Kapitel 4. Kontinuierliche Prüfung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Ohne kontinuierliches Feedback sind deine Bemühungen um schnelles Feedback in der Schwebe!
Im vorherigen Kapitel haben wir besprochen, wie das Hinzufügen von Tests in den richtigen Schichten der Anwendung die Feedback-Zyklen beschleunigt. Um die Qualität der Anwendung während des gesamten Entwicklungszyklus nahtlos zu regulieren, ist es unerlässlich, dieses schnelle Feedback kontinuierlich und nicht nur stoßweise zu erhalten. Dieses Kapitel ist der Ausarbeitung einer solchen kontinuierlichen Testpraxis gewidmet.
Kontinuierliches Testen (CT) ist der Prozess, bei dem die Qualität der Anwendung mit manuellen und automatisierten Testmethoden nach jeder inkrementellen Änderung validiert wird und das Team gewarnt wird, wenn die Änderung eine Abweichung von den geplanten Qualitätsergebnissen verursacht. Wenn zum Beispiel eine Funktion von den erwarteten Leistungswerten der Anwendung abweicht, wird das Team durch fehlgeschlagene Leistungstests sofort benachrichtigt. Das gibt dem Team die Möglichkeit, Probleme so früh wie möglich zu beheben, wenn sie noch relativ klein und überschaubar sind. Fehlt eine solche kontinuierliche Feedbackschleife, bleiben die Probleme möglicherweise über einen längeren Zeitraum unbemerkt, so dass sie sich mit der Zeit auf tiefere Ebenen des Codes ausbreiten und der Aufwand für ihre Behebung steigt.
Der CT-Prozess stützt sich stark auf die Praxis der kontinuierlichen Integration (CI), um automatisierte Tests für jede Änderung durchzuführen. Die Einführung von CI zusammen mit CT ermöglicht dem Team eine kontinuierliche Auslieferung (CD). Letztendlich macht das Trio aus CI, CD und CT das Team zu einem leistungsstarken Team, was anhand der vier Schlüsselkennzahlen Vorlaufzeit, Bereitstellungshäufigkeit, mittlere Zeit bis zur Wiederherstellung undProzentsatz der fehlgeschlagenen Änderungen gemessen wird. Diese Kennzahlen, die wir uns am Ende dieses Kapitels ansehen werden, geben Aufschluss über die Qualität der Bereitstellungspraktiken des Teams.
Dieses Kapitel vermittelt dir die Fähigkeiten, die du brauchst, um einen CT-Prozess für dein Team zu etablieren. Du lernst etwas über CI/CD/CT-Prozesse und Strategien, um mehrere Feedbackschleifen zu verschiedenen Qualitätsdimensionen zu erreichen. Eine angeleitete Übung zum Einrichten eines CI-Servers und zur Integration der automatisierten Tests ist ebenfalls enthalten.
Bauklötze
Als Grundlage für die Fähigkeit zum kontinuierlichen Testen führt dich dieser Abschnitt in die Terminologie und den allgemeinen CI/CD/CT-Prozess ein. Außerdem lernst du die grundlegenden Prinzipien und Umgangsformen kennen, die im Team sorgfältig verankert werden sollten, damit der Prozess erfolgreich ist. Beginnen wir mit einer Einführung in CI.
Einführung in die kontinuierliche Integration
Martin Fowler, Autor von einem halben Dutzend Büchern, darunter Refactoring: Improving the Design of Existing Code (Addison Wesley) und Chief Scientist bei Thoughtworks, beschreibt kontinuierliche Integration als "eine Softwareentwicklungspraxis, bei der die Mitglieder eines Teams ihre Arbeit häufig integrieren, in der Regel integriert jede Person mindestens einmal täglich, was zu mehreren Integrationen pro Tag führt." Betrachten wir ein Beispiel, um die Vorteile einer solchen Praxis zu verdeutlichen.
Zwei Teamkollegen, Allie und Bob, begannen unabhängig voneinander mit der Entwicklung einer Login- und einer Homepage. Die Arbeit begann am Morgen, und bis zum Mittag hatte Allie einen grundlegenden Anmeldevorgang und Bob eine grundlegende Struktur für die Homepage fertiggestellt. Beide testeten ihre jeweiligen Funktionen auf ihren lokalen Rechnern und setzten ihre Arbeit fort. Am Ende des Tages hatte Allie die Login-Funktionalität fertiggestellt, indem sie dafür sorgte, dass die Anwendung nach erfolgreichem Login auf einer leeren Startseite landete, da die Startseite für sie noch nicht verfügbar war. Bob vervollständigte die Homepage-Funktionalität, indem er den Benutzernamen in der Begrüßungsnachricht fest eincodierte, da ihm die Benutzerinformationen aus dem Login nicht zur Verfügung standen.
Am nächsten Tag meldeten beide, dass ihre Funktionen "fertig" seien! Aber sind sie wirklich fertig? Welcher der beiden Entwickler ist für die Integration der Seiten verantwortlich? Sollen sie für jedes Integrationsszenario in der gesamten Anwendung eine eigene User Story erstellen? Wenn ja, sind sie dann bereit, die Kosten für den doppelten Testaufwand zu tragen, der mit dem Testen der Integration Story verbunden ist? Oder sollten sie die Tests verschieben, bis die Integration abgeschlossen ist? Diese Fragen werden bei der kontinuierlichen Integration implizit beantwortet.
Wenn die CI eingehalten wird, teilen Allie und Bob ihre Arbeitsfortschritte im Laufe des Tages (schließlich hatten beide bis Mittag ein Grundgerüst ihrer Funktionalitäten fertig). Bob wird in der Lage sein, den notwendigen Integrationscode hinzuzufügen, um den Benutzernamen nach der Anmeldung zu abstrahieren (z. B. von einem JSON- oder JWT-Token), und Allie wird dafür sorgen, dass die Anwendung nach erfolgreicher Anmeldung auf der eigentlichen Startseite landet. Die Anwendung ist dann wirklich nutzbar und testbar!
In diesem Beispiel mag es wie ein geringer Mehraufwand erscheinen, die beiden Seiten am nächsten Tag zu integrieren. Wenn der Code jedoch später im Entwicklungszyklus entsteht und integriert wird, werden die Integrationstests kostspielig und zeitaufwändig. Je länger die Tests hinausgezögert werden, desto wahrscheinlicher ist es, dass sie verworrene Probleme finden, die schwer zu beheben sind und manchmal sogar eine Neufassung eines großen Teils der Software erfordern. Dies führt zu einer allgemeinen Angst der Teammitglieder vor der Integration - oft eine unausgesprochene Begleiterscheinung einer verzögerten Integration!
Die Praxis der kontinuierlichen Integration versucht im Wesentlichen, solche Integrationsrisiken zu verringern und das Team vor Ad-hoc-Überarbeitungen und Patches zu bewahren. Integrationsfehler werden dadurch zwar nicht vollständig beseitigt ( ), aber es ist einfacher, sie frühzeitig zu finden und zu beheben, wenn sie gerade erst aufkeimen.
Der CI/CT/CD-Prozess
Beginnen wir damit, die Prozesse der kontinuierlichen Integration und des Testens im Detail zu betrachten. Später werden wir sehen, wie sie miteinander verbunden sind und den kontinuierlichen Bereitstellungsprozess bilden.
Der CI/CT-Prozess besteht aus vier einzelnen Komponenten:
Das Versionskontrollsystem (VCS), das die gesamte Codebasis der Anwendung enthält und als zentrales Repository dient, aus dem alle Teammitglieder die neueste Version des Codes ziehen können und in das sie ihre Arbeit kontinuierlich integrieren können
Die automatisierten funktionalen und funktionsübergreifenden Tests, die die Anwendung validieren
Der CI-Server, der automatisch die automatisierten Tests gegen die neueste Version des Anwendungscodes bei jeder zusätzlichen Änderung ausführt
Die Infrastruktur, die den CI-Server und die Anwendung hostet
Der kontinuierliche Integrations- und Testworkflow beginnt mit dem Entwickler, der, sobald er einen kleinen Teil der Funktionalität fertiggestellt hat, seine Änderungen in ein gängiges Versionskontrollsystem (z. B. Git, SVN) überträgt. Das VCS verfolgt jede Änderung, die ihm übermittelt wird. Die Änderungen werden dann durch den kontinuierlichen Testprozess geschickt, bei dem der Anwendungscode vollständig gebaut wird und automatisierte Tests von einem CI-Server (z. B. Jenkins, GoCD) durchgeführt werden. Wenn alle Tests bestanden werden, gelten die neuen Änderungen als vollständig integriert. Wenn es Fehler gibt, behebt der Verantwortliche für den jeweiligen Code die Probleme so schnell wie möglich. Manchmal werden Änderungen aus dem VCS zurückgenommen, bis die Probleme behoben sind. Damit soll vor allem verhindert werden, dass andere den Code mit Fehlern übernehmen und ihre Arbeit darüber hinaus integrieren.
Wie in Abbildung 4-1 zu sehen ist, schiebt Allie ihren Code für die grundlegenden Anmeldefunktionen zusammen mit den Anmeldetests noch vor Mittag als Teil von Commit Cn in die gemeinsame Versionskontrolle.
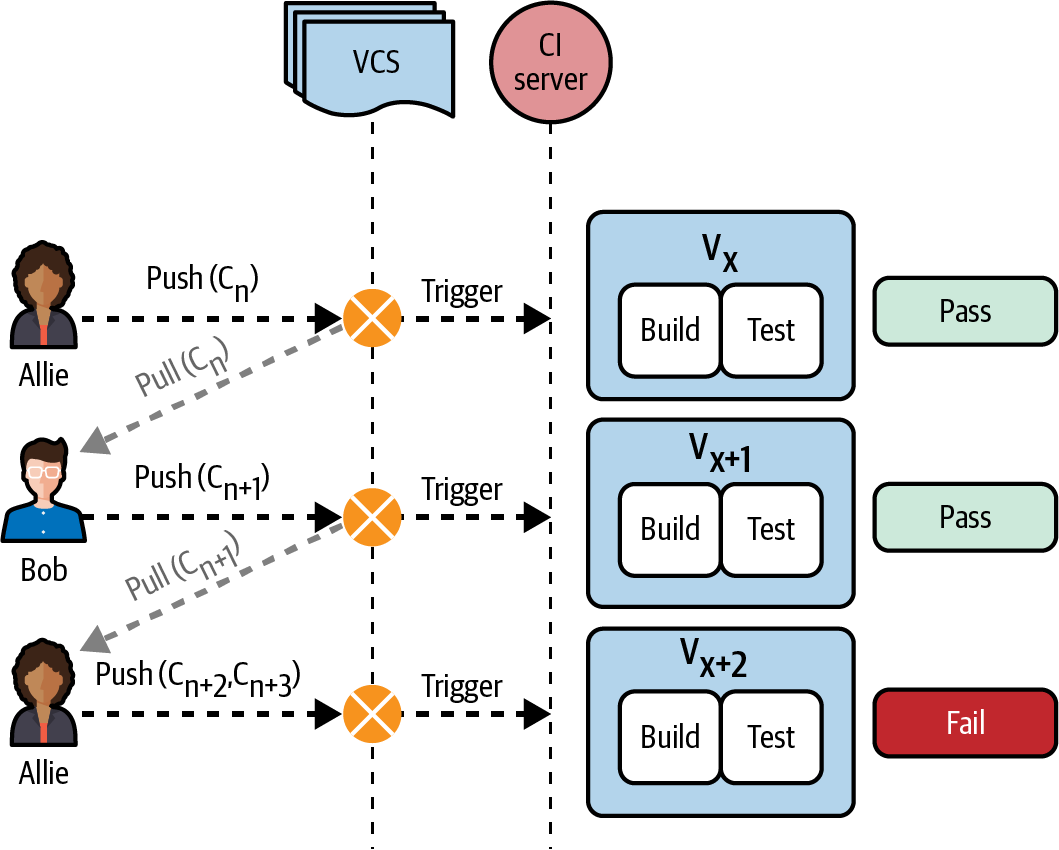
Abbildung 4-1. Komponenten in einem kontinuierlichen Integrations- und Testprozess
Hinweis
Im Git VCS ist ein Commit ein Schnappschuss der gesamten Codebasis zu einem bestimmten Zeitpunkt. Bei der kontinuierlichen Integration wird empfohlen, dass kleine inkrementelle Änderungen als unabhängige Commits auf dem lokalen Rechner gespeichert werden. Wenn die Funktionalität einen logischen Zustand erreicht hat, z. B. die Fertigstellung einer grundlegenden Anmeldefunktion, sollten die Commits in das gemeinsame VCS-Repository übertragen werden. Erst wenn die Änderungen in das VCS übertragen werden, beginnen die CI- und Testprozesse.
