Chapter 1. Pain Points of Centralized Data Responsibility
In the first decade of this century, there was a strong trend toward centralization of enterprise data: all the transactional data of a company needed for its IT operations was consolidated in one central monolithic database in order to have a single source of truth. In the operational data field, architects started to move away from the paradigm of having one central place of truth for transactional data. Since the rise of NoSQL and microservices, it has been a standard approach for individual services to maintain their own data store.
In the analytics data field, however, the centralization paradigm is still prevalent, in terms of both using centralized storage systems and maintaining central data teams that centralize data expertise. Analytical data is often used by overarching functions such as finance, management, or marketing, who need a holistic view of the entire business. The industry went through several iterations of analytical data architectures that innovated on how the data is physically stored and how it is processed. Yet, seemingly because of this need for a holistic view of data, no one dared to touch the general paradigm of central analytics data ownership as the gold standard to gain reliable insights about the business. In the next sections, we look at the currently most used analytics data approaches, their differences, and their commonalities.
The Data Warehouse Approach
The data warehouse approach is the oldest of these iterations and still successfully applies in many places. The approach, in its simplest form, is to collect data from different sources to then transform it so it can be combined in a common format before it is loaded into the warehouse. Furthermore, before making the data available to consumers, it is usually cleansed and quality-checked to a certain extent. The idea here is that consumers can rely on the data in the warehouse as the single source of truth about what happened at what time, with appropriate levels of data quality to engender trust.
One of the issues with this approach is that it does not scale well to a growing number of diverse data sources: the more data sources need to be integrated, the higher the likelihood of contradictions between the different sources. Therefore, it becomes harder and harder for the people maintaining the warehouse to curate the data to a consistent state. Also, the effort for central cleansing and quality control increases with a growing amount of data. The latter is particularly hard for a central team to do efficiently because they often lack the domain knowledge that the people who maintain the data-generating systems have. This leads to the curation becoming slower and slower until consumers get frustrated because the data they get served is not up to date. It is basically impossible to fulfill the promise of one perfect-quality, contradiction-free source of truth when dealing with a dynamic system (e.g., when you want to allow new data to be loaded into the warehouse and need to integrate new data sources frequently). This is a major fallacy often seen with large data warehouse projects.
The Data Lake Approach
The data lake approach, which appeared about a decade ago,1 addresses the curation bottleneck the data warehouse approach commonly exhibits with a growing number of diverse data sources. A data lake in its simplest form is a central data store with general accessibility into which data in almost any form or quantity can be put more or less as is. The curation, transformation, and schematization happens, if needed, at the time of consumption. The term schema-on-read, which is often used in this context, illustrates that data in the data lake has no fixed schema but is often stored in its raw form and is only interpreted or transformed into a schema when reading the data. This process usually has to be done by the people or the applications that consume data from the lake. Figure 1-1 shows how the ingestion from different sources into the lake happens as is, whereas the processing (e.g., cleansing and schematization) happens when users read data from the lake.
