Chapter 4. Services and API Management: The API Architecture
This chapter will cover the API Architecture, service-oriented architecture (SOA), and many modern data patterns. We’ll take a look at enterprise application integration, service orchestration and choreography, service (data) models, microservices, service meshes, GraphQL, and more. By the end of this chapter, you’ll have a solid grasp of the modern service-oriented architectures used to build scalability in distributed and real-time software systems. You will also understand how this architecture fits into the bigger picture and relates to the RDS Architecture, which we discussed in Chapter 3.
Introducing the API Architecture
The API Architecture, as you can imagine, receives its name from the application programming interface (API), which allows applications, software components, and services to communicate directly. Operational, transactional, and analytical systems that need to access each other’s data or initiate processes in real time are good examples of API patterns; so is interaction with cloud companies, external companies, and social networks. Services can also play a role when you, as a company, want to offer a rich user communication for your online digital channels. For example, users who are visiting the website of a travel agency might simultaneously see available flights and schedules from an airline operator.
The majority of API communication is synchronous and uses a request-response pattern, in which the (service) requestor sends a request to a replier system, which receives and processes the request, ultimately returning a message in response. The amount of data exchanged is generally small, which makes possible the real-time communication necessary for low-latency use cases. The opposite pattern is asynchronous data communication, in which no immediate response to continue processing is required. Data that is transmitted can be delivered in different unsynchronized or intermittent intervals. Messages that are sent by making HTTP calls to APIs can be parked, for example, in a message queue to be processed later. This subscription model is known as publish and subscribe, or pub/sub for short.
Because APIs can also be used asynchronously and combined with message queues and event-driven data processing, I mainly emphasize synchronous and request-response communication in this chapter. In Chapter 5, I will discuss event-driven processing, queuing, asynchronous communication, and how they overlap with SOA and APIs.
The API Architecture has a strong relationship with service-oriented architecture, which emerged more than a decade ago. SOA is widely used and is seen as a modern approach to software development and application connectivity. Although some architects and engineers say that “SOA is dead,” it is actively used and more than relevant because of trends such as microservices, Open APIs, and SaaS.
What Is Service-Oriented Architecture?
When you start reading about SOA, you will come across many different opinions; the author and developer Martin Fowler finds it impossible to describe SOA because it means so many different things to different people.
SOA, to me, is communication between applications through web services. It is about exposing business functionality. Some people call these services, others APIs. SOA is also used for abstracting and hiding application complexity because within SOA the applications (and their complexity) disappear into the background. Business functionality is provided instead.
SOA standardized the way applications communicate. Within SOA, application communication is done via standardized protocols, such as SOAP or JSON, and common software architectural styles, such as REST. SOA is about synchronous communication (waiting for the reply in order to continue) and asynchronous communication (not waiting).
SOA is also about decoupling and setting clear boundaries between applications and domains. It allows applications to change independently, without the need to change other applications as well. SOA thus can be used as a strategy to develop applications faster and maintain complex application landscapes.
Some architects and engineers will argue that SOA is about supplying business functionality or processes and not so much about the data. In a way this is valid, but it is important to realize that the core element is always data. If communications and network packages don’t carry any data, communication can never be established and SOA will never flourish. SOA, for this reason, is very much about the data. Other architects and engineers will argue that SOA is used only within the sphere of operational and transactional systems. I don’t consider this accurate because SOA is the architecture to connect applications from both the operational and analytical world in real time.
The abstraction, that functionality and data are encapsulated by services, to me is the biggest breakthrough of SOA. Instead of applications invoking or calling each other directly, they exchange data via well-defined service interfaces (Figure 4-1) using standard interoperability patterns. The complexity and data inside the service provider’s applications stay hidden and are no longer a concern to service consumers.2

