Capítulo 1. Introducción a los datos de entrenamiento
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Los datos nos rodean por todas partes: vídeos, imágenes, texto, documentos, así como datos geoespaciales, multidimensionales y mucho más. Sin embargo, en su forma bruta, estos datos son poco útiles para el aprendizaje automático supervisado (ML) y la inteligencia artificial (IA) de . ¿Cómo hacemos uso de estos datos? ¿Cómo registramos nuestra inteligencia para poder reproducirla mediante el ML y la IA? La respuesta es el arte de entrenar los datos: la disciplina de hacer útiles los datos brutos.
En este libro aprenderás
-
Conceptos de datos de entrenamiento totalmente nuevos (datos de IA)
-
La práctica cotidiana de los datos de entrenamiento
-
Cómo mejorar la eficacia de los datos de entrenamiento
-
Cómo transformar tu equipo para que esté más centrado en la IA/ML
-
Casos prácticos reales
Antes de poder abarcar algunos de estos conceptos, primero tenemos que comprender los fundamentos, que este capítulo desentrañará.
La formación de datos consiste en moldear, reformar, dar forma y digerir los datos brutos en nuevas formas: crear un nuevo significado a partir de los datos brutos para resolver problemas. Estos actos de creación y destrucción se sitúan en la intersección de la experiencia en la materia, las necesidades empresariales, y los requisitos técnicos. Es un conjunto diverso de actividades que atraviesan múltiples dominios.
En el centro de estas actividades está la anotación. La anotación produce datos estructurados que están listos para ser consumidos por un modelo de aprendizaje automático. Sin anotación, los datos brutos se consideran no estructurados, normalmente menos valiosos, y a menudo no utilizables para el aprendizaje supervisado. Por eso se necesitan datos de entrenamiento para los casos de uso del aprendizaje automático moderno, como la visión por ordenador, el procesamiento del lenguaje natural y el reconocimiento del habla.
Para cimentar esta idea en un ejemplo, consideremos la anotación en detalle. Cuando anotamos datos, estamos captando el conocimiento humano. Normalmente, este proceso tiene el siguiente aspecto: se presenta un medio, como una imagen, texto, vídeo, diseño 3D o audio, junto con un conjunto de opciones predefinidas (etiquetas). Un humano revisa el medio y determina las respuestas más adecuadas, por ejemplo, declarando que una región de una imagen es "buena" o "mala". Esta etiqueta proporciona el contexto necesario para aplicar los conceptos del aprendizaje automático(Figura 1-1).
Pero, ¿cómo lo conseguimos? ¿Cómo llegamos al punto en que el elemento multimedia adecuado, con el conjunto predefinido de opciones adecuado, se mostró a la persona adecuada en el momento adecuado? Hay muchos conceptos que conducen y siguen al momento en que esa anotación, o captura del conocimiento, se produce realmente. En conjunto, todos estos conceptos son el arte de los datos de entrenamiento.
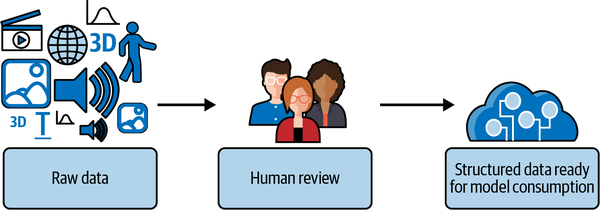
Figura 1-1. El proceso de los datos de entrenamiento
En este capítulo, introduciremos qué son los datos de entrenamiento, por qué son importantes, y nos sumergiremos en muchos conceptos clave que formarán la base del resto del libro.
Datos de entrenamiento Intentos
La finalidad de los datos de entrenamiento varía según los distintos casos de uso, problemas y escenarios. Exploremos algunas de las preguntas más comunes de , como ¿qué se puede hacer con los datos de entrenamiento? ¿Qué es lo que más interesa? ¿Qué pretende conseguir la gente con los datos de entrenamiento?
¿Qué puedes hacer con los datos de entrenamiento?
Los datos de entrenamiento son la base de los sistemas de IA/ML, la base que hace que estos sistemas funcionen.
Con los datos de entrenamiento, puedes construir y mantener sistemas modernos de ML, como los que crean automatizaciones de nueva generación, mejoran los productos existentes e incluso crean productos totalmente nuevos.
Para que sean más útiles, los datos brutos deben actualizarse y estructurarse de forma que sean consumibles por los programas de ML. Con los datos de entrenamiento, estás creando y manteniendo los nuevos datos y estructuras necesarios, como anotaciones y esquemas, para que los datos brutos sean útiles. Mediante este proceso de creación y mantenimiento, tendrás grandes datos de entrenamiento, y estarás en el camino hacia una gran solución global.
En la práctica, los casos de uso habituales se centran en unas pocas necesidades clave:
-
Mejorar un producto existente (por ejemplo, el rendimiento), aunque el ML no forme parte de él actualmente
-
Producción de un nuevo producto, incluidos los sistemas que funcionan de forma limitada o "única".
-
Investigación y desarrollo
Los datos de entrenamiento trascienden todas las partes de los programas de ML:
-
¿Entrenar un modelo? Requiere datos de entrenamiento.
-
¿Quieres mejorar el rendimiento? Requiere datos de entrenamiento de mayor calidad, diferentes o de mayor volumen.
-
¿Has hecho una predicción? Son datos de entrenamiento futuros que se acaban de generar.
Los datos de entrenamiento surgen antes de que puedas ejecutar un programa de ML; surgen durante la ejecución en términos de salida y resultados, e incluso más tarde en el análisis y el mantenimiento. Además, los problemas de los datos de entrenamiento tienden a ser de larga duración. Por ejemplo, después de poner en marcha un modelo, el mantenimiento de los datos de entrenamiento es una parte importante del mantenimiento de un modelo. Mientras que, en los entornos de investigación, un único conjunto de datos de entrenamiento puede ser invariable (por ejemplo, ImageNet), en la industria, los datos de entrenamiento son extremadamente dinámicos y cambian a menudo. Esta naturaleza dinámica hace cada vez más importante tener un gran conocimiento de los datos de entrenamiento.
La creación y el mantenimiento de datos novedosos es una de las principales preocupaciones de este libro. Un conjunto de datos, en un momento dado, es un resultado de los complejos procesos de entrenamiento de datos. Por ejemplo, una división Entrenamiento/Prueba/Val es un derivado de un conjunto original y novedoso. Y ese conjunto novedoso en sí mismo es simplemente una instantánea, una visión única de procesos de datos de entrenamiento más amplios. Del mismo modo que un programador puede decidir imprimir o registrar una variable, la variable impresa es sólo la salida; no explica el complejo conjunto de funciones que fueron necesarias para obtener el valor deseado. Uno de los objetivos de este libro es explicar los complejos procesos que hay detrás de la obtención de conjuntos de datos utilizables.
La anotación, el acto de los humanos de anotar directamente las muestras , es la parte "más alta" de los datos de entrenamiento. Por más alta, quiero decir que la anotación humana funciona sobre la recopilación de datos existentes (por ejemplo, de almacenamientos BLOB, bases de datos existentes, metadatos, sitios web).1 La anotación humana es también la verdad superior sobre conceptos de automatización como el preetiquetado y otros procesos que generan nuevos datos como predicciones y etiquetas. Estas combinaciones de trabajo humano de "alto nivel", datos existentes y trabajo de la máquina forman un núcleo de los conceptos mucho más amplios de datos de entrenamiento que se describen más adelante en este capítulo.
¿Qué es lo que más preocupa a los Datos de Formación?
Este libro abarca diversos aspectos relacionados con las personas, la organización y la técnica. Repasaremos cada uno de estos conceptos en detalle dentro de un momento, pero antes, pensemos en las áreas en las que se centran los datos de formación.
Por ejemplo, ¿cómo representa exactamente el problema el esquema, que es un mapa entre tus anotaciones y su significado para tu caso de uso? ¿Cómo te aseguras de que los datos brutos se recogen y utilizan de forma relevante para el problema? ¿Cómo se aplican la validación humana, el monitoreo, los controles y la corrección?
¿Cómo consigue y mantiene repetidamente grados aceptables de calidad cuando hay un componente humano tan grande? ¿Cómo se integra con otras tecnologías, incluidas las fuentes de datos y tu aplicación?
Para ayudar a organizar esto, puedes dividir a grandes rasgos el concepto general de datos de formación en los siguientes temas: esquema, datos brutos, calidad, integraciones y el papel humano. A continuación, profundizaré en cada uno de esos temas.
Esquema
Un esquema se forma mediante etiquetas, atributos , representaciones espaciales y relaciones con datos externos. Los anotadores utilizan el esquema al hacer anotaciones. Los esquemas son la columna vertebral de tu IA y fundamentales en todos los aspectos de los datos de entrenamiento.
