Chapter 4. Serverless Account Open API
A useful frontend user interface is often backed by transactional services that bring the user experience to life. As you explore the Account Open service, imagine it as part of a complete brokerage platform, which you’ll fully assemble by Chapter 6. A brokerage customer’s goal is to open a new account easily and reliably, so that they can start investing in stocks. Bear in mind that opening new brokerage accounts is a lower volume activity than the higher frequency trading activity that takes place once an account has been opened. In addition, while some accounts can be opened in a straight through processing mode, some require offline steps like proof of identity in a branch location, human approval, or handling of processing or data entry errors. To optimize reliability, the Account Open service is asynchronous and built with AWS serverless services that optimize resource usage and costs.
You can think of the Account Open service as your control plane. It creates the infrastructure, a brokerage account, which a customer needs to trade. Trading is the data plane, it is transactional, real time, and once created no longer has a dependency on the operation of the control plane to operate.
To simplify deployment and resilience test scenarios, this service performs only one business function, persistence to a NoSQL database. In the real world, a brokerage Account Open service would orchestrate a workflow that includes steps like compliance checks, customer validation, legal document generation, document vaulting, and persistence to a trading system of record. After this chapter, you will gain the knowledge needed to extrapolate resilience concepts to more complex serverless and event-driven workflows.
In this chapter, you will deploy and test an asynchronous microservice that reliably opens a new brokerage account on the AvailableTrade application. After deploying a prebuilt solution and test client, you will explore native AWS serverless resilience features and design patterns that help deal with:
-
Handling invalid input
-
Duplicate submissions
-
Queued message processing failures
-
Unanticipated load spikes
-
Poison pills
-
Regional impairment
-
Blue-green code deployments
Working through test scenarios, you’ll learn to mitigate common failure modes by inducing failures and then recovering. You’ll gain a thorough understanding of built-in serverless resilience features as well as design patterns.
Technical Requirements
In almost all web-enabled business scenarios, user-initiated activity begins with an HTTP request to an API. The request is first received by an HTTP listener that forwards the request to a processing component that performs work on request data and then provides a response. We can visualize this as a synchronous request flow (Figure 4-1) where the requestor waits until all processing is complete before receiving a response. A synchronous flow depends on external components to be available and operating within latency constraints to succeed. If there is a failure in any hard dependency, the response cannot be delivered to the customer. An error is returned, and the customer may need to reenter and resubmit the request later when the system is working. That is, if they don’t decide to go to another financial institution and open an account with a competitor instead.

Figure 4-1. A synchronous request flow
Synchronous request/response flows are appropriate for data plane operations. Examples of operations are adding an item to a shopping cart, credit card purchase transactions, or trading stocks. Account openings are typically complex, multistep, and potentially long-running workflows that in some cases have human review or approval activities. In these scenarios, it’s useful to apply asynchronous strategies. You can provide extremely fast API responses by introducing reliable queue-based messaging components that decouple the HTTP forwarder and the processing component. Applying this Fire-and-Forget pattern returns the response to the customer as soon as the request is reliably queued (Figure 4-2).

Figure 4-2. An asynchronous request flow
Then you can apply event-driven architectures to do further work and either use a callback or polling mechanism to notify the customer that the control plane operation is complete, their account is open. When implementing an asynchronous strategy, you’ll need to ensure both highly reliable message capture and success of the offline downstream processes. In addition, simple techniques like endpoint canaries are not enough to ensure the system is online. You’ll need to measure and monitor the end-to-end workflow, including queues, intermediate steps, and completion. Let’s start understanding the architecture and AWS serverless services to achieve a resilient asynchronous API.
Architecture Overview: An AWS Serverless Approach
When you use AWS serverless services, you offload infrastructure management tasks like provisioning capacity, managing servers, operating system (OS) patching, and OS version upgrades. AWS serverless provides ways to run code, store and manipulate data, and integrate applications. In the case of Amazon SQS and AWS Lambda, you can focus on application logic, and let AWS handle dynamically scaling up or down in response to load. For your Account Open use case, serverless is a great choice to optimize costs, simplify development, and build customer trust with a reliable system.
Note
This chapter will help you explore the resiliency responsibilities you can offload to AWS using serverless versus implementing patterns. If you make alternate architectural trade-offs by selecting different services in your design, the same high-level resilience strategies covered in this chapter still apply. However, your level of responsibility will vary depending on your AWS service choices.
Review the logical architecture diagram in Figure 4-3 for an overview of the AWS serverless services you’ll deploy and how data flows through the new Account Open service. Each AWS serverless service is an AWS regional service. As discussed in “AWS Responsibility”, AWS Regions are made up of Availability Zones. Availability Zones can contain one or more data centers. Serverless services spread work across AZs to provide high availability so that you usually don’t need to think about or configure the service beyond choosing an AWS Region. Multizonal high availability is built in.
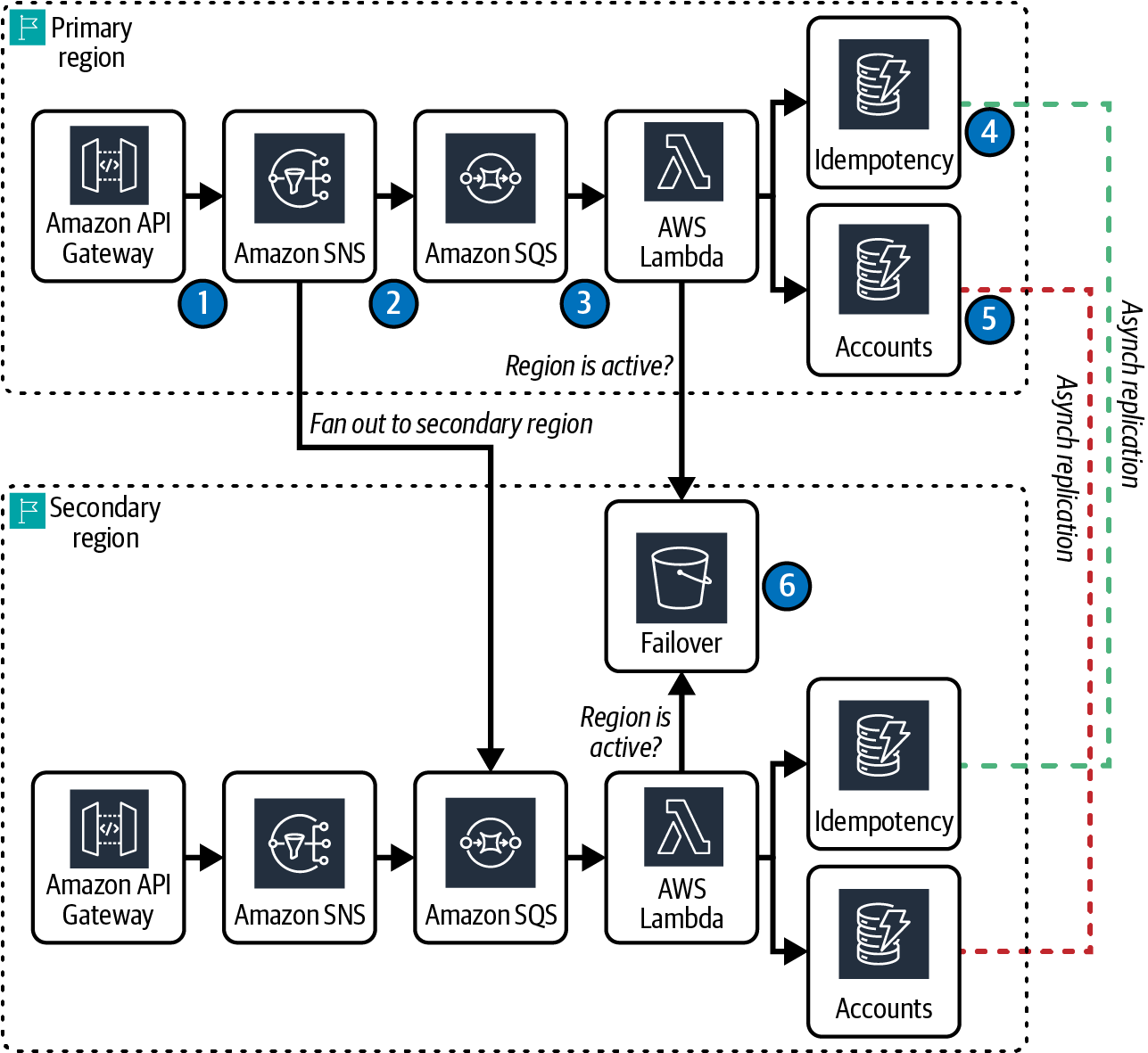
Figure 4-3. New Account Open AWS serverless architecture
The Account Open microservice is invoked with an HTTP request event from a web or mobile client, then passes the event to a queue with a notification. With a valid response from the event notifier, a response is returned to the client, and the message is queued before downstream processes consume it, and the new account record is finally stored in a NoSQL database. After persistence, or any other workflow steps you might build into your system, a customer can be notified that their account is ready. For this exercise, you’ll confirm completion by querying your database and observing metrics:
-
Amazon API Gateway is configured with a REST API that validates the request structure against a JSON schema, then POSTs an event to SNS.
