In the previous chapter, we explained how to optimize a schema, which is one of the necessary conditions for high performance. But working with the schema isn’t enough—you also need to design your queries well. If your queries are bad, even the best-designed schema will not perform well.
Query optimization, index optimization, and schema optimization go hand in hand. As you gain experience writing queries in MySQL, you will come to understand how to design schemas to support efficient queries. Similarly, what you learn about optimal schema design will influence the kinds of queries you write. This process takes time, so we encourage you to refer back to this chapter and the previous one as you learn more.
This chapter begins with general query design considerations—the things you should consider first when a query isn’t performing well. We then dig much deeper into query optimization and server internals. We show you how to find out how MySQL executes a particular query, and you’ll learn how to change the query execution plan. Finally, we look at some places MySQL doesn’t optimize queries well and explore query optimization patterns that help MySQL execute queries more efficiently.
Our goal is to help you understand deeply how MySQL really executes queries, so you can reason about what is efficient or inefficient, exploit MySQL’s strengths, and avoid its weaknesses.
The most basic reason a query doesn’t perform well is because it’s working with too much data. Some queries just have to sift through a lot of data and can’t be helped. That’s unusual, though; most bad queries can be changed to access less data. We’ve found it useful to analyze a poorly performing query in two steps:
Some queries ask for more data than they need and then throw some of it away. This demands extra work of the MySQL server, adds network overhead, [36] and consumes memory and CPU resources on the application server.
Here are a few typical mistakes:
- Fetching more rows than needed
One common mistake is assuming that MySQL provides results on demand, rather than calculating and returning the full result set. We often see this in applications designed by people familiar with other database systems. These developers are used to techniques such as issuing a
SELECTstatement that returns many rows, then fetching the firstNrows, and closing the result set (e.g., fetching the 100 most recent articles for a news site when they only need to show 10 of them on the front page). They think MySQL will provide them with these 10 rows and stop executing the query, but what MySQL really does is generate the complete result set. The client library then fetches all the data and discards most of it. The best solution is to add aLIMITclause to the query.- Fetching all columns from a multitable join
If you want to retrieve all actors who appear in Academy Dinosaur, don’t write the query this way:
mysql>
SELECT * FROM sakila.actor->INNER JOIN sakila.film_actor USING(actor_id)->INNER JOIN sakila.film USING(film_id)->WHERE sakila.film.title = 'Academy Dinosaur';That returns all columns from all three tables. Instead, write the query as follows:
mysql>
SELECT sakila.actor.* FROM sakila.actor...;- Fetching all columns
You should always be suspicious when you see
SELECT*. Do you really need all columns? Probably not. Retrieving all columns can prevent optimizations such as covering indexes, as well as adding I/O, memory, and CPU overhead for the server.Some DBAs ban
SELECT* universally because of this fact, and to reduce the risk of problems when someone alters the table’s column list.Of course, asking for more data than you really need is not always bad. In many cases we’ve investigated, people tell us the wasteful approach simplifies development, as it lets the developer use the same bit of code in more than one place. That’s a reasonable consideration, as long as you know what it costs in terms of performance. It may also be useful to retrieve more data than you actually need if you use some type of caching in your application, or if you have another benefit in mind. Fetching and caching full objects may be preferable to running many separate queries that retrieve only parts of the object.
Once you’re sure your queries retrieve only the data you need, you can look for queries that examine too much data while generating results. In MySQL, the simplest query cost metrics are:
None of these metrics is a perfect way to measure query cost, but they reflect roughly how much data MySQL must access internally to execute a query and translate approximately into how fast the query runs. All three metrics are logged in the slow query log, so looking at the slow query log is one of the best ways to find queries that examine too much data.
As discussed in Chapter 2, the standard slow query logging feature in MySQL 5.0 and earlier has serious limitations, including lack of support for fine-grained logging. Fortunately, there are patches that let you log and measure slow queries with microsecond resolution. These are included in the MySQL 5.1 server, but you can also patch earlier versions if needed. Beware of placing too much emphasis on query execution time. It’s nice to look at because it’s an objective metric, but it’s not consistent under varying load conditions. Other factors—such as storage engine locks (table locks and row locks), high concurrency, and hardware—can also have a considerable impact on query execution times. This metric is useful for finding queries that impact the application’s response time the most or load the server the most, but it does not tell you whether the actual execution time is reasonable for a query of a given complexity. (Execution time can also be both a symptom and a cause of problems, and it’s not always obvious which is the case.)
It’s useful to think about the number of rows examined when analyzing queries, because you can see how efficiently the queries are finding the data you need.
However, like execution time, it’s not a perfect metric for finding bad queries. Not all row accesses are equal. Shorter rows are faster to access, and fetching rows from memory is much faster than reading them from disk.
Ideally, the number of rows examined would be the same as the number returned, but in practice this is rarely possible. For example, when constructing rows with joins, multiple rows must be accessed to generate each row in the result set. The ratio of rows examined to rows returned is usually small—say, between 1:1 and 10:1—but sometimes it can be orders of magnitude larger.
When you’re thinking about the cost of a query, consider the cost of finding a single row in a table. MySQL can use several access methods to find and return a row. Some require examining many rows, but others may be able to generate the result without examining any.
The access method(s) appear in the type column in EXPLAIN’s output. The access types range
from a full table scan to index scans, range scans, unique index
lookups, and constants. Each of these is faster than the one before
it, because it requires reading less data. You don’t need to memorize the access types, but
you should understand the general concepts of scanning a table,
scanning an index, range accesses, and single-value accesses.
If you aren’t getting a good access type, the best way to solve the problem is usually by adding an appropriate index. We discussed indexing at length in the previous chapter; now you can see why indexes are so important to query optimization. Indexes let MySQL find rows with a more efficient access type that examines less data.
For example, let’s look at a simple query on the Sakila sample database:
mysql> SELECT * FROM sakila.film_actor WHERE film_id = 1;This query will return 10 rows, and EXPLAIN shows that MySQL uses the ref access type on the idx_fk_film_id index to execute the
query:
mysql> EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: const
rows: 10
Extra:EXPLAIN shows that MySQL
estimated it needed to access only 10 rows. In other words, the query
optimizer knew the chosen access type could satisfy the query
efficiently. What would happen if there were no suitable index for
the query? MySQL would have to use a less optimal access type, as we
can see if we drop the index and run the query again:
mysql>ALTER TABLE sakila.film_actor DROP FOREIGN KEY fk_film_actor_film;mysql>ALTER TABLE sakila.film_actor DROP KEY idx_fk_film_id;mysql>EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: film_actor type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 5073 Extra: Using where
Predictably, the access type has changed to a full table scan
(ALL), and MySQL now estimates
it’ll have to examine 5,073 rows to satisfy the query. The “Using
where” in the Extra column shows
that the MySQL server is using the WHERE clause to discard rows after the
storage engine reads them.
In general, MySQL can apply a WHERE clause in three ways, from best to
worst:
Apply the conditions to the index lookup operation to eliminate nonmatching rows. This happens at the storage engine layer.
Use a covering index (“Using index” in the
Extracolumn) to avoid row accesses, and filter out nonmatching rows after retrieving each result from the index. This happens at the server layer, but it doesn’t require reading rows from the table.Retrieve rows from the table, then filter nonmatching rows (“Using where” in the
Extracolumn). This happens at the server layer and requires the server to read rows from the table before it can filter them.
This example illustrates how important it is to have good
indexes. Good indexes help your queries get a good access type and
examine only the rows they need. However, adding an index doesn’t
always mean that MySQL will access and return the same number of
rows. For example, here’s a query that uses the COUNT() aggregate function: [37]
mysql> SELECT actor_id, COUNT(*) FROM sakila.film_actor GROUP BY actor_id;This query returns only 200 rows, but it needs to read thousands of rows to build the result set. An index can’t reduce the number of rows examined for a query like this one.
Unfortunately, MySQL does not tell you how many of the
rows it accessed were used to build the result set; it
tells you only the total number of rows it accessed. Many of these
rows could be eliminated by a WHERE clause and end up not contributing
to the result set. In the previous example, after removing the index
on sakila.film_actor, the query
accessed every row in the table and the WHERE clause discarded all but 10 of them.
Only the remaining 10 rows were used to build the result set.
Understanding how many rows the server accesses and how many it
really uses requires reasoning about the query.
If you find that a huge number of rows were examined to produce relatively few rows in the result, you can try some more sophisticated fixes:
Use covering indexes, which store data so that the storage engine doesn’t have to retrieve the complete rows. (We discussed these in the previous chapter.)
Change the schema. An example is using summary tables (discussed in the previous chapter).
Rewrite a complicated query so the MySQL optimizer is able to execute it optimally. (We discuss this later in this chapter.)
As you optimize problematic queries, your goal should be to find alternative ways to get the result you want—but that doesn’t necessarily mean getting the same result set back from MySQL. You can sometimes transform queries into equivalent forms and get better performance. However, you should also think about rewriting the query to retrieve different results, if that provides an efficiency benefit. You may be able to ultimately do the same work by changing the application code as well as the query. In this section, we explain techniques that can help you restructure a wide range of queries and show you when to use each technique.
One important query design question is whether it’s preferable to break up a complex query into several simpler queries. The traditional approach to database design emphasizes doing as much work as possible with as few queries as possible. This approach was historically better because of the cost of network communication and the overhead of the query parsing and optimization stages.
However, this advice doesn’t apply as much to MySQL, because it was designed to handle connecting and disconnecting very efficiently and to respond to small and simple queries very quickly. Modern networks are also significantly faster than they used to be, reducing network latency. MySQL can run more than 50,000 simple queries per second on commodity server hardware and over 2,000 queries per second from a single correspondent on a Gigabit network, so running multiple queries isn’t necessarily such a bad thing.
Connection response is still slow compared to the number of rows MySQL can traverse per second internally, though, which is counted in millions per second for in-memory data. All else being equal, it’s still a good idea to use as few queries as possible, but sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one. Don’t be afraid to do this; weigh the costs, and go with the strategy that causes less work. We show some examples of this technique a little later in the chapter.
That said, using too many queries is a common mistake in application design. For example, some applications perform 10 single-row queries to retrieve data from a table when they could use a single 10-row query. We’ve even seen applications that retrieve each column individually, querying each row many times!
Another way to slice up a query is to divide and conquer, keeping it essentially the same but running it in smaller “chunks” that affect fewer rows each time.
Purging old data is a great example. Periodic purge jobs may
need to remove quite a bit of data, and doing this in one massive
query could lock a lot of rows for a long time, fill up transaction
logs, hog resources, and block small queries that shouldn’t be
interrupted. Chopping up the DELETE
statement and using medium-size queries can improve performance
considerably, and reduce replication lag when a query is replicated.
For example, instead of running this monolithic query:
mysql> DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH);you could do something like the following pseudocode:
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH)
LIMIT 10000")
} while rows_affected > 0Deleting 10,000 rows at a time is typically a large enough task
to make each query efficient, and a short enough task to minimize the
impact on the server [38] (transactional storage engines may benefit from smaller
transactions). It may also be a good idea to add some sleep time
between the DELETE statements to
spread the load over time and reduce the amount of time locks are
held.
Many high-performance web sites use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join, and then performing the join in the application. For example, instead of this single query:
mysql>SELECT * FROM tag->JOIN tag_post ON tag_post.tag_id=tag.id->JOIN post ON tag_post.post_id=post.id->WHERE tag.tag='mysql';
You might run these queries:
mysql>SELECT * FROM tag WHERE tag='mysql';mysql>SELECT * FROM tag_post WHERE tag_id=1234;mysql>SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
This looks wasteful at first glance, because you’ve increased the number of queries without getting anything in return. However, such restructuring can actually give significant performance advantages:
Caching can be more efficient. Many applications cache “objects” that map directly to tables. In this example, if the object with the tag
mysqlis already cached, the application can skip the first query. If you find posts with an id of 123, 567, or 9098 in the cache, you can remove them from theIN()list. The query cache might also benefit from this strategy. If only one of the tables changes frequently, decomposing a join can reduce the number of cache invalidations.For MyISAM tables, performing one query per table uses table locks more efficiently: the queries will lock the tables individually and relatively briefly, instead of locking them all for a longer time.
