Capítulo 1. ¿Qué es Google BigQuery? ¿Qué es Google BigQuery?
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Arquitecturas de procesamiento de datos
Google BigQuery es un almacén de datos sin servidor y altamente escalable que incorpora un motor de consultas. El motor de consulta es capaz de ejecutar consultas SQL sobre terabytes de datos en cuestión de segundos, y petabytes en sólo minutos. Obtienes este rendimiento sin tener que gestionar ninguna infraestructura y sin tener que crear o reconstruir índices.
BigQuery tiene legiones de fans. Paul Lamere, ingeniero de Spotify, estaba encantado de poder hablar por fin en sobre cómo su equipo utiliza BigQuery para analizar rápidamente grandes conjuntos de datos: "BigQuery de Google es *da bomba*", tuiteó en febrero de 2016. "Puedo empezar con 2.200 millones de 'cosas' y calcular/resumir hasta 20.000 en menos de 1 minuto". La escala y la velocidad son sólo dos características notables de BigQuery. Lo que es más transformador es no tener que gestionar la infraestructura, porque la simplicidad inherente a las consultas ad hoc sin servidor puede abrir nuevas formas de trabajar.
Las empresas adoptan cada vez más la toma de decisiones basada en datos y fomentan una cultura abierta en la que los datos no se aíslan dentro de los departamentos. BigQuery, al proporcionar los medios tecnológicos para promulgar un cambio cultural hacia la agilidad y la apertura, desempeña un papel importante en el aumento del ritmo de la innovación. Por ejemplo, Twitter informó recientemente en su blog de que había sido capaz de democratizar el análisis de datos con BigQuery proporcionando algunas de sus tablas más utilizadas a los empleados de Twitter de diversos equipos (se mencionaron Ingeniería, Finanzas y Marketing).
Para Alpega Group, una empresa global de software logístico, el aumento de la innovación y la agilidad que ofrece BigQuery fueron clave. La empresa pasó de una situación en la que la analítica en tiempo real era imposible a poder ofrecer una analítica rápida y orientada al cliente casi en tiempo real. Como el Grupo Alpega no necesita mantener clústeres ni infraestructuras, su pequeño equipo técnico tiene ahora libertad para trabajar en el desarrollo de software y las capacidades de datos. "Eso nos abrió los ojos", dice el arquitecto jefe de la empresa, Aart Verbeke. "En un entorno convencional tendríamos que instalar, configurar, implementar y alojar cada uno de los bloques de construcción. Aquí simplemente nos conectamos a una superficie y la utilizamos según nuestras necesidades".
Imagina que diriges una cadena de tiendas de alquiler de material. Cobras a los clientes en función de la duración del alquiler, por lo que tus registros incluyen los siguientes datos que te permitirán facturar correctamente al cliente:
-
Dónde se alquiló el artículo
-
Cuando se alquiló
-
Dónde se devolvió el artículo
-
Cuando se devolvió
Tal vez registres la transacción en una base de datos cada vez que un cliente devuelve un artículo.1
A partir de este conjunto de datos, te gustaría averiguar cuántos alquileres "de ida" se produjeron cada mes en los últimos 10 años. Tal vez estés pensando en imponer un recargo por devolver el artículo en una tienda diferente y te gustaría averiguar qué fracción de los alquileres se vería afectada. Supongamos que querer saber la respuesta a estas preguntas es algo frecuente: es importante que puedas responder a estas preguntas ad hoc porque sueles tomar decisiones basadas en datos.
¿Qué tipo de arquitectura de sistema podrías utilizar? Repasemos algunas de las opciones.
Sistema de Gestión de Bases de Datos Relacionales
Al registrar las transacciones, probablemente las estés registrando en una base de datos relacional de procesamiento de transacciones (OLTP) en línea, como MySQL o PostgreSQL. Una de las principales ventajas de este tipo de bases de datos es que admiten consultas mediante el Lenguaje de Consulta Estructurado (SQL): tu personal no necesita utilizar lenguajes de alto nivel como Java o Python para responder a las preguntas que surjan. En su lugar, es posible escribir una consulta, como la siguiente, que puede enviarse al servidor de la base de datos:
SELECT EXTRACT(YEAR FROM starttime) AS year, EXTRACT(MONTH FROM starttime) AS month, COUNT(starttime) AS number_one_way FROM mydb.return_transactions WHERE start_station_name != end_station_name GROUP BY year, month ORDER BY year ASC, month ASC
Ignora los detalles de la sintaxis por ahora; cubrimos las consultas SQL más adelante en este libro. En su lugar, centrémonos en lo que esto nos dice sobre las ventajas e inconvenientes de una base de datos OLTP.
En primer lugar, fíjate en que SQL va más allá de ser capaz de obtener los datos brutos en columnas de la base de datos: la consulta anterior analiza la marca de tiempo y extrae de ella el año y el mes. También hace agregación (cuenta el número de filas), algo de filtrado (encuentra las rentas en las que las ubicaciones inicial y final son diferentes), agrupación (por año y mes) y ordenación. Una ventaja importante de SQL es la posibilidad de especificar lo que queremos y dejar que el software de la base de datos descubra la forma óptima de ejecutar la consulta.
Por desgracia, consultas como ésta son bastante ineficaces para que las realice una base de datos OLTP. Las bases de datos OLTP están ajustadas para mantener la coherencia de los datos; se trata de que puedas leer de la base de datos aunque se estén escribiendo datos simultáneamente en ella. Esto se consigue mediante un cuidadoso bloqueo para mantener la integridad de los datos. Para que el filtrado en station_name sea eficaz, tendrías que crear un índice en la columna nombre de la estación. Si el nombre de la estación está indexado, entonces y sólo entonces, la base de datos hace cosas especiales en el almacenamiento para optimizar la capacidad de búsqueda: se trata de una compensación, ralentizando un poco la escritura para mejorar la velocidad de lectura. Si el nombre de la estación no está indexado, filtrar sobre él será bastante lento. Incluso si el nombre de la estación es un índice, esta consulta en concreto será bastante lenta debido a toda la agregación, agrupación y ordenación. Las bases de datos OLTP no están diseñadas para este tipo de consulta ad hoc2 ad hoc que requiere recorrer todo el conjunto de datos.
Marco MapReduce
Dado que las bases de datos OLTP no se adaptan bien a las consultas ad hoc y a las consultas que requieren recorrer todo el conjunto de datos, los análisis con fines especiales que requieren dicho recorrido pueden codificarse en lenguajes de alto nivel como Java o Python. En 2003, Jeff Dean y Sanjay Ghemawat observaron que ellos y sus colegas de Google estaban implementando cientos de estos cálculos de propósito especial para procesar grandes cantidades de datos en bruto. En respuesta a esta complejidad, diseñaron una abstracción que permitía expresar estos cálculos en dos pasos: una función de mapa que procesaba un par clave/valor para generar un conjunto de pares clave/valor intermedios, y una función de reducción que combinaba todos los valores intermedios asociados a la misma clave intermedia.3 Este paradigma, conocido como MapReduce, adquirió una enorme influencia y condujo al desarrollo de Apache Hadoop.
Aunque el ecosistema Hadoop comenzó con una biblioteca construida principalmente en Java, ahora los análisis personalizados en clústeres Hadoop se suelen llevar a cabo utilizando Apache Spark. Los programas Spark pueden escribirse en Python o Scala, pero entre las capacidades de Spark está la de ejecutar consultas SQL ad hoc en conjuntos de datos distribuidos.
Por tanto, para averiguar el número de alquileres de ida, podrías establecer la siguiente cadena de datos:
-
Exporta periódicamente las transacciones a archivos de texto con valores separados por comas (CSV) en el Sistema de Archivos Distribuidos Hadoop (HDFS).
