Chapter 1. Full Stack Development in the Era of Serverless Computing
People have typically associated cloud computing with backend development and DevOps. However, over the past few years, this has started to change. With the rise of functions as a service (FaaS), combined with powerful abstractions in the form of managed services, cloud providers have lowered the barrier to entry for developers new to cloud computing, and for traditionally frontend developers.
Using modern tools, frameworks, and services like Amazon Web Services (AWS) Amplify and Firebase (among others), a single developer can leverage their existing skill set and knowledge of a single framework and ecosystem (like JavaScript) to build scalable full stack applications complete with all of the features that would in the past have required teams of highly skilled backend and DevOps engineers to build and maintain.
This book focuses on bridging the gap between frontend and backend development by taking advantage of this new generation of tools and services using the Amplify Framework. Here you’ll learn how to build scalable applications in the cloud directly from your frontend environment using the Amplify Command Line Interface (CLI). You’ll create and interact with various APIs and AWS services, such as authentication using Amazon Cognito, cloud storage using Amazon S3, APIs using Amazon API Gateway and AWS AppSync, and databases using Amazon DynamoDB.
By the final chapter, you will understand how to build real-world full stack applications in the cloud leveraging AWS services on the backend and React on the frontend. You’ll also learn how to use modern APIs from React, like hooks, and functional components, as well as React Context for global state management.
Modern Serverless Philosophy
The term serverless is commonly associated with FaaS. Though you will find varying definitions as to what it means, the term has recently grown to encompass more of a philosophy than a shared definition.
Many times when people talk about serverless, they are really describing how to most efficiently deliver business value with a focus on writing business logic, instead of coding supporting infrastructure for your business logic. Adopting a serverless mindset allows you to do this by consciously going out of your way to find and leverage FaaS, managed services, and smart abstractions, while only building custom solutions if an existing service just doesn’t yet exist.
More and more companies and developers are taking this approach, as it doesn’t make sense to reinvent the wheel. With the increase in popularity of this philosophy, there has also been an explosion of services and tools made available from startups and cloud providers to provide offerings that simplify backend complexity.
For an academic take on what serverless means, you may wish to read the 2019 paper written by a group at UC Berkeley, “Cloud Programming Simplified: A Berkeley View on Serverless Computing,”1. In this paper, the authors expanded the definition of serverless:
While cloud functions—packaged as FaaS (Function as a Service) offerings—represent the core of serverless computing, cloud platforms also provide specialized serverless frameworks that cater to specific application requirements as BaaS (Backend as a Service) offerings. Put simply, serverless computing = FaaS + BaaS.
Backend as a service (BaaS) typically refers to managed services like databases (Firestore, Amazon DynamoDB), authentication services (Auth0, Amazon Cognito), and artificial intelligence services (Amazon Rekognition, Amazon Comprehend), among other managed services. Berkeley’s redefinition of what serverless means underscores what is happening in the broader spectrum of this discussion as cloud providers begin to build more and better-managed services and put them in this bucket of serverless.
Characteristics of a Serverless Application
Now that you understand something about the philosophy around serverless, what are some of the characteristics of a serverless application? Though you may get varying answers as to what serverless is, following are some traits and characteristics that are generally agreed upon by the industry.
Decreased operational responsibilities
Serverless architectures typically allow you to shift more of your operational responsibilities to a cloud provider or third party.
When you decide to implement FaaS, the only thing you should have to worry about is the code running in your function. All of the server patching, updating, maintaining, and upgrading is no longer your responsibility. This goes back to the core of what cloud computing, and by extension serverless, attempts to offer: a way to spend less time managing infrastructure and spend more time building features and delivering business value.
Benefits of a Serverless Architecture
These days there are many ways to architect an application. The decisions that are made early on will impact not only the application life cycle, but also the development teams and ultimately the company or organization. In this book, I advocate for building your applications using serverless technologies and methodologies and lay out some ways in which you can do this. But what are the advantages of building your application like this, and why is serverless becoming so popular?
