It is downright sinful to teach the abstract before the concrete
As we saw in the previous chapter, Boyce/Codd normal form (BCNF for short) is defined in terms of functional dependencies. In fact, BCNF is really the normal form with respect to functional dependencies (just as—to get ahead of ourselves for a moment—5NF is really the normal form with respect to join dependencies). The overall purpose of the present chapter is to explain this observation; as the chapter title indicates, however, the various explanations and associated definitions are all (intentionally, of course) a little informal at this stage. (Informal, but not inaccurate; I won’t tell any deliberate lies.) A more formal treatment of the material appears in the next chapter.
To begin at the beginning: Let relation r have attributes A1, ..., An, of types T1, ..., Tn, respectively. By definition, then, if tuple t appears in relation r, then the value of attribute Ai in t is of type Ti (i = 1, ..., n). For example, if r is the current value of the shipments relvar SP (see Figure 1-1 in Chapter 1), then every tuple in r has an SNO value that’s of type CHAR, a PNO value that’s also of type CHAR, and a QTY value that’s of type INTEGER.
Now I can give a precise definition of first normal form:[34]
Definition: Let relation r have attributes A1, ..., An, of types T1, ..., Tn, respectively. Then r is in first normal form (1NF) if and only if, for all tuples t appearing in r, the value of attribute Ai in t is of type Ti (i = 1, ..., n).
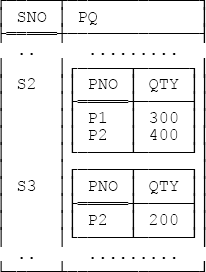
In other words, every relation is in 1NF, by definition! To say it in different words, 1NF just means each tuple in the relation contains exactly one value, of the appropriate type, for each attribute. Observe in particular that 1NF places no limitations on what those attribute types are allowed to be.[35] They can even be relation types; that is, relations with relation valued attributes—RVAs for short—are legal (you might be surprised to hear this, but it’s true). An example is given in Figure 4-1.
I’ll have more to say about RVAs in just a moment, but first I need to get a couple of small points out of the way. To start with, I need to define what it means for a relation to be normalized:
Definition: Relation r is normalized if and only if it’s in 1NF.
In other words, normalized and first normal form mean exactly the same thing—all normalized relations are in 1NF, all 1NF relations are normalized. The reason for this slightly strange state of affairs is that normalized was the original (historical) term; the term 1NF wasn’t introduced until people started talking about 2NF and higher levels of normalization, when a term was needed to describe relations that weren’t in one of those higher normal forms. Of course, it’s common nowadays for the term normalized to be used to mean some higher normal form (often 3NF specifically); indeed, I’ve used it that way myself in earlier chapters, as you might have noticed. Strictly speaking, however, that usage is sloppy and incorrect, and it’s probably better avoided unless there’s no chance of confusion.
Turning to my second “small point”: Observe now that all of the discussions in this section so far (the definitions in particular) have been framed in terms of relations, not relvars. But since every relation that can ever be assigned to a relvar is in 1NF by definition, no harm is done if we extend the 1NF concept in the obvious way to apply to relvars as well—and it’s desirable to do so, because (as we’ll see) all of the other normal forms are defined to apply to relvars, not relations. In fact, it could be argued that the reason 1NF is defined in terms of relations and not relvars has to do with the fact that it was, regrettably, many years before that distinction (i.e., the distinction between relations and relvars) was explicitly drawn, anyway.
Back to RVAs. I’ve said, in effect, that relvars with RVAs are legal; but now I need to add that from a design point of view, at least, such relvars are usually (not always) contraindicated. Now, this fact doesn’t mean you should avoid RVAs entirely (in particular, there’s no problem with query results that include RVAs)—it just means we don’t usually want RVAs “designed into the database,” as it were. I don’t want to get into a lot of detail on this issue in this book; let me just say that relvars with RVAs tend to look very much like the hierarchic structures found in older, nonrelational systems like IMS,[36] and all of the old problems that used to arise with hierarchies therefore raise their head once again. Here for reference is a list of some of those problems:
The fundamental point is that hierarchies are asymmetric; thus, while they might make some tasks “easier,” they certainly make others more difficult.