-
Para el análisis ad hoc, escribe un programa Spark que haga lo siguiente:
-
Carga los datos de los archivos de texto en un "DataFrame".
-
Ejecuta una consulta SQL, similar a la consulta de la sección anterior, salvo que el nombre de la tabla se sustituye por el nombre del DataFrame
-
Exporta el conjunto de resultados a un archivo de texto
-
-
Ejecuta el programa Spark en un clúster Hadoop.
Aunque aparentemente sencilla, esta arquitectura impone un par de costes ocultos. Guardar los datos en HDFS requiere que el clúster sea lo suficientemente grande. Un hecho infravalorado de la arquitectura MapReduce es que suele requerir que los nodos de cálculo accedan a datos que les son propios. Por tanto, el HDFS debe repartirse entre los nodos de cálculo del clúster. Dado que tanto el tamaño de los datos como las necesidades de análisis aumentan drástica pero independientemente, suele ocurrir que los clústeres estén infraprovisionados o sobreprovisionados.4 Por tanto, la necesidad de ejecutar programas Spark en un clúster Hadoop significa que tu organización tendrá que convertirse en experta en la gestión, monitoreo y aprovisionamiento de clústeres Hadoop. Puede que ésta no sea tu actividad principal.
BigQuery: Un motor SQL distribuido y sin servidor
¿Y si pudieras ejecutar consultas SQL como en un sistema de gestión de bases de datos relacionales (RDBMS), obtener un recorrido eficiente y distribuido por todo el conjunto de datos como en MapReduce, y no necesitar gestionar la infraestructura? Esa es la tercera opción, y es lo que hace que BigQuery sea tan mágico. BigQuery no tiene servidor, y puedes ejecutar consultas sin necesidad de gestionar la infraestructura. Te permite realizar análisis que procesan agregaciones sobre todo el conjunto de datos en segundos o minutos.
Pero no te fíes de nuestra palabra. Pruébalo ahora. Navega a https://console.cloud.google.com/bigquery (iniciando sesión en Google Cloud Platform y seleccionando tu proyecto si es necesario), copia y pega la siguiente consulta en la ventana,5 y haz clic en el botón "Ejecutar consulta":
SELECT EXTRACT(YEAR FROM starttime) AS year, EXTRACT(MONTH FROM starttime) AS month, COUNT(starttime) AS number_one_way FROM `bigquery-public-data.new_york_citibike.citibike_trips` WHERE start_station_name != end_station_name GROUP BY year, month ORDER BY year ASC, month ASC
Cuando la ejecutamos, la interfaz de usuario (UI) de BigQuery nos informó de que la consulta implicaba el procesamiento de 2,51 GB y nos dio el resultado en unos 2,7 segundos, como se ilustra en la Figura 1-1.
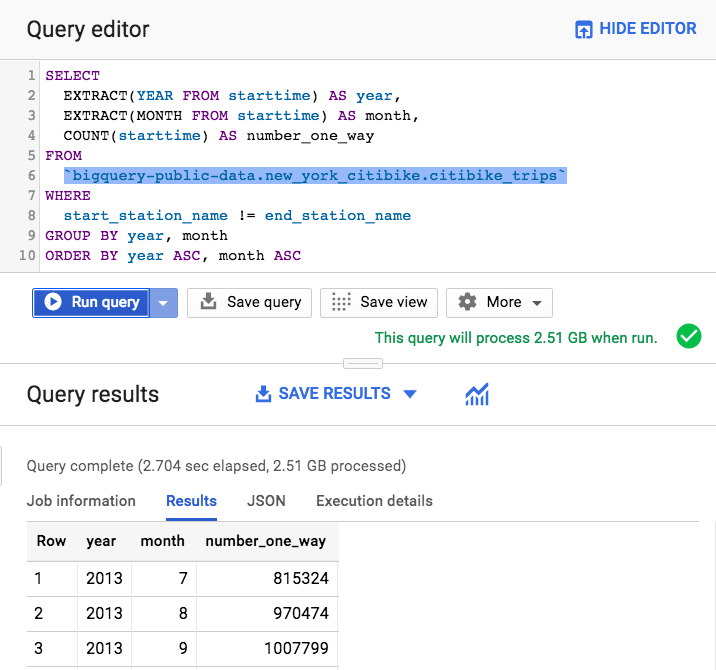
Figura 1-1. Ejecución de una consulta para calcular el número de alquileres unidireccionales en la interfaz web de BigQuery
El material que se alquila son bicicletas, por lo que la consulta anterior suma los alquileres de bicicletas de ida en Nueva York mes a mes a lo largo del conjunto de datos. El propio conjunto de datos es público (es decir, cualquiera puede consultar los datos que contiene) y ha sido publicado por la ciudad de Nueva York como parte de su iniciativa Ciudad Abierta. A partir de esta consulta, sabemos que en julio de 2013 hubo 815.324 alquileres de Citibike de un solo uso en la ciudad de Nueva York.
Ten en cuenta algunas cosas al respecto. Una es que pudiste ejecutar una consulta contra un conjunto de datos que ya estaba presente en BigQuery. Lo único que tuvo que hacer el propietario del proyecto que albergaba los datos fue darte6 acceso de "vista" a este conjunto de datos. No necesitabas poner en marcha un clúster ni iniciar sesión en uno. Sólo tenías que enviar una consulta al servicio y recibir los resultados. La consulta en sí estaba escrita en SQL:2011, por lo que la sintaxis resultaba familiar a los analistas de datos de todo el mundo. Aunque hicimos la demostración con gigabytes de datos, el servicio se escala bien incluso cuando hace agregaciones sobre terabytes a petabytes de datos. Esta escalabilidad es posible porque el servicio distribuye el procesamiento de la consulta entre miles de trabajadores casi instantáneamente.
Trabajar con BigQuery
BigQuery es un almacén de datos, lo que implica cierto grado de centralización y ubicuidad. La consulta que demostramos en la sección anterior se aplicó a un único conjunto de datos. Sin embargo, las ventajas de BigQuery se hacen aún más evidentes cuando hacemos uniones de conjuntos de datos de fuentes completamente distintas o cuando consultamos datos almacenados fuera de BigQuery.
Obtención de información entre conjuntos de datos
Los datos de alquiler de bicicletas proceden de la ciudad de Nueva York. ¿Qué tal si los comparamos con los datos meteorológicos de la Administración Nacional Oceánica y Atmosférica de EEUU (NOAA) para saber si hay menos alquileres de bicicletas los días de lluvia?7
-- Are there fewer bicycle rentals on rainy days?
WITH bicycle_rentals AS (
SELECT
COUNT(starttime) as num_trips,
EXTRACT(DATE from starttime) as trip_date
FROM `bigquery-public-data.new_york_citibike.citibike_trips`
GROUP BY trip_date
),
rainy_days AS
(
SELECT
date,
(MAX(prcp) > 5) AS rainy
FROM (
SELECT
wx.date AS date,
IF (wx.element = 'PRCP', wx.value/10, NULL) AS prcp
FROM
`bigquery-public-data.ghcn_d.ghcnd_2016` AS wx
WHERE
wx.id = 'USW00094728'
)
GROUP BY
date
)
SELECT
ROUND(AVG(bk.num_trips)) AS num_trips,
wx.rainy
FROM bicycle_rentals AS bk
JOIN rainy_days AS wx
ON wx.date = bk.trip_date
GROUP BY wx.rainy
Ignora la sintaxis específica de la consulta. Sólo observa que, en las líneas en negrita, estamos uniendo el conjunto de datos de alquiler de bicicletas con un conjunto de datos meteorológicos que procede de una fuente completamente distinta. Ejecutar la consulta da como resultado satisfactorio que, sí, los neoyorquinos son unos peleles: montan en bicicleta casi un 20% menos de veces cuando llueve:8
Row num_trips rainy 1 39107.0 false 2 32052.0 true
¿Qué significa poder compartir y consultar conjuntos de datos en un contexto empresarial? Diferentes partes de tu empresa pueden almacenar sus conjuntos de datos en BigQuery y compartirlos fácilmente con otras partes de la empresa e incluso con organizaciones asociadas. La naturaleza sin servidor de BigQuery proporciona los medios tecnológicos para romper los silos departamentales y agilizar la colaboración.