Scalability
One of the primary advantages of going serverless is out-of-the-box scalability. When building your application, you don’t have to worry about what would happen if the application becomes wildly popular and you onboard a large number of new users quickly—the cloud provider will handle this for you.
The cloud provider automatically scales your application, running the code in response to each interaction. In a serverless function, your code runs in parallel and individually processes each trigger (in turn, scaling with the size of the workload).
Not having to worry about scaling your servers and databases is a great advantage. It’s one less thing you have to worry about when architecting your application.
Cost
The pricing models of serverless architectures and traditional cloud-based or on-premises infrastructures differ greatly.
With the traditional approach, you often paid for computing resources whether or not they were utilized. This meant that if you wanted to make sure your application would scale, you needed to prepare for the largest workload you thought you might see regardless of whether you actually reached that point. This approach meant you were paying for unused resources for the majority of the life of your application.
With serverless technologies, you pay only for what you use. With FaaS, you’re billed based on the number of requests for your functions, the time it takes for your function code to execute, and the reserved memory for each function. With managed services like Amazon Rekognition, you are only charged for the images processed and minutes of video processed, etc.—again paying only for what you use.
This allows you to build features and applications with essentially no up-front infrastructure costs. Only if your application begins seeing increasing adoption and scaling do you begin to have to pay for the service.
The bill from your cloud provider is only one part of the total cost of your cloud infrastructure—there’s also the operations’ salaries. That cost decreases if you have fewer ops resources.
In addition, building applications in this way usually facilitates a faster time to market, decreasing overall development time and, therefore, development costs.
Developer velocity
With fewer features to build, developer velocity increases. Being able to spin up the types of features that are typical for most applications (e.g., databases, authentication, storage, and APIs) allows you to quickly focus on writing the core functionality and business logic for the features that you want to deliver.
Experimentation
If you are not investing a lot of time building out repetitive features, you are able to experiment more easily and with less risk.
When shipping a new feature, you often assess the risk (time and money involved with building the feature) against the possible return on investment (ROI). As the risk involved in trying out new things decreases, you are free to test out ideas that in the past may not have seen the light of day.
A/B testing (also known as bucket testing or split testing) is a way to compare multiple versions of an application to determine which one performs best. Because of the increase in developer velocity, serverless applications usually enable you to A/B test different ideas much more quickly and easily.
Security and stability
Because the services that you are subscribing to are the core competency of the service provider maintaining them, you are usually getting something that is much more polished and more secure than you could have built yourself. Imagine that a company’s core business model has been, for many years, the delivery of a pristine authentication service, having fixed issues and edge cases for thousands of companies and customers.
Now, imagine trying to replicate a service like that within your own team or organization. Though this is completely possible, choosing to use a service built and maintained by those whose only job is to build and maintain that exact thing is a safe bet that will ultimately save you time and money.
Another advantage of using these service providers is that they will strive for the least amount of downtime possible. This means that they are taking on the burden of not only building, deploying, and maintaining these services, but also doing everything they can to make sure that they are stable.
Less code
Most engineers will agree that, at the end of the day, code is a liability. What has value is the feature that the code delivers, not the code itself. When you find ways to deliver these features while simultaneously limiting the amount of code you need to maintain, and even doing away with the code completely, you are reducing overall complexity in your application.
With less complexity comes fewer bugs, easier onboarding for new engineers, and overall less cognitive load for those maintaining and adding new features. A developer can hook into these services and implement features with no knowledge of the actual backend implementation and with little to no backend code at all.
Different Implementations of Serverless
Let’s take a look at the different ways that you can build serverless applications as well as some of the differences between them.
Serverless Framework
One of the first serverless implementations, the Serverless Framework, is the most popular. It is a free and open source framework, launched in October 2015 under the name JAWS, and written using Node.js. At first, the Serverless Framework only supported AWS, but then it added support for cloud providers like Google and Microsoft Azure, among others.
