Chapter 4. How to Version, Build, and Test Your Code
In the first few chapters of this book, you wrote code using a variety of languages and tools, including JavaScript (Node.js), Bash, YAML (Ansible), HCL (OpenTofu, Packer), and so on. What did you do with all of that code? Is it just sitting on your computer? If so, that’s fine for learning and experimenting, where you’re the only one touching that code, but with most real-world code, software development is a team sport, and that means you need to figure out how to support many developers collaborating safely and efficiently on the same codebase.
In particular, you need to figure out how to solve the following problems:
- Code access
-
All the developers on your team need a way to access the same code so they can collaborate on it. Moreover, as multiple developers make changes to that code, you need some way to merge their changes together, handling any conflicts that arise, and ensuring that no one’s work is accidentally lost or overwritten.
- Automation
-
As teams of developers work on the code, there are a number of tasks that will come up again and again, such as downloading dependencies, building the code, packaging the code, and so on. To save everyone time, and to ensure consistency, you need some way to automate these common operations.
- Correctness
-
It’s hard enough to make your own code work, but when multiple people are modifying that code at the same time, you need to find a way to prevent constant bugs and breakages from slipping in.
To solve these problems, modern companies uses a combination of the following tools, which are the focus of this chapter:
-
Version control
-
Build system
-
Automated testing
The following sections will dive into each of these, and along the way, you’ll go through examples of using Git locally, opening pull requests in GitHub, using NPM to manage your build and dependencies, and writing automated tests for your Node.js and OpenTofu code. Let’s get started by understanding what version control is, why it’s important, and some recommended patterns for using it.
Version Control
A version control system (VCS) is a tool that allows you to store source code, share it with your team, integrate your work together, and track changes over time. I cannot imagine developing software without using a VCS. It’s a central part of every modern software delivery process. And there’s nothing modern about it: nearly 25 years ago, using version control was item #1 on the Joel Test (a quick test you can use to rate the quality of a software team), and the first version control system was developed roughly 50 years ago.
Despite all that, I still come across a surprising number of developers who don’t know how or why to use version control. If you’re one of these developers, it’s nothing to be ashamed of, and you’ll find that if you take a small amount of time to learn it now, it’s one of those skills that will benefit you for years to come.
Here’s what the next few sections will cover:
- Version control primer
-
A quick intro to version control concepts.
- Example: a crash course on Git
-
Get hands-on practice using version control by learning to work with Git.
- Example: store your code in GitHub
-
Get even more hands-on practice by learning to push your Git repo to GitHub.
- Version control recommendations
-
Learn how to write good commit messages, keep your codebase consistent, review code to catch bugs and spread knowledge, and ensure your version control system is protected against common security threats.
If you’re already familiar with version control and Git, feel free to skip the next two sections. However, I recommend you still go through the third section with the GitHub example, as many of the subsequent examples in the book build on top of GitHub (e.g., using GitHub actions for CI / CD in Chapter 5).
Version Control Primer
Have you ever written an essay in Microsoft Word? Maybe you start with a file called essay.doc, but then you realize you need to do some pretty major changes, so you create essay-v2.doc; then you decide to remove some big pieces, but you don’t want to lose them, so you put those in essay-backup.doc, and move the remaining work to essay-v3.doc; maybe you work on the essay with your friend Anna, so you email her a copy, and she starts making edits; at some point, she emails you back the doc with her updates, which you then manually combine with the work you’ve been doing, and save that under the new name essay-v4-anna-edit.doc; you keep emailing back and forth, and you keep renaming the file, until minutes before the deadline, you finally submit a file called something like essay-final-no-really-definitely-final-revision3-v58.doc.
Believe it or not, what you’re doing is essentially version control. You could represent it with the diagram shown in Figure 4-1:
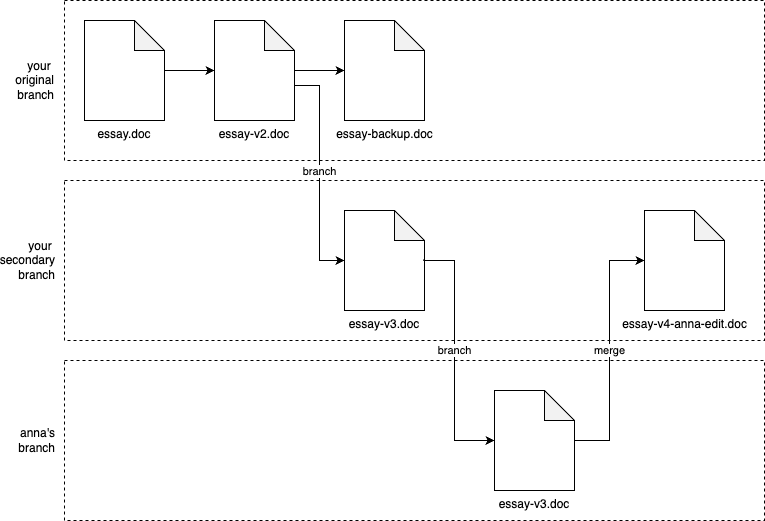
Figure 4-1. Visualizing your process with Word documents as version control
You start with essay.doc, and after some major edits, you commit your changes to a new revision called essay-v2.doc. Then, you realize that you need to break off in a new direction, so you could say that you’ve created a new branch from you original work, and in that new branch, you commit another new revision called essay-v3.doc. When you email Anna essay-v3.doc, and she starts her work, you could say that she’s working in yet another branch. When she emails you back, you manually merge the work in your branch and her branch together to create essay-v4-anna-edit.doc.
What you’ve just seen is the essence of version control: commits, branches, and merges. Admittedly, manually emailing and renaming Word docs isn’t a very good version control system, but it is version control!
A better solution would be to use a first-class VCS, which can perform these operations more effectively. The basic idea with a VCS is as follows:
- Repositories
-
You store files (code, documents, images, etc.) in a repository (repo for short).
- Branches
-
You start with everything in a single branch, often called something like
main. At any time, you can create a new branch from any existing branch, and work in your own branch independently. - Commits
-
Within any branch, you can edit files, and when you’re ready to store your progress in a new revision, you create a commit with your updates. The commit typically records not only the changes to the files, but also who made the changes, and a commit message that describes the changes.
- Merges
-
At any time, you can merge branches together. For example, it’s common to create a branch from
main, work in that branch for a while, and then merge your changes back intomain. - Conflicts
-
VCS tools can merge some types of changes completely automatically, but if there is a conflict (e.g., two people changed the same line of code in different ways), the VCS will ask you to resolve the conflict manually.
- History
-
The VCS tracks every commit in every branch in a commit log, which lets you see the full history of how the code changed, including all previous revisions of every file, what changed between each revision, and who made each change.
Learning about all these terms and concepts is useful, but really, the best way to understand version control is to try it out, as in the next section.
Example: A Crash Course on Git
There have been many version control systems developed over the years, including CVS, Subversion, Perforce, and Mercurial, but these days, the most popular, by far, is Git. According to the 2022 StackOverflow Developer Survey, 93% of developers use Git (96% if you look solely at professional developers). So if you’re going to learn one VCS, it should be Git.
Git basics
If you don’t have it already installed, follow these docs to install Git on your computer. Next, let Git know your name and email, as shown in Example 4-1:
Example 4-1. Configure your username and email in Git
$gitconfig--globaluser.name"<YOUR NAME>"$gitconfig--globaluser.email"<YOUR EMAIL>"
Create a new, empty folder on your computer just for experimenting with Git. For example, you could create a folder called git-practice within the system temp folder:
$mkdir/tmp/git-practice$cdgit-practice
Within the git-practice folder, write some text to a file called example.txt:
$echo'Hello, World!'>example.txt
It would be nice to have some version control for this file. With Git, that’s easy. You can turn any folder into a Git
repo by running git init:
$gitinitInitialized empty Git repository in /tmp/git-practice/.git/
The contents of your folder should now look something like this:
$tree-aL1.├── .git└── example.txt
You should see your original example.txt file, plus a new .git folder. This .git folder is where Git will record all the information about your branches, commits, revisions, and so on.
At any time, you can run the git status command to see the status of your repo:
$gitstatusOn branch mainNo commits yetUntracked files:(use "git add <file>..." to include in what will be committed)example.txt
The status command is something you’ll run often, as it gives you several useful pieces of information: what branch
you’re on (main is the default branch when you create a new Git repo); any commits you’ve made; and any changes
that haven’t been committed yet. To commit your changes, you first need to add the file(s) you want to commit to the
staging area using git add:
$gitaddexample.txt
Try running git status one more time:
$gitstatusOn branch mainNo commits yetChanges to be committed:(use "git rm --cached <file>..." to unstage)new file: example.txt
Now you can see that example.txt is in the staging area, ready to be committed. To commit the changes, use the
git commit command, passing in a description of the commit via the -m flag:
$gitcommit-m"Initial commit"
Git is now storing example.txt in its commit log. You can see this by running git log:
$gitlogcommit 7a536b3367981b5c86f22a27c94557412f3d915a (HEAD -> main)Author: Yevgeniy BrikmanDate: Sat Apr 20 16:01:28 2024 -0400Initial commit
For each commit in the log, you’ll see the commit ID, author, date, and commit message. Take special note of the commit ID: each commit has a different ID that you can use to uniquely identify that commit, and many Git commands take a commit ID as an argument. Under the hood, a commit ID is calculated by taking the SHA-1 hash of the contents of the commit, all the commit metadata (author, date, and so on), and the ID of the previous commit (you’ll learn more about SHA-1 and other hash functions in [Link to Come]).1 Commit IDs are 40 characters long, but in most commands, you can use just the first 7 characters, as that will be unique enough to identify commits in all but the largest repos.
Let’s make another commit. First, make a change to example.txt:
$echo'New line of text'>>example.txt
This adds a second line of text to example.txt. Run git status once again:
$gitstatusOn branch mainChanges not staged for commit:(use "git add <file>..." to update what will be committed)(use "git restore <file>..." to discard changes in working directory)modified: example.txt
Now Git is telling you that it sees changes locally, but these changes have not been added to the staging area. To see
what these changes are, run git diff:
$gitdiffdiff --git a/example.txt b/example.txtindex 8ab686e..3cee8ec 100644--- a/example.txt+++ b/example.txt@@ -1 +1,2 @@Hello, World!+New line of text
You should use git diff frequently to check what changes you’ve made before committing them. If the changes look good,
use git add to stage the changes and git commit to commit them:
$gitaddexample.txt$gitcommit-m"Add another line to example.txt"
Now, try git log again, adding the --oneline flag to get more concise output:
$gitlog--oneline02897ae (HEAD -> main) Add another line to example.txt0da69c2 Initial commit
Now you can see both of your commits, including their commit messages. This commit log is very powerful:
- Debugging
-
If something breaks in your code, the first question you typically ask is, “what changed?” The commit log gives you an easy way to answer that question.
- Reverting
-
You can use
git revert <ID>to automatically create a new commit that reverts all the changes in the commit with ID<ID>, thereby undoing the changes in that commit, while still preserving your Git history. Or you can usegit reset --hard <ID>to get rid of all commits after<ID>entirely, including removing them from history (use with care!). - Comparison
-
While
git diffcompares your local changes to the latest in the current branch, you can also usegit diff <COMMIT_1> <COMMIT_2>to compare any two commits, passing in IDs of those commits as arguments. - Author
-
You can use
git blameto annotate each line of a file with information about the last commit that modified that file, including the date, the commit message, and the author. Although you could use this to blame someone for causing a bug, as the name implies, the more common use case is to help you understand where any give piece of code came from, and why that change was made.
So far, all of your commits have been on the default branch (main), but in real-world usage, you typically use
multiple branches, which is the focus of the next section.
Git branching and merging
Let’s practice creating and merging Git branches. To create a new branch and switch to it, use the git checkout
command with the -b flag:
$gitcheckout-btestingSwitched to a new branch 'testing'
To see if it worked, you can use git status, as always:
$gitstatusOn branch testingnothing to commit, working tree clean
You can also use the git branch command at any time to see what branches are available and which one you’re on:
$gitbranchmain* testing
Any changes you commit now will go into the testing branch. To try this out, modify example.txt once again:
$echo'Third line of text'>>example.txt
Next, stage and commit your changes:
$gitaddexample.txt$gitcommit-m"Added a 3rd line to example.txt"
If you use git log, you’ll see your three commits:
$gitlog--oneline5b1a597 (HEAD -> testing) Added a 3rd line to example.txt02897ae (main) Add another line to example.txt0da69c2 Initial commit
But that third commit is only in the testing branch. You can see this by using git checkout to switch back to the
main branch:
$gitcheckoutmainSwitched to branch 'main'
Check the contents of example.txt: it’ll have only two lines. And if you run git log, it’ll have only two commits.
