Chapter 4. The Definition Phase (How to Frame Your Experiments)
NOW THAT YOU HAVE THE BASICS DOWN, itâs time to put them into action beginning in this chapter. Using the framework introduced in Chapter 3, weâll begin to flesh out each step in the process of designing an A/B test, and explain how the early and close involvement of designers is necessary to your teamâs success. Weâll be discussing the activities shown in Figure 4-1 that are outlined in a dotted line. Throughout, weâll revisit some of the common themes we highlighted in the Preface and Chapter 1.
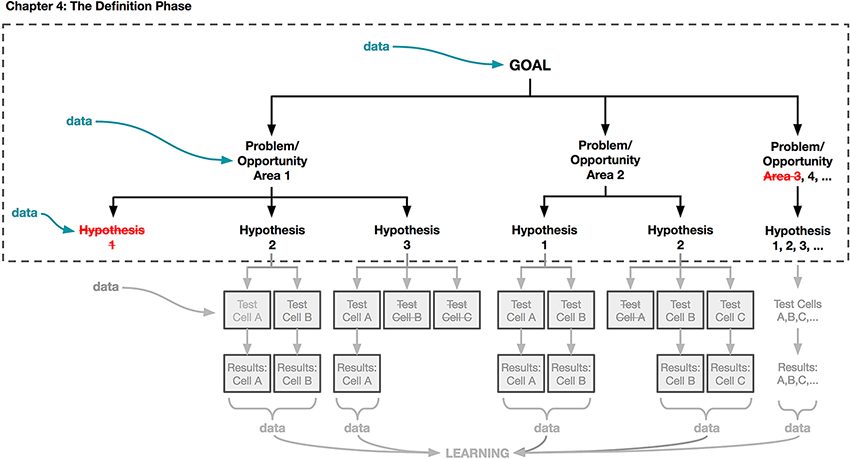
Figure 4-1. âThe Definition Phaseâ of our experimentation framework is where you frame the goal of your experiment and the hypotheses that you are interested in testing.
Taking a data-aware approach to design requires approaching your work with an open-minded attitude toward learning as much as you can about your users and which designs resonate with them. Adopting an approach of experimentation, and using data to explore and evaluate your ideas, will make you a better designer overall.
Weâre going to spend the bulk of this chapter laying out how you can define your goals, problems, and hypotheses to maximize your learning when designing with data. Recall that a hypothesis is a statement that captures the impact you believe your design will have on your users. In this chapter, weâll show you how to craft a strong hypothesis and how to âgo broadâ by generating as many hypotheses as possible. Then weâll discuss how to narrow down to one or a few hypotheses to focus on. You should revisit our discussion from Chapter 2 about how to formulate a hypothesis before diving into this chapter, but the most important thing for you to understand is that a key part of using a data-aware framework is articulating the âwhyâ behind your design and stating clearly your expectations regarding the ways in which your design will impact usersâ behaviors and sentiments. Doing so is critical to using experimentation and data analysis successfully in your design practice, because it keeps learning central to every test you create and run.
As we start our discussion about hypotheses, keep in mind our introduction to experimentation in Chapter 2. Experimentation is a way for you to have a conversation with your users; in each experiment, the designs you put in front of your users provide an opportunity to collect feedback about their experienceâthe behavioral data you get back from your experimental test design(s) is your usersâ response to your design options or âquestions.â As you get involved in more experiments, the iterative and continual process of testing ideas and options will help you learn more about your users: who they are, their needs and wants, and what works for them and what doesnât. Your basic goal in each experiment is to learn something about your users. You also gain the advantage of demonstrating through behavioral data that the work you are doing has business impact. Having clear strategic business and user experience goals defined will help guide and prioritize the experiments you pursue.
Getting Started: Defining Your Goal
âWithout goals, and plans to reach them, you are like a ship that has set sail with no destination.â
FITZHUGH DODSON
Beginning your experiment with a clear goal in mind is the first step to maximizing the learnings youâll get from your experiments. In this section, we aim to give you some helpful tips and questions to get started thinking about your goals. However, remember that we cannot be comprehensiveâevery circumstance, company, and design challenge is different. In your goal definition phase, maintaining close and collaborative relationships with product managers, engineers, and other partners on your team will help apply the initial thoughts in this chapter to your particular context.
We believe that first and foremost, you should focus your energy on things you care about. Experimentation as a framework and mindset can be applied to many types of questions; however, only your own personal curiosity and a true desire to learn will make your experiments a success. We invite you to think about the following questions:
Where do you want to spend your time and efforts making an impact?
What do you believe is good for your users?
Taking time to reflect regularly on these questions will help you put your own passion and desire to learn at the center of your goals and experimentation processâand will also help you communicate your perspective more clearly to others. Weâll talk more about communicating your ideas and findings to others later in the book in Chapter 7. But for now, letâs continue to focus on defining your specific design-related goals in experimental terms. Defining your goals is the first step in the broader experimentation framework we introduced in Chapter 3 (Figure 4-2).

Figure 4-2. Defining your goals is the first step in kicking off the framework for experimentation. Choosing goals you care about, and that make sense from an experience and business perspective, is crucial.
Beyond your own curiosity, we also encourage you to reflect on the following questions:
What are the user and business-critical issues that get construed in your company as opportunities, or as problems and issues?
Where are the biggest opportunities for you to improve upon your user experience?
Think about what investors, partners, colleagues, and customers value about your company and how you are currently measuring it. The best goals should articulate the impact you want to make on your product or user experience in a way that clearly ties back to your team and companyâs priorities.
![]() Returning to our summer camp example, some goals are stated in terms of quantitative metrics. For instance: âI want to increase the number of campers who enroll at our camp.â Other goals are more abstract or qualitative, such as: âI want to make camp more fun.â Regardless of how you define your goals, youâll need a way to measure whether or not youâre making progress toward them. Remember that all measurable things are rooted in human experiences, and most of the experiences youâll aim to impact are measurable in some way.
Returning to our summer camp example, some goals are stated in terms of quantitative metrics. For instance: âI want to increase the number of campers who enroll at our camp.â Other goals are more abstract or qualitative, such as: âI want to make camp more fun.â Regardless of how you define your goals, youâll need a way to measure whether or not youâre making progress toward them. Remember that all measurable things are rooted in human experiences, and most of the experiences youâll aim to impact are measurable in some way.
Often, a goal will have both qualitative and quantitative components. You shouldnât worry about classifying whether your goal is either qualitative or quantitative. For instance, think about the quantitative sign-up goal discussed before. If your goal is to increase the percentage of sign-up completions, you might also consider some of the qualities of the experience that would be important when getting more people through your sign-up process.
Defining Your Metric of Interest
Your goals should be measurable so that you can understand whether or not youâre approaching or achieving them. In Chapter 2, we told you that metrics are evaluative benchmarks that meaningfully track your businessâs health. When defining your goals, you should also be thoughtful about choosing a metric of interest that tracks your progress toward those goals. We often hear designers worry that theyâll become slave to metrics, and lose their ability to be creative. We want to take a moment to remind you here that designing with data is a creative process. You and your team should rally around both your metrics and your goal so that you have something to strive for. How you chase that goal is up to you. Making those decisions depends on design intuition and creative problem solving.
Although your company may have many metrics, you should strive to have a single metric of interest or each of the tests you run. This metric of interest will be how you measure the impact of a particular test. Remember that your metric of interest should be a reflection of the user behavior youâre hoping to influence. To weigh in on this topic we spoke with Chris Maliwat. Chris has led product at a number of fast-growing internet companies, including Skillshare, Gilt Group, Vuze, and most recently, Warby Parker. In addition, Chris has product experience from large and established data-centric companies like Facebook, Netflix, and eBay. This means that he has broad experience across both smaller companies and established industry giants.
Chris shared an example of an experiment he ran at eBay that illustrates the importance of clearly defining your success metrics ahead of time, and then clearly relating those metrics to the user behavior you care most about. The test was about providing more information in the eBay bidding flow when there was a higher risk of the transaction being unsatisfactory for the buyer or seller. From past data, they knew that buyers were less likely to pay for their item in certain scenarios. Not all âfraudulentâ transactions were malicious; for example, this could happen when a customer didnât realize that they were buying from someone in a different country, which could result in longer shipping times or higher shipping rates.
The team at eBay wanted to understand the trade-off between showing more information (and potentially adding friction to the purchasing process) and preventing âbuyerâs remorse,â which could occur when expectations about shipping time or cost were violated. They found that showing additional information resulted in fewer total bids per item, perhaps because the additional information shown increased friction. However, their test was successful; they ultimately designed an experience that was more transparent for their customers, reducing the scenarios where buyers didnât end up paying, and ultimately increasing long-term customer satisfaction and retention by reducing âbuyerâs remorse.â
There are a few user behaviors that eBay could have been focusing on: for instance, bidding on or purchasing items versus retention. The team was more interested in building long-lasting relationships with their users than optimizing for a single, in-the-moment, inadvertent purchase, which risked later product abandonment. The team chose metrics that aligned with this user goal, and assessed their test in relation to those metrics.
In practice, it can be a challenge to identify metrics that align with your goal. Recall that in Chapter 2 we gave an example from Coursera, and how they use proxy metrics such as test completion to anticipate one of their key metrics, credential completion. This is a great example of a practical consideration in choosing metrics: this proxy metric is necessary because credentials can take a long time to complete, and the teams at Coursera couldnât wait that long to collect data and learnings about their experiments.
Fundamentally, regardless of what metric of interest you and your team choose, a metric must always be measurable. Sometimes measuring the thing you care about can be challenging. We asked Jon Wiley of Google to tell us about how he approaches metrics that are more difficult to measure. His example of measuring âabandonmentâ shows how you may not be able to fully understand or capture everything you want to learn with A/B testing and itâs therefore important to find other ways to get at the underlying data you seek:
We have this notion of abandonment. Someone did a query on Google. Then, they did nothing else. They got there and they left. At the point that they abandoned, we donât know what happened.
In those cases, what metric do you measure? How do you know whether they found what they were looking for? Maybe they found it on the search results page and they were happy, so they left. Or maybe they didnât think any of the results were good. Then, why didnât they refine the query? Maybe they just didnât think Google was very good at that particular query. There are a lot of questions we have at a moment like that that are very difficult for us to measure in terms of these A/B tests.
We try to get at that in a couple of ways. We might bring folks into a lab and see if we can replicate what happens. We also ship surveys. Youâll get a little survey in the bottom-right corner thatâll ask, âAre you satisfied with these results?â We try to get some emotional or qualitative response from users and see if it matches up to the abandonment or if it measures abandonment, to try to determine whatâs going on here and why.
This is where a pitfall of A/B testing can emerge. Sometimes, itâs impossible to measure the behaviors you care about only through the behavioral data of A/B tests. As Jon said, leaning on other forms of data is one great way to minimize or circumvent this pitfall.