Die neue Änderung, Cn, löst eine eigene Pipeline im CI-Server aus. Jede Pipeline besteht aus mehreren aufeinanderfolgenden Phasen. Die erste ist die Build- und Testphase, in der die Anwendung erstellt und automatisierte Tests gegen sie durchgeführt werden. Dazu gehören alle Tests auf Mikro- und Makroebene, die in Kapitel 3 besprochen wurden, sowie Tests, die die Qualitätsdimensionen der Anwendung überprüfen (Leistung, Sicherheit usw.), die wir in den nächsten Kapiteln besprechen werden. Sobald diese Phase abgeschlossen ist, werden die Testergebnisse an Allie übermittelt. In diesem Fall wurde Allie's Code erfolgreich integriert und sie fährt mit ihrer Anmeldefunktion fort.
Später am Tag veröffentlicht Bob den Commit Cn+1 für die Homepage-Funktion, nachdem er die letzten Änderungen (Cn) aus dem gemeinsamen VCS gezogen hat. Cn+1 ist also ein Schnappschuss der Codebasis der Anwendung, der sowohl Allies als auch Bobs neue Änderungen enthält. Dies löst die Build- und Testphase im CI-Prozess aus. Die Tests, die gegen Cn+1 laufen, stellen sicher, dass Bobs neue Änderungen keine der vorherigen Funktionen beschädigt haben, einschließlich Allies neuestem Commit, da sie auch die Login-Tests hinzugefügt hat. Glücklicherweise hat Bob das nicht getan. In Abbildung 4-1 sehen wir jedoch, dass Allies Änderungen in den Commits Cn+2 und Cn+3 die Integration gestört haben und die Tests fehlgeschlagen sind. Sie muss diese Fehler beheben, bevor sie ihre Arbeit fortsetzen kann, da sie einen Fehler in das gemeinsame VCS eingebracht hat. Sie kann ihre Korrektur als weiteren Commit pushen und der Prozess wird fortgesetzt.
Stell dir den gleichen Arbeitsablauf in einem großen, verteilten Team vor, und du kannst verstehen, wie viel einfacher es für alle Teammitglieder ist, ihre Fortschritte zu teilen und ihre Arbeit nahtlos zu integrieren. Außerdem gibt es in großen Anwendungen in der Regel mehrere voneinander abhängige Komponenten, die ausführliche Integrationstests erfordern, und der kontinuierliche Testprozess gibt das dringend benötigte Vertrauen in die Feinheit ihrer Integration!
Mit dieser Art von Vertrauen, das durch die vollständig automatisierten Integrations- und Testprozesse gewonnen wird, ist das Team in der Lage, seinen Code in die Produktion zu bringen, wann immer das Geschäft es erfordert. Mit anderen Worten: Das Team ist für die kontinuierliche Bereitstellung gerüstet.
Die kontinuierliche Bereitstellung hängt von der Einhaltung der kontinuierlichen Integrations- und Testprozesse ab, damit die Anwendung jederzeit produktionsbereit ist. Außerdem muss ein automatischer Bereitstellungsmechanismus vorhanden sein, der mit einem einzigen Klick ausgelöst werden kann, um die Anwendung in jeder Umgebung bereitzustellen, sei es in der Qualitätssicherung oder in der Produktion. Abbildung 4-2 zeigt den kontinuierlichen Bereitstellungsprozess.
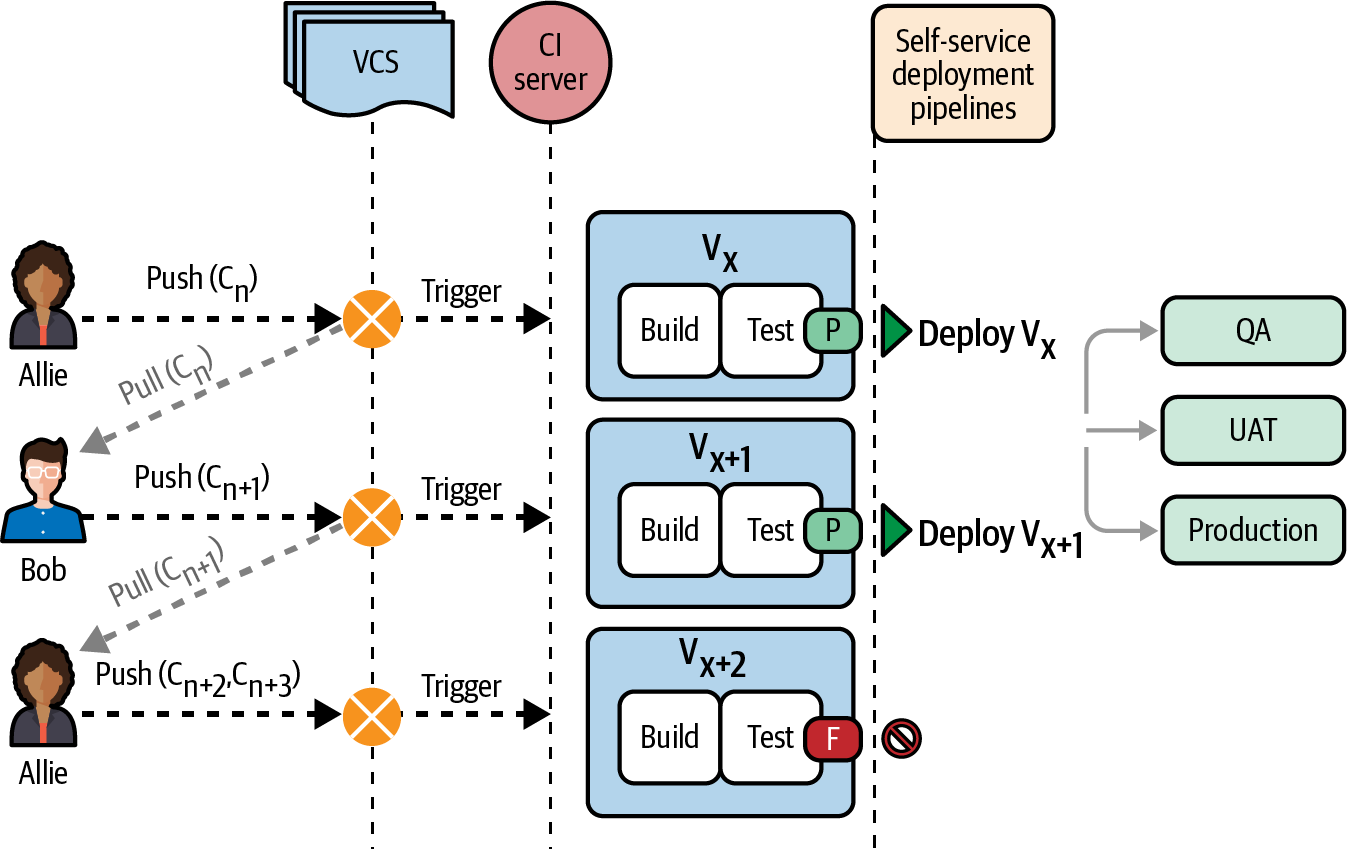
Abbildung 4-2. Kontinuierlicher Bereitstellungsprozess mit CI-, CT- und Deployment-Pipelines
Wie du siehst, umfasst der Continuous-Delivery-Prozess die CI/CT-Prozesse zusammen mit den Self-Service-Deployment-Pipelines. Diese Pipelines sind ebenfalls im CI-Server konfigurierte Stufen, die die Aufgabe haben, die "ausgewählte" Version der Anwendungsartefakte in der gewünschten Umgebung bereitzustellen.
Der CI-Server listet alle Commits mit dem Status ihrer Testergebnisse auf. Nur wenn alle Tests für einen Commit (oder eine Reihe von Commits) bestanden wurden, bietet er die Option an, diese bestimmte Anwendungsversion (V) einzusetzen. Nehmen wir zum Beispiel an, Allies Team möchte Feedback vom Unternehmen zu den grundlegenden Login-Funktionen erhalten, die in Commit Cn veröffentlicht wurden. Wie in Abbildung 4-2 zu sehen, kann das Team auf die Schaltfläche Deploy Vx klicken und die UAT-Umgebung (User Acceptance Testing) auswählen. Dadurch werden nur die bis zu diesem Zeitpunkt vorgenommenen Änderungen in der UAT-Umgebung bereitgestellt, d.h. Bobs Cn+1 und spätere Commits werden nicht bereitgestellt. Wie du siehst, stehen die Commits Cn+2 und Cn+3 nicht für den Einsatz zur Verfügung, da die Tests fehlgeschlagen sind.
Diese Art der kontinuierlichen Bereitstellung löst viele kritische Probleme, aber einer der wichtigsten Vorteile ist die Möglichkeit, Produktfunktionen zum richtigen Zeitpunkt auf den Markt zu bringen. Oft führen Verzögerungen bei der Veröffentlichung von Funktionen zu Umsatzeinbußen und zum Verlust von Kunden an die Konkurrenz. Außerdem wird der Bereitstellungsprozess aus Sicht des Teams vollständig automatisiert, wodurch die Abhängigkeit von bestimmten Personen, die am Tag der Bereitstellung zaubern, verringert wird; jeder kann jederzeit eine problemlose Bereitstellung in jeder Umgebung vornehmen. Die Automatisierung des Einsatzes verringert auch das Risiko inkompatibler Bibliotheken, fehlender oder falscher Konfigurationen und unzureichender Dokumentation.