Doing joins in the application makes it easier to scale the database by placing tables on different servers.
The queries themselves can be more efficient. In this example, using an
IN()list instead of a join lets MySQL sort row IDs and retrieve rows more optimally than might be possible with a join. We explain this in more detail later.You can reduce redundant row accesses. Doing a join in the application means you retrieve each row only once, whereas a join in the query is essentially a denormalization that might repeatedly access the same data. For the same reason, such restructuring might also reduce the total network traffic and memory usage.
To some extent, you can view this technique as manually implementing a hash join instead of the nested loops algorithm MySQL uses to execute a join. A hash join may be more efficient. (We discuss MySQL’s join strategy later in this chapter.)
If you need to get high performance from your MySQL server, one of the best ways to invest your time is in learning how MySQL optimizes and executes queries. Once you understand this, much of query optimization is simply a matter of reasoning from principles, and query optimization becomes a very logical process.
Tip
This discussion assumes you’ve read Chapter 1, which provides a foundation for understanding the MySQL query execution engine.
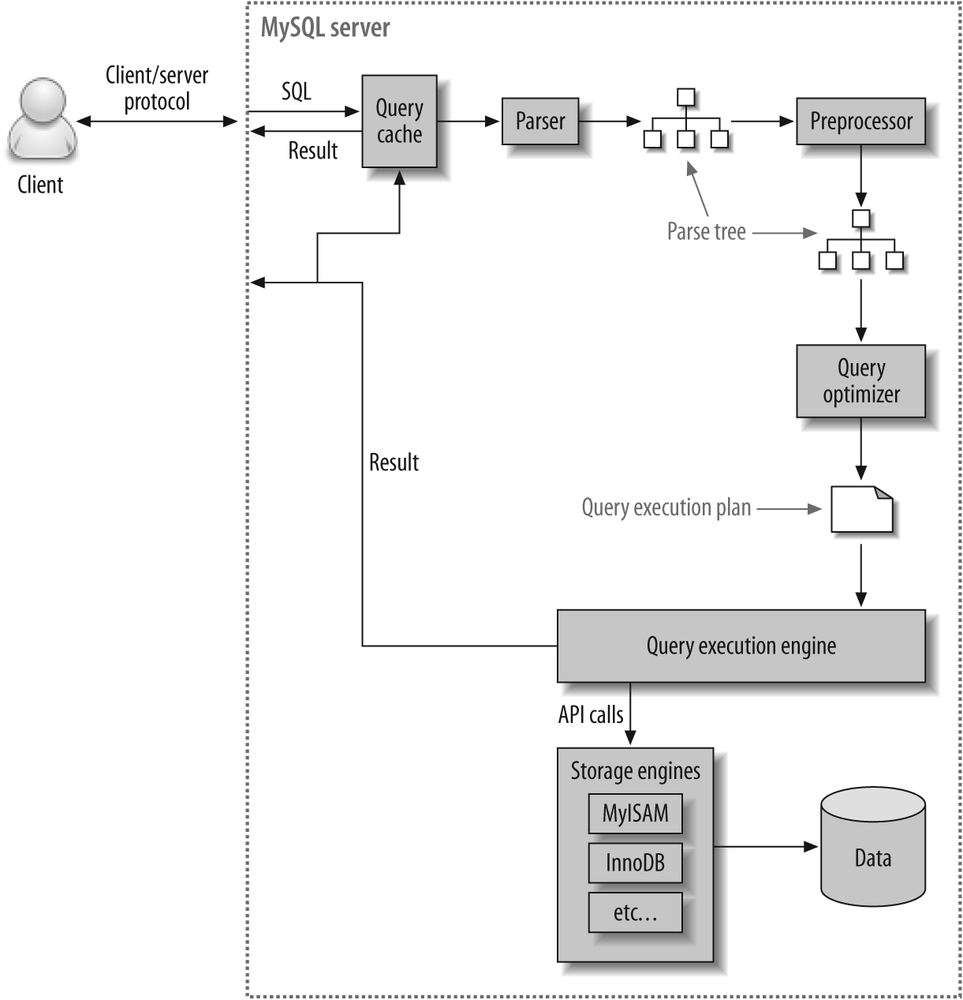
Figure 4-1 shows how MySQL generally executes queries.
Follow along with the illustration to see what happens when you send MySQL a query:
The client sends the SQL statement to the server.
The server checks the query cache. If there’s a hit, it returns the stored result from the cache; otherwise, it passes the SQL statement to the next step.
The server parses, preprocesses, and optimizes the SQL into a query execution plan.
The query execution engine executes the plan by making calls to the storage engine API.
The server sends the result to the client.
Each of these steps has some extra complexity, which we discuss in the following sections. We also explain which states the query will be in during each step. The query optimization process is particularly complex and important to understand.
Though you don’t need to understand the inner details of MySQL’s client/server protocol, you do need to understand how it works at a high level. The protocol is half-duplex, which means that at any given time the MySQL server can be either sending or receiving messages, but not both. It also means there is no way to cut a message short.
This protocol makes MySQL communication simple and fast, but it limits it in some ways too. For one thing, it means there’s no flow control; once one side sends a message, the other side must fetch the entire message before responding. It’s like a game of tossing a ball back and forth: only one side has the ball at any instant, and you can’t toss the ball (send a message) unless you have it.
The client sends a query to the server as a single packet of
data. This is why the max_allowed_packet configuration variable is
important if you have large queries. [39] Once the client sends the query, it doesn’t have the
ball anymore; it can only wait for results.
In contrast, the response from the server usually consists of
many packets of data. When the server responds, the client has to
receive the entire result set. It cannot simply
fetch a few rows and then ask the server not to bother sending the
rest. If the client needs only the first few rows that are returned,
it either has to wait for all of the server’s packets to arrive and
then discard the ones it doesn’t need, or disconnect ungracefully.
Neither is a good idea, which is why appropriate LIMIT clauses are so important.
Here’s another way to think about this: when a client fetches rows from the server, it thinks it’s pulling them. But the truth is, the MySQL server is pushing the rows as it generates them. The client is only receiving the pushed rows; there is no way for it to tell the server to stop sending rows. The client is “drinking from the fire hose,” so to speak. (Yes, that’s a technical term.)
Most libraries that connect to MySQL let you either fetch the whole result set and buffer it in memory, or fetch each row as you need it. The default behavior is generally to fetch the whole result and buffer it in memory. This is important because until all the rows have been fetched, the MySQL server will not release the locks and other resources required by the query. The query will be in the “Sending data” state (explained in “Query states” on Query states). When the client library fetches the results all at once, it reduces the amount of work the server needs to do: the server can finish and clean up the query as quickly as possible.
Most client libraries let you treat the result set as though you’re fetching it from the server, although in fact you’re just fetching it from the buffer in the library’s memory. This works fine most of the time, but it’s not a good idea for huge result sets that might take a long time to fetch and use a lot of memory. You can use less memory, and start working on the result sooner, if you instruct the library not to buffer the result. The downside is that the locks and other resources on the server will remain open while your application is interacting with the library. [40]
Let’s look at an example using PHP. First, here’s how you’ll usually query MySQL from PHP:
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_query('SELECT * FROM HUGE_TABLE', $link);
while ( $row = mysql_fetch_array($result) ) {
// Do something with result
}
?>The code seems to indicate that you fetch rows only when you
need them, in the while loop.
However, the code actually fetches the entire result into a buffer
with the mysql_query() function
call. The while loop simply
iterates through the buffer. In contrast, the following code doesn’t
buffer the results, because it uses mysql_unbuffered_query() instead of mysql_query():
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_unbuffered_query('SELECT * FROM HUGE_TABLE', $link);
while ( $row = mysql_fetch_array($result) ) {
// Do something with result
}
?>Programming languages have different ways to override buffering.
For example, the Perl DBD::mysql
driver requires you to specify the C client library’s mysql_use_result attribute (the default is
mysql_buffer_result). Here’s an
example:
#!/usr/bin/perl
use DBI;
my $dbh = DBI->connect('DBI:mysql:;host=localhost', 'user', 'p4ssword');
my $sth = $dbh->prepare('SELECT * FROM HUGE_TABLE', { mysql_use_result => 1 });
$sth->execute();
while ( my $row = $sth->fetchrow_array() ) {
# Do something with result
}Notice that the call to prepare() specified to “use” the result
instead of “buffering” it. You can also specify this when connecting,
which will make every statement unbuffered:
my $dbh = DBI->connect('DBI:mysql:;mysql_use_result=1', 'user', 'p4ssword');Each MySQL connection, or thread, has a
state that shows what it is doing at any given time. There are
several ways to view these states, but the easiest is to use the SHOW FULL PROCESSLIST command (the states
appear in the Command column). As
a query progresses through its lifecycle, its state changes many
times, and there are dozens of states. The MySQL manual is the
authoritative source of information for all the states, but we list
a few here and explain what they mean:
SleepQueryThe thread is either executing the query or sending the result back to the client.
LockedThe thread is waiting for a table lock to be granted at the server level. Locks that are implemented by the storage engine, such as InnoDB’s row locks, do not cause the thread to enter the
Lockedstate.AnalyzingandstatisticsThe thread is checking storage engine statistics and optimizing the query.
Copying to tmp table [on disk]The thread is processing the query and copying results to a temporary table, probably for a
GROUP BY, for a filesort, or to satisfy aUNION. If the state ends with “on disk,” MySQL is converting an in-memory table to an on-disk table.Sorting resultSending dataThis can mean several things: the thread might be sending data between stages of the query, generating the result set, or returning the result set to the client.
It’s helpful to at least know the basic states, so you can get a sense of “who has the ball” for the query. On very busy servers, you might see an unusual or normally brief state, such as
statistics, begin to take a significant amount of time. This usually indicates that something is wrong.
Before even parsing a query, MySQL checks for it in the query cache, if the cache is enabled. This operation is a case sensitive hash lookup. If the query differs from a similar query in the cache by even a single byte, it won’t match, and the query processing will go to the next stage.
If MySQL does find a match in the query cache, it must check privileges before returning the cached query. This is possible without parsing the query, because MySQL stores table information with the cached query. If the privileges are OK, MySQL retrieves the stored result from the query cache and sends it to the client, bypassing every other stage in query execution. The query is never parsed, optimized, or executed.
You can learn more about the query cache in Chapter 5.
The next step in the query lifecycle turns a SQL query into an execution plan for the query execution engine. It has several sub-steps: parsing, preprocessing, and optimization. Errors (for example, syntax errors) can be raised at any point in the process. We’re not trying to document the MySQL internals here, so we’re going to take some liberties, such as describing steps separately even though they’re often combined wholly or partially for efficiency. Our goal is simply to help you understand how MySQL executes queries so that you can write better ones.
To begin, MySQL’s parser breaks the query into tokens and builds a “parse tree” from them. The parser uses MySQL’s SQL grammar to interpret and validate the query. For instance, it ensures that the tokens in the query are valid and in the proper order, and it checks for mistakes such as quoted strings that aren’t terminated.
The preprocessor then checks the resulting parse tree for additional semantics that the parser can’t resolve. For example, it checks that tables and columns exist, and it resolves names and aliases to ensure that column references aren’t ambiguous.
Next, the preprocessor checks privileges. This is normally very fast unless your server has large numbers of privileges. (See Chapter 12 for more on privileges and security.)