Metric sensitivity
One consideration we havenât yet introduced when choosing metrics is metric sensitivity. Sensitivity refers to how much of a change in experience it takes to cause a change in the metric. For instance, net promoter score (NPS) is a common metric that many companies track. NPS ranges from â100 to +100 and measures the willingness of a companyâs customers to recommend the companyâs products or services to others. NPS is used as a proxy for gauging the customerâs overall satisfaction with a companyâs product or service and the customerâs loyalty to the brand, offering an alternative to customer satisfaction research. Proponents of NPS claim it is highly correlated with a companyâs revenue growth. However, NPS is a relatively insensitive metricâit takes a significant change in experience and a long time to change what users think about a company, and small changes like moving the placement of a button or tweaking the copy on a sign-up flow will not change such a holistic metric. Itâs important to select metrics that are capable of detecting and reflecting the change youâre making. Otherwise, you may observe no change in your metrics even though there was a meaningful change in your user experience. For example, a copy change might actually lead to more registrations on your website, which you wouldnât know by tracking NPS.
How do you deal with these types of situations? Although you should always strive to impact business critical metrics, some of the tests you run will likely focus on specific metrics of interest that are designed to measure the particular goal youâve set out to focus on. In these cases, itâs essential to understand how other metrics you develop relate to, reflect, and influence your companyâs key metrics overall.
When your company metrics are insensitive, you may have to choose more specific or specialized metrics. We encourage you to collaborate with others, with your âdata friends,â to define the metric of interest that best tracks the causal impact of your experiment and help you measure success against your goals. As a designer, you should be involved early in the conversation about how you will define success for your projectsâincluding helping to define metrics of interest. Defining your metrics of interest in advance will ensure that you and your teams avoid bias in the analysis of your results. When you have a clearly defined metric for design successâand therefore for business impactâagainst which to evaluate your test, itâs harder to look for âother evidenceâ to call an experiment successful when it didnât actually have the desired user behavioral outcome or impact.
This speaks to a broader point about why picking the right metric of interest for your experiment is important to avoid bias. Youâll want to be careful in structuring your test so that you donât judge the success of your design on a metric that âcanât fail.â You want your experiment to be fair. For example, letâs say you decide to add a feature to your experience. During the course of assessing that featureâs success, is it fairer to look at the number of clicks that it gets, or to measure the impact of adding that feature to your overall user experience (like impacting retention)? In this example, a feature will necessarily get more clicks if it exists than if it doesnât, so measuring âincreased clicksâ as your metric of interest will lead to an experiment that is not falsifiable. As you are defining your metric of interest, then, you should think about what you want to be different in your test group compared to your control group: Do you want these people to retain or subscribe at a higher rate? Engage with your product more frequently? It is these changes in user behavior that should be core to the metric of interest you choose to track.
Another example of this issue is when you measure the results from a self-selecting group as success. For example, letâs say that you have a new feature where search rates for users who saved a song is up by 10%. If we were to claim that getting this group to increase search rates by 10% was a success, it wouldnât be quite fair. In this case, we arenât comparing two randomized samples, but rather we are reporting the effect on a self-selecting group of usersâusers who have saved songs have already demonstrated their engagement with your product. A better metric would have been to just look at the search rates of users with the feature versus those who do not have that feature.
Tracking multiple metrics
In many cases, making meaningful changes in your companyâs key metrics is a long-term game that is the result of many smaller changes. Even in those cases most companies are concerned with avoiding negative impacts to their key metrics. In practice, most A/B tests track several metrics: they make decisions about the âsuccessâ or âfailureâ of the test against the metric of interest, but may look to key metrics to make sure no negative change was made, and secondary metrics to gain a richer understanding of the impact of the test. Secondary metrics are less central to your business and experimentâs success, but may still reflect important pieces of your experience or how your product is being used. Secondary metrics reveal positive side effects from improvement to the metric of interest. For example, your metric of interest may be increasing time onsite as a result of better content personalization, with a secondary metric tracking number of social recommendations made. These are great for exploring specific pieces and features or fine-tuning designs that might matter experientially without impacting your companyâs key metrics. Many feature teams define their own secondary metrics based on their goals; for instance, the iOS team at a social media company might measure how much content is created on iPhones. Although secondary metrics can be valuable and informative, one common pitfall we often see teams fall into is mistakenly targeting secondary metrics when they should be targeting key metrics or another metric of interest. In addition, secondary metrics are frequently targeted without teams thinking through how those metrics might impact the key metrics. If the improvement only affects a small subset of your user base or if you donât think your changes will affect important metrics, then it may not be the right place to focus your energy. Based on your particular circumstances, we encourage you to pause and confer with your team about whether exploring changes to secondary metrics is worthwhile; that is, should you invest the resources and time if you donât anticipate demonstrating a major impact on your companyâs key metrics?
To conclude this section, here are a few questions to ask yourself as youâre thinking about which metric(s) to choose for the goal you have defined:
If you were to ask everyone who is working on this project what the desired outcome is, what would they say?
If you were to ask your colleagues how they expect to measure the outcome of your work, are you all in agreement? Are you all aligned?
How are your metrics of interest related to your company goals?
Are you focused on affecting metrics that will have a meaningful effect on your business? If youâre also observing secondary metrics, what can you learn from them that you wonât see in your metric of interest?
Are the metrics you are targeting sufficiently ambitious? Are they too ambitious?
Can you effectively measure a change in your metric within the timeframe of your project? If not, are there proxy metrics you can use instead?
These questions will help you choose appropriate metrics, in the service of measuring your progress toward your goals. Remember that in Chapter 1 we told you that one of the major benefits of using data in your design process is that it reveals the impact of design. We believe that articulating and justifying your goals in terms of your metrics of interest and company key metrics is one of the best and most empowering ways to advocate for your users when it comes time to make design and product decisions. In fact, you can think of metrics as one of the unifying languages within your company: itâs one that will convey the value of your designs and your efforts to your key stakeholders and company investors most effectively. We believe that healthy and effective experimentation practices will add value to your company. Metrics therefore measure not only your success in that one experiment, but over time youâll know whether your data and experimentation practices are effective at your business in general.
To help illustrate the importance of metrics when defining goals, weâll share a few examples.
Getting the full picture
Katie Dill spoke to us about Airbnbâs key metrics and how they are working to establish metrics that are reflective of the business needs and also customer happiness and quality. Because Airbnbâs experience exists both online and offline, it can be harder to get a measure of the full experience. There is a transactional part of the experience where users are booking their stay online, but there is also an offline component where the âguestâ and the âhostâ are actually interacting in real life as well:
Iâm quite proud of the fact that our company has acknowledged that while our business metrics (we use âguest arrivalsâ) are the best classification for how successful we are, they canât be the only thing we focus on. We are now looking at quality measurements of various types, too. Weâre working hard to learn how they relate to each other, so we can use nights booked and quality metrics as complements to each other.
Measurement is critical in experience design, but first we need to understand what we want to learn and what we want to accomplish so we know weâre measuring the right thing. Measurement can shape your approach and cause you to focus on certain things over others. So before you settle on a metric you need to make sure itâs also the one that best depicts what success is. Design can play a key role in this conversation and help ensure weâre measuring whatâs key to a personâs enjoyment and fulfillment with an experience. Over time, itâs not just the purchases made on your platform, but the quality your customers experienced that will determine your success as a business and a brand.
As Katie highlights, having design involved in the conversation about what is going to be measured can be instrumental in making sure that you feel confident about what you are prioritizing in your experience and in judging whether or not itâs performing.
Your metrics may change over time
To weigh in on how metrics can evolve as the business evolves, we spoke to Eric Colson. Eric is the Chief Algorithms Officer at Stitch Fix, where his team helps to redefine retail shopping using a unique personalized experience for their customers by leveraging data, personalization, and human curation. Stitch Fix sends their customers a personalized selection of clothes and accessories with every order, which they call your âFix.â As the business went from an âon demandâ service to one which also offered an automatic cadenceâsomething more akin to a subscription service modelâtheir metrics needed to change to reflect the shift in their customersâ behavior. His story also points out how a small change to the design manifested as a big insight that eventually affected their business fairly dramatically:
Our business model was on demand; clients would schedule each shipment individually and whenever they wanted one. Early in 2012, we wanted to provide a way for clients to have a more effortless experience. So, we added the option to receive shipments automatically on a set cadence. Clients could opt in to this by checking an option box on the bottom of their account page. It was a subtleâwe didnât think many would opt in; perhaps just those who loved the service so much that they didnât want to have to remember to request a shipment every month. But, to our surprise, tons of clients started ticking the box. We had underestimated the convenience automatic shipments would provide. We later added different cadence optionsâevery other month, quarterly, every two months, and so on. Thereâs four cadences now and many of our customers opt in to this.
This merited a shift in how we view the success of our service. Our company was born out a transactional model. We cared about metrics relating to a successful transaction (e.g., the number of things sold, the amount of the sale, the feedback on the items, etc). But with so many clients interested in receiving shipments on an ongoing basis, we had to shift towards relationships. The outcome of each transaction/shipment is less important. What ultimately matters is the long-term relationship with the client. Are we adding enough value to her life to have her come back again and again? So we had to adjust our mindset and elevate retention to become our core-metric, rather than the transactional metrics we had focused on earlier.
Eric noted that the transition from focusing on one metric to the other took some effort for the team as well. At first, people were used to evaluating success based on which experience generated more transactions; it was very quick to see results because you could simply see how many things were purchased per shipment. The shift to retention required people to take a more long-term view when evaluating their efforts. You would have to see if customers continued to purchase from order to order and not just evaluate the experience based on a single transaction.
As an illustration of how key metrics are used to define a goal for your testing and experimentation, letâs consider Netflix. Because it is a subscription-based business, one of Netflixâs key metrics is retention, defined as the percentage of their customers who return month over month. Conceptually, you can imagine that someone who watches a lot of Netflix should derive a lot of value from the service and therefore be more likely to renew their subscription. In fact, the Netflix team found a very strong correlation between viewing hours and retention. So, for instance, if a user watched only one hour of Netflix per month, then they were not as likely to renew their monthly subscription as if they watched 15 hours of Netflix per month. As a result, the Netflix team used viewing hours (or content consumption) as their strongest proxy metric for retention, and many tests at Netflix had the goal of increasing the number of hours users streamed. Recalling our earlier discussion about metric sensitivity, you likely also see the parallel between Courseraâs test completion metric and Netflixâs viewing hours metric. Viewing hours is more sensitive and therefore easier to measure quickly.
Your companyâs key metrics should be aligned with your business goals. If your business goals change substantially, your metrics will change as well. As an example of how things can change over time as your business changes, consider Netflixâs transition from focusing on the DVD-by-mail business to streaming. In 2011, Netflix was very clearly a DVD rental business. The key metric for Netflix was then, as it is now, retention, as defined by measuring how many customers renewed their subscription month to month. At that time, customers could add DVDs to their âqueue.â When they sent back a DVD that they had finished watching, the next DVD slotted in the queue would automatically be sent to them. If there were no DVDs in the queue, then nothing would be sent. Adding DVDs to the queue was an indication that customers were planning to continue using the service; receiving a DVD in the mail just a few days after returning the one that had been watched encouraged customers to continue watching movies from Netflix. The more they continued to watch movies from Netflix, the more likely they were to continue as a customer by continuing to pay their subscription each month. At that time, a common goal for testing was around encouraging customers to add DVDs to their queue, because this behavior was seen as being key to the success of the business. As Netflix changed into a streaming business, the key proxy metric for retention instead became how many hours of video people were streaming. Adding movies to a queue wasnât as important as it was in the days of DVD rentals. The proxy metric that tests aimed to shift thus changed to reflect the shift in business strategy. Likewise, the goals and metrics used to measure the success of tests also changed.
