Kapitel 1. Eine Einführung in die Gleichzeitigkeit
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Gleichzeitigkeit ist ein interessantes Wort, weil es für verschiedene Leute in unserem Bereich unterschiedliche Dinge bedeutet. Neben "Gleichzeitigkeit" hast du vielleicht auch schon die Begriffe "asynchron", "parallel" oder "threaded" gehört. Manche verstehen unter diesen Begriffen das Gleiche, andere wiederum unterscheiden sehr genau zwischen diesen Begriffen. Wenn wir uns ein ganzes Buch lang mit der Gleichzeitigkeit von Programmen beschäftigen wollen, wäre es sinnvoll, zunächst einmal zu klären, was wir mit dem Begriff "Gleichzeitigkeit" meinen.
Wir werden uns in Kapitel 2 mit der Philosophie der Gleichzeitigkeit beschäftigen, aber jetzt wollen wir erst einmal eine praktische Definition annehmen, die als Grundlage für unser Verständnis dient.
Wenn die meisten Menschen das Wort "gleichzeitig" verwenden, meinen sie damit in der Regel einen Prozess, der gleichzeitig mit einem oder mehreren Prozessen stattfindet. Außerdem wird damit in der Regel impliziert, dass alle diese Prozesse ungefähr zur gleichen Zeit ablaufen. Nach dieser Definition kann man sich das leicht vorstellen: Menschen. Du liest gerade diesen Satz, während andere Menschen auf der Welt gleichzeitig ihr Leben leben. Sie existieren gleichzeitig mit dir.
Gleichzeitigkeit ist ein breites Thema in der Informatik, und aus dieser Definition ergeben sich alle möglichen Themen: Theorie, Ansätze zur Modellierung von Gleichzeitigkeit, Korrektheit der Logik, praktische Fragen - sogar theoretische Physik! Im Laufe des Buches werden wir einige dieser Themen anschneiden, aber wir werden uns hauptsächlich auf die praktischen Fragen konzentrieren, die mit dem Verständnis der Gleichzeitigkeit im Kontext von Go zu tun haben, insbesondere: wie Go die Gleichzeitigkeit modelliert, welche Probleme sich aus diesem Modell ergeben und wie wir Primitive innerhalb dieses Modells zusammenstellen können, um Probleme zu lösen.
In diesem Kapitel werfen wir einen Blick auf die Gründe, warum Nebenläufigkeit ein so wichtiges Thema in der Informatik geworden ist, warum Nebenläufigkeit schwierig ist und eine sorgfältige Untersuchung verdient, und - am wichtigsten - die Idee, dass Go trotz dieser Herausforderungen Programme klarer und schneller machen kann, indem es seine Nebenläufigkeitsprimitive nutzt.
Wie bei den meisten Wegen zum Verständnis, beginnen wir mit einem kleinen Rückblick. Werfen wir zunächst einen Blick darauf, wie die Gleichzeitigkeit zu einem so wichtigen Thema wurde.
Moore's Law, Web-Skala und das Chaos, in dem wir stecken
1965 schrieb Gordon Moore ein dreiseitiges Papier, in dem er sowohl die Konsolidierung des Elektronikmarktes hin zu integrierten Schaltkreisen als auch die Verdoppelung der Anzahl der Komponenten in einem integrierten Schaltkreis jedes Jahr für mindestens ein Jahrzehnt beschrieb. Im Jahr 1975 revidierte er diese Vorhersage und erklärte, dass sich die Anzahl der Bauteile in einem integrierten Schaltkreis alle zwei Jahre verdoppeln würde. Diese Vorhersage hat sich bis vor kurzem - etwa 2012 - mehr oder weniger bewahrheitet.
Mehrere Unternehmen sahen diese Verlangsamung der durch das Mooresche Gesetz vorhergesagten Geschwindigkeit voraus und begannen, nach alternativen Wegen zur Steigerung der Rechenleistung zu suchen. Wie das Sprichwort sagt, ist die Notwendigkeit die Mutter der Innovation, und so wurden die Multicore-Prozessoren geboren.
Das sah nach einem cleveren Weg aus, die Probleme des Mooreschen Gesetzes zu lösen, aber schon bald stießen die Informatiker an die Grenzen eines anderen Gesetzes: Amdahls Gesetz, benannt nach dem Computerarchitekten Gene Amdahl.
Das Amdahlsche Gesetz beschreibt eine Möglichkeit, den potenziellen Leistungsgewinn durch die parallele Implementierung der Lösung eines Problems zu modellieren. Einfach ausgedrückt besagt es, dass der Gewinn dadurch begrenzt wird, wie viel des Programms sequentiell geschrieben werden muss.
Stell dir zum Beispiel vor, du würdest ein Programm schreiben, das größtenteils auf einer grafischen Benutzeroberfläche basiert: Einem Benutzer wird eine Oberfläche präsentiert, er klickt auf ein paar Schaltflächen, und schon passiert etwas. Diese Art von Programm wird durch einen sehr großen sequenziellen Teil der Pipeline begrenzt: die menschliche Interaktion. Egal, wie viele Kerne du diesem Programm zur Verfügung stellst, es wird immer dadurch begrenzt, wie schnell der Benutzer mit der Benutzeroberfläche interagieren kann.
Betrachten wir nun ein anderes Beispiel: die Berechnung der Ziffern von Pi. Dank einer Klasse von Algorithmen, die Spigot-Algorithmen genannt werden, wird dieses Problem als peinlich parallel bezeichnet, was - obwohl es erfunden klingt - ein technischer Begriff ist, der bedeutet, dass es leicht in parallele Aufgaben aufgeteilt werden kann. In diesem Fall lassen sich erhebliche Gewinne erzielen, wenn du deinem Programm mehr Kerne zur Verfügung stellst, und dein neues Problem ist, wie du die Ergebnisse kombinieren und speichern kannst.
Das Amdahlsche Gesetz hilft uns, den Unterschied zwischen diesen beiden Problemen zu verstehen und zu entscheiden, ob die Parallelisierung der richtige Weg ist, um Leistungsprobleme in unserem System zu lösen.
Bei Problemen, die peinlich parallel sind, wird empfohlen, dass du deine Anwendung so schreibst, dass sie horizontal skalieren kann. Das bedeutet, dass du Instanzen deines Programms auf mehreren CPUs oder Maschinen laufen lassen kannst, wodurch sich die Laufzeit des Systems verbessert. Peinlich parallele Probleme passen so gut zu diesem Modell, weil es sehr einfach ist, dein Programm so zu strukturieren, dass du Teile eines Problems an verschiedene Instanzen deiner Anwendung senden kannst.