Grundsätze und Umgangsformen
Nachdem wir nun über die CI/CD/CT-Prozesse gesprochen haben, ist es wichtig, darauf hinzuweisen, dass diese Prozesse nur dann erfolgreich sein können, wenn alle Teammitglieder eine Reihe von gut definierten Prinzipien und die Etikette befolgen. Schließlich handelt es sich um einen automatisierten Weg, um gemeinsam an ihrer Arbeit zu arbeiten - seien es automatisierte Tests, Anwendungscode oder Infrastrukturkonfigurationen. Das Team sollte diese Grundsätze zu Beginn des Lieferzyklus festlegen und sie während des gesamten Zyklus immer wieder bekräftigen. Hier ist ein Mindestmaß an Prinzipien und Umgangsformen, die ein Team einhalten muss, um erfolgreich zu sein:
- Häufige Codeübertragungen durchführen
Die Teammitglieder sollten regelmäßig Code Commits machen und diese ins VCS stellen, sobald sie ein kleines Stück Funktionalität fertiggestellt haben, damit es getestet und für andere verfügbar ist, um darauf aufzubauen.
- Selbstgetesteten Code immer übertragen
Jedes Mal, wenn ein neues Stück Code übergeben wird, sollte es von automatisierten Tests im selben Commit begleitet werden. Martin Fowler nennt diese Praxis selbsttestenden Code. Wie wir bereits gesehen haben, hat Allie zum Beispiel ihre Login-Funktionalität zusammen mit Login-Tests übertragen. Dadurch wurde sichergestellt, dass ihr Commit nicht beschädigt wurde, als Bob seinen Code als nächstes committed hat.
- Befolge die Zertifizierungsprüfung für kontinuierliche Integration
Jedes Teammitglied sollte sicherstellen, dass sein Commit den kontinuierlichen Testprozess durchläuft, bevor es mit der nächsten Aufgabe weitermacht. Wenn die Tests fehlschlagen, müssen sie sie sofort beheben. Laut dem Continuous Integration Certification Test von Martin Fowler sollte eine fehlerhafte Build- und Testphase innerhalb von 10 Minuten repariert werden. Wenn das nicht möglich ist, sollte der fehlerhafte Commit rückgängig gemacht werden, sodass der Code stabil (oder grün) bleibt.
- Die fehlgeschlagenen Tests nicht ignorieren/auskommentieren
In der Eile, den Build und die Testphase erfolgreich abzuschließen, sollten Teammitglieder die fehlgeschlagenen Tests nicht auskommentieren und ignorieren. So einleuchtend die Gründe auch sind, warum man das nicht tun sollte, es ist eine gängige Praxis.
- Nicht auf einen kaputten Build pushen
Das Team sollte seinen Code nicht pushen, wenn die Build- und Testphase kaputt (oder rot) ist. Wenn du die Arbeit auf eine bereits fehlerhafte Codebasis aufbaust, werden die Tests erneut fehlschlagen. Dadurch wird das Team mit der zusätzlichen Aufgabe belastet, herauszufinden, welche Änderungen den Build ursprünglich beschädigt haben.
- Übernimm die Verantwortung für alle Misserfolge
Wenn Tests in einem Bereich des Codes fehlschlagen, an dem jemand nicht gearbeitet hat, der Test aber aufgrund seiner Änderungen fehlschlägt, liegt die Verantwortung für die Korrektur des Builds immer noch bei ihm. Falls nötig, können sie sich mit jemandem zusammentun, der das nötige Wissen hat, um das Problem zu beheben, aber letztendlich ist es eine grundlegende Voraussetzung, das Problem zu beheben, bevor sie zur nächsten Aufgabe übergehen. Diese Vorgehensweise ist wichtig, denn oft wird die Verantwortung für die Behebung der fehlgeschlagenen Tests hin- und hergeschoben, wodurch sich die Lösung der Probleme verzögert. Manchmal werden die Tests tagelang nicht in der KI ausgeführt, weil das Problem nicht behoben wird. Das führt dazu, dass der kontinuierliche Testprozess unvollständiges oder falsches Feedback für die Änderungen gibt, die in diesem offenen Zeitfenster vorgenommen wurden.
Viele Teams wenden zu ihrem eigenen Vorteil auch strengere Praktiken an, wie z. B. die Vorgabe, dass alle Mikro- und Makro-Tests auf den lokalen Rechnern bestanden werden müssen, bevor der Commit an das VCS übertragen wird, das Fehlschlagen der Build- und Testphase, wenn ein Commit die Codeabdeckungsschwelle nicht erreicht, die Veröffentlichung des Commit-Status (bestanden oder fehlgeschlagen) mit dem Namen der Person, die den Commit erstellt hat, für alle auf einem Kommunikationskanal wie Slack, laute Musik im Teambereich, wenn ein Build von einem dedizierten CI-Monitor fehlschlägt, und so weiter. Außerdem behalte ich als Tester im Team den Status der Tests im CI im Auge und sorge dafür, dass sie rechtzeitig behoben werden. Im Grunde genommen werden all diese Maßnahmen ergriffen, um die Praktiken des Teams rund um die CI/CT-Prozesse zu straffen und dadurch die richtigen Vorteile zu erzielen - obwohl die wichtigste Maßnahme, die immer am besten zu funktionieren scheint, darin besteht, das Team mit Wissen zu versorgen: nicht nur das "Wie", sondern auch das "Warum" hinter dem Prozess!
Strategie für kontinuierliche Tests
Nachdem du nun die Prozesse und Prinzipien kennst, geht es im nächsten Schritt darum, Strategien zu entwickeln und anzuwenden, die auf die Bedürfnisse deines Projekts zugeschnitten sind.
Im vorigen Abschnitt wurde der kontinuierliche Testprozess mit einer einzigen Build- und Testphase demonstriert, die alle Tests durchführt und in einer einzigen Schleife Feedback gibt. Du kannst den Feedback-Zyklus auch mit zwei unabhängigen Feedback-Schleifen beschleunigen: eine, die die Tests gegen den statischen Anwendungscode durchführt (z. B. alle Tests auf Mikroebene), und die andere, die die Tests auf Makroebene gegen die eingesetzte Anwendung durchführt. Das ist gewissermaßen eine leichte Verschiebung nach links, bei der wir die Fähigkeit der Mikroebene (Unit-, Integrations-, Vertragstests) nutzen, schneller zu laufen als die der Makroebene (API-, UI-, End-to-End-Tests), um schnelleres Feedback zu erhalten.
Abbildung 4-3 zeigt einen CT-Prozess mit zwei Stufen. Wie du hier siehst, ist es eine gängige Praxis, die Kompilierung der Anwendung mit den Tests auf Mikroebene als eine einzige Stufe in der CI zu kombinieren. Dies wird traditionell als Build- und Testphase bezeichnet. Wenn sich das Team an die Testpyramide hält, wie wir sie in Kapitel 3 besprochen haben, werden die Tests auf der Mikroebene am Ende ein breites Spektrum an Anwendungsfunktionen validieren. So kann das Team in dieser Phase schnell ein umfassendes Feedback zum Commit erhalten. Die Build- und Testphase sollte so schnell sein, dass sie innerhalb weniger Minuten abgeschlossen ist, so dass das Team gemäß den empfohlenen Prinzipien und Umgangsformen wartet, bis sie abgeschlossen ist, bevor es zur nächsten Aufgabe übergeht. Wenn es länger dauert, sollte das Team nach Möglichkeiten suchen, es zu verbessern - zum Beispiel, indem es die Build- und Testphase für jede Komponente parallelisiert, anstatt eine einzige Phase für die gesamte Codebasis zu haben.1
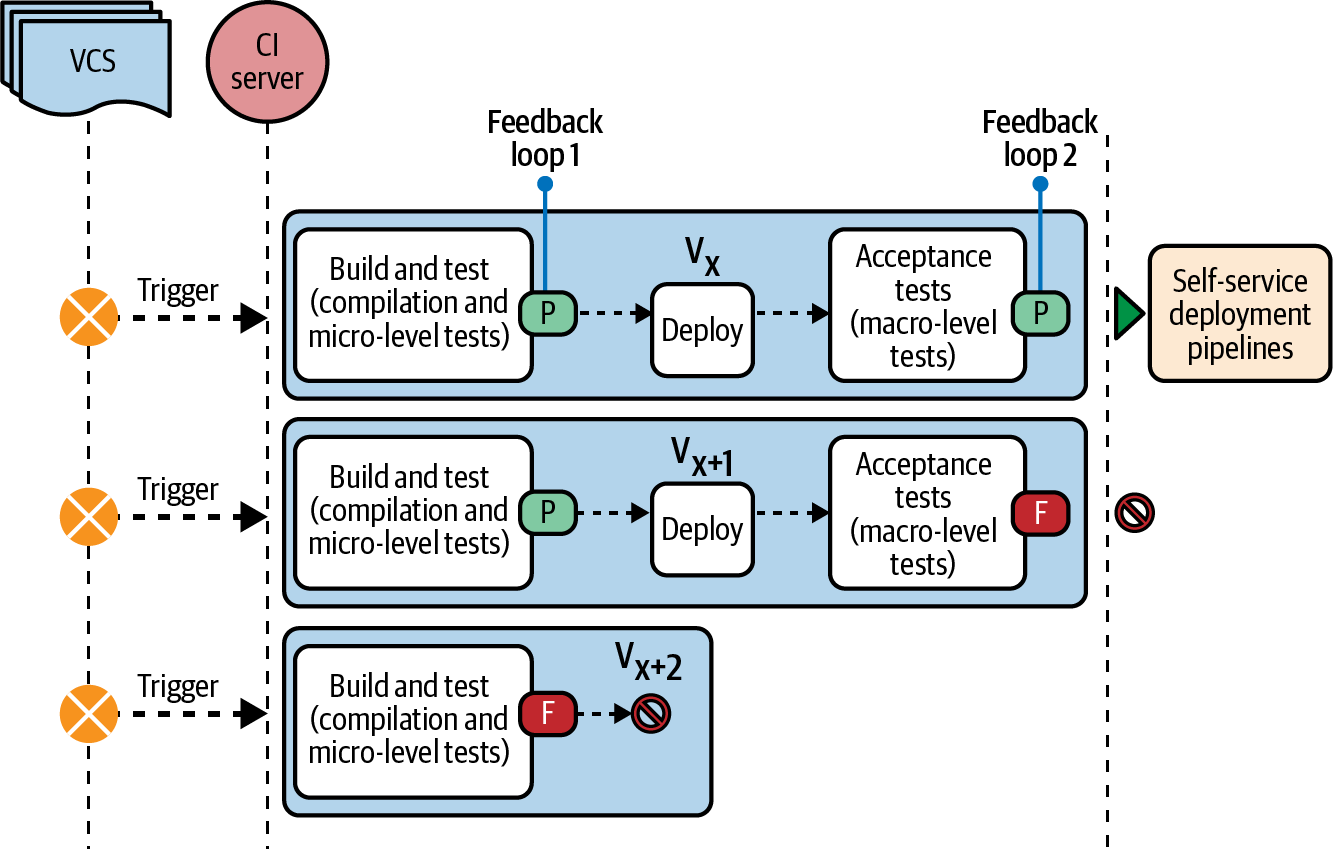
Abbildung 4-3. Der kontinuierliche Prüfprozess mit zwei Rückkopplungsschleifen
Hinweis
In ihrem Buch Continuous Delivery (Addison-Wesley Professional) schlagen Jez Humble und David Farley vor, dass die Build- und Testphase so kurz sein sollte, dass sie "ungefähr so viel Zeit in Anspruch nimmt, wie du für eine Tasse Tee, ein kurzes Gespräch, das Abrufen deiner E-Mails oder das Dehnen deiner Muskeln aufwenden kannst" ( ).