The parse tree is now valid and ready for the optimizer to turn it into a query execution plan. A query can often be executed many different ways and produce the same result. The optimizer’s job is to find the best option.
MySQL uses a cost-based optimizer, which means it tries to
predict the cost of various execution plans and choose the least
expensive. The unit of cost is a single random four-kilobyte data
page read. You can see how expensive the optimizer estimated a query
to be by running the query, then inspecting the Last_query_cost session variable:
mysql>SELECT SQL_NO_CACHE COUNT(*) FROM sakila.film_actor;+----------+ | count(*) | +----------+ | 5462 | +----------+ mysql>SHOW STATUS LIKE 'last_query_cost';+-----------------+-------------+ | Variable_name | Value | +-----------------+-------------+ | Last_query_cost | 1040.599000 | +-----------------+-------------+
This result means that the optimizer estimated it would need to do about 1,040 random data page reads to execute the query. It bases the estimate on statistics: the number of pages per table or index, the cardinality (number of distinct values) of indexes, the length of rows and keys, and key distribution. The optimizer does not include the effects of any type of caching in its estimates—it assumes every read will result in a disk I/O operation.
The optimizer may not always choose the best plan, for many reasons:
The statistics could be wrong. The server relies on storage engines to provide statistics, and they can range from exactly correct to wildly inaccurate. For example, the InnoDB storage engine doesn’t maintain accurate statistics about the number of rows in a table, because of its MVCC architecture.
The cost metric is not exactly equivalent to the true cost of running the query, so even when the statistics are accurate, the query may be more or less expensive than MySQL’s approximation. A plan that reads more pages might actually be cheaper in some cases, such as when the reads are sequential so the disk I/O is faster, or when the pages are already cached in memory.
MySQL’s idea of optimal might not match yours. You probably want the fastest execution time, but MySQL doesn’t really understand “fast”; it understands “cost,” and as we’ve seen, determining cost is not an exact science.
MySQL doesn’t consider other queries that are running concurrently, which can affect how quickly the query runs.
MySQL doesn’t always do cost-based optimization. Sometimes it just follows the rules, such as “if there’s a full-text
MATCH()clause, use aFULLTEXTindex if one exists.” It will do this even when it would be faster to use a different index and a non-FULLTEXTquery with aWHEREclause.The optimizer doesn’t take into account the cost of operations not under its control, such as executing stored functions or user-defined functions.
As we’ll see later, the optimizer can’t always estimate every possible execution plan, so it may miss an optimal plan.
MySQL’s query optimizer is a highly complex piece of software,
and it uses many optimizations to transform the query into an
execution plan. There are two basic types of optimizations, which we
call static and dynamic. Static
optimizations can be performed simply by inspecting the
parse tree. For example, the optimizer can transform the WHERE clause into an equivalent form by
applying algebraic rules. Static optimizations are independent of values, such
as the value of a constant in a WHERE clause. They can be performed once
and will always be valid, even when the query is reexecuted with
different values. You can think of these as “compile-time
optimizations.”
In contrast, dynamic optimizations are
based on context and can depend on many factors, such as which value
is in a WHERE clause or how many
rows are in an index. They must be reevaluated each time the query
is executed. You can think of these as “runtime
optimizations.”
The difference is important in executing prepared statements or stored procedures. MySQL can do static optimizations once, but it must reevaluate dynamic optimizations every time it executes a query. MySQL sometimes even reoptimizes the query as it executes it. [41]
Here are some types of optimizations MySQL knows how to do:
- Reordering joins
Tables don’t always have to be joined in the order you specify in the query. Determining the best join order is an important optimization; we explain it in depth in “The join optimizer” on The join optimizer.
- Converting
OUTER JOINs toINNER JOINs An
OUTER JOINdoesn’t necessarily have to be executed as anOUTER JOIN. Some factors, such as theWHEREclause and table schema, can actually cause anOUTER JOINto be equivalent to anINNER JOIN. MySQL can recognize this and rewrite the join, which makes it eligible for reordering.- Applying algebraic equivalence rules
MySQL applies algebraic transformations to simplify and canonicalize expressions. It can also fold and reduce constants, eliminating impossible constraints and constant conditions. For example, the term
(5=5 AND a>5)will reduce to justa>5. Similarly,(a<b AND b=c) AND a=5becomesb>5AND b=c AND a=5. These rules are very useful for writing conditional queries, which we discuss later in the chapter.COUNT(),MIN(), andMAX()optimizationsIndexes and column nullability can often help MySQL optimize away these expressions. For example, to find the minimum value of a column that’s leftmost in a B-Tree index, MySQL can just request the first row in the index. It can even do this in the query optimization stage, and treat the value as a constant for the rest of the query. Similarly, to find the maximum value in a B-Tree index, the server reads the last row. If the server uses this optimization, you’ll see “Select tables optimized away” in the
EXPLAINplan. This literally means the optimizer has removed the table from the query plan and replaced it with a constant.Likewise,
COUNT(*)queries without aWHEREclause can often be optimized away on some storage engines (such as MyISAM, which keeps an exact count of rows in the table at all times). See “Optimizing COUNT() Queries” on Optimizing Specific Types of Queries for details.- Evaluating and reducing constant expressions
When MySQL detects that an expression can be reduced to a constant, it will do so during optimization. For example, a user-defined variable can be converted to a constant if it’s not changed in the query. Arithmetic expressions are another example.
Perhaps surprisingly, even something you might consider to be a query can be reduced to a constant during the optimization phase. One example is a
MIN()on an index. This can even be extended to a constant lookup on a primary key or unique index. If aWHEREclause applies a constant condition to such an index, the optimizer knows MySQL can look up the value at the beginning of the query. It will then treat the value as a constant in the rest of the query. Here’s an example:mysql>
EXPLAIN SELECT film.film_id, film_actor.actor_id->FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id)->WHERE film.film_id = 1;+----+-------------+------------+-------+----------------+-------+------+ | id | select_type | table | type | key | ref | rows | +----+-------------+------------+-------+----------------+-------+------+ | 1 | SIMPLE | film | const | PRIMARY | const | 1 | | 1 | SIMPLE | film_actor | ref | idx_fk_film_id | const | 10 | +----+-------------+------------+-------+----------------+-------+------+
MySQL executes this query in two steps, which correspond to
the two rows in the output. The first step is to find the desired
row in the film table. MySQL’s
optimizer knows there is only one row, because there’s
a primary key on the film_id
column, and it has already consulted the index during the query
optimization stage to see how many rows it will find. Because the
query optimizer has a known quantity (the value in the WHERE clause) to use in the lookup, this
table’s ref type is const.
In the second step, MySQL treats the film_id column from the row found in the
first step as a known quantity. It can do this because the optimizer
knows that by the time the query reaches the second step, it will
know all the values from the first step. Notice that the film_actor table’s ref type is const, just as the film table’s was.
Another way you’ll see constant conditions applied is by
propagating a value’s constant-ness from one place to another if
there is a WHERE, USING, or ON clause that restricts them to being
equal. In this example, the optimizer knows that the USING clause forces film_id to
have the same value everywhere in the query—it must be equal to the
constant value given in the WHERE
clause.
- Covering indexes
MySQL can sometimes use an index to avoid reading row data, when the index contains all the columns the query needs. We discussed covering indexes at length in Chapter 3.
- Subquery optimization
MySQL can convert some types of subqueries into more efficient alternative forms, reducing them to index lookups instead of separate queries.
- Early termination
MySQL can stop processing a query (or a step in a query) as soon as it fulfills the query or step. The obvious case is a
LIMITclause, but there are several other kinds of early termination. For instance, if MySQL detects an impossible condition, it can abort the entire query. You can see this in the following example:mysql>
EXPLAIN SELECT film.film_id FROM sakila.film WHERE film_id = -1;+----+...+-----------------------------------------------------+ | id |...| Extra | +----+...+-----------------------------------------------------+ | 1 |...| Impossible WHERE noticed after reading const tables | +----+...+-----------------------------------------------------+This query stopped during the optimization step, but MySQL can also terminate execution sooner in some cases. The server can use this optimization when the query execution engine recognizes the need to retrieve distinct values, or to stop when a value doesn’t exist. For example, the following query finds all movies without any actors: [42]
mysql>
SELECT film.film_id->FROM sakila.film->LEFT OUTER JOIN sakila.film_actor USING(film_id)->WHERE film_actor.film_id IS NULL;This query works by eliminating any films that have actors. Each film might have many actors, but as soon as it finds one actor, it stops processing the current film and moves to the next one because it knows the
WHEREclause prohibits outputting that film. A similar “Distinct/not-exists” optimization can apply to certain kinds ofDISTINCT, NOT EXISTS(), andLEFT JOINqueries.- Equality propagation
MySQL recognizes when a query holds two columns as equal—for example, in a
JOINcondition—and propagatesWHEREclauses across equivalent columns. For instance, in the following query:mysql>
SELECT film.film_id->FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id)->WHERE film.film_id > 500;MySQL knows that the
WHEREclause applies not only to thefilmtable but to thefilm_actortable as well, because theUSINGclause forces the two columns to match.If you’re used to another database server that can’t do this, you may have been advised to “help the optimizer” by manually specifying the
WHEREclause for both tables, like this:... WHERE film.film_id > 500 AND film_actor.film_id > 500
This is unnecessary in MySQL. It just makes your queries harder to maintain.
IN()list comparisonsIn many database servers,
IN()is just a synonym for multipleORclauses, because the two are logically equivalent. Not so in MySQL, which sorts the values in theIN()list and uses a fast binary search to see whether a value is in the list. This is O(log n) in the size of the list, whereas an equivalent series ofORclauses is O(n) in the size of the list (i.e., much slower for large lists).
The preceding list is woefully incomplete, as MySQL performs more optimizations than we could fit into this entire chapter, but it should give you an idea of the optimizer’s complexity and intelligence. If there’s one thing you should take away from this discussion, it’s don’t try to outsmart the optimizer. You may end up just defeating it, or making your queries more complicated and harder to maintain for zero benefit. In general, you should let the optimizer do its work.
Of course, as smart as the optimizer is, there are times when it doesn’t give the best result. Sometimes you may know something about the data that the optimizer doesn’t, such as a fact that’s guaranteed to be true because of application logic. Also, sometimes the optimizer doesn’t have the necessary functionality, such as hash indexes; at other times, as mentioned earlier, its cost estimates may prefer a query plan that turns out to be more expensive than an alternative.
If you know the optimizer isn’t giving a good result, and you know why, you can help it. Some of the options are to add a hint to the query, rewrite the query, redesign your schema, or add indexes.
Recall the various layers in the MySQL server architecture, which we illustrated in Figure 1-1. The server layer, which contains the query optimizer, doesn’t store statistics on data and indexes. That’s a job for the storage engines, because each storage engine might keep different kinds of statistics (or keep them in a different way). Some engines, such as Archive, don’t keep statistics at all!
Because the server doesn’t store statistics, the MySQL query optimizer has to ask the engines for statistics on the tables in a query. The engines may provide the optimizer with statistics such as the number of pages per table or index, the cardinality of tables and indexes, the length of rows and keys, and key distribution information. The optimizer can use this information to help it decide on the best execution plan. We see how these statistics influence the optimizer’s choices in later sections.
MySQL uses the term “join” more broadly than you might be used
to. In sum, it considers every query a join—not just every query
that matches rows from two tables, but every query, period
(including subqueries, and even a SELECT against a single table).
Consequently, it’s very important to understand how MySQL executes
joins.
Consider the example of a UNION query. MySQL executes a UNION as a series of single queries whose
results are spooled into a temporary table, then read out again.
Each of the individual queries is a join, in MySQL terminology—and
so is the act of reading from the resulting temporary table.
