Kapitel 1. Die Entwicklung von Datenarchitekturen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Als Data Engineer willst du umfangreiche Daten-, Machine Learning-, Data Science- und KI-Lösungen entwickeln, die die modernste Leistung bieten. Du baust diese Lösungen auf, indem du große Mengen an Quelldaten aufnimmst, die Daten bereinigst, normalisierst und kombinierst und diese Daten schließlich den nachgelagerten Anwendungen über ein einfach zu nutzendes Datenmodell präsentierst.
Da die Datenmenge, die du aufnehmen und verarbeiten musst, immer weiter ansteigt, brauchst du die Möglichkeit, deine Speicherung horizontal zu skalieren. Außerdem brauchst du die Möglichkeit, deine Rechenressourcen dynamisch zu skalieren, um Verarbeitungs- und Verbrauchsspitzen zu bewältigen. Da du deine Datenquellen in einem Datenmodell zusammenfasst, musst du nicht nur Daten an Tabellen anhängen, sondern oft auch Datensätze einfügen, aktualisieren oder löschen (d.h. MERGE oder UPSERT), die auf einer komplexen Geschäftslogik basieren. Du möchtest diese Vorgänge mit Transaktionsgarantien durchführen können, ohne dass du ständig große Datendateien neu schreiben musst.
In der Vergangenheit wurden die oben genannten Anforderungen von zwei verschiedenen Tools erfüllt. Die horizontale Skalierbarkeit und die Entkopplung von Speicherung und Datenverarbeitung wurden von Cloud-basierten Data Lakes geboten, während relationale Data Warehouses Transaktionsgarantien boten. Herkömmliche Data Warehouses hingegen koppelten Speicherung und Rechenleistung eng an eine lokale Anwendung und verfügten nicht über das Maß an horizontaler Skalierbarkeit, das Data Lakes bieten.
Delta Lake bringt Funktionen wie Transaktionszuverlässigkeit und Unterstützung für UPSERTs und MERGEs in Data Lakes, während die dynamische horizontale Skalierbarkeit und die Trennung von Speicherung und Berechnung von Data Lakes beibehalten wird. Delta Lake ist eine Lösung für den Aufbau von Data Lakes, eine offene Datenarchitektur, die das Beste aus Data Warehouses und Data Lakes vereint.
In dieser Einführung werfen wir einen kurzen Blick auf relationale Datenbanken und wie sie sich zu Data Warehouses entwickelt haben. Als Nächstes werden wir uns mit den wichtigsten Treibern für die Entstehung von Data Lakes beschäftigen. Wir gehen auf die Vor- und Nachteile der einzelnen Architekturen ein und zeigen schließlich, wie die Delta Lake Speicherung die Vorteile der einzelnen Architekturen kombiniert und die Erstellung von Data-Lakehouse-Lösungen ermöglicht.
Eine kurze Geschichte der relationalen Datenbanken
In seinem historischen Aufsatz von 1970,1 führte E.F. Codd das Konzept ein, Daten als logische Beziehungen zu betrachten, unabhängig von der physischen Speicherung der Daten. Diese logische Beziehung zwischen Dateneinheiten wurde als Datenbankmodell oder Schema bekannt. Codds Schriften waren die Geburtsstunde der relationalen Datenbank. Die ersten relationalen Datenbanksysteme wurden Mitte der 1970er Jahre von IBM und UBC eingeführt.
Relationale Datenbanken und die ihnen zugrunde liegende SQL-Sprache wurden in den 1980er und 1990er Jahren zur Standardtechnologie für die Speicherung von Unternehmensanwendungen. Einer der Hauptgründe für diese Beliebtheit war, dass relationale Datenbanken ein Konzept namens Transaktionen bieten. Eine Datenbanktransaktion ist eine Abfolge von Operationen in einer Datenbank, die vier Eigenschaften erfüllt: Atomarität, Konsistenz, Isolation und Dauerhaftigkeit, die allgemein mit dem Akronym ACID bezeichnet werden.
Atomicity stellt sicher, dass alle Änderungen an der Datenbank als eine einzige Operation ausgeführt werden. Das bedeutet, dass die Transaktion nur dann erfolgreich ist, wenn alle Änderungen erfolgreich durchgeführt wurden. Wenn ich zum Beispiel mit dem Online-Banking-System Geld von meinem Sparkonto auf mein Girokonto überweise, garantiert die Eigenschaft Atomarität, dass der Vorgang nur dann erfolgreich ist, wenn das Geld von meinem Sparkonto abgezogen und meinem Girokonto gutgeschrieben wird. Der gesamte Vorgang wird entweder erfolgreich sein oder als komplette Einheit fehlschlagen.
Die Konsistenzeigenschaft garantiert, dass die Datenbank von einem konsistenten Zustand zu Beginn der Transaktion in einen anderen konsistenten Zustand am Ende der Transaktion übergeht. In unserem Beispiel würde die Überweisung des Geldes nur dann stattfinden, wenn das Sparkonto ausreichend gedeckt ist. Andernfalls würde die Transaktion fehlschlagen und die Salden würden in ihrem ursprünglichen, konsistenten Zustand bleiben.
Die Isolierung stellt sicher, dass sich gleichzeitige Operationen in der Datenbank nicht gegenseitig beeinflussen. Diese Eigenschaft stellt sicher, dass sich die Operationen mehrerer Transaktionen, die gleichzeitig ausgeführt werden, nicht gegenseitig beeinträchtigen.
Dauerhaftigkeit bezieht sich auf die Persistenz von bestätigten Transaktionen. Sie garantiert, dass eine erfolgreich abgeschlossene Transaktion auch im Falle eines Systemausfalls zu einem dauerhaften Zustand führt. In unserem Beispiel einer Geldüberweisung stellt die Dauerhaftigkeit sicher, dass die Aktualisierungen auf meinem Spar- und Girokonto dauerhaft sind und einen möglichen Systemausfall überstehen können.
In den 1990er Jahren entwickelten sich die Datenbanksysteme weiter, und die Einführung des Internets Mitte der 1990er Jahre führte zu einem explosionsartigen Anstieg der Datenmenge und der Notwendigkeit, diese Daten zu speichern. Unternehmensanwendungen setzten die Technologie der relationalen Datenbankmanagementsysteme (RDBMS) sehr effektiv ein. Flaggschiffprodukte wie SAP und Salesforce sammelten und verwalteten riesige Mengen an Daten.
Diese Entwicklung war jedoch nicht ohne Nachteile. Die Unternehmensanwendungen speicherten die Daten in ihren eigenen, proprietären Formaten, was zur Entstehung von Datensilos führte. Diese Datensilos waren im Besitz und unter der Kontrolle einer Abteilung oder eines Geschäftsbereichs. Im Laufe der Zeit erkannten die Unternehmen die Notwendigkeit, eine unternehmensweite Sicht auf diese verschiedenen Datensilos zu entwickeln, was zum Aufkommen von Data Warehouses führte.
Data Warehouses
Obwohl jede Unternehmensanwendung über eine Art von Berichtswesen verfügt, wurden Geschäftsmöglichkeiten verpasst, weil ein umfassender Überblick über das gesamte Unternehmen fehlte. Gleichzeitig erkannten die Unternehmen den Wert der Analyse von Daten über längere Zeiträume hinweg. Außerdem wollten sie in der Lage sein, die Daten auf mehrere übergreifende Themenbereiche wie Kunden, Produkte und andere Geschäftseinheiten aufzuteilen und zu analysieren.
Dies führte zur Einführung des Data Warehouse, eines zentralen relationalen Speichers für integrierte, historische Daten aus verschiedenen Datenquellen, der eine einzige integrierte, historische Sicht auf das Unternehmen mit einem einheitlichen Schema darstellt, das alle Perspektiven des Unternehmens abdeckt.
Data Warehouse Architektur
Eine einfache Darstellung einer typischen Data Warehouse-Architektur ist in Abbildung 1-1 zu sehen.
