Chapter 1. Introduction
Resilience refers to a system’s ability to withstand and recover from disruptions, failures, or unexpected events. It’s about preventing failures and ensuring the system can gracefully degrade, recover quickly, and provide some functionality even under stress.
So, how does an organization achieve resilience? Achieving this goal requires an ongoing pursuit on the part of organizations to invest in cloud expertise and engineering, automation tools, and a willingness to embrace a culture of continuous learning in resilience.
People, Processes, and Technology
Creating resilient systems involves more than just technology; it also requires integrating people and processes. While technology provides the tools and platforms for resilience, the people who implement and manage these tools and the processes they follow ultimately determine the success of resilient system design.
The Role of People
People are the driving force behind resilient systems. Skilled professionals, including business stakeholders, engineers, architects, operators, and other specialists, bring the necessary expertise to design, implement, and maintain these systems. Knowledge of the technical landscape and the organization’s business requirements ensures that the systems are built for optimal performance and resilience as required by the business.
Continuous training and development are essential for adapting to the rapidly evolving technology landscape. Ensuring that the team has up-to-date skills and knowledge allows team members to effectively utilize new tools and methodologies for resilience.
Building resilient systems requires cross-functional collaboration. Clear communication among teams, such as product, development, operations, and security, ensures that all aspects of the system are considered and that business requirements are addressed.
The team’s ability to respond quickly and adapt is required in the face of disruptions. A well-prepared and agile team can swiftly implement contingency plans, troubleshoot issues, and restore services, minimizing downtime and impact.
The Role of Processes
Processes provide the framework within which people operate, ensuring consistency, efficiency, and alignment with organizational goals. Well-defined processes standardize best practices, reduce errors, and enhance the system’s resilience.
Detailed incident response plans outline the steps to be taken during various disruptions. These plans should be regularly updated and tested to ensure effectiveness when actual incidents occur.
Implementing a change management process helps mitigate the risks associated with system updates and modifications. By carefully planning, testing, and monitoring changes, you can prevent unintended consequences that compromise system resilience.
Ongoing monitoring of system performance and regular reviews of resilience strategies ensure that the system remains robust against evolving disruptions. This process includes collecting data, analyzing trends, and making informed adjustments to improve resilience.
Comprehensive documentation of systems, processes, and incident histories facilitates knowledge sharing and ensures that all team members are informed and prepared. This practice helps maintain consistency and reduce dependency on individual expertise.
Integrating People, Processes, and Technology
Creating resilient systems requires a holistic approach integrating people, processes, and technology. Technology provides the tools, but only with skilled people to implement and manage it, and well-defined processes to guide its use, can the full potential of the technology be realized.
Empowering teams with the right tools and training, and fostering a continuous learning and improvement culture ensures they can effectively leverage technology to build resilient systems. It’s important to ensure that processes are designed to support and enhance the capabilities of the technology in use. This alignment helps maximize efficiency and effectiveness, leading to more resilient systems.
Encouraging a mindset focused on resilience across the organization helps proactively identify and address potential issues. This cultural shift ensures that resilience is not just an afterthought but an integral part of system design and operation.
Building resilient systems is a multifaceted endeavor that goes beyond the deployment of advanced technology. It requires the concerted efforts of skilled professionals, guided by well-defined processes, to ensure that systems can withstand and recover from disruptions. By recognizing the critical roles of people and processes, you can create a robust foundation for resilient system design, ensuring continuous and reliable service delivery in an ever-changing technological landscape.
Shared Responsibility Model
The AWS Shared Responsibility Model for resilience is a concept that every organization should understand. It is important to know where the responsibility lies between of the cloud and in the cloud to successfully build resilient workloads on AWS.
This book shows you how to take advantage of of the cloud while building in the cloud. With this knowledge, you can start engineering resilient workloads. In February 2021, AWS introduced the Shared Responsibility Model for resilience to clarify the responsibilities of AWS and its customers. This model outlines the distinct responsibilities of AWS, of the cloud, and its customers, in the cloud, regarding resilience.
Figure 1-1 shows this model, a framework to assist you in achieving cloud resilience. It clearly defines the roles and responsibilities of AWS as the cloud service provider and the customer as the custodian of their data and applications.
This model clarifies your role in ensuring the resilience of your workloads hosted on AWS. While AWS safeguards the underlying infrastructure (physical data centers, networking, and virtualization platforms) and AWS services, your responsibility lies in architecting, building, testing, and operating your workloads on AWS in a way that promotes resilience.
You understand your specific business needs, regulatory requirements, and risk tolerance levels best, so you are best positioned to tailor your resilience strategies to align with these unique factors. By taking ownership of your responsibilities within the shared model, you can customize and implement resilience measures most suitable for your specific use cases while adhering to resilient best practices.
You are responsible for data governance and security specific to your applications. Good data governance requires flexibility, allowing you to adjust resources and configurations, and implement new resilience controls to ensure scalability and adaptability in response to changing circumstances. You must ensure data availability and recover to a usable state in case of data corruption. You are also responsible for ensuring compliance with relevant regulations within your portion of the shared model, as you have the domain knowledge and insight necessary to meet these requirements for your industry.
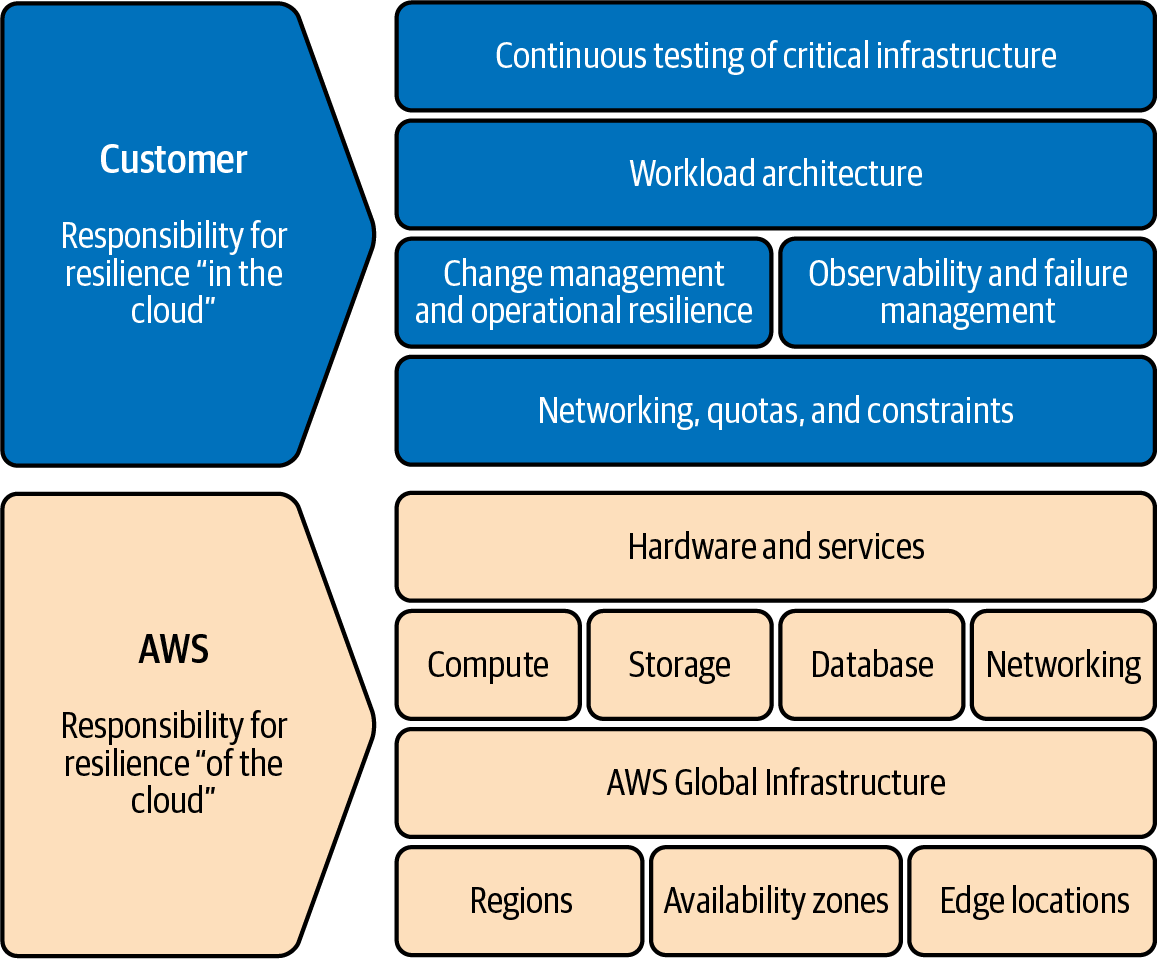
Figure 1-1. AWS Shared Responsibility Model for resilience
Ultimately, you are responsible for managing data and application resilience risks. By actively participating in the Shared Responsibility Model, you can assess risks, identify vulnerabilities, and implement mitigation strategies to minimize the impact of potential impairments. This proactive approach to risk management is essential for maintaining business continuity and protecting critical assets during disruptions.