So each branch gives you a copy of all the files in the repo, and you can modify them in that branch, in isolation, as
much as you want, without affecting any other branches.
Of course, working forever in isolation doesn’t usually make sense. You eventually will want to merge your work back
together. One way to do that with Git is to run git merge to merge the contents of the testing branch into the
main branch:
$gitmergetestingUpdating c4ff96d..c85c2bfFast-forwardexample.txt | 1 +1 file changed, 1 insertion(+)
You can see that Git was able to merge all the changes automatically, as there were no conflicts between the main and
testing branches. If you now look at example.txt, it will have three lines in it, and if you run git log, you’ll
see three commits.
Get your hands dirty
Here are a few exercises you can try at home to go deeper:
-
Learn how to use the
git tagcommand to create tags. -
Learn to use
git rebase. How does it compare togit merge?
Now that you know how to run Git locally, on your own computer, you’ve already learned something useful. If nothing else, you now have a way to store revisions of your work that’s much more effective than essay-v2.doc, essay-v3.doc, etc. But to see the full power of Git, you’ll want to use it with other developers, which is the focus of the next section.
Example: Store your Code in GitHub
Git is a distributed VCS, which means that every team member can have a full copy of the repository, and do commits, merges, and branches, completely locally. However, the most common way to use Git is to pick one copy of the repository as the central repository that will act as your source of truth. This central repo is the one everyone will initially get their code from, and as you make changes, you always push them back to this central repo.
The typical way to run such as a central repo is to use a hosting service. These not only host Git repos for you, but they also provide a number of other useful features, such as web UIs, user management, development workflows, issue tracking, security tools, and so on. The most popular hosting services for Git are GitHub, GitLab, and BitBucket. Of these, GitHub is the most popular by far.
In fact, you could argue that GitHub is what made Git popular. GitHub provided a great experience for hosting repos and collaborating with team members, and it has become the de facto home for most open source projects. So if you wanted to use or participate in open source, you often had to learn to use Git, and before you knew it, Git and GitHub were the dominant players in the market. Therefore, it’s a good idea to learn to use not only Git, but GitHub as well.
Let’s push the example code you’ve worked on while reading this book to GitHub. Go into the folder where you have your code:
$cdfundamentals-of-devops
If you’ve done all the examples up to this point, the contents of this folder should look something like this:
$tree-L2.├── ch1│ ├── ec2-user-data-script│ └── sample-app├── ch2│ ├── ansible│ ├── bash│ ├── packer│ └── tofu└── ch3├── ansible├── docker├── kubernetes├── packer└── tofu
Turn this into a Git repo by running git init:
$gitinitInitialized empty Git repository in /fundamentals-of-devops/.git/
If you run git status, you’ll see that there are no commits and no files staged for commit:
$gitstatusOn branch mainNo commits yetUntracked files:(use "git add <file>..." to include in what will be committed)ch1/ch2/ch3/
Before staging these files, you should create a new file in the root of the repo called .gitignore, with the contents shown in Example 4-2:
Example 4-2. The gitignore file (.gitignore)
*.tfstate *.tfstate.backup *.tfstate.lock.info
.terraform
*.key
*.zip
node_modules coverage
The .gitignore file specifies files you do not want Git to track:
OpenTofu state should not be checked into version control. You’ll learn why not, and the proper way to store state files in Chapter 5.
The .terraform folder is used by OpenTofu as a scratch directory and should not be checked in.
The Ansible examples in earlier chapters store SSH private keys locally in .key files. These are secrets, so they should be stored in an appropriate secret store (as you’ll learn about in [Link to Come]), and not in version control.
The
lambdamodule from Chapter 3 creates a Zip file automatically. This is a build artifact and should not be checked in.The node_modules and coverage folders are also scratch directories that should not be checked in. You’ll learn more about these folders later in this chapter.
I usually commit the .gitignore file first to ensure I don’t accidentally commit other files that don’t belong in version control:
$gitadd.gitignore$gitcommit-m"Add .gitignore"
With that done, you can use git add . to stage all the files and folders in your fundamentals-of-devops folder, and
then commit them:
$gitadd.$gitcommit-m"Example code for first few chapters"
The code is now in a Git repo on your local computer. Let’s now push it to a Git repo on GitHub.
If you don’t have a GitHub account already, sign up for one now (it’s free), and follow the authenticating on the command line docs to learn to authenticate to GitHub from your terminal.
Next, create a new repository in GitHub, give it a name, make the repo public, and click “Create repository,” as shown in Figure 4-2:
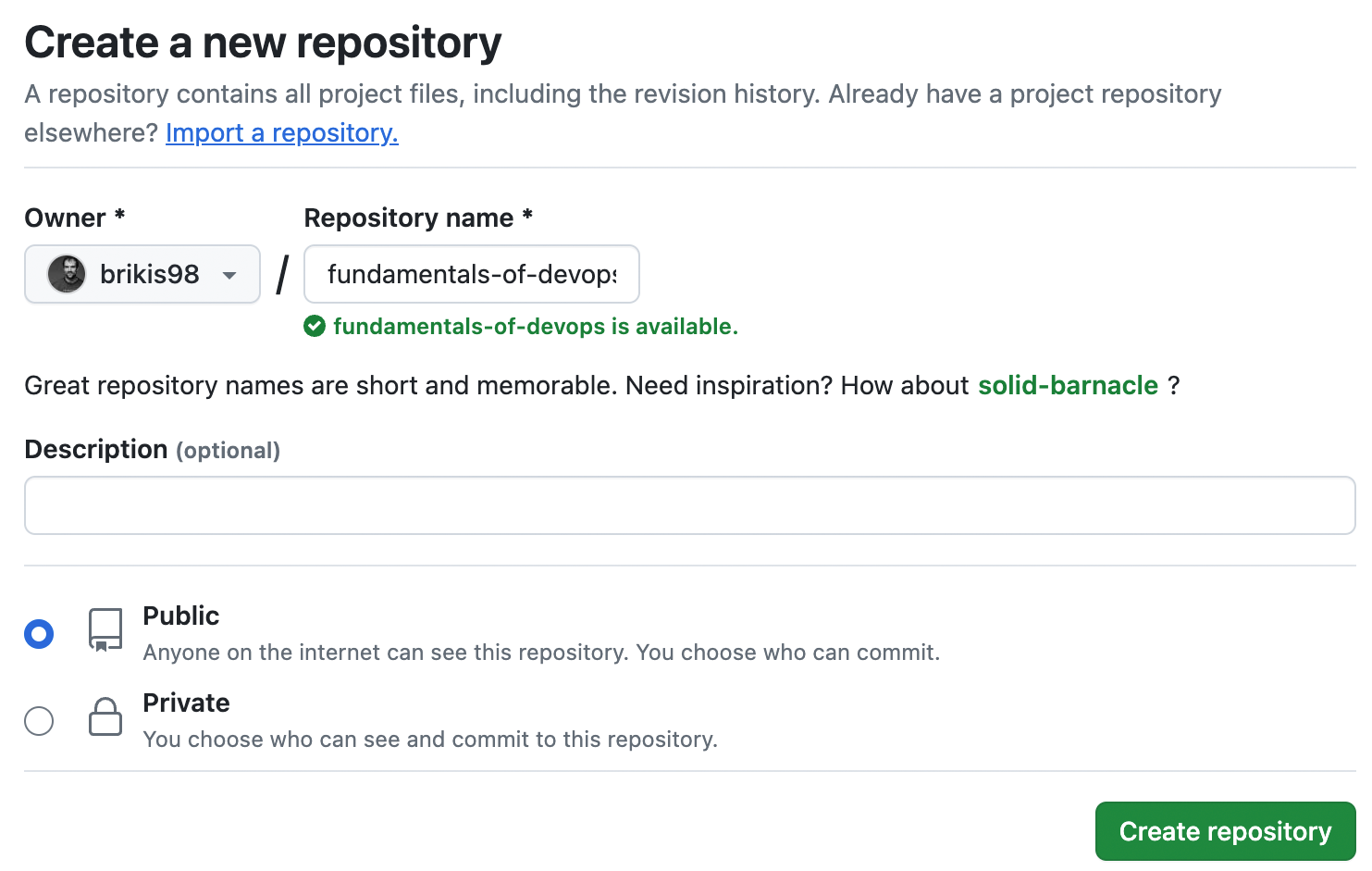
Figure 4-2. Create a new GitHub repo
This will create a new, empty repo for you that looks something like Figure 4-3:
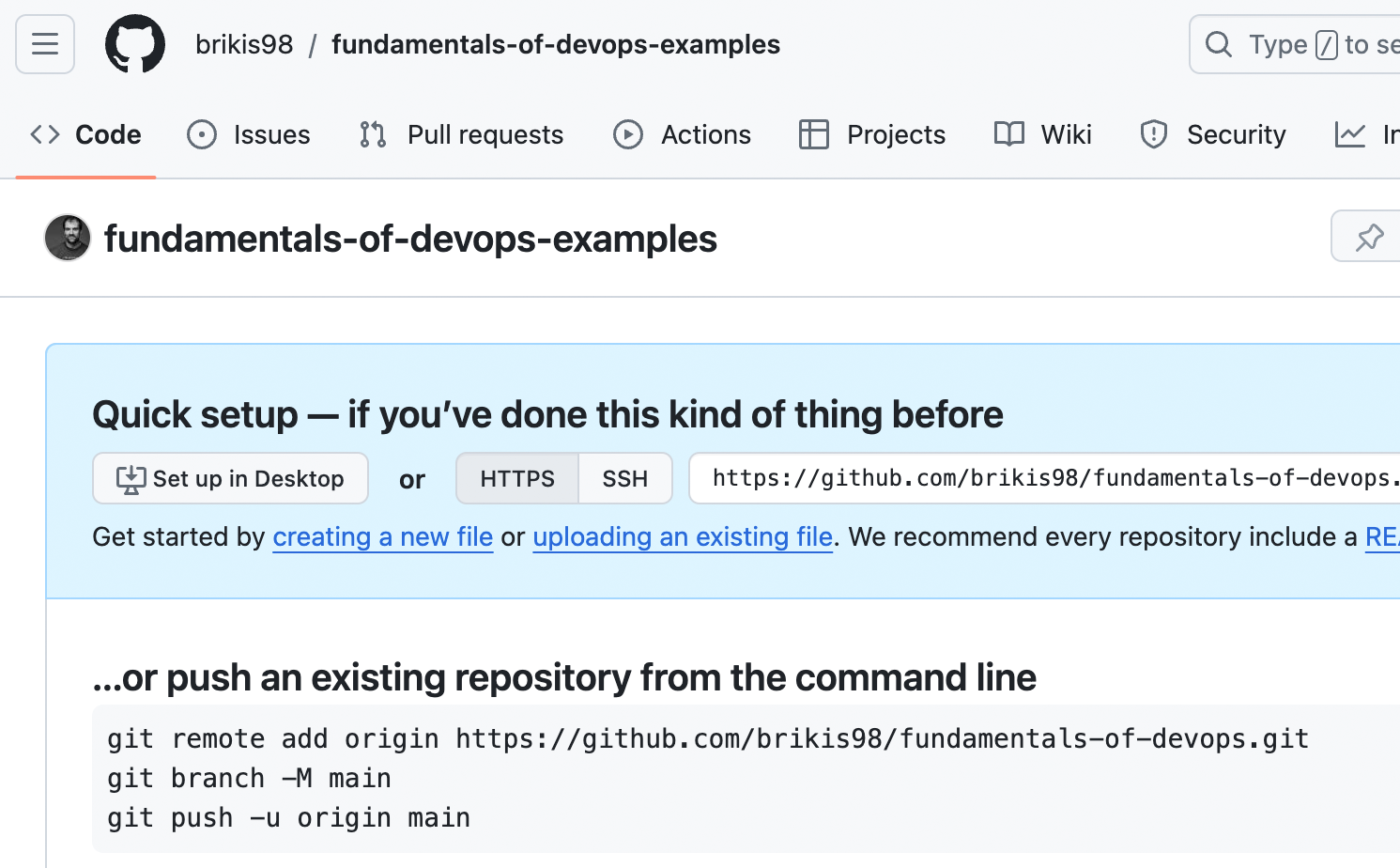
Figure 4-3. A newly created, empty GitHub repo
Copy and paste the git remote add command from that page to add a new remote, which is a Git repository hosted
remotely (i.e., somewhere on the Internet):
$gitremoteaddoriginhttps://github.com/<USERNAME>/<REPO>.git
The preceding command adds your GitHub repo as a remote named origin. You can name remotes whatever you want, but
origin is the convention for your team’s central repo, so you’ll see that used all over the place.