Die horizontale Skalierung wurde in den frühen 2000er Jahren viel einfacher, als sich ein neues Paradigma durchsetzte: Cloud Computing. Es gibt zwar Hinweise darauf, dass der Begriff bereits in den 1970er Jahren verwendet wurde, aber erst Anfang der 2000er Jahre setzte sich die Idee wirklich im Zeitgeist durch. Cloud Computing bedeutete eine neue Art der Skalierung und einen neuen Ansatz für die Anwendungsbereitstellung und horizontale Skalierung. Anstelle von Rechnern, die du sorgfältig kuratierst, mit Software versorgst und wartest, bedeutet Cloud Computing den Zugang zu riesigen Ressourcenpools, die auf Abruf in Rechnern für Arbeitslasten bereitgestellt werden. Die Maschinen wurden zu etwas fast Vergänglichem, das mit speziellen Eigenschaften für die Programme ausgestattet wurde, die darauf laufen sollten. Normalerweise (aber nicht immer) wurden diese Ressourcenpools in Rechenzentren anderer Unternehmen gehostet.
Dieser Wandel förderte eine neue Art des Denkens. Plötzlich hatten Entwicklerinnen und Entwickler relativ billigen Zugang zu riesigen Mengen an Rechenleistung, die sie zur Lösung großer Probleme nutzen konnten. Lösungen konnten nun ganz einfach viele Maschinen und sogar globale Regionen umfassen. Cloud Computing ermöglichte eine ganze Reihe neuer Lösungen für Probleme, die vorher nur von Tech-Giganten gelöst werden konnten.
Aber Cloud Computing brachte auch viele neue Herausforderungen mit sich. Die Bereitstellung dieser Ressourcen, die Kommunikation zwischen den Maschineninstanzen und die Zusammenfassung und Speicherung der Ergebnisse stellten allesamt Probleme dar, die es zu lösen galt. Eine der schwierigsten Aufgaben war es, herauszufinden, wie man Code gleichzeitig modellieren kann. Die Tatsache, dass Teile deiner Lösung auf verschiedenen Rechnern laufen konnten, verschärfte einige der Probleme, die bei der gleichzeitigen Modellierung eines Problems auftreten. Die erfolgreiche Lösung dieser Probleme führte bald zu einer neuen Art von Marke für Software, der Web-Skala.
Wenn Software web-skaliert ist, kann man unter anderem erwarten, dass sie peinlich parallel ist. Das heißt, dass web-skalierte Software in der Regel in der Lage ist, Hunderttausende (oder mehr) gleichzeitige Arbeitslasten zu bewältigen, indem weitere Instanzen der Anwendung hinzugefügt werden. Dies ermöglichte alle möglichen Eigenschaften wie rollierende Upgrades, eine elastische, horizontal skalierbare Architektur und eine geografische Verteilung. Es führte auch zu neuen Ebenen der Komplexität, sowohl was das Verständnis als auch die Fehlertoleranz angeht.
In dieser Welt der vielen Kerne, des Cloud Computing, der Web-Skalierung und der Probleme, die sich vielleicht parallelisieren lassen oder auch nicht, ist der moderne Entwickler vielleicht etwas überfordert. Der sprichwörtliche Schwarze Peter wurde an uns weitergereicht und von uns wird erwartet, dass wir die Herausforderung annehmen, Probleme innerhalb der Grenzen der uns zur Verfügung stehenden Hardware zu lösen. Im Jahr 2005 schrieb Herb Sutter einen Artikel für Dr. Dobb's mit dem Titel "The free lunch is over: Ein grundlegender Wandel in Richtung Gleichzeitigkeit in der Software". Der Titel ist treffend und der Artikel vorausschauend. Am Ende stellt Sutter fest: "Wir brauchen dringend ein höheres Programmiermodell für Gleichzeitigkeit, als es Sprachen heute bieten."
Um zu verstehen, warum Sutter eine so starke Sprache verwendet hat, müssen wir uns ansehen, warum es so schwer ist, Gleichzeitigkeit richtig zu machen.
Warum ist Gleichzeitigkeit schwierig?
Gleichzeitiger Code ist bekanntermaßen schwer zu beheben. In der Regel braucht es einige Iterationen, bis er wie erwartet funktioniert, und selbst dann ist es nicht ungewöhnlich, dass Fehler jahrelang im Code vorhanden sind, bevor eine Änderung des Timings (stärkere Festplattenauslastung, mehr angemeldete Benutzer usw.) dazu führt, dass ein zuvor unentdeckter Fehler auftaucht. Für dieses Buch habe ich sogar so viele Augen wie möglich auf den Code gerichtet, um dies zu verhindern.
Glücklicherweise stößt jeder auf die gleichen Probleme, wenn er mit nebenläufigem Code arbeitet. Aus diesem Grund konnten Informatiker die gemeinsamen Probleme benennen, so dass wir darüber diskutieren können, wie sie entstehen, warum sie entstehen und wie man sie lösen kann.
Also lass uns loslegen. Im Folgenden findest du einige der häufigsten Probleme, die die Arbeit mit nebenläufigem Code sowohl frustrierend als auch interessant machen.
Rennbedingungen
Eine Race Condition tritt auf, wenn zwei oder mehr Operationen in der richtigen Reihenfolge ausgeführt werden müssen, das Programm aber nicht so geschrieben wurde, dass diese Reihenfolge garantiert eingehalten wird.
Meistens zeigt sich das in einem so genannten Data Race, bei dem ein gleichzeitiger Vorgang versucht, eine Variable zu lesen, während ein anderer gleichzeitiger Vorgang zu einem unbestimmten Zeitpunkt versucht, in dieselbe Variable zu schreiben.
Hier ist ein einfaches Beispiel:
1vardataint2gofunc(){3data++4}()5ifdata==0{6fmt.Printf("the value is %v.\n",data)7}
In Go kannst du das Schlüsselwort
goverwenden, um eine Funktion gleichzeitig auszuführen. Auf diese Weise entsteht eine sogenannte Goroutine. Wir werden das im Abschnitt "Goroutinen" genauer erklären .
Hier versuchen die Zeilen 3 und 5 beide, auf die variablen Daten zuzugreifen, aber es gibt keine Garantie dafür, in welcher Reihenfolge dies geschehen wird. Bei der Ausführung dieses Codes gibt es drei mögliche Ergebnisse:
-
Es wird nichts gedruckt. In diesem Fall wurde Zeile 3 vor Zeile 5 ausgeführt.
-
"In diesem Fall wurden die Zeilen 5 und 6 vor Zeile 3 ausgeführt.
-
"In diesem Fall wurde Zeile 5 vor Zeile 3 ausgeführt, aber Zeile 3 wurde vor Zeile 6 ausgeführt.
Wie du siehst, können schon ein paar fehlerhafte Codezeilen zu enormen Schwankungen in deinem Programm führen.
Meistens werden Data Races eingeführt, weil die Entwickler das Problem sequentiell angehen. Sie gehen davon aus, dass eine Codezeile, die vor einer anderen steht, zuerst ausgeführt wird. Sie gehen davon aus, dass die obige Goroutine geplant und ausgeführt wird, bevor die Variable data in der Anweisung if gelesen wird.
