Chapter 1. Orientation
Cross-validation, RMSE, and grid search walk into a bar. The bartender looks up and says, “Who the heck are you?”
That was my attempt at a joke. If you’ve spent any time trying to decipher machine learning jargon, then maybe that made you chuckle. Machine learning as a field is full of technical terms, making it difficult for beginners to get started. One might see things like “deep learning,” “the kernel trick,” “regularization,” “overfitting,” “semi-supervised learning,” “cross-validation,” etc. But what in the world do they mean?
One of the core tasks in building a machine learning model is to evaluate its performance. It’s fundamental, and it’s also really hard. My mentors in machine learning research taught me to ask these questions at the outset of any project: “How can I measure success for this project?” and “How would I know when I’ve succeeded?” These questions allow me to set my goals realistically, so that I know when to stop. Sometimes they prevent me from working on ill-formulated projects where good measurement is vague or infeasible. It’s important to think about evaluation up front.
So how would one measure the success of a machine learning model? How would we know when to stop and call it good? To answer these questions, let’s take a tour of the landscape of machine learning model evaluation.
The Machine Learning Workflow
There are multiple stages in developing a machine learning model for use in a software application. It follows that there are multiple places where one needs to evaluate the model. Roughly speaking, the first phase involves prototyping, where we try out different models to find the best one (model selection). Once we are satisfied with a prototype model, we deploy it into production, where it will go through further testing on live data.1 Figure 1-1 illustrates this workflow.
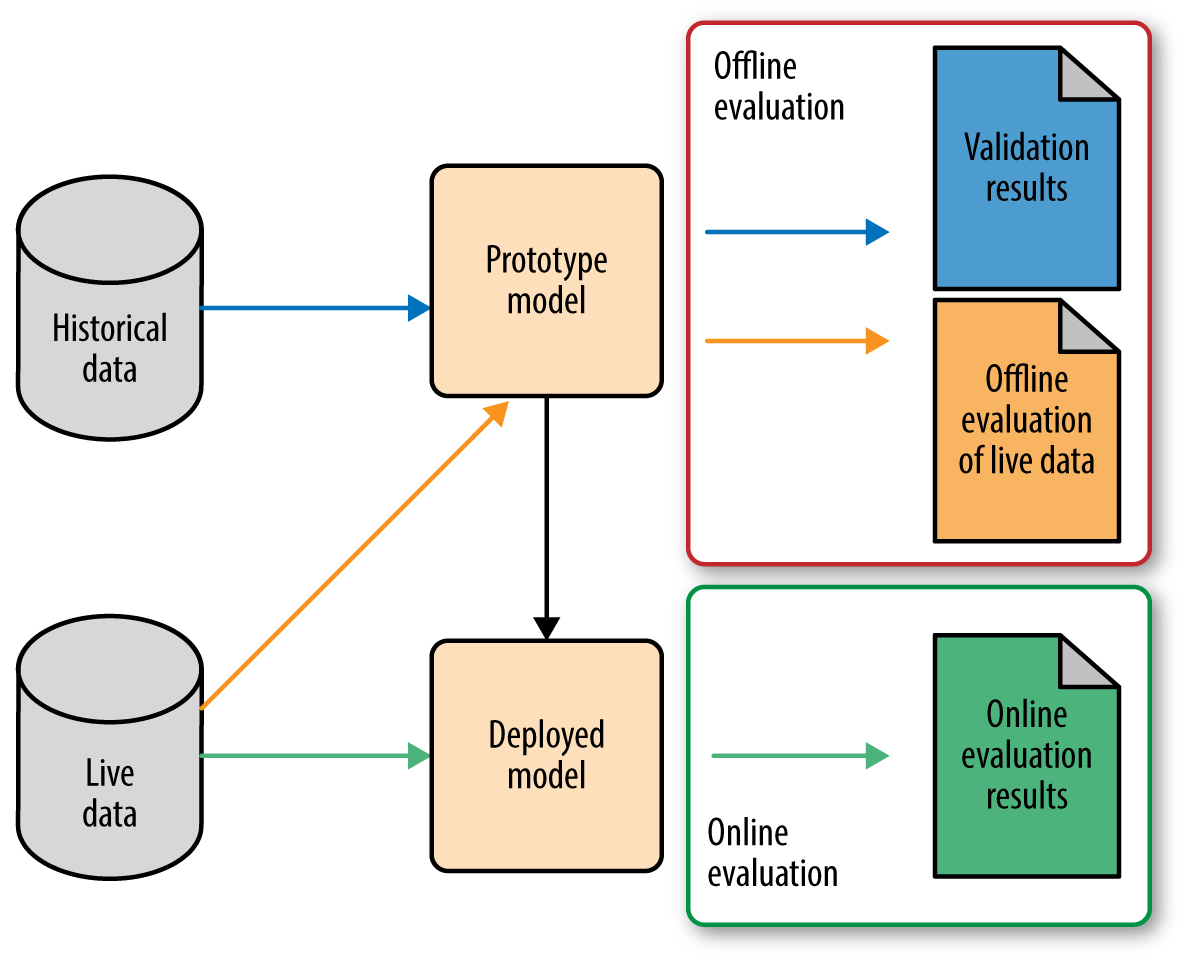
Figure 1-1. Machine learning model development and evaluation workflow
There is not an agreed upon terminology here, but I’ll discuss this workflow in terms of “offline evaluation” and “online evaluation.” Online evaluation measures live metrics of the deployed model on live data; offline evaluation measures offline metrics of the prototyped model on historical data (and sometimes on live data as well).
