Chapter 4. Inside Reconciliation
To be truly fluent in React, we need to understand what its functions
do. So far, we’ve understood JSX and React.createElement. We’ve also
understood the virtual DOM in some appreciable level of detail. Let’s
explore the practical applications of it
in React in this chapter, and
understand what ReactDOM.createRoot(element).render() does.
Specifically, we’ll explore how React builds its virtual DOM and then
updates the real DOM through a process called
reconciliation.
Understanding Reconciliation
As a quick recap, React’s virtual DOM is a blueprint of our desired UI state. React takes this blueprint and, through a process called reconciliation, makes it a reality in a given host environment; usually a web browser, but possibly other environments like shells, native platforms like iOS and Android, and more.
Consider the following code snippet:
import{useState}from"react";constApp=()=>{const[count,setCount]=useState(0);return(<main><div><h1>Hello,world!</h1><span>Count:{count}</span><buttononClick={()=>setCount(count+1)}>Increment</button></div></main>);};
This code snippet contains a declarative description of what we want our UI state to be: a tree of elements. Both our teammates and React can read this and understand we’re trying to create a counter app with an increment button that increments the counter. To understand reconciliation, let’s understand what React does on the inside when faced with a component like this.
First, the JSX becomes a tree of React elements. This is what we saw in Chapter 3. When invoked, the App component returns a React
element whose children are further React elements. React elements are
immutable (to us) and represent the desired state of the UI. They are
not the actual UI state. React elements are created by
React.createElement or the JSX < symbol, so this would be transpiled
into:
constApp=()=>{const[count,setCount]=useState(0);returnReact.createElement("main",null,React.createElement("div",null,React.createElement("h1",null,"Hello, world!"),React.createElement("span",null,"Count: ",count),React.createElement("button",{onClick:()=>setCount(count+1)},"Increment")));};
This would give us a tree of created React elements that looks something like this:
{type:"main",props:{children:{type:"div",props:{children:[{type:"h1",props:{children:"Hello, world!",},},{type:"span",props:{children:["Count: ",count],},},{type:"button",props:{onClick:()=>setCount(count+1),children:"Increment",},},],},},},}
This snippet represents the virtual DOM that comes from our
Counter component. Since this is the first render, this tree is now
committed to the browser using minimal calls to imperative DOM APIs. How
does React ensure minimal calls to imperative DOM APIs? It does so by
batching vDOM updates into one real DOM update, and touching the DOM as
little as possible for reasons discussed in earlier chapters. Let’s dive
into this in some more detail to fully understand batching.
Batching
In Chapter 3, we discussed document fragments in browsers as part of the DOM’s built-in APIs: lightweight containers that hold collections of DOM nodes that act like a temporary staging area where you can make multiple changes without affecting the main DOM until you finally append the document fragment to the DOM, triggering a single reflow and repaint.
In a similar vein, React batches updates to the real DOM during reconciliation, combining multiple vDOM updates into a single DOM update. This reduces the number of times the real DOM has to be updated and therefore lends itself to better performance for web applications.
To understand this, let’s consider a component that updates its state multiple times in quick succession:
functionExample(){const[count,setCount]=useState(0);consthandleClick=()=>{setCount((prevCount)=>prevCount+1);setCount((prevCount)=>prevCount+1);setCount((prevCount)=>prevCount+1);};return(<div><p>Count:{count}</p><buttononClick={handleClick}>Increment</button></div>);}
In this example, the handleClick function calls setCount three times
in quick succession. Without batching, React would update the real DOM
three separate times, even though the value of count only changed once.
This would be wasteful and slow.
However, because React batches updates, it makes one update to the DOM
with count + 3 instead of three updates to the DOM with count + 1 each
time.
To calculate the most efficient batched update to the DOM, React will
create a new vDOM tree as a fork of the current vDOM tree with the
updated values, where count is 3. This tree will need to be
reconciled with what is currently in the browser, effectively turning
0 into 3. React will then calculate that just one update is required
to the DOM using the new vDOM value 3 instead of manually updating the
DOM three times. This is how batching fits into the picture, and it is a part
of the broader topic we’re about to dive into: reconciliation, or the
process of reconciling the next expected DOM state with the current DOM.
Before we understand what modern-day React does under the hood, let’s explore how React used to perform reconciliation before version 16, with the legacy “stack” reconciler. This will help us understand the need for today’s popular Fiber reconciler.
