Chapter 4. Diving into the Delta Lake Ecosystem
Over the last few chapters, we’ve explored Delta Lake from the comfort of the Spark ecosystem. The Delta protocol, however, offers rich interoperability not only across the underlying table format but within the computing environment as well. This opens the doors to an expansive universe of possibilities for powering our lakehouse applications, using a single source of table truth. It’s time to break outside the box and look at the connector ecosystem.
The connector ecosystem is a set of ever-expanding frameworks, services, and community-driven integrations enabling Delta to be utilized from just about anywhere. The commitment to interoperability enables us to take full advantage of the hard work and effort the growing open source community provides without sacrificing the years we’ve collectively poured into technologies outside the Spark ecosystem.
In this chapter, we’ll discover some of the more popular Delta connectors while learning to pilot our Delta-based data applications from outside the traditional Spark ecosystem. For those of you who haven’t done much work with Apache Spark, you’re in luck, since this chapter is a love song to Delta Lake without Apache Spark and a closer look at how the connector ecosystem works.
We will be covering the following integrations:1
-
Flink DataStream Connector
-
Kafka Delta Ingest
-
Trino Connector
In addition to the four core connectors in this chapter, support for Apache Pulsar, ClickHouse, FINOS Legend, Hopsworks, Delta Rust, Presto, StarRocks, and general SQL import to Delta is also available at the time of writing.
What are connectors, you ask? We will learn all about them next.
Connectors
As people, we don’t like to set limits for ourselves. Some of us are more adventurous and love to think about the unlimited possibilities of the future. Others take a more narrow, straight-ahead approach to life. Regardless of our respective attitudes, we are bound together by our pursuit of adventure, search for novelty, and desire to make decisions for ourselves. Nothing is worse than being locked in, trapped, with no way out. From the perspective of the data practitioner, it is also nice to know that what we rely on today can be used tomorrow without the dread of contract renegotiations! While Delta Lake is not a person, the open source community has responded to the various wants and needs of the community at large, and a healthy ecosystem has risen up to ensure that no one will have to be tied directly to the Apache Spark ecosystem, the JVM, or even the traditional set of data-focused programming languages like Python, Scala, and Java.
The mission of the connector ecosystem is to ensure frictionless interoperability with the Delta protocol. Over time, however, fragmentation across the current (delta < 3.0) connector ecosystem has led to multiple independent implementations of the Delta protocol and divergence across the current connectors. To streamline support for the future of the Delta ecosystem, Delta Kernel was introduced to provide a common interface and expectations that simplify true interoperability within the Delta ecosystem.
Note
Kernel provides a seamless set of read- and write-level APIs that ensures correctness of operation and freedom of expression for the connector API implementation. This means that the behavior across all connectors will leverage the same set of operations, with the same inputs and outputs, while ensuring each connector can quickly implement new features without lengthy lead times or divergent handling of the underlying Delta protocol. Delta Kernel is introduced in Chapter 1.
There are a healthy number of connectors and integrations that enable interoperability with the Delta table format and protocols, no matter where we trigger operations from. Interoperability and unification are part of the core tenets of the Delta project and helped drive the push toward UniForm (introduced along with Delta 3.0), which provides cross-table support for Delta, Iceberg, and Hudi.
In the sections that follow, we’ll take a look at the most popular connectors, including Apache Flink, Trino, and Kafka Delta Ingest. Learning to utilize Delta from your favorite framework is just a few steps away.
Apache Flink
Apache Flink is “a framework and distributed processing engine for stateful computations over unbounded and bounded data streams...[that] is designed to run in all common cluster environments [and] perform computations at in-memory speed and at any scale.” In other words, Flink can scale massively and continue to perform efficiently while handling every increasing load in a distributed way, and while also adhering to exactly-once semantics (if specified in the CheckpointingMode) for stream processing, even in the case of failures or disruptions at runtime to a data application.
Tip
If you haven’t worked with Flink before and would like to, there is an excellent book by Fabian Hueske and Vasiliki Kalavri called Stream Processing with Apache Flink (O’Reilly) that will get you up to speed in no time.
The assumption from here going forward is that we either (a) understand enough about Flink to compile an application or (b) are willing to follow along and learn as we go. With that said, let’s look at how to add the delta-flink connector to our Flink applications.
Flink DataStream Connector
The Flink/Delta Connector is built on top of the Delta Standalone library and provides a seamless abstraction for reading and writing Delta tables using Flink primitives such as the DataStream and Table APIs. In fact, because Delta Lake uses Parquet as its common data format, there really are no special considerations for working with Delta tables aside from the capabilities introduced by the Delta Standalone library.
The standalone library provides the essential Java APIs for reading the Delta table metadata using the DeltaLog object. This allows us to read the full current version of a given table, or to begin reading from a specific version, or to find the approximate version of the table based on a provided ISO-8601 timestamp. We will cover the basic capabilities of the standalone library as we learn to use DeltaSource and DeltaSink in the following sections.
Tip
The full Java application referenced in the following sections is located in the book’s Git repository under /ch04/flink/dldg-flink-delta-app/.
As a follow-up for the curious reader, unit tests for the application provide a glimpse at how to use the Delta standalone APIs. You can walk through these under /src/test/ within the Java application.