ETL, EL y ELT
La forma tradicional de trabajar con almacenes de datos es empezar con un proceso de Extracción, Transformación y Carga (ETL), en el que los datos brutos de se extraen de su ubicación de origen, se transforman y luego se cargan en el almacén de datos. De hecho, BigQuery tiene un formato de almacenamiento en columnas nativo y muy eficiente9 que hace de la ETL una metodología atractiva. La canalización de datos, normalmente escrita en Apache Beam o Apache Spark, extrae los bits necesarios de los datos brutos (ya sean datos en flujo o archivos por lotes), transforma lo que ha extraído para hacer cualquier limpieza o agregación necesaria, y luego lo carga en BigQuery, como se muestra en la Figura 1-2.
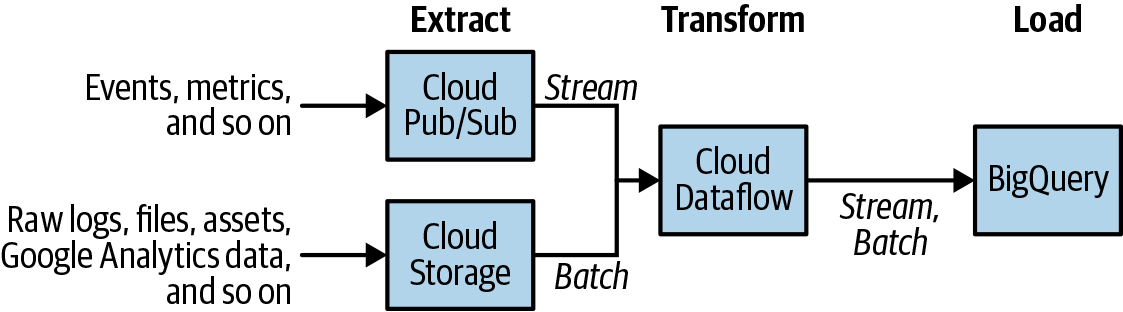
Figura 1-2. La arquitectura de referencia para ETL en BigQuery utiliza pipelines Apache Beam ejecutados en Cloud Dataflow y puede manejar tanto datos en streaming como en batch utilizando el mismo código
Aunque construir una canalización ETL en Apache Beam o Apache Spark suele ser bastante habitual, es posible implementar una canalización ETL puramente dentro de BigQuery. Dado que BigQuery separa cálculo y almacenamiento, es posible ejecutar consultas SQL de BigQuery contra archivos CSV (o JSON o Avro) que se almacenan tal cual en Google Cloud Storage; esta capacidad se denomina consulta federada. Puedes aprovechar las consultas federadas para extraer los datos mediante consultas SQL contra los datos almacenados en Google Cloud Storage, transformar los datos dentro de esas consultas SQL y, a continuación, materializar los resultados en una tabla nativa de BigQuery.
Si no es necesaria la transformación, BigQuery puede ingerir directamente formatos estándar como CSV, JSON o Avro en su almacenamiento nativo: un flujo de trabajo EL (Extraer y Cargar), por así decirlo. La razón para acabar con los datos cargados en el almacén de datos es que tener los datos en el almacenamiento nativo proporciona el rendimiento de consulta más eficiente.
Te recomendamos encarecidamente que diseñes para un flujo de trabajo EL si es posible, y pases a un flujo de trabajo ETL sólo si se necesitan transformaciones. Si es posible, haz esas transformaciones en SQL, y mantén toda la canalización ETL dentro de BigQuery. Si las transformaciones van a ser difíciles de implementar puramente en SQL, o si el canal necesita transmitir datos a BigQuery a medida que llegan, construye un canal Apache Beam y haz que se ejecute sin servidor utilizando Cloud Dataflow. Otra ventaja de implementar canalizaciones ETL en Beam/Dataflow es que, al tratarse de código programático, dichas canalizaciones se integran mejor con los sistemas de Integración Continua (IC) y pruebas unitarias.
Además de los flujos de trabajo ETL y EL, BigQuery permite realizar un flujo de trabajo de Extracción, Carga y Transformación (ELT). La idea es extraer y cargar los datos brutos tal cual y confiar en las vistas de BigQuery para transformar los datos sobre la marcha. Un flujo de trabajo ELT es especialmente útil si el esquema de los datos brutos está en proceso de cambio. Por ejemplo, puede que aún estés realizando un trabajo exploratorio para determinar si es necesario corregir una determinada marca de tiempo para la zona horaria local. El flujo de trabajo ELT es útil en la creación de prototipos y permite a una organización empezar a obtener información de los datos sin tener que tomar decisiones potencialmente irreversibles demasiado pronto.
La sopa de letras puede ser confusa, así que hemos preparado un resumen rápido en la Tabla 1-1.
| Flujo de trabajo | Arquitectura | Cuándo lo usarías |
|---|---|---|
| EL | Extrae datos de archivos en Google Cloud Storage. Cárgalos en el almacenamiento nativo de BigQuery. Puedes activarlo desde Cloud Composer, Cloud Functions o consultas programadas. |
Carga por lotes de datos históricos. Cargas periódicas programadas de archivos de registro (por ejemplo, una vez al día). |
| ETL | Extrae datos de Pub/Sub, Google Cloud Storage, Cloud Spanner, Cloud SQL, etc. Transforma los datos utilizando Cloud Dataflow. Haz que el canal de flujo de datos escriba en BigQuery |
Cuando es necesario controlar la calidad de los datos brutos, transformarlos o enriquecerlos antes de cargarlos en BigQuery. Cuando la carga de datos debe realizarse de forma continua, es decir, si el caso de uso requiere streaming. Cuando quieras integrarte con sistemas de integración continua/entrega continua (CI/CD) y realizar pruebas unitarias en todos los componentes. |
| ELT | Extraer datos de archivos en Google Cloud Storage. Almacena los datos en formato casi real en BigQuery. Transforma los datos sobre la marcha utilizando vistas BigQuery. |
Conjuntos de datos experimentales en los que aún no estás seguro de qué tipo de transformaciones son necesarias para que los datos sean utilizables. Cualquier conjunto de datos de producción en el que la transformación pueda expresarse en SQL. |
Los flujos de trabajo de la Tabla 1-1 están en el orden que solemos recomendar.
Analítica potente
Las ventajas de un almacén se derivan del tipo de análisis que puedes hacer con los datos que contiene. La forma principal de interactuar con BigQuery es a través de SQL, y como BigQuery es un motor SQL, puedes utilizar una amplia variedad de herramientas de Inteligencia de Negocio (BI) como Tableau, Looker y Google Data Studio para crear análisis, visualizaciones e informes impactantes sobre los datos almacenados en BigQuery. Por ejemplo, haciendo clic en el botón "Explorar en Data Studio" de la interfaz web de BigQuery, podemos crear rápidamente en una visualización de cómo varían por meses nuestros alquileres de bicicletas de un solo uso, como se muestra en la Figura 1-3.