-
Amazon Simple Notification Service (SNS) returns an HTTP 200 code to the API Gateway to confirm message receipt. SNS delivers the new account message out to an Amazon Simple Queue Service (SQS) queue residing both in the active primary AWS Region and in the secondary region.
-
AWS Lambda is configured with an event source mapping (ESM) that polls the SQS queue and runs custom code to process the Account Open message. The autoscaling Lambda adjusts capacity based on queue depth, processes messages, and includes logic to ensure idempotency. Once a new account is created in DynamoDB, the message is deleted from the primary and recovery AWS Region queues.
-
The idempotency feature of Powertools for AWS Lambda ensures that multiple attempts to process the same record result in a single outcome, and always return the same response. Idempotency is managed through an Amazon DynamoDB Global tables persistent store. In this service, the persistent store synchronizes idempotency data across the primary and secondary region. There is additional logic built into the Lambda function to ensure accounts are only processed once and only removed from both regional queues once the account is created successfully.
-
New account records are created in an Amazon DynamoDB global table and are replicated across regions. The table has point-in-time recovery (PITR) backups enabled, so backups are available at per-second granularity for the past 35 days.
-
Site switching is controlled with an indicator file placed in an S3 bucket. The regional Lambda function behaves in active or passive mode according to the indicator.
Deploying the AWS CDK Application
To deploy this application, start by activating your Python virtual environment and setting environment variables for the CDK solution. Be sure that you have reviewed the env.sh file for the primary and secondary regions you’ve selected, and that you have the required permissions and are using the correct AWS account.
Note that the commands in this chapter have been tested on Mac and Linux in the Bash and ZSH shells. Some commands may require slight changes to work on Windows. Ensure you are in the main project directory, AvailableTrade, and run the following commands:
cdAvailableTradesource.venv/bin/activatesourceenv.shcdAvailableTrade/src/account_opencdkdeploy--all--require-approvalnever
The first time you deploy the application, the deployment will run for several minutes as infrastructure is created and the application is deployed. This CDK application deploys two stacks in your primary region, and two stacks in your secondary region. Once deployed, your regional CloudFormation consoles should look like Figures 4-4 and 4-5.
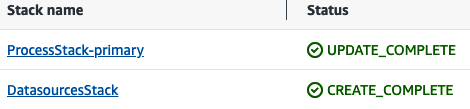
Figure 4-4. Primary AWS Region stacks
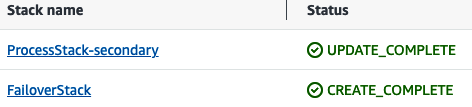
Figure 4-5. Secondary AWS Region stacks
To understand how these stacks are configured, reference the top-level CDK application file, AvailableTrade/src/account_open/app.py. The CDK application orchestrates the stacks, passing configuration inputs to them. The account number, AWS Region names, and credential variables were exported into your local CLI environment from env.sh. Constants are defined for table names that are reused across stacks as they are executed. Before testing the application, it is beneficial to understand the resources that each stack creates, and review how resources are partitioned into different stacks:
- FailoverStack
-
The FailoverStack creates an S3 bucket in the secondary AWS Region that you’ll use to indicate if the app should process requests in the primary or secondary region. Site switching is controlled from the secondary region, so you can be sure you’ll be able to force a switch when the primary AWS Region is impaired.
- DatasourcesStack
-
The DatasourcesStack is installed in the primary region. It configures two global DynamoDB tables: one is the persistent store for Lambda Powertools idempotency and the other is the NoSQL database for brokerage accounts. Global tables are multiactive and replicate changes in either region. DynamoDB replication is asynchronous and can be monitored in CloudWatch metrics under the path All → DynamoDB → ReceivingRegion → ReplicationLatency. It is not uncommon for this latency to be 1–2 seconds, so it is important to consider the implications of eventual consistency on a multi-region workload.
- ProcessStack
-
The ProcessStack is installed in both the primary and secondary regions. This stack builds the data processing for the Account Open API, so the same infrastructure resources are needed in both regions. The resources in the process stack include an API Gateway, an SNS topic, an SQS standard queue with a dead-letter queue (DLQ), and a Lambda function with logic to process requests and interact with SQS, DynamoDB, and S3.
The Lambda function actively processes messages in the active region, while the passive region verifies the results of active region processing before purging messages from the secondary queue.
- New Account service test client
-
Testing is a critical aspect of any modern software application. Many product teams have adopted unit testing practices like test-driven development (TDD) or behavior-driven development (BDD). The testing pyramid, coined by Mike Cohn in his book Succeeding with Agile (Addison-Wesley), helps you rationalize how to balance the amount of unit versus integration versus end-to-end UI testing. Repeatability and speed drive us to automate many of these tests and integrate them with our CI/CD processes. In the resilience world, we learn to apply resilience and chaos engineering where we design and test hypothesis about how our systems handle failure. See Figure 4-6 to understand how resilience fits within the test pyramid.
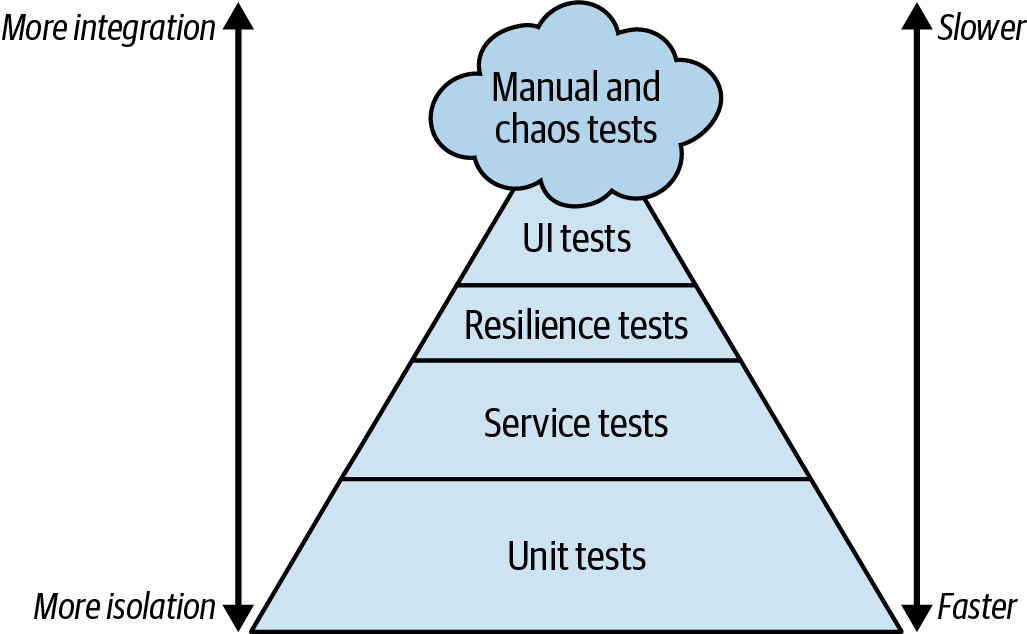
Figure 4-6. Test pyramid with resilience testing and chaos engineering
Resilience and chaos experiments both serve to validate and improve the resilience of your system. Resilience tests are deterministic tests that quickly validate self-healing capabilities of your system; they are similar to service integration tests and should be included in your CI/CD pipelines. Resilience tests are gating, and failures should stop a deployment to ensure your system can be relied on to tolerate faults that have been thought through and validated, either manually or with automation.
Chaos engineering experiments can be more time-consuming and can require research and analysis while the test is running. Due to this exploratory nature, these tests are aligned with the manual tests that reside in the cloud at the top of the pyramid. The name “chaos,” and infamous ideas about chaos testing in production, can scare IT teams and leaders away from giving serious consideration to the importance of chaos engineering. It is perfectly acceptable to perform chaos testing in preproduction environments.
As you design and build mission-critical systems, it’s imperative to reason about the failure modes of the system. Once you have identified potential failure modes, you can improve resiliency by embedding failure mode testing into your change management process.
Many of the scenarios that are validated in the following sections are manual and require you to investigate the deployment and understand how it works. In your real-world systems, the validations can and should be automated and enforced with assertions. The tests that execute quickly can be integrated into CI/CD pipelines, and when more complex, can be scheduled to run as a standalone job once or twice per day.
In the following lessons, you’ll use a command-line client built to assist you with validating resilience engineering scenarios. The following sections outline hands-on scenarios that apply common failure modes and resilience to them. While the set of scenarios is not exhaustive, it covers common scenarios that apply to real-world applications. The scenarios are intended to provide a hands-on foundation for resilience engineering so that you can effectively think about and validate resilience to mitigate failure in your systems. After working through the following lessons, you’ll gain confidence that the serverless applications you build can operate reliably when faced with common failure modes.
Sunny Day Scenario
When thinking about failure and validate failure modes, it goes without saying that you need to first understand your normal modes of operation.
To that end, start with a sunny day scenario that submits a well-formed, successful request.
This will help you get familiar with your application components and behaviors.
You’ll use the provided test client to issue a PUT request to the Account Open service and create a new account.
Once you’ve validated a successful request, you’ll learn where to look to see logs and data so that you can more easily navigate and explore the resilience engineering scenarios that follow.
Review the provided client located at AvailableTrade/src/account_open/tests/onboarding_test_client.py.
You can read the source code, or you can run the client with the -h argument to see the help files that list scenarios the client supports.