Competing metrics
In some cases, you might find that you have two teams that are working on metrics that feel like they are competing with each other. Katie Dill shared a story with us from Airbnb about how they handled a similar situation:
We have a âList Your Spaceâ flow where hosts can sign up and create a listing of their home. Two teams wanted to redesign this part of the product. One team wanted to improve efficiency and the conversion of hosts signing up. Whereas another team wanted to improve the readiness and preparedness of the hosts that went through the flow. These teamsâ goals were potentially at odds. One team would benefit from a more concise flow resulting in more sign-ups, while the other would benefit from a more in-depth flow resulting in fewer sign-ups. To ensure both goals would be addressed, and team collisions avoided, the teams banded together. A composite team was created with product managers and designers from both teams. They used both goals as their guiding lightâreadiness and conversionâand in the end tracked both metrics. They needed to make sure that one metric didnât increase at the detriment of the other. It was a tough project but everyone is happy with the result that helps many hosts sign-up well prepared to host.
In Katieâs example, you can see the importance of balancing metrics to deliver the best experience (e.g., host quality and host quantity have to work together). This is a good reminder for how itâs important to find the right metric(s) of interest for the goal youâre trying to achieve and how much those metrics might affect the behavior and incentive of the team to design the experience that can deliver those goals.
We fundamentally believe that successful businesses are built on successful user experiences. In other words, the best metrics will align well with both your usersâ needs and your business goals. Customers wonât sign up for your service unless they believe that it has value for them. Customers wonât stay with your service or use your products if they are too difficult to use or donât do what your customers want them to do. As you start to define how you will approach your goals, always ask yourself why you expect those approaches or solutions to positively impact your key business and experience metrics. And as you continue to learn more about your users and business through the data you get back from experiments, keep your eyes open for new metrics you could derive that are important to your business. This is where data, design principles, and business come together.
Refining Your Goals with Data
As we started to show you in Chapter 3, data can be immensely useful even in the early stages of the definition phase. We really want to emphasize that data isnât only used at the end of an A/B test to see which test cell was most successful, but that itâs used throughout the entire process of planning and executing your experiment. Data can be used to help inform and shape your goal and to provide you with insights into how you might go about achieving your goal via experimentation. In Figure 4-3, we show that data already plays a role even at the stage of defining your goal, even if only informallyâwe draw on prior assumptions and experiences to define goals.
As you consider and define your goal, think to yourself: what data do you have available to you right now? What evidence do you have about how people are currently using your product? Take stock of everything that you know about your experience currently and how users are reacting to it. Where do they get stuck? Where are their frustrations? How do your insights align with your company and business goals? If this is your first time really engaging with data, you will want to do a few things.

Figure 4-3. Data should feed into the definition phase of your experiment, as youâre defining your goals.
First, be as broad as possible about your definition of âdata.â As we showed in Chapter 2, data can come in many forms and be from many sources. Donât let your biases restrict the scope of the data that you consider in this phase. Being open-minded early in your process might allow you to stumble upon insights that you wouldnât have seen otherwise. Your user research, analysis, or marketing teams probably have many insights about your users that can help early in this process. Even if such teams arenât established at your company, though, there are other sources available that you might not have considered beforeâfor example, if you have a customer support team, hearing what people are complaining about and praising is a great source of information and data.
Once youâve gathered your data, remember that data has different levels of quality. So although we want you to be open-minded in collecting your data, you should be very disciplined and critical about deciding what data to leverage in making decisions. Here are some questions to ask yourself:
Who or what does the data represent? Is it just from a specific segment of your user base or does it come from a sample of your users that resembles and represents the entire user base? Recall that certain kinds of data (like tweets) indicate only the happiest or the angriest of customers and experiences.
Is it accurate? How has it been vetted for quality? Has the data been interpreted at any point, opening the possibility of bias?
On what dimensions does the data fall? What are the strengths and limitations of that type of data?
Was it collected recently enough to still apply to your company and business landscape today?
As weâve said throughout this book, you canât think about data in isolation. Think also about how this data reflects what your users are doing and what it tells you about their behavior. What are they trying to achieve? Think hard about how human emotions, actions, and behaviors are represented in your data. By doing so, your existing data can inform the types of goals youâll pursue in your data and design process, and the types of things you hope to learn.
To summarize, here are some questions to get you started thinking about how to leverage existing data to refine your goals prior to designing and testing:
What kind of data do you currently have access to that might give you insight into where you can make the most impact?
How can other forms of data provide insight into where there is an opportunity to improve performance?
What are some of your most engaged users doing? How can you encourage other users to do the same? What delights those users? Will the same things delight users you would like to attract to your service?
Why do they do what they do and how does that behavior make them more likely to continue using your product or service?
What do users who are most likely to convert do? What actions do they take?
What are your usersâ biggest pain points? Do pain points vary across cohorts and segments of your users?
What types of complaints do you hear in your customer service department, or through past user research?
Understanding this type of data can open your mind to possible problem areas and opportunities that will later help you to formulate different hypotheses and solutions that you might not have identified otherwise. If you donât have a lot of data available to you to help shape and inform your goal, you can also make a list of the kind of data you would like to have access to. You might find that you can invest in some user research or surveys within your company or through external agencies like UserTesting.com or UserZoom.com in order to gather some preliminary insights around your goal. Investing early and often in data will help you check your intuitions at every step of the process. The earlier you catch errors in your intuitions about your users or problems with your execution, the easier and less costly theyâll be to change.
![]() Returning to the summer camp metaphor, letâs imagine that although your camp is doing well, you still have empty capacity and you want to get even more campers to enroll. You make a goal to increase the number of campers who enroll at your camp. Now that you have this goal, you want to start thinking about how youâre going to get there.
Returning to the summer camp metaphor, letâs imagine that although your camp is doing well, you still have empty capacity and you want to get even more campers to enroll. You make a goal to increase the number of campers who enroll at your camp. Now that you have this goal, you want to start thinking about how youâre going to get there.
Identifying the Problem You Are Solving
So, youâve started thinking about a goal and how youâre going to measure your success at moving toward that goal. Once youâve articulated your goal, youâll have to think about how you will approach achieving it (Figure 4-4). Hopefully you had some data that helped you to refine your goal, and you feel excited about pursuing that goal. Right now, you donât need to know exactly how youâre going to achieve that goal. However, in many cases looking at past data helps you refine your existing goal and spur some ideas about a few approaches you could take to achieving that goal (what we are labeling here as âproblem/opportunity areasâ).

Figure 4-4. Now that you have your goal, itâs time to start thinking about different problems you could address or opportunities you could pursue in service of your goal.
Through analysis of the data and insights, you should be able to identify areas where there are problems that can be improved or opportunities to innovate toward your goal. For each of these areas, we can form a problem statement that explains it further and links it back to measurable criteria (usually the metric of interest youâre using to measure progress toward your goal). We encourage you to take a two-pronged approach to thinking about these addressable areas, in terms of problems and opportunities:
What are the biggest problems with your user experience that are impeding your goals? Where do users consistently have trouble? What are their biggest complaints?
What are the biggest opportunities for you to improve your experience? What are your âpower usersââthose who quickly adopt and use your most advanced featuresâdoing that might give you clues on possible opportunities?
![]() Identifying a few problem/opportunity areas where your designs could make an impact is the first step in beginning to craft your hypothesis. For example, letâs go back to the example goal of âincreasing the number of campers.â What might lead you to get more campers? You could break this out into two possible approaches: retain more old campers, or bring on more new campers. You could start by surveying campers who attended camp and didnât return the next summerâwhat did they do instead? Are they attending different summer camps, and if so, why? Are they taking summer classes instead, or traveling abroad? This might provide some insight into why theyâre leaving: is it because they didnât understand the value of camp? Because camp was too expensive? Or because their parents didnât think camp was educational enough? There are many possible reasons you might see a low return rate in campers. You could also try to understand why prospective campers donât attendâis it because they donât know about your camp? Because itâs too far away from home? Experimentation and data can help you identify many reasons, but using your intuition as a designer you might think of others that are worth exploring further.
Identifying a few problem/opportunity areas where your designs could make an impact is the first step in beginning to craft your hypothesis. For example, letâs go back to the example goal of âincreasing the number of campers.â What might lead you to get more campers? You could break this out into two possible approaches: retain more old campers, or bring on more new campers. You could start by surveying campers who attended camp and didnât return the next summerâwhat did they do instead? Are they attending different summer camps, and if so, why? Are they taking summer classes instead, or traveling abroad? This might provide some insight into why theyâre leaving: is it because they didnât understand the value of camp? Because camp was too expensive? Or because their parents didnât think camp was educational enough? There are many possible reasons you might see a low return rate in campers. You could also try to understand why prospective campers donât attendâis it because they donât know about your camp? Because itâs too far away from home? Experimentation and data can help you identify many reasons, but using your intuition as a designer you might think of others that are worth exploring further.
The following example, shared by Arianna McClain from her time working on an IDEO project focused on supermarket frozen meals, illustrates how looking at data in unexpected ways can help identify new design and business opportunities. She said:
It was dinnertime, and my colleagues were staring into the freezer of a 48-year-old man named John. As IDEO designers, we were working with a client to develop a new line of healthy food products, and John was one of the people who had invited us into his kitchen for research.
What we saw surprised us: stacked boxes of USDA certified organic, freezer aisle entrées intended for children. John was a bachelor with no kids, so why would he have kidsâ meals in his freezer? Simple: Because he wanted to eat healthy, and he believed that no company would make unhealthy food for kids.
Why is that interesting? In data research, John represents the classic âoutlier,â a person who stands out from the other members of the group. From a traditional data perspective, people may by default look at measures of central tendency or how the majority of people behaved. However, as designers we seek these outliers. From a business perspective, outliers may provide a new design opportunity that we might not pay attention to otherwise.
The underlying principle in Ariannaâs comment is that looking for surprising behaviors can inspire new product directions regardless of the type of data youâre using. In Ariannaâs words, learning from these âoutliersâ is a great way to inform potential opportunity areas or hypotheses to explore.
Another great example comes from Chris Maliwat, and his time at Warby Parker. Warby Parker is an eyeglass manufacturer that has both an online and offline component to their customer experience. Customers can browse frame styles online or in person in a Warby Parker showroom. Chris talked to us about how the team at Warby Parker looked at customer behavior in the retail experience and in the customerâs home as a way to inspire experiences that they would then design and test online. At first, Warby Parker assumed that a customer who started in their retail store would purchase their glasses in the retail store and that a customer who started with Warby Parker online would then purchase online. They originally approached the customer experience by considering only âone channelâ at a time. Instead they learned that their customers were âomni-channelâ shoppers who would often go back and forth between the online and retail experience.
However, their qualitative research showed that there were certain behaviors that made their customers more successful in the retail store if they started online and vice versa. One of those behaviors was âlist making.â Their researchers saw that people were more likely to make a purchase if they made notes for themselves on Post-its, took screenshots that they then printed, or simply remembered the names of the frame. Chris explained that prescription glasses are a âhigh considerationâ product where most people donât make a decision on what they want to buy right away. Chris said:
We realized that every time we force a consumer to start over with the consideration process, it means that they have to virtually or actually go down a path that theyâve gone down before and remake three or four decisions theyâve already made. We wanted to reduce the friction, and help them pick up where they left off. We wanted to recognize which real-life behaviors we could encourage by building features to bridge those gaps. So we made a list-making tool for people who were traversing from online to retail or from retail to online.
