Kapitel 1. Einführung in Cloud Native
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Softwareentwicklungslandschaft verändert sich ständig und entwickelt sich durch moderne Architekturparadigmen und Technologien weiter. Von Zeit zu Zeit erfährt die Softwarearchitektur mit dem Aufkommen bahnbrechender Technologien und Ansätze einen grundlegenden Wandel. Ein solcher Durchbruch ist die Cloud Native Architecture. Es handelt sich dabei um einen bedeutenden Wandel in der Entwicklung von Softwareanwendungen, der die Art und Weise verändert, wie wir Softwareanwendungen erstellen, bereitstellen und verwalten. Die Cloud Native Architecture hat sich zu einem Wegbereiter für Agilität, Geschwindigkeit, Sicherheit und Anpassungsfähigkeit von Softwareanwendungen entwickelt.
Dieses Kapitel hilft dir zu verstehen, was Cloud Native ist, indem wir die wichtigsten Merkmale von Cloud Native-Anwendungen untersuchen. Außerdem stellen wir eine Entwicklungsmethodik vor, die du während des gesamten Lebenszyklus von Cloud Native-Anwendungen anwenden kannst. Anschließend werden wir uns mit der Bedeutung von Design Patterns für die Entwicklung von Cloud Native-Anwendungen beschäftigen. Beginnen wir unsere Diskussion mit der Definition von Cloud Native.
Was ist Cloud Native?
Wie lautet also die offizielle Definition von Cloud Native? Die traurige Nachricht ist, dass es eine solche Definition nicht gibt. Cloud Native bedeutet für jeden Menschen etwas anderes. Die nächstliegende allgemeine Definition stammt von der Cloud Native Computing Foundation (CNCF), einer Organisation, die sich dem Aufbau nachhaltiger Ökosysteme und der Förderung von Gemeinschaften verschrieben hat, um das Wachstum und die Gesundheit von quelloffenen, cloud-nativen Anwendungen zu unterstützen. Die CNCF dient als herstellerneutrale Heimat für viele der am schnellsten wachsenden Open-Source-Projekte, die für die Entwicklung von Cloud-Native-Anwendungen genutzt werden können.
Cloud Native Definition von der CNCF
Cloud-native Technologien ermöglichen es Unternehmen, skalierbare Anwendungen in modernen, dynamischen Umgebungen wie öffentlichen, privaten und hybriden Clouds zu entwickeln und zu betreiben. Container, Service Meshes, Microservices, unveränderliche Infrastruktur und deklarative APIs sind Beispiele für diesen Ansatz. Diese Techniken ermöglichen lose gekoppelte Systeme, die widerstandsfähig, verwaltbar und beobachtbar sind. In Kombination mit einer robusten Automatisierung ermöglichen sie es den Ingenieuren, mit minimalem Aufwand häufig und vorhersehbar Änderungen vorzunehmen, die große Auswirkungen haben.
In diesem Buch verfolgen wir einen Bottom-up-Ansatz, um Cloud Native zu definieren. Wir betrachten alle Merkmale von Cloud Native-Anwendungen, indem wir jede Phase im Lebenszyklus einer Cloud Native-Anwendung durchlaufen - einschließlich Design, Entwicklung, Paketierung, Bereitstellung und Governance. Basierend auf diesen Merkmalen haben wir die folgende Definition entwickelt:
Cloud Native bedeutet, Softwareanwendungen als eine Sammlung unabhängiger, lose gekoppelter, geschäftsfähigkeitsorientierter Dienste (Microservices) zu erstellen, die in dynamischen Umgebungen (Public, Private, Hybrid, Multicloud) automatisiert, skalierbar, belastbar, verwaltbar und beobachtbar laufen können.
Die Untersuchung dieser Merkmale hilft uns, Cloud Native Applications besser zu verstehen. Schauen wir uns die Merkmale in unserer Definition genauer an.
Konzipiert als eine Sammlung von Microservices
Eine Cloud Native Anwendung ist als eine Sammlung von lose gekoppelten und unabhängigen Diensten konzipiert, die eine genau definierte Geschäftsfunktion erfüllen. Diese werden als Microservices bezeichnet. Microservices sind das grundlegende architektonische Prinzip, das für die Entwicklung von Cloud Native-Anwendungen unerlässlich ist. Ohne die Grundlagen der Microservices-Architektur zu kennen , ist es praktisch unmöglich, eine gute Cloud Native-Anwendung zu entwickeln .
Microservices-Architektur ist eine Art, Softwareanwendungen zu entwickeln. Vor dem Aufkommen der Microservices-Architektur haben wir Softwareanwendungen als monolithische Anwendungen für verschiedene komplexe Geschäftsszenarien entwickelt. Diese monolithischen Anwendungen sind von Natur aus komplex, schwer zu skalieren, teuer in der Wartung und behindern die Agilität der Entwicklungsteams. Monolithische Anwendungen kommunizieren untereinander über proprietäre Kommunikationsprotokolle und nutzen oft eine einzige Datenbank.
Tipp
Bei der Microservices-Architektur geht es darum, eine Softwareanwendung als eine Sammlung unabhängiger, autonomer (unabhängig entwickelter, bereitgestellter und skalierter), geschäftsfähigkeitsorientierter und lose gekoppelter Dienste aufzubauen.1
Dieserviceorientierte Architektur(SOA) hat sich als ein besserer Architekturstil herauskristallisiert, um die Einschränkungen der monolithischen Anwendungsarchitektur zu überwinden. SOA basiert auf dem Konzept der Modularität und dem Aufbau einer Softwareanwendung als eine Sammlung von Diensten, die eine bestimmte Geschäftsfunktion erfüllen. Die SOA-Umsetzungen, wie z. B. Webservices, wurden unter Verwendung komplexer Standards und Nachrichtenformate implementiert und führten zentralisierte monolithische Komponenten in die Architektur ein.
In einem typischen SOA-basierten Design werden Softwareanwendungen mit einer Reihe von grobkörnigen Diensten, wie z. B. Webservices, erstellt, die oft offene Standards und eine zentrale monolithische Integrationsschicht nutzen, die als der Enterprise Service Bus(ESB) bekannt ist. Auf diese Architektur kann eine API-Verwaltungsschicht aufgesetzt werden, damit du die Funktionen als verwaltete APIs bereitstellen kannst.
Abbildung 1-1 zeigt eine einfache Online-Einzelhandelsanwendung, die mit SOA entwickelt wurde. Alle Geschäftsfunktionen werden auf der Diensteebene als grobkörnige Dienste erstellt, die auf einem monolithischen Anwendungsserver laufen. Diese Dienste und die übrigen Systeme werden mithilfe eines ESB integriert. Dann wird ein API-Gateway als Eingangstür zur SOA-Implementierung eingesetzt, über das du deine Geschäftsfunktionen steuerst und verwaltest .
Dieser Ansatz hat sich für viele Unternehmen bewährt, und viele Unternehmenssoftwareanwendungen werden immer noch mit SOA entwickelt. Die damit verbundenen Komplexitäten und Einschränkungen behindern jedoch die Agilität bei der Entwicklung von Softwareanwendungen. Die meisten SOA-Implementierungen führen zu einem Mangel an unabhängig skalierbaren Anwendungen, zu Abhängigkeiten zwischen den Anwendungen, die eine unabhängige Anwendungsentwicklung und -bereitstellung behindern, zu Zuverlässigkeitsproblemen aufgrund einer zentralisierten Anwendung und zu Einschränkungen bei der Verwendung verschiedener Technologien für die Anwendung.
Die Microservices-Architektur hingegen beseitigt die Einschränkungen von SOA-Implementierungen, indem sie feinkörnigere und geschäftsorientierte Dienste einführt und gleichzeitig zentralisierte Komponenten wie ESB eliminiert. In der Microservices-Architektur wird eine Softwareanwendung als eine Sammlung autonomer und geschäftsfähigkeitsorientierter Dienste konzipiert, die von verschiedenen Teams unabhängig voneinander entwickelt, bereitgestellt und oft auch verwaltet werden. Die Granularität des Dienstes wird durch die Anwendung von Konzepten wie dem Bounded Context in dem Driven Design Paradigma bestimmt.2
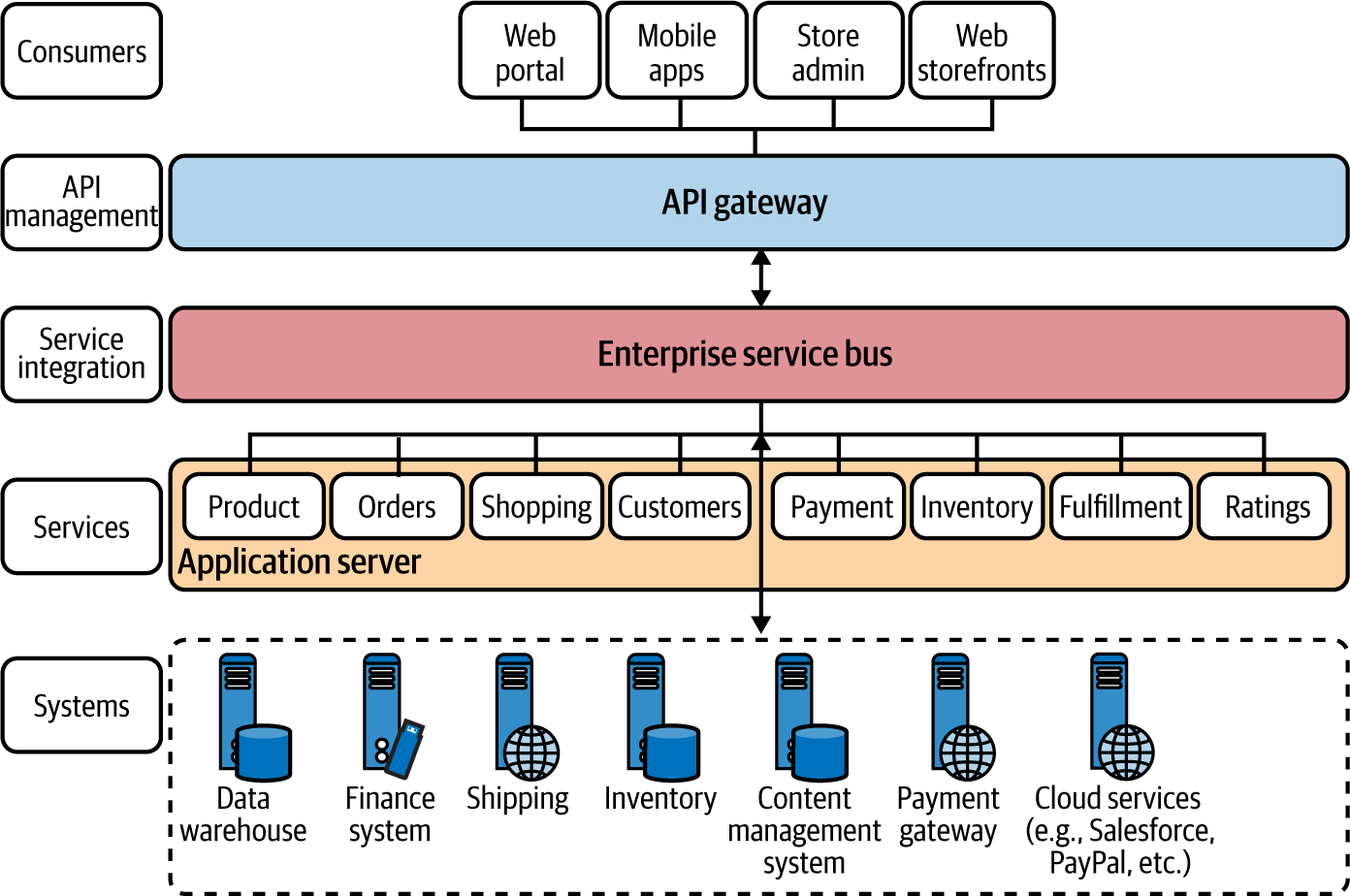
Abbildung 1-1. Ein Szenario für eine Online-Einzelhandelsanwendung, die mithilfe einer SOA/ESB mit API-Verwaltung erstellt wurde
Wir können unsere frühere SOA/ESB-basierte Online-Einzelhandelsanwendung in Microservices umwandeln, wie in Abbildung 1-2 dargestellt. Der Hauptgedanke dabei ist die Einführung von Microservices für jede Geschäfts fähigkeit, die wir während der Entwurfsphase identifizieren, da wir die Konzepte des domänengesteuerten Entwurfs (die später in diesem Kapitel erläutert werden) anwenden und die zentralisierte Integration auf der ESB-Schicht eliminieren.
