Chapter 4. Type Design
Show me your flowcharts and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t usually need your flowcharts; they’ll be obvious.
Fred Brooks, The Mythical Man Month (Addison-Wesley Professional)
The language in Fred Brooks’s quote is dated, but the sentiment remains true: code is difficult to understand if you can’t see the data or data types on which it operates. This is one of the great advantages of a type system: by writing out types, you make them visible to readers of your code. And this makes your code understandable.
Other chapters cover the nuts and bolts of TypeScript types: using them, inferring them, transforming them, and writing declarations with them. This chapter discusses the design of the types themselves. The examples in this chapter are all written with TypeScript in mind, but most of the ideas are more broadly applicable.
If you write your types well, then with any luck your flowcharts will be obvious, too.
Item 29: Prefer Types That Always Represent Valid States
If you design your types well, your code should be straightforward to write. But if you design your types poorly, no amount of cleverness or documentation will save you. Your code will be confusing and prone to bugs.
A key to effective type design is crafting types that can only represent a valid state. This item walks through a few examples of how this can go wrong and shows you how to fix them.
Suppose you’re building a web application that lets you select a page, loads the content of that page, and then displays it. You might write the state like this:
interfaceState{pageText:string;isLoading:boolean;error?:string;}
When you write your code to render the page, you need to consider all of these fields:
functionrenderPage(state:State){if(state.error){return`Error! Unable to load${currentPage}:${state.error}`;}elseif(state.isLoading){return`Loading${currentPage}...`;}return`<h1>${currentPage}</h1>\n${state.pageText}`;}
Is this right, though? What if isLoading and error are both set? What would that mean? Is it better to display the loading message or the error message? It’s hard to say! There’s not enough information available.
Or what if you’re writing a changePage function? Here’s an attempt:
asyncfunctionchangePage(state:State,newPage:string){state.isLoading=true;try{constresponse=awaitfetch(getUrlForPage(newPage));if(!response.ok){thrownewError(`Unable to load${newPage}:${response.statusText}`);}consttext=awaitresponse.text();state.isLoading=false;state.pageText=text;}catch(e){state.error=''+e;}}
There are many problems with this! Here are a few:
-
We forgot to set
state.isLoadingtofalsein the error case. -
We didn’t clear out
state.error, so if the previous request failed, then you’ll keep seeing that error message instead of a loading message or the new page. -
If the user changes pages again while the page is loading, who knows what will happen. They might see a new page and then an error, or the first page and not the second, depending on the order in which the responses come back.
The problem is that the state includes both too little information (which request failed? which is loading?) and too much: the State type allows both isLoading and error to be set, even though this represents an invalid state. This makes both
render() and changePage() impossible to implement well.
Here’s a better way to represent the application state:
interfaceRequestPending{state:'pending';}interfaceRequestError{state:'error';error:string;}interfaceRequestSuccess{state:'ok';pageText:string;}typeRequestState=RequestPending|RequestError|RequestSuccess;interfaceState{currentPage:string;requests:{[page:string]:RequestState};}
This uses a tagged union (also known as a “discriminated union”) to explicitly model the different states that a network request can be in. This version of the state is three to four times longer, but it has the enormous advantage of not admitting invalid states. The current page is modeled explicitly, as is the state of every request that you issue. As a result, the renderPage and changePage functions are easy to implement:
functionrenderPage(state:State){const{currentPage}=state;constrequestState=state.requests[currentPage];switch(requestState.state){case'pending':return`Loading${currentPage}...`;case'error':return`Error! Unable to load${currentPage}:${requestState.error}`;case'ok':return`<h1>${currentPage}</h1>\n${requestState.pageText}`;}}asyncfunctionchangePage(state:State,newPage:string){state.requests[newPage]={state:'pending'};state.currentPage=newPage;try{constresponse=awaitfetch(getUrlForPage(newPage));if(!response.ok){thrownewError(`Unable to load${newPage}:${response.statusText}`);}constpageText=awaitresponse.text();state.requests[newPage]={state:'ok',pageText};}catch(e){state.requests[newPage]={state:'error',error:''+e};}}
The ambiguity from the first implementation is entirely gone: it’s clear what the current page is, and every request is in exactly one state. If the user changes the page after a request has been issued, that’s no problem either. The old request still completes, but it doesn’t affect the UI.
For a simpler but more dire example, consider the fate of Air France Flight 447, an Airbus 330 that disappeared over the Atlantic on June 1, 2009. The Airbus was a fly-by-wire aircraft, meaning that the pilots’ control inputs went through a computer system before affecting the physical control surfaces of the plane. In the wake of the crash, many questions were raised about the wisdom of relying on computers to make such life-and-death decisions. Two years later when the black box recorders were recovered from the bottom of the ocean, they revealed many factors that led to the crash. A key factor was bad state design.
The cockpit of the Airbus 330 had a separate set of controls for the pilot and copilot. The “side sticks” controlled the angle of attack. Pulling back would send the airplane into a climb, while pushing forward would make it dive. The Airbus 330 used a system called “dual input” mode, which let the two side sticks move independently. Here’s how you might model its state in TypeScript:
interfaceCockpitControls{/** Angle of the left side stick in degrees, 0 = neutral, + = forward */leftSideStick:number;/** Angle of the right side stick in degrees, 0 = neutral, + = forward */rightSideStick:number;}
Suppose you were given this data structure and asked to write a getStickSetting function that computed the current stick setting. How would you do it?
One way would be to assume that the pilot (who sits on the left) is in control:
functiongetStickSetting(controls:CockpitControls){returncontrols.leftSideStick;}
But what if the copilot has taken control? Maybe you should use whichever stick is away from zero:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}returnleftSideStick;}
But there’s a problem with this implementation: we can only be confident returning the left setting if the right one is neutral. So you should check for that:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}elseif(rightSideStick===0){returnleftSideStick;}// ???}
What do you do if they’re both non-zero? Hopefully they’re about the same, in which case you could just average them:
functiongetStickSetting(controls:CockpitControls){const{leftSideStick,rightSideStick}=controls;if(leftSideStick===0){returnrightSideStick;}elseif(rightSideStick===0){returnleftSideStick;}if(Math.abs(leftSideStick-rightSideStick)<5){return(leftSideStick+rightSideStick)/2;}// ???}
But what if they’re not? Can you throw an error? Not really: the wing flaps need to be set at some angle!
On Air France 447, the copilot silently pulled back on his side stick as the plane entered a storm. It gained altitude but eventually lost speed and entered a stall, a condition in which the plane is moving too slowly to effectively generate lift. It began to drop.
To escape a stall, pilots are trained to push the controls forward to make the plane dive and regain speed. This is exactly what the pilot did. But the copilot was still silently pulling back on his side stick. And the Airbus function looked like this:
functiongetStickSetting(controls:CockpitControls){return(controls.leftSideStick+controls.rightSideStick)/2;}
Even though the pilot pushed the stick fully forward, it averaged out to nothing. He had no idea why the plane wasn’t diving. By the time the copilot revealed what he’d done, the plane had lost too much altitude to recover and it crashed into the ocean, killing all 228 people on board.
The point of all this is that there is no good way to implement getStickSetting given that input! The function has been set up to fail. In most planes the two sets of controls are mechanically connected. If the copilot pulls back, the pilot’s controls will also pull back. The state of these controls is simple to express:
interfaceCockpitControls{/** Angle of the stick in degrees, 0 = neutral, + = forward */stickAngle:number;}
And now, as in the Fred Brooks quote from the start of the chapter, our flowcharts are obvious. You don’t need a getStickSetting function at all.
As you design your types, take care to think about which values you are including and which you are excluding. If you only allow values that represent valid states, your code will be easier to write and TypeScript will have an easier time checking it. This is a very general principle, and several of the other items in this chapter will cover specific manifestations of it.
Item 30: Be Liberal in What You Accept and Strict in What You Produce
This idea is known as the robustness principle or Postel’s Law, after Jon Postel, who wrote it in the context of the TCP networking protocol:
TCP implementations should follow a general principle of robustness: be conservative in what you do, be liberal in what you accept from others.
A similar rule applies to the contracts for functions. It’s fine for your functions to be broad in what they accept as inputs, but they should generally be more specific in what they produce as outputs.
As an example, a 3D mapping API might provide a way to position the camera and calculate a viewport for a bounding box:
declarefunctionsetCamera(camera:CameraOptions):void;declarefunctionviewportForBounds(bounds:LngLatBounds):CameraOptions;
It is convenient that the result of viewportForBounds can be passed directly to setCamera to position the camera.
Let’s look at the definitions of these types:
interfaceCameraOptions{center?:LngLat;zoom?:number;bearing?:number;pitch?:number;}typeLngLat={lng:number;lat:number;}|{lon:number;lat:number;}|[number,number];
The fields in CameraOptions are all optional because you might want to set just the center or zoom without changing the bearing or pitch. The LngLat type also makes setCamera liberal in what it accepts: you can pass in a {lng, lat} object, a {lon, lat} object, or a [lng, lat] pair if you’re confident you got the order right. These accommodations make the function easy to call.
