Chapter 10. Editing History
In this chapter, we cover various techniques for editing repository history. Earlier chapters covered simple cases of this, focused on correcting individual commits; here, weâre concerned with larger changes: moving branches, merging or splitting repositories, systematically altering an entire history, and so on.
The caution given earlier bears repeating here: you should not generally use any of these techniques on history that has already been published to other people! It will break their ability to use the push/pull mechanism, which may be very difficult and awkward to recover from. Only use these on private repositories, or if you can coordinate the change with everyone involved. Itâs easiest if all users of a shared repository commit and push all their outstanding changes, then simply reclone it after you make your edits. Or, they can use git rebase instead as we are about to describe, if theyâre a bit more adventurous.
Rebasing
We have already covered special cases of rebasing, especially for editing a sequence of commits at a branch tip; here, we consider the general case. The general purpose of git rebase is to move a branch from one location to another. Since commits are immutable, they canât actually be moved (their parent commits would change), so this entails making new commits with the same changesets and metadata: author, committer, timestamps, and so on. The steps Git follows during a rebase are as follows:
- Identify the commits to be moved (more accuratedly, replicated).
- Compute the corresponding changesets (patches).
- Move HEAD to the new branch location (base).
- Apply the changesets in order, making new commits preserving author information.
- Finally, update the branch ref to point to the new tip commit.
The process of making new commits with the same changesets as existing ones is called âreplayingâ those commits. Step 4 can be modified with an âinteractive rebaseâ (git rebase --interactive (-i)), allowing you to edit the commits in various ways as you move them; see the earlier discussion of this feature (Editing a Series of Commits).
The most general form of the command is:
$ git rebase [--onto newbase] [upstream] [branch]which means to replay the commit set upstream..branch starting at newbase. The defaults are:
-
upstream:HEAD@{upstream} - The upstream of the current branch, if any
-
branch: - HEAD
-
newbase: -
The
upstreamargument, whatever its default or user-supplied value is
For example, given the commit graph in Figure 10-1, the command git rebase --onto C master topic would move the topic branch as shown in Figure 10-2.

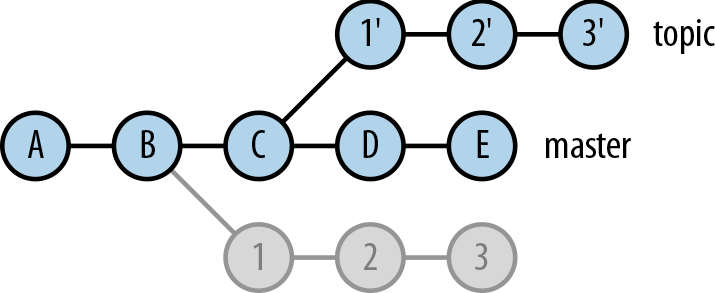
1â², 2â², and 3â² are new commits replicating the changesets of commits 1, 2, and 3. Calling B the âbaseâ of the original (unmerged portion of) the topic branch, this changes the base from B to C, thus ârebasingâ the branch.
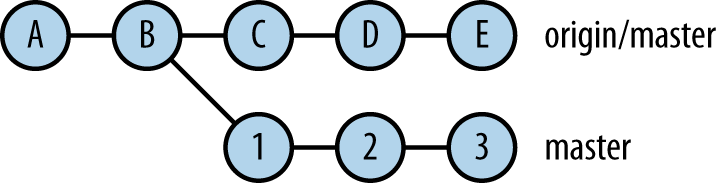
The behavior of the default arguments to git rebase reveals the simplest use of rebasing: keeping a sequence of local commits at the tip of a branch as the upstream progresses, rather than performing a merge. After doing a git fetch, you see that your local master branch has diverged from its upstream counterpart (see Figure 10-3).
Following the preceding defaults, the simple command:
$ git rebaseactually means:
$ git rebase --onto origin/master origin/master master
which in turn means to replay the commit set origin/master..master at origin/master, resulting in the change shown in Figure 10-4.

Your local commits 1, 2, and 3 have been shifted forward to remain based off the tip of the upstream master. This is such a common use of rebasing for certain workflows that there is a --rebase option to git pull that runs git rebase in between its fetch and merge steps (see Pull with Rebase). In this case, the final step merging origin/master into master will do nothing, since if the rebase is successful, the upstream branch origin/master is now already contained in the local master.
