Kapitel 1. Was uns die Natur und die Geschichte über den Maßstab gelehrt haben
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Was im großen Maßstab funktioniert, kann sich von der Skalierung dessen, was funktioniert, unterscheiden.
-Rohini Nilekani
Das Hauptziel dieses Buches ist es, dir wertvolle Informationen an die Hand zu geben, die es dir ermöglichen, deinen Deep Learning-Workload effizient und effektiv zu skalieren. In diesem Einführungskapitel gehen wir der Frage nach, was Skalierung bedeutet und wie du feststellst, wann du mit der Skalierung beginnen solltest. Wir werden uns mit den allgemeinen Gesetzen der Skalierung befassen und uns von der "Natur" als dem skalierbarsten System inspirieren lassen. Wir werden uns auch mit den sich entwickelnden Trends im Deep Learning befassen und untersuchen, wie Innovationen in den Bereichen Hardware, Software, Daten und Algorithmen zusammenkommen, um Deep Learning in großem Maßstab zu betreiben. Schließlich werden wir uns mit der Philosophie hinter der Skalierung befassen und erörtern, welche Faktoren du berücksichtigen solltest und welche Fragen du dir stellen solltest, bevor du mit der Skalierung beginnst.
Dieses Kapitel ist vor allem mit Philosophie und Geschichte gefüllt. Wenn du technisches Material bevorzugst, überspringe bitte den Abschnitt "Künstliche Intelligenz: Die Entwicklung von lernfähigen Systemen".
Die Philosophie der Skalierung
Die Skalierung eines Systems ( ) bedeutet, dass seine Kapazität durch Hinzufügen weiterer Ressourcen erhöht wird.1 Die Kapazität einer Brücke zu erhöhen, indem mehr Fahrspuren hinzugefügt werden, um mehr Fahrzeuge gleichzeitig aufnehmen zu können, ist ein Beispiel für die Skalierung der Brücke. Das Hinzufügen weiterer Replikate eines Dienstes, um zusätzliche gleichzeitige Nutzeranfragen zu bearbeiten und den Durchsatz zu erhöhen, ist ein Beispiel für die Skalierung des Dienstes. Wenn von Skalierung die Rede ist, geht man oft von einem hochgesteckten Ziel aus und beabsichtigt, ein Szenario oder eine Fähigkeit höherer Ordnung zu skalieren. Das Hinzufügen zusätzlicher Fahrspuren zu einer Brücke oder das Hinzufügen weiterer Replikate eines Dienstes mag wie ein einfaches Ziel erscheinen, aber wenn du anfängst, es zu zerlegen und seine Abhängigkeiten und den Plan zu seiner Ausführung zu entwirren, erkennst du die Herausforderungen und die Komplexität, die mit der Erfüllung des ursprünglichen Ziels der Skalierung verbunden sind.
Wie können wir diese aufgaben- und domänenspezifischen Herausforderungen bewerten? Sie sind im allgemeinen Gesetz der Skalierung erfasst.
Das allgemeine Gesetz der Skalierung
Das allgemeine Skalierungsgesetz ( y ∝ f(x)) definiert die Skalierbarkeit von y durch seine Abhängigkeit von der Variablen x. Die mathematische Beziehung, die durch f(x) gegeben ist, gilt nur für ein signifikantes Intervall von x, um zu verdeutlichen, dass die Skalierbarkeit per Definition begrenzt ist und es einen Wert von x gibt, bei dem die besagte (Skalierungs-)Beziehung zwischen x und y bricht. Diese Werte von x bestimmen die Grenzen der Skalierbarkeit von y. Der allgemeine Ausdruck f(x) zeigt, dass das Skalierungsgesetz viele Formen annimmt und sehr bereichs-/aufgabenspezifisch ist. Das allgemeine Skalierungsgesetz besagt auch, dass zwischen zwei Variablen keine Skalierungsbeziehung bestehen darf.
Die Länge eines elastischen Bandes zum Beispiel ist proportional zur aufgebrachten Kraft und zur Elastizität des Materials. Die Länge des Bandes nimmt zu, wenn mehr Kraft (Zug) ausgeübt wird. Doch irgendwann erreicht das Material bei weiterer Krafteinwirkung seine Zugfestigkeit und reißt. Das ist die Grenze des Materials und bestimmt, wie weit sich das Band ausdehnen kann. Allerdings steht die Elastizität des Bandes in keinem Verhältnis zu anderen Eigenschaften des Materials, wie z. B. seiner Farbe.
Die Geschichte des Skalierungsgesetzes ist auch heute noch interessant und relevant, denn sie unterstreicht die Herausforderungen und Grenzen, die mit der Skalierung einhergehen.
Geschichte des Skalierungsgesetzes
In der Göttlichen Komödie beschrieb der Schriftsteller und Philosoph Dante Alighieri im 14. Jahrhundert seine Vorstellung von der Hölle in poetischer Form als einen umgekehrten Kegel, der in neun konzentrischen Ringen zum Mittelpunkt der Erde hin abfällt. Seine Beschreibung wurde von einer Illustration von Sandro Botticelli begleitet, die als " Karte der Hölle" bekannt ist. Diese Darstellung wurde sehr wörtlich genommen und führte zu einer Untersuchung, um den Durchmesser des Kegels zu messen (die so genannte Halle der Hölle). Galileo Galilei, ein junger Mathematiker, nutzte Dantes poetischen Vers "Schon die Sonne war mit dem Horizont verbunden / Dessen Meridiankreis / Jerusalem mit seinem höchsten Punkt bedeckt" als Grundlage für seine Schlussfolgerung, dass der Durchmesser des Kreises der Kuppel gleich dem Radius der Erde sein muss und dass der Mittelpunkt des Dachs in Jerusalem liegen würde. Unter Berücksichtigung des Begriffs "Meridian" folgerte Galilei außerdem, dass die Grenze der Kuppel durch Frankreich verlaufen würde, und zwar an dem Punkt, an dem der Nullmeridian verläuft. Indem er die Spitze der Kuppel in Jerusalem und den Rand in Frankreich kartierte, schloss er, dass der gegenüberliegende Rand in Usbekistan liegen würde. Galileis Ableitung der Größe der Halle der Hölle ergab ein ziemlich großes Bauwerk. Er bezog sich auf die Kuppel der Kathedrale von Florenz, die 45,5 m breit und 1,5 m dick ist, und leitete daraus ab, dass das Dach der Halle 600 km dick sein müsste, um sein eigenes Gewicht zu tragen. Seine Arbeit kam gut an und verschaffte ihm eine Stelle als Dozent für Mathematik an der Universität Pisa.
Interessanterweise erkannte Galileo, dass die Struktur bei dieser Dicke nicht sehr stabil sein würde. Er stellte fest, dass die Dicke der Kuppel viel schneller zunehmen müsste als die Breite, um die Festigkeit des Bauwerks zu erhalten und es vor dem Einsturz zu bewahren. Galileos Schlussfolgerung wurde durch die Untersuchung von Tierknochen inspiriert, deren Dicke, wie er beobachtete, proportional viel schneller zunimmt als ihre Länge. Der längste und zugleich stärkste Knochen des Menschen, der Oberschenkelknochen, ist im Durchschnitt 48 cm lang und hat einen Durchmesser von 2,34 cm. Der Oberschenkelknochen eines Windhundes ist dagegen im Durchschnitt nur 19 cm lang und 0,13 cm dick (siehe Abbildung 1-1).2 Das ist ein Längenunterschied von nur 2,5 Mal, während der menschliche Oberschenkelknochen 18 Mal dicker ist als der eines Windhundes! Um den Vergleich fortzusetzen: Das zweitgrößte bekannte Tier der Welt (nach dem Blauwal), Tyrannosaurus rex, hatte einen Oberschenkelknochen mit einer Länge von 133 cm und einer Dicke von 43 cm.3
Auf der Grundlage seiner Studien stellte Galileo eine Begrenzung für die Größe der Tierknochen fest und schlussfolgerte, dass die Knochen ab einer bestimmten Länge unmöglich dick sein müssten, um die für die Stützung des Körpers erforderliche Kraft zu erhalten. Natürlich gibt es noch andere praktische Herausforderungen für das Leben auf der Erde, wie z. B. die Beweglichkeit und Mobilität, die zusammen mit Darwins Prinzipien die Größe der Tiere begrenzen. Ich verwende dieses natürliche Beispiel, um die Überlegungen zur Skalierung zu veranschaulichen, ein Thema, das im Mittelpunkt dieses Buches steht. Dieser historische Kontext veranschaulicht sehr schön, dass die Skalierung weder frei noch unbegrenzt ist und daher das Ausmaß der Skalierung gründlich überlegt werden sollte. "Warum skalieren?" ist eine ebenso wichtige Frage. Obwohl ein menschlicher Oberschenkelknochen das 30-fache des Gewichts eines Erwachsenen tragen kann, kann ein durchschnittlicher Mensch kaum das Doppelte seines eigenen Gewichts heben. Winzige Ameisen hingegen können das 50-fache ihres Gewichts heben!
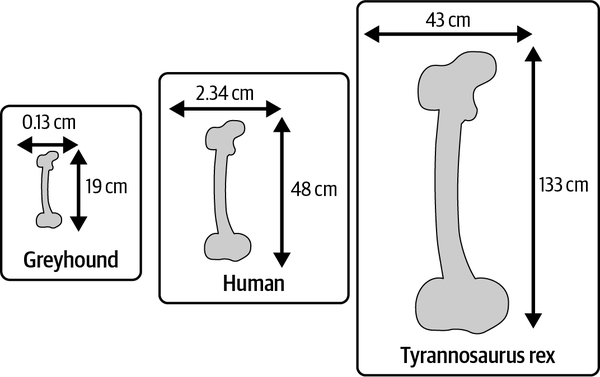
Abbildung 1-1. Der Maßstab der Oberschenkelknochen bei drei Arten: Windhund, Mensch und Tyrannosaurus rex
Letztlich führten Galileos Forschungen zum allgemeinen Skalierungsgesetz, das die Grundlage für viele Skalierungstheoreme in der modernen Wissenschaft und Technik bildet. In den Kapiteln 3, 5, 8 und 10 erfährst du mehr über einige dieser Gesetze, die auf Deep Learning-Szenarien anwendbar sind, wie z. B. das Moore'sche Gesetz, die Dennard-Skalierung, das Amdahl'sche Gesetz, das universelle Skalierungsgesetz von Gunther und das Skalierungsgesetz für Sprachmodelle.
Skalierbare Systeme
Das Beispiel aus dem vorigen Abschnitt zeigt, warum die Skalierung (z. B. die Vergrößerung eines Tieres) im Kontext des gesamten Systems (z. B. mit Blick auf die Lebensqualität des Tieres) und seiner gewünschten Fähigkeiten (z. B. schwere Gewichte heben) betrachtet werden muss. Es zeigt auch, dass es wichtig ist, skalierbare Systeme zu bauen.
Bei der Skalierung geht es in vielerlei Hinsicht darum, die Beschränkungen und Abhängigkeiten des Systems zu verstehen und die Dimensionen proportional zu skalieren, um den optimalen Zustand zu erreichen. Skalierung mit Optimierung ist effektiver als einfache Skalierung. Bei der Skalierung geht nämlich alles kaputt. Später in diesem Kapitel werden wir über Überlegungen zur effektiven Skalierung sprechen. Für den Moment wollen wir kurz auf die Natur als skalierbares System und die natürliche Tendenz zur Skalierung eingehen.
Die Natur als skalierbares System
Die Oberfläche des Planeten Erde beträgt etwa 197 Millionen Quadratmeilen (510 Millionen km2) und beherbergt mindestens 8,7 Millionen einzigartige Lebewesen.4 Die Gesamtbevölkerung von nur einer dieser 8,7 Millionen Arten, den Menschen, wird auf etwa 8 Milliarden geschätzt. Als Menschen besitzen wir die spektakuläre Fähigkeit, mit unseren Seh- und Hörsinnen unbegrenzt viele Daten zu verarbeiten. Noch faszinierender ist, dass wir uns dabei gar nicht bewusst anstrengen! Insgesamt kommunizieren wir in über 7.100 gesprochenen Sprachen.5 Wenn es einen Beweis dafür gibt, dass wir in großem Maßstab arbeiten, dann ist es die Welt, die uns umgibt.