At the moment, MySQL’s join execution strategy is simple: it
treats every join as a nested-loop join. This means MySQL runs a
loop to find a row from a table, then runs a nested loop to find a
matching row in the next table. It continues until it has found a
matching row in each table in the join. It then builds and returns a
row from the columns named in the SELECT list. It tries to build the next
row by looking for more matching rows in the last table. If it
doesn’t find any, it backtracks one table and looks for more rows there. It keeps backtracking until it
finds another row in some table, at which point, it looks for a
matching row in the next table, and so on. [43]
This process of finding rows, probing into the next table, and then backtracking can be written as nested loops in the execution plan—hence the name “nested-loop join.” As an example, consider this simple query:
mysql>SELECT tbl1.col1, tbl2.col2->FROM tbl1 INNER JOIN tbl2 USING(col3)->WHERE tbl1.col1 IN(5,6);
Assuming MySQL decides to join the tables in the order shown in the query, the following pseudocode shows how MySQL might execute the query:
outer_iter = iterator over tbl1 where col1 IN(5,6)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
while inner_row
output [ outer_row.col1, inner_row.col2 ]
inner_row = inner_iter.next
end
outer_row = outer_iter.next
endThis query execution plan applies as easily to a single-table
query as it does to a many-table query, which is why even a
single-table query can be considered a join—the single-table join is
the basic operation from which more complex joins are composed. It
can support OUTER JOINs, too. For
example, let’s change the example query as follows:
mysql>SELECT tbl1.col1, tbl2.col2->FROM tbl1 LEFT OUTER JOIN tbl2 USING(col3)->WHERE tbl1.col1 IN(5,6);
Here’s the corresponding pseudocode, with the changed parts in bold:
outer_iter = iterator over tbl1 where col1 IN(5,6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.nextif inner_rowwhile inner_row output [ outer_row.col1, inner_row.col2 ] inner_row = inner_iter.next endelseoutput [ outer_row.col1, NULL ]endouter_row = outer_iter.next end
Another way to visualize a query execution plan is to use what the optimizer folks call a “swim-lane diagram.” Figure 4-2 contains a
swim-lane diagram of our initial INNER
JOIN query. Read it from left to right and top to
bottom.

MySQL executes every kind of query in essentially the same
way. For example, it handles a subquery in the FROM clause by executing it first, putting
the results into a temporary table, [44] and then treating that table just like an ordinary
table (hence the name “derived table”). MySQL executes UNION queries with temporary tables too,
and it rewrites all RIGHT OUTER
JOIN queries to equivalent LEFT
OUTER JOIN. In short, MySQL coerces every kind of query
into this execution plan.
It’s not possible to execute every legal SQL query this way,
however. For example, a FULL OUTER
JOIN can’t be executed with nested loops and backtracking
as soon as a table with no matching rows is found, because it might
begin with a table that has no matching rows. This explains why
MySQL doesn’t support FULL OUTER
JOIN. Still other queries can be executed with nested
loops, but perform very badly as a result. We look at some of those
later.
MySQL doesn’t generate byte-code to execute a query, as many
other database products do. Instead, the query execution plan is
actually a tree of instructions that the query execution engine
follows to produce the query results. The final plan contains enough
information to reconstruct the original query. If you
execute EXPLAIN EXTENDED on a
query, followed by SHOW WARNINGS,
you’ll see the reconstructed query. [45]
Any multitable query can conceptually be represented as a tree. For example, it might be possible to execute a four-table join as shown in Figure 4-3.

This is what computer scientists call a balanced tree. This is not how MySQL executes the query, though. As we described in the previous section, MySQL always begins with one table and finds matching rows in the next table. Thus, MySQL’s query execution plans always take the form of a left-deep tree, as in Figure 4-4.

The most important part of the MySQL query optimizer is the join optimizer, which decides the best order of execution for multitable queries. It is often possible to join the tables in several different orders and get the same results. The join optimizer estimates the cost for various plans and tries to choose the least expensive one that gives the same result.
Here’s a query whose tables can be joined in different orders without changing the results:
mysql>SELECT film.film_id, film.title, film.release_year, actor.actor_id,->actor.first_name, actor.last_name->FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id)->INNER JOIN sakila.actor USING(actor_id);
You can probably think of a few different query plans.
For example, MySQL could begin with the film table, use the index on film_id in the film_actor table to find actor_id values, and then look up rows in
the actor table’s primary key.
This should be efficient, right? Now let’s use EXPLAIN to see how MySQL wants to execute
the query:
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 1
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: film
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.film_id
rows: 1
Extra:This is quite a different plan from the one suggested in the
previous paragraph. MySQL wants to start with the actor, table (we know this because it’s
listed first in the EXPLAIN
output) and go in the reverse order. Is this really more efficient?
Let’s find out. The STRAIGHT_JOIN
keyword forces the join to proceed in the order specified in
the query. Here’s the EXPLAIN
output for the revised query:
mysql> EXPLAIN SELECT STRAIGHT_JOIN film.film_id...\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 951
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 1
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.actor_id
rows: 1
Extra:This shows why MySQL wants to reverse the join order: doing so will enable it to examine fewer rows in the first table. [46] In both cases, it will be able to perform fast indexed lookups in the second and third tables. The difference is how many of these indexed lookups it will have to do:
Placing
filmfirst will require about 951 probes intofilm_actorandactor, one for each row in the first table.If the server scans the
actortable first, it will have to do only 200 index lookups into later tables.
In other words, the reversed join order will require less
backtracking and rereading. To double-check the optimizer’s choice, we executed the two query versions
and looked at the Last_query_cost
variable for each. The reordered query had an estimated cost of 241,
while the estimated cost of forcing the join order was 1,154.
This is a simple example of how MySQL’s join optimizer can reorder queries to make them less
expensive to execute. Reordering joins is usually a very effective
optimization. There are times when it won’t result in an optimal
plan, and for those times you can use STRAIGHT_JOIN and write the query in the
order you think is best—but such times are rare. In most cases, the
join optimizer will outperform a human.
The join optimizer tries to produce a query execution plan tree with the lowest achievable cost. When possible, it examines all potential combinations of subtrees, beginning with all one-table plans.
Unfortunately, a join over n tables will
have n-factorial combinations of join orders to
examine. This is called the search space of all
possible query plans, and it grows very quickly—a 10-table join can
be executed up to 3,628,800 different ways! When the search space
grows too large, it can take far too long to optimize the query, so
the server stops doing a full analysis. Instead, it resorts to shortcuts such as “greedy” searches when
the number of tables exceeds the optimizer_search_depth limit.
MySQL has many heuristics, accumulated through years of research and experimentation, that it uses to speed up the optimization stage. This can be beneficial, but it can also mean that MySQL may (on rare occasions) miss an optimal plan and choose a less optimal one because it’s trying not to examine every possible query plan.
Sometimes queries can’t be reordered, and the join optimizer
can use this fact to reduce the search space by eliminating choices.
A LEFT JOIN is a good example, as
are correlated subqueries (more about subqueries later). This is
because the results for one table depend on data retrieved from
another table. These dependencies help the join optimizer reduce the
search space by eliminating choices.
Sorting results can be a costly operation, so you can often improve performance by avoiding sorts or by performing them on fewer rows.
We showed you how to use indexes for sorting in Chapter 3. When MySQL can’t use an index to produce a sorted result, it must sort the rows itself. It can do this in memory or on disk, but it always calls this process a filesort, even if it doesn’t actually use a file.
If the values to be sorted will fit into the sort buffer, MySQL can perform the sort entirely in memory with a quicksort. If MySQL can’t do the sort in memory, it performs it on disk by sorting the values in chunks. It uses a quicksort to sort each chunk and then merges the sorted chunk into the results.
There are two filesort algorithms:
- Two passes (old)
Reads row pointers and
ORDER BYcolumns, sorts them, and then scans the sorted list and rereads the rows for output.The two-pass algorithm can be quite expensive, because it reads the rows from the table twice, and the second read causes a lot of random I/O. This is especially expensive for MyISAM, which uses a system call to fetch each row (because MyISAM relies on the operating system’s cache to hold the data). On the other hand, it stores a minimal amount of data during the sort, so if the rows to be sorted are completely in memory, it can be cheaper to store less data and reread the rows to generate the final result.
- Single pass (new)
Reads all the columns needed for the query, sorts them by the
ORDER BYcolumns, and then scans the sorted list and outputs the specified columns.This algorithm is available only in MySQL 4.1 and newer. It can be much more efficient, especially on large I/O-bound datasets, because it avoids reading the rows from the table twice and trades random I/O for more sequential I/O. However, it has the potential to use a lot more space, because it holds all desired columns from each row, not just the columns needed to sort the rows. This means fewer tuples will fit into the sort buffer, and the filesort will have to perform more sort merge passes.
MySQL may use much more temporary storage space for a filesort
than you’d expect, because it allocates a fixed-size record for each
tuple it will sort. These records are large enough to hold the
largest possible tuple, including the full length of each VARCHAR column. Also, if you’re using
UTF-8, MySQL allocates three bytes for each character. As a result,
we’ve seen cases where poorly optimized schemas caused the temporary
space used for sorting to be many times larger than the entire
table’s size on disk.
When sorting a join, MySQL may perform the filesort at two
stages during the query execution. If the ORDER BY clause refers only to columns
from the first table in the join order, MySQL can filesort this
table and then proceed with the join. If this happens, EXPLAIN shows “Using filesort” in the
Extra column. Otherwise, MySQL
must store the query’s results into a temporary table and then
filesort the temporary table after the join finishes. In this case,
EXPLAIN shows “Using temporary;
Using filesort” in the Extra
column. If there’s a LIMIT, it is
applied after the filesort, so the temporary table and the filesort
can be very large.
See “Optimizing for Filesorts” on Optimizing for Filesorts for more on how to tune the server for filesorts and how to influence which algorithm the server uses.
The parsing and optimizing stage outputs a query execution plan, which MySQL’s query execution engine uses to process the query. The plan is a data structure; it is not executable byte-code, which is how many other databases execute queries.
In contrast to the optimization stage, the execution stage is usually not all that complex: MySQL simply follows the instructions given in the query execution plan. Many of the operations in the plan invoke methods implemented by the storage engine interface, also known as the handler API. Each table in the query is represented by an instance of a handler. If a table appears three times in the query, for example, the server creates three handler instances. Though we glossed over this before, MySQL actually creates the handler instances early in the optimization stage. The optimizer uses them to get information about the tables, such as their column names and index statistics.
The storage engine interface has lots of functionality, but it needs only a dozen or so “building-block” operations to execute most queries. For example, there’s an operation to read the first row in an index, and one to read the next row in an index. This is enough for a query that does an index scan. This simplistic execution method makes MySQL’s storage engine architecture possible, but it also imposes some of the optimizer limitations we’ve discussed.
Tip
Not everything is a handler operation. For example, the server manages table locks. The handler may implement its own lower-level locking, as InnoDB does with row-level locks, but this does not replace the server’s own locking implementation. As explained in Chapter 1, anything that all storage engines share is implemented in the server, such as date and time functions, views, and triggers.
To execute the query, the server just repeats the instructions until there are no more rows to examine.
The final step in executing a query is to reply to the client. Even queries that don’t return a result set still reply to the client connection with information about the query, such as how many rows it affected.
If the query is cacheable, MySQL will also place the results into the query cache at this stage.
The server generates and sends results incrementally. Think back to the single-sweep multijoin method we mentioned earlier. As soon as MySQL processes the last table and generates one row successfully, it can and should send that row to the client.
This has two benefits: it lets the server avoid holding the row in memory, and it means the client starts getting the results as soon as possible. [47]
MySQL’s “everything is a nested-loop join” approach to query execution isn’t ideal for optimizing every kind of query. Fortunately, there are only a limited number of cases where the MySQL query optimizer does a poor job, and it’s usually possible to rewrite such queries more efficiently.