Conceptualmente, un esquema es el mapa entre la entrada humana y el significado para tu caso de uso. Define lo que el programa de ML es capaz de producir. Es el eslabón vital, lo que une el duro trabajo de todos. Así que, para decir lo obvio, es importante.
Un buen esquema es útil y relevante para tu necesidad específica. Suele ser mejor crear un esquema nuevo y personalizado, y luego seguir iterando sobre él para tus casos específicos. Es normal inspirarse en bases de datos específicas de un dominio, o completar ciertos niveles de detalle, pero asegúrate de que se hace en el contexto de la orientación para un esquema nuevo y novedoso. No esperes que un esquema existente en otro contexto funcione para los programas de ML sin más actualizaciones.
Entonces, ¿por qué es importante diseñarlo según tus necesidades específicas, y no según un conjunto predefinido?
En primer lugar, el esquema es tanto para anotación humana como para uso ML. Un esquema existente específico de un dominio puede estar diseñado para uso humano en un contexto diferente o para uso de máquinas en un contexto clásico, no ML. Este es uno de esos casos en los que dos cosas pueden parecer que producen resultados similares, pero en realidad el resultado se forma de formas totalmente distintas. Por ejemplo, dos funciones matemáticas diferentes pueden dar como resultado el mismo valor, pero ejecutarse con una lógica completamente distinta. La salida del esquema puede parecer similar, pero las diferencias son importantes para que sea fácil de anotar y utilizar en ML.
En segundo lugar, si el esquema no es útil, entonces ni siquiera sirven las grandes predicciones del modelo. Un fallo en el diseño del esquema probablemente conducirá en cascada a un fallo del sistema en su conjunto. El contexto aquí es que los programas de ML normalmente sólo pueden hacer predicciones basadas en lo que se incluye en el esquema.2 Es raro que un programa de ML produzca resultados relevantes que sean mejores que el esquema original. También es raro que prediga algo que un humano, o un grupo de humanos, que analicen los mismos datos brutos no puedan predecir.
Es frecuente ver esquemas que tienen un valor cuestionable. Por eso, realmente merece la pena pararse a pensar: "Si consiguiéramos etiquetar automáticamente los datos con este esquema, ¿nos sería realmente útil?" y "¿Puede un humano que mire los datos en bruto elegir razonablemente algo del esquema que se ajuste a ellos?".
En los primeros capítulos, trataremos los aspectos técnicos de los esquemas, y volveremos a tratar las cuestiones de los esquemas mediante ejemplos prácticos más adelante en el libro.
Datos brutos
Los datos brutos son cualquier forma de datos Binary Large Object (BLOB) o datos preestructurados que se tratan como una sola muestra a efectos de anotación. Algunos ejemplos son vídeos, imágenes, texto, documentos y datos geoespaciales y multidimensionales. Cuando pensamos en los datos brutos como parte de los datos de entrenamiento, lo más importante es que los datos brutos se recopilen y utilicen de forma relevante para el esquema.
Para ilustrar la idea de la relevancia de los datos brutos para un esquema, consideremos la diferencia entre oír un partido deportivo por la radio, verlo por televisión o asistir al partido en persona. Es el mismo acontecimiento independientemente del medio, pero recibes una cantidad de datos muy diferente en cada contexto. El contexto de la recogida de datos brutos, por TV, radio o en persona, enmarca el potencial de los datos brutos. Así, por ejemplo, si estuvieras intentando determinar automáticamente la posesión del balón, los datos brutos visuales probablemente se ajustarán mejor que los datos brutos radiofónicos.
En comparación con el software, los humanos somos buenos haciendo correlaciones contextuales automáticamente y trabajando con datos ruidosos. Hacemos muchas suposiciones, a menudo basándonos en fuentes de datos que no están presentes en el momento para nuestros sentidos. Esta capacidad de comprender el contexto por encima de las imágenes, sonidos, etc. percibidos directamente hace difícil recordar que el software es más limitado en este aspecto.
El software sólo tiene el contexto que se programa en él, ya sea mediante datos o líneas de código. Esto significa que el verdadero reto con los datos brutos es superar nuestras suposiciones humanas sobre el contexto para disponer de los datos correctos.
¿Cómo lo haces? Una de las formas más exitosas es comenzar con el esquema y, a continuación, mapear las ideas de recopilación de datos brutos en función de él. Puede visualizarse como una cadena de problema -> esquema -> datos brutos. Los requisitos del esquema siempre vienen definidos por el problema o el producto. De este modo, siempre hay una comprobación fácil: "Teniendo en cuenta el esquema y los datos brutos, ¿puede un ser humano emitir un juicio razonable?
Centrarse en el esquema también anima a pensar en nuevos métodos de recogida de datos, en lugar de limitarse a los métodos de recogida de datos existentes o más fáciles de alcanzar. Con el tiempo, se puede iterar conjuntamente sobre el esquema y los datos brutos; esto es sólo para empezar. Otra forma de relacionar el esquema con el producto es considerar que el esquema representa al producto. Así que, utilizando el tópico de "ajuste del producto al mercado", esto es "ajuste de los datos del producto".
Para poner las abstracciones anteriores en términos más concretos, hablaremos de algunos problemas comunes que surgen en la industria. Las diferencias entre los datos utilizados durante el desarrollo y la producción es una de las fuentes más comunes de errores. Es común porque es en cierto modo inevitable. Por eso es crucial poder llegar a cierto nivel de datos "reales" al principio del proceso de iteración. Tienes que esperar que los datos de producción sean diferentes, y planificarlo como parte de tu estrategia general de recopilación de datos.
El programa de datos sólo puede ver los datos brutos y las anotaciones, sólo lo que se le proporciona. Si un anotador humano se basa en conocimientos ajenos a lo que se puede entender a partir de la muestra presentada, es poco probable que el programa de datos disponga de ese contexto, y fracasará. Debemos recordar que todo el contexto necesario debe estar presente, ya sea en los datos o en las líneas de código del programa.
Recapitulando:
-
Los datos brutos tienen que ser relevantes para el esquema.
-
Los datos brutos deben ser lo más parecidos posible a los datos de producción.
-
Los datos brutos deben tener todo el contexto necesario en la propia muestra.
Anotaciones
Cada anotación es un único ejemplo de algo especificado en el esquema. Imagina dos acantilados con un espacio abierto en medio, el de la izquierda representando el esquema, y el de la derecha un único archivo de datos brutos. Una anotación es el puente concreto entre el esquema y los datos brutos, como se muestra en la Figura 1-2.
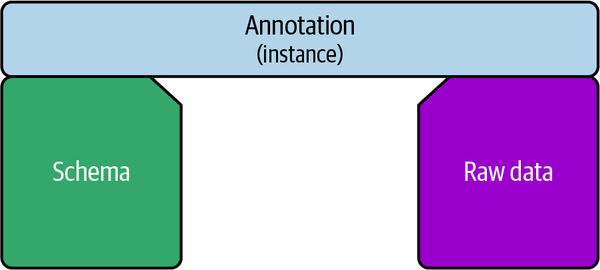
Figura 1-2. Relaciones entre el esquema, la anotación única y los datos brutos
Aunque el esquema es "abstracto", lo que significa que se hace referencia a él y se reutiliza entre múltiples anotaciones, cada anotación tiene los valores específicos reales que rellenan las respuestas a las preguntas del esquema.
Las anotaciones suelen ser la forma más numerosa de datos en un sistema de datos de entrenamiento, porque cada archivo suele tener decenas, o incluso cientos, de anotaciones. Una anotación también se conoce como "instancia" porque es una única instancia de algo en el esquema.
Más técnicamente, cada instancia de anotación suele contener una clave para relacionarla con una etiqueta o atributo dentro de un esquema y un archivo o archivo hijo que representa los datos brutos. En la práctica, cada archivo suele contener una lista de instancias.
Calidad
La calidad de los datos de formación se da naturalmente en un espectro. Lo que es aceptable en un contexto puede no serlo en otro.
Entonces, ¿cuáles son los principales factores que intervienen en la calidad de los datos de formación? Bueno, ya hemos hablado de dos de ellos: el esquema y los datos brutos. Por ejemplo:
-
Un mal esquema puede causar más problemas de calidad que unos malos anotadores.
-
Si el concepto no está claro en la muestra de datos brutos, es poco probable que lo esté para el programa de ML.
A menudo, la calidad de la anotación es el siguiente punto más importante de . La calidad de la anotación es importante, pero quizá no de la forma que cabría esperar. Concretamente, la gente tiende a pensar en la calidad de la anotación como "¿se anotó bien?". Pero "bien" a menudo está fuera del alcance. Para entender por qué la respuesta "correcta" está a menudo fuera de alcance, imaginemos que estamos anotando semáforos, y que el semáforo de la muestra que se te presenta está apagado (por ejemplo, por un fallo eléctrico) y tus únicas opciones del esquema son variaciones de un semáforo activo. Está claro que, o bien hay que actualizar el esquema para que incluya un semáforo "apagado", o nuestro sistema de producción nunca podrá utilizarse en un contexto en el que un semáforo pueda tener un fallo eléctrico.
