Capítulo 4. Principio de la Plataforma de Datos de Autoservicio
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La sencillez consiste en restar lo obvio y añadir lo significativo.
John Maeda
Hasta ahora he ofrecido dos cambios fundamentales hacia la malla de datos: una arquitectura de datos distribuida y un modelo de propiedad orientado a los dominios empresariales, y datos compartidos como un producto utilizable y valioso. Con el tiempo, estos dos cambios aparentemente sencillos y bastante intuitivos pueden tener consecuencias no deseadas: duplicación de esfuerzos en cada dominio, aumento del coste de funcionamiento y, probablemente, incoherencias e incompatibilidades a gran escala entre dominios.
Esperar que los equipos de ingeniería de dominio posean y compartan datos analíticos como un producto, además de crear aplicaciones y mantener productos digitales, plantea preocupaciones legítimas tanto a los profesionales como a sus líderes. Las preocupaciones que escucho a menudo de los líderes, en este punto de la conversación, incluyen: "¿Cómo voy a gestionar el coste de funcionamiento de los productos de datos de dominio, si cada dominio tiene que construir y poseer sus propios datos?". "¿Cómo voy a contratar a los ingenieros de datos, que ya son difíciles de encontrar, para dotar de personal a cada dominio?". "Esto parece mucha sobreingeniería y duplicación de esfuerzos en cada equipo". "¿Qué tecnología compro para proporcionar todas las características de usabilidad del producto de datos?". "¿Cómo hago cumplir la gobernanza de forma distribuida para evitar el caos?" "¿Y los datos copiados? ¿Cómo los gestiono? Y así sucesivamente. Del mismo modo, los equipos de ingeniería de dominio y los profesionales expresan preocupaciones como: "¿Cómo podemos ampliar la responsabilidad de nuestro equipo no sólo para crear aplicaciones que hagan funcionar la empresa, sino también para compartir datos?"
Abordar estas cuestiones es la razón de ser del tercer principio de la malla de datos, la infraestructura de datos de autoservicio como plataforma. No es que haya escasez de plataformas de datos y analítica, pero tenemos que hacer cambios en ellas para que puedan ampliar el uso compartido, el acceso y la utilización de datos analíticos , de forma descentralizada, para una nueva población de tecnólogos generalistas. Esta es la diferenciación clave de una plataforma de malla de datos.
La Figura 4-1 muestra la extracción de las capacidades agnósticas de cada dominio y el paso a una infraestructura de autoservicio como plataforma. La plataforma la construye y mantiene un equipo dedicado a ella.
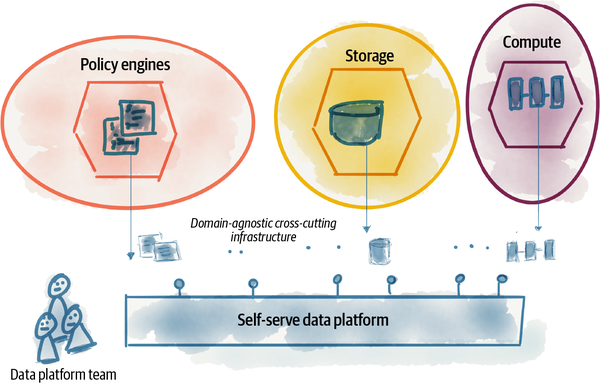
Figura 4-1. Extracción y recolección de infraestructura agnóstica de dominio en una plataforma de datos independiente
En este capítulo, aplico el pensamiento de plataforma a las capacidades de la infraestructura subyacente para aclarar qué queremos decir con el término plataforma en el contexto de la malla de datos. A continuación, comparto las características únicas de la plataforma subyacente de la malla de datos. En capítulos posteriores, como los Capítulos 9 y10, entraré en más detalles sobre las capacidades de la plataforma y cómo enfocar su diseño. Por ahora, hablemos de cómo la plataforma subyacente de la malla de datos es diferente de muchas soluciones que tenemos hoy en día.
Nota
En este capítulo, utilizo la expresión plataforma de malla de datos como abreviatura de un conjunto de capacidades de infraestructura de datos subyacentes. La forma singular del término plataforma no significa una única solución o un único proveedor con funciones estrechamente integradas. Es simplemente un marcador de posición para un conjunto de tecnologías que se pueden utilizar para lograr los objetivos mencionados en "Pensamiento sobre la plataforma de malla de datos", un conjunto de tecnologías que son independientes y, sin embargo, funcionan bien juntas.
Plataforma Data Mesh: Comparación y contraste
Existe un gran conjunto de soluciones tecnológicas que entran en la categoría de infraestructura de datos y que a menudo se plantean como una plataforma . He aquí una pequeña muestra de las capacidades de plataforma existentes:
-
Almacenamiento de datos analíticos en forma de lago, almacén o casa del lago
-
Marcos de procesamiento de datos y motores de computación para procesar datos en modo batch y streaming
-
Lenguajes de consulta de datos, basados en dos modos de programación computacional del flujo de datos o en sentencias algebraicas tipo SQL
-
Soluciones decatálogo de datos para permitir la gobernanza de los datos, así como el descubrimiento de todos los datos de una organización
-
Gestión de flujos de trabajo de canalización, orquestando tareas complejas de canalización de datos o flujos de trabajo de implementación de modelos ML
Muchas de estas capacidades siguen siendo necesarias para permitir la implementación de una malla de datos. Sin embargo, hay un cambio en el enfoque y los objetivos de una plataforma de malla de datos. Hagamos una rápida comparación y contraste.
La Figura 4-2 muestra una serie de características únicas de una plataforma de malla de datos en comparación con las existentes. Observa que la plataforma de malla de datos puede utilizar tecnologías existentes y, sin embargo, ofrecer estas características únicas.
La siguiente sección aclara cómo funciona la malla de datos para seguir construyendo plataformas de autoservicio.