Mit unserem unstillbaren Appetit auf Wissen und die Erkundung unserer Umgebung und darüber hinaus sind wir sicherlich durch die Anzahl der Stunden am Tag begrenzt. Diese Begrenzung hat zu einem starken Wunsch geführt, die Kleinigkeiten unseres Alltags zu automatisieren und mehr Zeit zu haben, um innerhalb der Grenzen des Tages mehr zu tun. Die Herausforderung bei der Automatisierung von Kleinigkeiten besteht darin, dass sie vielschichtig und rekursiv ist. Sobald du die unterste Schicht automatisiert hast, wird die nächste Schicht scheinbar zur neuen untersten Schicht, und du strebst danach, alles zu automatisieren.
Nehmen wir die Kommunikation als Beispiel. Früher waren unsere Vorfahren tagelang oder sogar monatelang unterwegs, um sich persönlich zu unterhalten. Der hohe Reiseaufwand war ein Hindernis, um das Ziel (das Gespräch) zu erreichen. Später machten schriftliche Kommunikationsformen den Hauptkommunikator nicht mehr von einer Reise abhängig; die Nachrichten konnten von einem Vermittler übermittelt werden. Im Laufe der Zeit entwickelten sich auch die Mittel zur Verbreitung schriftlicher Kommunikation über verschiedene Kanäle weiter, von Brieftauben über Postdienste bis hin zu Morsezeichen und Telegrafen. Darauf folgte das digitale Zeitalter der Nachrichten, von Faxen und E-Mails bis hin zur sozialen Kommunikation und der Verbreitung über Internetprogramme, wobei alles in der Größenordnung von Millisekunden abläuft. Wir leben heute in einer Zeit des Überflusses an Kommunikation, und zwar so sehr, dass wir nach Wegen suchen, um automatisch zu priorisieren, was wir aus der Fülle an Informationen verdauen, und sogar stochastische Ansätze zur Zusammenfassung von Inhalten in Betracht ziehen, um unsere Zeit optimal zu nutzen. In unserem Bestreben, die ursprünglichen Hindernisse für die Kommunikation (Zeit und Raum) zu beseitigen, haben wir ein neues Hindernis geschaffen, das eine neue Lösung erfordert. Wir versuchen nun, die Art und Weise, wie wir kommunizieren, zu skalieren, indem wir aktiv die Möglichkeiten der Gehirn-Computer-Schnittstelle erforschen und direkt zum Gedankenlesen übergehen.6
Unser visuelles System: Eine biologische Inspiration
Skalierung ist komplex. Deine Grenzen bestimmen, wie du skalierst, um deine Ziele zu erreichen. Das menschliche Sehsystem ist ein schönes Beispiel für ein skalierbares System. Es ist in der Lage, unendlich viele visuelle Signale zu verarbeiten - buchstäblich alles, von der Oberfläche deines Augapfels bis zum Horizont und alles dazwischen - durch eine winzige Linse mit einer Brennweite von etwa 17 mm. Es ist einfach großartig, dass wir all das sofort, unbewusst und ohne erkennbare Anstrengung tun können. Wissenschaftlerinnen und Wissenschaftler erforschen seit über hundert Jahren, wie das menschliche Sehsystem funktioniert, und obwohl wichtige Durchbrüche von Forschern wie David Hubel und Torsten Weisel erzielt wurden, sind wir weit davon entfernt, das komplexe7 sind wir noch weit davon entfernt, den komplexen Mechanismus zu verstehen, der es uns ermöglicht, unsere Umgebung wahrzunehmen.
Dein Gehirn hat etwa 100 Milliarden Neuronen. Jedes Neuron ist mit bis zu 10.000 anderen Neuronen verbunden, und es gibt bis zu 1.000 Billionen Synapsen, die Informationen zwischen ihnen übertragen. Ein so komplexes und skalierbares System kann nur gedeihen, wenn es praktisch und effizient ist. Dein visuelles System koordiniert mit etwa 1015 Synapsen und verbraucht dabei nur etwa so viel Energie wie eine einzelne LED-Glühbirne (etwa 12 Watt).8 Wenn man bedenkt, wie implizit und unbewusst dieser Prozess abläuft, ist er ein gutes Beispiel für minimalen Input und maximalen Output - allerdings um den Preis der Komplexität.
Als anpassungsfähiges Informationsverarbeitungssystem ist das menschliche Sehsystem phänomenal ausgeklügelt. Die kortikalen Zellen des Gehirns sind massiv parallel. Jede kortikale Zelle extrahiert unterschiedliche Informationen aus denselben Signalen. Diese Informationen werden dann zusammengeführt und verarbeitet, was zu Entscheidungen, Handlungen und Erfahrungen führt. Die Erinnerungen an deine Erfahrungen werden in extrem komprimierter Form im Hippocampus gespeichert. Unser biologisches System ist ein großartiges Beispiel für ein parallelisiertes, verteiltes System, das darauf ausgelegt ist, Informationen effizient zu verarbeiten. Wissenschaftler und Deep-Learning-Ingenieure haben sich viel von der Natur und der Biologie inspirieren lassen, was unterstreicht, wie wichtig es ist, effizient zu arbeiten und bei der Skalierung die Komplexität zu berücksichtigen. Dies wird auch der Leitgedanke dieses Buches sein: Ich werde mich auf die Prinzipien und Techniken für den Aufbau skalierbarer Deep-Learning-Systeme konzentrieren und dabei die Komplexität und Effizienz solcher Systeme berücksichtigen.
Viele der Fortschritte bei der Entwicklung intelligenter (KI-)Systeme wurden durch die innere Funktionsweise biologischer Systeme motiviert. Der grundlegende Baustein des Deep Learning, das Neuron, wurde von der Erregung biologischer Nervensysteme inspiriert. Auch das Convolutional Neural Network (CNN), eine effiziente Technik zur intelligenten Verarbeitung von Bildschirminhalten, wurde ursprünglich vom menschlichen Sehsystem inspiriert. Im folgenden Abschnitt erfährst du mehr über die Entwicklung lernfähiger Systeme und über neue Trends im Deep Learning.
Künstliche Intelligenz: Die Entwicklung von lernfähigen Systemen
1936 präsentierte Alan Turing die theoretische Formulierung für ein imaginäres Computergerät, das die "Geisteszustände" und Symbolmanipulationsfähigkeiten eines menschlichen Computers nachahmen kann.9 Diese Abhandlung mit dem Titel "On Computable Numbers, with an Application to the Entscheidungsproblem" (Über berechenbare Zahlen und ihre Anwendung auf das Entscheidungsproblem) hat den Bereich der modernen Informatik geprägt. Zwölf Jahre nachdem Turing seine Vision von "Rechenmaschinen" dargelegt hatte, beschrieb er viele der Kernkonzepte von "intelligenten Maschinen" oder "[Maschinen], die aus Erfahrung lernen können".10 Turing veranschaulichte, dass Computer Schach spielen können, indem sie sich den aktuellen Zustand merken, alle möglichen Züge in Betracht ziehen und denjenigen mit der größten Belohnung und der geringsten Bestrafung wählen. Seine Gedanken und Theorien waren jedoch weiter fortgeschritten als die Kapazität der damaligen Computerhardware, was die Realisierung von schachspielenden Computern stark einschränkte. Seine Vision von intelligenten Maschinen, die Schach spielen, wurde erst 1997, rund 50 Jahre später, verwirklicht, als Deep Blue von IBM den damaligen Weltmeister Garri Kasparow in einem Sechs-Spiele-Match schlug.
Es braucht vier zum Tango
In den letzten zehn Jahren ist die Vision des frühen 20. Jahrhunderts von intelligenten Systemen plötzlich viel realistischer geworden. Diese Entwicklung ist auf Innovationen in den Bereichen Hardware, Software und Daten ebenso zurückzuführen wie auf Lernalgorithmen. In diesem Abschnitt erfährst du mehr über die gemeinsamen Fortschritte in diesen vier Disziplinen und wie sie unsere Fortschritte bei der Entwicklung intelligenter Systeme beeinflusst haben .
Die Hardware
Der IBM-Computer Deep Blue verfügte über 256 parallele Prozessoren; er konnte 200 Millionen mögliche Schachzüge pro Sekunde untersuchen und 14 Züge vorausschauen. Der Erfolg von Deep Blue war eher auf Hardware-Fortschritte als auf KI-Techniken zurückzuführen, was in Noam Chomskys Bemerkung zum Ausdruck kam, dass das Ereignis "ungefähr so interessant war wie ein Bulldozer, der einen olympischen Gewichtheberwettbewerb gewinnt".
Diese historische Anekdote unterstreicht die Bedeutung der Rechenleistung für die Entwicklung von KI und maschinellem Lernen (ML). Historische Daten, wie in Abbildung 1-2 dargestellt, bestätigen die stark wachsende Nachfrage nach beschleunigten Berechnungen für die Entwicklung von KI. Sie zeigen auch, wie die Hardware- und Geräteindustrie aufgeholt hat, um die Nachfrage nach Milliarden von Gleitkommaberechnungen pro Sekunde zu befriedigen.11 Dieses Wachstum wurde größtenteils durch das in Kapitel 3 erläuterte Mooresche Gesetz ( ) gesteuert, das eine Verdoppelung der Transistoranzahl (auf einem Gerät) alle zwei Jahre vorhersagt. Mehr Transistoren ermöglichen eine schnellere Matrixmultiplikation auf der Ebene der elektronischen Schaltkreise. Die zunehmende Komplexität beim Bau solch leistungsfähiger Computer ist offensichtlich, denn die Überwindung des Mooreschen Gesetzes ist zu beobachten.12
NVIDIA ist das führende Unternehmen in der Branche für beschleunigte Berechnungen und hat mit seinem Hopper-Chip 1.979 Billionen Fließkommaoperationen pro Sekunde (1.979 teraFLOPs) für bfloat16 Datentypen erreicht. Auch Google hat mit seiner Tensor Processing Unit (TPU), deren Version 4 275 teraFLOPs (bfloat16) erreicht, einen wichtigen Beitrag zur Beschleunigung von KI-Berechnungen geleistet. Andere KI-Chips wie Intels Habana, die Intelligent Processing Units (IPUs) von Graphcore und die Wafer Scale Engine (WSE) von Cerebras wurden in den letzten Jahren ebenfalls aktiv entwickelt.13 Der Erfolg (oder Misserfolg) vieler Forschungsideen wird auf die Verfügbarkeit geeigneter Hardware zurückgeführt, die im Volksmund auch als Hardware-Lotterie bezeichnet wird.14
Die Einschränkungen und Zwänge, die sich aus der intensiven Energienutzung und den Emissionen ergeben, gehören zu den wichtigsten Herausforderungen für die Hardware. Einige sehr interessante Projekte, wie Microsofts Natick, erforschen nachhaltige Wege, um die steigenden Anforderungen an die Rechenleistung zu erfüllen. Mehr über die Hardware-Aspekte des Deep Learning erfährst du in den Kapiteln 3 und 5.
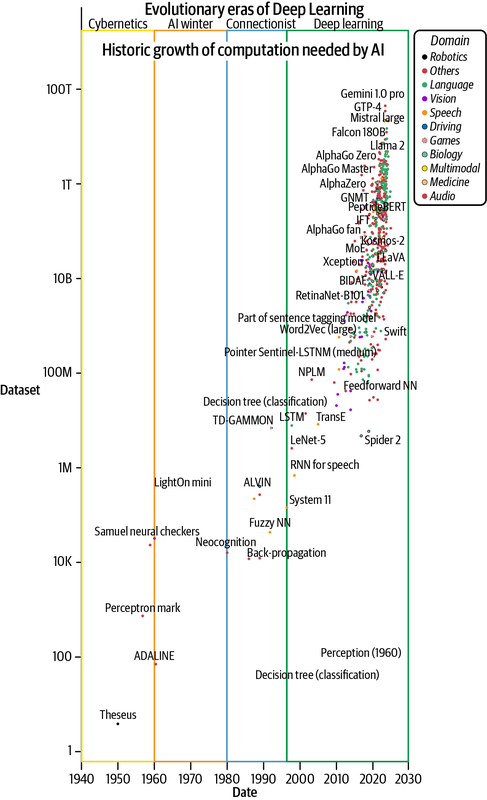
Abbildung 1-2. Zunahme des Rechenaufwands für die Entwicklung von KI-Modellen (dargestellt anhand von Daten aus Sevilla et al., 2022)
Die Daten
Nach der Hardware sind die Daten der zweitwichtigste Treibstoff für Deep Learning. Das enorme Wachstum der verfügbaren Daten und die Entwicklung von Techniken, um sie zu beschaffen, zu erstellen, zu verwalten und effektiv zu nutzen, haben den Erfolg von lernfähigen Systemen geprägt. Deep-Learning-Algorithmen sind datenhungrig, aber es ist uns gelungen, diese Bestie mit immer größeren Datenmengen zu füttern und bessere Systeme zu entwickeln (siehe Abbildung 1-3). Dies ist aufgrund des exponentiellen Wachstums der digital erstellten Inhalte möglich. So werden allein im Jahr 2020 schätzungsweise 64,2e-9 TB (64,2 Zettabytes) an Daten erzeugt - 32-mal mehr als die 2e-9 TB (2 ZB), die 2010 erzeugt wurden.15
Hinweis
In Kapitel 2 werden wir mehr über die Rolle von Daten beim Deep Learning erfahren. Es wurde eine ganze Reihe von Techniken entwickelt, um die Menge, die Vielfalt, den Wahrheitsgehalt und den Wert von Daten für die Entwicklung und Skalierung von Deep Learning-Modellen zu nutzen. Diese Techniken werden unter dem Begriff "datenzentrierte KI" erforscht, den wir in Kapitel 10 besprechen werden.