Hinweis
Techniken zur Umwandlung von monolithischen in Microservices werden in Building Microservices von Sam Newman (O'Reilly) ausführlich behandelt.
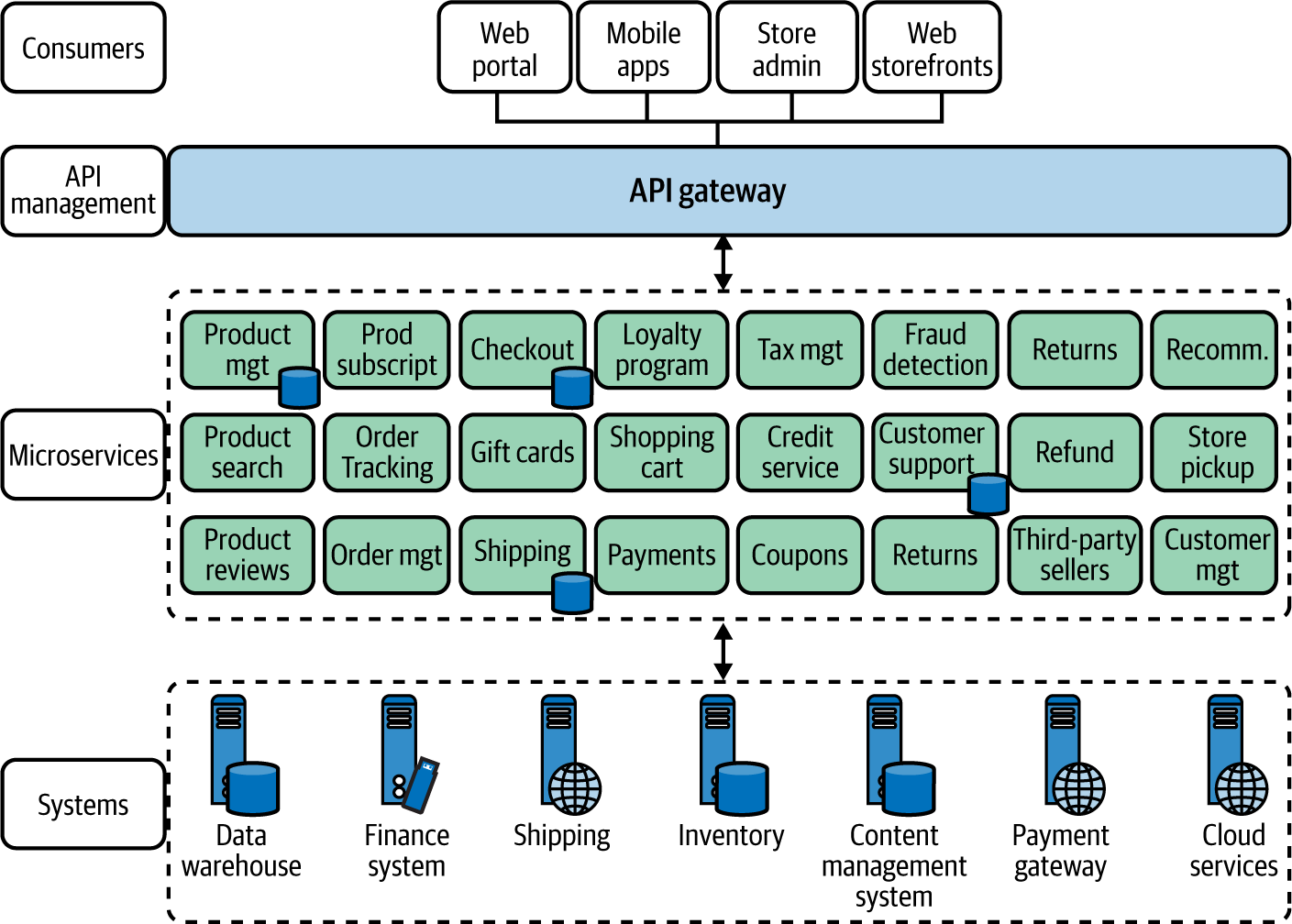
Abbildung 1-2. Eine Online-Einzelhandelsanwendung, die mit einer Microservices-Architektur erstellt wurde
Anstatt eine ESB-Schicht für die Integration der Dienste zu verwenden, erstellen die Microservices selbst die Kompositionen durch leichtgewichtige Interservice-Kommunikation, die erforderlich ist, um die vom Microservice angebotene Geschäftsfähigkeit aufzubauen. Daher werden diese Microservices als Smart Endpoints bezeichnet, die über dumb pipes verbunden sind, was sich auf die leichtgewichtige Kommunikationstechnik zwischen den Services bezieht.3 Microservices können sich mit anderen bestehenden Systemen verbinden und in manchen Fällen auch eine vereinfachte Schnittstelle (oft als Fassade bezeichnet) für diese Systeme bereitstellen.
Die Microservices nutzen keine gemeinsamen Datenbanken, und externe Parteien können nur über die Service-Schnittstelle auf die Daten zugreifen. Jeder Microservice muss sowohl die Geschäftslogik als auch die Funktionen für die Kommunikation zwischen den Services implementieren, z. B. Ausfallsicherheit und Sicherheit.
Da Cloud Native-Anwendungen als eine Sammlung von Microservices konzipiert sind, bezieht sich fast jedes Konzept, das du bei Microservices anwendest, auch auf den Cloud Native-Kontext. Deshalb besprechen wir die meisten Muster und Grundlagen der Microservices-Architektur im gesamten Buch .
Containerisierung und Container-Orchestrierung nutzen
So wie Microservices in der Phase des Entwurfs und der Entwicklung von nativen Cloud-Anwendungen wichtig sind ( ), sind auch Container für die Verpackung und den Betrieb von nativen Cloud-Anwendungen wichtig. Bei der Entwicklung nativer Cloud-Anwendungen werden die von uns erstellten Microservices in Container-Images verpackt und auf einem Container-Host ausgeführt. Um zu verstehen, was das wirklich bedeutet, müssen wir tiefer einsteigen.
Was sind Container?
Ein Container ist ein laufender Prozess, der vom Host-Betriebssystem und anderen Prozessen im System isoliert ist. Ein Container interagiert mit seinem eigenen privaten Dateisystem, das von einem Container-Image bereitgestellt wird. Das Container-Image ist eine Binärdatei, die alles enthält, was für die Ausführung einer Anwendung benötigt wird: den Anwendungscode, die Abhängigkeiten und die Laufzeit. Diese Container-Images sind unveränderlich und werden oft in einem Repository gespeichert, das als Container-Registry bekannt ist.
Um einen Container auszuführen, kannst du aus dem Container-Image einen laufenden Prozess erstellen, der als Container-Instanz bezeichnet wird. Die Container-Instanz läuft auf der Container-Laufzeit-Engine.
In Abbildung 1-3 wird die Ausführung von drei Microservice-Laufzeiten auf virtuellen Maschinen (VMs) mit der Ausführung auf einer Container-Laufzeit-Engine verglichen. Die Ausführung von Microservices als Container unterscheidet sich drastisch von der herkömmlichen VM-Ausführung, bei der ein vollwertiges Gastbetriebssystem mit virtuellem Zugriff auf die Host-Ressourcen über eine als Hypervisor bekannte Komponente ausgeführt wird. Da Container auf einer Container-Laufzeitumgebung laufen, teilen sie sich den Kernel des Host-Rechners, den Prozessor und den Speicher mit anderen Containern. Daher ist die Ausführung von Microservices auf Containern ein leichtgewichtiger, diskreter Prozess im Vergleich zur Ausführung auf einer VM. Eine Anwendung, die auf einer VM läuft und mehrere Minuten zum Laden braucht, kann in Containern in wenigen Sekunden geladen werden.
Der Prozess der Umwandlung von Microservices oder Anwendungen, die auf Containern laufen, wird als Containerisierung bezeichnet. Docker hat sich zur De-facto-Plattform für die Erstellung, den Betrieb und die gemeinsame Nutzung von containerisierten Anwendungen entwickelt.
Die Containerisierung macht deine Microservices portabel und garantiert eine konsistente Ausführung in verschiedenen Umgebungen. Container sind eine treibende Kraft, um Microservices unabhängig und autonom zu machen, denn sie sind autark und gekapselt, so dass du einen Service ersetzen oder aktualisieren kannst, ohne andere zu beeinträchtigen, und gleichzeitig die Ressourcen besser nutzen kannst als VMs. Außerdem machen sie zusätzliche Vorkonfigurationen zur Laufzeit überflüssig und sind im Vergleich zu VMs viel schlanker.