Undoing a Rebase
The final step of a successful rebase is to repoint the ref of the branch being moved, from the old tip commit to the new one. The original commits are not immediately expunged in any way, but merely abandoned: they are no longer reachable in the commit graph from any branch, and will eventually be garbage collected by Git if they remain that way for some time. To undo the rebase operation, then, all you need to do is move the branch ref back to its original spot, which you can discover using the reflog. After the git rebase, for example, your reflog would look something like this:
$ git log -g
b61101ac HEAD@{0}: rebase finished: returning to
refs/heads/master
b61101ac HEAD@{1}: rebase: 3
6f554c9a HEAD@{2}: rebase: 2
cb7496ab HEAD@{3}: rebase: 1
baa5d906 HEAD@{4}: checkout: moving from master to
baa5d906...
e3a1d5b0 HEAD@{5}: commit: 3
The checkout step is the beginning of the rebase as Git moves HEAD to the new base, the tip of the upstream origin/master (here at commit baa5d906). The rebase steps replay commits 1, 2, and 3 at the new location, and in the final step, the local master branch (full ref name refs/heads/master) is reset to the new tip commit. In the earliest reflog entry, you can see when you made your original version of commit 3, with commit ID e3a1d5b0. To return to that state, all you need to do is:
$ git reset --hard e3a1d5b0The original tip commit might not be at the same spot as shown here, since that depends on the exact sequence of commands you used, but it will show up somewhere earlier in the reflog.
Importing from One Repository to Another
Suppose you would like to combine two repositoriesâsay, to import the entire content of repository B as a subdirectory b of repository A. You could just copy the working tree of B into A and then add and commit it, of course, but you want to retain the history of repository B as well as the content. Though thatâs easy to say, itâs not immediately clear what this means. The Git history of each repository consists of an entire graph of individual content snapshots, branching and merging in possibly complex ways over time, and there are different ways in which you might want to combine the two. In this section, we discuss a few of them.
Importing Disconnected History
The simplest way to combine two repositories is simply to import the whole commit graph of one into the other, without connecting them in any way. Ordinarily, a repository has a single âroot commit,â that is, a commit with no parentsâthe first commit created after the repository was initialized, of which all other commits are descendants. However, there is nothing preventing you from having multiple root commits in a single repository, in which case the commit graph consists of multiple disconnected regions; in Figure 10-5, commits A and 1 are both root commits.

Hereâs how to import repository B into repository A in this fashion:
$ cd A
$ git remote add B URL
$ git fetch B
warning: no common commits
...
[new branch] master -> B/master
[new branch] zorro -> B/zorro
$ git for-each-ref --shell \
--format='git branch --no-track %(refname:short)
%(refname:short)' \
'refs/remotes/B/*' | sed -e 's:/:-:' | sh -x
$ git branch
B-master
B-zorro
master
$ git remote rm B
This recipe uses git for-each-ref, a versatile tool for generating scripts on the fly that apply to a given set of refs (in this case, branches). For each named ref, here selected by the pattern refs/remotes/B/* (all tracking branches for the remote B), it generates a separate git branch command substituting the names marked with %(â¦) to reflect that ref. This series of commands then goes through the Unix command sed rewriting B/foo to B-foo, and finally, the commands are run by feeding them into the Bourne shell (sh). (See git-for-each-ref(1) for more detail on this handy command for Git automation.)
The case of pulling in a completely disconnected commit graph is sufficiently unusual that Git warns you about it, saying that the repository youâre fetching has âno common commitsâ with this one.
After the fetch command, Git has copied the entire commit graph of B into the object database of A, but the only references in A to the new branches are remote-tracking ones: B/master and B/zorro. To finish incorporating B into A, we need to make local branches for these. The git for-each-ref incantation prepares and runs a set of Git commands that create a local branch named B-x for each remote branch B/x, by running git branch --no-track B-x B/x. The --no-track option avoids creating unnecessary tracking relationships that would just be removed later. We prefix the new branch names with B-, since there may be clashes (as here, where there is a master branch in each repository). Finally, when done, we remove the remote B, since we do not intend to continue tracking the other repository; the remote was just a mechanism to perform the import.