AWS Responsibility
First and foremost, let’s touch upon service-level agreements (SLAs). As a cloud provider, AWS offers SLAs to customers for its services. These agreements specify the level of service that AWS commits to delivering. Generally, SLAs define metrics relating to service reliability, availability, performance, and support. SLAs are financial contracts that establish trust and accountability between cloud service providers and their customers. They provide customers with assurance regarding the reliability and performance of cloud services and set clear expectations for the level of service they can expect to receive.
However, while AWS SLAs are a useful baseline, it’s important to complement them with your tailored objectives that align closely with your business goals, performance requirements, and risk tolerance. This approach ensures that you comprehensively understand your workload’s performance and reliability, and can take appropriate actions to optimize and manage it effectively.
We will discuss resilience goals in more detail in “Setting Objectives”.
In the context of systems and computing, fault isolation refers to the practice of designing and implementing systems that limit the impact of failures. Fault isolation can help ensure the reliability and availability of your applications by isolating impacts or failures within the fault isolation boundary where they occurred.
The AWS global infrastructure is an example of designing with fault isolation in mind. The infrastructure is a vast network of regions, availability zones, and data centers in key geographic areas worldwide. Each AWS Region has several Availability Zones (AZs), essentially isolated data centers with redundant power, cooling, and networking infrastructure. These AZs are linked by high-speed, low-latency connections, creating a highly resilient and fault-tolerant network, as shown in Figure 1-2.
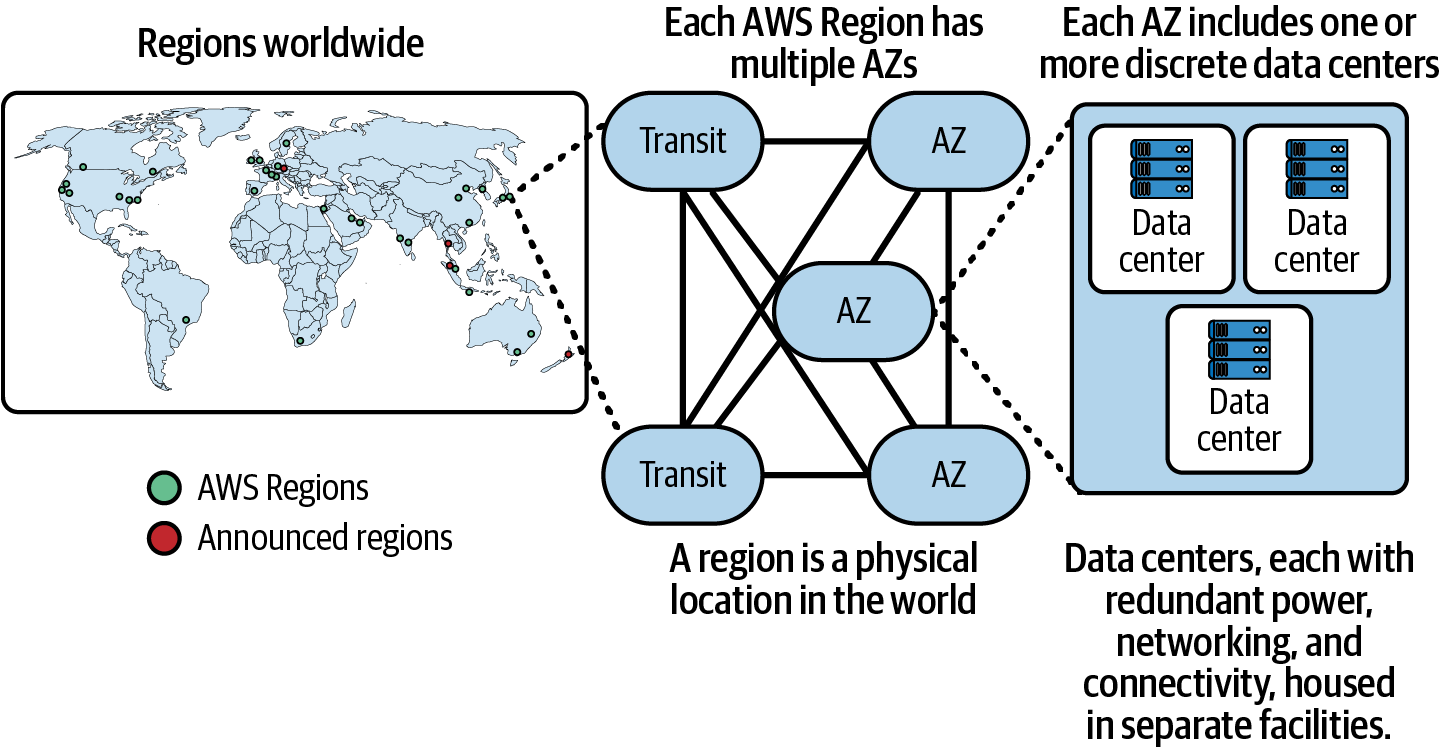
Figure 1-2. AWS global infrastructure
You can leverage the AWS global infrastructure to build and operate resilient workloads. Your architectures should span multiple Availability Zones within an AWS Region to achieve redundancy and fault tolerance. This way, you can achieve high availability and resilience, as any impairments of a zonal service or resource in one zone would not impact the availability of resources or zonal services in other Availability Zones. You can also deploy your workloads across multiple AWS Regions for an additional layer of fault isolation. Each AWS Region is isolated from the others, with its own set of Availability Zones. By replicating your data and workload across multiple AWS Regions, you can withstand regional impairments or disasters and maintain business continuity within your designed recovery objectives.
In addition to the existing AWS Regions, AWS has announced regions that have been publicly disclosed but are not yet available for general use. While these announced regions are not immediately usable, they can be factored into your long-term resilience planning, allowing you to prepare for future expansions of your global infrastructure footprint.
AWS also operates edge locations distributed worldwide. You can leverage the edge to cache and deliver content closer to end users, reducing latency and enhancing the resilience of your applications.
