Kapitel 1. Einführung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Obwohl in diesem Buch viel über Graphdatenmodelle gesprochen wird, ist es kein Buch über Graphentheorie.1 Wir brauchen nicht viel Theorie, um die Vorteile von Graphdatenbanken zu nutzen: Solange wir verstehen, was ein Graph ist, sind wir praktisch schon dabei. In diesem Sinne lasst uns unser Gedächtnis über Graphen im Allgemeinen auffrischen.
Was ist eine Grafik?
Formal gesehen ist ein Graph nur eine Sammlung von Knoten und Kanten - oder, um es einfacher auszudrücken, eine Menge von Knoten und die Beziehungen, die sie verbinden. Graphen stellen Entitäten als Knoten dar und die Art und Weise, wie diese Entitäten mit der Welt in Beziehung stehen, als Beziehungen. Mit dieser vielseitigen und aussagekräftigen Struktur können wir alle möglichen Szenarien modellieren, von der Konstruktion einer Weltraumrakete bis hin zu einem Straßensystem, von der Versorgungskette oder Herkunft von Lebensmitteln bis hin zur Krankengeschichte von Bevölkerungen und darüber hinaus.
Die Daten von Twitter lassen sich zum Beispiel leicht als Diagramm darstellen. In Abbildung 1-1 sehen wir ein kleines Netzwerk von Twitter-Nutzern. Jeder Knoten ist mit User beschriftet, was seine Rolle im Netzwerk angibt. Diese Knoten sind dann mit Beziehungen verbunden, die helfen, den semantischen Kontext herzustellen: Billy folgt Harry, und Harry folgt wiederum Billy. Ruth und Harry folgen sich ebenfalls gegenseitig, aber leider folgt Ruth zwar Billy, aber Billy hat das (noch) nicht erwidert.

Abbildung 1-1. Ein kleiner sozialer Graph
Natürlich ist der reale Graph von Twitter hunderte Millionen Mal größer als das Beispiel in Abbildung 1-1, aber er funktioniert nach genau denselben Prinzipien. In Abbildung 1-2 haben wir den Graphen um die von Ruth veröffentlichten Nachrichten erweitert.

Abbildung 1-2. Nachrichten veröffentlichen
Obwohl sie einfach ist, zeigt Abbildung 1-2 die Ausdruckskraft des Graphenmodells. Es ist leicht zu erkennen, dass Ruth eine Reihe von Nachrichten veröffentlicht hat. Ihre letzte Nachricht findest du, wenn du einer Beziehung mit der Bezeichnung CURRENT folgst. Die PREVIOUS Beziehungen bilden dann Ruths Zeitleiste.
Eine Übersicht über den Graphenraum
In den letzten Jahren sind zahlreiche Projekte und Produkte zur Verwaltung, Verarbeitung und Analyse von Diagrammen auf den Markt gekommen. Die schiere Anzahl der Technologien macht es selbst für diejenigen unter uns, die in diesem Bereich aktiv sind, schwierig, den Überblick über diese Tools und ihre Unterschiede zu behalten. Dieser Abschnitt bietet einen Überblick über die entstehende Graphenlandschaft.
Von 10.000 Fuß aus können wir den Diagrammraum in zwei Teile unterteilen:
- Technologien, die in erster Linie für die transaktionale Online-Persistenz von Graphen verwendet werden, auf die in der Regel direkt und in Echtzeit aus einer Anwendung heraus zugegriffen wird
-
Diese Technologien werden Graphdatenbanken genannt und sind das Hauptthema dieses Buches. Sie sind das Äquivalent zu "normalen" Online-Transaktionsverarbeitungsdatenbanken (OLTP) in der relationalen Welt.
- Technologien, die in erster Linie für Offline-Graph-Analysen verwendet werden und in der Regel in einer Reihe von Batch-Schritten durchgeführt werden
-
Diese Technologien können als Graph Compute Engines bezeichnet werden. Sie gehören zur gleichen Kategorie wie andere Technologien für die Analyse von Massendaten, z. B. Data Mining und Online Analytical Processing (OLAP).