BigQuery proporciona compatibilidad completa con SQL:2011, incluida la compatibilidad con matrices y uniones complejas. La compatibilidad con matrices, en particular, permite almacenar datos jerárquicos (como registros JSON) en BigQuery sin necesidad de aplanar los campos anidados y repetidos. Además de la compatibilidad con SQL:2011, BigQuery tiene algunas extensiones que lo hacen útil más allá del conjunto básico de casos de uso de almacenes de datos. Una de estas extensiones es la compatibilidad con una amplia gama de funciones espaciales que permiten realizar consultas basadas en la ubicación, incluida la posibilidad de unir dos tablas basándose en criterios de distancia o solapamiento.10 BigQuery es, por tanto, un potente motor para realizar análisis descriptivos.
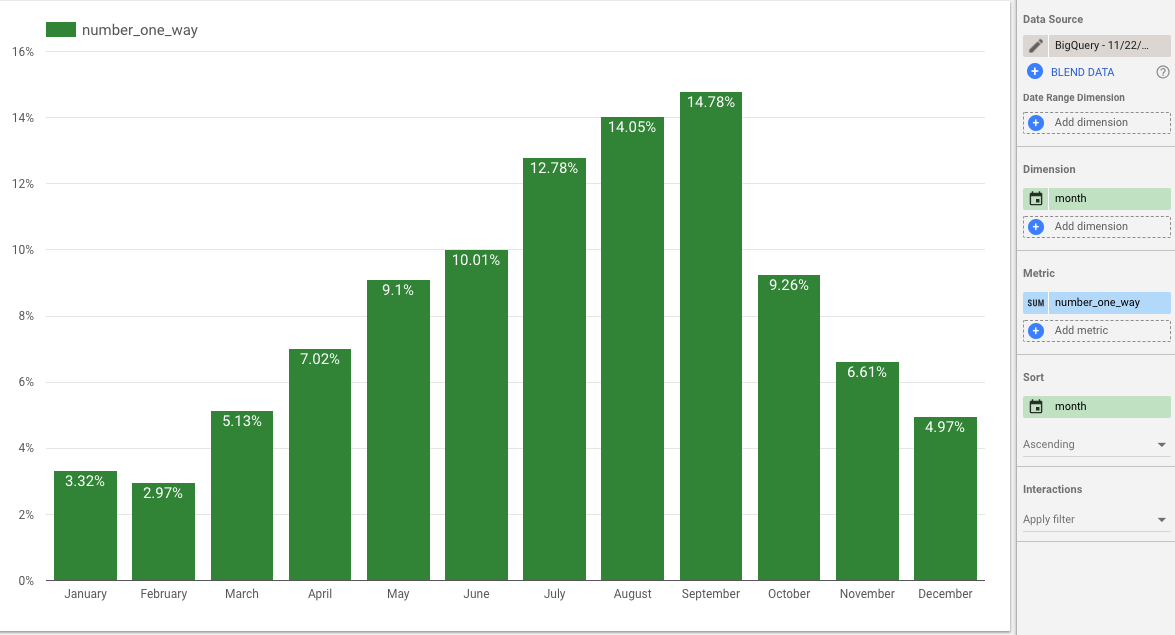
Figura 1-3. Visualización en Data Studio de cómo los alquileres de ida varían según el mes; casi el 15% de todos los alquileres de ida de bicicletas en Nueva York se producen en septiembre.
Otra extensión de BigQuery al SQL estándar permite crear modelos de aprendizaje automático y realizar predicciones por lotes. En el Capítulo 9 tratamos en detalle la capacidad de aprendizaje automático de BigQuery, pero lo esencial es que puedes entrenar un modelo de BigQuery y hacer predicciones sin tener que exportar nunca los datos fuera de BigQuery. Las ventajas de seguridad y localidad de datos de poder hacer esto son enormes. BigQuery es, por tanto, un almacén de datos que admite no sólo el análisis descriptivo, sino también el análisis predictivo.
Un almacén también implica poder almacenar distintos tipos de datos. De hecho, BigQuery puede almacenar datos de muchos tipos: columnas numéricas y textuales, sin duda, pero también datos geoespaciales y datos jerárquicos. Aunque puedes almacenar datos aplanados en BigQuery, no es necesario que lo hagas: los esquemas pueden ser ricos y bastante sofisticados. La combinación de consultas que tienen en cuenta la ubicación, los datos jerárquicos y el aprendizaje automático hacen de BigQuery una potente solución que va más allá del almacenamiento de datos y la inteligencia empresarial convencionales.
BigQuery admite la ingesta tanto de datos por lotes como de datos en flujo. Puedes transmitir datos directamente a BigQuery a través de una API REST. A menudo, los usuarios que desean transformar los datos -por ejemplo, añadiendo cómputos de ventana de tiempo- utilizan canalizaciones Apache Beam ejecutadas por el servicio Cloud Dataflow. Incluso mientras los datos fluyen hacia BigQuery, puedes consultarlos. Disponer de una infraestructura de consulta común tanto para los datos históricos (batch) como para los actuales (streaming) es extremadamente potente y simplifica muchos flujos de trabajo.
Simplicidad de gestión
Parte de las consideraciones de diseño de BigQuery es animar a los usuarios a centrarse en la información y no en la infraestructura. Cuando ingieres datos en BigQuery, no hay necesidad de pensar en diferentes tipos de almacenamiento, ni en sus ventajas relativas de velocidad y coste; el almacenamiento está totalmente gestionado. En el momento de escribir esto, el coste del almacenamiento desciende automáticamente a niveles inferiores si una tabla no se actualiza durante 90 días.11
Ya hemos hablado en de que la indexación no es necesaria; tus consultas SQL pueden filtrar en cualquier columna del conjunto de datos, y BigQuery se encargará de la planificación y optimización necesarias de las consultas. En general, te recomendamos que escribas las consultas de forma clara y legible y confíes en BigQuery para elegir una buena estrategia de optimización. En este libro hablamos del ajuste del rendimiento, pero el ajuste del rendimiento en BigQuery consiste principalmente en pensar con claridad y elegir adecuadamente las funciones SQL. No necesitarás realizar tareas de administración de bases de datos como replicación, desfragmentación o recuperación ante desastres; el servicio BigQuery se encarga de todo eso por ti.
Las consultas se escalan automáticamente a miles de máquinas y se ejecutan en paralelo. No necesitas hacer nada especial para permitir esta paralelización masiva. Las propias máquinas se aprovisionan de forma transparente para gestionar las distintas etapas de tu trabajo; no necesitas configurar esas máquinas de ninguna forma.
No tener que configurar la infraestructura conlleva menos complicaciones en términos de seguridad. Los datos en BigQuery se cifran automáticamente, tanto en reposo como en tránsito. BigQuery se ocupa de las consideraciones de seguridad que conlleva admitir consultas multiusuario y proporcionar aislamiento entre trabajos. Tus conjuntos de datos pueden compartirse utilizando la Gestión de Identidades y Accesos (IAM) de Google Cloud, y es posible organizar los conjuntos de datos (y las tablas y vistas dentro de ellos) para satisfacer diferentes necesidades de seguridad, tanto si necesitas apertura como auditabilidad o confidencialidad.
En otros sistemas, el aprovisionamiento de la infraestructura para la fiabilidad, la elasticidad, la seguridad y el rendimiento suele requerir mucho tiempo para hacerlo bien. Dado que estas tareas de administración de la base de datos se reducen al mínimo con BigQuery, las organizaciones que utilizan BigQuery descubren que libera el tiempo de sus analistas para centrarse en obtener información de sus datos.
Cómo surgió BigQuery
A finales de 2010, el director de la oficina de Google en Seattle sacó a varios ingenieros (uno de los cuales es autor de este libro) de sus proyectos y les dio una misión: construir un mercado de datos. Intentamos idear la mejor manera de crear un mercado viable. El principal problema era el tamaño de los datos, porque no queríamos ofrecer sólo un enlace de descarga. Un mercado de datos es inviable si la gente necesita descargar terabytes de datos para poder trabajar con ellos. ¿Cómo construir un mercado de datos que no requiriera que los usuarios empezaran descargando los conjuntos de datos en sus propias máquinas?