Tip
The information in this section applies to the MySQL server versions to which we have access at the time of this writing—that is, up to MySQL 5.1. Some of these limitations will probably be eased or removed entirely in future versions, and some have already been fixed in versions not yet released as GA (generally available). In particular, there are a number of subquery optimizations in the MySQL 6 source code, and more are in progress.
MySQL sometimes optimizes subqueries very badly. The worst offenders are IN() subqueries in the WHERE clause. As an example, let’s find all
films in the Sakila sample database’s sakila.film table whose casts include the
actress Penelope Guiness (actor_id=1). This feels natural to write
with a subquery, as follows:
mysql>SELECT * FROM sakila.film->WHERE film_id IN(->SELECT film_id FROM sakila.film_actor WHERE actor_id = 1);
It’s tempting to think that MySQL will execute this query from
the inside out, by finding a list of actor_id values and substituting them into
the IN() list. We said an IN() list is generally very fast, so you
might expect the query to be optimized to something like this:
-- SELECT GROUP_CONCAT(film_id) FROM sakila.film_actor WHERE actor_id = 1; -- Result: 1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980 SELECT * FROM sakila.film WHERE film_id IN(1,23,25,106,140,166,277,361,438,499,506,509,605,635,749,832,939,970,980);
Unfortunately, exactly the opposite happens. MySQL tries to “help” the subquery by pushing a correlation into it from the outer table, which it thinks will let the subquery find rows more efficiently. It rewrites the query as follows:
SELECT * FROM sakila.film WHEREEXISTS( SELECT * FROM sakila.film_actor WHERE actor_id = 1AND film_actor.film_id = film.film_id);
Now the subquery requires the film_id from the outer film table and can’t be executed first.
EXPLAIN shows the result as
DEPENDENT SUBQUERY (you can use
EXPLAIN EXTENDED to see exactly how
the query is rewritten):
mysql> EXPLAIN SELECT * FROM sakila.film ...;
+----+--------------------+------------+--------+------------------------+
| id | select_type | table | type | possible_keys |
+----+--------------------+------------+--------+------------------------+
| 1 | PRIMARY | film | ALL | NULL |
| 2 | DEPENDENT SUBQUERY | film_actor | eq_ref | PRIMARY,idx_fk_film_id |
+----+--------------------+------------+--------+------------------------+According to the EXPLAIN
output, MySQL will table-scan the film table and execute the subquery
for each row it finds. This won’t cause a noticeable
performance hit on small tables, but if the outer table is very large,
the performance will be extremely bad. Fortunately, it’s easy to
rewrite such a query as a JOIN:
mysql>SELECT film.* FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id)->WHERE actor_id = 1;
Another good optimization is to manually generate the IN() list by executing the subquery as a
separate query with GROUP_CONCAT().
Sometimes this can be faster than a JOIN.
MySQL has been criticized thoroughly for this particular type of subquery execution plan. Although it definitely needs to be fixed, the criticism often confuses two different issues: execution order and caching. Executing the query from the inside out is one way to optimize it; caching the inner query’s result is another. Rewriting the query yourself lets you take control over both aspects. Future versions of MySQL should be able to optimize this type of query much better, although this is no easy task. There are very bad worst cases for any execution plan, including the inside-out execution plan that some people think would be simple to optimize.
MySQL doesn’t always optimize correlated subqueries badly. If you hear advice to always avoid them, don’t listen! Instead, benchmark and make your own decision. Sometimes a correlated subquery is a perfectly reasonable, or even optimal, way to get a result. Let’s look at an example:
mysql>EXPLAIN SELECT film_id, language_id FROM sakila.film->WHERE NOT EXISTS(->SELECT * FROM sakila.film_actor->WHERE film_actor.film_id = film.film_id->)\G*************************** 1. row *************************** id: 1 select_type: PRIMARY table: film type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 951 Extra: Using where *************************** 2. row *************************** id: 2 select_type: DEPENDENT SUBQUERY table: film_actor type: ref possible_keys: idx_fk_film_id key: idx_fk_film_id key_len: 2 ref: film.film_id rows: 2 Extra: Using where; Using index
The standard advice for this query is to write it as a LEFT OUTER JOIN instead of using a subquery. In theory, MySQL’s execution plan
will be essentially the same either way. Let’s see:
mysql>EXPLAIN SELECT film.film_id, film.language_id->FROM sakila.film->LEFT OUTER JOIN sakila.film_actor USING(film_id)->WHERE film_actor.film_id IS NULL\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: film type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 951 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: film_actor type: ref possible_keys: idx_fk_film_id key: idx_fk_film_id key_len: 2 ref: sakila.film.film_id rows: 2 Extra: Using where; Using index;Not exists
The plans are nearly identical, but there are some differences:
The
SELECTtype againstfilm_actorisDEPENDENT SUBQUERYin one query andSIMPLEin the other. This difference simply reflects the syntax, because the first query uses a subquery and the second doesn’t. It doesn’t make much difference in terms of handler operations.The second query doesn’t say “Using where” in the
Extracolumn for thefilmtable. That doesn’t matter, though: the second query’sUSINGclause is the same thing as aWHEREclause anyway.The second query says “Not exists” in the
film_actortable’sExtracolumn. This is an example of the early-termination algorithm we mentioned earlier in this chapter. It means MySQL is using a not-exists optimization to avoid reading more than one row in thefilm_actortable’sidx_fk_film_idindex. This is equivalent to aNOTEXISTS()correlated subquery, because it stops processing the current row as soon as it finds a match.
So, in theory, MySQL will execute the queries almost identically. In reality, benchmarking is the only way to tell which approach is really faster. We benchmarked both queries on our standard setup. The results are shown in Table 4-1.
Table 4-1. NOT EXISTS versus LEFT OUTER JOIN
Query | Result in queries per second (QPS) |
|---|---|
| 360 QPS |
| 425 QPS |
Our benchmark found that the subquery is quite a bit slower!
However, this isn’t always the case. Sometimes a subquery can be faster. For example, it can work well when you just want to see rows from one table that match rows in another table. Although that sounds like it describes a join perfectly, it’s not always the same thing. The following join, which is designed to find every film that has an actor, will return duplicates because some films have multiple actors:
mysql>SELECT film.film_id FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id);
We need to use DISTINCT or
GROUP BY to eliminate the
duplicates:
mysql>SELECT DISTINCT film.film_id FROM sakila.film->INNER JOIN sakila.film_actor USING(film_id);
But what are we really trying to express with this query, and
is it obvious from the SQL? The EXISTS operator expresses the logical
concept of “has a match” without producing duplicated rows and
avoids a GROUP BY or DISTINCT operation, which might require a
temporary table. Here’s the query written as a subquery instead of a
join:
mysql>SELECT film_id FROM sakila.film->WHERE EXISTS(SELECT * FROM sakila.film_actor->WHERE film.film_id = film_actor.film_id);
Again, we benchmarked to see which strategy was faster. The results are shown in Table 4-2.
Table 4-2. EXISTS versus INNER JOIN
Query | Result in queries per second (QPS) |
|---|---|
| 185 QPS |
| 325 QPS |
In this example, the subquery performs much faster than the join.
We showed this lengthy example to illustrate two points: you should not heed categorical advice about subqueries, and you should use benchmarks to prove your assumptions about query plans and execution speed.
MySQL sometimes can’t “push down” conditions from the outside
of a UNION to the inside, where
they could be used to limit results or enable additional
optimizations.
If you think any of the individual queries inside a UNION would benefit from a LIMIT, or if you know they’ll be subject
to an ORDER BY clause once
combined with other queries, you need to put those clauses inside
each part of the UNION. For
example, if you UNION together
two huge tables and LIMIT the
result to the first 20 rows, MySQL will store both huge tables into
a temporary table and then retrieve just 20 rows from it. You can
avoid this by placing LIMIT 20 on
each query inside the UNION.
Index merge algorithms, introduced in MySQL 5.0, let
MySQL use more than one index per table in a query. Earlier versions
of MySQL could use only a single index, so when no single index was
good enough to help with all the restrictions in the WHERE clause, MySQL often chose a table
scan. For example, the film_actor
table has an index on film_id and
an index on actor_id, but neither
is a good choice for both WHERE
conditions in this query:
mysql>SELECT film_id, actor_id FROM sakila.film_actor->WHERE actor_id = 1 OR film_id = 1;
In older MySQL versions, that query would produce a table scan
unless you wrote it as the UNION
of two queries:
mysql>SELECT film_id, actor_id FROM sakila.film_actor WHERE actor_id = 1->UNION ALL->SELECT film_id, actor_id FROM sakila.film_actor WHERE film_id = 1->AND actor_id <> 1;
In MySQL 5.0 and newer, however, the query can use both
indexes, scanning them simultaneously and merging the results. There
are three variations on the algorithm: union for OR conditions, intersection for AND conditions, and unions of
intersections for combinations of the two. The following query uses
a union of two index scans, as you can see by examining the Extra column:
mysql>EXPLAIN SELECT film_id, actor_id FROM sakila.film_actor->WHERE actor_id = 1 OR film_id = 1\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: film_actor type: index_merge possible_keys: PRIMARY,idx_fk_film_id key: PRIMARY,idx_fk_film_id key_len: 2,2 ref: NULL rows: 29 Extra:Using union(PRIMARY,idx_fk_film_id);Using where
MySQL can use this technique on complex WHERE clauses, so you may see nested
operations in the Extra column
for some queries. This often works very well, but sometimes the algorithm’s
buffering, sorting, and merging operations use lots of CPU and
memory resources. This is especially true if not all of the indexes
are very selective, so the parallel scans return lots of rows to the
merge operation. Recall that the optimizer doesn’t account for this cost—it optimizes
just the number of random page reads. This can make it “underprice”
the query, which might in fact run more slowly than a plain table
scan. The intensive memory and CPU usage also tends to impact
concurrent queries, but you won’t see this effect when you run the
query in isolation. This is another reason to design realistic
benchmarks.
If your queries run more slowly because of this optimizer
limitation, you can work around it by disabling some indexes with
IGNORE INDEX, or just fall back
to the old UNION tactic.
Equality propagation can have unexpected costs sometimes. For
example, consider a huge IN()
list on a column the optimizer knows will be equal to some columns
on other tables, due to a WHERE,
ON, or USING clause
that sets the columns equal to each other.
The optimizer will “share” the list by copying it to the
corresponding columns in all related tables. This is normally
helpful, because it gives the query optimizer and execution engine
more options for where to actually execute the IN() check. But when the list is very
large, it can result in slower optimization and execution. There’s
no built-in workaround for this problem at the time of this
writing—you’ll have to change the source code if it’s a problem for
you. (It’s not a problem for most people.)
MySQL can’t execute a single query in parallel on many CPUs. This is a feature offered by some other database servers, but not MySQL. We mention it so that you won’t spend a lot of time trying to figure out how to get parallel query execution on MySQL!
MySQL can’t do true hash joins at the time of this writing—everything is a nested-loop join. However, you can emulate hash joins using hash indexes. If you aren’t using the Memory storage engine, you’ll have to emulate the hash indexes, too. We showed you how to do this in “Building your own hash indexes” on Hash indexes.
MySQL has historically been unable to do loose index scans, which scan noncontiguous ranges of an index. MySQL’s index scans generally require a defined start point and a defined end point in the index, even if only a few noncontiguous rows in the middle are really desired for the query. MySQL will scan the entire range of rows within these end points.
An example will help clarify this. Suppose we have a table
with an index on columns (a, b),
and we want to run the following query:
mysql> SELECT ... FROM tbl WHERE b BETWEEN 2 AND 3;Because the index begins with column a, but the query’s WHERE clause doesn’t specify column
a, MySQL will do a table scan and
eliminate the nonmatching rows with a WHERE clause, as shown in Figure 4-5.