Figure 4-1. Instead of invoking the application directly, the communication in SOA goes through API calls. The API interface usually has a different structure and hides the complexity of the inner application. Data therefore is transformed.
SOA dates to 2009, when the Open Group described it in a white paper that eventually became the SOA Source Book. The Open Group defines SOA as “an architectural style that supports service-orientation. Service-orientation is a way of thinking in terms of services and service-based development and the outcomes of services.”
The initial aim of SOA was to make the IT landscape more flexible and provide real-time communication between applications. Prior to SOA, most enterprise application communication took place via direct client-server calls, such as remote procedure calls (RPC).3
The drawback of direct application-to-application communication is that it involves coupling with the underlying application runtime environment. Applications that want to communicate, for example, via RPC methods, require the same client-server libraries and protocols. This doesn’t allow for great application diversity because not all libraries and protocols may be available for all languages. Another drawback is compatibility; versioning is more difficult to manage. If an application method changes, the other application also needs to change immediately, otherwise it might break. The last drawback is scalability: once the number of applications increases, the number of interfaces quickly becomes unmanageable. Typically the same problems are seen when building point-to-point interfaces between applications.
These drawbacks are the main reasons why engineers and architects started working on a new software architecture that is based on higher-level abstractions and the key concepts of application frontends, services, service repositories, and service buses. Applications and their application-specific protocols in this model are hidden and expose their functionality and data via services using standard web protocols, such as HTTP. The communication and integration between applications are done via service buses. The implementation of technologies and methodologies to facilitate this form of communication between (enterprise) applications is known as enterprise application integration.4
Enterprise Application Integration
In the early 2000s, with more popular usage of the web, the enterprise service bus (ESB) emerged as a new enterprise application integration platform, part of SOA, to handle communication between different applications. The service bus aims to connect all participants of services and applications with each other. It added new features above and beyond traditional message-oriented middleware (MOM) and client-server models, such as:5
- Orchestrating services
-
Composing several fine-grained services into a single higher-order composite service
- Rule-based routing
-
Receiving and distributing messages based on specified conditions
- Transformation to standard message formats
-
Transformation from one specific data format to another (this also includes data-interchange format transformations, such as SOAP/XML to JSON)
- Mediating for flexibility
-
Supporting multiple versions of the same interface for compatibility
- Adapting for connectivity
-
Supporting a wide range of systems for communicating to the backend application and transforming data from the application format to the bus format
The ESB promotes agility and flexibility because it enables companies to more quickly deliver services using buses and adapters. It turns traditional applications into modern applications with easy interfaces. The ESB also decouples applications by providing abstractions and taking care of mediation. The adapter connects the applications and ESB. The adapter also handles the protocol conversions between them. The way the ESB works is illustrated in Figure 4-2.
To facilitate the implementation of the ESB, many software vendors were making their applications and platforms ready for SOA by modernizing their application designs. Standards-based service interfaces emerged based on World Wide Web Consortium (W3C) standards, such as Simple Object Access Protocol (SOAP) with Extensible Markup Language (XML) as the default messaging format.
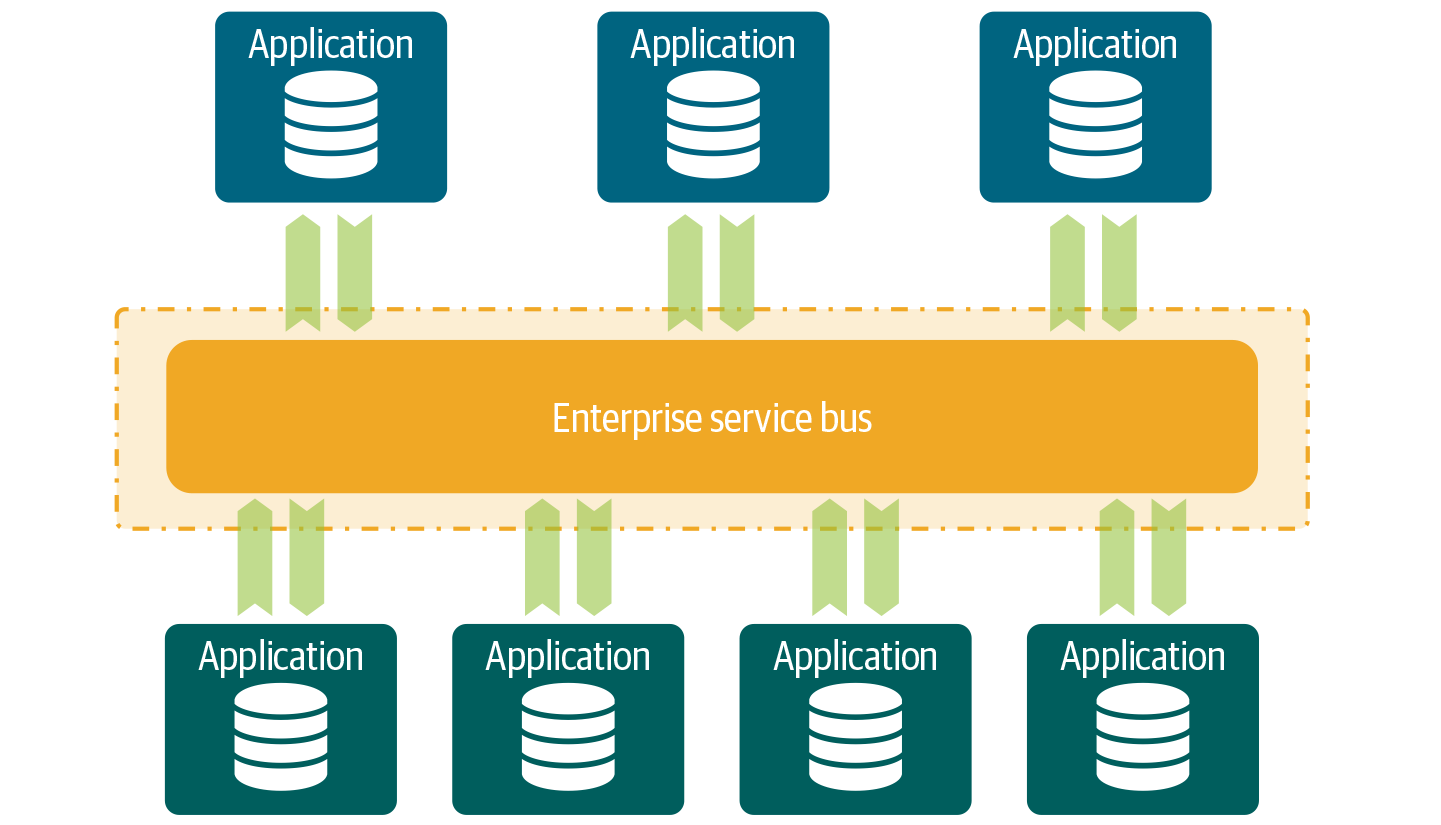
Figure 4-2. Instead of communicating directly to each other, applications communicate via the ESB.
SOAP became popular because it uses the Hypertext Transfer Protocol (HTTP) for network communication and has a similar solid structure as HyperText Markup Language (HTML), which is used to build websites. These same HTML and HTTP standards were and are the foundation for today’s internet communication. Based on these communication standards, the ESB acts as a transformation and integration broker, providing universal connectivity between the service providers and service consumers.
Besides transforming message formats and giving applications a modern communication jacket, the ESB also provides variations of communication in cases where more complex collaboration is required. Two of them are service orchestration and service choreography. They will be discussed in detail in the next sections because they make SOA more complex and challenging.
Service Orchestration
Within SOA, the roles of the service provider and service consumer are sometimes obscured when multiple services are combined. This can be done in several ways and makes integration and consumption more complex, so let’s take a moment to look at the options and differences.
Note
ESBs, within SOA, can become complex monoliths. I’ll also refer to this in “Similarities Between SOA and Enterprise Data Warehousing Architecture”, in reference to making the comparison with enterprise data warehousing.
This first pattern is service aggregation, in which multiple services are combined, wrapped together, and exposed as a single, larger aggregation service. This can be useful to remove the pain of management and satisfy the need of (one or multiple) service consumers. The aggregator in this scenario is responsible for coordinating, invoking, and combining the different services.
Within the aggregation there is also service orchestration, the coordination and execution of tasks to combine and integrate different services.6 This can be short-running, making fairly straightforward combinations like in the aggregation pattern, or long-running, combining services into a more complex flow that requires decision logic and different execution paths. Although service orchestration isn’t explicit about the duration, people predominantly use the term in the context of long(er)-running services. Service orchestration requires some disambiguation because it can be done for different reasons.
A common reason to orchestrate is for technical reasons, as commonly seen and applied within the context of the composite services, such as combining, splitting, transforming, inspecting, and discarding data. In some cases a simple service flow across services is needed.7 For example, in order to get all of a customer’s contract, another customer’s product service has to be called first.
Orchestration can also be done for another reason: business process management (BPM). The processes in this situation contain business logic and are typically long running. The coordination needed to manage the series of steps also requires the process statuses (state) of every step to be stored, and thus persisted in a database. Long-running business processes are interruptible and can wait for other processes (or human tasks). They are, in general, asynchronous, so for these types of processes the service orchestration pattern is typically accommodated with visual and intuitive BPM software for managing complex workflows and longer-running processes. Example products are TIBCO’s BPM and Camunda.
Warning
The process layer of the BPM software holds all the information of the data exchange flow between participants. This includes the sequence, dependencies, status, participant, parallel tasks, business rules, etc. You should never store application data in such a process layer: this is a common mistake. Instead, use the BPM API to start processes and retrieve information about the status of the workflow. Don’t use it for storing data about customers, products, or contracts because it hasn’t been designed for this purpose.
BPM is typically used when you need to orchestrate (long-running) processes across different applications from various domains. It helps domains to separate their business processes from their business application logic. However, when orchestrating processes and data within the application boundaries, it is better to do it individually, within the application itself.
When BPM is managing long-running processes, the nature of processing is typically asynchronous. BPM manages all dependencies, keeps track of the individual state of each process, and knows when to trigger, retrieve, and store data. The APIs that are used to invoke or call the processes are therefore sometimes called process APIs.
Service orchestration is often incorrectly mixed with other types of orchestration. In the context of service-oriented architecture, orchestration is about invoking and executing operational and functional processes needed to deliver an end-to-end service. Typically this form of orchestration uses application APIs and can be managed by BPM software. This appears as (3) in Figure 4-3.

