Kapitel 4. Datenbeobachtungen generieren
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wie in Kapitel 3 erläutert, kombiniert die Datenbeobachtung Technologie und Menschen, um Informationen über den Zustand eines Systems aus der Datenperspektive und die Erwartungen an diesen Zustand zu sammeln. Diese Informationen werden dann genutzt, um das System anpassungsfähiger oder widerstandsfähiger zu machen.
In diesem Kapitel wird erklärt, wie du die Praxis der Datenbeobachtung anwenden kannst. Ich beginne mit der "Datenbeobachtung an der Quelle", einer Methode zur Einführung von Erfassungsstrategien in deine tägliche Datenarbeit, und zeige dir, wie du ihre Auswirkungen auf die Effizienz minimieren kannst. Dann geht das Kapitel auf die Umsetzung von Erwartungen ein, die sich an den Lebenszyklus der Softwarebereitstellung anschließen, z. B. kontinuierliche Integration und kontinuierliches Deployment (CI/CD).
Wie bei jeder neuen Praxis und Technologie musst du die Eintrittsbarriere senken, um die Akzeptanz der Datenbeobachtung zu erhöhen; so haben die Menschen weniger Grund, gegen die Veränderung zu argumentieren. Aber auch die Menschen sind Teil der Lösung, denn ihre Beteiligung an dem Prozess ist entscheidend, um ihre Erwartungen zu ermitteln und die Regeln festzulegen. Zu diesem Zweck lernst du verschiedene Möglichkeiten kennen, wie du den Aufwand für die Erstellung von Beobachtungen verringern kannst und wie du sie zum richtigen Zeitpunkt im Entwicklungszyklus einführen kannst.
An der Quelle
In Kapitel 2 wurden die Quellen und Arten von Informationen erläutert, die dem Beobachter helfen. Aber wie generierst und sammelst du die Informationen aus diesen Quellen?
Es beginnt mit der Beobachtbarkeit der Daten an der Quelle. Der Begriff "Quelle" bezieht sich auf die Anwendungen, die für das Lesen, Umwandeln und Schreiben von Daten verantwortlich sind. Wie in Kapitel 3 erläutert, können diese Anwendungen entweder die Ursache von Problemen sein oder die Mittel, um sie zu lösen. Außerdem liegen die Anwendungen im Gegensatz zu den Daten selbst in unserer Kontrolle als Ingenieure und Organisationen.
Die Methode der Datenbeobachtung an der Quelle dreht sich also um die Fähigkeit der Anwendungen, Datenbeobachtungen nach dem in Kapitel 2 behandelten Modell zu generieren; mit anderen Worten, die Anwendungen werden datenbeobachtbar gemacht.
Reine Daten- und Analysebeobachtungen - wie z. B. Datenquellen, Schemata, Linien und Metriken - stehen im Zusammenhang mit Lese-, Transformations- und Schreibaktivitäten. Die in diesem Abschnitt beschriebenen Strategien gehen auf diese Aktivitäten ein und erklären, was bei ihrer Durchführung zu beachten ist.
Erzeugen von Datenbeobachtungen an der Quelle
Die Datenbeobachtung an der Quelle beginnt mit der Erstellung zusätzlicher Informationen, die das Verhalten bestimmter Aktivitäten mit Daten erfassen: Lesen, Umwandeln und Schreiben. Entwickler können zum Beispiel Zeilen von Protokollen hinzufügen, die die Informationen enthalten, die sie benötigen, um Einblicke in die Aktivitäten ihrer Anwendung zu erhalten. In der Anleitung werden die in Kapitel 2 beschriebenen Kanäle - also die Logs, Metriken und Traces - verwendet, um die Beobachtungen zu vermitteln, die in einem Logging-System zentralisiert werden können.
Im nächsten Abschnitt lernst du, wie du Datenbeobachtungen im JSON-Format erstellst, die in lokalen Dateien, einem lokalen Dienst, einem entfernten (Web-)Dienst oder ähnlichen Zielen gesammelt (veröffentlicht) werden können. Nach dem Kernmodell der Datenbeobachtung in Kapitel 2 würden die Datenquelle und die Schema-Entität einer Postgres-Tabelle zum Beispiel wie in Beispiel 4-1 aussehen.
Beispiel 4-1. Beispiel für als JSON kodierte Datenbeobachtungen
{"id":"f1813697-339f-5576-a7ce-6eff6eb63249","name":"gold.crm.customer","location":"main-pg:5432/gold/crm/table","format":"postgres"}{"id":"f1813697-339f-5576-a7ce-6eff6eb63249","data_source_ref":{"by_id":"e21ce0a8-a01e-5225-8a30-5dd809c0952e"},"fields":[{"name":"lastname","type":"string","nullable":true},{"name":"id","type":"int","nullable":false}]}
Die Möglichkeit, Datenbeobachtungen in demselben Modell auf einer zentralen Plattform zu sammeln, ist der Schlüssel, um den Wert der Datenbeobachtung im großen Maßstab zu generieren, z. B. über Anwendungen, Teams und Abteilungen hinweg. Deshalb ist die Verwendung des Kernmodells der Datenbeobachtung wichtig, um Datenbeobachtungen einfach zu aggregieren, insbesondere entlang von Linien.
Sehen wir uns an, wie man Datenbeobachtungen in Python mithilfe einer Low-Level-API erzeugt, die zur Einführung von Abstraktionen auf höherer Ebene verwendet wird (die in den nächsten Kapiteln behandelt werden).
Low-Level-API in Python
Diese Strategie, eine Low-Level-API zu verwenden, erfordert viel Zeit und Engagement von dir, da du jede Beobachtung explizit erstellen musst. Allerdings bietet dir diese Strategie auch die größte Flexibilität, da sie keine Abstraktionen auf höherer Ebene beinhaltet.
Auf der anderen Seite erfordert die Unterstützung der Datenbeobachtbarkeit auf dieser Ebene, insbesondere während der Erkundung und Wartung, dass der Entwickler konsequent ist und immer daran denkt, was er in der Produktion beobachten möchte (zum Beispiel sollte jeder erfahrene Entwickler so viele Zeilen für Protokolle und Prüfungen produzieren wie für die Geschäftslogik).1 Während der Entwicklung müssen die Entwickler dann die Änderungen an der Logik oder dem Verhalten der Anwendung durch die Erstellung der zugehörigen Beobachtungen sichtbar machen. Beispiele für solche Beobachtungen sind eine Verbindung zu einer neuen Tabelle, die Erstellung einer neuen Datei oder die Änderung einer Struktur mit einem neuen Feld.
In den folgenden Abschnitten wirst du ein komplettes Beispiel für eine in Python geschriebene Datenanwendung durchgehen, die neben der Datennutzung auch Datenbeobachtungen erzeugt, indem du Folgendes tust:
-
Verstehen von Anwendungen ohne Datenbeobachtungsmöglichkeit
-
Hinzufügen von Anweisungen zur Erzeugung von Datenbeobachtungen und deren Zweck
-
Erkenntnisse über die Vor- und Nachteile dieser Strategie gewinnen
Beschreibung der Datenpipeline
Im weiteren Verlauf des Kapitels werde ich eine in Python geschriebene Datenpipeline verwenden, mit der wir Daten beobachtbar machen. Der Code der Pipeline auf GitHub ermöglicht es dir, die Beispiele in diesem Kapitel auszuführen. Sie nutzt die Pandas-Bibliothek, um CSV-Dateien zu verarbeiten, und besteht aus zwei Anwendungen: Ingestion und Reporting, wie in Abbildung 4-1 dargestellt.
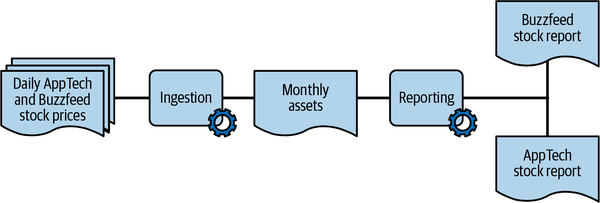
Abbildung 4-1. Struktur der Beispielpipeline
Beide Anwendungen (ingestion und reporting) verwenden Python und Pandas und nutzen Daten aus der Datenquelle "Tägliche Aktienkurse", um zwei nachgelagerte Berichte (BuzzFeed-Aktien und AppTech) zu erstellen.
Die Anwendung ingestion liest die CSV-Dateien mit den täglichen Aktienkursen, die das Börsenteam jeden Monat bereitstellt. Das Team hat die Dateien nach Jahr und Monat unterteilt und dann die Preise in monatlichen Ansichten zusammengeführt, die in einer separaten Datei gespeichert werden, wie in ingestion in Beispiel 4-2.
Beispiel 4-2. Anwendung zur Datenübernahme
importpandasaspdAppTech=pd.read_csv("data/AppTech.csv",parse_dates=["Date"],dtype={"Symbol":"category"},)Buzzfeed=pd.read_csv("data/Buzzfeed.csv",parse_dates=["Date"],dtype={"Symbol":"category"},)monthly_assets=pd.concat([AppTech,Buzzfeed])\.astype({"Symbol":"category"})monthly_assets.to_csv("data/monthly_assets.csv",index=False)
![]() Die Anwendung
Die Anwendung ingestion verarbeitet zwei CSV-Dateien für die folgenden Bestände:
-
BuzzFeed
-
AppTech
Die Anwendung liest die Dateien aus dem Ordner "../data", als Referenz; eine Zeile in diesen Dateien sieht so aus:
1 |
Date |
Symbol |
Open |
High |
Low |
Close |
AdjClose |
Volume |
2 |
2022-01-03 |
APCX |
14.725 |
15.200 |
14.25 |
14.25 |
14.25 |
1600 |
Während der Erkundung stellte unser Dateningenieur fest, dass die Dateien zwei Felder enthalten, die vorverarbeitet werden müssen. ![]() Das Feld
Das Feld Date muss als Datum geparst werden, ![]() und das Feld
und das Feld Symbol müssen als Kategorie behandelt werden.
