Chapter 1. The Entry-Level Stuff
Let’s start with a disclaimer: React was made to be used by all. In fact, you could go through life having never read this book and continue to use React without problems! This book dives much deeper into React for those of us who are curious about its underlying mechanism, advanced patterns, and best practices. It lends itself better to knowing how React works instead of learning how to use React. There are plenty of other books that are written with the intent to teach folks how to use React as an end user. In contrast, this book will help you understand React at the level of a library or framework author instead of an end user. In keeping with that theme, let’s go on a deep dive together, starting at the top: the higher-level, entry-level topics. We’ll start with the basics of React, and then dive deeper and deeper into the details of how React works.
In this chapter, we’ll talk about why React exists, how it works, and what problems it solves. We’ll cover its initial inspiration and design, and follow it from its humble beginnings at Facebook to the prevalent solution that it is today. This chapter is a bit of a meta chapter (no pun intended), because it’s important to understand the context of React before we dive into the details.
Why Is React a Thing?
The answer in one word is: updates. In the early days of the web, we had a lot of static pages. We’d fill out forms, hit Submit, and load an entirely new page. This was fine for a while, but eventually web experiences evolved significantly in terms of capabilities. As the capabilities grew, so did our desire for superior user experiences on the web. We wanted to be able to see things update instantly without having to wait for a new page to be rendered and loaded. We wanted the web and its pages to feel snappier and more “instant.” The problem was that these instant updates were pretty hard to do at scale for a number of reasons:
- Performance
-
Making updates to web pages often caused performance bottlenecks because we were prone to perform work that triggered browsers to recalculate a page’s layout (called a reflow) and repaint the page.
- Reliability
-
Keeping track of state and making sure that the state was consistent across a rich web experience was hard to do because we had to keep track of state in multiple places and make sure that the state was consistent across all of those places. This was especially hard to do when we had multiple people working on the same codebase.
- Security
-
We had to be sure to sanitize all HTML and JavaScript that we were injecting into the page to prevent exploits like cross-site scripting (XSS) and cross-site request forgery (CSRF).
To fully understand and appreciate how React solves these problems for us, we need to understand the context in which React was created and the world without or before React. Let’s do that now.
The World Before React
These were some of the large problems for those of us building web apps before React. We had to figure out how to make our apps feel snappy and instant, but also scale to millions of users and work reliably in a safe way. For example, let’s consider a button click: when a user clicks a button, we want to update the user interface to reflect that the button has been clicked. We’ll need to consider at least four different states that the user interface can be in:
- Pre-click
-
The button is in its default state and has not been clicked.
- Clicked but pending
-
The button has been clicked, but the action that the button is supposed to perform has not yet completed.
- Clicked and succeeded
-
The button has been clicked, and the action that the button is supposed to perform has completed. From here, we may want to revert the button to its pre-click state, or we may want the button to change color (green) to indicate success.
- Clicked and failed
-
The button has been clicked, but the action that the button is supposed to perform has failed. From here, we may want to revert the button to its pre-click state, or we may want the button to change color (red) to indicate failure.
Once we have these states, we need to figure out how to update the user interface to reflect them. Oftentimes, updating the user interface would require the following steps:
-
Find the button in the host environment (often the browser) using some type of element locator API, such as
document.querySelectorordocument.getElementById. -
Attach event listeners to the button to listen for click events.
-
Perform any state updates in response to events.
-
When the button leaves the page, remove the event listeners and clean up any state.
This is a simple example, but it’s a good one to start with. Let’s say we have a button labeled “Like,” and when a user clicks it, we want to update the button to “Liked.” How do we do this? To start with, we’d have an HTML element:
<button>Like</button>
We’d need some way to reference this button with JavaScript, so we’d
give it an id attribute:
<buttonid="likeButton">Like</button>
Great! Now that there’s an id, JavaScript can work with it to make it
interactive. We can get a reference to the button using
document.getElementById, and then we’ll add an event listener to the
button to listen for click events:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{// do something});
Now that we have an event listener, we can do something when the button is clicked. Let’s say we want to update the button to have the label “Liked” when it’s clicked. We can do this by updating the button’s text content:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{likeButton.textContent="Liked";});
Great! Now we have a button that says “Like,” and when it’s clicked, it
says “Liked.” The problem here is that we can’t “unlike” things.
Let’s fix that and update the button to say “Like” again if it’s
clicked in its “Liked” state. We’d need to add some state to the
button to keep track of whether or not it’s been clicked. We can do this
by adding a data-liked attribute to the button:
<buttonid="likeButton"data-liked="false">Like</button>
Now that we have this attribute, we can use it to keep track of whether or not the button has been clicked. We can update the button’s text content based on the value of this attribute:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{constliked=likeButton.getAttribute("data-liked")==="true";likeButton.setAttribute("data-liked",!liked);likeButton.textContent=liked?"Like":"Liked";});
Wait, but we’re just changing the textContent of the button! We’re not
actually saving the “Liked” state to a database. Normally, to do this we
had to communicate over the network, like so:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{varliked=likeButton.getAttribute("data-liked")==="true";// communicate over the networkvarxhr=newXMLHttpRequest();xhr.open("POST","/like",true);xhr.setRequestHeader("Content-Type","application/json;charset=UTF-8");xhr.onload=function(){if(xhr.status>=200&&xhr.status<400){// Success!likeButton.setAttribute("data-liked",!liked);likeButton.textContent=liked?"Like":"Liked";}else{// We reached our target server, but it returned an errorconsole.error("Server returned an error:",xhr.statusText);}};xhr.onerror=function(){// There was a connection error of some sortconsole.error("Network error.");};xhr.send(JSON.stringify({liked:!liked}));});
Of course, we’re using XMLHttpRequest and var to be
time relevant. React was released as open source software in 2013, and the more common
fetch API was introduced in 2015. In between XMLHttpRequest and
fetch, we had jQuery that often abstracted away some complexity with
primitives like $.ajax(), $.post(), etc.
If we were to write this today, it would look more like this:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{constliked=likeButton.getAttribute("data-liked")==="true";// communicate over the networkfetch("/like",{method:"POST",body:JSON.stringify({liked:!liked}),}).then(()=>{likeButton.setAttribute("data-liked",!liked);likeButton.textContent=liked?"Like":"Liked";});});
Without digressing too much, the point now is that we’re communicating
over the network, but what if the network request fails? We’d need to
update the button’s text content to reflect the failure. We can do this by adding a data-failed attribute to the
button:
<buttonid="likeButton"data-liked="false"data-failed="false">Like</button>
Now we can update the button’s text content based on the value of this attribute:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{constliked=likeButton.getAttribute("data-liked")==="true";// communicate over the networkfetch("/like",{method:"POST",body:JSON.stringify({liked:!liked}),}).then(()=>{likeButton.setAttribute("data-liked",!liked);likeButton.textContent=liked?"Like":"Liked";}).catch(()=>{likeButton.setAttribute("data-failed",true);likeButton.textContent="Failed";});});
There’s one more case to handle: the process of currently “liking” a
thing. That is, the pending state. To model this in code, we’d set yet
another attribute on the button for the pending state by adding
data-pending, like so:
<buttonid="likeButton"data-pending="false"data-liked="false"data-failed="false">Like</button>
Now we can disable the button if a network request is in process so that multiple clicks don’t queue up network requests and lead to odd race conditions and server overload. We can do that like so:
constlikeButton=document.getElementById("likeButton");likeButton.addEventListener("click",()=>{constliked=likeButton.getAttribute("data-liked")==="true";constisPending=likeButton.getAttribute("data-pending")==="true";likeButton.setAttribute("data-pending","true");likeButton.setAttribute("disabled","disabled");// communicate over the networkfetch("/like",{method:"POST",body:JSON.stringify({liked:!liked}),}).then(()=>{likeButton.setAttribute("data-liked",!liked);likeButton.textContent=liked?"Like":"Liked";likeButton.setAttribute("disabled",null);}).catch(()=>{likeButton.setAttribute("data-failed","true");likeButton.textContent="Failed";}).finally(()=>{likeButton.setAttribute("data-pending","false");});});
We can also make use of powerful techniques like debouncing and throttling to prevent users from performing redundant or repetitive actions.