Wenn du nebenläufigen Code schreibst, musst du die möglichen Szenarien akribisch durchgehen. Wenn du nicht einige der Techniken anwendest, die wir später im Buch behandeln werden, hast du keine Garantie, dass dein Code in der Reihenfolge ausgeführt wird, in der er im Quellcode steht. Ich finde es manchmal hilfreich, sich vorzustellen, dass zwischen den einzelnen Vorgängen eine große Zeitspanne vergeht. Stell dir vor, zwischen dem Aufruf der Goroutine und ihrer Ausführung vergeht eine Stunde. Wie würde sich der Rest des Programms verhalten? Was wäre, wenn zwischen der erfolgreichen Ausführung der Goroutine und dem Erreichen der Anweisung if eine Stunde vergehen würde? Diese Denkweise hilft mir, denn für einen Computer mag der Maßstab anders sein, aber die relativen Zeitunterschiede sind mehr oder weniger die gleichen.
Manche Entwickler tappen sogar in die Falle, ihren Code mit Schlafphasen zu überhäufen, nur weil dies ihre Gleichzeitigkeitsprobleme zu lösen scheint. Versuchen wir das mal in dem vorangegangenen Programm:
1vardataint2gofunc(){data++}()3time.Sleep(1*time.Second)// This is bad!4ifdata==0{5fmt.Printf("the value is %v.\n"data)6}
Haben wir unser Datenrennen gelöst? Nein. Tatsächlich ist es immer noch möglich, dass alle drei Ergebnisse in diesem Programm eintreten, es wird nur immer unwahrscheinlicher. Je länger wir zwischen dem Aufruf unserer Goroutine und der Überprüfung des Datenwerts schlafen, desto näher kommt unser Programm der Korrektheit - aber diese Wahrscheinlichkeit nähert sich asymptotisch der logischen Korrektheit; es wird nie logisch korrekt sein.
Außerdem haben wir jetzt eine Ineffizienz in unseren Algorithmus eingebaut. Wir müssen jetzt eine Sekunde lang schlafen, um die Wahrscheinlichkeit zu erhöhen, dass wir unser Datenrennen nicht sehen. Wenn wir die richtigen Tools verwenden würden, müssten wir vielleicht gar nicht warten oder die Wartezeit würde nur eine Mikrosekunde betragen.
Die Erkenntnis daraus ist, dass du immer logische Korrektheit anstreben solltest. Schlafphasen in deinem Code können eine praktische Möglichkeit sein, nebenläufige Programme zu debuggen, aber sie sind keine Lösung.
Race Conditions sind eine der heimtückischsten Arten von Gleichzeitigkeitsfehlern, weil sie sich oft erst Jahre nach dem Einsatz des Codes in der Produktion zeigen. Sie werden in der Regel durch eine Änderung in der Umgebung, in der der Code ausgeführt wird, oder durch ein noch nie dagewesenes Ereignis ausgelöst. In diesen Fällen scheint sich der Code korrekt zu verhalten, aber in Wirklichkeit besteht nur eine sehr hohe Wahrscheinlichkeit, dass die Operationen in der richtigen Reihenfolge ausgeführt werden. Früher oder später wird das Programm eine unbeabsichtigte Folge haben.
Atomarität
Wenn etwas als atomar gilt oder die Eigenschaft der Atomarität hat, bedeutet das, dass es in dem Kontext, in dem es funktioniert, unteilbar oder ununterbrechbar ist.
Was bedeutet das eigentlich, und warum ist es wichtig, das zu wissen, wenn man mit nebenläufigem Code arbeitet?
Das erste, was sehr wichtig ist, ist das Wort "Kontext". Etwas kann in einem Kontext atomar sein, aber nicht in einem anderen. Operationen, die im Kontext deines Prozesses atomar sind, sind möglicherweise im Kontext des Betriebssystems nicht atomar; Operationen, die im Kontext des Betriebssystems atomar sind, sind möglicherweise im Kontext deines Computers nicht atomar; und Operationen, die im Kontext deines Computers atomar sind, sind möglicherweise im Kontext deiner Anwendung nicht atomar. Mit anderen Worten: Die Atomarität einer Operation kann sich je nach dem aktuell definierten Bereich ändern. Diese Tatsache kann sowohl für als auch gegen dich arbeiten!
Wenn du über Atomarität nachdenkst, musst du oft als Erstes den Kontext oder den Bereich definieren, in dem die Operation als atomar angesehen wird. Daraus folgt alles Weitere.
Betrachten wir nun die Begriffe "unteilbar" und "ununterbrechbar". Diese Begriffe bedeuten, dass etwas, das atomar ist, in dem von dir definierten Kontext in seiner Gesamtheit geschieht, ohne dass etwas in diesem Kontext gleichzeitig geschieht. Das ist immer noch ein ganz schöner Brocken, also lass uns ein Beispiel anschauen:
i++
Dieses Beispiel ist so einfach, wie man es sich nur ausdenken kann, und doch zeigt es das Konzept der Atomarität auf. Es sieht zwar atomar aus, aber eine kurze Analyse offenbart mehrere Operationen:
-
Rufe den Wert von
iab. -
Erhöhe den Wert von
i. -
Speichere den Wert von
i.
Während jede dieser Operationen für sich genommen atomar ist, ist die Kombination der drei Operationen je nach Kontext möglicherweise nicht atomar. Das zeigt eine interessante Eigenschaft von atomaren Operationen: Wenn du sie kombinierst, entsteht nicht unbedingt eine größere atomare Operation. Ob die Operation atomar ist, hängt davon ab, in welchem Kontext du sie atomar haben möchtest. Wenn dein Kontext ein Programm ohne gleichzeitige Prozesse ist, dann ist dieser Code in diesem Kontext atomar. Wenn dein Kontext eine Goroutine ist, die i nicht an andere Goroutinen weitergibt, dann ist dieser Code atomar.
Warum ist uns das wichtig? Atomarität ist wichtig, denn wenn etwas atomar ist, ist es implizit auch in gleichzeitigen Kontexten sicher. So können wir logisch korrekte Programme zusammenstellen und - wie wir später sehen werden - sogar nebenläufige Programme optimieren.
Die meisten Anweisungen sind nicht atomar, ganz zu schweigen von Funktionen, Methoden und Programmen. Wenn Atomarität der Schlüssel zum Erstellen logisch korrekter Programme ist und die meisten Anweisungen nicht atomar sind, wie lassen sich diese beiden Aussagen miteinander vereinbaren? Wir werden später noch genauer darauf eingehen, aber kurz gesagt können wir die Atomarität mit verschiedenen Techniken erzwingen. Die Kunst besteht dann darin, zu bestimmen, welche Bereiche deines Codes atomar sein müssen und auf welcher Granularitätsebene. Auf einige dieser Herausforderungen gehen wir im nächsten Abschnitt ein.