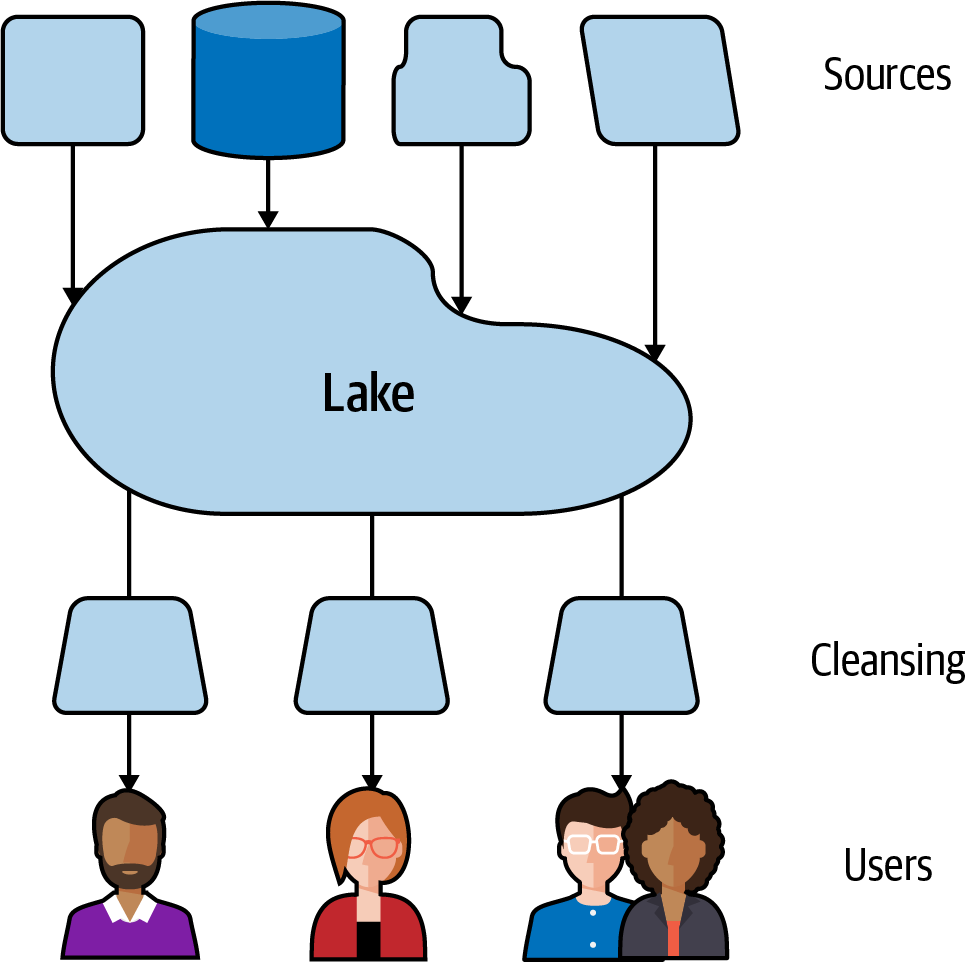
Figure 1-1. The data lake approach
This removes the bottleneck at ingestion time and therefore, at least initially, scales much better for a large number of diverse data sources. The work of curation and especially of cleansing is still needed, though, in order to allow for meaningful data applications. In general, this approach can also scale better on the consumption side, because individual data consumers or stakeholders can invest exactly the amount of effort for cleansing and curation of a particular dataset that they need for their data consumption scenario, and multiple data consumers can do so simultaneously. Of course, this sometimes leads to duplication of data and redundant data-processing efforts.
However, quality control in particular tends to get less efficient the further you go from the source where the data is generated for mainly two reasons. First, there is less detailed knowledge about the specifics of the data-generating systems to understand the issue at hand. Second, there are more intermediate transformation steps between the dataset to be corrected and the original source, so that issues need to be tracked and corrected through various layers of transformation. In the worst case, the data lake creates distance and anonymity between data producers and data consumers.
Therefore, the pain points with a data lake setup look different from those with a data warehouse setup. With a data lake, poorly documented data, data quality issues, and unclear data ownership are more commonly observed issues than with slow provisioning of data. It is also often hard to correlate different datasets in a data lake correctly. Data quality issues are then often attributed to the lack of central quality control and are therefore addressed with central rules and checks about what can go into the lake and what quality standards need to be met.
Centralized Data Responsibility
The fact that the data lake approach distributes certain tasks, such as cleansing, to consumers does not mean that it is a departure from the general paradigm of centralized data responsibility, which the data warehouse approach established. For example, there are data lake setups that make extensive use of distributed storage solutions and provide use case–specific lakeshore marts,2 which are maintained by their stakeholders. Nevertheless, there is usually still one or multiple central teams that own the data lake and make the connection between data producers and data consumers. That means that it remains the central team’s responsibility to make sure that data, for example, has a certain quality, is delivered in a timely fashion, and is continuously available. But central infrastructure teams are usually detached from both the specific use cases and the details of data generation in the source systems. Even if the members of such a central data team have the motivation to fulfill this responsibility, they usually lack the domain knowledge and the ability to fix issues directly. Instead, they need to urge data-producing teams to perform this task. You basically separate data producers and data consumers from each other, which usually leads to unnecessary friction, misunderstandings, and often a bad experience.
This way, central data teams—no matter whether they maintain a data warehouse, a data lake, or both—often get into a middleman position and quickly become a bottleneck when the number of data sources proliferates and when, simultaneously, data consumption use cases grow in number and in complexity. In the next chapter, we will reflect on what we can do about the pain points we have discussed so far and, in doing so, will introduce the pillars of the data mesh concept.
1 Martin Fowler, “DataLake,” MartinFowler.com, February 5, 2015, https://oreil.ly/xlhau.
2 See Fowler, “DataLake.”
Get Data Mesh in Practice now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