Sobald die Build- und Testphase abgeschlossen ist, werden in der Deployment-Phase die Artefakte der Anwendung in eine CI-Umgebung (auch Entwicklungsumgebung genannt) übertragen. In der nächsten Phase, die auch als Funktionstestphase oder Akzeptanztestphase bezeichnet wird, werden die Tests auf Makroebene mit der bereitgestellten Anwendung in der CI-Umgebung durchgeführt. Erst wenn diese Phase abgeschlossen ist, ist die Anwendung bereit für den Self-Service-Einsatz in anderen übergeordneten Umgebungen wie QA, UAT und Produktion.
Das Feedback aus dieser Phase kann länger dauern, da die Akzeptanztests länger dauern und die Phase nach der Bereitstellung der Anwendung ausgelöst wird, was ebenfalls Zeit kostet. Aber wenn Teams die Testpyramide richtig umsetzen, sollten die beiden Feedback-Schleifen weniger als eine Stunde in Anspruch nehmen. Das Beispiel aus Kapitel 3 bestätigt das: Als das Team ~200 Makro-Tests hatte, brauchte es 8 Stunden, um ein Feedback zu erhalten. Als es seine Teststruktur jedoch neu implementierte, um der Testpyramide zu entsprechen, brauchte es nur noch 35 Minuten vom Commit bis zum Self-Service-Deployment mit ~470 Mikro- und Makro-Tests.
Eine weitere Überlegung ist, dass Teammitglieder bei einer kurzen Feedbackschleife die Behebung der im kontinuierlichen Testprozess gefundenen Probleme auch dann priorisieren können, wenn sie kurz nach der Build- und Testphase eine neue Aufgabe übernommen haben. Wenn es mehrere Stunden dauert, könnten sie versucht sein, die fehlgeschlagenen Tests zu ignorieren und sie als Fehlerkarten zu erfassen, um sie später zu beheben. Das ist schädlich, denn es bedeutet, dass sie ihren neuen Code auf der Grundlage von Fehlern integrieren, und der neue Code wird auch nicht gründlich getestet, da die fehlgeschlagenen Tests ignoriert werden. Daher sollte das Team die beiden Rückkopplungsschleifen weiter beobachten und Maßnahmen ergreifen, um sie zu beschleunigen, z. B. durch Parallelisierung des Testlaufs, Implementierung der Testpyramide, Entfernen doppelter Tests und Refactoring der Tests, um Wartezeiten zu beseitigen und allgemeine Funktionen zu abstrahieren.2
Dieser kontinuierliche Testprozess kann weiter ausgebaut werden, um funktionsübergreifendes Feedback zu erhalten, wie in Abbildung 4-4 dargestellt. Teams können automatisierte Leistungs-, Sicherheits- und Zugänglichkeitstests als Teil der beiden bestehenden Feedbackschleifen durchführen oder separate Phasen im Anschluss an die Abnahmetestphase im CI-Server konfigurieren, um ein kontinuierliches, schnelles und ganzheitliches Feedback zur Qualität der Anwendung zu erhalten. In den nächsten Kapiteln lernst du Shift-Links-Strategien für funktionsübergreifende Tests kennen.
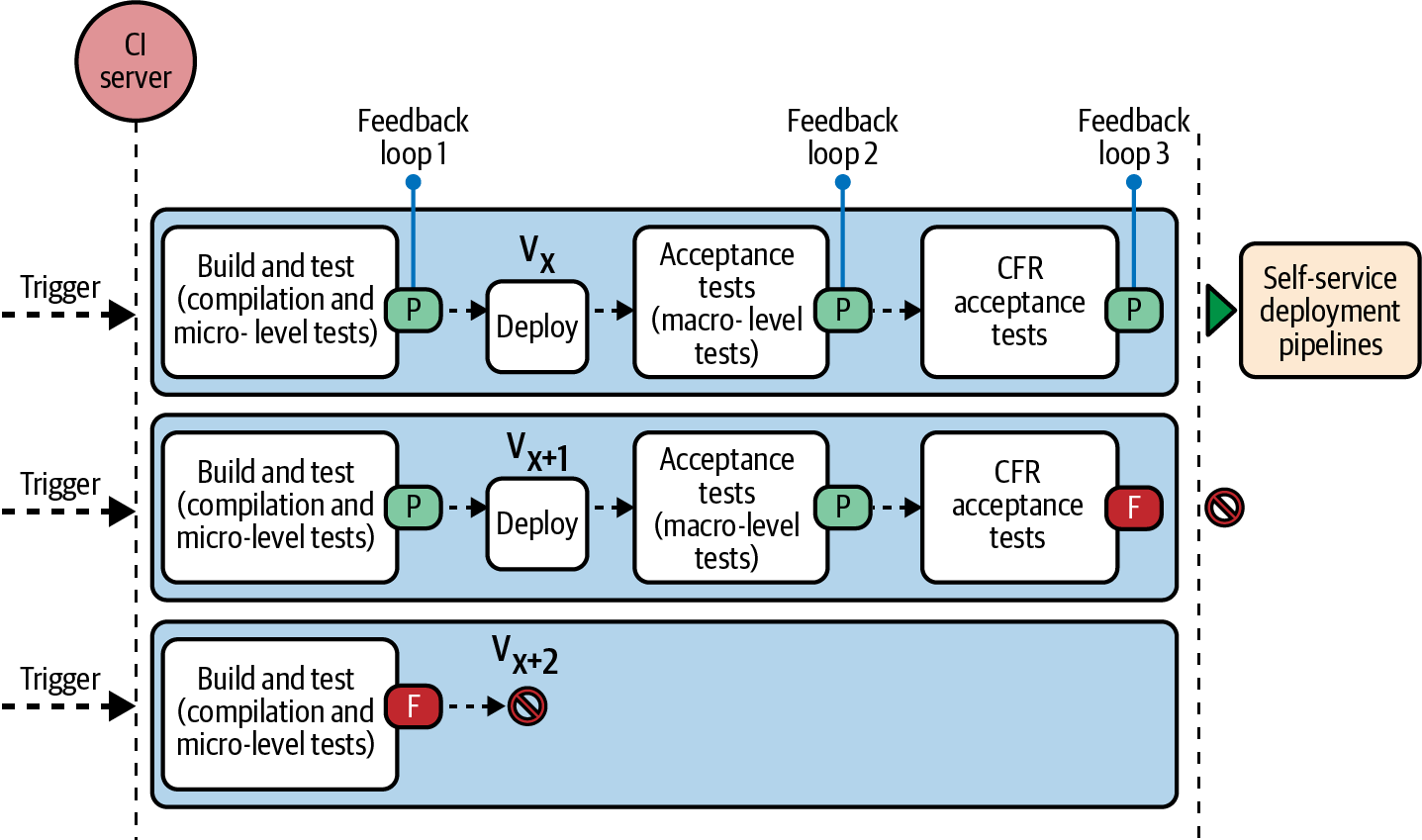
Abbildung 4-4. Der kontinuierliche Prüfprozess mit drei Feedbackschleifen
Wenn du alle Tests in einer verketteten Pipeline durchführst, kann es sehr viel Zeit und Ressourcen kosten, alle Phasen abzuschließen. Eine Möglichkeit, den CT-Prozess in diesem Fall strategisch zu gestalten, besteht darin, die Tests in Smoke-Tests und nächtliche Regressionstests aufzuteilen, wie in Abbildung 4-5 dargestellt.
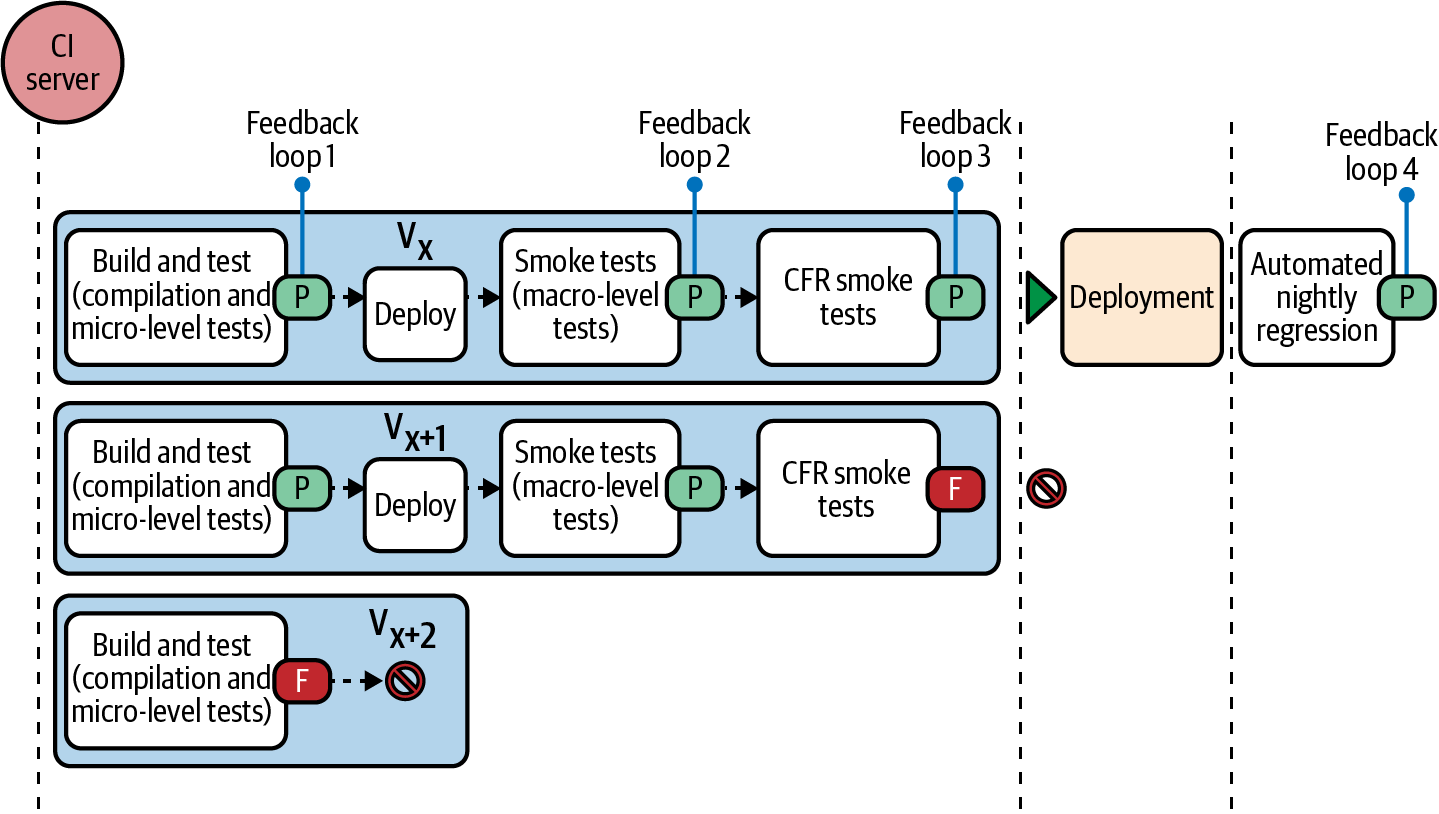
Abbildung 4-5. Der kontinuierliche Prüfprozess mit vier Rückkopplungsschleifen
Rauchprüfung ist ein Begriff aus der Welt der Elektrotechnik, bei dem Strom durch den Stromkreis geleitet wird, nachdem er abgeschlossen ist, um den durchgängigen Fluss zu beurteilen. Wenn es Probleme im Stromkreis gibt, gibt es Rauch (daher der Name). In ähnlicher Weise kannst du die Tests, die den End-to-End-Fluss jeder Funktion in der Anwendung abdecken, als Smoke-Test-Paket auswählen und sie nur in der Phase der Abnahmeprüfung durchführen. Auf diese Weise erhältst du schnell einen Überblick über den Status jedes Commits. Wie in Abbildung 4-5 zu sehen ist, ist der Commit nach der Smoke-Test-Phase bereit für die Self-Service-Bereitstellung.