Hinweis
Eine weitere Möglichkeit, den Graphenraum aufzuteilen, ist die Betrachtung der Graphenmodelle, die von den verschiedenen Technologien verwendet werden. Es gibt drei vorherrschende Graphenmodelle: den Eigenschaftsgraphen , Resource Description Framework (RDF)-Triples und Hypergraphen. Wir beschreiben diese Modelle ausführlich in Anhang A. Die meisten der gängigen Graphdatenbanken auf dem Markt verwenden eine Variante des Eigenschaftsgraphenmodells, weshalb wir uns im weiteren Verlauf dieses Buches auf dieses Modell stützen werden.
Graph-Datenbanken
Ein Graphdatenbankmanagementsystem (im Folgenden Graphdatenbank genannt) ist ein Online-Datenbankmanagementsystem mit Methoden zum Erstellen, Lesen, Aktualisieren und Löschen (CRUD), die ein Graphdatenmodell offenlegen. Graphdatenbanken werden in der Regel für den Einsatz in transaktionalen (OLTP) Systemen entwickelt. Dementsprechend sind sie in der Regel für die Transaktionsleistung optimiert und mit Blick auf die Transaktionsintegrität und Betriebsverfügbarkeit entwickelt worden.
Es gibt zwei Eigenschaften von Graphdatenbanken, die wir bei der Untersuchung von Graphdatenbanktechnologien berücksichtigen sollten:
- Die zugrunde liegende Speicherung
-
Einige Graphdatenbanken verwenden eine native Graphspeicherung, die für die Speicherung und Verwaltung von Graphen optimiert und konzipiert ist. Nicht alle Graphdatenbanktechnologien verwenden jedoch eine native Graphspeicherung. Einige seriellisieren die Graphdaten in eine relationale Datenbank, eine objektorientierte Datenbank oder einen anderen Allzweckdatenspeicher.
- Die Verarbeitungsmaschine
-
Einige Definitionen von verlangen, dass eine Graphdatenbank indexfreie Adjazenz verwendet, d. h., dass verbundene Knoten physisch auf einander in der Datenbank "zeigen".2 Hier gehen wir etwas weiter: Jede Datenbank, die sich aus Sicht des Nutzers wie eine Graphdatenbank verhält (d. h. ein Graphdatenmodell durch CRUD-Operationen offenlegt), gilt als Graphdatenbank. Wir erkennen jedoch die erheblichen Leistungsvorteile der indexfreien Adjazenz an und verwenden daher den Begriff native Graphverarbeitung, um Graphdatenbanken zu beschreiben, die die indexfreie Adjazenz nutzen.
Hinweis
Es ist wichtig zu wissen, dass native Graphspeicherung und native Graphverarbeitung weder gut noch schlecht sind - sie sind einfach klassische technische Kompromisse. Der Vorteil der nativen Speicherung von Graphen ist, dass ihr speziell entwickelter Stack auf Leistung und Skalierbarkeit ausgelegt ist. Der Vorteil der nicht-nativen Speicherung von Graphen ist dagegen, dass sie in der Regel von einem ausgereiften Nicht-Graph-Backend (wie z. B. MySQL) abhängt, dessen Produktionsmerkmale von den Betriebsteams gut verstanden werden. Die native Graphenverarbeitung (indexfreie Adjazenz) verbessert zwar die Traversalleistung, aber auf Kosten einiger Abfragen, die keine Traversals verwenden , ist sie schwierig oder speicherintensiv.
Beziehungen sind im Graphdatenmodell Bürger erster Klasse. Das ist in anderen Datenbankmanagementsystemen nicht der Fall, wo wir Verbindungen zwischen Entitäten mit Hilfe von Fremdschlüsseln oder Out-of-Band-Verarbeitung wie Map-Reduce ableiten müssen. Indem sie die einfachen Abstraktionen von Knoten und Beziehungen zu zusammenhängenden Strukturen zusammenfügen, können wir mit Graphdatenbanken beliebig komplexe Modelle erstellen, die sich eng an unsere Problemdomäne anlehnen. Die daraus resultierenden Modelle sind einfacher und gleichzeitig aussagekräftiger als die, die mit traditionellen relationalen Datenbanken und anderen NOSQL (Not Only SQL)-Speichern erstellt werden.