As a specific illustration of the previous point, queries in particular are asymmetric, as well as being more complicated than their symmetric counterparts. For example, consider what’s involved in formulating the queries “Get part numbers for parts supplied by supplier S2” and “Get supplier numbers for suppliers who supply part P2” against the relation of Figure 4-1. The natural language versions of these queries are symmetric with respect to each other, but their formulations in SQL—or Tutorial D, or some other formal language—most certainly aren’t (exercise for the reader).
Similar remarks apply to integrity constraints.
Similar remarks apply to updates, but more so.
There’s no guidance, in general, as to how to choose the “best” hierarchy.
Even “natural” hierarchies like organization charts and bill of materials structures are still best represented, usually, by nonhierarchic designs.
Well, by now you might be wondering, if all relvars are in 1NF by definition, what it might possibly mean not to be in 1NF. Perhaps surprisingly, this question does have a sensible answer. The point is, today’s commercial DBMSs don’t properly support relvars (or relations) at all—instead, they support a construct that for convenience I’ll call a table, though by that term I don’t necessarily mean to limit myself to the kinds of tables found in SQL systems specifically. And tables, as opposed to relvars, might indeed not be in 1NF. To elaborate:
Definition: A table is in first normal form (1NF)—equivalently, such a table is normalized—if and only if it’s a direct and faithful representation of some relvar.
So of course the question is: What does it mean for a table to be a direct and faithful representation of a relvar? There are five basic requirements, all of which are immediate consequences of the fact that the value of a relvar at any given time is (of course) always a relation specifically:
There’s no top to bottom ordering to the rows.
There’s no left to right ordering to the columns.
There are no duplicate rows.
Every row and column intersection contains exactly one value of the applicable type, and nothing else.
All columns are regular (see below).
Requirements 1-3 are self-explanatory,[37] but the other two merit a little more explanation, perhaps. Here’s an example of a table that violates Requirement 4:

The violation occurs because values in the PNO column aren’t individual part numbers as such but, rather, groups of part numbers (the group for S2 contains two part numbers, that for S3 contains one, and that for S4 contains three).
Note: The violation of Requirement 4 in the foregoing example would perhaps be clearer if column PNO, instead of being defined to be of type CHAR, was defined to be of some user defined type, perhaps also called PNO. Then it might be more obvious that values in that column weren’t of that type per se but were rather of type “PNO group.” Such considerations point the way to a reasonably precise definition of the term repeating group:
If you’re still confused over the difference between repeating group columns and RVAs, take another look at Figure 4-1. The RVA in that figure—viz., attribute PQ—is not a repeating group column (relations don’t allow repeating groups!). Rather, it’s an attribute whose type happens to be a certain relation type—to be specific, and using Tutorial D syntax, the relation type
RELATION { PNO CHAR , QTY INTEGER }—and values of that attribute are, precisely, relations of this type. So the relation in that figure does abide by the definition of 1NF.
Incidentally, Requirement 4 also means nulls are prohibited (nulls aren’t values).
Turning now to Requirement 5 (“All columns are regular”): What this requirement means is, first, that every column has a name, unique among the column names that apply to the table in question; second, that no row is allowed to contain anything extra, over and above the regular column values prescribed under Requirement 4. For example, there are no “hidden” columns that can be accessed only by special operators instead of by regular column references (i.e., by column name), and there are no columns that cause invocations of regular operators on rows to have irregular effects. In particular, therefore, there are no identifiers other than regular key values (no hidden row IDs or “object IDs,” as are unfortunately found in some SQL products today), and no hidden timestamps as are found in certain “temporal database” proposals in the literature.
To sum up: If any of the five requirements are violated, the table in question doesn’t “directly and faithfully” represent a relvar, and all bets are off. In particular, relational operators such as join are no longer guaranteed to work as expected (as you’ll already know if, as I assume, you’re familiar with SQL). The relational model deals with relations (meaning, more precisely, relation values and relation variables), and relations only.