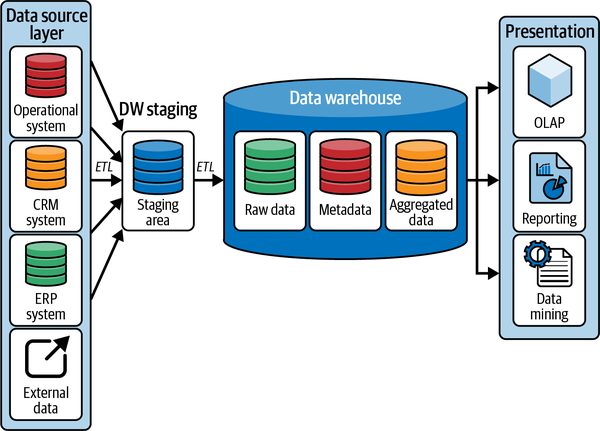
Abbildung 1-1. Data Warehouse Architektur
Wenn wir uns das Diagramm in Abbildung 1-1 ansehen, beginnen wir mit der Datenquellenschicht auf der linken Seite. Unternehmen müssen Daten aus einer Reihe von heterogenen Datenquellen aufnehmen. Während die Daten aus den ERP-Systemen ( ) des Unternehmens das Rückgrat des Organisationsmodells bilden, müssen wir diese Daten mit den Daten aus den operativen Systemen ergänzen, die das Tagesgeschäft abwickeln, wie z. B. Personalverwaltungssysteme (HR) und Workflow-Management-Software. Darüber hinaus möchten Unternehmen vielleicht auch die Kundeninteraktionsdaten nutzen, die von ihren Customer Relationship Management (CRM)- und Point of Sale (POS)-Systemen erfasst werden. Zusätzlich zu den hier aufgeführten Hauptdatenquellen müssen Daten aus einer Vielzahl externer Datenquellen in unterschiedlichen Formaten wie Tabellenkalkulationen, CSV-Dateien usw. aufgenommen werden.
Diese verschiedenen Quellsysteme können jeweils ihr eigenes Datenformat haben. Deshalb enthält das Data Warehouse einen Staging-Bereich, in dem die Daten aus den verschiedenen Quellen in einem gemeinsamen Format zusammengefasst werden können. Zu diesem Zweck muss das System die Daten aus den ursprünglichen Datenquellen aufnehmen. Der eigentliche Aufnahmeprozess variiert je nach Art der Datenquelle. Einige Systeme ermöglichen einen direkten Datenbankzugriff, andere wiederum erlauben die Aufnahme von Daten über eine API, während viele Datenquellen immer noch auf Dateiextrakten beruhen.
Als nächstes muss das Data Warehouse die Daten in ein standardisiertes Format umwandeln, damit die nachgelagerten Prozesse problemlos auf die Daten zugreifen können. Schließlich werden die transformierten Daten in den Staging-Bereich geladen. In relationalen Data Warehouses besteht dieser Staging-Bereich in der Regel aus einer Reihe flacher relationaler Staging-Tabellen ohne Primär- oder Fremdschlüssel oder einfache Datentypen.
Dieser Prozess, bei dem Daten extrahiert, in ein Standardformat umgewandelt und in das Data Warehouse geladen werden, wird gemeinhin als Extraktion, Transformationund Laden(ETL) bezeichnet. ETL-Tools können noch weitere Aufgaben mit den eingelesenen Daten durchführen, bevor sie schließlich in das Data Warehouse geladen werden. Zu diesen Aufgaben gehört die Beseitigung von doppelten Datensätzen. Da ein Data Warehouse die einzige Quelle der Wahrheit sein wird, wollen wir nicht, dass es mehrere Kopien der gleichen Daten enthält. Außerdem verhindern doppelte Datensätze die Erstellung eines eindeutigen Schlüssels für jeden Datensatz.
ETL-Tools ermöglichen es uns auch, Daten aus verschiedenen Datenquellen zu kombinieren. Zum Beispiel kann eine Sicht auf unsere Kunden in CRM-Systemen erfasst werden, während andere Attribute in einem ERP-System zu finden sind. Das Unternehmen muss diese verschiedenen Aspekte zu einer umfassenden Sicht auf einen Kunden zusammenführen. An dieser Stelle beginnen wir, ein Schema in das Data Warehouse einzuführen. In unserem Beispiel eines Kunden definiert das Schema die verschiedenen Spalten für die Kundentabelle, welche Spalten benötigt werden, den Datentyp und die Einschränkungen für jede Spalte und so weiter.
Kanonische, standardisierte Darstellungen von Spalten wie Datum und Uhrzeit sind wichtig. ETL-Tools können sicherstellen, dass alle zeitlichen Spalten im gesamten Data Warehouse nach demselben Standard formatiert sind.
Schließlich wollen die Unternehmen die Daten gemäß ihren Data-Governance-Standards auf ihre Qualität hin überprüfen. Dazu kann es gehören, dass Datenzeilen von geringer Qualität, die diesen Mindeststandard nicht erfüllen, gelöscht werden.
Data Warehouses werden physisch auf einer monolithischen Architektur implementiert, die aus einem einzigen großen Knoten besteht, der Speicher, Rechenleistung und Speicherung kombiniert. Diese monolithische Architektur zwingt Unternehmen dazu, ihre Infrastruktur vertikal zu skalieren, was zu einer teuren, oft überdimensionierten Infrastruktur führt, die für Spitzenlasten ausgelegt ist, während sie zu anderen Zeiten nahezu ungenutzt ist.
Ein Data Warehouse enthält in der Regel Daten, die wie folgt klassifiziert werden können:
- Metadaten
Kontextbezogene Informationen über die Daten. Diese Daten werden oft in einem Datenkatalog gespeichert. Er ermöglicht es den Datenanalysten, die im Data Warehouse gespeicherten Daten zu beschreiben, zu klassifizieren und leicht aufzufinden.
- Rohdaten
Die Daten werden in ihrem ursprünglichen Format ohne jegliche Bearbeitung aufbewahrt. Der Zugriff auf die Rohdaten ermöglicht es dem Data-Warehouse-System, die Daten im Falle von Ladefehlern erneut zu verarbeiten.
- Zusammenfassende Daten
Wird automatisch von dem zugrunde liegenden Datenverwaltungssystem erstellt. Die Zusammenfassungsdaten werden automatisch aktualisiert, wenn neue Daten in das Warehouse geladen werden. Sie enthalten Aggregationen über mehrere konforme Dimensionen. Der Hauptzweck der Zusammenfassungsdaten besteht darin, die Abfrageleistung zu beschleunigen.
Die Daten im Warehouse werden in der Präsentationsschicht konsumiert. Hier können die Verbraucher mit den im Warehouse gespeicherten Daten interagieren. Wir können grob zwei große Gruppen von Verbrauchern unterscheiden:
- Menschliche Verbraucher
Dies sind die Personen innerhalb der Organisation, die die Daten im Warehouse nutzen müssen. Diese Verbraucher können von Wissensarbeitern, die den Zugriff auf die Daten als wesentlichen Teil ihrer Arbeit benötigen, bis hin zu Führungskräften reichen, die typischerweise stark zusammengefasste Daten, oft in Form von Dashboards und Leistungskennzahlen (KPIs), nutzen.
- Interne oder externe Systeme
Die Daten in einem Data Warehouse können von einer Vielzahl von internen oder externen Systemen genutzt werden. Dazu gehören Tools für maschinelles Lernen und KI oder interne Anwendungen, die Warehouse-Daten nutzen müssen. Manche Systeme greifen direkt auf die Daten zu, andere arbeiten mit Datenextrakten, wieder andere nutzen die Daten direkt in einem Pub-Sub-Modell.
Die menschlichen Konsumenten werden verschiedene Analysewerkzeuge und -technologien nutzen, um aus den Daten verwertbare Erkenntnisse zu gewinnen:
- Berichtswerkzeuge
Diese Tools ermöglichen es dem Nutzer , Einblicke in die Daten durch Visualisierungen wie tabellarische Berichte und eine Vielzahl von grafischen Darstellungen zu erhalten.
- Tools für die analytische Online-Verarbeitung (OLAP)
Die Verbraucher müssen die Daten auf verschiedene Weise aufteilen und würfeln. OLAP-Tools stellen die Daten in einem mehrdimensionalen Format dar, so dass sie aus verschiedenen Perspektiven abgefragt werden können. Sie nutzen vorgespeicherte Aggregationen, die oft im Speicher abgelegt sind, um die Daten mit hoher Leistung bereitzustellen.
- Data Mining
Mit diesen Tools kann ein Datenanalyst durch mathematische Korrelationen und Klassifizierungen Muster in den Daten finden. Sie helfen dem Analysten dabei, zuvor verborgene Beziehungen zwischen verschiedenen Datenquellen zu erkennen. In gewisser Weise können Data-Mining-Tools als Vorläufer der modernen Data-Science-Tools angesehen werden.
Dimensionale Modellierung
Mit Data Warehouses entstand die Notwendigkeit eines umfassenden Datenmodells, das die verschiedenen Fachbereiche eines Unternehmens umfasst. Die Technik zur Erstellung dieser Modelle wurde als dimensionale Modellierung bekannt.