Note
An AWS edge location is a point of presence (PoP) within the AWS global network infrastructure. These PoPs are distributed globally, and strategically placed in major cities and regions worldwide. The primary purpose of these locations is to provide AWS services to end users with low latency and high data transfer speeds.
Additionally, you can run computing and processing data at the edge using Amazon CloudFront functions and AWS Lambda@Edge, which run closer to end users or devices.
Customer Responsibility
This section examines some of the methodologies, principles, and frameworks that you, the customer, can use when engineering and operating on AWS to meet your responsibilities as part of the Shared Responsibility Model.
When designing your system for resilience, we recommend working backward from the failure modes that can occur within it. We discuss this when we get to “Workload Architecture”. Still, if we take a simple example, we know that if a server gets terminated for any reason and there is no other server to take its place, then we see a single point of failure. So, if we were to design a resilient system, we would create this server with redundancy, preventing this failure.
Another important aspect of resilience is identifying whether a failure is happening within your system. Do you have the observability to identify the signal from that failure mode? And what happens when your observability detects that failure? Do you have alarms configured to either send notifications to a team, automatically mitigate the failure, or both?
You will want to test for these failures to validate that your processes are working as expected. The best practice is to automate and build these tests into your continuous integration and continuous delivery (CI/CD) pipeline. Most of our systems’ failures are self-inflicted, and because of this, change and failure management processes are important.
Finally, you want to get to a point where you practice continuous resilience, incorporating all the lessons from your hard work into your resilience lifecycle. This section explores all of these topics in depth.
Let’s start with setting your resilience objectives.
Setting Objectives
Building resilient systems requires setting clear goals to guide your efforts. These goals establish a roadmap for fortifying your system against disruptions, ensuring it can withstand failures and recover quickly.
By defining “resilient” for your specific system, you can effectively prioritize resources, measure progress, and ultimately minimize the impact of downtime on your business and its stakeholders.
Business impact analysis and risk assessment
A business impact analysis (BIA) and risk assessment are two processes that work together to understand potential threats to your system and how they can impact your business operations. The business conducts a BIA and risk assessment to help define resilience goals.
A BIA identifies and prioritizes critical business processes, systems, and resources. It is crucial in ensuring business continuity, going far beyond technology considerations. It delves into the heart of an organization’s operations, identifying critical processes, dependencies, and the potential ripple effects of disruptions. By understanding these intricate relationships, businesses can proactively address vulnerabilities and develop strategies to maintain essential functions despite unexpected events.
A BIA acknowledges that businesses are complex ecosystems where people, processes, and technology are interconnected. It recognizes that disruptions can impact IT systems, the workforce, supply chains, customer relationships, and overall reputation. By analyzing these diverse elements, businesses can develop comprehensive continuity plans that safeguard their most valuable assets, ensuring resilience and minimizing downtime.
A risk assessment proactively identifies potential threats and vulnerabilities that could disrupt your system. These include natural disasters, cyberattacks, hardware failures, software bugs, and human error. The assessment then evaluates the likelihood of each threat occurring and the severity of its potential impact.
Understanding the likelihood and severity of different risks helps you develop a more targeted approach to building system resilience. You can prioritize mitigation strategies for the most probable and impactful threats or critical applications, ensuring your system is better prepared to handle real-world challenges.
Resilience goals
When defining resilience goals, two key metrics are recovery objectives and availability goals. Recovery objectives define the maximum acceptable downtime after a disruption before functionality needs to be restored. At the same time, availability goals specify the percentage of time a system must be operational.
Why are resilience goals important? They help prioritize resources toward the areas that matter most, adapting to each system’s unique needs. For instance, an electronic trading platform with financial transactions might require stricter recovery objectives than a company website with mostly static content.
Furthermore, defining resilience goals establishes measurable targets to track progress and assess your system’s overall resilience.
Recovery objectives
The recovery time objective (RTO) specifies when you aim to recover your critical systems and resume normal business operations after a disruptive event.
The recovery point objective (RPO) specifies the maximum acceptable age of the data that an organization is willing to lose in a disaster or disruptive event.
Both are expressed as a specific duration, typically hours, minutes, or days, and are based on the recovered systems’ or processes’ business requirements, operational needs, and criticality. A shorter RPO indicates a lower tolerance for data loss, requiring more frequent backups or data replication to minimize the amount of data at risk. Conversely, a longer RPO may be acceptable for less critical data or applications that can tolerate longer periods of data loss without significant impact.
Downtime, defined as when a system is unavailable, can be caused by various factors like hardware failures, software bugs, or even natural disasters. The definition of downtime itself can vary depending on the organization. Downtime is usually not binary, either up or down, but varying shades of this. You may define downtime when error rates reach a certain point or when latency exceeds a certain threshold. It is important to have this conversation and define these goals with the business stakeholders to understand their expectations of the system and then convert those into the appropriate technology measurements. Even a few seconds of downtime can have severe consequences in mission-critical fields like healthcare or finance, so any interruption might be unacceptable. On the other hand, a noncritical system like an internal company directory might tolerate a few hours of downtime as long as users can still access other resources.
Bounded Recovery Time (BRT) refers to the maximum tolerable duration within which a system, process, or organization must be restored to an operational state following a disruption. Establishing a BRT is essential for effective resilience planning, as it provides a clear target for recovery efforts and helps prioritize resources. BRT is not merely a technical metric; it aligns with the overall BIA by considering the potential consequences of prolonged downtime. By defining an acceptable BRT, you can ensure that recovery strategies are tailored to minimize financial losses, reputational damage, and operational disruptions. BRT serves as a guiding principle for resilience, driving the development of robust backup systems, redundant infrastructure, and well-rehearsed recovery procedures.
The three Ms
MTBF, MTTD, and MTTR are all metrics that can be valuable in setting resilience goals by providing insights into your system’s uptime and downtime characteristics:
- Mean time between failures (MTBF)
-
Measures the average time between failures or incidents that cause downtime. It represents the expected time between failures in a system or component. MTBF indicates the predicted reliability of a system or component over time. A higher MTBF value indicates that the system or component is more reliable and experiences fewer failures on average, resulting in longer intervals between failures.
- Mean time to detect (MTTD)
-
Measures the average time to detect an incident or failure within a system or application. MTTD is an important performance indicator in incident management and response processes, as it reflects the effectiveness of your monitoring and detection capabilities in identifying issues and abnormalities. A shorter MTTD indicates that incidents are detected more quickly, allowing for faster response and resolution. This helps minimize the impact of incidents on service availability, performance, and user experience. Effective monitoring, alerting, and automated detection mechanisms contribute to reducing MTTD and improving overall incident response efficiency.
- Mean time to repair/recovery (MTTR)
-
Measures the average time to repair or recover from a failure or incident that causes downtime. It represents the time it takes to restore the system or application to regular operation after failure. MTTR is a key performance indicator in incident management and response processes, reflecting the efficiency and effectiveness of your incident resolution and recovery efforts. A shorter MTTR indicates that incidents are resolved quicker, minimizing downtime and promptly restoring the system or application’s regular operation. Effective incident response processes, automation, and well-defined recovery procedures contribute to reducing MTTR and improving overall system resilience and availability.
Figure 1-3 shows the three Ms on a timeline.