Installing the Connector
Everything starts with the connector. Simply add the delta-flink connector to your data application using Maven, Gradle, or sbt. The following example shows how to include the delta-flink connector dependency in a Maven project:
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>${delta-connectors-version}</version>
</dependency>
Warning
It is worth noting that Apache Flink is officially dropping support for the Scala programming language. The content for this chapter is written using Flink 1.17.1, which officially no longer has published Scala APIs. While you can still use Scala with Flink, Java and Python will be the only supported variants as we move toward the Flink 2.0 release. All of the examples, as well as the application code in the book’s GitHub repository, are therefore written in Java.
The connector ships with classes for reading and writing to Delta Lake. Reading is handled by the DeltaSource API, and writing is handled by the DeltaSink API. We’ll start with the DeltaSource API, move on to the DeltaSink API, and then look at an end-to-end application.
Note
The value of the delta-connectors-version property will change as new versions are released. For simplicity, all supported connectors are officially included in the main Delta repository. This change was made at the time of the Delta 3.0 release.
DeltaSource API
The DeltaSource API provides static builders to easily construct sources for bounded or unbounded (continuous) data flows. The big difference between the two variants is specific to the bounded (batch) or unbounded (streaming) operations on the source Delta table. This is analogous to the batch or microbatch (unbounded) processing with Apache Spark. While the behavior of these two processing modes differs, the configuration parameters differ only slightly. We’ll begin by looking at the bounded source and conclude with the continuous source, as there are more configuration options to cover in the latter.
Bounded mode
To create the DeltaSource object, we’ll be using the static forBoundedRowData method from the DeltaSource class. This builder takes the path to the Delta table and an instance of the application’s Hadoop configuration, as shown in Example 4-1.
Example 4-1. Creating the DeltaSource bounded builder
%PathsourceTable=newPath("s3://bucket/delta/table_name")ConfigurationhadoopConf=newConfiguration()varbuilder:RowDataBoundedDeltaSourceBuilder=DeltaSource.forBoundedRowData(sourceTablehadoopConf);
The object returned in Example 4-1 is a builder. Using the various options on the builder, we specify how we’d like to read from the Delta table, including options to slow down the read rates, filter the set of columns read, and more.
Builder options
The following options can be applied directly to the builder:
columnNames(string ...)-
This option provides us with the ability to specify the column names on a table we’d like to read while ignoring the rest. This functionality is especially useful on wide tables with many columns and can help alleviate unnecessary memory pressure for columns that will go unused anyway:
%builder.columnNames("event_time","event_type","brand","price");builder.columnNames(Arrays.asList("event_time","event_type","brand","price")); startingVersion(long)-
This option provides us with the ability to specify the exact version of the Delta table’s transaction to start reading from (in the form of a numeric
Long). This option and thestartingTimestampoption are mutually exclusive, as both provide a means of supplying a cursor (or transactional starting point) on the Delta table:%builder.startingVersion(100L); startingTimestamp(string)-
This option provides the ability to specify an approximate timestamp to begin reading from in the form of an ISO-8601
string. This option will trigger a scan of the Delta transaction history looking for a matching version of the table that was generated at or after the given timestamp. In the case where the entire table is newer than the timestamp provided, the table will be fully read:%builder.startingTimestamp("2023-09-10T09:55:00.001Z");The timestamp string can represent time with low precision—for example, as a simple date like
"2023-09-10"—or with millisecond precision, as in the previous example. In either case, the operation will result in the Delta table being read from a specific point in table time. parquetBatchSize(int)-
This option takes an integer controlling how many rows to return per internal batch, or generated split within the Flink engine:
%builder.option("parquetBatchSize",5000);
Generating the bounded source
Once we finish supplying the options to the builder, we generate the DeltaSource instance by calling build:
%finalDeltaSource<RowData>source=builder.build();
With the bounded source built, we can now read batches of our Delta Lake records off our tables—but what if we wanted to continuously process new records as they arrived? In that case, we can just use the continuous mode builder!
Continuous mode
To create this variation of the DeltaSource object, we’ll use the static forContinuousRowData method on the DeltaSource class. The builder is shown in Example 4-2, and we provide the same base parameters as were provided to the forBoundedRowData builder, which makes switching from batch to streaming super simple.
Example 4-2. Creating the DeltaSource continuous builder
%varbuilder=DeltaSource.forContinuousRowData(sourceTable,hadoopConf);
The object returned in Example 4-2 is an instance of the RowDataContinuousDeltaSourceBuilder, and just like the bounded variant, it enables us to provide options for controlling the initial read position within the Delta table based on the startingVersion or startingTimestamp, as well as some additional options that control the frequency with which Flink will check the table for new entries.
Builder options
The following options can be applied directly to the continuous builder; additionally, all the options of the bounded builder (columnNames, startingVersion, parquetBatchSize, and startingTimestamp) apply to the continuous builder as well:
updateCheckIntervalMillis(long)-
This option takes a numeric
Longvalue representing the frequency to check for updates to the Delta table, with a default value of 5,000 milliseconds:%builder.updateCheckIntervalMillis(60000L);If we know the table we are reading from is updated only periodically, then we can essentially reduce unnecessary I/O by using this setting. For example, if we know that new data will only ever be written on a one-minute cadence, then we can take a breather and set the frequency to check every minute. We can always modify this setting if there is a need to process faster, or slower, based on the behavior of the upstream Delta table.
ignoreDeletes(boolean)-
Setting this option allows us to ignore deleted rows. It is possible that your streaming application will never need to know that data from the past has been removed. If we are processing data in real time and considering the feed of data from our tables as append-only, then we are focused on the head of the table and can safely ignore the tail changes as data ages out.
ignoreChanges(boolean)-
Setting this option allows us to ignore changes to the table that occur upstream, including deleted rows, and other modifications to physical table data or logical table metadata. Unless the table is overwritten with a new schema, then we can continue to process while ignoring modifications to the table structure.