Die Anwendung liest und verarbeitet die täglichen Bestände, bevor sie sie im Speicher zur Verfügung stellt. Dann fügt die Anwendung sie in einer einzigen Variablen zusammen, die in diesem Fall ein neuer pandas DataFrame ist, der alle Kategorien in Symbol enthält.
![]() Das Skript schreibt das Ergebnis in denselben Ordner als neue Datei namens monthly_assets.csv. Auf diese Weise können andere Analysten oder Datentechniker dort beginnen, wenn sie alle täglichen Aktienkurse für weitere Analysen benötigen.
Das Skript schreibt das Ergebnis in denselben Ordner als neue Datei namens monthly_assets.csv. Auf diese Weise können andere Analysten oder Datentechniker dort beginnen, wenn sie alle täglichen Aktienkurse für weitere Analysen benötigen.
Nachdem dieses erste Skript ausgeführt wurde und die Datei verfügbar ist, können die übrigen Pipeline-Skripte ausgeführt werden, um die BuzzFeed- und AppTech-Aktienberichte zu erstellen. In diesem Beispiel gibt es nur ein Skript, die Berichts-Python-Datei, die in Beispiel 4-3 gezeigt wird.
Beispiel 4-3. Anwendung zur Datenmeldung
importpandasaspdall_assets=pd.read_csv("data/monthly_assets.csv",parse_dates=['Date'])apptech=all_assets[all_assets['Symbol']=='APCX']buzzfeed=all_assets[all_assets['Symbol']=='BZFD']buzzfeed['Intraday_Delta']=buzzfeed['Adj Close']-buzzfeed['Open']apptech['Intraday_Delta']=apptech['Adj Close']-apptech['Open']kept_values=['Open','Adj Close','Intraday_Delta']buzzfeed[kept_values].to_csv("data/report_buzzfeed.csv",index=False)apptech[kept_values].to_csv("data/report_appTech.csv",index=False)
Diese Anwendung führt die folgenden Aktionen durch:
![]() Liest die von der vorherigen Anwendung erstellte Datenquelle
Liest die von der vorherigen Anwendung erstellte Datenquelle
![]() Filtert die Daten für die beiden Berichte heraus, die er erstellt: BuzzFeed und AppTech.
Filtert die Daten für die beiden Berichte heraus, die er erstellt: BuzzFeed und AppTech.
![]() Berechnet die
Berechnet die Intraday_Delta Scores, also die täglichen Bestandsentwicklungen, die zu melden sind.
![]() Meldet die
Meldet die Open, Adj Close, und die berechneten Werte Intraday_Delta in den entsprechenden Dateien für jeden Bestand.
Um die Pipeline ordnungsgemäß auszuführen, ist es wichtig, die Abhängigkeiten zwischen den Reporting- und Ingestion-Anwendungen zu beachten. Das heißt, du musst die ingestion Anwendung erfolgreich ausgeführt werden, bevor du die reporting Anwendung ausführst. Andernfalls wird die Pipeline fehlschlagen. Eine Lösung, um dies zu erreichen, ist die Verwendung eines Orchestrators, der ingestion vor reporting ausführt, wie z. B. Dagster und Airflow. Der Orchestrator ist eigentlich eine weitere Anwendung, die man konfigurieren kann, indem man die Abhängigkeiten zwischen den Anwendungen auf der Datenebene explizit festschreibt. Die Anwendungen selbst wissen aber immer noch nichts über ihre nachgelagerten Abhängigkeiten.
Die Kehrseite der Hardcodierung der Abhängigkeiten in einem Orchestrator ist, dass es sich um ein neues Asset handelt, das gepflegt werden muss (z. B. die Genauigkeit der expliziten Abhängigkeiten). Außerdem gibt es zusätzliche Einschränkungen bei der Erstellung einer Pipeline, da die Teams unabhängig bleiben müssen und daher nicht einfach eine bestehende Pipeline aktualisieren können, um ihre eigenen Bedürfnisse zu erfüllen. Daher muss eine Erweiterung auf einer höheren Ebene erstellt werden, indem eine neue, separate DAG hinzugefügt wird, die die expliziten Abhängigkeiten aufheben könnte.
Kehren wir zu unserer Pipeline zurück und besprechen wir die funktionalen Abhängigkeiten zwischen den Anwendungen. Das heißt, dass ingestion erfolgreich ausgeführt werden muss, bevor reporting ausgeführt werden kann. Aber was bedeutet erfolgreich?
Definition des Status der Datenpipeline
Um festzustellen, ob eine Ausführung einer Datenpipeline erfolgreich ist, werde ich die entgegengesetzte Frage analysieren: Welche Arten von Fehlern können in der ingestion auftreten?
- Explizites Scheitern
- Dies führt zu einem Absturz der Anwendung. Diese Art von Fehler ist für den Orchestrator einfach zu handhaben, wenn du einen verwendest, denn es ist ein Flag, das die nächste Anwendung nicht auslöst: in unserem Beispiel die Anwendung
reporting. - Stiller Ausfall
- In diesem Fall wird die Anwendung beendet, ohne dass z. B. ein Fehlercode oder ein Protokoll erscheint. Da sie nicht wie erwartet läuft, musst du den Begriff der Erwartungen berücksichtigen, der in Kapitel 2 eingeführt wurde.
Ein Beobachter der ingestion Anwendung würde expliziten Fehlern wie diesen begegnen:
- Datei nicht gefunden Fehler
- Tritt auf, wenn eine der Datendateien, wie z. B. Buzzfeed.csv, im Ordner nicht verfügbar ist, weil sie umbenannt oder in Kleinbuchstaben geändert wurde oder die Datei nicht erstellt wurde, bevor die Anwendung
ingestionausgeführt wurde. - Tippfehler (
TypeError) - Tritt auf, wenn einige Werte nicht mit den Typen übereinstimmen, die der Funktion
read_csvzur Verfügung gestellt werden, z. B. wenn das Symbol eine Kategorie sein sollte. - Fehler bei hartkodierten Namen
- Treten auf, wenn eines der Felder, die explizit in dem Code verwendet werden, um auf die Werte zuzugreifen, wie z.B. der Spaltenname
Datein Beispiel 4-3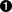 und
und Symbolin diesem Fall, nicht vorhanden ist oder der Name geändert wurde. - Dateisystem-Fehler
- Passiert, wenn die Dateien nicht lesbar sind oder der Ordner für den Benutzer, der die Anwendung ausführt, nicht beschreibbar ist.
- Speicherfehler
- Passiert, wenn die Dateien so groß werden, dass der der Anwendung zugewiesene Speicher nicht mehr ausreicht.
- Systemfehler
- Wird ausgelöst, wenn die Festplatte keinen Platz mehr hat, um das aggregierte Ergebnis zu schreiben.
Aber aus der Perspektive des Ingenieurs, der es beobachtet, zeigen die folgenden Beispiele stille Fehler:
-
Die Spalte
Datekann nicht als Datum geparst werden, weil sie falsch formatiert ist, das Muster geändert wurde oder die Zeitzone nicht konsistent ist. In diesem Fall ist die Spalte nicht mehr einedatetime, sondern eineobject. -
Die Spalte
Dateenthält Werte, aber nicht für den aktuellen Monat. Alle Werte sind vergangene oder zukünftige Daten. -
Die Spalte
Dateenthält Werte in der Zukunft, weil der Generator möglicherweise später ausgeführt wurde und Informationen über die Zukunft generiert hat, um sie mit dem Monat zu vergleichen, in dem er verarbeitet wird. Dies kann später zu Duplikaten oder inkonsistenten Werten für dieselben Daten führen und einige Aggregationen fehlschlagen lassen. -
Die Kategorie
Symboländert sich aus verschiedenen Gründen, z. B. wegen eines Tippfehlers oder einer Änderung der Großschreibung, der Länge oder der Referenz. Diese Kategorie wird in allen Dateien verwendet und als Kategorie in die Ausgabedatei geschrieben.
Außerdem könnte die Anwendung reporting die Anwendung ingestion als fehlgeschlagen betrachten, weil sie die folgenden Fehlschläge in reporting provoziert hat:
-
Die monatliche Aggregatdatei wurde nicht geschrieben, als die Berichterstattung begann, so dass sie nicht verfügbar ist, wenn das Berichtstool in einem bestimmten Intervall ausgeführt werden soll.
-
Eines der Felder, die zum Filtern in der Arithmetik verwendet werden, ist nicht verfügbar oder sein Name wurde geändert.
-
Die gleichen Fehler treten beim Lese-/Schreibzugriff, der Größe und dem Speicherplatz auf.
Außerdem kann reporting lautlos fehlschlagen, weil die stillen Ausfälle der ingestion
-
Die Symbole
APCXundENFAsind in der bereitgestellten Datei nicht verfügbar. -
Adj CloseoderOpenfehlende Werte sind, was zu Müll in derIntraday_DeltaAusgabe führt. Dieses Problem kann auch ein expliziter Fehler sein. In diesem Fall werden die Werte zuNAvon Pandas. -
Die aggregierte Datei enthält keine Informationen über den aktuellen Monat, aber die Daten liegen in der Vergangenheit.
Da jeder dieser Fehler auftreten kann, musst du wissen, wann er auftritt, und - noch besser - du musst ihn frühzeitig erkennen, um zu verhindern, dass er von der Anwendung ingestion weitergegeben wird (siehe "Fail Fast and Fail Safe").
Die expliziten Fehler sollten als Entwicklungspraxis bereits sichtbar gemacht worden sein, um diese Fehler explizit abzufangen (try…except in Python). Damit ein Beobachter jedoch stille Fehler erkennen und entdecken kann, muss die Anwendung die entsprechenden Beobachtungen liefern.
Datenbeobachtungen für die Datenpipeline
In diesem Abschnitt werde ich einen Überblick über die Datenbeobachtungen geben, die die Datenpipeline erzeugen muss. Dazu werfen wir einen kurzen Blick auf Abbildung 4-2, die zeigt, wie eine Low-Level-API das in Kapitel 2 vorgestellte Modell umsetzt. Es ist interessant festzustellen, dass sie eine ähnliche Struktur und sogar einige Entitäten (beschriftet) haben; in den nächsten Abschnitten werde ich auf jeden Teil einzeln eingehen, um diese Fakten hervorzuheben.