Entra en juego un principio popularizado por Jim Gray, el pionero de las bases de datos. Cuando tienes "grandes datos", dijo Gray, "quieres trasladar la computación a los datos, en lugar de trasladar los datos a la computación". Gray da más detalles:
La otra cuestión clave es que, a medida que los conjuntos de datos aumentan de tamaño, ya no es posible simplemente enviarlos por FTP o grep. ¡Un petabyte de datos es muy difícil de enviar por FTP! Así que llega un momento en que necesitas índices y acceso paralelo a los datos, y aquí es donde las bases de datos pueden ayudarte. Para el análisis de datos, una posibilidad es trasladar los datos a ti, pero la otra posibilidad es trasladar tu consulta a los datos. Puedes trasladar tus preguntas o los datos. A menudo resulta más eficaz mover las preguntas que mover los datos.12
En el caso del mercado de datos que estábamos construyendo, los usuarios no necesitarían descargar los conjuntos de datos a sus propias máquinas si hiciéramos posible que llevaran sus cálculos a los datos. No necesitaríamos proporcionar un enlace de descarga, porque los usuarios podrían trabajar con sus datos sin necesidad de trasladarlos.13
Nosotros, los Googlers que teníamos la tarea de construir un mercado de datos, tomamos la decisión de aplazar ese proyecto y centrarnos en construir un motor de cálculo y un sistema de almacenamiento en la nube. Después de asegurarnos de que los usuarios pudieran hacer algo con los datos, volveríamos atrás y añadiríamos funciones de mercado de datos.
¿En qué lenguaje deben escribir los usuarios sus cálculos cuando llevan el cálculo a los datos en la nube? Elegimos SQL por tres características clave. En primer lugar, SQL es un lenguaje versátil que permite a una gran variedad de personas, no sólo a los desarrolladores, hacer preguntas y resolver problemas con sus datos. Esta facilidad de uso era extremadamente importante para nosotros. En segundo lugar, SQL es "relacionalmente completo", lo que significa que cualquier cálculo sobre los datos puede hacerse utilizando SQL. SQL no sólo es fácil y accesible. También es muy potente. Por último, y muy importante para la elección de un lenguaje de computación en la nube, SQL no es "completo de Turing" en un aspecto clave: siempre termina.14 Como siempre termina, se puede alojar la computación SQL sin preocuparse de que alguien escriba un bucle infinito y monopolice toda la potencia de cálculo de un centro de datos.
A continuación, tuvimos que elegir un motor SQL. Google disponía de varios motores SQL internos que podían operar sobre datos, entre ellos algunos muy populares. El motor más avanzado se llamaba Dremel; se utilizaba mucho en Google y podía procesar registros de terabytes en cuestión de segundos. Dremel estaba ganando rápidamente adeptos a la construcción de pipelines MapReduce personalizados para hacer preguntas a sus datos.
Dremel había sido creado en 2006 por el ingeniero Andrey Gubarev, que estaba cansado de esperar a que MapReduces terminara. Los almacenes de columnas se estaban haciendo populares en la literatura académica, y rápidamente se le ocurrió un formato de almacenamiento de columnas(Figura 1-4) que podía manejar los búferes de protocolo (Protobufs) omnipresentes en Google.
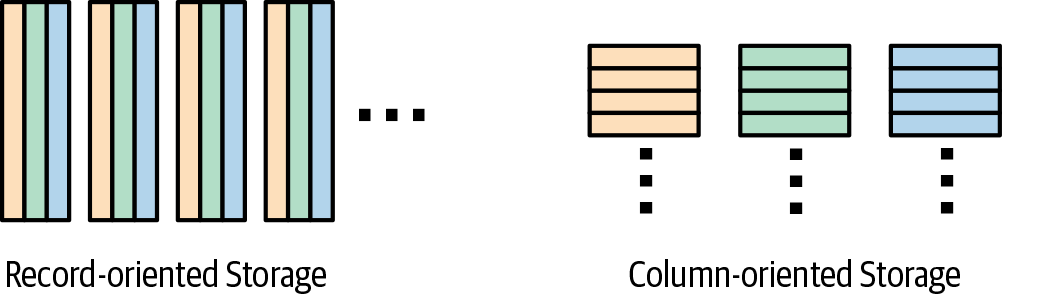
Figura 1-4. Los almacenes de columnas pueden reducir la cantidad de datos que leen las consultas que procesan todas las filas pero no todas las columnas
Aunque los almacenes de columnas son estupendos en general para la analítica, resultan especialmente útiles para el análisis de registros en Google, porque muchos equipos operan sobre un tipo de Protobuf que tiene cientos de miles de columnas. Si Andrey hubiera utilizado un almacén típico orientado a registros, los usuarios habrían tenido que leer los archivos fila por fila, leyendo así una enorme cantidad de datos en forma de campos que iban a descartar de todos modos. Al almacenar los datos columna por columna, Andrey consiguió que si un usuario sólo necesitaba unos pocos de los miles de campos de los Protobufs de registro, sólo tendría que leer una pequeña fracción del tamaño total de los datos. Ésta fue una de las razones por las que Dremel pudo procesar registros de terabytes en cuestión de segundos.
La otra razón por la que Dremel pudo procesar los datos tan rápido fue que su motor de consulta utilizaba computación distribuida. Dremel escaló a miles de trabajadores estructurando el cálculo como un árbol, con los filtros en las hojas y la agregación en la raíz.
En 2010, Google escaneaba petabytes de datos al día con Dremel, y muchas personas de la empresa lo utilizaban de una forma u otra. Era la herramienta perfecta para que nuestro incipiente equipo del mercado de datos la cogiera y la utilizara.
A medida que el equipo productizaba Dremel, le añadía un sistema de almacenamiento, lo hacía autoajustable y lo exponía a usuarios externos, se dio cuenta de que una versión en la nube de Dremel era quizá incluso más interesante que su misión original. El equipo cambió su nombre a "BigQuery", siguiendo la convención de nombres de "Bigtable", la base de datos NoSQL de Google.
En Google, Dremel se utiliza para consultar archivos que se encuentran en Colossus, el almacén de archivos de Google para almacenar datos. BigQuery añadió un sistema de almacenamiento que proporcionaba una abstracción de tablas, no sólo una abstracción de archivos. Este sistema de almacenamiento fue clave para que BigQuery fuera fácil de usar y siempre rápido, porque permitía funciones clave como las transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) y la optimización automática, y significaba que los usuarios no necesitaban gestionar archivos.
Al principio, BigQuery mantuvo sus raíces en Dremel y se centró en el análisis de registros. Sin embargo, a medida que más clientes querían hacer almacenamiento de datos y consultas más complejas, BigQuery añadió soporte mejorado para uniones y funciones SQL avanzadas como las funciones analíticas. En 2016, Google lanzó la compatibilidad con SQL estándar en BigQuery, lo que permitió a los usuarios ejecutar consultas utilizando SQL conforme a los estándares, en lugar del incómodo dialecto inicial "DremelSQL".
BigQuery no empezó como un almacén de datos, pero ha evolucionado hasta convertirse en uno a lo largo de los años. Esta evolución tiene cosas buenas y cosas malas. En el lado positivo, BigQuery se diseñó para resolver los problemas que la gente tiene con sus datos, aunque no encajen bien en los modelos de almacén de datos. En este sentido, BigQuery es más que un simple almacén de datos. En el lado negativo, sin embargo, hasta hace poco faltaban algunas funciones de almacén de datos que la gente espera, como un Lenguaje de Definición de Datos (DDL; por ejemplo, las sentencias CREATE) y un Lenguaje de Manipulación de Datos (DML; por ejemplo, las sentencias INSERT). Dicho esto, BigQuery se ha centrado en un doble camino: primero, añadir funciones diferenciadas que Google está en una posición única para proporcionar; y segundo, convertirse en un gran almacén de datos en la nube.