Synchronisierung des Speicherzugriffs
Nehmen wir an, wir haben einen Datenwettlauf: Zwei gleichzeitige Prozesse versuchen, auf denselben Speicherbereich zuzugreifen, und die Art, wie sie auf den Speicher zugreifen, ist nicht atomar. Unser vorheriges Beispiel für einen einfachen Datenwettlauf lässt sich mit ein paar Änderungen gut lösen:
vardataintgofunc(){data++}()ifdata==0{fmt.Println("the value is 0.")}else{fmt.Printf("the value is %v.\n",data)}
Wir haben hier eine else Klausel eingefügt, damit wir unabhängig vom Wert von data immer eine Ausgabe erhalten. Erinnere dich daran, dass es so, wie es geschrieben ist, einen Datenwettlauf gibt und die Ausgabe des Programms völlig unbestimmt sein wird.
Es gibt sogar einen Namen für einen Teil deines Programms, der exklusiven Zugriff auf eine gemeinsame Ressource benötigt. Man nennt ihn einen kritischen Abschnitt. In diesem Beispiel haben wir drei kritische Abschnitte:
-
Unsere Goroutine, die die
dataVariablen inkrementiert. -
Unsere
ifAnweisung, die überprüft, ob der Wert vondata0 ist. -
Unsere
fmt.PrintfAnweisung, die den Wert vondatafür die Ausgabe abruft.
Es gibt verschiedene Möglichkeiten, die kritischen Abschnitte deines Programms zu schützen, und Go hat einige bessere Ideen, wie man damit umgehen kann, aber eine Möglichkeit, dieses Problem zu lösen, ist, den Zugriff auf den Speicher zwischen deinen kritischen Abschnitten zu synchronisieren. Schauen wir uns an, wie das aussieht.
Der folgende Code ist kein idiomatisches Go (und ich empfehle dir nicht, deine Data-Race-Probleme auf diese Weise zu lösen), aber er demonstriert ganz einfach die Synchronisierung von Speicherzugriffen. Wenn dir einige der Typen, Funktionen oder Methoden in diesem Beispiel fremd sind, ist das kein Problem. Konzentriere dich auf das Konzept der Synchronisierung des Speicherzugriffs, indem du den Aufrufen folgst.
varmemoryAccesssync.Mutexvarvalueintgofunc(){memoryAccess.Lock()value++memoryAccess.Unlock()}()memoryAccess.Lock()ifvalue==0{fmt.Printf("the value is %v.\n",value)}else{fmt.Printf("the value is %v.\n",value)}memoryAccess.Unlock()
Hier fügen wir eine Variable hinzu, die es unserem Code ermöglicht, den Zugriff auf den Speicher der Variable
datazu synchronisieren. Wir werden den Typsync.Mutexin "Das sync-Paket" im Detail besprechen .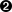
Hier erklären wir, dass unsere Goroutine exklusiven Zugriff auf diesen Speicher haben soll, bis wir etwas anderes deklarieren.

Hier erklären wir, dass die Goroutine mit diesem Speicher fertig ist.

Hier erklären wir noch einmal, dass die folgenden bedingten Anweisungen exklusiven Zugriff auf den Speicher der Variable
datahaben sollen.
Hier erklären wir, dass wir wieder einmal mit dieser Erinnerung fertig sind.
In diesem Beispiel haben wir eine Konvention erstellt, an die sich die Entwickler halten können. Jedes Mal, wenn Entwickler auf den Speicher der Variable data zugreifen wollen, müssen sie zuerst Lock aufrufen, und wenn sie fertig sind, müssen sie Unlock aufrufen. Der Code zwischen diesen beiden Anweisungen kann dann davon ausgehen, dass er exklusiven Zugriff auf data hat; wir haben den Zugriff auf den Speicher erfolgreich synchronisiert. Beachte auch, dass wir keine Garantie für exklusiven Zugriff haben, wenn sich Entwickler nicht an diese Konvention halten! Wir werden auf diese Idee im Abschnitt "Confinement" zurückkommen .
Du hast vielleicht bemerkt, dass wir zwar unseren Datenwettlauf gelöst haben, aber nicht die eigentliche Wettlaufbedingung! Die Reihenfolge der Operationen in diesem Programm ist immer noch unbestimmt, wir haben nur den Bereich der Unbestimmtheit ein wenig eingegrenzt. In diesem Beispiel wird entweder die Goroutine zuerst ausgeführt oder unsere beiden Blöcke if und else. Wir wissen immer noch nicht, was bei einer bestimmten Ausführung des Programms zuerst eintritt. Später werden wir uns mit den Werkzeugen befassen, mit denen wir diese Art von Problem lösen können.
Auf den ersten Blick scheint das ziemlich einfach: Wenn du feststellst, dass du kritische Abschnitte hast, füge Punkte hinzu, um den Zugriff auf den Speicher zu synchronisieren! Einfach, oder? Nun ja... irgendwie schon.
Es stimmt zwar, dass du einige Probleme lösen kannst, indem du den Zugriff auf den Speicher synchronisierst, aber wie wir gerade gesehen haben, löst das nicht automatisch Datenrennen oder logische Korrektheit. Außerdem können dadurch auch Wartungs- und Leistungsprobleme entstehen.
Wir haben bereits erwähnt, dass wir eine Konvention erstellt haben, um zu erklären, dass wir exklusiven Zugriff auf einen bestimmten Speicher benötigen. Konventionen sind großartig, aber sie können auch leicht ignoriert werden - vor allem in der Softwareentwicklung, wo die Anforderungen des Geschäfts manchmal mehr Gewicht haben als die Vernunft. Indem du den Zugriff auf den Speicher auf diese Weise synchronisierst, verlangst du von allen anderen Entwicklern, dass sie sich jetzt und in Zukunft an die gleiche Konvention halten. Das ist eine ziemlich hohe Anforderung. Zum Glück werden wir später in diesem Buch auch einige Möglichkeiten aufzeigen, wie wir unseren Kollegen helfen können, erfolgreicher zu sein.
Die Synchronisierung des Speicherzugriffs auf diese Weise hat auch Auswirkungen auf die Leistung. Wir heben uns die Details für später auf, wenn wir das Paket sync im Abschnitt "Das sync-Paket" untersuchen , aber die Aufrufe von Lock, die du siehst, können unser Programm langsam machen. Jedes Mal, wenn wir einen dieser Vorgänge ausführen, hält unser Programm für eine gewisse Zeit an. Das wirft zwei Fragen auf:
-
Werden meine kritischen Abschnitte wiederholt betreten und verlassen?
-
Wie groß sollten meine kritischen Abschnitte sein?
Die Beantwortung dieser beiden Fragen im Kontext deines Programms ist eine Kunst, und das erschwert den synchronisierten Zugriff auf den Speicher zusätzlich.
Die Synchronisierung des Speicherzugriffs hat auch einige Probleme mit anderen Techniken zur Modellierung gleichzeitiger Probleme, die wir im nächsten Abschnitt besprechen werden.