Figure 4-3. Orchestration is an umbrella term for workflow automation. Orchestration can be used in many different contexts.
Other forms of orchestration, which includes scheduling, automated configuration, and coordination, are:
-
Scheduling processes in operating systems (1), for example, cron in Unix-like systems.
-
Scheduling processes and tasks within the application boundaries (2), for example, internal/native application schedulers.
-
Data orchestration (4) for automating data processing, for example, data movements, data preparation, and ETL processes. Apache Airflow is a common tool for these type of activities.
-
Scheduling and orchestrating infrastructure (5), for example, VM provisioning orchestration, shutting down systems, etc. Popular tools in this space are Ansible, Puppet, Salt, and Terraform.
An additional form of orchestration is continuous integration and continuous delivery (CI/CD), which is the automated process of monitoring, building, testing, releasing, and integrating software. This form of orchestration typically uses and combines many other forms of orchestration, so it is not pictured in Figure 4-3.
Service Choreography
Another pattern that obscures the roles of service providers and consumers is service choreography, which refers to the global distribution of process interaction and business logic to independent parties collaborating to achieve some business end. With service choreography, the decision logic is distributed; each service observes the environment and acts autonomously. There is no centralized point, like with BPM, and no party has total control over the other parties’ processes. Each party owns a piece of the overall process. Within service choreography, as you can see in Figure 4-4, requests go back and forth in a sort of ping-pong effect between different service providers and consumers.