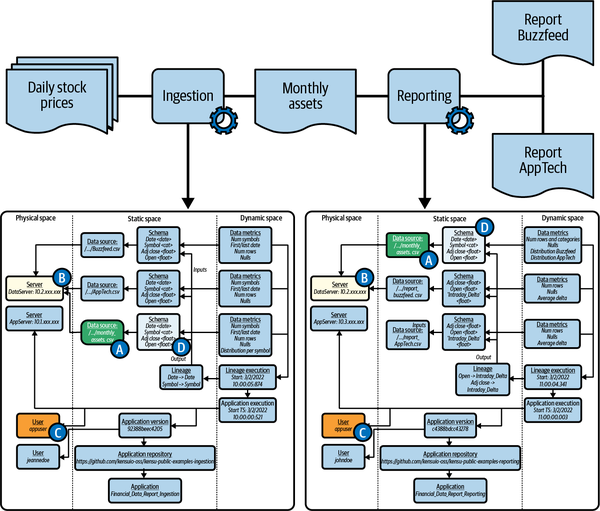
Abbildung 4-2. Die Beobachtungen zur Aufnahme und Meldung und ihre Ähnlichkeiten (eine größere Version dieser Abbildung ist unter https://oreil.ly/TaQGV verfügbar)
In diesem Diagramm siehst du, dass die Entitäten mit den Großbuchstaben A, B, C und D in Kreisen gekennzeichnet sind. Die "A"-Datenquellen heben die Beobachtungen hervor, die von der Anwendung ingestion über die von ihr erzeugten Daten und von reporting beim Lesen der Daten gemacht werden, wodurch die implizite Abhängigkeit deutlich wird.
In der Tat erzeugen beide Anwendungen mehrere ähnliche Beobachtungen, die alle Abhängigkeiten darstellen, die sie miteinander verbinden. In Abbildung 4-2 sind die folgenden ähnlichen Beobachtungen ebenfalls hervorgehoben:
-
Die "B"-Entitäten beobachten den Server, von dem die Daten abgerufen wurden.
-
Die "C"-Entitäten beobachten den Benutzer beim Ausführen von Befehlen.
-
Die "D"-Entitäten beachten das Schema der Daten, die durch die Ingestion erzeugt werden, so wie sie vom Reporting gelesen werden.
Schauen wir uns nun an, was wir zum Code der Anwendung hinzufügen müssen, um die in Abbildung 4-2 gezeigten Beobachtungen zu erzeugen. Da der Code in Python geschrieben ist, verwenden wir das Modul logging, um die in JSON kodierten Beobachtungen zu drucken.
Erzeugen von kontextbezogenen Daten Beobachtungen
In diesem Abschnitt behandle ich den Code, den benötigt, um Beobachtungen über den Ausführungskontext der in Abbildung 4-3 gezeigten ingestion Anwendung zu generieren (beachte, dass reporting denselben Code wiederverwenden kann).
Abbildung 4-3. Datenbeobachtungen über den Ausführungskontext der Anwendung ingestion
Füge den Code in Beispiel 4-4 am Anfang der Datei ein, um die Beobachtungen für die Anwendung ingestion zu erzeugen.
Beispiel 4-4. Erzeugen von Datenbeobachtungen über die Ingestion-Anwendung
app_user=getpass.getuser()repo=git.Repo(os.getcwd(),search_parent_directories=True)code_repo=repo.remote().urlcommit=repo.head.commitcode_version=commit.hexshacode_author=commit.author.nameapplication_name=os.path.basename(os.path.realpath(__file__))application_start_time=datetime.datetime.now().isoformat()
![]() Abrufen von Informationen zum Benutzernamen.
Abrufen von Informationen zum Benutzernamen.
![]() Abrufen von Git-Informationen.
Abrufen von Git-Informationen.
![]() Abrufen von Informationen über die Ausführung der Anwendung.
Abrufen von Informationen über die Ausführung der Anwendung.
Die zusätzlichen Anweisungen in Beispiel 4-5 erstellen Variablen für die Beobachtungen, aber es wird noch nichts mit ihnen gemacht. Um die Informationen zu protokollieren, wie bereits erwähnt hat, verwenden wir eine JSON-Darstellung des Informationsmodells, die wie in Beispiel 4-5 kodiert ist.
Beispiel 4-5. Modellierung von Datenbeobachtungen über die Ingestion-Laufzeit
application_observations={"name":application_name,"code":{"repo":code_repo,"version":code_version,"author":code_author},"execution":{"start":application_start_time,"user":app_user}}
Dieser Code erstellt das JSON, das aus allen bisher erstellten Beobachtungen besteht. In diesem Abschnitt geht es jedoch um die Verwendung einer Low-Level-API für die Beobachtung von Daten. Im weiteren Verlauf werden wir auf ein ähnliches Muster stoßen, was uns die Möglichkeit gibt, Funktionen zu erstellen, um den Code zu vereinfachen und ihn in den Anwendungen ingestion und reporting oder in anderen Python-Anwendungen gemeinsam zu nutzen.
Um eine API zu erstellen, erstellen wir ein Modell, das das Beobachtungskernmodell in JSON nachahmt, jede Entität in eine Klasse verwandelt und Beziehungen in Referenzen umwandelt (siehe Beispiel 4-6 ).
Beispiel 4-6. Modellierung der Anwendungsdatenbeobachtungen mit speziellen Klassen
classApplication:name:strdef__init__(self,name:str,repository:ApplicationRepository)->None:self.name=nameself.repository=repositorydefto_json(self):return{"name":self.name,"repository":self.repository.to_json()}classApplicationRepository:location:strdef__init__(self,location:str)->None:self.location=locationdefto_json(self):return{"location":self.location}app_repo=ApplicationRepository(code_repo)app=Application(application_name,app_repo)
Das bedeutet, dass die Anwendungsentität eine Application ![]() Klasse mit einem Eigenschaftsnamen, der den Namen der Datei als
Klasse mit einem Eigenschaftsnamen, der den Namen der Datei als application_name Variable enthalten kann, und einen Verweis auf eine ApplicationRepository Instanz haben muss. Diese ApplicationRepository Entität wird als ApplicationRepository ![]() Klasse kodiert, deren Eigenschaft
Klasse kodiert, deren Eigenschaft location als Git-Remote-Speicherort festgelegt ist. Diese Struktur erleichtert den Aufbau des Modells und die Erstellung einer JSON-Darstellung, die wiederverwendbar ist und zu einer Standardisierung führen kann.
Ein zusätzlicher Vorteil der Kodierung von Konzepten in API-Klassen ist, dass sie die Verantwortung haben, Helfer vorzuschlagen, um zugehörige Beobachtungen zu extrahieren, wie in Beispiel 4-7 ![]() .
.
Beispiel 4-7. Nutzung von Klassen zur Definition von Helfern für modellierte Entitäten
classApplicationRepository:location:str# [...]@staticmethoddeffetch_git_location():importgitcode_repo=git.Repo(os.getcwd(),search_parent_directories=True).remote().urlreturncode_repoclassApplication:name:str# [...]@staticmethoddeffetch_file_name():importosapplication_name=os.path.basename(os.path.realpath(__file__))returnapplication_nameapp_repo=ApplicationRepository(ApplicationRepository.fetch_git_location())app=Application(Application.fetch_file_name(),app_repo)
Diese Strategie könnte ein einfacher Weg sein, um das Modell umzusetzen. Wir bevorzugen jedoch einen anderen Ansatz, der die Verbindungen zwischen den Entitäten schwächt. In Beispiel 4-8 werden alle Informationen in einer JSON-Datei protokolliert, wobei die Entitäten in einem Informationsbaum mit Application an der Wurzel angeordnet sind. Diese Kodierung zwingt uns dazu, alle Beobachtungen zu erstellen, bevor wir die Wurzel, also die Application Instanz, protokollieren. Der Application Konstruktor würde dann so aussehen wie in Beispiel 4-8.
Beispiel 4-8. Aufgeblähter Konstruktor für die Anwendung ohne Trennung von Belangen
classApplication:name:strdef__init__(self,name:str,version:ApplicationVersion,repo:ApplicationRepository,execution:ApplicationExecution,server:Server,author:User)->None:pass
Um diese Komplexität und Einschränkung zu vermeiden, ist es besser, die Abhängigkeiten zwischen den Entitäten umzukehren. Anstatt die Application mit ihren ApplicationVersion oder ApplicationRepository enthält, erstellen wir Application allein und fügen dann einen schwachen Verweis auf sie aus ApplicationVersion und ApplicationRepository. Beispiel 4-9 zeigt, wie dieses Modell aussehen würde.
Beispiel 4-9. Umkehrung der Abhängigkeiten zwischen Entitäten und Einführung id
classApplicationRepository:location:strapplication:Applicationid:strdef__init__(self,location:str,application:Application)->None:self.location=locationself.application=applicationid_content=",".join([self.location,self.application.id])self.id=md5(content.encode("utf-8")).hexdigest()defto_json(self):return{"id":self.id,"location":self.location,"application":self.application.id}@staticmethoddeffetch_git_location():importgitcode_repo=git.Repo(os.getcwd(),search_parent_directories=True).remote().urlreturncode_repo
Mit diesem Modell können wir die Beobachtungen einzeln protokollieren - zwei Aufrufe an logging.info-reduzieren die Menge der zu speichernden Informationen. Da wir die Beziehungen zwischen den Entitäten neu zusammensetzen müssen, führen wir die Variable id ein, um die Menge der zu protokollierenden Informationen und der zu verknüpfenden Beobachtungen zu reduzieren. Anhand der Protokolle kann id die Verknüpfungen im Modell rekonstruieren, wie z. B. die Abhängigkeit zwischen ApplicationRepository und Application, da sie bereits protokolliert wurden ( id).