It’s easy to see that there’s a faster way to execute this query. The index’s structure (but not MySQL’s storage engine API) lets you seek to the beginning of each range of values, scan until the end of the range, and then backtrack and jump ahead to the start of the next range. Figure 4-6 shows what that strategy would look like if MySQL were able to do it.
Notice the absence of a WHERE clause, which isn’t needed because
the index alone lets us skip over the unwanted rows. (Again, MySQL
can’t do this yet.)

This is admittedly a simplistic example, and we could easily optimize the query we’ve shown by adding a different index. However, there are many cases where adding another index can’t solve the problem. One example is a query that has a range condition on the index’s first column and an equality condition on the second column.
Beginning in MySQL 5.0, loose index scans are possible in certain limited circumstances, such as queries that find maximum and minimum values in a grouped query:
mysql>EXPLAIN SELECT actor_id, MAX(film_id)->FROM sakila.film_actor->GROUP BY actor_id\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: film_actor type: range possible_keys: NULL key: PRIMARY key_len: 2 ref: NULL rows: 396 Extra:Using index for group-by
The “Using index for group-by” information in this EXPLAIN plan indicates a loose index scan.
This is a good optimization for this special purpose, but it is not
a general-purpose loose index scan. It might be better termed a
“loose index probe.”
Until MySQL supports general-purpose loose index scans, the workaround is to supply a constant or list of constants for the leading columns of the index. We showed several examples of how to get good performance with these types of queries in our indexing case study in the previous chapter.
MySQL doesn’t optimize certain MIN() and MAX() queries very well. Here’s an
example:
mysql> SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';Because there’s no index on first_name, this query performs a table
scan. If MySQL scans the primary key, it can theoretically stop
after reading the first matching row, because the primary key is
strictly ascending and any subsequent row will have a greater
actor_id. However, in this case,
MySQL will scan the whole table, which you can verify by profiling
the query. The workaround is to remove the MIN() and rewrite the query with a LIMIT, as
follows:
mysql>SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)->WHERE first_name = 'PENELOPE' LIMIT 1;
This general strategy often works well when MySQL would otherwise choose to scan more rows than necessary. If you’re a purist, you might object that this query is missing the point of SQL. We’re supposed to be able to tell the server what we want and it’s supposed to figure out how to get that data, whereas, in this case, we’re telling MySQL how to execute the query and, as a result, it’s not clear from the query that what we’re looking for is a minimal value. True, but sometimes you have to compromise your principles to get high performance.
MySQL doesn’t let you SELECT from a table while simultaneously
running an UPDATE on it. This
isn’t really an optimizer limitation, but knowing how MySQL executes
queries can help you work around it. Here’s an example of a query
that’s disallowed, even though it is standard SQL. The query updates
each row with the number of similar rows in the table:
mysql>UPDATE tbl AS outer_tbl->SET cnt = (->SELECT count(*) FROM tbl AS inner_tbl->WHERE inner_tbl.type = outer_tbl.type->);ERROR 1093 (HY000): You can't specify target table 'outer_tbl' for update in FROM clause
To work around this limitation, you can use a derived table,
because MySQL materializes it as a temporary table. This effectively
executes two queries: one SELECT
inside the subquery, and one multitable UPDATE with the joined results of the
table and the subquery. The subquery opens and closes the table
before the outer UPDATE opens the
table, so the query will now succeed:
mysql>UPDATE tbl->INNER JOIN(->SELECT type, count(*) AS cnt->FROM tbl->GROUP BY type->) AS der USING(type)->SET tbl.cnt = der.cnt;
In this section, we give advice on how to optimize certain kinds of queries. We’ve covered most of these topics in detail elsewhere in the book, but we wanted to make a list of common optimization problems that you can refer to easily.
Most of the advice in this section is version-dependent, and it may not hold for future versions of MySQL. There’s no reason why the server won’t be able to do some or all of these optimizations itself someday.
The COUNT() aggregate
function and how to optimize queries that use it is probably one of
the top 10 most misunderstood topics in MySQL. You can do a web search
and find more misinformation on this topic than we care to think
about.
Before we get into optimization, it’s important that you
understand what COUNT() really
does.
COUNT() is a special
function that works in two very different ways: it counts
values and rows. A value
is a non-NULL expression
(NULL is the absence of a value).
If you specify a column name or other expression inside the
parentheses, COUNT() counts how
many times that expression has a value. This is confusing for many
people, in part because values and NULL are confusing. If you need to learn
how this works in SQL, we suggest a good book on SQL fundamentals.
(The Internet is not necessarily a good source of accurate
information on this topic, either.)
The other form of COUNT()
simply counts the number of rows in the result. This is what MySQL
does when it knows the expression inside the parentheses can never
be NULL. The most obvious example
is COUNT(*), which is a special
form of COUNT() that does not
expand the * wildcard into the full list of columns in the table, as
you might expect; instead, it ignores columns altogether and counts
rows.
One of the most common mistakes we see is specifying column
names inside the parentheses when you want to count rows. When you
want to know the number of rows in the result, you should
always use COUNT(*). This communicates your intention
clearly and avoids poor performance.
A common misconception is that MyISAM is extremely fast for
COUNT() queries. It is fast, but
only for a very special case: COUNT(*) without a WHERE clause, which merely counts the
number of rows in the entire table. MySQL can optimize this away
because the storage engine always knows how many rows are in the
table. If MySQL knows col can
never be NULL, it can also
optimize a COUNT(col) expression
by converting it to COUNT(*)
internally.
MyISAM does not have any magical speed optimizations for counting rows when the query has a
WHERE clause, or for the more
general case of counting values instead of rows. It may be faster
than other storage engines for a given query, or it may not be. That
depends on a lot of factors.
You can sometimes use MyISAM’s COUNT(*) optimization to your advantage
when you want to count all but a very small number of rows that are
well indexed. The following example uses the standard World database
to show how you can efficiently find the number of cities whose
ID is greater than 5. You might write this query as
follows:
mysql> SELECT COUNT(*) FROM world.City WHERE ID > 5;If you profile this query with SHOW
STATUS, you’ll see that it scans 4,079 rows. If you negate
the conditions and subtract the number of cities whose IDs are less than or equal to 5 from the total number of cities, you can
reduce that to five rows:
mysql>SELECT (SELECT COUNT(*) FROM world.City) - COUNT(*)->FROM world.City WHERE ID <= 5;
This version reads fewer rows because the subquery is turned
into a constant during the query optimization phase, as you can see
with EXPLAIN:
+----+-------------+-------+...+------+------------------------------+ | id | select_type | table |...| rows | Extra | +----+-------------+-------+...+------+------------------------------+ | 1 | PRIMARY | City |...| 6 | Using where; Using index | | 2 | SUBQUERY | NULL |...| NULL | Select tables optimized away | +----+-------------+-------+...+------+------------------------------+
A frequent question on mailing lists and IRC channels is how
to retrieve counts for several different values in the same column
with just one query, to reduce the number of queries required. For
example, say you want to create a single query that counts how many
items have each of several colors. You can’t use an OR (e.g., SELECT
COUNT(color = 'blue' OR color = 'red') FROM items;),
because that won’t separate the different counts for the different
colors. And you can’t put the colors in the WHERE clause (e.g., SELECT COUNT(*) FROM items WHERE color = 'blue' AND
color = 'red';), because the colors are mutually
exclusive. Here is a query that solves this problem:
mysql>SELECT SUM(IF(color = 'blue', 1, 0)) AS blue,SUM(IF(color = 'red', 1, 0))->AS red FROM items;
And here is another that’s equivalent, but instead of using
SUM() uses COUNT() and ensures that the expressions
won’t have values when the criteria are false:
mysql>SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL)->AS red FROM items;
In general, COUNT() queries
are hard to optimize because they usually need to count a lot of
rows (i.e., access a lot of data). Your only other option for
optimizing within MySQL itself is to use a covering index, which we
discussed in Chapter 3. If
that doesn’t help enough, you need to make changes to your
application architecture. Consider summary tables (also covered in
Chapter 3), and possibly
an external caching system such as memcached.
You’ll probably find yourself faced with the familiar dilemma,
“fast, accurate, and simple: pick any two.”
This topic is actually spread throughout most of the book, but we mention a few highlights:
Make sure there are indexes on the columns in the
ONorUSINGclauses. See “Indexing Basics” on Indexing Basics for more about indexing. Consider the join order when adding indexes. If you’re joining tablesAandBon columncand the query optimizer decides to join the tables in the orderB, A, you don’t need to index the column on tableB. Unused indexes are extra overhead. In general, you need to add indexes only on the second table in the join order, unless they’re needed for some other reason.Try to ensure that any
GROUPBYorORDER BYexpression refers only to columns from a single table, so MySQL can try to use an index for that operation.Be careful when upgrading MySQL, because the join syntax, operator precedence, and other behaviors have changed at various times. What used to be a normal join can sometimes become a cross product, a different kind of join that returns different results, or even invalid syntax.
The most important advice we can give on subqueries is that you should usually prefer a join where possible, at least in current versions of MySQL. We covered this topic extensively earlier in this chapter.
Subqueries are the subject of intense work by the optimizer team, and upcoming versions of MySQL may have more subquery optimizations. It remains to be seen which of the optimizations we’ve seen will end up in released code, and how much difference they’ll make. Our point here is that “prefer a join” is not future-proof advice. The server is getting smarter all the time, and the cases where you have to tell it how to do something instead of what results to return are becoming fewer.
MySQL optimizes these two kinds of queries similarly in many cases, and in fact converts between them as needed internally during the optimization process. Both types of queries benefit from indexes, as usual, and that’s the single most important way to optimize them.
MySQL has two kinds of GROUP
BY strategies when it can’t use an
index: it can use a temporary table or a filesort to perform the
grouping. Either one can be more efficient for any given query. You
can force the optimizer to choose one method or the other with the
SQL_BIG_RESULT and SQL_SMALL_RESULT optimizer hints.
If you need to group a join by a value that comes from a lookup table, it’s usually more efficient to group by the lookup table’s identifier than by the value. For example, the following query isn’t as efficient as it could be:
mysql>SELECT actor.first_name, actor.last_name, COUNT(*)->FROM sakila.film_actor->INNER JOIN sakila.actor USING(actor_id)->GROUP BY actor.first_name, actor.last_name;
The query is more efficiently written as follows:
mysql>SELECT actor.first_name, actor.last_name, COUNT(*)->FROM sakila.film_actor->INNER JOIN sakila.actor USING(actor_id)->GROUP BY film_actor.actor_id;
Grouping by actor.actor_id
could be more efficient than grouping by film_actor.actor_id. You should profile
and/or benchmark on your specific data to see.
This query takes advantage of the fact that the actor’s first
and last name are dependent on the actor_id, so it will return the same
results, but it’s not always the case that you can blithely select
nongrouped columns and get the same result. You may even have the
server’s SQL_MODE configured to
disallow it. You can use MIN() or
MAX() to work around this when you
know the values within the group are distinct because they depend on the grouped-by column,
or if you don’t care which value you get:
mysql> SELECT MIN(actor.first_name), MAX(actor.last_name), ...;Purists will argue that you’re grouping by the wrong thing, and
they’re right. A spurious MIN() or
MAX() is a sign that the query
isn’t structured correctly. However, sometimes your only concern will
be making MySQL execute the query as quickly as possible. The purists
will be satisfied with the following way of writing the query:
mysql>SELECT actor.first_name, actor.last_name, c.cnt->FROM sakila.actor->INNER JOIN (->SELECT actor_id, COUNT(*) AS cnt->FROM sakila.film_actor->GROUP BY actor_id->) AS c USING(actor_id) ;
But sometimes the cost of creating and filling the temporary table required for the subquery is high compared to the cost of fudging pure relational theory a little bit. Remember, the temporary table created by the subquery has no indexes.