This demonstrates a general way of doing it; you can of course just run the appropriate git branch commands yourself to name the new branches as you wish, if there are few of them, or rename them afterward with git branch -m .old new
Although this is the easiest method of combining two histories, it is also not usually what you want to do, because you canât use the Git merge mechanism on branches that were originally part of distinct histories. This is because git merge looks for a âmerge baseâ: a common ancestor commit of the branches being mergedâand in this case, there is no such commit. You might use this technique if you have rearranged the history of a repository, but want to keep the original history around for reference, and itâs more convenient to have it both in one repository than split over two.
Importing Linear History
To import history so that it is connected to the commit graph of the receiving repository, you canât just use the existing commits of the donor repository as before, since you need new parent commit pointers to connect the two histories and you canât actually change commits. Instead, you must make new commits introducing the same content (as with git rebase). If the history you want to import is linearâeither the entire repository, or the branch youâre interested inâthen you can use git format-patch and git am to do this easily (these commands are described more fully in Patches with Commit Information). Hereâs a formula for adding the complete history of branch foo in repository B to the current branch in repository A:
$ cd A $ git --git-dir /path/to/B/.git format-patch --root --stdout foo | git am
This formats the commits on branch foo in repository B as a series of patches with accompanying metadata (author, committer, timestamps, and so on), and feeds that into git am, which applies the patches as new commits in repository A. Note that you canât refer to B here directly as a remote repository with a URL; you need a local copy to use, for which you can just clone B and check out the branch you want to import.
Because you are now applying patches rather than importing commits whole, you might encounter conflicts if the source and destination repositories have overlapping content (the same filenames). To avoid this, you can tell git am to prepend a directory to all filenames with --directory, thus depositing the files in the imported history inside a new directory. Combined with the -pn option, which first removes n leading directories from those filenames, and with limiting the source files via an argument to git format-patch, you can import a particular directory or other subset of files into a new directory without conflicts. Extending the preceding example:
$ cd A $ git --git-dir /path/to/B/.git format-patch --root --stdout foo -- src | git am -p2 --directory dst
This imports the history on the branch foo in repository B, limited to files in the directory src, and places those files in directory dst instead in repository A.
Without --root, just giving a rev foo means foo..HEAD: the recent commits on the current branch that are not in the history of foo. You can also give a range expression of your own to specify the commits to include (e.g., 9ec0eafb..master).
Warning
If the source branch history is not linear (contains merge commits), git format-patch wonât complain; it will just produce patches for all the nonmerge commits. This is likely to cause conflicts; see the next section.
Importing Nonlinear History
Because the git format-patch/git am technique works only on a linear source history, here is a recipe for importing a branch with a nonlinear history, using git rebase instead. You can use the present procedure on linear history as well, if you find the previous one too slow or unwieldy (as it might be; itâs simpler, but itâs not what those commands are really intended to do).
The following example adds the history of the branch isis in a remote repository to the tip of the current branch in this one (here, the master branch):
# Add the source repository as a temporary remote # named âtempâ. $ git remote add temp URL # Fetch the branch âisisâ from the remote. $ git fetch temp isis ... * branch isis -> FETCH_HEAD # Make a local branch named âimportâ for the remote # branch we want to bring in. $ git branch import FETCH_HEAD # Replay the âimportâ branch commits on the current # branch, preserving merges. $ git rebase --preserve-merges --root --onto HEAD import ... Successfully rebased and updated refs/heads/import. # Finally, fast-forward the local branch (master) to # its new tip (where âimportâ is now), and remove the # temporary branch and remote. $ git checkout master Switched to branch 'master' $ git merge import Updating dffbfac7..6193cf87 Fast-forward ... $ git branch -d import Deleted branch import (was 6193cf87). $ git remote rm temp
This technique copies the source branch into the current repository under a temporary name, uses git rebase to graft it onto the tip of the current branch, then moves the local branch up to its new tip and deletes the temporary import branch.
Unfortunately, git rebase lacks the capabilities provided by the various arguments and options to git format-patch and git am shown earlier, which let you relocate files as you import to avoid pathname conflicts. To get the same result, youâll need to clone the source repository and rearrange it first before importing from it. The section The Big Hammer: git filter-branch shows how to do this.
Commit Surgery: git replace
Sometimes, you really just need to replace a single commitâbut itâs buried in the middle of a complex history with multiple branches that would be difficult to rewrite using git rebase -i. For example, suppose you accidentally used the wrong committer name at one point, perhaps because you had GIT_COMMITTER_NAME set and forgot to change it for this repository with git config user.name:
$ git log --format='%h %an'
...