¿Qué hace posible BigQuery?
Desde una perspectiva arquitectónica, BigQuery es fundamentalmente diferente de los almacenes de datos locales como Teradata o Vertica, así como de los almacenes de datos en la nube como Redshift y Microsoft Azure Data Warehouse. BigQuery es el primer almacén de datos que es una solución escalable, por lo que el único límite de velocidad y escala es la cantidad de hardware del centro de datos.
En esta sección se describen algunos de los componentes que contribuyen al éxito y la singularidad de BigQuery.
Separación de cálculo y almacenamiento
En muchos almacenes de datos, la informática y el almacenamiento residen juntos en el mismo hardware físico. Esta colocación significa que para añadir más almacenamiento, puede que necesites añadir también más potencia de cálculo. O para añadir más potencia de cálculo, necesitarías también más capacidad de almacenamiento.
Si las necesidades de datos de todo el mundo fueran similares, esto no sería un problema; habría una proporción áurea coherente entre computación y almacenamiento con la que todo el mundo viviría. Pero en la práctica, uno u otro de los factores tiende a ser una limitación. Algunos almacenes de datos están limitados por la capacidad de cálculo, por lo que se ralentizan en las horas punta. Otros almacenes de datos están limitados por la capacidad de almacenamiento, por lo que los encargados del mantenimiento tienen que averiguar qué datos desechar.
Cuando separas el cálculo del almacenamiento, como hace BigQuery, significa que nunca tendrás que tirar los datos, a menos que ya no los quieras. Puede que esto no parezca gran cosa, pero tener acceso a datos completos es inmensamente poderoso. Puedes decidir que quieres calcular algo de otra manera, así que puedes volver a los datos brutos para volver a consultarlos. No podrías hacerlo si hubieras descartado los datos de origen por falta de espacio. Puede que decidas que quieres investigar por qué algún valor agregado muestra un comportamiento extraño. No podrías hacerlo si hubieras eliminado los datos que contribuyeron a la agregación.
El escalado informático es igualmente potente. Los recursos de BigQuery se denominan en términos de "ranuras", que son, a grandes rasgos, aproximadamente la mitad de un núcleo de CPU (trataremos las ranuras en detalle en el Capítulo 6). BigQuery utiliza slots como abstracción para indicar cuántos recursos informáticos físicos hay disponibles. ¿Las consultas van demasiado lentas? Añade más ranuras. ¿Más gente quiere crear informes? Añade más ranuras. ¿Quieres reducir gastos? Reduce las plazas.
Como BigQuery es un sistema multiarrendatario que gestiona grandes conjuntos de recursos de hardware, puede repartir las ranuras por consulta o por usuario. Es posible reservar hardware para tu proyecto u organización, o puedes ejecutar tus consultas en el pool compartido bajo demanda. Al compartir recursos de esta forma, BigQuery puede dedicar grandes cantidades de potencia informática a tus consultas. Si necesitas más potencia de cálculo de la que está disponible en la reserva bajo demanda, puedes comprar más a través de la API de reserva de BigQuery.
Varios clientes de BigQuery tienen reservas de decenas de miles de filas, lo que significa que si ejecutan sólo una consulta a la vez, esas consultas pueden consumir decenas de miles de núcleos de CPU a la vez. Con algunas suposiciones razonables sobre el número de ciclos de CPU por fila procesada, es bastante fácil ver que estas instancias pueden procesar miles de millones o incluso billones de filas por segundo.
En BigQuery, hay algunos clientes que tienen petabytes de datos pero utilizan una cantidad relativamente pequeña de ellos a diario. Otros clientes almacenan sólo unos pocos gigabytes de datos, pero realizan consultas complejas utilizando miles de CPU. No existe un enfoque único que sirva para todos los casos de uso. Afortunadamente, la separación entre cálculo y almacenamiento permite a BigQuery adaptarse a una amplia gama de necesidades de los clientes.
Infraestructura de almacenamiento y redes
BigQuery se diferencia de otros almacenes de datos en la nube en que las consultas se sirven principalmente desde discos giratorios en un sistema de archivos distribuido. La mayoría de los sistemas de la competencia necesitan almacenar los datos en caché dentro de los nodos de cálculo para obtener un buen rendimiento. BigQuery, en cambio, se basa en dos sistemas exclusivos de Google, el sistema de archivos Colossus y la red Jupiter, para garantizar que los datos puedan consultarse rápidamente independientemente de dónde residan físicamente en el clúster informático.
El tejido de red Júpiter de Google se basa en una configuración de red en la que se disponen conmutadores más pequeños (y, por tanto, más baratos) para proporcionar la capacidad para la que, de otro modo, se necesitaría un conmutador lógico mucho mayor. Esta topología de conmutadores, junto con una pila de software centralizada y hardware y software personalizados, permite un petabit de ancho de banda de bisección dentro de un centro de datos. Esto equivale a 100.000 servidores comunicándose a 10 Gb/s, y significa que BigQuery puede funcionar sin necesidad de colocar el cálculo y el almacenamiento. Si las máquinas que alojan los discos están en el otro extremo del centro de datos respecto a las máquinas que ejecutan el cálculo, éste se ejecutará efectivamente tan rápido como si las dos máquinas estuvieran en el mismo bastidor.
El rápido tejido de red resulta útil de dos formas: para leer datos de un disco y para pasar de una fase de consulta a otra. Como ya se ha dicho, la separación de cálculo y almacenamiento en BigQuery permite que cualquier máquina del centro de datos ingiera datos de cualquier disco de almacenamiento. Esto requiere, sin embargo, que los datos de entrada necesarios para las consultas se lean a través de la red a velocidades muy altas. Los detalles de la barajadura se describen en el Capítulo 6, pero por ahora basta con comprender que la ejecución de consultas distribuidas complejas suele requerir mover grandes cantidades de datos entre máquinas en etapas intermedias. Sin una red rápida que conecte las máquinas que realizan el trabajo, shuffle se convertiría en un cuello de botella que ralentizaría considerablemente las consultas.
La infraestructura de red proporciona algo más que velocidad: también permite el aprovisionamiento dinámico de ancho de banda. Los centros de datos de Google están conectados a través de una red troncal llamada B4 que está definida por software para asignar ancho de banda de forma elástica a los distintos usuarios, y proporcionar una calidad de servicio fiable para las operaciones de alta prioridad. Esto es crucial para implementar consultas concurrentes de alto rendimiento.
Sin embargo, una red rápida no es suficiente si el subsistema de disco es lento o carece de escala suficiente. Para soportar consultas interactivas, los datos deben leerse de los discos con la suficiente rapidez para que puedan saturar el ancho de banda de red disponible. El sistema de archivos distribuido de Google se llama Colossus y puede coordinar cientos de miles de discos reequilibrando constantemente los datos antiguos y fríos y distribuyendo los datos recién escritos uniformemente entre los discos.15 Esto significa que el rendimiento efectivo es de decenas de terabytes por segundo. Combinando este rendimiento efectivo con formatos de datos y almacenamiento eficientes, BigQuery proporciona la capacidad de consultar tablas de tamaño petabyte en cuestión de minutos.