At your CLI, run python onboarding_test_client.py -h:
(.venv)>$pythononboarding_test_client.py-h[±main●●●]usage:AccountOpenTestClient[-h]--testTEST[--request_tokenREQUEST_TOKEN][--user_idUSER_ID]TestAccountOpenResiliencyoptionalarguments:-h,--helpshowthishelpmessageandexit--testTESTChooseatesttorun1/Submitavalidrequest.2/Submitainvalidrequestmissingaccount_type.3/Retries-seetext,useCDKdeployments.4/Switchtosecondaryregion.5/Switchbacktoprimary.6/Testloadthrottling.7/Poisonpill,testDLQ.8/Testinrecovery/greenregion.--request_tokenREQUEST_TOKENUsespecifiedrequesttokeninsteadofgeneratingatrandom.Goodforidempotencytesting.--user_idUSER_IDCreateaccountsforspecifieduser_idinsteadofrandomlygeneratingauser_id.
The test client supports both valid and invalid requests. It also supports retries, switching to and back from the primary region, load, and poison pills. The client is a useful way to demonstrate examples, but you’ll want to develop your tests in a standard framework with assertions for your automation.
Time to dive in.
Send a valid request by specifying option value 1 to the --test argument flag.
Note that the --test argument is always required, and the test client will complain if you try to run it without specifying a valid test number.
At your CLI, type the command onboarding_test_client.py --test 1 to produce a valid response:
(.venv)>$pythononboarding_test_client.py--test1<Response[200]>
The HTTP 200 response code confirms your submission was accepted as allowable. This confirms that the API Gateway was able to successfully submit the response to the SNS topic. You need to look deeper to determine if an account has actually been created/opened.
Sign in to your AWS account and navigate to the DynamoDB console → Tables → Explore items.
Here you will find that both of your DynamoDB tables now contain a record.
Make a note of the generated request_token in the brokerage_accounts table because we will use it again in scenario 3.
In the menu bar of the AWS console, select the caret next to your current AWS Region and switch from the primary to the secondary region.
You’ll see that the record is present in the brokerage_accounts table in both AWS Regions because DynamoDB is globally replicating the records.
Refer to Figures 4-7
and 4-8 to see how your idempotency and brokerage_accounts records should look in the DynamoDB console.
If needed, you can run a query and filter by user_id.

Figure 4-7. Idempotency record

Figure 4-8. Brokerage account record
Now navigate to the CloudWatch console and choose LogGroups from the lefthand menu. You will see a number of log groups that have been created with your API deployment and your Lambda function. SQS and SNS logs have not been enabled as they are not needed to debug this application, but logging is supported for both if you need it.
Look for the log group named /aws/apigateway/welcome. If you explore the log stream within this log group, you’ll find a message indicating that logs are enabled for this API Gateway in this region. This log group is enabled when you initially provide API Gateway with a role containing permissions for CloudWatch.
Next, you will see a log group containing a random string of characters specific to your installation (denoted by Xs) called /aws/lambda/ProcessStack-primary-NewAccountXXXXXXXXX-XXXXXXXXX.
This string maps to the generated name for your Lambda function, and the log group contains streams for your Lambda executions.
You can change the log level on your Lambda with the environment variable LOG_LEVEL
defined in the AvailableTrade/src/account_open/stacks/process_stack.py file.
The API-Gateway-Execution-Logs_xxxxxx/prod, followed by the API ID and stage name, contain the request and response details and payloads for each API request. You may not want to log full request/response data in production to protect sensitive data and save space. In lower environments, this log helps to understand the interactions between the API Gateway with the HTTP client and the downstream request to SNS.
Finally, ProcessStack-primary-NewAccountApiLogsXXXXXXXXX-XXXXXXXXX contains API Gateway log entries that contain a single line for each request. These include the timestamp, requesting client IP address, and other high-level request data, including the response code. These logs are similar to web server access logs and are stored in JSON format so that you can query them or create metric filters. From a resilience standpoint, make sure you understand each log from your application so that you can effectively research issues. Being able to research issues in your application effectively helps you reduce your mean time to detect (MTTD) and mean time to recovery (MTTR). Your goal is to reduce MTTD and MTTR, while you increase the mean time between failures (MTBF).
Tip
Learn more in the whitepaper “Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS”.
In your secondary region, there are no API Gateway logs. This is because the test client only sent requests to the primary region. The client should only send requests to the API Gateway endpoint when you perform a regional failover. You’ll explore this further in “STOP: Business Continuity Regional Switchover”.
However, if you inspect the Lambda log streams by changing regions and navigating to the log group /aws/lambda/ProcessStack-secondary-NewAccountXXXXXXXXX-XXXXXXXXX, observe that the Lambda function was invoked in the secondary region. When your SNS topic received a message from the primary API Gateway, the subscriptions pushed messages to your SQS queue in both regions, and each corresponding regional Lambda function consumed them. Review the log messages to see that the recovery AWS Region function waited until the brokerage_accounts record had been replicated to the recovery AWS Region brokerage_accounts table. Then it safely purged the message from the secondary region queue. This wait-for-success approach ensures that if the primary AWS Region fails to process a message, the message will be available in the secondary region. If enough time passes, the message may have been moved to the DLQ, but it will be available for redrive in the case of a site switch recovery strategy. There’s more on this in “Self-Healing with Message Queue Retries”.
Tip
You won’t run out of storage for logs in the cloud, but you will accrue costs for log storage. Set a reasonable retention period for log groups in both regions. I’ve set mine to 5 days to avoid clutter and log storage charges.
In a production environment, you should configure a retention that supports both your business data retention requirements and operational support needs.
Explore the log statements of your Lambda processing logs in CloudWatch in both regions to see the log statements from the function execution. With this multi-region queue, your application needs the intelligence to handle a single request idempotent across regions.
In the active region, your primary, the Lambda ESM for SQS, polls for and pulls a message from the queue, sets the visibility timeout, and if it is the first to process it, creates a new account. If another Lambda is also processing the message, an idempotent response is returned; then the function execution exits.
Warning
By default, when Lambda encounters an error during a batch, all messages in that batch become visible in the queue again after the visibility timeout expires. Batch item failure is enabled in the Account Open service to address this. Lambda event source mappings still process messages “at least once,” and duplicate processing of records can still occur; so you must make your code idempotent. Learn more in the public documentation for “Using Lambda with Amazon SQS”.
Review the log events shown in Figure 4-9 where the current AWS Region is active.
The message is processed and finally stored in the brokerage_accounts table.
With successful account creation, the function publishes a custom CloudWatch metric NewAccountOpened,
a business-centric service-level indicator (SLI).
On the last line in Figure 4-9, you’ll see the CloudWatch embedded metric format (EMF),
which is used by default with Lambda Powertools.
The EMF allows you to generate custom metrics asynchronously in the form of logs,
allowing you to query and find detailed log event data for deeper insights.
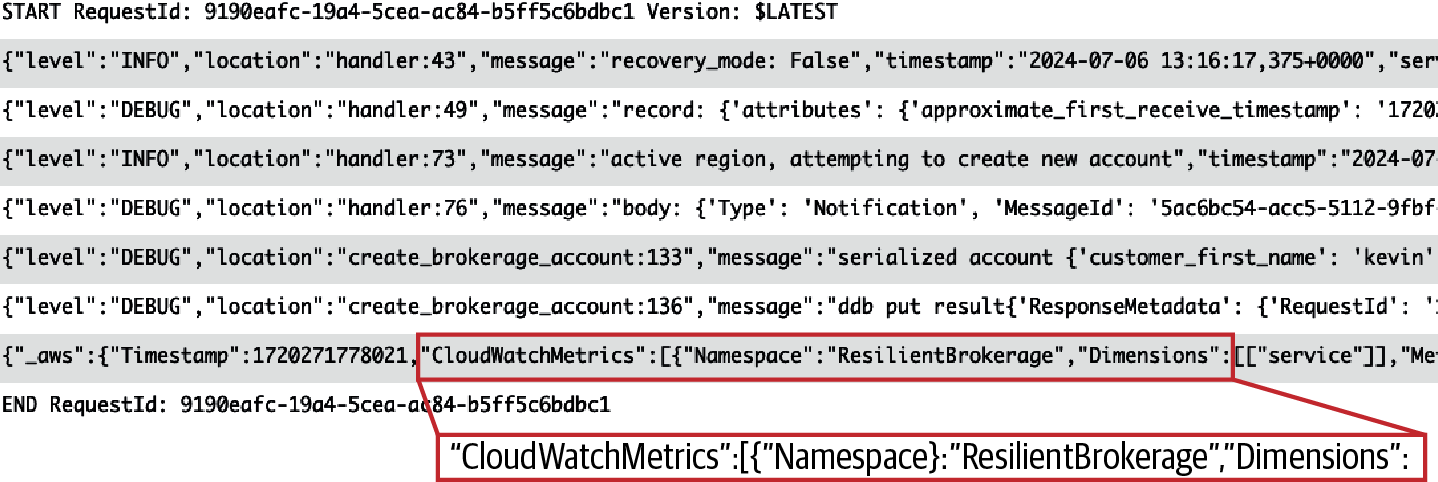
Figure 4-9. Active AWS Region successful processing logs
In the recovery AWS Region while in recovery mode, the message is still processed by Lambda, but it does not create a new account.