So much for 1NF; now I can begin to discuss some of the higher normal forms. Now, I’ve already said that Boyce/Codd normal form (BCNF) is defined in terms of functional dependencies, and in fact the same is true of second normal form (2NF) and third normal form (3NF) as well. Here then is a definition:
Definition: Let X and Y be subsets of the heading of relvar R; then the functional dependency (FD)
X → Y
holds in R if and only if, whenever two tuples of R agree on X, they also agree on Y. X and Y are the determinant and the dependant, respectively, and the FD overall can be read as either “X functionally determines Y” or “Y is functionally dependent on X,” or more simply just as “X arrow Y.”
For example, the FD {CITY} → {STATUS} holds in relvar S, as we know. Note the braces, by the way; X and Y in the definition are subsets of the heading of R, and are therefore sets (of attributes), even when, as in the example, they happen to be singleton sets. By the same token, X and Y values are tuples, even when, as in the example, they happen to be tuples of degree one.
By way of another example, the FD {SNO} → {SNAME,STATUS} also holds in relvar S, because {SNO} is a key—in fact, the only key—for that relvar, and there are always “arrows out of keys” (see the section KEYS immediately following this one). Note: In case it isn’t obvious, I use the term “arrow out of X” to mean there exists some Y such that the FD X → Y holds in the pertinent relvar (where X and Y are subsets of the heading of that relvar).
Now here’s a useful thing to remember: If the FD X → Y holds in relvar R, then the FD X+ → Y- also holds in relvar R for all supersets X+ of X and all subsets Y- of Y (just so long as X+ is still a subset of the heading, of course). In other words, you can always add attributes to the determinant or subtract them from the dependant, and what you get will still be an FD that holds in the relvar in question. For example, here’s another FD that holds in relvar S:
{ SNO , CITY } → { STATUS }(I started with the FD {SNO} → {SNAME,STATUS}, added CITY to the determinant, and dropped SNAME from the dependant.)
I also need to explain what it means for an FD to be trivial:
Definition: The FD X → Y is trivial if and only if there’s no way it can be violated.
For example, the following FDs all hold trivially for any relvar with attributes called STATUS and CITY:[38]
{ CITY , STATUS } → { CITY }
{ CITY , STATUS } → { STATUS }
{ CITY } → { CITY }
{ CITY } → { }To elaborate briefly (but considering just the first of these examples, for simplicity): If two tuples have the same value for CITY and STATUS, they certainly have the same value for CITY. In fact, it’s easy to see the FD X → Y is trivial if and only if Y is a subset of X. Now, when we’re doing database design, we don’t usually bother with trivial FDs because they’re, well, trivial; but when we’re trying to be formal and precise about these matters—in particular, when we’re trying to develop a theory of design—then we need to take all FDs into account, trivial ones as well as nontrivial.
I discussed the concept of keys in general terms in Chapter 1, but it’s time to get a little more precise about the matter and to introduce some more terminology. First, here for the record is a precise definition of the term candidate key:
Definition: Let K be a subset of the heading of relvar R. Then K is a candidate key (or just key for short) for R if and only if it possesses both of the following properties:
Uniqueness: No valid value for R contains two distinct tuples with the same value for K.
Irreducibility: No proper subset of K has the uniqueness property.
Aside: This is the first definition we’ve encountered that involves some kind of irreducibility, but we’ll meet several more in the pages ahead—irreducibility of one kind or another is ubiquitous, and important, throughout the field of design theory in general, as we’ll see. Regarding key irreducibility in particular, one reason (not the only one) why it’s important is that if we were to specify a “key” that wasn’t irreducible, the DBMS wouldn’t be able to enforce the proper uniqueness constraint. For example, suppose we told the DBMS (lying!) that {SNO,CITY} was a key, and in fact the only key, for relvar S. Then the DBMS couldn’t enforce the constraint that supplier numbers are “globally” unique; instead, it could enforce only the weaker constraint that supplier numbers are “locally” unique, in the sense that they’re unique within the pertinent city. End of aside.
I’m not going to discuss the foregoing definition any further here, since the concept is so familiar[39]—but observe how the next few definitions depend on it:
Definition: A key attribute for relvar R is an attribute of R that’s part of at least one key of R.