The viewportForBounds function takes in another “liberal” type:
typeLngLatBounds={northeast:LngLat,southwest:LngLat}|[LngLat,LngLat]|[number,number,number,number];
You can specify the bounds either using named corners, a pair of lat/lngs, or a four-tuple if you’re confident you got the order right. Since LngLat already accommodates three forms, there are no fewer than 19 possible forms for LngLatBounds (3 × 3 + 3 × 3 + 1). Liberal indeed!
Now let’s write a function that adjusts the viewport to accommodate a GeoJSON feature and stores the new viewport in the URL (we’ll assume we have a helper function to calculate the bounding box of a GeoJSON feature):
functionfocusOnFeature(f:Feature){constbounds=calculateBoundingBox(f);// helper functionconstcamera=viewportForBounds(bounds);setCamera(camera);const{center:{lat,lng},zoom}=camera;// ~~~ Property 'lat' does not exist on type ...// ~~~ Property 'lng' does not exist on type ...zoom;// ^? const zoom: number | undefinedwindow.location.search=`?v=@${lat},${lng}z${zoom}`;}
Whoops! Only the zoom property exists, but its type is inferred as number|undefined, which is also problematic. The issue is that the type declaration for viewportForBounds indicates that it is liberal not just in what it accepts but also in what it
produces. The only type-safe way to use the camera result is to introduce a code branch for each component of the union type.
The return type with lots of optional properties and union types makes viewportForBounds difficult to use. Its broad parameter type is convenient, but its broad return type is not. A more convenient API would be strict in what it produces.
One way to do this is to distinguish a canonical format for coordinates. Following JavaScript’s convention of distinguishing “array” and “array-like” (Item 17), you can draw a distinction between LngLat and LngLatLike. You can also distinguish between a fully defined Camera type and the partial version accepted by setCamera:
interfaceLngLat{lng:number;lat:number;};typeLngLatLike=LngLat|{lon:number;lat:number;}|[number,number];interfaceCamera{center:LngLat;zoom:number;bearing:number;pitch:number;}interfaceCameraOptionsextendsOmit<Partial<Camera>,'center'>{center?:LngLatLike;}typeLngLatBounds={northeast:LngLatLike,southwest:LngLatLike}|[LngLatLike,LngLatLike]|[number,number,number,number];declarefunctionsetCamera(camera:CameraOptions):void;declarefunctionviewportForBounds(bounds:LngLatBounds):Camera;
The loose CameraOptions type adapts the stricter Camera type. Using Partial<Camera> as the parameter type in setCamera would not work here since you do want to allow LngLatLike objects for the center property. And you can’t write "CameraOptions extends Partial<Camera>" since LngLatLike is a supertype of LngLat, not a subtype. (If this feels backwards, head over to Item 7 for a refresher.)
If this seems too complicated, you could also write the type out explicitly at the cost of some repetition:
interfaceCameraOptions{center?:LngLatLike;zoom?:number;bearing?:number;pitch?:number;}
In either case, with these new type declarations the focusOnFeature function passes the type checker:
functionfocusOnFeature(f:Feature){constbounds=calculateBoundingBox(f);constcamera=viewportForBounds(bounds);setCamera(camera);const{center:{lat,lng},zoom}=camera;// OK// ^? const zoom: numberwindow.location.search=`?v=@${lat},${lng}z${zoom}`;}
This time the type of zoom is number, rather than number|undefined. The viewportForBounds function is now much easier to use. If there were any other functions that produced bounds, you would also need to introduce a canonical form and a distinction between LngLatBounds and LngLatBoundsLike.
Is allowing 19 possible forms of bounding box a good design? Perhaps not. But if you’re writing type declarations for a library that does this, you need to model its behavior. Just don’t have 19 return types!
One of the most common applications of this pattern is to functions that take arrays as parameters. For example, here’s a function that sums the elements of an array:
functionsum(xs:number[]):number{letsum=0;for(constxofxs){sum+=x;}returnsum;}
The return type of number is quite strict. Great! But what about the parameter type of number[]? We’re not using many of its capabilities, so it could be looser. Item 17 discussed the ArrayLike type, and ArrayLike<number> would work well here. Item 14 discussed readonly arrays, and readonly number[] would also work well as a parameter type.
But if you only need to iterate over the parameter, then Iterable is the broadest type of all:
functionsum(xs:Iterable<number>):number{letsum=0;for(constxofxs){sum+=x;}returnsum;}
This works as you’d expect with an array:
constsix=sum([1,2,3]);// ^? const six: number
The advantage of using Iterable here instead of Array or ArrayLike is that it also allows generator expressions:
function*range(limit:number){for(leti=0;i<limit;i++){yieldi;}}constzeroToNine=range(10);// ^? const zeroToNine: Generator<number, void, unknown>constfortyFive=sum(zeroToNine);// ok, result is 45
If your function just needs to iterate over its parameter, use Iterable to make it work with generators as well. If you’re using for-of loops then you won’t need to change a single line of your code.
Things to Remember
-
Input types tend to be broader than output types. Optional properties and union types are more common in parameter types than return types.
-
Avoid broad return types since these will be awkward for clients to use.
-
To reuse types between parameters and return types, introduce a canonical form (for return types) and a looser form (for parameters).
-
Use
Iterable<T>instead ofT[]if you only need to iterate over your function parameter.
Item 31: Don’t Repeat Type Information in Documentation
/*** Returns a string with the foreground color.* Takes zero or one arguments. With no arguments, returns the* standard foreground color. With one argument, returns the foreground color* for a particular page.*/functiongetForegroundColor(page?:string){returnpage==='login'?{r:127,g:127,b:127}:{r:0,g:0,b:0};}
The code and the comment disagree! Without more context it’s hard to say which is right, but something is clearly amiss. As a professor of mine used to say, “when your code and your comments disagree, they’re both wrong!”
Let’s assume that the code represents the desired behavior. There are a few issues with this comment:
-
It says that the function returns the color as a
stringwhen it actually returns an{r, g, b}object. -
It explains that the function takes zero or one arguments, which is already clear from the type signature.
-
It’s needlessly wordy: the comment is longer than the function declaration and implementation!
TypeScript’s type annotation system is designed to be compact, descriptive, and readable. Its developers are language experts with decades of experience. It’s almost certainly a better way to express the types of your function’s inputs and outputs than your prose!
And because your type annotations are checked by the TypeScript compiler, they’ll never get out of sync with the implementation. Perhaps getForegroundColor used to return a string but was later changed to return an object. The person who made the change might have forgotten to update the long comment.
Nothing stays in sync unless it’s forced to. With type annotations, TypeScript’s type checker is that force! If you put type information in annotations rather than documentation, you greatly increase your confidence that it will remain correct as the code evolves.
A better comment might look like this:
/** Get the foreground color for the application or a specific page. */functiongetForegroundColor(page?:string):Color{// ...}
If you want to describe a particular parameter, use an @param JSDoc annotation. See Item 68 for more on this.
Comments about a lack of mutation are also suspect:
/** Sort the strings by numeric value (i.e. "2" < "10"). Does not modify nums. */functionsortNumerically(nums:string[]):string[]{returnnums.sort((a,b)=>Number(a)-Number(b));}
The comment says that this function doesn’t modify its parameter, but the sort method on Arrays operates in place, so it very much does. Claims in comments don’t count for much.
If you declare the parameter readonly instead (Item 14), then you can let TypeScript enforce the contract:
/** Sort the strings by numeric value (i.e. "2" < "10"). */functionsortNumerically(nums:readonlystring[]):string[]{returnnums.sort((a,b)=>Number(a)-Number(b));// ~~~~ ~ ~ Property 'sort' does not exist on 'readonly string[]'.}
A correct implementation of this function would either copy the array or use the immutable toSorted method:
/** Sort the strings by numeric value (i.e. "2" < "10"). */functionsortNumerically(nums:readonlystring[]):string[]{returnnums.toSorted((a,b)=>Number(a)-Number(b));// ok}
What’s true for comments is also true for variable names. Avoid putting types in them: rather than naming a variable ageNum, name it age and make sure it’s really a number.
An exception to this is for numbers with units. If it’s not clear what the units are, you may want to include them in a variable or property name. For instance, timeMs is a much clearer name than just time, and temperatureC is a much clearer name than temperature. Item 64 describes “brands,” which provide a more type-safe approach to modeling units.
Things to Remember
-
Avoid repeating type information in comments and variable names. In the best case it is duplicative of type declarations, and in the worst case it will lead to conflicting information.
-
Declare parameters
readonlyrather than saying that you don’t mutate them. -
Consider including units in variable names if they aren’t clear from the type (e.g.,
timeMsortemperatureC).