The recovery mode is read, observed as False, and the Lambda knows it is in the secondary region.
The function code skips the create_brokerage_account method, which is wrapped with an idempotency check, and instead checks for a record in the brokerage_accounts table.
It looks this record up using the global secondary index which does not require an account account_id.
Instead, it searches based on user_id and request_token, which are values in the unprocessed request.
Once the record is found, the secondary region Lambda will purge the message from the queue, as reflected in Figure 4-10.
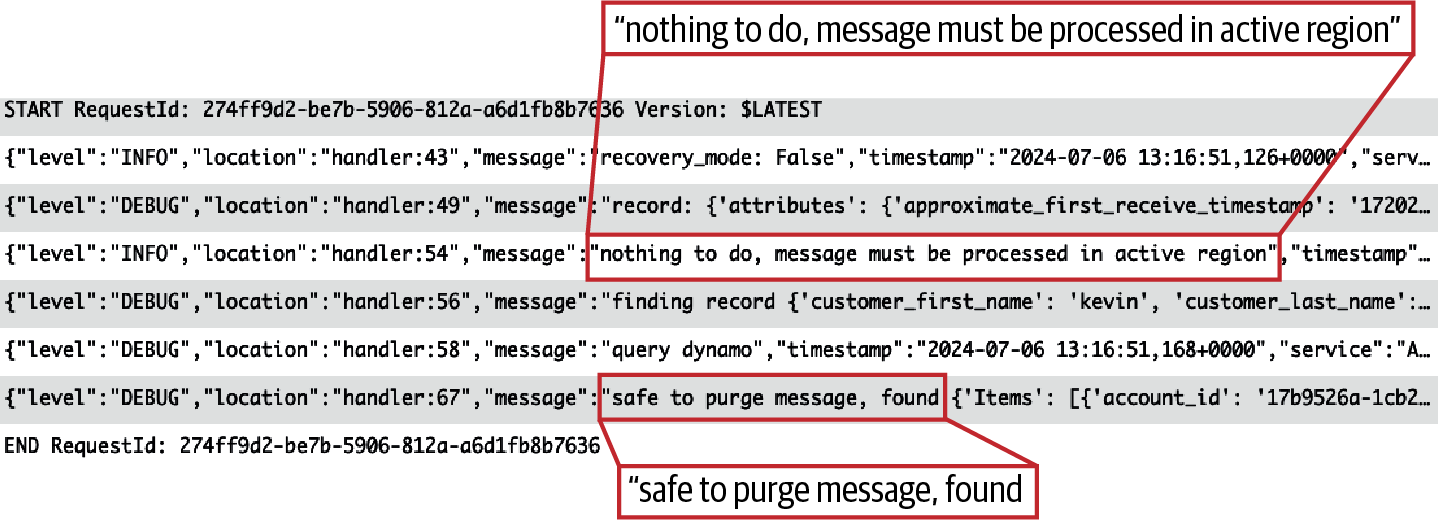
Figure 4-10. Recovery AWS Region successful processing logs
Congratulations. You’ve successfully followed a request moving through the Account Open system components. You learned about the logs emitted by different components of this system, and how active and recovery modes drive processing in the Lambda function. You are now ready to work through failure scenarios and recovery mechanisms.
Strongly Typed Service Contracts
One of the easiest ways to make a request fail to process is by inputting invalid data. This aligns to the adage “garbage in, garbage out.” The type of failure illustrated in this scenario is from incomplete or poorly formed requests due to invalid data. One of the simplest ways to be resilient to invalid input is to block it at the front door. A well-defined API interface will reject nonconforming requests up front with an HTTP error.
In API Gateway we use JSON Schema. This approach is simple, declarative, and stops requests that are not well-formed up front, even if UI validation did not require a correct value. In the process stack, a JSON Schema is configured for the API Gateway request model and then attached to the REST API for new accounts. This schema enforces the structure of the payload body, field data types, and the presence of required fields. If an incoming request does not confirm to the schema validation, the API returns an HTTP 400 code indicating a bad request.
To validate this scenario, at your CLI run python onboarding_test_client.py
--test 2 to send an invalid request.
This request is missing the required account_type field, and you see a 400 error when you run the test:
(.venv)>$pythononboarding_test_client.py--test2<Response[400]>
This request was rejected at the API layer before it could reach SNS and the SQS queues. The approach quickly informs the calling client of a bad request. It also avoids consuming application resources with work that is destined to fail. This work would otherwise backlog your queues, increase costs, and needlessly consume compute resources that could otherwise complete valid work. In your primary region, you can compare the API Gateway execution logs under the log group API-Gateway-Execution-Logs_xxxxxx/prod to see how a valid API request confirms delivery to SNS in Figure 4-11, as opposed to an invalid request rejected by the API validator in Figure 4-12.
A valid 200 response requires that API Gateway was able to transmit a message to SNS and receive a 200 from SNS. This asynchronous response success code confirms the message reached the SNS queue, but provides no insight into downstream processing. The important feedback to the customer relies on the fact that the message has been durably captured by your backend, and Account Open work will begin. API Gateway returns a 200 response to the client.
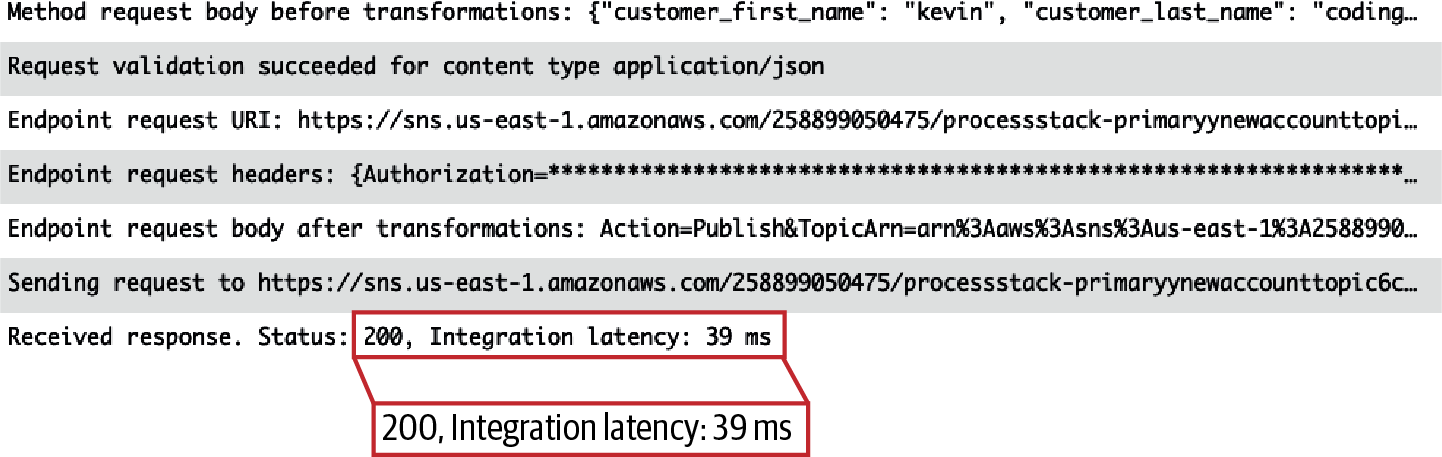
Figure 4-11. A valid API request confirms delivery to SNS
On the other hand, you can see a 400 returned with a validation reason, missing the account type, when the request does not adhere to the JSON schema. API Gateway does not make a call to SNS in this case; the request is immediately rejected.
Tip
You can learn more about how the best practice of providing service contracts per API improves resilience by visiting the AWS resilience Well-Architected whitepaper “Provide Service Contracts Per API”.
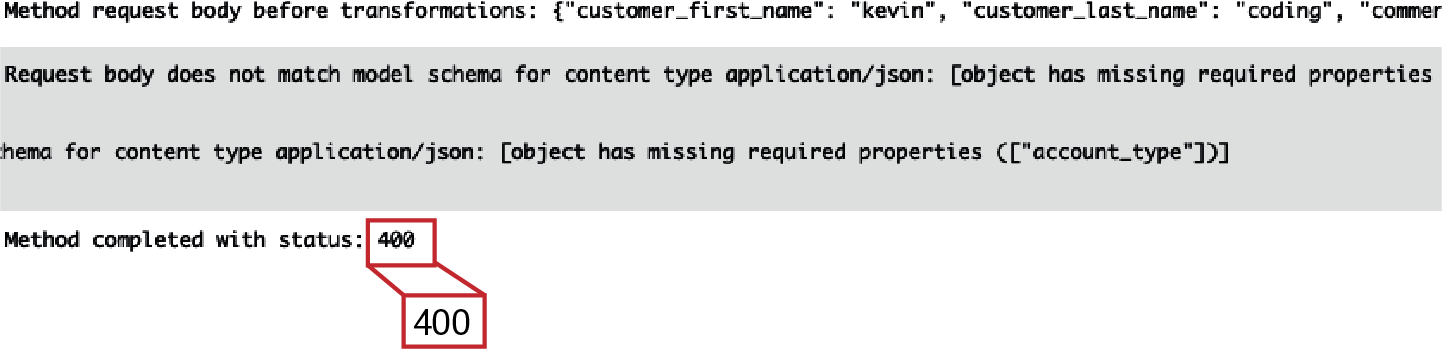
Figure 4-12. An invalid API request is rejected by the request validator
Idempotent Responses
When customers place web requests for new accounts or stock purchases, they expect to receive a single account or single charge. Multiple accounts being opened could result in customer frustration and confusion, or worse yet an overcharge. A duplicated outcome impacts a company’s reputation and needs to be avoided; therefore, responses need to be idempotent. A service that creates a single and repeatable outcome, even when the same request is submitted multiple times, demonstrates idempotency or is idempotent. The Account Open microservice can be relied on to return the same result even if the same call is made multiple times within the idempotency period.