Definition: A nonkey attribute for relvar R is an attribute of R that’s not part of any key of R.[40]
For example, in relvar SP, SNO and PNO are key attributes and QTY is a nonkey attribute.
Definition: A relvar is “all key” if and only if the entire heading is a key (in which case it’s the only key, necessarily)—equivalently, if and only if no proper subset of the entire is a key. Note: If a relvar is “all key,” then it certainly has no nonkey attributes, but the converse is false—a relvar can be such that all of its attributes are key attributes and yet not be “all key” (right?).
Definition: Let SK be a subset of the heading of relvar R. Then SK is a superkey for R if and only if it possesses the following property:
Uniqueness: No valid value for R contains two distinct tuples with the same value for SK.
More succinctly, a superkey for R is a subset of the heading of R that’s unique but not necessarily irreducible. In other words, we might say, loosely, that a superkey is a superset of a key (“loosely,” because of course the superset in question must still be a subset of the pertinent heading). Observe, therefore, that all keys are superkeys, but “most” superkeys aren’t keys. Note: A superkey that isn’t a key is sometimes said to be a proper superkey.
It’s convenient to define the notion of a subkey also:
Definition: Let SK be a subset of the heading of relvar R. Then SK is a subkey for R if and only if it’s a subset of at least one key of R. Note: A subkey that isn’t a key is sometimes said to be a proper subkey.
By way of example, consider relvar SP, which has just one key, {SNO,PNO}. That relvar has:
To close this section, note that if H and SK are the heading and a superkey, respectively, for relvar R, then the FD SK → H holds in R, necessarily; equivalently, the FD SK → Y holds in R for all subsets Y of H. The reason is that if two tuples of R have the same value for SK, then they must in fact be the very same tuple, in which case they obviously must have the same value for Y. Of course, all of these remarks apply in the important special case in which SK is not just a superkey but a key; as I put it earlier (very loosely, of course), there are always arrows out of keys. In fact, we can now make a more general statement: There are always arrows out of superkeys.
I need to introduce one more concept, FD irreducibility (a second kind of irreducibility, observe), before I can get on to the definitions of 2NF, 3NF, and BCNF:
Definition: The FD X → Y is irreducible with respect to relvar R (or just irreducible, if R is understood) if and only if it holds in R and X- → Y doesn’t hold in R for any proper subset X- of X.
For example, the FD {SNO,PNO} → {QTY} is irreducible with respect to relvar SP. Note: This kind of irreducibility is sometimes referred to more explicitly as left irreducibility (since it’s really the left side of the FD that we’re talking about), but I’ve chosen to elide that “left” here for simplicity.
Now—at last, you might be forgiven for thinking—I can define 2NF:
Definition: Relvar R is in second normal form (2NF) if and only if, for every key K of R and every nonkey attribute A of R, the FD K → {A} (which holds in R, necessarily) is irreducible.
Note: The following definition is logically equivalent to the one just given (see Exercise 4.5 at the end of the chapter) but can sometimes be more useful:
Definition: Relvar R is in second normal form (2NF) if and only if, for every nontrivial FD X → Y that holds in R, at least one of the following is true: (a) X is a superkey; (b) Y is a subkey; (c) X is not a subkey.
Points arising:
It would be extremely unusual to regard 2NF as the ultimate goal of the design process. In fact, both 2NF and 3NF are mainly of historical interest; they’re both regarded at best as stepping stones on the way to BCNF, which is of much more pragmatic (as well as theoretical) interest.
Definitions of 2NF in the literature often take the form “R is in 2NF if and only if it’s in 1NF and ... .” However, such definitions are usually based on a mistaken understanding of what 1NF is. As we’ve seen, all relvars are in 1NF, and the words “it’s in 1NF and” therefore add nothing.