Generating the continuous source
Once we finish configuring the builder, we generate the DeltaSource instance by calling build:
%finalDeltaSource<RowData>source=builder.build();
We have looked at how to build the DeltaSource object and have seen the connector configuration options, but what about table schema or partition column discovery? Luckily, there is no need to go into too much detail about those, since both are automatically discovered using the table metadata.
Table schema discovery
The Flink connector uses the Delta table metadata to resolve all columns and their types. For example, if we don’t specify any columns in our source definition, all columns from the underlying Delta table will be read. However, If we specify a collection of column names using the DeltaSource builder method (columnNames), then only that subset of columns will be read from the underlying Delta table. In both cases, the DeltaSource connector will discover the Delta table column types and convert them to the corresponding Flink types. This process of conversion from the internal Delta table data (Parquet rows) to the external data representation (Java types) provides us with a seamless way to work with our datasets.
Using the DeltaSource
After building the DeltaSource object (bounded or unbounded), we can now add the source into the streaming graph of our DataStream using an instance of the StreamingExecutionEnvironment.
Example 4-3 creates a simple execution environment instance and adds the source of our stream (DeltaSource) using fromSource. When we build the StreamExecutionEnvironment instance, we provide a WatermarkStrategy. Watermarks in Flink are similar in concept to watermarks for Spark Structured Streaming: they enable late-arriving data to be honored for a specific amount of time before they are considered too late to process and therefore dropped (ignored) for a given application.
Example 4-3. Creating the StreamExecutionEnvironment for our DeltaSource
%finalStreamExecutionEnvironmentenv=StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.enableCheckpointing(2000,CheckpointingMode.EXACTLY_ONCE);DeltaSource<RowData>source=...env.fromSource(source,WatermarkStrategy.noWatermarks(),"delta table source")
We now have a live data source for our Flink job supporting Delta. We can choose to add additional sources, join and transform our data, and even write the results of our transforms back to Delta using the DeltaSink, or anywhere else our application requires us to go.
Next, we’ll look at using the DeltaSink and then connect the dots with a full end-to-end example.
DeltaSink API
The DeltaSink API provides a static builder to egress to Delta Lake easily. Following the same pattern as the DeltaSource API, the DeltaSink API provides a builder class. Construction of the builder is shown in Example 4-4.
Example 4-4. Creating the DeltaSink builder
%PathdeltaTable=newPath("s3://bucket/delta/table_name")ConfigurationhadoopConf=newConfiguration()RowTyperowType=…RowDataDeltaSinkBuildersinkBuilder=DeltaSink.forRowData(sourceTable,hadoopConf,rowType);
The builder pattern for the delta-flink connector should already feel familiar at this point. The only difference with crafting this builder is the addition of the RowType reference.
Builder options
The following options can be applied directly to the builder:
withPartitionColumns(string ...)-
This builder option takes an array of strings that represent the subset of columns. The columns must exist physically in the stream.
withMergeSchema(boolean)-
This builder option must be set to true in order to opt into automatic schema evolution. The default value is false.
In addition to discussing the builder options, it is worth covering the semantics of exactly-once writes using the delta-flink connector.
Exactly-once guarantees
The DeltaSink does not immediately write to the Delta table. Rather, rows are appended to flink.streaming.sink.filesystem.DeltaPendingFile—not to be confused with Delta Lake—as these files provide a mechanism to buffer writes (deltas) to the filesystem as a series of accumulated changes that can be committed together. The pending files remain open for writing until the checkpoint interval is met (Example 4-7 shows how we set the checkpoint interval for our Flink applications), and the pending files are rolled over, which is the point at which the buffered records will be committed to the Delta log. We specify the write frequency to Delta Lake using the interval supplied when we enable checkpointing on our DataStream object.
Example 4-7. Setting the checkpoint interval and mode
%StreamExecutionEnvironment.getExecutionEnvironment().enableCheckpointing(2000,CheckpointingMode.EXACTLY_ONCE);
Using the checkpoint config above, we’d create a new transaction every two seconds at most, at which point the DeltaSink would use our Flink application appId and the checkpointId associated with the pending files. This is similar to the use of txnAppId and txnVersion for idempotent writes and will likely be unified in the future.
End-to-End Example
Now we’ll look at an end-to-end example that uses the Flink DataStream API to read from Kafka and write to Delta. The application source code and Docker-compatible environment are provided in the book’s GitHub repository under /ch04/flink/, including steps to initialize the ecomm.v1.clickstream Kafka topic, write (produce) records to be consumed by the Flink application, and ultimately write those records into Delta. The results of running the application can be seen in Figure 4-1, which shows the Flink UI and represents the end state of the application.