It’s generally a bad idea to select nongrouped columns in a
grouped query, because the results will be nondeterministic and could
easily change if you change an index or the optimizer decides to use a
different strategy. Most such queries we see are accidents (because
the server doesn’t complain), or are the result of laziness rather
than being designed that way for optimization purposes. It’s better to
be explicit. In fact, we suggest that you set the server’s SQL_MODE configuration variable to include
ONLY_FULL_GROUP_BY so it produces
an error instead of letting you write a bad query.
MySQL automatically orders grouped queries by the columns in the
GROUP BY clause, unless you specify
an ORDER BY clause explicitly. If
you don’t care about the order and you see this causing a filesort,
you can use ORDER BY NULL to skip
the automatic sort. You can also add an optional DESC or ASC keyword right after the GROUP BY clause to order the results in the
desired direction by the clause’s columns.
A variation on grouped queries is to ask MySQL to do
superaggregation within the results. You can do this with a WITH ROLLUP clause, but it might not be as
well optimized as you need. Check the execution method with EXPLAIN, paying attention to whether the
grouping is done via filesort or temporary table; try removing the
WITH ROLLUP and seeing if you get the same
group method. You may be able to force the grouping method with the
hints we mentioned earlier in this section.
Sometimes it’s more efficient to do superaggregation in your
application, even if it means fetching many more rows from the
server. You can also nest a subquery in the FROM clause or use a temporary table to
hold intermediate results.
The best approach may be to move the WITH ROLLUP functionality into your application
code.
Queries with LIMITs and
OFFSETs are common in systems that
do pagination, nearly always in conjunction with an ORDER BY clause. It’s helpful to have an
index that supports the ordering; otherwise, the server has to do a
lot of filesorts.
A frequent problem is having a high value for the offset. If your query looks like LIMIT 10000, 20, it is generating 10,020
rows and throwing away the first 10,000 of them, which is very
expensive. Assuming all pages are accessed with equal frequency, such
queries scan half the table on average. To optimize them, you can
either limit how many pages are permitted in a pagination view, or try
to make the high offsets more efficient.
One simple technique to improve efficiency is to do the offset on a covering index, rather than the full rows. You can then join the result to the full row and retrieve the additional columns you need. This can be much more efficient. Consider the following query:
mysql> SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;If the table is very large, this query is better written as follows:
mysql>SELECT film.film_id, film.description->FROM sakila.film->INNER JOIN (->SELECT film_id FROM sakila.film->ORDER BY title LIMIT 50, 5->) AS lim USING(film_id);
This works because it lets the server examine as little data as
possible in an index without accessing rows, and then, once the
desired rows are found, join them against the full table to retrieve
the other columns from the row. A similar technique applies to joins
with LIMIT clauses.
Sometimes you can also convert the limit to a positional query, which the server can execute as an index range scan. For example, if you precalculate and index a position column, you can rewrite the query as follows:
mysql>SELECT film_id, description FROM sakila.film->WHERE position BETWEEN 50 AND 54 ORDER BY position;
Ranked data poses a similar problem, but usually mixes GROUP BY into the fray. You’ll almost
certainly need to precompute and store ranks.
If you really need to optimize pagination systems, you should
probably use precomputed summaries. As an alternative, you can join
against redundant tables that contain only the primary key and the
columns you need for the ORDER BY.
You can also use Sphinx; see Appendix C for more information.
Another common technique for paginated displays is to add the
SQL_CALC_FOUND_ROWS hint to a query with a LIMIT, so you’ll know how many rows would
have been returned without the LIMIT. It may seem that there’s some kind of
“magic” happening here, whereby the server predicts how many rows it
would have found. But unfortunately, the server doesn’t really do
that; it can’t count rows it doesn’t actually find. This option just
tells the server to generate and throw away the rest of the result
set, instead of stopping when it reaches the desired number of rows.
That’s very expensive.
A better design is to convert the pager to a “next” link.
Assuming there are 20 results per page, the query should then use a
LIMIT of 21 rows and display only
20. If the 21st row exists in the results, there’s a next page, and
you can render the “next” link.
Another possibility is to fetch and cache many more rows than you need—say, 1,000—and then retrieve them from the cache for successive pages. This strategy lets your application know how large the full result set is. If it’s fewer than 1,000 rows, the application knows how many page links to render; if it’s more, the application can just display “more than 1,000 results found.” Both strategies are much more efficient than repeatedly generating an entire result and discarding most of it.
Even when you can’t use these tactics, using a separate COUNT(*) query to find the number of rows
can be much faster than SQL_CALC_FOUND_ROWS, if it can use a
covering index.
MySQL always executes UNION
queries by creating a temporary table and filling it with the UNION results. MySQL can’t apply as many
optimizations to UNION queries as you might be used to. You
might have to help the optimizer by manually “pushing down” WHERE, LIMIT, ORDER BY, and other conditions
(i.e., copying them, as appropriate, from the outer query into each
SELECT in the UNION).
It’s important to always use UNION ALL, unless you need the server to
eliminate duplicate rows. If you omit the ALL keyword, MySQL adds the distinct option to the temporary table,
which uses the full row to determine uniqueness. This is quite
expensive. Be aware that the ALL
keyword doesn’t eliminate the temporary table, though. MySQL always
places results into a temporary table and then reads them out again,
even when it’s not really necessary (for example, when the results
could be returned directly to the client).
MySQL has a few optimizer hints you can use to control the query plan if you’re not happy with the one MySQL’s optimizer chooses. The following list identifies these hints and indicates when it’s a good idea to use them. You place the appropriate hint in the query whose plan you want to modify, and it is effective for only that query. Check the MySQL manual for the exact syntax of each hint. Some of them are version-dependent. The options are:
HIGH_PRIORITYandLOW_PRIORITYThese hints tell MySQL how to prioritize the statement relative to other statements that are trying to access the same tables.
HIGH_PRIORITYtells MySQL to schedule aSELECTstatement before other statements that may be waiting for locks, so they can modify data. In effect, it makes theSELECTgo to the front of the queue instead of waiting its turn. You can also apply this modifier toINSERT, where it simply cancels the effect of a globalLOW_PRIORITYserver setting.LOW_PRIORITYis the reverse: it makes the statement wait at the very end of the queue if there are any other statements that want to access the tables—even if the other statements are issued after it. It’s rather like an overly polite person holding the door at a restaurant: as long as there’s anyone else waiting, it will starve itself! You can apply this hint toSELECT, INSERT, UPDATE, REPLACE, andDELETEstatements.These hints are effective on storage engines with table-level locking, but you should never need them on InnoDB or other engines with fine-grained locking and concurrency control. Be careful when using them on MyISAM, because they can disable concurrent inserts and greatly reduce performance.
The
HIGH_PRIORITYandLOW_PRIORITYhints are a frequent source of confusion. They do not allocate more or fewer resources to queries to make them “work harder” or “not work as hard”; they simply affect how the server queues statements that are waiting for access to a table.DELAYEDThis hint is for use with
INSERTandREPLACE. It lets the statement to which it is applied return immediately and places the inserted rows into a buffer, which will be inserted in bulk when the table is free. This is most useful for logging and similar applications where you want to insert a lot of rows without making the client wait, and without causing I/O for each statement. There are many limitations; for example, delayed inserts are not implemented in all storage engines, andLAST_INSERT_ID()doesn’t work with them.STRAIGHT_JOINThis hint can appear either just after the
SELECTkeyword in aSELECTstatement, or in any statement between two joined tables. The first usage forces all tables in the query to be joined in the order in which they’re listed in the statement. The second usage forces a join order on the two tables between which the hint appears.The
STRAIGHT_JOINhint is useful when MySQL doesn’t choose a good join order, or when the optimizer takes a long time to decide on a join order. In the latter case, the thread will spend a lot of time in “Statistics” state, and adding this hint will reduce the search space for the optimizer.You can use
EXPLAINto see what order the optimizer would choose, then rewrite the query in that order and addSTRAIGHT_JOIN. This is a good idea as long as you don’t think the fixed order will result in bad performance for someWHEREclauses. You should be careful to revisit such queries after upgrading MySQL, however, because new optimizations may appear that will be defeated bySTRAIGHT_JOIN.SQL_SMALL_RESULTandSQL_BIG_RESULTThese hints are for
SELECTstatements. They tell the optimizer how and when to use temporary tables and sort inGROUP BYorDISTINCTqueries.SQL_SMALL_RESULTtells the optimizer that the result set will be small and can be put into indexed temporary tables to avoid sorting for the grouping, whereasSQL_BIG_RESULTindicates that the result will be large and that it will be better to use temporary tables on disk with sorting.SQL_BUFFER_RESULTThis hint tells the optimizer to put the results into a temporary table and release table locks as soon as possible. This is different from the client-side buffering we described in “The MySQL Client/Server Protocol” on Query Execution Basics. Server-side buffering can be useful when you don’t use buffering on the client, as it lets you avoid consuming a lot of memory on the client and still release locks quickly. The tradeoff is that the server’s memory is used instead of the client’s.
SQL_CACHEandSQL_NO_CACHEThese hints instruct the server that the query either is or is not a candidate for caching in the query cache. See the next chapter for details on how to use them.
SQL_CALC_FOUND_ROWSThis hint tells MySQL to calculate a full result set when there’s a
LIMITclause, even though it returns onlyLIMITrows. You can retrieve the total number of rows it found viaFOUND_ROWS()(but see “Optimizing SQL_CALC_FOUND_ROWS” on Optimizing UNION for reasons why you shouldn’t use this hint).FOR UPDATEandLOCK IN SHARE MODEThese hints control locking for
SELECTstatements, but only for storage engines that have row-level locks. They enable you to place locks on the matched rows, which can be useful when you want to lock rows you know you are going to update later, or when you want to avoid lock escalation and just acquire exclusive locks as soon as possible.These hints are not needed for
INSERT … SELECTqueries, which place read locks on the source rows by default in MySQL 5.0. (You can disable this behavior, but it’s not a good idea—we explain why in Chapters Chapter 8 and Chapter 11.) MySQL 5.1 may lift this restriction under certain conditions.At the time of this writing, only InnoDB supports these hints, and it’s too early to say whether other storage engines with row-level locks will support them in the future. When using these hints with InnoDB, be aware that they may disable some optimizations, such as covering indexes. InnoDB can’t lock rows exclusively without accessing the primary key, which is where the row versioning information is stored.
USE INDEX, IGNORE INDEX, andFORCE INDEXThese hints tell the optimizer which indexes to use or ignore for finding rows in a table (for example, when deciding on a join order). In MySQL 5.0 and earlier, they don’t influence which indexes the server uses for sorting and grouping; in MySQL 5.1 the syntax can take an optional
FOR ORDER BYorFOR GROUP BYclause.FORCE INDEXis the same asUSE INDEX, but it tells the optimizer that a table scan is extremely expensive compared to the index, even if the index is not very useful. You can use these hints when you don’t think the optimizer is choosing the right index, or when you want to take advantage of an index for some reason, such as implicit ordering without anORDER BY. We gave an example of this in “Optimizing LIMIT and OFFSET” on Optimizing SQL_CALC_FOUND_ROWS, where we showed how to get a minimum value efficiently withLIMIT.
In MySQL 5.0 and newer, there are also some system variables that influence the optimizer:
optimizer_search_depthThis variable tells the optimizer how exhaustively to examine partial plans. If your queries are taking a very long time in the “Statistics” state, you might try lowering this value.
optimizer_prune_levelThis variable, which is enabled by default, lets the optimizer skip certain plans based on the number of rows examined.
Both options control optimizer shortcuts. These shortcuts are valuable for good performance on complex queries, but they can cause the server to miss optimal plans for the sake of efficiency. That’s why it sometimes makes sense to change them.