Wenn du dich für Smoke-Tests entscheidest, musst du sie mit nächtlichen Regressionstests ergänzen. Die nächtliche Regressionsphase wird unter im CI-Server so konfiguriert, dass die gesamte Testsuite einmal pro Tag ausgeführt wird, wenn das Team nicht arbeitet (z. B. kann sie so geplant werden, dass sie jeden Tag um 19.00 Uhr ausgeführt wird). Die Tests werden gegen die aktuelle Codebasis mit allen Commits des Tages durchgeführt. Das Team muss es sich zur Gewohnheit machen, die nächtlichen Regressionsergebnisse gleich am nächsten Tag zu analysieren und die Behebung von Fehlern und Umgebungsfehlern zu priorisieren. Manchmal kann dies Änderungen an den Testskripten erfordern, die ebenfalls für den Tag priorisiert werden müssen, damit der kontinuierliche Testprozess das richtige Feedback für die kommenden Commits liefert.
Du kannst diese beiden Strategien anwenden, um sowohl die funktionalen als auch die funktionsübergreifenden Tests aufzuteilen. So kannst du zum Beispiel den Leistungstest für einen einzelnen kritischen Endpunkt bei jedem Commit durchführen und die übrigen Leistungstests als Teil der nächtlichen Regression (Leistungstests werden in Kapitel 8 behandelt). Ebenso kannst du die statischen Sicherheitstests für den Code als Teil der Build- und Testphase und die funktionalen Sicherheitstests (siehe Kapitel 7) als Teil der nächtlichen Regressionsphase durchführen. So naheliegend das auch sein mag, der Nachteil eines solchen Ansatzes ist, dass das Feedback um einen Tag verzögert wird. Folglich verzögert sich auch die Behebung des Feedbacks; die Probleme werden als Fehler verfolgt und später behoben. Deshalb solltest du bei der Auswahl der Tests, die du im Rahmen der Smoke-Tests und der nächtlichen Regressionsphasen durchführst, vorsichtig sein. Beachte außerdem, dass nur Makro- und funktionsübergreifende Tests als Smoke-Tests eingestuft werden sollten; alle Tests auf Mikroebene sollten weiterhin in der Build- und Testphase durchgeführt werden.
Wenn die Anwendung noch jung ist, kannst du meist auf diese Strategien verzichten und das Privileg genießen, alle Tests bei jedem Commit auszuführen. Wenn die Anwendung dann wächst (und damit auch die Anzahl der Tests), kannst du die verschiedenen Methoden zur Optimierung der CI-Laufzeit implementieren und schließlich den Weg über Smoke-Tests und nächtliche Regressionen einschlagen.
Vorteile
Wenn du dich fragst, ob sich der ganze Aufwand für einen kontinuierlichen Testprozess lohnt, zeigt dir Abbildung 4-6 einige Vorteile, um dich und dein Team zu motivieren.
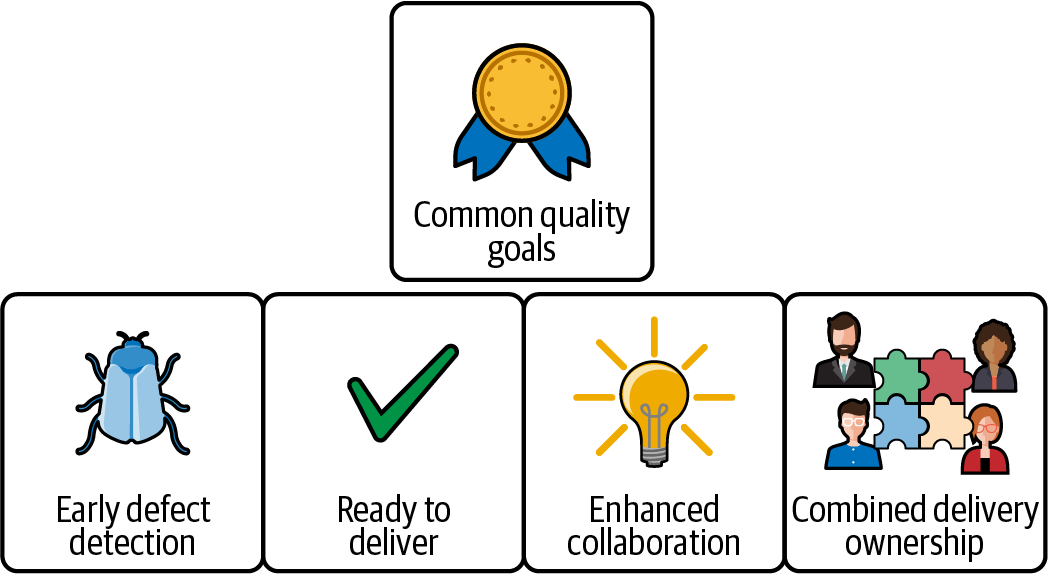
Abbildung 4-6. Vorteile des kontinuierlichen Prüfprozesses
Schauen wir uns jede dieser Möglichkeiten nacheinander an:
- Gemeinsame Qualitätsziele
Der Prozess des kontinuierlichen Testens stellt sicher, dass sich alle Teammitglieder eines gemeinsamen Qualitätsziels bewusst sind und darauf hinarbeiten - sowohl in Bezug auf funktionale als auch auf funktionsübergreifende Qualitätsaspekte - und dass ihre Arbeit kontinuierlich an diesem Ziel gemessen wird. Dies ist ein konkreter Weg, um Qualität einzubauen.
- Frühzeitige Fehlererkennung
Jedes Teammitglied erhält sofort Feedback zu seinen Commits, sowohl in Bezug auf funktionale als auch funktionsübergreifende Aspekte. Das gibt ihnen die Möglichkeit, Probleme zu beheben, während sie den entsprechenden Kontext haben, anstatt erst ein paar Tage oder Wochen später auf den Code zurückzukommen.
- Bereit zur Lieferung
Da der Code kontinuierlich getestet wird, ist die Anwendung immer in einem einsatzbereiten Zustand für jede Umgebung.
- Verbesserte Zusammenarbeit
Es ist einfacher, mit verteilten Teammitgliedern zusammenzuarbeiten, die ihre Arbeit miteinander teilen, und den Überblick darüber zu behalten, welcher Commit welche Probleme verursacht hat, wodurch Anschuldigungen vermieden und Feindseligkeiten eingeschränkt werden.
- Kombiniertes Eigentum an der Lieferung
Die Verantwortung für die Bereitstellung wird unter allen Teammitgliedern verteilt und nicht nur unter dem Testteam oder den leitenden Entwicklern, da jeder dafür verantwortlich ist, dass seine Commits bereit für die Bereitstellung sind.
Wenn du schon eine Weile in der Softwarebranche arbeitest, weißt du sicher, wie schwer es ist, einige dieser Vorteile anders zu erreichen!
Übung
Es ist Zeit, praktisch tätig zu werden. Die angeleitete Übung zeigt dir, wie du die automatisierten Tests, die du in Kapitel 3 erstellt hast, in ein VCS verschiebst, einen CI-Server einrichtest und die automatisierten Tests so in den CI-Server integrierst, dass die automatisierten Tests ausgeführt werden, sobald du einen Commit in das VCS verschiebst. Im Rahmen dieser Übung lernst du den Umgang mit Git und Jenkins.
Git
Das 2005 von Linus Torvalds, dem Schöpfer des Linux-Betriebssystemkerns, entwickelte Git ist das am weitesten verbreitete Open-Source-System zur Versionskontrolle. Laut einer Umfrage von Stack Overflow aus dem Jahr 2021 nutzen 90 % der Befragten Git. Es handelt sich um eine verteilte Versionskontrolle, d.h. jedes Teammitglied erhält eine Kopie der gesamten Codebasis mit der Historie der Änderungen. Das gibt den Teams eine große Flexibilität bei der Fehlersuche und der unabhängigen Arbeit.
Einrichtung
Für den Anfang brauchst du einen Ort, an dem du deine Code-Basis hosten kannst. GitHub und Bitbucket sind Unternehmen, die Cloud-basierte Angebote zum Hosten von Git-Repositories anbieten (ein Repository ist, einfach ausgedrückt, ein Speicherort für deine Codebasis). GitHub bietet die Möglichkeit, öffentliche Repositories kostenlos zu hosten, was es vor allem in der Open-Source-Gemeinde beliebt macht. Wenn du also für diese Übung noch kein GitHub-Konto hast, solltest du dir jetzt eines anlegen.
Navigiere in deinem GitHub-Konto zu Deine Repositories → Neu, um ein neues Repository für deine automatisierten Selenium-Tests zu erstellen. Gib einen Namen für das Repository an, z. B. FunctionalTests, und mache es zu einem öffentlichen Repository. Nach erfolgreicher Erstellung landest du auf der Seite zur Einrichtung des Repositorys. Notiere die URL für dein Repository(https://github.com/<DeinBenutzername>/FunctionalTests.git). Auf der Seite findest du auch eine Anleitung, wie du deinen Code mit Git-Befehlen in das Projektarchiv pushen kannst. Um diese Befehle auszuführen, musst du Git auf deinem Rechner einrichten und konfigurieren.