Item 32: Avoid Including null or undefined in Type Aliases
In this code, is the optional chain (?.) necessary? Could user ever be null?
functiongetCommentsForUser(comments:readonlyComment[],user:User){returncomments.filter(comment=>comment.userId===user?.id);}
Even assuming strictNullChecks, it’s impossible to say without seeing the definition of User. If it’s a type alias that allows null or undefined, then the optional chain is needed:
typeUser={id:string;name:string;}|null;
On the other hand, if it’s a simple object type, then it’s not:
interfaceUser{id:string;name:string;}
As a general rule, it’s better to avoid type aliases that allow null or undefined values. While the type checker won’t be confused if you break this rule, human readers of your code will be. When we read a type name like User, we assume that it represents a user, rather than maybe representing a user.
If you must include null in a type alias for some reason, do readers of your code a favor and use a name that’s unambiguous:
typeNullableUser={id:string;name:string;}|null;
But why do that when User|null is a more succinct and universally recognizable
syntax?
functiongetCommentsForUser(comments:readonlyComment[],user:User|null){returncomments.filter(comment=>comment.userId===user?.id);}
This rule is about the top level of type aliases. It’s not concerned with a null or
undefined (or optional) property in a larger object:
typeBirthdayMap={[name:string]:Date|undefined;};
Just don’t do this:
typeBirthdayMap={[name:string]:Date|undefined;}|null;
There are also reasons to avoid null values and optional fields in object types, but that’s a topic for Items 33 and 37. For now, avoid type aliases that will be confusing to readers of your code. Prefer type aliases that represent something, rather than representing something or null or undefined.
Item 33: Push Null Values to the Perimeter of Your Types
When you first turn on strictNullChecks, it may seem as though you have to add scores of if statements checking for null and undefined values throughout your code. This is often because the relationships between null and non-null values are implicit: when variable A is non-null, you know that variable B is also non-null and vice versa. These implicit relationships are confusing both for human readers of your code and for the type checker.
Values are easier to work with when they’re either completely null or completely non-null, rather than a mix. You can model this by pushing the null values out to the perimeter of your structures.
Suppose you want to calculate the min and max of a list of numbers. We’ll call this the “extent.” Here’s an attempt:
// @strictNullChecks: falsefunctionextent(nums:Iterable<number>){letmin,max;for(constnumofnums){if(!min){min=num;max=num;}else{min=Math.min(min,num);max=Math.max(max,num);}}return[min,max];}
The code type checks (without strictNullChecks) and has an inferred return type of number[], which seems fine. But it has a bug and a design flaw:
-
If the min or max is zero, it may get overridden. For example,
extent([0, 1, 2])will return[1, 2]rather than[0, 2]. -
If the
numsarray is empty, the function will return[undefined, undefined].
This sort of object with several undefineds will be difficult for clients to work with and is exactly the sort of type that this item discourages. We know from reading the source code that either both min and max will be undefined or neither will be, but that information isn’t represented in the type system.
Turning on strictNullChecks makes the issue with undefined more apparent:
functionextent(nums:Iterable<number>){letmin,max;for(constnumofnums){if(!min){min=num;max=num;}else{min=Math.min(min,num);max=Math.max(max,num);// ~~~ Argument of type 'number | undefined' is not// assignable to parameter of type 'number'}}return[min,max];}
The return type of extent is now inferred as (number | undefined)[], which makes the design flaw more apparent. This is likely to manifest as a type error wherever you call extent:
const[min,max]=extent([0,1,2]);constspan=max-min;// ~~~ ~~~ Object is possibly 'undefined'
The error in the implementation of extent comes about because you’ve excluded undefined as a value for min but not max. The two are initialized together, but this information isn’t present in the type system. You could make it go away by adding a check for max, too, but this would be doubling down on the bug.
A better solution is to put min and max in the same object and make this object either fully null or fully non-null:
functionextent(nums:Iterable<number>){letminMax:[number,number]|null=null;for(constnumofnums){if(!minMax){minMax=[num,num];}else{const[oldMin,oldMax]=minMax;minMax=[Math.min(num,oldMin),Math.max(num,oldMax)];}}returnminMax;}
The return type is now [number, number] | null, which is easier for clients to work with. min and max can be retrieved with either a non-null assertion:
const[min,max]=extent([0,1,2])!;constspan=max-min;// OK
or a single check:
constrange=extent([0,1,2]);if(range){const[min,max]=range;constspan=max-min;// OK}
By using a single object to track the extent, we’ve improved our design, helped TypeScript understand the relationship between null values, and fixed the bug: the
if (!minMax) check is now problem free.
(A next step might be to prevent passing non-empty lists to extent, which would remove the possibility of returning null altogether. Item 64 presents a way you might represent a non-empty list in TypeScript’s type system.)
A mix of null and non-null values can also lead to problems in classes. For instance, suppose you have a class that represents both a user and their posts on a forum:
classUserPosts{user:UserInfo|null;posts:Post[]|null;constructor(){this.user=null;this.posts=null;}asyncinit(userId:string){returnPromise.all([async()=>this.user=awaitfetchUser(userId),async()=>this.posts=awaitfetchPostsForUser(userId)]);}getUserName(){// ...?}}
While the two network requests are loading, the user and posts properties will be null. At any time, they might both be null, one might be null, or they might both be non-null. There are four possibilities. This complexity will seep into every method on the class. This design is almost certain to lead to confusion, a proliferation of null checks, and bugs.
A better design would wait until all the data used by the class is available:
classUserPosts{user:UserInfo;posts:Post[];constructor(user:UserInfo,posts:Post[]){this.user=user;this.posts=posts;}staticasyncinit(userId:string):Promise<UserPosts>{const[user,posts]=awaitPromise.all([fetchUser(userId),fetchPostsForUser(userId)]);returnnewUserPosts(user,posts);}getUserName(){returnthis.user.name;}}
Now the UserPosts class is fully non-null, and it’s easy to write correct methods on it. Of course, if you need to perform operations while data is partially loaded, then you’ll need to deal with the multiplicity of null and non-null states.
Don’t be tempted to replace nullable properties with Promises. This tends to lead to even more confusing code and forces all your methods to be async. Promises clarify the code that loads data but tend to have the opposite effect on the class that uses that data.
Things to Remember
-
Avoid designs in which one value being
nullor notnullis implicitly related to another value beingnullor notnull. -
Push
nullvalues to the perimeter of your API by making larger objects eithernullor fully non-null. This will make code clearer both for human readers and for the type checker. -
Consider creating a fully non-
nullclass and constructing it when all values are available.
Item 34: Prefer Unions of Interfaces to Interfaces with Unions
If you create an interface whose properties are union types, you should ask whether the type would make more sense as a union of more precise interfaces.
Suppose you’re building a vector drawing program and want to define an interface for layers with specific geometry types:
interfaceLayer{layout:FillLayout|LineLayout|PointLayout;paint:FillPaint|LinePaint|PointPaint;}
The layout field controls how and where the shapes are drawn (rounded corners? straight?), while the paint field controls styles (is the line blue? thick? thin? dashed?).
The intention is that a Layer will have matching layout and paint properties. A FillLayout should go with a FillPaint, and a LineLayout should go with a LinePaint. But this version of the Layer type also allows a FillLayout with a LinePaint. This possibility makes using the library more error prone and makes this interface difficult to work with.
A better way to model this is with separate interfaces for each type of layer:
interfaceFillLayer{layout:FillLayout;paint:FillPaint;}interfaceLineLayer{layout:LineLayout;paint:LinePaint;}interfacePointLayer{layout:PointLayout;paint:PointPaint;}typeLayer=FillLayer|LineLayer|PointLayer;
By defining Layer in this way, you’ve excluded the possibility of mixed layout and paint properties. This is an example of following Item 29’s advice to prefer types that only represent valid states.
By far the most common example of this pattern is the “tagged union” (or “discriminated union”). In this case, one of the properties is a union of string literal types:
interfaceLayer{type:'fill'|'line'|'point';layout:FillLayout|LineLayout|PointLayout;paint:FillPaint|LinePaint|PointPaint;}
As before, would it make sense to have type: 'fill' but then a LineLayout and PointPaint? Certainly not. Convert Layer to a union of interfaces to exclude this possibility:
interfaceFillLayer{type:'fill';layout:FillLayout;paint:FillPaint;}interfaceLineLayer{type:'line';layout:LineLayout;paint:LinePaint;}interfacePointLayer{type:'paint';layout:PointLayout;paint:PointPaint;}typeLayer=FillLayer|LineLayer|PointLayer;
The type property is the “tag” or “discriminant.” It can be accessed at runtime and gives TypeScript just enough information to determine which element of the union type you’re working with. Here, TypeScript is able to narrow the type of Layer in an if statement based on the tag:
functiondrawLayer(layer:Layer){if(layer.type==='fill'){const{paint}=layer;// ^? const paint: FillPaintconst{layout}=layer;// ^? const layout: FillLayout}elseif(layer.type==='line'){const{paint}=layer;// ^? const paint: LinePaintconst{layout}=layer;// ^? const layout: LineLayout}else{const{paint}=layer;// ^? const paint: PointPaintconst{layout}=layer;// ^? const layout: PointLayout}}
By correctly modeling the relationship between the properties in this type, you help TypeScript check your code’s correctness. The same code involving the initial Layer definition would have been cluttered with type assertions.