Now you can use git push <REMOTE> <BRANCH> to push the code from branch <BRANCH> of your local repo to the remote
named <REMOTE>. So to push your main branch to the GitHub repo you just created, you’d run the following:
$gitpushoriginmain
If you refresh your repo in GitHub, you should now see your code there, as shown in Figure 4-4:
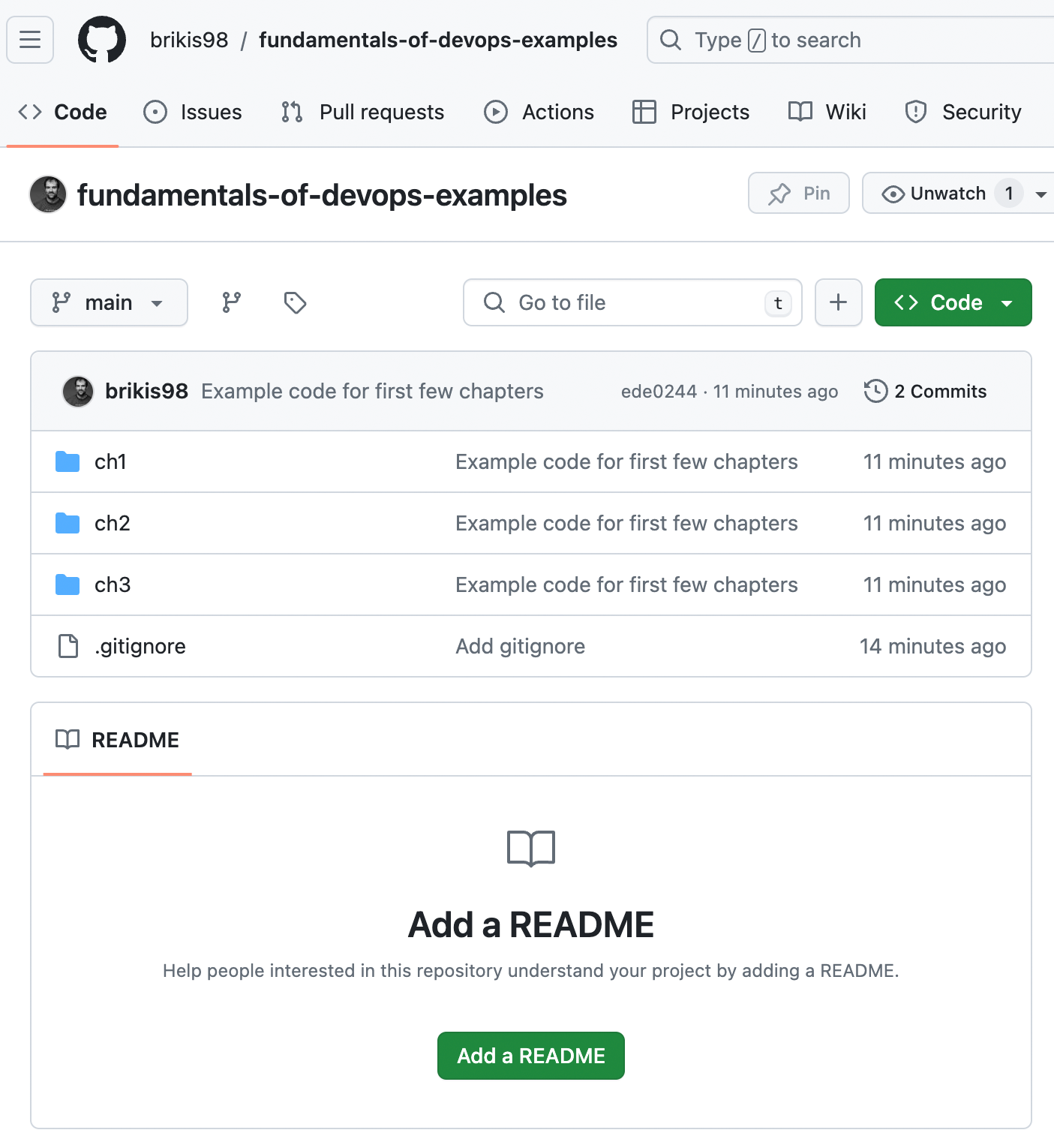
Figure 4-4. Your GitHub repo with code in it
Congrats, you just learned how to push your changes to a remote endpoint, which gets you halfway there with being able to collaborate with other developers. Now it’s time to learn the other half, which is how to pull changes from a remote endpoint.
Notice how GitHub prompts you to “Add a README” to your new repo. Adding documentation for your code is always a good idea, so let’s do it. Click the green Add a README button, and you’ll get a code editor in your browser where you can write the README in Markdown, as shown in Figure 4-5:
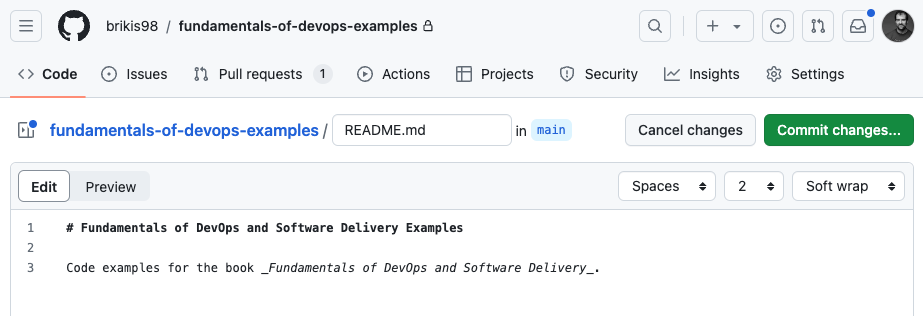
Figure 4-5. Filling in a README for the GitHub repo
Fill in a reasonable description for the repo and then click the “Commit changes…”
button. GitHub will prompt you for a commit message, so fill one in just like the -m flag on the command-line, and
click the “Commit changes” button. GitHub will commit the changes and then take you back to your repo, where you’ll be
able to see your README, as shown in Figure 4-6:
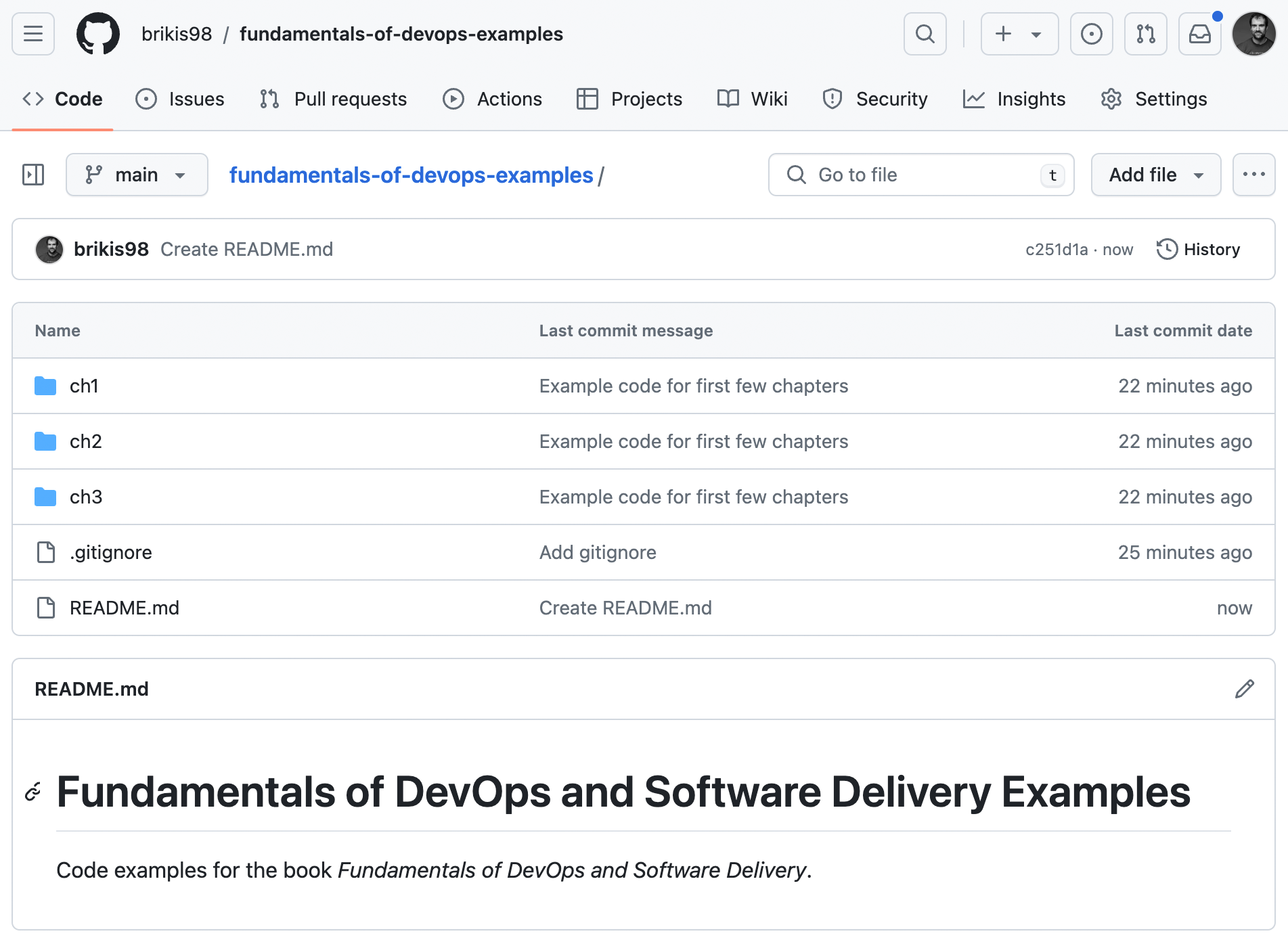
Figure 4-6. Your GitHub repo with a README
Notice that the repo in GitHub now has a README.md, but the copy on your own computer doesn’t. To get the latest code
onto your computer, run the git pull <REMOTE> <BRANCH> command, where <REMOTE> is the name of the remote to pull
from, and <BRANCH> is the branch to pull:
$gitpulloriginmain
The log output should show you that Git was able to pull the changes in and a summary of what changed, which should include the new README.md file. Congrats, you now know how to pull changes from a remote endpoint!
Note that if you didn’t have a copy of the repo locally on your computer at all, you couldn’t just run git pull.
Instead, you first need to use git clone to checkout the initial copy of the repo (note: you don’t actually need to
run this command, as you have a copy of this repo already, but just be aware of this for working with other repos
in the future):
$gitclonehttps://github.com/<USERNAME>/<REPO>
When you run git clone, Git will check out a copy of the repo <REPO> to a folder called <REPO> in your current
working directory. It’ll also automatically add the repo’s URL as a remote named origin.
So now you’ve seen the basic Git workflows:
-
git clone: Check out a fresh copy of a repo. -
git push origin <BRANCH>: Push changes from your local repo back to the remote repo, so all your other team members can see your work. -
git pull origin <BRANCH>: Pull changes from the remote repo to your local repo, so you can see the work of all your other team members.
This is the basic workflow, but what you’ll find is that many teams use a slightly different workflow to push changes, as discussed in the next section.
Example: Open a Pull Request in GitHub
A pull request (PR) is a request to merge one branch into another; in effect, you’re requesting that someone else
runs git pull on your repo/branch. GitHub popularized the PR workflow as the de facto way to make changes to open
source repos, and these days, many companies use PRs to make changes to private repos as well. The pull request
process is as follows:
-
You check out a copy of repo
R, create a branchB, and commit your changes to this branch. Note that if you have write access to repoR, you can create branchBdirectly in repoR. However, if you don’t have write access, which is usually the case ifRis an open source repo in someone else’s account, then you first create a fork of repoR, which is a copy of the repo in your own account, and then you create branchBin your fork. -
When you’re done with your work in branch
B, you open a pull request against repoR, requesting that the maintainer of that repo merges your changes from branchBinto some branch in repoR(typicallymain). -
The owner of repo
Rthen uses GitHub’s PR UI to review your changes, provide comments and feedback, and ultimately, decide to either merge the changes in, or close the PR unmerged.