Let’s look at an example. Actually, it’s usually more instructive with the normal forms to look at a counterexample rather than an example per se. Consider, therefore, a revised version of relvar SP—let’s call it SCP—that has an additional attribute CITY, representing the city of the applicable supplier. Here are some sample tuples:
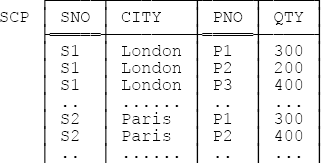
This relvar clearly suffers from redundancy: Every tuple for supplier S1 tells us S1 is in London, every tuple for supplier S2 tells us S2 is in Paris, and so on. And the relvar isn’t in 2NF—its sole key is {SNO,PNO}, and the FD {SNO,PNO} → {CITY} therefore certainly holds, but that FD isn’t irreducible: We can drop PNO from the determinant and what remains, {SNO} → {CITY}, is still an FD that holds in the relvar. Equivalently, we can say the FD {SNO} → {CITY} holds and is nontrivial; moreover, (a) {SNO} isn’t a superkey, (b) {CITY} isn’t a subkey, and (c) {SNO} is a subkey, and so—appealing now to the second of the definitions given above—the relvar isn’t in 2NF.
Points arising:
To repeat something I said in the previous section (and contrary to popular opinion, perhaps), 3NF is mainly of historical interest—it should be regarded at best as no more than a stepping stone on the way to BCNF. Note: The reason I say contrary to popular opinion, perhaps is that many of the “definitions” of 3NF commonly found (at least those in the popular literature) are actually definitions of BCNF—and BCNF, as I’ve already indicated, is important. Caveat lector.
Definitions of 3NF in the literature often take the form “R is in 3NF if and only if it’s in 2NF and ...”; I prefer a definition that makes no mention of 2NF. Note, however, that my definition of 3NF can in fact be derived from the second of the definitions I gave for 2NF by dropping condition (c) (“X is not a subkey”). It follows that 3NF implies 2NF—that is, if a relvar is in 3NF, then it’s certainly in 2NF.
We’ve already seen an example of a relvar that’s in 2NF but not 3NF: namely, the suppliers relvar S (see Figure 3-1 in Chapter 3). To elaborate: The nontrivial FD {CITY} → {STATUS} holds in that relvar, as we know; moreover, {CITY} isn’t a superkey and {STATUS} isn’t a subkey, and so the relvar isn’t in 3NF. (It’s certainly in 2NF, however. Exercise: Confirm this claim!)
As I said earlier, Boyce/Codd normal form (BCNF) is the normal form with respect to FDs—but now I can define it precisely:
Definition: Relvar R is in Boyce/Codd normal form (BCNF) if and only if, for every nontrivial FD X → Y that holds in R, X is a superkey.
Points arising:
It follows from the definition that the only FDs that hold in a BCNF relvar are either trivial ones (we can’t get rid of those, obviously) or arrows out of superkeys (we can’t get rid of those, either). Or as some people like to say: Every fact is a fact about the key, the whole key, and nothing but the key—though I must immediately add that this informal characterization, intuitively attractive though it is, isn’t really accurate, because it assumes among other things that there’s just one key.
The definition makes no reference to 2NF or 3NF. Note, however, that the definition can be derived from the 3NF definition by dropping condition (b) (“Y is a subkey”). It follows that BCNF implies 3NF—that is, if a relvar is in BCNF, then it’s certainly in 3NF.
By way of an example of a relvar that’s in 3NF but not BCNF, consider a revised version of the shipments relvar—let’s call it SNP—that has an additional attribute SNAME, representing the name of the applicable supplier. Suppose also that supplier names are necessarily unique (i.e., no two suppliers ever have the same name at the same time). Here then are some sample tuples:
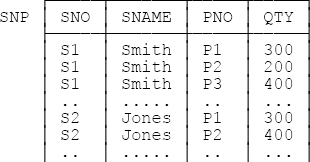
Once again we observe some redundancy: Every tuple for supplier S1 tells us S1 is named Smith, every tuple for supplier S2 tells us S2 is named Jones, and so on; likewise, every tuple for Smith tells us Smith’s supplier number is S1, every tuple for Jones tells us Jones’s supplier number is S2, and so on. And the relvar isn’t in BCNF. First of all, it has two keys, {SNO,PNO} and {SNAME,PNO}.[41] Second, every subset of the heading—{QTY} in particular—is (of course) functionally dependent on both of those keys. Third, however, the FDs {SNO} → {SNAME} and {SNAME} → {SNO} also hold; these FDs are certainly not trivial, nor are they arrows out of superkeys, and so the relvar isn’t in BCNF (though it is in 3NF).