Para pasar a un caso un poco más difícil de controlar, considera que si el semáforo está muy lejos o en un ángulo extraño, eso también limitará la capacidad del trabajador para anotarlo correctamente. A menudo, estos casos suenan como si debieran ser fácilmente manejables, pero en la práctica a menudo no lo son. Así que, de forma más general, los problemas reales con la calidad de la anotación tienden a girar en torno a problemas con el esquema y los datos brutos. Los anotadores sacan a la luz problemas con los esquemas y los datos en el transcurso de su trabajo. Una anotación de alta calidad tiene que ver tanto con la comunicación eficaz de estos problemas como con anotar "correctamente".
Nunca insistiré lo suficiente en que el esquema y los datos brutos merecen mucha atención. Sin embargo, anotar correctamente sigue siendo importante, y uno de los enfoques es hacer que varias personas examinen la misma muestra. Esto suele ser costoso, y alguien debe interpretar el significado de las múltiples opiniones sobre la misma muestra, lo que añade más costes. Para un caso utilizable en la industria, en el que el esquema tiene un grado razonable de complejidad, el metaanálisis de las opiniones es otro sumidero de tiempo.
Piensa en una multitud de personas viendo la repetición instantánea de un partido deportivo. Imagina intentar muestrear estadísticamente sus opiniones para obtener una "prueba" de lo que es "más correcto". En lugar de esto, tenemos un árbitro que revisa individualmente la situación y toma una determinación. Puede que el árbitro no tenga "razón" pero, para bien o para mal, la norma social es que el árbitro (o un proceso similar) tome la decisión.
Del mismo modo, a menudo se utiliza un enfoque más rentable. Un porcentaje de los datos se muestrea aleatoriamente para un bucle de revisión, y los anotadores plantean problemas con el esquema y el ajuste de los datos brutos, a medida que se producen. Este bucle de revisión y los procesos de garantía de calidad se tratarán con más profundidad más adelante.
Si el método de revisión falla, y parece que seguirías necesitando que varias personas anotaran los mismos datos para garantizar una alta calidad, probablemente tienes un mal ajuste de los datos del producto, y necesitas cambiar el esquema o la recopilación de datos brutos para solucionarlo.
Alejándonos del esquema, los datos brutos y la anotación, los otros grandes aspectos de la calidad son el mantenimiento de los datos y los puntos de integración con los programas de ML. La calidad incluye consideraciones de coste, uso previsto e índices de fallos esperados.
Recapitulando, la calidad está formada en primer lugar por el esquema y los datos brutos, después por los anotadores y los procesos asociados de , y se completa con el mantenimiento y la integración.
Integraciones
A menudo se dedica mucho tiempo y energía a "entrenar el modelo". Sin embargo, como entrenar un modelo es un concepto centrado principalmente en la ciencia de los datos técnicos, puede llevarnos a infravalorar otros aspectos importantes del uso eficaz de la tecnología.
¿Qué pasa con el mantenimiento de los datos de entrenamiento? ¿Qué pasa con los programas de ML que producen resultados útiles de los datos de entrenamiento, como el muestreo, la búsqueda de errores, la reducción de la carga de trabajo, etc., que no intervienen en el entrenamiento de un modelo? ¿Qué hay de la integración con la aplicación en la que se utilizarán los resultados del modelo o subprograma ML? ¿Y la tecnología que comprueba y monitoriza los conjuntos de datos? ¿El hardware? ¿Las notificaciones humanas? ¿Cómo se integra la tecnología en otras tecnologías?
Entrenar el modelo es sólo un componente. Para construir con éxito un programa de ML, un programa basado en datos, tenemos que pensar en cómo funcionan juntos todos los componentes tecnológicos. Y para poner manos a la obra, tenemos que ser conscientes del creciente ecosistema de datos de entrenamiento. La integración con la ciencia de datos es polifacética, no se trata sólo de un "resultado" final de anotaciones. Se trata del control humano continuo, el mantenimiento, el esquema, la validación, el ciclo de vida, la seguridad, etc. Un lote de anotaciones emitidas es como el resultado de una única consulta SQL, es una visión única y limitada de una base de datos compleja.
Algunos aspectos clave que debes recordar sobre el trabajo con integraciones:
-
Los datos de entrenamiento sólo son útiles si pueden ser consumidos por algo, normalmente dentro de un programa mayor.
-
La integración con la ciencia de datos tiene muchos puntos de contacto y requiere pensar a gran escala.
-
Conseguir entrenar un modelo es sólo una pequeña parte del ecosistema global.
El papel humano
Los humanos afectan a los programas de datos mediante controlando los datos de entrenamiento. Esto incluye determinar los aspectos que hemos tratado hasta ahora, el esquema, los datos brutos, la calidad y las integraciones con otros sistemas. Y, por supuesto, las personas intervienen en la anotación propiamente dicha, cuando los humanos examinan cada muestra individual.
Este control se ejerce en muchas etapas, y por muchas personas, desde el establecimiento de los datos de entrenamiento iniciales hasta la realización de evaluaciones humanas de los resultados de la ciencia de datos y la validación de los resultados de la ciencia de datos. Este gran volumen de personas implicadas es muy diferente del ML clásico.
Tenemos nuevas métricas, como cuántas muestras se aceptaron, cuánto tiempo se dedica a cada tarea, los ciclos de vida de los conjuntos de datos, la fidelidad de los datos en bruto, cómo es la distribución del esquema, etc. Estos aspectos pueden solaparse con términos de la ciencia de datos, como la distribución de clases, pero merece la pena pensar en ellos como conceptos separados. Por ejemplo, las métricas de los modelos se basan en la verdad fundamental de los datos de entrenamiento, de modo que si los datos son erróneos, las métricas son erróneas. Y como se explica en "Automatización de la garantía de calidad", las métricas en torno a algo como la concordancia de los anotadores pueden pasar por alto puntos más amplios de problemas de esquemas y datos brutos.
La supervisión humana es mucho más que métricas cuantitativas. Se trata de comprensión cualitativa. La observación humana, la comprensión humana del esquema, los datos brutos, las muestras individuales, etc., son de gran importancia. Esta visión cualitativa se extiende a los conceptos de negocio y casos de uso. Además, estas validaciones y controles pasan rápidamente de ser fácilmente definibles, a ser más bien una forma de arte, actos de creación. Por no hablar de las complicadas expectativas políticas y sociales que pueden surgir en torno al rendimiento y los resultados del sistema.
Trabajar con datos de entrenamiento es una oportunidad para crear: captar la inteligencia y las percepciones humanas de formas novedosas; enmarcar los problemas en un nuevo contexto de datos de entrenamiento; crear nuevos esquemas, recopilar nuevos datos brutos y utilizar otros métodos específicos de los datos de entrenamiento.
Esta creación, este control, es todo nuevo. Aunque hemos establecido patrones para diversos tipos de interacción entre humanos y ordenadores, hay mucho menos establecidos para las interacciones entre humanos y programas de ML: para la supervisión humana, un sistema basado en datos, en el que los humanos pueden corregir y programar directamente los datos.
Por ejemplo, esperamos que un oficinista medio sepa utilizar el procesador de textos, pero no esperamos que utilice herramientas de edición de vídeo. La formación de datos requiere expertos en la materia. Así que, del mismo modo que hoy en día un médico debe saber utilizar un ordenador para tareas comunes, ahora debe aprender a utilizar patrones de anotación estándar. A medida que surjan y se generalicen los programas basados en datos controlados por humanos, estas interacciones seguirán aumentando en importancia y variabilidad.
Oportunidades de datos de formación
Ahora que entendemos muchos de los fundamentos, vamos a enmarcar algunas oportunidades. Si estás pensando en añadir datos de entrenamiento a tu programa de ML/AI, algunas preguntas que puedes hacerte son:
-
¿Cuáles son las buenas prácticas?
-
¿Lo estamos haciendo de la forma "correcta"?
-
¿Cómo puede mi equipo trabajar más eficazmente con los datos de formación?
-
¿Qué oportunidades de negocio pueden desbloquear los proyectos centrados en los datos de formación?
-
¿Puedo convertir un proceso de trabajo existente, como un proceso de control de calidad, en datos de entrenamiento? ¿Qué pasaría si todos mis datos de entrenamiento pudieran estar en un solo lugar en lugar de barajar datos de A a B a C? ¿Cómo puedo ser más competente con las herramientas de datos de entrenamiento?
En términos generales, una empresa puede:
-
Aumentar los ingresos mediante el envío de nuevos productos de datos de IA/ML.
-
Mantén los ingresos existentes mejorando el rendimiento de un producto existente mediante datos de IA/ML.
-
Reduce los riesgos de seguridad: reduce los riesgos y costes de la exposición y pérdida de datos de IA/ML.