Let’s give it a shot. Create a new branch called update-readme in your repo:
$gitcheckout-bupdate-readme
Make a change to the README.md file. For example, add a URL to the end of the file. Run git diff to see what your
changes look like:
$gitdiffdiff --git a/README.md b/README.mdindex 843bd01..ad75c5e 100644--- a/README.md+++ b/README.md@@ -1,3 +1,5 @@#FundamentalsofDevOpsandSoftwareDeliveryExamplesCode examples for the book _Fundamentals of DevOps and Software Delivery_.++https://www.fundamentals-of-devops.com/
If the changes look good, add and commit them:
$gitaddREADME.md$gitcommit-m"Add URL to README"
Next, push your update-readme branch to the remote repo:
$gitpushoriginupdate-readme
You should see log output that looks something like this:
remote: remote: Create a pull request for 'update-readme' on GitHub by visiting: remote: https://github.com/<USERNAME>/<REPO>/pull/new/update-readme remote:
In the log output, GitHub conveniently shows you a URL for creating a pull request (you can also create PRs by going to
the Pull Requests tab of your repo in a web browser and clicking the New Pull Request button). Open that URL in your
web browser, and you should see a page where you can fill in a title and description for the PR. You can also scroll
down on that page to see the changes between your branch and main, which should be the same ones you saw when
running git diff. If those changes look OK, click the “Create pull request” button, and you’ll end up on the GitHub
PR UI, as shown in Figure 4-7:
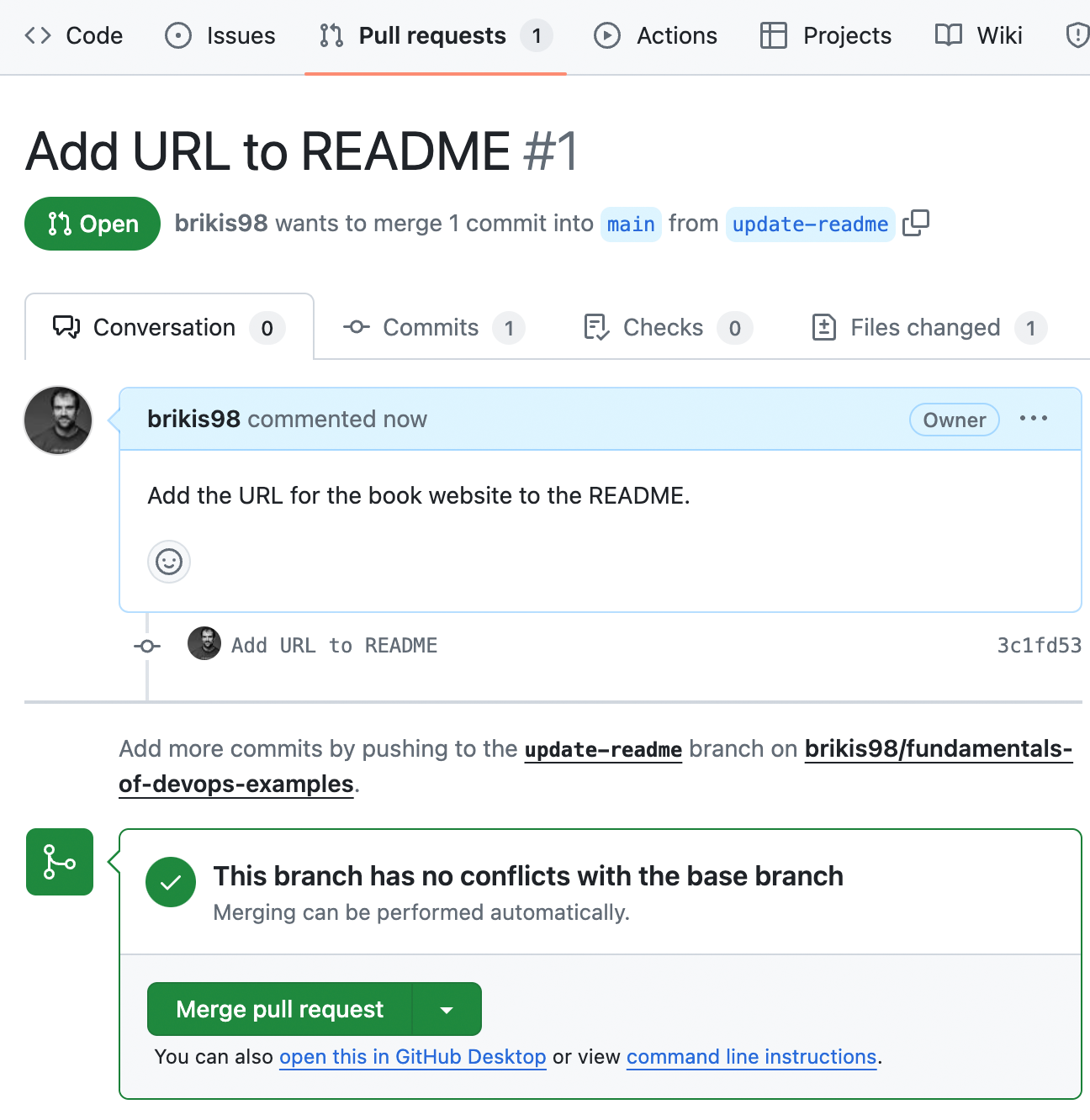
Figure 4-7. An open pull request in GitHub
You and all your team members can use this PR page to see the code changes (try clicking the “Files changed” tab
to get a view similar to git diff), discuss the changes, request reviewers, request changes, and so on. All of this
discussion gets stored in GitHub, so if later on, you’re trying to debug an issue or figure out why some code is the way
it is, these PR pages serve as a great source of history and context. As you’ll see in Chapter 5,
this is also the place where a lot of the CI / CD integration will happen. If the PR looks good, click “Merge pull
request,” and then “Confirm merge,” to merge the changes in.
Version Control Recommendations
Now that you understand what version control is, here are my recommendations:
-
Always use version control
-
Write good commit messages
-
Commit early and often
-
Use a code review process
-
Protect your code
Always use version control
The single most important recommendation with version control is: use it.
Key takeaway #1
Always manage your code with a version control system.
It’s easy, it’s cheap or free, and the benefits for software engineering are massive. If you’re writing code, always store that code in version control. No excuses.
Write good commit messages
Commit messages are important. When you’re trying to figure out what caused a bug or an outage, or staring at a
confusing piece of code, git log and git blame can be your best friends—but only if the commit messages are well
written. Good commit messages consist of two ingredients:
- Summary
-
The first line of the message should be a short (less than 50 characters), clear summary of the change.
- Context
-
If it’s a trivial change, a summary line can be enough, but for anything larger, add a new line, and then provide more information to help future coders (including a future you!) understand the context. In particular, focus on what changed and why it changed, which is context that you can’t get just by reading the code, rather than how, which should be clear from the code itself.
Here’s an example of such a commit message:
Fix bug with search auto complete A more detailed explaination of the fix, if necessary. Provide additional context that isn't obvious from reading the code. - Use bullet points - If appropriate Fixes #123. Jira #456.
Just adding these two simple ingredients, summary and context, will make your commit messages considerably better. If you’re able to follow these two rules consistently, you can level up your commit messages even further by following the instructions in How to Write a Good Commit Message. And for especially large projects and teams, you can also consider adopting Conventional Commits as a way to enforce even more structure in your commit messages.
Commit early and often
One of the keys to being a more effective programmer is learning how to take a large problem and break it down into small, manageable parts. As it turns out, one of the keys to using version control more effectively is learning to break down large changes into small, frequent commits. In fact, there are two ideals to aim for:
- Atomic commits
-
Each commit should do exactly one, small, relatively self-contained thing. You should be able to describe that thing in one short sentence—which, conveniently, you can use as the commit message summary. If you can’t fit everything into one sentence, then the commit is likely doing too many things at once, and should be broken down into multiple commits. For example, instead of a single, massive commit that implements an entire large feature, aim for a series of smaller commits, where each one implements some logical slice of that feature: e.g., the backend logic in one commit, the UI logic in another commit, the search logic in another commit, and so on.
- Atomic PRs
-
Each pull request does exactly one small, relatively self-contained thing. A single PR can contain multiple commits, so it’ll naturally be larger in scope than any one commit, but it should still represent a single set of cohesive changes: that is, changes that naturally and logically go together. If you find that your PR contains a list of somewhat unrelated changes, that’s usually a sign you should break it up into multiple PRs. A classic example of this is a PR that contains a new feature, but along the way, the author of the PR also fixed a couple bugs they came across, and refactored a bunch of code. Leaving the code cleaner than how you found it (the Boy Scout Rule) is a good idea, but for the sanity of the developers who will be reviewing your PR and the commit log, put each of these changes into its own PR. That is, the refactor should go in one PR, the bug fixes each in their own PRs, and finally, the new feature in its own PR.
Atomic commits and PRs are ideals, and sometimes you’ll fall short, but it’s always a good idea to strive towards these ideals, as they give you a number of benefits:
- More useful Git history
-
When you’re scanning your Git history, commits and PRs that do one thing are easier to understand than those that do many things.
- Less risk
-
A commit or PR that makes one atomic change is typically less risky, as it’s often self-contained enough that you could revert it, whereas commits and PRs that contain dozens of changes can be harder to revert, and therefore, riskier to merge in the first place.
- Cleaner mental model
-
To work in atomic units, you typically have to break the work down ahead of time. This often produces a cleaner mental model of the problem, and ultimately, better results.
- Easier code reviews
-
Reviewing small, self-contained changes is easy. Reviewing massive PRs with thousands of lines of unrelated changes is hard.
- Lower risk of data loss
-
Doing more frequent commits can be a lifesaver. For example, if you commit (and push) your changes hourly, then if your laptop dies, it’s an annoying, but minor loss, whereas if you commit only once every few days, it’s a huge setback.
- Less risky refactors
-
Committing more frequently gives you the ability to safely explore new directions. For example, you might try a major refactor, and after hours of work, realize it’s not working. If you made small commits all along the way, you can revert to any previous point instantly, whereas if you didn’t, you may have to undo your refactor manually, which is more time-consuming and error-prone.
- More frequent integration
-
As you’ll see in Chapter 5, one of the keys to working effectively as a team is to integrate your changes together regularly, and this tends to be easier if everyone is doing small, frequent commits.
Get your hands dirty
It’s normal not to get your commits and commit messages quite right initially. Often, you don’t know how to break something up into smaller, atomic parts until after you’ve done the whole thing. That’s OK! Learn to use the following Git tools to update your commit history and clean things up:
-
Amend commits:
git commit --amend -
Squash commits:
git merge --squashorgit rebase
Use a code review process
Every page in this book has been checked over by an editor. Why? Because even if you’re the smartest, most capable, most experienced writer, you can’t proofread your own work. You’re too close to the concepts, and you’ve rolled the words around your head for so long you can’t put yourself in the shoes of someone who is hearing them for the first time. Writing code is no different. In fact, if it’s impossible to write prose without independent scrutiny, surely it’s also impossible to write code in isolation; code has to be correct to the minutest detail, plus it includes prose for humans as well!
Jason Cohen, Making Software: What Really Works, and Why We Believe It by Andy Oram and Greg Wilson (O’Reilly Media)
Having your code reviewed by someone else is a highly effective way to catch bugs, reducing defect rates by as much as 50-80%.2 Code reviews are also an efficient mechanism to spread knowledge, culture, training, and a sense of ownership throughout the team. There are several different ways of doing code reviews:
- Enforce a pull request workflow
-
One option is to enforce that all changes are done through pull requests (you’ll see a way to do that in the next section), so that the maintainers of each repo can asynchronously review each change before it gets merged.
- Use pair programming
-
Another option is to use pair programming, a development technique where two programmers work together at one computer, with one person as the driver, responsible for writing the code, and the other as the observer, responsible for reviewing the code and thinking about the program at a higher level (the programmers regularly switch roles). The result is a bit like a constant code review process. Some companies use pair programming for all their coding, while others use it on an as-needed basis (e.g., for complex tasks or ramping up a new hire).
- Use formal inspections
-
A third option is to schedule a live meeting for a code review where you present the code to multiple developers, and go through it together, line-by-line. You can’t do this degree of scrutiny for every line of code, but for mission critical parts of your systems, this can be an effective way to catch bugs and get everyone on the same page.