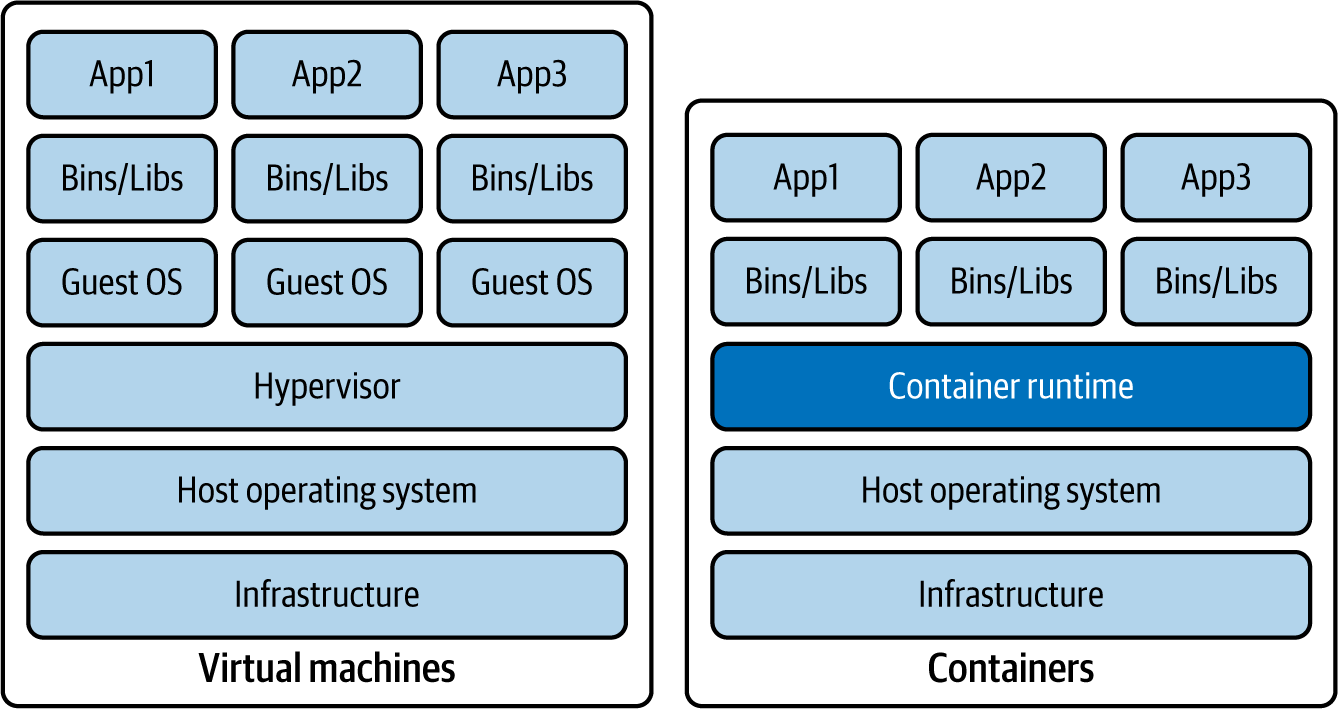
Abbildung 1-3. Vergleich der Anwendungsausführung auf virtuellen Maschinen und Containern
Die Containerisierung deiner Microservices und deren Ausführung mit Hilfe einer Container-Engine ist nur ein Teil des Entwicklungszyklus deiner Cloud Native Application. Aber wie verwaltest du die Ausführung deiner Container und den Lebenszyklus der Container? An dieser Stelle kommt die Container-Orchestrierung ins Spiel.
Warum Container-Orchestrierung?
Container orchestration ist der Prozess der Verwaltung des Lebenszyklus von Containern. Wenn du Cloud Native-Anwendungen in der Praxis betreibst, ist es fast unmöglich, Container manuell zu verwalten. Daher ist ein Container-Orchestrierungssystem ein wesentlicher Bestandteil beim Aufbau einer Cloud Native Architektur.
Schauen wir uns einige der wichtigsten Funktionen und Möglichkeiten eines Container-Orchestrierungssystems genauer an:
- Automatische Bereitstellung
- Automatisches Bereitstellen von Container-Instanzen und Deployment von Containern
- Hohe Verfügbarkeit
- Repariert Container automatisch, wenn eine Container-Laufzeit fehlschlägt
- Skalierung
- Je nach Bedarf werden automatisch Container-Instanzen hinzugefügt oder entfernt, um die Anwendung zu vergrößern oder zu verkleinern.
- Ressourcenmanagement
- Verteilt die Ressourcen auf die Container
- Dienstschnittstellen und Lastausgleich
- Macht Container für externe Systeme zugänglich und verwaltet die in den Containern ankommende Last
- Abstraktionen der Netzwerkinfrastruktur
- Bietet ein Netzwerk-Overlay, um die Kommunikation zwischen Containern aufzubauen
- Dienstentdeckung
- Bietet die integrierte Möglichkeit, Dienste mit einem Dienstnamen zu finden
- Steuerungsebene
- Bietet einen zentralen Ort zur Verwaltung und Überwachung eines containerisierten Systems
- Affinität
- Bereitstellung von Containern in der Nähe oder weit voneinander entfernt, um die Verfügbarkeit und Leistung zu verbessern
- Gesundheitsüberwachung
- Erkennt automatisch Ausfälle und bietet Selbstheilung
- Rollende Upgrades
- Koordiniert schrittweise Upgrades ohne Ausfallzeiten
- Komponentisierung und Isolierung
- Einführung einer logischen Trennung zwischen verschiedenen Anwendungsdomänen durch die Verwendung von Konzepten wie Namensräumen
In der Cloud-Native-Landschaft hat sich Kubernetes zum de facto Container-Orchestrierungssystem entwickelt.
Kubernetes
Kubernetes schafft eine Abstraktionsschicht über den Containern, um die Container-Orchestrierung zu vereinfachen, indem es das Deployment, die Skalierung, die Fehlertoleranz, das Networking und verschiedene andere Anforderungen an das Container-Management automatisiert, die wir bereits besprochen haben.
Da Kubernetes von mehreren Plattformen und Cloud-Anbietern übernommen wird, entwickelt es sich zur universellen Container-Management-Plattform. Alle großen Cloud-Provider bieten Kubernetes als Managed Service an.
Anwendungen, die für Kubernetes entwickelt wurden, können in jedem Cloud-Service oder lokalen Rechenzentrum, das Kubernetes unterstützt, eingesetzt werden, ohne dass Änderungen an der Anwendung vorgenommen werden müssen (solange du keine plattformspezifischen Funktionen wie Load Balancer verwendest). Kubernetes macht Anwendungs-Workloads portabel, leichter skalierbar und einfacher zu erweitern. Kubernetes ist jetzt die standardisierte Plattform, für die du deine Anwendung entwerfen kannst, damit sie nicht an die zugrunde liegende Infrastruktur gekoppelt ist. Kubernetes bringt wichtige Abstraktionen ein, die helfen, Anwendungen zu standardisieren und die Container-Orchestrierung zu vereinfachen(Abbildung 1-4).
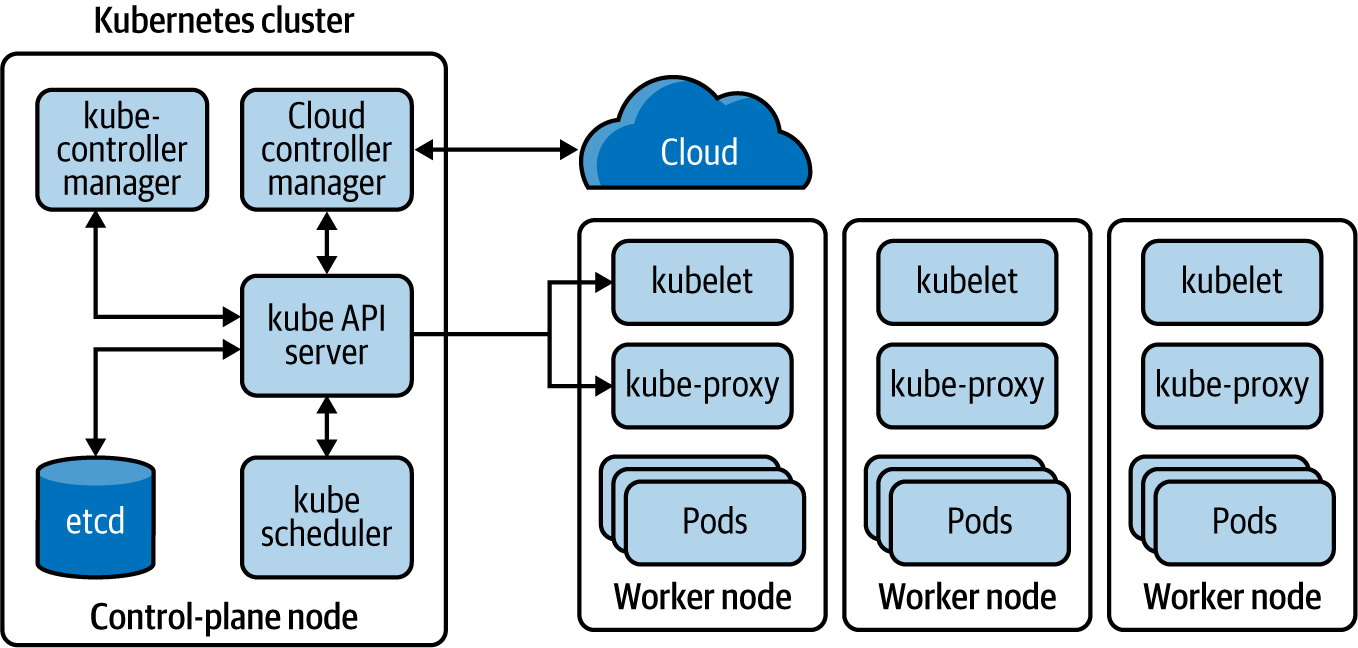
Abbildung 1-4. Grundlegende Komponenten einer Kubernetes-Plattform
Ein Kubernetes-Cluster besteht aus einer Reihe von Knotenpunkten, die auf virtuellen oder physischen Maschinen laufen. Unter diesen Knoten befinden sich mindestens ein Control-Plane-Knoten und mehrere Worker-Knoten. Der Control-Plane-Knoten ist für die Verwaltung und Planung der Anwendungsinstanzen im gesamten Cluster zuständig. Daher werden die Dienste, die der Kubernetes Control-Plane-Knoten ausführt, als Kubernetes Control-Plane bezeichnet.
Der Kubernetes-API-Server kümmert sich um die gesamte Kommunikation zwischen der Control-Plane und den Worker Nodes. Wenn ein bestimmter Workload einem bestimmten Knoten zugewiesen werden muss, weist das Zeitplannungsprogramm jedem Worker-Knoten Workloads auf der Grundlage der verfügbaren Ressourcen und Richtlinien zu. Auf jedem Kubernetes-Knoten läuft ein als Kubelet bezeichneter Agentenprozess, der die Knotenzustände verwaltet. Es ist die Komponente, die direkt mit dem Kubernetes-API-Server kommuniziert, um Anweisungen zu erhalten und den Status der einzelnen Knoten zu melden.
Ein Pod ist die grundlegende Bereitstellungseinheit für eine Anwendungslaufzeit, die auf einem bestimmten Knoten läuft. Ein Pod kann einen oder mehrere Container enthalten, die in ihm laufen. Einem Pod wird eine eindeutige IP-Adresse innerhalb des Kubernetes-Clusters zugewiesen.
Kubernetes vereinfacht die Bereitstellung und Verwaltung von Anwendungen weiter, indem es Abstraktionen wie Service, Deployment und ReplicaSet einführt. Ein Service bietet eine logische Gruppierung für eine Reihe von Pods als Netzwerkdienst, so dass ein Dienst mehrere Pods mit Lastausgleich haben kann. Ein ReplicaSet definiert die Anzahl der Replikate, die die Anwendung haben soll. Das Deployment regelt, wie Änderungen an der Anwendung ausgerollt werden.