The Serverless Framework utilizes a combination of a configuration file (serverless.yml), CLI, and function code to provide a nice experience for people wanting to deploy serverless functions and other AWS services to the cloud from a local environment. Getting up and running with the Serverless Framework can present a somewhat steep learning curve, especially for developers new to cloud computing. There is much terminology to learn and a lot that goes into understanding how cloud services work in order to build anything more than just a “Hello World” application.
Overall, the Serverless Framework is a good option if you understand to some extent how cloud infrastructure works, and are looking for something that will work with other cloud providers in addition to AWS.
The AWS Serverless Application Model
The AWS Serverless Application Model (AWS SAM) is an open source framework, released November 18, 2016, and built and maintained by AWS and the community. This framework only supports AWS.
SAM allows you to build serverless applications by defining the API Gateway APIs, AWS Lambda functions, and Amazon DynamoDB tables needed by your serverless application in YAML files. It uses a combination of YAML configuration and function code and a CLI to create, manage, and deploy serverless applications.
One advantage of SAM is that it is an extension of AWS CloudFormation, which is very powerful and allows you to do almost anything in AWS. This can also be a disadvantage to developers new to cloud computing and not familiar with AWS services, permissions, roles, and terminology, as you have to already be familiar with how the services work, the naming conventions to set them up, and how to wire it all together.
SAM is a good choice if you are familiar with AWS and are only deploying your serverless applications to AWS.
Amplify Framework
The Amplify Framework is a combination of four things: CLI, client library, toolchain, and web-hosting platform. Amplify’s purpose is to provide an easy way for developers to build and deploy full stack web and mobile applications that leverage the cloud. It enables not only features such as serverless functions and authentication, but also GraphQL APIs, machine learning (ML), storage, analytics, push notifications, and more.
Amplify provides an easy entry point into the cloud by doing away with terminology and acronyms that may be unfamiliar to newcomers to AWS and instead uses a category-name approach for referring to services. Rather than referring to the authentication service as Amazon Cognito, it’s referred to as auth, and the framework just uses Amazon Cognito under the hood.
Other options
More companies have started providing abstractions over serverless functions, usually intending to improve the negative user experience traditionally associated with working directly with AWS Lambda. A few popular options among these are Apex, Vercel, Cloudflare Workers, and Netlify Functions.
Many of these tools and frameworks still actually use AWS or some other cloud provider under the hood, so you are essentially going to be paying more in exchange for what they argue is a better user experience. Most of these tools do not offer much of the other suite of services available from AWS or other cloud providers; things like authentication, AI and ML services, complex object storage, and analytics may or may not be part of their offerings.
If you are interested in learning other ways of developing serverless applications, I would recommend checking out these options.
Introduction to AWS
In this section, I’ll give an overview of AWS and talk about why something like the Amplify Framework exists.
About AWS
AWS, a subsidiary of Amazon, was the first company to provide on-demand cloud computing platforms to developers. It first launched in 2004 with a single service: Amazon Simple Queue Service (Amazon SQS). In 2006, they officially relaunched with a total of three services: Amazon SQS, Amazon S3, and Amazon EC2. Since 2006, AWS has grown and remains the largest cloud computing provider in the world, continuing to add services every year. AWS now offers more than two hundred services.
With the current state of cloud computing moving more toward serverless technologies, the barrier to entry is being lowered. However, it is still often tough for either a frontend developer or someone new to cloud computing to get started.
With this new serverless paradigm, AWS saw an opportunity to create a framework that focused on enabling these traditionally frontend developers and developers new to cloud computing to get started building cloud applications.
Full Stack Serverless on AWS
Full stack serverless is about providing developers with everything needed on both ends of the stack to accomplish their objective of building scalable applications as quickly as possible. Here, we’ll look at how you can build applications in this way using AWS tools and services.
Amplify CLI
If you’re starting out with AWS, the sheer number of services can be overwhelming. In addition to the many services to sort between, each service often has its own steep learning curve. To help ease this, AWS has created the Amplify CLI.
The Amplify CLI provides an easy entry point for developers wanting to build applications on AWS. The CLI allows developers to create, configure, update, and delete cloud services directly from their frontend environment.