Looking at existing behaviors in the relationship between the online product and retail stores for Warby Parker helped the team uncover a major opportunity area: helping facilitate the decision-making process.
There is a danger in diving too deep or too quickly into problem-solving mode. By calling out âproblem/opportunity areasâ first, we hope to get you in the mindset of staying at the right level of thinking for this early stage in the process. Each âproblem/opportunity areaâ should be broad enough that you might generate at least a few hypotheses to explore within it. As a designer, you may have been trained to dive into proposing and exploring potential solutions immediately. We recognize that it may be a difficult transition to resist the desire to start thinking about solutions in the form of wireframes, interaction logic, and action flows immediately. Our goal in giving you these frameworks and asking you to be explicit about your goals, problem/opportunity areas, and the scope of your project is to encourage you to remain broad and open-minded as you approach every new problem. By avoiding the common pitfall of honing in on a single solution too early, you are forced to be more creative. We believe this will push you to be a better designer, and over time help you work toward more optimal solutions for your users.
Remember Where You Are
As we close out this section, we want to remind you one more time to think about the space of design activities you might be embarking on. This is a good time to review for yourself the nature of the work youâre taking on with each problem/opportunity area along the two dimensions we introduced in Chapter 2. You need to ask yourself whether your problem is of a global or local scope. Are you aiming to evaluate your ideas or explore more possibilities? In the next section, weâll begin to speak about generating hypotheses that align with the problem/opportunity areas youâre thinking about. In Figure 4-5, we show that taking time to scope your problem carefully at this point will help you decide what data and hypotheses are most appropriate for the design activity youâre working on, and being thoughtful at this point in the process will save you significant time later on.

Figure 4-5. Donât forget about where you are in the space of possible design activities, and think about how it might impact your approaches to data and your hypotheses.
When we talked about metrics, we expressed the idea that metrics help you measure not only your success toward your goal, but also whether your efforts were âworth it.â Resource limitations and prioritization are realities at the vast majority of companies, and make it impossible to chase every idea. When youâre thinking about global problems and opportunities, you may be looking to fundamentally change your approach. Deviating significantly from your existing experience requires more resources and effort than making small iterations. When you design in âunknown territoriesâ (as you often do when working on a global scope), you canât be sure in advance whether these territories will be fruitful or not or whether thereâs a much better solution to be found. In these cases, you should look hard for existing data or signals that indicate that these efforts might pay off in larger metrics increases. You can think of global problems and opportunities as being more high risk and high reward than local when working on a local scope, because with local problems your proposed changes will be more similar to the existing solution. As youâre scoping your problem or opportunity area, then, always consider how external sources of data can give you confidence (or counterevidence!) in support of your efforts. If you donât have signals to suggest that a global scope is worthwhile, consider whether you should be thinking about a local problem of opportunity instead.
You should also take into consideration how far along you are in the process of committing to a solution. In Chapter 2, we mentioned that exploratory problems can give you the freedom to stay open-minded without fear of being stuck launching work that isnât your best, whereas evaluatory work should be more vetted and closer to a solution youâd be proud to ship soon after the test. Once youâve decided which type of design challenge youâre solving, consider how whether youâre exploring or evaluating might impact the way you consider your metrics. In an evaluatory test, your goals will be clearly defined: you want to make sure that you havenât negatively impacted your metrics of interest, and that the positive impact of the design is sufficient to justify your efforts. With this kind of mentality, you will have a clear expectation about what should happen to your metrics. In exploratory work, however, you still have a clear and measurable goal in mind, but exactly how your designs will lead to that impact might not yet be clear. You therefore will approach your metrics with the mindset of observing what happens (perhaps in several secondary metrics as well as your key metrics) rather than seeing if an expected change happened. These types of problems can help inspire further experiments to gain greater confidence in the phenomenon you observed.
By this point, we hope that you have a clear sense of your goals, and some ways to approach defining the different problem and opportunity areas you could consider in service of meeting those goals. Now, weâll launch into a deeper discussion about how you as a designer should be involved in crafting well-formed hypotheses.
Building Hypotheses for the Problem at Hand
In Chapter 2, we introduced the idea of a hypothesis as a testable prediction of what you think will happen to your users if you make a change to your experience. You now know that defining clear hypotheses is important to ensure that your designs express a clear intention that you can learn from. You can think of your hypothesis as a north star that helps you stay focused, guiding you toward valuable insights that will be actionable and meaningful to you as a designer, and to achieving your business goals. Having a clear hypothesis is also an essential way to keep learning at the center of your experimentation practice.
What we havenât covered yet is how to actually generate a solid hypothesis. In this section, weâll walk you through the key components of building a hypothesis. Weâll also provide some secondary questions that will help you when crafting your hypothesis. Youâll notice that we deliberately used language to reflect what designers are most familiar with: user behaviors and experiences. This should help to set the foundation for the way you will design your hypothesis statement and test cells, the material we cover in Chapter 5.
One way to construct a strong hypothesis is:
For [user group(s)], if [change] then [effect] because [rationale], which will impact [measure].
We introduced a simpler version of this hypothesis framework in Chapter 2. Now, letâs talk a little bit more about each of the components in turn.
In a hypothesis, the user group component indicates who you hope your change will affect. In Chapter 2, we told you about the diversity of your user base and how certain grouping strategies can help you start to understand and represent this diversity. Based on previous data, you may be focusing on your entire population of users or only a subset. Here are a few questions to get you started thinking about the user group(s) youâre aiming to affect with this hypothesis:
What do you know about them as a demographic? Their habits?
How are you targeting these users in relation to your business?
What relationship do they have with your company?
Are these existing users? New users? Power users?
Youâll need to do something different to impact the user group(s) youâve defined. Recall from Chapter 2 that the change component is a broad statement of the types of changes youâll be making to your control (current) experience to encourage the user behavior youâre aiming to impact. This doesnât have to be a perfect expression of exactly how youâll design or implement the change; rather, it should represent the change abstractly while still leaving room for you to design several possible treatments of the hypothesis. Weâll discuss how to design different treatments of the same hypothesis in Chapter 5. As youâre thinking about the change your design will bring about, consider the following questions:
Are you introducing something completely new to the experience, or removing something?
Are you changing something about the existing experience?
Your goal in making a change to your experience is to impact your userâs behavior in some meaningful way. When you define the effect, youâre explicitly articulating the desired behavior you hope to bring about in your user group(s). This effect part of your hypothesis will probably be directly related to the problem or opportunity area you already defined, since your hypothesis represents an idea you have for targeting that particular area. The effect essentially calls out the specific behavior that will help you address that. As you revisit your problem or opportunity area, think about the following:
What was the problem you identified? What user behaviors can minimize or address this problem?
What was the opportunity area you identified? How can you incentivize behaviors that make this opportunity a reality? What are your power users doing?
In Chapter 3 and earlier in this chapter, we discussed how data can help you identify effective problem areas and ways to address them. The rationale part of a hypothesis is a statement of the evidence you have to support your hypothesis, or the common sense reasoning why you think your proposed change would drive the desired behaviors. In other words, why do you think that the change you make will have the desired outcome? By including your rationale in your hypothesis, youâre giving the reasons you believe your efforts will be justified. This is one way for you and your team to make sure youâre prioritizing hypotheses that will give you the most effective learning and the best shot of a successful test. Get started by asking yourself the following questions:
Does your rationale speak to your customersâ motivations or does it leverage a tactic or mechanism to make that change?
What kind of data have you seen to support this hypothesis and how consistent is that data?
Finally, the measure is the metric or metrics that you will ultimately try to impact. These describe how you will measure your success. You need to have your success metrics defined upfront, so that after you launch your tests you have an objective way to track their performance, therefore maximizing your learning. One more important note is that tracking your business success metrics is important, and the best business metrics will consider customer experience; however, you should also be thoughtful about whether you should track a qualitative measure of user sentiment as well. This is one way to triangulate your findings and ensure that your data reflects a holistic image of how your design changes affect your users. We already provided an in-depth discussion of choosing appropriate metrics (refer back to âDefining Your Metric of Interestâ as well as Chapter 2), but here are a few more questions to put it into the context of hypothesis generation:
Which metrics are you going to look at to understand if the impact you are making is the right one or big enough? How are these metrics related to the goal youâve already defined, and your businessâs goals?
Will you measure or factor in user sentiment, and if so, how? Will you use surveys, focus groups, and interviews?
As you continue to develop hypotheses and run more experiments, you might find that a number of these building blocks tend to be the same from hypothesis to hypothesis. For example, if you are consistently working with the same user group(s) every time, you might find it getting redundant to state the specific user group(s) in every hypothesis statement. It might occasionally make sense to create hypothesis statements that donât include every single one of these items, but we believe itâs important to periodically revisit all five of these areas in the course of your work to make sure that you remain aligned with the other folks you might be working with and the larger company goals. Our opinion is that the minimal good hypothesis will include the change youâre trying to make and the metric you will track to observe its effect. This is in service of holding yourself and your team accountable to your goal and knowing very concretely whether you have achieved it, which is at the core of making data-informed decisions.
Example: A Summer Camp Hypothesis
![]() Now that weâve introduced each of the building blocks in depth, letâs apply them to an example of a well-formed hypothesis. Letâs imagine that for your summer camp, youâre hoping to put to action your goal of enrolling more campers. Youâve noticed that historically only a small proportion of campers have come from urban areas. You wonder if offering a bus from major metropolitan cities to your camp will improve camp attendance from city children, as you believe that urban-based families are less likely to own cars than suburban-based families, making it harder for them to drop off their children at camp. You might say:
Now that weâve introduced each of the building blocks in depth, letâs apply them to an example of a well-formed hypothesis. Letâs imagine that for your summer camp, youâre hoping to put to action your goal of enrolling more campers. Youâve noticed that historically only a small proportion of campers have come from urban areas. You wonder if offering a bus from major metropolitan cities to your camp will improve camp attendance from city children, as you believe that urban-based families are less likely to own cars than suburban-based families, making it harder for them to drop off their children at camp. You might say:
For new potential campers from the city (user group), by providing free buses from major cities to camp (change) we will increase camp sign-ups from a previously underperforming population (effect) because the friction to go to camp will be lower (rationale). We will know this is true when we observe more urban campers at camp (measure).
You might want to learn whether or not providing a bus service will increase the sign-ups from potential city-based campers. You might have questions about whether different metropolitan areas will utilize the buses differently (you might expect that a two-hour bus ride from a nearby city is more appealing than an eight-hour bus ride from a city far away). You might also want to learn to what degree buses impact sign-ups to camp at all. Is the potential difficulty of simply finding transportation to camp a real reason why prospective campers might not sign up? Are there other reasons why urban interest in camp might be lower (including less comfort with the outdoor activities, less familiarity, or a higher density of city-based camps)? Considering all the different things you might want to learn, you can start to imagine how you might sequence different series of tests to build out your understanding of what works or doesnât work.
There is no strict way to formulate a hypothesis. The structure we described earlier was merely illustrative. As long as you capture the most important and relevant building blocks for your situation, your hypothesis will be clear and well formed. Here is another example of a format that might work for a hypothesis that is similar to the template that many tech companies use:
We predict that [doing this/building this feature/creating this experience] for [these people/personas] will achieve [these outcomes] because of [these reasons]. We will know this is true when we see [this impact to our metric of interest].