Alle diese Kubernetes-Objekte werden entweder mit YAML oder JavaScript Object Notation (JSON) spezifiziert und über die Kubernetes-Kontrollebene durch Interaktion mit dem Kubernetes-API-Server angewendet. Weitere Informationen zu Kubernetes findest du in der offiziellen Kubernetes-Dokumentation.
Serverlose Funktionen
Ein bestimmter Microservice einer Cloud-nativen Anwendung kann als serverlose Funktion modelliert werden. Diese programmatische Funktion dient der Geschäftsfähigkeit eines Microservices, der auf einer Cloud-Infrastruktur läuft. Bei serverlosen Funktionen werden die meisten Funktionen wie Verwaltung, Vernetzung, Ausfallsicherheit, Skalierbarkeit und Sicherheit bereits von der zugrunde liegenden serverlosen Plattform bereitgestellt.
Serverlose Plattformen wie AWS Lambda, Azure Functions und Google Cloud Functions bieten eine automatische Skalierung in Abhängigkeit von der Last, Unterstützung für mehrere Programmiersprachen und integrierte Funktionen in Bezug auf belastbare Kommunikation, Sicherheit und Beobachtbarkeit. Microservices, die Laststöße, Batch-Aufträge und ereignisgesteuerte Dienste unterstützen müssen, eignen sich für die Implementierung von serverlosen Funktionen.
Wenn du eine serverlose Funktion verwendest, kannst du darunter Container verwenden, aber das ist für den Microservice-Entwickler transparent. Du kannst einfach eine Funktion mit der Geschäftslogik deines Microservices schreiben und sie an die serverlose Plattform übergeben, damit diese sie ausführt. Die Details, wie die Funktion ausgeführt und bereitgestellt wird, bleiben für den Nutzer ebenfalls verborgen.
Virtuelle Maschinen
Du kannst dich dafür entscheiden, deine Microservices ohne Container zu betreiben. Auch wenn der Einsatz von Containern für die Entwicklung von Cloud Native-Anwendungen nicht zwingend erforderlich ist, musst du die Komplexität und den Overhead bewältigen, die mit dem Betrieb von Anwendungen auf VMs verbunden sind. Aus diesem Grund werden in den meisten realen Implementierungen von Cloud Native-Architekturen häufig Container, Container-Orchestrationen oder übergeordnete Abstraktionen wie serverlose Funktionen eingesetzt.
Automatisiere den Lebenszyklus der Entwicklung
Wenn es um die Bereitstellung von Cloud Native Applications geht, ist es wichtig, agil, schnell und sicher zu sein. Um dies zu erreichen, müssen wir den gesamten Lebenszyklus der Entwicklung von Cloud Native Applications rationalisieren und jeden möglichen Schritt automatisieren.
Bei derAutomatisierung von Cloud Native Applications geht es darum, die manuellen Aufgaben des Entwicklungslebenszyklus zu automatisieren. Dazu gehören Aufgaben wie die Durchführung von Integrationstests, Builds, Releases, Konfigurationsmanagement, Infrastrukturmanagement und kontinuierliche Integration (CI) und kontinuierliche Bereitstellung/Deployment (CD).
In dem in Abbildung 1-5 dargestellten Entwicklungslebenszyklus kannst du alle Phasen der Erstellung einer Cloud Native Application sehen.
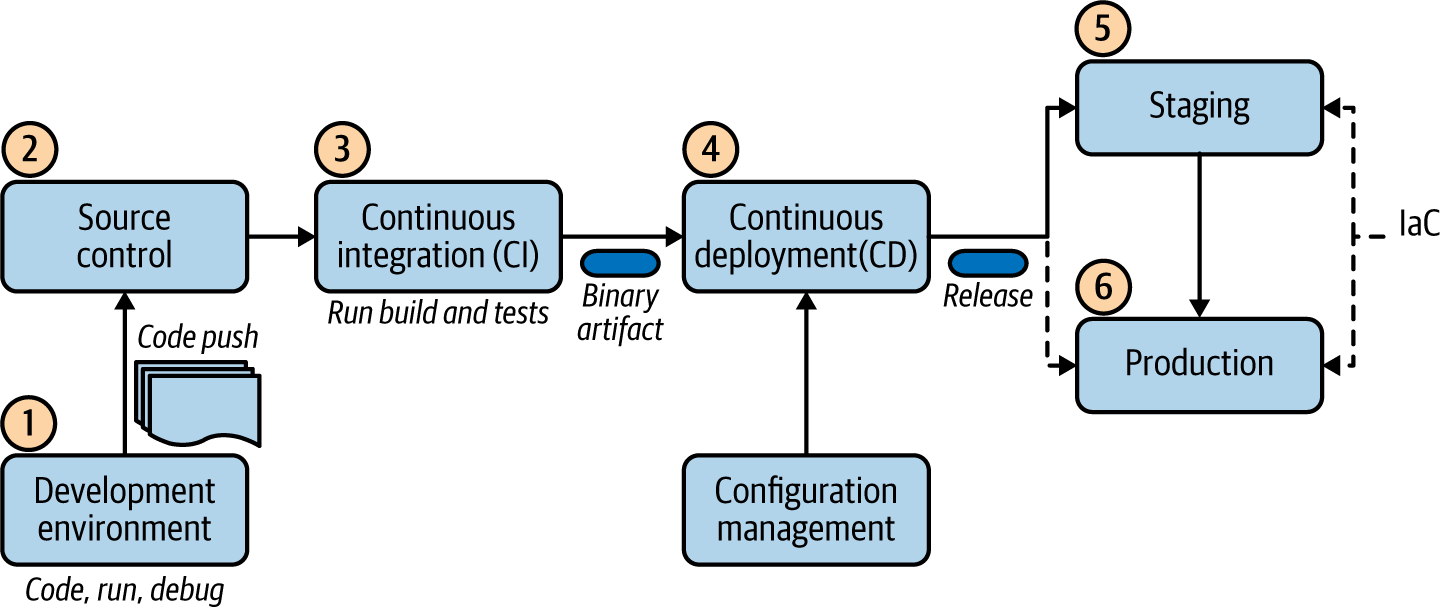
Abbildung 1-5. Lebenszyklus der Entwicklung Cloud-nativer Anwendungen
Der Lebenszyklus der Entwicklung beginnt damit, dass die Entwickler ihren Code entwickeln, ihn ausführen, debuggen und ihre Änderungen in ein zentrales Source-Control-Repository wie Git übertragen. Wenn ein Code-Push erfolgt, wird automatisch der kontinuierliche Integrationsprozess ausgelöst. Hier wird der Code gebaut, die Tests werden ausgeführt und die Anwendung wird in eine Binärdatei verpackt. Ein Continuous-Integration-Tool erstellt automatisch die neuen Codeänderungen und führt Unit-Tests aus, um Fehler sofort zu erkennen.
Bei der Bereitstellung von Artefakten in verschiedenen Umgebungen kommt der kontinuierliche Bereitstellungsprozess zum Einsatz. Er wählt das erstellte binäre Artefakt aus, wendet eine umgebungsspezifische Konfiguration an, indem er die Tools des Konfigurationsmanagements verwendet, und stellt die Version in einer bestimmten Umgebung bereit. In dieser Phase können wir mehrere parallele Testphasen durchführen, bevor wir die Änderungen in die Produktionsumgebung übertragen. Der endgültige Push in die Produktionsumgebung kann vollständig automatisiert sein oder einen manuellen Genehmigungsschritt beinhalten.
Der Unterschied zwischen Continuous Delivery und Continuous Deployment besteht darin, dass bei Continuous Delivery eine manuelle Genehmigung für die Aktualisierung in der Produktion erforderlich ist. Bei der kontinuierlichen Bereitstellung erfolgt die Aktualisierung automatisch und ohne ausdrückliche Genehmigung.
Bei der Automatisierung der Erstellung der Zielumgebung (Entwicklungs-, Staging- oder Produktionsumgebung) wird in der Regel die Technik der Infrastruktur als Code(IaC) verwendet. Beim IaC-Modell erfolgt die Verwaltung der Infrastruktur (Netzwerke, VMs, Load Balancer und Verbindungstopologie) über ein deklaratives Modell, das dem Quellcode einer Anwendung ähnelt. Mit diesem Modell können wir die benötigte Umgebung mithilfe des Deskriptors kontinuierlich erstellen, ohne dass wir manuell eingreifen müssen. Dadurch wird der Entwicklungsprozess schneller und effizienter, während die Konsistenz gewahrt bleibt und der Verwaltungsaufwand reduziert wird. Daher sind IaC-Techniken ein integraler Bestandteil der Continuous Delivery Pipeline.
Sobald wir den geplanten Zustand des Deployments definiert haben, können Plattformen wie Kubernetes mit Hilfe von Versöhnungsschleifen für die Aufrechterhaltung des Deployment-Status sorgen. Der Kerngedanke dabei ist, den Bereitstellungsstatus ohne Benutzereingriff aufrechtzuerhalten. Wenn wir zum Beispiel festlegen, dass eine bestimmte Anwendung zu einem bestimmten Zeitpunkt drei Replikate ausführen soll, sorgt Kubernetes Reconciliation dafür, dass immer drei Anwendungen laufen.
Dynamisches Management
Wenn cloud-native Anwendungen in einer Produktionsumgebung eingesetzt werden, müssen wir das Verhalten der Anwendung verwalten und beobachten. Hier sind einige der wichtigsten Funktionen, die für die dynamische Verwaltung von Cloud Native Applications erforderlich sind:
- Autoskalierung
- Skaliert die Anwendungsinstanzen je nach Verkehrsaufkommen oder Last nach oben oder unten
- Hohe Verfügbarkeit
- Im Falle eines Ausfalls können neue Instanzen im aktuellen Rechenzentrum erzeugt oder der Datenverkehr auf andere Rechenzentren verlagert werden.
- Ressourcenoptimierung
- Sorgt für eine optimale Ressourcennutzung mit dynamischer Skalierung und ohne Vorlaufkosten, aber mit automatischer Reaktion auf den Skalierungsbedarf in Echtzeit
- Beobachtbarkeit
- Ermöglicht Logs, Metriken und Tracing der Cloud Native Application mit zentraler Kontrolle
- Qualität der Dienstleistung (QoS)
- Ermöglicht End-to-End-Sicherheit, Drosselung, Konformität und Versionskontrolle für alle Anwendungen
- Zentrale Steuerungsebene
- Bietet einen zentralen Ort, um alle Aspekte der nativen Cloud-Anwendung zu verwalten
- Ressourcenbereitstellung
- Verwaltet die Ressourcenzuweisungen (CPU, Speicher, Speicherung, Netzwerk) für jede Anwendung
- Multicloud-Unterstützung
- Bietet die Möglichkeit, die Anwendung in verschiedenen Cloud-Umgebungen zu verwalten und auszuführen, einschließlich privater, hybrider und öffentlicher Clouds (da eine bestimmte Anwendung Komponenten und Dienste von mehreren Cloud-Providern benötigen kann)
Die meisten Funktionen des dynamischen Managements werden als Teil der beliebten Cloud-Dienste wie Amazon Web Services (AWS), Microsoft Azure und Google Cloud Platform (GCP) angeboten. Container und Container-Orchestrierungssysteme wie Kubernetes spielen eine wichtige Rolle bei der Demokratisierung deiner Anwendungen auf diesen Cloud-Plattformen, damit deine Anwendungen nicht an einen bestimmten Anbieter gebunden sind.