Traditionell begann die Entwicklung intelligenter Systeme mit einem stark kuratierten und beschrifteten Datensatz. In jüngster Zeit haben sich innovative Techniken wie das selbstüberwachte Lernen als sehr ökonomisch und effektiv erwiesen, wenn es darum geht, einen sehr großen Bestand an bereits verfügbaren, nicht beschrifteten Daten zu nutzen - das freie Wissen, das wir im Laufe der Geschichte in Form von Nachrichtenartikeln, Büchern und verschiedenen anderen Publikationen geschaffen haben.16 CoCa zum Beispiel, ein Modell für kontrastives, selbstüberwachtes Lernen, folgt diesem Prinzip und ist zum Zeitpunkt der Erstellung dieses Artikels mit einer Genauigkeit von 91 % der Spitzenreiter im ImageNet (siehe Abbildung 1-6 weiter unten in diesem Abschnitt).17 Darüber hinaus kuratieren Social-Media-Anwendungen automatisch riesige Mengen an beschrifteten multimodalen Daten (z. B. Bilddaten in Form von Bildern mit Beschriftungen/Kommentaren und Videos mit Bildern und Audio), die die Grundlage für leistungsfähigere generalistische Modelle bilden (mehr dazu in den Kapiteln 12 und 13).
Hinweis
Die Top-N-Genauigkeit ist ein Maß dafür, wie oft die richtige Bezeichnung unter den Top-N-Vorhersagen des Modells ist. Die Top-1-Genauigkeit gibt zum Beispiel an, wie oft die Vorhersage des Modells genau mit der erwarteten Antwort übereinstimmte, und die Top-5-Genauigkeit gibt an, wie oft die erwartete Antwort unter den Top-5-Vorhersagen des Modells war.
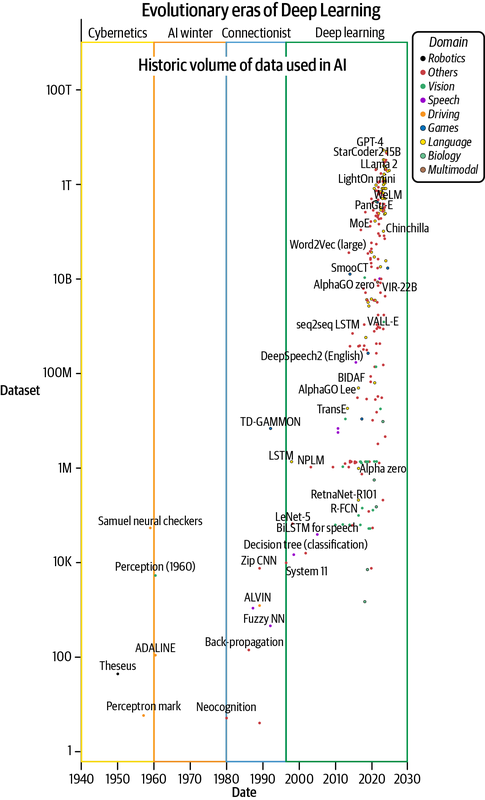
Abbildung 1-3. Wachstum der für das Training von KI-Modellen verwendeten Datenmengen (aufgetragen mit Daten aus Sevilla et al., 2022)
Die Software
Auch die Softwarelandschaft, die die Entwicklung von KI-Lösungen unterstützt, ist gewachsen. In der Anfangsphase von, etwa ab dem Jahr 2000, waren nur frühe Software-Frameworks wie MATLAB und das Lua-basierte Torch verfügbar. Darauf folgte die Gründungsphase, die um 2012 begann, als Frameworks für maschinelles Lernen wie Caffe, Chainer und Theano entwickelt wurden (siehe Abbildung 1-4). Es dauerte weitere vier Jahre, bis die Reifephase erreicht war, in der stabile Frameworks wie Apache MXNet, TensorFlow und PyTorch freundlichere APIs für die Modellentwicklung bereitstellten. Dank der Open-Source-Gemeinschaften auf der ganzen Welt, die gemeinsam daran arbeiten, die Stellung der Software-Werkzeuge für Deep Learning zu stärken, befinden wir uns jetzt in der Expansionsphase. Die Expansionsphase zeichnet sich durch ein wachsendes Ökosystem von Software und Tools aus, das die Entwicklung und Produktion von KI-Software beschleunigt .
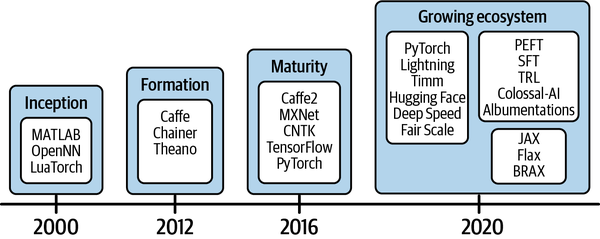
Abbildung 1-4. Die Entwicklungsphasen von Software und Werkzeugen für Deep Learning
Die gemeinschaftsgetriebene Open-Source-Entwicklung hat entscheidend dazu beigetragen, die Software, die Algorithmen und die Menschen zusammenzubringen, die für ein exponentielles Wachstum benötigt werden. Open-Source-Softwareprojekte zur Entwicklung von Deep Learning (wie PyTorch, JAX und TensorFlow), Stiftungen wie die Linux Foundation (verantwortlich für PyTorch und sein Ökosystem) und Foren zum Austausch von Forschungsergebnissen wie arXiv und Papers with Code haben Beiträge von Menschen auf der ganzen Welt gefördert und ermöglicht. Die Rolle, die die Open-Source-Gemeinschaften bei der Verbreitung intelligenter Systeme gespielt haben, ist geradezu heldenhaft.
Die (Deep Learning) Algorithmen
Die Vision lernfähiger intelligenter Systeme begann mit heuristikbasierten, regelbasierten Lösungen, die sich schnell zu datengesteuerten stochastischen Systemen weiterentwickelten. Abbildung 1-5 zeigt die Entwicklung und die steigende Popularität von Deep-Learning-Algorithmen im Laufe der Zeit. Sie veranschaulicht die Entwicklung von den Anfängen des klassischen maschinellen Lernens über Perzeptron-basierte flache neuronale Netze bis hin zu den tieferen und dichteren Schichten, die Deep Learning heute prägen. (Einen detaillierteren historischen Kontext findest du in der Sidebar "Geschichte des Deep Learning". Beachte, dass es sich hierbei um eine indikative Darstellung handelt, die die Popularität und das Wachstum von Deep Learning zeigt. Sie stellt nicht die absolute Popularität dar.) Wie du siehst, ist die Popularität von Deep Learning exponentiell gewachsen, aber es gab auch einige Flauten - die so genannten KI-Winter - aufgrundvon Beschränkungen und Einschränkungen, die überwunden werden mussten.
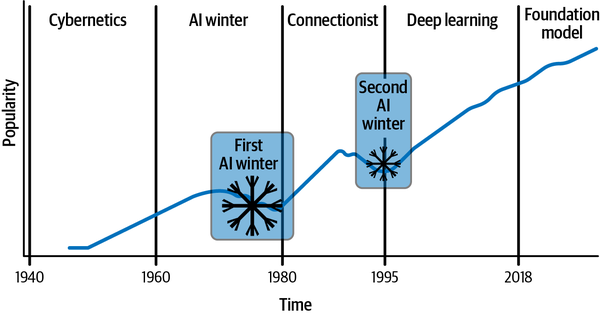
Abbildung 1-5. Die Entwicklung und wachsende Popularität von Deep Learning
Der zweite KI-Winter dauerte bis 1995 an. Zu diesem Zeitpunkt wurde den Forschern klar, dass sie Lösungen für die folgenden drei Probleme finden mussten, um mit neuronalen Netzen weiter erfolgreich zu sein:
- Ebenen effektiv skalieren
-
Während der Ära des konnektionistischen Lernens entdeckten die Forscher/innen, dass effektive Modelle für Deep Learning eine sehr große Anzahl von Schichten benötigen. Das einfache Hinzufügen weiterer Schichten zu neuronalen Netzen war aufgrund der Überanpassung keine praktikable Option (wie von Sepp Hochreiter und Yoshua Bengio et al. beschrieben).18
- Skalierung der Berechnungseffizienz
-
Leider hatte die Hardware-Lotterie zu dieser Zeit kein Glück! So dauerte es beispielsweise drei Tage, um ein Modell mit 9.760 Parametern zu trainieren, das auf der 1989 von Yann LeCun vorgeschlagenen LeNet-5-Architektur basierte, die fünf trainierbare Schichten hatte.19 Der beste Computer, der damals zur Verfügung stand, war nicht leistungsfähig genug, um schnelles Feedback zu liefern, und Hardwarebeschränkungen bremsten die Entwicklung.
- Skalierung der Eingabe
-
Wie in Abbildung 1-3 zu sehen ist, änderte sich die Menge der Daten, die für Deep Learning-Experimente verwendet wurden, von den 1940er Jahren bis etwa 1995 kaum. Auch die Fähigkeit, Daten zu erfassen, zu speichern und zu verwalten, war in dieser Zeit noch in der Entwicklung.
Es ist klar, dass der Umgang mit der Skalierung eine entscheidende Herausforderung für jedes Deep-Learning-System darstellt. Die bahnbrechende Forschung, die das Wachstum des Deep Learning beschleunigte, war das von Hinton et al. im Jahr 2006 entwickelte tiefe, dicht vernetzte Glaubensnetzwerk,20 das so viele Parameter hat wie 0,002 mm3 des Mäusekortex. Dies war das erste Mal, dass Deep Learning auch nur annähernd ein biologisches System modellieren konnte, egal wie klein es war. Wie in den Abbildungen 1-2 und 1-3 zu sehen ist, war dies auch das Jahr, in dem das Wachstum von Daten und Hardware an Dynamik gewann. Auch gemeinsame Open-Source-Bemühungen haben das Wachstum vorangetrieben, wie die Entwicklung nach der Veröffentlichung des ImageNet-Datensatzes im Jahr 2009 zeigt, die als "ImageNet-Moment" bezeichnet wird. Dieser Datensatz, der über 14 Millionen kommentierte Bilder von Alltagsgegenständen in etwa 20.000 Kategorien enthält, wurde Forschern zur Verfügung gestellt, um an der ImageNet Large Scale Visual Recognition Challenge (ILSVRC) teilzunehmen und Algorithmen für die skalierte Aufgabe zu entwickeln.21
Unter Hintons Aufsicht entwickelte Alex Krizhevsky 2017 eine Lösung für den ILSVRC, die die Konkurrenz um 10,8 % übertraf (bei 15,3 % Top-5-Fehler).22 Bei dieser Arbeit, die inzwischen unter dem Namen AlexNet bekannt ist, wurden neuartige verteilte Trainingstechniken eingesetzt, um die Entwicklung der Lösung auf zwei Grafikprozessoren mit sehr begrenztem Speicher zu skalieren. Abbildung 1-6 zeigt den Erfolgsverlauf (steigende Rate der Top-5-Genauigkeit) von ImageNet seit dieser bahnbrechenden Entwicklung.