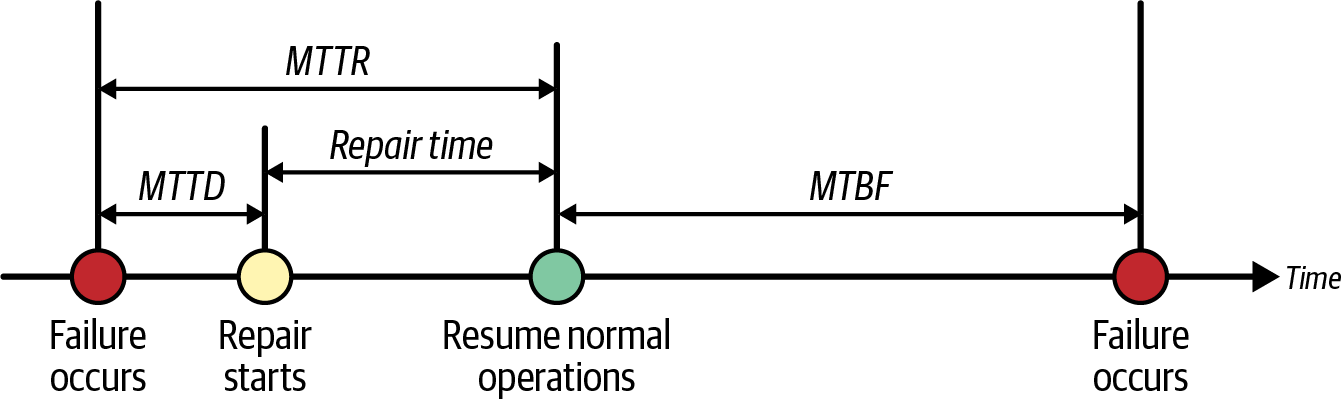
Figure 1-3. Relationship of Ms on an availability timeline
MTBF and MTTD can inform your recovery objectives. These metrics provide a historical perspective on how often your system experiences failures and how long they typically last. By understanding these averages, you can set a realistic recovery objective that reflects the time needed to recover from an outage based on past experiences. MTTR influences your BRT. A lower MTTR translates to a faster recovery, allowing you to set a tighter BRT time as your goal. Knowing your historical MTTR helps you determine an achievable target for how quickly you can restore functionality after a disruption.
First, when setting resilience goals, you want to establish your baselines. Analyze your historical data to establish MTBF, MTTD, and MTTR baseline values. Then, you can set improvement goals. As you implement resilience strategies, aim to improve your MTBF (reducing failures) and MTTR (faster recoveries). Make sure you are aligned with business needs. Consider the financial impact or user experience disruptions caused by downtime.
Use this information to set recovery objectives and BRT goals that balance technical feasibility with business needs.
You can build a more resilient system that aligns with your organization’s specific needs and downtime tolerance by continuously monitoring these metrics and striving to improve them. Remember, these metrics provide historical averages, and actual failures might deviate. However, they offer valuable insights to set realistic and achievable resilience goals. By setting clear resilience goals, aligning them with recovery objectives and availability goals, and implementing strategies to achieve bounded recovery times, you can build systems that are more resistant to disruptions and minimize the impact of downtime on your operations and user experience.
Note
These will be your resilience goals for your fictitious electronic trading application, AvailableTrade. You are responsible for the AvailableTrade application, where downtime can result in revenue loss. Your system logs reveal an average MTBF of 2 weeks (336 hours) and an MTTR of 2 hours. Based on this data, set a recovery objective of 4 hours (allowing some buffer time beyond your typical MTTR). Given your business needs and current MTTR, achieving a bounded recovery time of 1 hour might be a more strategic goal to minimize downtime and its financial impact.
Now that you have set your objectives, let’s learn some best practices and patterns for achieving them.
Workload Architecture
Workload architecture is the cornerstone of customer responsibility in the AWS cloud. Architecting, engineering, testing, and operating revolve around designing a resilient workload architecture.
To guide you in this endeavor, we’ll begin by exploring essential frameworks that empower you to enhance the resilience of your workload. These frameworks foster continuous learning and improvement, enabling you to adapt to evolving business needs and technological landscapes and ensuring that resilience is ingrained at every phase—design, implementation, testing, and ongoing evolution.
Following this, we’ll delve into fundamental resilience concepts, including high availability and disaster recovery, shedding light on how they fortify your workload against disruptions. Finally, we’ll dive deeply into each facet of the Shared Responsibility Model, clarifying the customer’s responsibilities in maintaining a resilient cloud environment.
Two core frameworks, the AWS Resilience Analysis Framework and the AWS Well-Architected Framework, are invaluable pillars in pursuing resilient system design on AWS. Let’s start our journey here by closely examining each of these frameworks, uncovering how they can equip you to build robust and dependable systems within the AWS ecosystem.
AWS Resilience Analysis Framework
The AWS Resilience Analysis Framework (RAF) is a comprehensive methodology designed to assess and enhance workload resilience. It provides a structured approach to identifying potential failure modes within user journeys that your applications support. At its core, the framework aims to identify vulnerabilities and weaknesses, enabling you to proactively address potential points of failure and implement resilience strategies to prevent or minimize the impact of disruptions. By conducting a thorough resilience analysis, you can gain insights into your current resilience posture, prioritize areas for improvement, and develop actionable plans to enhance resilience. RAF identifies the desired resilience properties of a workload. Desired properties are what you want to be true about the system.
Resilience is typically measured by availability, and RAF has defined five properties that are the characteristics of a highly available distributed system: redundancy, sufficient capacity, timely output, correct output, and fault isolation. When a desired resilience property is violated, it could cause a workload to be unavailable or perceived to be so. Based on these desired resilience properties, RAF identifies five common failure categories: single points of failure, excessive load, excessive latency, misconfigurations and bugs, and shared fate (SEEMS) that can cause a resilience property violation.
These failure categories provide a consistent method for categorizing potential failure modes:
- Single point of failure (SPOF)
-
Violates the redundancy resilience property. A failure in a single component disrupts the system due to a lack of redundancy.
- Excessive load
-
Violates the sufficient capacity resilience property. Overconsumption of a resource through excessive demand or traffic prevents the resource from performing its expected function. This can include reaching limits and quotas, which cause throttling and rejection of requests.
- Excessive latency
-
Violates the timely output property resilience property. System processing or network traffic latency exceeds the expected time, service-level objectives (SLOs), or SLAs.
- Misconfiguration and bugs
-
Violates the correct output resilience property. Software bugs or system misconfiguration leads to incorrect output.
- Shared fate
-
Violates the fault isolation resilience property. A fault caused by any of the previous failure categories crosses intended fault isolation boundaries. It cascades to other parts of the system or other customers.
While these are not exhaustive, and you may have other resilience property requirements, RAF gives you a good starting point for thinking about how failure modes affect the resilience of your workloads, and working toward corrective, preventative, or mitigation measures.
You will use RAF in this book as we work through your example application. You will create failures aligning with SEEMS, and implement preventative measures or mitigations to maintain the corresponding resilience property.
Note
You can find the prescriptive guidance for the AWS Resilience Analysis Framework used in this book at the AWS “Resilience Analysis Framework” documentation.
AWS Well-Architected Framework
The AWS Well-Architected Framework is a set of principles and best practices that helps architects, developers, and engineers design, build, test, and operate secure, efficient, high-performing, and resilient workloads on Amazon Web Services (AWS). It serves as a blueprint to help you navigate the complexities of the cloud and establish a strong foundation for your cloud infrastructure.
The framework is based on six key pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability. Each pillar defines best practices for designing, building, and operating workloads on AWS. Here, we’ll focus on the Reliability and Operational Excellence pillars for resilience.