Deadlocks, Livelocks und Starvation
In den vorangegangenen Abschnitten ging es um die Korrektheit von Programmen, denn wenn diese Probleme richtig behandelt werden, wird dein Programm nie eine falsche Antwort geben. Doch selbst wenn du diese Probleme erfolgreich bewältigst, gibt es noch eine andere Klasse von Problemen: Deadlocks, Livelocks und Starvation. Bei all diesen Problemen geht es darum, dass dein Programm zu jeder Zeit etwas Sinnvolles zu tun hat. Wenn du nicht richtig damit umgehst, kann dein Programm in einen Zustand geraten, in dem es gar nicht mehr funktioniert.
Deadlock
Ein festgefahrenes Programm ist ein Programm, in dem alle gleichzeitigen Prozesse aufeinander warten. In diesem Zustand wird sich das Programm ohne Eingriff von außen nicht mehr erholen.
Wenn das düster klingt, ist es das auch! Die Go-Laufzeitumgebung versucht, ihren Teil dazu beizutragen und erkennt einige Deadlocks (alle Goroutinen müssen blockiert oder "eingeschlafen" sein).1), aber das hilft dir nicht viel, um Deadlocks zu verhindern.
Um zu verdeutlichen, was ein Deadlock ist, schauen wir uns zunächst ein Beispiel an. Auch hier kannst du Typen, Funktionen, Methoden oder Pakete, die du nicht kennst, einfach ignorieren und den Codeaufrufen folgen.
typevaluestruct{musync.Mutexvalueint}varwgsync.WaitGroupprintSum:=func(v1,v2*value){deferwg.Done()v1.mu.Lock()deferv1.mu.Unlock()time.Sleep(2*time.Second)v2.mu.Lock()deferv2.mu.Unlock()fmt.Printf("sum=%v\n",v1.value+v2.value)}vara,bvaluewg.Add(2)goprintSum(&a,&b)goprintSum(&b,&a)wg.Wait()
Hier versuchen wir, den kritischen Abschnitt für den eingehenden Wert einzugeben.
Hier verwenden wir die Anweisung
defer, um den kritischen Abschnitt zu verlassen, bevorprintSumzurückkehrt.Hier schlafen wir für eine gewisse Zeit, um Arbeit zu simulieren (und eine Blockade auszulösen).
Wenn du versuchen würdest, diesen Code auszuführen, würdest du wahrscheinlich sehen:
fatal error: all goroutines are asleep - deadlock!
Warum? Wenn du genau hinsiehst, wirst du in diesem Code ein Zeitproblem erkennen. Nachfolgend siehst du eine grafische Darstellung des Vorgangs. Die Kästchen stehen für Funktionen, die horizontalen Linien für Funktionsaufrufe und die vertikalen Balken für die Lebenszeiten der Funktion am Kopf der Grafik(Abbildung 1-1).
Abbildung 1-1. Demonstration eines Zeitproblems, das zu einem Deadlock führt
Im Grunde haben wir zwei Zahnräder geschaffen, die sich nicht zusammen drehen können: Unser erster Aufruf von printSum sperrt a und versucht dann, b zu sperren, aber in der Zwischenzeit hat unser zweiter Aufruf von printSum b gesperrt und versucht, a zu sperren. Beide Goroutinen warten unendlich lange aufeinander.
Es scheint ziemlich offensichtlich zu sein, warum diese Blockade auftritt, wenn wir sie grafisch darstellen, aber wir würden von einer strengeren Definition profitieren. Es gibt einige Bedingungen, die erfüllt sein müssen, damit Deadlocks entstehen können. 1971 hat Edgar Coffman diese Bedingungen in einem Aufsatz aufgezählt. Diese Bedingungen sind heute als Coffman-Bedingungen bekannt und bilden die Grundlage für Techniken, die helfen, Deadlocks zu erkennen, zu verhindern und zu korrigieren.
Die Coffman-Bedingungen lauten wie folgt:
- Gegenseitiger Ausschluss
-
Ein gleichzeitiger Prozess hat zu einem bestimmten Zeitpunkt exklusive Rechte an einer Ressource.
- Warten auf Bedingung
-
Ein gleichzeitiger Prozess muss gleichzeitig eine Ressource halten und auf eine weitere Ressource warten.
- Kein Vorkaufsrecht
-
Eine Ressource, die von einem konkurrierenden Prozess gehalten wird, kann nur von diesem Prozess freigegeben werden und erfüllt somit diese Bedingung.
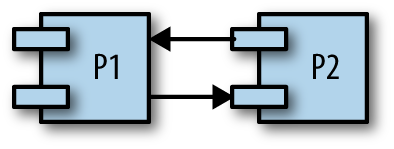
- Rundschreiben Warten
-
Ein gleichzeitiger Prozess (P1) muss auf eine Kette von anderen gleichzeitigen Prozessen (P2) warten, die wiederum auf ihn (P1) warten, damit er auch diese letzte Bedingung erfüllt.
Schauen wir uns unser ausgedachtes Programm an und prüfen, ob es alle vier Bedingungen erfüllt:
-
Die Funktion
printSumerfordert ausschließliche Rechte sowohl füraals auch fürb, so dass sie diese Bedingung erfüllt. -
Da
printSumentwederaoderbhält und auf das andere wartet, erfüllt es diese Bedingung. -
Wir haben keine Möglichkeit vorgesehen, dass unsere Goroutinen vorzeitig beendet werden können.
-
Unser erster Aufruf von
printSumwartet auf unseren zweiten Aufruf, und umgekehrt.
Ja, wir haben es definitiv mit einer Sackgasse zu tun.
Mit diesen Gesetzen können wir auch Deadlocks verhindern. Wenn wir sicherstellen, dass mindestens eine dieser Bedingungen nicht erfüllt ist, können wir verhindern, dass Deadlocks auftreten. Leider sind diese Bedingungen in der Praxis oft schwer zu verstehen und daher schwer zu verhindern. Das Internet ist übersät mit Fragen von Entwicklern wie dir und mir, die sich fragen, warum ein Codeschnipsel in eine Sackgasse geraten ist. Meistens ist es ziemlich offensichtlich, wenn jemand darauf hinweist, aber oft braucht es ein weiteres Paar Augen. Warum das so ist, besprechen wir im Abschnitt "Gleichzeitigkeitssicherheit bestimmen".
Livelock
Livelocks sind Programme, die aktiv gleichzeitige Operationen durchführen, aber diese Operationen bringen den Zustand des Programms nicht voran.
Bist du schon einmal in einem Flur auf eine andere Person zugegangen? Sie geht zur Seite, um dich vorbeizulassen, aber du hast gerade dasselbe getan. Also gehst du auf die andere Seite, aber auch sie hat das Gleiche getan. Wenn du dir vorstellst, dass das ewig so weitergeht, verstehst du die Schleusen.