Methodik für die Entwicklung von Cloud Native Apps
Für die Entwicklung von Cloud Native Applications musst du eine neue Entwicklungsmethodik anwenden, die sich von dem herkömmlichen Ansatz unterscheidet, den viele von uns praktiziert haben. Manche glauben, dass der Weg zur Entwicklung von Cloud Native Applications über die Zwölf-Faktoren-Methodik führt. Wir haben jedoch festgestellt, dass diese Methodik mehrere Lücken aufweist; sie deckt nicht alle Aspekte des Lebenszyklus der Entwicklung von Cloud Native Applications ab.
Deshalb haben wir eine umfassendere und pragmatischere Methodik für die Entwicklung von Cloud Native Apps entwickelt. Wir unterteilen diesen Ansatz in Phasen und greifen bei Bedarf auf einige der bestehenden Methoden zurück. Abbildung 1-6 veranschaulicht die wichtigsten Phasen unserer Methodik für die Entwicklung nativer Cloud-Anwendungen.
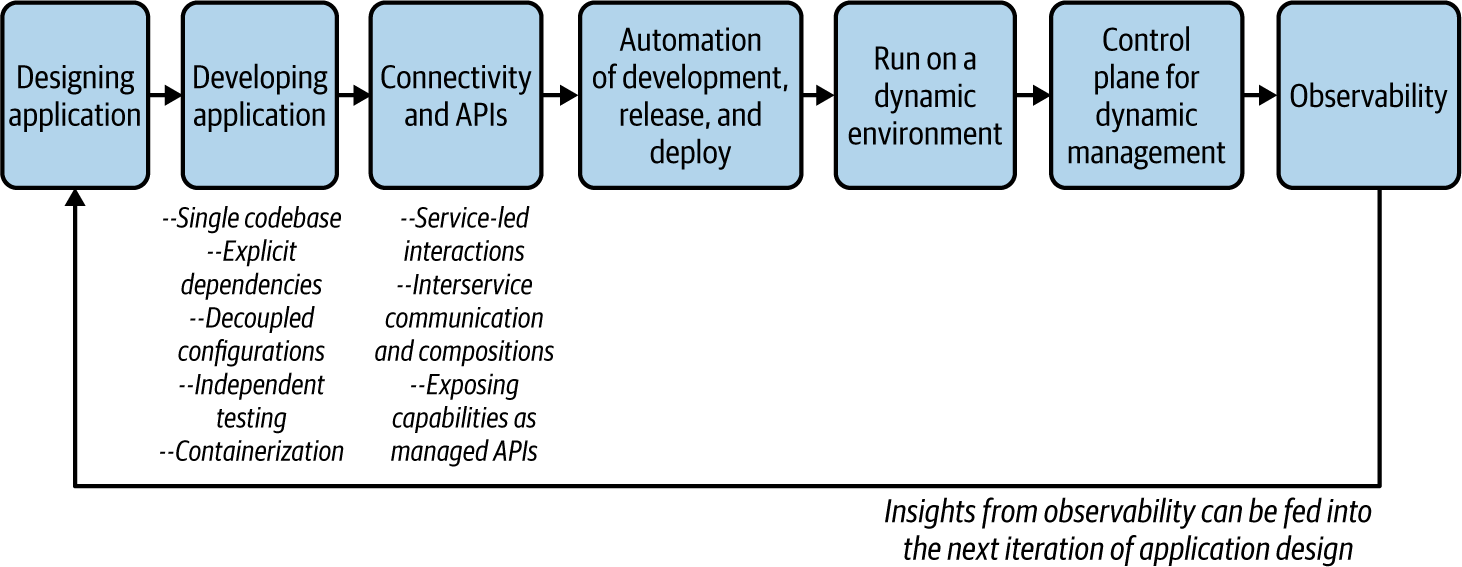
Abbildung 1-6. Methodik für die Entwicklung nativer Cloud-Anwendungen
Lass uns in die Details der einzelnen Phasen eintauchen.
Entwerfen der Anwendung
Wenn du eine Cloud-native Anwendung aufbaust, die aus Microservices besteht, kannst du nicht sofort mit der Anwendungsentwicklung beginnen. Du musst die Anwendung um die Geschäftsfunktionen herum entwerfen, die du abdecken willst. Dazu musst du die geschäftlichen Möglichkeiten, die die Anwendung bieten soll, sowie die externen Abhängigkeiten (Dienste oder Systeme), die die Anwendung nutzen muss , klar identifizieren .
Deshalb solltest du dir in der Entwurfsphase den geschäftlichen Anwendungsfall genauer ansehen und die Microservices identifizieren, die du erstellen möchtest. Für den Entwurf einer Cloud-Native-Anwendung kann die Methodik des domänengesteuerten Designs (DDD) verwendet werden, bei der komplexe Geschäftslogik abstrahiert und in den Softwarekomponenten dargestellt wird .4
Der DDD-Prozess beginnt mit der Analyse der Geschäftsdomäne (z. B. Einzelhandel oder Gesundheitswesen) und der Festlegung von Grenzen innerhalb dieser Domäne, auf die ein bestimmtes Domänenmodell anwendbar ist. Diese werden als begrenzte Kontexte bezeichnet. So kann ein Unternehmen z. B. begrenzte Kontexte wie Vertrieb, Personalwesen (HR), Support usw. haben. Jeder Bounded Context kann weiter in Aggregate unterteilt werden, d. h. in Gruppen von Domänenobjekten, die als eine Einheit behandelt werden können.
Diese gebundenen Kontexte können direkt auf einen Microservice abgebildet werden, müssen es aber nicht. Wenn wir eine Cloud Native-Anwendung entwerfen, können wir in der Regel mit einem Dienst für jeden Bounded Context beginnen und ihn im Laufe der Entwicklung in kleinere Dienste aufteilen, die um Aggregate herum aufgebaut werden. Sobald das DDD für die Cloud Native-Anwendung abgeschlossen ist, kannst du auch die Service-Schnittstellen/-Definitionen und die Kommunikationsstile festlegen und gleichzeitig die Microservices identifizieren.
Die Entwicklung der Anwendung
In der Entwicklungsphase bauen wir die Anwendung auf der Grundlage der geschäftlichen Anwendungsfälle und Serviceschnittstellen, die wir in der Entwurfsphase festgelegt haben. In diesem Abschnitt erläutern wir die wichtigsten Aspekte des Entwicklungsprozesses, die Cloud Native Applications ermöglichen.
Unabhängige Codebase
Jeder Microservice einer nativen Cloud-Anwendung sollte eine Codebasis haben, die in einem Versionskontrollsystem (wie Git) verfolgt wird. Mehrere Instanzen des Dienstes, bekannt als Deploys, werden ausgeführt. Wie in Abbildung 1-7 zu sehen ist, kannst du den Dienst in verschiedenen Umgebungen bereitstellen, z. B. in der Entwicklungs-, der Staging- und der Produktionsumgebung, die alle dieselbe Codebasis verwenden (allerdings können sie unterschiedliche Versionen der Codebasis verwenden).
Eine unabhängige Codebasis bedeutet, dass der Lebenszyklus des Microservices völlig unabhängig vom Rest des Systems sein kann. Und du kannst externe Abhängigkeiten wie Bibliotheken explizit importieren.
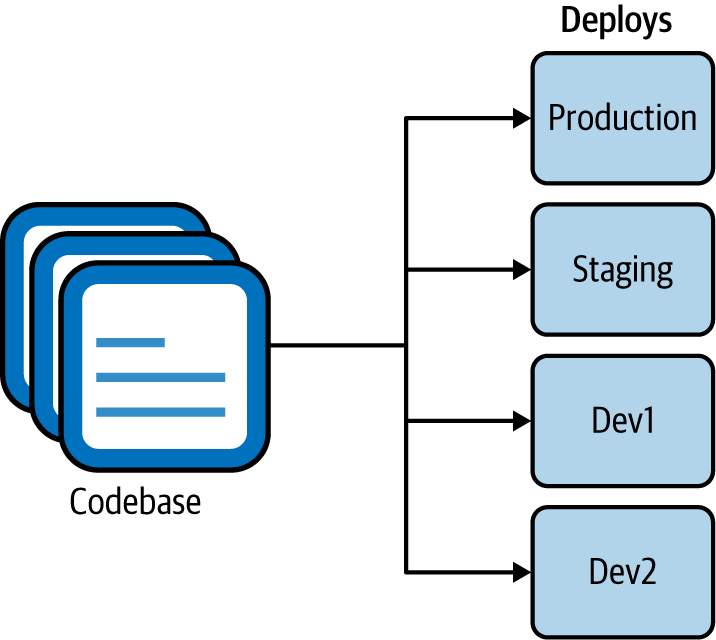
Abbildung 1-7. Eine einzelne Codebasis mit mehreren Implementierungen in verschiedenen Umgebungen
Explizite Abhängigkeiten
Alle Abhängigkeiten auf Code-Ebene eines Microservices müssen explizit deklariert und voneinander isoliert werden. Die Abhängigkeiten sollten in einem Manifest deklariert werden, das Teil des Microservice-Codes ist, und der Dienst sollte nicht von systemweiten Abhängigkeiten abhängen, die nicht explizit deklariert sind.
Entkoppelte Konfigurationen
Wie bereits erwähnt, enthalten Cloud Native-Anwendungen eine einzige Codebasis eines Dienstes, der in mehreren Umgebungen eingesetzt wird. Dies ist nur möglich, wenn die Konfiguration des Microservices vollständig vom Microservice-Code entkoppelt ist. Die Codebasis eines Dienstes ist umgebungsunabhängig, und die Konfiguration variiert zwischen den verschiedenen Bereitstellungen.
Unabhängige Prüfung
Ein Microservice sollte in sich geschlossene Tests haben, die seine Funktionalität unabhängig überprüfen. In der Regel sind diese Tests ein fester Bestandteil des Entwicklungszyklus des Microservices, und die Überprüfung des Microservices erfolgt während der Build- und Deployment-Phasen. Wir können diese Unit-Tests als betrachten, da sie auf den Bereich eines bestimmten Microservices beschränkt sind.
Da eine Cloud Native-Anwendung jedoch mehrere Microservices enthält, die zusammenarbeiten, um einen bestimmten geschäftlichen Anwendungsfall zu bedienen, können Unit-Tests allein nicht die Gesamtfunktionalität der Anwendung testen. Wir brauchen auch systemweite Tests, die so genannten Integrationstests. Diese Tests fassen Microservices und andere Systeme zusammen und testen sie als eine Einheit, um zu überprüfen, ob sie wie vorgesehen zusammenarbeiten, um die übergeordnete Geschäftsfunktion zu erfüllen. Weitere Einzelheiten zu Microservice-Tests findest du in "Testing Strategies in a Microservice Architecture" von Toby Clemson.