Finally, as I’m sure you know, the normalization discipline says: If relvar R isn’t in BCNF, then decompose it into projections that are. In the case of relvar SNP, either of the following decompositions will meet this objective:
Projecting on {SNO,SNAME} and {SNO,PNO,QTY}
Projecting on {SNO,SNAME} and {SNAME,PNO,QTY}
By the way, I can now explain why BCNF is the odd man out, as it were, in not having a name of the form “nth normal form.” I quote from the paper in which Codd first described this new normal form:[42]
More recently, Boyce and Codd developed the following definition: A [relvar] R is in third normal form if it is in first normal form and, for every attribute collection C of R, if any attribute not in C is functionally dependent on C, then all attributes in R are functionally dependent on C [i.e., C is a superkey].
So Codd was giving here what he regarded as a “new and improved” definition of third normal form. The trouble was, the new definition was, and is, strictly stronger than the old one; that is, any relvar that’s in 3NF by the new definition is certainly in 3NF by the old one, but the converse isn’t true—a relvar can be in 3NF by the old definition and not in 3NF by the new one (relvar SNP, discussed above, is a case in point). So what that “new and improved” definition defined was really a new and stronger normal form, which therefore needed a distinctive name of its own. However, by the time this point was sufficiently recognized, Fagin had already defined what he called fourth normal form, so that name wasn’t available.[43] Hence the anomalous name Boyce/Codd normal form.
4.1 How many FDs hold in relvar SP? Which ones are trivial? Which are irreducible?
4.2 Is it true that the concept of FD relies on the notion of tuple equality?
4.3 Give examples from your own work environment of (a) a relvar not in 2NF; (b) a relvar in 3NF but not 2NF; (c) a relvar in BCNF but not 3NF.
4.4 Prove the two definitions of 2NF given in the body of the chapter are logically equivalent.
4.5 Is it true that if a relvar isn’t in 2NF, then it must have a composite key?
4.6 Is it true that every binary relvar is in BCNF?
4.7 (Same as Exercise 1.4.) Is it true that every “all key” relvar is in BCNF?
4.8 Write Tutorial D CONSTRAINT statements to express the FDs {SNO} → {SNAME} and {SNAME} → {SNO} that hold in relvar SNP (see the section BOYCE/CODD NORMAL FORM). Note: This is the first exercise in any chapter that asks you to give an answer in Tutorial D. Of course, I realize you might not be completely conversant with that language; in all such exercises, therefore—for example, Exercises 4.14 and 4.15 below—please just do the best you can. I do think it worth your while at least to attempt the exercises in question.
4.9 Let R be a relvar of degree n. What’s the maximum number of FDs that can possibly hold in R (trivial as well as nontrivial)? What’s the maximum number of keys it can have?
4.10 Given that X and Y in the FD X → Y are both sets of attributes, what happens if either is the empty set?
4.11 Can you think of a situation in which it really would be reasonable to have a base relvar with an RVA?
4.12 There’s a lot of discussion in the industry at the time of writing of XML databases. But XML documents are inherently hierarchic in nature; so do you think the criticisms of hierarchies in the body of the chapter apply to XML databases? (Well, yes, they do, as I indicated in a footnote earlier in the chapter. So what do you conclude?)
4.13 In Chapter 1, I said I’d be indicating primary key attributes, in tabular pictures of relations, by double underlining. At that point, however, I hadn’t properly discussed the difference between relations and relvars; and now we know that keys in general apply to relvars, not relations. Yet we’ve seen several tabular pictures since then that represent relations as such (I mean, relations that aren’t just a sample value for some relvar)—see, e.g., Figure 4-1 for three examples[44]—and I’ve certainly been using the double underlining convention in those pictures. So what can we say about that convention now?