In diesem Beispiel hat die Anwendung id lokal erstellt, was zu einem schlechten Design führt, das über mehrere Ausführungen hinweg inkonsistent sein wird. Um dieses Problem zu umgehen, müssen wir einen funktionalen id definieren, der die Entitäten über verschiedene Ausführungen, Einsätze und Anwendungen hinweg identifizieren kann. Dieser Begriff ist in der Modellierung als Primärschlüssel bekannt. Du kannst einen Primärschlüssel z. B. als Eingabe für einen Hash-Algorithmus verwenden, der die id auf deterministische Weise generiert, in diesem Fall mit hashlib.
Beispiel 4-9 zeigt, wie man den Primärschlüssel verwendet, um id konsistent zu generieren, zum Beispiel mit md5 ![]() . Diese Strategie werden wir in diesem Kapitel immer wieder anwenden, um Entitäten zu erzeugen.
. Diese Strategie werden wir in diesem Kapitel immer wieder anwenden, um Entitäten zu erzeugen.
Datenbezogene Beobachtungen generieren
Im Folgenden werden die Beobachtungen der wichtigsten Datenbeobachtungskomponenten behandelt: Datenquelle, Schema und Datenmetriken. Abbildung 4-4 zeigt die Beobachtungen, die wir protokollieren müssen.
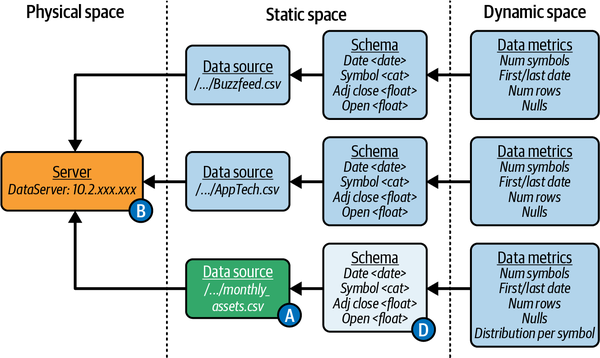
Abbildung 4-4. Entitäten Datenquelle, Schema und Datenmetriken der Ingestion.
Die zu erstellenden Beobachtungen beziehen sich auf die Datenquelle, die gelesen und geschrieben wird. Dann wird die Transformation (Lineage) angesprochen. Im Ingestion-Code werden viele Quellen mit der Funktion read_csv von Pandas gelesen.
Die Datenquelle ist vor allem der Dateipfad, der als Argument für die Funktion read_csv angegeben wird. Eine weitere Beobachtung ist das Format der Datenquelle, das sich aus der Tatsache ergibt, dass read_csv ohne spezielle Parser-Attribute wie z. B. sep verwendet wird und die Daten somit eine "echte" CSV-Datei sind.
Außerdem erhält read_csv keine Informationen über die Kopfzeile. Daher wird erwartet, dass die erste nicht leere Zeile die Spaltennamen sind, die dabei helfen, einen Überblick über die Daten zu bekommen, auf die die Anwendung ingestion zugreift.
Der Typ der Spalten ist eine weitere Information, die beobachtet werden kann. pandas leitet die meisten numerischen Typen ab. Zeichenketten, Kategorien und Daten werden jedoch als Objekte gespeichert. Die Funktion read_csv liefert zwei Hinweise: Date ist die Information date und Symbol ist eine kategorische Information, in diesem Fall eine Zeichenkette.
Mit den Werten erstellt Pandas eine DataFrame, eine Art Tabelle, mit der wir die bisher aufgeführten Informationen auffangen können. Darüber hinaus können wir mit DataFrame auch zusätzliche Informationen über die Werte selbst berechnen, z. B. deskriptive Statistiken. Wir verwenden die Funktion describe, um diese grundlegenden Statistiken für numerische Werte und andere Typen wie kategorische oder Datumswerte zu berechnen, indem wir das Argument include='all' verwenden.
Zum Schluss schreibt die Anwendung ingestion die monatliche CSV-Datei mit Hilfe der Funktion to_csv auf den Datenrahmen, der die zu schreibenden Werte enthält. Diese Funktion liefert fast die gleichen Informationen wie die Funktion read_csv. So können wir den Dateipfad, die Spalten und die Typen ableiten.
Sehen wir uns an, wie wir diese Beobachtungen in einer wiederverwendbaren API modellieren können. Die erste Klasse ist DataSource, die relativ einfach zu modellieren ist, wie in Beispiel 4-10 gezeigt. Wir wollen vor allem wissen, in welchem Format und wo sich die Datenquelle befindet, die die Anwendung liest oder schreibt ![]() . Daher wird sie den Pfad zur Datei modellieren.
. Daher wird sie den Pfad zur Datei modellieren.
Beispiel 4-10. DataSource Entitätsklasse
classDataSource:location:strformat:strid:strdef__init__(self,location:str,format:str=None)->None:self.location=locationself.format=formatid_content=",".join([self.location,self.application.id])self.id=md5(content.encode("utf-8")).hexdigest()defto_json(self):return{"id":self.id,"location":self.location,"format":self.format}
Außerdem wird id auf der Grundlage des angegebenen Pfads generiert, der relativ ist (beginnt mit ./) und sollte erweitert werden, um den absoluten Pfad zu verwenden. ![]() Wenn wir eine Datenbanktabelle verwenden, z. B. eine andere Methode als
Wenn wir eine Datenbanktabelle verwenden, z. B. eine andere Methode als read_csv, müssen wir weitere Hilfsprogramme hinzufügen, um Verbindungszeichenfolgen zu behandeln.
Als nächstes kann Beispiel 4-11 das Schema modellieren, das die Anwendung in der Datenquelle manipuliert.
Beispiel 4-11. Schema Entitätsklasse
classSchema:fields:list[tuple[str,str]]data_source:DataSourceid:strdef__init__(self,fields:list[tuple[str,str]],data_source:DataSource)->None:self.fields=fieldsself.data_source=data_sourcelinearized_fields=",".join(list(map(lambdax:x[0]+"-"+x[1],sorted(self.fields))))id_content=",".join([linearized_fields,self.data_source.id])self.id=hashlib.md5(id_content.encode("utf-8")).hexdigest()defto_json(self):fromfunctoolsimportreducejfields=reduce(lambdax,y:dict(**x,**y),map(lambdaf:{f[0]:f[1]},self.fields))return{"id":self.id,"fields":jfields,"data_source":self.data_source.id}@staticmethoddefextract_fields_from_dataframe(df:pd.DataFrame):fs=list(zip(df.columns.values.tolist(),map(lambdax:str(x),df.dtypes.values.tolist())))returnfs
Die Klasse Schema hat die Eigenschaft fields, die die Spalten der CSV-Datei modelliert. Hier können wir sie aus den Metadaten der Pandas DataFrame: columns und dtypes extrahieren. Wir haben sie so gewählt, dass sie die Felder als Liste von Paaren (Feldname, Feldtyp) darstellt ![]() .
.
Die letzte Klasse für diesen Teil ist DataMetrics, die die Metriken der Dateien modelliert, die die Anwendung ingestion liest und schreibt. Sie ist jedoch eine unvollständige Version der Klasse, da sie nur die Beziehung zu Schema kodiert. Sie muss erweitert werden, um sicherzustellen, dass sie Einblick in die Datenmetriken für eine bestimmte Verwendung bietet. Für diesen Zweck ist eine Lineage erforderlich, die später kommt (siehe Beispiel 4-15).
Die aktuelle Klasse sieht wie in Beispiel 4-12 aus.
Beispiel 4-12. DataMetrics Entitätsklasse
classDataMetrics:schema:Schemametrics:list[tuple[str,float]]id:strdef__init__(self,metrics:list[tuple[str,float]],schema:Schema)->None:self.metrics=metricsself.schema=schemaself.id=hashlib.md5(",".join([self.schema.id]).encode("utf-8")).hexdigest()defto_json(self):fromfunctoolsimportreducejfields=reduce(lambdax,y:dict(**x,**y),map(lambdaf:{f[0]:f[1]},self.metrics))return{"id":self.id,"metrics":jfields,"schema":self.schema.id}@staticmethoddefextract_metrics_from_dataframe(df:pd.DataFrame):d=df.describe(include='all',datetime_is_numeric=True)importmathimportnumbersmetrics={}filterf=lambdax:isinstance(x[1],numbers.Number)andnotmath.isnan(x[1])mapperf=lambdax:(field+"."+x[0],x[1])forfieldind.columns[1:]:msd=dict(filter(filterf,map(mapperf,d[field].to_dict().items())))metrics.update(msd)# metrics looks like:# {"Symbol.count": 20, "Symbol.unique": 1, "Symbol.freq": 20,# "Open.count": 20.0, "Open.mean": 3.315075, "Open.min": 1.68,# "Open.25%": 1.88425"Open.75%": 2.37, "Open.max": 14.725,# "Open.std": 3.7648500643766463, ...}returnlist(metrics.items())
Die Metriken wurden in dieser vereinfachten Form gewählt, um nur die numerischen beschreibenden Statistiken als Liste von Paaren (Metrikname, numerischer Wert) darzustellen. ![]() Diese Beobachtungen werden direkt aus dem Ergebnis der Funktion
Diese Beobachtungen werden direkt aus dem Ergebnis der Funktion describe umgerechnet, die auf der DataFrame aufgerufen wird, die die Datenwerte enthält. ![]()
Da wir nun alle Entitäten als Klassen definiert haben, können wir unseren Code (siehe Beispiel 4-13) aktualisieren, um sicherzustellen, dass er die Beobachtungen richtig generiert.