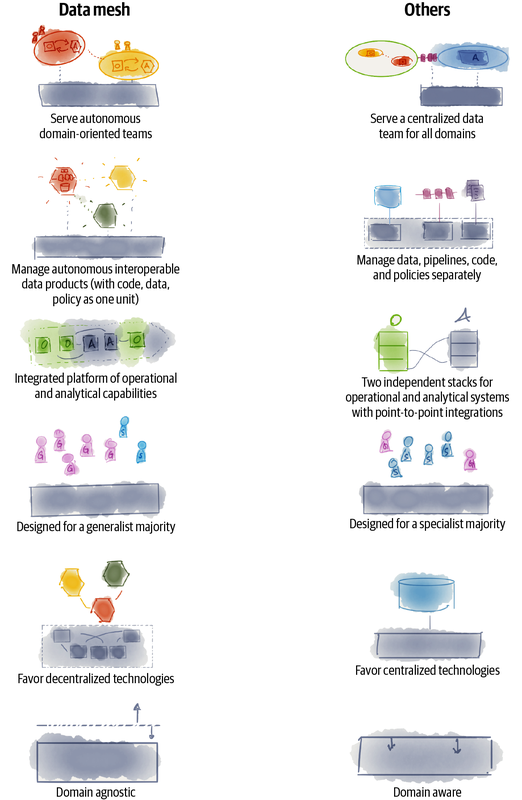
Figura 4-2. Características diferenciadoras de la plataforma de malla de datos
Servir a equipos autónomos orientados al dominio
La principal responsabilidad de la plataforma de malla de datos es capacitar a los equipos de ingeniería de dominio existentes o nuevos con las responsabilidades nuevas e integradas de construir, compartir y utilizar productos de datos de extremo a extremo; capturar datos de sistemas operativos y otras fuentes; y transformar y compartir los datos como un producto con los usuarios finales de datos.
La plataforma debe permitir a los equipos hacer esto de forma autónoma, sin depender de equipos de datos centralizados ni de intermediarios.
Muchas tecnologías de proveedores existentes se construyen con el supuesto de un equipo de datos centralizado, que captura y comparte datos para todos los dominios. Las suposiciones en torno a este control centralizado tienen profundas consecuencias técnicas, como:
-
El coste se estima y gestiona monolíticamente y no por recursos de dominio aislados.
-
La gestión de la seguridad y la privacidad asume que los recursos físicos de se comparten bajo la misma cuenta y no escalan a un contexto de seguridad aislado por producto de datos.
-
Una orquestación central de canalizaciones (DAG) supone la gestión de todas las canalizaciones de datos de forma centralizada-con un repositorio central de configuración de canalizaciones y un portal central de monitoreo. Esto entra en conflicto con las canalizaciones independientes, cada una pequeña y asignada a la implementación de un producto de datos.
Estos son algunos ejemplos para demostrar cómo las tecnologías existentes se interponen en el camino de los equipos de dominio que actúan de forma autónoma.
Gestión de productos de datos autónomos e interoperables
La malla de datos sitúa un nuevo constructo, un producto de datos orientado al dominio, en el centro de su enfoque. Se trata de un nuevo constructo arquitectónico que proporciona valor de forma autónoma. Codifica todo el comportamiento y los datos necesarios para proporcionar datos descubribles, utilizables, fiables y seguros a sus usuarios finales. Los productos de datos comparten datos entre sí y están interconectados en una malla. Las plataformas de malla de datos deben trabajar con este nuevo constructo y deben soportar la gestión de su ciclo de vida autónomo y de todos sus componentes.
Esta característica de la plataforma es diferente de las plataformas existentes en la actualidad, que gestionan el comportamiento, por ejemplo, los conductos de procesamiento de datos, los datos y sus metadatos, y la política que rige los datos como piezas independientes. Sin embargo, es posible crear la nueva abstracción de gestión de productos de datos sobre las tecnologías existentes, pero no es muy elegante.
Una plataforma continua de capacidades operativas y analíticas
El principio de propiedad de dominio exige una plataforma que permita a los equipos de dominio autónomos gestionar los datos de extremo a extremo. Esto cierra la brecha organizativa entre el plano operativo y el analítico. Por tanto, una plataforma de malla de datos debe ser capaz de proporcionar una experiencia más conectada. Tanto si el equipo construye y ejecuta una aplicación como si comparte y utiliza productos de datos para casos de uso analítico, la experiencia del equipo debe estar conectada y ser fluida. Para que la plataforma sea adoptada con éxito por los equipos de tecnología de dominio existentes, debe eliminar las barreras a la adopción, el cisma entre las pilas operativa y analítica.
La plataforma de malla de datos debe cerrar la brecha entre las tecnologías analíticas y operativas. Debe encontrar la forma de que trabajen juntas sin problemas, de un modo que resulte natural para un equipo de datos y aplicaciones orientado a dominios interfuncionales.
Por ejemplo, hoy en día el tejido de computación que ejecuta canalizaciones de procesamiento de datos como Spark se gestiona en una arquitectura de agrupación diferente, alejada y a menudo desconectada del tejido de computación que ejecuta servicios operativos, como Kubernetes. Para crear productos de datos que colaboren estrechamente con su microservicio correspondiente, es decir, productos de datos alineados con la fuente, necesitamos una integración más estrecha de los tejidos de computación. He trabajado con muy pocas organizaciones que hayan ejecutado ambos motores de computación en el mismo tejido de computación.
Debido a las diferencias inherentes entre los dos planos, hay muchas áreas de la plataforma en las que la tecnología de los sistemas operativos y analíticos debe seguir siendo diferente. Por ejemplo, considera el caso del rastreo con fines de depuración y auditoría. Los sistemas operativos utilizan los estándares OpenTelemetry para el rastreo de llamadas (API) a través de aplicaciones distribuidas, en una estructura similar a un árbol. Por otro lado, las cargas de trabajo de procesamiento de datos utilizan OpenLineage para rastrear el linaje de datos a través de conductos de datos distribuidos. Hay suficientes diferencias entre los dos planos como para tener en cuenta su brecha. Sin embargo, es importante que estos dos estándares se integren bien. Al fin y al cabo, en muchos casos, el recorrido de un dato comienza a partir de una llamada a la aplicación en respuesta a una acción del usuario.