Note
At this point, it’s worth mentioning that all of the topics we’re about to discuss are implementation details in React that can and likely will change over time. Here, we are isolating the mechanism of how React works from actual practical usage of React. The goal is that by understanding React’s internal mechanisms, we’ll have a better understanding of how to use React effectively in applications.
Prior Art
Previously, React used a stack data structure for rendering. To make sure we’re on the same page, let’s briefly discuss the stack data structure.
Stack Reconciler (Legacy)
In computer science, a stack is a linear data structure that follows the last in, first out (LIFO) principle. This means that the last element added to the stack will be the first one to be removed. A stack has two fundamental operations, push and pop, that allow elements to be added and removed from the top of the stack, respectively.
A stack can be visualized as a collection of elements that are arranged vertically, with the topmost element being the most recently added one. Here’s an ASCII illustration of a stack with three elements:
-----|3||___||2||___||1||___|
In this example, the most recently added element is 3, which is at the
top of the stack. The element 1, which was added first, is at the bottom
of the stack.
In this stack, the push operation adds an element to the top of the
stack. In code, this can be executed in JavaScript using an array and
the push method, like this:
conststack=[];stack.push(1);// stack is now [1]stack.push(2);// stack is now [1, 2]stack.push(3);// stack is now [1, 2, 3]
The pop operation removes the top element from the stack. In code, this
can be executed in JavaScript using an array and the pop method, like
this:
conststack=[1,2,3];consttop=stack.pop();// top is now 3, and stack is now [1, 2]
In this example, the pop method removes the top element (3) from the
stack and returns it. The stack array now contains the remaining
elements (1 and 2).
React’s original reconciler was a stack-based algorithm that was used to compare the old and new virtual trees and update the DOM accordingly. While the stack reconciler worked well in simple cases, it presented a number of challenges as applications grew in size and complexity.
Let’s take a quick look at why this was the case. To do so, we’ll consider an example where we’ve got a list of updates to make:
-
A nonessential computationally expensive component consumes CPU and renders.
-
A user types into an
inputelement. -
Buttonbecomes enabled if the input is valid. -
A containing
Formcomponent holds the state, so it rerenders.
In code, we’d express this like so:
importReact,{useReducer}from"react";constinitialState={text:"",isValid:false};functionForm(){const[state,dispatch]=useReducer(reducer,initialState);consthandleChange=(e)=>{dispatch({type:"handleInput",payload:e.target.value});};return(<div><ExpensiveComponent/><inputvalue={state.text}onChange={handleChange}/><Buttondisabled={!state.isValid}>Submit</Button></div>);}functionreducer(state,action){switch(action.type){case"handleInput":return{text:action.payload,isValid:action.payload.length>0,};default:thrownewError();}}
In this case, the stack reconciler would render the updates sequentially without being able to pause or defer work. If the computationally expensive component blocks rendering, user input will appear on screen with an observable lag. This leads to poor user experience, since the text field would be unresponsive. Instead, it would be far more pleasant to be able to recognize the user input as a higher-priority update than rendering the nonessential expensive component, and update the screen to reflect the input, deferring rendering the computationally expensive component.
There is a need to be able to bail out of current rendering work if interrupted by higher-priority rendering work, like user input. To do this, React needs to have a sense of priority for certain types of rendering operations over others.
The stack reconciler did not prioritize updates, which meant that less important updates could block more important updates. For example, a low-priority update to a tooltip might block a high-priority update to a text input. Updates to the virtual tree were executed in the order they were received.
In a React application, updates to the virtual tree can have different levels of importance. For example, an update to a form input might be more important than an update to an indicator showing the number of likes on a post, because the user is directly interacting with the input and expects it to be responsive.
In the stack reconciler, updates were executed in the order they were received, which meant that less important updates could block more important updates. For example, if a like counter update was received before a form input update, the like counter update would be executed first and could block the form input update.
If the like counter update takes a long time to execute (e.g., because it’s performing an expensive computation), this could result in a noticeable delay or jank in the user interface, especially if the user is interacting with the application during the update.
Another challenge with the stack reconciler was that it did not allow updates to be interrupted or cancelled. What this means is that even if the stack reconciler had a sense of update priority, there were no guarantees that it could work well with various priorities by bailing out of unimportant work when a high-priority update was scheduled.