Whatever process you pick for code reviews, you should define your code review guidelines up front, so you have a process that is consistent and repeatable across the entire team. That is, everyone knows what sorts of things to look for (e.g., automated tests), what sorts of things not to look for (e.g., code formatting, which should be automated), and how to communicate feedback effectively. For an example, have a look at Google’s Code Review Guidelines.
Protect your code
For many companies these days, the code you write is your most important asset—your secret sauce. Moreover, it’s also a highly sensitive asset: if someone can slip some malicious code into your codebase, it can be devastating, as that will bypass most security protections you put in place. Therefore, you should consider enabling the following security measures to protect your code:
- Signed commits
-
When you ran
git config, as shown in Example 4-1, you could’ve set your username and email to any value.Git doesn’t enforce any checking around these values, so you could make commits pretending to be someone else! Fortunately, most VCS hosts (GitHub, GitLab, etc.) allow you to enforce signed commits on your repos, where they reject any commit that doesn’t have a valid cryptographic signature. Typically, the way that it works is you create a GPG key, which consists of a public and private key pair. You store the private key on your own computer, where only you can access it, and you configure Git to use the private key to sign your commits. Next, you upload the public key to your VCS host, and enable commit signature verification (example instructions for GitHub), and then the VCS will use this public key to reject any commits that don’t have a valid signature (you’ll learn more about cryptographic signatures in [Link to Come]). - Branch protection
-
Most VCS hosts (GitHub, GitLab, etc.) allow you to enable branch protection, where you can enforce certain requirements before code can be pushed to certain branches. For example, you could use GitHub’s protected branches to require that all code changes to the
mainbranch are (a) submitted via pull requests, (b) those pull requests are reviewed by at least N other developers, and (c) certain checks, such as security scans, pass before those pull requests can be merged. This way, even if an attacker compromises one of your developer accounts, they still won’t be able to get code merged intomainwithout other developers seeing it and security scanners checking it.
Now that you know how to use a version control system to help everyone on your team work on the same code, the next step is ensure that you’re all working on that code in the same way: that is, building the code the same way, running the code the same way, using the same dependencies, and so on. This is where build system can come in handy, which is the focus of the next section.
Build System
Most software projects use a build system to automate important operations, such as compiling the code, downloading dependencies, packaging the app, running automated tests, and so on. The build system serves two audiences: the developers on your team, who run the build steps as part of local development, and various scripts, which run the build steps as part of automating your software delivery process.
Key takeaway #2
Use a build system to capture, as code, important operations and knowledge for your project, in a way that can be used both by developers and automated tools.
The reality is that for most software projects, you can’t not have a build system: either you use an off-the-shelf build system, or you end up creating your own out of ad hoc scripts, duct tape, and glue. I would recommend the former.
There are many off-the-shelf build tools out there. Some were originally designed for use with a specific programming language or framework: for example, Rake for Ruby, Gradle and Maven for Java, SBT for Scala, and NPM for JavaScript (Node.js). There are also some build tools that are largely language agnostic, such as Bazel, and the grandaddy of all build systems, Make.
Usually, the language-specific tools will give you the best experience with that language; I’d only go with the language-agnostic ones like Bazel in specific circumstances, such as massive teams that use dozens of different languages in a single repo. For the purposes of the book, since the sample app you’ve used in previous chapters is JavaScript (Node.js), let’s give NPM a shot, as per the next section.
Example: Configure your Build Using NPM
Example Code
As a reminder, you can find all the code examples in the book’s sample code repo in GitHub.
Let’s set up NPM as the build system for the Node.js sample app you’ve been using throughout the book. Head into the folder you created for running examples in this book, and create a new subfolder for this chapter and the sample app:
$cdfundamentals-of-devops$mkdir-pch4/sample-app$cdch4/sample-app
Copy the app.js file you first saw in “Example: Run the Sample App Locally” into the sample-app folder:
$cp../../ch1/sample-app/app.js.
Next, make sure you have Node.js installed, which should also install NPM for you. To use
NPM as a build system, you must first configure the build in a package.json file. You can create this file by hand,
or you can let NPM scaffold out an initial version of this file for you by running npm init:
$npminit
NPM will prompt you for information such as the package name, version, description, and so on. You can enter whatever data you want here, or hit ENTER to accept the defaults. When you’re done, you should have a package.json file that looks similar to Example 4-3:
Example 4-3. The generated NPM build file (ch4/sample-app/package.json)
{"name":"sample-app","version":"1.0.0","description":"Sample app for 'Fundamentals of DevOps and Software Delivery'","scripts":{"test":"echo \"Error: no test specified\" && exit 1"}}
Most of this initial data is metadata about the project. The part to focus on is the scripts object. NPM has a number
of built-in commands, such as npm install, npm start, npm test,
and so on. All of these have default behaviors, but in most cases, you can override what these commands do by
adding them to the scripts block. For example, npm init gives you an initial test command in the scripts block
that just exits with an error; you’ll change this value later in the chapter, when we discuss
automated testing.
For now, update the scripts block with a start command, which will define how to start your app, as shown in
Example 4-4:
Example 4-4. Add a start command to the scripts block (ch4/sample-app/package.json)
"scripts":{"start":"node app.js",},
Now you can use the npm start command to run your app:
$npmstart> sample-app@1.0.0 start> node app.jsListening on port 8080
Being able to use npm start over node app.js may not seem like much of a win, but there’s a big difference:
npm start is a well-known convention. Most Node.js and NPM users know to use npm start on a project. Most tools
that work with Node.js know about it as well.
You might know to run node app.js to start this app, but the other members of your team might not—especially as the
project grows larger, and instead of a single app.js file, there are thousands of source files, and it’s not
obvious which one to run. You could document the command in a README, but there’s a good risk it’ll go out of date.
By capturing this in your build system, which you run regularly, you are capturing this information in a way that is
more likely to be kept up-to-date. And as a bonus, you’re capturing in a way that both other developers (humans) and
other tools (automation) can leverage.
Of course, start isn’t the only command you would add. The idea would be to add all the common operations on your
project to the build. For example, in “Example: A Crash Course on Docker”, you created a Dockerfile to package the app as
a Docker image, and in order to build that Docker image for multiple CPU architectures (e.g., ARM64, AMD64), you had to
use a relatively complicated docker buildx command. This is a great thing to capture in your build.
First, copy the Dockerfile shown in Example 4-5 into the sample-app folder:
Example 4-5. Updated Dockerfile for the app (ch4/sample-app/Dockerfile)
FROMnode:21.7WORKDIR/home/node/appCOPYpackage.json.COPYapp.js.EXPOSE8080USERnodeCMD["npm","start"]
This is identical to the Dockerfile you saw in “Example: A Crash Course on Docker”, except for two changes:
Copy the package.json file into the Docker image, in addition to app.js.
Use
npm startto start the app, rather than hard-codenode app.js. This way, if you ever change how you run the app—which you will later in this chapter—the only thing you’ll need to update is package.json.
Second, create a script called build-docker-image.sh with the contents shown in Example 4-6:
Example 4-6. A script to build a Docker image (ch4/sample-app/build-docker-image.sh)
#!/usr/bin/env bashset-ename=$(npmpkggetname|tr-d'"')version=$(npmpkggetversion|tr-d'"')dockerbuildxbuild\--platform=linux/amd64,linux/arm64\--load\-t"$name:$version"\.
This script does the following:
Use
npm pkg getto read the values ofnameandversionfrom package.json. This ensures package.json is the single location where you manage the name and version of your app.Run the same
docker buildxcommand as before, setting the Docker image name and version to the values from (1).
Next, make the script executable:
$chmodu+xbuild-docker-image.sh
Finally, add a dockerize command to the scripts block in package.json that executes build-docker-image.sh, as
shown in Example 4-7:
Example 4-7. Add a dockerize command (ch4/sample-app/package.json)
"scripts":{"start":"node app.js","dockerize":"./build-docker-image.sh",},
Now, instead of trying to figure out a long, esoteric docker buildx command, members of your team can execute
npm run dockerize (note that you need npm run dockerize and not just npm dockerize as dockerize is custom
command, and not one of the ones built-into NPM):
$npmrundockerize> sample-app@v4 dockerize> docker buildx build --platform=linux/amd64,linux/arm64 -t sample-app:$(npm pkg get version | tr -d '"') .[+] Building 0.5s (14/14) FINISHED=> [internal] load build definition from Dockerfile(... truncated ...)=> [linux/amd64 4/4] COPY app.js .=> [linux/arm64 4/4] COPY app.js .
Now that you know how to use a build system to automate your workflow, let’s talk about another key responsibility of most build systems: managing dependencies.
Dependency Management
Most software projects these days rely on a large number of dependencies: that is, other software packages and libraries that your code uses. There are many kinds of dependencies:
- Code in the same repo
-
You may choose to break up the code in a single repo into multiple modules, and to have these modules depend on each other. This lets you develop parts of your codebase in isolation from the others, possibly with separate teams working on each part.
- Code in different repos
-
Your company may store code across multiple repos. This gives you even more isolation between the different parts of your software and makes it even easier for separate teams to take ownership of each part. Typically, when repo A depends on code in repo B, you depend on a specific version of that code. This version may correspond to a specific Git tag, or it could depend on a versioned artifact published from that repo: e.g., a Jar file for Java or a Gem for Ruby.
- Open source code
-
Perhaps the most common type of dependency these days is open source code. The 2024 Open Source Security and Risk Analysis Report found that 96% of codebases rely on open source and that 70% of all the code in those codebases originates from open source! The open source code almost always lives in separate repos, so again, you’ll typically depend on a specific version of that code.
Whatever type of dependency you have, the common theme is that you use a dependency so that you can leverage other people’s work. If you want to maximize that leverage, make sure to never copy & paste dependencies into your codebase. If you copy & paste a dependency, you run into a variety of problems:
- Transitive dependencies
-
Copy/pasting a single dependency is easy, but if that dependency has its own dependencies, and those dependencies have their dependencies, and so on (collectively known as transitive dependencies), then copy/pasting becomes difficult.
- Licensing
-
Copy/pasting may violate the license terms of that dependency, especially if you end up modifying that code because it now sits in your own repo. Be especially aware of dependencies that uses GPL-style licenses (known as copyleft or viral licenses), for if you modify the code in those dependencies, that may trigger a clause in the license that requires you to release your own code under the same license (i.e., you’ll be forced to open source your company’s proprietary code!).
- Staying up to date
-
If you copy/paste the code, to get any future updates, you’ll have to copy/paste new code, and new transitive dependencies, and make sure you don’t lose any changes your team members made along the way.
- Private APIs
-
You may end up using private APIs (since you can access those files locally) instead of the public ones that were actually designed to be used, which can lead to unexpected behavior, and make staying up to date even harder.
- Bloating your repo
-
Every dependency you copy into your VCS makes it larger and slower.
The better way to use dependencies is with a dependency management tool. Most build systems have dependency management tools built in, and the way they typically work is you define your dependencies as code, in the build configuration, including the version of the dependency you’re using, and the dependency management tool is then responsible for downloading that dependency, plus any transitive dependencies, and making it available to your code.
Key takeaway #3
Use a dependency management tool to pull in dependencies—not copy & paste.
Let’s try out an example with the Node.js sample app and NPM.
Example: Add Dependencies in NPM
So far, the Node.js sample app you’ve been using has not had any dependencies other than the http standard library
built into Node.js itself. Although you can build web apps this way, the more common approach is to use some sort of
web framework. For example, Express is a popular web framework for Node.js. To use it,
you can run:
$npminstallexpress--save
If you look into package.json, you will now have a new dependencies section, as shown in
Example 4-8:
Example 4-8. NPM managed dependencies (ch4/sample-app/package.json)
"dependencies":{"express":"^4.19.2"}
You should also see two other changes in the folder with the package.json file:
- node_modules
-
This is a scratch directory where NPM downloads dependencies. This folder should be in your .gitignore file so you do not check it into version control. Instead, whenever anyone checks out the repo the first time, they can run
npm install, and NPM will install all the dependencies they need automatically. - package-lock.json
-
This is a dependency lock file: it captures the exact dependencies that were installed. This is useful because in package.json, you can specify a version range instead of a specific version to install. For example, you may have noticed that
npm installset the version of Express to^4.19.2. Note the caret (^) at the front: this is called a caret version range, and it allows NPM to install any version of Express at or above 4.19.2 (so 4.20.0 would be OK, but not 5.0.0). So every time you runnpm install, you may get a new version of Express. This can be a good thing, as you may be picking up bug fixes or security patches. But it can also be frustrating in an automated environment, as your builds may not be reproducible. With a lock file, you can use thenpm cicommand instead ofnpm installto tell NPM to install the exact versions in the lock file, so the build output is exactly the same every time. You’ll see an example of this shortly.