Instead of a service-name approach (as used by the AWS Console and many other tools, like CloudFormation), the CLI takes a category-name approach. AWS has many service names (for example, Amazon S3, Amazon Cognito, and Amazon Pinpoint), which can be confusing to new developers. Rather than using the service names to create and configure these services, the CLI uses names like storage (Amazon S3), auth (Amazon Cognito), and analytics (Amazon Pinpoint) to give you a way to understand what the service actually does versus simply giving the service name.
The CLI has a host of commands that allow you to create, update, configure, and remove services without having to leave your frontend environment. You can also spin up and deploy new environments using the CLI in order to test out new features without affecting the main environment.
Once you’ve created and deployed features using the CLI, you can then use the Amplify client libraries to begin interacting with the services from your client-side application.
Amplify client
Building full stack applications requires a combination of both client-side tooling and backend services. In the past, the main way to interact with AWS services was using an AWS software development kit (SDK) such as Java, .NET, Node.js, and Python. These SDKs work well, but none of them are particularly well-suited for client-side development. Before Amplify, there was no simple method for building client-side applications using AWS. If you look at the documentation for the AWS Node.js SDK, you’ll also notice that it presents a steep learning curve for developers new to AWS.
The Amplify client is a library made especially to provide an easy-to-use API for JavaScript applications that need to interact with AWS services. Amplify also has client SDKs for React Native, native iOS, and native Android.
The approach that the Amplify client takes is to provide a higher level of abstraction and bake in best practices to provide a declarative, easy-to-use API. At the same time, it gives you full control over the interactions with your backend. It’s also built especially with the client in mind, with features like WebSocket and GraphQL subscription support. It utilizes localStorage for the browser and AsyncStorage for React Native to store security tokens like IdTokens and AccessTokens to persist user authentication.
Amplify also provides UI components for popular frontend and mobile frameworks including React, React Native, Vue, Angular, Ionic, native Android, and native iOS. These framework-specific components allow you to quickly get up and running with common features like authentication and complex object storage and retrieval without having to build out the frontend UI and deal with state.
The Amplify Framework does not support the entire suite of AWS services; instead, it supports a subset of them with almost all of them falling into the category of serverless. Using Amplify, it wouldn’t make much sense to offer support for interacting with with EC2, but it makes a lot of sense to offer support for working with Representational State Transfer (REST) and GraphQL APIs.
Amplify was created as an end-to-end solution to fill a previously unfilled gap, but it also encompasses a new way to build full stack cloud applications.
AWS AppSync
AWS AppSync is a managed API layer that uses GraphQL to make it easy for applications to interact with any data source, REST API, or microservice.
The API layer is one of the most important parts of an application. Modern applications typically interact with a large number of backend services and APIs; things like databases, managed services, third-party APIs, and storage solutions, among others. Microservice architecture is the usual term used for a large application built using a combination of modular components or services.
Most services and APIs will have varying implementation details, which creates a challenge when you’re working with a microservice architecture. This leads to inconsistent and sometimes messy code, as well as more cognitive load on the frontend developers making requests to these APIs.
One good approach to working with a microservice architecture is to provide a consistent API gateway layer that then takes all of the requests and forwards them on to the backend services. This allows a consistent interaction layer for your client to interact with, making development easier on the frontend.
GraphQL, a technology created and open sourced by Facebook, offers an especially good abstraction for creating an API gateway. GraphQL introduces a defined and consistent specification for interacting with APIs in the form of three operations: queries (reads), mutations (writes/updates), and subscriptions (real-time data). These operations are defined as part of a main schema that also provides a contract between the client and the server in the form of GraphQL types. GraphQL operations are not bound to any specific data source, so you as a developer are free to use them to interact with anything from a database, an HTTP endpoint, a microservice, or even a serverless function.
Typically, when building a GraphQL API, you need to deal with building, deploying, maintaining, and configuring your own API. With AWS AppSync, you can instead offload the server and API management as well as the security to AWS.
Modern applications often also have concerns such as real-time and offline support. Another benefit of AppSync is that it has built-in support for offline (Amplify client SDKs) as well as real time (GraphQL subscriptions) to enable developers to build these types of applications.