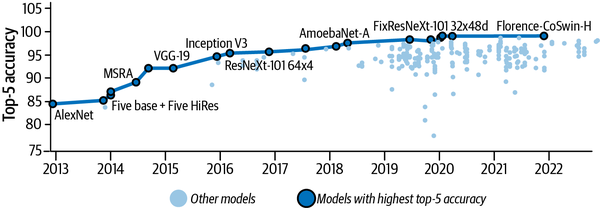
Abbildung 1-6. Top-5-Genauigkeit verschiedener Deep-Learning-Modelle auf dem ImageNet-Datensatz seit der Einführung von AlexNet (Darstellung basierend auf Daten von https://oreil.ly/mYfbq)
Ungefähr zu dieser Zeit begann auch die Industrie, sich ernsthaft für Deep Learning und seine Umsetzung zu interessieren; eine solide industrielle Basis sorgte für eine Finanzspritze, und Risikofinanzierungen beschleunigten nicht nur die Kommerzialisierung, sondern auch die zukünftige Forschung. Seit der Übernahme von Hintons DNNresearch durch Google im Jahr 2013 fließen die Gelder in großem Umfang in Deep Learning und machen es (bis 2023) zu einer 27-Milliarden-Dollar-Branche.23 Der Überfluss an Ressourcen und Unterstützung hat den Aufstieg des Deep Learning in den letzten zehn Jahren beschleunigt - und mit der Unterstützung der Industrie kam das interdisziplinäre Wachstum, das die kollektive Entwicklung der wissenschaftlichen Aspekte des Deep Learning und der Algorithmen sowie alles andere, was an der Schnittstelle von Hardware, Software und Daten liegt, vorangetrieben hat.
Nachdem du nun ein wenig mit der Geschichte vertraut bist, werfen wir im nächsten Abschnitt einen Blick auf die aktuellen Trends im Deep Learning und sehen, wie die Fähigkeit zur Skalierung die laufende Forschung und die Anpassung der Industrie beeinflusst.
Sich entwickelnde Deep Learning Trends
Zwanzig Jahre nach dem Erfolg von Deep Blue hat sich Deep Learning so weiterentwickelt, dass es regelbasierte Lösungen vollständig ersetzt und die menschliche Leistung bei bestimmten Aufgaben zunehmend übertrifft. AlphaGo,24 zum Beispiel hat dieses Niveau nach etwa vier Stunden Training auf einer Maschine mit 44 CPU-Kernen und einer TPU erreicht und kann durch seine neuartigen Algorithmen und Softwareimplementierungen in etwa neun Stunden annähernde Konvergenz erreichen. Sie hat Stockfish besiegt, eine der weltbesten Schachengines, die verschiedene Schachwettbewerbe gewonnen hat. Diese verbesserte Fähigkeit, bessere Lösungen als regelbasierte Software zu liefern, wird von der Software 2.0-Migration (die in Kapitel 2 näher erläutert wird) anerkannt, bei der traditionelle Software modellgesteuert wird.
Allgemeine Entwicklung des Deep Learning
Die Anwendung von Deep Learning in der Computer Vision, die mit Yann LeCuns Netzwerk zur Ziffernerkennung begann25 begann, hat sich heute auf viele Bildverarbeitungsaufgaben ausgeweitet, z. B. Bildklassifizierung, Objekterkennung und -segmentierung, Szenenverständnis, Beschriftung usw. Diese Lösungen werden heute auf der ganzen Welt entwickelt und eingesetzt. Die Effizienz war die Hauptmotivation für die in diesem Kapitel erwähnte Architektur der Faltungsneuronalen Netze, und angesichts der großen Menge an Bilddaten ist dies nach wie vor ein wichtiger Aspekt. CNN-basierte Modelle wie ResNet und EfficientNet haben sich bei Sehaufgaben als sehr erfolgreich erwiesen. Sie erreichen eine Top-1-Genauigkeit von etwa 90 %, wobei sie sorgfältig auf Effizienz und Skalierung achten. Diese Modelle eignen sich hervorragend für kleine räumliche Kontexte, aber sie skalieren nicht für größere räumliche Kontexte.
Die Transformer-Architektur von Google,26 die Token in langen Sequenzen auf parallelisierte Weise berücksichtigt, war bahnbrechend. Die Anforderungen an die Skalierung von Bildverarbeitungsmodellen für einen globalen Kontext haben dazu geführt, dass der Einsatz von Transformer-basierten Architekturen erforscht wurde. Ein solches Beispiel ist der Vision Transformer (ViT),27 Er zerlegt die Bilder in kleine Teile und merkt sich, wo diese Teile im globalen Bildraum liegen. In den letzten Jahren wurde der Großteil der Bildverarbeitungsforschung durch die Transformer-Architektur vorangetrieben. CoAtNet, eine Kombination aus CNN- und Transformer-Architekturen, hat 2,44 Milliarden Parameter und erreicht bei ImageNet-Aufgaben eine Top-1-Genauigkeit von 90,88 %. MaxViT, eine ViT-basierte Architektur, liegt bei der Genauigkeit nahe an CoAtNet, hat aber etwa fünfmal weniger Parameter (475 Millionen).28 Dennoch ist die Skalierung der Kontextgröße von Transformers aufgrund von Speicher- und Rechenbeschränkungen nach wie vor eine Herausforderung. Dies hat zu interessanten und innovativen Techniken wie MEGABYTE und LongViT geführt, die sehr große Kontexte verarbeiten können (z. B. Sequenzen von einer Million Byte oder Gigapixel-Bilder, die in der Pathologie verwendet werden).29 Bei der Skalierung geht es aber nicht nur um die Anzahl der Parameter, sondern auch um Daten-, Energie- und Kosteneinsparungen.
Es war die Transformer-Architektur, die die Innovation im Bereich der Sprachverarbeitung wiederbelebte, die vor 2017 stagniert hatte. Trotz ihrer Rechenschwäche (aufgrund quadratischer Berechnungen im Aufmerksamkeitsmodul) revolutionierte diese Architektur die Verarbeitung natürlicher Sprache vollständig. Wie in Abbildung 1-7 zu sehen ist, konnten Sprachmodelle, die auf dieser Architektur basieren, ihre Fähigkeiten mit der Anzahl der Parameter skalieren - ein Trend, der als Skalierungsgesetz von Sprachmodellen bezeichnet wird.30 Der Codex von OpenAI ist ein solches skalierbares Modell, das mit Open-Source-Code von GitHub trainiert wurde und die Art und Weise, wie Entwickler/innen heute programmieren, revolutioniert. Dieser Trend hielt bis mindestens Mitte 2021 an. Ende 2021 wurde die Skalierung vor allem über die Anzahl der Parameter ernsthaft überdacht, und es folgte ein Plateau mit einigen signifikanten Einbrüchen, die durch Modelle verursacht wurden, die eine wesentlich geringere Anzahl von Parametern verwendeten, aber trotzdem besser abschnitten als ihre Gegenspieler. Chinchilla ist ein solches Modell, das hauptsächlich über die Datenmenge skaliert; obwohl es 2,5 Mal weniger Parameter hat, übertrifft es immer noch GPT-3. LLaMA, ein weiteres vergleichbares Modell von Meta, hat ebenfalls an Popularität gewonnen und wird häufig verwendet. Dieser Trend ist in Abbildung 1-7 zu erkennen, die die Konzentrationszone der Modelle im Bereich 7B-200B aufzeigt, obwohl Modelle mit mehr als 1T Parametern entwickelt werden.

Abbildung 1-7. Die sich verändernde Landschaft des Skalierungsgesetzes von Sprachmodellen (aufgetragen mit Daten aus Sevilla et al., 2022)
Das Skalierungsgesetz von Deep-Learning-Modellen hat die Entwicklung von überparametrisierten Modellen und immer tieferen und dichteren Netzwerken begünstigt.31 Dieser Trend ist in allen Datenmodalitäten zu beobachten: Sehen, Sprache, Sprache usw. Wie bereits erwähnt, ist eine wichtige Innovation an der Schnittstelle von Daten und Algorithmen die selbstüberwachte Modellentwicklung.32 Diese Entwicklungen tragen dazu bei, dass große Allzweckmodelle mit neuen Fähigkeiten entstehen, die Aufgaben erfüllen können, ohne dass sie explizit dafür trainiert werden. Diese großen Modelle, besser bekannt als Basismodelle, nutzen eine Reihe komplexer, ausgereifter verteilter Trainingstechniken, um die verfügbaren Ressourcen effizient zu nutzen und die bestmöglichen Modelle zu erstellen. Ein weiterer aufkommender Trend ist die Entwicklung großer multimodaler Modelle (LMMs), die mit Daten aus verschiedenen Modalitäten (wie Text, Audio und Bilder) arbeiten können, wie CLIP und DALL-E, GPT-4, Gemini und Flamingo. Dies wiederum hat zu einem rasanten Wachstum der generativen Kunst geführt. Modelle wie Sora, GLIDE, Imagen und Stability.ai's Stable Diffusion haben die Kunstbranche aufgemischt.33
Keine dieser Entwicklungen wäre ohne Fortschritte bei Algorithmen, Hardware, Software und Daten möglich gewesen. In Teil I erfährst du mehr über diese Entwicklungen. In Teil II befassen wir uns mit den Details der verteilten Ausbildung und in Teil III tauchen wir tiefer in die effiziente und effektive Entwicklung großer Modelle, einschließlich Basismodellen, ein.
Evolution in spezialisierten Domänen
Neben den allgemeinen Fortschritten hat Deep Learning auch Prozesse und Techniken in speziellen Bereichen, wie den in diesem Abschnitt behandelten, massiv beeinflusst.
Mathe und Rechnen
Jahrhunderte lang glaubten Mathematikerinnen und Mathematiker, dass der Standard-Algorithmus zur Multiplikation von Matrizen der effizienteste sei. Dann, 1969, zeigte Volker Strassen, dass ein anderer Algorithmus überlegen ist. Die Bemühungen, die Matrixberechnung zu optimieren, sind ungebrochen. Die Überwindung des Mooreschen Gesetzes ( ) erforderte die Erforschung alternativer Techniken zur Skalierung der Matrixmultiplikation. Das Ergebnis war die Näherungsmultiplikation, die eine 100-fache Beschleunigung ermöglicht, aber für Szenarien, in denen es auf Genauigkeit ankommt, weniger praktisch ist.34 Die jüngste Entdeckung, die von DeepMind geleitet wurde, hat zum ersten Mal seit seiner Entdeckung vor einem halben Jahrhundert Verbesserungen an Straßen's Algorithmus durch den Einsatz des Deep-Learning-Systems AlphaTensor gezeigt.35
Proteinfaltung
Ein weiteres Beispiel für den Erfolg von Open-Source- und Community-getriebener Arbeit sind die Bemühungen, Probleme in der Proteinfaltungsforschung zu lösen, indem evolutionäre Proteinsequenzen automatisch von Ende zu Ende vorhergesagt werden. AlphaFold, ein weiteres Deep-Learning-System von DeepMind, skalierte den Proteindatensatz von 190.000 empirisch abgeleiteten Strukturen auf 0,2 Mrd. KI-generierte Proteinstrukturen.36 Ein großartiges Beispiel für Skalierung ist ProGen2, ein Modell mit 6,4 Mrd. Parametern, das mit verteilten Deep-Learning-Techniken entwickelt wurde, um das Training auf 256 Knoten auf TPUs zu verteilen.37 Der hitzige Wettbewerb führte zu ESMFold, einem Modell mit 15 B-Parametern, für dessen Entwicklung etwa 2.000 V100 NVIDIA-GPUs benötigt wurden und das bei der Inferenz sechsmal schneller als AlphaFold2 ist.38 Mit diesen Innovationen hat sich die Forschungsgemeinschaft im Bereich der Proteinfaltung von "das Problem der Proteinfaltung hat derzeit keine Lösung" zu "Deep Learning hat es (meistens) gelöst" entwickelt.
Simulierte Welt
Deep Learning hat einen großen Einfluss auf die virtuelle Realität und physikgesteuerte Simulationen, sogar auf das Design und die Planung von Textilien und andere verwandte Branchen. Die CVPR 2022 Keynote "Understanding Visual Appearance from Micron to Global Scale" von Kavita Bala, Dekanin für Computer- und Informationswissenschaften an der Cornell University, ist ein hervorragender Vortrag, der zeigt, wie Deep Learning die gesamte Branche verändert.
Du hast in diesem Kapitel viel über die Geschichte und Entwicklung von Deep Learning gelesen. Im folgenden Abschnitt werde ich den Fokus auf praktische Überlegungen und allgemeine Prinzipien legen, die für die Skalierung wichtig sind. Ich glaube, dass es wichtig ist, diese Themen zu verstehen, bevor ich darüber spreche, wie du deinen Deep Learning-Workload skalieren kannst, obwohl die Hinweise, die ich hier gebe, so allgemein sind, dass sie nicht nur für Deep Learning gelten, sondern für die Skalierung jeder Aufgabe, ob technisch oder nicht.