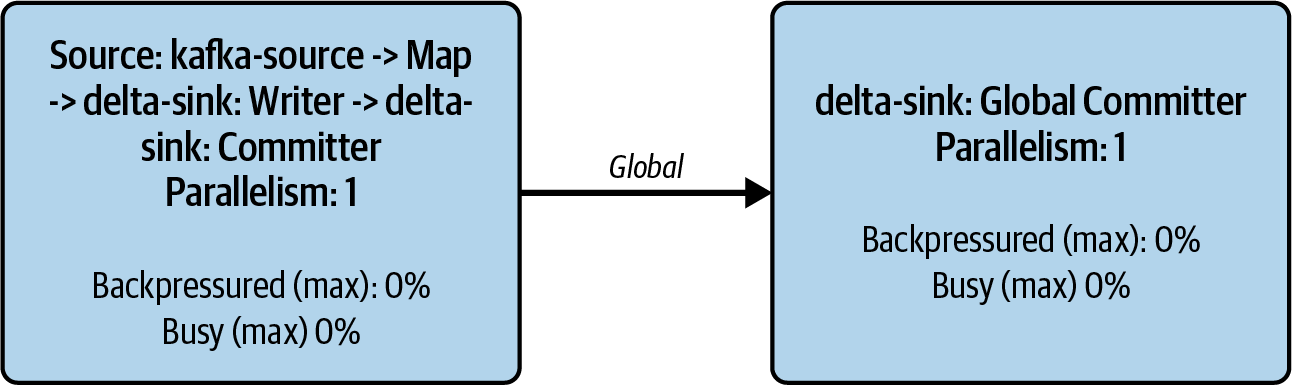
Figure 4-1. KafkaSource writing to our DeltaSink
Let’s define our DataStream using the KafkaSource connector and the DeltaSink from earlier in this section within the scope of Example 4-8.
Example 4-8. KafkaSource to DeltaSink DataStream
%publicDataStreamSink<RowData>createDataStream(StreamExecutionEnvironmentenv)throwsIOException{finalKafkaSource<Ecommerce>source=this.getKafkaSource();finalDeltaSink<RowData>sink=this.getDeltaSink(Ecommerce.ECOMMERCE_ROW_TYPE);finalDataStreamSource<Ecommerce>stream=env.fromSource(source,WatermarkStrategy.noWatermarks(),"kafka-source");returnstream.map((MapFunction<Ecommerce,RowData>)Ecommerce::convertToRowData).setParallelism(1).sinkTo(sink).name("delta-sink").setDescription("writes to Delta Lake").setParallelism(1);}
The example takes binary data from Kafka representing ecommerce transactions in JSON format. Behind the scenes, we deserialize the JSON data into ecommerce rows and then transform from the JVM object into the internal RowData representation required for writing to our Delta table. Then we simply use an instance of the DeltaSink to provide a terminal point for our DataStream.
Next, we call execute after adding some additional descriptive metadata to the resulting DataStreamSink, as we’ll see in Example 4-9.
Example 4-9. Running the end-to-end example
%publicvoidrun()throwsException{StreamExecutionEnvironmentenv=this.getExecutionEnvironment();DataStreamSink<RowData>sink=createDataStream(env);sink.name("delta-sink").setParallelism(NUM_SINKS).setDescription("writes to Delta Lake");env.execute("kafka-to-delta-sink-job");}
We’ve just scratched the surface on how to use the Flink connector for Delta Lake, and it is already time to take a look at another connector.
Note
To run the full end-to-end application, just follow the step-by-step overview in the book’s GitHub repository under ch04/flink/README.md.
In a similar vein as our end-to-end example with Flink, we’ll next be exploring how to ingest the same ecommerce data from Kafka; however, this time we’ll be using the Rust-based kafka-delta-ingest library.
Kafka Delta Ingest
The connector name sums up exactly what this little powerful library does. It reads a stream of records from a Kafka topic, optionally transforms each record (the data stream)—for example, from raw bytes to the deserialized JSON or Avro payload—and then writes the data into a Delta table. Behind the scenes, a minimal amount of user-provided configuration helps mold the connector to fulfill each specific use case. Due to the simplicity of the kafka-delta-ingest client, we reduce the level of effort required for one of the most critical phases of the data engineering life cycle—initial data ingestion into the lakehouse via Delta Lake.
The kafka-delta-ingest connector provides a daemon that simplifies the common step of streaming Kafka data into our Delta Lake tables. Getting started can also be done in four easy steps:
-
Install Rust.
-
Build the project.
-
Create your Delta table.
-
Run the ingestion flow.
Build the Project
This step ensures we have access to the source code.
Using git on the command line, simply clone the connector:
% git clone git@github.com:delta-io/kafka-delta-ingest.git \ && cd kafka-delta-ingest
Set up your local environment
From the root of the project directory, run the Docker setup utility:
% docker compose up setup
After the setup flow completes, we have localstack (which runs a local Amazon Web Services [AWS] instance), kafka (redpandas), and the confluent schema registry, as well as azurite for local Azure Storage. Having access to run our cloud-based workflows locally greatly reduces the pain of moving from the design phase of our applications into production.
Build the connector
Rust uses cargo for dependency management and to build your project. The cargo utility is installed for us by the rustup toolchain. From the project root, execute the following command:
% cargo build
At this point we’ll have the connector built and the Rust dependencies installed, and we can choose to either run the examples or connect to our own Kafka brokers and get started. The last section on using kafka-delta-ingest will cover running the end-to-end ingestion.2
Run the Ingestion Flow
For the ingestion application to function, we need to have two things—a source Kafka topic and a destination Delta table. There is a caveat with the generation of the Delta table, especially if you are familiar with Apache Spark–based Delta workflows: we must first create our destination Delta table in order to successfully run the ingestion flow.