Angetrieben durch die Schriften und Ideen von Visionären wie Bill Inmon und Ralph Kimball, wurde die dimensionale Modellierung erstmals in Kimballs bahnbrechendem Buch The Data Warehouse Toolkit vorgestellt : The Complete Guide to Dimensional Modeling.2 Kimball definiert eine Methodik, die sich auf einen Bottom-up-Ansatz konzentriert und sicherstellt, dass das Team so schnell wie möglich einen echten Mehrwert mit dem Data Warehouse erzielt.
Ein dimensionales Modell wird durch ein Sternschema beschrieben. Ein Sternschema organisiert die Daten für einen bestimmten Geschäftsprozess (z. B. den Verkauf) in einer Struktur, die einfache Analysen ermöglicht. Es besteht aus zwei Arten von Tabellen:
-
Eine Faktentabelle, die ist, ist die primäre oder zentrale Tabelle des Schemas. In der Faktentabelle werden die wichtigsten Messwerte, Kennzahlen oder "Fakten" des Geschäftsprozesses erfasst. Um bei unserem Beispiel des Geschäftsprozesses "Verkauf" zu bleiben, würde eine Faktentabelle für den Verkauf die verkauften Einheiten und den Verkaufsbetrag enthalten.
-
Faktentabellen haben eine klar definierte Struktur. Die Granularität wird durch die Kombination der Dimensionen (Spalten) bestimmt, die in der Tabelle dargestellt werden. Eine Umsatzfaktentabelle kann eine niedrige Granularität haben, wenn es sich nur um eine jährliche Zusammenfassung der Umsätze handelt, oder eine hohe Granularität, wenn sie Umsätze nach Datum, Filiale und Kundenidentifikation enthält.
-
-
Mehrere Dimensionstabellen die mit der Faktentabelle verbunden sind. Eine Dimension liefert den Kontext für den ausgewählten Geschäftsprozess. In einem Beispiel für ein Verkaufsszenario könnte die Liste der Dimensionen Produkt, Kunde, Verkäufer und Geschäft umfassen.
Die Dimensionstabellen "umgeben" die Faktentabelle, weshalb diese Art von Schemata als "Sternschemata" bezeichnet werden. Ein Sternschema besteht aus Faktentabellen, die über Primär- und Fremdschlüsselbeziehungen mit den zugehörigen Dimensionstabellen verbunden sind. Ein Sternschema für unseren Themenbereich Vertrieb ist in Abbildung 1-2 dargestellt.
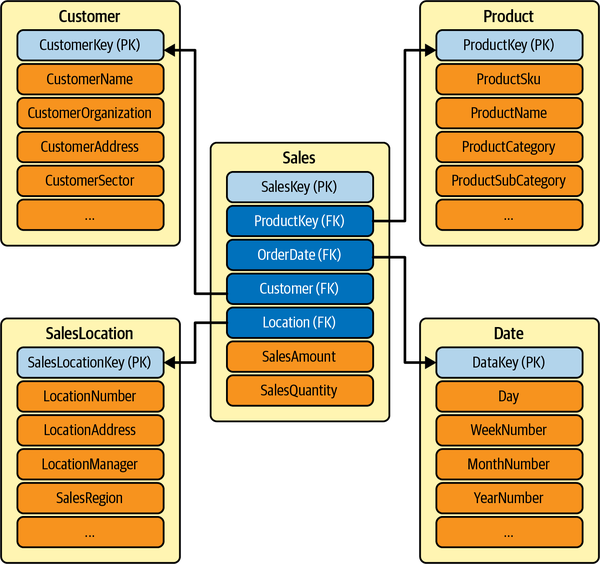
Abbildung 1-2. Dimensionsmodell des Verkaufs
Data Warehouse Vorteile und Herausforderungen
Data Warehouses haben inhärente Stärken, die sich in der Wirtschaft bewährt haben. Sie stellen hochwertige, bereinigte und normalisierte Daten aus verschiedenen Datenquellen in einem gemeinsamen Format bereit. Da die Daten aus den verschiedenen Abteilungen in einem gemeinsamen Format dargestellt werden, kann jede Abteilung die Ergebnisse im Einklang mit den anderen Abteilungen überprüfen. Zeitnahe, genaue Daten sind die Grundlage für fundierte Geschäftsentscheidungen.
-
Da sie große Mengen historischer Daten speichern, ermöglichen sie historische Einblicke und erlauben es den Nutzern, verschiedene Zeiträume und Trends zu analysieren.
-
Data Warehouses sind in der Regel sehr zuverlässig, da sie auf der zugrunde liegenden relationalen Datenbanktechnologie basieren, die ACID-Transaktionen ausführt.
-
Lagerhäuser werden mit modelliertStandard-Sternschema-Modellierungstechniken, die Faktentabellen und Dimensionen erstellen. Es gibt immer mehr vorgefertigte Templating-Modelle für verschiedene Themenbereiche, z. B. Vertrieb und CRM, was die Entwicklung solcher Modelle weiter beschleunigt.
-
Data Warehouses sind ideal für Business Intelligence und Reporting geeignet und beantworten im Grunde die Frage "Was ist passiert?" der Datenreifekurve. Ein Data Warehouse in Kombination mit Business Intelligence (BI)-Tools kann verwertbare Erkenntnisse für Marketing, Finanzen, Betrieb und Vertrieb liefern.
Der rasante Aufstieg des Internets und der sozialen Medien sowie die Verfügbarkeit von Multimediageräten wie Smartphones haben die herkömmliche Datenlandschaft durcheinander gebracht und den Begriff Big Data( ) entstehen lassen. Big Data wird definiert als Daten, die in immer größeren Mengen, mit höherer Geschwindigkeit, in einer größeren Vielfalt von Formaten und mit höherer Wahrhaftigkeit anfallen. Diese sind als die vier Vs der Daten bekannt:
- Band
Die Menge an Daten, die weltweit erstellt, erfasst, kopiert und verbraucht wird, nimmt rasant zu. Laut Statista wird das weltweite Datenaufkommen in den nächsten zwei Jahren auf mehr als 200 Zettabyte anwachsen (ein Zettabyte ist eine 2 hoch 70 Anzahl von Bytes).
- Geschwindigkeit
Im heutigen modernen Geschäftsklima sind zeitnahe Entscheidungen von entscheidender Bedeutung. Um diese Entscheidungen treffen zu können, müssen die Informationen schnell fließen, idealerweise so nah wie möglich an der Echtzeit. So müssen z. B. Anwendungen für den Aktienhandel fast in Echtzeit auf Daten zugreifen können, damit fortschrittliche Handelsalgorithmen Entscheidungen im Millisekundenbereich treffen können, und sie müssen diese Entscheidungen an ihre Stakeholder weitergeben. Der Zugang zu zeitnahen Daten kann Unternehmen einen Wettbewerbsvorteil verschaffen.
- Sorte
Vielfalt bezieht sich auf die Anzahl der verschiedenen "Arten" von Daten, die jetzt verfügbar sind. Die traditionellen Datentypen waren alle strukturiert und wurden in der Regel als relationale Datenbanken oder Auszüge daraus angeboten. Mit dem Aufkommen von Big Data kommen nun neue, unstrukturierte Datentypen hinzu. Unstrukturierte und halbstrukturierte Datentypen, wie z. B. Internet of Things (IoT)-Gerätenachrichten, Text, Audio und Video, müssen zusätzlich vorverarbeitet werden, um eine geschäftliche Bedeutung zu erhalten. Die Vielfalt zeigt sich auch in den verschiedenen Arten der Datenerfassung. Einige Datenquellen lassen sich am besten im Batch-Modus erfassen, während sich andere für eine inkrementelle Erfassung oder eine ereignisbasierte Erfassung in Echtzeit eignen, wie z. B. IoT-Datenströme.
- Wahrhaftigkeit
Wahrhaftigkeit definiert die Vertrauenswürdigkeit der Daten. Hier wollen wir sicherstellen, dass die Daten korrekt und von hoher Qualität sind. Die Daten können aus verschiedenen Quellen stammen; es ist wichtig, dass wir die Kontrollkette der Daten verstehen, sicherstellen, dass wir umfangreiche Metadaten haben und den Kontext verstehen, in dem die Daten gesammelt wurden. Außerdem wollen wir mit sicherstellen, dass unsere Sicht auf die Daten vollständig ist und keine Komponenten fehlen oder Fakten zu spät eintreffen.