-
Mejora la productividad desplazando el trabajo de los empleados más arriba en la cadena alimentaria de la automatización. Por ejemplo, aprendiendo continuamente de los datos, puedes crear tu motor de datos AI/ML.
Todos estos elementos pueden conducir a transformaciones a través de una organización, que trataré a continuación.
Transformación empresarial
La mentalidad de tu equipo y de tu empresa en torno a los datos de formación es importante. Daré más detalles en el Capítulo 7, pero de momento, aquí tienes algunas formas importantes de empezar a pensar en esto:
-
Empieza a ver todo el trabajo rutinario existente en la empresa como una oportunidad para crear datos de formación.
-
Date cuenta de que el trabajo no capturado en un sistema de datos de formación se pierde.
-
Empieza a hacer que la anotación forme parte de la jornada de cada trabajador de primera línea.
-
Define tus estructuras organizativas de liderazgo para apoyar mejor los esfuerzos de formación de datos.
-
Gestiona tus procesos de datos de formación a escala. Lo que funciona para un científico de datos individual puede ser muy diferente de lo que funciona para un equipo, y aún más diferente para una empresa con varios equipos.
Para conseguir todo esto, es importante implantar sólidas prácticas de datos de formación en tu equipo y organización. Para ello, necesitas crear en tu empresa una mentalidad centrada en los datos de formación. Esto puede ser complejo y puede llevar tiempo, pero merece la pena la inversión.
Para ello, implica a expertos en la materia en las discusiones sobre la planificación de tu proyecto. Aportarán ideas valiosas que ahorrarán tiempo a tu equipo. También es importante utilizar herramientas para mantener abstracciones e integraciones para la recogida, entrada y salida de datos brutos. Necesitarás nuevas bibliotecas para fines específicos de datos de formación, de modo que puedas basarte en la investigación existente. Disponer de las herramientas y sistemas adecuados ayudará a tu equipo a actuar con una mentalidad centrada en los datos. Y por último, asegúrate de que tú y tus equipos informáis y describís los datos de formación. Entender qué se hizo, por qué se hizo y cuáles fueron los resultados servirá de base para futuros proyectos.
Todo esto puede sonar desalentador ahora, así que vamos a desglosar las cosas un poco más. Cuando empieces a trabajar con datos de entrenamiento, aprenderás nuevos conceptos específicos de los datos de entrenamiento que te llevarán a cambiar de mentalidad. Por ejemplo, añadir nuevos datos y anotaciones formará parte de tus flujos de trabajo rutinarios. Estarás más informado a medida que establezcas los conjuntos de datos iniciales, los esquemas y otras configuraciones. Este libro te ayudará a familiarizarte con nuevas herramientas, nuevas API, nuevos SDK, etc., permitiéndote integrar herramientas de datos de formación en tu flujo de trabajo.
Eficacia de los datos de entrenamiento
La eficacia en los datos de entrenamiento es una función de muchas partes. Exploraremos esto con más detalle en los próximos capítulos, pero por ahora, considera estas preguntas:
-
¿Cómo podemos crear y mantener mejores esquemas?
-
¿Cómo podemos captar y conservar mejor los datos brutos?
-
¿Cómo podemos anotar de forma más eficaz?
-
¿Cómo podemos reducir los recuentos de muestras relevantes para que haya menos que anotar en primer lugar?
-
¿Cómo podemos poner al día a la gente sobre las nuevas herramientas?
-
¿Cómo podemos hacer que esto funcione con nuestra aplicación? ¿Cuáles son los puntos de integración?
Como ocurre con la mayoría de los procesos, hay muchas áreas en las que mejorar la eficacia, y este libro te mostrará cómo pueden ayudarte las buenas prácticas de formación de datos de .
Competencia en utillaje
Nuevas herramientas, como Diffgram, HumanSignal y más, ofrecen ahora muchas formas de ayudar a realizar tus objetivos de datos de entrenamiento. A medida que estas herramientas crecen en complejidad, ser capaz de dominarlas se hace más importante. Puede que hayas cogido este libro buscando una visión general, o para optimizar puntos de dolor específicos. El Capítulo 2 tratará sobre herramientas y compensaciones.
Oportunidades de mejora de los procesos
Considera algunas áreas comunes que la gente quiere mejorar, como:
-
La calidad de la anotación es deficiente, demasiado costosa, demasiado manual, demasiado propensa a errores
-
Duplicar el trabajo
-
El coste laboral de los expertos en la materia es demasiado alto
-
Demasiado trabajo rutinario o tedioso
-
Es casi imposible obtener suficientes datos brutos originales
-
El volumen de datos brutos supera claramente cualquier capacidad razonable de examinarlos manualmente
Puede que quieras una transformación empresarial más amplia, aprender nuevas herramientas u optimizar un proyecto o proceso concreto. La pregunta es, naturalmente, ¿cuál es el siguiente paso que debes dar, y por qué deberías darlo? Para ayudarte a responder, hablemos ahora de por qué son importantes los datos de formación.
Por qué son importantes los datos de formación
En esta sección, trataré por qué datos de entrenamiento es importante para tu organización, y por qué es esencial una sólida práctica de datos de entrenamiento. Estos son temas centrales a lo largo del libro, y volverás a verlos en el futuro.
En primer lugar, los datos de entrenamiento determinan lo que tu programa de IA, tu sistema, puede hacer. Sin datos de entrenamiento, no hay sistema. Con datos de entrenamiento, ¡las oportunidades sólo están limitadas por tu imaginación! Más o menos. Bueno, vale, en la práctica, sigue habiendo presupuesto, recursos como hardware y experiencia del equipo. Pero teóricamente, cualquier cosa que puedas formar en un esquema y registrar datos brutos, el sistema puede repetirla. Conceptualmente, el modelo puede aprender cualquier cosa. Es decir, la inteligencia y la capacidad del sistema dependen de la calidad del esquema y del volumen y la variedad de datos que puedas enseñarle. En la práctica, unos datos de entrenamiento eficaces te dan un perímetro clave cuando todo lo demás -presupuesto, recursos, etc.- es igual.
En segundo lugar, el trabajo de los datos de entrenamiento es previo al trabajo de la ciencia de datos. Esto significa que la ciencia de datos depende de los datos de entrenamiento. Los errores en los datos de entrenamiento fluyen hacia la ciencia de datos. O para utilizar el tópico: basura entra, basura sale. La Figura 1-3 muestra cómo es este flujo de datos en la práctica.
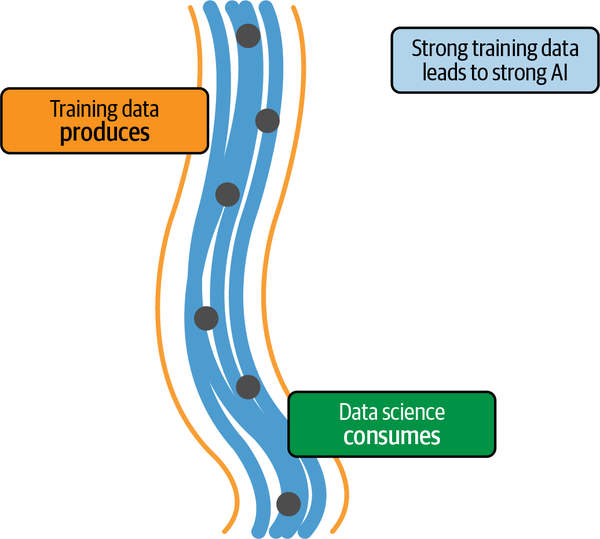
Figura 1-3. Posiciones conceptuales de los datos de entrenamiento y la ciencia de datos
En tercer lugar, el arte de los datos de entrenamiento representa un cambio en la forma de pensar sobre cómo construir sistemas de IA. En lugar de centrarnos excesivamente en mejorar los algoritmos matemáticos, paralelamente a ellos, seguimos optimizando los datos de entrenamiento para que se ajusten mejor a nuestras necesidades. Éste es el corazón de la transformación de la IA que se está produciendo, y el núcleo de la automatización moderna. Por primera vez, se está automatizando el trabajo del conocimiento.
Las aplicaciones ML se están generalizando
En 2005, un equipo universitario utilizó un enfoque basado en datos de entrenamiento3 para diseñar un vehículo, Stanley, capaz de conducir de forma autónoma en un recorrido todoterreno de 175 millas por el desierto, ganando el gran desafío de la Agencia de Proyectos de Investigación Avanzada de Defensa (DARPA). Unos 15 años más tarde, en octubre de 2020, una empresa automovilística hizo pública una controvertida tecnologíade conducción totalmente autónoma (FSD ), dando paso a una nueva era de concienciación de los consumidores. En 2021, la preocupación por el etiquetado de los datos empezó a mencionarse en las convocatorias de beneficios. En otras palabras, la corriente dominante empieza a estar expuesta a los datos de entrenamiento.