There are a handful of variables that can modify the kafka-delta-ingest application. We will begin with a tour of the basic environment variables in Table 4-1, and then Table 4-2 will provide us with some of the runtime variables (args) that are available to us when using this connector.
| Environment variable | Description | Default |
|---|---|---|
KAFKA_BROKERS |
The Kafka broker string; can be used to overwrite the location of the brokers for local testing, or for triage and recovery applications | localhost:9092 |
AWS_ENDPOINT_URL |
Used to run local tests via LocalStack | none |
AWS_ACCESS_KEY_ID |
Used to provide the application identity | test |
AWS_SECRET_ACCESS_KEY |
Used to authenticate the application identity | test |
AWS_DEFAULT_REGION |
Can be useful for running LocalStack or for bootstrapping separate S3 bucket locations | none |
| Argument | Description | Example |
|---|---|---|
allowed_latency |
Used to specify how long to fill the buffer and await new data before processing | --allowed_latency 60 |
app_id |
Used to run local tests via LocalStack | --app_id ingest-app |
auto_offset_reset |
Can be earliest or latest; this affects whether you read from the tail or the head of the Kafka topic |
--auto_offset_reset earliest |
checkpoints |
Will record the Kafka metadata for each processed ingestion batch; this allows for you to easily stop the application and start it back up again without data loss (unless Kafka deletes the data between runs, which can be checked in the delete policy for the topic) | --checkpoints |
consumer_group_id |
Provides a unique consumer name for the Kafka brokers; using the group ID, the brokers can distribute the processing of a large topic among multiple consumer applications without duplication | --consumer_group_id ecomm-ingest-app |
max_messages_per_batch |
Use this option to throttle the number of messages per application tick (loop); this can help keep your applications from running out of memory if there is an unexpected increase in the volume of the records being written to the topic | --max_messages_per_batch 1600 |
min_bytes_per_file |
Use this option to ensure that the underlying Delta table doesn’t become riddled with small files | --min_bytes_per_file 64000000 |
kafka |
Used to pass the Kafka broker string to the ingest application | --kafka 127.0.0.1:29092 |
Now all that is left to do is to run the ingestion application. If we are running the application using our environment variables, then the simplest command would provide the Kafka topic and the Delta table location. The command signature is as follows:
% cargo run ingest <topic> <delta_table_location>
Next, we’ll see a complete example:
% cargo run \ ingest ecomm.v1.clickstream file:///dldg/ecomm-ingest/ \ --allowed_latency 120 \ --app_id clickstream_ecomm \ --auto_offset_reset earliest \ --checkpoints \ --kafka 'localhost:9092' \ --max_messages_per_batch 2000 \ --transform 'date: substr(meta.producer.timestamp, `0`, `10`)' \ --transform 'meta.kafka.offset: kafka.offset' \ --transform 'meta.kafka.partition: kafka.partition' \ --transform 'meta.kafka.topic: kafka.topic'
With the simple steps we’ve explored together, we can now easily ingest data from our Kafka topics. We have set ourselves up for success by ensuring that the folks consuming our data do so with a high level of reliability. The more we can automate, the lower the chance of human error getting in the way and resulting in incidents or in the dreaded data loss.
In the next section, we are going to explore Trino. Both prior examples play nice alongside the Trino ecosystem, as they reduce the level of effort to ingest and transform data prior to writing solid tables that can be analyzed through more traditional SQL tooling.
Trino
Trino is a distributed SQL query engine designed to seamlessly connect to and interoperate with a myriad of data sources. It provides a connector ecosystem that supports Delta Lake natively.
Note
Trino is the community-supported fork of the Presto project and was initially designed and developed in-house at Facebook. Trino was known as PrestoSQL before it was given its present name in 2020.
To learn more about Trino, check out Trino: The Definitive Guide (O’Reilly).
Getting Started
All we need to get started with Trino and Delta Lake is any version of Trino newer than version 373. At the time of writing, Trino is currently at version 459.
Connector requirements
While the Delta connector is natively included in the Trino distribution, there are still additional things we need to consider to ensure a frictionless experience.
Connecting to OSS or Databricks Delta Lake:
-
Delta Tables written by Databricks Runtime 7.3 LTS, 9.1 LTS, 10.4 LTS, 11.3 LTS, and >= 12.2 LTS.
-
Deployments using AWS, HDFS, Azure Storage, and Google Cloud Storage (GCS) are fully supported.
-
Network access from the coordinator and workers to the Delta Lake storage.
-
Access to the Hive Metastore (HMS).
-
Network access to HMS from the coordinator and workers. Port 9083 is the default port for the Thrift protocol used by HMS.
Working locally with Docker:
-
Hive Metastore (HMS) service (standalone)
-
Postgres or supported relational database management system (RDBMS) to store the HMS table properties, columns, databases, and other configurations (can point to managed RDBMS like RDS for simplicity)
-
Amazon S3 or MinIO (for object storage for our managed data warehouse)
The Docker Compose configuration in Example 4-10 shows how to configure a simple Trino container for local testing.
Example 4-10. Basic Trino Docker Compose
services:trinodb:image:trinodb/trino:426-arm64platform:linux/arm64hostname:trinodbcontainer_name:trinodbvolumes:-$PWD/etc/catalog/delta.properties:/etc/trino/catalog/delta.properties-$PWD/conf:/etc/hadoop/conf/ports:-target:8080published:9090protocol:tcpmode:hostenvironment:-AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID-AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY-AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION:-us-west-1}networks:-dldg
The example in the next section assumes we have the following resources available to us:
-
Amazon S3 or MinIO (bucket provisioned, with a user, and roles set to allow read, write, and delete access). Using local MinIO to mock S3 is a simple way to try things out without any upfront costs. See the
docker composeexamples in the book’s GitHub repository under ch04/trinodb/. -
MySQL or PostgreSQL. This can run locally, or we can set it up on our favorite cloud provider; for example, AWS RDS is a simple way to get started.