Data Warehouses haben es schwer, mit diesen vier Vs umzugehen.
Herkömmliche Data Warehouse-Architekturen haben Schwierigkeiten, exponentiell wachsende Datenmengen zu bewältigen. Sie leiden sowohl unter Problemen bei der Speicherung als auch bei der Skalierbarkeit. Wenn die Datenmengen Petabytes erreichen, wird es schwierig, die Speicherung zu skalieren, ohne viel Geld auszugeben. Herkömmliche Data-Warehouse-Architekturen nutzen keine In-Memory- und Parallelverarbeitungstechniken, so dass sie das Data Warehouse nicht vertikal skalieren können.
Data Warehouse-Architekturen sind auch nicht geeignet, um die Geschwindigkeit von Big Data zu bewältigen. Data Warehouses unterstützen nicht die Art von Streaming-Architektur, die erforderlich ist, um Daten nahezu in Echtzeit zu verarbeiten. Die ETL-Datenladefenster können nur so weit verkürzt werden, bis die Infrastruktur zusammenbricht.
Während Data Warehouses sehr gut für die Speicherung strukturierter Daten geeignet sind, eignen sie sich nicht für die Speicherung und Abfrage der Vielzahl halbstrukturierter oder unstrukturierter Daten.
Data Warehouses haben keine eingebaute Unterstützung für die Verfolgung der Vertrauenswürdigkeit der Daten. Data Warehouse-Metadaten konzentrieren sich hauptsächlich auf das Schema und weniger auf die Herkunft, die Datenqualität und andere Wahrheitsvariablen.
Außerdem basieren Data Warehouses auf einem geschlossenen, proprietären Format und unterstützen in der Regel nur SQL-basierte Abfragetools. Aufgrund ihres proprietären Formats bieten Data Warehouses keine gute Unterstützung für Data Science- und Machine Learning-Tools.
Aufgrund dieser Einschränkungen sind Data Warehouses teuer in der Erstellung. Infolgedessen schlagen Projekte oft fehl, bevor sie in Betrieb gehen, und diejenigen, die in Betrieb gehen, haben es schwer, mit den sich ständig ändernden Anforderungen des modernen Geschäftsklimas und den vier Vs Schritt zu halten.
Die Einschränkungen der traditionellen Data-Warehouse-Architektur führten zu einer moderneren Architektur, die auf dem Konzept eines Data Lake basiert.
Einführung von Data Lakes
Ein Data Lake ist ein kosteneffizientes zentrales Repository, in dem strukturierte, halbstrukturierte oder unstrukturierte Daten in beliebiger Größe in Form von Dateien und Blobs gespeichert werden. Der Begriff "Datensee" stammt von der Analogie eines echten Flusses oder Sees, der das Wasser, in diesem Fall die Daten, enthält, mit mehreren Nebenflüssen, die das Wasser (auch "Daten" genannt) in Echtzeit in den See fließen lassen. Eine kanonische Darstellung eines typischen Datensees ist in Abbildung 1-3 zu sehen.
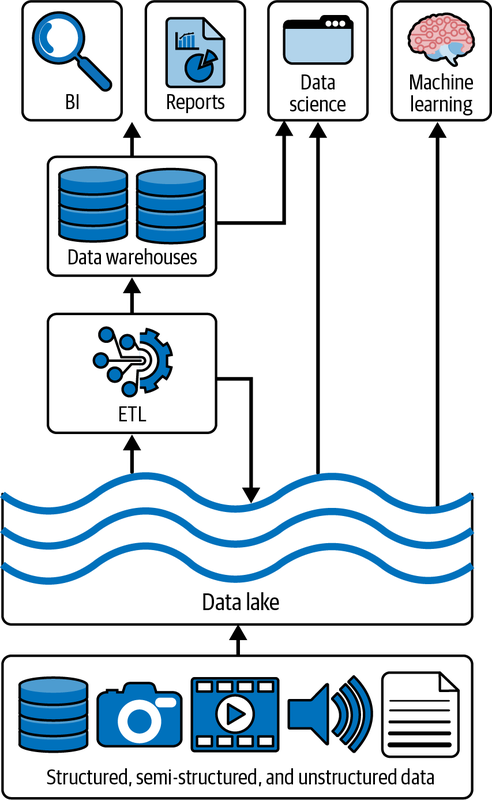
Abbildung 1-3. Kanonischer Datensee
Die ersten Data Lakes und Big Data-Lösungen wurden mit lokalen Clustern aufgebaut, die auf dem Open-Source-Framework Apache Hadoop basierten. Hadoop wurde eingesetzt, um große Datensätze von Gigabytes bis Petabytes effizient zu speichern und zu verarbeiten. Anstatt die Daten auf einem großen Computer zu speichern und zu verarbeiten, nutzte Hadoop das Clustering mehrerer handelsüblicher Rechenknoten, um große Datenmengen parallel und schneller zu analysieren.
Hadoop würde das MapReduce-Framework nutzen, um Rechenaufgaben über mehrere Rechenknoten zu parallelisieren. Das Hadoop Distributed File System (HDFS) war ein Dateisystem, das für den Betrieb auf Standard- oder Low-End-Hardware konzipiert war. HDFS war sehr fehlertolerant und unterstützte große Datensätze.
Ab 2015 begannen Cloud Data Lakes, wie Amazon Simple Storage Service (Amazon S3), Azure Data Lake Storage Gen 2 (ADLS) und Google Cloud Storage (GCS), HDFS zu ersetzen. Diese cloudbasierten Speichersysteme haben bessere Service-Level-Agreements (SLAs) (oft über 10 Neunen), bieten Georeplikation und vor allem extrem niedrige Kosten mit der Option, für Archivierungszwecke einen noch kostengünstigeren Cold Storage zu nutzen.
Auf der untersten Ebene ist die Einheit der Speicherung in einem Data Lake ein Blob von Daten. Blobs sind von Natur aus unstrukturiert und ermöglichen die Speicherung von halb- und unstrukturierten Daten, wie z. B. großen Audio- und Videodateien. Auf einer höheren Ebene bieten die Cloud-Speichersysteme zusätzlich zur Blob-Speicherung Dateisemantik und Sicherheit auf Dateiebene und ermöglichen so die Speicherung von hochstrukturierten Daten. Aufgrund ihrer Ingress- und Egress-Kanäle mit hoher Bandbreite ermöglichen Data Lakes auch Streaming-Anwendungen, z. B. die kontinuierliche Aufnahme großer Mengen von IoT-Daten oder Streaming-Medien.
Compute Engines ermöglichen es, große Datenmengen in einer ETL-ähnlichen Weise zu verarbeiten und an Verbraucher wie traditionelle Data Warehouses, maschinelles Lernen und KI-Tools zu liefern. Streaming-Daten können in Echtzeitdatenbanken gespeichert werden, und Berichte können mit herkömmlichen BI- und Reporting-Tools erstellt werden.
Data Lakes werden durch eine Vielzahl von Komponenten ermöglicht:
- Speicherung
Data Lakes erfordern sehr große, skalierbare Speichersysteme, wie sie typischerweise in Cloud-Umgebungen angeboten werden. Die Speicherung muss langlebig und skalierbar sein und sollte mit einer Vielzahl von Tools, Bibliotheken und Treibern von Drittanbietern interoperabel sein. Beachte, dass Data Lakes die Konzepte der Speicherung und des Rechnens trennen und beide unabhängig voneinander skalieren können. Die unabhängige Skalierung von Speicherung und Rechenleistung ermöglicht eine bedarfsgerechte, elastische Feinabstimmung der Ressourcen, wodurch unsere Lösungsarchitekturen flexibler werden. Die Ingress- und Egress-Kanäle zu den Speichersystemen sollten hohe Bandbreiten unterstützen, um die Aufnahme oder den Verbrauch großer Batch-Volumina oder den kontinuierlichen Fluss großer Mengen von Streaming-Daten, wie IoT und Streaming-Medien, zu ermöglichen.
- Berechne
Für die Verarbeitung der großen Datenmengen, die in der Speicherung gespeichert werden, sind große Mengen an Rechenleistung erforderlich. Auf den verschiedenen Cloud-Plattformen sind mehrere Compute-Engines verfügbar. Die beliebteste Compute Engine für Data Lakes ist Apache Spark. Spark ist eine Open-Source-Unified-Analytics-Engine, die über verschiedene Lösungen wie Databricks oder von anderen Cloud-Providern entwickelte Lösungen bereitgestellt werden kann. Big-Data-Compute-Engines werden Compute-Cluster nutzen. Compute-Cluster bündeln Rechenknoten, um komplette Datenerfassungs- und -verarbeitungsaufgaben zu bewältigen.