Maßstab im Kontext von Deep Learning
Die Skalierung im Kontext von Deep Learning ( ) ist mehrdimensional und besteht im Wesentlichen aus den folgenden drei Aspekten:
- Verallgemeinerbarkeit
-
Verbesserung der Fähigkeit von Modellen, auf verschiedene Aufgaben oder Demografien zu verallgemeinern
- Ausbildung und Entwicklung
-
Skalierung der Modellschulungstechnik, um die Entwicklungszeit zu verkürzen und gleichzeitig die Ressourcenanforderungen zu erfüllen
- Inferenz
-
Erhöhung der Gebrauchstauglichkeit des entwickelten Modells während des Dienstes
Alle diese Maßnahmen sind differenziert und erfordern unterschiedliche Strategien, um zu skalieren. Dieses Buch konzentriert sich jedoch vor allem auf die ersten beiden; die Ableitung (Bereitstellung, Bedienung und Wartung) ist nicht Gegenstand des Buches.
Sechs Überlegungen zur Entwicklung
gibt es sechs Überlegungen, die bei der Entwicklung einer Deep-Learning-Lösung unbedingt zu berücksichtigen sind. Nehmen wir einen realistischen Anwendungsfall als Grundlage, um diese Überlegungen zu untersuchen und zu entscheiden, wann eine Skalierung notwendig sein könnte und wie man sich darauf vorbereitet. Ich werde dieses Beispiel in diesem Abschnitt und im gesamten Buch immer wieder verwenden.
Nehmen wir an, du hast ein System entwickelt, das Satellitenbilder analysiert, um vorherzusagen, ob Dächer vorhanden sind und, wenn ja, welche Dachmaterialien verwendet wurden. Nehmen wir außerdem an, dass dieses System ursprünglich für Sydney, Australien, entwickelt wurde. Dein Modell ist ein überwachtes Modell, das auf dem Sehen basiert. Du hast also einen Grunddatensatz, der repräsentativ für die in Sydney verwendeten Dächer und Dachmaterialien ist, und das Modell wurde mit diesem Datensatz trainiert. Jetzt willst du deine Lösung auf jedes Dach der Welt übertragen!
Wenn du anfängst, diese Aufgabe zu zerlegen, wird dir schnell klar, dass du die sechs Aspekte, die in den folgenden Abschnitten beschrieben werden, berücksichtigen musst, um dieses Ziel zu erreichen.
Gut definiertes Problem
Für datengesteuerte Lösungen wie Deep Learning ist es wirklich wichtig, das genaue Problem zu verstehen, das man lösen muss, und zu wissen, ob man die richtigen Daten für dieses Problem hat.
Damit deine Lösung für jedes Dach der Welt geeignet ist, muss das Problem gut definiert werden. Überlege dir Fragen wie:
-
Erkennen wir immer noch nur das Vorhandensein eines Daches und die verwendeten Materialien? Oder werden wir auch den Stil des Daches bestimmen (z. B. Walm, Giebel, Flachdach)?
-
Wie unterscheiden sich die Materialien und Formen von Dächern in den verschiedenen Regionen?
-
Sind unsere Erfolgskriterien einheitlich, oder müssen wir unter bestimmten Umständen einen Kompromiss zwischen Sensitivität und Spezifität eingehen (z. B. für bestimmte Dächer oder bestimmte Regionen)?
-
Wie werden die niedrigsten und die höchsten akzeptablen Fehlerschwellen definiert und wie hoch sind sie? Gibt es noch andere Erfolgskriterien?
Diese Fragen sind von entscheidender Bedeutung, denn wenn die korrekte Erkennung von Iglu-Dächern genauso wichtig ist wie die korrekte Erkennung von Betondächern, kann es sein, dass die Komplexität der Daten unausgewogen ist, weil Betondächer so weit verbreitet sind, Iglus aber wahrscheinlich in deinem Datensatz unterrepräsentiert sind. Auch geografische Unterschiede, wie z. B. kanadische Dächer, die oft mit Schnee bedeckt sind, müssen sorgfältig berücksichtigt werden. Indem du dein Problem genau verstehst, kannst du die Grenzen deines Systems herausfinden und planen, wie du sie mit deinen Beschränkungen effektiv umgehen kannst. Die Skalierung ist schließlich begrenzt!
Domänenwissen (auch bekannt als die Beschränkungen)
Wie bereits erläutert hat, erfordert die Skalierung zur Erkennung von Dächern und Dachmaterialien ein sehr gutes Verständnis von Faktoren wie den folgenden:
-
Was macht ein Dach aus? Gibt es bestimmte Mindestmaße? Werden nur bestimmte Formen oder Materialien anerkannt?
-
Was ist eingeschlossen und was ist ausgeschlossen und warum? Gilt das Dach des Unterstands an einer Bushaltestelle als Dach? Was ist mit Pergolen?
-
Was sind die bereichsspezifischen Einschränkungen, die die Lösung befolgen muss?
Es ist wichtig, die Beziehungen zwischen Dächern und Dachmaterialien zu erfassen und zu sehen, wie die geografischen Gegebenheiten die Arten von Dachmaterialien einschränken. Zum Beispiel haben sich Gummidächer in Australien noch nicht durchgesetzt, aber in Kanada ist Gummi ein beliebtes Material, weil es Dächer vor extremen Witterungsbedingungen schützen kann. In Bezug auf Aussehen und Material sind Gummi- und Schindeldächer einander sehr viel ähnlicher als z. B. Metall- oder Farbverbunddächer. Das Domänenwissen, das sich aus einem umfassenden Verständnis des Problemraums ergibt, ist oft sehr hilfreich für die Erstellung von Einschränkungen und die Durchsetzung der Validierung. Mit dem Domänenwissen ist es zum Beispiel verständlich, wenn das Modell relative Wahrscheinlichkeiten von 0,5 bzw. 0,5 für Schindel- und Gummidachmaterialien vorhersagt; die Vorhersage derselben Wahrscheinlichkeiten für Ziegel und Beton wäre jedoch weniger verständlich, da sich das Aussehen dieser Materialien stark unterscheidet. Auch die Vorhersage von Kautschuk als Material für australische Dächer wird wahrscheinlich falsch sein. Ein gutes System versteht immer die Erwartungen des Nutzers - aberdiese können in einem datengesteuerten System wie einer Deep Learning-Lösung nur schwer durchgesetzt werden. Sie lassen sich leichter als Domänenanpassungsstrategien testen und durchsetzen.
Grundwahrheit
Dein Datensatz ist die Grundlage der Wissensbasis für deine Deep Learning-Lösung. Bei der Planung und Erstellung deines Datensatzes solltest du dir Fragen wie die folgenden stellen :
-
Wie können wir den Datensatz so kuratieren, dass er für Dächer auf der ganzen Welt repräsentativ ist?
-
Wie stellen wir Qualität und Verallgemeinerung sicher?
Dein Aufwand für die Beschriftung und Datenbeschaffung muss entsprechend skaliert werden, und das kann sehr schnell sehr teuer werden. Wenn du ein Deep Learning-System skalierst, wird die Fähigkeit, Daten schnell zu iterieren, entscheidend. Andrej Karpathy, ein unabhängiger Forscher und ehemaliger Direktor für KI bei Tesla, spricht in diesem Zusammenhang von einer "Datenmaschine": "Der Wettbewerbsvorteil bei der KI liegt nicht so sehr bei denen, die Daten haben, sondern bei denen, die eine Datenmaschine haben: wiederholte Datenerfassung, erneutes Training, Auswertung, Einsatz, Telemetrie. Und derjenige, der sie am schnellsten drehen kann."
Je größer du wirst, desto interessanter werden auch die ungewöhnlichen Szenarien in der "realen Welt". Skandinavische Grasdächer zum Beispiel sind eine sehr interessante Art von regionalspezifischen Dächern. In vielen anderen Teilen der Welt ist Rollrasen ein weniger verbreitetes Dachmaterial. In Gebieten, in denen es verwendet wird, musst du überlegen, wie diese Dächer von Betondächern mit Kunstrasen abgegrenzt werden können. Wie du solche Ausreißer identifizierst und erfaßt, ist ebenfalls eine interessante Herausforderung. Eine klare Vorstellung davon, wo du die Grenzen ziehst und welche Risiken du akzeptierst, ist wichtig für die Skalierung deines Systems. In Kapitel 10 erfährst du mehr über Techniken zur Bewältigung dieser Herausforderungen.
Modellentwicklung
Dein Ziel ist es, die Fähigkeit des Modells zu skalieren, Dächer und Dachmaterialien auf der ganzen Welt zu identifizieren. Daher müssen deine Skalierungsbemühungen über die Skalierung des Datensatzes (für eine bessere Darstellung und Verallgemeinerung) hinausgehen und die Kapazität des Modells und der beteiligten Techniken skalieren. Wie bereits erwähnt, muss dein Modell bei einer Globalisierung eine größere Vielfalt an Dachformen und Dachmaterialien kennenlernen. Wenn dein Modell nicht für diese Größenordnung ausgelegt ist, besteht die Gefahr einer Unteranpassung.
Du kannst fragen:
-
Wie planen wir die Experimente, um das optimale Modell für die skalierte Lösung zu finden?
-
Welchen Ansatz sollten wir wählen, um den Aufbau zu beschleunigen?
-
Wie können wir unsere Ausbildungsmethoden so verbessern, dass sie optimal sind? Wann brauchen wir verteilte Schulungen? Welche effizienten Ausbildungsstrategien sind für unseren Anwendungsfall relevant?
-
Sollten wir mit allen Daten entwickeln oder datenzentrierte Techniken wie Stichproben und Erweiterungen nutzen, um die Entwicklung zu beschleunigen?
Auch die Pläne für die Modellevaluierung erfordern ähnliche Überlegungen, ebenso wie die Strukturierung der Codebasis und die Planung und Erstellung von Automatisierungstests rund um die Modellentwicklung, um schnelle und zuverlässige Iterationen zu unterstützen. Du wirst im gesamten Buch über die Skalierung von Modellentwicklung und Trainingstechniken lesen, wobei der Schwerpunkt in Kapitel 11 ausdrücklich auf der Planung von Experimenten liegt.
Einsatz
Die Skalierung eines Systems, das die ganze Welt erreichen soll, erfordert auch ausgefeilte Einsatzstrategien. Auch wenn der Einsatz den Rahmen dieses Buches sprengen würde, empfehle ich, sich schon in der frühen Entwicklungsphase Gedanken über die Einsatzbedingungen zu machen.
Hier sind einige Fragen, die du beachten solltest:
-
Welche Einschränkungen wird unsere Einsatzumgebung haben?
-
Können wir genügend Rechenleistung und die gewünschte Latenzzeit bereitstellen, ohne die Bedienbarkeit der Nutzeranfragen für die von uns angestrebten Techniken zu beeinträchtigen?
-
Wie erhalten wir Qualitätskennzahlen aus den eingesetzten Umgebungen für Supportzwecke?
-
Wie können wir das Modell für verschiedene Hardware optimieren, bevor es eingesetzt wird?
-
Wird unsere Wahl der Werkzeuge dies unterstützen?
Die Geschwindigkeit der Datenverarbeitung und der Vorlauf des Modells haben direkte Auswirkungen auf die Betriebsfähigkeit des Systems. Die Aufwärm- und Bootstrap-Verzögerung beim Auftauchen der Modelldienste wirkt sich direkt auf die Skalierbarkeitsstrategien aus, die die Dienste für eine angemessene Betriebszeit anwenden müssen. Dies sind wichtige Daten, die in die Planung der Modellentwicklung einfließen sollten.
Feedback
Feedback ist entscheidend für Verbesserungen, und es gibt kein besseres Feedback als direktes Echtzeit-Feedback, direkt von deinen Nutzern. Ein gutes Beispiel für die Sammlung von Feedback ist GitHub Copilot. Copilot sammelt mehrmals Feedback, nachdem Code-Vorschläge gemacht wurden, um genaue Daten über die Nützlichkeit der gemachten Vorschläge zu sammeln und um festzustellen, ob die Vorschläge immer noch genutzt werden und wenn ja, in welchem Umfang sie geändert wurden. Dies ist eine großartige Möglichkeit, eine Datenmaschine zu erstellen.
Mit zunehmender Größe nimmt auch die Bedeutung von Feedback und Unterstützungssystemen zu. Wenn du über Feedback nachdenkst, solltest du dir im Wesentlichen folgende Fragen stellen:
-
Wie werden wir Feedback von den Nutzern einholen, um unser System kontinuierlich zu verbessern?
-
Können wir das Sammeln von Feedback automatisieren? Wie können wir sie in den Entwicklungsworkflow des Modells integrieren, um einen datenmotorähnlichen Aufbau zu realisieren?