Tip
You can learn how the best practice of making all responses idempotent improves resilience by visiting the AWS resilience Well-Architected whitepaper “Make All Responses Idempotent”.
In the process stack, the API for creating new accounts is configured to respond to HTTP PUT requests.
Using PUT communicates to API consumers that they should expect an idempotent outcome as defined in the HTTP specification that outlines the HTTP safe verbs.
It is important to be aware that a standard SQS queue guarantees at least once processing;
however, it could send a message to a consumer more than once.
An SQS FIFO queue supports exactly once processing, and the best effort ordering of a standard queue is acceptable;
a standard queue has been selected in this use case because the standard queue API calls are priced slightly less.
In addition, retries on the client side might send the same request more than once if they receive an error on a first request.
Client-side duplicate submissions are problematic and arise in scenarios where a service accepts and processes a request, but a network-related or other rare glitch causes a response failure prompting a client to retry.
The idempotent implementation in this application relies on a client assigning a universally unique identifier (UUID) for the request_token field of the request payload.
In the AvailableTrade/src/account_open/functions/new_account.py file, the Lambda Powertools idempotency library is used, along with custom logic for handling our multi-region design to enforce idempotency in and across regions.
In this implementation, the Powertools idempotency logic is exercised in the currently active AWS Region as follows.
First, the IdempotencyConfig for Powertools is made aware that it should check the
request_token to identify a unique request, as shown in the following code:
persistence_store=DynamoDBPersistenceLayer(table_name=idempotency_table)config=IdempotencyConfig(event_key_jmespath="request_token",expires_after_seconds=60*60*3)
When a message is processed, Powertools maintains and verifies request processing state in the idempotency table in DynamoDB for an entry with a matching request_token.
If found, the cached prior response is returned,
skipping execution of the idempotent create_brokerage_account function, as shown in the following code snippet. The idempotency expires_after_seconds lasts for 3 hours,
or 60 * 60 * 3 seconds, by setting a DynamoDB time-to-live (TTL) on the record:
@idempotent_function(data_keyword_argument='account_event',config=config,persistence_store=persistence_store,output_serializer=DataclassSerializer)defcreate_brokerage_account(account_event:dict)->Account:
It is important to recognize that due to the eventual consistency of cross-region database synchronization, idempotency is only reliable within a region.
You should include the DynamoDB ReplicationLatency and PendingReplicationCount metrics explained in monitoring global tables as part of your observability strategy for global tables.
Tip
You can learn more about capabilities provided by Lambda Powertools, including idempotency, logging, custom metrics, and event sources. Each of these features is used in the Account Open Lambda function of this application.
To validate the idempotency of the service, send a request that reuses an already used request_token.
First, run the client with the test argument of 1, which tells the service to send a valid request.
In this case, you will provide a predefined request_token, and the client will use your existing value instead of generating a new UUID.
The code will not publish an additional increment to the NewAccountOpened metric, as it skips the create_brokerage_account execution to achieve idempotency.
As you can see in the following command sample, a 200 success response is returned:
(.venv)>$pythononboarding_test_client.py--test1\--request_token<replace_with_your_token><Response[200]>
Once the request is processed, validate that the record has not been duplicated in DynamoDB.
You can also inspect the CloudWatch logs to see that log statements from the create_brokerage_account function were not emitted into the logs during function execution.
You can also validate this in the AWS DynamoDB console, or with this CLI query:
>$awsdynamodbquery--table-namebrokerage_accounts\--index-nameuser_request\--key-condition-expression"user_id = :u AND request_token = :r"\--expression-attribute-values\'{":u":{"S":"user169"}, ":r":{"S":"b267cc11-90df-426f-bd22-d9e0090d341a"} }'\--projection-expression"id"--region$AWS_PRIMARY_REGION|jq.Count1
Be sure to replace :u and :r values in the expression-attribute-values parameter with the values from your request.
The output should be 1, as shown on the last line;
a duplicate account was not created as long as you tried the second account within 3 hours of creating the first.
Self-Healing with Message Queue Retries
Impairments to the Lambda function of the Account Open service could cause processing of Account Open requests to fail. Impairments can come in the form of a code or configuration error, or even a cloud service impairment. If a failed request is not retried with success, a customer will not receive the account they applied for, or feedback about why it may not have been possible to open the account. Failing to open a requested account is a sure way to lose business.
When you use SQS as the event trigger for your Lambda function, you can configure built-in retry capabilities. Set the max_receive_count to the number or times a message should be retried when code or throttling issues cause message processing to fail. As failures necessitate retries, the likelihood of success improves when you provide small but increasing windows of time between retries for the system to recover.
This is called retrying with backoff.
The Lambda documentation explains the backoff strategy for message queue retries.
In this lesson, you’ll create a failure in Lambda, forcing SQS messages to be retried.
You configure Lambda retries by setting the visibilityTimeout which controls how long a message is invisible in a queue while a consumer, the Lambda function, processes it.
In the case of the Account Open service, messages are read off the queue in batches to improve throughput.
For batch processing, batch item failure reporting allows you to report partial success when processing queued messages in batches of up to 10 instead of failing an entire batch.
For SQS, the Lambda best practice is to set the visibilityTimeout to 6 times the Lambda function
timeout when report_batch_item_failures is set to True.
You can see the Lambda event source mapping configuration for SQS in the following lines from the process stack:
self.queue=sqs.Queue(self,"NewAccountQueue",dead_letter_queue=dead_letter_queue,encryption=sqs.QueueEncryption.UNENCRYPTED,visibility_timeout=cdk.Duration.seconds(6*function_timeout_seconds))...self.new_account_function.add_event_source(eventsources.SqsEventSource(self.queue,batch_size=10,max_concurrency=15,report_batch_item_failures=True,max_batching_window=cdk.Duration.seconds(1)))
Batching requires your Lambda function to format the SQS batch response as a list of any failed SQS message IDs.
These messages will not be purged from the queue like the successful ones are, and they will be retried once the visibilityTimeout expires and the ESM poller finds them in the queue again.
The following code shows a try/except collecting message IDs for failures:
batch_item_failures=[]sqs_batch_response={}ifactive_in_recoveryorpassive_in_primary:# don't process, code omitted from example else:forrecordinevent.records:try:body=json.loads(record["body"])account:Account=create_brokerage_account(account_event=json.loads(body['Message']))exceptExceptionasexc:batch_item_failures.append({"itemIdentifier":record.message_id})sqs_batch_response["batchItemFailures"]=batch_item_failuresreturnsqs_batch_response
To run this test scenario, temporarily introduce a failure into the Lambda function code in the active primary region.
Open the file AvailableTrade/src/account_open/functions/new_account.py in your editor.
Locate this code block within the body of the for loop that processes new account records:
try:# raise Exception("kaboom!!!") # forced failurelogger.debug(f'body:{body}')account:Account=create_brokerage_account(account_event=message)
Uncomment the raise Exception line by removing the leading # which will force a failure for any Account Open. In a real-world impairment, you’ll need observability in the form of metrics and alarms to drive your decision. Your code should now look like this:
try:raiseException("kaboom!!!")# forced failurelogger.debug(f'body:{body}')account:Account=create_brokerage_account(account_event=message)
Save your changes and deploy the updated function code to the primary region
by running the command cdk deploy ProcessStack-primary.
Make sure you are in the AvailableTrade/src/account_open directory
to run the CDK commands, and in AvailableTrade/src/account_open/tests when you run tests.
Using two shells can simplify this.
Once the deployment is complete, run a valid account scenario with your test client by executing python onboarding_test_client.py --test 1.
Check your CloudWatch logs, and you should see errors with the text Arguments: (Exception("kaboom!!!").
Query your SQS queue to verify that there is a message retained in the queue.
The queue attribute ApproximateNumberOfMessagesNotVisible displays the count of messages currently invisible.
Messages remain invisible and are skipped by ESM polling for the duration of the visibility timeout, 30 seconds in this application.
You can run this CLI command to verify the value of ApproximateNumberOfMessagesNotVisible:
exportqueue_url=$(\awssqslist-queues--regionus-east-2|jq-r'.QueueUrls[1]')awssqsget-queue-attributes--attribute-names\ApproximateNumberOfMessagesNotVisible--region$AWS_PRIMARY_REGION\--queue-url$queue_url|jq.Attributes.ApproximateNumberOfMessagesNotVisible"1"
In your logs you’ll also see log lines indicating repeated failures as the message is being retried.
Now, replace the # to comment out the forced failure in your function code, then save and redeploy with cdk deploy ProcessStack-primary.
Once the updated code is in place, the message will be picked up and processed successfully.