-
Hive Metastore (HMS) or Amazon Glue Data Catalog.
Next, we’ll learn how to configure the Delta Lake connector so that we can create a Delta catalog in Trino. If you want to learn more about using the Hive Metastore (HMS), including how to configure the hive-site.xml, how to include the required JARs for S3, and how to run HMS, you can read through “Running the Hive Metastore”. Otherwise, skip ahead to “Configuring and Using the Trino Connector”.
Running the Hive Metastore
If you already have a reliable metastore instance setup, you can modify the connection properties to use that instead. If you are looking to have a local setup, then we can begin with the creation of the hive-site.xml, which is shown in Example 4-11 and which is required to connect to both MySQL and Amazon S3.
Example 4-11. hive-site.xml for HMS
<configuration><property><name>hive.metastore.version</name><value>3.1.0</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://RDBMS_REMOTE_HOSTNAME:3306/metastore</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>RDBMS_USERNAME</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>RDBMS_PASSWORD</value></property><property><name>hive.metastore.warehouse.dir</name><value>s3a://dldgv2/delta/</value></property><property><name>fs.s3a.access.key</name><value>S3_ACCESS_KEY</value></property><property><name>fs.s3a.secret.key</name><value>S3_SECRET_KEY</value></property><property><name>fs.s3.path-style-access</name><value>true</value></property><property><name>fs.s3a.impl</name><value>org.apache.hadoop.fs.s3a.S3AFileSystem</value></property></configuration>
The configuration provides the nuts and bolts we need to access the metadata database, using the JDBC connection URL, username, and password properties, as well as the data warehouse, using the hive.metastore.warehouse.dir and the properties prefixed with fs.s3a.
Next, we need to create a Docker Compose file to run the metastore, which we do in Example 4-12.
Example 4-12. Docker Compose for the Hive Metastore
version:"3.7"services:metastore:image:apache/hive:3.1.3platform:linux/amd64hostname:metastorecontainer_name:metastorevolumes:-${PWD}/jars/hadoop-aws-3.2.0.jar:/opt/hive/lib/-${PWD}/jars/mysql-connector-java-8.0.23.jar:/opt/hive/lib/-${PWD}/jars/aws-java-sdk-bundle-1.11.375.jar:/opt/hive/lib/-${PWD}/conf:/opt/hive/confenvironment:-SERVICE_NAME=metastore-DB_DRIVER=mysql-IS_RESUME="true"expose:-9083ports:-target:9083published:9083protocol:tcpmode:hostnetworks:-dldg
With the metastore running, we are now in the driver’s seat to understand how to take advantage of the Trino connector for Delta Lake.
Configuring and Using the Trino Connector
Trino uses configuration files called catalogs. They are used to describe the catalog type (delta_lake, hive, and many more), and they enable us to tune a given catalog to optimize for reads and writes and to manage additional connector configurations. The minimum configuration for the Delta connector requires an addressable Hive Metastore location thrift:hostname:port (if using HMS). The other supported catalog at the time of writing is AWS Glue.
The code in Example 4-13 configures the connector pointing to the Hive Metastore.
Example 4-13. The Delta Lake connector properties
connector.name=delta_lake hive.metastore=thrift hive.metastore.uri=thrift://metastore:9083 delta.hive-catalog-name=metastore delta.compression-codec=SNAPPY delta.enable-non-concurrent-writes=true delta.target-max-file-size=512MB delta.unique-table-location=true delta.vacuum.min-retention=7d
Warning
The property delta.enable-non-concurrent-writes must be set to true if there is a chance of multiple writers making nonatomic changes to a table. This is most often the case with Amazon S3; setting the property to true ensures that the table remains consistent.
The property file from Example 4-13 can be saved as delta.properties. As long as the file is copied into the Trino catalog directory (/etc/trino/catalog/), then we’ll be able to read, write, and delete from the underlying hive.metastore.warehouse.dir, and do a whole lot more.
Let’s look at what’s possible.
Using Show Catalogs
Using show catalogs is a simple first step to ensure that the Delta connector has been configured correctly and shows up as a resource:
trino>showcatalogs;
Catalog --------- delta ... (6 rows)
As long as we see delta in the list, we can move on to creating a schema. This confirms that our catalog is correctly configured.
Creating a Schema
The notion of a schema is a bit overloaded. We have schemas that represent the structured data describing the columns of our tables, but we also have schemas representing traditional databases. Using create schema enables us to generate a managed location within our data warehouse that can act as a boundary for access and governance, as well as to separate the physical table data among bronze, silver, and golden tables. We’ll learn more about the medallion architecture in Chapter 9, but for now let’s create a bronze_schema to store some raw tables:
trino> create schema delta.bronze_schema;
CREATE SCHEMA
Tip
If we are greeted by an exception rather than seeing CREATE SCHEMA returned, then it’s likely due to permissions issues writing to the physical warehouse. The following is an example of such an exception:
Query 20231001_182856_00004_zjwqg failed: Got exception: java.nio.file.AccessDeniedException s3a://com.newfront.dldgv2/delta/bronze_schema.db: getFileStatus on s3a://com.newfront.dldgv2/delta/bronze_schema.db: com.amazonaws.services.s3.model.AmazonS3Exception: Forbidden (Service: Amazon S3; Status Code: 403;
We can fix the problem by modifying our identity and access management (IAM) permissions or by ensuring we are using the correct IAM roles.
