Chapter 8. Introduction and Overview
What makes distributed systems inherently different from single-node systems? Let’s take a look at a simple example and try to see. In a single-threaded program, we define variables and the execution process (a set of steps).
For example, we can define a variable and perform simple arithmetic operations over it:
int x = 1; x += 2; x *= 2;
We have a single execution history: we declare a variable, increment it by two, then multiply it by two, and get the result: 6. Let’s say that, instead of having one execution thread performing these operations, we have two threads that have read and write access to variable x.
Concurrent Execution
As soon as two execution threads are allowed to access the variable, the exact outcome of the concurrent step execution is unpredictable, unless the steps are synchronized between the threads. Instead of a single possible outcome, we end up with four, as Figure 8-1 shows.1
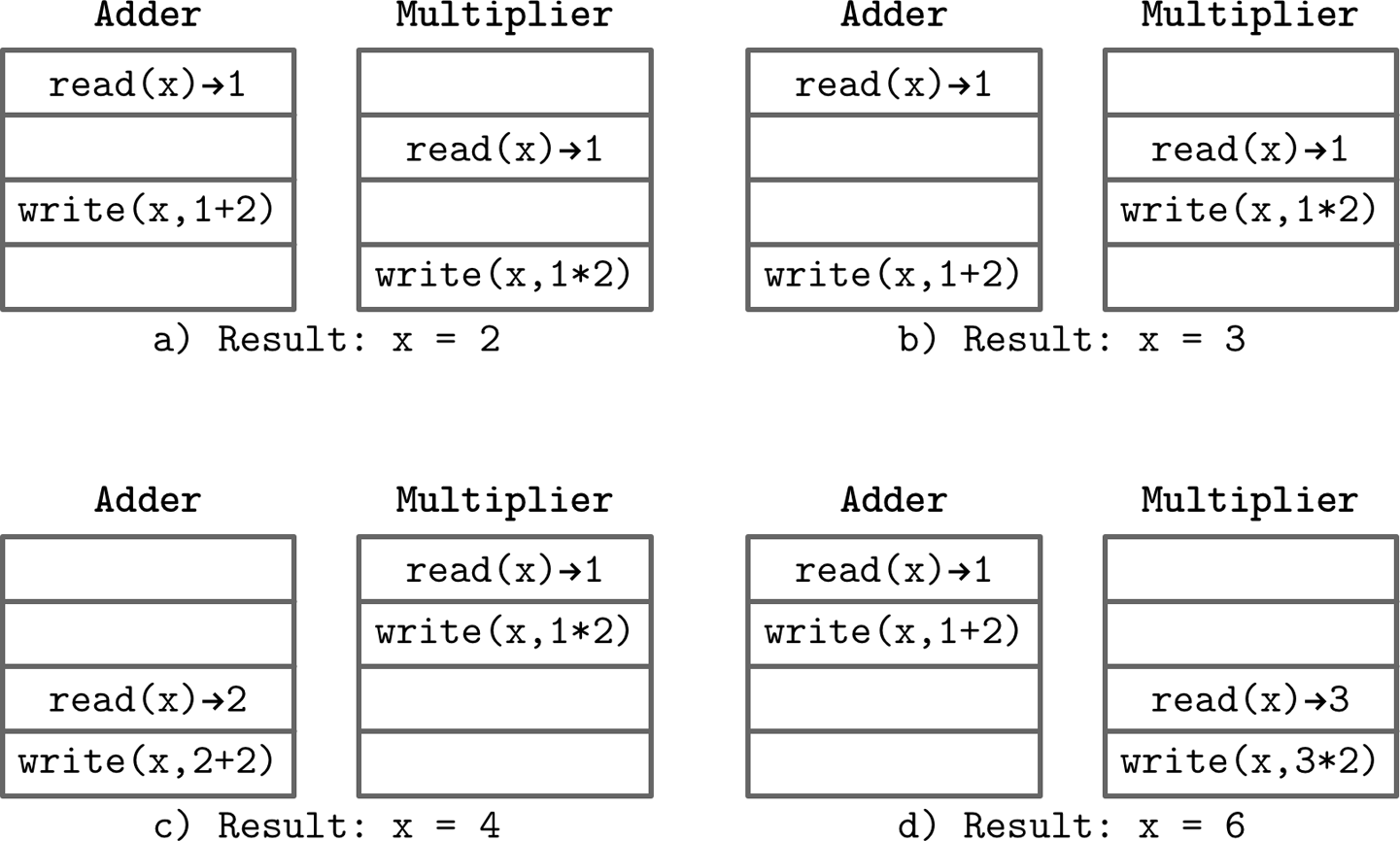
Figure 8-1. Possible interleavings of concurrent executions
-
a) x = 2, if both threads read an initial value, the adder writes its value, but it is overwritten with the multiplication result.
-
b) x = 3, if both threads read an initial value, the multiplier writes its value, but it is overwritten with the addition result.
-
c) x = 4, if the multiplier can read the initial value and execute its operation before the adder starts.
-
d) x = 6, ...
Get Database Internals now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