In this book, you will be using AWS AppSync along with various data sources (like DynamoDB for NoSQL and AWS Lambda for serverless functions) as the main API layer.
Introduction to the AWS Amplify CLI
You will be using Amplify CLI throughout this book to create and manage your cloud services. To learn how it works, you’ll be creating and deploying a service using the CLI in this section. Once the service is deployed, you’ll also learn how to remove it and then delete any backend resources associated with the deployment. Let’s take a look at how you can create your first service.
Installing and Configuring the Amplify CLI
To get started, you first need to install and configure the Amplify CLI:
~ npm install -g @aws-amplify/cli
Note
To use the CLI, you will first need to have Node.js version 10.x or greater and npm version 5.x or greater installed on your machine. To install Node.js, I recommend either visiting the Node.js installation page and following the installation instructions or using Node Version Manager (NVM).
After the CLI has been installed, you next need to configure it with an identity and access management (IAM) user in your AWS account. To do so, you’ll configure the CLI with a reference to a set of user credentials (access key ID and secret access key). Using these credentials, you’ll be able to create AWS services on behalf of this user directly from the CLI.
To create a new user and configure the CLI, you’ll run the configure command:
~ amplify configure
This will walk you through the following steps:
-
Specify the AWS region.
This will allow you to choose the region in which you’d like to create your user (and, by extension, the services associated with this user). Choose the region closest to you or a preferred region.
-
Specify the username.
This name will be the local reference of the user that you will be creating in your AWS account. I suggest using a name that you’ll be able to recognize later when referencing it, such as amplify-cli-us-east-1-user or mycompany-cli-admin.
Once you enter your name, the CLI will open up the AWS IAM dashboard. From here, you can accept the defaults by clicking Next: Permissions, Next: Tags, Next: Review, and Create user to create the IAM user.
In the next screen, you will be given the IAM user credentials: the access key ID and secret access key. See Figure 1-1.
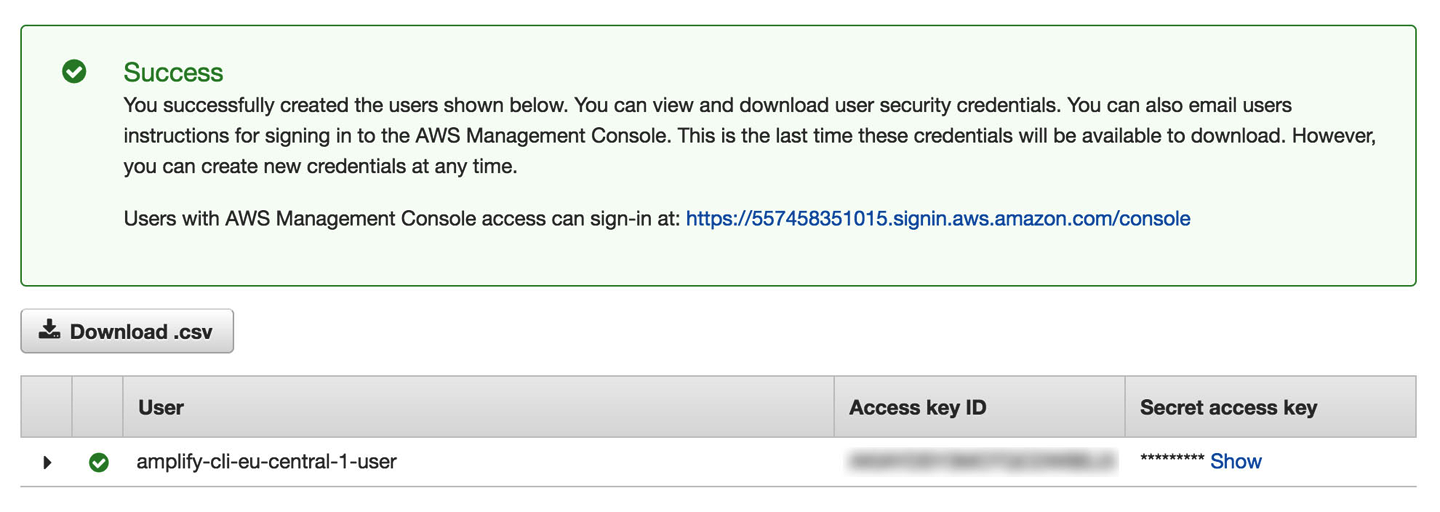
Figure 1-1. AWS IAM dashboard
Back in the CLI, paste in the values for the access key ID and secret access key. Now you’ve successfully configured the CLI and you can begin creating new services.