- Formate
Die Form der Daten auf der Festplatte definiert die Formate. Es gibt eine große Auswahl an Speicherformaten. Data Lakes verwenden meist standardisierte, quelloffene Formate, wie Parquet, Avro JSON oder CSV.
- Metadaten
Moderne, cloudbasierte Speicherungen speichern Metadaten (d.h. Kontextinformationen über die Daten). Dazu gehören verschiedene Zeitstempel, die beschreiben, wann die Daten geschrieben oder abgerufen wurden, Datenschemata und eine Vielzahl von Tags, die Informationen über die Nutzung und den Eigentümer der Daten enthalten.
Data Lakes haben einige sehr starke Vorteile. Eine Data-Lake-Architektur ermöglicht die Konsolidierung der Datenbestände eines Unternehmens an einem zentralen Ort. Data Lakes sind formatunabhängig und basieren auf Open-Source-Formaten wie Parquet und Avro. Diese Formate werden von einer Vielzahl von Tools, Treibern und Bibliotheken gut verstanden und ermöglichen eine reibungslose Interoperabilität.
Data Lakes werden auf ausgereiften Subsystemen für die Speicherung in der Cloud bereitgestellt, so dass sie von der Skalierbarkeit, der Überwachung, der einfachen Bereitstellung und den niedrigen Speicherkosten dieser Systeme profitieren. Automatisierte DevOps-Tools wie Terraform sind gut etabliert und ermöglichen eine automatisierte Bereitstellung und Wartung.
Im Gegensatz zu Data Warehouses unterstützen Data Lakes alle Datentypen, einschließlich halbstrukturierter und unstrukturierter Daten, und ermöglichen Arbeitslasten wie die Medienverarbeitung. Aufgrund ihrer Ingress-Kanäle mit hohem Durchsatz eignen sie sich sehr gut für Streaming-Anwendungen, z. B. für die Aufnahme von IoT-Sensordaten, Medien-Streaming oder Web-Clickstreams.
Mit zunehmender Beliebtheit und Verbreitung von Data Lakes erkannten Unternehmen jedoch auch einige Herausforderungen bei traditionellen Data Lakes. Während die zugrundeliegende Speicherung in der Cloud relativ kostengünstig ist, erfordert der Aufbau und die Pflege eines effektiven Data Lakes Expertenwissen, was zu hohen Personalkosten oder erhöhten Kosten für Beratungsleistungen führt.
Während es einfach ist, Daten in ihrer Rohform aufzunehmen, kann die Umwandlung der Daten in eine Form, die Geschäftswerte liefern kann, sehr teuer sein. Herkömmliche Data Lakes haben eine schlechte Latenz bei Abfragen und können daher nicht für interaktive Abfragen verwendet werden. Infolgedessen müssen die Datenteams des Unternehmens die Daten noch umwandeln und in ein Data Warehouse laden, was die Zeit bis zur Wertschöpfung verlängert. Dies führte zu einer Data Lake + Warehouse Architektur. Diese Architektur dominierte die Branche noch eine ganze Weile (wir haben persönlich Dutzende solcher Systeme implementiert), ist aber jetzt aufgrund des Aufkommens von Lakehouses im Niedergang begriffen.
Data Lakes verwenden in der Regel eine "Schema-on-Read"-Strategie, bei der die Daten in jedem beliebigen Format ohne Schemaerzwingung eingelesen werden können. Erst wenn die Daten gelesen werden, kann eine Art Schema angewendet werden. Diese fehlende Schemaerzwingung kann zu Problemen mit der Datenqualität führen und dazu, dass der ursprüngliche Data Lake zu einem "Datensumpf" wird.
Data Lakes bieten keine Transaktionsgarantien. Datendateien können nur angehängt werden, was dazu führt, dass bereits geschriebene Daten für eine einfache Aktualisierung teuer neu geschrieben werden müssen. Dies führt zu dem sogenannten "Small-File-Problem", bei dem mehrere kleine Dateien für eine einzige Entität erstellt werden. Wenn dieses Problem nicht gut gehandhabt wird, verlangsamen diese kleinen Dateien die Leseleistung des gesamten Data Lakes, was zu veralteten Daten und verschwendeter Speicherung führt. Data-Lake-Administratoren müssen diese kleinen Dateien in wiederholten Schritten zu größeren Dateien zusammenführen, die für effiziente Lesevorgänge optimiert sind.
Nachdem wir unter die Stärken und Schwächen von Data Warehouses und Data Lakes erörtert haben, stellen wir nun das Data Lakehouse vor, das die Stärken beider Technologien kombiniert und ihre Schwächen ausgleicht.
Daten-See-Haus
Armbrust, Ghodsi, Xin und Zaharia stellten das Konzept des Data Lakehouse erstmals im Jahr 2021 vor. Die Autoren definieren ein Lakehouse als "ein Datenmanagementsystem, das auf einer kostengünstigen und direkt zugänglichen Speicherung basiert, die auch analytische DBMS-Verwaltungs- und Leistungsmerkmale wie ACID-Transaktionen, Datenversionierung, Auditing, Indexierung, Caching und Abfrageoptimierung bietet."
Wenn wir diese Aussage auspacken, können wir ein Lakehouse als ein System definieren, das die Flexibilität, die niedrigen Kosten und die Skalierbarkeit eines Data Lakes mit dem Datenmanagement und den ACID-Transaktionen von Data Warehouses verbindet und die Einschränkungen beider Systeme ausgleicht. Wie Data Lakes nutzt auch die Lakehouse-Architektur kostengünstige Cloud-Speichersysteme mit der diesen Systemen eigenen Flexibilität und horizontalen Skalierbarkeit. Das Ziel eines Lakehouse ist es, bestehende Hochleistungsdatenformate wie Parquet zu nutzen und gleichzeitig ACID-Transaktionen (und andere Funktionen) zu ermöglichen. Um diese Fähigkeiten hinzuzufügen, verwenden Lakehouses ein offenes Tabellenformat, das diese bestehenden Datenformate um Funktionen wie ACID-Transaktionen, Operationen auf Datensatzebene, Indexierung und wichtige Metadaten erweitert. Dadurch können Datenbestände, die auf kostengünstigen Speichersystemen gespeichert sind, mit der gleichen Zuverlässigkeit gespeichert werden, die bisher nur in RDBMS möglich war. Delta Lake ist ein Beispiel für ein offenes Tabellenformat, das diese Art von Funktionen unterstützt.
Lakehouses eignen sich besonders gut für die meisten, wenn nicht sogar für alle Cloud-Umgebungen mit getrennten Rechenressourcen und Speicherungen. Verschiedene Rechenanwendungen können bei Bedarf auf völlig separaten Rechenknoten, wie z. B. einem Spark-Cluster, laufen, während sie direkt auf dieselben Speicherdaten zugreifen. Es ist jedoch auch denkbar, ein Lakehouse über ein On-Premises-Speichersystem wie das bereits erwähnte HDFS zu implementieren.
Vorteile von Data Lakehouse
Eine Übersicht über die Architektur des Seehauses ist in Abbildung 1-4 dargestellt.
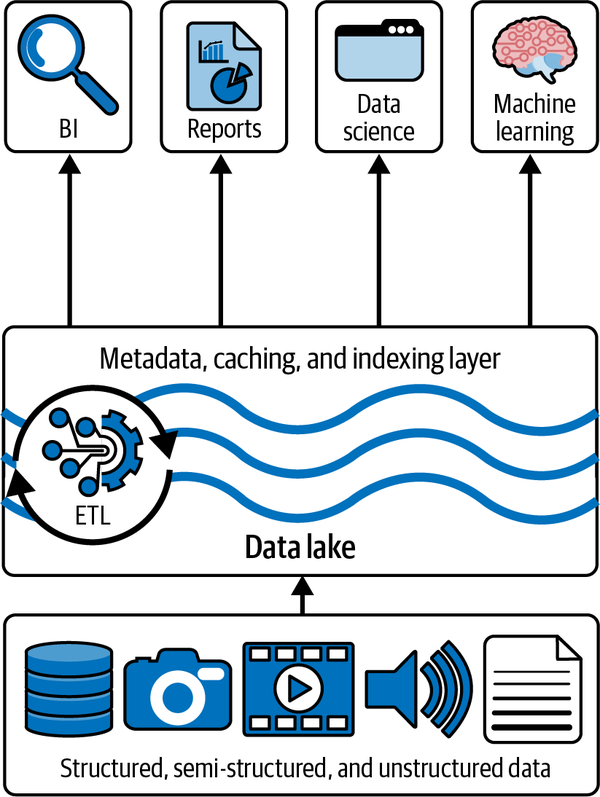
Abbildung 1-4. Überblick über die Architektur des Seehauses
Mit der Lakehouse-Architektur brauchen wir nicht mehr eine Kopie unserer Daten im Data Lake und eine weitere Kopie in einer Art Data-Warehouse-Speicherung zu haben. Vielmehr können wir unsere Daten über das Delta Lake Speicherformat und -protokoll aus dem Data Lake beziehen, und zwar mit einer vergleichbaren Leistung wie bei einem herkömmlichen Data Warehouse.