Note
As a quick aside, we mention debouncing and throttling. For clarity, debouncing delays a function’s execution until after a set time has passed since the last event trigger (e.g., waits for users to stop typing to process input), and throttling limits a function to running at most once every set time interval, ensuring it doesn’t execute too frequently (e.g., processes scroll events at set intervals). Both techniques optimize performance by controlling function execution rates.
OK, now our button is kind of robust and can handle multiple states—but some questions still remain:
-
Is
data-pendingreally necessary? Can’t we just check if the button is disabled? Probably not, because a disabled button could be disabled for other reasons, like the user not being logged in or not having permission to click the button. -
Would it make more sense to have a
data-stateattribute, wheredata-statecan be one ofpending,liked, orunliked, instead of so many other data attributes? Probably, but then we’d need to add a large switch/case or similar code block to handle each case. Ultimately, the volume of code to handle both approaches is incomparable: we still end up with complexity and verbosity either way. -
How do we test this button in isolation? Can we?
-
Why do we have the button initially written in HTML, and then later work with it in JavaScript? Wouldn’t it be better if we could just create the button in JavaScript with
document.createElement('button')and thendocument.appendChild(likeButton)? This would make it easier to test and would make the code more self-contained, but then we’d have to keep track of its parent if its parent isn’tdocument. In fact, we might have to keep track of all the parents on the page.
React helps us solve some of these problems but not all of them: for
example, the question of how to break up state into separate flags
(isPending, hasFailed, etc.) or a single state variable (like
state) is a question that React doesn’t answer for us. It’s a question
that we have to answer for ourselves. However, React does help us solve
the problem of scale: creating a lot of buttons that need to be
interactive and updating the user interface in response to events in a
minimal and efficient way, and doing this in a testable, reproducible,
declarative, performant, predictable, and reliable way.
Moreover, React helps us make state far more predictable by fully owning the state of the user interface and rendering based on that state. This is in stark contrast to having the state be owned and operated on by the browser, whose state can be largely unreliable due to a number of factors like other client-side scripts running on the page, browser extensions, device constraints, and so many more variables.
Our example with the Like button is a very simple example, but it’s a
good one to start with. So far, we’ve seen how we can use JavaScript to
make a button interactive, but this is a very manual process if we want
to do it well: we have to find the button in the browser, add an event
listener, update the button’s text content, and account for myriad edge
cases. This is a lot of work, and it’s not very scalable. What if we had
a lot of buttons on the page? What if we had a lot of buttons that
needed to be interactive? What if we had a lot of buttons that needed to
be interactive, and we needed to update the user interface in response
to events? Would we use event delegation (or event bubbling) and attach
an event listener to the higher document? Or should we attach event
listeners to each button?
As stated in the Preface, this book assumes we have a satisfactory understanding of this statement: browsers render web pages. Web pages are HTML documents that are styled by CSS and made interactive with JavaScript. This has worked great for decades and still does, but building modern web applications that are intended to service a significant (think millions) amount of users with these technologies requires a good amount of abstraction in order to do it safely and reliably with as little possibility for error as possible. Unfortunately, based on the example of the Like button that we’ve been exploring, it’s clear that we’re going to need some help with this.
Let’s consider another example that’s a little bit more complex than our Like button. We’ll start with a simple example: a list of items. Let’s say we have a list of items and we want to add a new item to the list. We could do this with an HTML form that looks something like this:
<ulid="list-parent"></ul><formid="add-item-form"action="/api/add-item"method="POST"><inputtype="text"id="new-list-item-label"/><buttontype="submit">Add Item</button></form>
JavaScript gives us access to Document Object Model (DOM) APIs. For the unaware, the DOM is an in-memory model of a web page’s document structure: it’s a tree of objects that represents the elements on your page, giving you ways to interact with them via JavaScript. The problem is, the DOMs on user devices are like an alien planet: we have no way of knowing what browsers they’re using, in what network conditions, and on what operating systems (OS) they’re working. The result? We have to write code that is resilient to all of these factors.
As we’ve discussed, application state becomes quite hard to predict when it updates without some type of state-reconciliation mechanism to keep track of things. To continue with our list example, let’s consider some JavaScript code to add a new item to the list:
(functionmyApp(){varlistItems=["I love","React","and","TypeScript"];varparentList=document.getElementById("list-parent");varaddForm=document.getElementById("add-item-form");varnewListItemLabel=document.getElementById("new-list-item-label");addForm.onsubmit=function(event){event.preventDefault();listItems.push(newListItemLabel.value);renderListItems();};functionrenderListItems(){for(i=0;i<listItems.length;i++){varel=document.createElement("li");el.textContent=listItems[i];parentList.appendChild(el);}}renderListItems();})();
This code snippet is written to look as similar as possible to early web applications. Why does this go haywire over time? Mainly because building applications intended to scale this way over time presents some footguns, making them:
- Error prone
-
addForm’sonsubmitattribute could be easily rewritten by other client-side JavaScript on the page. We could useaddEventListenerinstead, but this presents more questions:-
Where and when would we clean it up with
removeEventListener? -
Would we accumulate a lot of event listeners over time if we’re not careful about this?
-
What penalties will we pay because of it?
-
How does event delegation fit into this?
-
- Unpredictable
-
Our sources of truth are mixed: we’re holding list items in a JavaScript array, but relying on existing elements in the DOM (like an element with
id="list-parent") to complete our app. Because of these interdependencies between JavaScript and HTML, we have a few more things to consider:-
What if there are mistakenly multiple elements with the same
id? -
What if the element doesn’t exist at all?
-
What if it’s not a
ul? Can we append list items (lielements) to other parents? -
What if we use class names instead?
Our sources of truth are mixed between JavaScript and HTML, making the truth unreliable. We’d benefit more from having a single source of truth. Moreover, elements are added and removed from the DOM by client-side JavaScript all the time. If we rely on the existence of these specific elements, our app has no guarantees of working reliably as the UI keeps updating. Our app in this case is full of “side effects,” where its success or failure depends on some userland concern. React has remedied this by advocating a functional programming-inspired model where side effects are intentionally marked and isolated.
-
- Inefficient
-
renderListItemsrenders items on the screen sequentially. Each mutation of the DOM can be computationally expensive, especially where layout shift and reflows are concerned. Since we’re on an alien planet with unknown computational power, this can be quite unsafe for performance in case of large lists. Remember, we’re intending our large-scale web application to be used by millions worldwide, including those with low-power devices from communities across the world without access to the latest and greatest Apple M3 Max processors. What may be more ideal in this scenario, instead of sequentially updating the DOM per single list item, would be to batch these operations somehow and apply them all to the DOM at the same time. But maybe this isn’t worth doing for us as engineers because perhaps browsers will eventually update the way they work with quick updates to the DOM and automatically batch things for us.
These are some of the problems that have plagued web developers for years before React and other abstractions appeared. Packaging code in a way that was maintainable, reusable, and predictable at scale was a problem without much standardized consensus in the industry. This pain of creating reliable and scalable user interfaces was shared by many web companies at the time. It was at this point on the web that we saw the rise of multiple JavaScript-based solutions that aimed to solve this: Backbone, KnockoutJS, AngularJS, and jQuery. Let’s look at these solutions in turn and see how they solved this problem. This will help us understand how React is different from these solutions, and may even be superior to them.
jQuery
Let’s explore how we solved some of these issues earlier on the web using tools that predate React and thus learn why React is important. We’ll start with jQuery, and we’ll do so by revisiting our Like button example from earlier.