0922daf4 Richard E. Silverman
6426690c Richard E. Silverman
03f482d6 Bozo the Clown
27e9535f Richard E. Silverman
78d481d3 Richard E. Silverman
...Git has a command, git replace, which allows you to perform âcommit surgeryâ by replacing any commit with a different one, without disturbing the commits around it. Now, your first instinct at this point should be to say, âThatâs impossibleâ; weâve explained before that because commits point to their parents, itâs impossible to alter a commit that has children without recursively altering all commits after that point in the history as well. Thatâs still true, and git replace is actually a trick, as weâll see.
To fix commit 03f482d6, we first check it out and amend it with the correct author name, creating the new commit we want to use as a replacement:
$ git checkout 03f482d6 Note: checking out '03f482d6'. You are in 'detached HEAD' state... $ git commit --amend --reset-author -C HEAD [detached HEAD 42627abe] add big red nose ...
Now we have a new commit, 42627abe, which has the same content and parents as the faulty commit (and now, the correct author name). It is sitting off to the side on the commit graph shown in Figure 10-6.

And now we just need to get commit 6426690c to âbelieveâ that it has 42627abe as a parent instead of 03f482d6. The magic command is:
$ git replace 03f482d6 42627abeAnd now, after returning to the original location (say, master), we see this:
$ git log --format='%h %an'
...
0922daf4 Richard E. Silverman
6426690c Richard E. Silverman
03f482d6 Richard E. Silverman
27e9535f Richard E. Silverman
78d481d3 Richard E. Silverman
...This is, quite simply, a lie. This log claims that commit 03f482d6 now has a different author but the same commit ID, which is effectively impossible. What has happened is that git replace manages a list of object replacements, recorded in the namespace refs/replace; the name of a ref there is the ID of an object to replace, and its referent is the ID of the replacement:
$ git show-ref | grep refs/replace
42627abe6d4b1e19cb55⦠refs/replace/03f482d654930f7aa1â¦
While Git operates, whenever it retrieves the contents of an object in the object database it checks the replacement list first, and silently substitutes the contents of the replacement object, if any. Thus, in the preceding example, Git still displays the original commit ID, but shows the corrected author (which is in the content of the replacement commit).
Keeping It Real
The replacement list is an artifact of your repository; it alters your view of the commit graph, but not the graph itself. If you were to clone this repository or push to another one, the replacement would not be visible there. To make it âreal,â we have to actually rewrite all the subsequent commits, which you can do thus:
$ git filter-branch -- --allbut see the next section on git filter-branch for more on that command.
The usual workflow with this feature, then, is as follows:
-
Use
git replaceto make the commit graph appear as you want it. -
Use
git filter-branchto reify the change. - Push the changes elsewhere, if necessary.
You probably donât want to push while you have replacements in force, since you donât really know what youâre pushing!
Note
There is an older Git feature called âgraftsâ that does something similar; you edit the file .git/info/grafts to contain directives explicitly altering the parent list for given commits. Itâs harder to use, though, and is supplanted by git replace.
Warning
git replace affects only the commit you replace; even when you apply the replacement with git filter-branch, changes you make to the content (tree) of a commit do not ripple through to child commits. For example, suppose in the amended commit earlier you had deleted a file as well as fixed the author name. You might expect that this would cause that file to disappear from the entire history starting at that point, but it would not; instead, it would simply reappear in subsequent commits, since you did not change the trees of those commits. Use git rebase -i to effect such changes.
The Big Hammer: git filter-branch
git filter-branch is the most general tool for altering the history of a repository. It walks the portion of the commit graph you specify (by default, the current branch), applying various filters you supply and rewriting commits as necessary. You can use it to make wholesale programmatic alterations to the entire history. Since this is an advanced command, we will just sketch its operation and refer the reader to git-filter-branch(1) for more detail.