Da wir weiterhin die kostengünstigen cloudbasierten Speichertechnologien nutzen können und die Daten nicht mehr aus dem Data Lake in ein Data Warehouse kopieren müssen, können wir erhebliche Kosteneinsparungen erzielen, sowohl bei der Infrastruktur als auch beim Personal- und Beratungsaufwand.
Da weniger Datenbewegungen stattfinden und unser ETL vereinfacht ist, werden die Möglichkeiten für Datenqualitätsprobleme erheblich reduziert. Und schließlich, weil das Lakehouse die Fähigkeit besitzt, große Datenmengen und verfeinerte Dimensionsmodelle zu speichern, werden die Entwicklungszyklen verkürzt und die Zeit bis zur Wertschöpfung erheblich verkürzt.
Die Entwicklung von Data Warehouses über Data lakes zu einer Lakehouse-Architektur ist in Abbildung 1-5 dargestellt.
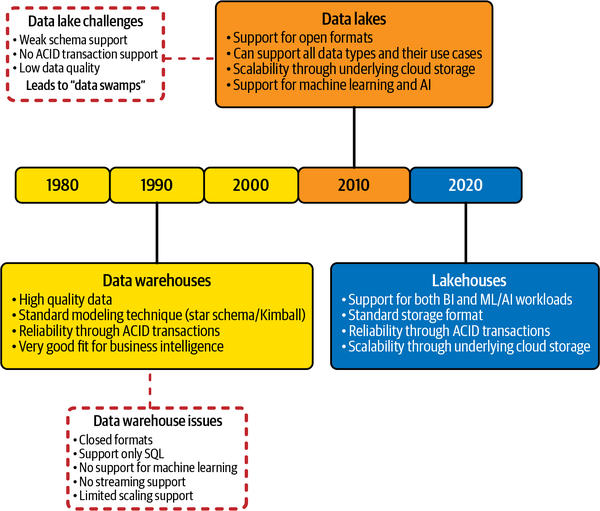
Abbildung 1-5. Entwicklung der Datenarchitekturen
Implementierung eines Seehauses
Wie wir bereits erwähnt haben, nutzen Lakehouses kostengünstige Objektspeicher wie Amazon S3, ADLS oder GCS und speichern die Daten von in einem Open-Source-Tabellenformat wie Apache Parquet. Da Lakehouse-Implementierungen jedoch ACID-Transaktionen mit diesen Daten durchführen, benötigen wir eine transaktionale Metadatenschicht über der Speicherung in der Cloud, die festlegt, welche Objekte Teil der Tabellenversion sind.
So kann ein Lakehouse Funktionen wie ACID-Transaktionen und Versionierung in dieser Metadatenschicht implementieren, während der Großteil der Daten in der kostengünstigen Objektspeicherung bleibt. Der Lakehouse-Kunde kann die Daten weiterhin in einem Open-Source-Format nutzen, mit dem er bereits vertraut ist.
Als Nächstes müssen wir uns mit der Systemleistung befassen. Wie wir bereits erwähnt haben, müssen die Implementierungen von Lakehouse eine hohe SQL-Leistung erreichen, um effektiv zu sein. Data Warehouses waren sehr gut darin, die Leistung zu optimieren, weil sie mit einem geschlossenen Speicherformat und einem bekannten Schema arbeiteten. Dies ermöglichte es ihnen, Statistiken zu führen, Cluster-Indizes zu erstellen, heiße Daten auf schnelle SSD-Geräte zu verschieben, usw.
In einem Lakehouse, das auf Open-Source-Standardformaten basiert, haben wir diesen Luxus nicht, da wir das Format der Speicherung nicht ändern können. Lakehouses können jedoch eine Fülle anderer Optimierungen nutzen, die die Datendateien unverändert lassen. Dazu gehören Caching, zusätzliche Datenstrukturen wie Indizes und Statistiken sowie Optimierungen des Datenlayouts.
Das letzte Werkzeug, mit dem analytische Workloads beschleunigen kann, ist die Entwicklung einer standardmäßigen Datenrahmen-API (DataFrame API). Die meisten populären ML-Tools wie TensorFlow und Spark MLlib unterstützen Datenrahmen (DataFrames). DataFrames wurden zuerst von R und Pandas eingeführt und bieten eine einfache Tabellenabstraktion der Daten mit einer Vielzahl von Transformationsoperationen, von denen die meisten aus der relationalen Algebra stammen.
In Spark ist die DataFrame-API deklarativ, und mit Lazy Evaluation wird ein Ausführungs-DAG (gerichteter azyklischer Graph) erstellt. Dieser Graph kann dann optimiert werden, bevor eine Aktion die zugrundeliegenden Daten im DataFrame verbraucht. Dadurch erhält das Lakehouse mehrere neue Optimierungsfunktionen, wie z. B. Caching und Hilfsdaten. Abbildung 1-6 zeigt, wie sich diese Anforderungen in das Gesamtdesign eines Lakehouse-Systems einfügen.
Da der Deltasee im Mittelpunkt dieses Buches steht, werden wir veranschaulichen, wie der Deltasee die Voraussetzungen für die Umsetzung eines Seehauses erleichtert.
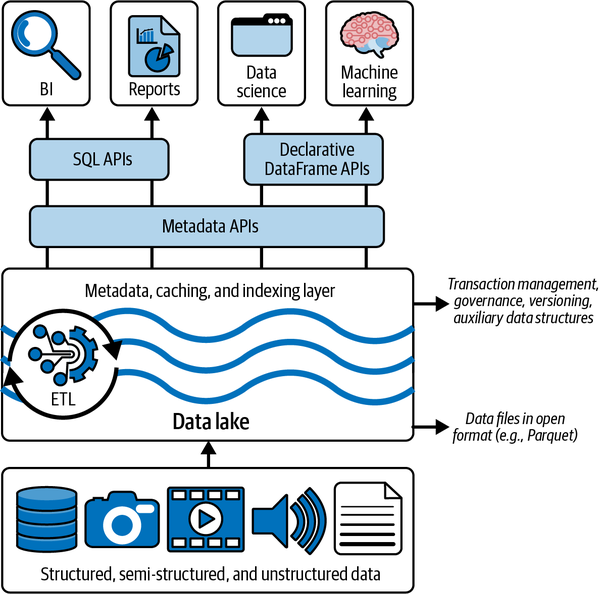
Abbildung 1-6. Umsetzung des Seehauses
Deltasee
Wie im vorigen Abschnitt erwähnt, kann eine mögliche Lakehouse-Lösung auf Delta Lake aufgebaut werden. Delta Lake ist ein offenes Tabellenformat, das Metadaten, Zwischenspeicherung und Indizierung mit einem Format für die Speicherung von Daten kombiniert. Zusammen bilden sie eine Abstraktionsebene, die ACID-Transaktionen und andere Verwaltungsfunktionen unterstützt.
Die Open-Table-Format- und Open-Source-Metadatenschicht von Delta Lake ermöglicht schließlich Lakehouse-Implementierungen. Delta Lake bietet ACID-Transaktionen, skalierbare Metadatenverarbeitung, ein einheitliches Prozessmodell, das Batch und Streaming umfasst, einen vollständigen Prüfungsverlauf und Unterstützung für SQL Data Manipulation Language (DML)-Anweisungen. Delta Lake kann auf bestehenden Data Lakes ausgeführt werden und ist mit verschiedenen Verarbeitungsmaschinen, einschließlich Apache Spark, voll kompatibel.
Delta Lake ist ein Open-Source-Framework, dessen Spezifikation unter https://delta.io zu finden ist . Die Arbeit von Armbrust et al. bietet eine detaillierte Beschreibung, wie Delta Lake ACID-Transaktionen ermöglicht.