Abbildung 1-3 zeigt einen bildlichen Überblick über einige der heute auf dem Markt befindlichen Graphdatenbanken, basierend auf ihren Speicherungs- und Verarbeitungsmodellen.
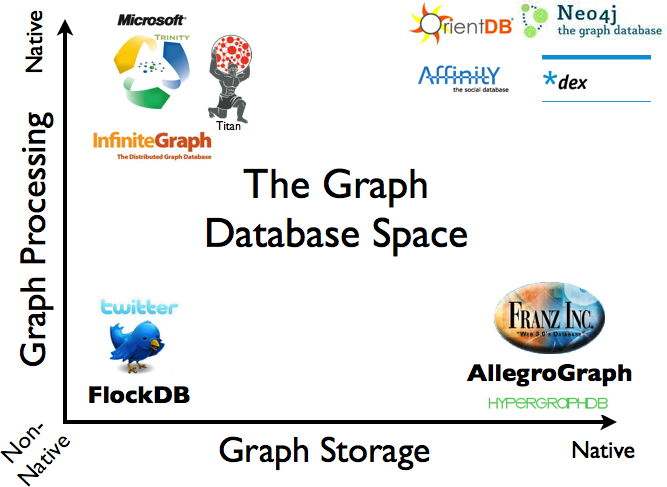
Abbildung 1-3. Ein Überblick über den Raum der Graphdatenbank
Graph Compute Engines
Eine Graphenberechnungs-Engine ist eine Technologie, die es ermöglicht, globale Graphenberechnungsalgorithmen auf großen Datensätzen laufen zu lassen. Graphenberechnungs-Engines wurden entwickelt, um z. B. Cluster in deinen Daten zu identifizieren oder Fragen zu beantworten wie: "Wie viele Beziehungen hat jeder in einem sozialen Netzwerk im Durchschnitt?"
Da der Schwerpunkt auf globalen Abfragen liegt, sind Graph Compute Engines normalerweise für das Scannen und Verarbeiten großer Datenmengen in Stapeln optimiert. In dieser Hinsicht ähneln sie anderen Stapelanalysetechnologien wie Data Mining und OLAP, die in der relationalen Welt verwendet werden. Während einige Graph Compute Engines eine Schicht zur Speicherung von Graphen enthalten, sind andere (und wohl die meisten) ausschließlich darauf ausgerichtet, Daten zu verarbeiten, die von einer externen Quelle eingespeist werden, und die Ergebnisse dann zur Speicherung an anderer Stelle zurückzugeben.
Abbildung 1-4 zeigt eine gängige Architektur für den Einsatz einer Graph Compute Engine. Die Architektur umfasst eine Datensatzdatenbank (SOR) mit OLTP-Eigenschaften (z. B. MySQL, Oracle oder Neo4j), die zur Laufzeit Anfragen der Anwendung (und letztlich der Nutzer) bedient und beantwortet. In regelmäßigen Abständen überträgt ein ETL-Auftrag (Extract, Transform, Load) Daten aus der System of Record-Datenbank in die Graph Compute Engine, um sie offline abzufragen und zu analysieren.