Because they work so well with TypeScript’s type checker, tagged unions are ubiquitous in TypeScript code. Recognize this pattern and apply it when you can. If you can represent a data type in TypeScript with a tagged union, it’s usually a good idea to do so.
If you think of optional fields as a union of their type and undefined, then they fit the “interface of unions” pattern as well. Consider this type:
interfacePerson{name:string;// These will either both be present or not be presentplaceOfBirth?:string;dateOfBirth?:Date;}
As Item 31 explained, the comment with type information is a strong sign that there might be a problem. There is a relationship between the placeOfBirth and dateOfBirth fields that you haven’t told TypeScript about.
A better way to model this is to move both of these properties into a single object. This is akin to moving null values to the perimeter (Item 33):
interfacePerson{name:string;birth?:{place:string;date:Date;}}
Now TypeScript complains about values with a place but no date of birth:
constalanT:Person={name:'Alan Turing',birth:{// ~~~~ Property 'date' is missing in type// '{ place: string; }' but required in type// '{ place: string; date: Date; }'place:'London'}}
Additionally, a function that takes a Person object only needs to do a single check:
functioneulogize(person:Person){console.log(person.name);const{birth}=person;if(birth){console.log(`was born on${birth.date}in${birth.place}.`);}}
If the structure of the type is outside your control (perhaps it’s coming from an API), then you can still model the relationship between these fields using a now-familiar union of interfaces:
interfaceName{name:string;}interfacePersonWithBirthextendsName{placeOfBirth:string;dateOfBirth:Date;}typePerson=Name|PersonWithBirth;
Now you get some of the same benefits as with the nested object:
functioneulogize(person:Person){if('placeOfBirth'inperson){person// ^? (parameter) person: PersonWithBirthconst{dateOfBirth}=person;// OK// ^? const dateOfBirth: Date}}
In both cases, the type definition makes the relationship between the properties more clear.
While optional properties are often useful, you should think twice before adding one to an interface. Item 37 explores more of the downsides of optional fields.
Things to Remember
-
Interfaces with multiple properties that are union types are often a mistake because they obscure the relationships between these properties.
-
Unions of interfaces are more precise and can be understood by TypeScript.
-
Use tagged unions to facilitate control flow analysis. Because they are so well supported, this pattern is ubiquitous in TypeScript code.
-
Consider whether multiple optional properties could be grouped to more accurately model your data.
Item 35: Prefer More Precise Alternatives to String Types
Recall from Item 7 that the domain of a type is the set of values assignable to that type. The domain of the string type is enormous: "x" and "y" are in it, but so is the complete text of Moby Dick (it starts with "Call me Ishmael…" and is about 1.2 million characters long). When you declare a variable of type string, you should ask whether a narrower type would be more appropriate.
Suppose you’re building a music collection and want to define a type for an album. Here’s an attempt:
interfaceAlbum{artist:string;title:string;releaseDate:string;// YYYY-MM-DDrecordingType:string;// E.g., "live" or "studio"}
The prevalence of string types and the type information in comments (Item 31) are strong indications that this interface isn’t quite right. Here’s what can go wrong:
constkindOfBlue:Album={artist:'Miles Davis',title:'Kind of Blue',releaseDate:'August 17th, 1959',// Oops!recordingType:'Studio',// Oops!};// OK
The releaseDate field is incorrectly formatted (according to the comment) and
'Studio' is capitalized where it should be lowercase. But these values are both strings, so this object is assignable to Album and the type checker doesn’t complain.
These broad string types can mask errors for valid Album objects, too. For example:
functionrecordRelease(title:string,date:string){/* ... */}recordRelease(kindOfBlue.releaseDate,kindOfBlue.title);// OK, should be error
The parameters are reversed in the call to recordRelease but both are strings, so the type checker doesn’t complain. Because of the prevalence of string types, code like this is sometimes called “stringly typed.” (Item 38 explores how repeated positional parameters of any type can be problematic, not just string.)
Can you make the types narrower to prevent these sorts of issues? While the complete text of Moby Dick would be a ponderous artist name or album title, it’s at least plausible. So string is appropriate for these fields. For the releaseDate field, it’s better to use a Date object and avoid issues around formatting. Finally, for the recordingType field, you can define a union type with just two values (you could also use an enum, but I generally recommend avoiding these; see Item 72):
typeRecordingType='studio'|'live';interfaceAlbum{artist:string;title:string;releaseDate:Date;recordingType:RecordingType;}
With these changes, TypeScript is able to do a more thorough check for errors:
constkindOfBlue:Album={artist:'Miles Davis',title:'Kind of Blue',releaseDate:newDate('1959-08-17'),recordingType:'Studio'// ~~~~~~~~~~~~ Type '"Studio"' is not assignable to type 'RecordingType'};
There are advantages to this approach beyond stricter checking. First, explicitly defining the type ensures that its meaning won’t get lost as it’s passed around. If you wanted to find albums of just a certain recording type, for instance, you might define a function like this:
functiongetAlbumsOfType(recordingType:string):Album[]{// ...}
How does the caller of this function know what recordingType is expected to be? It’s just a string. The comment explaining that it’s 'studio' or 'live' is hidden in the definition of Album, where the user might not think to look.
Second, explicitly defining a type allows you to attach documentation to it (see Item 68):
/** What type of environment was this recording made in? */typeRecordingType='live'|'studio';
When you change getAlbumsOfType to take a RecordingType, the caller is able to click through and see the documentation (see Figure 4-1).

Figure 4-1. Using a named type instead of string makes it possible to attach documentation to the type that is surfaced in your editor.
Another common misuse of string is in function parameters. Say you want to write a function that pulls out all the values for a single field in an array. The Underscore and Ramda utility libraries call this pluck:
functionpluck(records,key){returnrecords.map(r=>r[key]);}
How would you type this? Here’s an initial attempt:
functionpluck(records:any[],key:string):any[]{returnrecords.map(r=>r[key]);}
This type checks but isn’t great. The any types are problematic, particularly on the return value (see Item 43). The first step to improving the type signature is introducing a generic type parameter:
functionpluck<T>(records:T[],key:string):any[]{returnrecords.map(r=>r[key]);// ~~~~~~ Element implicitly has an 'any' type// because type '{}' has no index signature}
TypeScript is now complaining that the string type for key is too broad. And it’s right to do so: if you pass in an array of Albums then there are only four valid values for key (“artist,” “title,” “releaseDate,” and “recordingType”), as opposed to the vast set of strings. This is precisely what the keyof Album type is:
typeK=keyofAlbum;// ^? type K = keyof Album// (equivalent to "artist" | "title" | "releaseDate" | "recordingType")
So the fix is to replace string with keyof T:
functionpluck<T>(records:T[],key:keyofT){returnrecords.map(r=>r[key]);}
This passes the type checker. We’ve also let TypeScript infer the return type. How does it do? If you mouse over pluck in your editor, the inferred type is:
functionpluck<T>(record:T[],key:keyofT):T[keyofT][];
T[keyof T] is the type of any possible value in T. If you’re passing in a single string as the key, this is too broad. For example:
constreleaseDates=pluck(albums,'releaseDate');// ^? const releaseDates: (string | Date)[]
The type should be Date[], not (string | Date)[]. While keyof T is much narrower than string, it’s still too broad. To narrow it further, we need to introduce a second type parameter that is a subtype of keyof T (probably a single value):
functionpluck<T,KextendskeyofT>(records:T[],key:K):T[K][]{returnrecords.map(r=>r[key]);}
The type signature is now completely correct. We can check this by calling pluck in a few different ways:
constdates=pluck(albums,'releaseDate');// ^? const dates: Date[]constartists=pluck(albums,'artist');// ^? const artists: string[]consttypes=pluck(albums,'recordingType');// ^? const types: RecordingType[]constmix=pluck(albums,Math.random()<0.5?'releaseDate':'artist');// ^? const mix: (string | Date)[]constbadDates=pluck(albums,'recordingDate');// ~~~~~~~~~~~~~~~// Argument of type '"recordingDate"' is not assignable to parameter of type ...
The language service is even able to offer autocomplete on the keys of Album (as shown in Figure 4-2).
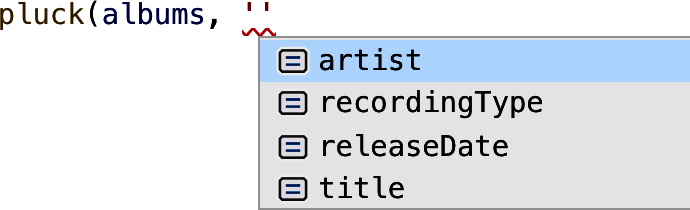
Figure 4-2. Using a parameter type of keyof Album instead of string results in better autocomplete in your editor.
string has some of the same problems as any: when used inappropriately, it permits invalid values and hides relationships between types. This thwarts the type checker and can hide real bugs. TypeScript’s ability to define subsets of string is a powerful way to bring type safety to JavaScript code. Using more precise types will both catch errors and improve the readability of your code.