Containerisierung
Die meisten der Konzepte, die wir in den vorherigen Schritten besprochen haben, können durch die Containerisierung der von dir erstellten Microservices demonstriert werden. Die Containerisierung ist zwar nicht zwingend erforderlich, um Cloud Native Applications zu erstellen, aber sie ist sehr nützlich, um die meisten ihrer Eigenschaften und Anforderungen umzusetzen.
Die Kapselung einer nativen Cloud-Anwendung in einem einzigen Paket mit allen Abhängigkeiten, Laufzeiten und Konfigurationen wird durch die Containerisierung ermöglicht. Durch die Containerisierung (mit Technologien wie Docker) werden Microservices unveränderlich, d.h. sie können jederzeit gestartet oder gestoppt werden und fehlerhafte Instanzen werden verworfen, anstatt repariert oder aktualisiert zu werden. Das setzt voraus, dass die Microservices, die wir containerisieren, schnell starten und zuverlässig heruntergefahren werden können. Deshalb funktioniert die Containerisierung am besten, wenn du containernative Frameworks und Technologien einsetzt. (Wenn eine schnelle Startzeit aufgrund einer inhärenten Einschränkung der Anwendungen, die wir containerisieren, nicht erreicht werden kann, bieten Container-Orchestrierungssysteme wie Kubernetes Bereitschafts- und Liveness-Checks, um sicherzustellen, dass die Anwendungen bereit sind, ihre Kunden zu bedienen).
Bei der Entwicklung von Microservices ist es oft erforderlich, sich mit anderen Microservices zu verbinden und/oder Geschäftsfähigkeiten für externe Verbraucher als APIs bereitzustellen. Wir gehen auf diese Anforderungen in der nächsten Phase ein, indem wir die Konnektivität herstellen.
Konnektivität, Zusammensetzungen und APIs
Wie bereits zu Beginn dieses Kapitels erläutert hat, sind Cloud Native Applications verteilte Anwendungen, die über Netzwerkkommunikation miteinander verbunden sind. Da wir sie als eine Sammlung von Microservices entwerfen, müssen wir oft Interaktionen zwischen diesen Services und externen Systemen herstellen. Daher sind die Konnektivität zwischen den Diensten und die richtige Definition von APIs und Serviceschnittstellen von entscheidender Bedeutung.
Servicegeleitete Interaktionen
Alle Microservices und Anwendungen von sollten ihre Fähigkeiten als Dienst offenlegen. Ebenso sollten alle externen Fähigkeiten und Ressourcen, die ein Microservice in Anspruch nimmt, als Dienst deklariert werden (oft als Backing Service bezeichnet).
Der Begriff "Service" ist eine Abstraktion , die die Interaktion zwischen Microservices in vielerlei Hinsicht erleichtert. Ein Dienst ermöglicht die dynamische Erkennung von Diensten und führt ein Repository/Register mit Metadaten zu den Diensten. Außerdem ermöglicht er die Umsetzung von Konzepten wie dem Lastausgleich. Deshalb ist die Service-Abstraktion in Container-Orchestrierungsplattformen wie Kubernetes als Abstraktion erster Klasse integriert. Wenn du also eine Cloud Native-Anwendung mit einer Reihe von Microservices erstellst, können ihre Fähigkeiten als Dienste deklariert werden (z. B. ein Kubernetes-Dienst). Jede externe Anwendung/jeder externe Dienst oder jede Ressource (z. B. eine Datenbank oder ein Message Broker), die wir nutzen, sollte ebenfalls als Dienst deklariert werden, den wir über das Netzwerk nutzen können.
Dienststellenübergreifende Kommunikation und Zusammensetzungen
Die Interaktion zwischen Diensten und anderen Systemen ist ein wichtiger Bestandteil der Entwicklung von Cloud Native Applications. Diese Interaktionen finden über das Netzwerk statt und nutzen verschiedene Kommunikationsmuster und -protokolle. Diese Interaktionen können die Nutzung mehrerer Dienste, die Erstellung von Kompositionen, die Erstellung ereignisbasierter Konsumenten oder Produzenten usw. beinhalten. Außerdem müssen wir bestimmte Funktionen - wie z. B. Sicherheit auf Anwendungsebene, robuste Kommunikation (Circuit Breaker, Wiederholungslogik mit Backoff und Timeouts), Routing, Veröffentlichung von Metriken und Traces für Observability-Tools - als Teil der Interservice-Kommunikationslogik entwickeln, obwohl sie nicht wirklich Teil der Geschäftslogik sind. (Wir besprechen die Interservice-Kommunikation und Komposition ausführlich in den Kapiteln 2, 3 und 5).
Daher musst du als Entwickler von Diensten über die erforderlichen Fähigkeiten in dem Technologie-Stack verfügen, den du für die Erstellung der Dienste verwendest. Einige der Commodity-Funktionen, die nicht direkt mit der Geschäftslogik der Dienste zu tun haben (z. B. belastbare Kommunikation), können außerhalb der Anwendungsschicht implementiert werden (oft unter Verwendung der zugrunde liegenden Laufzeitplattformen wie dem Cloud-Provider, auf dem unsere Anwendungen laufen). Wir werden all diese Muster in den nächsten Kapiteln im Detail besprechen.
Fähigkeiten als verwaltete APIs bereitstellen
Für bestimmte Funktionen von kann der Begriff des Dienstes auch auf das Konzept einer verwalteten API ausgeweitet werden. Da die meisten Geschäftsfunktionen einer nativen Cloud-Anwendung externen und internen Parteien zugänglich gemacht werden können, wollen wir sie zu einem verwalteten Dienst/API machen. Das bedeutet, dass du ein API-Gateway und eine Verwaltungsebene (API-Verwaltungs-/Kontrollebene) verwenden kannst, um Funktionen (der APIs, die du den Verbrauchern zur Verfügung stellst) zu implementieren, wie z. B. Sicherheit, Drosselung, Zwischenspeicherung, Versionierung, Monetarisierung (Erzielung von Einnahmen aus den offengelegten APIs), Aktivierung eines Entwicklerportals usw.
Das API-Gateway ist die Eingangstür zu deinen Fähigkeiten, und ein Entwicklerportal kann ein Ökosystem um deine APIs herum aufbauen. Die API-Verwaltung sollte sowohl für die externe als auch für die interne Nutzung deiner Dienste erfolgen. Die API-Verwaltung ist jedoch nicht in Container-Orchestrierungsplattformen wie Kubernetes integriert. Daher musst du explizit API-Verwaltungstechnologien einsetzen, um deine Microservices als verwaltete APIs bereitzustellen.
Automatisierung von Entwicklung, Freigabe und Einsatz
Wie wir bereits in diesem Kapitel erwähnt haben, ist die Automatisierung möglichst vieler Schritte im Entwicklungs-, Freigabe- und Auslieferungsprozess ein wichtiger Bestandteil der Entwicklung von Cloud Native Applications. Die verschiedenen Phasen der Entwicklung von Cloud Native Applications (wie Testen, Code Push, Build, Integrationstests, Freigabe, Bereitstellung und Betrieb) sollten durch den Einsatz von Continuous Integration, Continuous Deployment, IaC und Continuous Delivery Techniken und Frameworks automatisiert werden.
Laufen in einer dynamischen Umgebung
In der laufenden oder Ausführungsphase deiner nativen Cloud-Anwendung kannst du die Anwendungen so einrichten, dass sie in einer Ausführungsumgebung bereitgestellt und ausgeführt werden, wie in der vorherigen Phase. Dabei geht es vor allem darum, dass deine Anwendung unabhängig von der Ausführungsumgebung ist und in verschiedenen Ausführungsumgebungen (Dev, Staging, Production usw.) ohne Änderungen am Anwendungscode ausgeführt werden kann. Da du Container als Bereitstellungsmodell verwendest, enthält die Ausführungslaufzeit oft ein Container-Orchestrierungssystem. Die Ausführungsumgebung kann eine lokale Umgebung, eine öffentliche, hybride oder private Cloud oder sogar mehrere Cloud-Umgebungen sein.
Da Kubernetes die beliebteste Wahl für die Container-Orchestrierung ist, können wir es als universelle Laufzeitabstraktion nutzen, um unsere Anwendungen so einzusetzen, dass sie sich in allen Ausführungsumgebungen und Multicloud-Szenarien gleich verhalten. Die Dynamik der Umgebung - einschließlich der Bereitstellung von Containern, der Ressourcenverwaltung, der Unveränderlichkeit und der automatischen Skalierung - kann vollständig an Kubernetes ausgelagert werden. Da die Container-Orchestrierungsplattform die meisten Funktionen für die dynamische Ausführung bereitstellt, muss sich die Anwendung nur um die Funktionen kümmern, die in ihrem Zuständigkeitsbereich liegen (z. B. Skalierung, Gleichzeitigkeitsanforderungen einer einzelnen Laufzeit).
Die Orchestrierungsplattformen wie Kubernetes führen deine Anwendung standardmäßig als zustandslosen Prozess aus (der Zustand der Anwendung wird nicht verwaltet oder persistiert). Wenn die Anwendung jedoch einen Zustand benötigt, musst du explizit einen externen Zustandsspeicher verwenden, um den Anwendungszustand außerhalb deiner Anwendung zu halten (z. B. in einem Datenspeicher), damit du den Anwendungszustand vom Lebenszyklus des Containers entkoppeln kannst. Wenn du vorhast, Cloud-native Anwendungen in einem lokalen Rechenzentrum oder einer privaten Cloud zu betreiben, kannst du trotzdem von Kubernetes profitieren, da es sich um viele komplexe Aspekte der Container-Orchestrierung kümmert.
Control Plane für dynamisches Management
In dieser Phase verwenden wir eine zentrale Verwaltungs- und Administrationsschicht, die als Control Plane bekannt ist und mit der du das Verhalten der dynamischen Umgebungen, in denen deine Anwendungen ausgeführt werden, steuern kannst. Diese Steuerungsebene ist der wichtigste Interaktionspunkt zwischen den DevOps und den Entwicklern, die ihre Anwendung in einer Laufzeitumgebung ausführen. In der Regel bestehen solche Cloud-Kontrollebenen aus einer Weboberfläche sowie einer Representational State Transfer (REST) oder Remote Procedure Call (RPC) API. Die meisten Cloud-Provider bieten solche Steuerungsebenen als Teil ihres Cloud-Service-Angebots an.
Beobachtbarkeit und Überwachung
Sobald du deine Anwendungen bereitstellst und ausführst, besteht die nächste Phase der Entwicklung von Cloud-nativen Anwendungen darin, ihr Laufzeitverhalten zu beobachten. Im Zusammenhang mit einer Softwareanwendung bedeutet Beobachtbarkeit die Fähigkeit, den Zustand eines Systems zu verstehen und zu erklären, ohne neuen Code zu implementieren. Dies ist wichtig für die Fehlerbehebung, die Aufzeichnung von Geschäftstransaktionen, die Identifizierung von Anomalien, die Erkennung von Geschäftsmustern, die Gewinnung von Erkenntnissen und so weiter.