Figure 4-4. Service choreography is a decentralized approach for service participation and communication. In this example, the logic of what services to call next is spread across many. Each owns a specific part of the process. The logic that controls the interactions between the services sits outside the central platform. The services decide who to call next and in what specific order.
Service choreography, aggregation, and orchestration can also be combined. Several services and process can be managed centrally, while others can independently trigger workflows from other aggregated services. In all situations the roles of the service provider and consumer are obscured, since domains can hardly guarantee the overall integrity.
Note
Martin Fowler suggests an interesting pattern for applications that communicate and depend on information from other applications in his post called Event Collaboration. Instead of making requests when data is needed, applications raise events when things change. Other applications listen to these events and react appropriately. This is very much in line with the Streaming Architecture, which we will discuss in Chapter 5.
In the last couple of sections, I have mainly focused on services through the lens of process interaction and aggregation. In the next section, I want to look closer at another way of distinguishing services by observing the context in which they operate.
Public Services and Private Services
Sometimes people classify SOA services into two types: public and private. Public services, sometimes referred to as business services, deliver specific business functionality. They are required and contribute to solving a specific business problem. Some provide grouped data and represent it in a way that is meaningful to the business. Other services initiate a process, trigger a business workflow, or touch on behavioral aspects. Business services tend to be abstract, are the authority for specific business functionality, and operate across application boundaries.
Private services, or technical services, are services that don’t necessarily represent business functionalities. They are used as part of the internal logic and provide technical data or infrastructure functionality, such as exposing a table of a database as is. Private services can be input for public services. If so, they are wrapped into another service that will eventually deliver the business functionality.
Note
Some people use the terms infrastructure services or platform services, which are services that abstract the infrastructure concerns from the domains. These services are typically standardized across an organization and involve functionalities that apply to all domains, such as authentication, authorization, monitoring, logging, debugging, or auditing.
Private services in general have a higher degree of coupling since they are less agnostic and don’t abstract to a business problem. Some argue that these services shouldn’t be published in the central repository since they are not suited to a wide audience and operate only within application boundaries.
Service Models and Canonical Data Models
When connecting different applications, engineers and developers need a common understanding of the data models and business functionality that different services provide. This is what service models and canonical data models are for. A service model describes what the service interface looks like and how the data and its entities, relationships, and attributes are modeled. Depending on its richness, it may also include definitions, dependencies with other services, version numbers, syntax, protocol, and other information, such as application owners, production status, and so on.
The goal of a service model is to provide information that makes it easier to use and integrate services. It is typically platform-agnostic and doesn’t try to describe the system. Service models are used in different scopes and exist in different formats. Some exist only in documentation and describe the most used context; others live in tools as code and describe the data and all its attributes and protocols.
Canonical data models differ from service models in that they aim to define services and languages in a standard and unified manner. While service models stay closer to the application, canonical models are used to align and standardize the various service models. Some people desire to apply unification across all services, using a global schema. As a result, canonical models tend to be large and complex.
Similarities Between SOA and Enterprise Data Warehousing Architecture
The ESB, aggregation, and layering of atomic services, and unification by using a central canonical model, make SOA more complicated than necessary. I draw a parallel between the traditional SOA implementations and enterprise data warehousing architecture because many of their challenges are similar.
Canonical model sizing
The first similarity is the scale at which canonical models are used. Many organizations try to use one single enterprise canonical model to describe all services. The enterprise canonical model requires cross-coordination between all the different teams and parties involved. Services in this approach typically end up with tons of optional attributes because everyone insists on seeing their unique requirements reflected. The end result is a monster interface model that compromises to include everybody’s needs but isn’t specific to anyone. It is so generic that nobody can tell what services exactly deliver or do.
ESB as wrapper for legacy middleware
The next similarity is the layering and aggregating of services. A pragmatic approach to delivering new services is quickly wrapping (Figure 4-5) existing services into new ones. Before you know it there is an endless cascading effect of service calls. Services are called without knowing exactly where data is coming from or what other services or processes are being initiated. Typically the same happens with BPM. Technical orchestration and process orchestration are mixed, or all domain and process logic is brought centrally together, making it hard to oversee what processes belong together.
The typical integration layer we have seen within the older middleware systems is another interesting puzzle for many organizations. Prior to the ESB, additional middleware layers and components were used.8 Many of these architectures still exist and do a large part of the message routing, integration, transformation, and process orchestration, including managing and persisting the state of many of these processes. Some enterprises encapsulate these legacy middleware systems with the ESB. The complexity is abstracted, opening the way for more modern communication, such as using JSON instead of RPC. Providing the ancient middleware with a new ESB jacket increases complexity because the layering (Figure 4-5) continues. Different platforms and system are stacked on each other so that every change to the backend systems needs to be worked on in many different places.

Figure 4-5. One risk of layering services on top of other services is that data is pulled out and nobody knows where exactly it is coming from. Another risk is that nobody is willing to take ownership for these services.
ESB managing application state
The last observation I want to share is about positioning the ESB for state management.9 Rather than taking care of the state in the application or a business process management capability, the ESB is used to orchestrate long-running business processes or to persist the state that belongs to applications. The ESB becomes a database. The risk of this approach is tight coupling. If the ESB goes down for whatever reason, the state is lost, and all the processes might lose their actual status. Another potential risk is when applications change: if a change is required to the state as well and all applications rely on the state persisted in the ESB, careful cross-coordination is required to carefully make all changes. The ESB, in principle, should be stateless, with the exception of temporary session management and caching.
Modern View on SOA
ESB integration platforms made SOA more complex than it should be. Enterprises took the “E” in ESB literally and implemented monoliths into their organization to take care of all the service integration. Central teams dictated what good reusability and design of services would be, and the heavy cross-communication frustrated innovation and team agility.
Meanwhile, the modularity of applications and design has been changing with the rise of microservices. Thinking regarding the digital ecosystem, the cloud, SaaS, and the API economy spread APIs outside boundaries of enterprises. Modern databases and applications support RESTful APIs out of the box. Not surprisingly, a new view on SOA is needed.
API Gateway
Service creation and integration have been difficult for a long time. Backend applications have long been complex, and transforming communication to the right data format has often been a challenge. The ESB gave companies a big advantage because it easily exposed complex applications as modern applications using their communication and transformation capabilities.
With RESTful APIs and the modernization trend in applications, however, communication and service integration between applications started to change. Representational state transfer (REST) is an architectural pattern used in modern web-based applications to communicate statelessness.10 It is based on simplicity: resources—simple represented chunks of related information—are identified by Uniform Resource Identifiers (URIs) and can be connected with hypermedia links.11 It also uses HTTP with uniform interface methods. RESTful APIs became popular due to their interoperability and flexibility and are used in websites, mobile apps, games, and more.
Note
RESTful APIs commonly use CRUD (create, read, update, delete). CRUD maps to the primitive operations to be performed in a database or data repository. You typically directly handle records or data objects. REST, on the other hand, operates on resource representations, each one identified by a URL. These are typically not data objects but complex high-level abstractions. For example, a resource can be a customer’s contract. This means a resource is not only a record in a “contract” table but also the relationships with the “customer” resource, the “agreement” that contract is attached to, and perhaps some other content it belongs to.
As RESTful APIs became popular, the message formats and protocols started to change as well. The SOAP protocol, with its relatively large XML message format, changed to JSON (JavaScript Object Notation). JSON is faster because its syntax is small and lightweight. Another significant benefit is that JSON messages can be easily cached or stored into document-oriented databases. API and integration platforms can store data that has been previously requested, then serve that data upon demand.
Note
RESTful APIs, in some cases, could be obfuscated to the consumers with additional layers or intermediaries for carrying out instructions without exposing their position in the hierarchy to the consumer. This is typically a requirement for providing enhanced scalability (caching and load balancing) and security.
Modern applications and changes in protocols and message designs also started to influence the enterprise service bus. A more lightweight integration component started to emerge, known as the API gateway. An API gateway doesn’t have the overhead of adapters or the complex integration functionality of the ESB but still allows encapsulation and provides the management capabilities to control, secure, manage, and report on API usage.
Responsibility Model
Based on these trends and the need to break up the ESB monolith, what should our new SOA look like? Instead of using the central model, the responsibility of building and exposing services will be given back to the underlying domains. With a decentralized model, domains can evolve at their own speed without holding up other domains. In this new model, responsibility for business logic, executing process, persisting data, and validating context also goes back to the domains. Using the ESB or API gateway as a (centralized) database will be forbidden; aggregation and orchestration are allowed only within the domain. This model is illustrated in Figure 4-6.
As you can see, this model is completely in line with the design principles presented in Chapter 2 and in the RDS, respectively. Instead of funneling all the data and integration from domains into the central ESB, domains need to develop, maintain, and expose their services themselves. The same read-optimized design principles will apply here.