Lass uns einen Code schreiben, der dieses Szenario veranschaulicht. Zuerst werden wir ein paar Hilfsfunktionen einrichten, die das Beispiel vereinfachen. Um ein funktionierendes Beispiel zu haben, verwendet der Code hier mehrere Themen, die wir noch nicht behandelt haben. Ich rate davon ab, ihn im Detail zu verstehen, bis du das Paket sync gut kennst. Stattdessen empfehle ich dir, den Codeaufrufen zu folgen, um die wichtigsten Punkte zu verstehen, und dich dann dem zweiten Codeblock zuzuwenden, der das Herzstück des Beispiels enthält.
cadence:=sync.NewCond(&sync.Mutex{})gofunc(){forrangetime.Tick(1*time.Millisecond){cadence.Broadcast()}}()takeStep:=func(){cadence.L.Lock()cadence.Wait()cadence.L.Unlock()}tryDir:=func(dirNamestring,dir*int32,out*bytes.Buffer)bool{fmt.Fprintf(out," %v",dirName)atomic.AddInt32(dir,1)takeStep()ifatomic.LoadInt32(dir)==1{fmt.Fprint(out,". Success!")returntrue}takeStep()atomic.AddInt32(dir,-1)returnfalse}varleft,rightint32tryLeft:=func(out*bytes.Buffer)bool{returntryDir("left",&left,out)}tryRight:=func(out*bytes.Buffer)bool{returntryDir("right",&right,out)}
tryDirlässt eine Person versuchen, sich in eine Richtung zu bewegen und gibt zurück, ob sie erfolgreich war oder nicht. Jede Richtung wird durch die Anzahl der Personen dargestellt, die versuchen, sich in diese Richtung zu bewegen,dir.Zuerst erklären wir unsere Absicht, uns in eine Richtung zu bewegen, indem wir diese Richtung um eins erhöhen. Wir werden das Paket
atomicin Kapitel 3 im Detail besprechen. Für den Moment musst du nur wissen, dass die Operationen dieses Pakets atomar sind.Damit das Beispiel einen Livelock demonstrieren kann, muss sich jede Person mit der gleichen Geschwindigkeit, der sogenannten Kadenz, bewegen.
takeStepsimuliert eine konstante Kadenz zwischen allen Beteiligten.Hier erkennt die Person, dass sie nicht in diese Richtung gehen kann und gibt auf. Wir zeigen dies an, indem wir die Richtung um eins verringern.
walk:=func(walking*sync.WaitGroup,namestring){varoutbytes.Bufferdeferfunc(){fmt.Println(out.String())}()deferwalking.Done()fmt.Fprintf(&out,"%v is trying to scoot:",name)fori:=0;i<5;i++{iftryLeft(&out)||tryRight(&out){return}}fmt.Fprintf(&out,"\n%v tosses her hands up in exasperation!",name)}varpeopleInHallwaysync.WaitGrouppeopleInHallway.Add(2)gowalk(&peopleInHallway,"Alice")gowalk(&peopleInHallway,"Barbara")peopleInHallway.Wait()
Ich habe eine künstliche Grenze für die Anzahl der Versuche gesetzt, damit das Programm endet. In einem Programm, das eine Livelock hat, gibt es möglicherweise keine solche Begrenzung, deshalb ist es ein Problem!
Zuerst wird die Person versuchen, nach links zu gehen, und wenn das fehlschlägt, versucht sie, nach rechts zu gehen.
Mit dieser Variable kann das Programm warten, bis beide Personen entweder in der Lage sind, sich gegenseitig zu überholen, oder aufgeben.
Dies ergibt die folgende Ausgabe:
Alice is trying to scoot: left right left right left right left right left right Alice tosses her hands up in exasperation! Barbara is trying to scoot: left right left right left right left right left right Barbara tosses her hands up in exasperation!
Du kannst sehen, dass Alice und Barbara sich immer wieder in die Quere kommen, bevor sie schließlich aufgeben.
Dieses Beispiel zeigt einen sehr häufigen Grund, warum Livelocks geschrieben werden: Zwei oder mehr gleichzeitige Prozesse versuchen, ohne Koordination eine Blockade zu verhindern. Wenn die Personen im Flur miteinander vereinbart hätten, dass sich nur eine Person bewegt, gäbe es kein Livelock: Eine Person würde stillstehen, die andere würde sich auf die andere Seite bewegen und sie würden weitergehen.
Meiner Meinung nach sind Livelocks schwieriger zu erkennen als Deadlocks, weil es so aussehen kann, als würde das Programm arbeiten. Wenn ein Programm mit einem Livelock auf deinem Rechner läuft und du einen Blick auf die CPU-Auslastung wirfst, um festzustellen, ob es etwas tut, könntest du denken, dass es das tut. Je nach Livelock könnte es sogar andere Signale aussenden, die dich glauben lassen, es würde arbeiten. Und doch würde dein Programm die ganze Zeit über ein ewiges Spiel mit dem Flur-Mischmasch spielen.
Livelocks sind eine Untergruppe einer größeren Gruppe von Problemen, die als Starvation bezeichnet wird. Damit befassen wir uns als Nächstes.
Hungersnot
Starvation ist eine Situation, in der ein gleichzeitiger Prozess nicht alle Ressourcen erhält, die er zur Ausführung seiner Arbeit benötigt.
Als wir über Livelocks gesprochen haben, war die Ressource, die jeder Goroutine vorenthalten wurde, eine gemeinsame Sperre. Livelocks sollten getrennt von Starvation diskutiert werden, da bei einem Livelock alle gleichzeitigen Prozesse gleichermaßen ausgehungert werden und keine Arbeit verrichtet wird. Im Allgemeinen bedeutet Aushungern, dass es einen oder mehrere gierige Prozesse gibt, die einen oder mehrere gleichzeitige Prozesse auf unfaire Weise daran hindern, ihre Arbeit so effizient wie möglich oder überhaupt zu erledigen.
Hier ist ein Beispiel für ein Programm mit einer gierigen Goroutine und einer höflichen Goroutine:
varwgsync.WaitGroupvarsharedLocksync.Mutexconstruntime=1*time.SecondgreedyWorker:=func(){deferwg.Done()varcountintforbegin:=time.Now();time.Since(begin)<=runtime;{sharedLock.Lock()time.Sleep(3*time.Nanosecond)sharedLock.Unlock()count++}fmt.Printf("Greedy worker was able to execute %v work loops\n",count)}politeWorker:=func(){deferwg.Done()varcountintforbegin:=time.Now();time.Since(begin)<=runtime;{sharedLock.Lock()time.Sleep(1*time.Nanosecond)sharedLock.Unlock()sharedLock.Lock()time.Sleep(1*time.Nanosecond)sharedLock.Unlock()sharedLock.Lock()time.Sleep(1*time.Nanosecond)sharedLock.Unlock()count++}fmt.Printf("Polite worker was able to execute %v work loops.\n",count)}wg.Add(2)gogreedyWorker()gopoliteWorker()wg.Wait()
Das ergibt:
Polite worker was able to execute 289777 work loops. Greedy worker was able to execute 471287 work loops
Der gierige Worker hält während seiner gesamten Arbeitsschleife gierig an der gemeinsamen Sperre fest, während der höfliche Worker versucht, nur dann zu sperren, wenn er es muss. Beide Arbeiter machen die gleiche Menge an simulierter Arbeit (sie schlafen für drei Nanosekunden), aber wie du sehen kannst, hat der gierige Arbeiter in der gleichen Zeit fast doppelt so viel Arbeit erledigt!