Esta comercialización va más allá de los titulares sobre los resultados de la investigación en IA. En los últimos años, hemos visto aumentar drásticamente las exigencias impuestas a la tecnología. Esperamos poder hablar con un software y que nos entienda, obtener automáticamente buenas recomendaciones y contenidos personalizados. Las grandes empresas tecnológicas, las startups y las empresas por igual recurren cada vez más a la IA para hacer frente a esta explosión de combinaciones de casos de uso.
El conocimiento, las herramientas y las buenas prácticas de la IA se expanden rápidamente. Lo que antes era dominio exclusivo de unos pocos, ahora se está convirtiendo en conocimiento común y en llamadas a API preconstruidas. Estamos en la fase de transición, pasando de las demostraciones de I+D a las primeras fases de los casos de uso en el mundo real de la industria.
Las expectativas en torno a la automatización se están redefiniendo. El control de crucero, para un comprador de un coche nuevo, ha pasado de limitarse a "mantener una velocidad constante" a incluir "mantener el carril, marcar la distancia y mucho más". No se trata de consideraciones futuras. Son expectativas actuales de consumidores y empresas. Indican necesidades claras y presentes de tener una estrategia de IA y de disponer de competencia en ML y datos de formación en tu empresa.
La base del éxito de la IA
El aprendizaje automático consiste en aprender de los datos. Históricamente, esto significaba crear conjuntos de datos en forma de registros, o datos tabulares similares como "Anthony vio un vídeo".
Estos sistemas siguen teniendo un valor significativo. Sin embargo, tienen algunos límites. No nos ayudarán a hacer cosas que la IA moderna basada en datos de entrenamiento puede hacer, como construir sistemas para entender un TAC u otras imágenes médicas, entender las tácticas de fútbol o, en el futuro, manejar un vehículo.
La idea que subyace a este nuevo tipo de IA es que un humano diga expresamente: "Éste es un ejemplo del aspecto de un jugador que pasa la pelota", "Éste es el aspecto de un tumor" o "Esta parte de la manzana está podrida".
Esta forma de expresión es similar a cómo en un aula un profesor explica conceptos a los alumnos: con palabras y ejemplos. Los profesores ayudan a llenar el vacío entre los libros de texto, y los alumnos construyen una comprensión multidimensional a lo largo del tiempo. En los datos de entrenamiento, el anotador actúa como el profesor, rellenando el hueco entre el esquema y los datos brutos.
Los datos de formación están aquí para quedarse
Como ya se ha dicho, los casos de uso para los datos modernos de IA/ML están pasando de la I+D a la industria. Estamos al principio de una larga curva en ese ciclo empresarial. Naturalmente, los detalles cambian rápidamente. Sin embargo, las ideas conceptuales en torno a pensar en el trabajo diario como una anotación, animar a la gente a esforzarse cada vez más por realizar un trabajo único, y la supervisión de programas de ML cada vez más capaces, están aquí para quedarse.
Por el lado de la investigación, tanto los algoritmos como las ideas sobre cómo utilizar los datos de entrenamiento siguen mejorando. Por ejemplo, la tendencia es que ciertos tipos de modelos necesiten cada vez menos datos para ser eficaces. Cuantas menos muestras necesite un modelo para aprender, más importancia se da a la creación de datos de entrenamiento con mayor amplitud y profundidad. Y en la otra cara de la moneda, muchos casos de uso de la industria suelen requerir cantidades aún mayores de datos para alcanzar los objetivos empresariales. En ese contexto empresarial, la necesidad de que cada vez más personas participen en el entrenamiento de los datos ejerce una mayor presión sobre las herramientas.
En otras palabras, las direcciones de expansión de la investigación y la industria dan cada vez más importancia a los datos de entrenamiento a lo largo del tiempo.
Los datos de entrenamiento controlan el programa de ML
La cuestión en cualquier sistema es el control. ¿Dónde está el control? En el código informático normal, es la lógica escrita por el ser humano en forma de bucles, sentencias if, etc. Esta lógica define el sistema.
En el aprendizaje automático clásico, los primeros pasos de incluyen definir las características de interés y un conjunto de datos. A continuación, un algoritmo genera un modelo. Aunque pueda parecer que el algoritmo tiene el control, el verdadero control se ejerce al elegir las características y los datos, que determinan los grados de libertad del algoritmo.
En un sistema de aprendizaje profundo, el algoritmo hace su propia selección de características. El algoritmo intenta determinar (aprender) qué características son relevantes para un objetivo determinado. Ese objetivo está definido por los datos de entrenamiento. De hecho, los datos de entrenamiento son la principal definición del objetivo.
Funciona así Una parte interna del algoritmo, llamada función de pérdida, describe una parte clave de cómo el algoritmo puede aprender una buena representación de este objetivo. El algoritmo utiliza la función de pérdida para determinar lo cerca que está del objetivo definido en los datos de entrenamiento.
Más técnicamente, la pérdida es el error que queremos minimizar durante el entrenamiento del modelo. Para que una función de pérdida tenga significado humano, debe haber algún objetivo definido externamente, como un objetivo empresarial que tenga sentido en relación con la función de pérdida. Ese objetivo empresarial puede definirse en parte a través de los datos de entrenamiento.
En cierto sentido, se trata de un "objetivo dentro de un objetivo"; el objetivo de los datos de entrenamiento es relacionarse lo mejor posible con el objetivo empresarial, y el objetivo de la función de pérdida es relacionar el modelo con los datos de entrenamiento. Así que, recapitulando, el objetivo de la función de pérdida es optimizar la pérdida, pero sólo puede hacerlo teniendo algún punto de referencia precursor, que viene definido por los datos de entrenamiento. Por lo tanto, para omitir conceptualmente al intermediario de la función de pérdida, los datos de entrenamiento son la "verdad fundamental" de la corrección de la relación del modelo con el objetivo definido por el ser humano. O dicho de otro modo: el objetivo humano define los datos de entrenamiento, que a su vez definen el modelo.
Nuevos tipos de usuarios
En el desarrollo tradicional de software existe cierto grado de dependencia entre el usuario final y el ingeniero. El usuario final no puede decir realmente si el programa es "correcto", y el ingeniero tampoco.
Es difícil para un usuario final decir lo que quiere hasta que no se ha construido un prototipo del mismo. Por tanto, tanto el usuario final como el ingeniero dependen el uno del otro. Esto se denomina dependencia circular. La capacidad de mejorar el software proviene de la interacción entre ambos, de poder iterar juntos.
Con los datos de entrenamiento, los humanos controlan el significado del sistema cuando realizan la supervisión literal. Los científicos de datos lo controlan cuando trabajan en los esquemas, por ejemplo al elegir abstracciones como las plantillas de etiquetas.
Por ejemplo, si yo, como anotador, etiquetara un tumor como canceroso, cuando en realidad es benigno, estaría controlando la salida del sistema de forma perjudicial. En este contexto, conviene comprender que no hay validación posible para eliminar nunca al 100% este control. La ingeniería no puede, tanto por el volumen de datos como por la falta de experiencia en la materia, controlar el sistema de datos.
Antes se suponía que los científicos de datos sabían lo que era "correcto". La teoría era que podían definir algunos ejemplos de "correcto", y entonces, mientras los supervisores humanos se ciñeran en general a esa guía, sabían lo que era correcto. Inmediatamente surgen ejemplos de todo tipo de complicaciones: ¿Cómo puede saber un científico de datos angloparlante si una traducción al francés es correcta? ¿Cómo puede saber un científico de datos si la opinión médica de un médico sobre una imagen de rayos X es correcta? La respuesta corta es: no pueden. A medida que crece el papel de los sistemas de IA, los expertos en la materia necesitan cada vez más ejercer el control sobre el sistema de formas que superan a la ciencia de datos.4
Consideremos por qué esto es diferente del concepto tradicional de "basura dentro, basura fuera". En un programa tradicional, un ingeniero puede garantizar que el código es "correcto" con, por ejemplo, una prueba unitaria. Esto no significa que dé la salida deseada por el usuario final, sólo que el código hace lo que el ingeniero cree que debe hacer. Así que, para reformularlo, la promesa es "oro entra, oro sale", siempre que el usuario ponga oro, obtendrá oro.
Escribir una prueba unitaria de IA es difícil en el contexto de los datos de entrenamiento. En parte, esto se debe a que los controles de que dispone la ciencia de datos, como un conjunto de validación, siguen basándose en el control (hacer anotaciones) ejecutado por supervisores de IA individuales.
Además, los supervisores de IA pueden estar sujetos a las abstracciones que la ingeniería defina para que las utilicen. Sin embargo, si pueden definir ellos mismos el esquema, se entretejen más profundamente en el tejido del propio sistema, lo que difumina aún más las líneas entre "contenido" y "sistema".
Esto difiere claramente de los sistemas clásicos. Por ejemplo, en una plataforma de redes sociales, tu contenido puede ser el valor, pero sigue estando claro cuál es el sistema literal (la casilla en la que escribes, los resultados que ves, etc.) y el contenido que publicas (texto, imágenes, etc.).