Befolge dazu die folgenden Schritte:
Lade Git herunter und installiere es mit den folgenden Befehlen von deiner Eingabeaufforderung aus:
// macOS $ brew install git // Linux $ sudo apt-get install git
Wenn du mit Windows arbeitest, lade das Installationsprogramm von der offiziellen Git for Windows Seite herunter.
Überprüfe die Installation, indem du den folgenden Befehl ausführst:
$ git --version
Jedes Mal, wenn du einen Commit machst, muss er mit einem Benutzernamen und einer E-Mail-Adresse verknüpft werden, damit er verfolgt werden kann. Gib deinen Benutzernamen und deine E-Mail-Adresse mit diesen Befehlen an Git weiter, damit es sie automatisch zuordnet, wenn du einen Commit machst:
$ git config --global user.name "yourUsername" $ git config --global user.email "yourEmail"
Überprüfe die Konfiguration, indem du diesen Befehl ausführst:
$ git config --global --list
Arbeitsablauf
Der Arbeitsablauf in Git besteht aus vier Phasen, die dein Code durchläuft, wie in Abbildung 4-7 dargestellt. Jede Phase hat einen anderen Zweck, wie du noch lernen wirst.
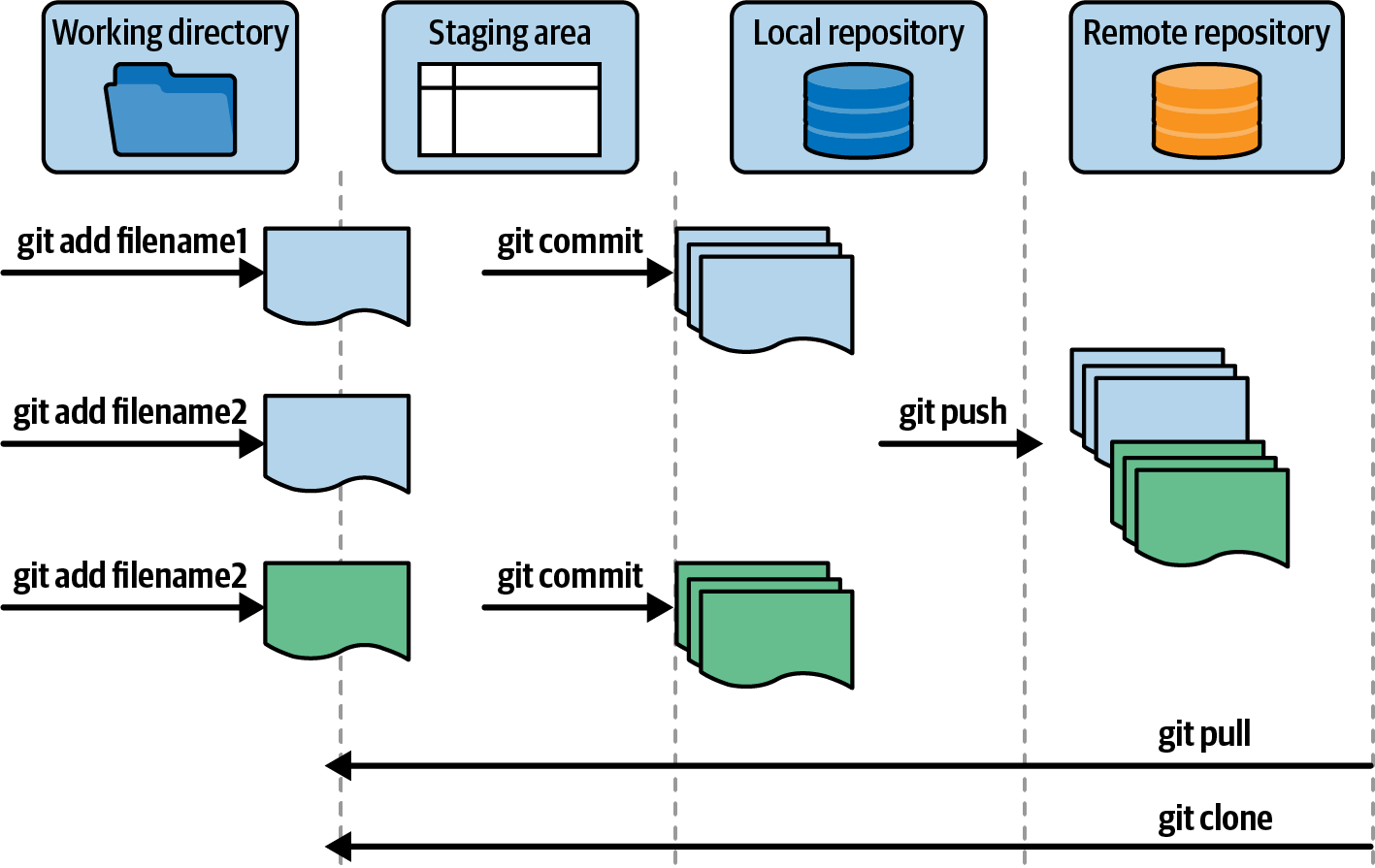
Abbildung 4-7. Git-Workflow mit vier Stufen
Die erste Stufe ist dein Arbeitsverzeichnis, in dem du Änderungen an deinem Testcode vornimmst (neue Tests hinzufügen, Testskripte korrigieren usw.). Die zweite Stufe ist der lokale Bereitstellungsbereich, in den du jeden kleinen Arbeitsschritt, wie z. B. die Erstellung einer Seitenklasse, einfügst, sobald du ihn abgeschlossen hast. So behältst du den Überblick über die Änderungen, die du vornimmst, damit du sie später überprüfen und wiederverwenden kannst. Die dritte Stufe ist dein lokales Repository. Wie bereits erwähnt, stellt Git jedem eine Kopie des gesamten Projektarchivs zusammen mit dem Verlauf auf seinem lokalen Rechner zur Verfügung. Sobald du eine funktionierende Teststruktur hast, kannst du einen Commit machen, der alles, was du in der Staging Area hinzugefügt hast, in dein lokales Repository verschiebt. So kannst du bei Fehlern den gesamten Code in einem Stück zurückgeben. Wenn du mit allen erforderlichen Änderungen fertig bist - in diesem Fall, wenn du einen Test vollständig fertiggestellt hast und ihn als Teil der CI-Pipeline laufen lassen willst - kannst du ihn in das Remote-Repository pushen. Der neue Test ist dann auch für alle Mitglieder deines Teams verfügbar.
Die Git-Befehle, um den Code durch die verschiedenen Phasen zu bewegen, sind in Abbildung 4-7 dargestellt. Du kannst sie jetzt Schritt für Schritt wie folgt ausprobieren:
Gehe in deinem Terminal zu dem Ordner, in dem du in Kapitel 3 deine automatisierten Selenium-Tests erstellt hast. Führe den folgenden Befehl aus, um das Git-Repository zu initialisieren:
$ cd /path/to/project/ $ git init
Mit diesem Befehl wird der Ordner .git in deinem aktuellen Arbeitsverzeichnis angelegt.
Füge deine gesamte Testsuite zum Staging-Bereich hinzu, indem du den folgenden Befehl ausführst:
$ git add .
Du kannst stattdessen eine bestimmte Datei (oder ein Verzeichnis) mit
git add filename.Commit deine Änderungen in das lokale Repository mit einer lesbaren Nachricht, die den Kontext des Commits erklärt, indem du den folgenden Befehl mit dem entsprechenden Nachrichtentext ausführst:
$ git commit -m "Adding functional tests"
Du kannst die Schritte 2 und 3 kombinieren, indem du den optionalen Parameter mit
-aanhängst, d.h,git commit -am "message".Um deinen Code in das öffentliche Repository zu pushen, musst du zunächst seinen Speicherort in deinem lokalen Git angeben. Dazu führst du den folgenden Befehl aus:
$ git remote add origin
https://github.com/<yourusername>/FunctionalTests.git
Im nächsten Schritt musst du die Datei in das öffentliche Repository pushen. Beim Pushen musst du dich mit deinem GitHub-Benutzernamen und deinem persönlichen Zugangs-Token authentifizieren. Ein persönliches Zugangstoken ist ein kurzlebiges Passwort, das GitHub aus Sicherheitsgründen ab August 2021 für alle Vorgänge vorschreibt. Um dein persönliches Zugangstoken zu erhalten, gehe zu deinem GitHub-Konto, navigiere zu Einstellungen → Entwicklereinstellungen → "Persönliche Zugangstoken", klicke auf "Neues Token generieren" und fülle die erforderlichen Felder aus. Verwende das Token, wenn du nach der Eingabeaufforderung den folgenden Befehl ausführst:
$ git push -u origin master
Tipp
Wenn du dich nicht jedes Mal authentifizieren möchtest, wenn du mit dem öffentlichen Repository interagierst, kannst du den SSH-Authentifizierungsmechanismus einrichten.
Öffne dein GitHub-Konto und verifiziere das Repository.
Wenn du mit Teammitgliedern zusammenarbeitest, musst du ihren Code aus dem öffentlichen Repository auf deinen Rechner ziehen. Das kannst du mit dem Befehl git pull tun. Wenn du bereits ein Repository für Funktionstests für dein Team hast, kannst du mit git clone repoURL verwenden, um eine Kopie deines lokalen Repositorys zu erhalten, anstatt git init.
Verschiedene andere Git-Befehle, wie git merge, git fetch und git reset, machen unser Leben einfacher. Erforsche sie bei Bedarf in der offiziellen Dokumentation.
Jenkins
Im nächsten Schritt richtest du einen Jenkins CI-Server auf deinem lokalen Rechner ein und integrierst die automatisierten Tests aus deinem Git-Repository.
Hinweis
Dieser Teil der Übung soll dir ein Verständnis dafür vermitteln, wie kontinuierliches Testen mit CI/CD-Tools in der Praxis umgesetzt werden kann, und nicht dazu dienen, dir DevOps beizubringen. Teams können Entwickler mit speziellen DevOps-Fähigkeiten einstellen oder eine DevOps-Rolle haben, die die Erstellung und Wartung der CI/CD/CT-Pipeline verwaltet. Dennoch ist es wichtig, dass sowohl Entwickler/innen als auch Tester/innen mit dem CI/CD/CT-Prozess und seiner Funktionsweise vertraut sind, da sie mit diesem Prozess interagieren und Fehler aus erster Hand beheben werden. Aus Sicht der Tester/innen ist es außerdem wichtig zu lernen, den CT-Prozess an die spezifischen Projektanforderungen anzupassen und sicherzustellen, dass die Testphasen entsprechend der CT-Strategie des Teams richtig verkettet sind.