Rerun the CLI command as follows to verify that ApproximateNumberOfMessagesNotVisible is now 0, and you can check your logs to validate processing success:
awssqsget-queue-attributes\--attribute-namesApproximateNumberOfMessagesNotVisible\--region$AWS_PRIMARY_REGION--queue-url$queue_url\|jq.Attributes.ApproximateNumberOfMessagesNotVisible"0"
Recall that following best practices, the visibility timeout is set to 6 times the Lambda function timeout of 5 seconds which is 30 seconds.
You’ll have a window of 7–8 minutes of backing off with retries to fix and redeploy your code during this lesson.
After this, Lambda will stop retrying your message and move it to the DLQ, causing false negatives when you check the queue for invisible messages.
If a message does move to the DLQ, you can use dead-letter queue redrive to push it back to the main queue after deploying your fixed code to complete your test.
Rate Limiting: Throttle Unanticipated Load
Turn up the heat and attempt to stress your application with a burst of higher traffic rates than planned for. Spikes in traffic may originate from valid sources like a marketing promotion or news coverage, generating increased interest. Alternatively, traffic spikes can originate from nefarious sources like bot farms, scammers creating fake accounts for fraudulent purposes, or distributed denial of service attacks.
When websites experience sudden bursts of unanticipated traffic, that traffic can rapidly consume and exhaust resources. This can cause an application to fail, or in the case of serverless cloud applications, scale out and run up costs. Amazon API Gateway has account-level quotas, per region, for requests per second (RPS). Setting throttle limits on a per API or API stage basis ensures that a single API cannot consume the account-level quota, impacting other APIs in the account.
A variety of approaches are used to shed unauthentic traffic. For example, you could use a captcha or a web application firewall (WAF) with rules to block robots and rate-limit IPs originating high volumes of traffic, as demonstrated in Chapter 3. Another load-shedding mitigation technique is API Gateway request throttling. Throttling is a practice where requests are counted against planned-for capacity. If the planned capacity is exceeded, a burst over capacity may be absorbed for a short time, but ultimately, overcapacity traffic will be rejected.
In this application, the throttle rate is set to 100 concurrent requests with a throttle burst rate of 25. API Gateway uses a token bucket algorithm to implement throttling. See Figure 4-13 which illustrates how each request takes a token from the bucket while tokens are refilled at the throttle rate per second.
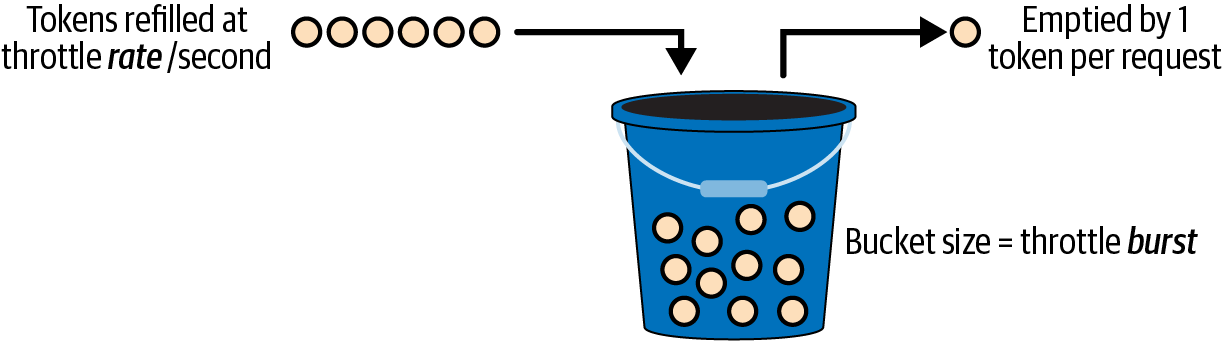
Figure 4-13. Tokens are refilled at the throttle rate
If the bucket is emptied faster than it is filled, requests will be throttled once the bucket is empty. As traffic subsides, the bucket fills up again.
Tip
You can learn more about how to apply the throttle request best practice to improve your resilience by visiting the AWS resilience Well-Architected whitepaper “Throttle requests”.
To run this scenario, first, confirm that your primary AWS Region is active by issuing a switch to the primary AWS Region with your test client:
(.venv)>$pythononboarding_test_client.py--test5PrimaryAWSregionisalreadyactive
The load test prepared for this workload runs an Artillery.io scenario. There are many options for load testing tools. AWS provides a ready-to-use solution that relies on Taurus. Taurus helps you automate common open source testing tools (Apache JMeter, Selenium, Gatling, and many others), and once deployed to Amazon Elastic Container Service (ECS) on Fargate, supports large-scale distributed test automation. Artillery was selected for this lesson because of the ease of use for small-scale local CLI testing.
If you haven’t already installed Artillery with npm, do it now by running the command npm install -g artillery@latest.
Once installed, you can confirm your installation with the --version flag, as follows:
> $ artillery --version
___ __ _ ____
_____/ | _____/ /_(_) / /__ _______ __ ___
/____/ /| | / ___/ __/ / / / _ \/ ___/ / / /____/
/____/ ___ |/ / / /_/ / / / __/ / / /_/ /____/
/_/ |_/_/ \__/_/_/_/\___/_/ \__ /
/____/
VERSION INFO:
Artillery: 2.0.16
Node.js: v22.3.0
OS: darwin
Open the file AvailableTrade/src/account_open/tests/new-account-load-test.yml and review the configuration. This is a simple test inspired by the Artillery.io first test example. The test runs three phases of load, including warm-up for initial scaling, ramp-up to steady state, and finally a spike phase. Load phases are defined in the config phase of the YAML file.
The scenario phase executes HTTP PUT requests against the Account Open service endpoint with a valid payload.
Built-in random number generators are used for creating mostly unique user_id and reqeust_token pairs.
Overlap is OK for this test, so these random generators suffice and keep the test simple to create and maintain.
For more rigorous tests, you can extend Artillery by adding UUID generators or other customizations you may need either with existing plug-ins or by writing your own.
To run this test, you’ll issue the artillery run command and provide the YAML configuration file as a parameter via the test client: python onboarding_test_client.py --test 4.
The test client will capture the URL of your service in the primary AWS Region and pass it to Artillery, which will then run your test scenario through the traffic phases:
eliftest=='6':command="artillery run account-load-test.yml --variables '{\"url\":\"{url}\"}'".replace("{url}",get_url())(command)os.system(command)
Rather than focus on the details of interpreting Artillery output, instead we’ll dive into how the Account Open service behaves.
When API Gateway throttles requests, it returns HTTP 429 Too Many Requests errors.
In a production system, it is a good idea to configure a metric over the API Gateway access logs on 429 errors, and monitor with alerting on throttle breaches so you can handle them appropriately.
Navigate to the CloudWatch Logs Insights console in your primary region.
Choose the ProcessStack-primary-NewAccountApiLogsXXXXXXXXX-XXXXXXXXX, then paste in and run the following query.
Your output should look like Figure 4-14.
filter @message like /429/
| stats count(*) as rateLimitCount by bin(15s)
| sort rateLimitCount desc
CloudWatch Logs Insights enables you to query logs with SQL-like syntax to retrieve by keywords or field values, perform aggregation, and sort output. The results of the load test are shown in Figure 4-15, grouped by increments of 15 seconds. You can see how the throttles increase as load increases, and then finally clear out as the token bucket is refilled when traffic subsides. This test ran for about 3 minutes.
Figure 4-14. Run a CloudWatch Logs Insights query
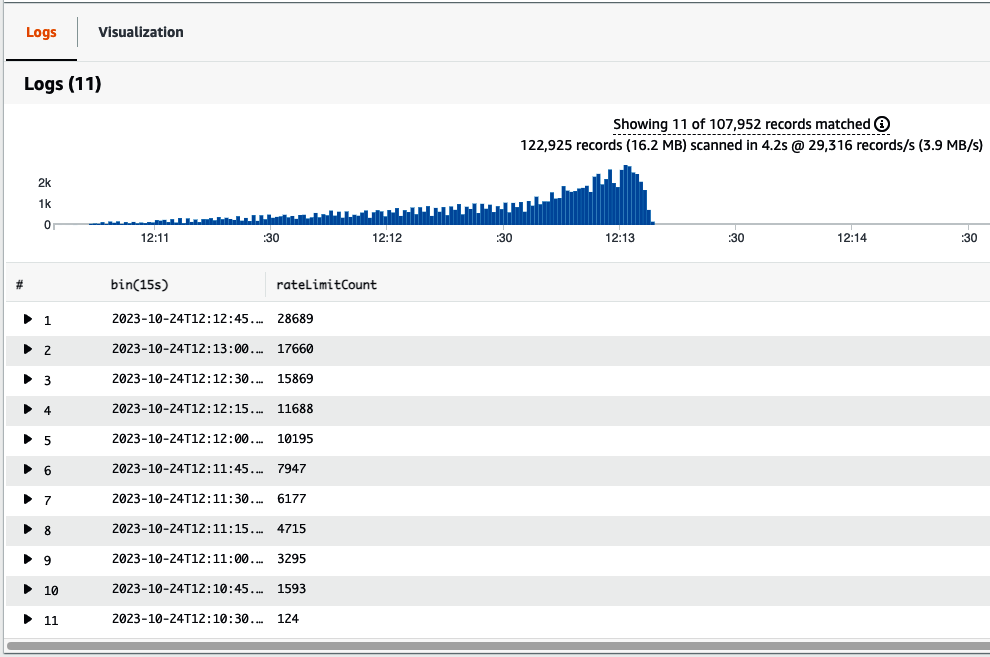
Figure 4-15. Access logs 429 throttling results
When running your analysis on logs to research errors, be aware that access logs have the least data—one line per request. It is less expensive to scan and query these logs than scan the contents of the API Gateway execution logs that include validation, request, response, and integration details. CloudWatch Insights queries are billed by the amount of data scanned. Monitor access log HTTP response codes for common API Gateway errors that reject requests like 403 and 429. For more complex errors that can happen in your Lambda function, monitor your application logs.