Das Feedback muss umgesetzt werden, sonst ist das Feedbacksystem sinnlos. Im Zusammenhang mit einer Daten-Engine bietet die Messung der Lücken und die kontinuierliche Iteration, um diese Lücken zu schließen, erhebliche Vorteile beim Aufbau eines datengesteuerten Systems, z. B. einer Deep-Learning-Lösung. Darin liegt der Wettbewerbsvorteil.
Überlegungen zur Skalierung
Die Skalierung von ist kompliziert. Die mythische "peinlich parallele Arbeitslast", bei der wenig oder gar kein Aufwand für die Aufteilung und Parallelisierung von Aufgaben erforderlich ist, gibt es in Wirklichkeit nicht. Grafikprozessoren (GPUs) werden beispielsweise als peinlich parallele Geräte für Matrixberechnungen vermarktet, aber ihre Verarbeitungskapazität wird durch ihre Speicherbandbreite gedrosselt, was den praktischen Rechendurchsatz begrenzt (siehe Kapitel 3). Wie bereits erwähnt, liegt die eigentliche Herausforderung bei der Skalierung darin, die Grenzen von Subsystemen zu verstehen und mit ihnen zu arbeiten, um das gesamte System zu skalieren.
In diesem Abschnitt geht es um die Fragen, die du dir stellen solltest, bevor du versuchst, zu skalieren, und um den Rahmen für die Skalierung.
Fragen, die du vor der Skalierung stellen solltest
Das sprichwörtliche Sprichwort "Alle Wege führen nach Rom" gilt auch für die Skalierung. Oft gibt es viele Wege, um den gewünschten Umfang zu erreichen. Das Ziel sollte sein, den optimalsten Weg zu wählen.
Um zum Beispiel die Latenzzeit deines Trainingsprozesses zu halbieren, musst du vielleicht skalieren. Das könntest du:
-
Skaliere deine Hardware, indem du dich für leistungsfähigere Computer entscheidest.
-
Skaliere deinen Ausbildungsprozess, indem du eine verteilte Ausbildung nutzt.
-
Reduziere das Berechnungsbudget deines Prozesses oder Programms auf Kosten der Genauigkeit/Präzision.
-
Optimiere die Eingabe, z. B. durch Komprimierung des Datensatzes mithilfe der Datendestillation (siehe Kapitel 10).
Wenn du finanziell eingeschränkt bist und nicht in der Lage bist, mehr oder leistungsfähigere Geräte zu finanzieren, dann ist wahrscheinlich Option 3 oder 4 die optimale Lösung. Wenn du bei der Präzision keine Kompromisse eingehen kannst, ist Option 4 die optimale Lösung. Andernfalls ist Option 3 wahrscheinlich die am niedrigsten hängende Frucht, um die Latenzzeit zu verkürzen.
Die in diesem Kapitel behandelten Themen lassen sich in die folgenden Fragen zusammenfassen, die du dir unbedingt stellen solltest, bevor du mit der Skalierung beginnst. Die Beantwortung dieser Fragen wird dir helfen, deine Optionen zu definieren und deine Skalierung effektiver zu gestalten:
-
Was skalieren wir?
-
Wie werden wir den Erfolg messen?
-
Brauchen wir wirklich eine Skalierung?
-
Was sind die Auswirkungen (d.h. die nachgelagerten Folgen)?
-
Was sind die Zwänge?
-
Wie werden wir skalieren?
-
Ist unsere Skalierungstechnik optimal?
Wenn du dir diese Fragen stellst, musst du nicht nur sicherstellen, dass du den Umfang und die Grenzen der Skalierung gut kennst, sondern auch, dass du gute Kennzahlen zur Messung deines Erfolgs definiert hast. Cassie Kozyrkov, CEO von Data Scientific und zuvor Chief Decision Scientist bei Google, hat einen hervorragenden Artikel mit dem Titel "Metric Design for Data Scientists and Business Leaders" verfasst39 in dem sie aufzeigt, wie wichtig es ist, zuerst Kennzahlen zu definieren, bevor man Entscheidungen trifft. Occams Rasiermesser, das Prinzip der Sparsamkeit, unterstreicht die Bedeutung der Einfachheit, aber nicht auf Kosten der Notwendigkeit. Es ist die Regel Nr. 1 für effiziente Skalierung, die du berücksichtigen musst, wenn du dich fragst: "Müssen wir wirklich skalieren?" Die folgenden Kapitel dieses Buches sollen tief in die Ansätze und Techniken der Skalierung eintauchen und dir dabei helfen, festzustellen, ob die von dir gewählte Skalierungstechnik für deinen Anwendungsfall optimal ist.
Merkmale von skalierbaren Systemen
Ian Gorton behandelt in seinem Buch Foundations of Scalable Systems ausführlich die Prinzipien eines skalierbaren Systems, die bei der Skalierung von Systemen verwendeten Entwurfsmuster und die mit der Skalierung verbundenen Herausforderungen : Designing Distributed Architectures. Gortons Buch ist keine Voraussetzung für dieses Buch, aber es ist eine empfehlenswerte Lektüre, wenn du ein wenig Hintergrundwissen in Softwareentwicklung hast. In diesem Abschnitt werden vier Merkmale eines skalierbaren Systems beschrieben, die du bei der Vorbereitung auf die Skalierung deines Arbeitsaufkommens beachten solltest.
Verlässlichkeit
Die wichtigste Eigenschaft eines skalierbaren Systems ist die Zuverlässigkeit. Ein zuverlässiges System schlägt selten fehl. Und wenn es doch einmal ausfällt, schlägt es vorhersehbar fehl, so dass das abhängige System und die Benutzer/innen mit dem Ausfall zurechtkommen. Mit anderen Worten: Ein zuverlässiges System ist in der Lage, (seltene) Ausfälle zu bewältigen und sich von Ausfallszenarien zu erholen. Hier ein Beispiel: Alle 224,641e+18 FLOPs, die du bisher durchgeführt hast, gingen verloren, als das Training aufgrund eines Netzwerkfehlers nach zwei Monaten mit 500 A100 GPU-Knoten zum Stillstand kam. Wenn das System wieder hochfährt, bist du dann in der Lage, vom letzten fertig berechneten Zustand aus weiterzumachen und dich zu erholen? Ein zuverlässiges System ist in der Lage, diesen Ausfall zu verkraften und sich ordnungsgemäß zu erholen.
Die allgemein bekannten Metriken zur Definition eines zuverlässigen Systems sind die folgenden:
- Wiederherstellungspunkt-Ziel (RPO)
-
RPO ist definiert als die Zeitspanne, die du zurückgehen kannst, um die Daten nach einem Ausfall wiederherzustellen. Beim Checkpointing zum Beispiel bestimmt das Intervall, das du festlegst - die Häufigkeit, mit der du die intermittierenden Gewichte und Trainingszustände (Optimierer usw.) speicherst - deinen RPO. Dies kann als Anzahl von Schritten oder Epochen festgelegt werden.
- Ziel für die Wiederherstellungszeit (RTO)
-
RTO ist definiert als die Zeit, die es braucht, um sich zu erholen und wieder in den Zustand unmittelbar vor dem Absturz zurückzukommen.
- Ausfallzeitrate
-
Die Ausfallrate ist der prozentuale Anteil der Zeit, in der das System als nicht verfügbar oder nicht ansprechbar beobachtet wird.
Verfügbarkeit
Die Verfügbarkeit definiert die Wahrscheinlichkeit, dass ein System betriebsbereit und funktionsfähig ist. Der Goldstandard für hochverfügbare Systeme ist fünf Neunen, d.h .das System ist 99,999% der Zeit verfügbar und funktionsfähig. Die Verfügbarkeit eines auf Deep Learning basierenden Systems auf fünf Neunen zu bringen, ist ein komplizierter Prozess. TikTok, der kleine Video-Sharing-Dienst von ByteDance Ltd, ist seit 2017 international im Einsatz. In fünf Jahren hat das Unternehmen seine Dienste zur Personalisierung von Benutzerinhalten auf 150 Länder ausgeweitet und über 1 Milliarde Benutzer/innen betreut. Die Systemarchitektur, genannt Monolith,40 Die Systemarchitektur, Monolith genannt, kombiniert Online- und Offline-Lernen, um nutzerrelevante Inhalte bereitzustellen und durch die Verwendung von Vorhersagetechniken für die Klickrate (DeepFM) Nutzer/innen zu binden. Obwohl die Verfügbarkeit von TikTok insgesamt hoch ist, kam es gelegentlich zu Ausfällen (bis zu fünf Stunden).
Anpassungsfähigkeit
Anpassungsfähigkeit sagt aus, wie belastbar ein System ist, um die wachsenden Skalierungsanforderungen zu erfüllen. Bist du in der Lage, das Training über die Anzahl der verfügbaren GPUs zu skalieren? Wie gut ist der Trainingscode in der Lage, mit Ausfällen umzugehen, z. B. wenn ein Knoten während des Trainings verloren geht? Dies sind nur einige der Überlegungen, die in den Bereich der Anpassungsfähigkeit fallen. Einige leicht zu lösende Herausforderungen in der Softwareentwicklung entpuppen sich im Bereich des Deep Learning als unglaublich schwierige Probleme.
Leistung
Leistung wird auf viele Arten definiert, insbesondere für Deep Learning-basierte Systeme. Einerseits gibt es Kennzahlen, die angeben, wie gut die Stochastizität deines Deep Learning-Systems ist und ob es den gewünschten Standard erfüllt. Auf der anderen Seite gibt es technische Kennzahlen, die die Leistung des Systems messen - sie beziehen sich darauf, wie viele Ressourcen es verbraucht (RAM, CPU), wie hoch die Durchsatzrate ist usw. - und die du bei der Skalierung überwachen kannst. Im Idealfall ist die Skalierung ein günstiges Ereignis für die stochastischen Metriken und Kennzahlen, die die Erwartungen und das Verhalten des Systems bestimmen. Du möchtest z. B. nicht, dass die Genauigkeit der Dacherkennung sinkt, wenn du dein Dacherkennungssystem geografisch skalierst. Allerdings wird erwartet, dass sich die technischen Metriken ihren jeweiligen Skalierungsgesetzen anpassen. Wenn du die API, die das Modell bedient, so skalierst, dass die Durchsatzrate doppelt so hoch ist, musst du damit rechnen, dass sich die Speicheranforderungen ändern, auch wenn dies nur minimale Auswirkungen auf die Latenzzeit hat.
Überlegungen zu skalierbaren Systemen
Das berühmte Sprichwort "Beim Skalieren geht alles kaputt!" ist eine deutliche Erinnerung an Murphys Gesetz. Das sollte nicht überraschen, denn bei der Skalierung geht es darum, mit den Einschränkungen zu arbeiten - entweder um sie aufzulösen oder zu umgehen. Dies erfordert ein hohes Maß an Sorgfalt und Überlegung. In den folgenden Abschnitten geht es um einige der Faktoren, die bei der Entwicklung skalierbarer Systeme zu beachten sind, sowie um einige allgemein nützliche Entwurfsmuster für die Skalierung.
Einzelne Fehlerquellen vermeiden
Ein Single Point of Failure (SPOF) ist eine Komponente, deren Ausfall das gesamte System zum Stillstand bringen kann. Nehmen wir an, ein Modell wird in großem Maßstab auf 1.000 A100-GPUs trainiert. Alle diese Rechner kommunizieren mit einem verteilten Datenspeicher, um die für das Training benötigten Daten zu lesen. Wenn dieser Datenspeicher fehlschlägt, kommt das Training zum Stillstand; der Datenspeicher ist also ein Single Point of Failure. Es ist also wichtig, die Präsenz von SPOFs zu minimieren, wenn es möglich ist, sie zu beseitigen.
Planung für hohe Verfügbarkeit
In haben wir im vorherigen Abschnitt darüber gesprochen, warum die Verfügbarkeit ein wichtiges Merkmal eines skalierbaren Systems ist. Um diese Diskussion fortzusetzen, müssen alle Komponenten eines skalierbaren Systems hochverfügbar sein. Hochverfügbarkeit wird durch die drei Rs erreicht: Zuverlässigkeit, Ausfallsicherheit und Redundanz. Das heißt, die Komponenten des Systems müssen so konzipiert sein, dass sie zuverlässig sind (d.h., dass sie selten ausfallen und wenn doch, dann vorhersehbar), belastbar (d.h., dass sie nachgelagerte Ausfälle bewältigen können, ohne das gesamte System zum Stillstand zu bringen) und redundant (d.h., dass eine Redundanz eingebaut ist, so dass im Falle eines Ausfalls eine redundante Komponente einspringen kann, ohne dass das gesamte System beeinträchtigt wird).