Einrichtung
Jenkins ist ein Open-Source-CI-Server. Um zu nutzen, lade das Installationspaket für dein Betriebssystem herunter und befolge die Standard-Installationsprozedur. Sobald er installiert ist, starte den Jenkins-Dienst. Unter macOS kannst du den Jenkins-Dienst mit den folgenden brew Befehlen installieren und starten:
$ brew install jenkins-lts $ brew services start jenkins-lts
Nachdem der Dienst erfolgreich gestartet wurde, öffne die Jenkins Web UI unter http://localhost:8080/. Die Seite führt dich durch die folgenden Konfigurationsaktivitäten:
Schalte Jenkins mit einem eindeutigen Administrator-Passwort frei, das bei der Installation generiert wurde. Auf der Webseite wird dir der Pfad zu dem Ort angezeigt, an dem sich dieses Passwort auf deinem lokalen Rechner befindet.
Lade die häufig verwendeten Jenkins-Plug-ins herunter und installiere sie.
Erstelle ein Administratorkonto. Mit diesem Konto wirst du dich jedes Mal bei Jenkins anmelden.
Nach der anfänglichen Konfiguration gelangst du über zur Jenkins Dashboard-Seite, wie in Abbildung 4-8 zu sehen ist.
Abbildung 4-8. Jenkins Dashboard-Ansicht
Arbeitsablauf
Befolge nun die folgenden Schritte , um eine neue Pipeline für deine automatisierten Tests einzurichten:
Gehe im Jenkins Dashboard zu Jenkins verwalten → Globale Werkzeugkonfiguration, um die Umgebungsvariablen
JAVA_HOMEundMAVEN_HOMEzu konfigurieren (siehe 4-9 und 4-10). Du kannst auch den Befehlmvn -vin dein Terminal eingeben, um beide Speicherorte zu erhalten.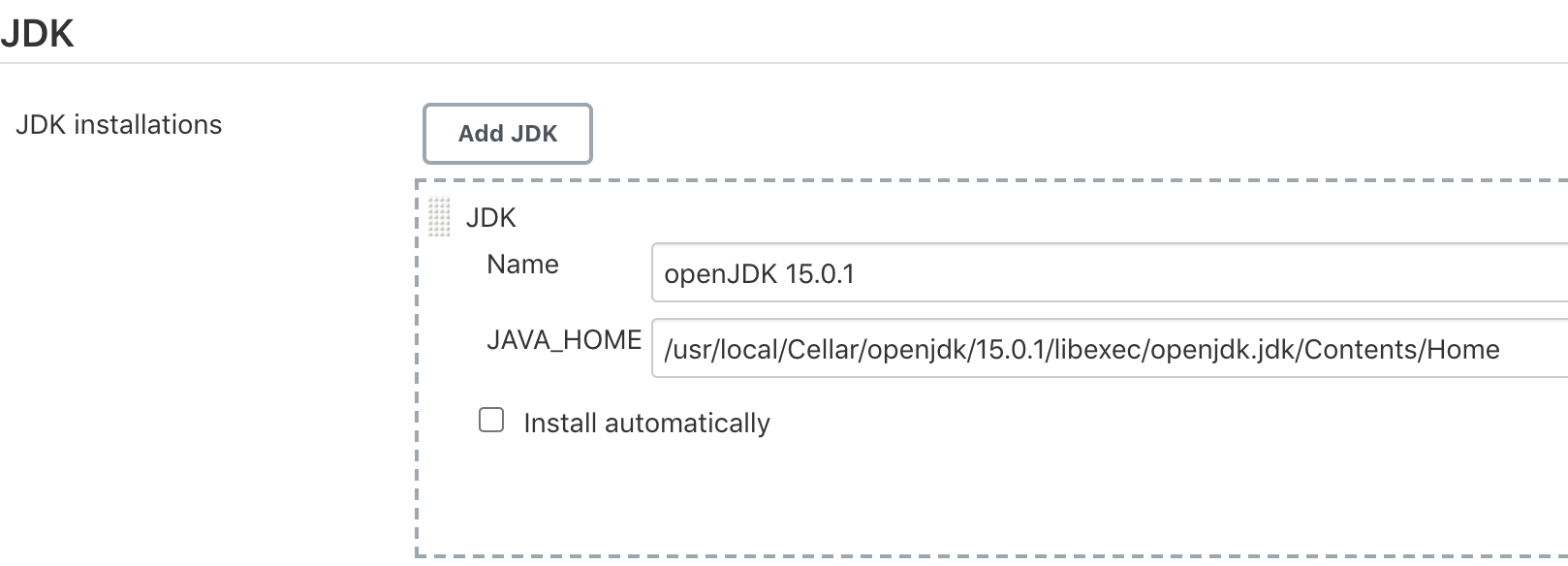
Abbildung 4-9.
JAVA_HOMEin Jenkins konfigurieren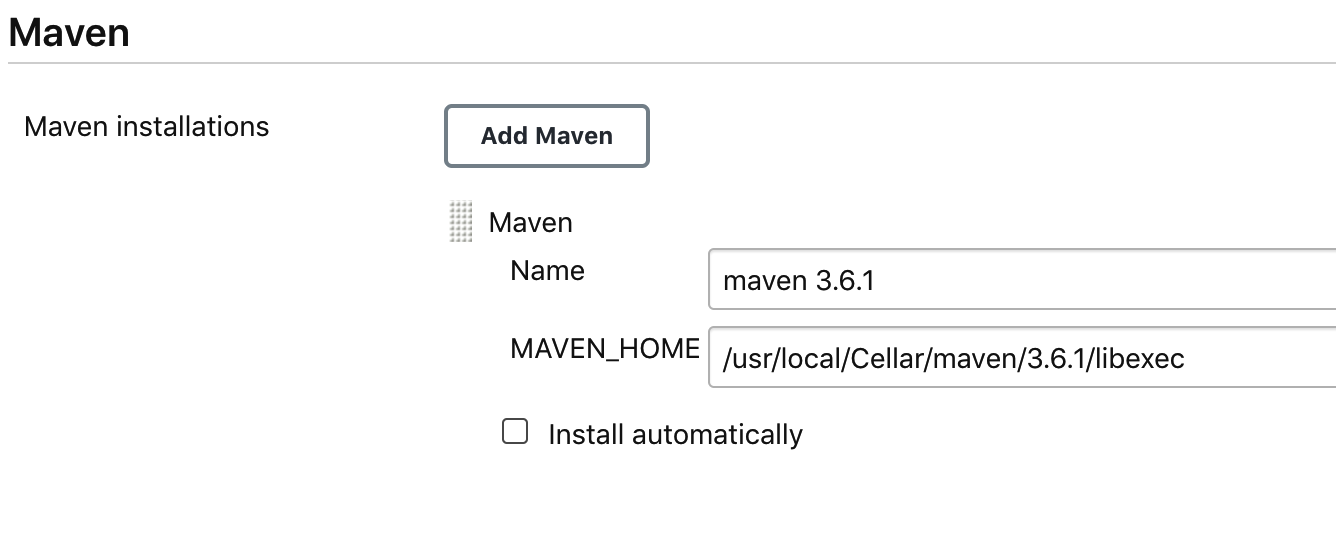
Abbildung 4-10.
MAVEN_HOMEin Jenkins konfigurierenWenn du zur Dashboard-Ansicht zurückkehrst, wähle die Option "Neues Element" im linken Bereich, um eine neue Pipeline zu erstellen. Gib einen Namen für die Pipeline ein, z. B. "Funktionstests", und wähle die Option "Freestyle-Projekt". Dadurch gelangst du zur Konfigurationsseite der Pipeline, wie in Abbildung 4-11 zu sehen.
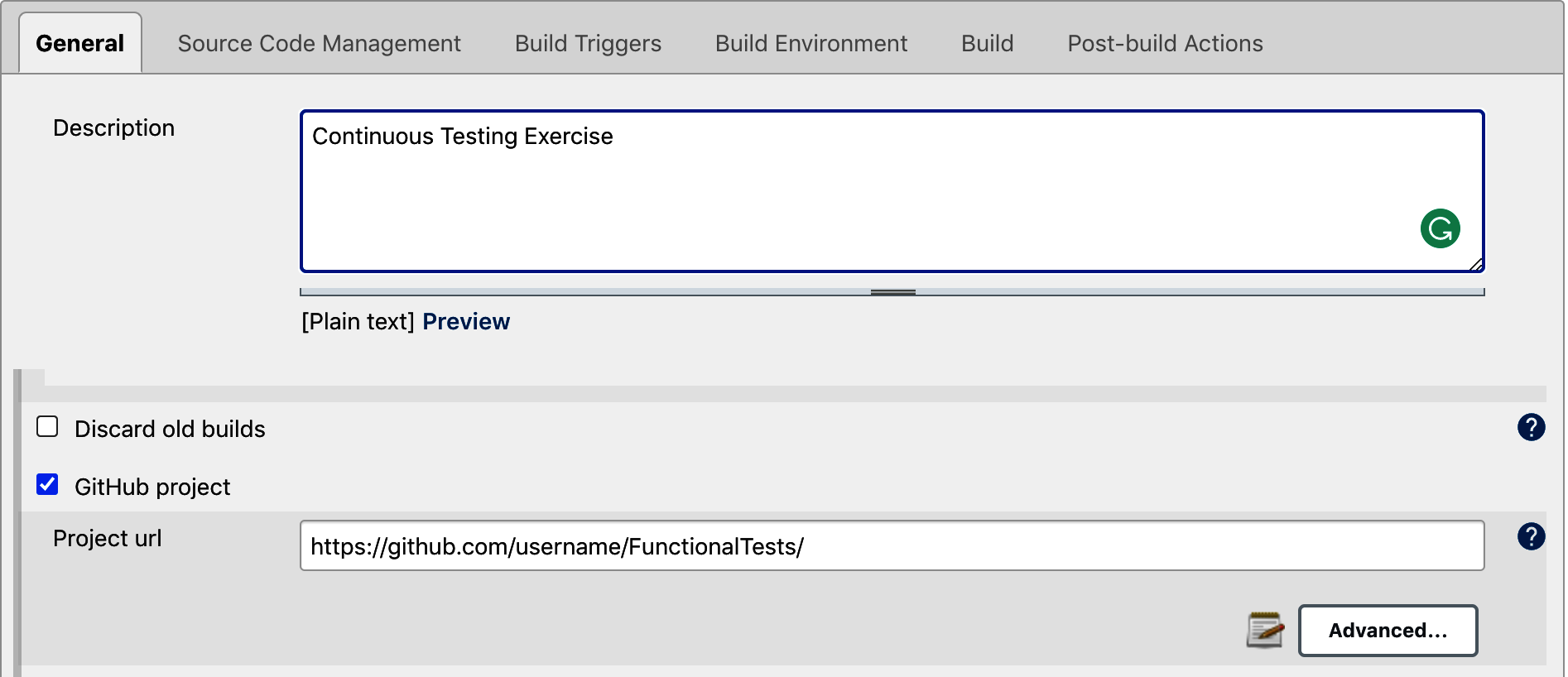
Abbildung 4-11. Die Jenkins-Pipeline-Konfigurationsseite
Gib die folgenden Details ein, um deine Pipeline zu konfigurieren:
Füge auf der Registerkarte "Allgemein" eine Pipeline-Beschreibung hinzu. Wähle "GitHub-Projekt" und gib die URL deines Repositorys ein (ohne die Erweiterung .git ).