Finally, take notice of the queue metrics shown in Figure 4-16, a screenshot of the SQS monitoring tab. You’ll see that as traffic ramped up, messages started to back up in the Account Open queue.
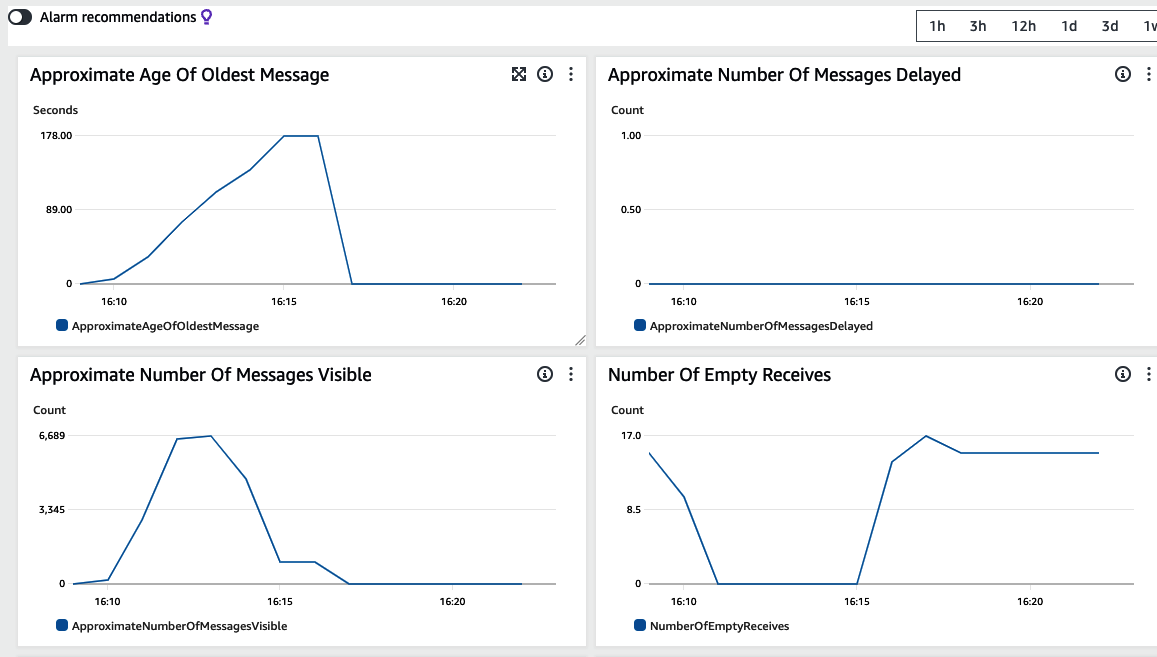
Figure 4-16. SQS load tests backlogging
The speed at which Lambda consumes this backlog is proportionate to the max number of concurrent Lambdas.
The max_concurrency is configured in the event source mapping for SQS, and in this application it is set to 15.
The max_concurrency limits Lambda queue consumption to 15 concurrent executions:
self.new_account_function.add_event_source(eventsources.SqsEventSource(self.queue,batch_size=10,max_concurrency=15,report_batch_item_failures=True,max_batching_window=cdk.Duration.seconds(1)))
In this type of architecture, you can experiment with throttle limits and concurrency to understand how your system will perform under load. How quickly you scale and consume the messages often depends on the amount of account concurrency you need to reserve for other Lambda functions servicing other operations. Consider whether your queues can face backlog situations like those demonstrated here, and think about what you’d do to handle a large queue backlog. You just learned how to shed requests based on an API Gateway throttle; other options include bounding your queue length, shedding requests once the queue grows to a certain length, or creating and moving messages to a sideline queue. With a sideline queue, new inbound work is not held up behind a backlog.
Surviving a Poison Pill
In messaging systems, a poison pill is a message that cannot be processed due to a code defect or invalid data that causes processing failure. The effect of this could be Lambda execution failure if the payload causes an unhandled exception. Lambda execution failures that cause repeated message retries can result in reduced servicing of valid requests and increased Lambda billing costs, with no productive work being completed. If too many erroneous messages occur, and they continue to pile up, they will begin to consume your Lambda concurrency. Too many poison pills can cause queues to backlog, and account delivery to customers can be delayed. Based on the size of the backlog and resulting latency, the reputation of your business can be affected.
If ordering is important, and you use a FIFO queue, this problem becomes acute more quickly. Fortunately, the Account Open service does not require strict ordering. The poison pill scenario where invalid messages get stuck in a queue can be partially mitigated with a dead-letter queue (DLQ). In SQS a DLQ is not a default, but if you configure one, SQS will move poisoned messages that cannot be processed into another queue.
In this test, processing of your test request will pass API Gateway validation,
but will fail in Lambda execution because it’s missing the required beneficiaries list.
The beneficiaries list was not defined as required in your JSON schema,
but it is required in the Python dataclasses code
running in your Lambda that serializes content into JSON,
then saves the JSON data to DynamoDB.
Test number 5 issues the poison pill.
To get started run python onboarding_test_client.py --test 5 to issue a PUT request.
This message will propagate from SNS to SQS, but the Lambda execution fails when processing the message.
Looking into the CloudWatch log group /aws/lambda/ProcessStack-primary- NewAccountXXXXXXXXX-XXXXXXXXX for the Lambda function, you’ll see stack traces with this error text: TypeError("__init__() missing 1 required positional argument: 'beneficiaries'").
The message will be retried until the configured three attempts, as specified in the DLQ’s max_receive_count, are exhausted, and then it will be moved to a DLQ.
This is defined in the process stack, as shown in the following code snippet:
dead_letter_queue=sqs.DeadLetterQueue(max_receive_count=3,queue=dlq)
After a few moments, you’ll be able to see the poison pill message moved to the DLQ. Once retries have expired, you can run the following command to verify the message in the DLQ, or you can validate this by looking into the SQS console. If the message has not yet been moved to the DLQ, the command will output 0:
exportqueue_url=$(awssqslist-queues--regionus-east-2|\jq-r'.QueueUrls[0]')awssqsget-queue-attributes--attribute-namesApproximateNumberOfMessages\--region$AWS_PRIMARY_REGION--queue-url$queue_url\|jq.Attributes.ApproximateNumberOfMessages"1"
You just learned how consuming messages from SQS with Lambda and a DLQ allows your system to sideline poison pills, either due to message content or code defects, to a DLQ. Without a Lambda and using the SQS SDK clients, it is more challenging to deal with poison pills. Lambda’s ability to scale and batch messages with the ESM simplify this resilience pattern. Instead of backing up your queue, poison pill messages are preserved for operational research, after which they can be addressed.
As an operational process for your system, you can:
-
Fix the message contents and resubmit using the SQS API.
-
Discard it from the queue by purging it.
-
Update your code and redrive messages, which pushes the message back into the main queue.
A redrive on this lesson’s test messages will fail again due to missing beneficiaries, so it can be purged. A redrive is often more suited to address reprocessing of intermittent errors, like a bad code deployment that was subsequently rolled back.
STOP: Business Continuity Regional Switchover
During the rare event that you are unable to open new accounts in the primary region, you can maintain business continuity by switching your application to the secondary region. A switchover can be necessitated in the unusual event that an AWS serverless service like Lambda suffers a temporary impairment. More commonly, a switchover is performed during continuity testing, or in response to a failure event that is not easily understood or quickly rolled back due to code or configuration changes to be able to achieve a bounded recovery.
In this lesson, to emulate a regional outage, you will temporarily break your Lambda function again, and again only in the primary region.
Open the file AvailableTrade/src/account_open/functions/new_account.py in your editor.
Once again, locate this code block within the body of the for loop that processes Account Open records:
try:# raise Exception("kaboom!!!") # forced failurelogger.debug(f'body:{body}')account:Account=create_brokerage_account(account_event=message)
Uncomment the raise Exception line by removing the leading #, and save your changes. In a real-world impairment, you’ll need observability in the form of metrics and alarms to drive your decision.
You can see in the except clause that Account Open failures are tracked with a metric that you can use to send an alarm to your support team.
Your code should now look like this (the except block did not change):
try:raiseException("kaboom!!!")# forced failurelogger.debug(f'body:{body}')account:Account=create_brokerage_account(account_event=message)exceptExceptionasexc:logger.error('failed to create account',exc)batch_item_failures.append({"itemIdentifier":record.message_id})metrics.add_metric(name="NewAccountFailure",unit=MetricUnit.Count,value=1)
Now, deploy the process stack in the primary AWS Region by running the command cdk deploy ProcessStack-primary and then push a new request with python onboarding_test_client.py --test 1.