This item focused on finite sets of strings, but TypeScript also lets you model infinite sets, for example, all the strings that start with “http:”. For these, you’ll want to use template literal types, which are the subject of Item 54.
Things to Remember
-
Avoid “stringly typed” code. Prefer more appropriate types where not every
stringis a possibility. -
Prefer a union of string literal types to
stringif that more accurately describes the domain of a variable. You’ll get stricter type checking and improve the development experience. -
Prefer
keyof Ttostringfor function parameters that are expected to be properties of an object.
Item 36: Use a Distinct Type for Special Values
JavaScript’s string split method is a handy way to break a string around a delimiter:
> 'abcde'.split('c')
[ 'ab', 'de' ]
Let’s write something like split, but for arrays. Here’s an attempt:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=vals.indexOf(val);return[vals.slice(0,index),vals.slice(index+1)];}
This works as you’d expect:
> splitAround([1, 2, 3, 4, 5], 3) [ [ 1, 2 ], [ 4, 5 ] ]
If you try to splitAround an element that’s not in the list, however, it does something quite unexpected:
> splitAround([1, 2, 3, 4, 5], 6) [ [ 1, 2, 3, 4 ], [ 1, 2, 3, 4, 5 ] ]
While it’s not entirely clear what the function should do in this case, it’s definitely not that! How did such simple code result in such strange behavior?
The root issue is that indexOf returns -1 if it can’t find the element in the array. This is a special value: it indicates a failure rather than success. But -1 is just an ordinary number. You can pass it to the Array slice method and you can do arithmetic on it. When you pass a negative number to slice, it interprets it as counting back from the end of the array. And when you add 1 to -1, you get 0. So this evaluates as:
[vals.slice(0,-1),vals.slice(0)]
The first slice returns all but the last element of the array, and the second slice returns a complete copy of the array.
This behavior is a bug. Moreover, it’s unfortunate that TypeScript wasn’t able to help us find this problem. The root issue was that indexOf returned -1 when it couldn’t find the element, rather than, say null. Why is that?
Without hopping in a time machine and visiting the Netscape offices in 1995, it’s hard to know the answer for sure. But we can speculate! JavaScript was heavily influenced by Java, and its indexOf has this same behavior. In Java (and C), a function can’t return a primitive or null. Only objects (or pointers) are nullable. So this behavior may derive from a technical limitation in Java that JavaScript does not share.
In JavaScript (and TypeScript), there’s no problem having a function return a number or null. So we can wrap indexOf:
functionsafeIndexOf<T>(vals:readonlyT[],val:T):number|null{constindex=vals.indexOf(val);returnindex===-1?null:index;}
If we plug that into our original definition of splitAround, we immediately get two type errors:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=safeIndexOf(vals,val);return[vals.slice(0,index),vals.slice(index+1)];// ~~~~~ ~~~~~ 'index' is possibly 'null'}
This is exactly what we want! There are always two cases to consider with indexOf. With the built-in version, TypeScript can’t distinguish them, but with the wrapped version, it can. And it sees here that we’ve only considered the case where the array contained the value.
The solution is to handle the other case explicitly:
functionsplitAround<T>(vals:readonlyT[],val:T):[T[],T[]]{constindex=safeIndexOf(vals,val);if(index===null){return[[...vals],[]];}return[vals.slice(0,index),vals.slice(index+1)];// ok}
Whether this is the right behavior is debatable, but at least TypeScript has forced us to have that debate!
The root problem with the first implementation was that indexOf had two distinct cases, but the return value in the special case (-1) had the same type as the return value in the regular case (number). This meant that from TypeScript’s perspective there was just a single case, and it wasn’t able to detect that we didn’t check for -1.
This situation comes up frequently when you’re designing types. Perhaps you have a type for describing merchandise:
interfaceProduct{title:string;priceDollars:number;}
Then you realize that some products have an unknown price. Making this field optional or changing it to number|null might require a migration and lots of code changes, so instead you introduce a special value:
interfaceProduct{title:string;/** Price of the product in dollars, or -1 if price is unknown */priceDollars:number;}
You ship it to production. A week later your boss is irate and wants to know why you’ve been crediting money to customer cards. Your team works to roll back the change and you’re tasked with writing the postmortem. In retrospect, it would have been much easier to deal with those type errors!
Choosing in-domain special values like -1, 0, or "" is similar in spirit to turning off strictNullChecks. When strictNullChecks is off, you can assign null or
undefined to any type:
// @strictNullChecks: falseconsttruck:Product={title:'Tesla Cybertruck',priceDollars:null,// ok};
This lets a huge class of bugs slip through the type checker because TypeScript doesn’t distinguish between number and number|null. null is a valid value in all types. When you enable strictNullChecks, TypeScript does distinguish between these types and it’s able to detect a whole host of new problems. When you choose an in-domain special value like -1, you’re effectively carving out a non-strict niche in your types. Expedient, yes, but ultimately not the best choice.
null and undefined may not always be the right way to represent special cases since their exact meaning may be context dependent. If you’re modeling the state of a network request, for example, it would be a bad idea to use null to mean an error state and undefined to mean a pending state. Better to use a tagged union to represent these special states more explicitly. Item 29 explores this example in more detail.
Things to Remember
-
Avoid special values that are assignable to regular values in a type. They will reduce TypeScript’s ability to find bugs in your code.
-
Prefer
nullorundefinedas a special value instead of0,-1, or"". -
Consider using a tagged union rather than
nullorundefinedif the meaning of those values isn’t clear.
Item 37: Limit the Use of Optional Properties
As your types evolve, you’ll inevitably want to add new properties to them. To avoid invalidating existing code or data, you might choose to make these properties optional. While this is sometimes the right choice, optional properties do come at a cost and you should think twice before adding them.
Imagine you have a UI component that displays numbers with a label and units. Think “Height: 12 ft” or “Speed: 10 mph”:
interfaceFormattedValue{value:number;units:string;}functionformatValue(value:FormattedValue){/* ... */}
You build a big web application using this component. Perhaps part of it displays formatted information about a hike you’ve taken (“5 miles at 2 mph”):
interfaceHike{miles:number;hours:number;}functionformatHike({miles,hours}:Hike){constdistanceDisplay=formatValue({value:miles,units:'miles'});constpaceDisplay=formatValue({value:miles/hours,units:'mph'});return`${distanceDisplay}at${paceDisplay}`;}
One day you learn about the metric system and decide to support it. To support both metric and imperial, you add a corresponding option to FormattedValue. If needed, the component will do a unit conversion before displaying the value. To minimize changes to existing code and tests, you decide to make the property optional:
typeUnitSystem='metric'|'imperial';interfaceFormattedValue{value:number;units:string;/** default is imperial */unitSystem?:UnitSystem;}
To let the user configure this, we’ll also want to specify a unit system in our app-wide configuration:
interfaceAppConfig{darkMode:boolean;// ... other settings .../** default is imperial */unitSystem?:UnitSystem;}
Now we can update formatHike to support the metric system:
functionformatHike({miles,hours}:Hike,config:AppConfig){const{unitSystem}=config;constdistanceDisplay=formatValue({value:miles,units:'miles',unitSystem});constpaceDisplay=formatValue({value:miles/hours,units:'mph'// forgot unitSystem, oops!});return`${distanceDisplay}at${paceDisplay}`;}
We set unitSystem in one call to formatValue but not the other. This is a bug that means our metric users will see a mix of imperial and metric units.
In fact, our design is a recipe for exactly this sort of bug. In every place that we use the formatValue component, we need to remember to pass in a unitSystem. Whenever we don’t, metric users will see confusing imperial units like yards, acres, or foot-pounds.
It would be nice if there were a way to automatically find every place where we forgot to pass in a unitSystem. This is exactly the sort of thing that type checking is good at, but we’ve kept it from helping us by making the unitSystem property optional.
If you make it required instead, you’ll get a type error everywhere you forgot to set it. You’ll have to fix these one by one, but it’s much better to have TypeScript find these mistakes than to hear about them from confused users!
The “default is imperial” documentation comment is also worrisome. In TypeScript, the default value of an optional property on an object is always undefined. To implement an alternative default, our code is likely to be littered with lines like this:
declareletconfig:AppConfig;constunitSystem=config.unitSystem??'imperial';
Every one of these is an opportunity for a bug. Perhaps another developer on your team forgets that imperial is the default (why is it the default anyway?) and assumes it should be metric:
constunitSystem=config.unitSystem??'metric';
Once again the result will be inconsistent display.
If you need to support old values of the AppConfig interface (perhaps they’re saved as JSON on disk or in a database) then you can’t make the new field required. What you can do instead is split the type in two: one type for un-normalized configurations read from disk, and another with fewer optional properties for use in your app:
interfaceInputAppConfig{darkMode:boolean;// ... other settings .../** default is imperial */unitSystem?:UnitSystem;}interfaceAppConfigextendsInputAppConfig{unitSystem:UnitSystem;// required}
If changing an optional property to required in a subtype feels strange, see Item 7. You could also use Required<InputAppConfig> here.