Auf der Registerkarte Quellcodeverwaltung wählst du Git aus und gibst die URL deines Repositorys ein (dieses Mal mit der Erweiterung .git ). Jenkins verwendet diese URL, um
git cloneauszuführen.Auf der Registerkarte Build Triggers (Build-Auslöser) findest du einige Optionen, mit denen du festlegen kannst, wann und wie die Pipeline automatisch gestartet werden soll . Mit der Option Poll SCM kannst du zum Beispiel das Git-Repository alle zwei Minuten nach neuen Änderungen abfragen und den Testlauf starten, wenn es welche gibt. Mit der Option Regelmäßig bauen kannst du den Testlauf in festen Abständen planen, auch wenn es keine neuen Codeänderungen gibt. Damit lassen sich nächtliche Regressionen konfigurieren. Mit der Option "GitHub-Hook-Trigger für GITScm-Polling" kannst du ein GitHub-Plug-in so konfigurieren, dass es einen Trigger an Jenkins sendet, sobald es neue Änderungen gibt. Um es einfach zu halten, wähle Poll SCM und gib diesen Wert ein, um das Repository für funktionale Tests alle zwei Minuten abzufragen:
H/2 * * * *.Da dein Selenium WebDriver-Framework für funktionale Tests Maven verwendet, wähle auf der Registerkarte Build die Option "Maven-Targets auf oberster Ebene aufrufen". Wähle dein lokales Maven, das du in Kapitel 3 konfiguriert hast. Gib im Feld "Ziele" die Maven-Lebenszyklusphase ein, die von der Pipeline ausgeführt werden soll:
test. Damit wird der Befehlmvn testaus dem Projektverzeichnis ausgeführt.Auf der Registerkarte "Post-build Actions" kannst du mehrere Pipelines verketten, d.h. die CFR-Tests-Pipeline auslösen, nachdem die Pipeline für funktionale Tests bestanden wurde, und eine vollständige CD-Pipeline erstellen.4
Speichere und navigiere zur Dashboard-Ansicht. Du siehst die erstellte Pipeline, wie in Abbildung 4-12 dargestellt.

Abbildung 4-12. Deine Pipeline im Jenkins Dashboard
Klicke in der Dashboard-Ansicht auf den Namen der Pipeline und wähle auf der Zielseite im linken Bereich die Option Jetzt bauen. Die Pipeline klont das Repository auf deinem lokalen Rechner und führt den Befehl
mvn testaus. Du kannst sehen, wie sich der Chrome-Browser im Rahmen der Testausführung öffnet und schließt.Auf der gleichen Seite findest du den Ordner Workspace. In diesem Ordner findest du die lokale geklonte Kopie des Codes aus dem Repository und die Berichte, die nach dem Ausführen der Tests erstellt werden; du kannst sie zu Debugging-Zwecken verwenden.
Wähle im unteren Bereich des linken Fensters auf derselben Seite den aktuellen Build Count der Pipeline-Ausführung aus. Du hast die Möglichkeit, die Konsolenausgabe im linken Bereich der Landing Page anzuzeigen. In dieser Ansicht werden die Live-Ausführungsaktivitäten zum Debuggen angezeigt.
Herzlichen Glückwunsch, damit ist dein CI-Setup komplett!
Ebenso musst du die Phasen der jeweiligen Tests (statischer Code, Akzeptanz, Smoke, CFR) entsprechend deiner Strategie für kontinuierliche Tests hinzufügen, um das End-to-End-CD-Setup für das Projekt zu vervollständigen. Achte darauf, dass die Stufen nicht nur bei Änderungen des Anwendungscodes ausgelöst werden, sondern auch bei Änderungen der Konfiguration, der Infrastruktur und des Testcodes!
Die vier Schlüsselmetriken
Das Endergebnis all dieser Anstrengungen, die du in die Einrichtung deiner CI/CD/CT-Prozesse (und die Einhaltung der oben genannten Prinzipien und Umgangsformen) investiert hast, ist das Team, das sich nach den vier Schlüsselmetriken (4KM), die von Googles DevOps Research and Assessment (DORA)-Team ermittelt wurden, als Elite- oder Hochleistungsteam qualifiziert. DORA formulierte die 4KM auf der Grundlage umfangreicher Untersuchungen und erläuterte, wie diese Kennzahlen verwendet werden können, um das Leistungsniveau eines Softwareteams als elitär, hoch, mittel oder niedrig einzustufen. Das Buch Accelerate von Jez Humble, Gene Kim und Nicole Forsgren ist eine hervorragende Lektüre, um die Details der Forschung zu erfahren.
Kurz gesagt, die vier Schlüsselmetriken geben uns die Möglichkeit, das Liefertempo eines Teams und die Stabilität seiner Veröffentlichungen zu messen. Sie sind:
- Vorlaufzeit
Die Zeit, die von der Übermittlung des Codes bis zur Bereitstellung für die Produktion vergeht
- Häufigkeit des Einsatzes
Die Häufigkeit, mit der die Software in der Produktion oder in einem App Store bereitgestellt wird
- Mittlere Zeit bis zur Wiederherstellung
Die Zeit, die benötigt wird, um alle Serviceausfälle wiederherzustellen oder Ausfälle zu beheben
- Prozentsatz des Fehlschlagens ändern
Der Prozentsatz der für die Produktion freigegebenen Änderungen , die eine nachträgliche Korrektur erfordern, wie z. B. Rollbacks zu einer früheren Version oder Hotfixes, oder die eine Verschlechterung der Servicequalität verursachen
Die ersten beiden Kennzahlen, Vorlaufzeit und Bereitstellungshäufigkeit, geben Aufschluss über das Liefertempo des Teams. Sie messen, wie schnell ein Team den Endnutzern einen Mehrwert liefern kann und wie häufig es einen Mehrwert für die Endnutzer schafft. In der Eile, einen Mehrwert für die Kunden zu schaffen, sollte das Team jedoch keine Kompromisse bei der Stabilität der Software eingehen. Die letzten beiden Kennzahlen bestätigen dies. Die mittlere Zeit bis zur Wiederherstellung und der Prozentsatz der fehlgeschlagenen Änderungen geben Aufschluss über die Stabilität der Software, die veröffentlicht wird. In der heutigen Welt sind Softwarefehler unvermeidlich, und diese Kennzahlen messen, wie einfach es ist, sich von diesen Fehlern zu erholen und wie oft solche Fehler bei neuen Versionen auftreten. Wie du siehst, vermitteln die 4KM ein klares Bild von der Leistung eines Softwareteams, indem sie dessen Geschwindigkeit, Reaktionsfähigkeit und Fähigkeit, Qualität und Stabilität zu liefern, messen.
Die Ziele für ein Eliteteam laut DORA-Forschung sind in Tabelle 4-1 dargestellt.
| Metrisch | Ziel |
|---|---|
| Häufigkeit des Einsatzes | On-Demand (mehrere Einsätze pro Tag) |
| Vorlaufzeit | Weniger als ein Tag |
| Mittlere Zeit bis zur Wiederherstellung | Weniger als eine Stunde |
| Prozentsatz des Fehlschlagens ändern | 0-15% |
Wie bereits erwähnt, besteht einer der Hauptvorteile eines rigorosen CI/CD/CT-Prozesses darin, dass dein Team in der Lage ist, den Kunden bei Bedarf einen Mehrwert zu liefern. Wenn du automatisierte Tests in den richtigen Anwendungsschichten platzierst, kannst du deinen Code im Rahmen des kontinuierlichen Testprozesses testen und ihn innerhalb von Stunden bereitstellen (d.h. deine Vorlaufzeit beträgt weniger als einen Tag). Wenn deine funktionalen und funktionsübergreifenden Anforderungsprüfungen automatisiert und als Teil des CT-Prozesses durchgeführt werden, sollte es auch kein Problem sein, den Prozentsatz der fehlgeschlagenen Änderungen innerhalb des empfohlenen Bereichs von 0-15 % zu halten. Die Anstrengungen, die du in diesem Bereich unternimmst, ermöglichen es deinem Team, den "Elite"-Status gemäß der DORA-Definition zu erreichen. Die DORA-Forschung zeigt auch, dass Eliteteams zum Erfolg eines Unternehmens beitragen, und zwar in Bezug auf Gewinn, Aktienkurs, Kundenbindung und andere Kriterien. Und wenn es dem Unternehmen gut geht, kümmert es sich gut um seine Mitarbeiter, oder?
Die wichtigsten Erkenntnisse
Hier sind die wichtigsten Erkenntnisse aus diesem Kapitel:
Der kontinuierliche Testprozess validiert die Qualität der Anwendung sowohl in Bezug auf funktionale als auch funktionsübergreifende Aspekte auf automatisierte Weise bei jeder inkrementellen Änderung.
Kontinuierliche Tests hängen stark vom kontinuierlichen Integrationsprozess ab. Kontinuierliche Integration und kontinuierliches Testen wiederum ermöglichen die kontinuierliche Bereitstellung von Software für Kunden auf Abruf.
Kontinuierliche Integrations- und Testprozesse verlangen von den Teams, dass sie strenge Prinzipien und Umgangsformen befolgen, damit sie fruchtbar sind.
Plane deinen kontinuierlichen Testprozess so, dass du in mehreren Schleifen kontinuierlich schnelles Feedback erhältst.
Die Vorteile des kontinuierlichen Testens sind zahlreich, und viele davon - wie die Festlegung gemeinsamer Qualitätsziele für alle Rollen und Teams, die gemeinsame Verantwortung für die Lieferung und die verbesserte Zusammenarbeit in verteilten Teams - sind auf andere Weise nur schwer zu erreichen.
Auch wenn DevOps-Ingenieure für die Einrichtung und Pflege von CI/CD zuständig sind, ist es wichtig, dass die Tester im Team die Strategie für kontinuierliche Tests entwickeln und sicherstellen, dass die Feedbackschleifen korrekt ausgelöst werden. Vor allem aber sollten sie die CI/CD-Praktiken des Teams genau im Auge behalten, um sicherzustellen, dass sich der Aufwand für die Erstellung und Pflege von Tests lohnt.
Wenn du rigorose CI/CD/CT-Prozesse befolgst, wird dein Team zu einem Eliteteam, wie es die DORA-Forschung definiert. Und ein Eliteteam trägt zum Erfolg des gesamten Unternehmens bei!
1 Mehr zu diesem und anderen allgemein vorgeschriebenen CI/CD-Grundsätzen der Branche findest du in The DevOps Handbook (IT Revolution Press) von Gene Kim, Jez Humble, Patrick Debois und John Willis.
2 Jez Humble und David Farley erörtern solche Optimierungstechniken ausführlicher in Continuous Delivery.
3 Weitere Einzelheiten findest du in dem Buch Accelerate von Jez Humble, Gene Kim und Nicole Forsgren (IT Revolution Press).
4 Weitere Informationen zur Arbeit mit Pipelines findest du in der Jenkins-Dokumentation.
Get Full Stack Testing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