Now that Express is installed, you can rewrite the code in app.js to use the Express framework, as shown in Example 4-9:
Example 4-9. The sample app rewritten using Express.js (ch4/sample-app/app.js)
constexpress=require('express');constapp=express();constport=process.env.PORT||8080;app.get('/',(req,res)=>{res.send('Hello, World!');});app.listen(port,()=>{console.log(`Example app listening on port${port}`);});
This app listens on port 8080 and responds with “Hello, World!” just as before, but because you’re using a framework, it’ll be a lot easier to evolve this code into a real app by leveraging all the features built into Express: e.g., routing, templating, error-handling, middleware, security, and so on. You’ll see examples of this shortly.
There’s one more thing you need to do now that the app has dependencies: you need to update the Dockerfile to install dependencies, as shown in Example 4-10.
Example 4-10. Update the Docker file to run npm install (ch4/sample-app/Dockerfile)
FROMnode:21.7WORKDIR/home/node/appCOPYpackage.json.COPYpackage-lock.json.RUNnpmci--only=productionCOPYapp.js.EXPOSE8080USERnodeCMD["npm","start"]
You need to make two changes to the Dockerfile:
Copy not only package.json, but also package-lock.json into the Docker image.
Run
npm ci, which, as mentioned earlier, is very similar tonpm install, except it’s designed to do a clean install, where it installs the exact dependencies in the lock file. This is meant to be used in automated environments, where you want reproducible builds. Note also the use of the--only=productionflag to tell NPM to only install the production dependencies. You can have adevDependenciesblock on package.json where you define dependencies only used in the dev environment (e.g., tooling for automated testing, as you’ll see shortly), and there’s no need to bloat the Docker image with these dependencies.
You can now try running npm start to check that the app runs with its use of the Express framework as a dependency,
or npm run dockerize to check that the Docker image still builds correctly.
Get your hands dirty
To avoid introducing too many new tools, I used NPM as a build system in this chapter, as it comes natively with Node.js. However, for production use cases, you may want to try out one of these more modern and robust build systems:
Now that you’ve seen how a version control system allows your team members to work on the same code, and a build system allows your team members to work the same way, let’s turn our attention to one of the most important tools for allowing your team members to get work done quickly: automated tests.
Automated Testing
Programming can be scary. One of the underappreciated costs of technical debt is the psychological impact it has on developers. There are thousands of programmers out there who are scared of doing their jobs. Perhaps you’re one of them.
You get a bug report at three in the morning and after digging around, you isolate it to a tangled mess of spaghetti code. There is no documentation. The developer who originally wrote the code no longer works at the company. You don’t understand what the code is doing. You don’t know all the places it gets used. What you have here is legacy code.
Legacy code. The phrase strikes disgust in the hearts of programmers. It conjures images of slogging through a murky swamp of tangled undergrowth with leaches beneath and stinging flies above. It conjures odors of murk, slime, stagnancy, and offal. Although our first joy of programming may have been intense, the misery of dealing with legacy code is often sufficient to extinguish that flame.
Michael Feathers, Working Effectively with Legacy Code (Pearson)
Legacy code is scary. You’re afraid because you still have scars from the time you tried to fix one bug only to reveal three more; the “trivial” change that took two months; the tiny performance tweak that brought the whole system down and pissed off all of your coworkers. So now you’re afraid of your own codebase.
Fortunately, there is a solution: automated testing, where you write test code to validate that your production code works the way you expect it to. The main reason to write automated tests is not that tests prove the correctness of your code (they don’t) or that you’ll catch all bugs with tests (you won’t), but that a good suite of automated tests gives you the confidence to make changes quickly.
The key word is confidence: tests provide a psychological benefit as much as a technical one. If you have a good test suite, you don’t have to keep the state of the whole program in your head. You don’t have to worry about breaking other people’s code. You don’t have to repeat the same boring, error-prone manual testing over and over again. You just run a single test command and get rapid feedback on whether things are working.
Key takeaway #4
Use automated tests to give your team the confidence to make changes quickly.
In 2008, I had just started a job as a Software Engineer at TripAdvisor, and as my first task, my manager asked me to
add a new sort option to the web page that listed all the hotels in a city. It was a quick task—just enough
to become familiar with the codebase—and I was able to get it done and pushed to production in my first week.
The same day my new code went live, I was in my manager’s office for our first one-on-one meeting, and I told him about
getting the task done. He was excited and wanted to see it, so I watched as he went to the hotel listings page for
Paris, selected the new sort option, and waited. And waited. And waited. It took nearly two hours for the page to load.
Or maybe it was two minutes; it’s hard to tell when you’re sweating profusely, and wondering if you’re going to be
fired in your first week on the job. Later that night—much later—I figured out that my sorting code called
a function that, under the hood, made two database calls. I was calling this function during sort comparisons, and as
it takes roughly n log n comparisons to sort n items, where n = 2,000 for a city like Paris, that works
out to roughly 40,000 database calls—for a single page load.
I didn’t get fired that day. Instead, I had a good chat with my manager about testing. I had tested my code manually, but I hadn’t written any automated tests, and as a result, nearly melted our database. From that experience, I quickly learned about all the different types of automated tests:
- Compiler
-
If you’re using a statically-typed language (e.g., Java, Scala, Go, TypeScript), you can compile the code to identify (a) syntactic issues and (b) type errors. If you’re using a dynamically-typed language (e.g., Ruby, Python, JavaScript), you can pass the code through the interpreter to identify syntactic issues.
- Static analysis / linting
-
These are tools that read and check your code “statically”—that is, without executing it—to automatically identify potential issues. Examples: ShellCheck for Bash, ESLint for JavaScript, SpotBugs for Java, RuboCop for Ruby.
- Policy tests
-
In the last few years, policy as code tools have become more popular as a way to define and enforce company policies and legal regulations in code. Examples: Open Policy Agent, Sentinel, Intercept. Many of these tools are based on static analysis, except they give you flexible languages to define what sorts of rules you want to check. Some rely on plan testing, as described next.
- Plan tests
-
Whereas static analysis is a way to test your code without executing it at all, plan testing is a way to partially execute your code. This typically only applies to tools that can generate an execution plan without actually executing the code. For example, OpenTofu has a
plancommand that shows you what changes the code would make to your infrastructure without actually making those changes: so in effect, you are running all the read operations of your code, but none of the write operations. You can write automated tests against this sort of plan output using tools such as Open Policy Agent and Terratest. - Unit tests
-
This is the first of the test types that fully execute your code to test it. The idea with unit tests is to execute only a single “unit” of your code. What a unit is depends on the programming language, but it’s typically a small part of the code, such as one function or one class. You typically mock any dependencies outside of that unit (e.g., databases, other services, the file system), so that the test solely executes the unit in question. Had I written some unit tests for my sorting code at TripAdvisor, I would’ve had to mock out the database, and might’ve realized how many database calls my code was making, catching the bug long before it made it to production. Some programming languages have unit testing tools built in, such as testing for Go and unittest for Python, whereas other languages rely on 3rd party tools for unit testing, such as JUnit for Java and Jest for JavaScript.
- Integration tests
-
Just because you’ve tested a unit in isolation and it works, doesn’t mean that multiple units will work when you put them together. That’s where integration testing comes in. Here, you test multiple units of your code (e.g., multiple functions or classes), often with a mix of real dependencies (e.g., a database) and mocked dependencies (e.g., a mock remote service).
- End-to-end (E2E) tests
-
End-to-end tests verify that your entire product works as a whole: that is, your run your app, all the other services you rely on, all your databases and caches, and so on, and test them all together. These often overlap with the idea of acceptance tests, which verify your product works from the perspective of the user or customer (“does the product solve the problem the user cares about”). If I had created an E2E test for my sorting code at TripAdvisor, I might have noticed that the test took ages to run on larger cities, and caught the bug then.
- Performance tests
-
Most unit, integration, and E2E tests verify the correctness of a system under ideal conditions: one user, low system load, and no failures. Performance tests verify the stability and responsiveness of a system in the face of heavy load and failures. If I had created performance tests for my sorting code at TripAdvisor, it would’ve been obvious that my change had severely degraded performance.
Automated tests are how you fight your fear. They are how you fight legacy code. In fact, in the same book I quoted earlier, Michael Feathers writes, “to me, legacy code is simply code without tests.” I don’t know about you, but I don’t want to add more legacy code to this world, so that means it’s time to write some tests!
Example: Add Automated Tests for the Node.js App
Look again at the Node.js sample app code in Example 4-9, and ask yourself, how do you
know this code actually works? So far, the way you’ve answered that question is through manual testing, where you
manually ran the app with npm start and checked URLs in your browser. This works fine for a tiny, simple app, but
once the app grows larger (hundreds of URLs to check) and your team grows larger (hundreds of developers making
changes), manual testing will become too time-consuming and error-prone.
The idea with automated testing is to write code that performs the testing steps for you, taking advantage of the fact that computers can perform these checks far faster and more reliably than a person. Let’s add an end-to-end test for the sample app: that is, a test that makes an HTTP request to the app, and checks the response. To do that, you first need to split app.js into two parts: one part that configures the app, and one that has the app listen on a port. That will allow you to more easily write automated tests for the part that configures the app, and to run those tests concurrently, without having to worry about getting errors due to trying to listen on the same port.
First, update app.js to solely configure the Express app, and to export it, as shown in Example 4-11:
Example 4-11. Update app.js to only create the app, but not listen on a port (ch4/sample-app/app.js)
constexpress=require('express');constapp=express();app.get('/',(req,res)=>{res.send('Hello, World!');});module.exports=app;
Next, create a new file called server.js that imports the code from app.js and has it listen on a port, as shown in Example 4-12:
Example 4-12. Create server.js to listen on a port (ch4/sample-app/server.js)
constapp=require('./app');constport=process.env.PORT||8080;app.listen(port,()=>{console.log(`Example app listening on port${port}`);});
Make sure to update the start command in package.json to now use server.js instead of app.js, as shown in
Example 4-13:
Example 4-13. Update the start command to run server.js (ch4/sample-app/package.json)
"start":"node server.js",
You should also update the Dockerfile to copy not only app.js, but all .js files, including server.js, as shown
in Example 4-14:
Example 4-14. Update Dockerfile to copy all .js files (ch4/sample-app/Dockerfile)
... (earlier lines omitted) ...RUNnpmci--only=productionCOPY*.js.EXPOSE8080... (later lines omitted) ...
Copy all
.jsfiles from the current folder into the Docker image.
Next, you need to install some testing libraries, including Jest as a testing framework and
SuperTest as a library for testing HTTP apps. Use npm install to add these
dependencies, but this time, use the --save-dev flag to save them as dev dependencies. This way, they’ll be available
during development (where you run tests), but won’t be packaged into your app for production deployments (where you
don’t run tests).
$npminstall--save-devjestsupertest
This will update package.json with a new devDependencies section, as shown in Example 4-15:
Example 4-15. package.json now includes dev dependencies (ch4/sample-app/package.json)
{"devDependencies":{"jest":"^29.7.0","supertest":"^7.0.0"}}
Next, update the test command in package.json to run Jest, as shown in Example 4-16:
Example 4-16. Update the test command to run Jest (ch4/sample-app/package.json)
"scripts":{"test":"jest --verbose"}
Finally, you can add a test in a new file called app.test.js, as shown in Example 4-17:
Example 4-17. Add an automated test for the app (ch4/sample-app/app.test.js)
constrequest=require('supertest');constapp=require('./app');describe('Test the app',()=>{test('Get / should return Hello, World!',async()=>{constresponse=awaitrequest(app).get('/');expect(response.statusCode).toBe(200);expect(response.text).toBe('Hello, World!');});});
Here’s how this test works:
Import the app code from app.js.
Use the
describefunction to group several tests together.Use the
testfunction to define individual tests.Use the SuperTest library (imported under the name
request) to fire up the app and make an HTTP GET request to it at the “/” URL.Use the
expectmatcher to check that the response status code is a 200 OK.
Use
expectto check that the response body is the text “Hello, World!”