To recap, we’ve got a Like button in the browser that we’d like to make interactive:
<buttonid="likeButton">Like</button>
With jQuery, we’d add “like” behavior to it as we did earlier, like this:
$("#likeButton").on("click",function(){this.prop("disabled",true);fetch("/like",{method:"POST",body:JSON.stringify({liked:this.text()==="Like"}),}).then(()=>{this.text(this.text()==="Like"?"Liked":"Like");}).catch(()=>{this.text("Failed");}).finally(()=>{this.prop("disabled",false);});});
From this example, we observe that we’re binding data to the user interface and using this data binding to update the user interface in place. jQuery as a tool is quite active in directly manipulating the user interface itself.
jQuery runs in a heavily “side-effectful” way, constantly interacting with and altering state outside of its own control. We say this is “side-effectful” because it allows direct and global modifications to the page’s structure from anywhere in the code, including from other imported modules or even remote script execution! This can lead to unpredictable behavior and complex interactions that are difficult to track and reason about, as changes in one part of the page can affect other parts in unforeseen ways. This scattered and unstructured manipulation makes the code hard to maintain and debug.
Modern frameworks address these issues by providing structured, predictable ways to update the UI without direct DOM manipulation. This pattern was common at the time, and it is difficult to reason about and test because the world around the code, that is, the application state adjacent to the code, is constantly changing. At some point, we’d have to stop and ask ourselves: “what is the state of the app in the browser right now?”—a question that became increasingly difficult to answer as the complexity of our applications grew.
Moreover, this button with jQuery is hard to test because it’s just an event handler. If we were to write a test, it would look like this:
test("LikeButton",()=>{const$button=$("#likeButton");expect($button.text()).toBe("Like");$button.trigger("click");expect($button.text()).toBe("Liked");});
The only problem is that $('#likeButton') returns null in the
testing environment because it’s not a real browser. We’d have to mock
out the browser environment to test this code, which is a lot of work.
This is a common problem with jQuery: it’s hard to test because it’s
hard to isolate the behavior it adds. jQuery also depends heavily on
the browser environment. Moreover, jQuery shares ownership of the user
interface with the browser, which makes it difficult to reason about and
test: the browser owns the interface, and jQuery is just a guest. This
deviation from the “one-way data flow” paradigm was a common problem
with libraries at the time.
Eventually, jQuery started to lose its popularity as the web evolved and the need for more robust and scalable solutions became apparent. While jQuery is still used in many production applications, it’s no longer the go-to solution for building modern web applications. Here are some of the reasons why jQuery has fallen out of favor:
- Weight and load times
-
One of the significant criticisms of jQuery is its size. Integrating the full jQuery library into web projects adds extra weight, which can be especially taxing for websites aiming for fast load times. In today’s age of mobile browsing, where many users might be on slower or limited data connections, every kilobyte counts. The inclusion of the entire jQuery library can, therefore, negatively impact the performance and experience of mobile users.
A common practice before React was to offer configurators for libraries like jQuery and Mootools where users could cherry-pick the functionality they desired. While this helped ship less code, it did introduce more complexity into the decisions developers had to make, and into the overall development workflow.
- Redundancy with modern browsers
-
When jQuery first emerged, it addressed many inconsistencies across browsers and provided developers with a unified way to handle these differences in the context of selecting and then modifying elements in the browser. As the web evolved, so did web browsers. Many features that made jQuery a must-have, such as consistent DOM manipulation or network-oriented functionality around data fetching, are now natively and consistently supported across modern browsers. Using jQuery for these tasks in contemporary web development can be seen as redundant, adding an unnecessary layer of complexity.
document.querySelector, for example, quite easily replaces jQuery’s built-in$selector API. - Performance considerations
-
While jQuery simplifies many tasks, it often comes at the cost of performance. Native runtime-level JavaScript methods improve with each browser iteration and thus at some point may execute faster than their jQuery equivalents. For small projects, this difference might be negligible. However, in larger and more complex web applications these complexities can accumulate, leading to noticeable jank or reduced responsiveness.
For these reasons, while jQuery played a pivotal role in the web’s evolution and simplified many challenges faced by developers, the modern web landscape offers native solutions that often make jQuery less relevant. As developers, we need to weigh the convenience of jQuery against its potential drawbacks, especially in the context of current web projects.
jQuery, despite its drawbacks, was an absolute revolution in the way we interacted with the DOM at the time. So much so that other libraries emerged that used jQuery but added more predictability and reusability to the mix. One such library was Backbone, which was an attempt to solve the same problems React solves today, but much earlier. Let’s dive in.
Backbone
Backbone, developed in the early 2010s, was one of the first solutions to the problems we’ve been exploring in the world before React: state dissonance between the browser and JavaScript, code reuse, testability, and more. It was an elegantly simple solution: a library that provided a way to create “models” and “views.” Backbone had its own take on the traditional MVC (Model-View-Controller) pattern (see Figure 1-1). Let’s understand this pattern a little bit to help us understand React and form the basis of a higher-quality discussion.
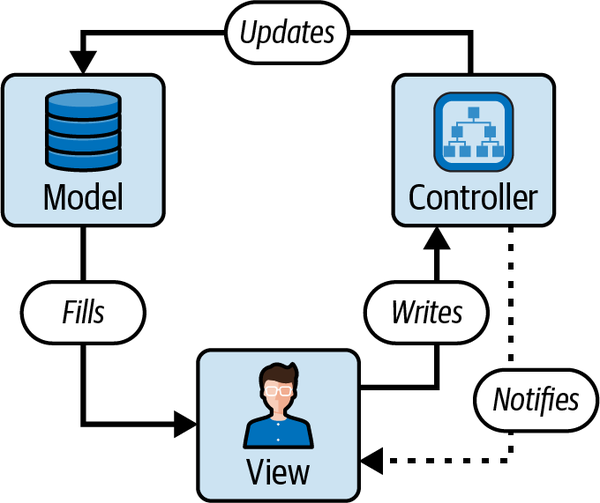
Figure 1-1. Traditional MVC pattern
The MVC pattern
The MVC pattern is a design philosophy that divides software applications into three interconnected components to separate internal representations of information from how that information is presented to or accepted from the user. Here’s a breakdown:
- Model
-
The Model is responsible for the data and the business rules of the application. The Model is unaware of the View and Controller, ensuring that the business logic is isolated from the user interface.
- View
-
The View represents the user interface of the application. It displays data from the Model to the user and sends user commands to the Controller. The View is passive, meaning it waits for the Model to provide data to display and does not fetch or save data directly. The View also does not handle user interaction on its own, but delegates this responsibility to the next component: the Controller.
- Controller
-
The Controller acts as an interface between the Model and the View. It takes the user input from the View, processes it (with potential updates to the Model), and returns the output display to the View. The Controller decouples the Model from the View, making the system architecture more flexible.
The primary advantage of the MVC pattern is the separation of concerns, which means that the business logic, user interface, and user input are separated into different sections of the codebase. This not only makes the application more modular but also easier to maintain, scale, and test. The MVC pattern is widely used in web applications, with many frameworks like Django, Ruby on Rails, and ASP.NET MVC offering built-in support for it.
The MVC pattern has been a staple in software design for many years, especially in web development. However, as web applications have evolved and user expectations for interactive and dynamic interfaces have grown, some limitations of the traditional MVC have become apparent. Here’s where MVC can fall short and how React addresses these challenges:
- Complex interactivity and state management
-
Traditional MVC architectures often struggle when it comes to managing complex user interfaces with many interactive elements. As an application grows, managing state changes and their effects on various parts of the UI can become cumbersome as controllers pile up, and can sometimes conflict with other controllers, with some controllers controlling views that do not represent them, or the separation between MVC components not accurately scoped in product code.