Almacenamiento gestionado
El sistema de almacenamiento de BigQuery se basa en la idea de que, cuando se trata de almacenamiento estructurado, la abstracción adecuada es la tabla, no el archivo. Algunos otros sistemas de procesamiento de datos basados en la nube y de código abierto exponen el concepto de archivo a los usuarios, lo que les obliga a gestionar el tamaño de los archivos y a asegurarse de que el esquema sigue siendo coherente. Aunque es posible crear archivos de un tamaño adecuado para un almacén de datos estático, es notoriamente difícil mantener tamaños de archivo óptimos para datos que cambian con el tiempo. Del mismo modo, es difícil mantener un esquema coherente cuando tienes un gran número de archivos con esquemas autodescriptivos (por ejemplo, Avro o Parquet): normalmente, cada actualización de software de los sistemas que producen esos archivos provoca cambios en el esquema. BigQuery garantiza que todos los datos contenidos en una tabla tengan un esquema coherente e impone una ruta de migración adecuada para los datos históricos. Al abstraer del usuario los formatos de datos subyacentes y los tamaños de los archivos, BigQuery puede proporcionar una experiencia sin fisuras, de modo que las consultas sean siempre rápidas.
Hay otra ventaja en que BigQuery gestione su propio almacenamiento: BigQuery puede seguir haciéndose más rápido de forma transparente para el usuario final. Por ejemplo, las mejoras en los formatos de almacenamiento pueden aplicarse automáticamente a los datos del usuario. Del mismo modo, las mejoras en la infraestructura de almacenamiento están disponibles inmediatamente. Como BigQuery gestiona todo el almacenamiento, los usuarios no tienen que preocuparse de las copias de seguridad ni de la replicación. Todo, desde las actualizaciones y la replicación hasta las copias de seguridad y la restauración, es gestionado de forma transparente y automática por el sistema de gestión del almacenamiento.
Una ventaja clave de trabajar con almacenamiento estructurado al nivel de abstracción de una tabla (en lugar de un archivo) y de proporcionar gestión de almacenamiento a estas tablas de forma transparente para el usuario final es que las tablas permiten a BigQuery admitir funciones similares a las de una base de datos, como DML. Puedes ejecutar una consulta que actualice o elimine filas de una tabla y dejar que BigQuery determine la mejor forma de modificar el almacenamiento para reflejar esta información. Las operaciones de BigQuery son ACID; es decir, todas las consultas se confirmarán completamente o no se confirmarán en absoluto. Ten la seguridad de que tus consultas nunca verán el estado intermedio de otra consulta, y las consultas iniciadas después de que otra consulta finalice nunca verán datos antiguos. Tienes la posibilidad de ajustar el almacenamiento especificando directivas que controlen cómo se almacenan los datos, pero éstas operan en el nivel de abstracción de las tablas, no de los archivos. Por ejemplo, es posible controlar cómo se particionan y agrupan las tablas (veremos estas funciones en detalle en el Capítulo 7) y mejorar así el rendimiento y/o reducir el coste de las consultas sobre esas tablas.
El almacenamiento gestionado está fuertemente tipado, lo que significa que los datos se validan al entrar en el sistema. Como BigQuery gestiona el almacenamiento y sólo permite a los usuarios interactuar con él a través de sus API, puede contar con que los datos subyacentes no se modificarán fuera de BigQuery. Así, BigQuery puede garantizar que no se producirá ningún error de validación en el momento de la lectura sobre ninguno de los datos presentes en su almacenamiento gestionado. Esta garantía también implica un esquema autorizado, lo que resulta útil a la hora de averiguar cómo consultar tus tablas. Además de mejorar el rendimiento de las consultas, la presencia de un esquema autoritativo ayuda cuando se intenta dar sentido a los datos que tienes, porque un esquema BigQuery no sólo contiene información sobre tipos, sino también anotaciones y descripciones de tablas sobre cómo se pueden utilizar los campos.
Una desventaja del almacenamiento gestionado es que resulta más difícil acceder directamente a los datos y procesarlos utilizando otros marcos de trabajo. Por ejemplo, si los datos hubieran estado disponibles en el nivel de abstracción de los archivos, podrías haber ejecutado directamente un trabajo Hadoop sobre un conjunto de datos BigQuery. BigQuery aborda este problema proporcionando una API paralela estructurada para leer los datos. Esta API te permite leer a toda velocidad desde trabajos Spark o Hadoop, pero también proporciona funciones adicionales, como proyección, filtrado y reequilibrio dinámico.
Integración con Google Cloud Platform
Google Cloud sigue el principio de diseño denominado "separación de responsabilidades", según el cual un pequeño número de productos de alta calidad y muy centrados en se integran estrechamente entre sí. Por tanto, es importante tener en cuenta la totalidad de Google Cloud Platform (GCP) al comparar BigQuery con otros productos de bases de datos.
Diversos productos de GCP amplían la utilidad de BigQuery o facilitan la comprensión de cómo se utiliza BigQuery. En este libro hablamos en detalle de muchos de estos productos relacionados, pero conviene ser consciente de la separación general de responsabilidades:
-
Los registros de monitoreo y auditoría de Stackdriver proporcionan formas de comprender el uso de BigQuery en tu organización. En marzo de 2020, Stackdriver pasó a llamarse Cloud Logging y Cloud Monitoring.
-
Cloud Dataproc ofrece la posibilidad de leer, procesar y escribir en tablas BigQuery utilizando programas Apache Spark. Por ello, BigQuery puede funcionar como capa de almacenamiento de un lago de datos basado en Hadoop. En Google Cloud, la línea entre almacén de datos y lago de datos es difusa.
-
Las consultas federadas permiten a BigQuery consultar datos almacenados en en Google Cloud Storage, Cloud SQL (una base de datos relacional), Bigtable (una base de datos NoSQL), Spanner (una base de datos distribuida) o Google Drive (que ofrece hojas de cálculo). Gracias a las consultas federadas, BigQuery puede funcionar como motor de procesamiento de un lago de datos cuya capa de almacenamiento esté en Cloud Storage.
-
La API de Prevención de Pérdida de Datos en la Nube de Google te ayuda a gestionar los datos sensibles y proporciona la capacidad de redactar o enmascarar la Información de Identificación Personal (IPI) de tus tablas.
-
Otras API de aprendizaje automático amplían las posibilidades de los datos almacenados en BigQuery; por ejemplo, la API de Lenguaje Natural de la Nube puede identificar personas, lugares, sentimientos y mucho más en textos de forma libre (como los de las opiniones de los clientes) almacenados en alguna columna de la tabla.
-
AutoML Tablas y AutoML Texto pueden crear modelos de aprendizaje automático personalizados de alto rendimiento a partir de datos contenidos en tablas de BigQuery.
-
El Catálogo de Datos en la Nube ofrece la posibilidad de descubrir los datos que posee toda tu organización.
-
Puedes utilizar Cloud Pub/Sub para ingerir datos de streaming y Cloud Dataflow para transformarlos y cargarlos en BigQuery. También puedes utilizar Cloud Dataflow para realizar consultas de streaming. Por supuesto, puedes consultar interactivamente los datos de streaming dentro del propio BigQuery.16
-
Data Studio proporciona gráficos y cuadros de mando basados en datos de BigQuery. Looker proporciona una plataforma de datos de Business Intelligence (BI) empresarial con una capa semántica. Herramientas de terceros como Tableau también admiten BigQuery como backend.
-
Cloud AI Platform ofrece la posibilidad de entrenar sofisticados programas de aprendizaje automático a partir de datos almacenados en BigQuery. También permite ajustar los hiperparámetros de los modelos ML de BigQuery e implementarlos para la predicción en línea.
-
Cloud Scheduler y Cloud Functions permiten programar o activar consultas BigQuery como parte de flujos de trabajo más amplios.
-
Cloud Data Fusion proporciona herramientas de integración de datos y conectores de arrastrar y soltar. Cloud Dataflow ofrece la posibilidad de crear canalizaciones ETL con estado.
-
Cloud Composer permite orquestar trabajos de BigQuery junto con tareas que deban realizarse en Cloud Dataflow u otros marcos de procesamiento, ya sea en Google Cloud o en las instalaciones en una configuración de nube híbrida.