Use npm test to run this test:
$npmtestPASS ./app.test.jsTest the app✓ Get / should return Hello, World! (12 ms)Test Suites: 1 passed, 1 totalTests: 1 passed, 1 totalTime: 0.308 s, estimated 1 s
The test passed! And it took all of 0.308 seconds, which is a whole lot faster than any manual testing you can do. And that’s just for one test; the difference in testing speed only increases as you add more tests. For example, add a second endpoint to app.js as shown in Example 4-18:
Example 4-18. Add a second endpoint to app.js (ch4/sample-app/app.js)
app.get('/name/:name',(req,res)=>{res.send(`Hello,${req.params.name}!`);});
When you go to /name/xxx, this endpoint will return the text “Hello, xxx!” Under the hood, this works because the
/name/:name syntax tells Express.js to extract the :name part of the path and make it available under
req.params.name. Test this out by running npm start, opening up the URL http://localhost:8080/name/Bob, and you
will see:
Hello, Bob!
Update app.test.js to add a test for this new endpoint, as shown in Example 4-19:
Example 4-19. Add an automated test for the new endpoint (ch4/sample-app/app.test.js)
test('Get /name/Bob should return Hello, Bob!',async()=>{constresponse=awaitrequest(app).get('/name/Bob');expect(response.statusCode).toBe(200);expect(response.text).toBe('Hello, Bob!');});
This test automates the /name/Bob check you just did manually. Re-run the tests:
$npmtestPASS ./app.test.jsTest the app✓ Get / should return Hello, World! (13 ms)✓ Get /name/Bob should return Hello, Bob! (5 ms)Test Suites: 1 passed, 1 totalTests: 2 passed, 2 totalTime: 0.339 s, estimated 1 s
Excellent, you now have tests for both endpoints, and these tests run in just 0.339 seconds. However, there’s a
serious bug—a security vulnerability—hidden in that second endpoint. To see it, run npm start once more, and try
opening the following URL:
http://localhost:8080/name/%3Cscript%3Ealert(%22hi%22)%3C%2Fscript%3E
You should see something that looks like Figure 4-8:
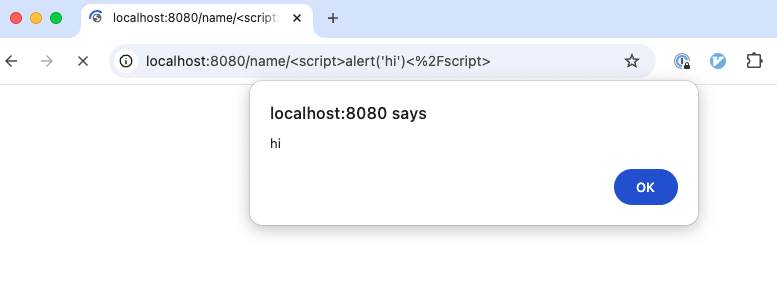
Figure 4-8. An example of an injection attack
What you just saw is an example of an injection attack, where a user includes malicious code in their input, and your
application ends up executing that code. In particular, this was a type of injection attack called cross-site
scripting (XSS), where the malicious code was a <script> tag (URL encoded, which is why you see funky characters
like %3C and %2F) that executed some JavaScript code. The code it executed was alert("hi"), which is pretty
harmless, but it could’ve been anything, and your browser would’ve executed that code on your behalf. Hackers exploit
this all the time: for example, a 2014 XSS vulnerability in eBay allowed
hackers to manipulate listings, gain access to seller accounts, and steal payment details.
Injection attacks are one of the most common, and most exploited, vulnerabilities in software (see the
OWASP Top Ten), so it’s important
to fix this issue. The way to prevent injection attacks is to sanitize all user-provided data (such as data passed in
via URL parameters like :name) by stripping out “unsafe” characters. Which characters are “unsafe” depends on how you
plan to use that data. For example, if you are using that data in a query to a database, you need to strip out
characters specific to the Structured Query Language (SQL) (you’ll learn about databases and SQL queries in
[Link to Come]). If you are using that data in HTML, as in the Node.js sample app, you need to strip out
characters specific to HTML: e.g., the left bracket, <, should be replaced with \<, which will render as a left
bracket, but won’t be executed as actual HTML (so injected <script> tags won’t work).
A good way to fix this bug is to write an automated test for it first, specifying the expected (escaped) output, and then working on the implementation code until that test passes. This is known as test-driven development, a topic you’ll learn more about later in this chapter. Update app.test.js with a new test, as shown in Example 4-20:
Example 4-20. Add an automated test that checks the new endpoint sanitizes user input (ch4/sample-app/app.test.js)
constmaliciousUrl='/name/%3Cscript%3Ealert("hi")%3C%2Fscript%3E';constsanitizedHtml='Hello, <script>alert("hi")</script>!'test('Get /name should sanitize its input',async()=>{constresponse=awaitrequest(app).get(maliciousUrl);expect(response.statusCode).toBe(200);expect(response.text).toBe(sanitizedHtml);});
You can see that this test runs the malicious URL from before, and that it is expecting the resulting HTML to be fully sanitized. Re-run the tests:
$npmtestFAIL ./app.test.jsTest the app✓ Get / should return Hello, World! (13 ms)✓ Get /name/Bob should return Hello, Bob! (3 ms)✕ Get /name should sanitize its input (3 ms)● Test the app › Get /name should sanitize its inputexpect(received).toBe(expected) // Object.is equalityExpected: "Hello, <script>alert("hi")</script>!"Received: "Hello, <script>alert(\"hi\")</script>!"32 | const response = await request(app).get(maliciousUrl);33 | expect(response.statusCode).toBe(200);> 34 | expect(response.text).toBe(sanitizedHtml);| ^35 | });36 | // end::express_app_tests_describe_name_sanitize[]37 |at Object.toBe (app.test.js:34:27)Test Suites: 1 failed, 1 totalTests: 1 failed, 2 passed, 3 totalTime: 0.254 s, estimated 1 s
As expected, the test fails, as the current code does not sanitize user input. Now you can work on the implementation
code until the test passes. The best way to sanitize input is to use battle-tested libraries to do it for you. For
sanitizing HTML, most HTML templating libraries will sanitize input automatically. Express.js works with a number of
HTML templating libraries, including Pug,
Mustache, and Embedded JavaScript (EJS). Let’s give EJS a shot. First,
use npm install to install EJS:
$npminstall--saveejs
Next, configure the Express app to use EJS as a template engine by updating app.js as shown in Example 4-21:
Example 4-21. Configure the Express app to use EJS (ch4/sample-app/app.js)
constapp=express();app.set('view engine','ejs');
You should also update the new endpoint in app.js to render an EJS template instead of doing string interpolation, as shown in Example 4-22:
Example 4-22. Render an EJS template (ch4/sample-app/app.js)
app.get('/name/:name',(req,res)=>{res.render('hello',{name:req.params.name});});
This code renders an EJS template called hello, passing it the :name parameter. Create this EJS template under
views/hello.ejs, with the contents shown in Example 4-23:
Example 4-23. The hello EJS template (ch4/sample-app/views/hello.ejs)
Hello,<%=name%>!
In EJS, the <%= xxx %> syntax renders the value of xxx, while automatically sanitizing HTML characters. To check
that this is working, run the tests one more time:
$npmtestPASS ./app.test.jsTest the app✓ Get / should return Hello, World! (15 ms)✓ Get /name/Bob should return Hello, Bob! (7 ms)✓ Get /name should sanitize its input (2 ms)Test Suites: 1 passed, 1 totalTests: 3 passed, 3 totalTime: 0.32 s, estimated 1 s
Congrats, all your tests are now passing! And these tests take just 0.32 seconds, which is far faster than you could test those three endpoints manually.
Get your hands dirty
Here are a few exercises you can try at home to go deeper:
-
Try creating other types of automated tests for the Node.js app: e.g., static analysis, unit tests, performance tests.
-
Add the
--coverageflag to thejestcommand to enable code coverage, which will show you what percentage of your code is executed by your automated tests. Use this as an input to the quality of your testing: 100% code coverage isn’t necessarily the goal, but if your tests only execute, say, 20% of your code, how much confidence can you really get from your test suite?
The process you just went through is a good example of the typical way you write code when you have a good suite of automated test to lean on: you make a change, you re-run the tests, you make another change, you rerun the tests again, and so on, adding new tests as necessary. With each iteration, your test suite gradually improves, you build more and more confidence in your code, and you can go faster and faster.
Key takeaway #5
Automated testing makes you more productive while coding by providing a rapid feedback loop: make a change, run the tests, make another change, re-run the tests, and so on.
Rapid feedback loops are a big part of the DevOps methodology, and a big part of being more productive as a programmer. Note that this not only makes you more productive in fixing the HTML sanitization bug, but now you also have a regression test in place that will prevent that bug from coming back. This is a massive boost to productivity that often gets overlooked.
Key takeaway #6
Automated testing makes you more productive in the future, too: you save a huge amount of time not having to fix bugs because the tests prevented those bugs from slipping through in the first place.
All the benefits of automated testing apply not only to application code, but infrastructure code, too. Let’s try it out in the next section.
Example: Add Automated Tests for the OpenTofu Code
As an example of infrastructure testing, let’s add an E2E test using
OpenTofu’s built-in test command for the lambda-sample OpenTofu
module you created in Chapter 3. Copy that module, unchanged, into a new folder for this
chapter:
$cdfundamentals-of-devops$mkdir-pch4/tofu/live$cp-rch3/tofu/live/lambda-samplech4/tofu/live$cdch4/tofu/live/lambda-sample
To test this module, you need to add a small helper module for checking HTTP endpoints. The book’s
sample code repo includes a module called test-endpoint in the
ch4/tofu/modules/test-endpoint folder that can make an HTTP request to an endpoint you specify. Normally, you could
use this module directly from GitHub, but currently, the test command has a limitation where it can only use local
modules, so git clone the sample code repo (if you haven’t already) to the devops-book folder and
make a copy of the test-endpoint module:
$cdfundamentals-of-devops$mkdir-pch4/tofu/modules$cp-r../devops-book/ch4/tofu/modules/test-endpointch4/tofu/modules
Next, in the lambda-sample module, create a file called deploy.tftest.hcl, with the contents shown in
Example 4-24:
Example 4-24. Automated test for the lambda-sample module (ch4/tofu/live/lambda-sample/deploy.tftest.hcl)
run"deploy"{command=apply}run"validate"{command=applymodule{source="../../modules/test-endpoint"}variables{endpoint=run.deploy.api_endpoint}assert{condition=data.http.test_endpoint.status_code==200error_message="Unexpected status: ${data.http.test_endpoint.status_code}"}assert{condition=data.http.test_endpoint.response_body=="Hello, World!"error_message="Unexpected body: ${data.http.test_endpoint.response_body}"}}
This automated test is written in the same language (HCL) as the rest of OpenTofu code. You put these tests into
files with the .tftest.hcl extension, and they primarily consist of run blocks that OpenTofu executes
sequentially:
The first
runblock will runapplyon thelambda-samplemodule itself.The second
runblock will runapplyas well, but this time on atest-endpointmodule, as described in (3).This
moduleblock is how you tell therunblock to runapplyon thetest-endpointmodule, which is the module you copied from the book’s sample code repo.Read the API Gateway endpoint output from the
lambda-samplemodule and pass it in as theendpointinput variable for thetest-endpointmodule.assertblocks are used to check if the code actually works as you expect. This firstassertblock checks that thetest-endpointmodule’s HTTP request got a response status code of 200 OK.The second
assertblock checks that thetest-endpointmodule’s HTTP request got a response body with the text “Hello, World!”
To run this test, authenticate to AWS as described in “Authenticating to AWS on the command line”, and use the tofu test
command (these tests take several minutes to run, so be patient):
$tofutestdeploy.tftest.hcl... passrun "deploy"... passrun "validate"... passSuccess! 2 passed, 0 failed.
Congrats, you now have automated tests for your infrastructure! Under the hood, OpenTofu ran apply, deployed your
real resources, validated they worked as expected, and then, at the end of the test, ran destroy to clean everything
up again. With this sort of testing, you can have a reasonable degree of confidence that your module creates
infrastructure that really works.
Get your hands dirty
Here are a few exercises you can try at home to go deeper:
-
Add other types of tests for your OpenTofu code: e.g., static analysis (Terrascan, Trivy), policy enforcement (Open Policy Agent, Sentinel), integration tests (Terratest).
-
Add a new endpoint in your
lambdamodule and add a new automated test to validate the endpoint works as expected.
Now that you’ve tried a few examples of automated tests, let’s go through some recommendations for how to make your testing more effective.