React, with its component-based architecture and virtual DOM, makes it easier to reason about state changes and their effects on the UI by essentially positing that UI components are like a function: they receive input (props) and return output based on those inputs (elements). This mental model radically simplified the MVC pattern because functions are fairly ubiquitous in JavaScript and much more approachable when compared to an external mental model that is not native to the programming language like MVC.
- Two-way data binding
-
Some MVC frameworks utilize two-way data binding, which can lead to unintended side effects if not managed carefully, where in some cases either the view becomes out of sync with the model or vice versa. Moreover, with two-way data binding the question of data ownership often had a crude answer, with an unclear separation of concerns. This is particularly interesting because while MVC is a proven model for teams that fully understand the appropriate way to separate concerns for their use cases, these separation rules are seldom enforced—especially when faced with high-velocity output and rapid startup growth—and thus separation of concerns, one of the greatest strengths of MVC, is often turned into a weakness by this lack of enforcement.
React leverages a pattern counter to two-way data binding called “unidirectional data flow” (more on this later) to prioritize and even enforce a unidirectional data flow through systems like Forget (which we will also discuss further in the book). These approaches make UI updates more predictable, enable us to separate concerns more clearly, and ultimately are conducive to high-velocity hyper-growth software teams.
- Tight coupling
-
In some MVC implementations, the Model, View, and Controller can become tightly coupled, making it hard to change or refactor one without affecting the others. React encourages a more modular and decoupled approach with its component-based model, enabling and supporting colocation of dependencies close to their UI representations.
We don’t need to get too much into the details of this pattern since this is a React book, but for our intents and purposes here, models were conceptually sources of data, and views were conceptually user interfaces that consumed and rendered that data. Backbone exported comfortable APIs to work with these models and views, and provided a way to connect the models and views together. This solution was very powerful and flexible for its time. It was also a solution that was scalable to use and allowed developers to test their code in isolation.
As an example, here’s our earlier button example, this time using Backbone:
constLikeButton=Backbone.View.extend({tagName:"button",attributes:{type:"button",},events:{click:"onClick",},initialize(){this.model.on("change",this.render,this);},render(){this.$el.text(this.model.get("liked")?"Liked":"Like");returnthis;},onClick(){fetch("/like",{method:"POST",body:JSON.stringify({liked:!this.model.get("liked")}),}).then(()=>{this.model.set("liked",!this.model.get("liked"));}).catch(()=>{this.model.set("failed",true);}).finally(()=>{this.model.set("pending",false);});},});constlikeButton=newLikeButton({model:newBackbone.Model({liked:false,}),});document.body.appendChild(likeButton.render().el);
Notice how LikeButton extends Backbone.View and how it has a
render method that returns this? We’ll go on to see a similar
render method in React, but let’s not get ahead of ourselves. It’s
also worth noting here that Backbone didn’t include an actual
implementation for render. Instead, you either manually mutated the
DOM via jQuery, or used a templating system like Handlebars.
Backbone exposed a chainable API that allowed developers to colocate logic as properties on objects. Comparing this to our previous example, we can see that Backbone has made it far more comfortable to create a button that is interactive and updates the user interface in response to events.
It also does this in a more structured way by grouping logic together.
Also note that Backbone has made it more approachable to test
this button in isolation because we can create a LikeButton instance
and then call its render method to test it.
We test this component like so:
test("LikeButton initial state",()=>{constlikeButton=newLikeButton({model:newBackbone.Model({liked:false,// Initial state set to not liked}),});likeButton.render();// Ensure render is called to reflect the initial state// Check the text content to be "Like" reflecting the initial stateexpect(likeButton.el.textContent).toBe("Like");});
We can even test the button’s behavior after its state changes, as in the case of a click event, like so:
test("LikeButton",async()=>{// Mark the function as async to handle promiseconstlikeButton=newLikeButton({model:newBackbone.Model({liked:false,}),});expect(likeButton.render().el.textContent).toBe("Like");// Mock fetch to prevent actual HTTP requestglobal.fetch=jest.fn(()=>Promise.resolve({json:()=>Promise.resolve({liked:true}),}));// Await the onClick method to ensure async operations are completeawaitlikeButton.onClick();expect(likeButton.render().el.textContent).toBe("Liked");// Optionally, restore fetch to its original implementation if neededglobal.fetch.mockRestore();});
For this reason, Backbone was a very popular solution at the time. The alternative was to write a lot of code that was hard to test and hard to reason about with no guarantees that the code would work as expected in a reliable way. Therefore, Backbone was a very welcome solution. While it gained popularity in its early days for its simplicity and flexibility, it’s not without its criticisms. Here are some of the negatives associated with Backbone.js:
- Verbose and boilerplate code
-
One of the frequent criticisms of Backbone.js is the amount of boilerplate code developers needed to write. For simple applications, this might not be a big deal, but as the application grows, so does the boilerplate, leading to potentially redundant and hard-to-maintain code.
- Lack of two-way data binding
-
Unlike some of its contemporaries, Backbone.js doesn’t offer built-in two-way data binding. This means that if the data changes, the DOM doesn’t automatically update, and vice versa. Developers often need to write custom code or use plug-ins to achieve this functionality.
- Event-driven architecture
-
Updates to model data can trigger numerous events throughout the application. This cascade of events can become unmanageable, leading to a situation where it’s unclear how changing a single piece of data will affect the rest of the application, making debugging and maintenance difficult. To address these issues, developers often needed to use careful event management practices to prevent the ripple effect of updates across the entire app.
- Lack of composability
-
Backbone.js lacks built-in features for easily nesting views, which can make composing complex user interfaces difficult. React, in contrast, allows for seamless nesting of components through the children prop, making it much simpler to build intricate UI hierarchies. Marionette.js, an extension of Backbone, attempted to address some of these composition issues, but it does not provide as integrated a solution as React’s component model.
While Backbone.js has its set of challenges, it’s essential to remember that no tool or framework is perfect. The best choice often depends on the specific needs of the project and the preferences of the development team. It’s also worth noting how much web development tools depend on a strong community to thrive, and unfortunately Backbone.js has seen a decline in popularity in recent years, especially with the advent of React. Some would say React killed it, but we’ll reserve judgment for now.
KnockoutJS
Let’s compare this approach with another popular solution at the time: KnockoutJS. KnockoutJS, developed in the early 2010s, was a library that provided a way to create “observables” and “bindings,” making use of dependency tracking whenever state changes.
KnockoutJS was among the first, if not the first, reactive JavaScript libraries, where reactivity is defined as values updating in response to state changes in an observable manner. Modern takes on this style of reactivity are sometimes called “signals” and are prevalent in libraries like Vue.js, SolidJS, Svelte, Qwik, modern Angular, and more. We cover these in Chapter 10 in more detail.
Observables were conceptually sources of data, and bindings were conceptually user interfaces that consumed and rendered that data: observables were like models, and bindings were like views.
However, as a bit of an evolution of the MVC pattern we discussed previously, KnockoutJS instead worked more along a Model-View-ViewModel or MVVM-style pattern (see Figure 1-2). Let’s understand this pattern in some detail.
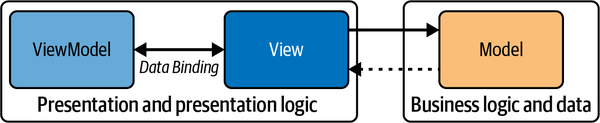
Figure 1-2. MVVM pattern
MVVM pattern
The MVVM pattern is an architectural design pattern that’s particularly popular in applications with rich user interfaces, such as those built using platforms like WPF and Xamarin. MVVM is an evolution of the traditional Model-View-Controller (MVC) pattern, tailored for modern UI development platforms where data binding is a prominent feature. Here’s a breakdown of the MVVM components:
- Model
- View
- ViewModel
-
-
Exposes data and commands for the View to bind to. The data here is often in a format that’s display ready.