Diseñado para una mayoría generalista
Otro obstáculo para la adopción de plataformas de datos en la actualidad es el nivel de especialización propia que asume cada proveedor de tecnología: la jerga y los conocimientos específicos del proveedor. Esto ha llevado a la creación de escasos roles especializados, como los ingenieros de datos.
En mi opinión, hay unas cuantas razones para esta especialización no escalable: falta de normas y convenciones (de facto), falta de incentivos para la interoperabilidad tecnológica y falta de incentivos para hacer que los productos sean supersencillos de usar. Creo que éste es el residuo de la mentalidad de la gran plataforma monolítica, según la cual un único proveedor puede proporcionar funcionalidad de sopa a nueces para almacenar tus datos en su plataforma y adjuntar sus servicios adicionales para mantener los datos allí y su procesamiento bajo su control.
Una plataforma de malla de datos debe romper este patrón y comenzar con la definición de un conjunto de convenciones abiertas que promuevan la interoperabilidad entre diferentes tecnologías y reduzcan el número de lenguajes y experiencias propietarios que un especialista debe aprender para generar valor a partir de los datos. Incentivar y capacitar a los desarrolladores generalistas con experiencias, lenguajes y API fáciles de aprender es un punto de partida para reducir la carga cognitiva de los desarrolladores generalistas. Para ampliar el desarrollo basado en datos a una mayor población de profesionales, las plataformas de malla de datos deben seguir siendo relevantes para los tecnólogos generalistas. Deben pasar a un segundo plano, encajar de forma natural en las herramientas y lenguajes de programación nativos que utilizan los generalistas, y apartarse de su camino.
Ni que decir tiene que esto debe conseguirse sin comprometer las prácticas de ingeniería de software que dan lugar a soluciones sostenibles. Por ejemplo, muchas plataformas de bajo código o sin código prometen trabajar con datos, pero se comprometen con las pruebas, el versionado, la modularidad y otras técnicas. Con el tiempo se vuelven imposibles de mantener.
Nota
La frase tecnólogo generalista (expertos) se refiere a la población de tecnólogos a los que a menudo se hace referencia como personas en forma de T o de goteo de pintura. Se trata de desarrolladores experimentados en un amplio espectro de la ingeniería de software que, en distintos momentos, se centran y adquieren profundos conocimientos en una o dos áreas.
La cuestión es que es posible profundizar en una o dos áreas mientras se exploran muchas otras.
Contrasta con los especialistas, que sólo son expertos en un área concreta; su enfoque en la especialización no les permite explorar un espectro diverso.
En mi opinión, los futuros generalistas podrán trabajar con datos y crear y compartir datos a través de productos de datos, o utilizarlos para la ingeniería de características y el entrenamiento de ML cuando el modelo ya haya sido desarrollado por científicos de datos especializados. Esencialmente, utilizarán la IA como un servicio.
En la actualidad, la mayor parte del trabajo con datos requiere especialización y exige un gran esfuerzo para adquirir experiencia durante un largo periodo de tiempo. Esto inhibe la entrada de tecnólogos generalistas y ha provocado una escasez de especialistas en datos.
Favorecer las tecnologías descentralizadas
Otra característica común de las plataformas existentes es la centralización del control. Algunos ejemplos son las herramientas centralizadas de orquestación de canalizaciones, los catálogos centralizados, el esquema centralizado de almacenes, la asignación centralizada de recursos informáticos/de almacenamiento, etc. La razón de que la malla de datos se centre en la descentralización mediante la propiedad del dominio es evitar la sincronización organizativa y los cuellos de botella que, en última instancia, ralentizan la velocidad del cambio. Aunque en apariencia se trata de una preocupación organizativa, la tecnología y la arquitectura subyacentes influyen directamente en la comunicación y el diseño organizativos. Una solución tecnológica monolítica o centralizada conduce a puntos de control y equipos centralizados.
Las plataformas de malla de datos deben considerar la descentralización de las organizaciones en el intercambio de datos, el control y la gobernanza en el centro de su diseño. Inspeccionan todos los aspectos centralizados del diseño que puedan dar lugar a la sincronización de los equipos, la centralización del control y el acoplamiento estrecho entre equipos autónomos.
Dicho esto, hay muchos aspectos de la infraestructura que deben gestionarse de forma centralizada para reducir las tareas innecesarias que cada equipo de dominio realiza al compartir y utilizar datos, por ejemplo, configurar clústeres informáticos de procesamiento de datos. Aquí es donde brilla una plataforma de autoservicio eficaz, que gestiona de forma centralizada los recursos subyacentes al tiempo que permite a los equipos independientes lograr sus resultados de extremo a extremo, sin dependencias estrechas de otros equipos.
Dominio agnóstico
La malla de datos crea una clara delimitación de responsabilidades entre los equipos de dominio -que se centran en crear productos orientados al negocio, servicios que idealmente se basan en datos y productos de datos- y los equipos de plataforma, que se centran en los habilitadores técnicos para los dominios. Esto difiere de la actual delimitación de responsabilidades, en la que el equipo de datos suele ser responsable de la amalgama de datos específicos del dominio para su uso analítico, así como de la infraestructura técnica subyacente.
Esta delimitación de responsabilidades debe reflejarse en las capacidades de la plataforma. La plataforma debe lograr un equilibrio entre proporcionar capacidades agnósticas del dominio, al tiempo que permite modelar, procesar y compartir datos específicos del dominio en toda la organización. Esto exige un profundo conocimiento de los desarrolladores de datos y la aplicación del pensamiento de producto a la plataforma .