4.14 (Repeated from the body of the chapter.) Give Tutorial D formulations of the following queries against the relation shown in Figure 4-1:
Get part numbers for parts supplied by supplier S2.
Get supplier numbers for suppliers who supply part P2.
4.15 Suppose we need to update the database to show that supplier S2 supplies part P5 in a quantity of 500. Give Tutorial D formulations of the required update against (a) the non RVA design of Figure 1-1, (b) the RVA design of Figure 4-1.
4.16 Here are some definitions of 1NF from the technical literature. In view of the explanations given in the body of the present chapter, do you have any comments on them?
First normal form (1NF) ... states that the domain of an attribute must include only atomic (simple, indivisible) values and that the value of any attribute in a tuple must be a single value from the domain of that attribute ... 1NF disallows having a set of values, a tuple of values, or a combination of both as an attribute value for a single tuple ... 1NF disallows “relations within relations” or “relations as attribute values within tuples” ... the only attribute values permitted by 1NF are single atomic (or indivisible) values (Ramez Elmasri and Shamkant B. Navathe, Fundamentals of Database Systems, 4th edition, Addison-Wesley, 2004)
A relation is in first normal form if every field contains only atomic values, that is, no lists or sets (Raghu Ramakrishnan and Johannes Gehrke, Database Management Systems, 3rd edition, McGraw-Hill, 2003)
First normal form is simply the condition that every component of every tuple is an atomic value (Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom, Database Systems: The Complete Book, Prentice Hall, 2002)
A domain is atomic if elements of the domain are considered to be indivisible units ... we say that a relation schema R is in first normal form (1NF) if the domains of all attributes of R are atomic (Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, Database System Concepts, 4th edition, McGraw-Hill, 2002)
A relation is said to be in first normal form (abbreviated 1NF) if and only if it satisfies the condition that it contains scalar values only (C. J. Date, An Introduction to Database Systems, 6th edition, Addison-Wesley, 1995)
[34] One reviewer accused me of rewriting history with this definition. Guilty as charged, perhaps—but I do have my reasons; to be specific, earlier “definitions” of the concept were all, in my opinion, either too vague to be useful or flat out wrong. See SQL and Relational Theory for further discussion.
[35] The relational model does, though. To paraphrase the answer to Exercise 2.2 in Appendix D, there are two small exceptions, both of which I’ll simplify just slightly here: First, no relation in the database can have an attribute of any pointer type; second, if relation r is of type T, then no attribute of r can itself be of type T (think about it!). However, these exceptions have nothing to do with 1NF as such.
[36] And, perhaps more to the point, newer ones like XML (see Exercise 4.12).
[37] Though I note in passing that Requirement 2 in particular effectively means SQL tables are never normalized—except, possibly, if they happen to have just one column. However, the disciplines recommended in SQL and Relational Theory allow you, among other things, to treat such tables (for the most part) as if they were normalized after all.
[38] In connection with the last of these examples in particular, see Exercise 4.10.
[39] Do note, however, that there’s no suggestion that relvars have just one key. Au contraire, in fact: A relvar can have any number of distinct keys, subject only to a limit that’s a logical consequence of the degree of the relvar in question. See Exercise 4.9.
[40] As a historical note, I remark that key and nonkey attributes were called prime and nonprime attributes, respectively, in Codd’s original normalization papers (see Appendix C).
[41] That’s why I didn’t show any double underlining when I showed the sample tuples—there are two candidate keys, and there doesn’t seem to be any good reason to make either of them “more equal than the other.”
[42] E. F. Codd: “Recent Investigations into Relational Data Base Systems,” Proc. IFIP Congress, Stockholm, Sweden (1974).
[43] Actually, when Raymond Boyce first came up with what became that “new and improved” normal form, he did call it fourth normal form! (The paper in which he first described the concept—IBM Technical Disclosure Bulletin 16, No. 1 (June 1973)—had the title “Fourth Normal Form and its Associated Decomposition Algorithm.”) I don’t know why that name was subsequently rejected (though I have my suspicions).
[44] Yes, I do mean three.
Get Database Design and Relational Theory now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