-
Handles user input, often through command patterns.
-
Contains the presentation logic and transforms data from the Model into a format that can be easily displayed by the View.
-
Notably, the ViewModel is unaware of the specific View that’s using it, allowing for a decoupled architecture.
The key advantage of the MVVM pattern is the separation of concerns similar to MVC, which leads to:
- Testability
-
The decoupling of ViewModel from View makes it easier to write unit tests for the presentation logic without involving the UI.
- Reusability
-
The ViewModel can be reused across different views or platforms.
- Maintainability
-
With a clear separation, it’s easier to manage, extend, and refactor code.
- Data binding
-
The pattern excels in platforms that support data binding, reducing the amount of boilerplate code required to update the UI.
Since we discussed both MVC and MVVM patterns, let’s quickly contrast them so that we can understand the differences between them (see Table 1-1).
| Criteria | MVC | MVVM |
|---|---|---|
Primary purpose |
Primarily for web applications, separating user interface from logic. |
Tailored for rich UI applications, especially with two-way data binding, like desktop or SPAs. |
Components |
Model: data and business logic. View: user interface. Controller: manages user input, updates View. |
Model: data and business logic. View: user interface elements. ViewModel: bridge between Model and View. |
Data flow |
User input is managed by the Controller, which updates the Model and then the View. |
The View binds directly to the ViewModel. Changes in the View are automatically reflected in the ViewModel and vice versa. |
Decoupling |
View is often tightly coupled with the Controller. |
High decoupling as ViewModel doesn’t know the specific View using it. |
User interaction |
Handled by the Controller. |
Handled through data bindings and commands in the ViewModel. |
Platform suitability |
Common in web application development (e.g., Ruby on Rails, Django, ASP.NET MVC). |
Suited for platforms supporting robust data binding (e.g., WPF, Xamarin). |
From this brief comparison, we can see that the real difference between MVC and MVVM patterns is one of coupling and binding: with no Controller between a Model and a View, data ownership is clearer and closer to the user. React further improves on MVVM with its unidirectional data flow, which we’ll discuss in a little bit, by getting even narrower in terms of data ownership, such that state is owned by specific components that need them. For now, let’s get back to KnockoutJS and how it relates to React.
KnockoutJS exported APIs to work with these observables and bindings. Let’s look at how we’d implement the Like button in KnockoutJS. This will help us understand “why React” a little better. Here’s the KnockoutJS version of our button:
functioncreateViewModel({liked}){constisPending=ko.observable(false);consthasFailed=ko.observable(false);constonClick=()=>{isPending(true);fetch("/like",{method:"POST",body:JSON.stringify({liked:!liked()}),}).then(()=>{liked(!liked());}).catch(()=>{hasFailed(true);}).finally(()=>{isPending(false);});};return{isPending,hasFailed,onClick,liked,};}ko.applyBindings(createViewModel({liked:ko.observable(false)}));
In KnockoutJS, a “view model” is a JavaScript object that contains
keys and values that we bind to various elements in our page using the
data-bind attribute. There are no “components” or “templates” in
KnockoutJS, just a view model and a way to bind it to an element in the
browser.
Our function createViewModel is how we’d create a view model with
Knockout. We then use ko.applyBindings to connect the view model to
the host environment (the browser). The ko.applyBindings function
takes a view model and finds all the elements in the browser that
have a data-bind attribute, which Knockout uses to bind them to the
view model.
A button in our browser would be bound to this view model’s properties like so:
<buttondata-bind="click:onClick,text:liked?'Liked':isPending?[...]></button>
Note that this code has been truncated for simplicity.
We bind the HTML element to the “view model” we created using our
createViewModel function, and the site becomes interactive. As you can
imagine, explicitly subscribing to changes in observables and then
updating the user interface in response to these changes is a lot of
work. KnockoutJS was a great library for its time, but it also required a lot of boilerplate code to get things done.
Moreover, view models often grew to be very large and complex, which led to increasing uncertainty around refactors and optimizations to code. Eventually, we ended up with verbose monolithic view models that were hard to test and reason about. Still, KnockoutJS was a very popular solution and a great library for its time. It was also relatively easy to test in isolation, which was a big plus.
For posterity, here’s how we’d test this button in KnockoutJS:
test("LikeButton",()=>{constviewModel=createViewModel({liked:ko.observable(false)});expect(viewModel.liked()).toBe(false);viewModel.onClick();expect(viewModel.liked()).toBe(true);});
AngularJS
AngularJS was developed by Google in 2010. It was a pioneering JavaScript framework that had a significant impact on the web development landscape. It stood in sharp contrast to the libraries and frameworks we’ve been discussing by incorporating several innovative features, the ripples of which can be seen in subsequent libraries, including React. Through a detailed comparison of AngularJS with these other libraries and a look at its pivotal features, let’s try to understand the path it carved for React.
Two-way data binding
Two-way data binding was a hallmark feature of AngularJS that greatly simplified the interaction between the UI and the underlying data. If the model (the underlying data) changes, the view (the UI) gets updated automatically to reflect the change, and vice versa. This was a stark contrast to libraries like jQuery, where developers had to manually manipulate the DOM to reflect any changes in the data and capture user inputs to update the data.
Let’s consider a simple AngularJS application where two-way data binding plays a crucial role:
<!DOCTYPE html><html><head><scriptsrc="https://ajax.googleapis.com/ajax/libs/angularjs/1.8.2/angular.min.js"></script></head><bodyng-app=""><p>Name:<inputtype="text"ng-model="name"/></p><png-if="name">Hello, {{name}}!</p></body></html>
In this application, the ng-model directive binds the value of the
input field to the variable name. As you type into the input field,
the model name gets updated, and the view—in this case, the greeting
"Hello, {{name}}!"—gets updated in real time.
Modular architecture
AngularJS introduced a modular architecture that allowed developers to logically separate their application’s components. Each module could encapsulate a functionality and could be developed, tested, and maintained independently. Some would call this a precursor to React’s component model, but this is debated.
Here’s a quick example:
varapp=angular.module("myApp",["ngRoute","appRoutes","userCtrl","userService",]);varuserCtrl=angular.module("userCtrl",[]);userCtrl.controller("UserController",function($scope){$scope.message="Hello from UserController";});varuserService=angular.module("userService",[]);userService.factory("User",function($http){//...});
In the preceding example, the myApp module depends on several other
modules: ngRoute, appRoutes, userCtrl, and userService. Each
dependent module could be in its own JavaScript file, and could be
developed separately from the main myApp module. This concept was
significantly different from jQuery and Backbone.js, which didn’t have a
concept of a “module” in this sense.
We inject these dependencies (appRoutes, userCtrl, etc.)
into our root app using a pattern called dependency injection that
was popularized in Angular. Needless to say, this pattern was prevalent
before JavaScript modules were standardized. Since then, import and
export statements quickly took over. To contrast these dependencies
with React components, let’s talk about dependency injection a little
more.
Dependency injection
Dependency injection (DI) is a design pattern where an object receives its dependencies instead of creating them. AngularJS incorporated this design pattern at its core, which was not a common feature in other JavaScript libraries at the time. This had a profound impact on the way modules and components were created and managed, promoting a higher degree of modularity and reusability.
Here is an example of how DI works in AngularJS:
varapp=angular.module("myApp",[]);app.controller("myController",function($scope,myService){$scope.greeting=myService.sayHello();});app.factory("myService",function(){return{sayHello:function(){return"Hello, World!";},};});
In the example, myService is a service that is injected into the
myController controller through DI. The controller does not need to
know how to create the service. It just declares the service as a
dependency, and AngularJS takes care of creating and injecting it. This
simplifies the management of dependencies and enhances the testability
and reusability of components.