In any web application, not all updates are created equal: a random unexpected notification appearing is not as important as responding to my click on a button because the latter is a deliberate action that warrants an immediate reaction, whereas the former isn’t even expected and may not even be welcome.
In the stack reconciler, updates could not be interrupted or cancelled, which meant that unnecessary updates, like showing a toast, were sometimes made at the expense of user interactions. This could result in unnecessary work being performed on the virtual tree and the DOM, which negatively impacted the performance of the application.
The stack reconciler presented a number of challenges as applications grew in size and complexity. The main challenges were centered around jank and user interfaces being slow to respond. To address these challenges, the React team developed a new reconciler called the Fiber reconciler, which is based on a different data structure called a Fiber tree. Let’s explore this data structure in the next section.
The Fiber Reconciler
The Fiber reconciler involves the use of a different data structure called a “Fiber” that represents a single unit of work for the reconciler. Fibers are created from React elements that we covered in Chapter 3, with the key difference being that they are stateful and long-lived, while React elements are ephemeral and stateless.
Mark Erikson, the maintainer of Redux and a prominent React expert, describes Fibers as “React’s internal data structure that represents the actual component tree at a point in time.” Indeed, this is a good way to think about Fibers, and it’s on-brand for Mark who, at the time of writing, works on time-travel debugging React apps full time with Replay: a tool that allows you to rewind and replay your app’s state for debugging. If you haven’t already, check out Replay.io for more information.
Similar to how the vDOM is a tree of elements, React uses a Fiber tree in reconciliation which, as the name suggests, is a tree of Fibers that is directly modeled after the vDOM.
Fiber as a Data Structure
The Fiber data structure in React is a key component of the Fiber reconciler. The Fiber reconciler allows updates to be prioritized and executed concurrently, which improves the performance and responsiveness of React applications. Let’s explore the Fiber data structure in more detail.
At its core, the Fiber data structure is a representation of a component instance and its state in a React application. As discussed, the Fiber data structure is designed to be a mutable instance and can be updated and rearranged as needed during the reconciliation process.
Each instance of a Fiber node contains information about the component it represents, including its props, state, and child components. The Fiber node also contains information about its position in the component tree, as well as metadata that is used by the Fiber reconciler to prioritize and execute updates.
Here’s an example of a simple Fiber node:
{tag:3,// 3 = ClassComponenttype:App,key:null,ref:null,props:{name:"Tejas",age:30},stateNode:AppInstance,return:FiberParent,child:FiberChild,sibling:FiberSibling,index:0,//...}
In this example, we have a Fiber node that represents a ClassComponent
called App. The Fiber node contains information about the component’s:
tag-
In this case it’s
3, which React uses to identify class components. Each type of component (class components, function components, Suspense and error boundaries, fragments, etc.) has its own numerical ID as Fibers. type-
Apprefers to the function or class component that this Fiber represents. props-
(
{name: "Tejas", age: 30}) represent the input props to the component, or input arguments to the function. stateNode-
The instance of the
Appcomponent that this Fiber represents.Its position in the component tree:
return,child,sibling, andindexeach give the Fiber reconciler a way to “walk the tree,” identifying parents, children, siblings, and the Fiber’s index.
Fiber reconciliation involves comparing the current Fiber tree with the next Fiber tree and figuring out which nodes need to be updated, added, or removed.
During the reconciliation process, the Fiber reconciler creates a Fiber
node for each React element in the virtual DOM. There is a
function called createFiberFromTypeAndProps that does this. Of course,
another way of saying “type and props” is by calling them React
elements. As we recall, a React element is this: type and props:
{type:"div",props:{className:"container"}}
This function returns a Fiber derived from elements. Once the Fiber
nodes have been created, the Fiber reconciler uses a work loop to
update the user interface. The work loop starts at the root Fiber node
and works its way down the component tree, marking each Fiber node as
“dirty” if it needs to be updated. Once it reaches the end, it walks
back up, creating a new DOM tree in memory, detached from the browser,
that will eventually be committed (flushed) to the screen. This is
represented by two functions: beginWork walks downward, marking
components as “need to update,” and
completeWork walks back
up, constructing a tree of real DOM elements detached from the browser.
This off-screen rendering process can be interrupted and thrown away at
any time, since the user doesn’t see it.