En conjunto, BigQuery y el ecosistema GCP tienen características que abarcan varios otros productos de bases de datos de otros proveedores en la nube; puedes utilizarlos como almacén de análisis, pero también como sistema ELT, lago de datos (consultas sobre archivos) o fuente de BI. El resto de este libro ofrece una amplia visión de cómo puedes utilizar BigQuery en todos sus aspectos.
Seguridad y cumplimiento
La integración con GCP va más allá de la mera interoperabilidad con otros productos. Las funciones transversales que ofrece la plataforma proporcionan una seguridad y un cumplimiento coherentes.
El hardware más rápido y el software más avanzado sirven de poco si no puedes confiarles tus datos. El modelo de seguridad de BigQuery está estrechamente integrado con el resto de GCP, por lo que es posible adoptar una visión holística de la seguridad de tus datos. BigQuery utiliza el sistema de control de acceso IAM de Google para asignar permisos específicos a usuarios individuales o grupos de usuarios. BigQuery también se vincula estrechamente con los controles de políticas de la Nube Privada Virtual (VPC) de Google, que pueden protegerte contra usuarios que intenten acceder a los datos desde fuera de tu organización, o que intenten exportarlos a terceros. Tanto los controles IAM como VPC están diseñados para funcionar en todos los productos de Google Cloud, por lo que no tienes que preocuparte de que determinados productos creen un agujero de seguridad.
BigQuery está disponible en todas las regiones donde Google Cloud tiene presencia, lo que te permite procesar los datos en el lugar que elijas. En el momento de escribir estas líneas, Google Cloud tiene más de dos docenas de centros de datos en todo el mundo, y se están abriendo otros nuevos a gran velocidad. Si tienes razones empresariales para mantener los datos en Australia o Alemania, es posible hacerlo. Sólo tienes que crear tu conjunto de datos con el código de región de Australia o Alemania, y todas tus consultas a los datos se harán dentro de esa región.
Algunas organizaciones tienen requisitos aún más estrictos sobre la ubicación de los datos, que van más allá de dónde se almacenan y procesan. En concreto, quieren asegurarse de que sus datos no puedan copiarse ni salir de su región física. GCP tiene controles de región física que se aplican a todos los productos; puedes crear una política de "controles de servicio VPC" que impida el movimiento de datos fuera de una región seleccionada. Si tienes activados estos controles, los usuarios no podrán copiar datos entre regiones ni exportarlos a cubos de Google Cloud Storage en otra región.
Resumen
BigQuery es un almacén de datos altamente escalable que proporciona análisis SQL rápidos sobre grandes conjuntos de datos de forma sin servidor. Aunque los usuarios aprecian la escala y la velocidad de BigQuery, los directivos de las empresas suelen apreciar las ventajas transformadoras que se derivan de poder realizar consultas ad hoc de forma sin servidor, abriendo la toma de decisiones basada en datos a todas las partes de la empresa.
Para ingerir datos en BigQuery, puedes utilizar una canalización EL (utilizada habitualmente para cargas periódicas de archivos de registro), una canalización ETL (utilizada habitualmente cuando hay que enriquecer los datos o controlar su calidad) o una canalización ELT (utilizada habitualmente para trabajos de exploración).
BigQuery está diseñado para cargas de trabajo de análisis de datos (OLAP) y ofrece compatibilidad total con SQL:2011. BigQuery puede alcanzar su escala y velocidad porque se basa en ideas de ingeniería innovadoras, como el uso de almacenamiento columnar, la compatibilidad con campos anidados y repetidos, y la separación de computación y almacenamiento, sobre la que Google llegó a publicar artículos. BigQuery forma parte del ecosistema GCP de herramientas de análisis de grandes datos y se integra estrechamente tanto con las piezas de infraestructura (como seguridad, monitoreo y registro) como con las piezas de procesamiento de datos y aprendizaje automático (como streaming, Cloud DLP y AutoML) de la plataforma.
1 En realidad, tendrás que empezar a llevar los registros en el momento en que los clientes tomen prestado el material, para saber si se han fugado con él. Sin embargo, ¡es bastante pronto en este libro para preocuparse por eso!
2 En este libro, utilizamos consulta "ad hoc" para referirnos a una consulta que se escribe sin ningún intento de preparar la base de datos con antelación utilizando funciones como los índices.
3 Jeffrey Dean y Sanjay Ghemawat, "MapReduce: Simplified Data Processing on Large Clusters", OSDI '04: Sixth Symposium on Operating Systems Design and Implementation, San Francisco, CA (2004), pp. 137-150. Disponible en https://research.google.com/archive/mapreduce-osdi04.pdf.
4 En Google Cloud Platform, Cloud Dataproc (la oferta gestionada de Hadoop) aborda este dilema de una manera diferente. Debido al gran ancho de banda biseccional disponible en los centros de datos de Google, los clústeres de Cloud Dataproc pueden ser específicos para cada trabajo: los datos se almacenan en Google Cloud Storage y se leen por cable bajo demanda. Esto sólo es posible si los anchos de banda son lo suficientemente altos como para aproximarse a las velocidades de disco. No lo intentes en casa.
5 Para que te resulte más cómodo copiar y pegar, puedes encontrar todo el código y los fragmentos de consulta de este libro(incluida la consulta del ejemplo) en el repositorio de GitHub de este libro.
6 No a ti específicamente. Se trata de un conjunto de datos público, y su propietario concedió este permiso a todos los usuarios autentificados. Puedes ser menos permisivo con tus datos, compartiendo el conjunto de datos sólo con aquellos dentro de tu dominio o dentro de tu equipo.
7 Este código puede descargarse del repositorio GitHub del libro.
8 Ten en cuenta que ambos autores viven en Seattle, donde llueve 150 días al año.
9 Puedes encontrar más detalles sobre el formato de almacenamiento en columnas en "Cómo surgió BigQuery".
10 Por ejemplo, para calcular métricas de conversión basadas en la distancia que tendría que recorrer un cliente para comprar un producto.
11 Creemos que todas las menciones de precios son correctas en el momento de escribir este libro, pero consulta las hojas de políticas y precios correspondientes, ya que están sujetas a cambios.
12 Jim Gray sobre la eCiencia: Un método científico transformado", de El cuarto paradigma: Data-Intensive Scientific Discovery, ed. Tony Hey, Stewart Tansley y Kristin Tolle. Tony Hey, Stewart Tansley y Kristin Tolle (Microsoft, 2009), xiv. Disponible en https://oreil.ly/M6zMN.
13 Hoy en día, BigQuery ofrece la posibilidad de exportar tablas y resultados a Google Cloud Storage, ¡así que, después de todo, acabamos creando el enlace de descarga! Pero BigQuery no es sólo un enlace de descarga: la mayoría de los usos de BigQuery implican operar con los datos in situ.
14 SQL tiene una palabra clave RECURSIVA, pero como muchos motores SQL, BigQuery no la admite. En su lugar, BigQuery ofrece mejores formas de tratar los datos jerárquicos mediante el soporte de matrices y anidamiento.
15 Para saber más sobre Colossus, consulta http://www.pdsw.org/pdsw-discs17/slides/PDSW-DISCS-Google-Keynote.pdf y https://www.wired.com/2012/07/google-colossus/.
16 La separación de responsabilidades aquí es que Cloud Dataflow es mejor para el procesamiento continuo y rutinario, mientras que BigQuery es mejor para el procesamiento interactivo y ad hoc. Tanto Cloud Dataflow como BigQuery manejan datos por lotes, así como datos en streaming, y es posible ejecutar consultas SQL dentro de Cloud Dataflow.
Get Google BigQuery: La Guía Definitiva now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