Notice that our language is very specific hereâwe say âpredictâ rather than âbelieveâ because while a false belief can make you wrong, a prediction can be false without any reflection on you. This is the mindset you should take when experimenting: your experiment may reveal evidence against your hypothesis or prediction(s), but you didnât fail in your reasoning process nor did your predictions fail. This is an important principle to remember throughout the experimentation. Though many experiments may reveal data that counter your initial intuitions or your well-formulated predictions, the outcome is a critical learning you can use to make the process of experimentation a success for you, regardless of the specific outcome.
Hypotheses can be narrow or broad. Much of this might depend on the nature of the goal you are trying to achieve and how mature your product/experience is. Here are some examples of hypotheses that different companies could pursue, based on their specific business focus and their specific offerings:
For a photo-sharing platform a hypothesis could be: We predict that by giving all users a way to add effects and filters to their photos, more people will use our product because it makes their pictures look better and is more fun to use. We will know this is true if we observe increased user engagement with the app.
For an online professional networking platform, a hypothesis could be: We predict that by adding a progress bar showing users how much of their profile theyâve filled out that more users will complete their profiles because they feel a need to accomplish the task. We will know this is true when we see a higher percentage of completed profiles in our service.
For an online social networking platform also interested in supporting real-time communications, a hypothesis could be: By making a separate experience focused only on text messaging, we will attract more users to our messaging service because the app can be more targeted and simplified.
For an online flight comparison service, a hypothesis could be: Because we know that users in Japan more often make a decision to purchase a flight on popularity than price, we predict that ranking flight results by popularity for users in Japan will increase user confidence in recommendations, thereby decreasing bounce rate (defined as the percentage of users who leave the website). We will know this is true when we observe a statistically significant 2% decrease in bounce rate in that market.
For an ecommerce platform, a hypothesis could be: We predict that providing more information about shipping costs, and making that information salient through design, we will decrease unwanted orders and increase customer satisfaction.
In addition to using your own internal data, thinking more broadly about the competitive landscape of your product (including offline experiences!), your user group(s), and other trends can help you identify particular hypotheses to pursue within your target problem/opportunity areas.
Asking some of the following questions might help you as you look for ideas:
Are there any emerging trends that could inform, affect, or change your customersâ behavior in a way that you are not considering now?
Who are your users? Do they match the users you would like to have in the future? How are they similar or different from each other? (Think back to our discussion in Chapter 2 of new versus existing users.)
What are some of the current gaps in your product, experience, or service that you can fill?
What are competitors or other companies in the space doing that is successful but different from your experience?
Now that weâve introduced some concrete thoughts on how to go about building a hypothesis, we want to walk you through a concrete example of how this played out at Netflix.
Example: Netflixâtransitioning from DVD rentals to Streaming
As an example of creating a hypothesis, consider this example from Netflix when they were transitioning from a company that was known for its DVD rental business to one that would lead the market in video streaming. The Netflix website was divided up into several major areasâthe first two tabs in the navigation were âDVDâ and âWatch Instantlyâ (Figure 4-6). At that time, the âDVDâ tab had been the first and default tab for many years. A lot of work had been done to optimize that experience for first-time use. There was a lot of testing around what behaviors were important to encourage right after the user had signed up (e.g., âAdd 6 DVDs to your queueâ) and on welcome messaging (Figure 4-7 and Figure 4-8). Because the âWatch Instantlyâ tab was not the default tab, it hadnât received the same degree of optimization.

Figure 4-6. âBrowse DVDsâ and âWatch Instantlyâ were the first two tabs on the Netflix web experience.

Figure 4-7. Because âBrowse DVDsâ was always the default tab, it received a lot of optimization.

Figure 4-8. Another way in which the âBrowse DVDsâ tab was optimized.
Given that the company wanted to understand the extent to which the tab placement could both affect peopleâs impression of the company and the number of movies people streamed, a hypothesis was put forward to change the first tab from being âBrowse DVDsâ to âWatch Instantlyâ (shown in Figure 4-9). At that time the companyâs core metrics were focused on both DVD consumption and streaming consumptionâthat is, how many DVDs were added to a userâs queue as well as how much they streamed. The belief was that because the DVD business was so well established at the time, moving it to the second tab would not negatively impact the core metrics for the company. This hypothesis could be formulated as:
By making the âWatch Instantlyâ tab the first tab on the website, more users will stream from Netflix without negatively impacting the number of DVDs they add to their queue, resulting in more consumption of Netflix (DVDs and streaming) because the streaming option is more prominent.
Though we are focused simply on creating hypotheses in this chapter, itâs worth sharing the results of this test with you now. In this case, the hypothesis performed well enough that Netflix was able to keep âWatch Instantlyâ as the first tab. It increased streaming hours, allowing Netflix to start reaping the benefits of making a bold move toward a streaming value proposition despite not having optimized the streaming service as much as the DVD service at that point in time.

Figure 4-9. After their A/B test, the Netflix team decided to put âWatch Instantlyâ as the first tab.
Having this data confirmed that they could move forward without negatively impacting the business and this allowed Netflix to move faster on a large, strategic decision than they might have otherwise. Now, though the overall results were positive on the test cell with the Watch Instantly tab first, itâs hard to pinpoint whether or not there were any negative effects because that treatment didnât have any optimization for first-time messaging. Itâs hard to know, but we can conclusively state that putting the âWatch Instantlyâ tab first moved metrics in the desired direction. Knowing how unlikely it is that you crafted the best experience and design with your first go, itâs a fair bet to conclude that further iterations could only improve the streaming numbers even more.
At this point, itâs easy to imagine what other kinds of hypotheses could be crafted, knowing that first hypothesis tested well. What other hypotheses would you want to explore if you were on the team at Netflix and wanted to find more ways to impact your goal of increasing Netflix consumption? We hope youâll find that hypothesis building is infectious: once you see the impact of one, itâs easy to get excited and start to brainstorm a multitude of other hypotheses to consider testing. This is the joy of experimentation. Because building hypotheses is lightweight, creative, and fun, you can come up with many ideas to consider quickly.
The Importance of Going Broad
We often hear designers worry that A/B testing and using data in the design process might stifle creativity. As you read this book, you might share those concerns. How can you still express your creativity within the confines of this framework? What about designerâs intuition, which might not fit neatly into the steps weâve outlined? We recognize your concerns; one of the themes that youâll continue to see us emphasize throughout this book is that a data-aware framework will encourage you to explore many different possibilities. This breadth is the ultimate way to bring creativity to your process, and encourage others on your team to get onboard with this creative approach to design and problem solving.
Up until now, weâve shown how you can use data to identify your goals and understand the nature of your problem/opportunity area. Weâve also talked about how to structure and craft a hypothesis statement. So although the process we have covered so far looks something like Figure 4-10, where a problem/opportunity area lends itself to a single hypothesis, in actuality itâs more like Figure 4-11, where there may be multiple hypotheses that address the same problem or opportunity area. In this section, weâll talk about how to go broad in your generation of hypotheses.

Figure 4-10. Generating a hypothesis based on a problem/opportunity area to address a specific goal.

Figure 4-11. Generating multiple hypotheses for a problem/opportunity area to address a specific goal.
As part of ensuring that you are constantly learning from your designs, we believe that generating a large variety of different hypotheses prior to designing forces you and your team to be more creative. This will force you to think about very different ways to solve your problem, and therefore help you to generate a greater diversity of solutions. In fact, you could have also identified a number of problem/opportunity areas that might each generate more hypotheses, so Figure 4-12 could be a more accurate representation of the way weâd want you to work with data.

Figure 4-12. Breaking a key goal out into several problem/opportunity areas that could have impact on that goal, and deriving multiple hypotheses for each.
As a designer, youâre probably already familiar with this kind of âgoing broadâ process. Brainstorming and exploring many divergent designs is common in design practice. We want you to do the same thing in the framework of experimentation: what hypotheses can you brainstorm? What other tests might you consider running to expand your learning? What will different experiences provide to your users? What are you curious about? If you let your curiosity guide you early on, youâll never run out of questions to ask or hypotheses to pursue. What is most exciting about going broad early is that the stakes of thinking âbigâ are lowâyou can generate a bunch of hypotheses in service of pushing the envelope of creativity and thinking about as many divergent hypotheses as possible with little cost or effort. As you become closer to prioritizing or choosing hypotheses, youâll have cast a broad net of ideas letting you and your team make thoughtful choices about the best hypotheses to further pursue.
Notably, though weâve reiterated the importance of allowing data to feed into your hypothesis generation, it is important to remember that this is in service of being data first but not data only. Design intuition is a powerful tool for generating hypotheses in unexplored territory; this is especially the case where there may not be strong evidence for which hypotheses are the most critical to test. At the hypothesis generation phase, you need not weed out these hypotheses. They are worth noting and considering alongside other data-backed hypotheses later on, and you can always decide not to pursue them due to potential risk later on. Remember that hypothesis generation is meant to be lightweight and nonbinding, so you shouldnât restrict yourself or your creativity too early on in the process.
Now weâll share just a few thoughts on how you might generate many divergent hypotheses at this stage in your process. Once youâve identified a problem area or an opportunity, the easiest way to generate multiple hypotheses is to keep some of the building blocks of your hypothesis statement constant while brainstorming other possibilities for other pieces.
Multiple Ways to Influence a Metric
![]() As you may have already seen in your experience as a designer, there are often many behaviors that can drive the same eventual result. For instance, think back to the summer camp example from before. Remember that your goal is to increase enrollment for the campâs upcoming summer session. Youâve identified several problem/opportunity areas toward that goal, but now youâre going to focus on one specific opportunity area: increasing the number of new campers. We built one hypothesis earlierâthat providing buses to camp would increase registrations from urban campersâbut we can build more by thinking more broadly.
As you may have already seen in your experience as a designer, there are often many behaviors that can drive the same eventual result. For instance, think back to the summer camp example from before. Remember that your goal is to increase enrollment for the campâs upcoming summer session. Youâve identified several problem/opportunity areas toward that goal, but now youâre going to focus on one specific opportunity area: increasing the number of new campers. We built one hypothesis earlierâthat providing buses to camp would increase registrations from urban campersâbut we can build more by thinking more broadly.
Start by brainstorming a list of all the possible desired behaviors (effects) that might impact your goal. Each of these could be the seed of many new hypotheses, because for each behavior there are many changes that could encourage that behavior. In this way, you can generate hypotheses both iteratively and in parallel. For instance:
We predict that by providing a discount to families who refer new campers to camp, existing campers will tell their friends about camp, which will lead to an increase in new campers. We will know this is true if we observe an increase in the number of campers next year.
We predict that by advertising in parenting magazines, more families will know about camp, which will lead to an increase in new campers. We will know this is true if we observe an increase in the number of campers next year.
We predict that by offering a discount to first-time campers, more new families will be able to afford sending their children to camp, resulting in an increase in new campers. We will know this is true if we observe an increase in the number of campers next year.
All of these examples speak to different behaviors (in italics) that might lead to reaching the same goalâincreasing the number of new campers. You might have different guesses for which hypothesis is most likely to give you the best results or you might find them equally compelling. Weâll talk more about how to narrow down your choices to the hypothesis that you want to test later in the chapter.