The Reliability pillar of the AWS Well-Architected Framework ensures that workloads perform consistently and predictably, even under varying conditions. It focuses on building systems that can withstand disruptions and minimize downtime while maintaining availability, resilience, and fault tolerance. Key areas of emphasis under the Reliability pillar include architectural best practices, fault tolerance mechanisms, recovery strategies, and performance optimization to enhance the reliability of AWS workloads.
The Operational Excellence pillar of the AWS Well-Architected Framework is about optimizing operational processes and procedures to efficiently manage and maintain AWS workloads. It highlights the importance of automating tasks, continuously improving processes, and empowering teams to make informed decisions. Key areas of emphasis within the Operational Excellence pillar include defining operational standards, implementing automation, monitoring and logging, incident management, and resource optimization to enhance the efficiency, reliability, and security of AWS workloads.
Note
You can find the prescriptive guidance for the AWS Well-Architected Framework used in this book at “Reliability Pillar: AWS Well-Architected Framework” and “Operational Excellence Pillar: AWS Well-Architected Framework”.
High availability
High availability (HA) focuses on preventing downtime or minimizing its impact during minor disruptions, ensuring your system remains operational most of the time. These disruptions are typically caused by hardware or software failures within the system itself. HA systems employ automated recovery and self-healing mechanisms to mitigate these failures.
One key concept of high availability is redundancy. These systems typically utilize redundant components such as servers, storage, applications, and data replication. If one component fails, another seamlessly takes over, minimizing service disruption and ensuring continuity.
High availability is not just about uptime; it’s also about efficiency. These systems often possess self-healing capabilities like automatically restarting failed applications. This reduces the need for manual intervention and speeds up recovery times, bolstering confidence in the system’s resilience and the efficiency of your investment.
Highly available systems are designed with adaptability, empowering you to handle increased traffic or workload demands. They are often horizontally scalable, meaning they can effortlessly adapt to real-time needs, ensuring high availability even under heavy load. This flexibility allows you to optimize resource utilization and cost while maintaining availability, giving you greater control over your system’s performance.
Effective management is important for achieving high availability. Centralized management tools empower administrators to monitor system health, configure components, and efficiently perform maintenance activities. Advanced monitoring capabilities track system performance, resource utilization, and potential issues, enabling proactive identification and resolution of problems before they escalate into outages. Additionally, real-time alerting mechanisms notify administrators of possible issues or failures, facilitating prompt intervention and minimizing downtime.
Note
To learn more about availability, see the AWS whitepaper “Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS”.
Disaster recovery
Disaster recovery is an essential part of business continuity. It focuses on recovering from disasters that can cause complete system outages. These plans cover both the technological aspects of recovery and the human resources and established processes needed to restore operations effectively.
Defining a disaster recovery strategy involves a systematic approach, including identifying critical business functions, prioritizing recovery objectives, establishing RTOs and RPOs, and designing a comprehensive recovery plan outlining specific steps to be taken during and after a disaster. Proactively addressing disaster recovery in this way helps you protect your operations, data, and reputation, ensuring a swift and efficient return to normalcy even after a catastrophic event.
Disaster recovery in AWS differs significantly from traditional on-premise workload recovery strategies. The AWS Global Infrastructure helps mitigate concerns related to spare hardware, natural disasters, fire risks, and power outages. Failing servers can be easily replaced, and the distribution of availability zones within a region can help minimize the impact of power interruptions, fires, and natural disasters.
When considering potential disaster scenarios in AWS, the focus shifts toward failure modes that could render primary workloads inoperable. These scenarios may include data corruption, regional service impairments, and problematic deployments. Understanding these unique challenges in the cloud environment empowers you to tailor your disaster recovery strategies accordingly, ensuring the continuity of your critical applications and services.
Disaster recovery strategies
Let’s examine each disaster recovery strategy shown in Figure 1-4, with recovery objectives as the dimension.
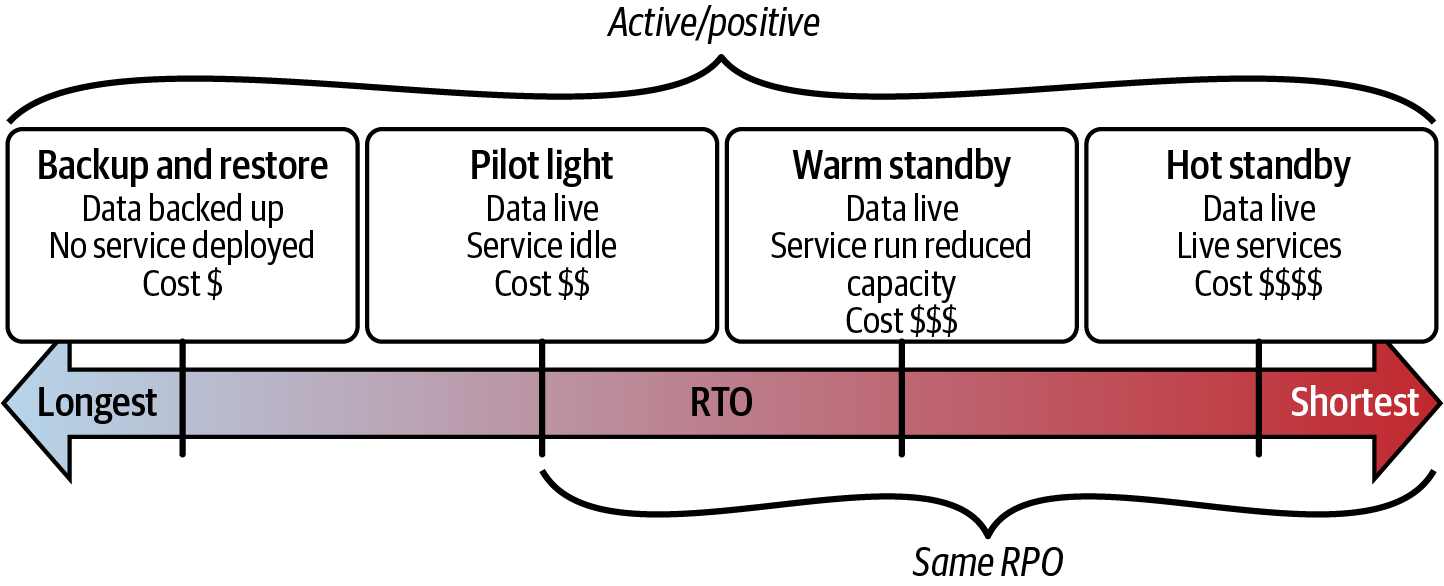
Figure 1-4. Disaster recovery strategies
The backup and restore strategy involves regularly creating backups of critical data and system configurations, which are stored in a secure and separate location. This strategy is fundamental and suitable for most organizations. It’s cost-effective and ideal for situations where a complete system outage isn’t a critical concern. However, recovery times can be longer depending on the complexity of the restore process.
A backup and restore strategy should not be confused with backing up data. While regular data backups are essential for protecting against data corruption (whether accidental or malicious), a comprehensive backup and restore strategy goes beyond mere backup creation. It encompasses the entire process of backing up data and ensuring the capability to efficiently and reliably restore all critical components of your workload, including data, configurations, networking infrastructure, and compute resources in the event of a disruption or disaster.
Data backups are a fundamental component of any workload, acting as a safety net against data loss. They are required to be part of your overall data management strategy. However, a well-defined backup and restore strategy is a holistic approach that ensures you can recover your data and restore your entire operational environment within a time frame that aligns with your recovery objectives.
The pilot light strategy maintains a minimal, preconfigured infrastructure in a recovery environment. This “pilot light” can be scaled up during a disaster using automation tools and scripts to provision additional resources and deploy application components. This strategy suits scenarios where recovery time objectives can support the time for scaling out resources in a disaster. It’s ideal for less critical applications or limited budgets.