The Fiber architecture takes inspiration from a concept called “double buffering” in the game world, where the next screen is prepared offscreen and then “flushed” to the current screen. To better grasp the Fiber architecture, let’s understand this concept in a little more detail before we move further.
Double Buffering
Double buffering is a technique used in computer graphics and video processing to reduce flicker and improve perceived performance. The technique involves creating two buffers (or memory spaces) for storing images or frames, and switching between them at regular intervals to display the final image or video.
Here’s how double buffering works in practice:
-
The first buffer is filled with the initial image or frame.
-
While the first buffer is being displayed, the second buffer is updated with new data or images.
-
When the second buffer is ready, it is switched with the first buffer and displayed on the screen.
-
The process continues, with the first and second buffers being switched at regular intervals to display the final image or video.
By using double buffering, flicker and other visual artifacts can be reduced, since the final image or video is displayed without interruptions or delays.
Fiber reconciliation is similar to double buffering such that when updates happen, the current Fiber tree is forked and updated to reflect the new state of a given user interface. This is called rendering. Then, when the alternate tree is ready and accurately reflects the state a user expects to see, it is swapped with the current tree similarly to how video buffers are swapped in double buffering. This is called the commit phase of reconciliation or a commit.
By using a work-in-progress tree, the Fiber reconciler presents a number of benefits:
-
It can avoid making unnecessary updates to the real DOM, which can improve performance and reduce flicker.
-
It can compute the new state of a UI off-screen, and throw it away if a newer higher-priority update needs to happen.
-
Since reconciliation happens off-screen, it can even pause and resume without messing up what the user currently sees.
With the Fiber reconciler, two trees are derived from a user-defined tree of JSX elements: one tree containing “current” Fibers, and another tree containing work-in-progress Fibers. Let’s explore these trees a little more.
Fiber Reconciliation
Fiber reconciliation happens in two phases: the render phase and the commit phase. This two-phase approach, shown in Figure 4-1, allows React to do rendering work that can be disposed of at any time before committing it to the DOM and showing a new state to users: it makes rendering interruptible. To be a little bit more detailed, what makes rendering feel interruptible are the heuristics employed by the React scheduler of yielding the execution back to the main thread every 5 ms, which is smaller than a single frame even on 120 fps devices.

Figure 4-1. Reconciliation flow in the Fiber reconciler
We’ll dive more into the details around the scheduler in Chapter 7 as we explore React’s concurrent features. For now, though, let’s walk through these phases of reconciliation.
The render phase
The render phase starts when a state-change event occurs in the
current tree. React does the work of making the changes off-screen
in the alternate tree by recursively stepping through each Fiber and
setting flags that signal updates are pending (see Figure 4-2). As we alluded to earlier,
this happens in a function called beginWork internally in React.
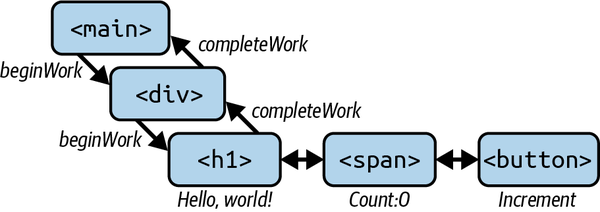
Figure 4-2. Call order of the render phase
beginWork
beginWork is responsible for setting flags on Fiber nodes in the work-in-progress tree about whether or not they should update. It sets a
bunch of flags and then recursively goes to the next Fiber node, doing
the same thing until it reaches the bottom of the tree. When it
finishes, we start calling completeWork on the Fiber nodes and walk
back up.
The signature of beginWork is as follows:
functionbeginWork(current:Fiber|null,workInProgress:Fiber,renderLanes:Lanes):Fiber|null;
More on completeWork later. For now, let’s dive into beginWork. Its
signature includes the following arguments:
current-
A reference to the Fiber node in the current tree that corresponds to the work-in-progress node being updated. This is used to determine what has changed between the previous version and the new version of the tree, and what needs to be updated. This is never mutated and is only used for comparison.
workInProgress-
The Fiber node being updated in the work-in-progress tree. This is the node that will be marked as “dirty” if updated and returned by the function.
renderLanes-
Render lanes is a new concept in React’s Fiber reconciler that replaces the older
renderExpirationTime. It’s a bit more complex than the oldrenderExpirationTimeconcept, but it allows React to better prioritize updates and make the update process more efficient. SincerenderExpirationTimeis deprecated, we’ll focus onrenderLanesin this chapter.It is essentially a bitmask that represents “lanes” in which an update is being processed. Lanes are a way of categorizing updates based on their priority and other factors. When a change is made to a React component, it is assigned a lane based on its priority and other characteristics. The higher the priority of the change, the higher the lane it is assigned to.