Paradigmen skalieren
Die folgenden drei Skalierungsparadigmen werden heute üblicherweise verwendet:
- Horizontal
-
Bei der horizontalen Skalierung wird dasselbe System mehrmals repliziert. Die Replikate müssen sich dann untereinander abstimmen, um denselben Dienst in großem Umfang zu erbringen. Ein sehr gutes Beispiel für horizontale Skalierung ist das verteilte Training, bei dem mehrere Knotenpunkte hinzugefügt werden und jeder Knotenpunkt nur bestimmte unabhängige Teile eines größeren Datensatzes betrachtet. Diese Art der skalierten Ausbildung wird als verteilte Datenparallelität bezeichnet; wir werden sie in den Kapiteln 6 und 7 näher erläutern.
- Vertikal
-
Bei der vertikalen Skalierung werden die Fähigkeiten des Systems durch das Hinzufügen weiterer Ressourcen zu einer bestehenden Komponente skaliert. Das Hinzufügen weiterer Speicherkarten, um den Arbeitsspeicher um 50 % zu erhöhen, ist ein Beispiel für vertikale Skalierung aus der Sicht des Knotens. Diese Art der skalierten Ausbildung wird in den Kapiteln 8 und 9 näher erläutert.
- Hybrid
-
Bei der hybriden Skalierung werden sowohl horizontale als auch vertikale Skalierungstechniken angewandt, um über beide Dimensionen hinweg zu skalieren. Diese Art der skalierten Ausbildung wird in den Kapiteln 8 und 9 näher erläutert.
Koordinierung und Kommunikation
Koordination und Kommunikation sind das Herzstück eines jeden Systems. Wenn ein System skaliert wird, entsteht Druck auf das vom System genutzte Kommunikationsnetz. Es gibt zwei Hauptkommunikationsparadigmen:
- Synchron
-
Synchrone Kommunikation erfolgt in Echtzeit, wobei zwei oder mehr Komponenten gleichzeitig Informationen austauschen. Diese Art der Kommunikation ist sehr durchsatzintensiv. Wenn der Umfang (z. B. die Anzahl der Komponenten) zunimmt, wird diese Art der Kommunikation sehr schnell zum Engpass.
- Asynchron
-
Bei der asynchronen Kommunikation tauschen zwei oder mehr Komponenten Informationen über die Zeit aus. Asynchrone Kommunikation bietet Flexibilität und entlastet die Kommunikation, aber sie geht auf Kosten der Diskontinuität.
Kommunikation und Koordination sind auch bei der Skalierung von Deep-Learning-Systemen entscheidend. Ein Beispiel dafür ist der stochastische Gradientenabstieg (SGD), eine Technik zur Ermittlung der optimalen Modellgewichte, die ursprünglich synchron war. Diese Technik wurde sehr schnell zu einem Engpass bei der Skalierung des Trainings und führte zum Vorschlag ihres asynchronen Gegenstücks, dem asynchronen SGD (ASGD).41 Mehr über die Herausforderungen bei der Koordination und Kommunikation erfährst du in den Kapiteln 5 und 6.
Caching und intermittierende Speicherung
Das Abrufen von Informationen erfordert in jedem System Kommunikation, aber die Reisen zum Abrufen von Informationen aus der Speicherung sind oft teuer. Dies wird in Deep-Learning-Szenarien noch verschärft, da die Informationen über Rechenknoten und GPU-Geräte verteilt sind, was das Abrufen von Informationen aufwändig und teuer macht. Caching ist eine sehr beliebte Technik, um häufig benötigte Informationen in einer ineffizienten Speicherung zu speichern und so Engpässe bei diesen Informationen zu vermeiden. Heutige Systeme sind durch Speicher und Kommunikation stärker eingeschränkt als durch die Rechenleistung; deshalb kann Caching auch hilfreich sein, um die Latenzzeit zu verringern.
Prozesszustand
Die Kenntnis des aktuellen Zustands eines Prozesses oder Systems ist entscheidend, um die nächste Stufe zu erreichen. Wie viele Kontextinformationen eine Komponente benötigt, bestimmt, ob sie zustandsfähig ist oder nicht: Zustandslose Prozesse und Operationen benötigen überhaupt keine Kontextinformationen, während zustandsfähige Prozesse dies tun. Zustandslosigkeit vereinfacht die Skalierung. Zum Beispiel ist die Berechnung des Punktprodukts zweier Matrizen eine völlig zustandslose Operation, da sie nur eine elementweise Operation auf den Indizes der Matrix erfordert. Die Zustandslosigkeit der Matrixmultiplikation ermöglicht die sogenannte peinliche Parallelisierung von Tensorberechnungen. Umgekehrt ist die Gradientenakkumulation, eine Deep-Learning-Technik, die zur Skalierung der Stapelgröße unter engen Speicherbeschränkungen verwendet wird, sehr zustandsabhängig. Die Verwendung von möglichst zustandslosen Komponenten und Techniken reduziert die Komplexität des Systems und minimiert Engpässe bei der Skalierung.
Anständige Wiederherstellung und Checkpointing
Ausfälle kommen vor, wie die Tatsache zeigt, dass der Goldstandard für die Verfügbarkeit von Diensten bei fünf Neunen liegt (d. h. 99,999 % Betriebszeit). Damit wird anerkannt, dass selbst bei den hochverfügbarsten Systemen irgendwann ein Ausfall auftreten wird. Die Raffinesse eines skalierbaren Systems liegt darin, einen effizienten Weg zur Wiederherstellung zu haben, wenn ein Fehler auftritt, wie bereits erwähnt. Checkpointing ist eine gängige Technik, um intermittierende Zustände aufrechtzuerhalten und als Checkpoint zu speichern, um eine Wiederherstellung vom letzten bekannten guten Zustand zu ermöglichen und den RPO zu maximieren.
Wartbarkeit und Beobachtbarkeit
Die Wartbarkeit eines Systems ist wichtig, denn sie steht in direktem Zusammenhang mit seinem Fortbestand. Wenn die Komplexität eines Systems zunimmt, wie es bei einer Skalierung zu erwarten ist, steigen auch die Kosten für seine Wartung. Die Beobachtbarkeit, die durch Überwachungs- und Benachrichtigungstools erreicht wird, erhöht den Komfort bei der Arbeit mit und der Wartung von komplexen Systemen erheblich. Wenn es zu Ausfällen kommt, ist es außerdem viel einfacher, diese zu erkennen und zu beheben, was zu einer kürzeren RTO führt.
Effektiv skalieren
In diesem Kapitel hast du einen Einblick in die Bedeutung einer effektiven Skalierung erhalten. Wie du gesehen hast, ist es wichtig, dein Skalierungsziel, deine Grenzen und Engpässe zu kennen und innerhalb deines Skalierungsrahmens sorgfältig zu arbeiten, um dieses Ziel zu erreichen.
Das alte Zimmermannssprichwort "Zweimal messen, einmal schneiden" hat sich in vielen Bereichen durchgesetzt und sich auch bei der Softwareentwicklung bewährt. Wenn du qualitativ hochwertige Systeme entwickeln und gleichzeitig das Risiko von Fehlern und katastrophalen Ausfällen minimieren willst, ist es sehr nützlich, dies im Hinterkopf zu behalten! Dasselbe Prinzip gilt auch für Deep Learning-basierte Systeme. "Zweimal messen und einmal schneiden" ist eine wichtige Strategie für eine effektive Skalierung. Sie bietet einen dringend benötigten Rahmen, um:
-
Kenne die aktuellen Benchmarks und weise auf bekannte Einschränkungen hin.
-
Teste Ideen und Theorien zur Lösung in einer simulierten Umgebung und gib schnelles Feedback.
-
Gewinnen Sie Vertrauen in die Lösung und verringern Sie das Risiko von Fehlern/unbeabsichtigten Gewinnen.
-
Erkenne subtile, nicht offensichtliche Engpässe frühzeitig.
-
Quantifiziere die überarbeiteten Benchmarks, wenn die Lösung umgesetzt ist.
-
Setze Verbesserungsstrategien schnell um, indem du sie schrittweise anwendest.
Bei der Effizienz geht es auch um die effektive Nutzung der verfügbaren Ressourcen. Die Kosten für ineffektive Deep-Learning-Praktiken sind zu hoch, auch wenn der Adrenalinschub, den Deep-Learning-Anwender/innen durch das "Burrr" der GPUs ausgelöst werden, einem Potenzgesetz entspricht. Und diese Kosten beschränken sich nicht nur auf Geld und Zeit, sondern haben auch Auswirkungen auf die Umwelt und die Gesellschaft, denn der Energieverbrauch dieser Verfahren und die daraus resultierenden negativen, unumkehrbaren Auswirkungen auf den Klimawandel verursachen eine enorme Menge an Kohlenstoffemissionen. Das Training eines großen Sprachmodells wie GPT3 kann 500 Tonnen Kohlendioxidemissionen verursachen - das entspricht etwa 600 Flügen zwischen London und New York. Klimaschonendere Computer wie der französische Supercomputer BLOOM, der für das Training verwendet wird und größtenteils mit Kernenergie betrieben wird, stoßen weniger Kohlenstoff aus als herkömmliche GPUs; dennoch erzeugt BLOOM während des Trainings schätzungsweise 25 Tonnen Kohlendioxidemissionen (das entspricht 30 Flügen von London nach New York).42 Techniken wie Pretraining, few-shot learning und transfer learning zielen darauf ab, die Trainingszeit zu verkürzen und das Gelernte für andere Aufgaben zu nutzen. Vor allem das Pretraining legt den Grundstein für Effizienzsteigerungen durch Wiederverwendbarkeit. Contrastive Learning-Implementierungen wie CoCa, CLIP und SigLIP sind großartige Beispiele für Pretraining in großem Maßstab, das durch Selbstüberwachung erreicht wird.43 Modell-Benchmarks aus dem Training mit festen GPU-Budgets können sehr nützliche Erkenntnisse für die Modellauswahl liefern, die es dir ermöglichen, effizient zu skalieren.44
Wenn es um den Klimawandel geht, ist die Begrenzung des Kohlendioxidausstoßes während der Ausbildung jedoch nur eine Wohlfühlmaßnahme - sie ist zwar groß, aber nur eine einmalige Ausgabe. Hugging Face schätzt, dass BLOOM bei der Durchführung von Inferenzen etwa 19 kg Kohlendioxid pro Tag ausstößt. Das sind laufende Kosten, die sich in etwa dreieinhalb Jahren auf mehr als die Ausbildungskosten summieren werden.45 Das sind ernsthafte Bedenken, und das Mindeste, was wir tun können, ist sicherzustellen, dass wir die uns zur Verfügung stehenden Ressourcen so effizient wie möglich nutzen, indem wir die Experimente so planen, dass möglichst wenig Trainingszyklen verschwendet werden und die volle Kapazität der GPUs und CPUs genutzt wird. Im Laufe dieses Buches werden wir diese Konzepte und verschiedene Techniken zur effektiven und effizienten Entwicklung von Deep-Learning-Modellen untersuchen.
Zusammenfassung
Laut Forbes setzen im Jahr 2021 76% der Unternehmen auf KI.46 McKinsey berichtet, dass Deep Learning bis zu 40 % des jährlichen Umsatzes in der Analytik ausmacht und prognostiziert, dass KI bis 2030 eine zusätzliche Wirtschaftsleistung von 13 Billionen Dollar erbringen könnte.47 Durch Open Sourcing und die Beteiligung der Community werden KI und Deep Learning zunehmend demokratisiert. Wenn es jedoch um die Skalierung geht, verbleibt der Hebel aufgrund der damit verbundenen Kosten hauptsächlich bei MAANG (früher FAANG) und Organisationen mit massiven Finanzmitteln. Die Skalierung ist eine der größten Herausforderungen für ML-Praktiker/innen.48 Das sollte nicht überraschen, denn die Skalierung einer Deep-Learning-Lösung erfordert nicht nur ein gründliches Verständnis von maschinellem Lernen und Softwareentwicklung, sondern auch Datenexpertise und Hardwarekenntnisse. Die Entwicklung von Lösungen, die dem Industriestandard entsprechen, liegt an der Schnittstelle von Hardware, Software, Algorithmen und Daten.