In other words, it’s complicated. As we can see, there are a lot of colors and boxes and arrows in Figure 1-1.
Why is it so complicated? Two reasons. First of all, note that online and offline evaluations may measure very different metrics. Offline evaluation might use one of the metrics like accuracy or precision-recall, which we discuss in Chapter 2. Furthermore, training and validation might even use different metrics, but that’s an even finer point (see the note in Chapter 2). Online evaluation, on the other hand, might measure business metrics such as customer lifetime value, which may not be available on historical data but are closer to what your business really cares about (more about picking the right metric for online evaluation in Chapter 5).
Secondly, note that there are two sources of data: historical and live. Many statistical models assume that the distribution of data stays the same over time. (The technical term is that the distribution is stationary.) But in practice, the distribution of data changes over time, sometimes drastically. This is called distribution drift. As an example, think about building a recommender for news articles. The trending topics change every day, sometimes every hour; what was popular yesterday may no longer be relevant today. One can imagine the distribution of user preference for news articles changing rapidly over time. Hence it’s important to be able to detect distribution drift and adapt the model accordingly.
One way to detect distribution drift is to continue to track the model’s performance on the validation metric on live data. If the performance is comparable to the validation results when the model was built, then the model still fits the data. When performance starts to degrade, then it’s probable that the distribution of live data has drifted sufficiently from historical data, and it’s time to retrain the model. Monitoring for distribution drift is often done “offline” from the production environment. Hence we are grouping it into offline evaluation.
Evaluation Metrics
Chapter 2 focuses on evaluation metrics. Different machine learning tasks have different performance metrics. If I build a classifier to detect spam emails versus normal emails, then I can use classification performance metrics such as average accuracy, log-loss, and area under the curve (AUC). If I’m trying to predict a numeric score, such as Apple’s daily stock price, then I might consider the root-mean-square error (RMSE). If I am ranking items by relevance to a query submitted to a search engine, then there are ranking losses such as precision-recall (also popular as a classification metric) or normalized discounted cumulative gain (NDCG). These are examples of performance metrics for various tasks.
Offline Evaluation Mechanisms
As alluded to earlier, the main task during the prototyping phase is to select the right model to fit the data. The model must be evaluated on a dataset that’s statistically independent from the one it was trained on. Why? Because its performance on the training set is an overly optimistic estimate of its true performance on new data. The process of training the model has already adapted to the training data. A more fair evaluation would measure the model’s performance on data that it hasn’t yet seen. In statistical terms, this gives an estimate of the generalization error, which measures how well the model generalizes to new data.
So where does one obtain new data? Most of the time, we have just the one dataset we started out with. The statistician’s solution to this problem is to chop it up or resample it and pretend that we have new data.
One way to generate new data is to hold out part of the training set and use it only for evaluation. This is known as hold-out validation. The more general method is known as k-fold cross-validation. There are other, lesser known variants, such as bootstrapping or jackknife resampling. These are all different ways of chopping up or resampling one dataset to simulate new data. Chapter 3 covers offline evaluation and model selection.
Hyperparameter Search
You may have heard of terms like hyperparameter search, auto-tuning (which is just a shorter way of saying hyperparameter search), or grid search (a possible method for hyperparameter search). Where do those terms fit in? To understand hyperparameter search, we have to talk about the difference between a model parameter and a hyperparameter. In brief, model parameters are the knobs that the training algorithm knows how to tweak; they are learned from data. Hyperparameters, on the other hand, are not learned by the training method, but they also need to be tuned. To make this more concrete, say we are building a linear classifier to differentiate between spam and nonspam emails. This means that we are looking for a line in feature space that separates spam from nonspam. The training process determines where that line lies, but it won’t tell us how many features (or words) to use to represent the emails. The line is the model parameter, and the number of features is the hyperparameter.
Hyperparameters can get complicated quickly. Much of the prototyping phase involves iterating between trying out different models, hyperparameters, and features. Searching for the optimal hyperparameter can be a laborious task. This is where search algorithms such as grid search, random search, or smart search come in. These are all search methods that look through hyperparameter space and find good configurations. Hyperparameter tuning is covered in detail in Chapter 4.
Online Testing Mechanisms
Once a satisfactory model is found during the prototyping phase, it can be deployed to production, where it will interact with real users and live data. The online phase has its own testing procedure. The most commonly used form of online testing is A/B testing, which is based on statistical hypothesis testing. The basic concepts may be well known, but there are many pitfalls and challenges in doing it correctly. Chapter 5 goes into a checklist of questions to ask when running an A/B test, so as to avoid some of the pernicious pitfalls.
A less well-known form of online model selection is an algorithm called multiarmed bandits. We’ll take a look at what it is and why it might be a better alternative to A/B tests in some situations.
Without further ado, let’s get started!
1 For the sake of simplicity, we focus on “batch training” and deployment in this report. Online learning is a separate paradigm. An online learning model continuously adapts to incoming data, and it has a different training and evaluation workflow. Addressing it here would further complicate the discussion.
Get Evaluating Machine Learning Models now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