Comparison with Backbone.js and Knockout.js
Backbone.js and Knockout.js were two popular libraries used around the time AngularJS was introduced. Both libraries had their strengths, but they lacked some features that were built into AngularJS.
Backbone.js, for example, gave developers more control over their code and was less opinionated than AngularJS. This flexibility was both a strength and a weakness: it allowed for more customization, but also required more boilerplate code. AngularJS, with its two-way data binding and DI, allowed for more structure. It had more opinions that led to greater developer velocity: something we see with modern frameworks like Next.js, Remix, etc. This is one way AngularJS was far ahead of its time.
Backbone also didn’t have an answer to directly mutating the view (the DOM) and often left this up to developers. AngularJS took care of DOM mutations with its two-way data binding, which was a big plus.
Knockout.js was primarily focused on data binding and lacked some of the other powerful tools that AngularJS provided, such as DI and a modular architecture. AngularJS, being a full-fledged framework, offered a more comprehensive solution for building single-page applications (SPAs). While AngularJS was discontinued, today its newer variant called Angular offers the same, albeit enhanced, slew of comprehensive benefits that make it an ideal choice for large-scale applications.
AngularJS trade-offs
AngularJS (1.x) represented a significant leap in web development practices when it was introduced. However, as the landscape of web development continued to evolve rapidly, certain aspects of AngularJS were seen as limitations or weaknesses that contributed to its relative decline. Some of these include:
- Performance
-
AngularJS had performance issues, particularly in large-scale applications with complex data bindings. The digest cycle in AngularJS, a core feature for change detection, could result in slow updates and laggy user interfaces in large applications. The two-way data binding, while innovative and useful in many situations, also contributed to the performance issues.
- Complexity
-
AngularJS introduced a range of novel concepts, including directives, controllers, services, dependency injection, factories, and more. While these features made AngularJS powerful, they also made it complex and hard to learn, especially for beginners. A common debate, for example, was “should this be a factory or a service?” leaving a number of developer teams puzzled.
- Migration issues to Angular 2+
-
When Angular 2 was announced, it was not backward compatible with AngularJS 1.x. and required code to be written in Dart and/or TypeScript. This meant that developers had to rewrite significant portions of their code to upgrade to Angular 2, which was seen as a big hurdle. The introduction of Angular 2+ essentially split the Angular community and caused confusion, paving the way for React.
- Complex syntax in templates
-
AngularJS’s allowance for complex JavaScript expressions within template attributes, such as
on-click="$ctrl.some.deeply.nested.field = 123", was problematic because it led to a blend of presentation and business logic within the markup. This approach created challenges in maintainability, as deciphering and managing the intertwined code became cumbersome.Furthermore, debugging was more difficult because template layers weren’t inherently designed to handle complex logic, and any errors that arose from these inline expressions could be challenging to locate and resolve. Additionally, such practices violated the principle of separation of concerns, which is a fundamental design philosophy advocating for the distinct handling of different aspects of an application to improve code quality and maintainability.
In theory, a template ought to call a controller method to perform an update, but nothing restricted that.
- Absence of type safety
-
Templates in AngularJS did not work with static type-checkers like TypeScript, which made it difficult to catch errors early in the development process. This was a significant drawback, especially for large-scale applications where type safety is crucial for maintainability and scalability.
- Confusing
$scopemodel -
The
$scopeobject in AngularJS was often found to be a source of confusion due to its role in binding data and its behavior in different contexts because it served as the glue between the view and the controller, but its behavior was not always intuitive or predictable.This led to complexities, especially for newcomers, in understanding how data was synchronized between the model and the view. Additionally,
$scopecould inherit properties from parent scopes in nested controllers, making it difficult to track where a particular$scopeproperty was originally defined or modified.This inheritance could cause unexpected side effects in the application, particularly when dealing with nested scopes where parent and child scopes could inadvertently affect each other. The concept of scope hierarchy and the prototypal inheritance on which it was based were often at odds with the more traditional and familiar lexical scoping rules found in JavaScript, adding another layer of learning complexity.
React, for example, colocates state with the component that needs it, and thus avoids this problem entirely.
- Limited development tools
-
AngularJS did not offer extensive developer tools for debugging and performance profiling, especially when compared to the DevTools available in React like Replay.io, which allows extensive capabilities around time-travel debugging for React applications.
Enter React
It was around this time that React rose to prominence. One of the core ideas that React presented was the component-based architecture. Although the implementation is different, the underlying idea is similar: it is optimal to build user interfaces for the web and other platforms by composing reusable components.
While AngularJS used directives to bind views to models, React introduced JSX and a radically simpler component model. Yet, without the ground laid by AngularJS in promoting a component-based architecture through Angular modules, some would argue the transition to React’s model might not have been as smooth.
In AngularJS, the two-way data binding model was the industry standard; however, it also had some downsides, such as potential performance issues on large applications. React learned from this and introduced a unidirectional data flow pattern, giving developers more control over their applications and making it easier to understand how data changes over time.
React also introduced the virtual DOM as we’ll read about in Chapter 3: a concept that improved performance by minimizing direct DOM manipulation. AngularJS, on the other hand, often directly manipulated the DOM, which could lead to performance issues and other inconsistent state issues we recently discussed with jQuery.
That said, AngularJS represented a significant shift in web development practices, and we’d be remiss if we didn’t mention that AngularJS not only revolutionized the web development landscape when it was introduced, but also paved the way for the evolution of future frameworks and libraries, React being one of them.
Let’s explore how React fits into all of this and where React came from at this point in history. At this time, UI updates were still a relatively hard and unsolved problem. They’re far from solved today, but React has made them noticeably less hard, and has inspired other libraries like SolidJS, Qwik, and more to do so. Meta’s Facebook was no exception to the problem of UI complexity and scale. As a result, Meta created a number of internal solutions complementary to what already existed at the time. Among the first of these was BoltJS: a tool Facebook engineers would say “bolted together” a bunch of things that they liked. A combination of tools was assembled to make updates to Facebook’s web user interface more intuitive.
Around this time, Facebook engineer Jordan Walke had a radical idea that did away with the status quo of the time and entirely replaced minimal portions of web pages with new ones as updates happened. As we’ve seen previously, JavaScript libraries would manage relationships between views (user interfaces) and models (conceptually, sources of data) using a paradigm called two-way data binding. In light of this model’s limitations, as we’ve discussed earlier, Jordan’s idea was to instead use a paradigm called one-way data flow. This was a much simpler paradigm, and it was much easier to keep the views and models in sync. This was the birth of the unidirectional architecture that would go on to be the foundation of React.
React’s Value Proposition
OK, history lesson’s over. Hopefully we now have enough context to begin to understand why React is a thing. Given how easy it was to fall into the pit of unsafe, unpredictable, and inefficient JavaScript code at scale, we needed a solution to steer us toward a pit of success where we accidentally win. Let’s talk about exactly how React does that.
Declarative versus imperative code
React provides a declarative abstraction on the DOM. We’ll talk more about how it does this in more detail later in the book, but essentially it provides us a way to write code that expresses what we want to see, while then taking care of how it happens, ensuring our user interface is created and works in a safe, predictable, and efficient manner.
Let’s consider the list app that we created earlier. In React, we could rewrite it like this:
functionMyList(){const[items,setItems]=useState(["I love"]);return(<div><ul>{items.map((i)=>(<likey={i/* keep items unique */}>{i}</li>))}</ul><NewItemFormonAddItem={(newItem)=>setItems([...items,newItem])}/></div>);}
Notice how in the return, we literally write something that looks like
HTML: it looks like what we want to see. I want to see a box with a
NewItemForm, and a list. Boom. How does it get there? That’s for React
to figure out. Do we batch list items to add chunks of them at once? Do
we add them sequentially, one by one? React deals with how this is
done, while we merely describe what we want done. In further chapters,
we’ll dive into React and explore exactly how it does this at the time
of writing.