The
renderLanesvalue is passed to thebeginWorkfunction in order to ensure that updates are processed in the correct order. Updates that are assigned to higher-priority lanes are processed before updates that are assigned to lower-priority lanes. This ensures that high-priority updates, such as updates that affect user interaction or accessibility, are processed as quickly as possible.In addition to prioritizing updates,
renderLanesalso helps React better manage concurrency. React uses a technique called “time slicing” to break up long-running updates into smaller, more manageable chunks.renderLanesplays a key role in this process, as it allows React to determine which updates should be processed first, and which updates can be deferred until later.After the render phase is complete, the
getLanesToRetrySynchronouslyOnErrorfunction is called to determine if any deferred updates were created during the render phase. If there are deferred updates, theupdateComponentfunction starts a new work loop to handle them, usingbeginWorkandgetNextLanesto process the updates and prioritize them based on their lanes.We dive much deeper into render lanes in Chapter 7, the upcoming chapter on concurrency. For now, let’s continue following the Fiber reconciliation flow.
completeWork
The completeWork function applies updates to the work-in-progress
Fiber node and constructs a new real DOM tree that represents the
updated state of the application. It constructs this tree detached from
the DOM out of the plane of browser visibility.
If the host environment is a browser, this means doing things like
document.createElement or newElement.appendChild. Keep in mind, this
tree of elements is not yet attached to the in-browser document: React
is just creating the next version of the UI off-screen. Doing this work
off-screen makes it interruptible: whatever next state React is
computing is not yet painted to the screen, so it can be thrown away in
case some higher-priority update gets scheduled. This is the whole point
of the Fiber
reconciler.
The signature of completeWork is as follows:
functioncompleteWork(current:Fiber|null,workInProgress:Fiber,renderLanes:Lanes):Fiber|null;
Here, the signature is the same signature as beginWork.
The completeWork function is closely related to the beginWork
function. While beginWork is responsible for setting flags about
“should update” state on a Fiber node,
completeWork is responsible
for constructing a new tree to be committed to the host environment.
When completeWork reaches the top and has constructed the new DOM
tree, we say that “the render phase is completed.” Now, React moves on to the
commit phase.
The commit phase
The commit phase (see Figure 4-3) is responsible for updating the actual DOM with the changes that were made to the virtual DOM during the render phase. During the commit phase, the new virtual DOM tree is committed to the host environment, and the work-in-progress tree is replaced with the current tree. It’s in this phase that all effects are also run. The commit phase is divided into two parts: the mutation phase and the layout phase.
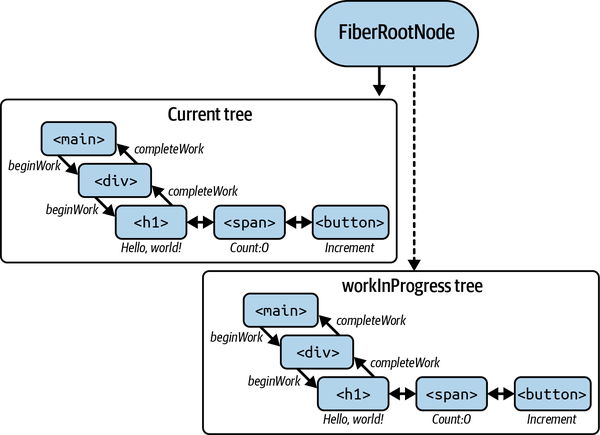
Figure 4-3. The commit phase with FiberRootNode
The mutation phase
The mutation phase is the first part of the commit phase, and it is
responsible for updating the actual DOM with the changes that were made
to the virtual DOM. During this phase, React identifies updates that
need to be made and calls a special function called
commitMutationEffects. This function applies the updates that were
made to Fiber nodes in the alternate tree during the render phase to the
actual DOM.