The warm standby strategy replicates the production environment infrastructure and data in a separate recovery environment. This replica is kept synchronized with the primary environment but doesn’t actively process transactions. Some computing resources are running for a warm standby, which differs from a pilot light where there are none. In a disaster, the recovery environment can be more quickly scaled up than a pilot light to handle production traffic and take over operations. This strategy is a good choice when downtime is costly, but a hot standby might not be justified. It balances cost and recovery time objectives, with you deciding how warm you want your recovery environment to be.
The hot standby strategy maintains a fully operational and synchronized copy of the production environment in a separate recovery environment. This redundant environment is ready to take over operations in a disaster with minimal downtime. The exact number of computing resources in the production environment run for a hot standby. This strategy is ideal for mission-critical applications where even a brief outage can have significant consequences. It ensures the fastest possible failover, but comes at a higher cost due to the need to maintain a fully operational replica.
By carefully considering your business needs, resilience goals, and budget constraints, you can select the most appropriate strategy and implement a comprehensive disaster recovery plan. Remember, a well-tested and documented disaster recovery plan is critical for ensuring business continuity during disruptions.
Multi-region considerations
Developing multi-region workloads on AWS involves considerations and trade-offs that you must understand to create efficient and cost-effective AWS multi-region workloads.
If your business drivers require it, consider using multi-region architectures. These drivers may include compliance with regulatory requirements that mandate data storage within specific regions, such as data sovereignty. Global and geographically dispersed user bases may require multi-region deployments to improve performance by reducing latency. Multi-region deployments can also provide redundancy and mitigation for your system’s specific failure modes, such as an AWS regional service impairment. In a disruption in one AWS Region, the workload can be failed over to another, reducing downtime.
While multi-region systems can offer significant benefits for high availability, scalability, latency, and compliance, they can also introduce additional complexity in managing and operating geographically dispersed resources, as well as additional infrastructure, resources, and data transfer costs.
Aligning your technical decisions with your business strategy is key to successful multi-region deployments. You will also have to consider the balance between data consistency and latency. Replicating data across multiple regions ensures data availability and resilience but introduces data consistency and synchronization challenges. To balance data consistency and latency, you can implement strategies such as multimaster data stores, eventual consistency, or conflict resolution mechanisms; however, depending on the complexity of your workload, this can prove challenging to achieve and operate.
You will also need to decide on a failover strategy and the granularity of your failover. Deciding the level at which to failover (entire system, application, service, user journey, or portfolio) has advantages and disadvantages. If you choose not to failover a whole system, one consideration should be how upstream and downstream services will behave with dependencies running in a different region. You should comprehensively test these failover scenarios to validate performance and latency impacts. This ensures that timeouts and retries won’t cause cascading failures during an actual failover.
By understanding business drivers, considerations, and trade-offs, you can design efficient and cost-effective multi-region architectures on AWS that deliver optimal performance, resilience, and scalability while meeting your business requirements.
Note
To learn more about multi-region considerations, see the “AWS Multi-Region Fundamentals” whitepaper.
Networking
Networking can be nuanced within the AWS Shared Responsibility Model. While AWS owns and maintains the underlying global network infrastructure, ensuring its resilience, your responsibility lies in building your networking layer on top of it. This includes configuring virtual private clouds (VPCs), routing, and establishing connections between on-premises data centers and AWS.
A resilient network architecture is essential for uninterrupted critical business operations, particularly in sectors where even brief downtime can lead to significant financial losses or reputational damage. These networks ensure business continuity through redundant data transmission paths, failover mechanisms, optimized performance, reduced latency, and efficient data transfer among users, applications, and services.
Crucially, networks play a vital role in disaster recovery plans by providing alternative communication paths and failover mechanisms. This enables the replication and recovery of data during disaster scenarios.
When designing your AWS network, consider leveraging native AWS services and features that support data replication across regions. Services like Amazon S3 Cross-Region Replication, Amazon Aurora Global Database, and Amazon DynamoDB global tables offer built-in replication capabilities, simplifying the process compared to building your networking pathways using AWS Direct Connect or AWS VPN.
By adhering to best practices and effectively utilizing AWS services, you can create a network architecture that withstands various disruptions, including hardware and software failures, power outages, cyberattacks, network congestion, and resource limitations. Identifying these failure modes and conducting experiments allows network administrators to implement preventative measures, prepare backup plans, and respond effectively to minimize downtime and maintain network stability.
To optimize traffic routing, employ load balancers to distribute incoming traffic across multiple instances or resources. AWS load balancers automatically scale and distribute traffic to healthy instances, ensuring high availability and fault tolerance. Deploying load balancers across multiple availability zones further enhances availability and resilience. Amazon Route 53 enables you to configure various routing policies and health checks, directing traffic to healthy resources and distributing the load across multiple instances or regions. This minimizes the impact of failures within any single fault isolation boundary.
Establish private connectivity using AWS Direct Connect or AWS VPN for secure and reliable communication between on-premises resources and AWS services. This reduces reliance on the public internet for service-to-service communication.
Finally, implement network monitoring and automation tools to track network performance, detect anomalies, and trigger automated incident responses. Identifying and resolving potential issues is key to minimizing downtime and maintaining a resilient network.
Quotas
Effective management of service quotas on AWS is essential for organizations leveraging cloud services. Service quotas are predefined thresholds that restrict the maximum usage of AWS resources or operations within an account or AWS Region. These quotas help maintain the AWS environment stability, reliability, and cost-effectiveness.
Exceeding service quotas can lead to resource exhaustion, causing service degradation or outages. By staying within predefined quotas, you mitigate the risk of service disruptions and ensure the availability and performance of your applications and workloads.
Start by gaining a comprehensive understanding of the various service quotas imposed by AWS. These quotas vary across different AWS services and dictate the maximum number of resources or operations allowed within an account or AWS Region. This knowledge will empower you to make informed decisions about your resource usage.
Note
To learn more about quotas, see “AWS Service Quotas”.
Implement monitoring and quota management strategies. Continuously monitor resource usage metrics using tools like AWS CloudTrail and Amazon CloudWatch. Integrate alarms into your observability platform to trigger automatic quota increase requests when predefined thresholds are met.
Leverage the AWS Service Quotas API to request quota increases for specific services or resources, and automate quota checks and requests within your deployment and infrastructure management processes. This proactive approach allows you to identify and address potential quota limitations before they impact your services.
Optimize resource allocation by prioritizing critical workloads and applications. Use AWS resource tagging to categorize and track resource usage, facilitating efficient allocation based on business priorities and usage patterns. This minimizes wastage and maximizes resource utilization. Review and optimize resource usage and allocation regularly. By analyzing usage patterns, identifying optimization opportunities, and implementing measures to improve resource efficiency, you can be reassured that your AWS resources are utilized effectively, minimizing costs and maintaining service availability.
Change Management
Managing change effectively lends itself to seamless application operation and maintaining operational resilience. A structured change management process mitigates risks, maintains stability, prevents unintended consequences, ensures compliance, promotes collaboration, facilitates rollback and recovery, and encourages continuous improvement.
Establish a formal change control process that outlines how changes are requested, evaluated, approved, implemented, and documented. With its clear roles and responsibilities for all stakeholders, this process empowers each individual, safeguards against potential disruptions, mitigates risks, maintains stability, and prevents unintended consequences. Foster effective communication and collaboration among cross-functional teams involved in the change management process. Encourage open dialogue, feedback sharing, and knowledge exchange.