Testing Recommendations
Almost any kind of automated testing is better than none, but there are some automated testing patterns that tend to be more effective than others. The following are my recommendations:
-
The test pyramid
-
What to test
-
Test-Driven Development (TDD)
Let’s go through these one at a time, starting with the test pyramid.
The test pyramid
One question that comes up often is, which testing approach should you use? Unit tests? Integration tests? E2E tests? The answer is: a mix of all of them! Each type of test has different types of errors they can catch, plus different strengths and weaknesses, as summarized in Table 4-1:
| Compiler | Static analysis | Policy tests | Plan tests | Unit tests | Integration tests | E2E tests | Perf tests | |
|---|---|---|---|---|---|---|---|---|
Syntax errors |
|
|
|
|
|
|
|
|
Type errors |
|
|
|
|
|
|
|
|
Compliance errors |
|
|
|
|
|
|
|
|
Unit functionality |
|
|
|
|
|
|
|
|
Interaction of units |
|
|
|
|
|
|
|
|
System functionality |
|
|
|
|
|
|
|
|
Functionality under load |
|
|
|
|
|
|
|
|
Speed |
|
|
|
|
|
|
|
|
Stability |
|
|
|
|
|
|
|
|
Ease of use |
|
|
|
|
|
|
|
|
a Unit tests for application code are typically fast. Unit tests for infrastructure code are typically moderate, at best. | ||||||||
The only way to be confident your code works as expected is to combine multiple types of tests. That doesn’t mean that you use all the different types of tests in equal proportion. In most cases, you want the proportion of tests to follow the test pyramid shown in Figure 4-9:
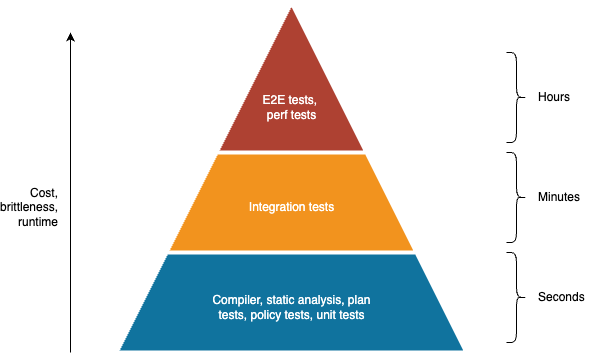
Figure 4-9. The test pyramid
The idea of the test pyramid is that, as you go up the pyramid, the cost and complexity of writing the tests, the brittleness of the tests, and the runtime of the tests all increase. Therefore, you typically want to do as much testing as you can with the types of tests that are fast to write, fast to run, and stable, which means the majority of your testing (the base of the pyramid), should leverage the compiler, static analysis, plan tests, policy tests, and unit tests. You then have a smaller number of integration tests (the middle of the pyramid), and an even smaller number of very high-value end-to-end and performance tests (the top of the pyramid).
Moreover, you don’t have to add all the different types of tests at once. Instead, pick the ones that give you the best bang for your buck and add those first. Almost any testing is better than none. If all you can add for now is static analysis or unit tests, then that’s still better than no tests. Or maybe the highest value in your use case is a single end-to-end test that verifies your system really works: that’s a perfectly fine starting point, too. Start with something, anything that gives you value, and then add more and more tests incrementally.
What to test
Another question that comes up often is, what should you test? There are some testing purists out there who believe that every line of code must be tested and that your tests must achieve 100% code coverage. I am not one of them.
There is no doubt that tests offer a huge amount of value. But they also have a cost. Writing tests, maintaining them, and ensuring they run quickly and reliably can take a lot of time. In many cases, this overhead is worth it. In some cases, it’s not. In practice, I’ve found that deciding if you should invest in adding automated tests for a certain part of your code comes down to continuously evaluating your testing strategy and making trade-offs between the following factors:
- The cost of bugs
-
The higher the cost of bugs, the more you should invest in automated testing. If you’re building a prototype that you’ll most likely throw away in a week, the cost of bugs is low, and tests aren’t as important. If you’re working on code that processes payments, manages user data, or is related to security, the cost of bugs is high, and automated tests are more important.
- The likelihood of bugs
-
The higher the likelihood of bugs, the more you should invest in automated testing. As a general rule, the larger the codebase, and the more people that work on it, the higher the likelihood of bugs, so you should expect to invest more in testing as you scale.
- The cost of testing
-
The lower the cost of testing, the more you should invest in automated testing. With most languages and tools, setting up unit tests is so easy, the tests run so fast, and the improvement to code quality and correctness is so high that it is almost always worth investing in unit tests. On the other hand, integration tests, end-to-end tests, and performance tests are each progressively more expensive to set up, so you need to be more thoughtful how much to invest in those.
- The cost of not having tests
-
It’s possible to get lost in an analytical cost/benefit analysis and conclude that tests aren’t worth it. Many companies do just that. But you have to remember that this has a cost, too: fear. When you work in a codebase without tests, you end up with a bunch of developers who are afraid to make changes. So if every time you go to add a new feature or deploy something to production, you find your team hesitating and stalling, then you are paying a high cost for not having tests. In those cases, the cost of automated tests is far lower than the cost of having a paralyzed dev team.
One thing that impacts both the cost of writing tests and the benefits you get from those tests is when you write those tests. Trying to add tests several years after you write the code tends to be more expensive and not as beneficial; adding tests a day after you write the code tends to be cheaper and have more benefits; and as it turns out, adding tests before you write the code may be the lowest cost and most beneficial option of all, as discussed in the next section.
Test-Driven Development (TDD)
The mere act of trying to write tests for your code will force you to take a step back and ask some important questions: How do I structure the code so I can test it? What dependencies do I have? What are the common use cases? What are the corner cases?
If you find that your code is hard to test, it’s almost always a sign that it needs to be refactored for other reasons, too. For example, if the code is hard to test because it uses lots of mutable state and side effects, then it’s likely that code is also hard to understand, maintain, and reuse. If the code is difficult to test because it has many complex interactions with its dependencies, then it’s likely that the code is too tightly coupled and will be difficult to change. If the code is hard to test because there are too many use cases to cover, then that’s a sign that the code is doing too much and needs to be broken up.
In other words, tests not only help you write correct code, they also provide feedback that leads to a better design. You get the most benefit from this feedback if you write the test code before you write the implementation code. This is known as test-driven development (TDD).
The TDD cycle is:
-
Add placeholders for the new functionality (e.g., function signatures), just enough for the code to compile, but not the full implementation.
-
Add tests for the new functionality.
-
Run all the tests. The new tests should fail, but all other tests should pass.
-
Implement the new functionality.
-
Rerun the tests. Everything should now pass.
-
Refactor the code until you have a clean design, re-running the tests regularly to check everything is still working.
One of the unexpected consequences of using TDD is that the design of your code emerges as a result of a repeated test-code-test cycle. Without TDD, you often end up shipping the first design you can think of; with TDD, the very act of trying to figure out how to write tests forces you to iterate on your design, and you often ship something more effective.
In fact, TDD affects not only the design of small parts of your code, but also the design of your entire system. Some TDD practitioners use TDD only for writing unit tests up front, but you can also use TDD with integration tests, end-to-end tests, and performance tests. Thinking about integration tests up front forces you to consider how the different parts of your system will communicate with one another. Thinking about end-to-end tests up front forces you to think through how to deploy everything. Thinking about performance tests up front forces you to think about where your bottlenecks are and what metrics you need to gather to identify them.
Being forced to think through all of this up front, simply because you try to write tests first, can have a profoundly positive impact on the final design. If I had used TDD to write my sorting code at TripAdvisor, I would’ve written the tests first, realized that my code depended on the database, and that would’ve led to a different design that prevented the bug before I had written even a single line of implementation code. If you want to see more examples of how TDD leads to better code, see the recommended resources on automated testing in [Link to Come].
It’s also worth mentioning that writing tests up front increases the chances that you’ll have thorough test coverage, because it forces you to write code incrementally. Tests can be tedious to write, so it’s easier if you only have to do a few at a time: write a few tests and then a little bit of implementation, then a few more tests, then a little more implementation, and so on. It’s less effective to spend weeks writing thousands of lines of implementation code and then try to go back and do a marathon session of writing test cases for all of it. You’ll get bored and end up with far less code coverage. You’ll also miss many corner cases because you’ll forget the nuances of implementation code you wrote weeks ago.
Note that not all types of coding are a good fit for TDD. For example, if you’re doing exploratory coding, where you don’t yet know exactly what you’re building, and you’re just exploring the problem space by coding and messing with data, TDD might not be a good fit. If you don’t know what result you’re looking for, you can’t write a test for it. In that case, writing tests shortly after you write the code is still valuable.
Also, if you’re working on an existing codebase that doesn’t have any tests (a legacy codebase), then you might feel like TDD doesn’t apply, as the development is already done. However, you can still use TDD for any changes you make to the codebase. It’s very similar to the standard TDD process, but with a couple steps at the front:
-
Write a test for the functionality you’re about to modify.
-
Run all the tests. They should all pass.
-
Use standard TDD for any new functionality or changes you’re about to make.
This way, you incrementally build out the test coverage for the codebase, specifically in those parts of the code that you’re modifying. Each test you add for the existing functionality gives you a way to prove to yourself that you truly understand how that code works, which can make it less scary to start making changes; and each test you add for new functionality gives you all the standard benefits of TDD. And when you’re done, you leave the codebase with at least a few tests in place, which will make it less scary—make it feel less like legacy code—for the next developer.
TDD is also useful for bug fixing. If you found a bug in production, that means there was no test that caught the problem, so a good way to start on the fix is, as a first step, to write a failing test that reproduces the bug (test-driven bug fixing), just as you did when fixing the HTML sanitization bug in the sample app earlier in this chapter. The failing test proves you understand the cause of the bug and, after you fix it, leaves you with a regression test that will prevent the bug from coming back.
Conclusion
Reminder: commit your code!
While working through this chapter, you’ve probably made a lot of code changes in the ch4 folder: e.g., updating package.json with build steps and dependencies, switching to an Express app, adding automated tests for the app and infrastructure code, and so on. If you haven’t already, make sure to commit all this code—especially changes in the sample-app and tofu folders—so you don’t lose it and can iterate on it in future chapters:
$cdfundamentals-of-devops/ch4$gitaddsample-apptofu$gitcommit-m"Add ch4 sample code"$gitpushoriginmain
You’ve now taken a big step forward in allowing your team members to collaborate on your code by following the 6 key takeaways from this Chapter:
-
Always manage your code with a version control system.
-
Use a build system to capture, as code, important operations and knowledge for your project, in a way that can be used both by developers and automated tools.
-
Use a dependency management tool to pull in dependencies—not copy & paste.
-
Use automated tests to give your team the confidence to make changes quickly.
-
Automated testing makes you more productive while coding by providing a rapid feedback loop: make a change, run the tests, make another change, re-run the tests, and so on.
-
Automated testing makes you more productive in the future, too: you save a huge amount of time not having to fix bugs because the tests prevented those bugs from slipping through in the first place.
This is terrific progress, but it doesn’t solve the collaboration problem fully. You have a version control system, but if teams go off and work in branches for months, it becomes difficult to merge their work back together; you have automated tests, but developers don’t always remember to run them, so broken code still slips by; and you have a build system that automates some operations, but deployments are still largely manual. To collaborate efficiently as a team, you not only need to use version control, build systems, and automated tests, but you also need to combine them in a specific way, using two software delivery practices. These practices are called continuous integration and continuous delivery, and they are the focus of Chapter 5.
1 This method of calculating commit IDs is brilliant. First, it ensures that commit IDs are consistent without a central mechanism for issuing IDs: the same commit done on any computer, anywhere in the world, at any time always gets the exact same ID. Second, it ensures commits can’t be tampered with: change even 1 bit of the contents, metadata, or history, and you get a totally different SHA-1 hash. Third, it gives you an efficient way to compare commits: you can compare commits using just the IDs, without having to send the full contents; even more interestingly, you can compare the full history just by comparing IDs, as the commit ID calculation includes the ID of the previous commit, which, in turn, includes the ID of its predecessor, and so on, so two commit IDs are only equal if their entire history is equal.
2 See “Software Defect-Removal Efficiency” by Capers Jones, IEEE Computer, April 1996 and Handbook of Walkthroughs, Inspections, and Technical Reviews: Evaluating Programs, Projects, and Products by Daniel P. Freedman and Gerald M. Weinberg, Dorset House.
Get Fundamentals of DevOps and Software Delivery now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