Beispiel 4-13. Ingestion-Anwendung mit Datenbeobachtungsentitäten
app=Application(Application.fetch_file_name())app_repo=ApplicationRepository(ApplicationRepository.fetch_git_location(),app)AppTech=pd.read_csv("data/AppTech.csv",parse_dates=["Date"],dtype={"Symbol":"category"},)AppTech_DS=DataSource("data/AppTech","csv")AppTech_SC=Schema(Schema.extract_fields_from_dataframe(AppTech),AppTech_DS)AppTech_M=DataMetrics(DataMetrics.extract_metrics_from_dataframe(AppTech),AppTech_SC)Buzzfeed=pd.read_csv("data/Buzzfeed.csv",parse_dates=["Date"],dtype={"Symbol":"category"},)Buzzfeed_DS=DataSource("data/Buzzfeed","csv")Buzzfeed_SC=Schema(Schema.extract_fields_from_dataframe(Buzzfeed),Buzzfeed_DS)Buzzfeed_M=DataMetrics(DataMetrics.extract_metrics_from_dataframe(Buzzfeed),Buzzfeed_SC)monthly_assets=pd.concat([AppTech,Buzzfeed])\.astype({"Symbol":"category"})monthly_assets.to_csv("data/monthly_assets.csv",index=False)monthly_assets_DS=DataSource("data/monthly_assets","csv")monthly_assets_SC=Schema(Schema.extract_fields_from_dataframe(monthly_assets),monthly_assets_DS)monthly_assets_M=DataMetrics(DataMetrics.extract_metrics_from_dataframe(monthly_assets),monthly_assets_SC)
Code Evolution
Diese Version des Codes erfordert enorme Änderungen und eine zusätzliche Schicht von Anweisungen. Wenn wir diesen Code überprüfen, um zu verstehen, was er tut, können wir besser verstehen, was wir wie beachten müssen. Die Beispiele 4-14 und 4-21 zeigen vereinfachte Versionen mit einer Funktion, die doppelte Anweisungen entfernt.
Außerdem werden in den nächsten Abschnitten viele Strategien vorgestellt, um die Anzahl der Änderungen zu reduzieren und so weit zu kommen, dass die Datenbeobachtung fast automatisch und unsichtbar ist.
Wir haben jetzt Code, der die Beobachtungen erzeugt, die wir brauchen, um das Datenverhalten zu beobachten, wenn wir die Anwendung ingestion ausführen. Ein Großteil des Codes ist jedoch fast identisch. Die Funktion ![]() in Beispiel 4-14 kann verwendet werden, um den größten Teil des Rauschens zu entfernen.
in Beispiel 4-14 kann verwendet werden, um den größten Teil des Rauschens zu entfernen.
Beispiel 4-14. Duplizierter Code in eine übergeordnete Funktion verpacken
defobservations_for_df(df_name:str,df_format:str,df:pd.DataFrame)->None:ds=DataSource(df_name,df_format)sc=Schema(Schema.extract_fields_from_dataframe(df),ds)ms=DataMetrics(DataMetrics.extract_metrics_from_dataframe(df),sc)
In diesem Abschnitt arbeiten wir mit Dateien, aber was ist, wenn du stattdessen mit Tabellen arbeiten musst und SQL zum Lesen, Umwandeln und Schreiben der Daten verwendest? Wenn SQL direkt für diese Vorgänge verwendet wird, enthält es die gleichen Operationen wie ein Python-Code. Das heißt, er liest Tabellen, wandelt sie um und schreibt sie schließlich; zum Beispiel ein Einfügen eines Sub-Selects. Allerdings bietet SQL nicht viele Möglichkeiten, um Informationen zu generieren , wie z. B. die Extraktion von Metadaten oder Metriken. Eine andere Anwendung, für die der Datenbankserver zuständig sein sollte, führt das SQL aus.
Erinnere dich daran, dass SQL eine Menge Informationen enthält, die deine Anwendung ausnutzen kann. Sie enthält die Namen der Tabellen, Spalten, Typen und durchgeführten Transformationen. Wenn du die Abfragen analysierst, erhältst du ähnliche Ergebnisse, wie in Beispiel 4-14 dargestellt. Ich empfehle diese Extraktionsstrategie für SQL-Abfragen, weil eine SQL-Abfrage wahrscheinlich das Ergebnis mehrerer Iterationen und Experimente ist, bis sie genau das tut, was sie tun soll (wie jeder andere Code auch). Daher implementiert die SQL-Abfrage alle Annahmen, die in jeder Iteration gemacht werden - zum Beispiel auch die folgenden:
-
IS NOT NULLsteht für die Annahme, dass Spalten null sein können und es in Ordnung ist, sie herauszufiltern (vorausgesetzt, dass ihre Anzahl keinen Einfluss auf die endgültige Logik hat). -
cast("Amount" as "INT64")steht für die Annahme, dass dieAmountimmer als Ganzzahl gegossen werden kann.
Eine SQL-Abfrage ist ein Programm
SQL ist eine prozedurale Logik. Wie Python-Logik ist sie in einer domänenspezifischen Sprache (DSL) kodiert und wird, wie Pandas, als Zeichenkette vom Datenbankserver gesendet und verarbeitet. In der Tat ist sie einem Python-Code sehr ähnlich, da sie eine Zeichenkette ist, die von der Python-Ausführung gesendet und verarbeitet wird.
Nachdem wir die ingestion Fähigkeit hinzugefügt haben, Daten und Anwendungsbeobachtungen zu generieren, können wir an einem weiteren Bereich arbeiten, der noch mehr Informationen liefern wird - Beobachtungen über den analytischen Teil - wenn die Anwendung eingesetzt wird.
Erzeugen von Beobachtungen zu abstammungsbezogenen Daten
Um Beobachtungen über die Interaktion auf der Datenebene zwischen den Anwendungen in der Pipeline bis hinunter zur Spaltenebene zu machen, werde ich in diesem Abschnitt erläutern, wie man die in Abbildung 4-5 gezeigte Lineage-Entität erzeugt.
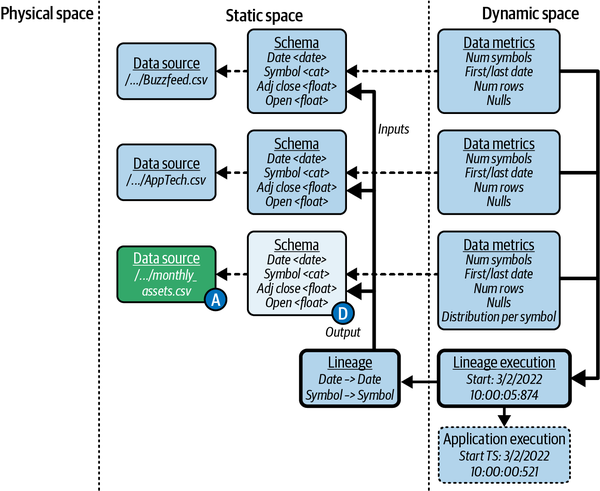
Abbildung 4-5. Entitäten, die die von der Anwendung ingestion ausgeführte Linie darstellen
Wie in Kapitel 2 besprochen, verbindet der Teil des Modells, der die Linie verbindet - in diesem Fall der Datenfluss und die Transformationen - die Beobachtungen aus der Hauptkomponente des Bereichs der Datenbeobachtbarkeit mit der Anwendungskomponente. Er befindet sich im Bereich der analytischen Beobachtbarkeit, am Schnittpunkt aller drei Bereiche.
Um diesen Teil zu kodieren, müssen wir Beobachtungen darüber machen, welche Datenquellen (Inputs) verwendet werden, um andere Datenquellen (Outputs) zu erzeugen. Für die ingestion helfen die CSV-Dateien der Aktien bei der Erstellung der CSV-Datei monthly_assets. Wenn du eine Ebene tiefer gehst, verkettet ingestion alle Werte aus allen Spalten und schreibt das Ergebnis dann in eine Datei. Die Abstammung auf der Feldebene ist direkt, d.h. die Namen der Eingabe- und Ausgabespalten sind identisch und eine Ausgabe bezieht ihren Wert nur aus dieser Spalte für jede Eingabedatenquelle.
Beispiel 4-15 zeigt, wie man die Generierung der Lineage -OutputDataLineage ![]() - in die Anwendung
- in die Anwendung reporting mit einer eigenen Klasse einbindet, die die Abhängigkeiten eines Outputs mit seinen Inputs definiert.
Beispiel 4-15. Klasse zur Modellierung von Abstammungsbeobachtungen
classOutputDataLineage:schema:Schemainput_schemas:list[tuple[Schema,dict]]id:strdef__init__(self,schema:Schema,input_schemas_mapping:list[tuple[Schema,dict]])->None:self.schema=schemaself.input_schemas_mapping=input_schemas_mappingself.id=hashlib.md5(",".join([self.schema.id]).encode("utf-8")\+self.linearize().encode("utf-8")).hexdigest()defto_json(self):return{"id":self.id,"schema":self.schema.id,"input_schemas_mapping":self.input_schemas_mapping}
Beispiel 4-16 zeigt einen statischen Funktionsteil von OutputDataLineage, der jede Eingabe mit der Ausgabe auf Feldebene abbildet und sie auf diese Weise verbindet: output_field -> list of input fields für jede Eingabe ![]() . Der
. Der generate_direct_mapping Helfer bindet die Datenquellen mit einer allzu einfachen Heuristik, die die Ausgabedatenquellen zuordnet, wenn die Feldnamen übereinstimmen.
Diese Strategie schlägt in den meisten realen Anwendungsfällen fehl, vor allem bei Aggregationen, die ein sorgfältigeres Tracking erfordern, um alle Verbindungen zu verwalten.
Du kannst diese Situation vermeiden, indem du eine der Strategien anwendest, die im nächsten Kapitel besprochen werden.
Beispiel 4-16. Hilfsmethode zur einfachen Erstellung einer Abstammung
@staticmethoddefgenerate_direct_mapping(output_schema:Schema,input_schemas:list[Schema]):input_schemas_mapping=[]output_schema_field_names=[f[0]forfinoutput_schema.fields]forschemaininput_schemas:mapping={}forfieldinschema.fields:iffield[0]inoutput_schema_field_names:mapping[field[0]]=[field[0]]iflen(mapping):input_schemas_mapping.append((schema,mapping))returninput_schemas_mappingdefinelinearize(self):[...]returnlinearized
Dann definiere ich in Beispiel 4-17 die Lineage-Ausführung, ApplicationExecution, ![]() , die die Verbindung mit den kontextuellen (anwendungsbezogenen) Beobachtungen herstellt.