Der Delta Lake bietet die folgenden Vorteile:
- Transaktionsbezogene ACID-Garantien
Delta Lake stellt sicher, dass alle Daten Lake-Transaktionen, die mit Spark oder einer anderen Verarbeitungs-Engine durchgeführt werden, für die Dauerhaftigkeit festgeschrieben und anderen Lesern auf atomare Weise zugänglich gemacht werden. Dies wird durch das Delta-Transaktionsprotokoll ermöglicht. In Kapitel 2 werden wir das Transaktionsprotokoll im Detail behandeln.
- Volle DML-Unterstützung
Herkömmliche Data Lakes unterstützen keine transaktionalen, atomaren Aktualisierungen der Daten. Delta Lake unterstützt alle DML-Operationen, einschließlich Löschungen und Aktualisierungen, sowie komplexe Szenarien für die Zusammenführung oder das Hochladen von Daten. Diese Unterstützung vereinfacht die Erstellung von Dimensionen und Faktentabellen beim Aufbau eines modernen Data Warehouse (MDW) erheblich.
- Audit-Geschichte
Das Delta Lake Transaktionsprotokoll zeichnet jede Änderung an den Daten in der Reihenfolge auf, in der sie vorgenommen wurde. Das Transaktionsprotokoll ist somit ein vollständiger Prüfpfad für alle an den Daten vorgenommenen Änderungen. So können Administratoren und Entwickler nach versehentlichen Löschungen und Änderungen auf frühere Versionen der Daten zurückgreifen. Diese Funktion wird als Zeitreise bezeichnet und in Kapitel 6 ausführlich beschrieben.
- Vereinheitlichung von Batch und Streaming in einem Verarbeitungsmodell
Delta Lake kann mit Batch- und Streaming-Senken oder -Quellen arbeiten. Es kann MERGEs auf einem Datenstrom durchführen, was eine häufige Anforderung bei der Zusammenführung von IoT-Daten mit Geräte-Referenzdaten ist. Es ermöglicht auch Anwendungsfälle, in denen wir CDC-Daten aus externen Datenquellen erhalten. Wir werden das Streaming in Kapitel 8 ausführlich behandeln.
- Durchsetzung und Entwicklung von Schemata
Delta Lake erzwingt ein Schema, wenn Daten aus dem Lake schreibt oder liest. Wenn es jedoch explizit für eine Datenentität aktiviert wird, ermöglicht es eine sichere Schema-Evolution, so dass Anwendungsfälle möglich sind, in denen sich die Daten weiterentwickeln müssen. Die Durchsetzung und Entwicklung von Schemata wird in Kapitel 7 behandelt.
- Umfangreiche Unterstützung von Metadaten und Skalierung
Die Fähigkeit, große Datenmengen zu verarbeiten, ist großartig, aber wenn die Metadaten nicht entsprechend skaliert werden können, greift die Lösung zu kurz. Delta Lake skaliert alle Metadatenverarbeitungsvorgänge, indem es Spark oder andere Compute-Engines einsetzt und so die Metadaten für Petabytes von Daten effizient verarbeiten kann.
Eine Lakehouse-Architektur besteht aus drei Schichten, wie in Abbildung 1-7 dargestellt. Die Speicherebene des Lakehouse basiert auf Standard-Cloud-Speichertechnologien wie ADLS, GCS oder Amazon S3. Damit verfügt das Lakehouse über eine hoch skalierbare, kostengünstige Speicherung.
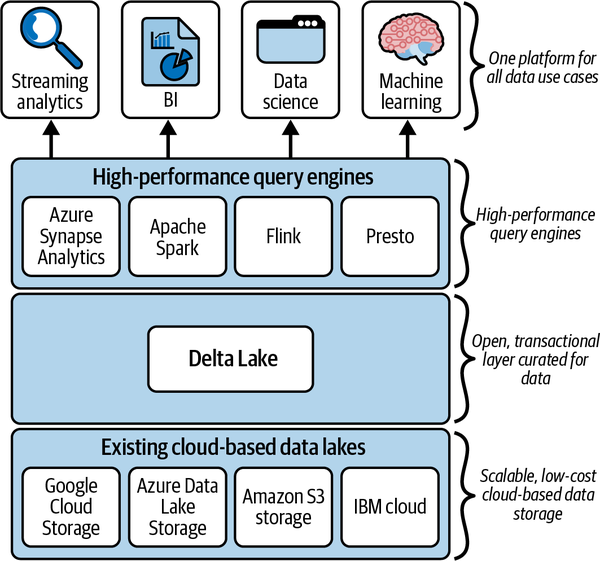
Abbildung 1-7. Mehrschichtige Architektur des Seehauses
Die Transaktionsschicht des Lakehouses wird von Delta Lake bereitgestellt. Sie bietet ACID-Garantien für das Lakehouse und ermöglicht eine effiziente Umwandlung von Rohdaten in kuratierte, verwertbare Daten. Neben der ACID-Unterstützung bietet Delta Lake eine Vielzahl zusätzlicher Funktionen, wie DML-Unterstützung, skalierbare Metadatenverarbeitung, Streaming-Unterstützung und ein umfangreiches Audit-Log. Die oberste Schicht des Lakehouse-Stacks besteht aus leistungsstarken Abfrage- und Verarbeitungs-Engines, die die zugrunde liegenden Rechenressourcen der Cloud nutzen. Zu den unterstützten Abfrage-Engines gehören:
-
Apache Spark
-
Apache Hive
-
Presto
-
Trino
Eine vollständige Liste der unterstützten Compute Engines findest du auf der Delta Lake Website.
Die Architektur des Medaillons
Ein Beispiel für die Architektur eines Seehauses am Delta Lake ist in Abbildung 1-8 dargestellt. Dieses Architekturmuster mit Bronze-, Silber- und Gold-Schichten wird oft als Medaillon-Architektur bezeichnet. Obwohl es nur eines von vielen Lakehouse-Architekturmustern ist, eignet es sich hervorragend für moderne Data Warehouses, Data Marts und andere analytische Lösungen.
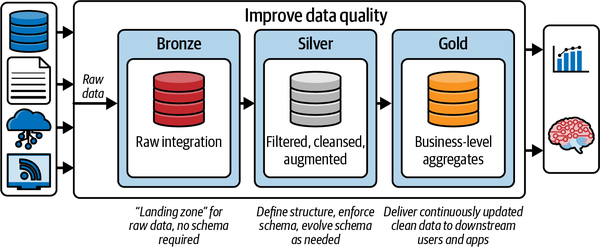
Abbildung 1-8. Architektur der Data Lakehouse Lösung
Auf der obersten Ebene haben wir drei Komponenten in dieser Lösung. Auf der linken Seite befinden sich die verschiedenen Datenquellen. Eine Datenquelle kann viele Formen annehmen; hier findest du einige Beispiele:
-
Eine Reihe von CSV- oder TXT-Dateien auf einem externen Datensee
-
Eine lokale Datenbank, wie z.B. Oracle oder SQL Server
-
Streaming-Datenquellen, wie Kafka oder Azure Event Hubs
-
REST-APIs von einem SAS-Dienst wie Salesforce oder ADP
Die zentrale Komponente implementiert die Medaillon-Architektur. Die Medaillon-Architektur ist ein Datenentwurfsmuster, mit dem die Daten in einem Seehaus logisch in Bronze-, Silber- und Gold-Schichten organisiert werden. In der Bronzeschicht landen die Daten, die wir von unseren Quellsystemen auf der linken Seite aufgenommen haben. Die Daten in der Bronze-Zone werden in der Regel "so wie sie sind" angelandet, können aber mit zusätzlichen Metadaten wie Datum und Uhrzeit des Ladens, Verarbeitungskennzeichen usw. ergänzt werden.
In der Silberschicht werden die Daten aus der Bronzeschicht bereinigt, normalisiert, zusammengeführt und angepasst. Hier wird die Unternehmenssicht der Daten über die verschiedenen Fachbereiche hinweg allmählich zusammengeführt.
Die Daten in der Gold-Schicht sind "verbrauchsfertige" Daten. Diese Daten können im Format eines klassischen Sternschemas vorliegen, das Dimensionen und Faktentabellen enthält, oder sie können in einem beliebigen Datenmodell vorliegen, das für den konsumierenden Anwendungsfall geeignet ist.