Weâre sure you can imagine that even for the preceding hypotheses there are multiple changes you could make to encourage the same behavior. Taking just the first example, where the desired behavior is that existing campers will tell their friends about camp, you could probably begin to brainstorm other possible changes beyond just offering a referral discount: what if camp was more fun? What if campers got âswagâ like sweatshirts that they could wear when they returned back home from camp, prompting conversation with friends? What if you posted photos on social media and tagged the campers so that their friends would see? As you can see, brainstorming different behaviors and different changes can occur in parallel. Changing these two factors is often the easiest way to generate many hypotheses, and weâd encourage you to start going broad by focusing on these two building blocks.
Focus on New and Existing Users
Thinking about the user component of your hypothesis can be more challenging, but has the potential to make huge impacts to your metrics. Recalling our conversation about different cohorts and segments in Chapter 2, there are a few ways you could approach hypotheses regarding different users or user groups:
Broaden your user base by targeting new users (e.g., by opening new markets, expanding advertising efforts to new populations, etc.)
Provide a better experience to an existing set of users (e.g., to improve retention of those cohorts or segments)
Speaking to the first point, we want to take a moment to pause here to remind you that though itâs important to consider your current users, you should be equally thoughtful about who your future users may be. The users you currently attract and target may be very different from the users that you would like to have in the future. The success of your business depends heavily on you continuing to attract and retain new users in the future. For instance, early adopters of new technologies are often more tech-savvy than the average person, and are more tolerant of poor experiences because theyâre highly motivated to use your product. As you try to grow your user base, you might find that a broader or different set of users will have different behaviors, needs, or abilities than your initial user group. Another example might be a company that initially launches in the United States but then decides to expand internationally. While it might turn out that the experience you are designing has broad appeal right from the start, itâs rare that an experience wonât need to take into account different needs from an evolving and growing user base. One rule of thumb is that if your business is fairly mature and youâve saturated a market then you should focus on your existing users, but if youâre at the early stages of growth as a company, then you should focus on new/future users.
Remember the three Coursera segments that we introduced in Chapter 2? Recall that Coursera thinks about lifelong learners, seasoned professionals, and unseasoned professionals as three segments with very different needs who are currently using their product offering. John Ciancutti also shared an example from Coursera about how there is potentially a fourth segment that the company might not be thinking about just yet, but that could be very promising for the business in the future. According to him:
Most of the world hasnât spent the last 200 years building universities. Developing markets would need 10,000 more universities just to get to the baseline of first-world post-secondary education. They would need a million more instructors than they have today. But in fact, theyâre losing instructors and colleges there because thereâs a global competition for that talent. Structurally, theyâre not going to do it the way the United States did it. They donât have those 200 years; they want to do it now.
If youâre at Coursera, today thereâs not a business model thatâs going to meet the developing markets segment. You have to make choices. The easiest way to make money in 2016 is to go after those affluent lifelong learners who want to give you money. Thereâs a lot of temptation to do that, but if youâre going after the biggest possible future demographic, you go after the people who want the credentials. 93% of humans never get a post secondary education of any kind, but middle-class jobs today require it. So thereâs a gap. The question is, are we going to roll the dice and go with the big thing?
As John shared, considering a new segment of users is potentially a great way to open new doors for a business. However, the types of people who would use Coursera in an emerging market are very different than the lifelong learner segment. You can imagine that if Coursera decided to explore these emerging market learners, theyâd need to be thoughtful about using data to understand how those folks react to their product offering.
With these factors in mind, consider how the selected users or user groups might affect your hypotheses. Will your business be more successful if you start to target a new set of users or a different set of user groups, or should you iterate on the experience for existing users? Is your demographic currently shifting, resulting in new confusions or opportunities to improve?
As a very simple example, consider Facebook. When it first launched, Facebook was available only to college students at a select set of universities. In order to register, a user needed to be part of the college community. In 2005, when Facebook expanded to high schools, it required an invitation to join. Then in 2006 when Facebook was opened to anyone, the requirements changed againâusers simply needed an email address and verification that they were 13 years or older. As Facebook grew in size and became more open, users became more concerned about privacy. The needs of the users also changed as the user groups who were interested and or were targeted for company growth evolved. In 2007, Facebook had 100,000 company group pages focused on attracting customers. Recognizing that many businesses saw Facebook as a place to promote their companies, Facebook created Pages in 2009, an offering specifically designed for businesses. âUsersâ of Facebook for Business had then, and still have, different interests, needs, and goals than the average person on Facebook. You can see how shifts in the companyâs user base to include new user groups with different needs may have large or small but significant effects on requirements of the product. These changes present new opportunities for different hypotheses to be formed over time as well. A concept like âPagesâ may not have made sense for design exploration and experimentation when Facebook first launched, but it made a lot more sense to test and explore once they saw that businesses were using their platform. An area for exploration for them might have been, âHow can we adapt our current interface, which is very consumer and individual focused, to be used for businesses?â
To the second point, you could also think about how to improve your experience for an existing group of users. We discussed that your user base of urban campers is small at camp. This might be an issue of awareness or âfitâ for camp, but letâs say youâve realized that campers who grew up in the city are not retained as well as campers from the suburbs once theyâve come to camp. You want to figure out how to keep these city campers coming back to increase the number of campers who are at camp next year. Figuring out what isnât working about your existing experience for users you already have is a great opportunity to collaborate with your user research or data analyst friendsâthey probably have interesting insights about the challenges your current users face, which might prompt new hypotheses about how to improve things. For instance, maybe city kids donât come as prepared to camp because they donât know about the importance of bug spray and good hiking boots. Providing a packing list is one concrete and cheap way to address this problem, and a hypothesis you might pursue.
We donât need to tell you that what is the right experience for your users will change over time. Users and user groups change, technology changes, and business strategy changes will all impact what your customers expect from you and what their needs are. Keeping abreast of these external changes might mean that you need to come up with new hypotheses to test in order to reach your goal or that some of the assumptions you had about former hypotheses that tested well have now changed and you need to rethink those ideas. One benefit of the experimentation mindset, rather than just running one-off A/B tests, is that once you become comfortable and excited with this way of thinking, youâll always be ahead of the game forming new and testable hypotheses as the market evolves. And an important implication of this is that as the world around you changes, the hypotheses that have the potential to succeed may change as well: hypotheses youâve tested might perform differently under these new conditions. We encourage you to keep records of old hypotheses, even if you donât pursue them straight away, as they could encourage experiments you run somewhere down the line.
Revisit the Scope of Your Problem
Just now, we spoke about how you could vary the change, desired behavior, and user profile(s) to generate more hypotheses. One rule of thumb to remember is that the scope of the problem you are trying to solve could impact how many of these hypothesis dimensions you vary away from your control experience. For instance, for a local problem, you might be making a different change, but otherwise focus on the same users, desired behavior, or metrics. However, for a more global problem, your hypothesis might deviate away from your control in more than one way: maybe your hypothesis has to do with changing or expanding the users or user groups in which you are interested, or targeting a new behavior, or measuring additional or different variables, as opposed to just making different product changes.
As we discussed in Chapter 2, local problems are generally ones where you have decided to focus on one area of your customer experience. You are already familiar with the territory, and are looking to optimize the existing experience by making only one or two small changes to your existing experience. You can think of local problems as those where the different hypotheses represent smaller changes to the user experience, giving you more trustworthy data about exactly how the small changes impact your users and your metric of interest. In global changes, remember that youâre trying to come up with the best possible solution by being open-minded to radical changes that might dramatically alter your userâs experience, the user groups you are serving, or your business model.
Earlier, we told you that for local problems, your hypothesis might only reflect a different change relative to the control experience, keeping the users, measures, and desired behaviors the same. However, though weâve often heard concern from designers about these âlocal optimizations,â in practice such changes can have huge measurable impact on the health of an experience and business. In other words, small changes to the experience donât necessarily imply small impact. And, local experiments are often the only way to be very confident of the impact about specific components of the experience, since they let you âtease apartâ the causal impact of each individual change.
By contrast, your hypotheses for a global problem should be much more diverse. Even though your intuition might tell you that thinking narrowly enough for a local problem is more challenging, we would contend that thinking as broad as you should for a global problem is actually much harder. We encourage you to challenge yourself and think deeply about how you could leverage each component of the hypothesis. How can targeting different users or user groups help you address your selected problem or opportunity area? What different behaviors can you encourage in those different users or user groups and with what incentives? What might you change about your experience to drive the behavior youâd like to see? As you can see, you might have an exponential number of different hypotheses you can generate by targeting each of the building blocks of your hypothesis in turn.
In the next example from Netflix, we will look at a global experiment that tested highly divergent hypotheses.
Example: Netflix on the PlayStation 3
When Netflix first launched on the PlayStation, the experience was fairly basic (Figure 4-13). Users had to click through one title at a time, making it challenging to evaluate many possible movies to watch, and the experience generally didnât scale well to a growing catalog of streaming content.

Figure 4-13. The original Netflix design on the Sony PlayStation.
When A/B testing capabilities came to the PS3, the Netflix team was eager to get to work on optimizing their experience. This was the first time that the team had the opportunity to experiment with a TV interface, and they acknowledged that they had yet to develop a well-honed instinct about what works and what doesnât work in that environment. They didnât feel confident that the current design was the right one and knew there was a strong chance that the ârightâ design was significantly different from what was in market. Therefore, it was important to try some different ideas.
If you recall, earlier in this chapter we shared the example of how âviewing hoursâ, or the amount of Netflix content that was consumed, was the strongest proxy metric for retention for Netflix. So the team starated by rearticulating that the goal on the PlayStation was the same as the goal for all other Netflix devicesâto maximize the number of hours of content consumed. Getting customers to watch more TV and movies through Netflix was the key measurement of success for the team.
In order to solve these problems, the team started by brainstorming different hypotheses for what was most important to address in the new user experience. Design worked closely with product management and gathered cross-functional teams from across the company. They defined different hypotheses for various design concepts based on their understanding of the limitations of the existing design. Although more initial hypotheses were generated during the project, weâll share just four of them here:
- Hypothesis 1
âBy clearly giving users easier access to the entire catalog, they will be more likely to explore the breadth of the catalog and find a movie that they like, which will result in more hours of content consumption.â
In the original experience, many users expressed a concern that they were only getting access to a limited part of the catalog. The basis for Hypothesis 1 was to ensure that the user felt confident that they had access to the entire catalog. The downside of allowing users to browse the entire catalog might result in a more complicated experience.
- Hypothesis 2
âBy providing users with a simple interface that replicates the website experience, users will apply their existing understanding of how Netflix works, which will result in more hours of content consumption.â
In the second hypothesis, the team strove to focus on simplicity as the core basis of the hypothesis. Rather than focusing on providing users with depth of access to the catalog, they thought about how to make things easier. One aspect of this hypothesis was that the website was an understood paradigm for Netflix users and replicating that interface on the TV would result in more streaming due to the familiarity and ease of navigating through the experience.
- Hypothesis 3
âBy separating the act of navigation from the act of browsing for a movie or TV show, the interface and experience will be simpler, which will result in more hours of content consumption.â
Here the driving concept was that you could simplify the experience more by separating the navigation from the content itself. This was based on the insight that people generally know that they want to watch a âdramaâ before they even launch Netflix. By simplifying the available choices based on this knowledge and guiding them through a step-by-step process to select the movie, the team assumed the process would be faster and easier. The team took away as many distractions of choice as they could at each step along the way.