Pensamiento sobre la Plataforma Data Mesh
Plataforma: superficie elevada y nivelada sobre la que pueden colocarse personas o cosas.
Lenguas de Oxford
La palabra plataforma es una de las frases más utilizadas en nuestra jerga técnica cotidiana y está salpicada por todas las estrategias técnicas de las organizaciones. Es de uso común, pero difícil de definir y sujeta a interpretación.
Para fundamentar nuestra comprensión de la plataforma en el contexto de la malla de datos, recurro al trabajo de algunas de mis fuentes de confianza:
Una plataforma digital es una base de API de autoservicio, herramientas, servicios, conocimientos y asistencia que se organizan como un producto interno convincente. Los equipos autónomos de entrega pueden hacer uso de la plataforma para entregar características del producto a un ritmo mayor, con una coordinación reducida.
Evan Bottcher, "De qué hablo cuando hablo de plataformas"
El propósito de un equipo de plataforma es permitir a los equipos alineados con la corriente entregar el trabajo con una autonomía sustancial. El equipo alineado con la corriente mantiene la plena propiedad de construir, ejecutar y arreglar su aplicación en producción. El equipo de plataforma proporciona servicios internos para reducir la carga cognitiva que se exigiría a los equipos alineados con la corriente para desarrollar estos servicios subyacentes.
La plataforma simplifica una tecnología que de otro modo sería compleja y reduce la carga cognitiva de los equipos que la utilizan.
Matthew Skelton y Manuel Pais, Equipo Topologías
Las plataformas se diseñan interacción a interacción. Por tanto, el diseño de toda plataforma debe comenzar con el diseño de la interacción central que permite entre productores y consumidores. La interacción principal es la forma más importante de actividad que tiene lugar en una plataforma: el intercambio de valor que atrae a la mayoría de los usuarios a la plataforma en primer lugar.1
Geoffrey G. Parker y otros, Plataforma Revolución)
Una plataforma tiene unos cuantos objetivos clave que me gusta extraer y aplicar a la malla de datos:
- Permite a los equipos autónomos obtener valor de los datos
- Una característica común que vemos es la capacidad de permitir a los equipos que utilizan la plataforma completar su trabajo y lograr sus resultados con una sensación de autonomía y sin necesidad de que otro equipo se implique directamente en su flujo de trabajo, por ejemplo, mediante dependencias de backlog. En el contexto de la malla de datos, un objetivo clave de una plataforma de malla de datos es capacitar a los equipos de dominio con nuevas responsabilidades para compartir los datos analíticos de, o utilizar los datos analíticos para crear productos basados en ML, de forma autónoma. La capacidad de utilizar las capacidades de la plataforma a través de API de autoservicio es fundamental para permitir la autonomía.
- Intercambiar valor con productos de datos autónomos e interoperables
- Otro aspecto clave de una plataforma es diseñar intencionadamente qué valor se intercambia y cómo. En el caso de la malla de datos, los productos de datos son la unidad de intercambio de valor, entre usuarios y proveedores de datos. Una plataforma de malla de datos debe incorporar en su diseño el intercambio sin fricciones de productos de datos como unidad de valor.
- Acelerar el intercambio de valor reduciendo la carga cognitiva
- Para simplificar y acelerar el trabajo de los equipos de dominio en la entrega de valor, las plataformas deben ocultar la complejidad técnica y fundacional. Esto reduce la carga cognitiva de los equipos de dominio para que se centren en lo que importa; en el caso de la malla de datos, esto es crear y compartir productos de datos.
- Ampliar el intercambio de datos
- La malla de datos es una solución que se ofrece para resolver el problema de la escala organizativa a la hora de obtener valor de sus datos. Por lo tanto, el diseño de la plataforma debe tener en cuenta la escala: compartir datos a través de los principales dominios dentro de la organización, así como a través de los límites de confianza fuera de la organización en la red más amplia de socios. Uno de los obstáculos a esta escala es la falta de interoperabilidad del intercambio de datos, de forma segura, a través de múltiples plataformas. Una plataforma de malla de datos debe diseñar la interoperabilidad con otras plataformas para compartir productos de datos.
- Apoyar una cultura de innovación integrada
- Una plataforma de malla de datos apoya una cultura de innovación eliminando las actividades que no contribuyen directamente a la innovación, al facilitar realmente la búsqueda de datos, la captura de perspectivas y el uso de datos para el desarrollo de modelos de ML.
La Figura 4-3 muestra estos objetivos aplicados a un ecosistema de equipos de dominio que comparten y utilizan productos de datos.

Figura 4-3. Objetivos de la plataforma de malla de datos
Ahora, hablemos de cómo una plataforma de malla de datos logra estos objetivos.
Permitir que los equipos autónomos obtengan valor de los datos
Al diseñar la plataforma , es útil tener en cuenta las funciones de los usuarios de la plataforma y su recorrido al compartir y utilizar productos de datos. La plataforma puede entonces centrarse en cómo crear una experiencia sin fricciones para cada trayecto. Por ejemplo, consideremos dos de los principales personajes del ecosistema de malla de datos: los desarrolladores de productos de datos y los usuarios de productos de datos. Por supuesto, cada uno de estos personajes incluye un espectro de personas con diferentes conjuntos de habilidades, pero para esta conversación podemos centrarnos en los aspectos de sus viajes que son comunes en todo este espectro. Hay otros roles, como el propietario del producto de datos, cuyo recorrido es igual de importante para lograr el resultado de crear productos de datos de éxito; en aras de la brevedad, los dejo fuera de este ejemplo.
Habilitar a los desarrolladores de productos de datos
El viaje de entrega de un desarrollador de productos de datos implica desarrollar un producto de datos; probarlo, implementarlo, monitorizarlo y actualizarlo; y mantener su integridad y seguridad, teniendo en cuenta la entrega continua. En resumen, el desarrollador gestiona el ciclo de vida de un producto de datos, trabajando con su código, datos y políticas como una unidad. Como puedes imaginar, hay que aprovisionar bastante infraestructura para gestionar este ciclo de vida.