, die die Verbindung mit den kontextuellen (anwendungsbezogenen) Beobachtungen herstellt.
Beispiel 4-17. Klasse zur Modellierung der Ausführung einer Lineage
classDataLineageExecution:lineage:OutputDataLineageapplication_execution:ApplicationExecutionstart_time:strid:strdef__init__(self,lineage:OutputDataLineage,application_execution:ApplicationExecution)->None:self.lineage=lineageself.application_execution=application_executionself.start_time=datetime.datetime.now().isoformat()self.id=hashlib.md5(",".join([self.lineage.id,self.application_execution.id,self.start_time]).encode("utf-8")).hexdigest()defto_json(self):return{"id":self.id,"lineage":self.lineage.id,"application_execution":self.application_execution.id,"start_time":self.start_time}
Das in Kapitel 2 vorgestellte Kernmodell der Datenbeobachtbarkeit verknüpft die Datenmetrik-Entität mit der Ausführung der Lineage, um die Daten bei ihrer Verwendung oder Änderung sichtbar zu machen. Daher passen wir das Modell DataMetrics an, um diese Verknüpfung darzustellen, indem wir die Eigenschaft lineage_execution ![]() hinzufügen, wie in Beispiel 4-18 gezeigt.
hinzufügen, wie in Beispiel 4-18 gezeigt.
Beispiel 4-18. Hinzufügen der Lineage-Ausführung zur Metrik für den Kontext
classDataMetrics:schema:Schemalineage_execution:DataLineageExecutionmetrics:list[tuple[str,float]]id:strdef__init__(self,metrics:list[tuple[str,float]],schema:Schema,lineage_execution:DataLineageExecution)->None:self.metrics=metricsself.schema=schemaself.lineage_execution=lineage_executionid_content=",".join([self.schema.id,self.lineage_execution.id]self.id=hashlib.md5(id_content).encode("utf-8")).hexdigest()defto_json(self):fromfunctoolsimportreducejfields=reduce(lambdax,y:dict(**x,**y),map(lambdaf:{f[0]:f[1]},self.metrics))return{"id":self.id,"metrics":jfields,"schema":self.schema.id,"lineage_execution":self.lineage_execution.id}@staticmethoddefextract_metrics_from_df(df:pd.DataFrame):d=df.describe(include='all',datetime_is_numeric=True)importmathimportnumbersmetrics={}filterf=lambdax:isinstance(x[1],numbers.Number)andnotmath.isnan(x[1])mapperf=lambdax:(field+"."+x[0],x[1])forfieldind.columns[1:]:msd=dict(filter(filterf,map(mapperf,d[field].to_dict().items())))metrics.update(msd)returnlist(metrics.items())
Jetzt sind alle Teile bereit, um die in Abbildung 4-5 gezeigten Beobachtungen zu erstellen. Das fertige ingestion Skript kannst du im GitHub-Repository einsehen.
Wrap-Up: Die Daten-Beobachtungs-Daten-Pipeline
Bevor wir analysieren, wie die Beobachtungen bei den zu Beginn dieses Abschnitts vorgestellten expliziten und stillen Fehlern helfen , wenden wir an, was wir bisher für die Anwendung ingestion getan haben, um die Anwendungsdaten reporting beobachtbar zu machen. Siehe Beispiel 4-19.
Beispiel 4-19. Berichtsanwendung mit ausführlichen, aus dem Code generierten Datenbeobachtungen
importApplicationRepository.fetch_git_locationimportApplicationVersion.fetch_git_versionapp=Application(Application.fetch_file_name())app_repo=ApplicationRepository(fetch_git_location(),app)git_user=User(ApplicationVersion.fetch_git_author())app_version=ApplicationVersion(fetch_git_version(),git_user,app_repo)current_user=User("Emanuele Lucchini")app_exe=ApplicationExecution(app_version,current_user)all_assets=pd.read_csv("data/monthly_assets.csv",parse_dates=['Date'])apptech=all_assets[all_assets['Symbol']=='APCX']buzzfeed=all_assets[all_assets['Symbol']=='BZFD']buzzfeed['Intraday_Delta']=buzzfeed['Adj Close']-buzzfeed['Open']apptech['Intraday_Delta']=apptech['Adj Close']-apptech['Open']kept_values=['Open','Adj Close','Intraday_Delta']buzzfeed[kept_values].to_csv("data/report_buzzfeed.csv",index=False)apptech[kept_values].to_csv("data/report_appTech.csv",index=False)all_assets_ds=DataSource("data/monthly_assets.csv","csv")all_assets_sc=Schema(Schema.extract_fields_from_dataframe(all_assets),all_assets_ds)buzzfeed_ds=DataSource("data/report_buzzfeed.csv","csv")buzzfeed_sc=Schema(Schema.extract_fields_from_dataframe(buzzfeed),buzzfeed_ds)apptech_ds=DataSource("data/report_appTech.csv","csv")apptech_sc=Schema(Schema.extract_fields_from_dataframe(apptech),apptech_ds)# First lineagelineage_buzzfeed=OutputDataLineage(buzzfeed_sc,OutputDataLineage.generate_direct_mapping(buzzfeed_sc,[all_assets_sc]))lineage_buzzfeed_exe=DataLineageExecution(lineage_buzzfeed,app_exe)all_assets_ms_1=DataMetrics(DataMetrics.extract_metrics_from_df(all_assets),all_assets_sc,lineage_buzzfeed_exe)buzzfeed_ms=DataMetrics(DataMetrics.extract_metrics_from_df(buzzfeed),buzzfeed_sc,lineage_buzzfeed_exe)# Second lineagelineage_apptech=OutputDataLineage(apptech_sc,OutputDataLineage.generate_direct_mapping(apptech_sc,[all_assets_sc]))lineage_apptech_exe=DataLineageExecution(lineage_apptech,app_exe)all_assets_ms_2=DataMetrics(DataMetrics.extract_metrics_from_df(all_assets),all_assets_sc,lineage_apptech_exe)apptech_ms=DataMetrics(DataMetrics.extract_metrics_from_df(apptech),apptech_sc,lineage_apptech_exe)
Indem wir die Beobachtungen auf diese Weise hinzufügen, bleiben die Änderungen ähnlich wie bei der Anwendung ingestion. Dieser Ansatz ermöglicht es uns, Gewohnheiten und Abstraktionen zu entwickeln, wie z. B. ein Framework, das die Anzahl der erforderlichen Änderungen reduziert - fast ein implizites Gesetz in der Entwicklung.
In Beispiel 4-19 siehst du, dass die Beobachtungen, die für die Eingänge generiert werden, an das Ende ![]() verschoben wurden. Wir haben uns aus Gründen der Einfachheit des Beispiels für diese Implementierung entschieden. Ein Vorteil ist, dass die zusätzlichen Berechnungen am Ende durchgeführt werden, ohne den Geschäftsablauf zu beeinträchtigen. Der Nachteil ist, dass, wenn zwischendurch etwas fehlschlägt, keine Beobachtungen über die Datenquellen und ihr Schema gesendet werden. Natürlich ist es möglich, diese Situation mit einigen Anpassungen am Code zu vermeiden. Außerdem müssen wir für diese Einführung in eine Low-Level-API einige Boilerplate hinzufügen, um die richtigen Informationen zu generieren, was im Verhältnis zum Geschäftscode wie Lärm klingen mag. Behalte jedoch im Hinterkopf, dass das Skript ursprünglich keine Protokolle enthielt. Im Allgemeinen werden Protokolle sporadisch hinzugefügt, um Informationen über das Verhalten des Skripts zu erhalten, was wir auch getan haben, allerdings für die Daten.
verschoben wurden. Wir haben uns aus Gründen der Einfachheit des Beispiels für diese Implementierung entschieden. Ein Vorteil ist, dass die zusätzlichen Berechnungen am Ende durchgeführt werden, ohne den Geschäftsablauf zu beeinträchtigen. Der Nachteil ist, dass, wenn zwischendurch etwas fehlschlägt, keine Beobachtungen über die Datenquellen und ihr Schema gesendet werden. Natürlich ist es möglich, diese Situation mit einigen Anpassungen am Code zu vermeiden. Außerdem müssen wir für diese Einführung in eine Low-Level-API einige Boilerplate hinzufügen, um die richtigen Informationen zu generieren, was im Verhältnis zum Geschäftscode wie Lärm klingen mag. Behalte jedoch im Hinterkopf, dass das Skript ursprünglich keine Protokolle enthielt. Im Allgemeinen werden Protokolle sporadisch hinzugefügt, um Informationen über das Verhalten des Skripts zu erhalten, was wir auch getan haben, allerdings für die Daten.
Behalte auch diese Punkte im Hinterkopf:
-
Wir haben den
OutputDataLineage.generate_direct_mappingHelper so verwendet, wie er ist, um ein Lineage Mapping zwischen den Outputs und Inputs zu erstellen. Das wird jedoch nicht funktionieren, weil wirAdj CloseundOpenaus der Datei monthly_assets.csv in der neuen SpalteIntraday_Deltazusammengefasst haben. Da die Felder nicht denselben Namen haben, wird die "direkte" Heuristik diese Abhängigkeit nicht erkennen. -
Es wird eine Warnmeldung angezeigt, wenn dieselben Beobachtungen ein zweites Mal für die monthly_assets gemeldet werden. Das haben wir getan, weil wir Lineage pro Ausgabe kodiert haben. Wir haben jetzt zwei Lineages, die jeweils Ausgaben für die Dateien report_buzzfeed.csv und report_AppTech.csv erzeugen. Da die Ausgabe dieselben Daten wie die (gefilterte) Eingabe wiederverwendet, müssen wir für jede Ausgabe melden, wie die Eingabe aussieht, damit sie nicht als Duplikate angezeigt werden. Alternativ könnten wir die Beobachtungen wiederverwenden oder das Modell anpassen, um diese Doppelung zu vermeiden. Du könntest stattdessen die folgenden Optionen in Betracht ziehen:
-
Wenn wir unsere Strategie dahingehend ändern, dass wir jedes Mal lesen, wenn auf die Daten zugegriffen wird, anstatt sie in den Speicher zu laden, dann sind die Beobachtungen nicht mehr identisch, wenn sich die Daten zwischen den beiden Schreibvorgängen ändern. Wenn eine Ausgabe Probleme hat, ziehen wir es vor, die Beobachtungen der Eingabe mit dieser Linie zu synchronisieren. Die Wahrscheinlichkeit dieser Situation steigt, wenn du bedenkst, dass jeder Schreibvorgang Stunden und nicht nur Sekunden dauern kann.