Ahora que pensamos en términos de forma y contenido, ¿cómo encaja de nuevo el control? Algunos ejemplos de control son
-
Las abstracciones, como el esquema, definen un nivel de control.
-
La anotación, literalmente mirar las muestras, define otro nivel de control.
Mientras que la ciencia de datos puede controlar los algoritmos de , los controles de los datos de entrenamiento suelen actuar en calidad de "supervisión", por encima del algoritmo.
Datos de entrenamiento en la naturaleza
Hasta ahora hemos tratado muchos conceptos y teoría, pero entrenar datos en la práctica puede ser algo complejo y difícil de hacer bien.
¿Qué dificulta los datos de entrenamiento?
La aparente sencillez de la anotación de datos oculta la enorme complejidad, las novedosas consideraciones, los nuevos conceptos y las nuevas formas de arte que implica. Puede parecer que un humano selecciona una etiqueta adecuada, los datos pasan por un proceso mecánico, y voilà, tenemos una solución, ¿verdad? Pues no del todo. He aquí algunos elementos comunes que pueden resultar difíciles.
Los expertos en la materia (PYME) trabajan con los técnicos de nuevas formas y viceversa. Estas nuevas interacciones sociales introducen nuevos retos "personales". Los expertos tienen experiencias individuales, creencias, prejuicios inherentes y experiencias previas. Además, los expertos de múltiples campos pueden tener que trabajar juntos más estrechamente de lo habitual. Los usuarios manejan interfaces de anotación novedosas con pocas expectativas comunes sobre cómo es el diseño estándar.
Los retos adicionales incluyen:
-
El problema en sí puede ser difícil de articular, con respuestas poco claras o soluciones mal definidas.
-
Aunque el conocimiento esté bien formado en la cabeza de una persona, y ésta esté familiarizada con la interfaz de anotación, introducir ese conocimiento con precisión puede ser tedioso y llevar mucho tiempo.
-
A menudo hay una cantidad voluminosa de trabajo de etiquetado de datos con múltiples conjuntos de datos que gestionar y retos técnicos en torno al almacenamiento, acceso y consulta de las nuevas formas de datos.
-
Dado que se trata de una disciplina nueva, falta experiencia organizativa y una excelencia operativa que sólo puede llegar con el tiempo.
-
Las organizaciones con una fuerte cultura clásica de ML pueden tener problemas para adaptarse a esta área fundamentalmente diferente, aunque operacionalmente crítica. Este punto ciego de pensar que ya han comprendido e implantado el ML, cuando en realidad es una forma totalmente distinta.
-
Al tratarse de una nueva forma de arte, las ideas y conceptos generales no son bien conocidos. Hay una falta de concienciación, acceso o familiaridad con las herramientas de datos de formación adecuadas.
-
Los esquemas pueden ser complejos, con miles de elementos, incluidas estructuras condicionales anidadas. Y los formatos multimedia imponen retos como las series, las relaciones y la navegación 3D.
-
La mayoría de las herramientas de automatización introducen nuevos retos y dificultades.
Aunque los retos son innumerables y a veces difíciles, abordaremos cada uno de ellos en este libro para proporcionarte una hoja de ruta que tú y tu organización podéis poner en práctica para mejorar los datos de formación.
El arte de supervisar máquinas
Hasta este punto, hemos cubierto algunos de los aspectos básicos y algunos de los retos en torno a los datos de entrenamiento. Dejemos por un momento de lado la ciencia y centrémonos en el arte. La aparente sencillez de la anotación oculta el enorme volumen de trabajo que conlleva. La anotación es a los datos de entrenamiento lo que mecanografiar es a escribir. Pulsar simplemente las teclas de un teclado no aporta valor si no cuentas con el elemento humano que informa de la acción y realiza la tarea con precisión.
Los datos de formación son un nuevo paradigma sobre el que está surgiendo una creciente lista de mentalidades, teorías, investigaciones y normas. Implica representaciones técnicas, decisiones sobre las personas, procesos, herramientas, diseño de sistemas y una variedad de nuevos conceptos específicos.
Una cosa que hace que los datos de entrenamiento sean tan especiales es que captan el conocimiento, la intención, las ideas y los conceptos del usuario sin especificar "cómo" ha llegado a ellos. Por ejemplo, si etiqueto un "pájaro", no le estoy diciendo al ordenador qué es un pájaro, la historia de los pájaros, etc., sólo que es un pájaro. Esta idea de transmitir un alto nivel de intención es diferente de la mayoría de las perspectivas clásicas de programación. A lo largo de este libro, volveré sobre esta idea de considerar los datos de entrenamiento como una nueva forma de codificación.
Algo nuevo para la Ciencia de Datos
Aunque un modelo de ML puede consumir un conjunto de datos de entrenamiento específico de , este libro desentrañará la miríada de conceptos en torno a los conceptos abstractos de los datos de entrenamiento. En términos más generales, los datos de entrenamiento no son ciencia de datos. Tienen objetivos diferentes. Los datos de entrenamiento producen datos estructurados; la ciencia de datos los consume. Los datos de entrenamiento trasladan el conocimiento humano del mundo real al ordenador. La ciencia de datos es volver a mapear esos datos en el mundo real. Son las dos caras diferentes de la moneda.
De forma similar a cómo un modelo es consumido por una aplicación, los datos de entrenamiento deben ser consumidos por la ciencia de datos para ser útiles. El hecho de que se utilicen de este modo no debe restarles importancia. Los datos de entrenamiento siguen requiriendo mapeos de conceptos a una forma utilizable por la ciencia de datos. La cuestión es tener abstracciones claramente definidas entre ellos, en lugar de conjeturas ad hoc sobre los términos.
Parece más razonable pensar en la formación de datos como un arte practicado por todas las demás profesiones, que practican expertos en la materia de todos los ámbitos de la vida, que pensar en la ciencia de datos como el punto de partida que todo lo abarca. Teniendo en cuenta cuántos expertos en la materia y personas no técnicas están implicadas, la alternativa más bien absurda parecería suponer que la ciencia de datos se eleva por encima de todo. Es perfectamente natural que, para la ciencia de datos, los datos de entrenamiento sean sinónimo de datos etiquetados y un subconjunto de las preocupaciones generales; pero para muchos otros, los datos de entrenamiento son su propio dominio.
Aunque intentar llamar a cualquier cosa nuevo dominio o forma de arte es automáticamente presuntuoso, me consuela saber que simplemente estoy etiquetando algo que la gente ya está haciendo. De hecho, las cosas tienen mucho más sentido cuando las tratamos como un arte propio y dejamos de meterlas con calzador en otras categorías dadas ya existentes. Trataré este tema con más detalle en el capítulo 7.
Dado que los datos de entrenamiento como dominio con nombre son nuevos, el lenguaje y las definiciones siguen siendo fluidos. Los siguientes términos están estrechamente relacionados:
-
Datos de entrenamiento
-
Etiquetado de datos
-
Supervisión humano-ordenador
-
Anotación
-
Programa de datos
Según el contexto, esos términos pueden corresponder a varias definiciones:
-
El arte global de los datos de entrenamiento
-
El acto de anotar, como dibujar geometrías y responder a preguntas sobre esquemas
-
La definición de lo que queremos conseguir en un sistema de aprendizaje automático, el estado ideal deseado
-
El control del sistema de LD, incluida la corrección de los sistemas existentes
-
Un sistema que se basa en datos controlados por el ser humano
Por ejemplo, puedo referirme a la anotación como un subcomponente específico del concepto general de datos de entrenamiento. También puedo decir "trabajar con datos de entrenamiento", para referirme al acto de anotar. Como área novedosa en desarrollo, la gente puede decir etiquetado de datos y referirse sólo a los fundamentos literales de la anotación, mientras que otros se refieren al concepto global de datos de entrenamiento.
En resumen, no merece la pena que se obsesione demasiado con ninguno de esos términos, y normalmente se necesita el contexto en el que se utilizan para entender su significado.
Ecosistema del Programa de ML
Los datos de entrenamiento interactúan con un ecosistema creciente de programas y conceptos adyacentes. Es habitual enviar datos de un programa de datos de entrenamiento de a un programa de modelado de ML, o instalar un programa de ML en una plataforma de datos de entrenamiento. Los datos de producción, como las predicciones, suelen enviarse a un programa de datos de entrenamiento para su validación, revisión y control posterior. La vinculación entre estos diversos programas sigue ampliándose. Más adelante en este libro cubrimos algunos de los detalles técnicos de la ingesta y el flujo de datos.
Tipos de soportes de datos brutos
Los datos vienen en muchos tipos de medios. Los tipos de medios populares de incluyen imágenes, vídeos, texto, PDF/documento, HTML, audio, series temporales, 3D/DICOM, geoespaciales, fusión de sensores y multimodales. Aunque los tipos de medios populares suelen ser los mejor soportados en la práctica, en teoría se puede utilizar cualquier tipo de medio. Las formas de anotación incluyen atributos (opciones detalladas), geometrías, relaciones y mucho más. Cubriremos todo esto con gran detalle a medida que avance el libro, pero es importante tener en cuenta que si existe un tipo de medio, es probable que alguien esté intentando extraer datos de él.