El aprovisionamiento y la gestión de la infraestructura subyacente para la gestión del ciclo de vida de un producto de datos requiere un conocimiento especializado de las herramientas actuales y es difícil de replicar en cada dominio. Por lo tanto, la plataforma de malla de datos debe implementar todas las capacidades necesarias que permitan a un desarrollador de productos de datos construir, probar, desplegar, asegurar y mantener un producto de datos sin preocuparse del aprovisionamiento de recursos de la infraestructura subyacente. Debe permitir todas las capacidades agnósticas de dominio y multifuncionales .
En última instancia, la plataforma debe permitir al desarrollador del producto de datos centrarse únicamente en los aspectos específicos del dominio del desarrollo del producto de datos:
-
Código de transformación, la lógica específica del dominio que genera y mantiene los datos
-
Pruebas en tiempo de compilación para verificar y mantener la integridad de los datos del dominio
-
Pruebas en tiempo de ejecución para monitorizar continuamente que el producto de datos cumple sus garantías de calidad
-
Desarrollar los metadatos de un producto de datos, como, su esquema, documentación, etc.
-
Declaración de los recursos de infraestructura necesarios
Del resto debe ocuparse la plataforma de malla de datos, por ejemplo, del aprovisionamiento de infraestructura: almacenamiento, cuentas, computación, etc. Un enfoque de autoservicio expone un conjunto de API de plataforma para que el desarrollador del producto de datos declare sus necesidades de infraestructura y deje que la plataforma se ocupe del resto. Esto se trata en detalle en el Capítulo 14.
Habilitar a los usuarios de productos de datos
El viaje de los usuarios de datos -ya sea analizando datos para crear perspectivas o desarrollando modelos de aprendizaje automático- comienza con el descubrimiento de los datos. Una vez descubiertos los datos, necesitan acceder a ellos, y luego comprenderlos y profundizar en ellos para explorarlos más a fondo. Si los datos han demostrado ser adecuados, seguirán utilizándolos. El uso de los datos no se limita a un acceso único; los consumidores siguen recibiendo y procesando nuevos datos para mantener actualizados sus modelos de aprendizaje automático o sus percepciones. La plataforma de malla de datos construye los mecanismos subyacentes que facilitan ese viaje y proporciona las capacidades necesarias para que los consumidores de productos de datos realicen su trabajo sin fricciones.
Para que la plataforma permita este viaje, de forma autónoma, debe reducir la necesidad de intervención manual. Por ejemplo, debe eliminar la necesidad de perseguir al equipo que creó los datos o al equipo de gobierno para justificar y obtener acceso a los datos. La plataforma automatiza el proceso que facilita las solicitudes de acceso y concede el acceso basándose en la evaluación automatizada del consumidor .
Intercambiar valor con productos de datos autónomos e interoperables
Un punto de vista interesante de sobre la plataforma de malla de datos es verla como una plataforma multilateral: una que crea valor principalmente al permitir interacciones directas entre dos (o más) partes distintas. En el caso de la malla de datos, esas partes son desarrolladores de productos de datos, propietarios de productos de datos y usuarios de productos de datos.
Esta lente particular puede ser una fuente de creatividad sin límites para construir una plataforma cuyo éxito se mida directamente intercambiando valor, es decir, productos de datos. El valor puede intercambiarse en la malla, entre productos de datos, o en el perímetro de la malla, entre los productos finales, como un modelo ML, un informe o un cuadro de mando, y los productos de datos. La malla se convierte esencialmente en el mercado de datos de la organización. Esta característica particular de la plataforma de malla de datos puede ser un catalizador para un cambio de cultura dentro de la organización, promoviendo el intercambio al siguiente nivel.
Como se ha comentado en la sección anterior, un aspecto importante del intercambio de valor es poder hacerlo de forma autónoma, sin que la plataforma se interponga. Para los desarrolladores de productos de datos, esto significa poder crear y servir sus productos de datos sin la necesidad constante de ayuda o dependencia del equipo de la plataforma.
Crear valor de orden superior componiendo productos de datos
El intercambio de valor va más allá del uso de un único producto de datos y a menudo se extiende a la composición de múltiples productos de datos. Por ejemplo, las perspectivas interesantes sobre los oyentes de Daff se generan mediante la correlación cruzada de su comportamiento al escuchar música, los artistas que siguen, su demografía, sus interacciones con los medios sociales, la influencia de su red de amigos y los acontecimientos culturales que les rodean. Son múltiples productos de datos y hay que correlacionarlos y componerlos en una matriz de características.
La plataforma hace posible la compatibilidad de los productos de datos. Por ejemplo, las plataformas permiten la vinculación de productos de datos, cuando un producto de datos utiliza datos y tipos de datos (esquema) de otro producto de datos. Para que esto sea posible sin problemas, la plataforma proporciona una forma estandarizada y sencilla de identificar productos de datos, direccionar productos de datos, conectarse a productos de datos, leer datos de productos de datos, etc. Estas sencillas funciones de la plataforma crean una malla de dominios heterogéneos con interfaces homogéneas. Trataré este tema en el Capítulo 13.
Acelerar el intercambio de valor reduciendo la carga cognitiva
Cognitiva La carga se introdujo por primera vez en el campo de la ciencia cognitiva como la cantidad de memoria de trabajo necesaria para retener información temporal para resolver un problema o aprender.2 Hay múltiples factores que influyen en la carga cognitiva, como la complejidad intrínseca del tema en cuestión o cómo se presenta la tarea o la información.
Las plataformas se consideran cada vez más una forma de reducir la carga cognitiva de los desarrolladores para realizar su trabajo. Lo hacen ocultando la cantidad de detalles e información que se presenta al desarrollador: abstrayendo la complejidad.