- Hypothesis 4
âBy replicating a TV-like experience where discovery is based on video streaming, users will serendipitously find more things to watch, which will result in more hours of content consumption.â
In this final hypothesis, the team started to think about how people watch TV today. In other contexts, people are used to turning on the TV, sitting back, and just flipping through channels to serendipitously find something to watch. This hypothesis aimed to replicate that experience within Netflix, by allowing customers to decide what to watch through the act of watching.
The team believed that by launching these different experiences to their users, they would get directional guidance about what the potential impact was for what each of the four hypotheses represented. This example illustrates how even when tackling a large global problem, A/B testing and experimentation can be used to explore the impact of a few concrete hypotheses against a specific metric (consumption time). Weâve intentionally not shown you the designs that were created for each of these hypotheses because we wanted to make a point of abstracting the work of making a hypothesis from the work of designing it. We know and understand that for most designers a natural way of working is to design and craft a hypothesis or set of hypotheses at the same time. This is, of course, completely fine. However, we have found it helpful to at least consider each of these as a separate step so that you are conscientiously making sure that you are not jumping too quickly to a specific solution that you get attached to before exploring all the other possibilities that you might be able to explore.
Weâll take a deeper look at this example and the different designs that were made to represent each hypothesis in Chapter 5 and Chapter 6. For now, we hope you can see how each of these concepts tried to serve the same goal (increasing the amount of time people spend watching Netflix) even though the approaches were different. To really learn the most from this A/B test, the team also explored secondary metrics in order to understand the strengths and weaknesses of each version. When there are many different ways to reach your goal, your job will be to find out which approach will help you achieve that goal in the best possible way.
Involve Your Team and Your Data Friends
We hope that this chapter has empowered you to start generating many hypotheses to address your design goals and problems. We want to take a quick moment here to remind you about other members of your team and organization who can bring their own superpowers to the process of building hypotheses. This is valuable not only to build team consensus on hypotheses that will shape the teamâs work going forward, but also because different members of your team have unique expertise that can inform your hypotheses.
If you work with product managers, they will often have unique insight into the business or strategic goals. These strategic goals should inform the metrics that have the highest priority in your hypothesis, and have the potential to shape what behaviors you consider encouraging in your users. Similarly, these strategic goals may put limitations on what you can and canât change based on the strategic priorities of your company.
Anyone on your team who focuses on working with data, such as user researchers or data analysts from across the organization, have specialized knowledge about your users. One point we want to emphasize is that past learning should inform future hypotheses. By partnering closely with all kinds of data specialists, you can apply that past knowledge to your hypothesis generation, inspiring you to think of alternative hypotheses that you otherwise would not have considered.
Finally, your engineering partners can help you understand the potential engineering impact of different hypotheses. Although you donât need to nail down exactly what the implementation will be while generating hypotheses, your engineering friends will be able to clue you into roughly how much work different ideas take to pursue. Sometimes these are obvious (of course, redoing a whole home page is harder than changing the size or color of a button), but they may be less obvious as well.
Which Hypotheses to Choose?
The bulk of this chapter so far has focused on going broad, and by this point, you should be excited about the many potential hypotheses to explore. But as weâve reminded you throughout this book so far, one of the main decisions youâll need to constantly make when designing with data is determining when your efforts are worth it. Will you learn enough to justify the time and resources it takes to collect that data? Is it appropriate for your current goals and needs?
Similarly, these questions apply to selecting which hypotheses you should pursue. Youâve mostly been reflecting and working with your team to scope and define your goals, identify problems and opportunities to address, and generate hypotheses. Selecting appropriate hypotheses to move forward designing and A/B testing is important because from here on out, every additional step requires making the time and resource investments weâve started to allude to earlier.
In this next section, weâll explore some of the main considerations when selecting hypotheses. Youâll first need to determine which hypotheses you can remove and which you can refine and tighten, at which point youâll need to prioritize the ones youâve narrowed down to. As you begin to reduce the number of hypotheses, you might find that as you explore the ideas youâve generated, many of them are impossible or impractical to execute due to past data or the realities of pursuing that hypothesis. Of the remaining hypotheses, your decisions about which ones to pursue might depend on which hypotheses have the strongest evidence in favor of them already, or which will be most helpful for learning or pursuing your strategic and tactical goals. In this way, youâll be able to decide on one or a small set of hypotheses to start designing and testing.
Consider Potential Impact
One lightweight way to help prioritize potential hypotheses is by doing small or rudimentary calculations about the potential impact of your hypothesis. These small calculations require only a little bit of arithmetic but can help you see whether learning that your hypothesis is true will have impact.
For instance, in his talk âData Driven Products Now!â Dan McKinley shares a couple of examples from his time at Etsy of how simple estimation (what he calls âapplied common senseâ) could help project the potential value of different hypotheses before building anything.1 He shares two examples of reasonable-sounding product ideas that turned out to have very different potential impacts: building a landing page for local furniture, or emailing people that give up in the middle of purchases.
By looking at some metrics they already tracked, McKinley found out that the furniture landing page would have nominal impact for the business, and the experiment would need to run for more than six years to reach sufficient powerâhardly feasible at all, and not worthwhile! Comparatively, emails to people who gave up in the midst of a purchase had much bigger potential impact to the business: due to the promising estimations, the team rolled out the feature and it wound up contributing to 1.5% of Etsyâs total sales in a year (a huge success for such a seemingly small feature!).
The point weâre trying to emphasize here is that making some ballpark estimations early on is a great way to vet potential hypotheses to understand their impact. You might only be thinking of orders of magnitude ($10K potential revenue versus $100K potential revenue versus $1M potential revenue?), but this is often enough to give you a sense of whether to further explore a hypothesis or not.
Using What You Already Know
At the end of our hypothesis generation section, we closed with a note reminding you to involve other members of your team and your âdata friends.â To be clear, your team is not only helpful in generating hypotheses, but they can be invaluable in selecting them as well. Your âdata friends,â in particular, may have many types of data and past insights available at their disposal: past A/B tests, user research, surveys, and market research, among others. This expert knowledge can start to provide a lens through which you can start pruning some hypotheses and prioritizing others. Selecting the best hypotheses is another instance where past data should inform future data.
Start by sitting down with your data friends to discuss the hypotheses youâve already generated. You might want to ask some of the following questions to begin your conversation:
Have we conducted research about any similar hypotheses before?
Similar users or user groups? Similar changes? Similar desired behaviors? Similar rationales?
How have these types of hypotheses been performed in the past?
What types of changes have successfully impacted this metric in the past?
Remember to be open-minded about the types of data that inform your hypotheses; sometimes you might have weak signals from previous tests that were not relevant at the time, but apply well to your current hypotheses. Insights need not map one-to-one in order to be useful or worth considering.
That said, you should always be cognizant about confirmation bias, or the tendency to look for evidence that confirms your existing thoughts or beliefs. Even if your company does a good job of documenting past research in reports or other formats, we strongly encourage you to take the time to collaborate with your data friends, since they can put the findings in context and help you avoid confirmation bias. Plus, your data friends can help you look for evidence that disproves or contradicts your hypothesis, which is an important part of a balanced approach to using data to explore hypotheses. Being balanced with the data you explore early on requires skill but will pay off later.
So how should you actually go about leveraging past data in service of slimming down hypotheses? Strong contradicting evidence and data might suggest that you should prune that hypothesis: perhaps itâs not worth exploring further because youâve already been down that path and found it fruitless. Further investment might be a waste of time. However, as we mentioned earlier in the chapter, you might also be curious about how to prioritize different hypotheses. The questions we introduced before can help you prioritize based on expected payoff: if you already have some evidence that supports your hypothesis, you might have more confidence that your test will be successful (that your results will show a positive change in your metrics of interest).
Thereâs another way to use past data to prioritize hypotheses that might be less obvious. Throughout this book so far, weâve tried to emphasize the importance of approaching design with a learning mindset. With this in mind, remember that while you should always be aiming to make positive changes in your metrics, that shouldnât be your sole purpose; you also want to make sure that for every test you clearly learn something about your users and the types of designs and experiences that work, because it is this type of knowledge that will carry forward and hone your design intuition in the future.
To that end, you might want to also ask data-focused folks at your company about open questions they still have that align with your general goals and problem/opportunity area. Aptly chosen hypotheses can help you triangulate with past research findings, or understand confusing previous results. Consider also asking the following questions of your data friends:
What have you found in past similar research? Is there an opportunity to triangulate with or strengthen those previous findings?
Have you seen any surprising results in similar research? Can pursuing this hypothesis provide clarity into that past finding?
We hope that in this way, youâre able to begin collaborating with your data friends and past research to inform future data and designs. This is one essential step in both pruning and prioritizing your hypotheses as you move forward toward the design and execution stage of an A/B test.
Using Other Methods to Evaluate Your Hypotheses
Your company hopefully already has past insights available that can guide your hypothesis selection process. However, in certain cases, you might also want to invest in evaluating your hypotheses using other research methods, which may be lightweight or (what have been called) âquick and dirtyâ methods or through âpilot studies.â Pilot studies are small-scale preliminary studies that you carry out prior to a full-scale study. Pilot studies allow you to iterate on your study design through evaluation of feasibility, time, cost, and sample size, likely effect size or statistical variability, and, most importantly, potentially have adverse effects on your users. Putting effort upfront into these kinds of explorations means you can assess whether your expected payoff executing, launching, and analyzing a large-scale A/B test is worth it. Oftentimes, collecting feedback from smaller groups of users and assessing sentiment toward or usability of your proposed hypothesized design(s) is well worth it. This is especially true if you find yourself in situations where youâre about to embark on a very large and costly global test, and you want stronger signals before making that commitment. Another method you can use to start evaluating your hypothesis is a survey. Surveys allow you to collect small to medium amounts of data from users about their attitudes and emotions (but not, importantly, their behaviors). In this method, you can collect self-reported data, which can be both quantitative or qualitative.
In 2014, Spotify was looking to redesign their interface with the goal of unifying the design and experience. In the past, the interfaceâs dominant color varied significantly across platforms, and the team wanted to take a united stance on whether to pursue a light UI or a dark UI, while ensuring that existing users would be OK with the change. They crafted two hypotheses to address this concern:
- Hypothesis 1
âBy unifying the Spotify experience using a dark UI, users will feel that the music and content are more central, and therefore will perceive Spotify to be more accessible and attractive.â
- Hypothesis 2
âBy unifying the Spotify experience using a light UI, users will feel that the app is fresher and more consistent with the existing experience, and therefore will perceive Spotify to be more accessible and attractive.â
To assess these two hypotheses, Spotify conducted a survey using the different design prototypes with 1,600 people from the United States and Germany, and measured self-reported attitudinal data around the different designs. From this, they found that one of their dark UI iterations performed much better than the light UIs, and the team decided to move forward with the hypothesis of uniting under a dark interface.
Additionally, generating low-fidelity mocks or prototypes (e.g., wireframes, sketches, or noncode prototypes such as those built in InVision) to collect a pulse check on your hypothesis is a great way to get insights from other sources prior to your A/B test. You need not focus yet on optimizing or perfecting design ideas. These mocks donât need to be the same design you ultimately launch in an A/B test, but they should help convey the hypothesis youâre planning to convey so that you can get quick feedback about those ideas before you invest in an A/B test.