-
Die Anwendung
reportingerzeugt bei jedem Durchlauf alle Ausgaben, aber durch späteres Refactoring kann dies geändert und parametrisierbar gemacht werden. So kann zum Beispiel nur eine Ausgabe erstellt werden, wie die von BuzzFeed. Daher wird jederreportingDatensatz durch unabhängige Läufe erzeugt. In diesem Fall bilden die Beobachtungen dies bereits angemessen ab, sodass wir die Logik nicht anpassen müssen. Mit anderen Worten: Wenn wir die Beobachtungen eines bestimmten Inputs so oft senden, wie er verwendet wird, um einen Output zu erzeugen, entspricht das der Realität, anstatt zu versuchen, Daten zu optimieren, die wie Duplikate aussehen könnten.
-
Kümmern wir uns um den ersten Punkt und stellen sicher, dass die Lineage die tatsächlichen Verbindungen zwischen den Datenquellen darstellen kann. Um dies auf vereinfachte Weise zu tun, werden wir die in Beispiel 4-19 eingeführte Hilfsfunktion mit zusätzlichen Informationen aktualisieren. Beispiel 4-20 ![]() zeigt die neue Version dieser Hilfsfunktion, die jetzt ein Argument enthält, um eine nicht-direkte Zuordnung für jede Eingabe zu liefern. In späteren Abschnitten werden Strategien vorgestellt, mit denen dieser häufige Anwendungsfall viel einfacher, effizienter, wartbarer und genauer behandelt werden kann, z. B. durch die Verwendung von Monkey Patching.
zeigt die neue Version dieser Hilfsfunktion, die jetzt ein Argument enthält, um eine nicht-direkte Zuordnung für jede Eingabe zu liefern. In späteren Abschnitten werden Strategien vorgestellt, mit denen dieser häufige Anwendungsfall viel einfacher, effizienter, wartbarer und genauer behandelt werden kann, z. B. durch die Verwendung von Monkey Patching.
Beispiel 4-20. Generierte Abstammung auf Feldebene basierend auf übereinstimmenden Feldnamen
@staticmethoddefgenerate_direct_mapping(output_schema:Schema,input_schemas:list[tuple[Schema,dict]]):input_schemas_mapping=[]output_schema_field_names=[f[0]forfinoutput_schema.fields]for(schema,extra_mapping)ininput_schemas:mapping={}forfieldinschema.fields:iffield[0]inoutput_schema_field_names:mapping[field[0]]=[field[0]]mapping.update(extra_mapping)iflen(mapping):input_schemas_mapping.append((schema,mapping))returninput_schemas_mapping
Beispiel 4-21 zeigt den letzten Teil der Beobachtungen der reporting Anwendung.
Beispiel 4-21. Berichtsanwendung macht Daten mit sauberem Code beobachtbar
# First lineageintraday_delta_mapping={"Intraday_Delta":['Adj Close','Open']}a=(all_assets_sc,intraday_delta_mapping)lineage_buzzfeed=OutputDataLineage(buzzfeed_sc,OutputDataLineage.generate_direct_mapping(buzzfeed_sc,[(all_assets_sc,intraday_delta_mapping)]))lineage_buzzfeed_exe=DataLineageExecution(lineage_buzzfeed,app_exe)all_assets_ms_1=DataMetrics(DataMetrics.extract_metrics_from_df(all_assets),all_assets_sc,lineage_buzzfeed_exe)buzzfeed_ms=DataMetrics(DataMetrics.extract_metrics_from_df(buzzfeed),buzzfeed_sc,lineage_buzzfeed_exe)# Second lineagelineage_apptech=OutputDataLineage(apptech_sc,OutputDataLineage.generate_direct_mapping(apptech_sc,[(all_assets_sc,intraday_delta_mapping)]))lineage_apptech_exe=DataLineageExecution(lineage_apptech,app_exe)all_assets_ms_2=DataMetrics(DataMetrics.extract_metrics_from_df(all_assets),all_assets_sc,lineage_apptech_exe)apptech_ms=DataMetrics(DataMetrics.extract_metrics_from_df(apptech),apptech_sc,lineage_apptech_exe)
Datenbeobachtungen zur Behebung von Fehlern in der Datenpipeline nutzen
Jetzt können wir unsere Pipeline bereitstellen, ausführen und überwachen, indem wir die Beobachtungen nutzen, die sie bei jedem Durchlauf generiert. Die Low-Level-API erforderte einiges an zusätzlichem Aufwand und Überzeugung. Dennoch sind wir mit den Ergebnissen zufrieden. Jede Minute, die wir für diese Aufgaben aufwenden, bringt uns den 100-fachen Nutzen in Form von vermiedenen Umsatzeinbußen - gemäß der Qualitätskostenregel 1-10-100 -, wenn in der Produktion Probleme auftreten.
Schauen wir uns die Probleme an, die in diesem Abschnitt auf erwähnt wurden, beginnend mit den ingestion Bewerbungsfehlern, die auftreten können:
- Eingabedateien nicht gefunden
- Die
DataSourceBeobachtungen werden bei jedem Lauf gesendet. Nachdem sie gelesen wurden, senden die fehlgeschlagenen Läufe also keine von ihnen. Selbst für jemanden, der die Anwendungslogik nicht kennt, ist es klar, dass die bisher verwendeten Dateien fehlen. - Tippfehler beim Lesen
- Die
SchemaBeobachtungen werden gesendet und enthalten die Feldnamen, die mit ihrem Typ verbunden sind. Daher ist der erwartete Typ für den Beobachter klar, ohne dass er die Anwendung oder die Dateien der Vormonate aufrufen muss. - Fehler aufgrund von fehlenden Feldern
- Die gleichen Beobachtungen wie bei "Typfehler beim Lesen" helfen dem Beobachter, schnell zu erkennen, welche Felder in den vorherigen Durchläufen vorhanden waren, die im aktuellen Durchlauf fehlen.
- Dateisystem-Fehler
- Die von der Pandas-Bibliothek ausgelöste Ausnahme liefert normalerweise den Pfad, der zu einem Fehler geführt hat. Die verbleibende Information, die dem Beobachter zur Verfügung steht, um das Problem zu identifizieren, ist der Server, den dieser Pfad verwendet hat. Die IP, die in den Serverbeobachtungen auf
DataSourceangegeben ist, gibt sofort Aufschluss darüber, welcher Server mit diesem Pfad verbunden war. - Speicherfehler
-
Dieses Problem tritt vor allem dann auf, wenn die Datenmenge plötzlich ansteigt. Es können viele Fälle in Betracht gezogen werden, aber sie werden meist intuitiv vom Beobachter gehandhabt, indem er
DataMetricsBeobachtungen verwendet, die die Anzahl der Zeilen, das Schema mit der Anzahl der Felder oder die Anzahl vonDataSourcesenthalten. Trotzdem kann es erforderlich sein, dass die Beobachtungen früher als am Ende des Skripts gesendet werden, wie in den folgenden beiden Fällen:-
Eine der Eingabedateien hat eine größere Größe als zuvor. Die Datei wird leicht erkannt, weil keine
DataMetricsfür sie verfügbar ist. -
Der Output ist stark gewachsen, weil alle Dateien gewachsen sind. Der Größenunterschied wird erkannt, weil die
DataMetricsfür die Ausgaben fehlen. Auch dieDataMetricsfür die Eingaben zeigen einen Anstieg der Anzahl der Zeilen.
-
- Speicherplatzfehler im Dateisystem
-
Diese Fehler treten höchstwahrscheinlich beim Schreiben der Ausgabe auf, wenn man bedenkt, dass es hier um die Beobachtbarkeit von Daten geht. Die gleichen Informationen wie bei "Speicherfehler" geben dem Beobachter sofort Aufschluss darüber, warum der verfügbare Speicherplatz nicht mehr ausreicht und welche Dateien nicht geschrieben werden konnten.
Die
Dateist nicht als Datum parsbar-
In diesem Fall hat das Schema die Typbeobachtung für das Datumsfeld von
dateauf etwas anderes geändert, z.B.stroderobject.
DateSpalte enthält keine Werte für das aktuelle Jahr/Monat-
Die
DataMetricsBeobachtungen beinhalten den minimalen und maximalen Zeitstempel, der einen sofortigen Einblick in den Unterschied zwischen der Ausführungszeit und den verfügbaren Daten gibt. Nehmen wir zum Beispiel an, der maximale Zeitstempel liegt zwei Tage vor dem Zeitpunkt, an dem die Datenquelle gelesen wird, dann können die Daten als zu alt angesehen werden, wenn der akzeptable Zeitraum nur einen Tag beträgt.
DateSpalte enthält Werte in der Zukunft-
Das ist ganz einfach, denn die gleiche Art von Beobachtungen wie beim vorherigen Ausfall aufgrund fehlender Werte für den aktuellen Monat gibt dir diese Sichtbarkeit.
SymbolKategorien geändert-
Wenn wir nur numerische
DataMetricsbetrachten, können wir diesen Fall schnell anhand der Anzahl der Kategorien erkennen, die in der Ausgabedatei wachsen würden. Eine oder einige der Dateien wären nicht mehr konsistent, da sie sich auf verschiedene Kategorien beziehen würden.