Figure 4-6. Instead of using the heavy ESB, the services and APIs will be decoupled from the domains via the lightweight API gateway.
For service orientation, we can set some additional principles:
-
Expose business functionality using the REST resource model (see “Resource-Oriented Architecture”) instead of complex systems. This requires a lot of work and focuses on understanding business concepts and their properties, naming relationships properly, designing schema accordingly, getting the identities and uniqueness right, and so on.
-
Optimize as close as possible to the data and avoid orchestration in the data layer.
-
Keep domain logic in your domain.
-
Build services for consumers using the right level of granularity.12
-
Simplify and use modern community standards.
-
Allow service orchestration (combining multiple API endpoints into one) only within the boundaries of the domain (bounded context).
-
Use domain identifiers consistently so that domains can identify the interconnections between resources.
Following these guidelines and set of principles helps to make your API Architecture scalable. It allows domains to stay decoupled while leveraging other services without applying too much repeatable work.
The New Role of the ESB
With the new decoupling patterns clarified, we can have a critical look at the ESB. Only in cases of heavy lifting will the ESB be required; for all other use cases, the API gateway is better positioned. Consequently, the ESB will be positioned solely to solve the problem of legacy system modernization and heavy technical integration, as captured in Figure 4-7.
By bringing the ESB one level down closer to the legacy domains, and making the domains responsible, we also force the domains to take a more critical look at their applications. Today, many databases and even legacy platforms can be encapsulated more easily with additional API technologies. IBM’s z/OS Connect, for example, can be used to hide legacy mainframe complexity with RESTful APIs. Microsoft SQL Server and Oracle, with REST Data Services, have similar ways of providing RESTful APIs for their platforms without requiring an ESB.

Figure 4-7. By positioning the API gateway for modern communication, we position the ESB to decouple legacy systems.
Another way of modernizing traditional or legacy applications is to deploy a small set of functions or microservices close to the database or application. These functions work in a similar way to encapsulating. The big benefit of these patterns is that both data optimization and service creation are the concern of the domains. Domains are forced to see their APIs as their products.
This new positioning of the ESB and API gateway requires a governance model to ensure the domains take their responsibilities seriously. Service contracts, which are considered as data delivery contracts (see “Data Delivery Contracts and Data Sharing Agreements”), are an important part of the API governance.
Service Contracts
By pushing responsibilities closer to the domains, creation and maintenance of services are moved from the central team to the domains. In cases with many teams, the most important thing is that all teams agree on the specifications and design of the API. This is where API or service contracts come in.13
An API or service contract is a document that captures how the API is designed (structure, protocol, version, methods, etc.) and can be used for setting up agreements between service providers and service consumers. The common form of creating API contracts is OpenAPI-Specifications (formerly known as the Swagger Specification). The benefit of documenting these contracts in code is that both humans and systems can interpret the specifications. Service providers can also receive test procedures from the service consumers, so any change can be tested to validate if the service breaks. Pacto and Pact are two open source frameworks that can help in the creation and maintenance of these contracts.
Service Discovery
To keep track of services, I recommend maintaining a list of all (business) APIs in a service registry. A service registry is a tool that stores all critical API information in a central repository. This promotes reuse of services and avoids API proliferation (see Figure 4-8).

Figure 4-8. The service registry keeps track of all services and what APIs are exposed and consumed by whom. In a federated model with multiple API gateways, metadata and API registration are especially crucial.
Another benefit is that it provides service discovery,14 which allows you to track the API network location, its health status (availability, response time), version numbers, number of consumers, etc. Netflix Eureka is an open source example of such a service registry. The service registry is a great tool, especially in a distributed environment with multiple cloud vendors and many API gateways.
Microservices
Now that we’ve broken up our complex and tightly integrated service-oriented architecture, by promoting the decoupling of services from domains, we are ready for a new trend: microservices. Microservices architecture is an architecture pattern that breaks down applications into even smaller, more manageable parts. Some people like to use the term loosely coupled services, which immediately shows you the overlap with SOA.
To explain better what microservices are truly about, let’s quickly explain what an application is. An application is a computer program designed to perform a group of coordinated functions or tasks. Applications are usually built with three different tiers: presentation, business, and the data.
The way organizations can develop their applications and utilize the underlying technical infrastructure has changed over the last couple of years. More recent approaches involve slicing the application into multiple parts. This allows us to work on individual application parts, resulting in a higher agility and the ability to more flexibly scale the individual parts. This approach is illustrated in Figure 4-9.

