Instead of relying only on information_schema for retrieving table definition and metadata during operations, we are introduced to the dictionary object cache, which is a least recently used (LRU)-based in-memory cache of partition definitions, table definitions, stored program definitions, charset, and collation information. This major change in how the server accesses metadata about tables reduces I/O and is efficient, especially if a subset of tables is what sees the most activity and therefore is in the cache most often. The .ibd and .frm files are replaced with serialized dictionary information (.sdi) per table.
The InnoDB Engine
InnoDB is the default transactional storage engine for MySQL and the most important and broadly useful engine overall. It was designed for processing many short-lived transactions that usually complete rather than being rolled back. Its performance and automatic crash recovery make it popular for nontransactional storage needs too. If you want to study storage engines, it is well worth your time to study InnoDB in depth to learn as much as you can about it, rather than studying all storage engines equally.
Note
It is best practice to use the InnoDB storage engine as the default engine for any application. MySQL made that easy by making InnoDB the default engine a few major versions ago.
InnoDB is the default MySQL general-purpose storage engine. By default, InnoDB stores its data in a series of datafiles that are collectively known as a tablespace. A tablespace is essentially a black box that InnoDB manages all by itself.
InnoDB uses MVCC to achieve high concurrency, and it implements all four SQL standard isolation levels. It defaults to the REPEATABLE READ isolation level, and it has a next-key locking strategy that prevents phantom reads in this isolation level: rather than locking only the rows you’ve touched in a query, InnoDB locks gaps in the index structure as well, preventing phantoms from being inserted.
InnoDB tables are built on a clustered index, which we will cover in detail in Chapter 8 when we discuss schema design. InnoDB’s index structures are very different from those of most other MySQL storage engines. As a result, it provides very fast primary key lookups. However, secondary indexes (indexes that aren’t the primary key) contain the primary key columns, so if your primary key is large, other indexes will also be large. You should strive for a small primary key if you’ll have many indexes on a table.
InnoDB has a variety of internal optimizations. These include predictive read-ahead for prefetching data from disk, an adaptive hash index that automatically builds hash indexes in memory for very fast lookups, and an insert buffer to speed inserts. We cover these in Chapter 4 of this book.
InnoDB’s behavior is very intricate, and we highly recommend reading the “InnoDB Locking and Transaction Model” section of the MySQL manual if you’re using InnoDB. Because of its MVCC architecture, there are many subtleties you should be aware of before building an application with InnoDB. Working with a storage engine that maintains consistent views of the data for all users, even when some users are changing data, can be complex.
As a transactional storage engine, InnoDB supports truly “hot” online backups through a variety of mechanisms, including Oracle’s proprietary MySQL Enterprise Backup and the open source Percona XtraBackup. We’ll dive into backup and restore in detail in Chapter 10.
Beginning with MySQL 5.6, InnoDB introduced online DDL, which at first had limited use cases that expanded in the 5.7 and 8.0 releases. In-place schema changes allow for specific table changes without a full table lock and without using external tools, which greatly improve the operationality of MySQL InnoDB tables. We will be covering options for online schema changes, both native and external tools, in Chapter 6.
JSON Document Support
First introduced to InnoDB as part of the 5.7 release, the JSON type arrived with automatic validation of JSON documents as well as optimized storage that allows for quick read access, a significant improvement to the trade-offs of old-style binary large object (BLOB) storage engineers used to resort to for JSON documents. Along with the new data type support, InnoDB also introduced SQL functions to support rich operations on JSON documents. A further improvement in MySQL 8.0.7 adds the ability to define multivalued indexes on JSON arrays. This feature can be a powerful way to even further speed up read-access queries to JSON types by matching the common access patterns to functions that can map the JSON document values. We go over the use and performance implications of the JSON data type in “JSON Data” in Chapter 6.
Data Dictionary Changes
Another major change in MySQL 8.0 is removing file-based table metadata storage and moving to a data dictionary using InnoDB table storage. This change brings all of InnoDB’s crash-recovery transactional benefits to operations like changes to tables. This change, while much improving the management of data definitions in MySQL, does also require major changes in operating a MySQL server. Most notably, back-up processes that used to rely on the table metadata files now have to query the new data dictionary to extract table definitions.
Atomic DDL
Finally, MySQL 8.0 introduced atomic data definition changes. This means that data definition statements now can either wholly finish successfully or be wholly rolled back. This becomes possible through creating a DDL-specific undo and redo log that InnoDB relies on to track the change—another place where InnoDB’s proven design has been expanded to the operations of MySQL server.
Summary
MySQL has a layered architecture, with server-wide services and query execution on top and storage engines underneath. Although there are many different plug-in APIs, the storage engine API is the most important. If you understand that MySQL executes queries by handing rows back and forth across the storage engine API, you’ve grasped the fundamentals of the server’s architecture.
In the past few major releases, MySQL has settled on InnoDB as its primary development focus and has even moved its internal bookkeeping around table metadata, authentication, and authorization after years in MyISAM. This increased investment from Oracle in the InnoDB engine has led to major improvements such as atomic DDLs, more robust online DDLs, better resilience to crashes, and better operability for security-minded deployments.
InnoDB is the default storage engine and the one that should cover nearly every use case. As such, the following chapters focus heavily on the InnoDB storage engine when talking about features, performance, and limitations, and only rarely will we touch on any other storage engine from here on out.
1 One exception is InnoDB, which does parse foreign key definitions because the MySQL server doesn’t yet implement them itself.
2 MySQL 5.5 and newer versions support an API that can accept thread-pooling plug-ins, though not commonly used. The common practice for thread pooling is done at access layers, which we discuss in Chapter 5.
3 We definitely recommend you read the documentation on exclusive versus shared locks, intention locking, and record locks.
4 There are metadata locks, which are used when dealing with table name changes or changing schemas, and in 8.0 we are introduced to “application level locking functions.” In the course of run-of-the-mill data changes, internal locking is left to the InnoDB engine.
5 Although this is a common academic exercise, most banks actually rely on daily reconciliation and not on strict transactional operations during the day.
6 For more information, read a summary of ANSI SQL by Adrian Coyler and an explanation of consistency models by Kyle Kingsbury.
7 As you will see later in this chapter, some storage engines lock entire tables, and others implement more complex row-based locking. All that logic lives for the most part in the storage engine layer.
8 These locking hints are frequently abused and should usually be avoided.
9 SELECT…FOR SHARE is a MySQL 8.0 feature that replaces SELECT…LOCK IN SHARE MODE of previous versions.
10 We recommend reading this blog post by Jeremy Cole to get a deeper understanding of records structure in InnoDB.
11 For a lot more detail on how InnoDB handles multiple versions of its records, see this blog post by Jeremy Cole.
12 There is no formal standard that defines MVCC, so different engines and databases implement it very differently, and no one can say any of them is wrong.
Get High Performance MySQL, 4th Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