Working with Tables
Table compatibility between the Trino and Delta ecosystems requires that we follow some guidelines. We’ll look at data type interoperability and then create a table, add some rows, and view the Delta metadata, including the transaction history and tracking changes for Change Data Feed (CDF)–enabled tables. We’ll conclude by looking at table optimization and vacuuming.
Data types
There are a few caveats to creating tables using Trino, especially when it comes to type mapping differences between Trino and Delta Lake. The table shown in Table 4-3 can be used to ensure that the appropriate types are used and to steer clear of incompatibility if our aim is interoperability.
| Delta data type | Trino data type |
|---|---|
BOOLEAN |
BOOLEAN |
INTEGER |
INTEGER |
BYTE |
TINYINT |
SHORT |
SMALLINT |
LONG |
BIGINT |
FLOAT |
REAL |
DOUBLE |
DOUBLE |
DECIMAL(p,s) |
DECIMAL(p,s) |
STRING |
VARCHAR |
BINARY |
VARBINARY |
DATE |
DATE |
TIMESTAMPNTZ (TIMESTAMP_NTZ) |
TIMESTAMP(6) |
TIMESTAMP |
TIMESTAMP(3) WITH TIME ZONE |
ARRAY |
ARRAY |
MAP |
MAP |
STRUCT(...) |
ROW(...) |
CREATE TABLE options
The supported table options (shown in Table 4-4) can be applied to our table using the WITH clause of the CREATE TABLE operation. This enables us to specify options on our tables that Trino wouldn’t otherwise understand. In the case of partitioning, Trino won’t automatically discover partitions, which could be a problem when it comes to the performance of SQL queries.
| Property name | Description | Default |
|---|---|---|
location |
Filesystem location uniform resource identifier (URI) for table. This option is deprecated. | Will use a managed table mapped to the location of the hive.metastore.warehouse.dir or Glue Catalog equivalent |
partitioned_by |
Columns to partition the table by | No partitions |
checkpoint_interval |
How often to commit changes to Delta Lake | Every 10 for open source software (OSS), and every 100 for Databricks (DBR) |
change_data_feed_enabled |
Track changes made to the table for use in change data capture (CDC)/Change Data Feed (CDF) applications | false |
column_mapping_mode |
How to map the underlying Parquet columns: options (ID, name, none) | none |
Creating tables
We can create tables using the longform <catalog>.<schema>.<table> syntax, or the shortform syntax <table> after calling use delta.<schema>. Example 4-14 provides an example using the shortform create.
Example 4-14. Creating a Delta table with Trino
trino>usedelta.bronze_schema;CREATETABLEecomm_v1_clickstream(event_dateDATE,event_timeVARCHAR(255),event_typeVARCHAR(255),product_idINTEGER,category_idBIGINT,category_codeVARCHAR(255),brandVARCHAR(255),priceDECIMAL(5,2),user_idINTEGER,user_sessionVARCHAR(255))WITH(partitioned_by=ARRAY['event_date'],checkpoint_interval=30,change_data_feed_enabled=false,column_mapping_mode='name');
The table generated using the DDL statement in Example 4-14 creates a managed table in our data warehouse that will be partitioned daily. The table structure represents the ecommerce data from the “Apache Flink” section earlier in this chapter.
Inspecting tables
If we are not the owners of a given table, we can use describe to learn about the table through its metadata:
trino>describedelta.bronze_schema."ecomm_v1_clickstream";
Column | Type | Extra | Comment ---------------+--------------+-------+--------- event_date | date | | event_time | varchar | | event_type | varchar | | product_id | integer | | category_id | bigint | | category_code | varchar | | brand | varchar | | price | decimal(5,2) | | user_id | integer | | user_session | varchar | | (10 rows)
Using INSERT
Rows can be inserted directly using the command line, or through the use of the Trino client:
trino>INSERTINTOdelta.bronze_schema."ecomm_v1_clickstream"VALUES(DATE'2023-10-01','2023-10-01T19:10:05.704396Z','view',...),(DATE('2023-10-01'),'2023-10-01T19:20:05.704396Z','view',...);INSERT:2rows
Querying Delta tables
Using the select operator allows you to query your Delta tables:
trino>selectevent_date,product_id,brand,price->fromdelta.bronze_schema."ecomm_v1_clickstream";
event_date | product_id | brand | price ------------+------------+---------+-------- 2023-10-01 | 44600062 | nars | 35.79 2023-10-01 | 54600062 | lancome | 122.79 (2 rows)
Creating tables with selection
We can create a table using another table. This is referred to as CREATE TABLE AS, and it allows us to create a new physical Delta table by referencing another table:
trino>CREATETABLEdelta.bronze_schema."ecomm_lite"ASselectevent_date,product_id,brand,priceFROMdelta.bronze_schema."ecomm_v1_clickstream";
Table Operations
There are many table operations to consider for optimal performance, and for decluttering the physical filesystem in which our Delta tables live. Chapter 5 covers the common maintenance and table utility functions, and the following section covers what functions are available within the Trino connector.
Vacuum
The vacuum operation will clean up files that are no longer required in the current version of a given Delta table. In Chapter 5 we go into more detail about why vacuuming is required, as well as the caveats to keep in mind to support table recovery and rolling back to prior versions with time travel.
With respect to Trino, the Delta catalog property delta.vacuum.min-retention provides a gating mechanism to protect a table in case of an arbitrary call to vacuum with a low number of days or hours:
trino>CALLdelta.system.vacuum('bronze_schema','ecomm_v1_clickstream','1d');
Retention specified (1.00d) is shorter than the minimum retention configured in the system (7.00d). Minimum retention can be changed with delta.vacuum.min-retention configuration property or delta.vacuum_min_retention session property
Otherwise, the vacuum operation will delete the physical files that are no longer needed by the table.