Um dich für den Rest des Buches zu orientieren, wurden in diesem Kapitel die Geschichte und die Ursprünge des Skalierungsgesetzes und die Entwicklung des Deep Learning besprochen. Du hast über aktuelle Trends gelesen und erfahren, wie das Wachstum von Deep Learning durch Fortschritte bei Hardware, Software und Daten ebenso vorangetrieben wurde wie durch die Algorithmen selbst. Du hast auch erfahren, was du bei der Skalierung deiner Deep-Learning-Lösungen beachten musst und welche Auswirkungen die Skalierung auf die Deep-Learning-Entwicklung hat. Die Komplexität, die mit der Skalierung einhergeht, ist enorm und die Kosten, die damit verbunden sind, sind nicht unerheblich. Eines ist jedoch sicher: Skalierung ist ein Abenteuer und macht eine Menge Spaß! Ich freue mich darauf, dir in diesem Buch ein tieferes Verständnis der Skalierung von Deep Learning zu vermitteln. In den folgenden drei Kapiteln lernst du zunächst die grundlegenden Konzepte des Deep Learning kennen und erhältst praktische Einblicke in das Innenleben des Deep Learning Stacks.
1 Bondi, André B. 2000. "Merkmale der Skalierbarkeit und ihre Auswirkungen auf die Leistung". In Proceedings of the Second International Workshop on Software and Performance (WOSP '00), 195-203. https://doi.org/10.1145/350391.350432.
2 Hutchinson, John R., Karl T. Bates, Julia Molnar, Vivian Allen, und Peter J. Makovicky. 2011. "A Computational Analysis of Limb and Body Dimensions in Tyrannosaurus rex with Implications for Locomotion, Ontogeny, and Growth". PLoS One 6, no. 10: e26037. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3192160.
3 Hutchinson et al., "A Computational Analysis", e26037; Persons, W. Scott IV, Philip J. Currie, and Gregory M. Erickson. 2019. "An Older and Exceptionally Large Adult Specimen of Tyrannosaurus rex". The Anatomical Record 303, no. 4: 656-72. https://doi.org/10.1002/ar.24118.
4 National Geographic. n.d. "Biodiversität". Zugriff am 9. Februar 2024. https://education.nationalgeographic.org/resource/biodiversity.
5 Ethnologue. n.d. Languages of the World. Zugriff am 9. Februar 2024. https://www.ethnologue.com.
6 Fields, R. Douglas. 2020. "Mind Reading and Mind Control Technologies Are Coming." Observations (Blog), 10. März 2020. https://blogs.scientificamerican.com/observations/mind-reading-and-mind-control-technologies-are-coming.
7 Wurtz, Robert H. 2009. "Der Einfluss von Hubel und Wiesel". The Journal of Physiology 587: 2817-23. https://doi.org/10.1113%2Fjphysiol.2009.170209.
8 Jorgensen, Timothy J. 2022. "Ist das menschliche Gehirn ein biologischer Computer?" Princeton University Press, 14. März 2022. https://press.princeton.edu/ideas/is-the-human-brain-a-biological-computer.
9 Turing, Alan. 1936. "On Computable Numbers, with an Application to the Entscheidungsproblem". In Proceedings of the London Mathematical Society s2-43, 544-46. https://doi.org/10.1112/plms/s2-43.6.544.
10 Turing, Alan. 1948. "Intelligent Machinery". Bericht für das National Physical Laboratory. Nachgedruckt in Mechanical Intelligence: Collected Works of A. M. Turing, Bd. 1, herausgegeben von D.C. Ince, 107-27. Amsterdam: North Holland, 1992. https://weightagnostic.github.io/papers/turing1948.pdf.
11 Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, und Pablo Villalobos. 2022. "Compute Trends Across Three Eras of Machine Learning". arXiv, 9. März 2022. https://arxiv.org/abs/2202.05924.
12 Heffernan, Virginia. 2022. "Is Moore's Law Really Dead?" WIRED, November 22, 2022. https://www.wired.com/story/moores-law-really-dead.
13 Heffernan, "Is Moore's Law Really Dead? " https://www.wired.com/story/moores-law-really-dead.
14 Hooker, Sara. 2020. "Die Hardware-Lotterie". arXiv, 21. September 2020. https://arxiv.org/abs/2009.06489.
15 Taylor, Petroc. 2023. "Volumen der weltweit erstellten, erfassten, kopierten und verbrauchten Daten/Informationen von 2010 bis 2020, mit Prognosen von 2021 bis 2025". Statista, November 16, 2023. https://www.statista.com/statistics/871513/worldwide-data-created.
16 Chen, Ting, Simon Kornblith, Mohammad Norouzi, und Geoffrey Hinton. 2020. "A Simple Framework for Contrastive Learning of Visual Representations". arXiv, 1. Juli 2020. https://arxiv.org/abs/2002.05709.
17 Yu, Jiahui, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, und Yonghui Wu. 2022. "CoCa: Contrastive Captioners Are Image-Text Foundation Models". arXiv, 14. Juni 2022. https://arxiv.org/abs/2205.01917.
18 Hochreiter, S. 1990. "Implementierung und Anwendung eines 'neuronalen' Echtzeit-Lernalgorithmus für reaktive Umgebungen." Institut für Informatik, Technische Universität München. https://www.bioinf.jku.at/publications/older/fopra.pdf; Bengio, Y., P. Simard, und P. Frasconi. 1994. "Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Transactions on Neural Networks 5, no. 2: 157-66. https://doi.org/10.1109/72.279181.
19 LeCun, Y., B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, und L.D. Jackel. 1989. "Backpropagation angewandt auf die Erkennung von handgeschriebenen Postleitzahlen". Neural Computation 1, no. 4: 541-51. https://doi.org/10.1162/neco.1989.1.4.541.
20 Hinton, Geoffrey E., Simon Osindero, und Yee-Whye Teh. 2006. "A Fast Learning Algorithm for Deep Belief Nets". Neural Computation 18, no. 7: 1527-54. https://doi.org/10.1162/neco.2006.18.7.1527.
21 Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, und Fei-Fei Li. 2009. "ImageNet: A Large-Scale Hierarchical Image Database". In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 248-55. http://dx.doi.org/10.1109/CVPR.2009.5206848.
22 Krizhevsky, Alex, Ilya Sutskever, und Geoffrey E. Hinton. 2012. "ImageNet Classification with Deep Convolutional Neural Networks". In Advances in Neural Information Processing Systems (NIPS 2012) 25, Nr. 2. https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf.
23 Thomas, Owen. 2013. "Google hat ein Startup gekauft, um Stimmen und Objekte zu erkennen." Business Insider, 13. März 2013. https://www.businessinsider.com/google-buys-dnnresearch-2013-3; Saha, Rachana. 2024. "Deep Learning Market Expected to Reach US$127 Billion by 2028". Analytics Insight, 19. Februar 2024. https://www.analyticsinsight.net/deep-learning-market-expected-to-reach-us127-billion-by-2028.
24 Silver, David, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, et al. 2018. "A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play". Science 362, no. 6419: 1140-1144. https://doi.org/10.1126/science.aar6404.
25 Turing, "Intelligent Machinery", 107-27.
26 Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, und Illia Polosukhin. 2017. "Attention Is All You Need." arXiv, 6. Dezember 2017. https://arxiv.org/abs/1706.03762.
27 Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weißenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2021. "An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale." arXiv, June 3, 2021. https://arxiv.org/abs/2010.11929.
28 Silver et al., "A General Reinforcement Learning Algorithm," 1140-1144; Tu, Zhengzhong, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. 2022. MaxViT: Multi-Axis Vision Transformer. arXiv, September 9, 2022. https://arxiv.org/abs/2204.01697.
29 Yu, Lili, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer und Mike Lewis. 2023. "MEGABYTE: Predicting Million-Byte Sequences with Multiscale Transformers". arXiv, 19. Mai 2023. https://arxiv.org/abs/2305.07185; Wang, Wenhui, Shuming Ma, Hanwen Xu, Naoto Usuyama, Jiayu Ding, Hoifung Poon, and Furu Wei. 2023. "Wenn ein Bild 1.024 x 1.024 Wörter wert ist: A Case Study in Computational Pathology." arXiv, Dezember 6, 2023. https://arxiv.org/abs/2312.03558.
30 Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, et al. 2020. "Scaling Laws for Neural Language Models". arXiv, 23. Januar 2020. https://arxiv.org/abs/2001.08361.
31 Kaplan et al., "Scaling Laws for Neural Language Models ", https://arxiv.org/abs/2001.08361
32 Gorton, Ian. 2022. Foundations of Scalable Systems: Designing Distributed Architectures. Sebastopol, CA: O'Reilly Media.
33 Heikkilä, Melissa. 2022. "Inside a Radical New Project to Democratize AI". MIT Technology Review, Juli 12, 2022. https://www.technologyreview.com/2022/07/12/1055817/inside-a-radical-new-project-to-democratize-ai/amp.
34 Blalock, Davis, und John Guttag. 2021. "Multiplying Matrices Without Multiplying". arXiv, 21. Juni 2021. https://arxiv.org/abs/2106.10860.
35 Fawzi, Alhussein, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, et al. 2022. "Discovering Faster Matrix Multiplication Algorithms with Reinforcement Learning". Nature 610: 47-53. https://doi.org/10.1038/s41586-022-05172-4.
36 Hassabis, Demis. 2022. AlphaFold deckt die Struktur des Proteinuniversums auf. DeepMind Blog, 28. Juli 2022. https://deepmind.google/discover/blog/alphafold-reveals-the-structure-of-the-protein-universe.
37 Nijkamp, Erik, Jeffrey Ruffolo, Eli N. Weinstein, Nikhil Naik, und Ali Madani. 2022. "ProGen2: Exploring the Boundaries of Protein Language Models." arXiv, 27. Juni 2022. https://arxiv.org/abs/2206.13517.
38 Lin, Zeming, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, et al. 2023. "Evolutionäre Vorhersage der Proteinstruktur auf atomarer Ebene mit einem Sprachmodell". Science 379, no. 6637: 1123-30. https://doi.org/10.1126/science.ade2574.
39 Kozyrkov, Cassie. 2022. "Metric Design for Data Scientists and Business Leaders". Towards Data Science, 23. Oktober 2022. https://towardsdatascience.com/metric-design-for-data-scientists-and-business-leaders-b8adaf46c00.
40 Liu, Zhuoran, Leqi Zou, Xuan Zou, Caihua Wang, Biao Zhang, Da Tang, Bolin Zhu, et al. 2022. "Monolith: Real Time Recommendation System With Collisionless Embedding Table." arXiv, 27. September 2022. https://arxiv.org/abs/2209.07663.
41 Dean, Jeffrey, und Luiz André Barroso. 2013. "The Tail at Scale". Communications of the ACM 56, no. 2: 74-80. https://doi.org/10.1145/2408776.2408794; Chen, Jianmin, Xinghao Pan, Rajat Monga, Samy Bengio, and Rafal Jozefowicz. 2017. "Revisiting Distributed Synchronous SGD." arXiv, 21. März 2017. https://arxiv.org/abs/1604.00981.
42 Heikkilä, Melissa. 2022. "Warum wir den CO2-Fußabdruck von KI besser messen müssen". MIT Technology Review, November 15, 2022. https://www.technologyreview.com/2022/11/15/1063202/why-we-need-to-do-a-better-job-of-measuring-ais-carbon-footprint.
43 Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. "Learning Transferable Visual Models from Natural Language Supervision." arXiv, February 26, 2021. https://arxiv.org/abs/2103.00020; Zhai, Xiaohua, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid Loss for Language Image Pre-Training. arXiv, 27. September 2023. https://arxiv.org/abs/2303.15343.
44 Geiping, Jonas, und Tom Goldstein. 2022. "Cramming: Training a Language Model on a Single GPU in One Day." arXiv, December 28, 2022. https://arxiv.org/abs/2212.14034.
45 Heikkilä, "Why We Need to Do a Better Job of Measuring AI's Carbon Footprint", https://www.technologyreview.com/2022/11/15/1063202/why-we-need-to-do-a-better-job-of-measuring-ais-carbon-footprint.
46 Columbus, Louis. 2021. "76% der Unternehmen priorisieren KI und maschinelles Lernen in den IT-Budgets für 2021." Forbes, 17. Januar 2021. https://www.forbes.com/sites/louiscolumbus/2021/01/17/76-of-enterprises-prioritize-ai--machine-learning-in-2021-it-budgets.
47 Bughin, Jacques, Jeongmin Seong, James Manyika, Michael Chui und Raoul Joshi. 2018. "Notes from the AI Frontier: Modeling the Impact of AI on the World Economy". Diskussionspapier des McKinsey Global Institute. https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-modeling-the-impact-of-ai-on-the-world-economy.
48 Thormundsson, Bergur. 2022. "Challenges Companies Are Facing When Deploying and Using Machine Learning from 2018, 2020 and 2021. Statista, April 6, 2022. https://www.statista.com/statistics/1111249/machine-learning-challenges.
Get Deep Learning im Maßstab now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