You can apply the following filters, whose string arguments are passed to the shell. When they run, the environment contains the following variables reflecting the commit being rewritten:
-
GIT_COMMIT(commit ID) -
GIT_AUTHOR_NAME -
GIT_AUTHOR_EMAIL -
GIT_AUTHOR_DATE -
GIT_COMMITTER_NAME -
GIT_COMMITTER_EMAIL -
GIT_COMMITTER_DATE
The filters are:
-
--env-filter -
Modifies the environment in which the commit will happen (e.g., you can change the author name by setting and exporting
GIT_AUTHOR_NAME). -
--tree-filter -
Modifies commit contents by altering the working tree. Git treats the resulting tree as if you had run
git add -Af, reflecting all new and deleted files while ignoring the usual âignoreâ rules in .gitignore and so on. -
--index-filter -
Modifies commit contents by altering the index. If you can effect the changes you want solely by manipulating the index, then this is much faster than
--tree-filtersince it does not have to check out the working tree. We give an example of this in Expunging Files. -
--parent-filter - Modifies the commitâs parent list, transforming the list from stdin to stdout. The list is in the format specified by git-commit-tree(1).
-
--msg-filter - Modifies the commit message, transforming the message from stdin to stdout.
-
--commit-filter -
Git runs this instead of the normal
git commit-treeto actually perform the commit. -
--tag-name-filter - Transforms the names of tags pointing to rewritten objects from stdin to stdout.
The value of this option is not a shell command, but rather a directory name:
-
--subdirectory-filter - Consider only history relevant to the given directory, and rewrite pathnames to make it the new project root. This creates a new history containing only files in that directory, with it as the new top of the repository.
As a hedge against mistakes, git filter-branch stores the original branch refs in the namespace refs/original (which you can change with --original). It will refuse to overwrite existing original refs without --force.
The arguments to git filter-branch are interpreted as by git rev-list, selecting the commits to be visited; to use arguments beginning with hyphens, separate them from the filter-branch options with -- as usual. For example, the default argument is HEAD, but you can rewrite all branches with one command: git filter-branch -- --all.
It does not make sense to specify commits to rewrite by commit ID:
$ git filter-branch 27e9535f
Which ref do you want to rewrite?because when done, git filter-branch needs to update an existing ref to point to the rewritten branch. Ordinarily, you will give a branch name. If you limit the commit range using the negation of a ref, such as master..topic (equivalent to ^master topic), then only the refs mentioned in the positive sense will be updated; here, Git will visit the commits on topic that are not on master, but update only the topic branch when done.
Examples
Expunging Files
Suppose you discover that you have accidentally littered your history with some cruft, such as *.orig and *.rej files from patching, or *~ backup files from Emacs. You can expunge all such files from your entire project history with this command:
$ git filter-branch --index-filter 'git rm -q --cached --ignore-unmatch *.orig *.rej *~' -- --all
You might then add these patterns to your ignore rules, to prevent this from happening again.
Shifting to a Subdirectory
This recipe (using bash syntax) shifts the root of the current project into a subdirectory named sub:
$ git filter-branch --index-filter 'git ls-files -s | perl -pe "s-\\t-$&sub/-" | GIT_INDEX_FILE=$GIT_INDEX_FILE.new git update-index --index-info && mv "$GIT_INDEX_FILE.new" "$GIT_INDEX_FILE"' HEAD
This is adapted from an example in git-filter-branch(1), but using Perl instead of sed for better portability (the original does not work with BSD-style sed commands, such as the one in OS X). It works by rewriting the output of git ls-files like so:
100644 6b1ad9fa764e36⦠0 bar 100644 e69de29bb2d1d6⦠0 foo/bar
which becomes:
100644 6b1ad9fa764e36⦠0 sub/bar 100644 e69de29bb2d1d6⦠0 sub/foo/bar
and updating the index accordingly for each commit. You can use this on a clone of the source repository in the git rebase recipe given earlier, to import one repository history into a subdirectory of another.
Updating Tags
In Commit Surgery: git replace, we said to use git filter-branch to apply object replacements made with git replace to the commit graph. There is a problem with this as given, though: it breaks any existing tags pointing to rewritten commits, since they remain untouched and continue to point to the old commits no longer on the rewritten branches. You can avoid this like so:
$ git filter-branch --tag-name-filter cat -- --allSince --tag-name-filter rewrites tag names from stdin to stdout, cat acts as the identity filter and has Git rewrite all tags with their existing names unchanged as needed.
Notes
Keep in mind when importing history in these ways, that while Git preserves the author timestamps in rewritten commits, git log orders its output by the commit timestamps, which will be new. The new history may thus show commits in an unexpected order. This is correct though: the commitâs content was created at one time, and that content was then committed to another repository at a later time. Unfortunately, git log does not have an option to order by author timestamp instead.
Get Git Pocket Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