Table optimization
Depending on the size of the table parts created as we make modifications to our tables with Trino, we run the risk of creating too many small files representing our tables. A simple technique to combine the small files into larger files is bin-packing optimize (which we cover in Chapter 5 and in the performance-tuning deep dive in Chapter 10). To trigger compaction, we can call ALTER TABLE with EXECUTE:
trino>ALTERTABLEdelta.bronze_schema."ecomm_v1_clickstream"EXECUTEoptimize;
We can also provide more hints to change the behavior of the optimize operation. The following will ignore files greater than 10 MB:
trino>ALTERTABLEdelta.bronze_schema."ecomm_v1_clickstream"->EXECUTEoptimize(file_size_threshold=>'10MB')
The following will only attempt to compact table files within the partition (event_date = "2023-10-01"):
trino>ALTERTABLEdelta.bronze_schema."ecomm_v1_clickstream"EXECUTEoptimizeWHEREevent_date="2023-10-01"
Table history
Each transaction is recorded in the <table>$history metadata table:
trino>describedelta.bronze_schema."ecomm_v1_clickstream$history";
Column | Type | Extra | Comment ----------------------+-----------------------------+-------+--------- version | bigint | | timestamp | timestamp(3) with time zone | | user_id | varchar | | user_name | varchar | | operation | varchar | | operation_parameters | map(varchar, varchar) | | cluster_id | varchar | | read_version | bigint | | isolation_level | varchar | | is_blind_append | boolean | |
We can query the metadata table. Let’s look at the last three transactions for our ecomm_v1_clickstream table:
trino>selectversion,timestamp,operation->fromdelta.bronze_schema."ecomm_v1_clickstream$history";
version | timestamp | operation
---------+-----------------------------+--------------
0 | 2023-10-01 19:47:35.618 UTC | CREATE TABLE
1 | 2023-10-01 19:48:41.212 UTC | WRITE
2 | 2023-10-01 23:01:13.141 UTC | OPTIMIZE
(3 rows)
Change Data Feed
The Trino connector provides functionality for reading Change Data Feed (CDF) entries to expose row-level changes between two versions of a Delta Lake table. When the change_data_feed_enabled table property is set to true on a specific Delta Lake table, the connector records change events for all data changes on the table:
trino>usedelta.bronze_schema;CREATETABLEecomm_v1_clickstream(...)WITH(change_data_feed_enabled=true);
Now each row of each transaction is recorded (with the operation type), enabling us to rebuild the state of a table or to walk through the changes to a table after a specific point in time.
For example, if we’d like to view all changes since version 0 of a table, we could execute the following:
trino>selectevent_date,_change_type,_commit_version,_commit_timestampfromTABLE(delta.system.table_changes(schema_name=>'bronze_schema',table_name=>'ecomm_v1_clickstream',since_version=>0));
and view the changes made. In the example use case, we’ve simply inserted two rows:
event_date | _change_type | _commit_version | _commit_timestamp ------------+--------------+-----------------+----------------------------- 2023-10-01 | insert | 1 | 2023-10-01 19:48:41.212 UTC 2023-10-01 | insert | 1 | 2023-10-01 19:48:41.212 UTC (2 rows)
Viewing table properties
It is useful to be able to view the table properties associated with our tables. We can use the metadata table <table>$properties to view the associated Delta TBLPROPERTIES:
trino>select*fromdelta.bronze_schema."ecomm_v1_clickstream$properties";
key | value ---------------------------------+------- delta.enableChangeDataFeed | true delta.columnMapping.maxColumnId | 10 delta.columnMapping.mode | name delta.checkpointInterval | 30 delta.minReaderVersion | 2 delta.minWriterVersion | 5
Modifying table properties
If we want to modify the underlying table properties of our Delta table, we’ll need to use the Delta connectors alias for the supported table properties. For example, change_data_feed_enabled will map to the delta.enableChangeDataFeed property:
trino>ALTERTABLEdelta.bronze_schema."ecomm_v1_clickstream"SETPROPERTIES"change_data_feed_enabled"=false;
Deleting tables
Using the DROP TABLE operation, we can permanently remove a table that is no longer needed:
trino>DROPTABLEdelta.bronze_schema."ecomm_lite";
There is a lot more that we can do with the Trino connector that is out of scope for this book; for now we will say goodbye to Trino and conclude this chapter.
Conclusion
During the time we spent together in this chapter, we learned how simple it can be to connect our Delta tables as either the source or the sink for our Flink applications. We then learned to use the Rust-based kafka-delta-ingest application to simplify the data ingestion process that is the bread and butter of most data engineers working with high-throughput streaming data. By reducing the level of effort required to simply read a stream of data and write it into our Delta tables, we end up in a much better place in terms of cognitive burden. When we start to think about all data in terms of tables—bounded or unbounded—the mental model can be applied to tame even the most wildly data-intensive problems. On that note, we concluded the chapter by exploring the native Trino connector for Delta. We discovered how simple configuration opens up the doors to analytics and insights, all while ensuring we continue to have a single source of data truth residing in our Delta tables.
1 For the full list of evolving integrations, see “Delta Lake Integrations” on the Delta Lake website.
2 The full ingestion flow application is available in the book’s GitHub repository under ch04/rust/kafka-delta-ingest.
Get Delta Lake: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