You’ll want to add some normalization code:
functionnormalizeAppConfig(inputConfig:InputAppConfig):AppConfig{return{...inputConfig,unitSystem:inputConfig.unitSystem??'imperial',};}
This split solves a few problems:
-
It allows the config to evolve and maintain backward compatibility without adding complexity throughout the application.
-
It centralizes the application of default values.
-
It makes it hard to use an
InputAppConfigwhere anAppConfigis expected.
These sorts of “under construction” types come up frequently with network code. See UserPosts in Item 33 for another example.
As you add more optional properties to an interface, you’ll run into a new problem: if you have N optional properties then there are 2N possible combinations of them. That’s a lot of possibilities! If you have 10 optional properties, have you tested all 1,024 combinations? Do all the combinations even make sense? It’s likely that there’s some structure to these options, perhaps some that are mutually exclusive. If so, then your state should model this (see Item 29). This is a problem with options in general, not just optional properties.
Finally, optional properties are a possible source of unsoundness in TypeScript. Item 48 discusses this in more detail.
As you’ve seen, there are lots of reasons to avoid optional properties. So when should you use them? They’re largely unavoidable when describing existing APIs or evolving APIs while maintaining backward compatibility. For huge configurations, it may be prohibitively expensive to fill in all optional fields with default values. And some properties truly are optional: not everyone has a middle name, so an optional middleName property on a Person type is an accurate model. But be aware of the many drawbacks of optional properties, know how to mitigate them, and think twice before adding an optional property if there’s a valid alternative.
Things to Remember
-
Optional properties can prevent the type checker from finding bugs and can lead to repeated and possibly inconsistent code for filling in default values.
-
Think twice before adding an optional property to an interface. Consider whether you could make it required instead.
-
Consider creating distinct types for un-normalized input data and normalized data for use in your code.
Item 38: Avoid Repeated Parameters of the Same Type
What does this function call do?
drawRect(25,50,75,100,1);
Without looking at the function’s parameter list, it’s impossible to say. Here are a few possibilities:
-
It draws a 75 × 100 rectangle with its top left at (25, 50) with an opacity of 1.0.
-
It draws a 50 × 50 rectangle with corners at (25, 50) and (75, 100), with a stroke width of one pixel.
Without more context, it’s hard to know whether this function is being called correctly. And because all the parameters are of the same type, number, the type checker won’t be able to help you if you mix up the order or pass in a width and height instead of a second coordinate.
Suppose this was the function declaration:
functiondrawRect(x:number,y:number,w:number,h:number,opacity:number){// ...}
Any function that takes consecutive parameters of the same type is error prone because the type checker won’t be able to catch incorrect invocations. One way to improve the situation would be to take in distinct Point and Dimension types:
interfacePoint{x:number;y:number;}interfaceDimension{width:number;height:number;}functiondrawRect(topLeft:Point,size:Dimension,opacity:number){// ...}
Because the function now takes three parameters with three different types, the type checker is able to distinguish between them. An incorrect invocation that passes in two points will be an error:
drawRect({x:25,y:50},{x:75,y:100},1.0);// ~// Argument ... is not assignable to parameter of type 'Dimension'.
An alternative fix would be to combine all the parameters into a single object:
interfaceDrawRectParamsextendsPoint,Dimension{opacity:number;}functiondrawRect(params:DrawRectParams){/* ... */}drawRect({x:25,y:50,width:75,height:100,opacity:1.0});
Refactoring a function to take an object rather than positional parameters improves clarity for human readers. And, by associating names with each number, it helps the type checker catch incorrect invocations as well.
As your code evolves, functions may be modified to take more and more parameters. Even if positional parameters worked well at first, at some point they will become a problem. As the saying goes, “If you have a function with 10 parameters, you probably missed some.” Once a function takes more than three or four parameters, you should refactor it to take fewer. (typescript-eslint’s max-params rule can enforce this.)
When the types of the parameters are the same, you should be even more wary of positional parameters. Even two parameters might be a problem.
There are a few exceptions to this rule:
-
If the arguments are commutative (the order doesn’t matter), then there’s no problem.
max(a, b)andisEqual(a, b), for example, are unambiguous. -
If there’s a “natural” order to the parameters, then the potential for confusion is reduced.
array.slice(start, stop)makes more sense thanstop,start, for example. Be careful with this, though: developers might not always agree what a “natural” order is. (Is it year, month, day? Month, day, year? Day, month, year?)
As Scott Meyers wrote in Effective C++, “Make interfaces easy to use correctly and hard to use incorrectly.” It’s hard to argue with that!
Item 39: Prefer Unifying Types to Modeling Differences
TypeScript’s type system gives you powerful tools to map between types. Item 15 and Chapter 6 explain how to use many of them. Once you realize that you can model a transformation using the type system, you may feel an overwhelming urge to do so. And this will feel productive. So many types! So much safety!
If it’s available to you, though, a better option than modeling the difference between two types is to eliminate the difference between those two types. Then no type-level machinery is required, and the cognitive burden of keeping track of which version of a type you’re working with goes away.
To make this more concrete, imagine you have an interface that derives from a database table. Databases typically use snake_case for column names, so this is how your data comes out:
interfaceStudentTable{first_name:string;last_name:string;birth_date:string;}
TypeScript code typically uses camelCase property names. To make the Student type more consistent with the rest of your code, you might introduce an alternate version of Student:
interfaceStudent{firstName:string;lastName:string;birthDate:string;}
You can write a function to convert between these two types. More interestingly, you can use template literal types to type this function. Item 54 walks through how to do this, but the end result is that you can generate one type from the other:
typeStudent=ObjectToCamel<StudentTable>;// ^? type Student = {// firstName: string;// lastName: string;// birthDate: string;// }
Amazing! After the thrill of finding a compelling use case for fancy type-level programming wears off, you may find yourself running into lots of errors from passing one version of the type to a function that’s expecting the other:
asyncfunctionwriteStudentToDb(student:Student){awaitwriteRowToDb(db,'students',student);// ~~~~~~~// Type 'Student' is not assignable to parameter of type 'StudentTable'.}
It’s not obvious from the error message, but the problem is that you’ve forgotten to call your conversion code:
asyncfunctionwriteStudentToDb(student:Student){awaitwriteRowToDb(db,'students',objectToSnake(student));// ok}
While it’s helpful that TypeScript flagged this mistake before it caused a runtime error, it would be simpler to have just a single version of the Student type in your code so that this error is impossible to make.
There are two versions of the Student type. Which should you choose?
-
To adopt the camelCase version, you’ll need to set up some kind of adapter to make sure your database returns camelCased version of the columns. You’ll also need to make sure that whatever tool you use to generate TypeScript types from your database knows about this transformation. The advantage of this approach is that your database interfaces will look just like all your other types.
-
To adopt the snake_case version, you don’t need to do anything at all. You just need to accept a superficial inconsistency in the naming convention for a deeper consistency in your types.
Either of these approaches is feasible, but the latter is simpler.
The general principle is that you should prefer unifying types to modeling small differences between them. That being said, there are some caveats to this rule.
First, unification isn’t always an option. You may need the two types if the database and the API aren’t under your control. If this is the case, then modeling these sorts of differences systematically in the type system will help you find bugs in your transformation code. It’s better than creating types ad hoc and hoping they stay in sync.
Second, don’t unify types that aren’t actually representing the same thing! “Unifying” the different types in a tagged union would be counterproductive, for example, because they presumably represent different states that you want to keep separate.
Things to Remember
-
Having distinct variants of the same type creates cognitive overhead and requires lots of conversion code.
-
Rather than modeling slight variations on a type in your code, try to eliminate the variation so that you can unify to a single type.
-
Unifying types may require some adjustments to runtime code.
-
If the types aren’t in your control, you may need to model the variations.
Item 40: Prefer Imprecise Types to Inaccurate Types
In writing type declarations you’ll inevitably find situations where you can model behavior in a more precise or less precise way. Precision in types is generally a good thing because it will help your users catch bugs and take advantage of the tooling that TypeScript provides. But take care as you increase the precision of your type declarations: it’s easy to make mistakes, and incorrect types can be worse than no types at all.
Suppose you are writing type declarations for GeoJSON, a format we’ve seen before in Item 33. A GeoJSON geometry can be one of a few types, each of which has differently shaped coordinate arrays:
interfacePoint{type:'Point';coordinates:number[];}interfaceLineString{type:'LineString';coordinates:number[][];}interfacePolygon{type:'Polygon';coordinates:number[][][];}typeGeometry=Point|LineString|Polygon;// Also several others
This is fine, but number[] for a coordinate is a bit imprecise. Really these are latitudes and longitudes, so perhaps a tuple type would be better:
typeGeoPosition=[number,number];interfacePoint{type:'Point';coordinates:GeoPosition;}// Etc.