Aprendizaje automático centrado en datos
Los expertos en la materia y la gente que introduce datos pueden acabar dedicando de cuatro a ocho horas al día, todos los días, a tareas de formación de datos como la anotación. Es una tarea que requiere mucho tiempo, y puede convertirse en su trabajo principal. En algunos casos, el 99% del tiempo total del equipo se dedica a los datos de formación y el 1% al proceso de modelado, por ejemplo, utilizando una solución de tipo AutoML o contando con un gran equipo de PYMES.5
La IA centrada en los datos significa centrarse en los datos de entrenamiento como algo importante en sí mismo: crear nuevos datos, nuevos esquemas, nuevas técnicas de captura de datos brutos y nuevas anotaciones realizadas por expertos en la materia. Significa desarrollar programas con los datos de entrenamiento en el centro e integrar profundamente los datos de entrenamiento en aspectos de tu programa. Antes estaba el móvil primero, y ahora están los datos primero.
Con la mentalidad centrada en los datos puedes:
-
Utiliza o añade puntos de recogida de datos, como nuevos sensores, nuevas cámaras, nuevas formas de capturar documentos, etc.
-
Añade nuevos conocimientos humanos en forma, por ejemplo, de nuevas anotaciones, por ejemplo, de expertos en la materia.
Los fundamentos de un enfoque centrado en los datos son:
-
La mayor parte del trabajo está en los datos de entrenamiento, y el aspecto de la ciencia de datos está fuera de nuestro control.
-
Hay más grados de libertad con los datos de entrenamiento y el modelado que con las mejoras del algoritmo por sí solas.
Cuando combino esta idea de la IA centrada en los datos con la idea de ver la amplitud y profundidad de los datos de entrenamiento como su propio arte, empiezo a ver los vastos campos de oportunidades. ¿Qué construirás con los datos de entrenamiento?
Fallas
Es habitual que cualquier sistema tenga una variedad de fallos y aún así "funcione" en general. Los programas de datos son similares. Por ejemplo, algunas clases de fallos son esperables, y otras no. Sumerjámonos en ello.
Los programas de datos funcionan cuando sus conjuntos de supuestos asociados siguen siendo ciertos, como los supuestos en torno al esquema y los datos brutos. Estos supuestos suelen ser más obvios en el momento de la creación, pero pueden cambiarse o modificarse como parte de un ciclo de mantenimiento de datos.
Para sumergirnos en un ejemplo visual, imagina un sistema de detección de aparcamientos. El sistema puede tener vistas muy diferentes, como se muestra en la Figura 1-4. Si creamos un conjunto de datos de entrenamiento basado en una vista descendente (izquierda) y luego intentamos utilizar una vista a nivel de coche (derecha), probablemente obtendremos una clase de fallo "inesperado".

Figura 1-4. Comparación de las principales diferencias en los datos brutos que probablemente provocarían un fallo inesperado
¿Por qué hubo un fallo? Un sistema de aprendizaje automático entrenado sólo con imágenes desde una vista descendente, como en la imagen de la izquierda, tiene dificultades para funcionar en un entorno en el que las imágenes son desde una vista frontal, como se muestra en la imagen de la derecha. En otras palabras, el sistema no entendería el concepto de coche y aparcamiento desde una vista frontal si nunca ha visto una imagen así durante el entrenamiento.
Aunque esto pueda parecer obvio, un problema muy similar causó un fallo real en un sistema de las Fuerzas Aéreas de EEUU, lo que les llevó a pensar que su sistema era materialmente mejor de lo que era en realidad.
¿Cómo podemos evitar fallos como éste? Bueno, para éste en concreto, es un claro ejemplo de por qué es importante que los datos que utilizamos para entrenar un sistema coincidan estrechamente con los datos de producción. ¿Qué ocurre con los fallos que no aparecen específicamente en un libro?
El primer paso es conocer las buenas prácticas en materia de datos de entrenamiento. Antes, al hablar de las funciones humanas, mencioné la importancia de la comunicación con los anotadores y los expertos en la materia. Los anotadores deben ser capaces de señalar los problemas, especialmente los relacionados con la alineación de los esquemas y los datos brutos. Los anotadores están en una posición única para sacar a la luz problemas fuera del ámbito de las instrucciones y esquemas especificados, por ejemplo, cuando aparece ese "sentido común" de que algo no va bien.
Los administradores deben ser conscientes del concepto de crear un esquema novedoso y bien denominado. Los datos brutos deben ser siempre relevantes para el esquema, y el mantenimiento de los datos es un requisito.
Los modos de fallo salen a la luz durante el desarrollo mediante discusiones sobre el esquema, el uso previsto de los datos y las conversaciones con los anotadores.
El historial de desarrollo también afecta a los datos de entrenamiento
Cuando pensamos en los programas clásicos de software , su desarrollo histórico los inclina hacia determinados estados de funcionamiento. Una aplicación diseñada para un smartphone tiene un contexto determinado, y puede ser mejor o peor que una aplicación de escritorio en ciertas cosas. Una aplicación de hoja de cálculo puede ser más adecuada para el escritorio; un sistema de envío de dinero no permite ediciones aleatorias. Una vez que se ha escrito un programa así, resulta difícil cambiar aspectos fundamentales, o "desprejuiciarlo". La aplicación de envío de dinero tiene muchas suposiciones basadas en que el usuario final no puede "deshacer" una transacción.
La historia del desarrollo de un determinado modelo, accidental o intencionada, también afecta a los datos de entrenamiento. Imagina una aplicación de inspección de cultivos diseñada principalmente en torno a las enfermedades que afectan a los cultivos de patatas. Se hicieron suposiciones sobre todo, desde el formato de los datos brutos (por ejemplo, que los medios se capturan a determinadas alturas), hasta los tipos de enfermedades, pasando por el volumen de las muestras. Es poco probable que funcione bien para otros tipos de cultivos. El esquema original puede hacer suposiciones que queden obsoletas con el tiempo. El historial del sistema afectará a la capacidad de modificarlo en el futuro.
Lo que no son los datos de entrenamiento
Los datos de entrenamiento no son un algoritmo de ML. No está vinculado a un enfoque específico de aprendizaje automático.
Más bien, es la definición de lo que queremos conseguir. El reto fundamental es identificar y mapear eficazmente el significado humano deseado en una forma legible por la máquina.
La eficacia de los datos de entrenamiento depende principalmente de lo bien que se relacionen con el significado definido por el ser humano que se les haya asignado y de lo razonablemente que representen el uso real del modelo. En la práctica, las elecciones en torno a los datos de entrenamiento de tienen un gran impacto en la capacidad de entrenar un modelo con eficacia.
IA Generativa
Los conceptos de IA Generativa (GenAI), como los transformadores generativos preentrenados (GPT) y los grandes modelos lingüísticos (LLM), se hicieron muy populares a principios de 2023. Aquí trataré brevemente cómo se relacionan estos conceptos con los datos de entrenamiento.
En el momento de escribir estas líneas, este ámbito avanza muy rápidamente. Los principales actores comerciales están siendo extremadamente restrictivos en lo que comparten públicamente, por lo que hay mucha especulación y exageración, pero poco consenso. Por lo tanto, lo más probable es que parte de esta sección sobre IA Generativa esté desfasada para cuando la leas.
Podemos empezar con el concepto de aprendizaje no supervisado. El objetivo general del aprendizaje no supervisado en el contexto de la GenAI es trabajar sin etiquetas humanas recién definidas. Sin embargo, el "preentrenamiento" de los LLM se basa en material de origen humano. Así que sigues necesitando datos, y normalmente datos generados por humanos, para obtener algo que sea significativo para los humanos. La diferencia es que, al "preentrenar" una IA generativa, los datos no necesitan inicialmente etiquetas para crear un resultado, lo que hace que a la GenAI se la conozca cariñosamente como el "monstruo" no supervisado. Este "monstruo", como se muestra en la Figura 1-5, aún debe ser domado con supervisión humana.
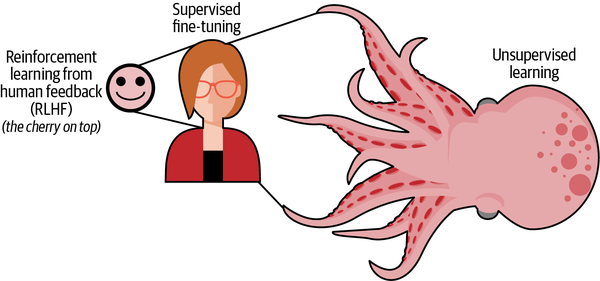
Figura 1-5. Relación del aprendizaje no supervisado con el ajuste fino supervisado y la alineación humana
A grandes rasgos, éstas son las principales formas en que la GenAI interactúa con la supervisión humana:
- Alineación humana
- La supervisión humana es crucial para construir y mejorar los modelos GenAI.