Prioritize the ability to roll back changes in case of unforeseen issues. Develop and regularly test a well-documented rollback plan, making it readily accessible for swift action. Alternatively, mitigation strategies like fixing forward, isolating and redirecting traffic, or degrading functionality should be established if complete rollback isn’t feasible.
Conduct risk assessments for proposed changes, evaluating factors like downtime risk, data loss risk, and security implications. Thorough testing and validation before implementing changes in production environments instill confidence in the impact of these changes on workload resilience. Maintain detailed documentation for all workload changes, including rationale, implementation details, and associated risks. This documentation is a valuable reference for future change management activities and troubleshooting.
Leverage automation tools and scripts to streamline change management processes and minimize manual errors. Where automation isn’t possible, implement methods to reduce errors in manual processes, such as two-person verification and well-documented procedures. Implement monitoring and reporting mechanisms to track the impact of changes on workload resilience. Monitor key performance indicators (KPIs) and metrics to identify deviations from expected behavior.
Regularly evaluate and refine change management practices based on feedback, lessons learned, and industry best practices. Update change management policies, procedures, and documentation to ensure they remain effective and aligned with business objectives.
Failure Management
Failures are inevitable in modern technological environments despite careful planning and implementation. Therefore, having a well-defined failure management process can help mitigate risks and maintain operational efficiency. This process provides a structured framework for effectively anticipating, identifying, and responding to failures, minimizing downtime, and swiftly initiating recovery measures. Timely resolution of failures is crucial for fulfilling regulatory mandates and mitigating financial losses from service interruptions.
To establish an intuitive failure management process, configure monitoring thresholds and alarms to trigger alerts based on predefined criteria, such as abnormal resource utilization, performance degradation, or service disruptions. Automated alerts can notify relevant teams promptly, enabling them to take corrective action or initiate automated remediation scripts before failures escalate.
Another key aspect of the failure management process is the development of response playbooks. These playbooks outline predefined response actions for different failures and incidents, and are best created collaboratively with cross-functional teams. This collaboration is essential for defining response procedures, escalation paths, and communication protocols for various scenarios, ensuring a comprehensive and effective incident response.
Integrate automation tools and scripts into the incident response system to automate remediation actions and response workflows. This can include automated scripts for restarting services, reallocating resources, rolling back configurations, or triggering failover mechanisms. Leverage infrastructure as code (IaC) and configuration management tools to automate resource provisioning and configuration during incident response. Additionally, consider implementing orchestration tools or workflow automation platforms to orchestrate complex incident response workflows and coordinate remediation actions across multiple systems and teams. Utilize workflow automation capabilities to define conditional logic, decision points, and dependencies within response workflows.
Continuous improvement is a cornerstone of any failure management process. Thorough post-incident and root cause analysis (RCA) for failures or incidents is essential for identifying contributing factors, lessons learned, and areas for improvement. Regularly reviewing and updating the automated incident response system, based on feedback from post-incident reviews and infrastructure or application architecture changes, is critical. Conducting periodic tabletop exercises, simulations, and drills to test the automated response system’s effectiveness and identify improvement areas is also essential. The goal is to continuously optimize response playbooks, automation scripts, and workflows to enhance the efficiency, accuracy, and effectiveness of failure management processes.
Observability
Observability provides real-time insights into system performance, health, and behavior, serving as a proactive tool. It plays a pivotal role in preventing disruptions by enabling you to identify and address potential issues before they escalate into significant disruptions.
At the heart of observability are three pillars: logs, metrics, and traces. Each pillar offers a unique perspective on your system’s functions, contributing to a comprehensive understanding of its overall health and performance.
- Logs
-
Logs are a detailed journal of your system’s activities, capturing specific events within your application or infrastructure. They often contain timestamps, messages, and relevant data about each event. By analyzing logs, you can gain valuable insights into the chronological order of events, troubleshoot specific issues, identify root causes of errors, and understand user behavior patterns.
- Metrics
-
Metrics are numerical measurements that provide a quantitative view of your system’s performance over time. They represent continuous data streams aggregated and summarized at regular intervals. Metrics allow you to monitor trends, identify performance bottlenecks, and gauge the overall health of your system. They are essential for scaling your infrastructure and ensuring optimal resource utilization.
- Traces
-
Traces delve into the flow of requests within your system, mapping the complete journey of a user request as it traverses different components and services. They often include timestamps, identifiers, and detailed information about each step in handling the request. Traces are invaluable for understanding complex, distributed systems where requests involve multiple services. They help pinpoint performance issues within specific parts of the request flow and identify potential bottlenecks.
While each pillar offers valuable insights on its own, their true power lies in their synergy. Logs provide context for metrics, metrics help identify trends in logs, and traces offer a detailed view of what the logs and metrics represent within a specific request flow. Analyzing all three pillars together gives you a holistic understanding of your system’s behavior. This comprehensive view lets you diagnose problems effectively, optimize performance, and ensure a seamless user experience.
Furthermore, observability empowers postmortem analyses of failure incidents. By examining logs, metrics, and traces collected during and after an incident, you can gain deep insights into the root causes and underlying issues that contributed to the failure. This data-driven approach allows you to identify patterns, vulnerabilities, and areas for improvement, fostering a culture of continuous learning and refinement, ultimately leading to more resilient systems.
In the context of resilient design, observability serves as an early warning system, alerting you to potential problems before they cause significant disruptions. By leveraging observability tools and techniques, you can proactively address issues, minimize downtime, and ensure your workloads’ continuous availability and performance.
Continuous Testing and Chaos Engineering
Testing is a recurring theme throughout this book, and while we will dive into it quite a bit, the subject is vast enough to warrant its own book. The fundamental principle is this: you should be testing everything. This encompasses all your application code, IaC, change management processes, failure management processes, recovery processes, observability monitoring, and alerting mechanisms. Testing should be an ongoing practice, enabling you to learn from observations and continuously enhance your systems. We will explore this further in “Continuous Resilience”.
Traditional code testing techniques, such as unit tests, integration tests, and regression tests, are pivotal in maintaining code quality and detecting potential issues early in the development lifecycle. Integrating these automated tests into your CI/CD pipeline is a must. These tests validate individual code units, ensure the smooth interaction of different modules or components, and ensure that new code changes do not lead to functionality regressions. While traditional testing effectively catches bugs, performance issues, and integration problems, it often struggles to replicate the complexities and unpredictability of real-world scenarios. Unexpected events and failures can result in severe system disruptions and costly downtime, underscoring the need for more comprehensive testing approaches.
Chaos engineering is a disciplined approach to identifying system vulnerabilities by proactively introducing controlled disruptions. It operates on the principle that intentionally injecting failures into a system can uncover weaknesses and potential points of failure before they manifest in a real-world scenario. This allows for proactive remediation, strengthening the system’s resilience and ensuring it can withstand unexpected disruptions.
Traditional testing verifies that a system functions as expected under normal operating conditions. Chaos engineering, on the other hand, goes beyond the norm, intentionally pushing systems to their limits to expose vulnerabilities that may not be apparent in traditional testing scenarios. By simulating real-world failures, chaos engineering helps you understand how your systems behave under stress and identify areas for improvement.
Best practices in chaos engineering include:
- Start small and gradually increase complexity
-
Begin with simple experiments and progressively increase the complexity and severity of disruptions as you gain confidence in your system’s ability to handle them.
- Define clear hypotheses and metrics
-
Each experiment should have a clearly defined hypothesis and measurable metrics to determine whether the system behaved as expected.