Figure 4-9. A traditional three-tier application compared to microservices. Within a microservices application, each microservice is expected to have its own data. Synchronous communication between components is typically done via APIs.
Another benefit of slicing the application up into a microservices architecture is that the application components, known as microservices, can be developed, tested, and deployed individually and independently. In this architecture each component runs in its own dedicated process, which makes it much more scalable. Instead of scaling applications entirely, we can now scale individual application components up and down. There are some other characteristics worth mentioning as well:
-
Each microservice can have its own runtime, libraries, tools, and functions. These don’t have to be the same. You can mix Python, Java, JavaScript, PHP, or anything you want.
-
Containerization, or using containers that carry a lightweight execution environment, is a popular way of deploying.
-
Each microservice typically holds its own data in a dedicated database.15 The databases you use can also differ between microservices.
-
Services are logically organized and managed around bounded contexts.
-
Communication to other microservices generally takes place via lightweight mechanisms, such as JSON with REST, gRPC, and Thrift.
The last line item is probably the one that creates the most confusion. Within microservices there are some generic components required to facilitate the communication, one of which is the API gateway.
The Role of the API Gateway Within Microservices
Microservices usually communicate in the same way applications do within SOA. What makes it even more confusing is that when large or complex microservice-based applications are developed, API gateways are used to decouple the individual microservices. Additionally, multiple microservices from a single domain could be isolated from other domains by using an API gateway. The API gateway, in this type of architecture, offers the same benefits in the microservices architecture as within SOA, shown in Figure 4-10.

Figure 4-10. An API gateway is used for API communication within microservices.
The microservices trend is accommodated with another big trend: scalable containerized and serverless platforms. As of today, Kubernetes is a popular open source container platform, which is perfectly capable of managing large-scale microservices workloads. Each microservice is typically deployed as a single service inside and runs as a container. Running hundreds or thousands of microservices on such a platform is not unusual.
Functions
Function as a service (FaaS) is another model of how microservices architectures can be designed. It is a relatively new category of cloud computing services via which individual “functions,” actions, or pieces of business logic are deployed and executed. FaaS allows engineers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with this process. In this compute model, functions are spun up on-demand in a pay-per-usage license. This model of hiding infrastructure is also known as serverless.16
Each function typically has an API that corresponds to that function. The APIs in this model are needed to invoke or wake functions up. The principles for these functions and corresponding APIs are the exact same on all other APIs. When internally used within the domain boundaries, functions are allowed to be consumed directly. When crossing the boundaries, serverless APIs must be owned, contracted, and registered in the API repository.
Although the functions are camouflaged by the API gateway, there is significant overlap with event-driven architectures (Chapter 5). Functions in many cases are used in asynchronous scenarios. The main reason is that functions can be slow. In cloud computing, the majority of the fast resources are reserved for expensive, or compute-intensive, applications. The remaining “cheap” compute is then given to the serverless functions. Because of this, functions don’t have very predictable response times. Another reason why functions overlap with event-driven architectures is that functions typically run asynchronously. They can use message queues to store their result and wait for other processes (functions) to be picked up.
Service Mesh
When it comes to managing microservices on a large-scale platform, there’s another pattern for controlling the communication, which is called a service mesh. A service mesh is a layer (proxy) dedicated to handling service-to-service communication. The overlap between the service mesh and API gateway is significant, although there are some subtle differences. Both handle decoupling, monitoring, discovery, routing, authentication, and throttling. The main difference is in internal service-to-service communication. Communication within the service mesh is not routed externally but stays within the internal service boundaries in which the microservices operate. Figure 4-11 illustrates both communication patterns.

Figure 4-11. When scaling up the amount of microservices, it becomes important to decouple the different domains.
On the left you see all the microservices of the services provider. All internal communication within the provider’s boundaries is handled by the service mesh (acting as an internal API gateway). When communication is required with another party, for example, microservices or applications from a different domain or environment, the traffic needs to be routed externally. You can either use the service mesh or an additional API gateway for this. In the last situation, the API gateway handles the external routing, authentication, and incoming traffic from outside the boundary, while the service mesh takes care of the fine-grained control of the “inner” application architecture.
Note
Multiple API gateways tackle distributed data management challenges in your architecture. Some implementations support a distributed architecture based on groups of API gateways in an administrative environment. Apigee, Kong, MuleSoft, and WSO2, for example, allow you to deploy several nodes that let you manage and control all internal and external APIs from a central cockpit. The benefit is that all of these instances are managed as a single unit, utilizing the same configuration and policies.
You might wonder if you always need both. As of today the best practice is to use them side by side, but as both the service mesh and API Gateway evolve, I expect many of the features will be incorporated and concepts will merge. But there’s also an architectural difference between using the service mesh for enterprise decoupling of domains. If the service mesh’s primary role is to orchestrate microservices within a specific domain, it is more logical to have the API gateway orchestrating between the domains. A pragmatic solution is to deploy an additional API gateway—as a microservice—on the microservices platform. Apigee, for example, uses a microgateway that can be deployed directly on Kubernetes.
Microservices Boundaries
Another observation you likely made when looking at Figure 4-11 are the logical boundaries placed around the microservices of the services provider and services consumer. If many microservices are running on the same platform, it is important to draw logical lines. Scoping and decomposing services are important because they help domains manage their complexity and dependencies with other domains. The domain-driven design model is used for setting the boundaries on the services. If the bounded context changes, the boundary changes as well, and services must be decoupled. When following this logic, you could end up decoupling a microservice twice.
The first decoupling takes place within the boundaries of the domain, on the level of the internal service-to-service communication: one microservice is decoupled from another microservice within the same domain. The second decoupling takes place on the level of domain-to-domain communication: microservices that want to communicate to microservices from a different domain are decoupled once more. In the first situation, the design of microservices APIs could be more technical. These APIs aren’t supposed to be directly shared to other domains, nor are they published in the service catalog. In the situation of domain-to-domain communication, APIs have to be optimized for consumers, so read-optimized design principles have to be followed.
Microservices Within the API Reference Architecture
For fitting the microservices architecture into the overall API Architecture, let’s look at a picture.
We can observe, first, that the API gateway has a prominent role in the architecture for decoupling all API domain-to-domain communication. Second, domain-to-domain services must be registered in the service repository. Last, read-optimized design principles apply to all of these APIs.
In Figure 4-12 we also see three different design patterns:
-
At the left are the legacy applications, which require additional decoupling via the ESB. The service of the ESB can be wrapped into the API gateway.
-
In the middle sit the modern applications, which can be exposed directly via the API gateway. In this pattern the application uses modern communication, such as REST/JSON.
-
At the right sits microservices communication. Microservices communicate internally via the service mesh. APIs, which need to be exposed externally, are decoupled via the API gateway.