- Mejoras en la eficiencia
- Los modelos GenAI pueden utilizarse para mejorar las tareas de supervisión tediosas (como la segmentación de imágenes).
- Trabajar conjuntamente con la IA supervisada
- Los modelos GenAI pueden utilizarse para interpretar, combinar, interactuar y utilizar resultados supervisados.
- Conocimiento general de la IA
- La IA se menciona a diario en los principales medios de comunicación y en las convocatorias de las empresas. El entusiasmo general en torno a la IA ha aumentado drásticamente.
Ampliaré el concepto de alineación humana en el siguiente subapartado.
También puedes utilizar GenAI para ayudar a mejorar la eficacia de los datos de entrenamiento supervisado. Algunos frutos "al alcance de la mano", en términos de segmentación genérica de objetos, clasificación genérica de categorías ampliamente aceptadas, etc., son posibles (con algunas advertencias) mediante los sistemas GenAI actuales. Trataré este tema con más detalle en el Capítulo 8, cuando hable de la automatización.
Trabajar en tándem con la IA supervisada está fuera del alcance de este libro, más allá de afirmar brevemente que hay sorprendentemente poco solapamiento. Tanto la GenAI como los sistemas supervisados son elementos básicos importantes.
Los avances en GenAI han hecho que la IA vuelva a ser noticia de primera plana. Como resultado, las organizaciones se están replanteando sus objetivos de IA y están dedicando más energía a las iniciativas de IA en general, no sólo a la GenAI. Para distribuir un sistema GenAI, se necesita alineación humana (en otras palabras, datos de entrenamiento). Para lanzar un sistema de IA completo, a menudo se necesita GenAI + IA supervisada. Aprender las habilidades de este libro para trabajar con datos de entrenamiento te ayudará con ambos objetivos.
La alineación humana es la supervisión humana
La supervisión humana, tema central de este libro, es a menudo denominada alineación humana en el contexto de la IA generativa. La gran mayoría de los conceptos tratados en este libro también se aplican a la alineación humana, con algunas modificaciones específicas para cada caso.
El objetivo no es tanto que el modelo aprenda directamente a repetir una representación exacta, sino más bien "dirigir" los resultados no supervisados. Aunque exactamente qué métodos de "dirección" de la alineación humana son los mejores es objeto de acalorados debates, entre los ejemplos concretos de enfoques populares actuales de la alineación humana se incluyen:
-
Supervisión directa, como pares de preguntas y respuestas, clasificación de los resultados (por ejemplo, preferencia personal, de mejor a peor) y señalización de preocupaciones específicamente iteradas, como "no es seguro para el trabajo". Este enfoque fue clave para la fama de GPT-4.
-
Supervisión indirecta, como usuarios finales que votan arriba/abajo, que proporcionan comentarios de forma libre, etc. Normalmente, esta información debe pasar por algún proceso adicional antes de ser presentada al modelo.
-
Definir un conjunto "constitucional" de instrucciones que establezcan principios específicos de supervisión humana (alineación humana) para que los siga el sistema GenAI.
-
Ingeniería de prompts, es decir, que define prompts "similares al código", o codificación en lenguaje natural.
-
Integración con otros sistemas para comprobar la validez de los resultados.
Hay poco consenso sobre los mejores enfoques, o sobre cómo medir los resultados. Me gustaría señalar que muchos de estos enfoques se han centrado en el texto, la salida multimodal limitada (pero aún texto) y la generación de medios. Aunque esto pueda parecer extenso, es una subsección relativamente limitada del concepto más general de que los humanos atribuyen un significado repetible a conceptos arbitrarios del mundo real.
Además de la falta de consenso, también hay investigaciones contradictorias en este ámbito. Por ejemplo, dos extremos comunes del espectro son que algunos afirman observar un comportamiento emergente, y otros afirman que los puntos de referencia fueron elegidos a dedo y que se trata de un resultado falso (por ejemplo, que el conjunto de pruebas se confunde con los datos de entrenamiento). Aunque parece claro que la supervisión humana tiene algo que ver, exactamente qué nivel, y cuánto, y qué técnica es una cuestión abierta en el caso de GenAI. De hecho, algunos resultados muestran que los modelos pequeños alineados por humanos pueden funcionar tan bien o mejor que los modelos grandes.
Aunque puede que notes algunas diferencias en la terminología, muchos de los principios de este libro se aplican tanto a la alineación GenAI como a los datos de entrenamiento. En concreto, todas las formas de supervisión directa son supervisión de datos de entrenamiento. Unas notas antes de terminar con el tema GenAI: No cubro específicamente la ingeniería de prompts en este libro, ni otros conceptos específicos de GenAI. Sin embargo, si quieres construir un sistema GenAI, seguirás necesitando datos, y la supervisión de alta calidad seguirá siendo una parte crítica de los sistemas GenAI en un futuro previsible.
Resumen
Este capítulo ha introducido ideas de alto nivel sobre los datos de entrenamiento para el aprendizaje automático. Recapitulemos por qué son importantes los datos de entrenamiento:
-
Los consumidores y las empresas muestran cada vez más expectativas en torno a la incorporación del ML, tanto para los sistemas existentes como para los nuevos, lo que aumenta la importancia de los datos de entrenamiento.
-
Sirve de base para desarrollar y mantener programas modernos de ML.
-
Entrenar datos es un arte y un nuevo paradigma. Es un conjunto de ideas en torno a nuevos programas basados en datos, y está controlado por humanos. Está separado del ML clásico, y comprende nuevas filosofías, conceptos e implementaciones.
-
Constituye la base de los nuevos productos de IA/ML, manteniendo los ingresos de las líneas de negocio existentes, al sustituir o mejorar los costes mediante actualizaciones de IA/ML, y es un terreno fértil para la I+D.
-
Como tecnólogo o como experto en la materia, ahora es una habilidad importante que hay que tener.
El arte de entrenar datos es distinto de la ciencia de datos. Se centra en el control del sistema, con el objetivo de que el propio sistema aprenda. Entrenar datos no es un algoritmo ni un único conjunto de datos. Es un paradigma que abarca funciones profesionales, desde expertos en la materia, a científicos de datos, ingenieros y más. Es una forma de pensar sobre los sistemas que abre nuevos casos de uso y oportunidades.
Antes de seguir leyendo, te animo a que repases estos conceptos clave de alto nivel de este capítulo:
-
Las principales áreas de preocupación son los esquemas, los datos brutos, la calidad, las integraciones y el papel humano.
-
Los datos de entrenamiento clásicos tienen que ver con el descubrimiento, mientras que los datos de entrenamiento modernos son un arte creativo; el medio para "copiar" el conocimiento.
-
Los algoritmos de aprendizaje profundo generan modelos basados en datos de entrenamiento. Los datos de entrenamiento definen el objetivo, y el algoritmo define cómo trabajar hacia ese objetivo.
-
Los datos de entrenamiento que sólo se validan "en un laboratorio" probablemente fracasarán sobre el terreno. Esto puede evitarse utilizando principalmente datos de campo como punto de partida, alineando el diseño del sistema y esperando actualizar rápidamente los modelos.
-
Los datos de entrenamiento son como el código.
En el próximo capítulo hablaremos de la configuración de tu sistema de datos de entrenamiento y de las herramientas.
1 En la mayoría de los casos, esos datos existentes se consideran una "muestra", aunque hayan sido creados por un humano en algún momento anterior.
2 Sin otras deducciones ajenas a nuestro ámbito de interés.
3 De "Stanley_(vehículo)", Wikipedia, consultado el 8 de septiembre de 2023: "Stanley se caracterizaba por un enfoque basado en el aprendizaje automático para la detección de obstáculos. Para corregir un error común cometido por Stanley al principio de su desarrollo, el Equipo de Carreras de Stanford creó un registro de "reacciones y decisiones humanas" e introdujo los datos en un algoritmo de aprendizaje vinculado a los controles del vehículo; esta acción sirvió para reducir en gran medida los errores de Stanley. El registro informático de la conducción humana también hizo que Stanley fuera más preciso en la detección de sombras, un problema que había causado muchos de los fallos del vehículo en el Gran Desafío DARPA de 2004."
4 Existen métodos estadísticos para coordinar las opiniones de los expertos, pero siempre son "adicionales"; sigue teniendo que existir una opinión.
5 Estoy simplificando demasiado. Más en detalle, la diferencia clave es que, aunque un producto de formación AutoML de ciencia de datos y alojamiento puede ser complejo en sí mismo, simplemente hay menos gente trabajando en él.
6 Lee el artículo de Will Douglas Heaven, "Google's Medical AI Was Super Accurate in a Lab. Real Life Was a Different Story", MIT Technology Review, 27 de abril de 2020.
Get Datos de entrenamiento para el aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