You publish your more precise types to the world and wait for the adulation to roll in. Unfortunately, a user complains that your new types have broken everything. Even though you’ve only ever used latitude and longitude, a position in GeoJSON is allowed to have a third element, an elevation, and potentially more. In an attempt to make the type declarations more precise, you’ve gone too far and made the types inaccurate! To continue using your type declarations, your user will have to introduce type assertions or silence the type checker entirely with as any. Perhaps they’ll give up and start writing their own declarations.
As another example, consider trying to write type declarations for a Lisp-like language defined in JSON:
12"red"["+",1,2]// 3["/",20,2]// 10["case",[">",20,10],"red","blue"]// "red"["rgb",255,0,127]// "#FF007F"
The Mapbox library uses a system like this to determine the appearance of map features across many devices. There’s a whole spectrum of precision with which you could try to type this:
-
Allow anything.
-
Allow strings, numbers, and arrays.
-
Allow strings, numbers, and arrays starting with known function names.
-
Make sure each function gets the correct number of arguments.
-
Make sure each function gets the correct type of arguments.
The first two options are straightforward:
typeExpression1=any;typeExpression2=number|string|any[];
A type system is said to be “complete” if it allows all valid programs. These two types will allow all valid Mapbox expressions. There will be no false positive errors. But with such simple types there will be many false negatives: invalid expressions that aren’t flagged as such. In other words, the types are not very precise.
Let’s see if we can improve the precision without losing the completeness property. To avoid regressions, we should introduce a test set of expressions that are valid and expressions that are not. (Item 55 is all about testing types.)
constokExpressions:Expression2[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression2[]=[true,// ~~~ Type 'boolean' is not assignable to type 'Expression2'["**",2,31],// Should be an error: no "**" function["rgb",255,0,127,0],// Should be an error: too many values["case",[">",20,10],"red","blue","green"],// (Too many values)];
To go to the next level of precision, you can use a union of string literal types as the first element of a tuple:
typeFnName='+'|'-'|'*'|'/'|'>'|'<'|'case'|'rgb';typeCallExpression=[FnName,...any[]];typeExpression3=number|string|CallExpression;constokExpressions:Expression3[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression3[]=[true,// Error: Type 'boolean' is not assignable to type 'Expression3'["**",2,31],// ~~ Type '"**"' is not assignable to type 'FnName'["rgb",255,0,127,0],// Should be an error: too many values["case",[">",20,10],"red","blue","green"],// (Too many values)];
There’s one new caught error and no regressions. Pretty good! One complication is that our type declarations have become more closely related to our Mapbox version. If Mapbox adds a new function, then the type declarations need to add it, too. These types are more precise, but they’re also higher maintenance.
What if you want to make sure that each function gets the correct number of
arguments? This gets trickier since the types now need to be recursive to reach down into all the function calls. TypeScript allows this, though we do need to take some care to convince the type checker that our recursion isn’t infinite. There are a few ways to do this. One is to define CaseCall (which must be an array of even length) with an
interface rather than a type.
This is possible, if a bit awkward:
typeExpression4=number|string|CallExpression;typeCallExpression=MathCall|CaseCall|RGBCall;typeMathCall=['+'|'-'|'/'|'*'|'>'|'<',Expression4,Expression4,];interfaceCaseCall{0:'case';[n:number]:Expression4;length:4|6|8|10|12|14|16;// etc.}typeRGBCall=['rgb',Expression4,Expression4,Expression4];
Let’s see how we’ve done:
constokExpressions:Expression4[]=[10,"red",["+",10,5],["rgb",255,128,64],["case",[">",20,10],"red","blue"],];constinvalidExpressions:Expression4[]=[true,// ~~~ Type 'boolean' is not assignable to type 'Expression4'["**",2,31],// ~~~~ Type '"**"' is not assignable to type '"+" | "-" | "/" | ...["rgb",255,0,127,0],// ~ Type 'number' is not assignable to type 'undefined'.["case",[">",20,10],"red","blue","green"],// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~// Types of property 'length' are incompatible.// Type '5' is not assignable to type '4 | 6 | 8 | 10 | 12 | 14 | 16'.];
Now all the invalid expressions produce errors. And it’s interesting that you can express something like “an array of even length” using a TypeScript interface. But some of these error messages are a bit confusing, particularly the one about Type '5'.
Is this an improvement over the previous, less precise types? The fact that you get errors for more incorrect usages is definitely a win, but confusing error messages will make this type more difficult to work with. As Item 6 explained, language services are as much a part of the TypeScript experience as type checking, so it’s a good idea to look at the error messages resulting from your type declarations and try autocomplete in situations where it should work. If your new type declarations are more precise but break autocomplete, then they’ll make for a less enjoyable TypeScript development experience.
The complexity of this type declaration has also increased the odds that a bug will creep in. For example, Expression4 requires that all math operators take two parameters, but the Mapbox expression spec says that + and * can take more. Also, - can take a single parameter, in which case it negates its input. Expression4 incorrectly flags errors in all of these:
constmoreOkExpressions:Expression4[]=[['-',12],// ~~~~~~ Type '["-", number]' is not assignable to type 'MathCall'.// Source has 2 element(s) but target requires 3.['+',1,2,3],// ~ Type 'number' is not assignable to type 'undefined'.['*',2,3,4],// ~ Type 'number' is not assignable to type 'undefined'.];
Once again, in trying to be more precise we’ve overshot and become inaccurate. These inaccuracies can be corrected, but you’ll want to expand your test set to convince yourself that you haven’t missed anything else. Complex code generally requires more tests, and the same is true of types.
As you refine types, it can be helpful to think of the “uncanny valley” metaphor. As a cartoonish drawing becomes more true to life, we tend to perceive it as becoming more realistic. But only up to a point. If it goes for too much realism, we tend to hyperfocus on the few remaining inaccuracies.
In the same way, refining very imprecise types like any is almost always helpful. You and your coworkers will perceive this as an improvement to type safety and productivity. But as your types get more precise, the expectation that they’ll also be accurate increases. You’ll start to trust the types to catch most errors, and so the inaccuracies will stand out more starkly. If you spend hours tracking down a type error, only to find that the types are inaccurate, it will undermine confidence in your type declarations and perhaps TypeScript itself. It certainly won’t boost your productivity!
Things to Remember
-
Avoid the uncanny valley of type safety: complex but inaccurate types are often worse than simpler, less precise types. If you cannot model a type accurately, do not model it inaccurately! Acknowledge the gaps using
anyorunknown. -
Pay attention to error messages and autocomplete as you make typings increasingly precise. It’s not just about correctness: developer experience matters, too.
-
As your types grow more complex, your test suite for them should expand.
Item 41: Name Types Using the Language of Your Problem Domain
There are only two hard problems in Computer Science: cache invalidation and naming things.
Phil Karlton
This book has had much to say about the shape of types and the sets of values in their domains, but much less about what you name your types. But this is an important part of type design, too. Well-chosen type, property, and variable names can clarify intent and raise the level of abstraction of your code and types. Poorly chosen types can obscure your code and lead to incorrect mental models.
Suppose you’re building out a database of animals. You create an interface to represent one:
interfaceAnimal{name:string;endangered:boolean;habitat:string;}constleopard:Animal={name:'Snow Leopard',endangered:false,habitat:'tundra',};
There are a few issues here:
-
nameis a very general term. What sort of name are you expecting? A scientific name? A common name? -
The boolean
endangeredfield is also ambiguous. What if an animal is extinct? Is the intent here “endangered or worse”? Or does it literally mean endangered?
-
The
habitatfield is very ambiguous, not just because of the overly broadstringtype (Item 35), but also because it’s unclear what’s meant by “habitat.” -
The variable name is
leopard, but the value of thenameproperty is “Snow Leopard.” Is this distinction meaningful?
Here’s a type declaration and value with less ambiguity:
interfaceAnimal{commonName:string;genus:string;species:string;status:ConservationStatus;climates:KoppenClimate[];}typeConservationStatus='EX'|'EW'|'CR'|'EN'|'VU'|'NT'|'LC';typeKoppenClimate=|'Af'|'Am'|'As'|'Aw'|'BSh'|'BSk'|'BWh'|'BWk'|'Cfa'|'Cfb'|'Cfc'|'Csa'|'Csb'|'Csc'|'Cwa'|'Cwb'|'Cwc'|'Dfa'|'Dfb'|'Dfc'|'Dfd'|'Dsa'|'Dsb'|'Dsc'|'Dwa'|'Dwb'|'Dwc'|'Dwd'|'EF'|'ET';constsnowLeopard:Animal={commonName:'Snow Leopard',genus:'Panthera',species:'Uncia',status:'VU',// vulnerableclimates:['ET','EF','Dfd'],// alpine or subalpine};
This makes a number of improvements:
-
namehas been replaced with more specific terms:commonName,genus, andspecies. -
endangeredhas becomestatus, aConservationStatustype that uses a standard classification system from the IUCN. -
habitathas becomeclimatesand uses another standard taxonomy, the Köppen climate classification.