Figure 4-12. API Architecture doesn’t exclude microservices, nor do microservices exclude API Architecture. The service mesh or API gateway used within microservices can be perfectly combined with API Architecture.
Grouping the application and services together on a domain level is in line with what has been described in Chapter 2. By placing the ESB, API gateway, and service mesh under the API Architecture umbrella, we create a single pane of glass from which we can oversee and control all service communication. Each domain is ring-fenced, speaks its own domain language, and uses the first-hand language for external communication. The only exception to this rule is the APIs that will be exposed to the “external ecosystems.”
Ecosystem Communication
In Chapter 1, we discussed that many organizations are exploring new API- and web-based business models. Companies across industries have concluded that they have to work closely together with other digital companies to expand, innovate, disrupt, or just be competitive. This trend is expected to continue and will force your architecture to make a clear split between internal (service) communication with consumers and external (service) communication with consumers.17 There are three important reasons for this:
-
The language organizations use internally is under control of the company, but externally, this isn’t often the case. The format and structure of how APIs are designed is often dictated by other parties or by regulation. PSD2, as I mentioned in Chapter 1, is dictated by the European banking sector and forces banks to strictly organize their APIs by accounts, counterparties, transactions, etc. The consequence of this dictation is that additional translation is often required when reusing existing internal services.
-
APIs that are exposed to the public web require additional attention because external parties are not always trusted or known. To secure your APIs safely, they need to be monitored and throttled and have identity service providers for safe access.
-
You might want to throttle (limit the amount of calls) based on the commercial agreements you make. Commercially provided external APIs often have a consumption plan and are billed based on the number of API calls. API monitoring can be different because we need to distinguish between different API users.
The external and public web service communication requires an additional layer in our architecture, a layer that sits between internal services and external consumers. This API layer is illustrated in Figure 4-13.

Figure 4-13. The external API gateway has the special role of translating and securing APIs for external consumers.
Can the internal and external API gateway be the same? Technically, you could use the same platform to route both the internal and external traffic. However, one of the key considerations is API business strategy. The success of open APIs depends on their ability to attract external developers. The goal of open APIs is to develop valuable applications that developers and users actually want to use. A different platform would allow for faster innovation because it would be more loosely coupled from the internal environment.
Another reason to separate internal corporate communication from external traffic is the different security controls on the external environment. External traffic requires additional logging, DDoS protection, different identity providers, and so on.
External APIs and ecosystem communication are expected to have a great impact on your API strategy because it requires you to distinguish between internal and external service communication. Another objective that impacts your architecture is channel communication, which is about delivering a rich customer experience.
API-Based Communication Channels
One key objective is to use APIs for online web-based channels, where communication happens with customers and content is provided to other business parties. APIs are a major building block of the API Architecture. APIs are important enough that we need to differentiate between “domain” API communication and “channel” communication.
Domain communication is the generic API communication we have talked about so far: application-to-application connectivity between domains. An example could be an API call from the CRM system to a financial payment system.
Channel communication is different because the APIs are used for direct communication to end-user customers. It is more about human interaction than system-to-system interaction. This form of interaction can include web, smartphone, and machine interaction; chatbots; gaming; video; and speech recognition systems. Because the online channels are often the trademark of the company, it is important to offer great user interface and experience, which requires additional components in the architecture for entitlement checks, request handling and validation, state management, caching, web security, and so on. These components, which are illustrated in Figure 4-14, are part of a channel’s domain and interact closely with the API gateway.
The reason for having these components in the channel’s domain, close to the end-user, is that improving user experience is a dedicated activity in itself. Web application security, such as form validation, is different from API security. The user experience also needs to be fast, which can drastically change the way API interaction is done. Making lots of API calls to server-side resources can significantly slow down the user experience. A simple pick list of countries is better stored in a dedicated (cached) component, close to the end users, than retrieved over the network via the API gateway every time. You want to make fewer calls and be more efficient in what you retrieve. This means that you need to add additional functionality to your architecture.

Figure 4-14. A channel layer can hosts its own components and has an additional security layer for web communication.
GraphQL
A typical component within a channel environment is a GraphQL service. GraphQL is a query language for selecting exactly the fields you want to have from an API. Network communication overhead is reduced, and combinations of resources can be made when querying and combining different API endpoints.
Note
GraphQL allows schema federation, or organizing your schemas as a single data graph to provide a unified interface for querying all of your backing data sources. Again, don’t fall into the pitfall of creating an enterprise data model or a central gateway model. The schema stitching and federated design inherently holds at the degree of the client use case on the domain and how it’s used. If you want to know more about this, I encourage you to read Visual Design of GraphQL Data: A Practical Introduction with Legacy Data and Neo4j by Thomas Frisendal.
The GraphQL services in the API Architecture can be deployed only within the channel’s domain, or as a capability for domain-to-domain communication. In the latter setup, all of the principles discussed in Chapter 2 should be followed: the GraphQL endpoints have to follow the same API governance, including mandatory service contracts and backward compatibility rules.
Backend for Frontend
Another way to improve the user experience and meet frontend clients’ needs is to handle user interface and experience-related logic processing with an additional layer or components. You can optimize this layer for specific frontends. Mobile or single-page applications, for example, could have different optimizations and require different components than desktop-based web traffic. You may want to utilize GraphQL in this layer.
Sam Newman describes the design philosophy of leveraging services and applying optimizations and abstractions without incurring a common representation or being bound to each other as “backends for frontends”.
Metadata
API metadata management is an important aspect of the architecture. It helps service consumers find services, which improves reusability. A start would be to publish every API, including attributes and descriptions, in a central repository. Many modern API management platforms have such a repository, but if you don’t want to use a commercial vendor, an open source API management solution also works. API Umbrella, Swagger, and Kong are some popular examples.
It is especially important to keep track of all APIs in a distributed environment where multiple API gateways, ESBs, and service meshes are deployed. This only works if each integration capability is connected to the metadata repository (Figure 4-15). Doing so lets you know what services belong to what domains and what domains are interacting. Having this insight is a great advantage for managing the overall landscape.