Wenn wir davon ausgehen, dass beide Arbeiter die gleiche Größe des kritischen Abschnitts haben, kommen wir nicht zu dem Schluss, dass der Algorithmus des gierigen Arbeiters effizienter ist (oder dass die Aufrufe von Lock und Unlock langsam sind - das sind sie nicht), sondern dass der gierige Arbeiter seinen Zugriff auf die gemeinsame Sperre unnötigerweise über seinen kritischen Abschnitt hinaus ausgedehnt hat und die Goroutine des höflichen Arbeiters (durch Aushungern) daran hindert, ihre Arbeit effizient auszuführen.
Beachte hier unsere Technik, um die Aushungerung zu erkennen: eine Metrik. Hungersnot ist ein gutes Argument für die Aufzeichnung und Erfassung von Metriken. Eine Möglichkeit, Hunger zu erkennen und zu beheben, besteht darin, zu protokollieren, wann die Arbeit erledigt ist, und dann festzustellen, ob die Arbeitsrate so hoch ist, wie du sie erwartest.
Aushungern kann also dazu führen, dass sich dein Programm ineffizient oder falsch verhält. Das vorherige Beispiel zeigt eine Ineffizienz, aber wenn du einen nebenläufigen Prozess hast, der so gierig ist, dass er einen anderen nebenläufigen Prozess komplett daran hindert, seine Arbeit zu erledigen, hast du ein größeres Problem.
Wir sollten auch den Fall in Betracht ziehen, dass die Aushungerung von außerhalb des Go-Prozesses kommt. Denke daran, dass Hungersnot auch für CPU, Speicher, Datei-Handles, Datenbankverbindungen gelten kann: Jede Ressource, die gemeinsam genutzt werden muss, ist ein Kandidat für Hungersnot.
Bestimmung der Gleichzeitigkeitssicherheit
Schließlich kommen wir zu dem schwierigsten Aspekt der Entwicklung von nebenläufigem Code, der allen anderen Problemen zugrunde liegt: Menschen. Hinter jeder Codezeile steht mindestens ein Mensch.
Wie wir festgestellt haben, ist nebenläufiger Code aus unzähligen Gründen schwierig. Wenn du als Entwickler/in versuchst, all diese Probleme in den Griff zu bekommen, während du neue Funktionen einführst oder Fehler in deinem Programm behebst, kann es wirklich schwierig sein, das Richtige zu tun.
Wenn du mit einem leeren Blatt Papier anfängst und eine sinnvolle Methode zur Modellierung deines Problemraums entwickeln musst und Gleichzeitigkeit im Spiel ist, kann es schwierig sein, die richtige Abstraktionsebene zu finden. Wie machst du die Gleichzeitigkeit für den Aufrufer sichtbar? Welche Techniken wendest du an, um eine Lösung zu schaffen, die sowohl einfach zu benutzen als auch zu ändern ist? Welches ist der richtige Grad an Gleichzeitigkeit für dieses Problem? Obwohl es Möglichkeiten gibt, strukturiert über diese Probleme nachzudenken, bleibt es eine Kunst.
Als Entwickler/in, der/die sich mit bestehendem Code auseinandersetzt, ist es nicht immer offensichtlich, welcher Code die Gleichzeitigkeit nutzt und wie man den Code sicher nutzt. Nimm diese Funktionssignatur:
// CalculatePi calculates digits of Pi between the begin and end// place.funcCalculatePi(begin,endint64,pi*Pi)
Pi mit großer Genauigkeit zu berechnen ist etwas, das man am besten nebenbei macht, aber dieses Beispiel wirft eine Menge Fragen auf:
-
Wie mache ich das mit dieser Funktion?
-
Bin ich dafür verantwortlich, dass mehrere gleichzeitige Aufrufe dieser Funktion ausgeführt werden?
-
Es sieht so aus, als würden alle Instanzen der Funktion direkt auf die Instanz von
Pizugreifen, deren Adresse ich übergebe. Bin ich dafür verantwortlich, den Zugriff auf diesen Speicher zu synchronisieren, oder übernimmt der TypPidies für mich?
Eine Funktion wirft all diese Fragen auf. Stell dir ein Programm mittlerer Größe vor, und du kannst dir vorstellen, wie komplex die Gleichzeitigkeit sein kann.
Kommentare können hier wahre Wunder bewirken. Wie wäre es, wenn die Funktion CalculatePi stattdessen wie folgt geschrieben würde:
// CalculatePi calculates digits of Pi between the begin and end// place.//// Internally, CalculatePi will create FLOOR((end-begin)/2) concurrent// processes which recursively call CalculatePi. Synchronization of// writes to pi are handled internally by the Pi struct.funcCalculatePi(begin,endint64,pi*Pi)
Wir wissen jetzt, dass wir die Funktion einfach aufrufen können und uns keine Gedanken über Gleichzeitigkeit oder Synchronisierung machen müssen. Wichtig ist, dass der Kommentar diese Aspekte abdeckt:
-
Wer ist für die Gleichzeitigkeit verantwortlich?
-
Wie wird der Problemraum auf Gleichzeitigkeitsprimitiven abgebildet?
-
Wer ist für die Synchronisierung verantwortlich?
Wenn du Funktionen, Methoden und Variablen in Problembereichen erklärst, in denen es um Gleichzeitigkeit geht, tue deinen Kollegen und dir selbst einen Gefallen: Mach dich auf die Seite der ausführlichen Kommentare und versuche, diese drei Aspekte zu berücksichtigen.
Bedenke auch, dass die Zweideutigkeit dieser Funktion vielleicht darauf hindeutet, dass wir sie falsch modelliert haben. Vielleicht sollten wir stattdessen einen funktionalen Ansatz wählen und sicherstellen, dass unsere Funktion keine Nebeneffekte hat:
funcCalculatePi(begin,endint64)[]uint
Die Signatur dieser Funktion allein beseitigt alle Fragen der Synchronisierung, aber es bleibt immer noch die Frage, ob Gleichzeitigkeit verwendet wird. Wir können die Signatur noch einmal ändern, um ein weiteres Signal auszusenden, was passiert:
funcCalculatePi(begin,endint64)<-chanuint
Hier sehen wir die erste Verwendung eines so genannten Kanals. Aus Gründen, die wir später im Abschnitt "Kanäle" erkunden werden , deutet dies darauf hin, dass CalculatePi mindestens eine Goroutine hat und wir uns nicht die Mühe machen sollten, unsere eigene zu erstellen.
Diese Änderungen haben dann Auswirkungen auf die Leistung, die berücksichtigt werden müssen, und wir stehen wieder vor dem Problem, Klarheit und Leistung in Einklang zu bringen. Klarheit ist wichtig, weil wir möglichst sichergehen wollen, dass alle, die in Zukunft mit diesem Code arbeiten, das Richtige tun, und Leistung ist aus offensichtlichen Gründen wichtig. Beides schließt sich nicht gegenseitig aus, aber es ist schwierig, beides zu vereinen.