With such low-fidelity mocks, you can use other methods to evaluate your hypothesis. Usability studies, for instance, provide observed, behavioral, qualitative data from a small sample of users to help you identify possible usability issues. Many companies utilize usability tests to help eliminate possible hypotheses that donât perform well in lab settings. However, usability testing is also extremely valuable in ensuring that you give the A/B test you ultimately launch the best chance of succeeding, by avoiding results that fail due to usability issues rather than due to inherent issues with the hypothesis itself.
Similarly, small-sample user research methodologies like interviews and âcard sortsââa method of helping to design or evaluate information structures where people organize topics into categories that they label based on what makes sense to themâcan help explore and validate concepts surrounding a hypothesis. These moderated methods let you dive deeply with your sample of users in order to understand the reasons behind their answers to your questions, and gain a nuanced understanding of their needs and desires. This kind of depth provides a valuable jumping-off point to evaluate hypotheses, since youâll be able to collect a signal about why the hypothesis might be consistent or inconsistent with your goal so you can improve it or select hypotheses that better align.
Using other methodologies to explore and vet your hypotheses ahead of time can help steer you away from hypotheses that are not as promising as they seemed prior to testing. They can also help you prioritize hypotheses by signaling the likelihood of success or the possible magnitude of success of that hypothesis. By using supplementary research methods to evaluate your hypotheses, you can make the most informed decisions about which hypotheses are worth pursuing through a proper design and test phase.
Consider the Reality of Your Test
Weâve talked a lot about how you can make informed decisions about which hypotheses to pursue, by leveraging your broader team and their knowledge of existing data, and collecting further data to help evaluate your hypothesis. Our discussion of hypothesis selection has focused on selecting hypotheses that maximize the potential for learning and that give you the greatest chance of having your efforts pay off. However, the practical considerations of launching your test will also dictate which hypotheses you can pursue through to a completed A/B test. This is because you need to make sure that the data that youâll get out of the test is hygienic and actionable. In other words, you need to make sure that you can reasonably collect the data that you need from the appropriate and representative group of users, in a reasonable length of time, and in a way that you can reasonably detect a meaningful effect if there is one. Here, weâll walk you through a few key considerations when thinking about whether you can realistically test a particular hypothesis.
How much measurable impact do you believe your hypothesis can make?
Recall that in Chapter 2 we introduced the concept of statistical power. Power is the ability of your test to measure an effect, if it exists in the world. If your A/B test has insufficient power, you wonât know whether your result is because no difference between your test cell and your control exists in the world, or because you just didnât have a strong enough lens to see it.
We want our experiment to robustly test our hypothesis so we need to have sufficient power to detect a difference in the control and treatment when a difference actually exists. A power analysis will determine the minimum detectable effect (MDE); this is the minimum change youâd need to see (this can be positive or negative) in the metric to have a chance to observe a change with statistical significance. So, for instance, a power analysis might reveal that the minimum detectable effect would require that you observe at least a 10% increase in the number of campers next year to conclude that the difference is statistically significant.
Why does the minimum detectable effect matter in the hypothesis selection phase? Letâs continue on with the example of a 10% minimum detectable effect in the change in how many campers you have. Youâll need to ask yourself for each hypothesis whether you really believe that the change youâre proposing can make that big of an impact. This is where design intuition becomes critically important, because youâll have to make a judgment call about this. In some cases, youâll conclude that your hypothesis doesnât âthink big enough,â giving you the license to consider more ambitious changes to your existing experience.
Can you draw all the conclusions you want to draw from your test?
Making sure you have a big enough sample size to detect an effect is an important part of considering whether you can test a hypothesis. It is best practice to run experiments with a small percentage of your users to ensure that you donât disrupt your userâs experience by changing the experience and design of your product too often. This puts a practical limitation on your hypotheses, because you can only test hypotheses when you have a big enough user base to generate an appropriate sample. When might this matter for the hypothesis selection process?
Sometimes, one metric is constrained by another. If youâre trying to evaluate your hypotheses on the basis of app open rate and app download rate, for instance, app download rate is the upper bound for app open rate because you must download the app in order to open it. This means that app open rate will require a bigger sample to measure, and youâll need to have at least that big of a sample in your test. This is important to think about from a methodological standpoint, because hypotheses that target app open rate can only be tested with that bigger sample. Knowing this, youâll have to decide whether pursuing those hypotheses is worthwhileâlarger samples mean you have to run your test for longer and require introducing your experimental experience to more users, which means taking on more risk. You should have a clear reason to care about app open rate in this type of test that justifies that additional cost and risk.
Similarly, if you plan to segment your results youâll have to keep that in mind too. Letâs say your experiment is focused on testing the user experience on all the devices for which you have designs but you particularly care about users who primarily use your mobile device experience(s)âletâs call those users the âmobileâ user group. When you analyze the results for all devices combined, youâll have a larger sample size and more power. But youâll also need to make sure that you have a large enough mobile-only sample to draw conclusions about the mobile device user experience specifically. Again, this involves taking on more cost and rolling out an experiment to a bigger constituency of your users. Plus this constitutes more risk to your experience, since youâre exposing more of your users to an as-yet-unproven, experimental design. In this kind of situation, you should very carefully vet hypotheses that target your mobile users specifically.
Balancing learning and speed
One more important factor to consider when you think about power and minimum detectable effect is how long youâre willing to wait to get that learning. The principle here is that users are allocated to your experiment over time because best practice is to launch the experiment to only a small sample of your user base. Say you need 1,000 people in your sample. Youâre trying to follow best practice, so you decide to allocate 1% of your users to the experimental condition. The trouble is that if your website only has 1,000 unique visitors per day then youâll only allocate 10 users each day to the test cell, and it will take 100 days to gather enough data to draw conclusions.
In those cases, youâll have to ask yourself: Do you have enough time to wait for the results to come in before you make a decision? Or, do you have enough users that you can collect enough data in a short length of time? (The previous example wouldnât be an issue if you had 1,000,000 unique visitors per dayâyouâd have enough data after one day!) If you canât answer âyesâ to these questions for a given hypothesis, you might not be able to collect clean data about it through an A/B test, and you might want to dismiss that hypothesis for now.
The second consideration for balancing learning and speed is how long you will need to keep your test user group living with the test experience. It will often take time for your usersâ behavior to change, and depending on the behavior that you are hoping to impact, you may need more or less time depending on the details of the test you are running. Recall that some metrics may take longer to measure than others. It is in this situation that having good proxy metrics will help to minimize the time you need to keep a test running. A clear example of this is offering something like a 30-day money-back guarantee to your users. You would need to leave this test up for at least 30 days to see how many of the people who bought your product or service actually end up returning it within the 30-day period. Although you may have increased the number of purchases (and can measure those results right away), you wonât know whether the purchases you added will actually contribute to the bottom line until after the 30-day period is over.
The third consideration is that youâll want to run your experiment for at least one full business cycle in order to minimize bias in your sample. Depending on the nature of your business, your cycle may be a day, a week, or longer. The intuition here is that your product may be used differently at different points in your business cycle: on weekdays or weekends, for instance. Having an experiment that runs only during weekdays could cause bias if the product usage or users are very different on weekends (consider parents, working professionals, etc.) You may need to let your experiment run longer in order to get learnings that generalize and are free of bias.
In this section, we showed you how our abstract conversation about statistical power in Chapter 2 becomes more concrete as you generate and select hypotheses. We encourage you to be proactive about considering the minimum detectable effect and whether you have sufficient power to evaluate your hypotheses early in designing your A/B test. All too often we see teams invest heavily into A/B tests, only to reach the heartbreaking conclusion at the end that they werenât able to see an effect if it existed. Remember, even if you have to abandon an exciting hypothesis now due to practical considerations, thereâs always the hope that you could evaluate it in the future when your user base grows or you have more time to explore.
Keep Your Old Hypotheses in Your Back Pocket
Weâve given you some considerations on how to select hypotheses in this chapter, by prioritizing hypotheses that give you a greater chance of success over those that donât and pruning hypotheses that donât currently make sense to test due to practical considerations about your launch and past research and insights. However, we want to take a second to remind you not to give up on the hypotheses that you really believe in, even if you canât test them immediately.
Experimentation is a mindset and an iterative process, which means that it is constantly building on itself and improving. As your experience evolves, experimentation will allow the data and insights that guide your future design directions to be crisper and more relevant, bringing to the foreground hypotheses that you might have had to table at first due to lack of evidence or even counterevidence. Who knows what the future of your experience and product will be? By hanging onto hypotheses that you didnât pursue before, youâll make your next iteration of generating hypotheses easier and faster, and youâll always be ready to learn when the next opportunity arises.
This holds even when your hypothesis fails. Remember, A/B tests are run in the real world rather than in isolation. This makes them sensitive to the changing nature of your evolving user base and trends in design, technology, and the world. You simply canât hold these factors constant, and sometimes theyâll impact the performance of certain hypotheses. For hypotheses you really believe in, itâs possible that exploring that hypothesis again in the future will lead to a different outcome. We encourage you to hang onto those ideasâthey just might be what you need someday in the future.
Summary
This chapter illustrated the importance of creating a strong hypothesis statement and the value of tying that statement back to your companyâs key metrics and overarching business goals. We also talked about the importance of âgoing broadâ and trying to generate as many different hypotheses as you can before you embark on the process of designing how those hypotheses are represented or manifest in your experience, and then slimming down to select one or a few hypotheses to move forward with.
Throughout this chapter, you might have sensed similarities between generating many hypotheses and your existing design process, where you likely develop many possible designs. These processes are nearly the same, but in hypothesis development you think about high-level goals you want to achieve and the underlying user behaviors that will get you there rather than the way they manifest as design. That being said, we firmly believe that your existing skills as a designer are critical to hypothesis generation and can allow you to be more creative in how you craft your hypotheses.
Itâs a surprisingly common mistake for teams to move too quickly past this first stage of clearly articulating what it is that they are trying to accomplish. Often people fall prey to this because of eagerness; we all want to roll up our sleeves and build, whether that means designing or implementing engineering solutions. Having a clearly defined hypothesis that the entire team is aligned around can help you to avoid the frustration of finding out late in your test process that you are focused on the âwrongâ things. Having several strong hypothesis statements that you can revisit again and again throughout your experimentation journey will give you a north star that you can check yourself against along the way. Understanding what it is that you want to learn from your statement and how youâd measure the outcome of your work in the beginning will help to ensure that the results you get at the end of the process will be both actionable and useful. By rallying around well-crafted hypotheses youâll foster a mindset of designing to learn rather than designing to ship, letting you be successful in every test even when the test itself fails.
Questions to Ask Yourself
What are the goals that you want to achieve for your company and how do they align with the experiences that you are going to be designing in your product?
What are the things that are most important for you to learn from your experiment(s)?
If you break down your hypothesis into the different partsâchange, effect, users or user groups, measure, and rationaleâwhat are the things you would hold constant and what are the kinds of things that you would change?
What data have you leveraged in generating and getting inspiration for your hypotheses?
Have you generated the full range of possible hypotheses before narrowing down? Will these hypotheses broaden your understanding of your product, experience and users?
Get Designing with Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