Figure 4-15. The metadata layer provides insight into all API communication.
Another area where the metadata helps is service contracts between service providers and service consumers. With Pacto and Pact, you might consider storing all contracts, including integration tests, in a central repository. Making all of the contracts transparent gives insight into complexity and dependencies.
The last area where metadata plays an important role is security and identity service providers. We’ll address this in Chapter 7, but what you need to know for now is that metadata determines what consumers have access to what services.
Using RDSs for Real-Time and Intensive Reads
The API Architecture doesn’t stand alone; it can be combined with the RDS Architecture. Once RDSs achieve sufficient performance, you can use them to absorb all API read queries by provisioning RDSs or read-oriented microservices that act as caches and hold data locally, boosting data consumption.
By doing so, you can implement the CQRS (see “What Is CQRS?”) pattern, as pictured in Figure 4-16, for real-time communication. The API gateway, as part of the API Architecture, will segregate and route queries from command service requests. In this model, strongly consistent queries—reads that guarantee the most up-to-date results—and commands are still routed to the operational systems. The remaining read queries—eventually consistent queries—go to the RDSs.18

Figure 4-16. CQRS for real-time reads: All strong consistent reads and commands are served by the API Architecture and all other reads by the RDS Architecture.
An alternative for deploying APIs directly on your RDSs is to deploy read-oriented microservices that act as caches from which data is directly consumed. Each microservice in this architecture holds a particular piece of valuable data in its own data store and serves it out via an API. You can draw a parallel with resource-oriented architecture, in which each microservice caches data for one particular resource. Again, in the Scaled Architecture, the API Architecture does the segregation between all commands and queries.
As you learned in Chapter 3, with CQRS you can greatly improve the scalability and performance of your architecture. You can optimize to handle queries more efficiently. This also works in a distributed environment, where the operational system sits on one side of the network and the query part on the other side. When the query load is very high, CQRS is the only way to tackle distributed data management challenges.
Summary
In a rapidly changing enterprise landscape, you can think of the API Architecture described in this chapter as a way to refresh your API strategy. The fundamentals of service-oriented architecture remain, but with clearer responsibilities, modern patterns and principles, and a more flexible architecture.
The API Architecture, because of its REST architecture, is also a great way to go distributed with all of your data. You can deploy multiple API gateways and service meshes at the same time while staying fully in control using the metadata. Potentially, each team or domain can use its own API gateway for providing its services. You can stay in control by using metadata repositories that hold information about which services are available and how they are consumed.
The modularity and request/response model of the API Architecture also allow highly modular microsolutions for specific use cases. This makes the architecture highly scalable. The caveat here is that you must follow the same principles of the RDS Architecture, discussed in Chapter 2. APIs should be seen as products used to generate, send, and receive data in real time. They must be owned and optimized for readability and easy consumption. They should use the domain’s ubiquitous language and should not incorporate business logic from other domains.
In the next chapter we will examine the Streaming Architecture, which focuses on asynchronous messaging and event-driven communication.
1 Roy Fielding defined REST in his 2000 PhD dissertation Architectural Styles and the Design of Network-based Software Architectures.
2 The observation of encapsulation and inner application complexity and data flow between application via the services has been very well described by Pat Helland in the paper “Data on the Outside Versus Data on the Inside”.
3 RPC is similar to the client-server model. It is a pattern to let one program use and request application functionality from another program located on another system on the network. Rather than using messages, RPC uses an interface description language (IDL) for communication between the client and server. The IDL interpreter must be implemented on both sides.
4 Enterprise application integration (EAI) is the use of technologies and services across an enterprise to enable the integration of software applications and hardware systems.
5 Message-oriented middleware is software or hardware infrastructure that supports sending and receiving messages between distributed systems. It is a key building block of the ESB, used to route messages and support reliable processing of these messages.
6 Some people also use the term service composition. Service composability principles encourage designing services in such a way that they can be easily reused in multiple solutions, meaning that existing services can be used to create new services. While service composition denotes the fact that services are combined, it does not elaborate on how this is done.
7 Service flows, also called microflows, are noninterruptible and generally run in a single thread and in only one transaction. They are short in duration and typically use synchronous services only. The process state usually isn’t persisted.
8 Middleware, or message-oriented middleware (MOM), is an umbrella term for technologies and products supporting sending and receiving messages between systems. The ESB can be considered middleware but especially emphasizes the application and data integration aspects.
9 State management refers to the management of the state of applications, such as user inputs, process statuses, and so on.
10 Codecademy explains Representational State Transfer (REST).
11 HATEOAS (Hypermedia as the Engine of Application State) is used to link REST resources. RESTful API has a tutorial.
12 Filipe Ximenes and Flávio Juvenal have written a blog about how RESTful APIs can represent resources that are correctly formatted, linked, and versioned.
13 Martin Fowler goes into depth about what advantages consumer-driven contracts offer.
14 Service discovery is also used within the microservices architecture.
15 Also, still debatable, but probably good to mention, is that a degree of redundancy is allowed when having one database per microservice.
16 Serverless doesn’t mean that there aren’t any servers. It is a cloud-computing execution model. With serverless, all the infrastructure details are masked from the user. Martin Fowler describes this well.
17 Here, internal doesn’t refer to internal application APIs. In this case, internal means within the organizational or enterprise boundaries.
18 Werner Vogels, CTO of Amazon, explains nicely what eventual consistency is about.
Get Data Management at Scale now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