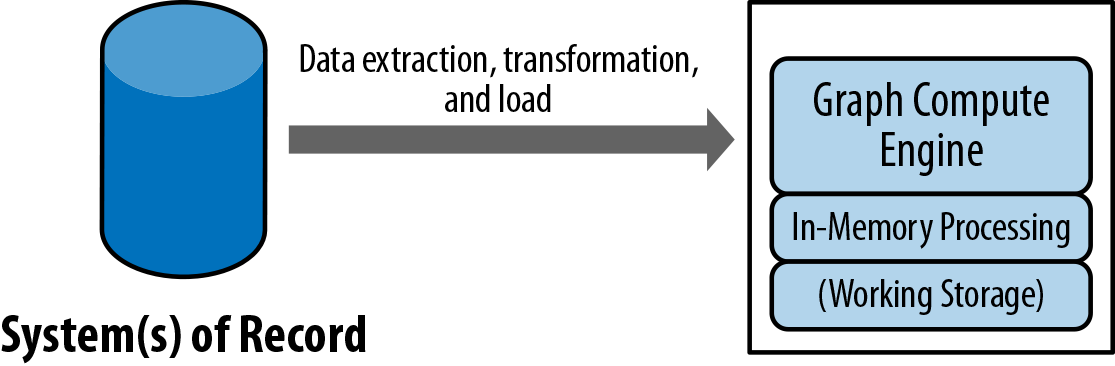
Abbildung 1-4. Eine Übersicht über eine typische Graph Compute Engine-Bereitstellung
Es gibt eine Vielzahl von verschiedenen Arten von Graphberechnungs-Engines. Vor allem gibt es In-Memory-/Single-Machine-Graph-Compute-Engines wie Cassovary und verteilte Graph-Compute-Engines wie Pegasus oder Giraph. Die meisten verteilten Graph Compute Engines basieren auf dem Pregel-Whitepaper, das von Google verfasst wurde und die Graph Compute Engine beschreibt, die Google zum Ranking von Seiten verwendet.
Die Macht der Graphdatenbanken
Ungeachtet der Tatsache, dass so gut wie alles als Graph modelliert werden kann, leben wir in einer pragmatischen Welt mit Budgets, Projektlaufzeiten, Unternehmensstandards und standardisierten Fähigkeiten. Die Tatsache, dass eine Graphdatenbank eine leistungsstarke, aber neuartige Datenmodellierungstechnik bietet, reicht nicht aus, um eine etablierte, gut verstandene Datenplattform zu ersetzen; es muss auch einen unmittelbaren und sehr bedeutenden praktischen Nutzen geben. Im Fall von Graphdatenbanken besteht diese Motivation in einer Reihe von Anwendungsfällen und Datenmustern, deren Leistung sich um eine oder mehrere Größenordnungen verbessert, wenn sie in einem Graphen implementiert werden, und deren Latenzzeit im Vergleich zur Stapelverarbeitung von Aggregaten viel geringer ist. Zusätzlich zu diesem Leistungsvorteil bieten Graphdatenbanken ein extrem flexibles Datenmodell und eine Art der Bereitstellung, die den heutigen agilen Softwareentwicklungspraktiken entspricht.
Leistung
Ein überzeugender Grund für die Wahl einer Graphdatenbank ist also die schiere Leistungssteigerung beim Umgang mit verknüpften Daten gegenüber relationalen Datenbanken und NOSQL-Speichern. Im Gegensatz zu relationalen Datenbanken, bei denen die Leistung von Join-intensiven Abfragen mit zunehmender Datenmenge abnimmt, bleibt die Leistung bei einer Graphdatenbank in der Regel relativ konstant, auch wenn die Datenmenge wächst. Das liegt daran, dass die Abfragen auf einen Teil des Graphen beschränkt sind. Daher ist die Ausführungszeit für jede Abfrage nur proportional zur Größe des Teils des Graphen, der für diese Abfrage durchlaufen wird, und nicht zur Größe des gesamten Graphen.
Flexibilität
Als Entwickler und Datenarchitekten wollen wir die Daten so miteinander verbinden, wie es die Domäne vorschreibt, damit sich die Struktur und das Schema mit unserem wachsenden Verständnis des Problembereichs entwickeln können und nicht von vornherein festgelegt werden, wenn wir am wenigsten über die tatsächliche Form und die Feinheiten der Daten wissen. Graphdatenbanken gehen diesen Wunsch direkt an. Wie wir in Kapitel 3 zeigen, drückt das Graphdatenmodell die geschäftlichen Anforderungen auf eine Weise aus, die es der IT ermöglicht, mit der Geschwindigkeit des Unternehmens mitzuhalten.