Das Ziel der Medaillon-Architektur ist es, die Struktur und Qualität der Daten schrittweise und progressiv zu verbessern, während sie die einzelnen Schichten der Architektur durchlaufen, wobei jede Schicht einen bestimmten Zweck erfüllt. Dieses Datenentwurfsmuster wird in Kapitel 10 noch ausführlicher behandelt, aber es ist wichtig zu verstehen, wie ein Lakehouse zusammen mit Delta Lake zuverlässige, leistungsfähige Datenentwurfsmuster oder Multihop-Architekturen unterstützen kann. Entwurfsmuster wie die Medaillon-Architektur bieten einige der architektonischen Grundlagen für die Vereinheitlichung deiner Datenpipelines in einem Lakehouse, um mehrere Anwendungsfälle zu unterstützen (z. B. Batch-Daten, Streaming-Daten und maschinelles Lernen).
Das Delta-Ökosystem
Wie wir in diesem Kapitel dargelegt haben, ermöglicht Delta Lake den Aufbau von Data Lakehouse-Architekturen, mit denen Data Warehousing und Machine Learning/AI-Anwendungen direkt auf einem Data Lake gehostet werden können. Delta Lake ist heute das am weitesten verbreitete Lakehouse-Format und wird derzeit von über 7.000 Unternehmen genutzt, die täglich Exabytes an Daten verarbeiten.
Data Warehouses und maschinelle Lernanwendungen sind jedoch nicht das einzige Anwendungsziel von Delta Lake. Neben der transaktionalen ACID-Unterstützung, die Data Lakes Zuverlässigkeit verleiht, ermöglicht Delta Lake die nahtlose Aufnahme und Nutzung von Streaming- und Batch-Daten mit einer einzigen Lösungsarchitektur.
Eine weitere wichtige Komponente von Delta Lake ist Delta Sharing, das es Unternehmen ermöglicht, Datensätze auf sichere Weise zu teilen. Delta Lake 3.0 unterstützt jetzt eigenständige Reader und Writer, sodass jeder Client (Python, Ruby oder Rust) Daten direkt in Delta Lake schreiben kann, ohne dass eine Big-Data-Engine wie Spark oder Flink erforderlich ist. Delta Lake wird mit einem erweiterten Satz von Open-Source-Konnektoren ausgeliefert, darunter Presto, Flink und Trino. Die Delta Lake Speicherschicht wird inzwischen auf vielen Plattformen eingesetzt, darunter ADLS, Amazon S3 und GCS. Alle Komponenten von Delta Lake 2.0 wurden von Databricks als Open Source zur Verfügung gestellt.
Der Erfolg von Delta Lake und den Seehäusern hat ein völlig neues Ökosystem hervorgebracht, das auf der Delta-Technologie basiert. Dieses Ökosystem besteht aus einer Vielzahl von Einzelkomponenten, darunter das Delta Lake Speicherformat, Delta Sharing und Delta Connectors.
Delta Lake Speicherung
Das Delta Lake Speicherformat ist eine Open-Source-Speicherschicht, die auf Cloud-basierten Data Lakes läuft. Sie fügt Data-Lake-Dateien und -Tabellen Transaktionsfunktionen hinzu und bringt Data-Warehouse-ähnliche Funktionen in einen Standard-Data-Lake. Die Delta Lake Speicherung ist die Kernkomponente des Ökosystems, da alle anderen Komponenten von dieser Schicht abhängen.
Delta Sharing
Die gemeinsame Nutzung von Daten ist ein häufiger Anwendungsfall in Unternehmen. Ein Bergbauunternehmen möchte zum Beispiel IoT-Daten von den Motoren seiner riesigen Minenfahrzeuge sicher mit dem Hersteller für vorbeugende Wartung und Diagnosezwecke teilen. Ein Hersteller von Thermostaten möchte vielleicht HVAC-Daten sicher mit einem öffentlichen Versorgungsunternehmen austauschen, um die Auslastung des Stromnetzes an Tagen mit hoher Auslastung zu optimieren. In der Vergangenheit war es jedoch sehr schwierig, eine sichere und zuverlässige Lösung für den Datenaustausch zu implementieren, die eine teure, individuelle Entwicklung erforderte.
Delta Sharing ist ein Open-Source-Protokoll für den sicheren Austausch großer Datensätze von Delta Lake-Daten. Es ermöglicht den Nutzern die sichere Freigabe von Daten, die in Amazon S3, ADLS oder GCS gespeichert sind. Mit Delta Sharing können die Nutzer/innen direkt auf die freigegebenen Daten zugreifen und ihre bevorzugten Tools wie Spark, Rust, Power BI usw. verwenden, ohne zusätzliche Komponenten einsetzen zu müssen. Beachte, dass die Daten über Cloud-Provider hinweg geteilt werden können, ohne dass eine eigene Entwicklung erforderlich ist.
Delta Sharing ermöglicht u.a. folgende Anwendungsfälle:
-
Die in ADLS gespeicherten Daten können von einer Spark Engine auf AWS verarbeitet werden.
-
In Amazon S3 gespeicherte Daten können von Rust auf GCP verarbeitet werden.
In Kapitel 9 findest du eine ausführliche Beschreibung des Delta-Sharing.
Delta-Steckverbinder
Das Hauptziel von Delta Connectors3,4 ist es, Delta Lake mit anderen Big Data Engines außerhalb von Apache Spark zu verbinden. Delta Connectors sind Open-Source-Konnektoren, die eine direkte Verbindung zu Delta Lake herstellen. Das Framework umfasst Delta Standalone, eine native Java-Bibliothek, die das direkte Lesen und Schreiben von Delta Lake-Tabellen ermöglicht, ohne dass ein Apache Spark-Cluster erforderlich ist. Verbrauchende Anwendungen können Delta Standalone nutzen, um sich direkt mit den Delta-Tabellen zu verbinden, die von ihrer Big Data-Infrastruktur geschrieben wurden. Damit entfällt die Notwendigkeit, Daten in ein anderes Format zu duplizieren, bevor sie genutzt werden können.
Andere native Bibliotheken sind verfügbar für:
- Bienenstock
Der Hive Connector liest Delta-Tabellen direkt aus Apache Hive.
- Flink
Der Flink/Delta Connector liest und schreibt Delta-Tabellen aus der Apache Flink-Anwendung. Der Konnektor enthält eine Senke zum Schreiben von Delta-Tabellen aus Apache Flink und eine Quelle zum Lesen von Delta-Tabellen mit Flink.
- sql-delta-import
Dieser Konnektor ermöglicht den Import von Daten aus einer JDBC-Datenquelle direkt in eine Delta-Tabelle.
- Power BI
Der Power BI Connector ist eine benutzerdefinierte Power Query-Funktion, mit der Power BI eine Delta-Tabelle aus jeder von Microsoft Power BI unterstützten dateibasierten Datenquelle lesen kann.
Delta Connectors ist ein schnell wachsendes Ökosystem, in dem regelmäßig weitere Konnektoren verfügbar werden. In der kürzlich angekündigten Version 3.0 von Delta Lake ist sogar Delta Kernel enthalten. Mit Delta Kernel und seinen vereinfachten Bibliotheken ist es nicht mehr nötig, die Details des Delta-Protokolls zu verstehen. macht es viel einfacher, Konnektoren zu erstellen und zu warten.
Fazit
Angesichts des Volumens, der Geschwindigkeit, der Vielfalt und des Wahrheitsgehalts von Daten haben die Grenzen und Herausforderungen von Data Warehouses und Data Lakes zu einem neuen Paradigma von Datenarchitekturen geführt. Die Lakehouse-Architektur, die durch die Weiterentwicklung offener Tabellenformate wie Delta Lake entstanden ist, stellt eine moderne Datenarchitektur dar, die die besten Elemente ihrer Vorgänger nutzt, um einen einheitlichen Ansatz für eine Datenplattform zu schaffen.
Wie bereits im Vorwort erwähnt, wird dieses Buch mehr als nur an der Oberfläche kratzen; es wird in einige der Kernfunktionen von Delta Lake eintauchen, die bereits in diesem Kapitel angesprochen wurden. Du wirst lernen, wie du Delta Lake am besten einrichtest, Anwendungsfälle für verschiedene Funktionen identifizierst, bewährte Methoden kennenlernst und was du dabei beachten solltest und vieles mehr. Es wird Datenpraktikern immer wieder Kontext und Beweise dafür liefern, wie dieses Open-Table-Format eine moderne Datenplattform in Form einer Lakehouse-Architektur unterstützt. Am Ende dieses Buches wirst du dich sicher fühlen, wenn du mit Delta Lake loslegst und eine moderne Data Lakehouse-Architektur aufbaust.
Get Delta Lake: Auf und davon now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