Initializing Your First Amplify Project
Now that the CLI has been installed and configured, you can create your first project. This step is usually done within the root of your client application. Since you will be using React for most of this book, we’ll start by initializing a new React project:
~ npx create-react-app amplify-app# after creating the React app, change into the new directory~cdamplify-app
Now you need to install the Amplify that you’ll be using on the client. The libraries you’ll be using are AWS Amplify and AWS Amplify React for the React-specific UI components:
~ npm install aws-amplify @aws-amplify/ui-react
Next, you can create an Amplify project. To do so, you’ll run the init command:
~ amplify init
This will walk you through the following steps:
-
Enter a name for the project.
This will be the local name for the project, usually something that describes what the project is or what it does.
-
Enter a name for the environment.
This will be a reference to the initial environment that you will be working in. Typical environments in this workflow could be something like dev, local, or prod but could be anything that makes sense to you.
-
Choose your default editor.
This will set your editor preference. The CLI will later use this preference to open your text editor with files that are part of the current project.
-
Choose the type of app that you’re building.
This will determine whether the CLI should configure, build, and run commands if you are using JavaScript. For this example, choose javascript.
-
What JavaScript framework are you using?
This will determine a few base build and start commands. For this example, choose react.
-
Choose your source directory path.
This allows you to set the directory where your source code will live. For this example, choose src.
-
Choose your distribution directory path.
For web projects, this will be the folder containing the complied JavaScript source code as well as your favicon, HTML, and CSS files. For this example, choose build.
-
Choose your build command.
This specifies the command for compiling and bundling your JavaScript code. For this example, use npm run-script build.
-
Choose your start command.
This specifies the command to server your application locally. For this example, use npm run-script start.
-
Do you want to use an AWS profile?
Here, choose Y and then pick the AWS profile you created when you ran
amplify configure.
Now, the Amplify CLI will initialize your new Amplify project.
When the initialization is complete, you will have two additional resources created for you in your project: a file called aws-exports located in the src directory and a folder named amplify located in your root directory. These files contain the following:
- The aws-exports file
-
The aws-exports file is a key-value pairing of the resource categories created for you by the CLI along with their credentials.
- The amplify folder
-
This folder holds all of the code and configuration files for your Amplify project. In this folder you’ll see two subfolders: the backend and #current-cloud-backend folders.
- The backend folder
-
This folder contains all of the local code for your project such as the GraphQL schema for an AppSync API, the source code for any serverless functions, and infrastructure as code representing the current local status of the Amplify project.
- The #current-cloud-backend folders
-
This folder holds the code and configurations that reflect what resources were deployed in the cloud with your last Amplify
pushcommand. It helps the CLI differentiate between the configuration of the resources already provisioned in the cloud and what is currently in your local backend directory (which reflects your local changes).
Now that you’ve initialized your project, you can add your first cloud service: authentication.
Creating and Deploying Your First Service
To create a new service, you can use the add command from Amplify:
~ amplify add auth
This will walk you through the following steps:
-
Do you want to use the default authentication and security configuration?
This gives you the option of creating an authentication service using a default configuration (MFA on sign-up, password at sign-in), creating an authentication configuration with social providers, or creating a completely custom authentication configuration. For this example, choose Default configuration.
-
How do you want users to be able to sign in?
This will allow you to specify the required sign-in property. For this example, accept the default by choosing Username.
-
Do you want to configure advanced settings?