Como desarrollador de productos de datos, debería poder expresar cuáles son mis deseos agnósticos de dominio sin describir exactamente cómo implementarlos. Por ejemplo, como desarrollador debería poder declarar la estructura de mis datos, su periodo de conservación, su tamaño potencial y su clase de confidencialidad, y dejar que la plataforma cree las estructuras de datos, aprovisione el almacenamiento, realice el cifrado automático, gestione las claves de cifrado, rote automáticamente las claves, etc. Esto es complejidad agnóstica de dominio a la que, como desarrollador o usuario de datos, no debería estar expuesto.
Existen muchas técnicas para abstraer la complejidad sin sacrificar la configurabilidad. Se suelen aplicar los dos métodos siguientes.
Complejidad abstracta mediante modelado declarativo
En los últimos años, las plataformas operativas como los orquestadores de contenedores, por ejemplo Kubernetes, o las herramientas de aprovisionamiento de infraestructuras, por ejemplo Terraform, han establecido un nuevo modelo para abstraer la complejidad mediante el modelado declarativo del estado objetivo. Esto contrasta con otros métodos, como el uso de instrucciones imperativas para ordenar cómo construir el estado objetivo. Esencialmente, el primero se centra en el qué, y el segundo en el cómo. Este enfoque ha tenido mucho éxito a la hora de simplificar la vida de un desarrollador.
En muchos escenarios, el modelado declarativo encuentra limitaciones muy rápidamente. Por ejemplo, definir la lógica de transformación de datos mediante declaraciones alcanza un rendimiento decreciente en cuanto la lógica se vuelve compleja.
Sin embargo, los sistemas que pueden describirse a través de su estado, como la infraestructura aprovisionada, se prestan bien a un estilo declarativo. Lo mismo ocurre con la infraestructura de malla de datos como plataforma. El estado objetivo de la infraestructura para gestionar el ciclo de vida de un producto de datos puede definirse de forma declarativa.
Abstraer la complejidad mediante la automatización
Eliminar la intervención humana y los pasos manuales del viaje del desarrollador del producto de datos mediante la automatización es otra forma de reducir la complejidad, en particular la complejidad derivada de los errores manuales a lo largo del proceso. Las oportunidades para automatizar aspectos de la implementación de una malla de datos son omnipresentes. El aprovisionamiento de la propia infraestructura de datos subyacente puede automatizarse mediante técnicas de infraestructura como código.3 de código. Además, muchas acciones del flujo de valor de los datos, desde la producción hasta el consumo, pueden automatizarse.
Por ejemplo, hoy en día el proceso de aprobación de la certificación o verificación de datos suele hacerse manualmente. Esta es un área de inmensas oportunidades para la automatización. La plataforma puede automatizar la verificación de la integridad de los datos, aplicar métodos estadísticos en la comprobación de la naturaleza de los datos, e incluso utilizar el aprendizaje automático para descubrir valores atípicos inesperados. Esta automatización elimina la complejidad del proceso de verificación de datos.
Compartir datos a gran escala
Un problema que he observado en el panorama actual de la tecnología de big data es la falta de normas para soluciones interoperables que lleven a compartir datos a escala, por ejemplo, la falta de un modelo unificado de autenticación y autorización al acceder a los datos, la ausencia de normas para expresar y transmitir derechos de privacidad con los datos, y la falta de normas para presentar aspectos de temporalidad de los datos. Estas normas ausentes inhiben la ampliación de la red de datos utilizables más allá de los límites de la confianza organizativa.
Y lo que es más importante, en el panorama de la tecnología de datos falta la filosofía Unix:
Esta es la filosofía Unix: Escribe programas que hagan una cosa y la hagan bien. Escribe programas que trabajen juntos...
Doug McIlroy
Creo que tuvimos una suerte increíble con personas muy especiales (McIlroy, Ritchie, Thompson y otros) que sembraron la cultura, la filosofía y la forma de construir software en el mundo operativo. Por eso hemos conseguido construir sistemas poderosamente escalables y complejos mediante la integración laxa de servicios sencillos y pequeños.
Por alguna razón, hemos abandonado esta filosofía en lo que se refiere a los sistemas de big data, quizás debido a aquellos primeros supuestos (véase "Características de la arquitectura analítica de datos") que sembraron la cultura. Tal vez, porque en algún momento decidimos separar los datos (el cuerpo) de su código (el alma), lo que llevó a establecer una filosofía diferente a su alrededor.
Si una plataforma de malla de datos quiere escalar de forma realista la compartición de datos, dentro y fuera de los límites de una organización, debe adoptar de todo corazón la filosofía Unix y, sin embargo, adaptarla a las necesidades únicas de la gestión y compartición de datos. Debe diseñar la plataforma como un conjunto de servicios interoperables que puedan ser implementados por distintos proveedores con distintas implementaciones, pero que funcionen bien con el resto de servicios de la plataforma.
Tomemos la observabilidad como ejemplo de una capacidad que proporciona la plataforma: la capacidad de monitorizar el comportamiento de todos los productos de datos de la malla y detectar cualquier interrupción, error o acceso no deseado, y notificarlo a los equipos pertinentes para que recuperen sus productos de datos. Para que la observabilidad funcione, hay múltiples servicios de la plataforma que deben cooperar: los productos de datos que emiten y registran información sobre su funcionamiento; el servicio que captura los registros y métricas emitidos y proporciona una visión holística de la malla; los servicios que buscan, analizan y detectan anomalías y errores dentro de esos registros; y los servicios que notifican a los desarrolladores cuando las cosas van mal. Para construir esto bajo la filosofía Unix, necesitamos poder elegir estos servicios y conectarlos entre sí. La clave de una integración sencilla de estos servicios es la interoperabilidad,4 un lenguaje común y unas API mediante las cuales se expresen y compartan los registros y las métricas. Sin una norma de este tipo, caemos en una única solución monolítica (pero bien integrada) que limita el acceso a los datos a un único entorno de alojamiento. No conseguimos compartir y observar los datos en todos los entornos .