In der Phase der Beobachtbarkeit und Überwachung musst du die wichtigsten Aspekte der Beobachtbarkeit in deiner Cloud Native Application aktivieren. Dazu gehören Logging, Metriken, Tracing und Service-Visualisierung. Für jeden dieser Aspekte gibt es spezielle Tools, und die meisten Cloud-Provider bieten diese Funktionen standardmäßig als Managed Cloud Services an. Auf der Ebene des Anwendungscodes musst du möglicherweise Agenten oder Client-Bibliotheken aktivieren, ohne den Code deiner Anwendung zu ändern.
Damit haben wir alle Phasen der Methodik zur Erstellung von Cloud Native Applications besprochen.
Design Patterns für die Entwicklung von Cloud Native Apps
In den vorangegangenen Abschnitten von haben wir uns mit den wichtigsten Merkmalen von Cloud Native Applications und der Methodik für ihre Entwicklung beschäftigt. Wie du gesehen hast, erfordert die Cloud Native Architecture eine erhebliche Veränderung der Methodik, Technologie und Architektur für die Entwicklung von Softwareanwendungen.
Wir können uns nicht einfach an die herkömmlichen Entwurfsmuster für die Entwicklung von Softwareanwendungen halten. Einige Muster sind veraltet, andere müssen geändert oder optimiert werden, und es entstehen neue Muster, die den besonderen Anforderungen der Cloud Native Architecture gerecht werden. Diese Muster können in verschiedenen Phasen des Lebenszyklus einer Cloud Native Application angewandt werden. Während sich die Branche in der Regel auf die Bereitstellung und Lieferung von Cloud Native Applications konzentriert, wird die Komplexität des Aufbaus der Geschäftslogik, der Verwendung verschiedener Kommunikationsmuster und der Verbindung von Cloud Native Applications oft übersehen.
In diesem Buch konzentrieren wir uns auf die Entwurfsmuster, die du bei der Entwicklung von Cloud Native Applications verwenden kannst. Diese Muster musst du anwenden, wenn du die Geschäftslogik von Cloud Native Applications aufbaust, sie miteinander verbindest und es externen Parteien ermöglichst, sie zu nutzen. Je nach Art der Cloud Native-Anwendung und den Mustern, die du für ihre Erstellung verwendest, können auch die übergreifenden Fähigkeiten wie Bereitstellung, Skalierung, Sicherheit und Beobachtbarkeit unterschiedlich umgesetzt werden. Wir besprechen diese Fähigkeiten aus der Perspektive der Entwicklung von Cloud Native Applications und gehen bei Bedarf auf sie ein.
In den folgenden Kapiteln untersuchen wir Muster im Kontext von sechs Schlüsselbereichen: Kommunikation, Konnektivität und Komposition, Datenmanagement, ereignisgesteuerte Architektur, Stream-Verarbeitung sowie API-Verwaltung und -Nutzung. Fassen wir jeden Bereich kurz zusammen.
Kommunikationsmuster
Wie du bereits gelernt hast, besteht eine Cloud Native Anwendung aus einer Sammlung von Microservices, die über ein Netzwerk verteilt sind. Bei den Cloud Native-Kommunikationsmustern geht es darum, wie diese Dienste sowohl untereinander als auch mit externen Einheiten kommunizieren können.
Um auch nur einen einfachen Anwendungsfall zu erstellen, muss deine Anwendung externe Dienste in Anspruch nehmen (z. B. einen anderen Dienst, eine Datenbank oder einen Message Broker). Daher ist die Interaktion zwischen deiner Anwendung und diesen externen Diensten eine der häufigsten und gleichzeitig komplexesten Aufgaben bei der Entwicklung von Cloud Native Applications.
Die meisten konventionellen Kommunikationsmuster und -technologien aus der Welt des verteilten Computings sind im Kontext der Entwicklung von Cloud-nativen Anwendungen nicht direkt anwendbar. Wir müssen Kommunikationsmuster auswählen, die sowohl für die Cloud-nativen Eigenschaften der Anwendung (z. B. Muster, die Service-Autonomie und Skalierbarkeit ermöglichen) als auch für den geschäftlichen Anwendungsfall (z. B. können einige Liefergarantien erforderlich sein, während andere Echtzeitantworten benötigen) geeignet sind.
Die dienstübergreifende Kommunikation zwischen nativen Cloud-Anwendungen wird entweder mit synchronen oder asynchronen Kommunikationsmustern umgesetzt. Bei der synchronen Kommunikation verwenden wir Muster wie Anfrage/Antwort und RPC. Bei der asynchronen Kommunikation verwenden wir Muster wie queue-based und publisher-subscriber (pub-sub) Messaging. In den meisten realen Anwendungsfällen musst du beide Kategorien zusammen verwenden, um die Service-Interaktionen aufzubauen. Definitionen von Serviceschnittstellen und -verträgen spielen ebenfalls eine wichtige Rolle, wenn es um Kommunikationsmuster geht, denn sie sind die Standardmethode, um auszudrücken, wie ein bestimmter Dienst genutzt werden kann.
Zusätzlich zu den Interaktionen zwischen den Diensten müssen bestimmte Cloud-native Anwendungen möglicherweise mit externen Parteien wie Frontend-Clients oder Backing-Diensten kommunizieren. Als Anwendungsentwickler musst du mit vielen beweglichen Teilen und einer Vielzahl von Interaktionen mit externen Diensten und Systemen arbeiten.
In Kapitel 2 werden alle diese Kommunikationsmuster sowie die dazugehörigen Implementierungstechnologien und -protokolle im Detail besprochen.
Konnektivität und Zusammensetzungsmuster
Je mehr Microservices du hast, desto mehr Interservice-Kommunikation wird stattfinden. Deshalb musst du bei der Entwicklung nativer Cloud-Anwendungen bestimmte Fähigkeiten und Abstraktionen einbringen, die die Komplexität der Kommunikation zwischen den Diensten reduzieren. An dieser Stelle kommen die Konnektivitäts- und Kompositionsmuster ins Spiel.
Konnektivität
Im Kontext der Kommunikation zwischen Diensten bedeutet Konnektivität, dass ein zuverlässiger, sicherer, auffindbarer, verwaltbarer und beobachtbarer Kommunikationskanal zwischen den Diensten eingerichtet wird. Wenn zum Beispiel ein bestimmter Dienst einen anderen Dienst aufruft, musst du bestimmte Zuverlässigkeitsmuster anwenden, wie z. B. Wiederholungsversuche oder den Aufbau eines sicheren Kommunikationskanals. Sie sind nicht Teil der Geschäftslogik der Anwendung, aber sie sind für den Aufbau einer starken Konnektivität unerlässlich.
In Kapitel 3 besprechen wir verschiedene Muster in Bezug auf belastbare Kommunikation, Sicherheit, Service Discovery, Traffic Routing und Beobachtbarkeit in der Interservice-Kommunikation. Wir werden auch untersuchen, wie Infrastrukturen für die Interservice-Konnektivität, wie z. B. ein Service-Mesh und eine Sidecar-Architektur, diese Anforderungen erfüllen.
Kompositionen
Bei der Entwicklung von Cloud-nativen Anwendungen ist es üblich, einen Dienst zu erstellen, indem ein oder mehrere andere Dienste oder Systeme integriert werden. Diese werden als Compositions bezeichnet (auch bekannt als Composite Services und Integration Services).
Wie wir zu Beginn des Kapitels besprochen haben, wurden Dienste und Systeme vor der Cloud Native-Ära häufig mit SOA aufgebaut. Bei einer SOA werden alle Dienste, Daten und Systeme über einen ESBintegriert, so dass bei der Erstellung von Kompositionen ESB die Standardwahl war. In dieser Architektur wurde eine Vielzahl von Kompositionsmustern verwendet, die gemeinhin als Enterprise Integration Patterns(EIPs) bekannt sind.
In der Cloud-Native-Ära verwenden wir jedoch keine zentrale Kompositionsschicht. Alle diese Aufgaben müssen als Teil der von uns entwickelten Dienste erledigt werden. In Kapitel 3 werden wir uns daher mit all diesen Kompositionsmustern beschäftigen und herausfinden, welche wir bei der Entwicklung von Cloud Native-Anwendungen anwenden sollten.
Datenmanagement-Muster
Die meisten nativen Cloud-Anwendungen, die du entwickelst, müssen sich um die Datenverwaltung kümmern. Deine Anwendung wird oft von einer Datenbank unterstützt, die als dauerhafte Speicherung für den Anwendungsstatus oder die Geschäftsdaten dient, die für die Erstellung des Dienstes erforderlich sind. Wie du bereits gelernt hast, sind Cloud-native Anwendungen von Natur aus verteilt. Daher erfolgt auch die Datenverwaltung völlig dezentral.
In konventionellen monolithischen Anwendungen hatten wir früher einen zentralen, gemeinsamen Datenspeicher, mit dem viele Anwendungen interagierten. Bei Cloud-nativen Anwendungen gehört der Datenspeicher einem bestimmten Microservice, und externe Parteien können nur über die Schnittstelle dieses Services mit ihm interagieren. Mit diesem Ansatz der getrennten Datenverwaltung wird der Zugriff, die gemeinsame Nutzung und die Synchronisierung von Daten zwischen Microservices zur Herausforderung. Deshalb ist die Kenntnis der Cloud Native Data Management Patterns für die Entwicklung von Cloud Native Applications unerlässlich.
In Kapitel 4 untersuchen wir eine breite Palette von Cloud-nativen Datenverwaltungsmustern, die dezentrales Datenmanagement, Datenkomposition, Datenskalierung, Datenspeicherimplementierungen, Transaktionsverarbeitung und Caching umfassen.
Muster der ereignisgesteuerten Architektur
Als wir die cloud-nativen Kommunikationsmuster besprochen haben, haben wir asynchrones Messaging als eine Technik zur Kommunikation zwischen den Diensten diskutiert. Das ist die Grundlage für ereignisgesteuerte Cloud Native-Anwendungen. Die ereignisgesteuerte Architektur(EDA) ist in der Anwendungsentwicklung seit Jahrzehnten weit verbreitet. Im Zusammenhang mit Cloud Native Applications spielt EDA eine wichtige Rolle, denn sie ist eine hervorragende Möglichkeit, autonome Microservices zu ermöglichen. Im Gegensatz zu synchronen Kommunikationstechniken wie Abfragen oder RPC ermöglicht EDA entkoppelte Interaktionen zwischen Microservices.
Daher widmen wir uns in Kapitel 5 den meisten gängigen EDA-Mustern und der Frage, wie sie für die Entwicklung von Cloud-nativen Anwendungen genutzt werden können. Wir befassen uns mit verschiedenen Aspekten der Cloud Native EDA, darunter Muster für die Auslieferung von Ereignissen (warteschlangenbasiert, pub-sub), Auslieferungssemantik und -zuverlässigkeit, Ereignisschemata und damit verbundene Implementierungstechnologien und Protokolle.