Dann müssen wir uns überlegen, unter welchen Umständen die
reportingAnwendung die Ingestion-Anwendung als fehlgeschlagen betrachten könnte, und gegebenenfalls, welchereportingAnwendung ein Beobachter verwenden könnte. Zu diesen Situationen gehören die folgenden:Die monatliche aggregierte Datei ist nicht verfügbar
-
Die DataSource-Beobachtung oder
DataMetricswurde von der Anwendung nicht gesendet.ingestionAnwendung gesendet.
Die Aggregation verwendet fehlende Felder, wie z. B.
Close-
Im Schema der monatlichen Daten, die von der Anwendung
ingestiongesendet werden, fehlen diese Felder ebenfalls.
Fehler bei Lese-/Schreibzugriff, Größe und Platz
-
Für den
reportingBeobachter gelten die gleichen Lösungen wie für deningestionBeobachter. Es gibt keine Verzerrung der Informationen zwischen Teams oder Teammitgliedern.
APCXundENFASymbole-
Die Anzahl der Kategorien, die der
ingestionBeobachter meldet, hat sich geändert, was in einigen Fällen einen Hinweis darauf gibt, was passiert ist. Wir könnenDataMetricsjedoch erweitern, um auch nicht-numerische Beobachtungen zu melden und die Kategorien zu melden.
Fehlende Werte in
Adj CloseoderOpenführen zu abnormalen Zahlen-
Die
DataMetrics"Anzahl der Nullen" deckt diesen Fall ab, denn wenn die Anzahl der Nullen größer als Null ist, wird die Berechnung derIntraday_DeltaNAs zurückgeben.
Falsches Datum im monatlichen Vermögen
-
Die gleichen Lösungen, die der
ingestionBeobachter bei Datumsfehlern anwendet, gelten auch hier. Die Anwendung könnte zum Beispiel den Mindest- und Höchstwert für die SpalteDateim Vergleich zum aktuell gemeldeten Monat verwenden.
-
Wir sind jetzt in der Lage, mit verschiedenen Situationen umzugehen, in denen die Daten die Ursache für ein Problem sind. Ohne dieses Wissen wären in solchen Situationen lange, stressige Meetings nötig, um sie zu verstehen, und anstrengende Stunden oder Tage für die Fehlersuche, die sich zu Monaten ausweiten könnten, weil wir in der Produktion nicht auf die Daten zugreifen können.
Die bisher diskutierten Probleme sind solche, von denen wir wissen, dass sie auftreten können. Es gibt jedoch noch viele andere Probleme, die sich in der Pipeline ausbreiten können und über die wir noch wenig wissen - die unbekannten Unbekannten. Zum Beispiel sind die Werte eines der Bestände für einen vergangenen Monat falsch, weil beim CSV-Export Fehler in die Daten eingefügt wurden. Dieses Problem wird bei mindestens einer deiner Anwendungen auftreten, und bei anderen ähnlichen.
Aufgrund dieser Unbekannten dürfen die Datenbeobachtungen nicht nur auf vordefinierte Fälle beschränkt werden, sondern die Anwendungen müssen so viele Beobachtungen wie möglich melden - unter Berücksichtigung möglicher Einschränkungen bei den Rechenressourcen und der Zeit -, um einen Überblick über die erwartete oder nicht erfüllte Situation zu erhalten. In diesem Beispiel wäre die Verteilung der monatlichen Bestandswerte später für den Vergleich mit anderen Monaten nützlich, und sie könnten Hinweise darauf geben, ob die Werte gleich oder ähnlich sind.
Der Vorteil der Low-Level-Protokollierung besteht darin, dass du völlig flexibel entscheiden kannst, was du sichtbar machen möchtest. Beispiele dafür sind benutzerdefinierte Metriken und Key Performance Indicators (KPIs).
Nicht alle Aufträge sind gleich; jedes Unternehmen, jedes Projekt und jede Anwendung hat ihre eigenen Besonderheiten. Du wirst wahrscheinlich bestimmte Kennzahlen kontrollieren, egal ob sie mit verbrauchten oder produzierten Daten verknüpft sind. Eine solche Kennzahl für eine Tabelle könnte die Summe der Anzahl der Artikel multipliziert mit den Kosten pro Einheit abzüglich des von einem Webservice erhaltenen Betrags sein, count(items) * cost_per_unit. Das Ergebnis muss immer größer als Null sein. Dies kann einfach in den Quellcode eingefügt werden, muss aber vom Ingenieur hinzugefügt werden, da es sich um spezifische Metriken handelt, die mit der Geschäftslogik (und der Semantik der Spalten) verbunden sind.
Ein weiterer Grund für die Anpassung von Beobachtungen sind KPIs - Zahlen, die von den Stakeholdern angefordert werden und für das zugrunde liegende Geschäft wichtig sind. KPIs werden oft in regelmäßigen Abständen gemeldet oder auf Anfrage berechnet und in zufälligen oder festen Abständen verwendet. Ihre Bedeutung ist jedoch so groß, dass die Stakeholder hohe Erwartungen an sie stellen und wenig bis keine Zeit haben, auf Korrekturen zu warten. Deshalb musst du auch Transparenz darüber schaffen, wie sich die KPIs im Laufe der Zeit entwickeln, denn wenn ein Stakeholder Zweifel daran hat, beginnt die Zeit in dem Moment zu ticken, in dem er dich nach ihrer Korrektheit fragt. Um die Reaktionsfähigkeit zu erhöhen, musst du generell wissen, wie sich die KPIs entwickeln. Du musst erkennen, wie sie sich verändern, bevor sie es tun, und verstehen, warum sie sich aufgrund ihrer historischen Werte und ihrer Herkunft verändern.
Wie du bei der Aktualisierung der Anwendung reporting vielleicht schon vermutet hast, ist die Definition der API - das Modell, die Kodierung und die Funktionen - keine Aufgabe für jede einzelne Anwendung. Vielmehr musst du sie standardisieren und anwendungsübergreifend wiederverwenden. Durch die Standardisierung wird der Arbeitsaufwand pro Anwendung reduziert. Noch wichtiger ist, dass die Beobachtungen unabhängig von der Anwendung einheitlich sind, um den Beobachtern die Arbeit zu erleichtern, das Verhalten der anderen Anwendungen, die an der zu analysierenden Pipeline beteiligt sind, abzugleichen.
Die Standardisierung ist auch hilfreich, um Entitäten anwendungsübergreifend wiederzuverwenden, wie z. B. assets_monthly DataSource, das die Ausgabe der Anwendung ingestion und die Eingabe der Anwendung reporting ist. Durch die einheitliche Darstellung der Beobachtungen kannst du den Status der gesamten Pipeline konsolidieren, indem du die Entitäten anwendungsübergreifend wiederverwendest.
Ein Teil der Architektur zur Unterstützung der Datenbeobachtung muss ein externes System umfassen, das die Beobachtungen zusammenfasst, um systematisch einen globalen Überblick zu schaffen. Durch Beobachter, die sich auf diese aggregierte Sicht verlassen und auf dieser Grundlage handeln, kann das System einige der Aktionen ausführen, die derzeit von den Beobachtern durchgeführt werden - hier kommt das maschinelle Lernen ins Spiel.
Fazit
In diesem Kapitel haben wir uns umfassend mit der Beobachtbarkeit von Daten an der Quelle und ihrer Bedeutung für die Verbesserung der Datenqualität und der operativen Exzellenz befasst. Wir haben uns mit dem Konzept der Erzeugung von Datenbeobachtungen im Code von Datenanwendungen befasst und dabei hervorgehoben, wie wichtig es ist, den Code zur Erzeugung von Beobachtungen in verschiedene Komponenten der Anwendung einzubauen. Zu diesen Komponenten gehören die Anwendung selbst, die genutzten Daten, ihre Beziehungen und ihr Inhalt.
Außerdem haben wir die Entwicklung einer Python-API zur Datenbeobachtung auf niedriger Ebene besprochen, die Entwicklern ein leistungsfähiges Toolset zur nahtlosen Integration von Datenbeobachtungsfunktionen in ihre Anwendungen bietet. Mit dieser API können Praktiker/innen Datenbeobachtungen erstellen, Datenflüsse verfolgen und die Zuverlässigkeit und Genauigkeit ihrer Daten sicherstellen.
Um diese Konzepte zu untermauern, haben wir ein voll funktionsfähiges Beispiel vorgestellt, das die Umwandlung einer in Python geschriebenen, nicht datenbeobachtbaren Datenpipeline in eine robuste und datenbeobachtungsgesteuerte Pipeline zeigt. Durch die Nutzung der speziellen Python-API für Datenbeobachtung haben wir gezeigt, wie Datenbeobachtungen generiert, erfasst und genutzt werden können, um die Transparenz zu erhöhen, Probleme zu erkennen und kontinuierliche Verbesserungen voranzutreiben.
Die in diesem Kapitel vorgestellten Prinzipien und Strategien dienen als Grundlage für die Integration von Datenbeobachtung in die Struktur von Datenanwendungen. Wenn Unternehmen diese Praktiken anwenden, können sie sicherstellen, dass ihre Datenpipelines robust und zuverlässig sind und wertvolle Erkenntnisse mit einem hohen Maß an Vertrauen liefern können.
Trotz der hohen Anpassungsfähigkeit und Flexibilität von Low-Level-Logging kann der anfängliche Aufwand die Einführung behindern. Dieses Argument gilt auch für die Einführung von Tests. Deshalb ist es wichtig, die Komplexität der Nutzung auf dieser Ebene zu vereinfachen. Außerdem müssen wir nach alternativen Ansätzen suchen, die das Low-Level-Logging ergänzen und gleichzeitig die breite Akzeptanz der Datenbeobachtung in Teams und bei Einzelpersonen fördern. In den folgenden Abschnitten werden wir uns mit diesem Thema befassen und mit der Erforschung ereignisbasierter Systeme beginnen.
1 Das hat mich dazu gebracht, über die datenbeobachtungsbasierte Entwicklungsmethode nachzudenken.
Get Grundlagen der Beobachtbarkeit von Daten now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