Do we then depend on class names to reference HTML elements? Do we
getElementById in JavaScript? Nope. React creates unique “React
elements” for us under the hood that it uses to detect changes and make
incremental updates so we don’t need to read class names and other
identifiers from user code whose existence we cannot guarantee: our
source of truth becomes exclusively JavaScript with React.
We export our MyList component to React, and React gets it on the
screen for us in a way that is safe, predictable, and performant—no
questions asked. The component’s job is to just return a description of
what this piece of the UI should look like. It does this by using a
virtual DOM (vDOM), which is a lightweight description of the intended UI
structure. React then compares the virtual DOM after an update happens
to the virtual DOM before an update happens, and turns that into
small, performant updates to the real DOM to make it match the virtual
DOM. This is how React is able to make updates to the DOM.
The virtual DOM
The virtual DOM is a programming concept that represents the real DOM but as a JavaScript object. If this is a little too in the weeds for now, don’t worry: Chapter 3 is dedicated to this and breaks things down in a little more detail. For now, it’s just important to know that the virtual DOM allows developers to update the UI without directly manipulating the actual DOM. React uses the virtual DOM to keep track of changes to a component and rerenders the component only when necessary. This approach is faster and more efficient than updating the entire DOM tree every time there is a change.
In React, the virtual DOM is a lightweight representation of the actual DOM tree. It is a plain JavaScript object that describes the structure and properties of the UI elements. React creates and updates the virtual DOM to match the actual DOM tree, and any changes made to the virtual DOM are applied to the actual DOM using a process called reconciliation.
Chapter 4 is dedicated to this, but for our contextual discussion here, let’s look at a small summary with a few examples. To understand how the virtual DOM works, let’s bring back our example of the Like button. We will create a React component that displays a Like button and the number of likes. When the user clicks the button, the number of likes should increase by one.
Here is the code for our component:
importReact,{useState}from"react";functionLikeButton(){const[likes,setLikes]=useState(0);functionhandleLike(){setLikes(likes+1);}return(<div><buttononClick={handleLike}>Like</button><p>{likes}Likes</p></div>);}exportdefaultLikeButton;
In this code, we have used the useState hook to create a state
variable likes, which holds the number of likes. To recap what we
might already know about React, a hook is a special function that allows
us to use React features, like state and lifecycle methods, within
functional components. Hooks enable us to reuse stateful logic without
changing the component hierarchy, making it easy to extract and share
hooks among components or even with the community as self-contained
open source packages.
We have also defined a function handleLike that increases the value of
likes by one when the button is clicked. Finally, we render the Like button and the number of likes using JSX.
Now, let’s take a closer look at how the virtual DOM works in this example.
When the LikeButton component is first rendered, React creates a
virtual DOM tree that mirrors the actual DOM tree. The virtual DOM
contains a single div element that contains a button element and a
p element:
{$$typeof:Symbol.for('react.element'),type:'div',props:{},children:[{$$typeof:Symbol.for('react.element'),type:'button',props:{onClick:handleLike},children:['Like']},{$$typeof:Symbol.for('react.element'),type:'p',props:{},children:[0,' Likes']}]}
The children property of the p element contains the value of the Likes
state variable, which is initially set to zero.
When the user clicks the Like button, the handleLike function is
called, which updates the likes state variable. React then creates a
new virtual DOM tree that reflects the updated state:
{type:'div',props:{},children:[{type:'button',props:{onClick:handleLike},children:['Like']},{type:'p',props:{},children:[1,' Likes']}]}
Notice that the virtual DOM tree contains the same elements as before,
but the children property of the p element has been updated to reflect
the new value of likes, going from 0 to 1. What follows is a process
called reconciliation in React, where the new vDOM is
compared with the old one. Let’s briefly discuss this process.
After computing a new virtual DOM tree, React performs a process called reconciliation to understand the differences between the new tree and the old one. Reconciliation is the process of comparing the old virtual DOM tree with the new virtual DOM tree and determining which parts of the actual DOM need to be updated. If you’re interested in how exactly this is done, Chapter 4 goes into a lot of detail about this. For now, let’s consider our Like button.
In our example, React compares the old virtual DOM tree with the new
virtual DOM tree and finds that the p element has changed:
specifically that its props or state or both have changed. This enables
React to mark the component as “dirty” or “should be updated.” React
then computes a minimal effective set of updates to make on the actual
DOM to reconcile the state of the new vDOM with the DOM, and eventually
updates the actual DOM to reflect the changes made to the virtual DOM.
React updates only the necessary parts of the actual DOM to minimize the number of DOM manipulations. This approach is much faster and more efficient than updating the entire DOM tree every time there is a change.
The virtual DOM has been a powerful and influential invention for the modern web, with newer libraries like Preact and Inferno adopting it once it was proven in React. We will cover more of the virtual DOM in Chapter 4, but for now, let’s move on to the next section.
The component model
React highly encourages “thinking in components”: that is, breaking your app into smaller pieces and adding them to a larger tree to compose your application. The component model is a key concept in React, and it’s what makes React so powerful. Let’s talk about why:
-
It encourages reusing the same thing everywhere so that if it breaks, you fix it in one place and it’s fixed everywhere. This is called DRY (Don’t Repeat Yourself) development and is a key concept in software engineering. For example, if we have a
Buttoncomponent, we can use it in many places in our app, and if we need to change the style of the button, we can do it in one place and it’s changed everywhere. -
React is more easily able to keep track of components and do performance magic like memoization, batching, and other optimizations under the hood if it’s able to identify specific components over and over and track updates to the specific components over time. This is called keying. For example, if we have a
Buttoncomponent, we can give it akeyprop and React will be able to keep track of theButtoncomponent over time and “know” when to update it, or when to skip updating it and continue making minimal changes to the user interface. Most components have implicit keys, but we can also explicitly provide them if we want to. -
It helps us separate concerns and colocate logic closer to the parts of the user interface that the logic affects. For example, if we have a
RegisterButtoncomponent, we can put the logic for what happens when the button is clicked in the same file as theRegisterButtoncomponent, instead of having to jump around to different files to find the logic for what happens when the button is clicked. TheRegisterButtoncomponent would wrap a more simpleButtoncomponent, and theRegisterButtoncomponent would be responsible for handling the logic for what happens when the button is clicked. This is called composition.
React’s component model is a fundamental concept that underpins the framework’s popularity and success. This approach to development has numerous benefits, including increased modularity, easier debugging, and more efficient code reuse.
Immutable state
React’s design philosophy emphasizes a paradigm wherein the state of our application is described as a set of immutable values. Each state update is treated as a new, distinct snapshot and memory reference. This immutable approach to state management is a core part of React’s value proposition, and it has several advantages for developing robust, efficient, and predictable user interfaces.
By enforcing immutability, React ensures that the UI components reflect a specific state at any given point in time. When the state changes, rather than mutating it directly, you return a new object that represents the new state. This makes it easier to track changes, debug, and understand your application’s behavior. Since state transitions are discrete and do not interfere with each other, the chances of subtle bugs caused by a shared mutable state are significantly reduced.
In coming chapters, we’ll explore how React batches state updates and processes them asynchronously to optimize performance. Because state must be treated immutably, these “transactions” can be safely aggregated and applied without the risk of one update corrupting the state for another. This leads to more predictable state management and can improve app performance, especially during complex state transitions.
The use of immutable state further reinforces best practices in software development. It encourages developers to think functionally about their data flow, reducing side effects and making the code easier to follow. The clarity of an immutable data flow simplifies the mental model for understanding how an application works.