Here’s an full-pseudocode example of how commitMutationEffects might
be
implemented:
functioncommitMutationEffects(Fiber){switch(Fiber.tag){caseHostComponent:{// Update DOM node with new props and/or childrenbreak;}caseHostText:{// Update text content of DOM nodebreak;}caseClassComponent:{// Call lifecycle methods like componentDidMount and componentDidUpdatebreak;}// ... other cases for different types of nodes}}
During the mutation phase, React also calls other special functions,
such as commitUnmount and commitDeletion, to remove nodes from the
DOM that are no longer needed.
The layout phase
The layout phase is the second part of the commit phase, and it is
responsible for calculating the new layout of the updated nodes in the
DOM. During this phase, React calls a special function called
commitLayoutEffects. This function calculates the new layout of the
updated nodes in the DOM.
Like commitMutationEffects, commitLayoutEffects is also a massive
switch statement that calls different functions, depending on the type of
node being updated.
Once the layout phase is complete, React has successfully updated the actual DOM to reflect the changes that were made to the virtual DOM during the render phase.
By dividing the commit phase into two parts (mutation and layout), React is able to apply updates to the DOM in an efficient manner. By working in concert with other key functions in the reconciler, the commit phase helps to ensure that React applications are fast, responsive, and reliable, even as they become more complex and handle larger amounts of data.
Effects
During the commit phase of React’s reconciliation process, side effects are performed in a specific order, depending on the type of effect. There are several types of effects that can occur during the commit phase, including:
- Placement effects
-
These effects occur when a new component is added to the DOM. For example, if a new button is added to a form, a placement effect will occur to add the button to the DOM.
- Update effects
-
These effects occur when a component is updated with new props or state. For example, if the text of a button changes, an update effect will occur to update the text in the DOM.
- Deletion effects
-
These effects occur when a component is removed from the DOM. For example, if a button is removed from a form, a deletion effect will occur to remove the button from the DOM.
- Layout effects
-
These effects occur before the browser has a chance to paint, and are used to update the layout of the page. Layout effects are managed using the
useLayoutEffecthook in function components and thecomponentDidUpdatelifecycle method in class components.
In contrast to these commit-phase effects, passive effects are
user-defined effects that are scheduled to run after the browser has had
a chance to paint. Passive effects are managed using the useEffect
hook.
Passive effects are useful for performing actions that are not critical to the initial rendering of the page, such as fetching data from an API or performing analytics tracking. Because passive effects are not performed during the render phase, they do not affect the time required to compute a minimal set of updates required to bring a user interface into the developer’s desired state.
Putting everything on the screen
React maintains a FiberRootNode atop both trees that points to one of
the two trees: the current or the workInProgress tree. The
FiberRootNode is a key data structure that is responsible for managing
the commit phase of the reconciliation process.
When updates are made to the virtual DOM, React updates the
workInProgress tree, while leaving the current tree unchanged. This
allows React to continue rendering and updating the virtual DOM, while
also preserving the current state of the
application.
When the rendering process is complete, React calls a function called
commitRoot, which is responsible for committing the changes made to
the workInProgress tree to the actual DOM. commitRoot switches the
pointer of the FiberRootNode from the current tree to the
workInProgress tree, making the workInProgress tree the new current
tree.
From this point on, any future updates are based on the new current tree. This process ensures that the application remains in a consistent state, and that updates are applied correctly and efficiently.
All of this appears to happen instantly in the browser. This is the work of reconciliation.
Chapter Review
In this chapter, we explored the concept of React reconciliation and
learned about the Fiber reconciler. We also learned about Fibers, which
enable efficient and interruptible rendering in concert with a powerful
scheduler. We also learned about the render phase and the commit phase,
which are the two main phases of the reconciliation process. Finally, we
learned about the FiberRootNode: a key data structure responsible for
managing the commit phase of the reconciliation process.
Review Questions
Let’s ask ourselves a few questions to test our understanding of the concepts in this chapter:
-
What is React reconciliation?
-
What’s the role of the Fiber data structure?
-
Why do we need two trees?
-
What happens when an application updates?
If we can answer these questions, we should be well on our way to understanding the Fiber reconciler and the reconciliation process in React.
Up Next
In Chapter 5, we’ll look at common questions in React and explore
some advanced patterns. We’ll answer questions around how often to use useMemo and when to use React.lazy. We’ll also explore how to use
useReducer and useContext to manage state in React applications.
See you there!
Get Fluent React now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