Betrachte nun diese Kommunikationsschwierigkeiten und versuche, sie auf Projekte in Teamgröße zu übertragen.
Wow, das ist ein Problem.
Die gute Nachricht ist, dass Go Fortschritte dabei gemacht hat, diese Art von Problemen einfacher zu lösen. Die Sprache selbst begünstigt Lesbarkeit und Einfachheit. Die Art und Weise, wie sie die Modellierung deines nebenläufigen Codes unterstützt, fördert Korrektheit, Zusammensetzbarkeit und Skalierbarkeit. Die Art und Weise, wie Go mit Nebenläufigkeit umgeht, kann sogar dazu beitragen, Problemdomänen klarer zu formulieren! Schauen wir uns an, warum dies der Fall ist.
Einfachheit im Angesicht der Komplexität
Bis jetzt habe ich ein ziemlich düsteres Bild gezeichnet. Nebenläufigkeit ist sicherlich ein schwieriges Gebiet in der Informatik, aber ich möchte dir Hoffnung machen: Diese Probleme sind nicht unlösbar, und mit den Nebenläufigkeits-Primitiven von Go kannst du deine nebenläufigen Algorithmen sicherer und klarer ausdrücken. Die Laufzeit- und Kommunikationsschwierigkeiten, die wir besprochen haben, sind mit Go keineswegs gelöst, aber sie sind deutlich einfacher geworden. Im nächsten Kapitel werden wir herausfinden, wie dieser Fortschritt zustande gekommen ist. Hier wollen wir uns ein wenig mit der Idee beschäftigen, dass Go's Nebenläufigkeitsprimitive es tatsächlich einfacher machen, Problemdomänen zu modellieren und Algorithmen klarer auszudrücken.
Die Laufzeitumgebung von Go übernimmt die meiste Arbeit und bietet die Grundlage für die meisten der Go-Nebenläufigkeitsfunktionen. Wir heben uns die Diskussion darüber, wie das alles funktioniert, für Kapitel 6 auf, aber hier werden wir besprechen, wie diese Dinge dein Leben einfacher machen.
Lassen Sie uns zunächst über Go's gleichzeitigen Garbage Collector mit niedriger Latenz sprechen. Unter Entwicklern gibt es oft Diskussionen darüber, ob Garbage Collectors in einer Sprache sinnvoll sind. Kritiker behaupten, dass Garbage Collectors die Arbeit in allen Problembereichen verhindern, die Echtzeitleistung oder ein deterministisches Leistungsprofil erfordern - dass es einfach nicht akzeptabel ist, alle Aktivitäten in einem Programm anzuhalten, um Müll zu beseitigen. Das hat zwar seine Berechtigung, aber die hervorragende Arbeit, die am Garbage Collector von Go geleistet wurde, hat die Zahl derer, die sich mit den Details der Speicherbereinigung von Go beschäftigen müssen, drastisch reduziert. Seit Go 1.8 liegen die Pausen bei der Speicherbereinigung in der Regel zwischen 10 und 100 Mikrosekunden!
Wie kann dir das helfen? Die Speicherverwaltung kann ein weiteres schwieriges Problemfeld in der Informatik sein, und wenn sie mit der Gleichzeitigkeit kombiniert wird, kann es außerordentlich schwierig werden, korrekten Code zu schreiben. Wenn du zu den meisten Entwicklern gehörst, die sich keine Gedanken über Pausen von 10 Mikrosekunden machen müssen, hat Go die Verwendung von Nebenläufigkeit in deinem Programm viel einfacher gemacht, da du nicht gezwungen bist, Speicher zu verwalten, geschweige denn über mehrere gleichzeitige Prozesse hinweg.
Die Laufzeit von Go sorgt auch automatisch dafür, dass gleichzeitige Operationen auf Betriebssystem-Threads gemultiplext werden. Was das genau bedeutet, erfährst du im Abschnitt über "Goroutines". Um zu verstehen, wie dir das hilft, musst du nur wissen, dass du damit nebenläufige Probleme direkt auf nebenläufige Konstrukte abbilden kannst, anstatt dich mit den Feinheiten des Startens und Verwaltens von Threads und der gleichmäßigen Verteilung der Logik auf die verfügbaren Threads zu beschäftigen.
Angenommen, du schreibst einen Webserver und möchtest, dass jede angenommene Verbindung gleichzeitig mit jeder anderen Verbindung bearbeitet wird. In einigen Sprachen musst du, bevor dein Webserver Verbindungen annimmt, wahrscheinlich eine Sammlung von Threads erstellen, die auch als Thread-Pool bezeichnet wird, und dann die eingehenden Verbindungen den Threads zuordnen. Dann musst du in jedem Thread, den du erstellt hast, eine Schleife über alle Verbindungen in diesem Thread laufen lassen, um sicherzustellen, dass sie alle CPU-Zeit erhalten. Außerdem musst du deine Logik für die Verbindungsbearbeitung so schreiben, dass sie pausieren kann, damit sie sich die Zeit mit den anderen Verbindungen fair teilt.
Puh! Im Gegensatz dazu würdest du in Go eine Funktion schreiben und ihrem Aufruf das Schlüsselwort go voranstellen. Alles andere, was wir besprochen haben, erledigt die Laufzeitumgebung automatisch! Wenn du dein Programm entwirfst, was denkst du, nach welchem Modell du eher zur Gleichzeitigkeit greifen würdest? Was denkst du, welches Modell wird eher richtig sein?
Go's Gleichzeitigkeits-Primitive machen es auch einfacher, größere Probleme zu komponieren. Wie wir im Abschnitt "Kanäle" sehen werden , bietet Go mit dem Kanal-Primitiv eine kompatible, nebenläufige und sichere Methode zur Kommunikation zwischen gleichzeitigen Prozessen.
Ich habe die meisten Details, wie diese Dinge funktionieren, überflogen, aber ich wollte dir einen Eindruck davon vermitteln, wie Go dich dazu einlädt, Nebenläufigkeit in deinem Programm zu nutzen, um deine Probleme auf klare und performante Weise zu lösen. Im nächsten Kapitel werden wir über die Philosophie der Gleichzeitigkeit sprechen und darüber, warum Go so viel richtig gemacht hat. Wenn du dich gleich in den Code stürzen willst, solltest du zu Kapitel 3 blättern.
1 Es gibt einen akzeptierten Vorschlag, der es der Laufzeit ermöglicht, partielle Deadlocks zu erkennen, aber er wurde noch nicht umgesetzt. Weitere Informationen findest du unter https://github.com/golang/go/issues/13759.
2 Wir haben keine Garantie dafür, in welcher Reihenfolge die Goroutinen ausgeführt werden oder wie lange sie brauchen, um zu starten. Es ist denkbar, wenn auch unwahrscheinlich, dass eine Goroutine beide Sperren erwirbt und freigibt, bevor die andere beginnt, und so den Deadlock vermeidet!
Get Gleichzeitigkeit in Go now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