Apoya una cultura de innovación integrada
A día de hoy, la innovación continua debe ser sin duda una de las competencias básicas de cualquier empresa. Eric Ries introdujo el Lean Startup5 para demostrar cómo innovar científicamente mediante ciclos cortos y rápidos de construir-medir-aprender. Desde entonces, el concepto se ha aplicado a la gran empresa a través de Lean Enterprise6-una metodología de innovación a escala.
La cuestión es que para hacer crecer una cultura de la innovación -una cultura de construir, probar y refinar ideas rápidamente- necesitamos un entorno que libere a su gente del trabajo innecesario y de la complejidad y fricción accidentales y les permita experimentar. La plataforma de malla de datos elimina el trabajo manual innecesario, oculta la complejidad y agiliza los flujos de trabajo de los desarrolladores y usuarios de productos de datos, para liberarlos y que puedan innovar utilizando los datos. Una sencilla prueba de fuego para evaluar la eficacia de una plataforma de malla de datos en este sentido es medir el tiempo que tarda un equipo en idear un experimento basado en datos y llegar a utilizar los datos necesarios para ejecutar el experimento. Cuanto más corto sea el tiempo, más madura habrá llegado a ser la plataforma de malla de datos.
Otro punto clave es: ¿quién está capacitado para hacer los experimentos? La plataforma de malla de datos ayuda a un equipo de dominio a innovar y realizar experimentos basados en datos. Las innovaciones basadas en datos ya no son exclusivas del equipo central de datos. Deben incorporarse a cada equipo de dominio en el desarrollo de sus servicios, productos o procesos.
Transición a una plataforma de malla de datos de autoservicio
Hasta ahora, he hablado de las principales diferencias entre las plataformas de datos existentes y la malla de datos, y he cubierto los principales objetivos de la plataforma de malla de datos. A continuación, me gustaría dejarte algunas medidas que puedes tomar en la transición de a tu plataforma de malla de datos.
Diseña primero las API y los protocolos
Cuando inicies tu andadura en una plataforma, ya sea comprándola, construyéndola o, muy probablemente, ambas cosas, empieza por seleccionar y diseñar las interfaces que la plataforma expone a sus usuarios. Las interfaces pueden ser API programáticas. Puede haber interfaces gráficas o de línea de comandos. En cualquier caso, decide primero las interfaces y luego la implementación de éstas mediante diversas tecnologías.
Este enfoque está bien adoptado por muchas ofertas en la nube. Por ejemplo, los proveedores de almacenamiento blob en la nube exponen API REST7 para publicar, obtener o eliminar objetos. Puedes aplicar esto a todas las capacidades de tu plataforma.
Además de las API, decide los protocolos y normas de comunicación que permitan la interoperabilidad. Inspirándonos en Internet -un ejemplo de arquitectura distribuida masivamente-, decide sobre los protocolos de cintura estrecha8 protocolos. Por ejemplo, decide los protocolos que rigen cómo expresan su semántica los productos de datos, en qué formato codifican sus datos variables en el tiempo, qué lenguajes de consulta admite cada uno, qué SLO garantiza cada uno, etc.
Prepárate para la adopción generalista
Ya he comentado antes que una plataforma de malla de datos debe estar diseñada para lamayoría generalista ("Diseñado para una mayoría generalista"). En la actualidad, muchas organizaciones tienen dificultades para encontrar especialistas en datos, como ingenieros de datos, mientras que existe una gran población de desarrolladores generalistas deseosos de trabajar con datos. El mundo fragmentado, amurallado y altamente especializado de las tecnologías de big data ha creado un fragmento igualmente amurallado de tecnólogos de datos hiperespecializados.
En tu evaluación de las tecnologías de plataforma, favorece las que se adapten mejor a un estilo natural de programación conocido por muchos desarrolladores. Por ejemplo, si estás eligiendo una herramienta de orquestación de canalizaciones, elige las que se presten a una programación sencilla de funciones Python -algo familiar para un desarrollador generalista- en lugar de las que intenten crear otro lenguaje específico del dominio (DSL) en YAML o XML con notaciones esotéricas.
En realidad, habrá un espectro de productos de datos en cuanto a su complejidad, y un espectro de desarrolladores de productos de datos en cuanto a su nivel de especialización. La plataforma debe satisfacer este espectro para movilizar la entrega de productos de datos a escala. En cualquier caso, sigue siendo necesaria la aplicación de prácticas de ingeniería perennes para construir productos de datos resistentes y mantenibles.
Haz un inventario y simplifica
La separación del plano analítico de datos y el plano operativo nos ha dejado con dos pilas tecnológicas inconexas, una que se ocupa de los datos analíticos y otra para crear y ejecutar aplicaciones y servicios. A medida que los productos de datos se integran e incrustan en el mundo operativo, surge la oportunidad de hacer converger las dos plataformas y eliminar duplicidades.
En los últimos años, el sector ha experimentado un exceso de inversión en tecnologías que se comercializan como soluciones de datos. En muchos casos, sus homólogos operativos son perfectamente adecuados para hacer el trabajo. Por ejemplo, he visto una nueva clase de herramientas de integración continua y entrega continua (CI/CD) comercializadas como DataOps. Evaluando estas herramientas más de cerca, apenas ofrecen ninguna capacidad diferenciadora que no puedan ofrecer los motores CI/CD existentes.
Cuando empieces, haz un inventario de los servicios de plataforma que ha adoptado tu organización y busca oportunidades para simplificar.
Espero que la plataforma de malla de datos sea un catalizador en la simplificación del panorama tecnológico y una colaboración más estrecha entre las plataformas operativas y analíticas.