Immutability also enables powerful developer tools, such as time-travel debugging with tools like Replay.io, where developers can step forward and backward through the state changes of an application to inspect the UI at any point in time. This is only feasible if every state update is kept as a unique and unmodified snapshot.
React’s commitment to immutable state updates is a deliberate design choice that brings numerous benefits. It aligns with modern functional programming principles, enabling efficient UI updates, optimizing performance, reducing the likelihood of bugs, and improving the overall developer experience. This approach to state management underpins many of React’s advanced features and will continue to be a cornerstone as React evolves.
Releasing React
Unidirectional data flow was a radical departure from the way we had been building web apps for years, and it was met with skepticism. The fact that Facebook was a large company with a lot of resources, a lot of users, and a lot of engineers with opinions made its upward climb a steep one. After much scrutiny, React was an internal success. It was adopted by Facebook and then by Instagram.
It was then made open source in 2013 and released to the world where it was met with a tremendous amount of backlash. People heavily criticized React for its use of JSX, accusing Facebook of “putting HTML in JavaScript” and breaking separation of concerns. Facebook became known as the company that “rethinks best practices” and breaks the web. Eventually, after slow and steady adoption by companies like Netflix, Airbnb, and The New York Times, React became the de facto standard for building user interfaces on the web.
A number of details are left out of this story because they fall out of the scope of this book, but it’s important to understand the context of React before we dive into the details: specifically the class of technical problems React was created to solve. Should you be more interested in the story of React, there is a full documentary on the history of React that is freely available on YouTube under React.js: The Documentary by Honeypot.
Given that Facebook had a front-row seat to these problems at enormous scale, React pioneered a component-based approach to building user interfaces that would solve these problems and more, where each component would be a self-contained unit of code that could be reused and composed with other components to build more complex user interfaces.
A year after React was released as open source software, Facebook released Flux: a pattern for managing data flow in React applications. Flux was a response to the challenges of managing data flow in large-scale applications, and it was a key part of the React ecosystem. Let’s take a look at Flux and how it fits into the React.
The Flux Architecture
Flux is an architectural design pattern for building client-side web applications, popularized by Facebook (now Meta) (see Figure 1-3). It emphasizes a unidirectional data flow, which makes the flow of data within the app more predictable.
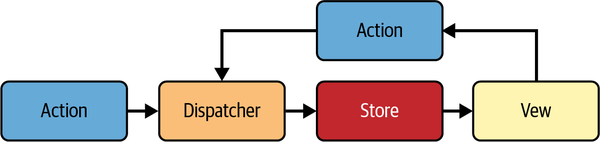
Figure 1-3. The Flux architecture
Here are the key concepts of the Flux architecture:
- Actions
-
Actions are simple objects containing new data and an identifying type property. They represent the external and internal inputs to the system, like user interactions, server responses, and form inputs. Actions are dispatched through a central dispatcher to various stores:
// Example of an action object{type:'ADD_TODO',text:'Learn Flux Architecture'} - Dispatcher
-
The dispatcher is the central hub of the Flux architecture. It receives actions and dispatches them to the registered stores in the application. It manages a list of callbacks, and every store registers itself and its callback with the dispatcher. When an action is dispatched, it is sent to all registered callbacks:
// Example of dispatching an actionDispatcher.dispatch(action); - Stores
-
Stores contain the application state and logic. They are somewhat similar to models in the MVC architecture, but they manage the state of many objects. They register with the dispatcher and provide callbacks to handle the actions. When a store’s state is updated, it emits a change event to alert the views that something has changed:
// Example of a storeclassTodoStoreextendsEventEmitter{constructor(){super();this.todos=[];}handleActions(action){switch(action.type){case"ADD_TODO":this.todos.push(action.text);this.emit("change");break;default:// no op}}} - Views
-
Views are React components. They listen to change events from the stores and update themselves when the data they depend on changes. They can also create new actions to update the system state, forming a unidirectional cycle of data flow.
The Flux architecture promotes a unidirectional data flow through a system, which makes it easier to track changes over time. This predictability can later be used as the basis for compilers to further optimize code, as is the case with React Forget (more on this later).
Benefits of the Flux Architecture
The Flux architecture brings about a variety of benefits that help manage complexity and improve the maintainability of web applications. Here are some of the notable benefits:
- Single source of truth
-
Flux emphasizes having a single source of truth for the application’s state, which is stored in the stores. This centralized state management makes the application’s behavior more predictable and easier to understand. It eliminates the complications that come with having multiple, interdependent sources of truth, which can lead to bugs and inconsistent state across the application.
- Testability
-
Flux’s well-defined structures and predictable data flow make the application highly testable. The separation of concerns among different parts of the system (like actions, dispatcher, stores, and views) allows for unit testing each part in isolation. Moreover, it’s easier to write tests when the data flow is unidirectional and when the state is stored in specific, predictable locations.
- Separation of concerns (SoC)
-
Flux clearly separates the concerns of different parts of the system, as described earlier. This separation makes the system more modular, easier to maintain, and easier to reason about. Each part has a clearly defined role, and the unidirectional data flow makes it clear how these parts interact with each other.
The Flux architecture provides a solid foundation for building robust, scalable, and maintainable web applications. Its emphasis on a unidirectional data flow, single source of truth, and Separation of Concerns leads to applications that are easier to develop, test, and debug.
Wrap-Up: So…Why Is React a Thing?
React is a thing because it allows developers to build user interfaces with greater predictability and reliability, enabling us to declaratively express what we’d like on the screen while React takes care of the how by making incremental updates to the DOM in an efficient manner. It also encourages us to think in components, which helps us separate concerns and reuse code more easily. It is battle-tested at Meta and designed to be used at scale. It’s also open source and free to use.
React also has a vast and active ecosystem, with a wide range of tools, libraries, and resources available to developers. This ecosystem includes tools for testing, debugging, and optimizing React applications, as well as libraries for common tasks such as data management, routing, and state management. Additionally, the React community is highly engaged and supportive, with many online resources, forums, and communities available to help developers learn and grow.
React is platform-agnostic, meaning that it can be used to build web applications for a wide range of platforms, including desktop, mobile, and virtual reality. This flexibility makes React an attractive option for developers who need to build applications for multiple platforms, as it allows them to use a single codebase to build applications that run across multiple devices.
To conclude, React’s value proposition is centered around its component-based architecture, declarative programming model, virtual DOM, JSX, extensive ecosystem, platform agnostic nature, and backing by Meta. Together, these features make React an attractive option for developers who need to build fast, scalable, and maintainable web applications. Whether you’re building a simple website or a complex enterprise application, React can help you achieve your goals more efficiently and effectively than many other technologies. Let’s review.
Chapter Review
In this chapter, we covered a brief history of React, its initial value proposition, and how it solves the problems of unsafe, unpredictable, and inefficient user interface updates at scale. We also talked about the component model and why it has been revolutionary for interfaces on the web. Let’s recap what we’ve learned. Ideally, after this chapter you are more informed about the roots of React and where it comes from as well as its main strengths and value proposition.
Review Questions
Let’s make sure you’ve fully grasped the topics we covered. Take a moment to answer the following questions:
-
What was the motivation to create React?
-
How does React improve on prior patterns like MVC and MVVM?
-
What’s so special about the Flux architecture?
-
What are the benefits of declarative programming abstractions?
-
What’s the role of the virtual DOM in making efficient UI updates?
If you have trouble answering these questions, this chapter may be worth another read. If not, let’s explore the next chapter.
Up Next
In Chapter 2 we will dive a little deeper into this declarative abstraction that allows us to express what we want to see on the screen: the syntax and inner workings of JSX—the language that looks like HTML in JavaScript that got React into a lot of trouble in its early days, but ultimately revealed itself to be the ideal way to build user interfaces on the web, influencing a number of future libraries for building user interfaces.
Get Fluent React now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