This will allow you to walk through additional advanced settings for things like additional sign-up attributes and Lambda triggers. You do not need any of these for this example, so accept the default by choosing No, I am done.
Now, you’ve successfully configured the authentication service and are now ready to deploy. To deploy the authentication service, you can run the
pushcommand:~ amplify push
-
Are you sure you want to continue?
Choose Y.
After the deployment is complete, your authentication service has successfully been created. Congratulations, you’ve deployed your first feature. Now, let’s test it out.
There are several ways to interact with the authentication service in a React application. You can use the Auth class from Amplify, which has over 30 methods available (methods like signUp, signIn, signOut, etc.), or you can use the framework-specific components like withAuthenticator that will scaffold out an entire authentication flow, complete with preconfigured UI. Let’s try out the withAuthenticator higher-order (HOC) component.
First, configure the React app to work with Amplify. To do so, open src/index.js and add the following code below the last import statement:
importAmplifyfrom'aws-amplify'importconfigfrom'./aws-exports'Amplify.configure(config)
Now, the app has been configured and you can begin interacting with the authentication service. Next, open src/App.js and update the file with the following code:
importReactfrom'react'import{withAuthenticator,AmplifySignOut}from'@aws-amplify/ui-react'functionApp(){return(<div><h1>HellofromAWSAmplify</h1><AmplifySignOut/></div>)}exportdefaultwithAuthenticator(App)
At this point, you can test it out by launching the app:
~npmstart
Now, your app should be launched with the preconfigured authentication flow in front of it. See Figure 1-2.
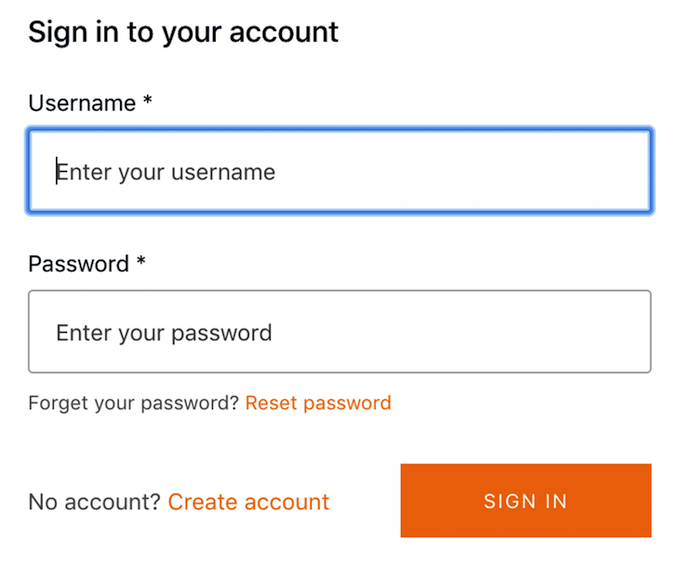
Figure 1-2. withAuthenticator HOC component
Deleting the Resources
Once you no longer need a feature or a project, you can remove it using the CLI.
To remove an individual feature, you can run the remove command:
~ amplify remove auth
To delete an entire Amplify project along with all of the corresponding resources that have been deployed in your account, you can run the delete command:
~ amplify delete
Summary
Cloud computing is growing at a rapid pace as more and more companies have come to rely on the cloud for the majority of their workloads. With this growth in usage, knowledge of cloud computing is becoming a valuable addition to your skill set.
The paradigm of serverless, a subset of cloud computing, is also rapidly growing in popularity among business users, as it offers all of the benefits of cloud computing while also featuring automatic scaling, while needing little to no maintenance.
Tools like the Amplify Framework are making it easier for developers of all backgrounds to get up and running with cloud as well as serverless computing. In the next chapters, you’ll learn how to build real-world full stack serverless applications in the cloud, utilizing cloud services and the Amplify Framework.
1 Eric Jonas, Johann Schleier-Smith et al. “Cloud Programming Simplified: A Berkeley View on Serverless Computing” (Feb. 10, 2019), http://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/EECS-2019-3.html.
Get Full Stack Serverless now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