Graphen sind von Natur aus additiv, d.h. wir können neue Arten von Beziehungen, neue Knoten, neue Beschriftungen und neue Untergraphen zu einer bestehenden Struktur hinzufügen, ohne bestehende Abfragen und Anwendungsfunktionen zu beeinträchtigen. Diese Dinge wirken sich im Allgemeinen positiv auf die Produktivität der Entwickler und das Projektrisiko aus. Dank der Flexibilität des Graphenmodells müssen wir unsere Domäne nicht im Voraus bis ins kleinste Detail modellieren - eine Praxis, die angesichts sich ändernder Geschäftsanforderungen geradezu töricht ist. Die additive Natur von Graphen bedeutet auch, dass wir tendenziell weniger Migrationen durchführen und so den Wartungsaufwand und das Risiko reduzieren.
Agilität
Wir wollen in der Lage sein, unser Datenmodell im Gleichschritt mit dem Rest unserer Anwendung weiterzuentwickeln, und zwar mit einer Technologie, die den heutigen inkrementellen und iterativen Softwareentwicklungsverfahren entspricht. Moderne Graphdatenbanken ermöglichen uns eine reibungslose Entwicklung und eine reibungslose Systemwartung. Insbesondere die Schemafreiheit des Graphen-Datenmodells in Verbindung mit der Testbarkeit der Programmierschnittstelle (API) und der Abfragesprache einer Graphen-Datenbank ermöglichen es uns, eine Anwendung kontrolliert weiterzuentwickeln.
Gleichzeitig fehlen Graphdatenbanken, gerade weil sie schemafrei sind, die schemaorientierten Datenverwaltungsmechanismen, die wir aus der relationalen Welt kennen. Das ist aber kein Risiko, sondern erfordert eine viel sichtbarere und handlungsfähigere Art der Governance. Wie wir in Kapitel 4 zeigen, wird Governance in der Regel auf programmatische Weise angewendet, indem Tests eingesetzt werden, um das Datenmodell und die Abfragen zu testen und die Geschäftsregeln durchzusetzen, die von dem Diagramm abhängen. Diese Praxis ist nicht mehr umstritten: Mehr noch als die relationale Entwicklung passt die Entwicklung von Graphdatenbanken gut zu den heutigen agilen und testgetriebenen Softwareentwicklungspraktiken, so dass sich Graphdatenbank-gestützte Anwendungen im Gleichschritt mit sich ändernden Geschäftsumgebungen entwickeln können.
Zusammenfassung
In diesem Kapitel haben wir das Eigenschaftsmodell des Graphen kennengelernt, ein einfaches, aber aussagekräftiges Werkzeug zur Darstellung zusammenhängender Daten. Eigenschaftsgraphen erfassen komplexe Bereiche auf ausdrucksstarke und flexible Weise, während Graphdatenbanken die Entwicklung von Anwendungen, die unsere Graphenmodelle bearbeiten, erleichtern.
Im nächsten Kapitel werden wir uns genauer ansehen, wie verschiedene Technologien die Herausforderung der verknüpften Daten angehen, angefangen bei relationalen Datenbanken über aggregierte NOSQL-Speicher bis hin zu Graphdatenbanken. Im Laufe der Diskussion werden wir sehen, warum Graphen und Graphdatenbanken die besten Mittel für die Modellierung, Speicherung und Abfrage vernetzter Daten sind. In späteren Kapiteln wird dann gezeigt, wie man eine graphdatenbankbasierte Lösung entwirft und implementiert.
1 Für Einführungen in die Graphentheorie siehe Richard J. Trudeau, Introduction To Graph Theory (Dover, 1993) und Gary Chartrand, Introductory Graph Theory (Dover, 1985). Eine hervorragende Einführung, wie Graphen Einblick in komplexe Ereignisse und Verhaltensweisen geben, finden Sie in David Easley und Jon Kleinberg, Networks, Crowds, and Markets: Reasoning about a Highly Connected World (Cambridge University Press, 2010).
2 Siehe Rodriguez, Marko A., und Peter Neubauer. 2011. "The Graph Traversal Pattern". In Graph Data Management: Techniques and Applications, ed. Sherif Sakr und Eric Pardede, 29-46. Hershey, PA: IGI Global.
Get Graphdatenbanken, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