It’s easy to forget about MySQL’s user-defined variables, but they can be a powerful technique for writing efficient queries. They work especially well for queries that benefit from a mixture of procedural and relational logic. Purely relational queries treat everything as unordered sets that the server somehow manipulates all at once. MySQL takes a more pragmatic approach. This can be a weakness, but it can be a strength if you know how to exploit it, and user-defined variables can help.
User-defined variables are temporary containers for values, which
persist as long as your connection to the server lives. You define them
by simply assigning to them with a SET or SELECT statement: [48]
mysql>SET @one := 1;mysql>SET @min_actor := (SELECT MIN(actor_id) FROM sakila.actor);mysql>SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;
You can then use the variables in most places an expression can go:
mysql> SELECT ... WHERE col <= @last_week;Before we get into the strengths of user-defined variables, let’s take a look at some of their peculiarities and disadvantages and see what things you can’t use them for:
They prevent query caching.
You can’t use them where a literal or identifier is needed, such as for a table or column name, or in the
LIMITclause.They are connection-specific, so you can’t use them for interconnection communication.
If you’re using connection pooling or persistent connections, they can cause seemingly isolated parts of your code to interact.
They are case sensitive in MySQL versions prior to 5.0, so beware of compatibility issues.
You can’t explicitly declare these variables’ types, and the point at which types are decided for undefined variables differs across MySQL versions. The best thing to do is initially assign a value of
0for variables you want to use for integers,0.0for floating-point numbers, or '' (the empty string) for strings. A variable’s type changes when it is assigned to; MySQL’s user-defined variable typing is dynamic.The optimizer might optimize away these variables in some situations, preventing them from doing what you want.
Order of assignment, and indeed even the time of assignment, can be nondeterministic and depend on the query plan the optimizer chose. The results can be very confusing, as you’ll see later.
The
:=assignment operator has lower precedence than any other operator, so you have to be careful to parenthesize explicitly.Undefined variables do not generate a syntax error, so it’s easy to make mistakes without knowing it.
One of the most important features of variables is that you can assign a value to a variable and use the resulting value at the same time. In other words, an assignment is an L-value. Here’s an example that simultaneously calculates and outputs a “row number” for a query:
mysql>SET @rownum := 0;mysql>SELECT actor_id, @rownum := @rownum + 1 AS rownum->FROM sakila.actor LIMIT 3;+----------+--------+ | actor_id | rownum | +----------+--------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +----------+--------+
This example isn’t terribly interesting, because it just shows that we can duplicate the table’s primary key. Still, it has its uses—one of which is ranking. Let’s write a query that returns the 10 actors who have played in the most movies, with a rank column that gives actors the same rank if they’re tied. We start with a query that finds the actors and the number of movies:
mysql>SELECT actor_id, COUNT(*) as cnt->FROM sakila.film_actor->GROUP BY actor_id->ORDER BY cnt DESC->LIMIT 10;+----------+-----+ | actor_id | cnt | +----------+-----+ | 107 | 42 | | 102 | 41 | | 198 | 40 | | 181 | 39 | | 23 | 37 | | 81 | 36 | | 106 | 35 | | 60 | 35 | | 13 | 35 | | 158 | 35 | +----------+-----+
Now let’s add the rank, which should be the same for all the actors who played in 35 movies. We use three variables to do this: one to keep track of the current rank, one to keep track of the previous actor’s movie count, and one to keep track of the current actor’s movie count. We change the rank when the movie count changes. Here’s a first try:
mysql>SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;mysql>SELECT actor_id,->@curr_cnt := COUNT(*) AS cnt,->@rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,->@prev_cnt := @curr_cnt AS dummy->FROM sakila.film_actor->GROUP BY actor_id->ORDER BY cnt DESC->LIMIT 10;+----------+-----+------+-------+ | actor_id | cnt | rank | dummy | +----------+-----+------+-------+ | 107 | 42 | 0 | 0 | | 102 | 41 | 0 | 0 | ...
Oops—the rank and count never got updated from zero. Why did this happen?
It’s impossible to give a one-size-fits-all answer. The problem
could be as simple as a misspelled variable name (in this example it’s
not), or something more involved. In this case, EXPLAIN shows there’s a temporary table and
filesort, so the variables are being evaluated at a different time from
when we expected.
This is the type of inscrutable behavior you’ll often experience with MySQL’s user-defined variables. Debugging such problems can be tough, but it can really pay off. Ranking in SQL normally requires quadratic algorithms, such as counting the distinct number of actors who played in a greater number of movies. A user-defined variable solution can be a linear algorithm—quite an improvement.
An easy solution in this case is to add another level of temporary
tables to the query, using a subquery in the FROM clause:
mysql>SET @curr_cnt := 0, @prev_cnt := 0, @rank := 0;->SELECT actor_id,->@curr_cnt := cnt AS cnt,->@rank := IF(@prev_cnt <> @curr_cnt, @rank + 1, @rank) AS rank,->@prev_cnt := @curr_cnt AS dummy->FROM (->SELECT actor_id, COUNT(*) AS cnt->FROM sakila.film_actor->GROUP BY actor_id->ORDER BY cnt DESC->LIMIT 10->) as der;+----------+-----+------+-------+ | actor_id | cnt | rank | dummy | +----------+-----+------+-------+ | 107 | 42 | 1 | 42 | | 102 | 41 | 2 | 41 | | 198 | 40 | 3 | 40 | | 181 | 39 | 4 | 39 | | 23 | 37 | 5 | 37 | | 81 | 36 | 6 | 36 | | 106 | 35 | 7 | 35 | | 60 | 35 | 7 | 35 | | 13 | 35 | 7 | 35 | | 158 | 35 | 7 | 35 | +----------+-----+------+-------+
Most problems with user variables come from assigning to them and reading them at
different stages in the query. For example, it doesn’t work predictably
to assign them in the SELECT
statement and read from them in the WHERE clause. The following query might look
like it will just return one row, but it doesn’t:
mysql>SET @rownum := 0;mysql>SELECT actor_id, @rownum := @rownum + 1 AS cnt->FROM sakila.actor->WHERE @rownum <= 1;+----------+------+ | actor_id | cnt | +----------+------+ | 1 | 1 | | 2 | 2 | +----------+------+
This happens because the WHERE
and SELECT are different stages in
the query execution process. This is even more obvious when you add
another stage to execution with an ORDER
BY:
mysql>SET @rownum := 0;mysql>SELECT actor_id, @rownum := @rownum + 1 AS cnt->FROM sakila.actor->WHERE @rownum <= 1->ORDER BY first_name;
This query returns every row in the table, because the ORDER BY added a filesort and the WHERE is evaluated before the filesort. The
solution to this problem is to assign and read in the
same stage of query execution:
mysql>SET @rownum := 0;mysql>SELECT actor_id, @rownum AS rownum->FROM sakila.actor->WHERE (@rownum := @rownum + 1) <= 1;+----------+--------+ | actor_id | rownum | +----------+--------+ | 1 | 1 | +----------+--------+
Pop quiz: what will happen if you add the ORDER BY back to this query? Try it and see.
If you didn’t get the results you expected, why not? What about the
following query, where the ORDER BY
changes the variable’s value and the WHERE clause evaluates it?
mysql>SET @rownum := 0;mysql>SELECT actor_id, first_name, @rownum AS rownum->FROM sakila.actor->WHERE @rownum <= 1->ORDER BY first_name, LEAST(0, @rownum := @rownum + 1);
The answer to most unexpected user-defined variable behavior can
be found by running EXPLAIN and
looking for “Using where,” “Using temporary,” or “Using filesort” in the
Extra column.
The last example introduced another useful hack: we placed the
assignment in the LEAST() function,
so its value is effectively masked and won’t skew the results of the
ORDER BY (as we’ve written it, the
LEAST() function will always return
0). This trick is very helpful when
you want to do variable assignments solely for their side effects: it
lets you hide the return value and avoid extra columns, such as the
dummy column we showed in a previous
example. The GREATEST(), LENGTH(), ISNULL(),
NULLIF(), COALESCE(), and IF() functions are also useful for this
purpose, alone and in combination, because they have special behaviors.
For instance, COALESCE() stops
evaluating its arguments as soon as one has a defined value.
You can put variable assignments in all types of statements, not
just SELECT statements. In fact, this
is one of the best uses for user-defined variables. For example, you can rewrite
expensive queries, such as rank calculations with subqueries, as cheap
once-through UPDATE
statements.
It can be a little tricky to get the desired behavior, though.
Sometimes the optimizer decides to consider the variables compile-time constants and refuses to perform
assignments. Placing the assignments inside a function like LEAST() will usually help. Another tip is to
check whether your variable has a defined value before executing the
containing statement. Sometimes you want it to, but other times you
don’t.
With a little experimentation, you can do all sorts of interesting things with user-defined variables. Here are some ideas:
As we’ve said, trying to outsmart the MySQL optimizer usually is not a good idea. It generally creates more work and increases maintenance costs for very little benefit. This is especially relevant when you upgrade MySQL, because optimizer hints used in your queries might prevent new optimizer strategies from being used.
The way the MySQL optimizer uses indexes is a moving target. New MySQL versions change how existing indexes can be used, and you should adjust your indexing practices as these new versions become available. For example, we’ve mentioned that MySQL 4.0 and older could use only one index per table per query, but MySQL 5.0 and newer can use index merge strategies.
Besides the big changes MySQL occasionally makes to the query optimizer, each incremental release typically includes many tiny changes. These changes usually affect small things, such as the conditions under which an index is excluded from consideration, and let MySQL optimize more special cases.
Although all this sounds good in theory, in practice some queries perform worse after an upgrade. If you’ve used a certain version for a long time, you have likely tuned certain queries just for that version, whether you know it or not. These optimizations may no longer apply in newer versions, or may degrade performance.
If you care about high performance you should have a benchmark suite that represents your particular workload, which you can run against the new version on a development server before you upgrade the production servers. Also, before upgrading, you should read the release notes and the list of known bugs in the new version. The MySQL manual includes a user-friendly list of known serious bugs.
Most MySQL upgrades bring better performance overall; we don’t mean to imply otherwise. However, you should still be careful.
[36] Network overhead is worst if the application is on a different host from the server, but transferring data between MySQL and the application isn’t free even if they’re on the same server.
[37] See “Optimizing COUNT() Queries” on Optimizing Specific Types of Queries for more on this topic.
[38] Maatkit’s mk-archiver tool makes these types of jobs easy.
[39] If the query is too large, the server will refuse to receive any more data and throw an error.
[40] You can work around this with SQL_BUFFER_RESULT, which we see a bit
later.
[41] For example, the range check query plan reevaluates
indexes for each row in a JOIN. You can see this query plan by
looking for “range checked for each record” in the Extra column in EXPLAIN. This query plan also
increments the Select_full_range_join server
variable.
[42] We agree, a movie without actors is strange, but the Sakila sample database lists no actors for “SLACKER LIAISONS,” which it describes as “A Fast-Paced Tale of a Shark And a Student who must Meet a Crocodile in Ancient China.”
[43] As we show later, MySQL’s query execution isn’t quite this simple; there are many optimizations that complicate it.
[44] There are no indexes on the temporary table, which is
something you should keep in mind when writing complex joins
against subqueries in the FROM clause. This applies to UNION queries, too.
[45] The server generates the output from the execution plan. It thus has the same semantics as the original query, but not necessarily the same text.
[46] Strictly speaking, MySQL doesn’t try to reduce the number of rows it reads. Instead, it tries to optimize for fewer page reads. But a row count can often give you a rough idea of the query cost.
[47] You can influence this behavior if needed—for example, with
the SQL_BUFFER_RESULT hint. See
the “Query Optimizer Hints” on Optimizing UNION, later in this chapter.
[48] In some contexts you can assign with a plain = sign, but we think it’s better to avoid ambiguity and always use :=.
Get High Performance MySQL, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