Stream-Processing-Muster
In EDAs bearbeiten wir jeweils ein einzelnes Ereignis. Mit anderen Worten: Die Geschäftslogik des Microservices ist so geschrieben, dass sie jeweils nur ein Ereignis verarbeitet. Es gibt keine Korrelation zwischen aufeinander folgenden Ereignissen. Ein Stream hingegen ist eine Folge von Ereignissen oder Datenelementen, die im Laufe der Zeit zur Verfügung gestellt werden. Diese Ereignisse werden von der Anwendung auf zustandsorientierte Weise verarbeitet.
Die Implementierungs- und Bereitstellungsarchitektur eines solchen Microservices unterscheidet sich drastisch von der eines ereignisgesteuerten Microservices, denn er muss Zustände verwalten, Daten effizient verarbeiten, verschiedene Skalierungs- und Gleichzeitigkeitssemantiken verwalten und so weiter. Deshalb haben wir Kapitel 6 den Stream-basierten Cloud Native Patterns gewidmet.
Die Idee, eine Anwendungslogik zu entwickeln, die einen solchen Datenstrom verarbeitet oder erzeugt, wird allgemein als Stream Processing bezeichnet. Die Entwicklung nativer Cloud-Anwendungen mithilfe einer Stream-basierten Architektur wird immer üblicher, da sie es den Microservices ermöglicht, riesige kontinuierliche Datenströme zustandsorientiert zu verarbeiten.
API-Verwaltung und Verbrauchsmuster
In den meisten mittelgroßen oder großen Anwendungsfällen der nativen Cloud-Architektur musst du bestimmte Geschäftsfunktionen deiner Anwendungen externen oder internen Parteien zugänglich machen, die außerhalb des Anwendungsbereichs liegen. Du musst diese Fähigkeiten als Managed Services oder APIs zur Verfügung stellen. So hast du mehr Kontrolle darüber, wie externe Parteien diese Funktionen nutzen, und kannst diese APIs leicht entdecken und Feedback dazu geben.
Die Bereitstellung dieser Funktionen erfolgt häufig über eine separate API-Gateway-Schicht, die als Eingangstür zu allen APIs dient, die du bereitstellst. Das API-Gateway umfasst auch eine Verwaltungsebene und ein Entwicklerportal, die um die bereitgestellten APIs herum aufgebaut sind. In Kapitel 7 werden verschiedene Muster für die Verwaltung und Nutzung von APIs behandelt.
Nachdem du nun die grundlegenden Konzepte der Cloud Native Application Development kennengelernt hast, wollen wir diese Konzepte in ein Referenzmodell einordnen, damit du verstehst, wie sie in einer realen Cloud Native Application Architecture eingesetzt werden.
Referenzarchitektur für Cloud Native Apps
In den meisten realen cloud-nativen Anwendungen sehen wir häufig eine Kombination von Entwicklungsstrategien. Abbildung 1-8 zeigt diese verschiedenen Strategien in einer verallgemeinerten Architektur. Diese Referenzarchitektur umfasst mehrere Microservices, die mit unterschiedlichen Kommunikationsmustern kommunizieren. Jeder Dienst kann seinen eigenen Daten- oder Persistenzspeicher verwenden, und es gibt auch eine gemeinsame oder private Event-Broker-Infrastruktur. Die Interaktion zwischen den Microservices repräsentiert alle Kommunikationsmuster, die wir implementieren können. Jede Kommunikationsverbindung kann mit Hilfe von Konnektivitätsmustern implementiert werden, die sich auf Zuverlässigkeit, Sicherheit, Routing usw. beziehen.
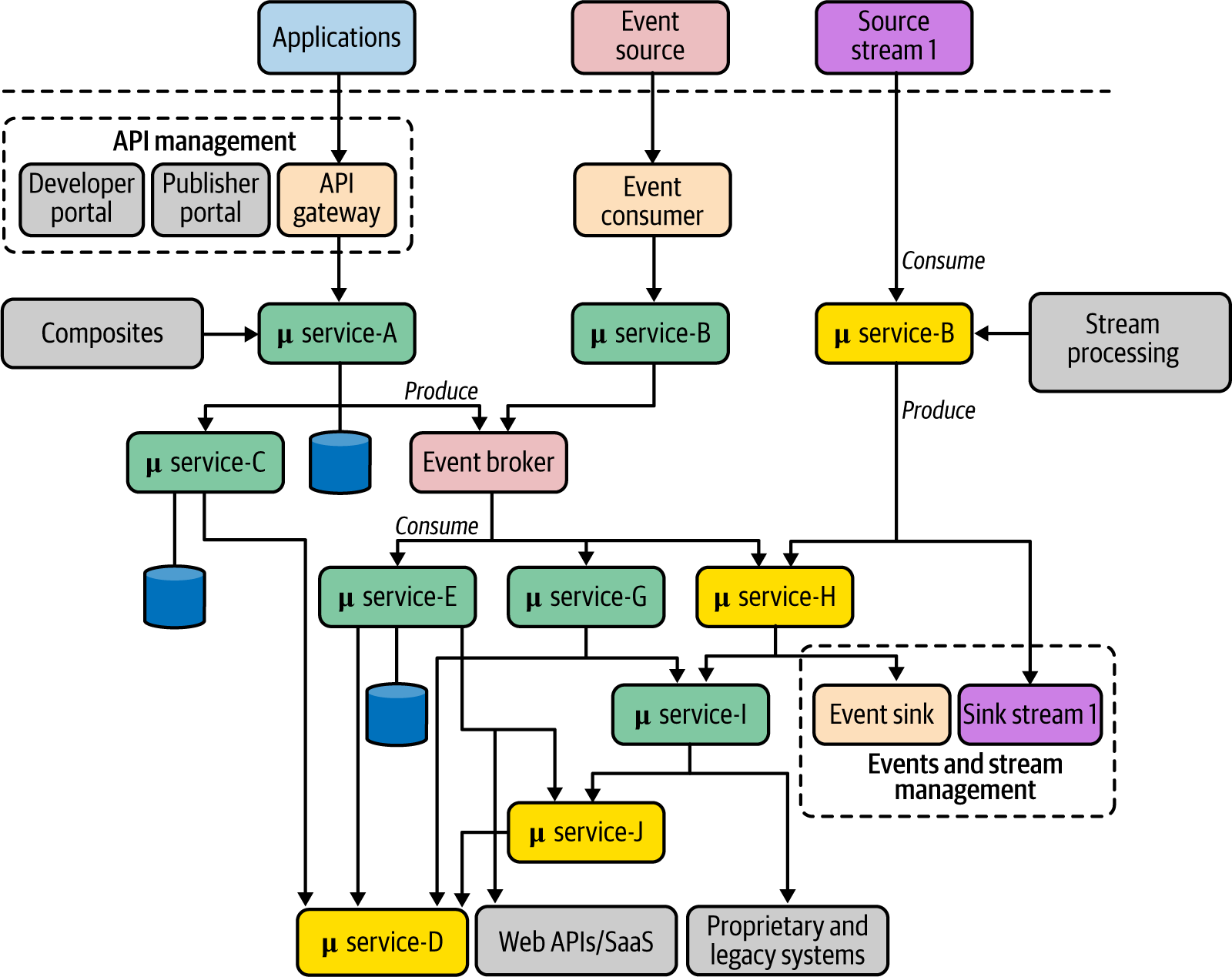
Abbildung 1-8. Eine verallgemeinerte Architektur für die Erstellung von Cloud-nativen Anwendungen mit APIs, Ereignissen und Streams
Wie du siehst, bilden Microservices Kompositionen aus einem oder mehreren Diensten, wie z. B. die Microservices A, E und G. Solche Dienste werden mit verschiedenen Kompositionsmustern erstellt. Wenn diese Anwendung als verwaltete Geschäftsfunktion außerhalb des Bereichs deiner Anwendung bereitgestellt werden muss, kannst du die API-Verwaltung nutzen. Alle externen Anwendungen können diese Fähigkeiten über ein API-Gateway nutzen, und du verwaltest sie über die anderen Komponenten der API-Verwaltungsschicht. Für die Dienste, die auf der EDA basieren, ist es oft unerlässlich, eine Event-Broker-Lösung einzurichten. Die Dienste können einen gemeinsam genutzten Broker als einfache Eventing-Infrastruktur nutzen oder auch ihre eigenen Event-Broker haben.
Stream-Processing-Dienste verfolgen einen ähnlichen Ansatz, aber die Stream-Processing-Logik kann mit ganz anderen Mustern und Technologien implementiert werden. Sowohl ereignis- als auch streambasierte Dienste verfügen über ein Ereignis-/Stream-Management für die Erzeugerseite (Senke) des Dienstes.
Diese Referenzarchitektur mag auf den ersten Blick komplex erscheinen, aber in den folgenden Kapiteln gehen wir auf jeden Aspekt ein und erforschen die Muster, Implementierungstechnologien und Protokolle, die du verwenden kannst, um sie zu realisieren.
Zusammenfassung
Cloud Native ist ein moderner Architekturstil, der es Unternehmen ermöglicht, Softwareanwendungen agil, zuverlässig, sicher, skalierbar und verwaltbar bereitzustellen. Cloud Native ist eine Art, Softwareanwendungen als eine Sammlung lose gekoppelter, geschäftsfähigkeitsorientierter Dienste zu entwickeln, die in dynamischen Umgebungen automatisiert, skalierbar, belastbar, verwaltbar und beobachtbar laufen können.
Cloud-native Anwendungen werden als eine Sammlung von Microservices konzipiert, in Container verpackt und mit Container-Orchestrierungssystemen wie Kubernetes verwaltet, mit CI/CD automatisiert und in einer dynamischen Umgebung verwaltet und beobachtet. Wenn wir all diese Merkmale berücksichtigen, können wir eine vollständige und pragmatische Methodik für die Entwicklung von Cloud Native Apps anwenden, die Design, Entwicklung, Vernetzung, API-Verwaltung sowie Ausführung und Verwaltung in einer dynamischen Umgebung umfasst.
Bei der Entwicklung von Cloud Native Applications können wir eine breite Palette von Entwurfsmustern anwenden. In diesem Buch konzentrieren wir uns vor allem auf die Entwicklungsmuster, die du anwenden musst, wenn du die Geschäftslogik von Cloud Native-Anwendungen erstellst, sie verbindest und externen Parteien die Nutzung ermöglichst. Wir besprechen diese Muster in sechs Schlüsselbereichen: Kommunikation, Konnektivität und Komposition, Datenmanagement, ereignisgesteuerte Architektur, Stream Processing sowie API-Verwaltung und -Konsum. Im nächsten Kapitel befassen wir uns mit den Kommunikationsmustern für Cloud Natives.
1 Quelle: Microservices for the Enterprise von Kasun Indrasiri und Prabath Siriwardena (Apress).
2 Quelle: Kapitel 2 von Microservices for the Enterprise.
3 Weitere Informationen findest du in "Smart Endpoints and Dumb Pipes" von Martin Fowler.
4 Weitere Informationen über domänenorientiertes Design findest du in Domain-Driven Design von Eric Evans (Addison-Wesley Professional).
Get Design Patterns für Cloud Native Anwendungen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