The Lambda function code will fail and begin the process of retrying.
If you are observing logs in CloudWatch, you’ll see the following log error lines in your primary AWS Region log:
Exception: kaboom!!! ... Message: 'failed to create account'
Instead of fixing the code this time, you’ll recover by switching regions. You can issue a site switch by running test 6 with your test client:
(.venv)>$pythononboarding_test_client.py--test6failover-bucket-us-west-1-998541053034Switchedtosecondaryregion
This command will upload the AvailableTrade/src/account_open/tests/failures.txt file to your recovery AWS Region failover S3 bucket, as well as emit the bucket name and a message confirming switchover. Look into your S3 bucket to confirm the placement of the indicator file. To list files in the bucket with your CLI, use the following command or validate in the S3 console:
>$awss3lsfailover-bucket-$AWS_SECONDARY_REGION-$AWS_ACCOUNT_ID2023-10-2115:41:23103failover.txt
As the Lambda function processes each message in a batch, it checks for the presence of the failover.txt file to determine if it is currently running in an active or passive region, as shown in this code:
defin_recovery_mode():objects=s3_client.list_objects_v2(Bucket=failover_bucket)forobjinobjects.get('Contents',[]):if'failover.txt'inobj['Key']:returnTruereturnFalse
Whenever the Account Open function determines it is running in an inactive
region, Lambda will run in recovery mode.
In this mode, Lambda will query the brokerage_accounts table using a global secondary index (GSI) with a
partition_key of user_id, the sort_key of request_token.
Only once the brokerage_account record is found will it purge the account request message from the SQS queue.
This ensures that a new account is created for a valid request, even if the primary (not active) AWS Region continues to accept Account Open requests but fails to process them.
Check the Lambda logs in the primary AWS Region again, and you’ll find an entry like the following log excerpt.
The brokerage_account record has been found.
The recovery AWS Region still had a copy of the request in its SQS queue.
When you activated recovery mode, the recovery AWS Region became the active region.
Lambda processed the Account Open, then the primary AWS Region Lambda ran in recovery mode and purged the message from its queue:
{"level":"DEBUG","location":"handler:66","message":"safe to purge message, found {'Items': [{'account_id':'6a3f7722-04b5-466a-8e0d-7f7b32aeeb76'}], 'Count': 1, 'ScannedCount': 1,'ResponseMetadata': {'RequestId':'C0JKC8U06JT73FLF5QMA7N2393VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode':200, 'HTTPHeaders': {'server': 'Server', 'date': 'Mon, 23 Oct 2023 21:05:10GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '98','connection': 'keep-alive', 'x-amzn-requestid':'C0JKC8U06JT73FLF5QMA7N2393VV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32':'2383576647'}, 'RetryAttempts': 0}}","timestamp":"2023-10-23 21:05:10,745+0000","service":"AccountOpen","xray_trace_id":"1-6536e006-feaaa67c99852e0822c1c4a2"}
The pattern you just executed is called Standby Takes Over Primary (STOP). In this lesson, you manufactured a simple code-induced failure. Then you invoked recovery to observe how to switch your active region quickly and reliably with the STOP pattern. No matter which custom component or AWS service is not working properly in the primary AWS Region, the failure is mitigated by a data plane operation in the recovery AWS Region to drive the secondary region taking over as primary.
Returning to Business as Usual
It is important to make a business continuity decision and perform a regional switchover both to rehearse and to maintain business continuity in light of regional impairments. Performing an AWS Region switch does require some analysis and should be done with care. The same care should be applied when returning to your primary region. In both scenarios, ensure the target environment is healthy, and after switching, ensure that all messages have been processed from queues as expected.
To return to business as usual, you can comment out the exception line # raise Exception("kaboom!!!") in your Account Open Lambda function and redeploy to the primary AWS Region with cdk deploy ProcessStack-primary.
For this test, run test 7 from the test client without needing to worry about any data cleanup:
(.venv)>$pythononboarding_test_client.py--test7failover-bucket-us-west-1-998541053034Switchedtoprimaryregion
Once you have switched back over, you can rerun the sunny day scenario to validate that processing accounts in the primary region, and your code is again operating normally, business as usual.
Blue-Green Testing
Changes to your code or infrastructure can lead to failures in your service
when defects or misconfigurations are introduced.
Blue-green testing is a way to test code deployments
without exposing new changes to your end users until after you validate your new deployment with test users.
In a deployment like the new Account Open service, it is relatively easy to demonstrate a blue-green test.
The code is already written to find greentest_ users and process them in the recovery AWS Region where you can deploy your changes.
This allows the primary active AWS Region to continue processing real user traffic, while the secondary region mimics being active but only for greentest_ users.
Review the conditional clause in the new_account.py Lambda source code to understand the greentest_ logic; the code snippet is shown here:
green_test="greentest_"inmessage["user_id"]if(active_in_recoveryorpassive_in_primary)andnotgreen_test:...
Put blue-green testing into action by introducing a simple change to your Lambda,
API Gateway, or other component in the service.
A simple change that is easy to validate is introducing or updating a log statement.
This lesson leaves it up to you to think of and try out a change of your choice.
Once your changes are ready, deploy them with the command cdk deploy ProcessStack-secondary.
Once the deployment is complete, you can push a request to the API endpoint in the secondary region.
Test 8 in the test client is configured to send a valid request to the secondary region.
In Chapter 6, you’ll configure a custom domain for the Account Open endpoint with failover routing,
giving you control of which region your client applications route traffic to.
To validate your changes, run the command python onboarding_test_client.py --test 8 --user_id greentest_1234.
Once your request has been published, use what you’ve learned in the previous scenarios to validate your changes.
Once you are comfortable that your changes work as desired, you are safe to make your green environment blue:
-
Site-switch production traffic to the secondary region.
-
Deploy your code to the primary region, then validate the primary AWS Region with a test user.
-
Finally, switch back to the primary with your new code deployed.
Of course, if your changes did not work as expected, you can roll back deploy fixes and retest before exposing new features to real user traffic.
There are many more serverless patterns to explore as you continue your journey through resiliency. As you build more complex workloads and to support your business requirements, be sure to understand the features of each service you use. AWS Lambda supports function aliases that allow you to deploy multiple versions of a single function. API Gateway supports multiple stages, so you can deploy and support a multiple version of an API. Combining the two supports versioning strategies and single-region blue-green strategies. AWS Lambda supports provisioned concurrency that can prewarm your Lambda for a preset level of concurrency to more rapidly handle spikes without a cold-start induced latency. This can be effective for traffic spikes and emergency failover scenarios.
Cleaning Up
The resources you created in this chapter accrue charges when services are invoked and for data storage. To avoid costs, remove the applications and data you’ve created. If you plan to work through each chapter in Part II, you can leave this stack installed until you have worked through Chapters 2–7. But be aware that if you stop working through the lessons and leave your infrastructure running, you will be charged for it.
Before you delete your stacks with the CDK,
delete resources protected by a DeletionPolicy, including the DynamoDB tables, S3 bucket, and CloudWatch logs.
This is the only chapter that uses a deletion policy to demonstrate another way to protect resources that contain data.
For simplicity, all other chapters allow the CDK to automatically tear down data resources.
-
Navigate to the S3 console or use the CLI to delete your failover bucket. If your failover.txt file is in the bucket, switch back to primary using test 5 or manually delete the file.
-
Navigate to the CloudWatch LogGroups console in your primary region. Select the four LogGroups for this solution and delete them. Switch to the secondary AWS Region and repeat.
-
Navigate to the secondary AWS Region DynamoDB console. Choose both the brokerage accounts and the idempotency table. Remove deletion protection. Delete each table.
-
Navigate to the primary AWS Region DynamoDB console once the tables in your secondary AWS Region finish deleting.
-
Ensure that both the brokerage accounts and idempotency table have completed updates.
-
Select both tables and remove deletion protection.
-
Delete both tables. If you encounter errors while turning off deletion protection on any tables, wait a few seconds and try again.
-
Finally, delete all remaining resources by running cdk destroy --all to delete the stacks.
Summary
In this chapter, you learned how to configure some built-in serverless resilience features and implement some serverless resilience design patterns. Strongly typed contracts and throttling at the API Gateway layer load-shed invalid messages or traffic spikes without invoking compute or backlogging message systems. You learned how to implement idempotency logic in your code to avoid duplicate processing both in a single AWS Region and across AWS Regions with SQS. The Lambda ESM facilitates retries and interacts with a dead-letter queue. When SQS and Lambda retries don’t eventually succeed, like in the case of a poison pill, messages can be sidelined to allow valid messages to continue to be processed. You also learned the benefit of a blue-green multi-region strategy and how to use it to test out new code deployments. However, if you don’t require a multi-region design, almost all the lessons in this chapter worked for a single region.
In the next chapter, the microservice architecture will focus on a stock trading API. You’ll learn about resilience in a severless container API workload backed by a cloud native relational database. Code-level design patterns will demonstrate secret management and caching, credential rotation, circuit breakers, and retries. AWS service configuration features will include how to recover container tasks quickly, configure health checks, and induce rollbacks on bad deployments. Finally, you’ll learn how to configure the API for an active-passive multi-region architecture, including both AWS regional failover at the HTTP API endpoint and the database.
Get Engineering Resilient Systems on AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