Crear API de nivel superior para gestionar productos de datos
La plataforma de malla de datos debe introducir un nuevo conjunto de API para gestionar los productos de datos como una nueva abstracción ("Gestión de productos de datos autónomos e interoperables"). Mientras que muchas plataformas de datos, como los servicios que obtienes de tus proveedores en la nube, incluyen API de utilidad de nivel inferior -almacenamiento, catálogo, cálculo-, la plataforma de malla de datos debe introducir un nivel superior de API que se ocupen de un producto de datos como un objeto.
Por ejemplo, considera las API para crear un producto de datos, descubrir un producto de datos, conectarse a un producto de datos, leer de un producto de datos, asegurar un producto de datos, etc. Consulta el Capítulo 9 para ver el esquema lógico de un producto de datos.
Cuando establezcas tu plataforma de malla de datos, empieza con API de alto nivel que funcionen con la abstracción de un producto de datos.
Construye experiencias, no mecanismos
Me he encontrado con numerosas situaciones de construcción/compra de plataformas, en las que la articulación de la plataforma se ancla en los mecanismos que incluye, en contraposición a las experiencias que permite. Este enfoque a la hora de definir la plataforma suele conducir a un desarrollo hinchado de la misma y a la adopción de tecnologías demasiado ambiciosas y caras.
Tomemos como ejemplo la catalogación de datos. Casi todas las plataformas con las que me he cruzado tienen un catálogo de datos en su lista de mecanismos, lo que lleva a la compra de un producto de catálogo de datos con la lista más larga de funciones, y luego a sobreajustar los flujos de trabajo del equipo para que se ajusten al funcionamiento interno del catálogo. Este proceso suele durar meses.
En cambio, tu plataforma puede empezar con la articulación de la experiencia única de descubrir productos de datos. Después, construye o compra las herramientas y mecanismos más sencillos que permitan esta experiencia. A continuación, aclara, repite y refactoriza para la siguiente experiencia.
Empieza con la base más sencilla, luego cosecha para evolucionar
Dada la extensión de este capítulo en el que se discuten los objetivos y las características únicas de una plataforma de malla de datos, puede que te estés preguntando: "¿Puedo empezar a adoptar la malla de datos hoy mismo, o debo esperar algún tiempo para construir primero la plataforma?". La respuesta es que empieces a adoptar una estrategia de malla de datos hoy mismo, aunque no tengas una plataforma de malla de datos.
Puedes empezar con la base más sencilla posible. Es muy probable que tu marco de cimentación más pequeño posible esté compuesto por las tecnologías de datos que ya has adoptado, especialmente si ya estás operando analíticamente en la nube. Las utilidades de la capa inferior que puedes utilizar como base incluyen las típicas tecnologías de almacenamiento, marcos de procesamiento de datos, motores de consulta federados, etc.
A medida que crece el número de productos de datos, se desarrollan normas y se descubren formas comunes de abordar problemas similares en todos los productos de datos. A continuación, seguirás haciendo evolucionar la plataforma como un marco cosechado mediante la recopilación de capacidades comunes en todos los productos de datos y equipos de dominio .
Recuerda que la propia plataforma de malla de datos es un producto. Es un producto interno, aunque construido a partir de muchas herramientas y servicios diferentes de múltiples proveedores. Los usuarios del producto son los equipos internos. Requiere propiedad técnica del producto, planificación a largo plazo y mantenimiento a largo plazo. Aunque sigue evolucionando y pasa por un crecimiento evolutivo, su vida comienza hoy como un producto mínimo viable (MVP).9
Recapitula
El principio de la malla de datos de una plataforma de autoservicio viene al rescate para reducir la carga cognitiva que los otros dos principios imponen a los equipos de ingeniería de dominio existentes: sé dueño de tus datos analíticos y compártelos como un producto.
Comparte capacidades comunes con las plataformas de datos existentes: proporciona acceso a almacenamiento políglota, motores de procesamiento de datos, motores de consulta, streaming, etc. Sin embargo, se diferencia de las plataformas existentes en sus usuarios: equipos de dominio autónomos formados principalmente por tecnólogos generalistas. Gestiona una construcción de nivel superior de un producto de datos que encapsula datos, metadatos, código y política como una unidad.
Su propósito es dar superpoderes a los equipos de dominio, ocultando la complejidad de bajo nivel tras abstracciones más sencillas y eliminando la fricción de sus recorridos para lograr su resultado de intercambiar productos de datos como unidad de valor. Y, en última instancia, libera a los equipos para innovar con los datos. Para ampliar el intercambio de datos, más allá de un único entorno de implementación o unidad organizativa o empresa, favorece las soluciones descentralizadas que sean interoperables .
Continuaré nuestra inmersión profunda en la plataforma en el Capítulo 10 y hablaré de los servicios específicos que podría ofrecer una plataforma de malla de datos.
1 Geoffrey G. Parker, Marshall W. Van Alstyne y Sangeet Paul Choudary, Platform Revolution, (Nueva York: W.W. Norton & Company, 2016).
2 John Sweller, "Carga cognitiva durante la resolución de problemas: Efectos sobre el aprendizaje", Ciencia Cognitiva, 12(2) (abril de 1988): 257-85.
3 Kief Morris, Infraestructura como código, (Sebastopol, CA: O'Reilly, 2021).
4 OpenLineage es un intento de estandarizar los registros de seguimiento.
5 Eric Ries, "The Lean Startup", 8 de septiembre de 2008.
6 Jez Humble, Joanne Molesky y Barry O'Reilly, Lean Enterprise, (Sebastopol, CA: O'Reilly, 2015).
7 Consulta la Referencia de la API de Amazon S3 como ejemplo.
8 Saamer Akhshabi y Constantine Dovrolis, "The Evolution of Layered Protocol Stacks Leads to an Hourglass-Shaped Architecture", ponencia de la conferencia SIGCOMM (2011).
9 Ries, "El Lean Startup".
Get Datos de malla now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