If you needed more information about the fields in the first version of this type, you’d have to go find the person who wrote them and ask. In all likelihood, they’ve left the company or don’t remember. Worse yet, you might run git blame to find out who wrote these lousy types, only to find that it was you!
The situation is much improved with the second version. If you want to learn more about the Köppen climate classification system or track down what the precise meaning of a conservation status is, then there are a myriad of resources online to help you.
Every domain has specialized vocabulary to describe its subject. Rather than inventing your own terms, try to reuse terms from the domain of your problem. These vocabularies have often been honed over years, decades, or centuries and are well understood by people in the field. Using these terms will help you communicate with users and increase the clarity of your types.
Take care to use domain vocabulary accurately: co-opting the language of a domain to mean something different is even more confusing than inventing your own.
These same considerations apply to other labels as well, such as function parameter names, tuple labels, and index type labels.
Here are a few other rules to keep in mind as you name types, properties, and variables:
-
Make distinctions meaningful. In writing and speech it can be tedious to use the same word over and over. We introduce synonyms to break the monotony. This makes prose more enjoyable to read, but it has the opposite effect on code. If you use two different terms, make sure you’re drawing a meaningful distinction. If not, you should use the same term.
-
Avoid vague, meaningless names like “data,” “info,” “thing,” “item,” “object,” or the ever-popular “entity.” If Entity has a specific meaning in your domain, fine. But if you’re using it because you don’t want to think of a more meaningful name, then you’ll eventually run into trouble: there may be multiple distinct types called “Entity” in your project, and can you remember what’s an Item and what’s an Entity?
-
Name things for what they are, not for what they contain or how they are computed.
Directoryis more meaningful thanINodeList. It allows you to think about a directory as a concept, rather than in terms of its implementation. Good names can increase your level of abstraction and decrease your risk of inadvertent collisions.
Things to Remember
-
Reuse names from the domain of your problem where possible to increase the readability and level of abstraction of your code. Make sure you use domain terms accurately.
-
Avoid using different names for the same thing: make distinctions in names meaningful.
-
Avoid vague names like “Info” or “Entity.” Name types for what they are, rather than for their shape.
Item 42: Avoid Types Based on Anecdotal Data
The other items in this chapter have discussed the many benefits of good type design and shown what can go wrong without it. A well-designed type makes TypeScript a pleasure to use, while a poorly designed one can make it miserable to use. But this does put quite a bit of pressure on type design. Wouldn’t it be nice if you didn’t have to do this yourself?
At least some of your types are likely to come from outside your program: specifications, file formats, APIs, or database schemas. It’s tempting to write declarations for these types yourself based on the data you’ve seen, perhaps the rows in your test database or the responses you’ve seen from a particular API endpoint.
Resist this urge! It’s far better to import types from another source or generate them from a specification. When you write types yourself based on anecdotal data, you’re only considering the examples you’ve seen. You might be missing important edge cases that could break your program. When you use more official types, TypeScript will help ensure that this doesn’t happen.
In Item 30 we used a function that calculated the bounding box of a GeoJSON feature. Here’s what a definition might look like:
functioncalculateBoundingBox(f:GeoJSONFeature):BoundingBox|null{letbox:BoundingBox|null=null;consthelper=(coords:any[])=>{// ...};const{geometry}=f;if(geometry){helper(geometry.coordinates);}returnbox;}
How would you define the GeoJSONFeature type? You could look at some GeoJSON features in your repo and sketch out an interface:
interfaceGeoJSONFeature{type:'Feature';geometry:GeoJSONGeometry|null;properties:unknown;}interfaceGeoJSONGeometry{type:'Point'|'LineString'|'Polygon'|'MultiPolygon';coordinates:number[]|number[][]|number[][][]|number[][][][];}
The function passes the type checker with this definition. But is it really correct? This check is only as good as our homegrown type declarations.
A better approach would be to use the formal GeoJSON spec.1 Fortunately for us, there are already TypeScript type declarations for it on DefinitelyTyped. You can add these in the usual way:2
$ npm install --save-dev @types/geojson + @types/geojson@7946.0.14
With these declarations, TypeScript flags an error:
import{Feature}from'geojson';functioncalculateBoundingBox(f:Feature):BoundingBox|null{letbox:BoundingBox|null=null;consthelper=(coords:any[])=>{// ...};const{geometry}=f;if(geometry){helper(geometry.coordinates);// ~~~~~~~~~~~// Property 'coordinates' does not exist on type 'Geometry'// Property 'coordinates' does not exist on type 'GeometryCollection'}returnbox;}
The problem is that this code assumes that a geometry will have a coordinates property. This is true for many geometries, including points, lines, and polygons. But a GeoJSON geometry can also be a GeometryCollection, a heterogeneous collection of other geometries. Unlike the other geometry types, it does not have a coordinates property.
If you call calculateBoundingBox on a feature whose geometry is a GeometryCollection, it will throw an error about not being able to read property 0 of
undefined. This is a real bug! And we caught it by sourcing types from the
community.
One option for fixing the bug is to explicitly disallow GeometryCollections:
const{geometry}=f;if(geometry){if(geometry.type==='GeometryCollection'){thrownewError('GeometryCollections are not supported.');}helper(geometry.coordinates);// OK}
TypeScript is able to refine the type of geometry based on the check, so the reference to geometry.coordinates is allowed. If nothing else, this results in a clearer error message for the user.
But the better solution is to support GeometryCollections! You can do this by pulling out another helper function:
constgeometryHelper=(g:Geometry)=>{if(g.type==='GeometryCollection'){g.geometries.forEach(geometryHelper);}else{helper(g.coordinates);// OK}}const{geometry}=f;if(geometry){geometryHelper(geometry);}
Our handwritten GeoJSON types were based only on our own experience with the format, which did not include GeometryCollections. This led to a false sense of security about our code’s correctness. Using community types based on a spec gives you confidence that your code will work with all values, not just the ones you happen to have seen.
Similar considerations apply to API calls. If there’s an official TypeScript client for the API you’re working with, use that! But even if not, you may be able to generate TypeScript types from an official source.
If you’re using a GraphQL API, for example, it includes a schema that describes all its queries and mutations, as well as all the types. There are many tools available to add TypeScript types to GraphQL queries. Head to your favorite search engine and you’ll quickly be on the path to type safety.
Many REST APIs publish an OpenAPI schema. This is a file that describes all the endpoints, HTTP verbs (GET, POST, etc.), and types using JSON Schema.
Say we’re using an API that lets us post comments on a blog. Here’s what an OpenAPI schema might look like:
// schema.json{"openapi":"3.0.3","info":{"version":"1.0.0","title":"Sample API"},"paths":{"/comment":{"post":{"requestBody":{"content":{"application/json":{"schema":{"$ref":"#/components/schemas/Comment"}}}}},"responses":{"200":{/* ... */}}}},"components":{"schemas":{"CreateCommentRequest":{"properties":{"body":{"type":"string"},"postId":{"type":"string"},"title":{"type":"string"}},"type":"object","required":["postId","title","body"]}}}}
The paths section defines the endpoints and associates them with types, which are found in the components/schemas section. All the information we need to generate types is here. There are many ways to get types out of an OpenAPI Schema. One is to extract the schemas and run them through json-schema-to-typescript:
$ jq .components.schemas.CreateCommentRequest schema.json > comment.json
$ npx json-schema-to-typescript comment.json > comment.ts
$ cat comment.ts
// ....
export interface CreateCommentRequest {
body: string;
postId: string;
title: string;
}
This results in nice, clean interfaces that will help you interact with this API in a type-safe way. TypeScript will flag type errors in your request bodies and the response types will flow through your code. The important thing is that you didn’t write the types yourself. Rather, they’re generated from a reliable source of truth. If a field is optional or can be null, TypeScript will know about it and force you to handle that possibility.
A next step here would be to add runtime validation and connect the types directly to the endpoints with which they’re associated. There are many tools that can help you with this, and Item 74 will return to this example.
When you generate types, you do need to ensure that they stay in sync with the API schema. Item 58 discusses strategies for handling this.
What if there’s no spec or official schema available? Then you’ll have to generate types from data. Tools like quicktype can help with this. But be aware that your types may not match reality: there may be edge cases that you’ve missed. (An exception would be if your data set is finite, for example, a directory of 1,000 JSON files. Then you know that you haven’t missed anything!)
Even if you’re not aware of it, you are already benefiting from code generation. TypeScript’s type declarations for the browser DOM API, which are explored in Item 75, are generated from the API descriptions on MDN. This ensures that they correctly model a complicated system and helps TypeScript catch errors and misunderstandings in your own code.
1 GeoJSON is also known as RFC 7946. The very readable spec is at http://geojson.org.
2 The unusually large major version number matches the RFC number. This was cute at the time but has proven a nuisance in practice.
Get Effective TypeScript, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