- Prioritize blast radius control
-
Implement safeguards to limit the impact of experiments and prevent them from affecting production environments or users.
- Automate experiments
-
Automate the execution and analysis of chaos experiments to ensure consistency and repeatability.
- Continuous learning
-
Analyze each experiment’s results, identify improvement areas, and implement changes to enhance system resilience.
Chaos engineering shifts the approach from reactive to proactive, empowering you to anticipate and mitigate potential failures before they occur. Chaos engineering represents a paradigm shift in how you approach system resilience. By deliberately introducing controlled disruptions, you can gain invaluable insights into the behavior of your systems under stress. This knowledge empowers you to make informed decisions regarding system design, infrastructure investments, and operational procedures, ultimately enhancing your technology stack’s overall reliability, robustness, and resilience.
AWS Fault Injection Service (FIS) is a powerful tool for implementing chaos engineering principles, enabling you to proactively enhance your AWS workloads’ resilience. It’s a fully managed service that allows you to inject controlled disruptions, simulating real-world failures like EC2 instance terminations, API throttling, Availability Zone power outages, or network latency. By observing how your applications and infrastructure respond under stress, you can identify and address vulnerabilities before they impact your customers.
Using AWS FIS, you gain several key advantages:
- Simplified chaos experiments
-
FIS eliminates the need to build and manage your own chaos engineering tools, saving you valuable time and resources.
- Safe fault injection
-
With FIS, you can conduct fault injection experiments in a safe and controlled environment. This ensures that your experiments don’t impact production systems, giving you the confidence to test without fear of disrupting your operations.
- Comprehensive insights
-
Using FIS, you gain comprehensive insights into the results of your chaos experiments. FIS offers detailed reports and metrics, helping you pinpoint vulnerabilities and prioritize remediation efforts, thereby strengthening your infrastructure’s resilience.
- Automated chaos testing
-
Integrate FIS with your CI/CD pipelines to seamlessly incorporate chaos experiments into your regular testing processes, fostering a culture of continuous improvement.
- Scalable experiments
-
FIS enables you to easily replicate experiments across multiple AWS accounts and AWS Regions, ensuring consistent testing across your entire infrastructure.
By leveraging FIS, you streamline the implementation of chaos engineering on AWS. This accelerates your journey toward building more resilient and reliable systems and strengthens your confidence in your infrastructure’s ability to withstand unexpected disruptions. With FIS, you can proactively identify and address weaknesses, ultimately improving the overall customer experience and minimizing the impact of potential failures.
CI/CD and Automation
Continuous integration and continuous delivery (CI/CD) are integral to building resilient systems. CI/CD practices automate the process of integrating, testing, and deploying code changes, fostering a culture of rapid iteration and continuous improvement. This streamlined approach minimizes human error, accelerates the delivery of new features and fixes, and enables swift identification and resolution of issues, reducing potential vulnerabilities that could lead to outages.
The standardized and repeatable nature of CI/CD processes eliminates variability and potential errors associated with manual processes. This consistency ensures reliable and predictable deployments across environments, reducing the risk of configuration drift and unexpected failures. CI/CD is more than just tools and processes; it’s a mindset prioritizing continuous value delivery while maintaining system stability. By fostering collaboration, automation, and continuous improvement, CI/CD empowers organizations to build resilient systems that adapt to changing requirements, withstand disruptions, and deliver a seamless user experience.
Consider these best practices to maximize the benefits of CI/CD in building resilient systems. Encourage developers to commit code changes frequently, ideally multiple times a day. Committing code often reduces the risk of merge conflicts and makes isolating and fixing issues easier. Implement a comprehensive suite of automated tests covering your application’s various aspects, including unit, integration, and end-to-end tests. Automated testing ensures that code changes don’t introduce new bugs or regressions. Additionally, it provides rapid feedback to developers on the results of their code changes, enabling them to address issues promptly and maintain the quality of the codebase.
Treat your infrastructure as code and use immutable patterns. Instead of modifying existing infrastructure, create new instances for each deployment, ensuring consistency and reducing the risk of configuration drift. Implement monitoring and observability tools to gain real-time insights into your applications’ performance and health. Observability lets you quickly detect and respond to issues, minimizing their impact.
Automate the deployment process to reduce human error and ensure consistent deployments across different environments. Have well-defined rollback strategies to quickly revert to a previous stable version of your application if a deployment fails or causes issues. Finally, integrate security testing into your CI/CD pipeline to identify and address security vulnerabilities early in development, reducing the risk of security breaches.
By implementing these best practices, you can leverage CI/CD to build more resilient systems that quickly adapt to changes, recover from failures, and deliver a reliable and consistent user experience.
Continuous Resilience
Continuous resilience involves a commitment to strengthening organizational capabilities, processes, and systems to withstand and recover from various disruptions.
Unlike traditional approaches, continuous resilience emphasizes a proactive and iterative approach to resilience building. It focuses on ongoing analysis, refinement, and optimization of applications and processes to ensure that resilience goals remain efficient, effective, and aligned with evolving business needs.
Creating a culture of continuous resilience can be challenging for organizations. It requires a shift in mindset from reactive to proactive resilience management, and buy-in from executives and stakeholders. By embracing continuous resilience, you can build software systems that are functional, adaptable, and capable of handling disruptions effectively. This proactive approach minimizes downtime, ensures business continuity, and contributes to overall business success.
Remember, resilience is a journey, not a sprint. The word “continuous” is used throughout this book to emphasize the ongoing nature of resilience building. It requires a sustained commitment to learning, adaptation, and improvement to ensure that your systems remain resilient in the face of ever-changing challenges.
Summary
This chapter has provided you with a comprehensive understanding of the multifaceted nature of building resilient systems. You’ve learned that resilience goes beyond technology, encompassing people, processes, and a Shared Responsibility Model between AWS and you, the customer.
You’ve firmly grasped the importance of setting clear resilience goals, conducting business impact analysis, and assessing risks to identify critical vulnerabilities. This understanding lets you appreciate the significance of defining recovery objectives like RTO, RPO, and downtime tolerance. You’ve also explored the concept of BRT and the relevance of MTBF, MTTD, and MTTR in setting realistic resilience targets.
Furthermore, you’ve delved into the AWS Resilience Analysis Framework and the AWS Well-Architected Framework, gaining valuable insights into how these frameworks can guide you in designing and implementing resilient workloads on AWS. You’ve also recognized the critical importance of high availability strategies in minimizing downtime during minor disruptions, and which disaster recovery strategies to employ to recover from significant impairments within your recovery time frames.
Additionally, you’ve explored the considerations and trade-offs involved in multi-region deployments, emphasizing the importance of aligning technical decisions with your business strategies.
You’ve learned about the nuances of networking in the AWS Shared Responsibility Model and the importance of effective quota management. You now understand the critical role of change management, failure management, and observability in building resilient systems. You’ve also recognized the significance of continuous testing and chaos engineering, including the benefits of using AWS Fault Injection Service to identify and address vulnerabilities proactively.
You’ve learned about the importance of CI/CD and automation in streamlining development and deployment processes, minimizing errors, and ensuring consistency. Finally, you’ve been introduced to continuous resilience, emphasizing the ongoing nature of resilience building and the need for a proactive and iterative approach to adapting to evolving challenges.
Armed with this foundational knowledge, you’re now ready to embark on your resilience journey. In the next chapter, we will guide you through setting up your hands-on environment, and then you can start applying these concepts firsthand in the hands-on exercises and begin building resilient systems on AWS.
Get Engineering Resilient Systems on AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

